
Unsupervised Anomaly Detection and Segmentation on Dirty Datasets

Abstract
:
1. Introduction
- Unsupervised anomaly detection methods degrade in performance due to noise. We propose a framework PaIRE to address unsupervised anomaly detection when the training set contains noise;
- A slope sliding window method is designed to reduce the effect of noise for improving the noise resistance of the proposed model;
- An iterative module is proposed to make the model estimate the distribution of normal samples more accurately from the dirty dataset;
2. Related Works
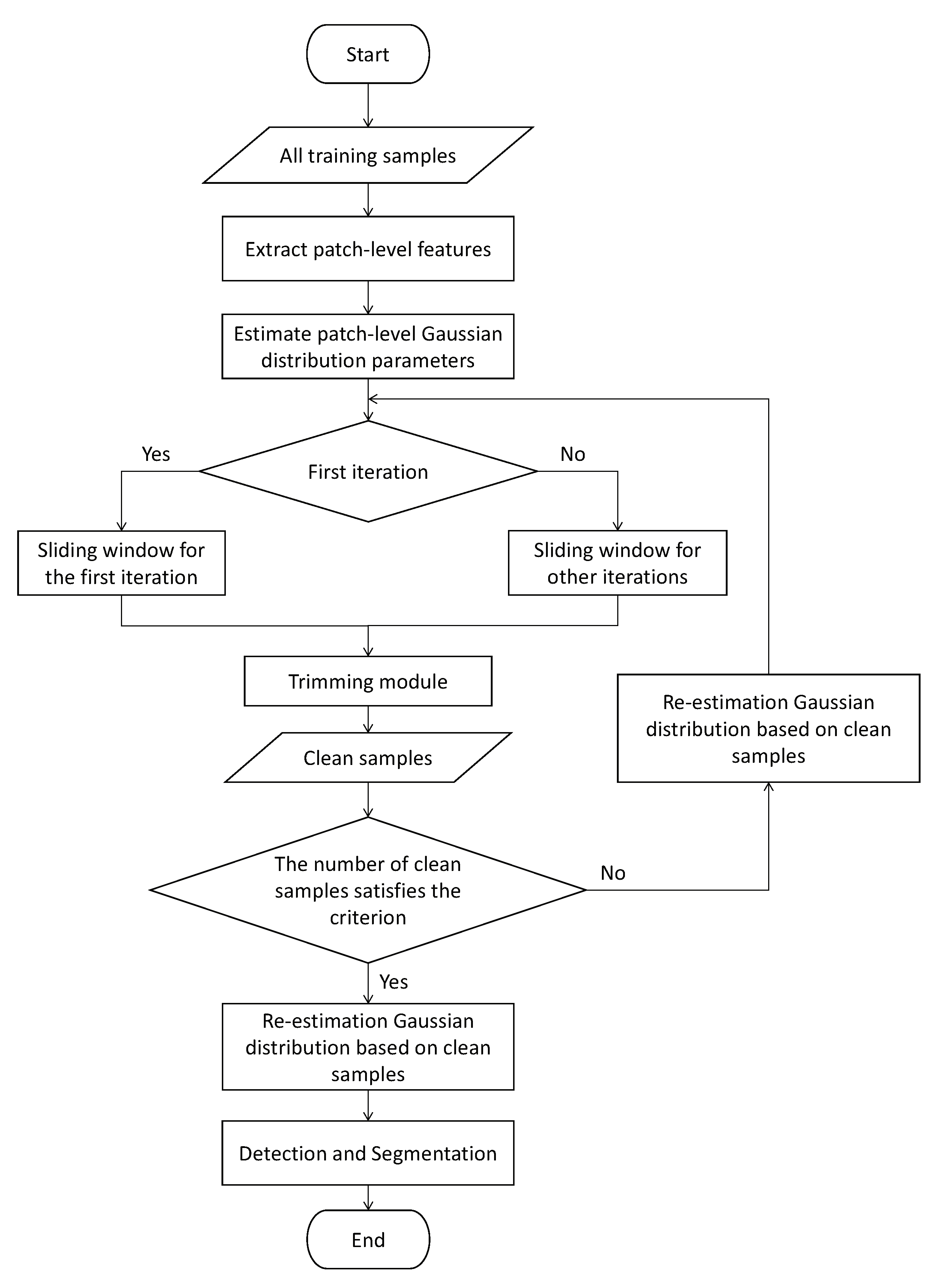
3. Proposed Method
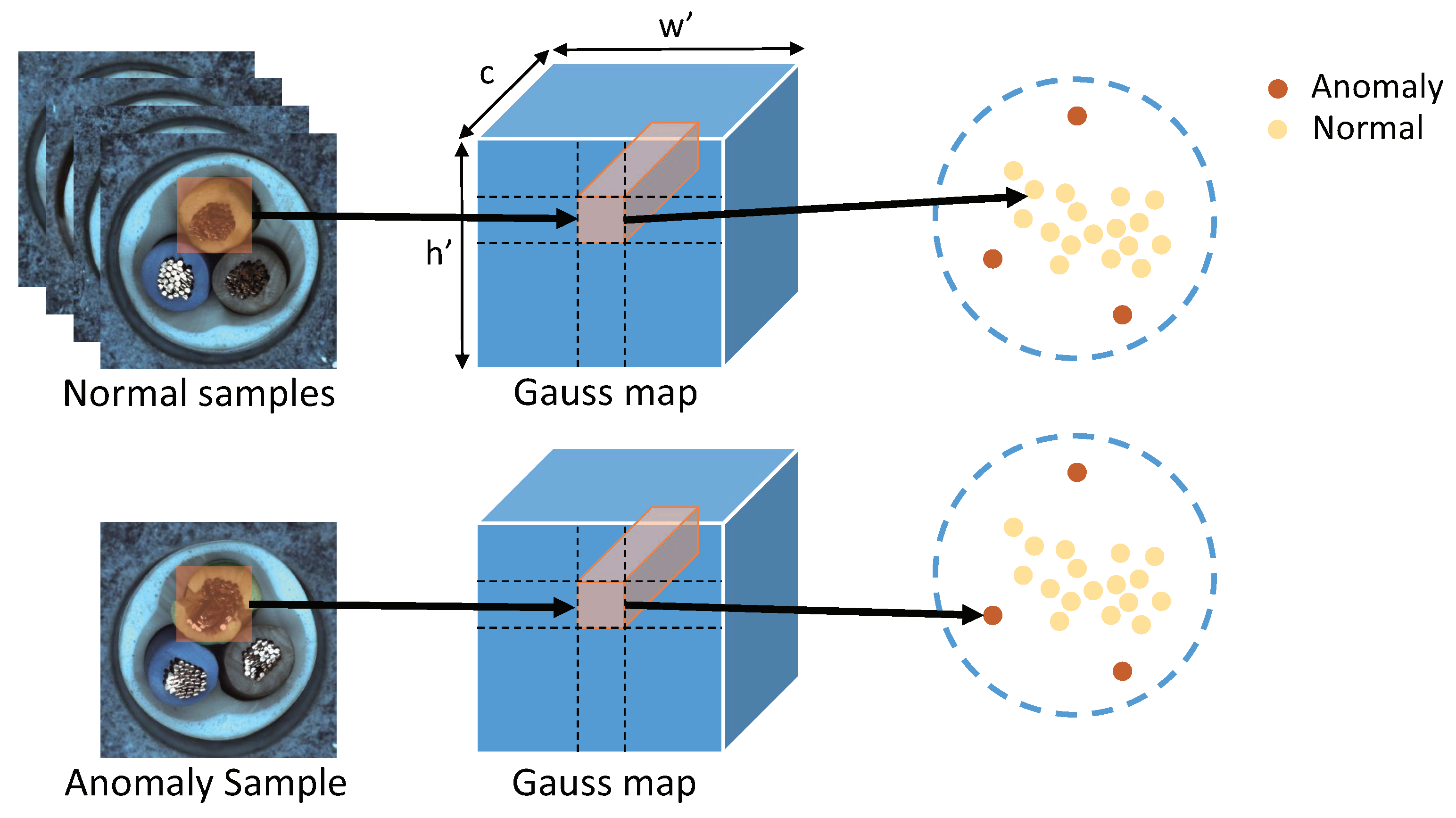
3.1. Patch Feature Extraction
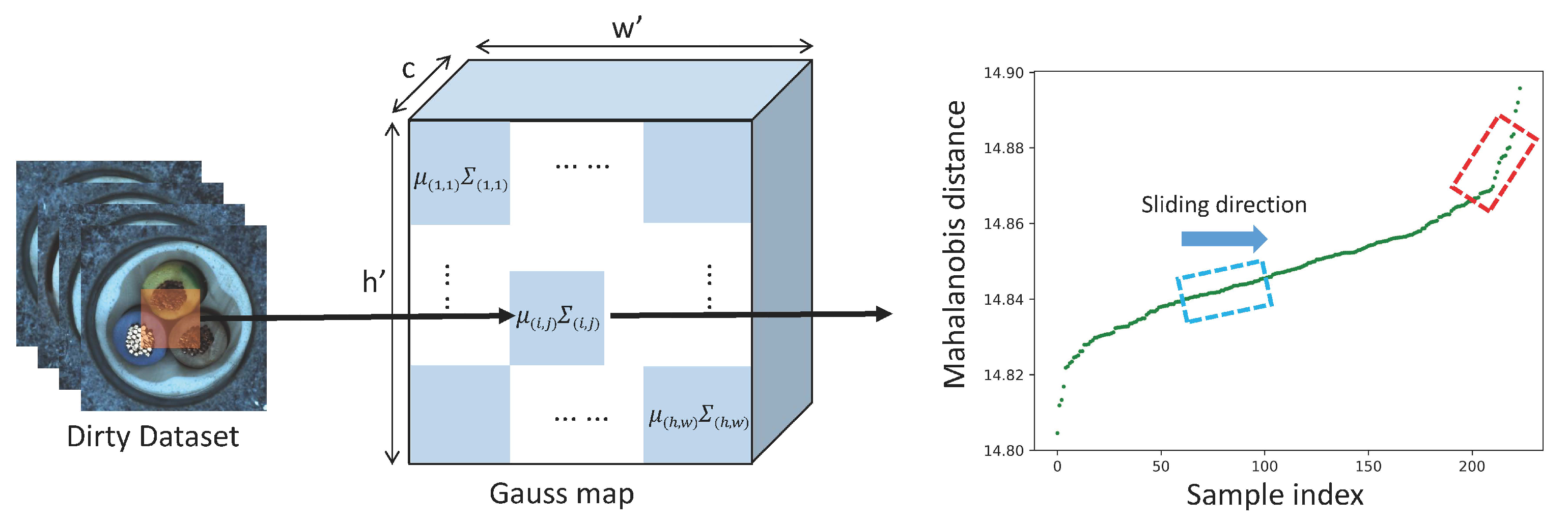
3.2. Trimming Patch-Level Gaussian Distribution
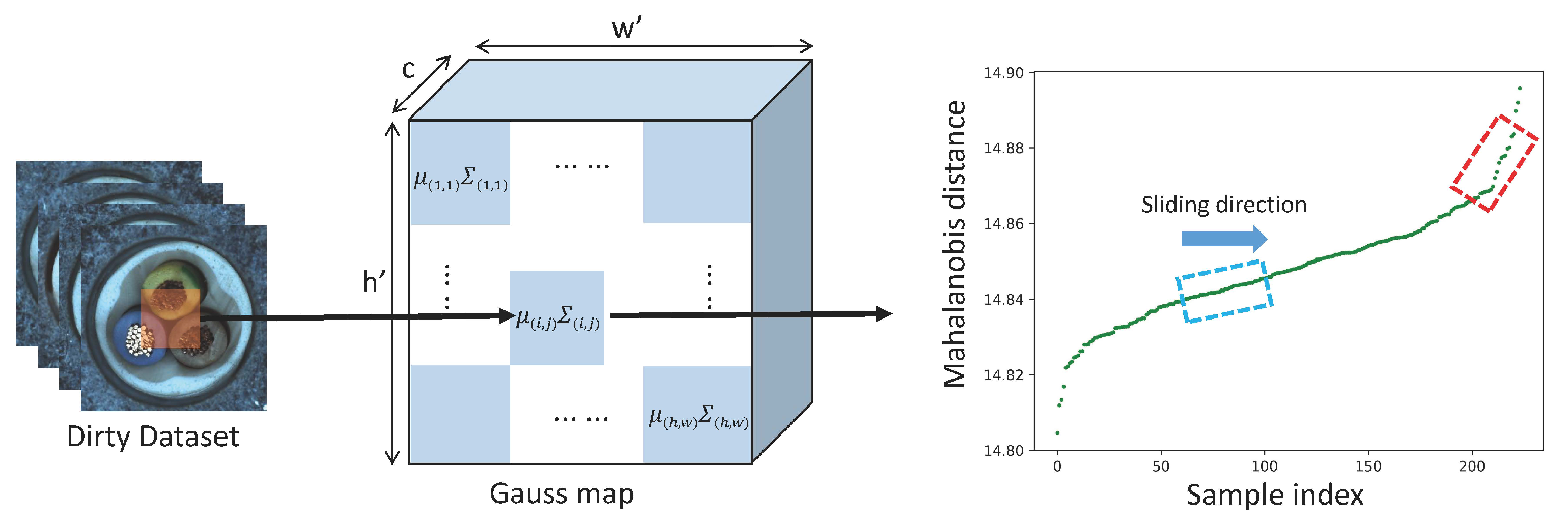
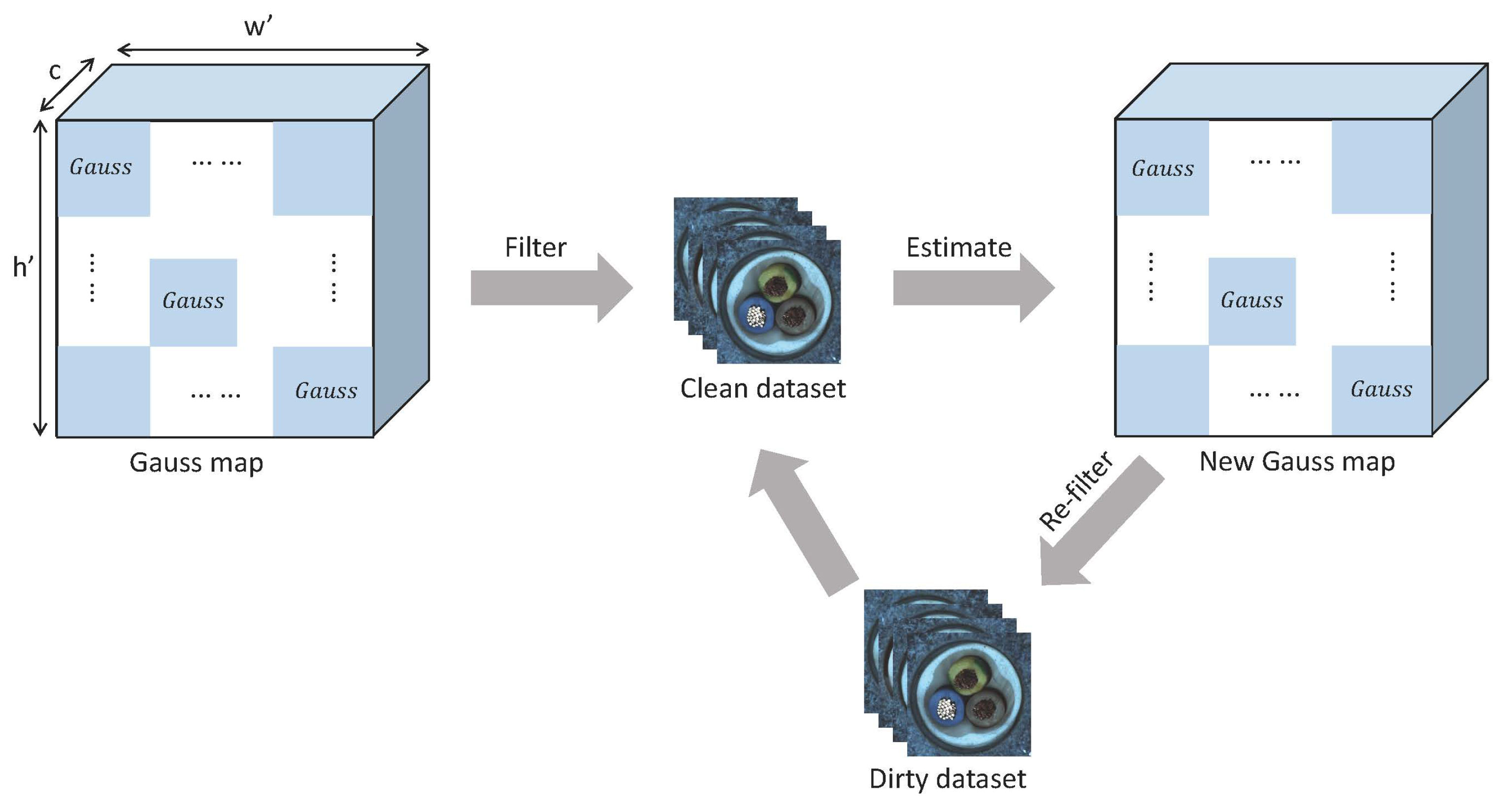
3.3. Iterative Filtering
3.3.1. Iterative Processing
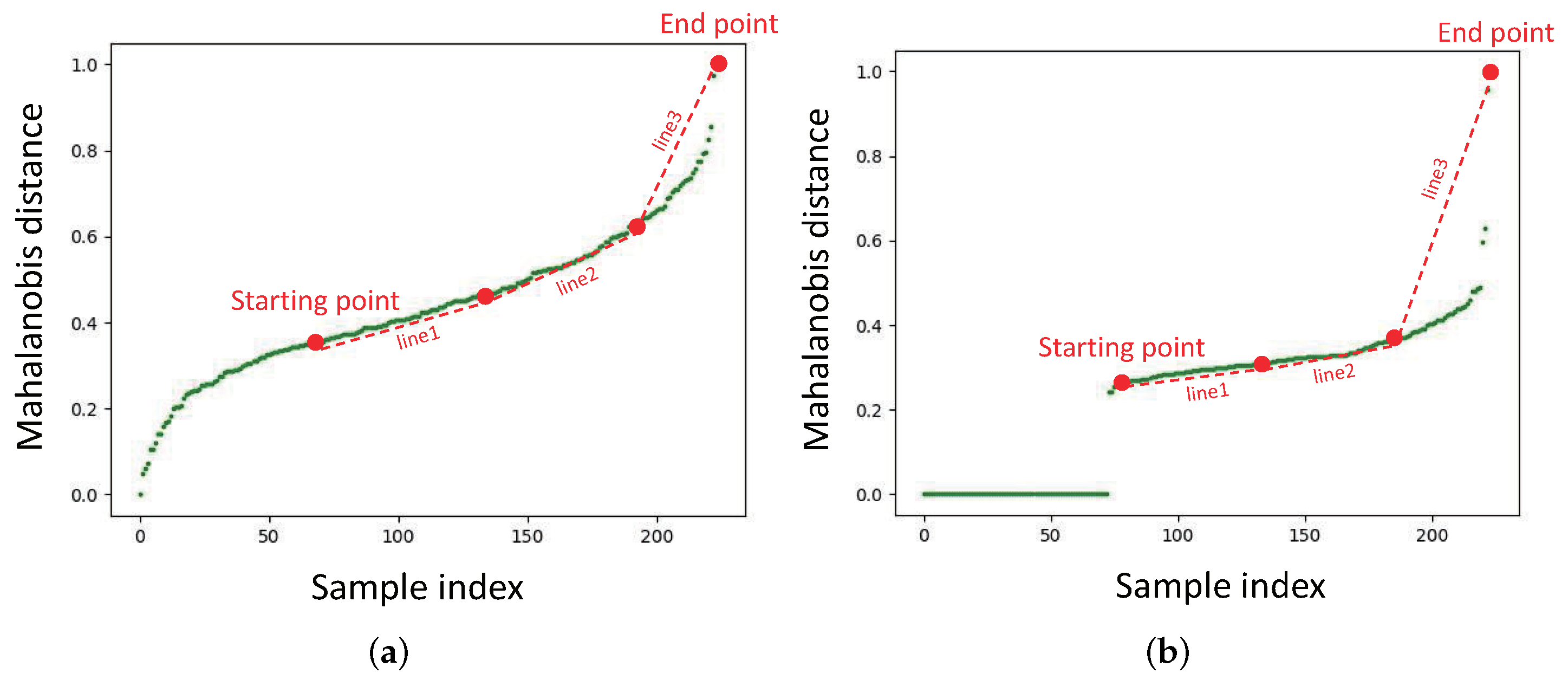
3.3.2. Different Strategy for Sliding Window
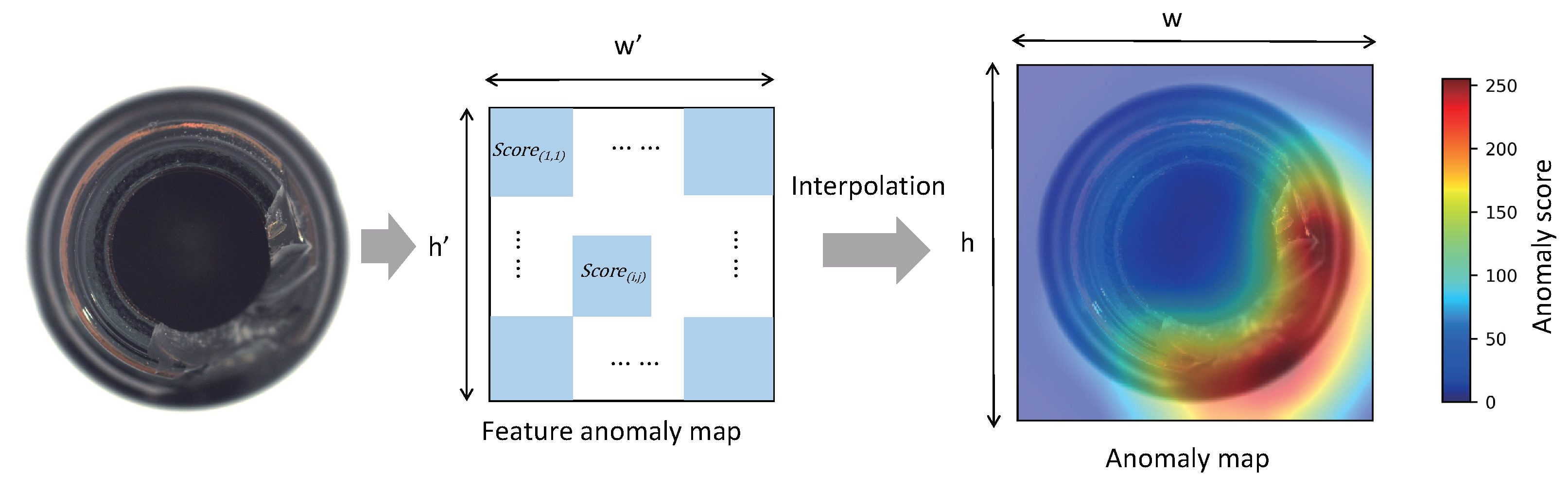
3.4. Anomaly Detection and Segmentation
3.5. Flowchart of PaIRE
4. Experiment
4.1. Construction of the Dirty Datasets
- MVTec [35]: An industrial anomaly detection dataset containing 10 object categories and 5 texture categories. Each category has a test set with multiple real anomaly samples and a training set with only normal samples.To simulate the dirty dataset, we randomly selected a certain number of anomaly samples from the test set to be added to the training set and removed an equal number of normal samples from the training set. The test set remained unchanged. The number of randomly selected anomaly samples occupy 5%, 10%, 15%, 20%, 25%, and 30% ratio of the training set. We use the data augmentation by rotation and flip if there are insufficient anomaly samples in the test set. The details of the composition of the dirty MVTec dataset are shown in Table 1.
- BTAD [36]: BeanTech Anomaly Detection Dataset. The dataset contains a total of 2830 real-world images of three industrial products, which showcased body and surface defects with the size of 600 × 600. The training set only contains normal samples. The same approach simulates the dirty dataset as MVTec was used. If the real anomaly samples are insufficient, the same rotation and flip data augmentation are used.
- KolektorSDD2 [37]: A surface-defect detection dataset with over 3000 images containing several types of defects obtained while addressing a real-world industrial problem. In the original KSDD2 dataset, the training set contains 10% of the anomaly samples. On the KSDD2 dataset, we use the same strategy as before to simulate the dirty dataset with noise ratios of 15%, 20%, 25%, and 30%.
4.2. Comparison Experiments
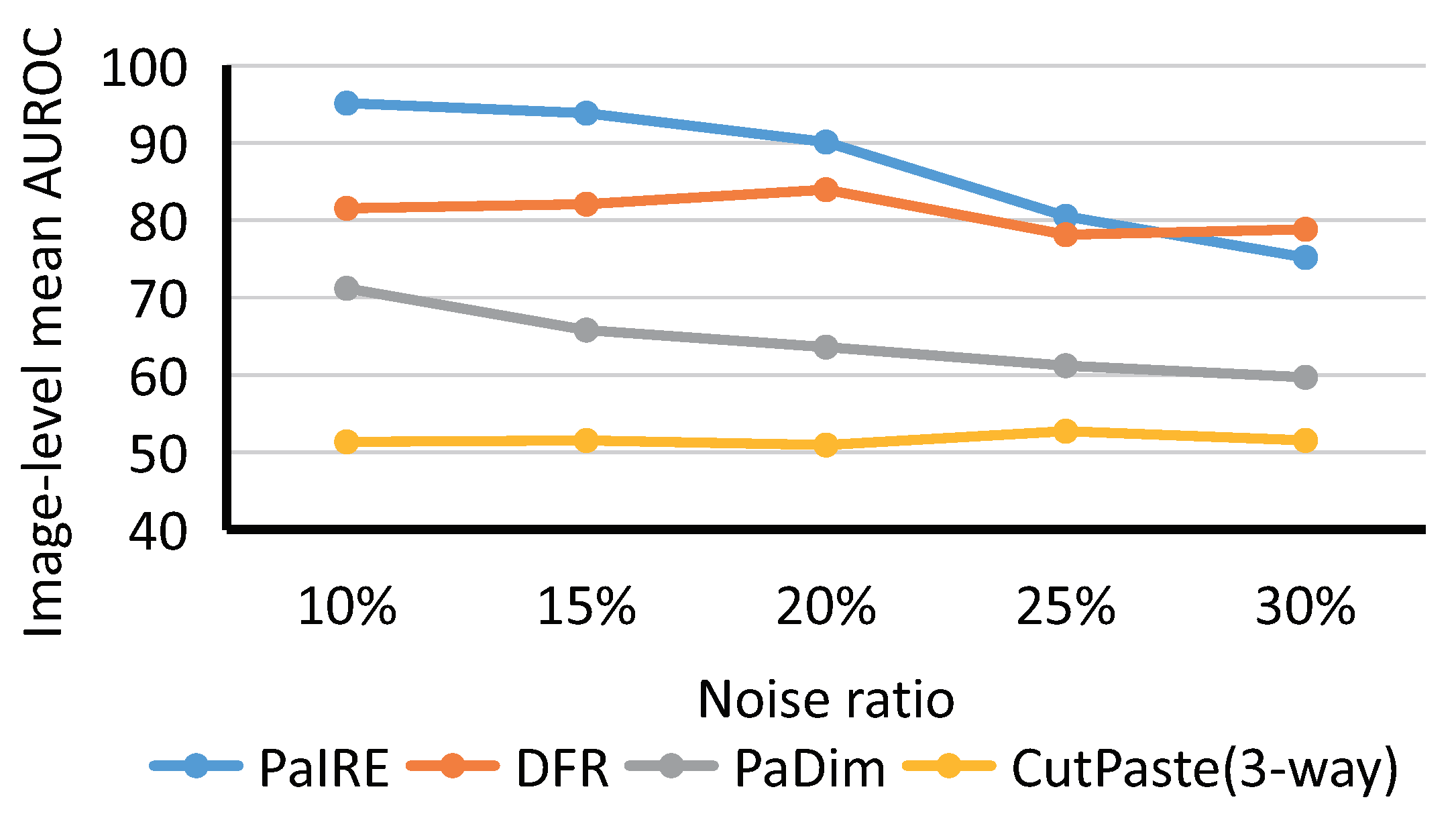
4.2.1. Experiments on Dirty MVTec Dataset
4.2.2. Experiments on Dirty BTAD Dataset
4.2.3. Experiments on Dirty KSDD2 Dataset
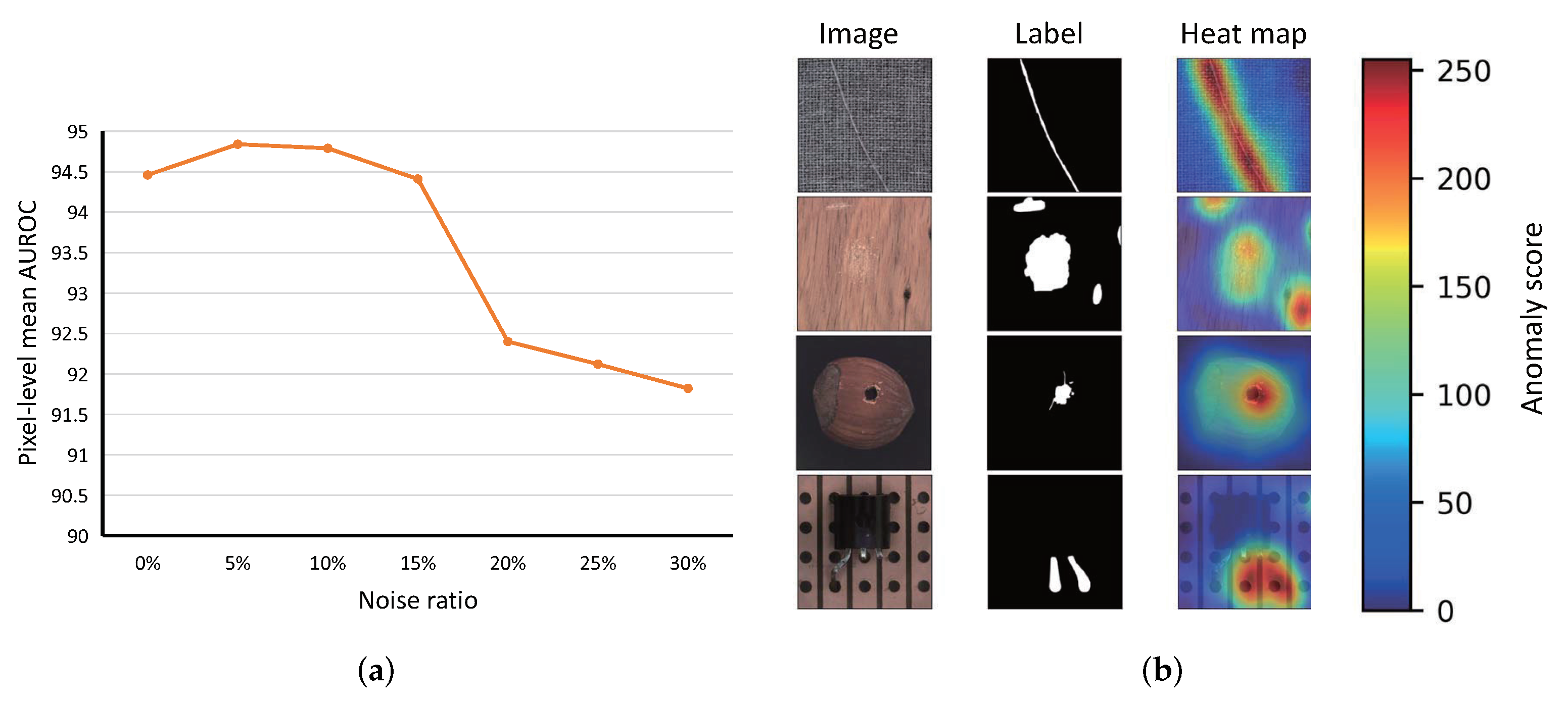
4.3. Discussion
5. Ablation Study
5.1. Trimming Method and Iterative Filtering
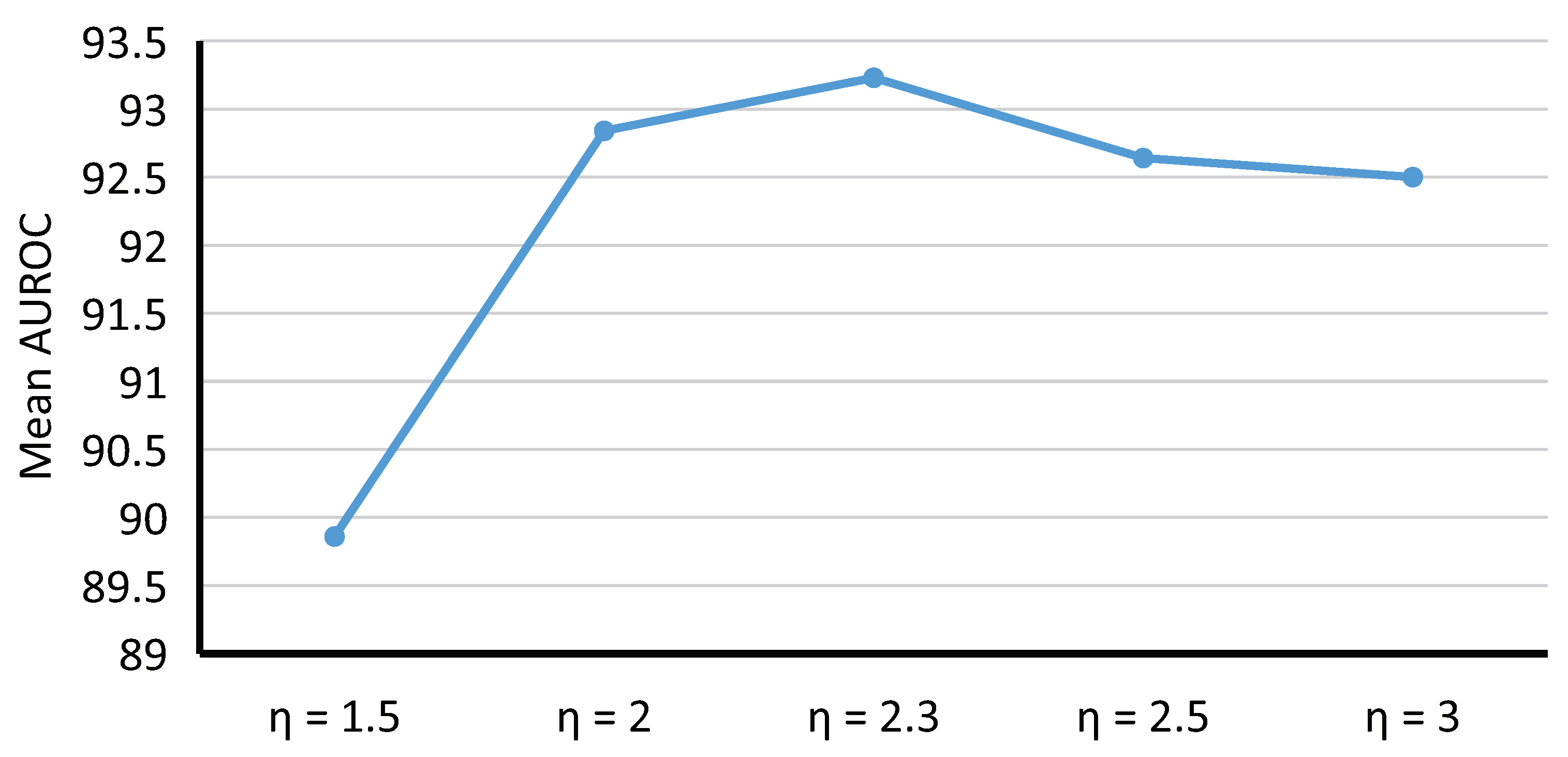
5.2. Effect of Mahalanobis Distance Threshold on Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, A. Computer-vision-based fabric defect detection: A survey. IEEE Trans. Ind. Electron. 2008, 55, 348–363. [Google Scholar] [CrossRef]
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learning for anomaly detection: A review. ACM Comput. Surv. 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-based defect detection and classification approaches for industrial applications—A survey. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ruff, L.; Kauffmann, J.R.; Vandermeulen, R.A.; Montavon, G.; Samek, W.; Kloft, M.; Dietterich, T.G.; Müller, K.-R. A unifying review of deep and shallow anomaly detection. Proc. IEEE 2021, 109, 756–795. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Wilcox, R.R.; Rousselet, G.A. A guide to robust statistical methods in neuroscience. Current Protoc. Neurosci. 2018, 82, 8–42. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 3, 1443–1471. [Google Scholar] [CrossRef]
- Yi, J.; Yoon, S. Patch svdd: Patch-level svdd for anomaly detection and segmentation. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef] [Green Version]
- Golan, I.; El-Yaniv, R. Deep anomaly detection using geometric transformations. arXiv 2018, arXiv:1805.10917. [Google Scholar]
- Sohn, K.; Li, C.-L.; Yoon, J.; Jin, M.; Pfister, T. Learning and evaluating representations for deep one-class classification. arXiv 2020, arXiv:2011.02578. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; PMLR: Cambridge, MA, USA, 2020; pp. 1597–1607. [Google Scholar]
- Schlüter, H.M.; Tan, J.; Hou, B.; Kainz, B. Self-supervised out-of-distribution detection and localization with natural synthetic anomalies (nsa). arXiv 2021, arXiv:2109.15222. [Google Scholar]
- Li, C.-L.; Sohn, K.; Yoon, J.; Pfister, T. Cutpaste: Self-supervised learning for anomaly detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 9664–9674. [Google Scholar]
- Rippel, O.; Mertens, P.; Merhof, D. Modeling the distribution of normal data in pre-trained deep features for anomaly detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6726–6733. [Google Scholar]
- Defard, T.; Setkov, A.; Loesch, A.; Audigier, R. Padim: A patch distribution modeling framework for anomaly detection and localization. In Proceedings of the ICPR 2020-25th International Conference on Pattern Recognition Workshops and Challenges, Milan, Italy, 10–11 January 2021. [Google Scholar]
- Zheng, Y.; Wang, X.; Deng, R.; Bao, T.; Zhao, R.; Wu, L. Focus your distribution: Coarse-to-fine non-contrastive learning for anomaly detection and localization. arXiv 2021, arXiv:2110.04538. [Google Scholar]
- Cohen, N.; Hoshen, Y. Sub-image anomaly detection with deep pyramid correspondences. arXiv 2020, arXiv:2005.02357. [Google Scholar]
- Wang, G.; Han, S.; Ding, E.; Huang, D. Student-teacher feature pyramid matching for anomaly detection. arXiv 2021, arXiv:2103.04257. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Proceedings of the International Conference on Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 146–157. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Langs, G.; Schmidt-Erfurth, U. f-anogan: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal. 2019, 54, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Deecke, L.; Vandermeulen, R.; Ruff, L.; Mandt, S.; Kloft, M. Image anomaly detection with generative adversarial networks. Poceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Riva del Garda, Italy, 19–23 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–17. [Google Scholar]
- Sabokrou, M.; Khalooei, M.; Fathy, M.; Adeli, E. Adversarially learned one-class classifier for novelty detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3379–3388. [Google Scholar]
- Akcay, S.; Atapour-Abarghouei, A.; Breckon, T.P. Ganomaly: Semi-supervised anomaly detection via adversarial training. In Proceedings of the Asian conference on computer vision, Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 622–637. [Google Scholar]
- Venkataramanan, S.; Peng, K.-C.; Singh, R.V.; Mahalanobis, A. Attention guided anomaly localization in images. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 485–503. [Google Scholar]
- Bergmann, P.; Löwe, S.; Fauser, M.; Sattlegger, D.; Steger, C. Improving unsupervised defect segmentation by applying structural similarity to autoencoders. arXiv 2018, arXiv:1807.02011. [Google Scholar]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S.; Hengel, A.v.d. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1705–1714. [Google Scholar]
- Li, Z.; Li, N.; Jiang, K.; Ma, Z.; Wei, X.; Hong, X.; Gong, Y. Superpixel masking and inpainting for self-supervised anomaly detection. BMVC 2020. Available online: https://www.bmvc2020-conference.com/assets/papers/0275.pdf (accessed on 27 February 2022).
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- You, S.; Tezcan, K.C.; Chen, X.; Konukoglu, E. Unsupervised lesion detection via image restoration with a normative prior. In Proceedings of the International Conference on Medical Imaging with Deep Learning, London, UK, 8–10 July 2019; pp. 540–556. [Google Scholar]
- Pirnay, J.; Chai, K. Inpainting transformer for anomaly detection. arXiv 2021, arXiv:2104.13897. [Google Scholar]
- Tan, D.S.; Chen, Y.-C.; Chen, T.P.-C.; Chen, W.-C. Trustmae: A noise-resilient defect classification framework using memory-augmented auto-encoders with trust regions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2021; pp. 276–285. [Google Scholar]
- Li, T.; Wang, Z.; Liu, S.; Lin, W.-Y. Deep unsupervised anomaly detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2021; pp. 3636–3645. [Google Scholar]
- Yang, J.; Shi, Y.; Qi, Z. Dfr: Deep feature reconstruction for unsupervised anomaly segmentation. arXiv 2020, arXiv:2012.07122. [Google Scholar]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9592–9600. [Google Scholar]
- Božič, J.; Tabernik, D.; Skočaj, D. Mixed supervision for surface-defect detection: From weakly to fully supervised learning. Comput. Ind. 2021, 129, 103459. [Google Scholar] [CrossRef]
- Mishra, P.; Verk, R.; Fornasier, D.; Piciarelli, C.; Foresti, G.L. Vt-adl: A vision transformer network for image anomaly detection and localization. arXiv 2021, arXiv:2104.10036. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | 5% | 10% | 15% | 20% | 25% | 30% |
|---|---|---|---|---|---|---|
| bottle | 198 | 188 | 178 | 167 | 157 | 146 |
| 11 | 21 | 31 | 42 | 52 | 63 | |
| cable | 213 | 201 | 190 | 179 | 168 | 157 |
| 11 | 23 | 34 | 45 | 56 | 67 | |
| capsule | 208 | 197 | 186 | 175 | 164 | 153 |
| 11 | 122 | 33 | 44 | 55 | 66 | |
| carpet | 266 | 252 | 238 | 224 | 210 | 196 |
| 14 | 28 | 42 | 56 | 70 | 84 | |
| grid | 250 | 238 | 224 | 211 | 198 | 185 |
| 14 | 26 | 40 | 53 | 66 | 79 | |
| hazelnut | 371 | 352 | 332 | 313 | 293 | 274 |
| 20 | 39 | 59 | 78 | 98 | 117 | |
| leather | 233 | 221 | 208 | 196 | 184 | 172 |
| 12 | 24 | 37 | 49 | 61 | 73 | |
| metal nut | 209 | 198 | 187 | 176 | 165 | 154 |
| 11 | 22 | 33 | 44 | 55 | 66 | |
| pill | 254 | 240 | 227 | 214 | 200 | 187 |
| 13 | 27 | 40 | 53 | 67 | 80 | |
| screw | 304 | 288 | 272 | 256 | 240 | 224 |
| 16 | 32 | 48 | 64 | 80 | 96 | |
| tile | 219 | 207 | 196 | 184 | 173 | 161 |
| 11 | 23 | 34 | 46 | 57 | 69 | |
| toothbrush | 57 | 54 | 51 | 48 | 45 | 42 |
| 3 | 6 | 9 | 12 | 15 | 18 | |
| transistor | 202 | 192 | 181 | 170 | 160 | 149 |
| 11 | 21 | 32 | 43 | 53 | 64 | |
| wood | 235 | 222 | 210 | 198 | 185 | 173 |
| 12 | 25 | 37 | 49 | 62 | 74 | |
| zipper | 228 | 216 | 204 | 192 | 180 | 168 |
| 12 | 24 | 36 | 48 | 60 | 72 |
| Noise Ratio | PaIRE | PaDim | DFR | CutPaste |
|---|---|---|---|---|
| 0% | 92.19 | 95.06 | 94.90 | 95.2 |
| 5% | 93.86 | 82.11 | 92.51 | 80.48 |
| 10% | 93.50 | 69.95 | 91.49 | 61.06 |
| 15% | 93.79 | 59.27 | 90.25 | 50.58 |
| 20% | 92.94 | 42.75 | 89.30 | 34.71 |
| 25% | 92.05 | 33.31 | 88.70 | 22.94 |
| 30% | 91.36 | 30.5 | 88.26 | 19.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; Yu, X.; Wang, L. Unsupervised Anomaly Detection and Segmentation on Dirty Datasets. Future Internet 2022, 14, 86. https://doi.org/10.3390/fi14030086
Guo J, Yu X, Wang L. Unsupervised Anomaly Detection and Segmentation on Dirty Datasets. Future Internet. 2022; 14(3):86. https://doi.org/10.3390/fi14030086
Chicago/Turabian StyleGuo, Jiahao, Xiaohuo Yu, and Lu Wang. 2022. "Unsupervised Anomaly Detection and Segmentation on Dirty Datasets" Future Internet 14, no. 3: 86. https://doi.org/10.3390/fi14030086