1. Introduction
A “crypto winter” basically means that the prices for so-called cryptocurrencies such as Bitcon, Ethereeum, Solana, etc. fell sharply on the crypto exchanges and then stay low. The signs were all around in 2022: the failure of the Terra Luna crypto project in May 2022 sent an icy blast through the market, then the cryptocurrency lending platform Celsius Network halted withdrawals, prompting a sell-off that pushed Bitcoin to a 17-month low.
This study logged such a “crypto winter” on Twitter more by accident than by intention. Twitter was simply selected as an appropriate use case to evaluate a unified logging solution for cloud-native systems. The intent was to log Tweets containing stock symbols like $USD or $EUR. It turned out that most symbols used on Twitter are not related to currencies like $USD (US-Dollar) or stocks like $AAPL (Apple) but to Cryptocurrencies like $BTC (Bitcoin) or $ETH (Ethereum). However, although some data of this 2022 crypto winter will be presented in this paper, this paper will put the methodical part more into focus and will address how such and further data could be collected more systematically in distributed cloud-native applications. The paper will at least show that even complex observability of distributed systems can be reached, simply by logging events to stdout.
Observability measures how well a system’s internal state can be inferred from knowledge of its external outputs. The concept of observability was initially introduced by the Hungarian-American engineer Rudolf E. Kálmán for linear dynamical systems [
1,
2]. However, observability also applies to information systems and is of particular interest to fine-grained and distributed cloud-native systems that come with a very own set of observability challenges.
Traditionally, the responsibility for observability is (was?) with operations (Ops). However, this evolved into a collection of different technical methods and a culture for collaboration between software development (Dev) and IT operations (Ops). With this emergence of DevOps, we can observe a shift of Ops responsibilities to developers. Thus, observability is evolving more and more into a Dev responsibility. Observability should ideally already be considered during the application design phase and not be regarded as some “add-on” feature for later expansion stages of an application. The current discussion about observability began well before the advent of cloud-native technologies like Kubernetes. A widely cited blog post by Cory Watson from 2013 shows how engineers at Twitter looked for ways to monitor their systems as the company moved from a monolithic to a distributed architecture [
3,
4,
5]. One of the ways Twitter did this was by developing a command-line tool that engineers could use to create their dashboards to keep track of the charts they were creating. While Continuous Integration and Continuous Deliver/Deployment (CI/CD) tools and container technologies often bridge Dev and Ops in one direction, observability solutions close the loop in the opposite direction, from Ops to Dev [
4]. Observability is thus the basis for data-driven software development (see
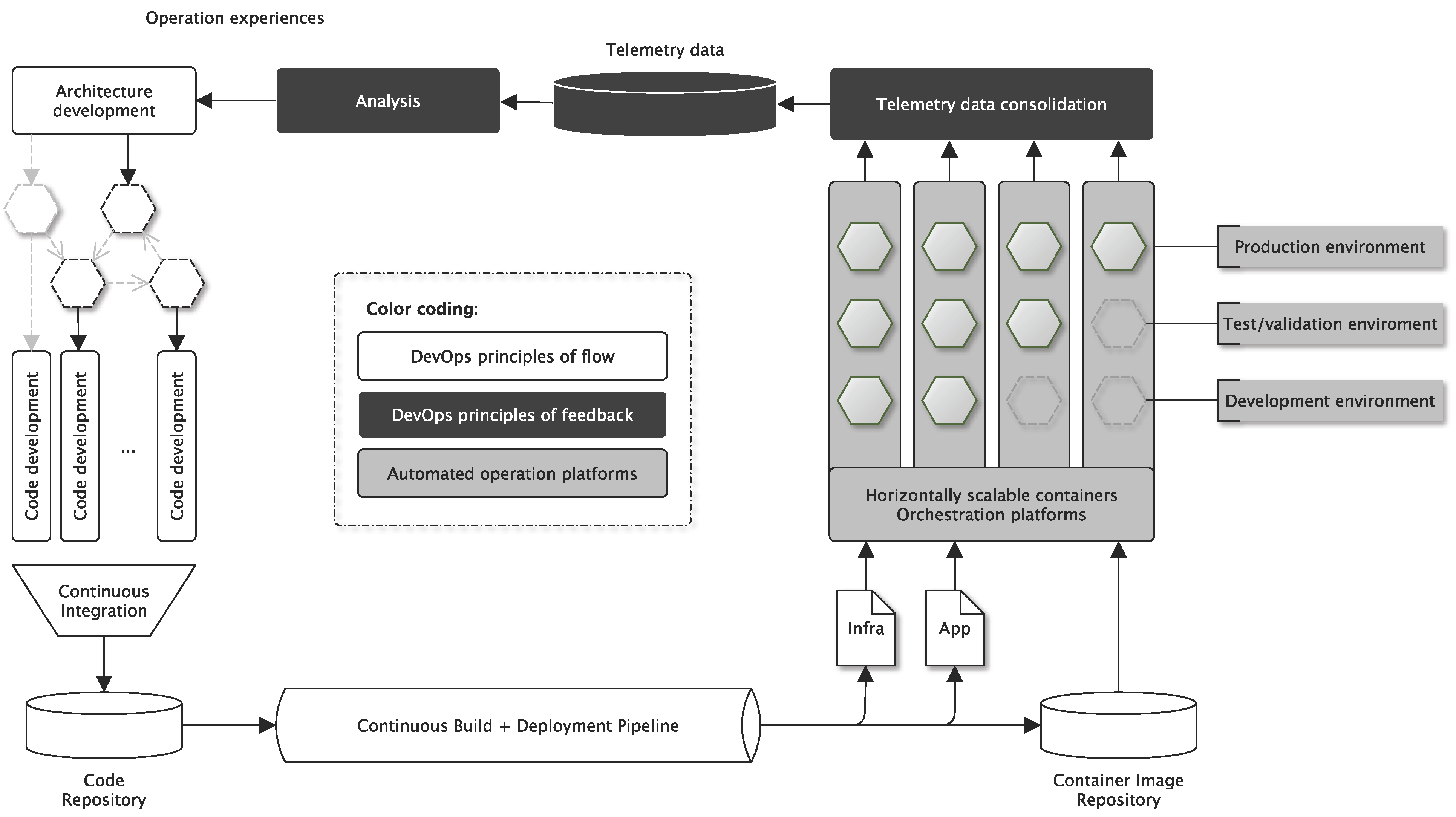
Figure 1 and [
6]). As developments around cloud(-native) computing progressed, more and more engineers began to “live in their dashboards”. They learned that it is not enough to collect and monitor data points but that it is necessary to address this problem more systematically.
2. Problem Description
Today, observability is often understood as a triad. Observability of distributed information systems is typically achieved through the collection and processing of metrics (quantitative data primarily as time-series), distributed tracing data (execution durations of complex system transactions that flow through services of a distributed system), and logging (qualitative data of discrete system events often associated with timestamps but encoded as unstructured strings). Consequently, three stacks of observability solutions have emerged, and the following somehow summarizes the current state of the art.
Metrics: Here, quantitative data are often collected in time series, e.g., how many requests a system is currently processing. The metrics technology stack is often characterized by tools such as Prometheus and Grafana.
Distributed tracing involves following the path of transactions along the components of a distributed system. The tracing technology stack is characterized by tools such as Zipkin or Jaeger, and the technologies are used to identify and optimize particularly slow or error-prone substeps of distributed transaction processing.
Logging is probably as old as software development itself, and many developers, because of the log ubiquity, are unaware that logging should be seen as part of holistic observability. Logs are usually stored in so-called log files. Primarily qualitative events are logged (e.g., user XYZ logs in/out). An event is usually attached to a log file in a text line. Often, the implicit and historically justifiable assumption prevails with developers that these log files are read and evaluated primarily by administrators (thus humans). However, this is hardly the case anymore. It is becoming increasingly common for the contents of these log files to be forwarded to a central database through “log forwarders” so that they can be evaluated and analyzed centrally. The technology stack is often characterized by tools such as Fluentd, FileBeat, LogStash for log forwarding, databases such as ElasticSearch, Cassandra or simply S3 and user interfaces such as Kibana.
Incidentally, all three observability pillars have in common that software to be developed must be somehow instrumented. This instrumentation is normally done using programming language-specific libraries. Developers often regard distributed tracing instrumentation in particular as time-consuming. In addition, which metric types (counter, gauge, histogram, history, and more) are to be used in metric observability solutions such as Prometheus often depends on Ops experience and is not always immediately apparent to developers. Certain observability hopes fail simply because of wrongly chosen metric types. Only system metrics such as Central Processing Unit (CPU), memory, and storage utilization can be easily captured in a black-box manner (i.e., without instrumentation in the code). However, these data are often only of limited use for the functional assessment of systems. For example, CPU utilization provides little information about whether conversion rates in an online store are developing in the desired direction.
Thus, current observability solutions are often based on these three stovepipes for logs, metrics, and traces. The result is an application surrounded by a complex observability system whose isolated datasets can be difficult to correlate.
Figure 2 focuses on the application (i.e., the object to be monitored) and triggers the question, whether it is justified to use three complex subsystems and three types of instrumentation, which always means three times the instrumentation and data analysis effort of isolated data silos.
The often-used tool combination of ElasticSearch, LogStash, and Kibana is used for logging and has even been given a catchy acronym: ELK-Stack [
7,
8]. The ELK stack can be used to collect metrics and using the Application Performance Management (APM) plugin [
9] also for distributed tracing. Thus, at least for the ELK stack, the three stovepipes are not clearly separable or disjoint. The separateness is somewhat historically “suggested” rather than technologically given. Nevertheless, this tripartite division into metrics, tracing, and logging is very formative for the industry, as shown, for example, by the OpenTelemetry project [
10]. OpenTelemetry is currently in the incubation stage at the Cloud Native Computing Foundation and provides a collection of standardized tools, Application Programming Interfaces (APIs), and Software Development Kits (SDKs) to instrument, generate, collect, and export telemetry data (metrics, logs, and traces) to analyze the performance and behaviour of software systems. OpenTelemetry thus standardizes observability but hardly aims to overcome the columnar separation into metrics, tracing, and logging.
In past and current industrial action research [
4,
6,
11,
12], I came across various cloud-native applications and corresponding engineering methodologies like the 12-factor app (see
Section 4.1). However, this previous research was not primarily concerned with observability or instrumentation per se. Especially, no instrumentation libraries have been developed, like it was done in this research. Instrumentation and observability were—as so often—only used in the context of evaluation or assessment of system performance. The instrumentation usually followed the analysis stack used. Developers who perform Distributed Tracing use Distributed Tracing Libraries for instrumentation. Developers who perform metric instrumentation use metric libraries. Those who log events use logging libraries. This instrumentation approach is so obvious that hardly any developer thinks about it. However, the result is disjoint observability data silos. This paper takes up this observation and asks whether uniform instrumentation helps avoid these observability data silos. In various projects, we have used instrumentation oriented towards the least complex case, logging, and have only slightly extended it for metrics and distributed tracing.
We learned that the discussion around observability is increasingly moving beyond these three stovepipes and taking a more nuanced and integrated view. There is a growing awareness of integrating and unifying these three pillars, and more emphasis is being placed on analytics.
Each of the three pillars of observability (logs, metrics, traces) is little more than a specific application of time series analysis. Therefore, the obvious question is how to instrument systems to capture events in an unobtrusive way that operation platforms can efficiently feed them into existing time series analysis solutions [
13]. In a perfect world, developers should not have to worry too much about such kind of instrumentation, whether it is qualitative events, quantitative metrics, or tracing data from transactions moving along the components of distributed systems.
In statistics, time series analysis deals with the inferential statistical analysis of time series. It is a particular form of regression analysis. The goal is often the prediction of trends (trend extrapolation) regarding their future development. Another goal might be detecting time series anomalies, which might indicate unwanted system behaviours. A time series is a chronologically ordered sequence of values or observations in which the arrangement of the results of the characteristic values necessarily from the course of time (e.g., stock prices, population development, weather data, but also typical metrics and events occurring in distributed systems, like CPU utilization or login-attempts of users).
The
research question arises whether these three historically emerged observability stovepipes of logs, metrics and distributed traces could be handled in a more integrated way and with a more straightforward instrumentation approach. The results of this action research study show that this unification potential could be surprisingly easy to realize if we exploit consequently the shared characteristic of time-series analysis in all three stovepipes. This paper presents the followed research methodology in
Section 3 and its results in
Section 4 (including a logging prototype in
Section 4.4 as the
main contribution of this paper to the field). The evaluation of this logging prototype is presented in
Section 5. A critical discussion is done in
Section 6. Furthermore, the study presents related work in
Section 7 and concludes its findings as well as future promising research directions in
Section 8.
4. Results of the Software-Prototyping
The analysis of cloud-native methodologies like the 12-factor app [
18] has shown that, to build observability, one should take a more nuanced and integrated view to integrate and unify these three pillars of metrics, traces, and logs to enable more agile and convenient analytics in feedback information flow in DevOps cycles (see
Figure 1). Two aspects that gained momentum in cloud-native computing are of interest:
Because both aspects guided the implementation of the logging prototype deeply, they will be explained in more detail providing the reader with the necessary context.
4.1. Twelve-Factor Apps
The 12-factor app is a method [
18] for building software-as-a-service applications that pay special attention to the dynamics of organic growth of an application over time, the dynamics of collaboration between developers working together on a codebase, and avoiding the cost of software erosion. At its core, 12 rules (factors) should be followed to develop well-operational and evolutionarily developable distributed applications. This methodology harmonizes very well with microservice architecture approaches [
3,
19,
20,
21,
22,
23] and cloud-native operating environments like Kubernetes [
24], which is why the 12-factor methodology is becoming increasingly popular. Incidentally, the 12-factor methodology does not contain any factor explicitly referring to observability, certainly not in the triad of metrics, tracing and logging. However, factor XI recommends how to handle logging:
Logs are the stream of aggregated events sorted by time and summarized from the output streams of all running processes and supporting services. Logs are typically a text format with one event per line. […]
A twelve-factor app never cares about routing or storing its output stream. It should not attempt to write to or manage log files. Instead, each running process writes its stream of events to stdout. […] On staging or production deploys, the streams of all processes are captured by the runtime environment, combined with all other streams of the app, and routed to one or more destinations for viewing or long-term archiving. These archiving destinations are neither visible nor configurable to the app—they are managed entirely from the runtime environment.
4.2. From Logging to Structured Logging
The logging instrumentation is quite simple for developers and works mainly programming language specific but basically according to the following principle illustrated in Python.
A logging library must often be imported, defining so-called log levels such as DEBUG, INFO, WARNING, ERROR, FATAL, and others. While the application is running, a log level is usually set via an environment variable, e.g., INFO. All log calls above this level are then written to a log file.
For example, line 5 would create the following entry in a log file:
In a 12-factor app, this logging would be configured so that events are written directly to Stdout (console). The runtime environment (e.g., Kubernetes with FileBeat service installed) then routes the log data to the appropriate database taking work away from the developer that they would otherwise have to invest in log processing. This type of logging is well supported across many programming languages and can be consolidated excellently with the ELK stack (or other observability stacks).
Logging (unlike distributed tracing and metrics collection) is often not even perceived as (complex) instrumentation by developers. Often, it is done on their own initiative. However, one can systematize this instrumentation somewhat and extend it to so-called “structured logging”. Again, the principle is straightforward. One simply does not log lines of text like
but, instead, the same information in a structured form, e.g., using JSON:
In both cases, the text is written to the console. In the second case, however, a structured text-based data format is used that is easier to evaluate. In the case of a typical logging statement like “User Max Mustermann tries to log in”, the text must first be analyzed to determine the user. This text parsing is costly on a large scale and can also be very computationally intensive and complex if there is plenty of log data in a variety of formats (which is the common case in the real world).
However, in the case of structured logging, this information can be easily extracted from the JavaScript Object Notation (JSON) data field “user". In particular, more complex evaluations become much easier with structured logging as a result. However, the instrumentation does not become significantly more complex, especially since there are logging libraries for structured logging. The logging looks in the logging prototype log12 of this study like this:
The resulting log files are still readable for administrators and developers (even if a bit more unwieldy) but much better processable and analyzable by databases such as ElasticSearch. Quantitative metrics can also be recorded in this way. Structured logging can thus also be used for the recording of quantitative metrics:
Furthermore, this structured logging approach can also be used to create tracings. In distributed tracing systems, a trace identifier (ID) is created for each transaction that passes through a distributed system. The individual steps are so-called spans. These are also assigned an identifier (span ID). The span ID is then linked to the trace ID, and the runtime is measured and logged. In this way, the time course of distributed transactions can be tracked along the components involved, and, for example, the duration of individual processing steps can be determined.
4.3. Resulting and Simplified Logging Architecture
Thus, the two principles to print logs simply to standard outout (stdout) and to log in a structured and text-based data format are applied consequently. The resulting observability system complexity thus reduces from
Figure 2 to
Figure 4 because all system components can collect log, metric, and trace information in the same style that can be routed seamlessly from an operation platform provided log forwarder (already existing technology) to a central analytical database.
4.4. Study Outcome: Unified Instrumentation via a Structured Logging Library (Prototype)
This paper will briefly explain below the way to capture events, metrics, and traces using the logging prototype that emerged. The prototype library log12 was developed in Python 3 but can be implemented in other programming languages analogously.
log12 will create automatically for each event additional key–value attributes like a unique identifier (that is used to relate child events to parent events and even remote events in distributed tracing scenarios) and start and completion timestamps that can be used to measure the runtime of events (although known from distributed tracing libraries but not common for logging libraries). It is explained:
how to create a log stream;
how an event in a log stream is created and logged;
how a child event can be created and assigned to a parent event (to trace and record runtimes of more complex and dependent chains of events within the same process);
and how to make use of the distributed tracing features to trace events that pass through a chain of services in a distributed service of services system).
The following lines of code create a log stream with the name “logstream” that is logged to stdout, see Listing 1:
| Listing 1. Creating an event log stream in log12. |
![Futureinternet 14 00274 i007]() |
Each event and child events of this stream are assigned a set of key–value pairs:
general = “value”
tag = “foo”
service_mark = “test”
These log-stream-specific key–value pairs can be used to define selection criteria in analytical databases like ElasticSearch to filter events of a specific service only. The following lines of code demonstrate how to create a parent event and child events, see Listing 2.
| Listing 2. Event logging in log12 using blocks as structure. |
![Futureinternet 14 00274 i008]() |
Furthermore, it is possible to log events in the event stream without the block style, see Listing 3. That might be necessary for programming languages that do not support closing resources (here a log stream) at the end of a block. In this case, programmers are responsible for closing events using the
.info(),
.warn(),
.error() log levels.
| Listing 3. Event logging in log12 without blocks. |
![Futureinternet 14 00274 i009]() |
Using this type of logging to forward events along Hypertext Transfer Protocol (HTTP) requests is also possible. This usage of HTTP-Headers is the usual method in distributed tracing. Two main capabilities are required for this [
25]. First, extracting header information received by an HTTP service process must be possible. Secondly, it must be possible to inject the tracing information in follow-up upstream HTTP requests (in particular, the trace ID and span ID of the process initiating the request).
Listing 4 shows how
log12 supports this with an extract attribute at event creation and an inject method of the event that extracts relevant key–value pairs from the event so that they can be passed as header information along an HTTP request.
| Listing 4. Extraction and injection of tracing headers in log12. |
![Futureinternet 14 00274 i010]() |
7. Related Work
The three pillars of metrics, traces, and logs have also been tackled in a recently published survey on anomaly detection and root cause analysis [
30]. However, very often observability is reduced on tools and benchmarks for automated log parsing [
31] or interesting publications like [
32] focus on advances and challenges in log analysis. Publications like [
33,
34] report on empirical studies regarding how developers log or how to improve logging in general. Studies like [
35,
36] focus more on anomaly detection in logs. However, all log-related studies are meanwhile a bit outdated. In addition, very often logging is related to log file analysis in the context of IT security and anomaly detection only [
37].
More recent studies look at observability from a more all-encompassing point of view. Ref. [
38] focus explicitly on the observability and monitoring of distributed systems. Ref. [
39] focuses microservices in this observability context. Ref. [
40] focuses the need of multi-level observability especially in orchestration approaches. In addition, Ref. [
41] considers scalable observability data management. An interesting and recent overview on observability of distributed edge and container-based microservices is provided by [
42]. This survey provides a list of microservice-focused managed and unified observability services (Dynatrace, Datadog, New Relic, Sumo Logic, Solar Winds, Honeycomb). The presented research prototype of this study heads into the same direction but tries to pursue the problem primarily on the instrumenting side using a more lightweight and unified approach. Thus, to address the client-side of the problem is obviously harder economical exploitable, which is why the industry might address the problem preferably on the managed service side.
Of logs, metrics, and distributed traces, distributed tracing is still considered in the most detail. In particular, the papers around Dapper [
25] (a large-scale distributed systems tracing infrastructure initially operated by Google) should be mentioned here, which had a significant impact on this field. A black box approach without instrumenting needs for distributed tracing is presented by [
43]. It reports on end-to-end performance analysis of large-scale internet services mainly by statistical means. However, these black-box approaches are pretty limited in their expressiveness since operations must record large data sets to derive transactions along distributed systems’ components simply due to their observable network behaviour. In the meantime, it has become an abode to accept the effort of white-box instrumentation to be able to determine and statistically evaluate precise transaction processes. In this context, Ref. [
44] compares and evaluates existing open tracing tools. Ref. [
45] provides an overview of how to trace distributed component-based systems. In addition, Ref. [
46] focuses on automated analysis of distributed tracing and corresponding challenges and research directions. This study, however, has seen tracing as only one of three aspects of observability and therefore follows a broader approach. Most importantly, this study has placed its focus on the instrumentation side of observability and less on the database and time series analysis side.
7.1. Existing Instrumenting Libraries and Observability Solutions
Although the academic coverage of the observability field is expandable, in practice, there is an extensive set of existing solutions, especially for time series analysis and instrumentation. A complete listing is beyond the scope of this paper. However, from the disproportion of the number of academic papers to the number of real existing solutions, one quickly recognizes the practical relevance of the topic.
Table 1 contains a list of existing database products often used for telemetry data consolidation to give the reader an overview without claiming completeness. This study used ElasticSearch as an analytical database.
Table 2 lists several frequently used forwarding solutions that developers can use to forward data from the point of capture to the databases listed in
Table 1. In the context of this study, FileBeat was used as a log forwarding solution. It could be proved that this solution is also capable of forwarding traces and metrics if applied in a structured logging setting.
An undoubtedly incomplete overview of instrumentation libraries for different products and languages is given in
Table 3, presumably because each programming language comes with its own form of logging in the shape of specific libraries. To avoid this language-binding is hardly possible in the instrumentation context unless one pursues “esoteric approaches” like [
43]. The logging library prototype is strongly influenced by the Python standard logging library but also by structlog for structured logging but without actually using these libraries.
7.2. Standards
There are hardly any observability standards. However, a noteworthy standardization approach is the OpenTelemetry Specification [
10] of the Cloud Native Computing Foundation [
66], which tries to standardize the way of instrumentation. This approach corresponds to the core idea, which this study also follows. Nevertheless, the standard is still divided into Logs [
67], Metrics [
68] and Traces [
69], which means that the conceptual triad of observability is not questioned. On the other hand, approaches like the OpenTelemetry Operator [
70] for Kubernetes enable injecting auto-instrumentation libraries for Java, Node.js and Python into Kubernetes operated applications, which is a feature that is currently not addressed by the present study. However, so-called service meshes [
71,
72] also use auto-instrumentation. A developing standard here is the so-called Service Mesh Interface (SMI) [
73].
8. Conclusions and Future Research Directions
Cloud-native software systems often have a much more decentralized structure and many independently deployable and (horizontally) scalable components, making it more complicated to create a shared and consolidated picture of the overall decentralized system state [
74,
75]. Today, observability is often understood as a triad of collecting and processing metrics, distributed tracing data, and logging—but why except for historical reasons?
This study presents a unified logging library for Python [
29] and a unified logging architecture (see
Figure 4) that uses a structured logging approach. The evaluation of four use cases shows that several thousand events per minute are easily processable and can be used to handle logs, traces, and metrics the same. At least, this study was able with a straightforward approach to log the world-wide Twitter event stream of stock market symbols over a period of six months without any noteworthy problems. As a side effect, some interesting aspects of how crypto-currencies are reflected on Twitter could be derived. This might be of minor relevance for this study but shows the overall potential of a unified and structured logging based observability approach.
The presented approach relies on an easy-to-use programming language-specific logging library that follows the structured logging approach. The long-term observation results of more than six months indicate that a unification of the current observability triad of logs, metrics, and traces is possible without the necessity to develop utterly new toolchains. The reason is the flexibility of the underlying structured logging approach. This kind of flexibility is a typical effect of data format standardization. The trick is to
use structured logging and
apply log forwarding to a central analytical database
in a systematic infrastructure- or platform-provided way.
Further research should therefore be concentrated on the instrumenting and less on the log forwarding and consolidation layer. If we instrument logs, traces, and metrics in the same style using the same log forwarding, we automatically generate correlatable data in a single data source of truth, and we simplify analysis.
Thus, the observability road ahead may have several paths. On the one hand, we should standardize the logging libraries in a structured style like log12 in this study or the OpenTelemetry project in the “wild”. Logging libraries should be comparably implemented in different programming languages and shall generate the same structured logging data. Thus, we have to standardize the logging SDKs and the data format. Both should be designed to cover logs, metrics, and distributed traces in a structured format. To simplify instrumentation further, we should additionally think about auto-instrumentation approaches, for instance, proposed by the OpenTelemetry Kubernetes Operator [
70] and several Service Meshes like Istio [
76,
77] and corresponding standards like SMI [
73].

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}