
A Semantic Preprocessing Framework for Breaking News Detection to Support Future Drone Journalism Services

 , ,
, ,  ,
,  and
and 
Abstract
:1. Introduction
- Breaking news detection and geolocation inference, which produce notifications to be sent to a drone handling system or individual drone operators.
- Flight-plan preparation.
- Semi-autonomous waypoint-based guidance.
2. Related Work
3. Materials and Methods
3.1. Assumptions and Setup
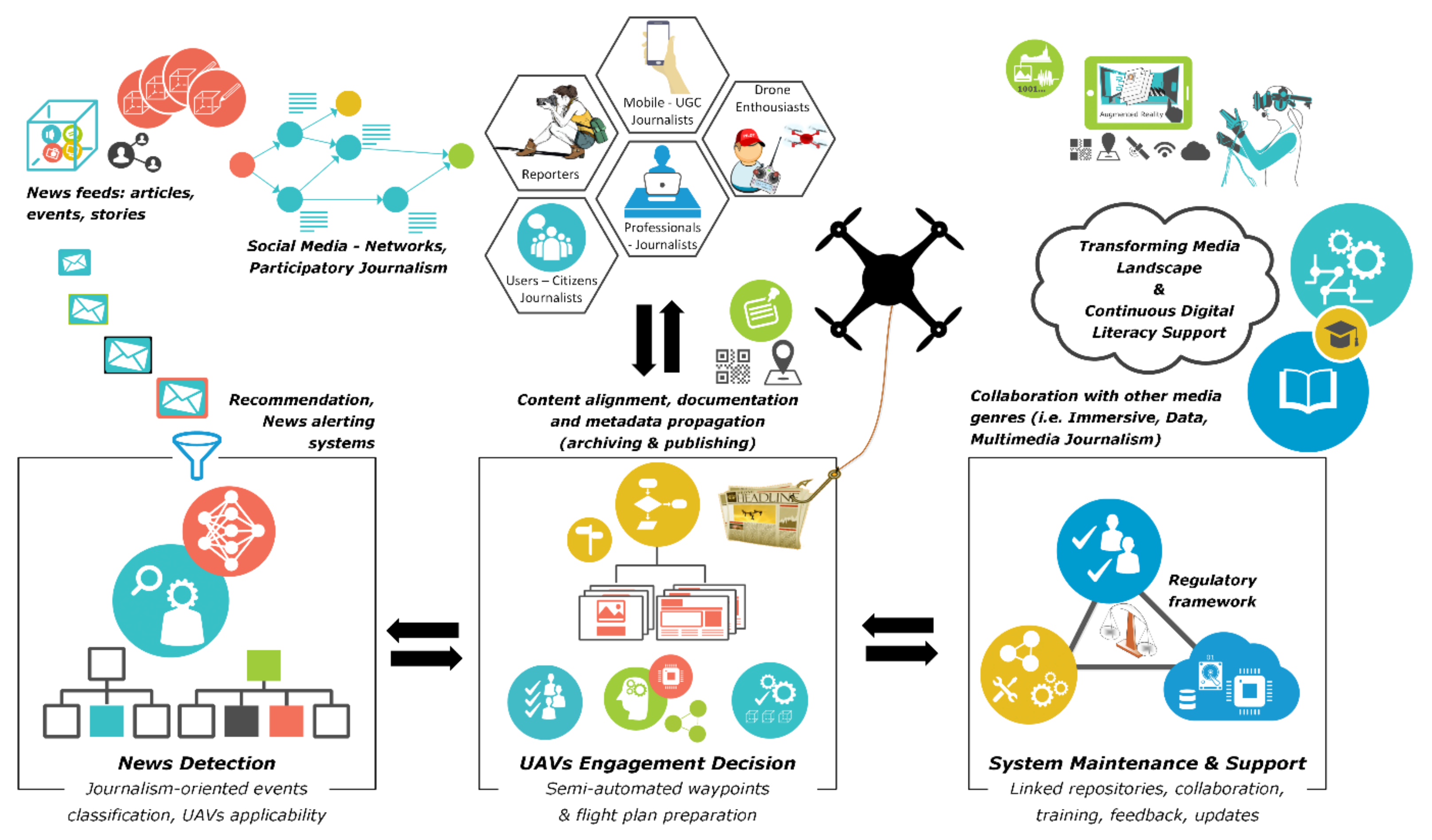
3.2. Architecture
- To gather original data heterogeneous data sources (web, social media);
- To process and analyze input data to form an event classification taxonomy extracting breaking news;
- To create automated alerts to trigger drone applicability;
- To support semi-automated/supervised drone navigation (and tagging) through a set of waypoints (with the notes that a safe landing zone is always needed, predefined, or detected in deployment time, while PIC in the communication range is required at all times);
- To develop user-friendly dashboards for drone control;
- To synchronize aerial footage with ground-captured AV streams (e.g., UGC) and propagate related annotations based on spatiotemporal and semantic metadata (i.e., topic, timestamps, GPS, etc.);
- To investigate AV processing techniques for the detection of points/areas of interest in arbitrary images and video sequences;
- To provide information, training, and support about drone utilization in public based on local regulations and ethical codes;
- To implement semantic processing and management automation for the captured content in batch mode, which could be utilized in combination with the other publishing channels and UGC streams (i.e., for analysis, enhancement, and publishing purposes).
- A prototype web service with open access to external (third-party) news sources for the detection of breaking news;
- Pilot software automating aspects of drone-based newsgathering;
- Content storage and management repository with indexing and retrieval capabilities;
- On-demand support and training on the new services.
3.3. Framework Description
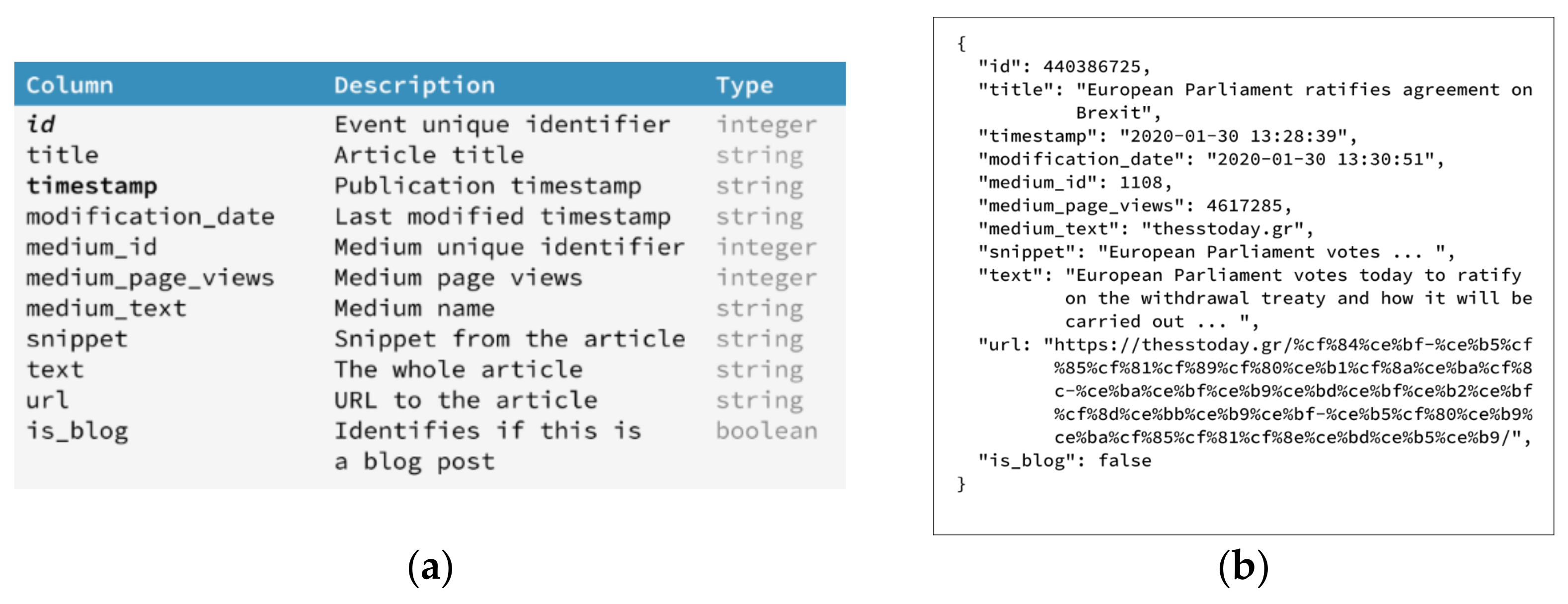
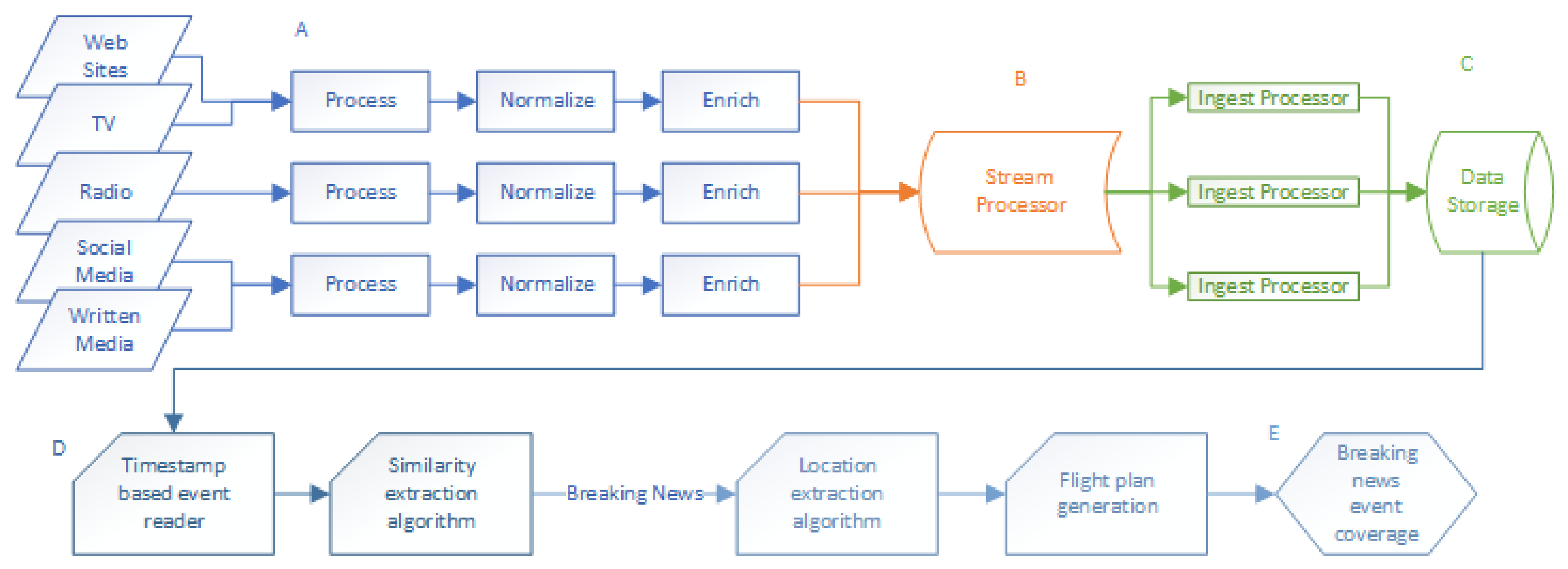
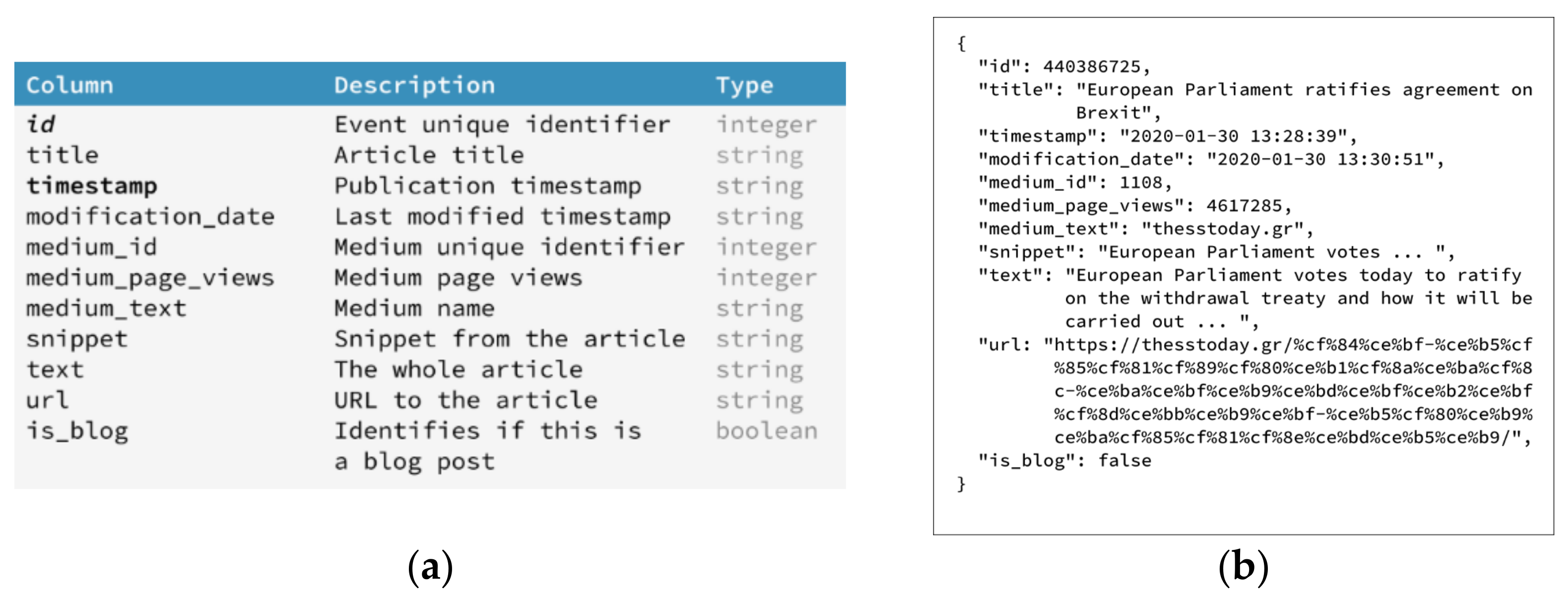
3.4. Data Retrieval and Management
3.5. Breaking News Discovery
| Algorithm 1 Breaking news detection |
| 1: while forever do 2: ▷ get the articles of the past h hours 3: get articles[“timestamp >= now-h”] 4: for article in articles do 5: int counter 6: title ← get_title(article) 7: title_vector ← get_vec(title) 8: for tmp_article in articles do 9: tmp_title ← get_title(tmp_article) 10: tmp_title_vector ← get_vec(tmp_title) 11: s ← similarity(title_vector, tmp_title_article) 12: if s >= t then 13: increment counter 14: end if 15: end for 16: if counter >= m then 17: classify article as breaking 18: end if 19: end for 20: end while |
3.6. Geolocation Inference
- Geo-tags from the associated sources [56];
- Geolocation extraction from named entities, such as [19]:
- ○
- Geopolitical entities (i.e., countries, cities, and states);
- ○
- Locations (i.e., mountains and bodies of water);
- ○
- Faculties (i.e., buildings, airports, highways, etc.);
- ○
- Organizations (i.e., companies, agencies, institutions, etc.).
3.7. Topic Detection
4. Experimental Results
4.1. Concept Validation through Audience Analysis
Demographics
4.2. Qualitative System Validation Using Experts (News and Media Professionals)
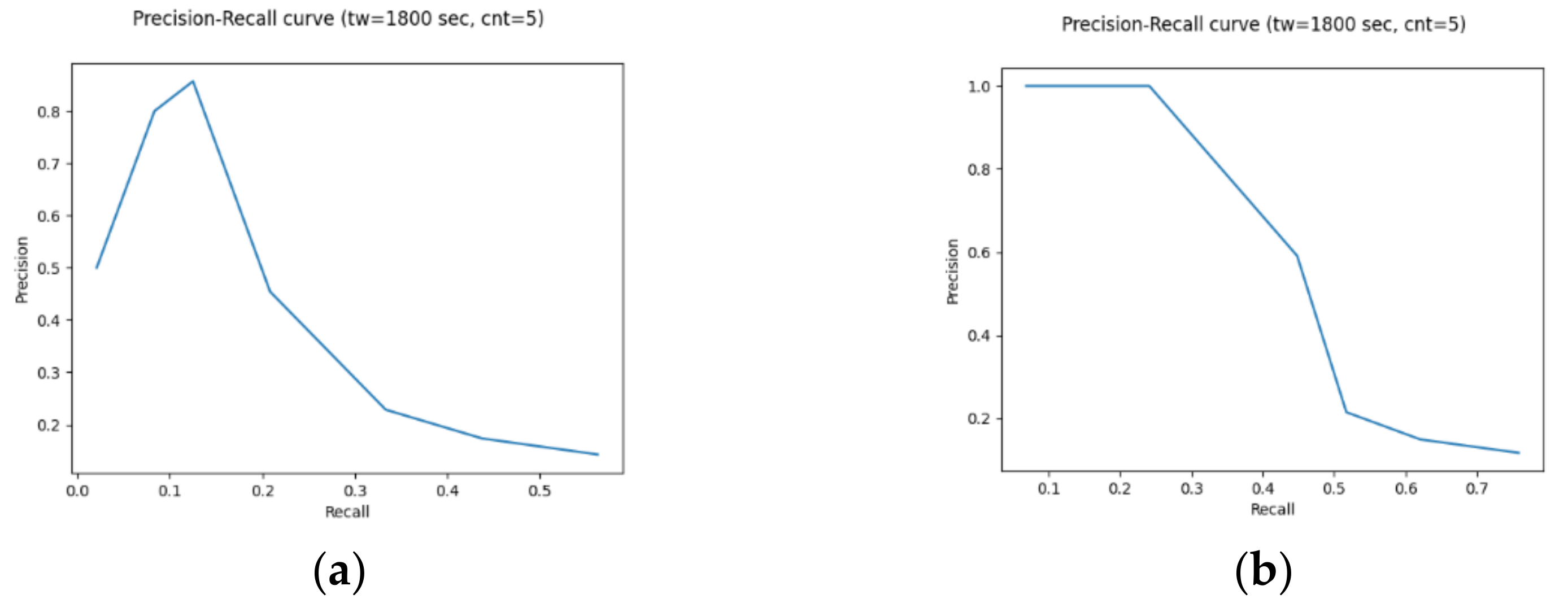
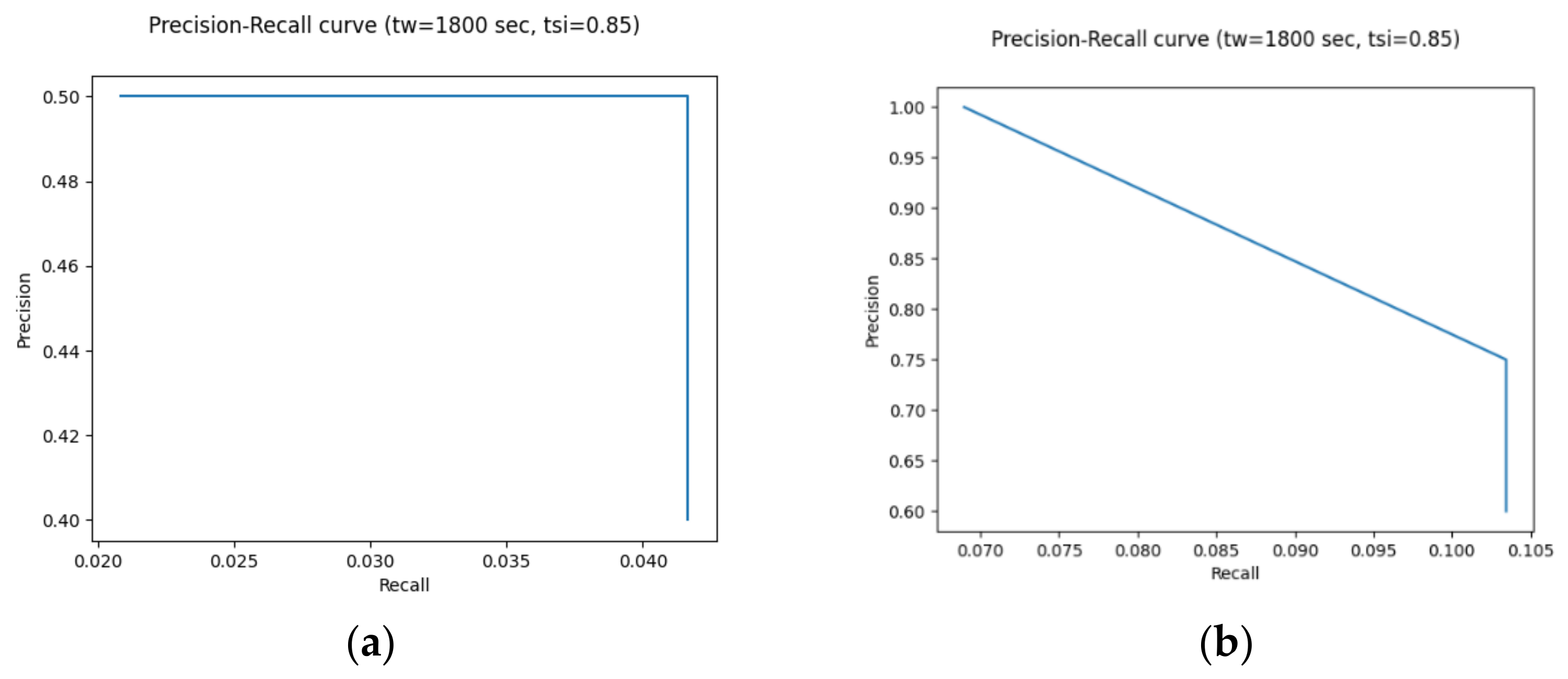
4.3. Preliminary System Evaluation on Real-World Data
5. Discussion
6. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Drones and Journalism: How Drones Have Changed News Gathering. Available online: https://www.simulyze.com/blog/drones-and-journalism-how-drones-have-changed-news-gathering (accessed on 23 March 2017).
- Taking Visual Journalism into the Sky with Drones. Available online: https://www.nytimes.com/2018/05/02/technology/personaltech/visual-journalism-drones.html (accessed on 2 May 2018).
- Gynnild, A. The robot eye witness: Extending visual journalism through drone surveillance. Digit. J. 2014, 2, 334–343. [Google Scholar] [CrossRef]
- Hirst, M. Navigating Social Journalism: A Handbook for Media Literacy and Citizen Journalism, 1st ed.; Routledge: Abingdon, UK, 2019. [Google Scholar]
- How Drones Can Influence the Future of Journalism. Available online: https://medium.com/journalism-innovation/how-drones-can-influence-the-future-of-journalism-1cb89f736e86 (accessed on 17 December 2016).
- Palino, T.; Shapira, G.; Narkhede, N. Kakfa: The Definitive Guide; O’Reilly: Newton, MA, USA, 2017. [Google Scholar]
- Dörr, K.N.; Hollnbuchner, K. Ethical Challenges of Algorithmic Journalism. Digit. J. 2017, 5, 404–419. [Google Scholar] [CrossRef]
- Ntalakas, A.; Dimoulas, C.A.; Kalliris, G.; Veglis, A. Drone journalism: Generating immersive experiences. J. Media Crit. 2017, 3, 187–199. [Google Scholar] [CrossRef] [Green Version]
- Harvard, J. Post-Hype Uses of Drones in News Reporting: Revealing the Site and Presenting Scope. Media Commun. 2020, 8, 85–92. [Google Scholar] [CrossRef]
- Virginia Tech. Mid-Atlantic Aviation Partnership. Available online: https://maap.ictas.vt.edu (accessed on 13 December 2018).
- Valchanov, I.; Nikolova, M.; Tsankova, S.; Ossikovski, M.; Angova, S. Mapping Digital Media Content. New Media Narrative Creation Practices; University of National and World Economy: Sofia, Bulgaria, 2019. [Google Scholar]
- Dörr, K.N. Mapping the field of Algorithmic Journalism. Digit. J. 2015, 4, 700–722. [Google Scholar] [CrossRef] [Green Version]
- Haim, M.; Graefe, A. Automated news: Better than expected? Digit. J. 2017, 5, 1044–1059. [Google Scholar] [CrossRef]
- Fillipidis, P.M.; Dimoulas, C.; Bratsas, C.; Veglis, A. A unified semantic sports concepts classification as a key device for multidimensional sports analysis. In Proceedings of the 13th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Zaragoza, Spain, 6–7 September 2018; pp. 107–112. [Google Scholar]
- Fillipidis, P.M.; Dimoulas, C.; Bratsas, C.; Veglis, A. A multimodal semantic model for event identification on sports media content. J. Media Crit. 2018, 4, 295–306. [Google Scholar]
- Shangyuan, W.; Edson, C.T., Jr.; Charles, T.S. Journalism Reconfigured. J. Stud. 2019, 20, 1440–1457. [Google Scholar] [CrossRef]
- Vrysis, L.; Vryzas, N.; Kotsakis, R.; Saridou, T.; Matsiola, M.; Veglis, A.; Arcila-Calderón, C.; Dimoulas, C. A Web Interface for Analyzing Hate Speech. Future Internet 2021, 13, 80. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. 2014. Available online: https://nlp.stanford.edu/pubs/glove.pdf (accessed on 9 November 2021).
- Katsaounidou, A.; Dimoulas, C. Integrating Content Authentication Support in Media Services. In Encyclopedia of Information Science and Technology, 4th ed.; Khosrow-Pour, M., Ed.; IGI Global: Hershey, PA, USA, 2017. [Google Scholar]
- Katsaounidou, A.; Dimoulas, C.; Veglis, A. Cross-Media Authentication and Verification: Emerging Research and Opportunities: Emerging Research and Opportunities; IGI Global: Hershey, PA, USA, 2018. [Google Scholar]
- Shahbazi, Z.; Byun, Y.C. Fake Media Detection Based on Natural Language Processing and Blockchain Approaches. IEEE Access 2021, 9, 128442–128453. [Google Scholar] [CrossRef]
- Symeonidis, A.L.; Mitkas, P.A. Agent Intelligence through Data Mining; Springer Science & Business Media: Berlin, Germany, 2006. [Google Scholar]
- Xiang, W.; Wang, B. A Survey of Event Extraction from Text. IEEE Access 2019, 7, 173111–173137. [Google Scholar] [CrossRef]
- Piskorski, J.; Zavarella, V.; Atkinson, M.; Verile, M. Timelines: Entity-centric Event Extraction from Online News. In Proceedings of the Text 2 Story 20 Workshop 2020, Lisbon, Portugal, 14 April 2020; pp. 105–114. [Google Scholar]
- Stamatiadou, M.E.; Thoidis, I.; Vryzas, N.; Vrysis, L.; Dimoulas, C. Semantic Crowdsourcing of Soundscapes Heritage: A Mojo Model for Data-Driven Storytelling. Sustainability 2021, 13, 2714. [Google Scholar] [CrossRef]
- Chatzara, E.; Kotsakis, R.; Tsipas, N.; Vrysis, L.; Dimoulas, C. Machine-Assisted Learning in Highly-Interdisciplinary Media Fields: A Multimedia Guide on Modern Art. Educ. Sci. 2019, 9, 198. [Google Scholar] [CrossRef] [Green Version]
- Drone Journalism: Newsgathering Applications of Unmanned Aerial Vehicles (UAVs) in Covering Conflict, Civil Unrest and Disaster. Available online: https://assets.documentcloud.org/documents/1034066/final-drone-journalism-during-conflict-civil.pdf (accessed on 10 October 2016).
- Culver, K.B. From Battlefield to Newsroom: Ethical Implications of Drone Technology in Journalism. J. Mass Media Ethics 2014, 29, 52–64. [Google Scholar] [CrossRef]
- Sidiropoulos, E.A.; Vryzas, N.; Vrysis, L.; Avraam, E.; Dimoulas, C.A. Collecting and Delivering Multimedia Content during Crisis. In Proceedings of the EJTA Teacher’s Conference 2018, Thessaloniki, Greece, 18–19 October 2018. [Google Scholar]
- Vryzas, N.; Sidiropoulos, E.; Vrysis, L.; Avraam, E.; Dimoulas, C.A. A mobile cloud computing collaborative model for the support of on-site content capturing and publishing. J. Media Crit. 2018, 4, 349–364. [Google Scholar]
- Vryzas, N.; Sidiropoulos, E.; Vrysis, L.; Avraam, E.; Dimoulas, C. jReporter: A Smart Voice-Recording Mobile Application. In Proceedings of the 146th Audio Engineering Society Convention, Dublin, Ireland, 20–23 March 2019. [Google Scholar]
- Sidiropoulos, E.; Vryzas, N.; Vrysis, L.; Avraam, E.; Dimoulas, C. Growing Media Skills and Know-How in Situ: Technology-Enhanced Practices and Collaborative Support in Mobile News-Reporting. Educ. Sci. 2019, 9, 173. [Google Scholar] [CrossRef] [Green Version]
- Vryzas, N.; Sidiropoulos, E.; Vrysis, L.; Avraam, E.; Dimoulas, C. Machine-assisted reporting in the era of Mobile Journalism: The MOJO-mate platform. Strategy Dev. Rev. 2019, 9, 22–43. [Google Scholar] [CrossRef]
- Petráček, P.; Krátký, V.; Saska, M. Dronument: System for Reliable Deployment of Micro Aerial Vehicles in Dark Areas of Large Historical Monuments. IEEE Robot. Autom. Lett. 2020, 5, 2078–2085. [Google Scholar] [CrossRef]
- Krátký, V.; Alcántara, A.; Capitán, J.; Štěpán, P.; Saska, M.; Ollero, A. Autonomous Aerial Filming With Distributed Lighting by a Team of Unmanned Aerial Vehicles. IEEE Robot. Autom. Lett. 2021, 6, 7580–7587. [Google Scholar] [CrossRef]
- Bok, K.; Noh, Y.; Lim, J.; Yoo, J. Hot topic prediction considering influence and expertise in social media. Electron. Commer Res. 2019, 21, 671–687. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, G.; Zhou, T.; Wang, L. TDT_CC: A Hot Topic Detection and Tracking Algorithm Based on Chain of Causes. In International Conference on Intelligent Information Hiding and Multimedia Signal Processing; Springer: Cham, Switzerland, 2018; Volume 109, pp. 27–34. [Google Scholar] [CrossRef]
- Hoang, T.; Nguyen, T.; Nejdl, W. Efficient Tracking of Breaking News in Twitter. In Proceedings of the 10th ACM Conference on Web Science (WebSci’19), New York, NY, USA, 26 June 2019; pp. 135–136. [Google Scholar] [CrossRef]
- Shukla, A.; Aggarwal, D.; Keskar, R. A Methodology to Detect and Track Breaking News on Twitter. In Proceedings of the Ninth Annual ACM India Conference, Gandhinagar, India, 21–23 October 2016; pp. 133–136. [Google Scholar] [CrossRef]
- Jishan, S.; Rahman, H. Breaking news detection from the web documents through text mining and seasonality. Int. J. Knowl. Web Intell. 2016, 5, 190–207. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, J.; Li, D.; Yu, H.; Liu, G. Hot Topic Detection Based on a Refined TF-IDF Algorithm. IEEE Access 2019, 7, 26996–27007. [Google Scholar] [CrossRef]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning Based Text Classification: A Comprehensive Review. arXiv 2021, arXiv:2004.03705. [Google Scholar] [CrossRef]
- Xu, G.; Meng, Y.; Chen, Z.; Qiu, X.; Wang, C.; Yao, H. Research on Topic Detection and Tracking for Online News Texts. IEEE Access 2019, 7, 58407–58418. [Google Scholar] [CrossRef]
- Web Scrapping Using Python and Beautiful Soup. Available online: https://towardsdatascience.com/web-scraping-5649074f3ead (accessed on 20 March 2020).
- Avraam, E.; Veglis, A.; Dimoulas, C. Publishing Patterns in Greek Media Websites. Soc. Sci. 2021, 10, 59. [Google Scholar] [CrossRef]
- Dean, A.; Crettaz, V. Event Streams in Action, 1st ed.; Manning: Shelter Island, NY, USA, 2019. [Google Scholar]
- Psaltis, A. Streaming Data, 1st ed.; Manning: Shelter Island, New York, NY, USA, 2017. [Google Scholar]
- Papadopoulos, S.; Datta, K.; Madden, S.; Mattson, T. The TileDB array data storage manager. Proc. VLDB Endow. 2016, 10, 349–360. [Google Scholar] [CrossRef] [Green Version]
- TileDB. Available online: https://docs.tiledb.com/main/ (accessed on 23 January 2021).
- Guo, W.; Zeng, Q.; Duan, H.; Ni, W.; Liu, C. Process-extraction-based text similarity measure for emergency response plans. Expert Syst. Appl. 2021, 183, 115301. [Google Scholar] [CrossRef]
- Yang, S.; Huang, G.; Ofoghi, B.; Yearwood, J. Short text similarity measurement using context-aware weighted biterms. Concurr. Comput. Pract. Exp. 2020, e5765. [Google Scholar] [CrossRef]
- Shahmirzadi, O.; Lugowski, A.; Younge, K. Text Similarity in Vector Space Models: A Comparative Study. In Proceedings of the 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 17 February 2020; pp. 659–666. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the Workshop at ICLR, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Azunre, P. Transfer Learning; Manning: Shelter Island, NY, USA, 2021. [Google Scholar]
- Bodrunova, S.S.; Orekhov, A.V.; Blekanov, I.S.; Lyudkevich, N.S.; Tarasov, N.A. Topic Detection Based on Sentence Embeddings and Agglomerative Clustering with Markov Moment. Future Internet 2020, 12, 144. [Google Scholar] [CrossRef]
- Middleton, S.E.; Kordopatis-Zilos, G.; Papadopoulos, S.; Kompatsiaris, Y. Location extraction from social media: Geoparsing, location disambiguation, and geotagging. ACM Trans. Inf. Syst. 2018, 36, 40. [Google Scholar] [CrossRef] [Green Version]
- Dong, W.; Wang, Z.; Charikar, M.; Li, K. High-confidence near-duplicate image detection. In Proceedings of the 2nd ACM International Conference on Multimedia Retrieval, Hong Kong, China, 5–8 June 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 1–8. [Google Scholar]
- Li, X.; Larson, M.; Hanjalic, A. Geo-distinctive visual element matching for location estimation of images. IEEE Trans. Multimed. 2017, 20, 1179–1194. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Shang, W.; Yan, M. News Text Classification Model Based on Topic model. In Proceedings of the IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; p. 16263408. [Google Scholar] [CrossRef]
- Patel, S.; Suthar, S.; Patel, S.; Patel, N.; Patel, A. Topic Detection and Tracking in News Articles. In Proceedings of the International Conference on Information and Communication Technology for Intelligent Systems, Ahmedabad, India, 25–26 March 2017. [Google Scholar] [CrossRef]
- Dimoulas, C.; Papanikolaou, G.; Petridis, V. Pattern classification and audiovisual content management techniques using hybrid expert systems: A video-assisted bioacoustics application in Abdominal Sounds pattern analysis. Expert Syst. Appl. 2011, 38, 13082–13093. [Google Scholar] [CrossRef]
- Rinaldi, A.M.; Russo, C.; Tommasino, C. A Knowledge-Driven Multimedia Retrieval System Based on Semantics and Deep Features. Future Internet 2020, 12, 183. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Survey Question | Empirical Results, Subject to Test |
|---|---|
| In your experience, how many common words should the title of two articles contain to be considered to refer to the same event? | One-four or over five words, depending on the length of the title. |
| In your experience, what is the maximum time difference of the articles under comparison to being considered as referring to the same extraordinary event? | From thirty minutes to over three hours, with the shortest duration to provide stronger indications. However, this does not matter if it is an extraordinary event it will be constantly updated. |
| When developing an algorithmic system for automated comparison between different articles, would it make sense to use? | Multiple sequential or sliding time-windows, with a degree of overlapping. |
| What criteria would you use to determine the importance of an article? | Number of sources that simultaneously appear, number of “reliable” sources, specific thematic classification (e.g., natural disaster), number of sharing posts and/or reactions (likes, comments, etc.). |
| What extra fields would you consider important for the purpose? | Author’s name listed, images attached/enclosed, sources and their reliability. |
| Questions Answered in Likert Scale | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
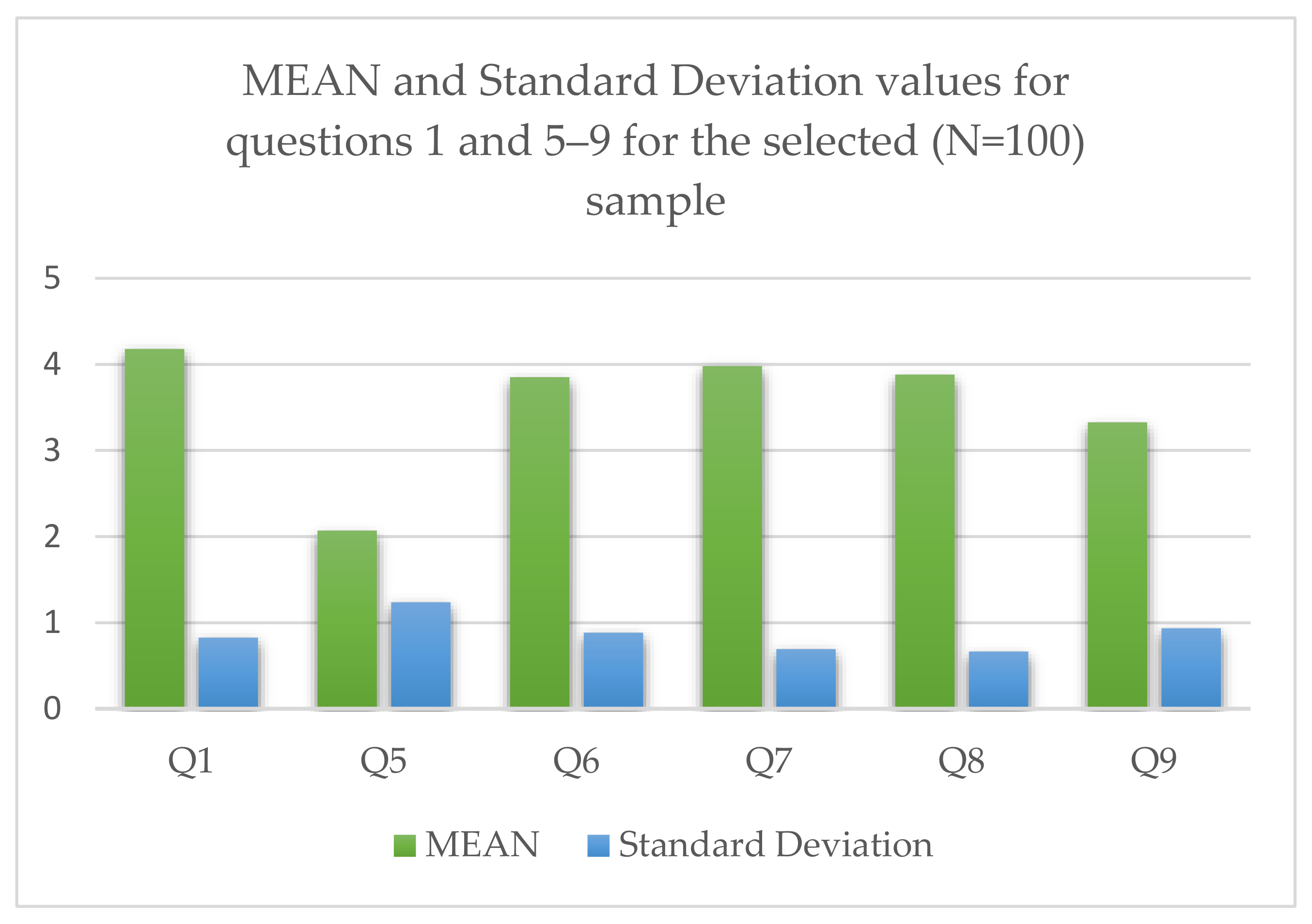
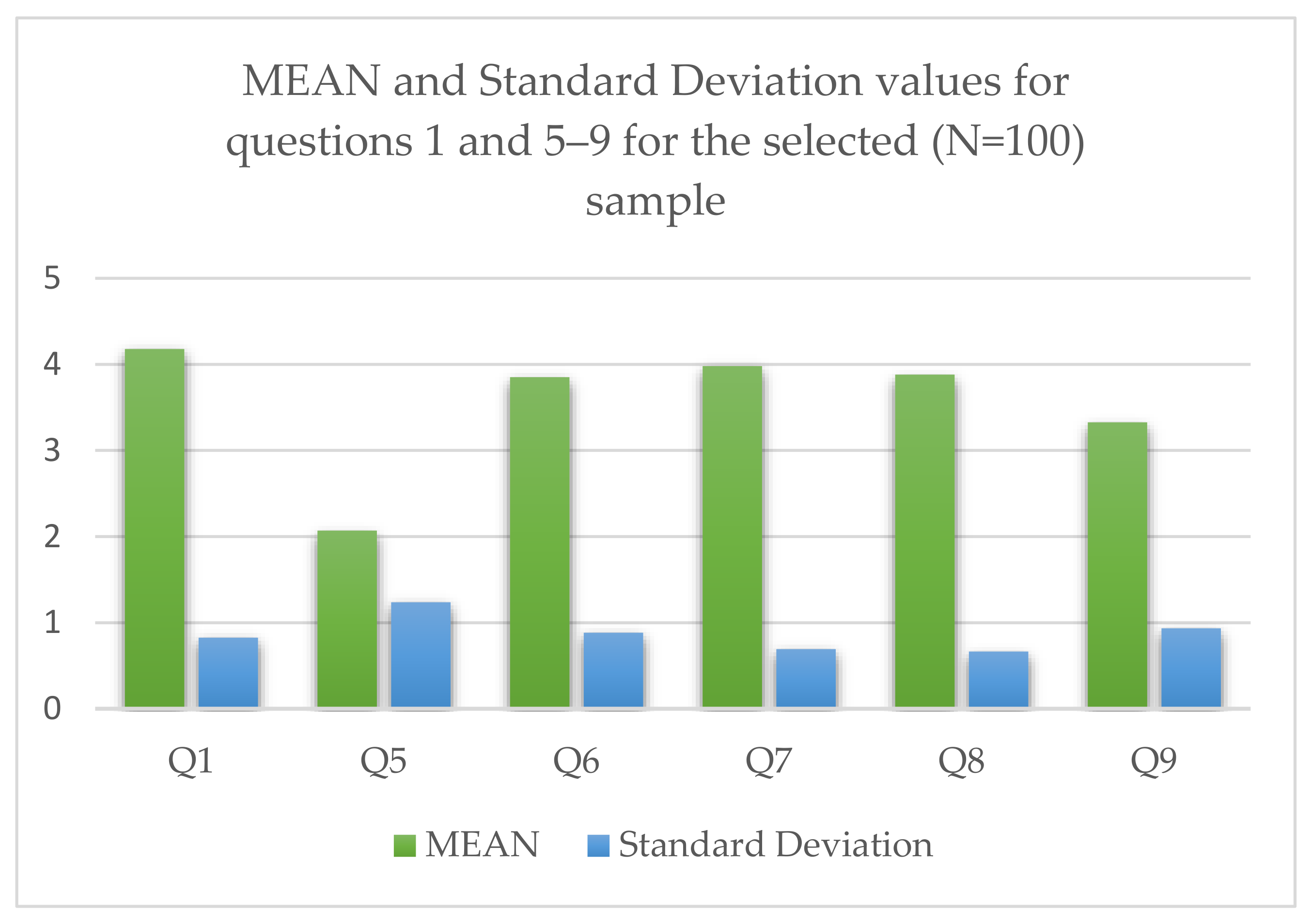
| Q1 | I am interested in breaking news | 0 | 4% | 15% | 40% | 41% |
| Q2 | Cross check upon breaking news alert is necessary | 0 | 0 | 8% | 46% | 46% |
| Q3 | An automated breaking news alert system would be useful | 1% | 6% | 16% | 59% | 18% |
| Q4 | I would use an automated breaking news alert system | 2% | 4% | 19% | 53% | 22% |
| Q5 | I am familiar with the term “drone journalism” | 46% | 21% | 18% | 9% | 6% |
| Q6 | Citizen journalists’ contribution with multimodal data (image, video, text) makes breaking news detection easier | 2% | 4% | 24% | 47% | 23% |
| Q7 | Contribution with multimodal data (image, video, text) by citizen journalists’ that use mobile devices with geo-tagging capabilities makes breaking news detection easier | 0 | 4% | 16% | 60% | 20% |
| Q8 | Citizen journalists’ contribution with multimodal data (image, video, text) makes local breaking news reporting easier | 0 | 2% | 23% | 60% | 15% |
| Q9 | Citizen journalists’ contribution with multimodal data (image, video, text) leads to misconceptions | 2% | 15% | 41% | 31% | 11% |
| Question | E1 | E2 | E3 | E4 | E5 | E6 | E7 | E8 | E9 | E10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
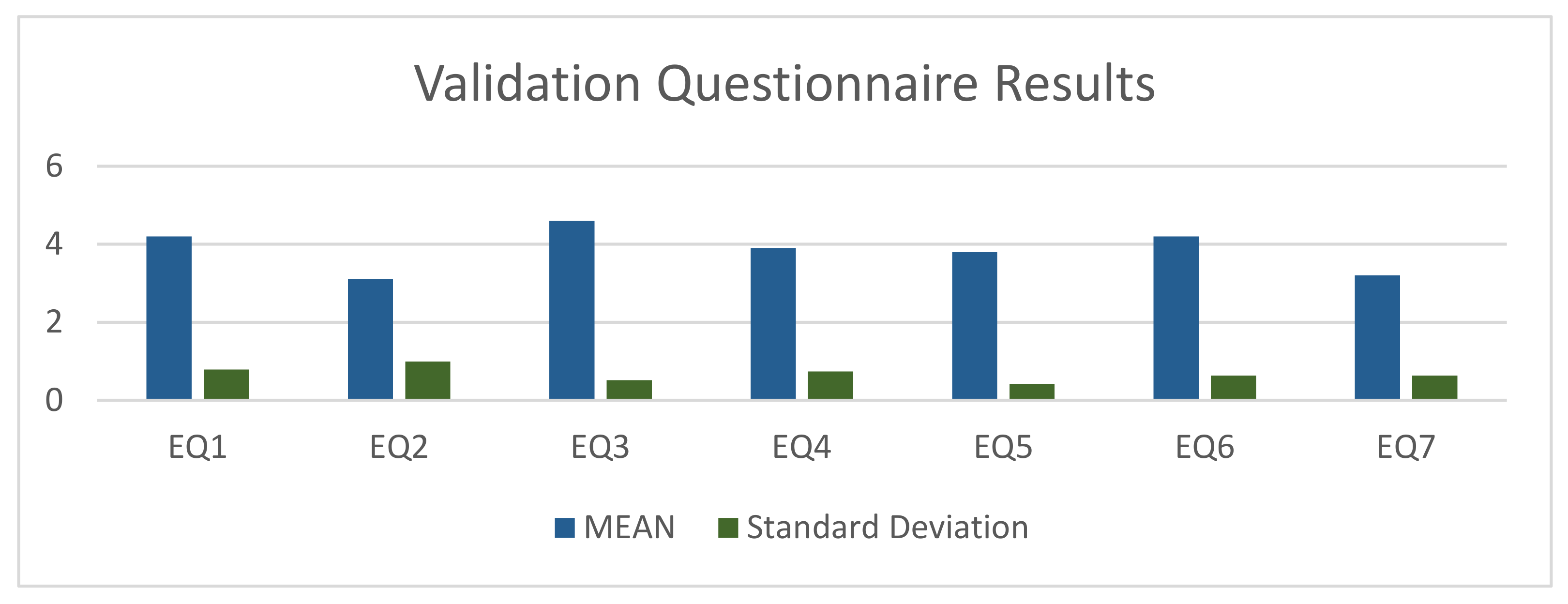
| EQ1 | Would you be interested in a system that collects all the news articles to create a data set? | 4 | 5 | 4 | 3 | 3 | 4 | 5 | 5 | 4 | 5 |
| EQ2 | Would you be interested in a system to look up information? | 2 | 3 | 2 | 2 | 3 | 3 | 3 | 4 | 4 | 5 |
| EQ3 | Would you be interested in a system that would allow you to compare articles with each other? | 5 | 5 | 4 | 4 | 4 | 5 | 4 | 5 | 5 | 5 |
| EQ4 | Would you be interested in an automatic emergency detection system? | 3 | 5 | 5 | 4 | 4 | 3 | 4 | 4 | 3 | 4 |
| EQ5 | An automatic breaking news system is useful. | 3 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 3 | 4 |
| EQ6 | I would use an automatic emergency detection system. | 3 | 5 | 5 | 4 | 4 | 4 | 4 | 4 | 4 | 5 |
| EQ7 | I would trust an automatic emergency detection system. | 2 | 3 | 3 | 3 | 3 | 3 | 3 | 4 | 4 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niarchos, M.; Stamatiadou, M.E.; Dimoulas, C.; Veglis, A.; Symeonidis, A. A Semantic Preprocessing Framework for Breaking News Detection to Support Future Drone Journalism Services. Future Internet 2022, 14, 26. https://doi.org/10.3390/fi14010026
Niarchos M, Stamatiadou ME, Dimoulas C, Veglis A, Symeonidis A. A Semantic Preprocessing Framework for Breaking News Detection to Support Future Drone Journalism Services. Future Internet. 2022; 14(1):26. https://doi.org/10.3390/fi14010026
Chicago/Turabian StyleNiarchos, Michail, Marina Eirini Stamatiadou, Charalampos Dimoulas, Andreas Veglis, and Andreas Symeonidis. 2022. "A Semantic Preprocessing Framework for Breaking News Detection to Support Future Drone Journalism Services" Future Internet 14, no. 1: 26. https://doi.org/10.3390/fi14010026
APA StyleNiarchos, M., Stamatiadou, M. E., Dimoulas, C., Veglis, A., & Symeonidis, A. (2022). A Semantic Preprocessing Framework for Breaking News Detection to Support Future Drone Journalism Services. Future Internet, 14(1), 26. https://doi.org/10.3390/fi14010026