
CPU-GPU-Memory DVFS for Power-Efficient MPSoC in Mobile Cyber Physical Systems



Abstract
:1. Introduction and Motivation
- Studying the effect of DVFS on memory in regard to the total power consumption and performance of executing applications in a mobile MPSoC.
- Proposing a novel approach—CGM-DVFS—to perform DVFS on CPU-GPU-memory in a mobile MPSoC to cater for the performance requirements of executing applications, while consuming the least amount power.
- An experimental evaluation of CGM-DVFS on a real hardware platform, Odroid XU4, and a comparative study between CGM-DVFS and state-of-the-art approaches to optimise power consumption.
- A comparative study and analysis between CGM-DVFS and state-of-the-art delayed reinforcement learning approaches to show that CGM-DVFS is better suited to achieving close-to-optimal power consumption.
2. Effect of DVFS on Memory
3. Related Works
4. System Model and Problem Formulation
4.1. Hardware and Software Infrastructure
4.2. Problem Formulation
5. Proposed Methodology: CGM-DVFS
5.1. Overview of CGM-DVFS
5.2. Steps in Detail: Profiling, Fetch Desired Config and Set Desired DVFS
5.3. Justification of the Design Choices
6. Experimental Results
6.1. Experimental Applications
6.2. Evaluation and Comparative Study
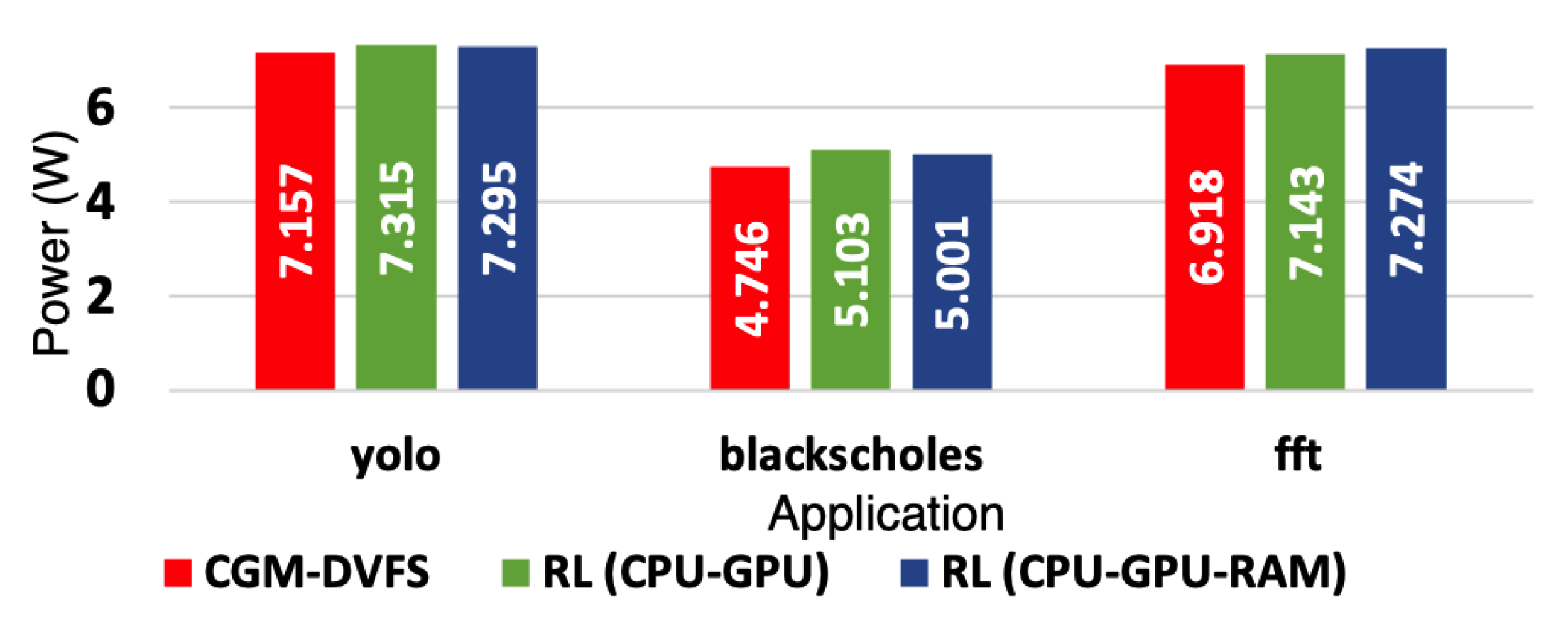
6.3. Comparative Study between CGM-DVFS and Delayed-Reinforcement-Learning Approaches
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cho, H.D.; Engineer, P.D.P.; Chung, K.; Kim, T. Benefits of the Big. LITTLE Architecture. Available online: https://s3.ap-northeast-2.amazonaws.com/global.semi.static/Benefits_of_the_bigLITTLE_Architecture.pdf (accessed on 4 February 2022).
- Singh, A.K.; Dey, S.; McDonald-Maier, K.; Basireddy, K.R.; Merrett, G.V.; Al-Hashimi, B.M. Dynamic Energy and Thermal Management of Multi-Core Mobile Platforms: A Survey. IEEE Des. Test 2020, 37, 25–33. [Google Scholar] [CrossRef]
- Singh, A.K.; Shafique, M.; Kumar, A.; Henkel, J. Mapping on multi/many-core systems: Survey of current and emerging trends. In Proceedings of the 2013 50th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 29 May–7 June 2013; pp. 1–10. [Google Scholar]
- Dey, S.; Singh, A.K.; Wang, X.; McDonald-Maier, K. User Interaction Aware Reinforcement Learning for Power and Thermal Efficiency of CPU-GPU Mobile MPSoCs. In Proceedings of the 2020 DATE IEEE, Grenoble, France, 9–13 March 2020. [Google Scholar]
- Dey, S.; Singh, A.K.; Wang, X.; McDonald-Maier, K. Edgecoolingmode: An agent based thermal management mechanism for dvfs enabled heterogeneous mpsocs. In Proceedings of the 2019 VLSID IEEE, Delhi, India, 5–9 January 2019. [Google Scholar]
- Reddy, B.K.; Singh, A.K.; Biswas, D.; Merrett, G.V.; Al-Hashimi, B.M. Inter-cluster Thread-to-core Mapping and DVFS on Heterogeneous Multi-cores. IEEE Trans. Multi-Scale Comput. Syst. 2018, 4, 369–382. [Google Scholar] [CrossRef]
- Dey, S.; Singh, A.K.; Saha, S.; Wang, X.; McDonald-Maier, K.D. RewardProfiler: A Reward Based Design Space Profiler on DVFS Enabled MPSoCs. In Proceedings of the 2019 CSCloud/2019 EdgeCom IEEE, Paris, France, 21–23 June 2019. [Google Scholar]
- Odroid-XU4. Available online: https://www.hardkernel.com/shop/odroid-xu4-special-price/ (accessed on 4 February 2022).
- Exynos 5 Octa (5422). Available online: https://www.samsung.com/exynos (accessed on 23 July 2018).
- Kim, M.; Kim, K.; Geraci, J.R.; Hong, S. Utilization-aware load balancing for the energy efficient operation of the big. LITTLE processor. In Proceedings of the 2014 Design, Automation & Test in Europe Conference & Exhibition (DATE) IEEE, Dresden, Germany, 24–28 March 2014. [Google Scholar]
- Bienia, C. Benchmarking Modern Multiprocessors. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 2011. [Google Scholar]
- Dey, S.; Singh, A.K.; Prasad, D.K.; Mcdonald-Maier, K.D. SoCodeCNN: Program Source Code for Visual CNN Classification Using Computer Vision Methodology. IEEE Access 2019, 7, 157158–157172. [Google Scholar] [CrossRef]
- Pathania, A.; Jiao, Q.; Prakash, A.; Mitra, T.I. Integrated CPU-GPU power management for 3D mobile games. In Proceedings of the 2014 51st ACM/EDAC/IEEE DAC IEEE, San Francisco, CA, USA, 1–5 June 2014. [Google Scholar]
- Isuwa, S.; Dey, S.; Singh, A.K.; McDonald-Maier, K. TEEM: Online Thermal-and Energy-Efficiency Management on CPU-GPU MPSoCs. In Proceedings of the 2019 DATE IEEE, Florence, Italy, 25–29 March 2019; pp. 438–443. [Google Scholar]
- Hsieh, C.Y.; Park, J.-G.; Dutt, N.; Lim, S.-S. Memory-aware cooperative CPU-GPU DVFS governor for mobile games. In Proceedings of the 2015 13th IEEE Symposium on Embedded Systems For Real-time Multimedia (ESTIMedia), Amsterdam, The Netherlands, 8–9 October 2015; pp. 1–8. [Google Scholar]
- John, G.H. When the Best Move Isn’t Optimal: Q-Learning with Exploration. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.6.5630&rep=rep1&type=pdf (accessed on 4 February 2022).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Woo, S.C.; Ohara, M.; Torrie, E.; Singh, J.P.; Gupta, A. The SPLASH-2 programs: Characterization and methodological considerations. ACM SIGARCH Comput. Archit. News 1995, 23, 24–36. [Google Scholar] [CrossRef]
- Roy Longbottom’s PC Benchmark Collection. Available online: http://www.roylongbottom.org.uk (accessed on 10 October 2018).
- Longbottom, R. Whetstone Benchmark History and Results. Available online: https://www.researchgate.net/profile/Roy-Longbottom/publication/318755466_Whetstone_Benchmark_History_and_Results/links/597b906aaca272d568b85fea/Whetstone-Benchmark-History-and-Results.pdf (accessed on 10 October 2018).
- Rivest, R.L.; Shamir, A.; Adleman, L.M. Cryptographic Communications System and Method. U.S. Patent 4,405,829, 20 September 1983. [Google Scholar]
- These Were the 10 Most-Downloaded Apps of the Decade. Available online: https://www.ndtv.com/offbeat/these-were-the-10-most-downloaded-apps-of-the-decade-2150290 (accessed on 10 October 2018).
- Thakkar, J. Types of Encryption: 5 Encryption Algorithms and How to Choose the Right One. 2020. Available online: https://securityboulevard.com/2020/05/types-of-encryption-5-encryption-algorithms-how-to-choose-the-right-one/ (accessed on 10 October 2018).
- Dey, S.; Singh, A.K.; McDonald-Maier, K.D. P-EdgeCoolingMode: An Agent Based Performance Aware Thermal Management Unit for DVFS Enabled Heterogeneous MPSoCs. IET Comput. Digit. Tech. 2019, 13, 514–523. [Google Scholar] [CrossRef] [Green Version]
- Mandal, S.K.; Bhat, G.; Patil, C.A.; Doppa, J.R.; Pande, P.P.; Ogras, U.Y. Dynamic resource management of heterogeneous mobile platforms via imitation learning. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2842–2854. [Google Scholar] [CrossRef]
- Singh, A.K.; Basireddy, K.R.; Prakash, A.; Merrett, G.V.; Al-Hashimi, B.M. Collaborative adaptation for energy-efficient heterogeneous mobile SoCs. IEEE Trans. Comput. 2019, 69, 185–197. [Google Scholar] [CrossRef] [Green Version]
- Dey, S.; Singh, A.K.; Wang, X.; McDonald-Maier, K.D. DeadPool: Performance Deadline Based Frequency Pooling and Thermal Management Agent in DVFS Enabled MPSoCs. In Proceedings of the 2019 6th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2019 5th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), Paris, France, 21–23 June 2019. [Google Scholar]
- David, R.; Bogdan, P.; Marculescu, R. Dynamic power management for multicores: Case study using the Intel SCC. In Proceedings of the 2012 IEEE/IFIP 20th International Conference on VLSI and System-on-Chip (VLSI-SoC), Santa Cruz, CA, USA, 7–10 October 2012; pp. 147–152. [Google Scholar]
- Bogdan, P.; Marculescu, R.; Jain, S. Dynamic power management for multidomain system-on-chip platforms: An optimal control approach. ACM Trans. Des. Autom. Electron. Syst. (TODAES) 2013, 18, 1–20. [Google Scholar] [CrossRef]
- Li, X.; Li, G. An Adaptive CPU-GPU Governing Framework for Mobile Games on big. LITTLE Architectures. IEEE Trans. Comput. 2020, 70, 1472–1483. [Google Scholar] [CrossRef]
- Deng, Q.; Meisner, D.; Bhattacharjee, A.; Wenisch, T.F.; Bianchini, R. MultiScale: Memory system DVFS with multiple memory controllers. In Proceedings of the 2012 ACM/IEEE International Symposium on Low Power Electronics and Design, Redondo Beach, CA, USA, 30 July–1 August 2012. [Google Scholar]
- Deng, Q.; Meisner, D.; Bhattacharjee, A.; Wenisch, T.F.; Bianchini, R. Coscale: Coordinating cpu and memory system dvfs in server systems. In Proceedings of the 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture, Vancouver, BC, Canada, 1–5 December 2012. [Google Scholar]
- Chang, K.K.; Yağlıkçı, A.G.; Ghose, S.; Agrawal, A.; Chatterjee, N.; Kashyap, A.; Lee, D.; O’Connor, M.; Hassan, H.; Mutlu, O. Understanding reduced-voltage operation in modern DRAM devices: Experimental characterization, analysis, and mechanisms. In Proceedings of the ACM on Measurement and Analysis of Computing Systems, Urbana-Champaign, IL, USA, 5–9 June 2017. [Google Scholar]
- Begum, R.; Werner, D.; Hempstead, M.; Prasad, G.; Challen, G. Energy-performance trade-offs on energy-constrained devices with multi-component DVFS. In Proceedings of the 2015 IEEE International Symposium on Workload Characterization, Atlanta, GA, USA, 4–6 October 2015. [Google Scholar]
- Begum, R.; Hempstead, M.; Srinivasa, G.P.; Challen, G. Algorithms for CPU and DRAM DVFS under inefficiency constraints. In Proceedings of the 2016 IEEE 34th International Conference on Computer Design (ICCD), Scottsdale, AZ, USA, 2–5 October 2016. [Google Scholar]
- Mendis, H.R.; Chen, W.M.; Indrusiak, L.S.; Kuo, T.W.; Hsiu, P.C. Impact of memory frequency scaling on user-centric smartphone workloads. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018. [Google Scholar]
- Gensh, R.; Aalsaud, A.; Rafiev, A.; Xia, F.; Iliasov, A.; Romanovsky, A.; Yakovlev, A. Experiments with Odroid-xu3 Board; Available online: https://eprints.ncl.ac.uk/file_store/production/213859/D9F017EA-31CC-4A4A-AEF9-BDA775890FAB.pdf (accessed on 4 February 2022).
- Odroid SmartPower2. Available online: https://www.odroid.co.uk/odroid-smart-power-2 (accessed on 23 July 2018).
- Budiu, R. Multitasking on Mobile Devices. In White Paper of Nielsen Norman Group logoNielsen Norman Group; NNGroup: Fremont, CA, USA, 2015. [Google Scholar]
- Soo, S. Object Detection Using Haar-Cascade Classifier; Institute of Computer Science, University of Tartu: Tartu, Estonia, 2014; pp. 1–12. [Google Scholar]
- Kalafatić, Z. Traffic Sign Detection and Recognition. Available online: https://shorturl.at/stDO6 (accessed on 4 February 2022).
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Iranfar, A.; Kamal, M.; Afzali-Kusha, A.; Pedram, M.; Atienza, D. Thespot: Thermal stress-aware power and temperature management for multiprocessor systems-on-chip. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2018, 37, 1532–1545. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benchmark Applications | ||
|---|---|---|
| Type | Name (Execution Option) | Abbreviation |
| Compute | Whetstone | wht. |
| Compute | blackscholes (native) | blks. |
| Memory | x264 (simlarge) | x264 |
| Memory | dedup (simlarge) | ded. |
| Memory | canneal (simlarge) | cann. |
| Mixed | FFT (simlarge) | fft |
| Mixed | facesim (simlarge) | fsim. |
| Mixed | streamcluster (native) | strm. |
| Mixed | Youtube in Chromium browser | ytub. |
| Mixed | RSA | rsa |
| App | Pow. Max (W) | Pow. Save. Middle (%) | Pow. Save. Min (%) | Perf. Middle (%) | Perf. Min (%) |
|---|---|---|---|---|---|
| idle | 3.313 | 5.192 | 5.886 | - | - |
| wht. | 3.556 | 4.415 | 5.202 | −2.121 | −3.638 |
| blks. | 5.474 | 5.298 | 9.81 | −2.483 | −7.823 |
| x264 | 8.748 | 13.649 | 20.085 | −6.486 | −16.993 |
| ded. | 7.893 | 11.136 | 18.282 | −7.674 | −14.598 |
| cann. | 7.919 | 10.317 | 16.782 | −7.847 | −12.773 |
| fft | 7.41 | 4.575 | 14.008 | −2.939 | −15.834 |
| fsim. | 5.378 | 4.574 | 9.967 | −3.475 | −7.558 |
| strm. | 10.11 | 1.82 | 25.124 | −2.116 | −16.883 |
| ytub. | 7.014 | 1.725 | 7.214 | - | - |
| rsa | 6.119 | 1.994 | 4.935 | −1.032 | −1.894 |
| App | Perf. | MRPI | RProfiler. | Inter. | Next | N_Mod. |
|---|---|---|---|---|---|---|
| face | 21.08 | 14.59 | 9.28 | 17.81 | 8.61 | −3.17 |
| yolo | 24.46 | 8.79 | 4.049 | 19.82 | 2.16 | 1.89 |
| render | 18.00 | 9.40 | 8.39 | 15.34 | 8.12 | 8.89 |
| stream | 32.81 | 23.17 | 24.34 | 29.55 | 19.40 | 17.58 |
| traffic | 19.74 | 9.17 | 4.02 | 15.57 | 0.48 | −0.03 |
| classify | 33.48 | 26.80 | 15.36 | 30.2 | 11.42 | 6.93 |
| blks. | 12.43 | 5.13 | 3.83 | 11.34 | 6.10 | 5.10 |
| strm. | 21.20 | 18.80 | 11.97 | 15.99 | 2.62 | 0.60 |
| fft | 12.21 | 9.04 | 9.42 | 11.40 | 3.15 | 4.89 |
| App | Perf. | MRPI | RProfiler. | Inter. | Next | N_Mod. |
|---|---|---|---|---|---|---|
| face | 25.57 | 14.16 | 13.18 | 19.38 | 11.29 | 3.04 |
| yolo | 19.43 | 8.13 | 6.74 | 15.67 | 6.44 | 5.19 |
| render | 20.80 | 8.06 | 5.38 | 18.80 | 3.90 | 6.27 |
| stream | 13.93 | 6.428 | 3.83 | 12.16 | 3.99 | 1.82 |
| traffic | 23.25 | 8.71 | 3.96 | 16.58 | 2.63 | 0.38 |
| classify | 24.50 | 21.24 | 4.30 | 22.42 | 4.92 | 2.29 |
| blks. | 12.43 | 5.13 | 3.83 | 11.34 | 4.46 | 2.49 |
| strm. | 21.20 | 18.80 | 11.97 | 15.99 | 13.39 | 11.67 |
| fft | 12.21 | 9.04 | 9.42 | 11.40 | 10.95 | 12.08 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dey, S.; Isuwa, S.; Saha, S.; Singh, A.K.; McDonald-Maier, K. CPU-GPU-Memory DVFS for Power-Efficient MPSoC in Mobile Cyber Physical Systems. Future Internet 2022, 14, 91. https://doi.org/10.3390/fi14030091
Dey S, Isuwa S, Saha S, Singh AK, McDonald-Maier K. CPU-GPU-Memory DVFS for Power-Efficient MPSoC in Mobile Cyber Physical Systems. Future Internet. 2022; 14(3):91. https://doi.org/10.3390/fi14030091
Chicago/Turabian StyleDey, Somdip, Samuel Isuwa, Suman Saha, Amit Kumar Singh, and Klaus McDonald-Maier. 2022. "CPU-GPU-Memory DVFS for Power-Efficient MPSoC in Mobile Cyber Physical Systems" Future Internet 14, no. 3: 91. https://doi.org/10.3390/fi14030091