
Topology Inference and Link Parameter Estimation Based on End-to-End Measurements †




Abstract
:1. Introduction
- (i)
- link-level NT that regards the estimation of per link Quality of Service (QoS) parameters (e.g., loss rates, delays, jitter) based on end-to-end path measurements,
- (ii)
- path-level NT that concerns the estimation of the origin-destination (OD) traffic intensity matrix based on link-level measurements [5], and
- (iii)
- topology inference for reconstructing the topology of the network itself, which is considered unknown.
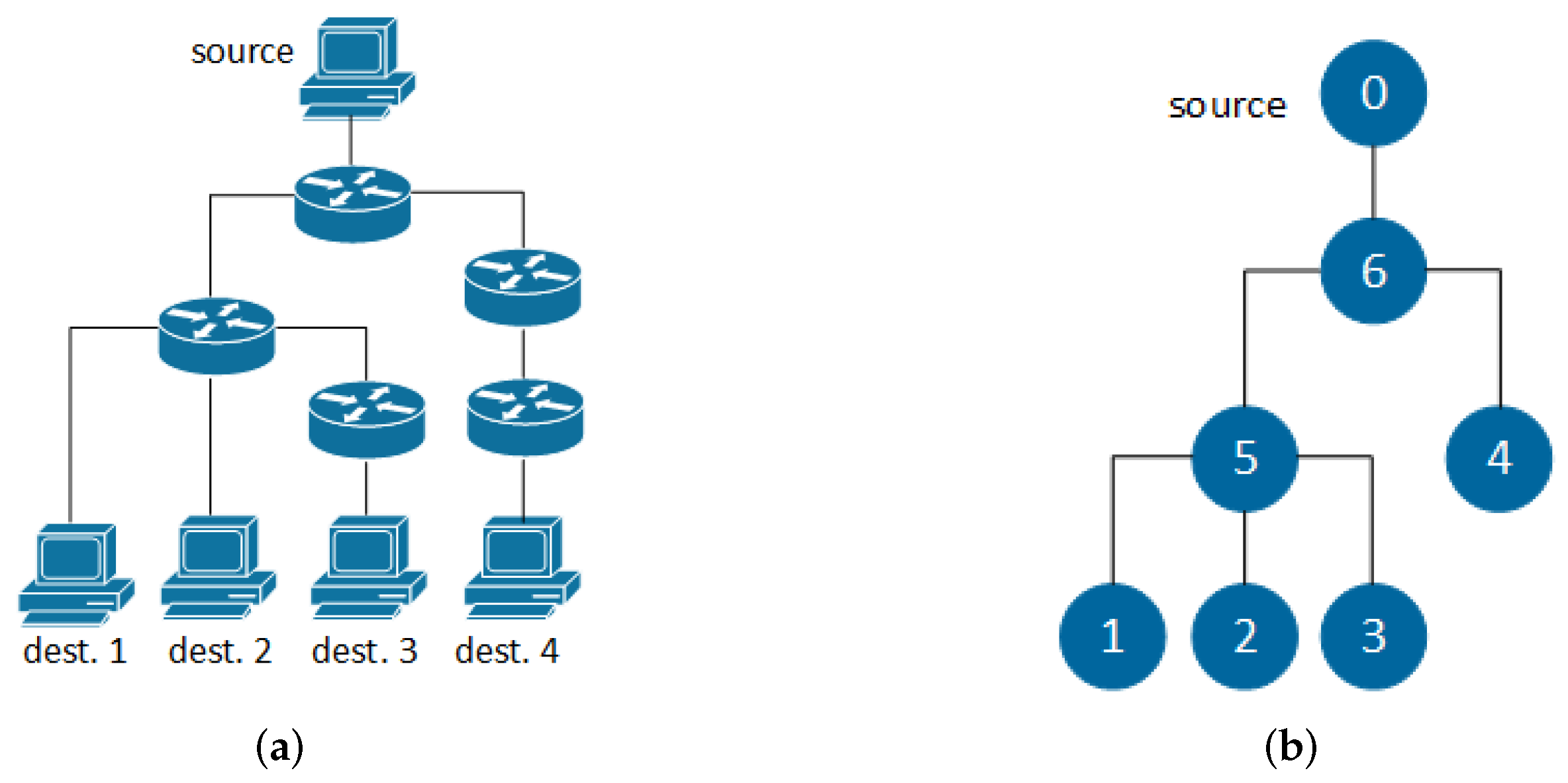
- The logical routing tree can be considered as the “skeleton” of the underlying physical topology, including only its intermediate branching points. To infer physical routing trees, we extend the nearest neighbor (NN) chain-enhanced agglomerative clustering algorithm [13] by incorporating information about hop counts.
- The reduction update formula, which is used at every iteration for calculating the distances between the newly generated parent and the rest nodes, is a critical feature of clustering algorithms. Taking that into consideration, we explore several reduction update formulas that guarantee the correctness of the proposed algorithm, and we examine their impact on the estimation accuracy of the link performance parameters.
- We implement the proposed clustering algorithm with all extensions and alternative options discussed in this paper, creating a complete command-line-based network tomography tool. We publish [14] the source code under a permissive free software license, along with detailed documentation.
- We extensively evaluate the performance of the proposed algorithm, over a comprehensive set of criteria, with real topologies constructed in an open large-scale testbed.
- We design and implement a practical application of the proposed NN-extended clustering algorithm that combines the NT-based monitoring with change point analysis for performance anomaly detection. The respective source code is also publicly available [14].
2. Network Model and Problem Formulation
2.1. Probing Model
2.2. Multicast Additive Metrics
- ,
- if and only if , and
- , otherwise.
- , where is the success rate (i.e., the complement of loss rate) of link e.
- , where is a random variable that expresses the random queuing delay of link e and is the square of jitter of link e, with jitter defined as the standard deviation of delay in order to be additive.
3. Topology Inference and Estimation of Link Parameters
3.1. Distance-Based Agglomerative Hierarchical Clustering
- loss rate of link and
- jitter of link
- The input of the algorithm is the source node s, the set of destination nodes D, and the estimated pairwise distances between terminal nodes calculated as described in Section 2.2.
- The output of the algorithm is the logical routing tree and the link lengths , from which we can obtain the link parameters .
- At initialization, we start by adding the source and the destinations to the set of nodes, , and we initialize the set of edges equal to the empty set, .
- For every pair of nodes i and j of the routing tree, the lowest common ancestor, , is the node that is located the farthest from the root and has both nodes as descendants. The depth of the lowest common ancestor, , expresses the length of the shared path from s to i and j. Given that there is a one-to-one mapping between the pairwise distances and the LCA depths, we can equivalently employ the latter to infer the routing tree and estimate the link parameters. To that end, at the step construction of LCA depths matrix, we compute the matrix of LCA depths using the equations
- At the neighbor selection step, we choose the two nodes that are deemed siblings and are about to be joined. Taking into account that the LCA depth of two nodes expresses the length of their shared path, we select the nodes i and j that are mutual or reciprocal nearest neighbor (RNNs), meaning that, for each one, their LCA depth is the largest among all others: . The idea is that two siblings must have the largest shared path with one another, compared to all other nodes. Such RNNs can be found efficiently by constructing nearest neighbor (NN) chains [16]. Essentially, a NN chain follows paths in the nearest neighbor graph of the clusters, until the paths terminate in a pair of RNNs. It starts at an arbitrary initial node, and it is iteratively extended from the current node at the top of the chain, say i, to its nearest neighbor j such that , until it necessarily terminates at a pair of RNNs. After joining the discovered RNNs, the rest NN chain is still valid and, therefore, it is not discarded. Each node (either destination or intermediate created parent) enters the NN chain only once, where it remains until it is joined with another node.
- At reduction step, we create node u as the parent of the previously found RNNs i and j, and we calculate its LCA depth with the remaining nodes . The choice of the employed reduction update formula is a crucial issue, which we analyze in Section 3.3.
- Tree reconstruction regards the update of the data structures related to the part of the tree that has been recovered up to this moment. In greater detail, we remove the found RNNs i and j from set D, ; we add the newly created parent node u to sets V and D, ; we add the two new edges to set E, ; and we connect i and j to u with link lengths and .
- Finally, if there is only one node left in set D (stopping condition ), we connect that remaining node with the source and we terminate the algorithm, otherwise we return to the neighbor selection step and we repeat the process.
3.2. Inferring Physical Routing Trees
3.3. Reduction Update Formulas
- the single reduction update formula:
- the complete reduction update formula:
- the average reduction update formula:
- the weighted reduction update formula:
4. Performance Evaluation
4.1. Experimental Setup
4.2. Results and Discussion
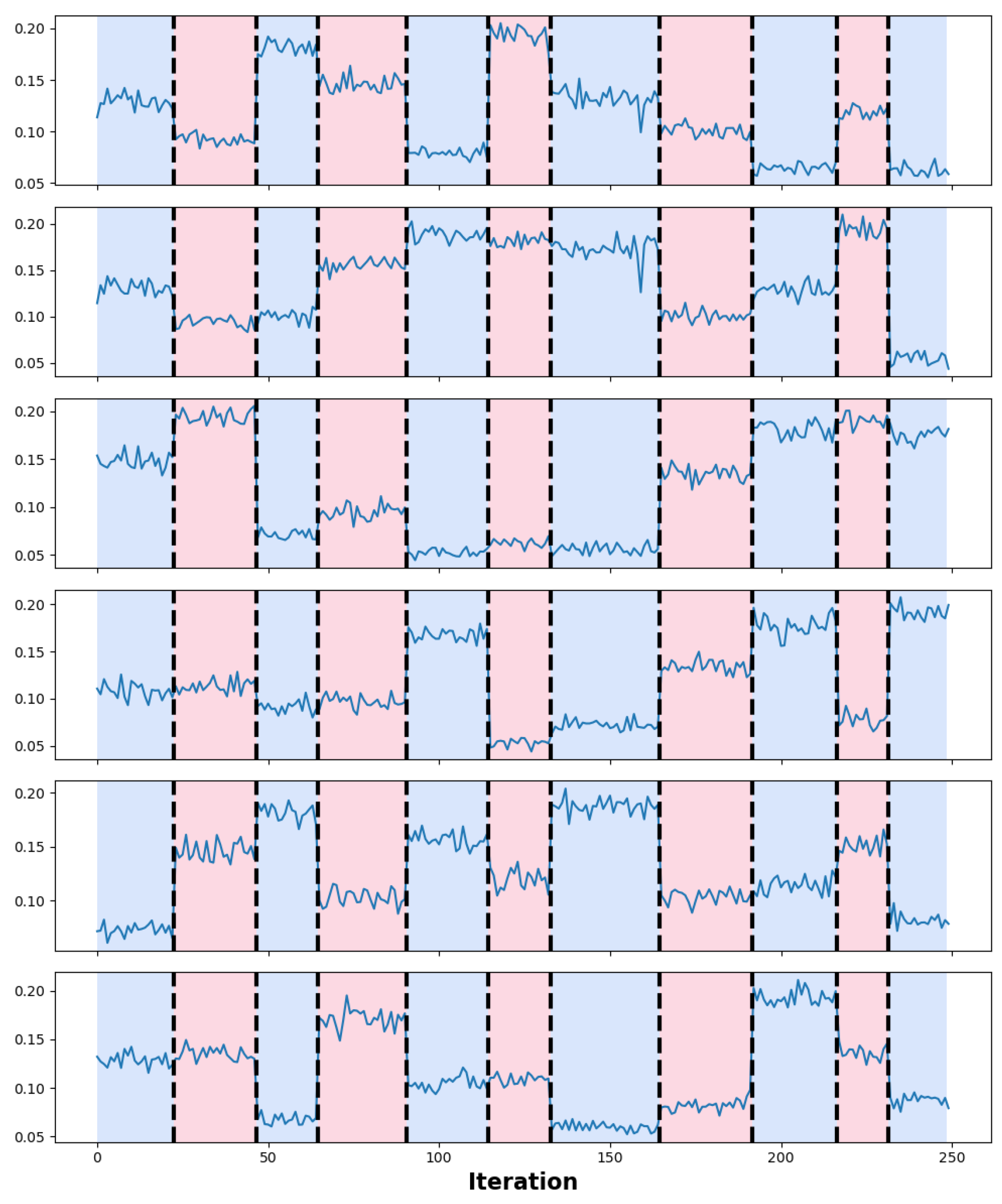
5. Motivating Detection Application
- We want to demonstrate the practical value of our technical content and point out that it is not limited to theoretical contributions.
- We aim to motivate the adoption and further extension of our methods by researchers and developers working on related problems by providing a ready-to-use open-source implementation of an NT-enabled network service.
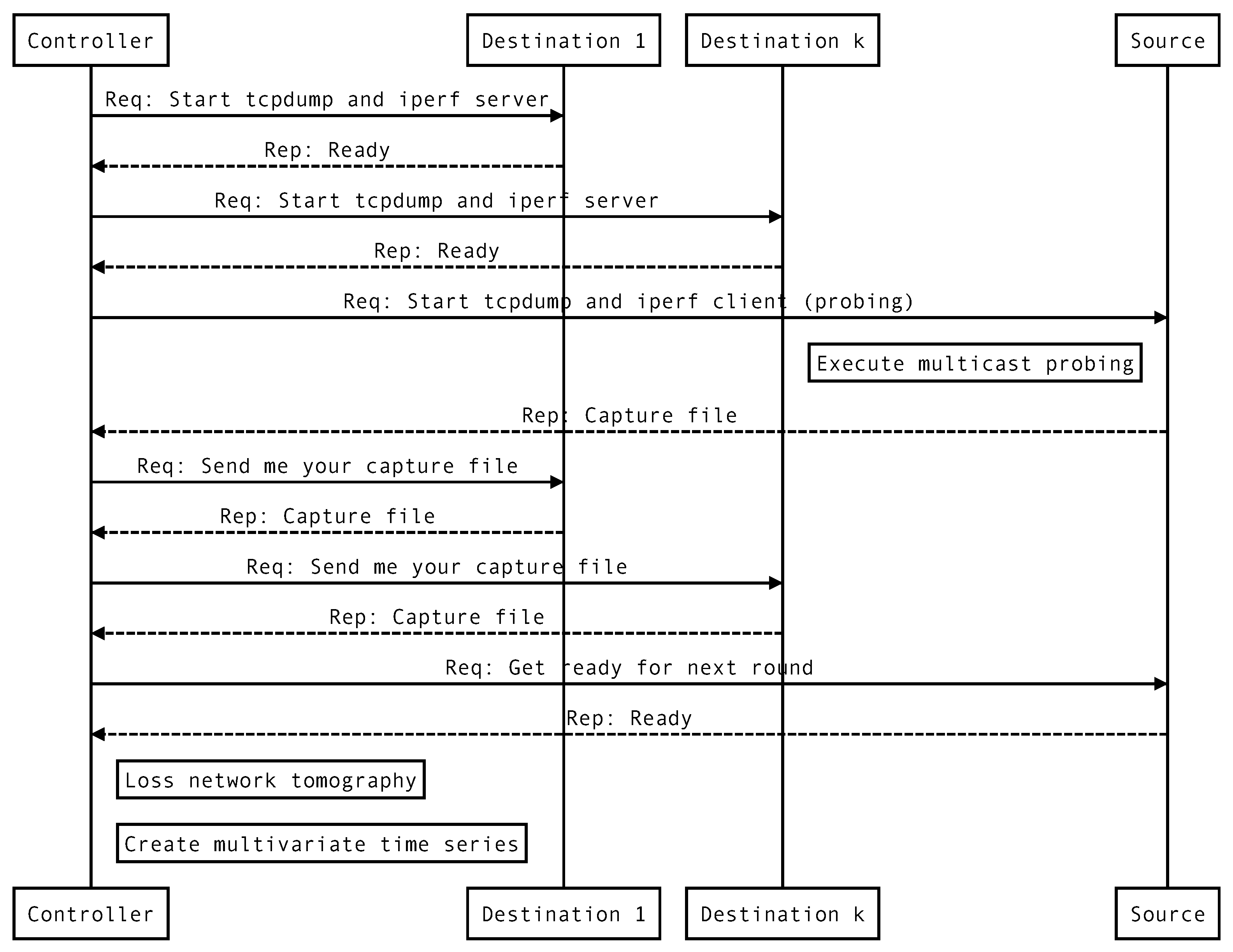
- We try to highlight some representative tools and outline the overall process that can be followed for performing validation trials and experiments with real equipment.
- (i)
- execute active multicast probing at the periphery of the network,
- (ii)
- apply the NN-extended clustering algorithm to estimate the loss rates of all links,
- (iii)
- repeat the previous two steps at regular intervals/rounds and record the obtained estimates in a multivariate time series, and
- (iv)
- perform offline change point analysis on the multivariate time series to detect the breakpoints, i.e., the rounds where the loss rates’ distribution changes significantly.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| INT | In-band Network Telemetry |
| PFE | Programmable Forwarding Engine |
| SDN | Software Defined Networking |
| NT | Network Tomography |
| QoS | Quality of Service |
| OD | Origin-Destination |
| NN | Nearest Neighbor |
| SSM | Source-Specific Multicast |
| MLE | Maximum Likelihood Estimator |
| LCA | Lowest Common Ancestor |
| RNNs | Reciprocal Nearest Neighbor |
| TTL | Time-To-Live |
| RMSE | Root Mean Square Error |
References
- Haxhibeqiri, J.; Isolani, P.H.; Marquez-Barja, J.M.; Moerman, I.; Hoebeke, J. In-Band Network Monitoring Technique to Support SDN-Based Wireless Networks. IEEE Trans. Netw. Serv. Manag. 2021, 18, 627–641. [Google Scholar] [CrossRef]
- Sonchack, J.; Michel, O.; Aviv, A.J.; Keller, E.; Smith, J.M. Scaling Hardware Accelerated Network Monitoring to Concurrent and Dynamic Queries with *Flow. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 823–835. [Google Scholar]
- Kakkavas, G.; Stamou, A.; Karyotis, V.; Papavassiliou, S. Network Tomography for Efficient Monitoring in SDN-Enabled 5G Networks and Beyond: Challenges and Opportunities. IEEE Commun. Mag. 2021, 59, 70–76. [Google Scholar] [CrossRef]
- Kakkavas, G.; Gkatzioura, D.; Karyotis, V.; Papavassiliou, S. A Review of Advanced Algebraic Approaches Enabling Network Tomography for Future Network Infrastructures. Future Internet 2020, 12, 20. [Google Scholar] [CrossRef] [Green Version]
- Kakkavas, G.; Kalntis, M.; Karyotis, V.; Papavassiliou, S. Future Network Traffic Matrix Synthesis and Estimation Based on Deep Generative Models. In Proceedings of the 2021 International Conference on Computer Communications and Networks (ICCCN), Athens, Greece, 19–22 July 2021. [Google Scholar] [CrossRef]
- Caceres, R.; Duffield, N.G.; Horowitz, J.; Towsley, D.F. Multicast-based inference of network-internal loss characteristics. IEEE Trans. Inf. Theory 1999, 45, 2462–2480. [Google Scholar] [CrossRef] [Green Version]
- Duffield, N.; Horowitz, J.; Presti, F.L.; Towsley, D. Multicast topology inference from measured end-to-end loss. IEEE Trans. Inf. Theory 2002, 48, 26–45. [Google Scholar] [CrossRef]
- Presti, F.L.; Duffield, N.; Horowitz, J.; Towsley, D. Multicast-based inference of network-internal delay distributions. IEEE/ACM Trans. Netw. 2002, 10, 761–775. [Google Scholar] [CrossRef] [Green Version]
- Liang, G.; Yu, B. Maximum pseudo likelihood estimation in network tomography. IEEE Trans. Signal Process. 2003, 51, 2043–2053. [Google Scholar] [CrossRef]
- Duffield, N.; Horowitz, J.; Presti, F.L.; Towsley, D. Explicit Loss Inference in Multicast Tomography. IEEE Trans. Inf. Theory 2006, 52, 3852–3855. [Google Scholar] [CrossRef]
- Ni, J.; Xie, H.; Tatikonda, S.; Yang, Y. Efficient and Dynamic Routing Topology Inference from End-to-End Measurements. IEEE/ACM Trans. Netw. 2010, 18, 123–135. [Google Scholar] [CrossRef]
- Ni, J.; Tatikonda, S. Network Tomography Based on Additive Metrics. IEEE Trans. Inf. Theory 2011, 57, 7798–7809. [Google Scholar] [CrossRef]
- Kakkavas, G.; Karyotis, V.; Papavassiliou, S. A Distance-based Agglomerative Clustering Algorithm for Multicast Network Tomography. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020. [Google Scholar] [CrossRef]
- Kakkavas, G. Inferential Network Monitoring. Available online: https://gitlab.com/gkakkavas/lca-rnn-extension (accessed on 7 January 2022).
- Buneman, P. The Recovery of Trees from Measures of Dissimilarity. In Mathematics the Archeological and Historical Sciences; Edinburgh University Press: Edinburgh, UK, 1971; pp. 387–395. [Google Scholar]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview, II. WIREs Data Min. Knowl. Discov. 2017, 7. [Google Scholar] [CrossRef] [Green Version]
- Müllner, D. Modern hierarchical, agglomerative clustering algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Virtual Wall. Available online: https://doc.ilabt.imec.be/ilabt/virtualwall/ (accessed on 7 January 2022).
- Federation For Fire Plus. Available online: https://www.fed4fire.eu/ (accessed on 7 January 2022).
- Aminikhanghahi, S.; Cook, D.J. A survey of methods for time series change point detection. Knowl. Inf. Syst. 2016, 51, 339–367. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Truong, C.; Oudre, L.; Vayatis, N. Selective review of offline change point detection methods. Signal Process. 2020, 167, 107299. [Google Scholar] [CrossRef] [Green Version]
- Hintjens, P. ØMQ—The Guide. Available online: https://zguide.zeromq.org/ (accessed on 5 January 2022).
- Killick, R.; Fearnhead, P.; Eckley, I.A. Optimal Detection of Changepoints with a Linear Computational Cost. J. Am. Stat. Assoc. 2012, 107, 1590–1598. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Physical | Single | Complete | Average | Weighted | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Routing Tree | 2k | 5k | 10k | 2k | 5k | 10k | 2k | 5k | 10k | 2k | 5k | 10k | |
| Type | # Nds | Root Mean Square Error for Loss Rate Estimation (%) | |||||||||||
| Bin. | 8 | 0.6369 | 0.4859 | 0.3879 | 0.5892 | 0.3714 | 0.4061 | 0.6124 | 0.4248 | 0.3961 | 0.6124 | 0.4248 | 0.3961 |
| Bin. | 16 | 1.1824 | 0.6066 | 0.4431 | 1.8491 | 0.7492 | 0.4333 | 1.2346 | 0.6496 | 0.3912 | 1.2189 | 0.6442 | 0.3902 |
| Bin. | 24 | 1.2486 | 0.4924 | 0.4086 | 1.2859 | 0.5643 | 0.4939 | 1.1297 | 0.4881 | 0.4152 | 1.1393 | 0.5087 | 0.3963 |
| Bin. | 32 | 1.5678 | 0.9790 | 0.7226 | 1.5692 | 0.9542 | 0.5588 | 1.1749 | 0.8423 | 0.4649 | 1.1980 | 0.8354 | 0.4399 |
| Gen. | 10 | 0.7798 | 0.3335 | 0.4609 | 0.7787 | 0.3172 | 0.6394 | 0.6826 | 0.3180 | 0.5238 | 0.6627 | 0.3177 | 0.5357 |
| Gen. | 20 | 1.1571 | 0.5012 | 0.3354 | 0.9676 | 0.6972 | 0.3640 | 0.9334 | 0.5398 | 0.3079 | 0.8770 | 0.5344 | 0.3173 |
| Gen. | 30 | 0.9128 | 0.5867 | 0.6108 | 0.8889 | 0.5476 | 0.4623 | 0.7308 | 0.5169 | 0.4707 | 0.7432 | 0.5157 | 0.4718 |
| Gen. | 40 | 1.2380 | 0.8134 | 0.6406 | 1.2977 | 0.8368 | 0.6924 | 1.0557 | 0.6950 | 0.5111 | 1.1451 | 0.6597 | 0.5120 |
| Type | # Nds | Root Mean Square Error for Jitter Estimation (ms) | |||||||||||
| Bin. | 8 | 2.2884 | 2.2625 | 1.8829 | 2.4840 | 2.3450 | 1.9747 | 2.3589 | 2.2891 | 1.9122 | 2.3589 | 2.2891 | 1.9122 |
| Bin. | 16 | 10.7957 | 5.1186 | 3.3833 | 7.5524 | 4.7407 | 4.0048 | 7.7135 | 4.7855 | 3.6110 | 7.1554 | 4.7276 | 3.3867 |
| Bin. | 24 | 9.0789 | 5.2434 | 4.0306 | 8.9049 | 4.7218 | 3.4756 | 7.7404 | 4.7545 | 3.6221 | 7.6445 | 4.6965 | 3.4926 |
| Bin. | 32 | 13.4703 | 7.4144 | 4.4306 | 14.6285 | 10.1443 | 6.5357 | 10.9308 | 7.0454 | 4.3438 | 11.0575 | 6.7905 | 4.4002 |
| Gen. | 10 | 1.9835 | 1.5422 | 1.4080 | 3.6359 | 1.5546 | 1.5469 | 1.8689 | 1.3350 | 1.4610 | 2.1025 | 1.3607 | 1.4249 |
| Gen. | 20 | 7.7615 | 4.5666 | 3.2201 | 9.3203 | 5.8837 | 3.8564 | 6.0876 | 4.7976 | 3.1658 | 5.7866 | 4.7219 | 3.1139 |
| Gen. | 30 | 7.3599 | 6.0090 | 3.2523 | 12.8225 | 8.3969 | 5.1931 | 7.4152 | 5.2917 | 3.5243 | 6.8374 | 5.2616 | 3.4022 |
| Gen. | 40 | 11.8077 | 6.4343 | 5.0352 | 14.0348 | 7.7253 | 6.7969 | 10.3950 | 5.2412 | 4.4222 | 10.2611 | 5.1472 | 4.2874 |
| Physical Tree | Single | Complete | Average | Weighted | |
|---|---|---|---|---|---|
| Type | # Nds | Loss Rate Estimation Execution Time (s) | |||
| Bin. | 8 | 0.2665 | 0.2614 | 0.2592 | 0.2645 |
| Bin. | 16 | 0.3005 | 0.3042 | 0.2988 | 0.2989 |
| Bin. | 24 | 0.3950 | 0.3940 | 0.4008 | 0.3976 |
| Bin. | 32 | 0.4626 | 0.4586 | 0.4578 | 0.4555 |
| Gen. | 10 | 0.2879 | 0.2847 | 0.2876 | 0.2878 |
| Gen. | 20 | 0.3669 | 0.3655 | 0.3699 | 0.5344 |
| Gen. | 30 | 0.4797 | 0.4857 | 0.4798 | 0.4793 |
| Gen. | 40 | 0.5346 | 0.5285 | 0.5357 | 0.5281 |
| Type | # Nds | Jitter Estimation Execution Time (s) | |||
| Bin. | 8 | 0.3229 | 0.3257 | 0.3212 | 0.3272 |
| Bin. | 16 | 0.4459 | 0.4515 | 0.4459 | 0.4448 |
| Bin. | 24 | 0.6800 | 0.6871 | 0.6803 | 0.6816 |
| Bin. | 32 | 0.9027 | 0.9021 | 0.9127 | 0.9140 |
| Gen. | 10 | 0.3823 | 0.3783 | 0.3830 | 0.3809 |
| Gen. | 20 | 0.6514 | 0.6620 | 0.6668 | 0.6620 |
| Gen. | 30 | 1.0172 | 1.0143 | 1.0189 | 1.0104 |
| Gen. | 40 | 1.3413 | 1.3435 | 1.3496 | 1.3294 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kakkavas, G.; Karyotis, V.; Papavassiliou, S. Topology Inference and Link Parameter Estimation Based on End-to-End Measurements. Future Internet 2022, 14, 45. https://doi.org/10.3390/fi14020045
Kakkavas G, Karyotis V, Papavassiliou S. Topology Inference and Link Parameter Estimation Based on End-to-End Measurements. Future Internet. 2022; 14(2):45. https://doi.org/10.3390/fi14020045
Chicago/Turabian StyleKakkavas, Grigorios, Vasileios Karyotis, and Symeon Papavassiliou. 2022. "Topology Inference and Link Parameter Estimation Based on End-to-End Measurements" Future Internet 14, no. 2: 45. https://doi.org/10.3390/fi14020045
APA StyleKakkavas, G., Karyotis, V., & Papavassiliou, S. (2022). Topology Inference and Link Parameter Estimation Based on End-to-End Measurements. Future Internet, 14(2), 45. https://doi.org/10.3390/fi14020045