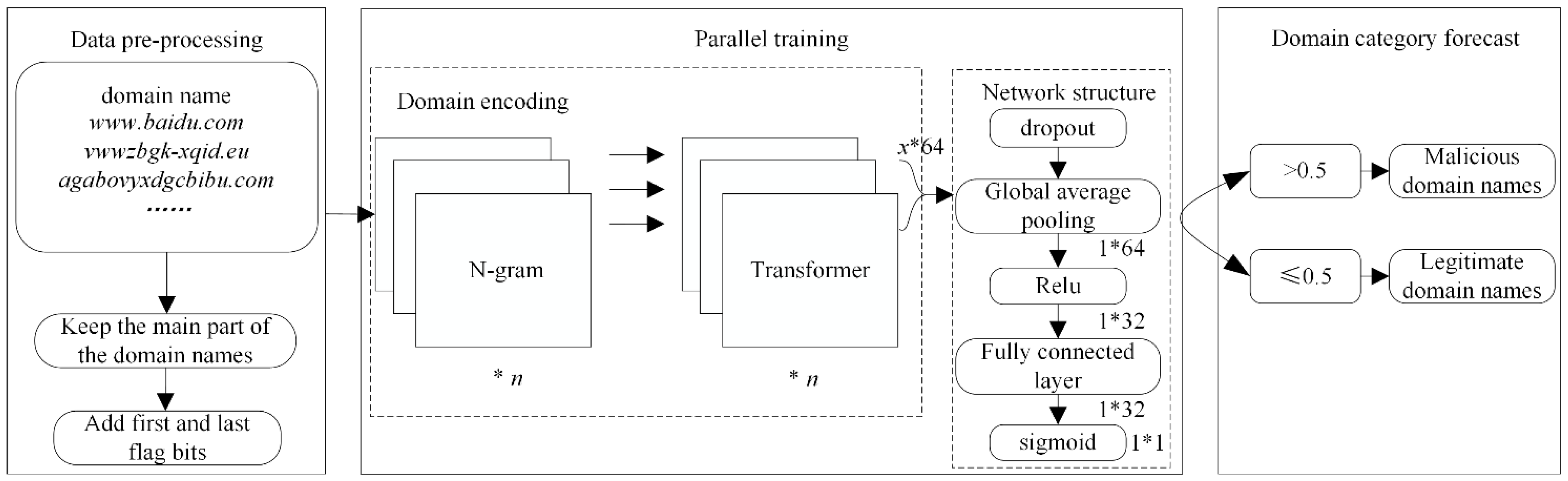
4.2. Data Analysis
Ten thousand legitimate and ten thousand malicious domain names were randomly selected as the dataset for the experiment. For each domain name, because the characteristics of legitimate and malicious domain names at the first level are not obvious, the first-level domain was discarded and constituted the dataset D. The training set and test set in the experiment were partitioned using the sklearn module at 40% for the test set. After mixing the malicious domain names from 360 Network Security Lab, 10,000 data were randomly selected, and each family had no more than 1400 malicious domains.
The selected families of malicious domain names and the number of them are shown in
Table 2. Refer to Vranken [
20] for a detailed description of the dataset, and refer to the DGALab study to classify the types of DGA. The column ‘DGA type’ indicates whether the DGA is Static DGA (Static), Seed-based (Seed), or Date-based (Date) [
21]. The column ‘Number’ indicates the count of domain names; the column ‘Length’ indicates the length (min, max) of the second-level domain names. The last two columns show examples of second-level domain names.
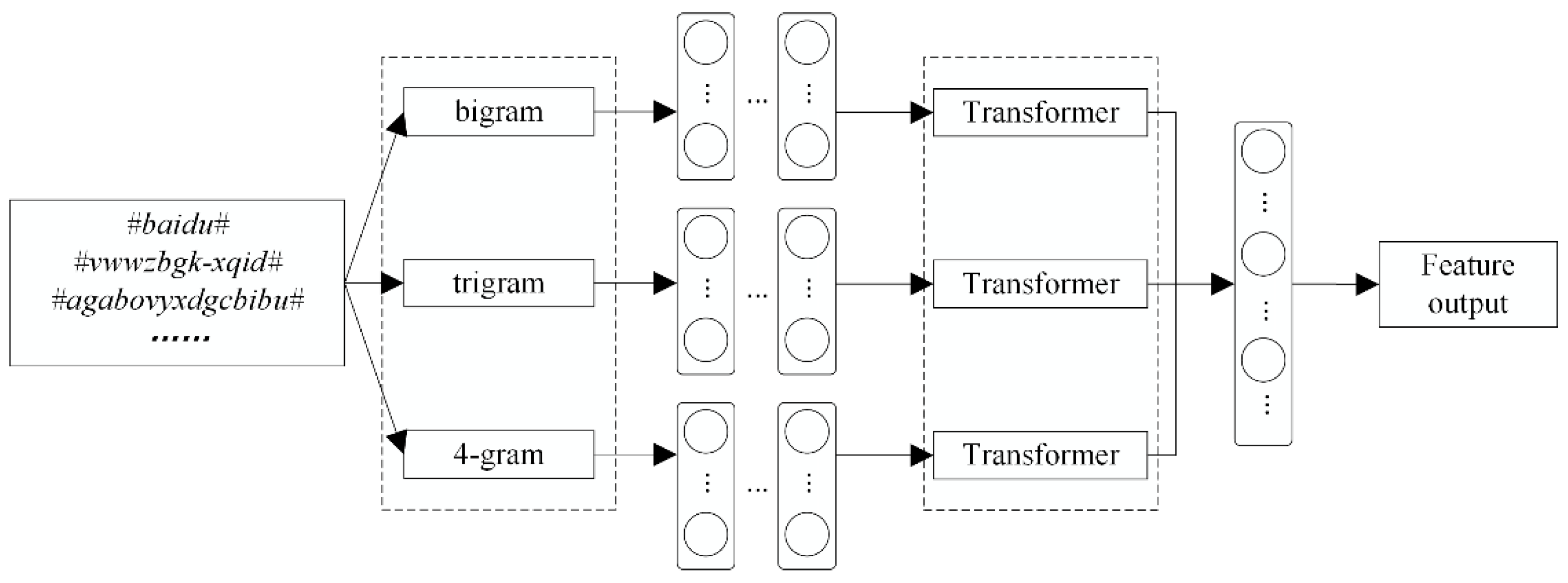
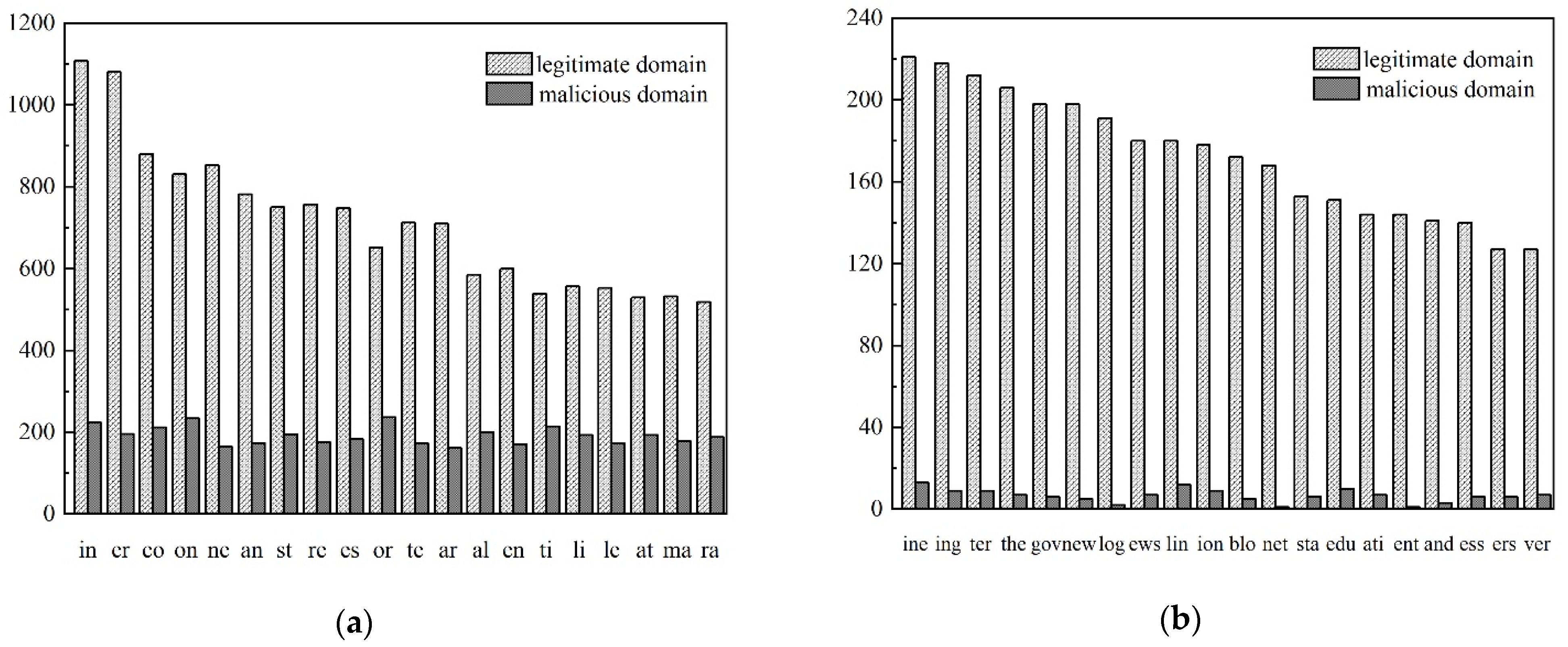
For dataset
D, there were 1417 phrase elements after bigram processing, 31,220 phrase elements after trigram processing, 127,469 phrase elements after 4-g processing, and 138,636 phrase elements after 5-g processing. The N-gram algorithm was used for the legitimate and malicious domain names in
D. The distribution of the phrase elements of the domain names was obtained as shown in
Figure 5a,b.
From the N-gram distribution (N = 2 or 3) results of legitimate and malicious domain names, there was a great difference in the frequency of phrase elements of malicious and legitimate domain names. The distribution of phrase elements of malicious domain names was more uniform, while the distribution of phrase elements of legitimate domain names varied greatly, so the phrase elements generated after bigram segmentation had better domain name classification characteristics. When N = 4 or 5, legitimate domain names still had a good frequency distribution of phrase elements. Malicious domain names have an increased variety of phrase elements, become more random, and correspond to fewer phrase elements.
The numerical characteristics of the phrase elements after N-gram algorithm processing are analyzed. The data analysis uses mean, variance, skewness, and kurtosis as indicators of numerical characteristics to analyze the results of N-gram processing for two types of domain names. The results are shown in
Table 3.
From
Table 3, it can be concluded that, when
N = 1, it is equivalent to performing the frequency statistics of letters, ignoring the order relationship between letters. When
N = 2, 3, 4, and 5, the phrase element variance of legitimate domain names is larger than that of malicious domain names. The smaller the value, the more uniform the distribution of domain name phrase elements, which is a randomly generated domain name. The larger the variance, the more the frequency distribution of the phrase elements deviates from the mean, which is more likely a domain name generated by human intervention. The skewness of phrase elements of legitimate domain names is larger than that of phrase elements of malicious domain names. In terms of data distribution, malicious domain names have better symmetry than legitimate domain names. In terms of kurtosis, the data distribution of malicious domain names fits more closely to the normal distribution than the data distribution of legitimate domain names.
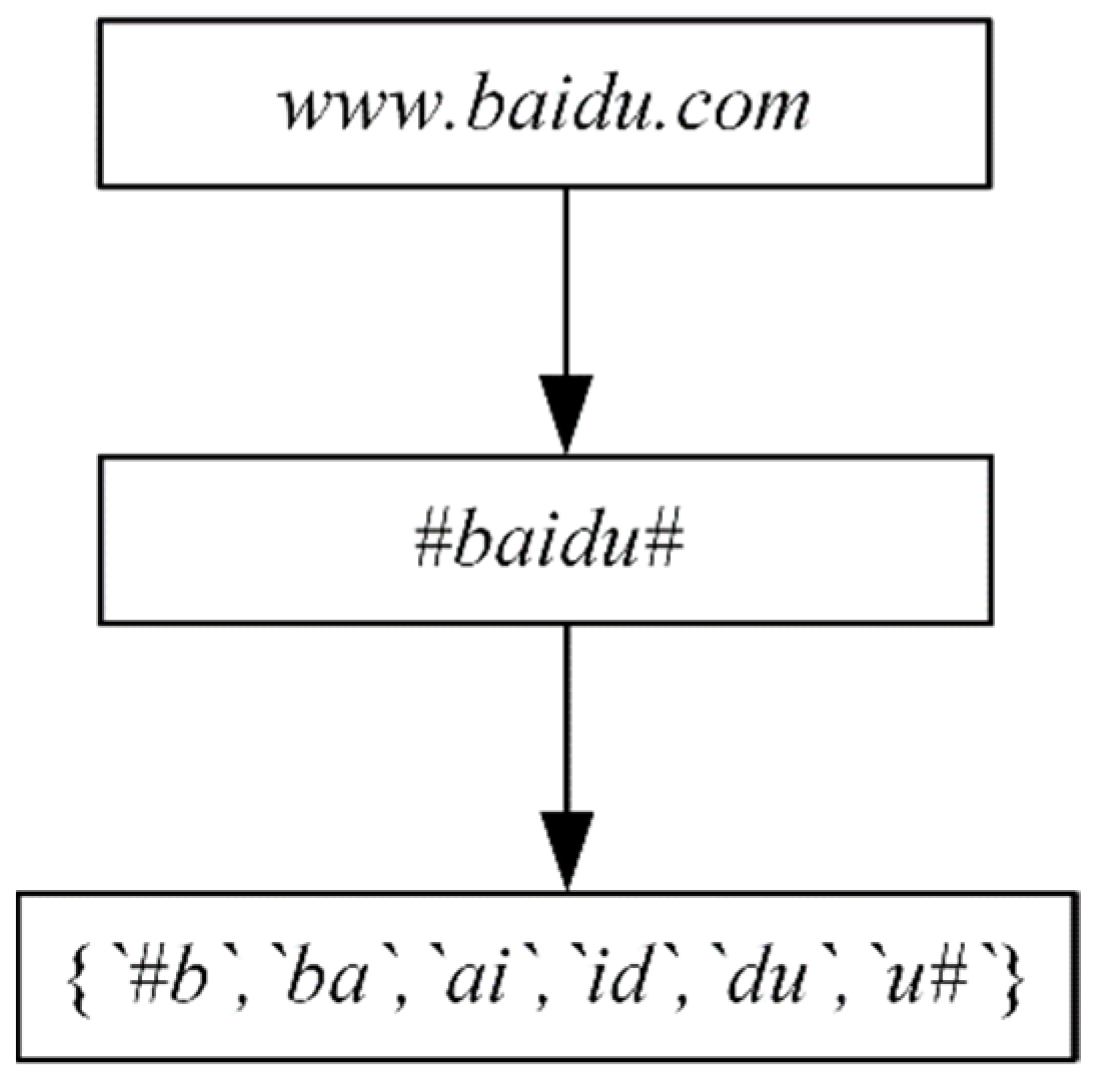
Taking the data after bigram processing as an example, the experiment uses the word-hashing technique to add the flag bit “#” at the beginning and end of each second-level domain name, and the number of data elements increases from 1417 to 1486. The increase of the first and last flag bits marks part of the location information of the domain name, which enriches the features in the recognition process without causing significant redundancy. Therefore, the data pre-processing method of adding the first and last flag bits and using the N-gram algorithm can effectively extract the character frequency and character location information features of domain names.
4.3. Experimental Results and Analysis
To validate the results of the proposed parallel detection model based on the N-gram algorithm and Transformer to identify malicious domain names, four sets of experiments were designed based on the same dataset.
The optimal parallel model was selected to detect malicious domain names by changing the parallelism and combining N-gram algorithms in the parallel detection model;
By changing the head value in the Transformer model, the appropriate number of heads was selected as a parameter in the model training;
In order to verify the detection effect of the model proposed in this paper, the Naive Bayesian and XGBoost machine learning algorithms and RNN, LSTM, and Bi-LSTM models in deep learning were selected to compare with the model designed in this paper;
Through ablation experiments, we compare the number of features, training time, and evaluation metrics to analyze the effects of adding sign bits and L1 regularization in a single detection model and compare the effects of adding sign bits in a parallel detection model.
The following experiments are implemented in the keras deep learning framework, Tensorflow back-end, and sklearn module.
4.3.1. Evaluation Indicators
Accuracy (
Acc) was used in the experiments to evaluate the classification accuracy of the algorithm for domain names, and
recall was used to evaluate the model’s classification of malicious domain names. The accuracy formula is shown in Equation (8).
where
TP denotes the number of malicious domain names predicted to be malicious,
FN denotes the number of malicious domain names predicted to be legitimate,
TN denotes the number of legitimate domain name predicted to be legitimate, and
FP denotes the number of legitimate domain names predicted to be malicious.
The formula for calculating the
recall is shown in Equation (9).
From Equation (9), we can see the total number of malicious domain names in the dataset, so the recall can calculate the model’s effectiveness in detecting malicious domain names. The detection effects of different network models will also be compared using the precision and F1-score.
4.3.2. Parallel Detection Model Construction Experiments
In order to select a malicious domain detection model with better results, possible combinations of N-gram algorithms in the proposed parallel detection model are analyzed. In the single N-gram experiment when , although more features can be captured and the ability to predict characters is significantly improved, a large number of sparse matrices are generated in the model. This can lead to distortion of the calculated probabilities, and a large parameter space can cause a dimensional disaster; thus, the model will have a considerable time and memory loss during training, resulting in the experiment not being carried out smoothly. Based on the original N-gram and Transformer detection models, the features are optimized using a feature selection algorithm based on L1 regularization. After feature gain processing, in addition to achieving the filtering feature purpose, the high-dimensional matrices are also dimensionally reduced, which reduces the experimental time and memory loss, making the experiments feasible.
Different combinations of
N were tested to explore the most suitable N-gram combination and Transformer composition for the parallel detection model. The experimental procedure is shown in
Table 4.
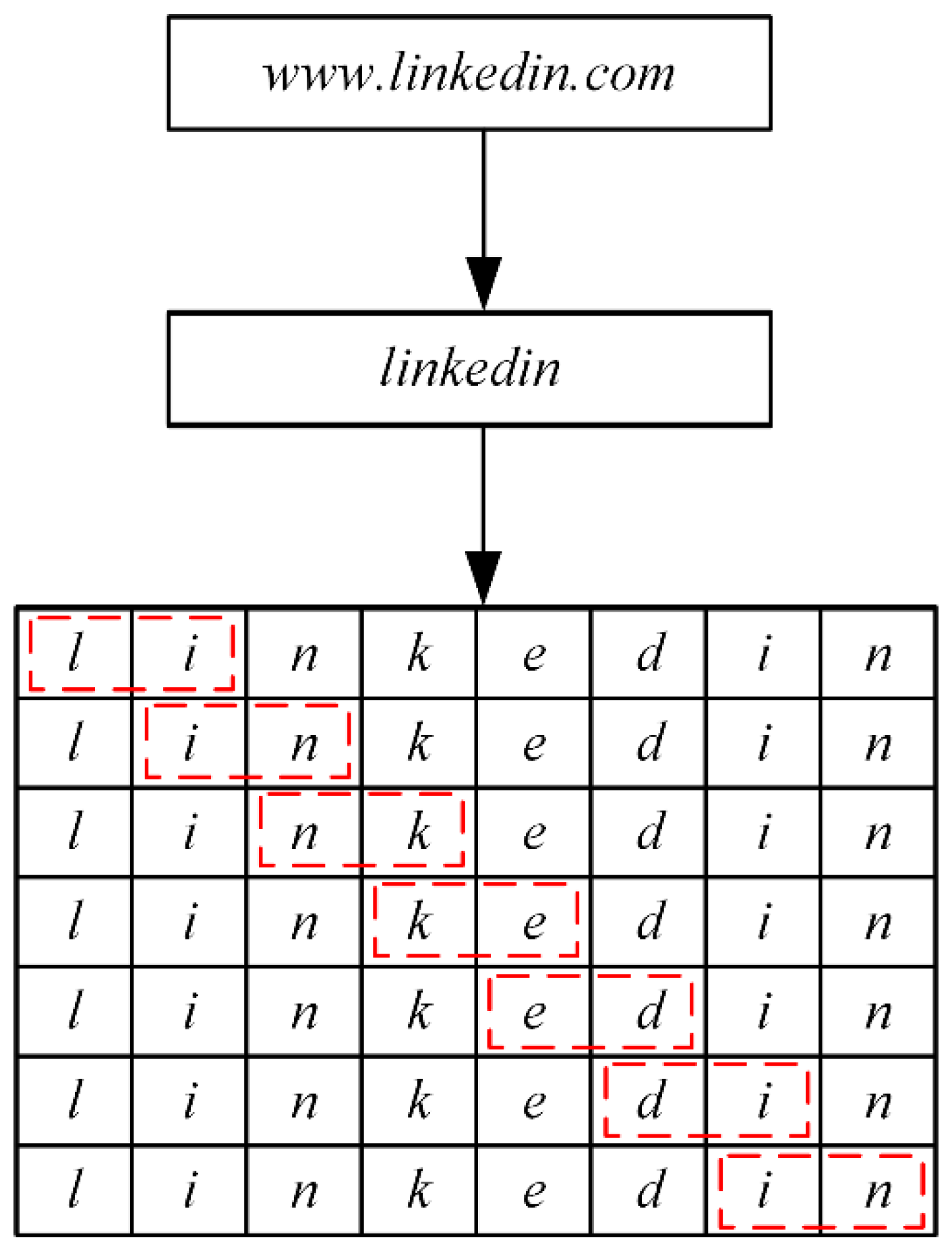
The experimental results show that, for a single N-gram algorithm, the number of phrase elements in the domain names must be reduced because the basic units of the phrase elements are expanding, and the number of phrase elements matching the same category in the domain names must be reduced as the N-value changes. Therefore, the effective features obtained from training are reduced. Taking “linkedin” as an example, there are 749 “li” phrase elements in the dataset. After trigram processing, there are 192 “lin” phrase elements in the dataset, which is less than the result of binary phrase element processing. At the same time, the accuracy of the trained model decreases, and the recall increases, indicating overfitting.
The features extracted by a single algorithm are expanded for the parallel detection model by stitching the features from different N-gram algorithms and Transformer processing. As can be seen from
Table 4, the parallel detection model, including bigram, has better detection results and achieves the best results at
N = 2, 3, and 4. However, it is not the case that the more parallel approaches are included, the better the detection results are. It is found that the model detection accuracy and recall decrease when 5-g is included, but then the detection results become better again if
N = 1 is included in the model. The domain location and text features are extracted more comprehensively after learning with the multi-head attention mechanism. The model combined with bigram had improved accuracy and recall over the single bigram-based model.
After comparing the experimental results, the model using the parallel combination of bigram, trigram, 4-g, and Transformer at N = 2, 3, 4 was more effective in identifying malicious domain names.
4.3.3. Multi-Head Attention Head Comparison Experiment
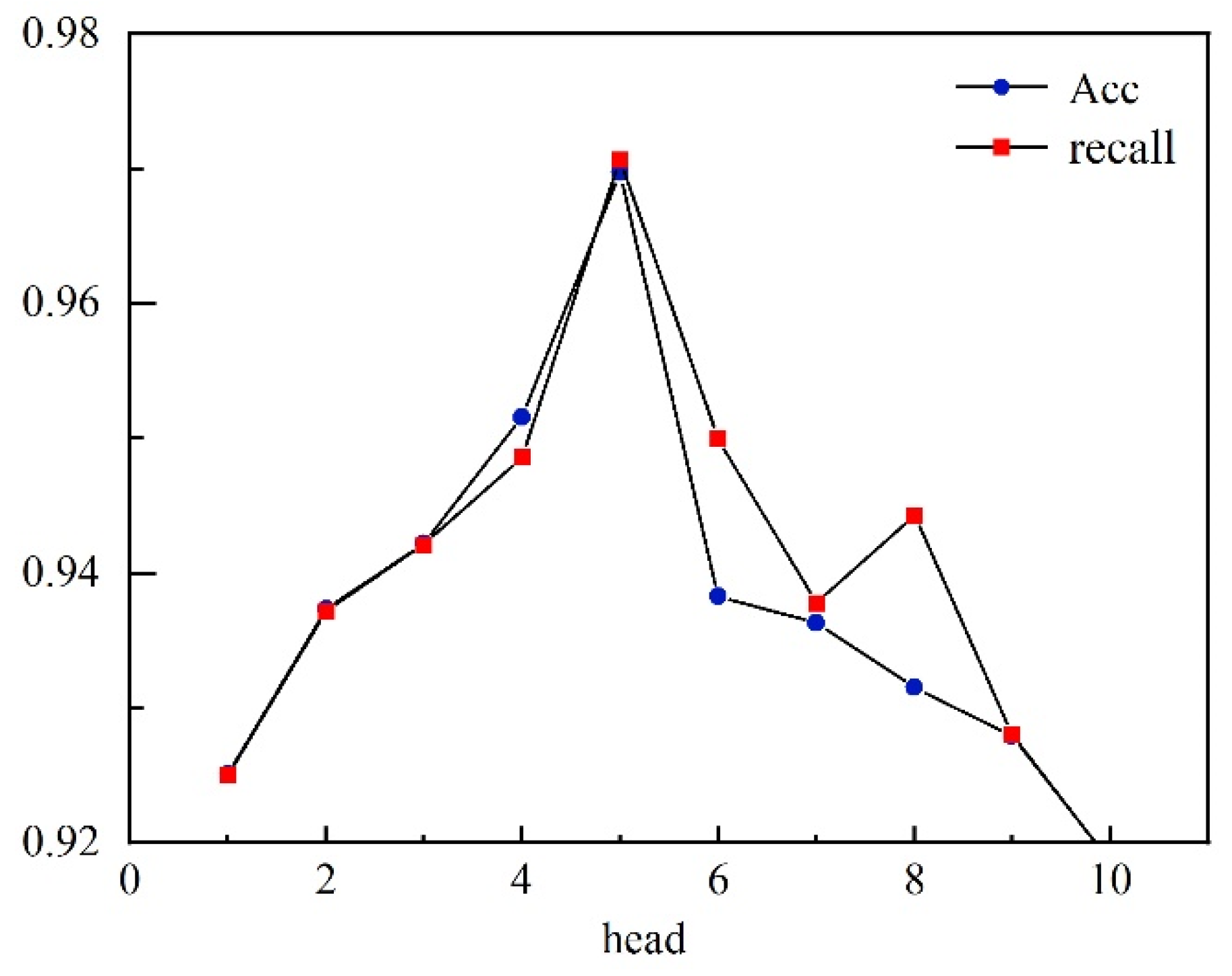
In the Transformer model, the number of heads also affects the experiment, which is conducted by changing the heads value; the experimental results are shown in
Figure 6.
From
Figure 6, we see that the model achieves the best results regarding accuracy and
recall when the number of heads is five. At this time, changing the number of heads does not improve the detection effect of the model, and increasing the number of linear mappings to the feature matrix does not allow the extraction of effective features in the increased linear space.
According to the results of this experiment, the head value of five in the detection model optimizes the detection of malicious domain names.
4.3.4. Network Model Comparison Experiment
The Naive Bayesian algorithm, XGBoost algorithm, RNN model, LSTM model, Bi-LSTM model, and the parallel detection model proposed in this paper were selected for comparison. The experimental results are shown in
Table 5.
Machine learning algorithms, such as the Naive Bayesian algorithm and XGBoost algorithm, require human selection of features and the process takes a lot of time. The features extracted with bigram alone cannot accurately distinguish legitimate domain names from malicious ones. After the word embedding process, RNN, LSTM, and Bi-LSTM improve the accuracy and recall compared to machine learning algorithms and focus more on the features of character frequency provided by word embedding. However, they lack the learning of similarity between phrase elements compared to the Transformer model, which introduces a multi-head attention mechanism. As can be seen from the precision, the N-Trans model predicts fewer errors in the results for malicious domains. In terms of the speed of feature learning, the Transformer model significantly improves the speed of training compared to the model that relies on the sequential relationship between elements due to its ability to operate in parallel. Combined with the F1 score, the N-Trans model can better distinguish malicious domain names from legitimate domain names compared with other network models.
Since the parallel detection model can effectively extract the location information and multi-text features of domain characters, and the model can capture more features among word combinations, it achieves better results in the malicious domain names classification problem.
4.3.5. Ablation Experiments
In order to further verify the impact of each part of the detection model on the experiments, the single N-gram and Transformer malicious domain name detection models proposed in this paper are first subjected to ablation experiments. Firstly, we use bigram and Transformer experiments, and to verify the effectiveness of word-hashing, we use the word-hashing processed dataset for malicious domain name detection. After that, we compare the models before and after feature gain by adding L1 regularization to verify the effect of feature gain on the model; the experimental results are shown in
Table 6.
When the L1 regularization was removed, the features processed by the parallel detection model increased significantly; the number of features obtained without adding the first and last flag bits was 160,106, and the number of features obtained after adding the first and last flag bits was 181,018, which means the experiment could not be carried out smoothly. Therefore, only the effect of adding the flag bits on the parallel detection model is verified. The ablation experiments were performed with or without adding the flag bits; the results are shown in
Table 7.
Table 6 and
Table 7 show that adding flag bits can increase the first and last position information in the domain names string, resulting in a small increase in the accuracy and
recall of the model detection. After adding L1 regularization, the time for model training was significantly reduced; at the same time, the detection effect of the model was optimized, and the accuracy and
recall of detection were further improved. The results show that adding the first and last marker bits can enrich the features learned by the model; L1 regularization makes the experiment feasible, reduces the training time and memory consumption, and the features after L1 regularization gain can detect malicious domain names more accurately.
In summary, the parallel detection model based on the N-gram and Transformer framework proposed in this paper can effectively and accurately detect malicious domain names.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}