
Real-Time Detection of Vine Trunk for Robot Localization Using Deep Learning Models Developed for Edge TPU Devices

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
- Using the new state-of-the-art MobileDet Edge TPU and MobileNet edge TPU as the backbone of the state-of-the-art SSD model to detect trunk of vines.
- Deployment of the models in real-time on the Raspberrypi with TPU.
- Comparison of the performance of models on the VineSet dataset with previously used models not designed for TPU.
- Investigation of the influence of the size of the input of the model on the performance of the object detection models.
- Investigation of the influence of the size of the training dataset on the performance of the object recognition models.
- Examining the effect of training set diversity on the performance of object detection models.
- Investigating the impact of having thermal images in the training dataset.
- Investigating the impact of augmentation of the dataset before splitting it into training and test sets.
- Analysis of the detection results of the models.
2. Materials and Methods
2.1. Dataset
- The first and most important point was that the dataset was augmented before splitting the data into train and test. When performing the splits, the same image could appear in different splits with small changes in angle or brightness, which would have made the validation and testing step less effective (see Section 3.4).
- Second, our computational power was limited. Training the DL models requires a system with very high computational power (GPU) and memory. The more input data, the more training time and the more memory required.
2.2. SSD Object Detection Model
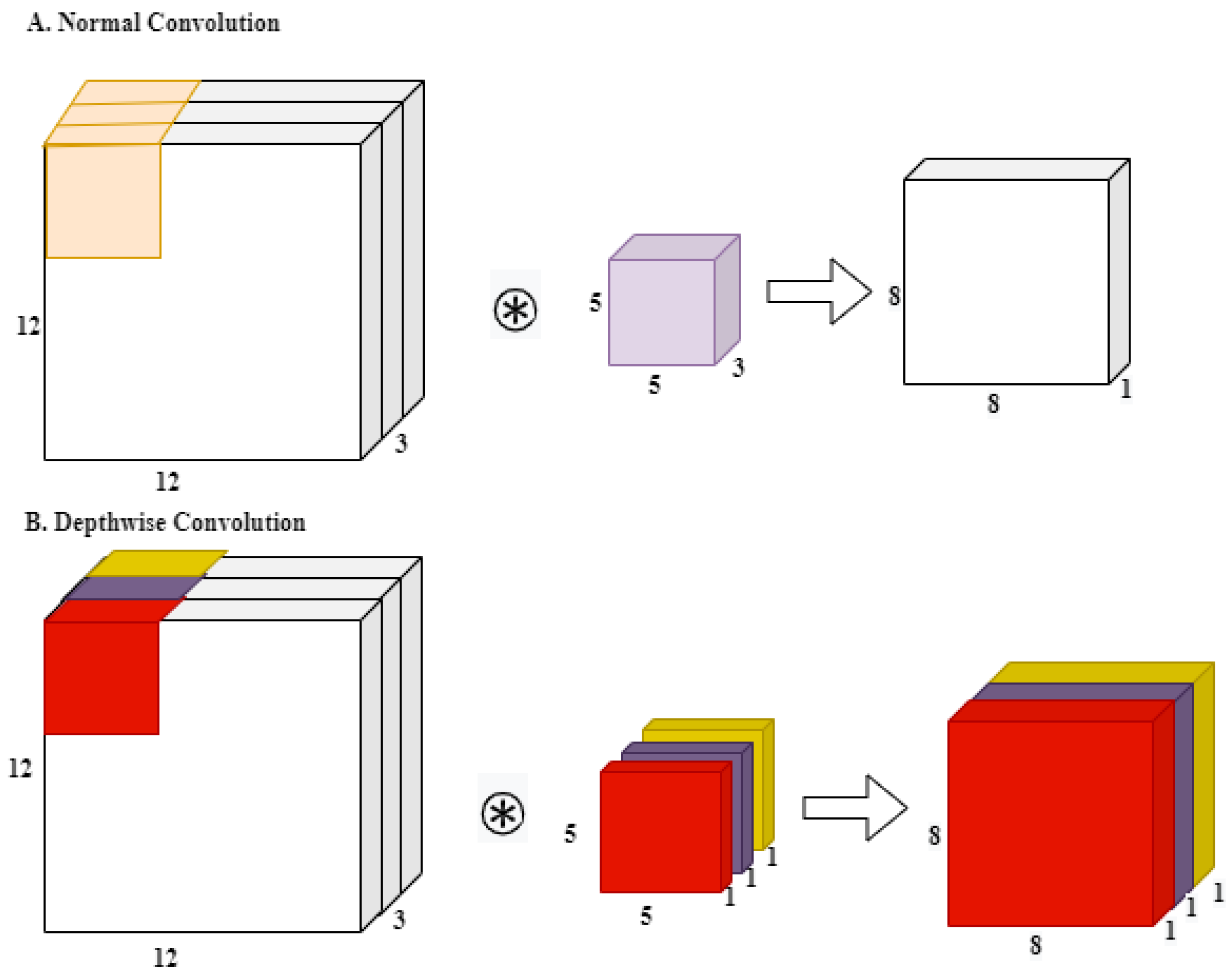
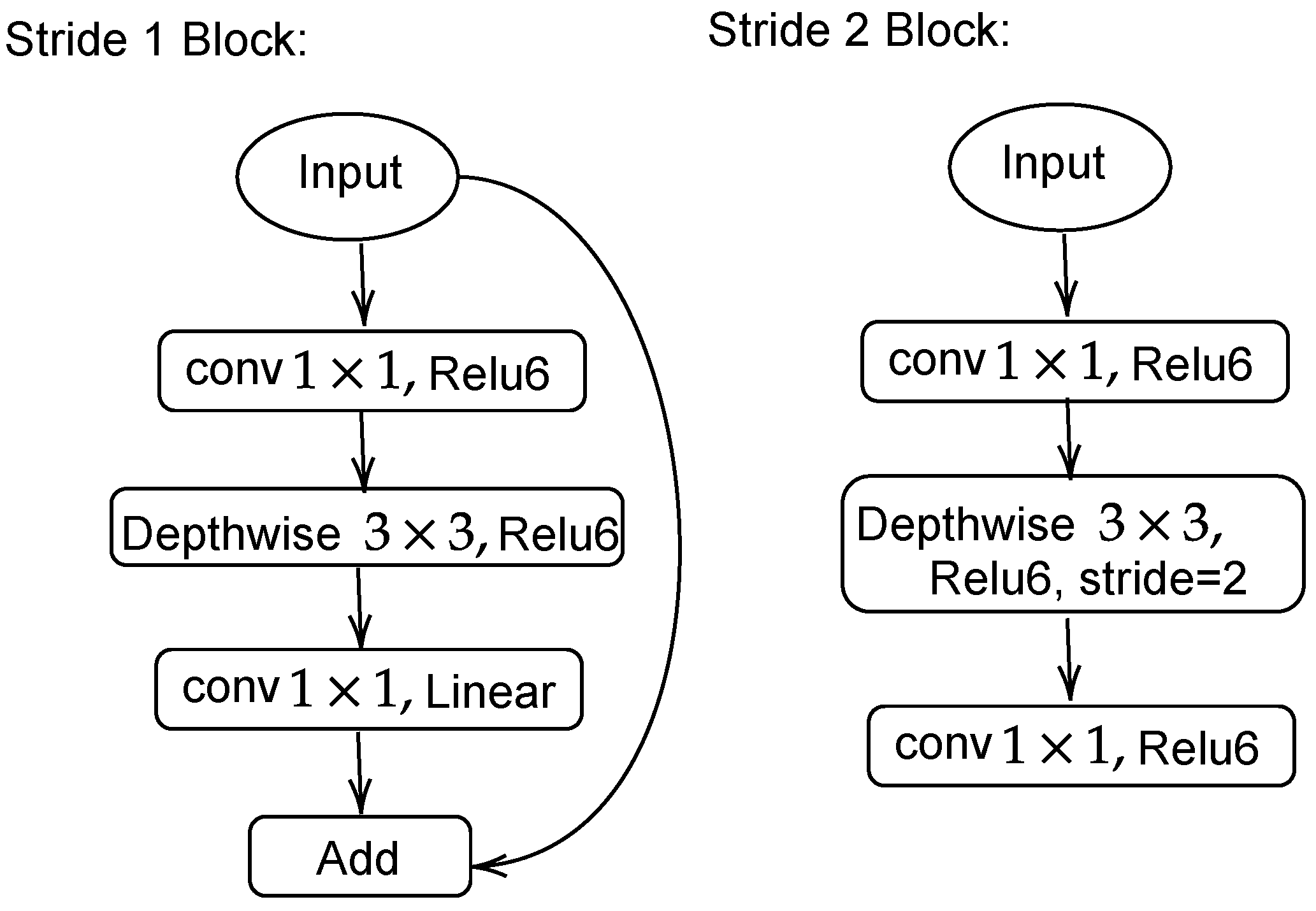
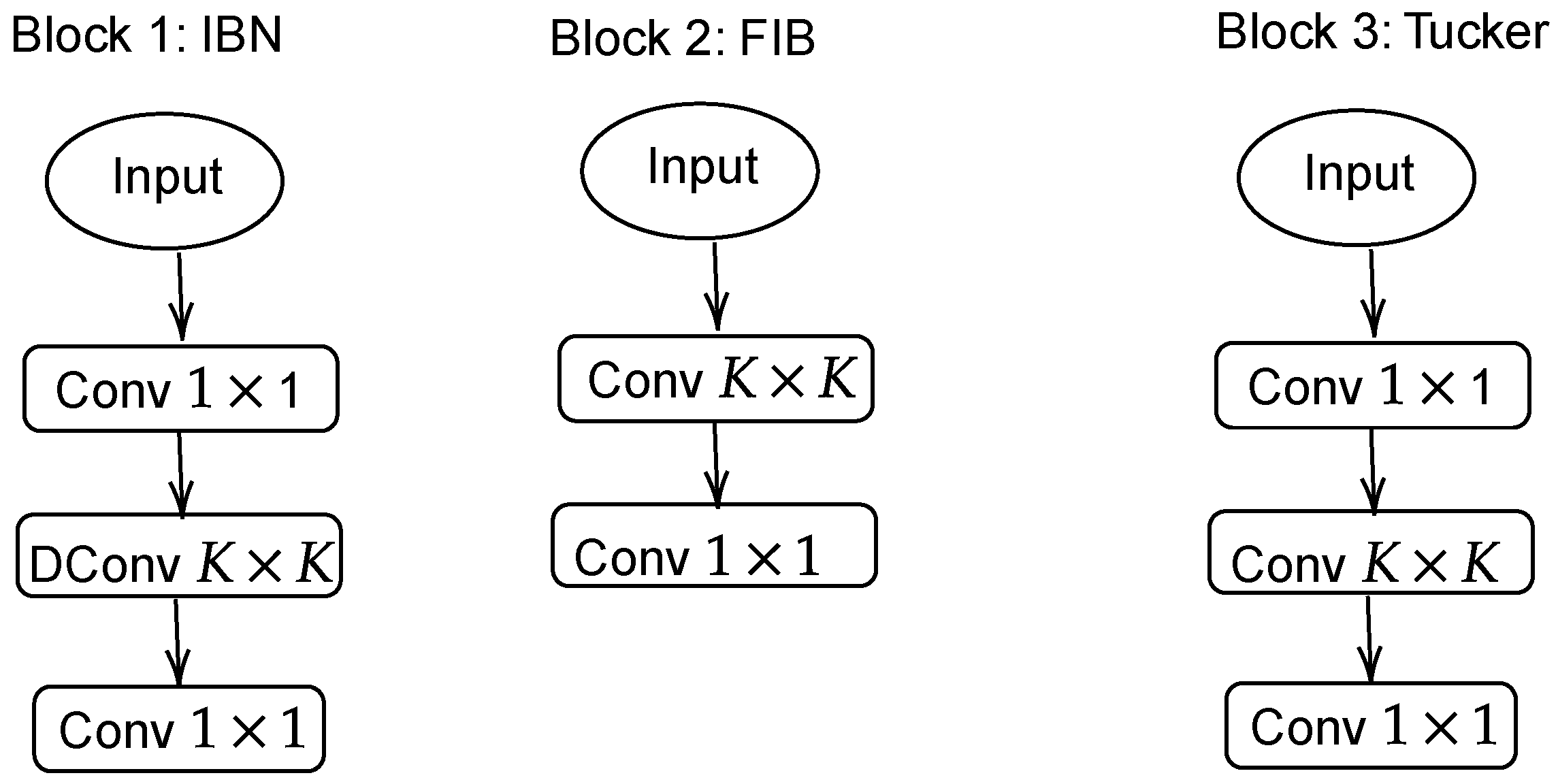
2.3. SSD Backbones
2.4. Hardware Used
2.5. Metric for Evaluation
2.6. Training Configuration
3. Results and Discussions
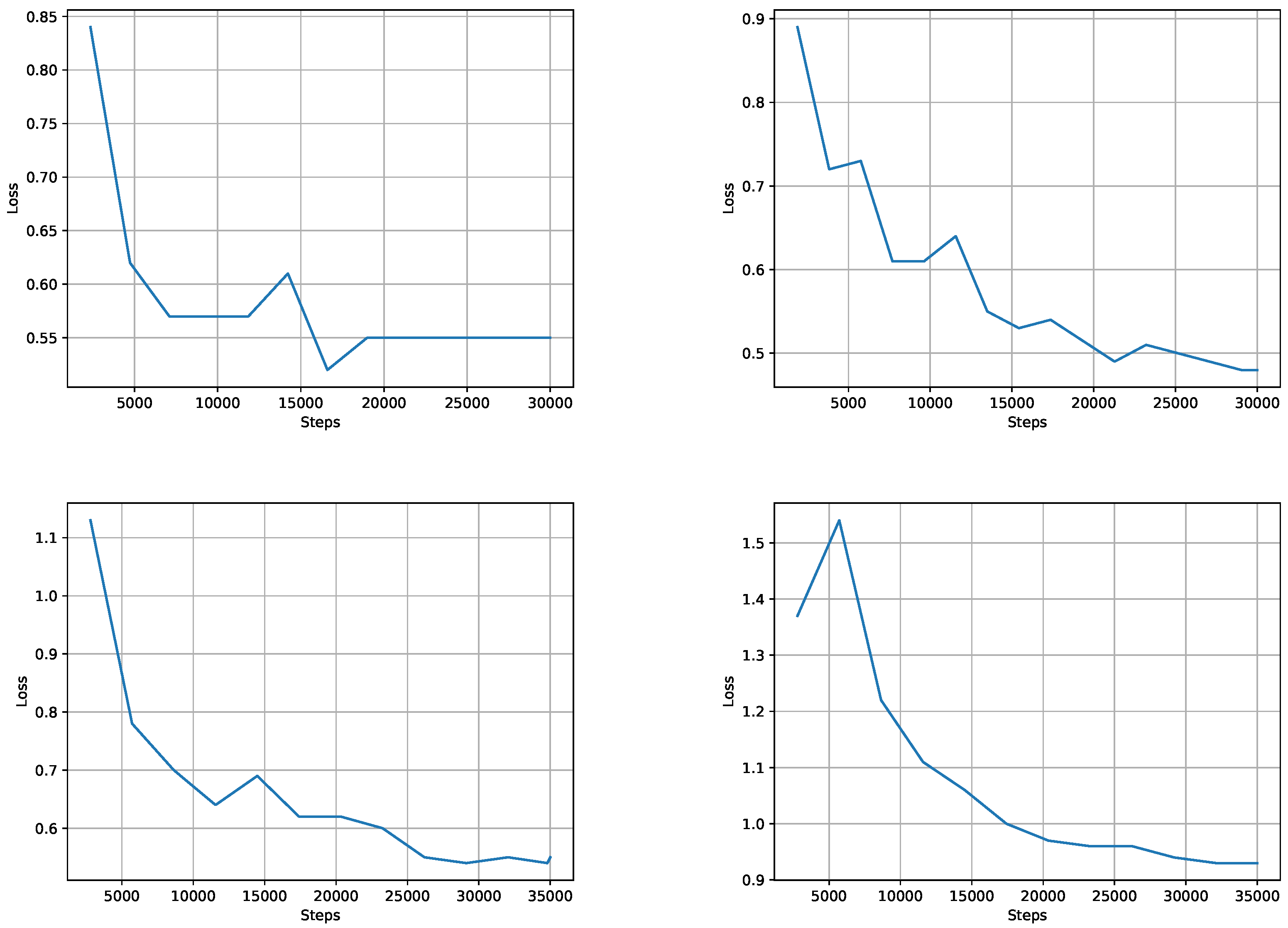
3.1. Performance of the Models during Training
3.2. Comparison of the Performance of the Models
3.3. Effect of Some Parameters on the Performance of the Model
3.4. Effect of Data Augmentation before Splitting Data into Training and Test Set
3.5. Analysis of the Trunk Detection Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Clark, M.; Tilman, D. Comparative analysis of environmental impacts of agricultural production systems, agricultural input efficiency, and food choice. Environ. Res. Lett. 2017, 12, 064016. [Google Scholar] [CrossRef]
- Baiano, A. An Overview on Sustainability in the Wine Production Chain. Beverages 2021, 7, 15. [Google Scholar] [CrossRef]
- Rodrigo-Comino, J. Five decades of soil erosion research in “terroir”. The State-of-the-Art. Earth-Sci. Rev. 2018, 179, 436–447. [Google Scholar] [CrossRef]
- Jastrzębska, M.; Kostrzewska, M.; Saeid, A. Chapter 2—Sustainable agriculture: A challenge for the future. In Smart Agrochemicals for Sustainable Agriculture; Chojnacka, K., Saeid, A., Eds.; Academic Press: Cambridge, MA, USA, 2022; pp. 29–56. [Google Scholar] [CrossRef]
- Hopmans, J.W.; Qureshi, A.; Kisekka, I.; Munns, R.; Grattan, S.; Rengasamy, P.; Ben-Gal, A.; Assouline, S.; Javaux, M.; Minhas, P.; et al. Chapter One—Critical knowledge gaps and research priorities in global soil salinity. In Advances in Agronomy; Academic Press: Cambridge, MA, USA, 2021; Volume 169, pp. 1–191. [Google Scholar] [CrossRef]
- Nalla, K.; Pothabathula, S.V.; Kumar, S. Chapter 21—Applications of Computational Methods in Plant Pathology. In Natural Remedies for Pest, Disease and Weed Control; Egbuna, C., Sawicka, B., Eds.; Academic Press: Cambridge, MA, USA, 2020; pp. 243–250. [Google Scholar] [CrossRef]
- Loures, L.; Chamizo, A.; Ferreira, P.; Loures, A.; Castanho, R.; Panagopoulos, T. Assessing the Effectiveness of Precision Agriculture Management Systems in Mediterranean Small Farms. Sustainability 2020, 12, 3765. [Google Scholar] [CrossRef]
- Verdouw, C.; Wolfert, S.; Tekinerdogan, B. Internet of Things in agriculture. CAB Rev. 2016, 11, 1–12. [Google Scholar] [CrossRef]
- Zantalis, F.; Koulouras, G.; Karabetsos, S.; Kandris, D. A Review of Machine Learning and IoT in Smart Transportation. Future Internet 2019, 11, 94. [Google Scholar] [CrossRef] [Green Version]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Alibabaei, K.; Gaspar, P.D.; Lima, T.M.; Campos, R.M.; Girão, I.; Monteiro, J.; Lopes, C.M. A Review of the Challenges of Using Deep Learning Algorithms to Support Decision-Making in Agricultural Activities. Remote Sens. 2022, 14, 638. [Google Scholar] [CrossRef]
- Kerkech, M.; Hafiane, A.; Canals, R. Vine disease detection in UAV multispectral images using optimized image registration and deep learning segmentation approach. Comput. Electron. Agric. 2020, 174, 105446. [Google Scholar] [CrossRef]
- Silver, D.L.; Monga, T. In Vino Veritas: Estimating Vineyard Grape Yield from Images Using Deep Learning. In Advances in Artificial Intelligence; Meurs, M.J., Rudzicz, F., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 212–224. [Google Scholar]
- Ghiani, L.; Sassu, A.; Palumbo, F.; Mercenaro, L.; Gambella, F. In-Field Automatic Detection of Grape Bunches under a Totally Uncontrolled Environment. Sensors 2021, 21, 3908. [Google Scholar] [CrossRef]
- Milella, A.; Marani, R.; Petitti, A.; Reina, G. In-field high throughput grapevine phenotyping with a consumer-grade depth camera. Comput. Electron. Agric. 2019, 156, 293–306. [Google Scholar] [CrossRef]
- Majeed, Y.; Karkee, M.; Zhang, Q.; Fu, L.; Whiting, M.D. Determining grapevine cordon shape for automated green shoot thinning using semantic segmentation-based deep learning networks. Comput. Electron. Agric. 2020, 171, 105308. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:cs.CV/1905.02244. [Google Scholar]
- Xiong, Y.; Liu, H.; Gupta, S.; Akin, B.; Bender, G.; Wang, Y.; Kindermans, P.J.; Tan, M.; Singh, V.; Chen, B. MobileDets: Searching for Object Detection Architectures for Mobile Accelerators. arXiv 2021, arXiv:cs.CV/2004.14525. [Google Scholar]
- Cloud Tensor Processing Units (tpus). Available online: https://cloud.google.com/tpu/docs/tpus (accessed on 27 June 2022).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision-ECCV 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Aguiar, A.S.; Magalhães, S.A.; dos Santos, F.N.; Castro, L.; Pinho, T.; Valente, J.; Martins, R.; Boaventura-Cunha, J. Grape Bunch Detection at Different Growth Stages Using Deep Learning Quantized Models. Agronomy 2021, 11, 1890. [Google Scholar] [CrossRef]
- Aghi, D.; Mazzia, V.; Chiaberge, M. Local Motion Planner for Autonomous Navigation in Vineyards with a RGB-D Camera-Based Algorithm and Deep Learning Synergy. Machines 2020, 8, 27. [Google Scholar] [CrossRef]
- Pinto de Aguiar, A.S.; Neves dos Santos, F.B.; Feliz dos Santos, L.C.; de Jesus Filipe, V.M.; Miranda de Sousa, A.J. Vineyard trunk detection using deep learning—An experimental device benchmark. Comput. Electron. Agric. 2020, 175, 105535. [Google Scholar] [CrossRef]
- Aguiar, A.S.; Monteiro, N.N.; Santos, F.N.D.; Solteiro Pires, E.J.; Silva, D.; Sousa, A.J.; Boaventura-Cunha, J. Bringing Semantics to the Vineyard: An Approach on Deep Learning-Based Vine Trunk Detection. Agriculture 2021, 11, 131. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Yazdanbakhsh, A.; Seshadri, K.; Akin, B.; Laudon, J.; Narayanaswami, R. An Evaluation of Edge TPU Accelerators for Convolutional Neural Networks. arXiv 2021, arXiv:cs.LG/2102.10423. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications. arXiv 2018, arXiv:cs.CV/1804.03230. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Yu, H.; Chen, C.; Du, X.; Li, Y.; Rashwan, A.; Hou, L.; Jin, P.; Yang, F.; Liu, F.; Kim, J.; et al. TensorFlow Model Garden. Available online: https://github.com/tensorflow/models (accessed on 27 June 2022).
- Nagel, M.; Fournarakis, M.; Amjad, R.A.; Bondarenko, Y.; van Baalen, M.; Blankevoort, T. A White Paper on Neural Network Quantization. arXiv 2021, arXiv:2106.08295. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbones | MobileNet-V1 | MobileNet-V2 | MobileNet Edge TPU | MobileDet Edge TPU |
|---|---|---|---|---|
| Training time (s) | 0.23 | 0.30 | 0.19 | 0.19 |
| No. Parameters (million) | 5.49 | 4.57 | 2.99 | 3.25 |
| Backbone | mAP% | Inference Time (ms) | |||
|---|---|---|---|---|---|
| PC | RaspberryPi | RaspberryPi | |||
| GPU | CPU | TPU | CPU | TPU | |
| MobileDet Edge TPU | 89 | 84.4 | 84.6 | 1048.277 | 47.75 |
| MobileNet Edge TPU | 86.7 | 84.8 | 86.6 | 1235.73 | 47.79 |
| MobileNet-V1 | 84 | 79.9 | 81.3 | 861.4 | 45.73 |
| MobileNet-V2 | 88 | 82.8 | 83.2 | 773.717 | 47.969 |
| Backbone | mAP% | Inference Time (ms) | |||
|---|---|---|---|---|---|
| PC | RaspberryPi | RaspberryPi | |||
| GPU | CPU | TPU | CPU | TPU | |
| MobileDet Edge TPU () | 89 | 84.4 | 84.6 | 456.98 | 47.75 |
| MobileDet Edge TPU () | 77 | 67.4 | 67 | 1235.73 | 27 |
| MobileDet Edge TPU () | 81 | 77 | 77.5 | 456.98 | 47.75 |
| (trained on 20% of images) | |||||
| MobileDet Edge TPU () | 87 | 82.6 | 83 | 456.98 | 47.75 |
| (without thermal images in training set) | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alibabaei, K.; Assunção, E.; Gaspar, P.D.; Soares, V.N.G.J.; Caldeira, J.M.L.P. Real-Time Detection of Vine Trunk for Robot Localization Using Deep Learning Models Developed for Edge TPU Devices. Future Internet 2022, 14, 199. https://doi.org/10.3390/fi14070199
Alibabaei K, Assunção E, Gaspar PD, Soares VNGJ, Caldeira JMLP. Real-Time Detection of Vine Trunk for Robot Localization Using Deep Learning Models Developed for Edge TPU Devices. Future Internet. 2022; 14(7):199. https://doi.org/10.3390/fi14070199
Chicago/Turabian StyleAlibabaei, Khadijeh, Eduardo Assunção, Pedro D. Gaspar, Vasco N. G. J. Soares, and João M. L. P. Caldeira. 2022. "Real-Time Detection of Vine Trunk for Robot Localization Using Deep Learning Models Developed for Edge TPU Devices" Future Internet 14, no. 7: 199. https://doi.org/10.3390/fi14070199