1. Introduction
Nowadays, social networks play an increasingly big role in social and political life, with prominent examples of user discussions shaping public opinion on a variety of important issues. Extraction of public views from social media datasets is a goal that unites sociolinguistic tasks such as sentiment analysis, emotion, and topic extraction, finding product-related recommendations, political polarization analysis, or detection of hidden user communities may be performed via text classification, fuzzy or non-fuzzy clustering, text summarization, text generation, and other techniques of information retrieval. At their intersection, study areas such as sentiment analysis or topic modeling studies have formed.
In particular, topicality extraction is a task that most often employs probabilistic clustering such as topic modeling [
1,
2,
3], its extensions, or combinations with sentiment analysis [
4] or other classes of tasks. However, topic modeling, despite its wide area of application, has many well-known disadvantages. Among them is topic instability [
5,
6,
7], difficulties with interpretation [
8], artifacts of topic extraction [
9], and low quality of topicality extraction for very short texts that need to be pooled to receive distinguishable topics [
10]. However, an even bigger problem lies in the fact that, for fast enough assessment of topicality, topic modeling may not fit, as it provides only hints to topics via top words but does not summarize the meaning of the texts relevant to a given topic. Nor does it help outline the themes of specific elements of networked discussions, such as comment threads or ‘echo chamber’ modules. Moreover, topic modeling takes the dynamics of discussions for statics of a collected dataset, and even topic evolution studies do not allow for clear extraction of particular meanings of discussion fragments and cannot trace how exactly the discussion themes change [
11]. This is just one example of how text summarization could have helped social media studies. Thus, it is regrettable that text summarization techniques are not developed for it.
Their lack is even more regrettable as, today, a range of new-generation deep learning models for text summarization are available that provide for significantly better results for summarization of structurally diverse and noisy texts. Of them, transfer-learning Transformer-based models have produced state-of-the-art results (see
Section 2.2). They, though, need to be adapted for tasks relevant for social media datasets and fine-tuned with regard to the specific features of the data such as use of specific language and platform affordances that shape the data properties, e.g., short/varying length, high level of noise, presence of visual data, etc. Here, the advantage is that, for neural-network text summarization models, problems similar to those in topic modeling may be resolved somewhat easier, by pre-training and fine-tuning instead of development of specialized models of model extensions.
Despite this, we still have no clear understanding which Transformer-based model(s) work best with social media data, due to the scarcity of comparative research. Each of these models has notable drawbacks and need pre-testing and fine-tuning for social media data; only after such fine-tuning may these models be compared in quality. This is the first research gap, which we identify and address regarding these new models that may be used for text summarization, such as those based on BART and Transformer architectures, which have not yet been compared after their fine-tuning for particular types of data.
For some time already, text summarization studies have used text collections from Reddit. Among different social media platforms, Reddit is undeniably one of the most prominent platforms. First, it differs from others thanks to higher structural heterogeneity of discussion groups (subreddits), which also implies opinion diversity. Second, it has many times sparked large-scale cross-platform discussions leading to cross-national outrage (e.g., on the Boston Marathon Bombing suspects in 2013) and shaped trends in developed economies (e.g., AMC and Gamestop stock investments changing financial strategies of Wall Street). At one point, it used to be the third most popular website in the USA. Third, and most important for text summarization studies, it has platform affordances that demand users create author text summarizations that may be used as target texts.
Compared to other discussion platforms such as Twitter or Facebook, Reddit has been under-researched for application of automated text analysis in general, and of transfer learning in particular. Examples of the recent Reddit-based opinion explorations include studying COVID-19 publications using statistical techniques (with Reddit being just one of many datasets) [
12], community detection using topic information [
13], and applying sentiment analysis to Reddit data [
14], but such studies do not seem to form a notable field within opinion mining from social media. On the other hand, for abstractive text summarization studies, Reddit, in effect, is today the only social media platform that has provided multiple datasets of user-generated content—or, more precisely, users’ self-authored summaries, thanks to its “Too Long; Didn’t Read” (TL;DR) feature that allows discussion participants leave human summarizations for posts. Text summarization studies, thus, employ Reddit datasets to test models—but next-to-never are applied to answer sociological or communication science questions with the help of these models, which leaves the question of their applicability open. This is the second research gap that we address. The most recent works that involve Reddit [
15,
16] compare deep-learning extractive and abstractive summarization, and abstractive models, especially BART and its extensions, are shown to have the best results in comparison with ground truth. However, newer models such as T5 and LongFormer have not yet been tested on Reddit, even if T5 has already been used in summarization studies [
17].
Out of it, one can clearly see that text summarization studies for social media are still at the very early stage of development, and the highly advanced neural-network models that produce good results for other types of textual data are still to be applied to various social media platforms beyond Reddit. We see this as the third research gap. Today, the scarcity of labeled datasets for text summarization studies highly limits the development of text summarization models for other platforms; we will perform a step further here and apply the models to real-world data on Twitter.
Moreover, as we have shown above, social media data have a complicated nature. They are not only noisy, but also structurally diverse. What matters sociologically is not only the meaning of single posts but also that of pools of user posts and/or comments that correspond to elements of networked discussion structure. Summarization of text pools exists, but not for social media data; this is the fourth gap that we address.
Thus, this study aims at several consecutive steps in expanding today’s abstractive summarization studies in their application to social media data. First, it is the fine-tuning and comparative assessment of Transformer-based abstractive summarization models for the Reddit data. As per other scholars, we use Reddit as an exemplary platform, but add T5 and LongFormer models to BERTSum and BART already tested on Reddit. We perform this by utilizing a research pipeline that includes data collection and preprocessing; model loading, fine-tuning, and application; and comparative assessment of the results and their visualization. As stated above, the chosen models are first fine-tuned on a standard open-source-labeled Reddit dataset, to receive the large-scale pre-trained models adapted to social media analysis. Second, the chosen fine-tuned model is additionally tested on posts collected from a specific subreddit of 150,000 posts, to define how well the fine-tuned models work against the original versions. Third, we apply the fine-tuned model to pools of the most popular comments and juxtapose the respective summarizations, to see by human assessment whether the model can, in principle, be applied to pooled social media data. However, the fine-tuned models, due to the known limitation of their capacity (they work best with texts or text pools limited to 512 tokens) do not provide for solving real-world analysis of comment threads or discussion outbursts. This is why, fourth, we apply enlarged Transformer-based models to Twitter data in three languages, to discover how enlarged models would work with pooled data and with non-English texts. In particular, we test the selected models on Twitter data of 2015, using the discussion on the Charlie Hebdo massacre on three languages (English, German, and French), and show that, despite the fine-tuning and its satisfactory results for Reddit in English, the models need more work for German and French, while it works well for short English texts.
Thus, the novelty of this paper lies in three aspects. First, we fine-tune the models and choose between the LongFormer, Bart, and T5 ones. Second, we test the fine-tuned models on the new Reddit dataset, which can be considered testing on raw data. Third, we test our models on Twitter data on three languages and show that they need additional work for the languages other than English, while short texts provide fewer complications than expected.
The remainder of this paper is organized as follows.
Section 2 provides a review on deep learning in text summarization studies, including how text summarizations have been applied to Reddit data until now.
Section 3 provides the fine-tuning methodology, including the research pipeline and evaluation metrics, as described above.
Section 4 provides the results of comparative assessment of the fine-tuned models.
Section 5 describes the new real-world dataset, provides examples the resulting summaries for posts and pools of comments, as well as and their human assessment. In the absence of labeled target collections for comment pools, we use post summaries as targets for summarizations of the respective pools of comments. In
Section 6, to overcome the limitations of the original models, we apply the enlarged models to Twitter data on three languages. We conclude by putting our results at the background of today’s leading research.
5. The Model Application to Real-World Reddit Posts and Comments
5.1. Applying the Model to the Dataset of Unlabeled Reddit Posts
The chosen model has been tested on new data to show its efficiency on the previously unseen data. In our previous practice of working with automated text analysis, we have seen multiple times that the models that are believed to work well by automatic metrics do not really provide for satisfactory results when the result is human assessed. This is why we have applied the fine-tuned T5 model to the unlabeled data, to assess by human eye the user summaries (TL;DRs) vs. machine summaries and reveal possible shortcomings. We especially underline here that the Transformer-based models especially fine-tuned for a certain type of data (Reddit) have not been previously tested on the raw data from the platform; before our tests, only non-fine-tuned models were applied to massive Reddit datasets, and the results were compared to data of a different nature, which did not lead to better performance for opinion mining from social media.
We have obtained the data from ‘r/wallstreetbets’ subreddit, one of the most popular on Reddit (of over 10 million users). Recently, it has been the origin point of a major social-economic discussion involving stock trades. We have collected this subreddit in order to test the model on the data that do not belong to any existing dataset specifically prepared for summarization tests; thus, the collected data may be called real-world, unlabeled, or raw data. The top posts were collected, most of them dated circa mid-2020 (around the time of the highest user engagement). A total of 150,000 posts were collected.
First, we received the automated summaries and assessed them per se (as sentences) in the working group that contained experienced Internet researchers, communication scientists, and linguists. Here, we need to note that not many posts on Reddit have the TL;DR addition; this is why it is important to assess the automated summaries vs. both the posts themselves, not only vs. TL;DRs. We have assessed both.
When juxtaposed to the posts themselves, the summaries were coherent short sentences with clear relation to post title (see
Table 3); although, the extent of this connection requires further automated testing. The summaries correctly reflected the nature of posts, including the first-person speech (‘I hate the market…’), user’s opinion/position (‘Weird price is now around where the volumes dropped off’), argumentation structure (‘This post is not about the fundamentals in the first place’), and emotions (‘The bastards who steal thousands of years off the regular man’s lives…’). There were some shortcomings in logic (‘I hate the market, and I don’t think we need to talk to each other’) and grammar, e.g., some rare statements with no predicate. We have also spotted some hint of extraction, rather than abstraction, for shorter texts where key short phrases were added to abstractive parts of summaries (‘There are a lot of factors out here. It is not a meme.’). In addition, when the posts were changed many times (e.g., had ‘Edit 5′, ‘Edit 6′, etc.) or had many multi-vector reasons the author gave to argue his/her position, the machine tended to summarize with excessive generalization (‘There are a lot of factors here’; ‘There is a good reason for GME’). However, the summaries, in general, mirrored the contents of the Reddit posts correctly and to the point. For examples of posts with no TL;DR and their summaries, see
Appendix A.
More surprising results were brought when we have tried to compare the automated summaries to user TL;DRs (see
Table 4). The number of the posts with TL;DRs was very small and, thus, could be closely assessed by the experts. The machine summaries corresponded to the user summaries in only circa 50% of posts. However, this was not due to the low quality of post summarization, but because the Reddit users did not properly use the TL;DR function, making sarcastic, aggressive, or non-sensical claims under ‘TL;DR’. Where user summaries truly reflected the essence of the posts, the machine summaries closely resembled the user TL;DRs. However, where the authors used TL;DR for conveying some emotional message, swearing, or slang-based claims, the machine summary could not create a similar one, as it was oriented to the post, not to TL;DR (see
Table 4, line 4). In case when the posts consisted of links and its TL;DR had words, the machine returned unreliable results (see
Table 4, line 5).
This revelation problematizes the Reddit-based summarization research, as it poses a fundamental question: Do we teach the machine to ‘ideally’ summarize the post, or do we teach it to produce human-like summaries (with all the ironic and unpredictable uses of TL;DRs), as this is not the same?
All in all, the fine-tuned T5 model showed its high capacity for summarizing posts correctly and close to human summaries and may be recommended for further practical of the data from Reddit—however, with no orientation to the TL;DR section of the posts, as this section itself might be highly misleading.
5.2. The Model Application to Pools of Comments
As stated above, for social media analysis, it is crucial to have a possibility to summarize pools of user posts and/or comments. Thus, we have conducted tests on a collection of comments from the abovementioned collection of posts.
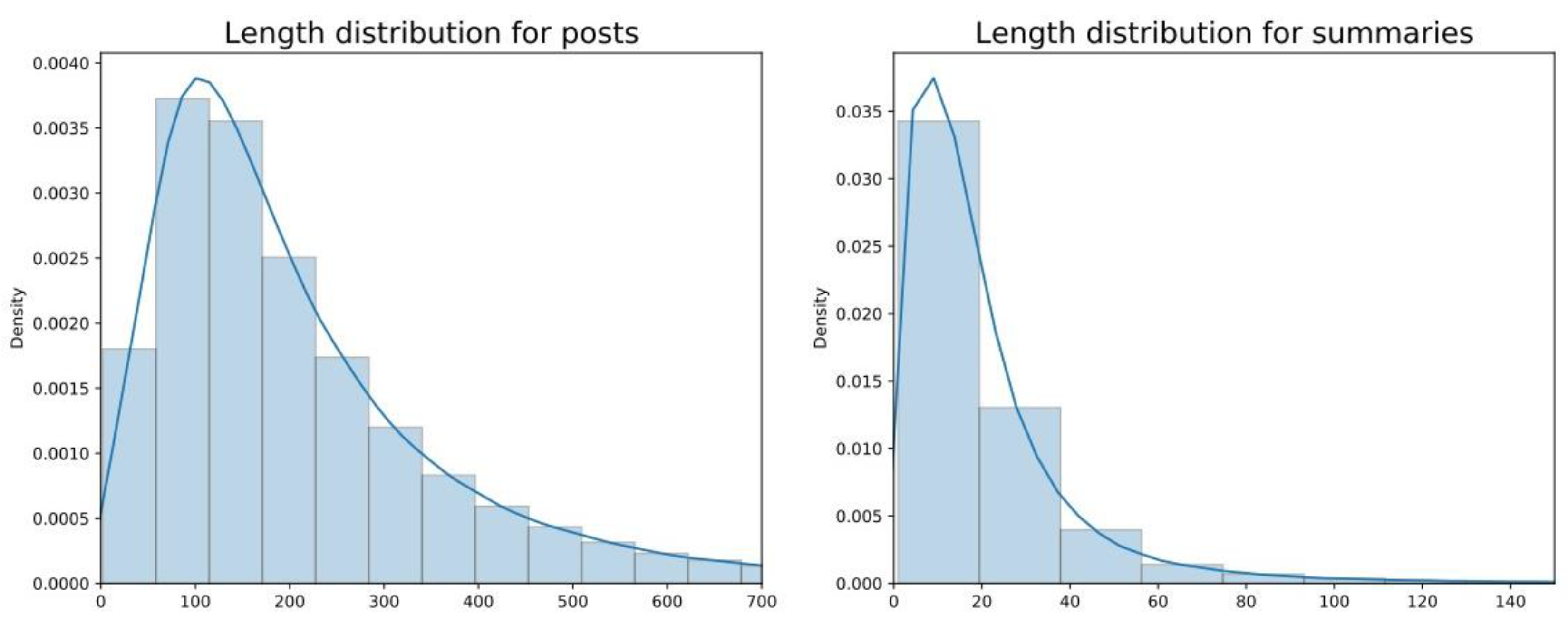
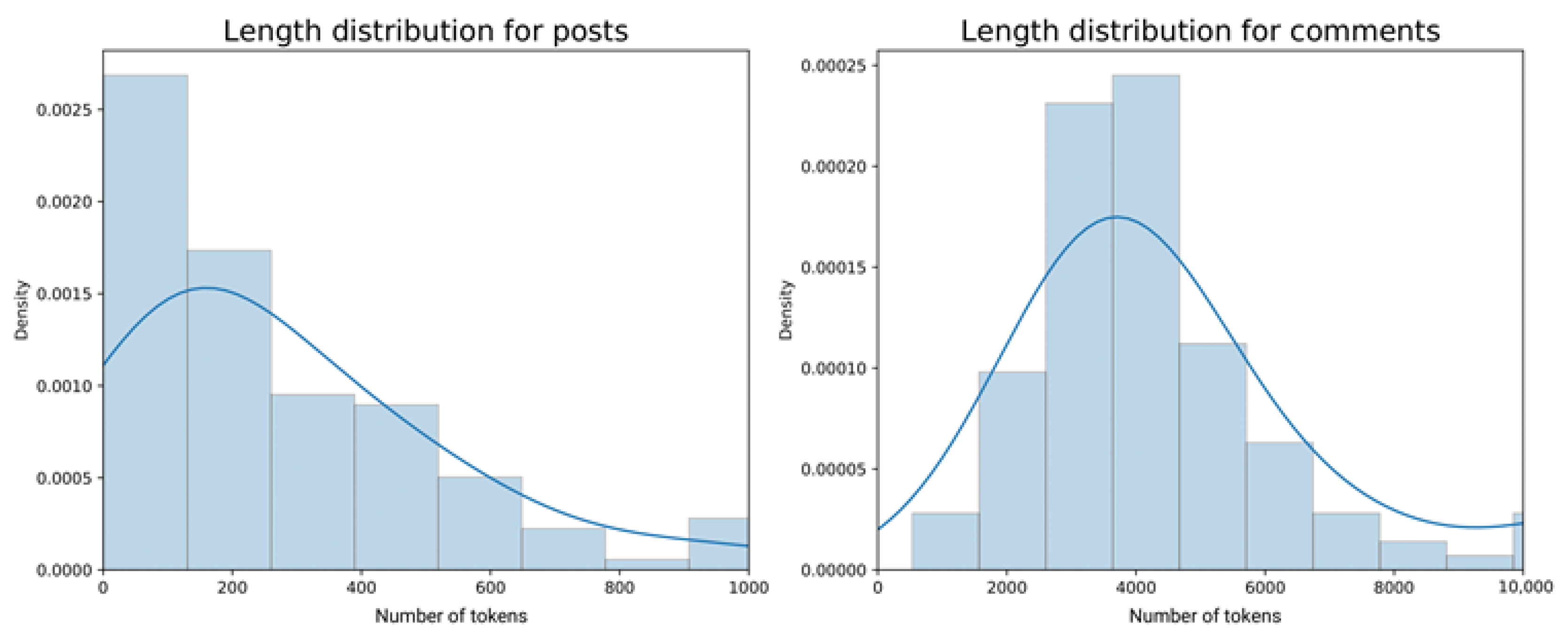
The test sub-dataset of comments was collected on the basis of their popularity. As the model we applied had a limitation of working best with the 512-token texts, we had to limit the length of each pool; this limitation was not relevant for posts, most of which were shorter, but it was crucial for the comment pools (see
Figure 4 for the length distribution in the sub-datasets of posts and comment pools).
Due to their high volume and the model limitations, the collection of comments had the following logic. First, we uploaded the top popular 30% of all comments per post, without additional subsequent answers to comments. Even after this, as
Figure 4 demonstrates, the average length of comment pools subjected to summarization was ~4000 words, instead of ~150+ words for the posts. Thus, only the most popular comments of the 30% pools that fitted to the 512-token limitation were summarized.
On the comments, the fine-tuned model has, in general, shown stronger results than the non-fine-tuned model, and the baseline threshold of 512 tokens was, technically, not an issue. This means that abstractive summarization can be directly applied to summarize pools of user texts, e.g., the posts/comments by one author, discussion threads, or topic-related pools previously discovered by topic modeling techniques.
Human assessment has shown that some comment summaries are capable of capturing both the topicality of the post and the general mood of commenters, e.g., their opposition to the author (see
Table 5, line 1, the post on prices of shares), just as their shared sentiment with the author of the post (see
Table 5, line 2, the post on wage wars). The comments also had some grammar structures typical for argumentation (‘This is not about the market, it’s about how much you are willing to pay attention to your own product’, see
Table 5, line 1). Examples of comment summaries may also be found in
Appendix A.
However, this was the case in less than 50% cases. In many enough cases, the summaries conveyed only the basic opinion (see
Table 5, line 3) or the basic emotion, often quite a rude one (see
Table 5, line 4). There are also cases where the comments are unanimously supportive of the author, and the post, its TL;DR, and its automated post summary are clear, but the comments are not summarized well and only convey minor elements of meaning (see
Table 5, line 5).
All in all, summarizing the comments looks less successful than that of posts, which is expected, given that there are up to dozens of texts that are summarized. They all have varying user emotions, micro-topics, and argumentation structures. Our advice here would be to deal with sub-pools of comments delineated technically (e.g., comment threads), topically (e.g., via topic modeling), or via clustering (e.g., via agglomerative clustering with the Markov moment [
55]).
One more reason for smaller success could be that the comments to be summarized were of highly varying length, not only of different emotionality or topicality. This is why we have decided to apply the Transformer-based methods to pools of texts where the length does not vary that significantly. Such datasets can be found on Twitter.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


