1. Introduction
Phishing is a sort of fraud that is one of the greatest threats on the Internet; it refers to false webpages that look and behave like actual webpages. Cybercriminals typically prey on individuals who lack essential digital security awareness through social engineering [
1]. The objective is to dupe people into transmitting sensitive data such as their username, password, bank account number, or credit card number [
2]. This form of crime can jeopardize users’ and organizations’ credibility and financial security; in some situations, phishing is the initial event that can lead to economic losses and more significant disruptions [
3]; it can result in millions of dollars in losses every day [
4]. According to the latest quarterly report from the Anti-Phishing Working Group (APWG) [
5], since early 2020, the number of recent phishing assaults has more than doubled. As reported in the third quarter of 2021, the number of new unique phishing websites detected was 730,372, representing a rise of 30 percent from the second quarter of 2021. Moreover, between years, the number of phishing websites increased. Meanwhile, according to Phislabs’s data [
6], during 2019 83.9% of phishing attacked services are financial, email, cloud, payment, and SaaS.
According to Abutair & Belghith [
7], no single approach or strategy can detect all phishing websites ideally. The problem is that the website’s content is liable to change, and the website’s operational lifespan is limited. Machine learning (ML) is a promising and intelligent approach. This approach detects new phishing websites by analyzing a range of indicators, better known as features. Research on this topic attempts to implement several methods and algorithms using machine learning. The Hybrid Ensemble Feature Selection method uses a Cumulative Distribution Function gradient (CDF-g) algorithm to identify the automated feature cut-off rank.
Additionally, Chiew et al. [
8] employ an ensemble technique called function perturbation. Due to this approach, Random Forest (RF) outperformed Naïve Bayes (NB), JRip, PART Classifier, and Support Vector Machines (SVM). With hybrid Natural language processing (NLP) and words vector-based features, RF receives the most excellent accuracy rating [
9]. Furthermore, Nazz [
10] uses a way that ranks the features based on the maximum variance using Principal Component Analysis (PCA). Next, Nazz applies RF, SVM, and Logistic Regression (LR) machine learning algorithms; the result is RF and SVM make better performance by accuracy. Each of these studies used a unique method for selecting features. Recent dataset comes with several features, and the assumption is some researchers use 50–100% of the total features, with complex computational time. For instance, Alotaibi and Alotaibi [
11] used 23 from 48 features, Naaz [
10] used all the features for 49, Hutchinson et al. [
12] used 16 from 30 features, Karabatak and Mustafa [
13] used 27 from 30 features, and Zaini et al. [
14] used 15 from 30 features
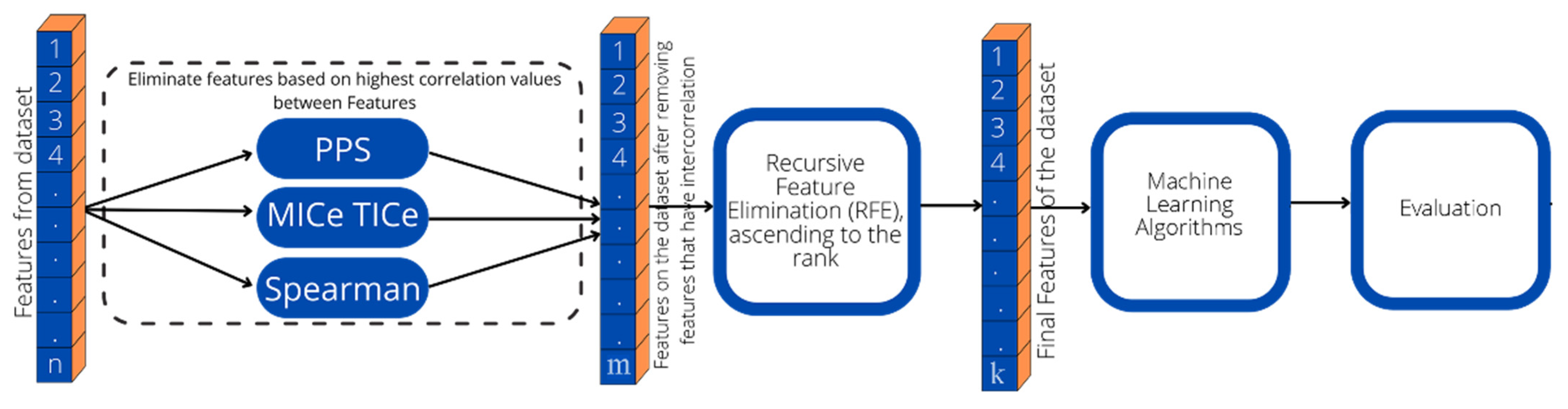
This paper’s hypothesis is that reducing low-impact features lead to simpler compu-tation with an insignificant decline in the recognition rate for the web phishing dataset. In this paper, three scenarios of feature selection followed by machine learning classification. Hence, the objectives and contributions of this paper are to propose the optimal feature selection scenario for detecting phishing websites using machine learning. We observe feature selection, and recursive feature elimination by gradually decreasing and making new subset features. Additionally, this paper conducts a comparative analysis of three correlation methods combined with a machine learning algorithm: Spearman, Power Predictive Score (PPS), and Maximal Information Coefficient (MICe) with Total Information Coefficient (TICe) on selecting features from a dataset. Moreover, a performance comparison of four Random Forest (RF), Support Vector Machine (SVM), Decision Tree (DT) and AdaBoost algorithms on selected features is evaluated.
The remaining paper is organized as follows: the second section discusses material and methods, the result is presented in
Section 3,
Section 4 presents the discussion, and we draw our conclusion in
Section 5.
4. Discussion
The remaining feature in each scenario then tested for classification purposes using Machine Learning algorithms.
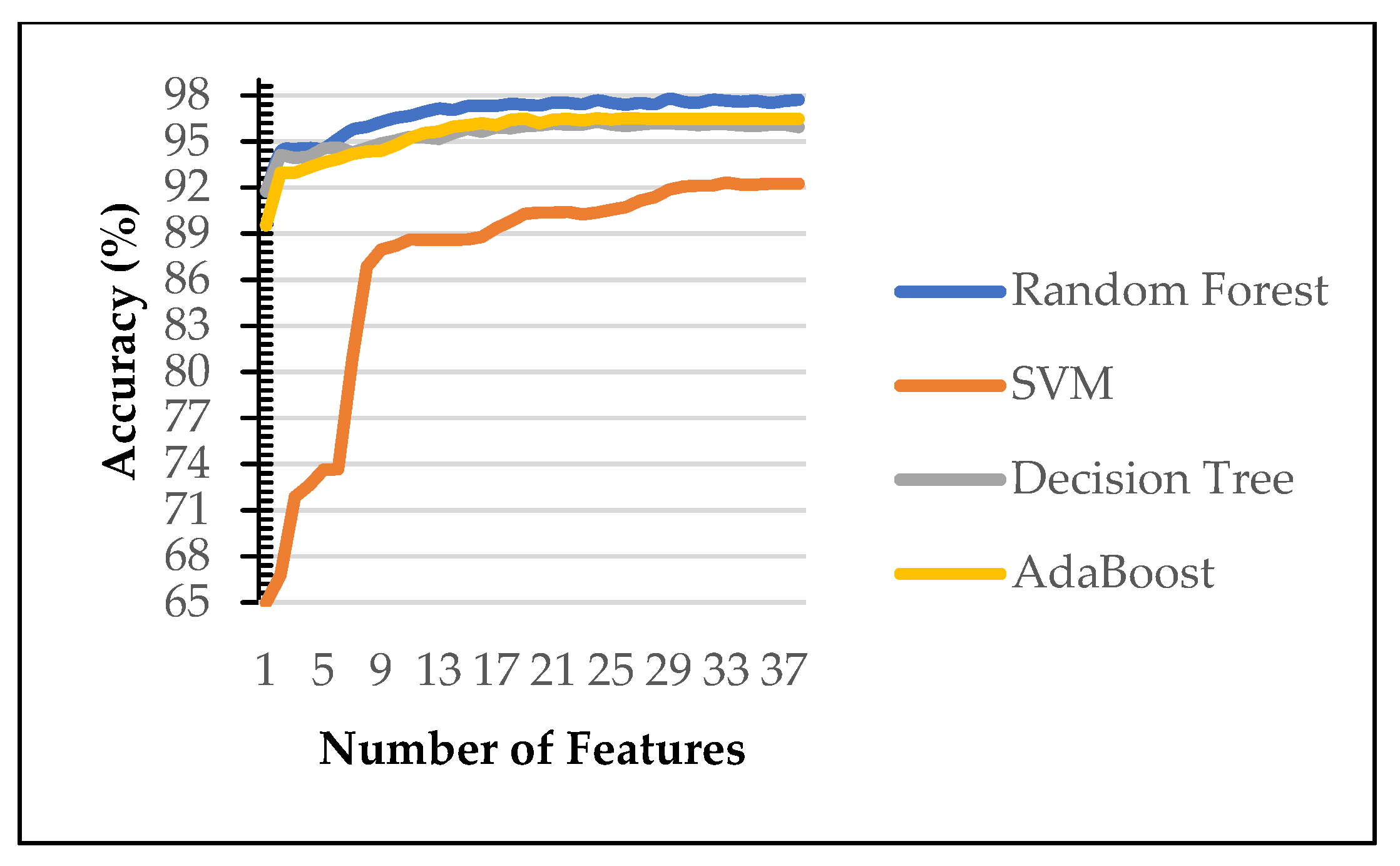
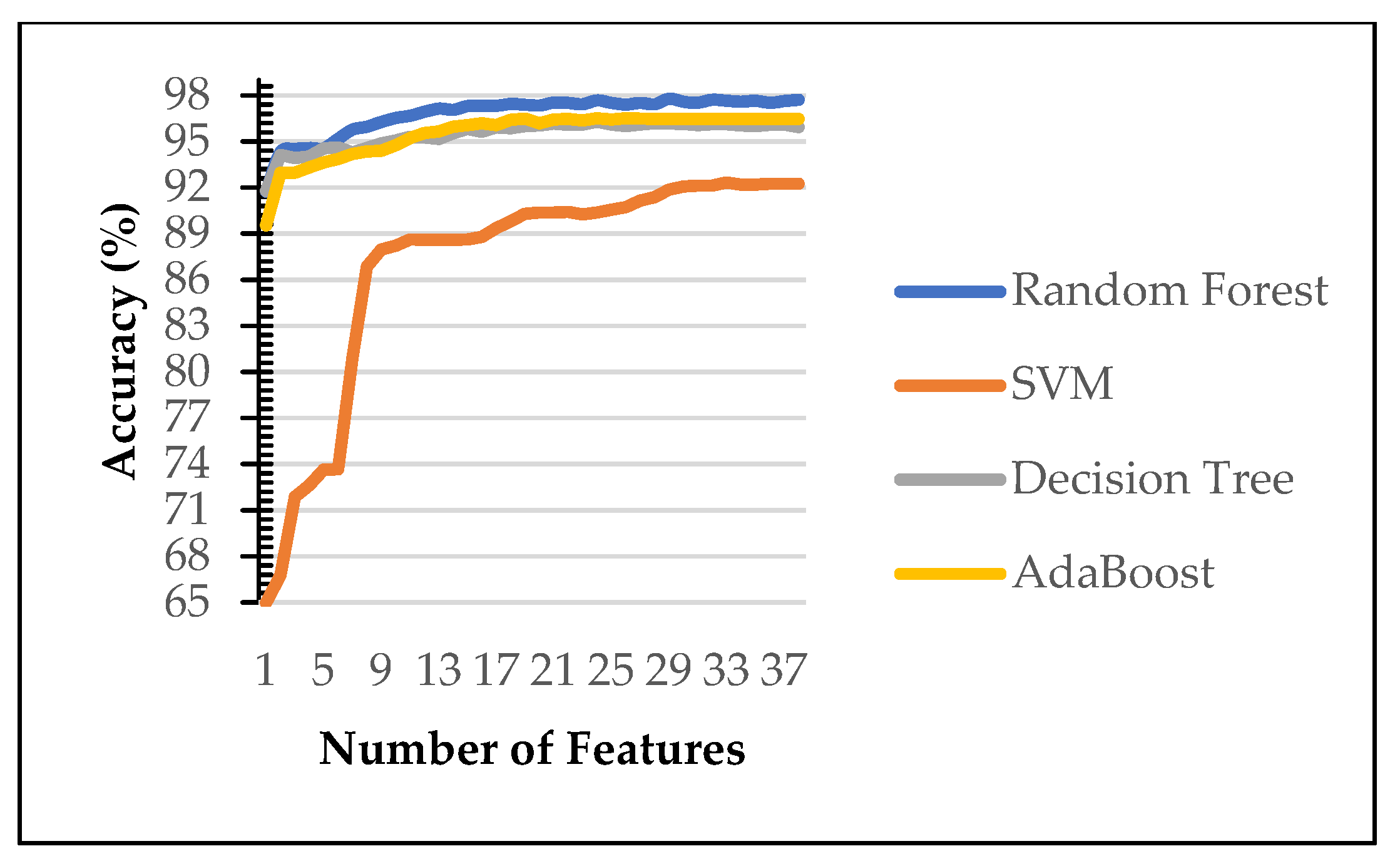
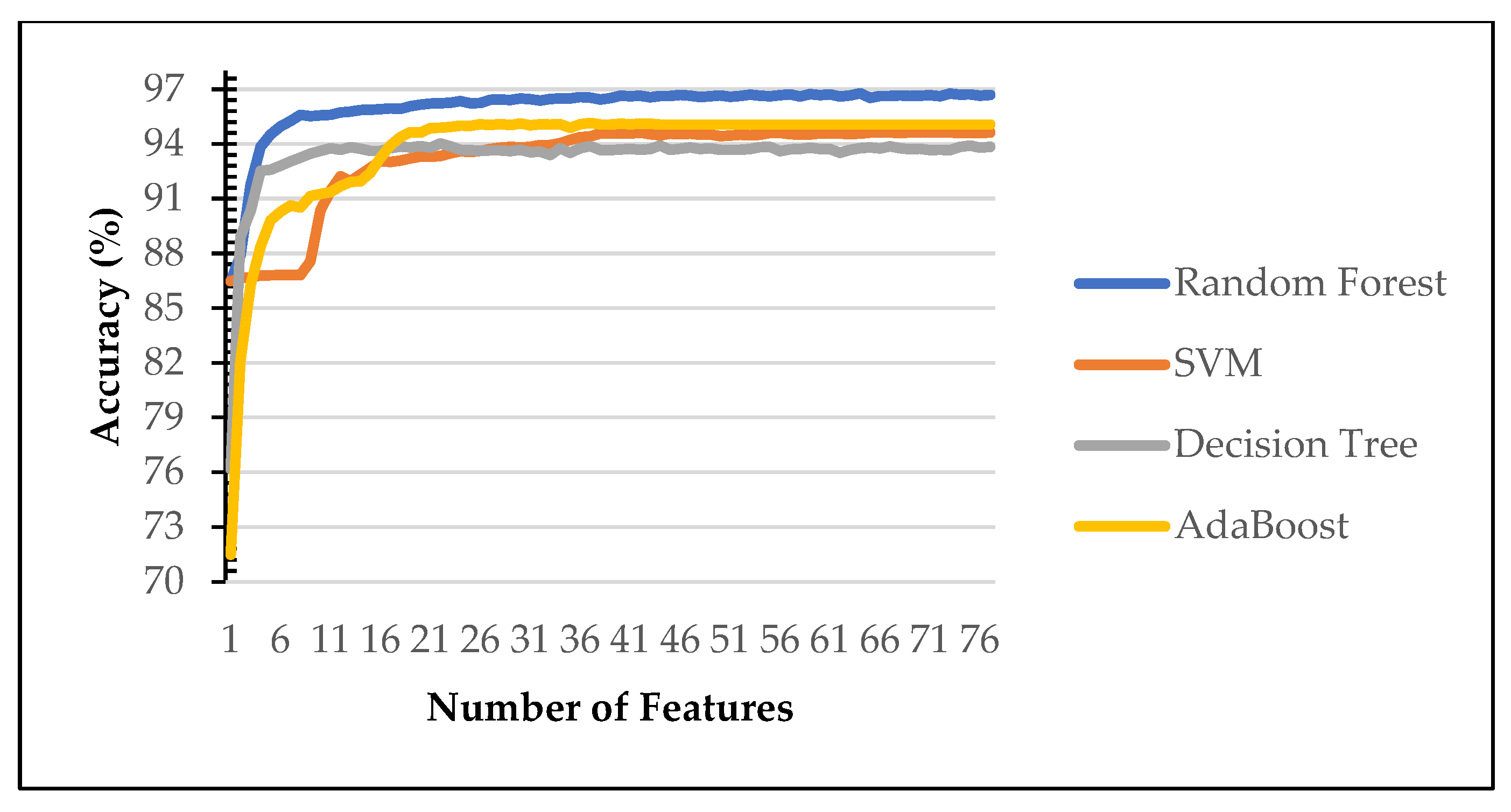
Figure 3 and
Figure 4 show the performance of machine learning algorithms on various number of selected features on the first scenario using Power Predictive score (PPS) and Recursive Feature Elimination (RFE). Random forest (RF) consistently achieves the best performance of each features subset on both dataset (blue line). Therefore, the rest of the paper evaluated on random forest algorithms only. Our finding identify RF is the best performing algorithms as reported in [
8,
9,
36]. Therefore, the rest of the experiment was carried out on random forest (RF).
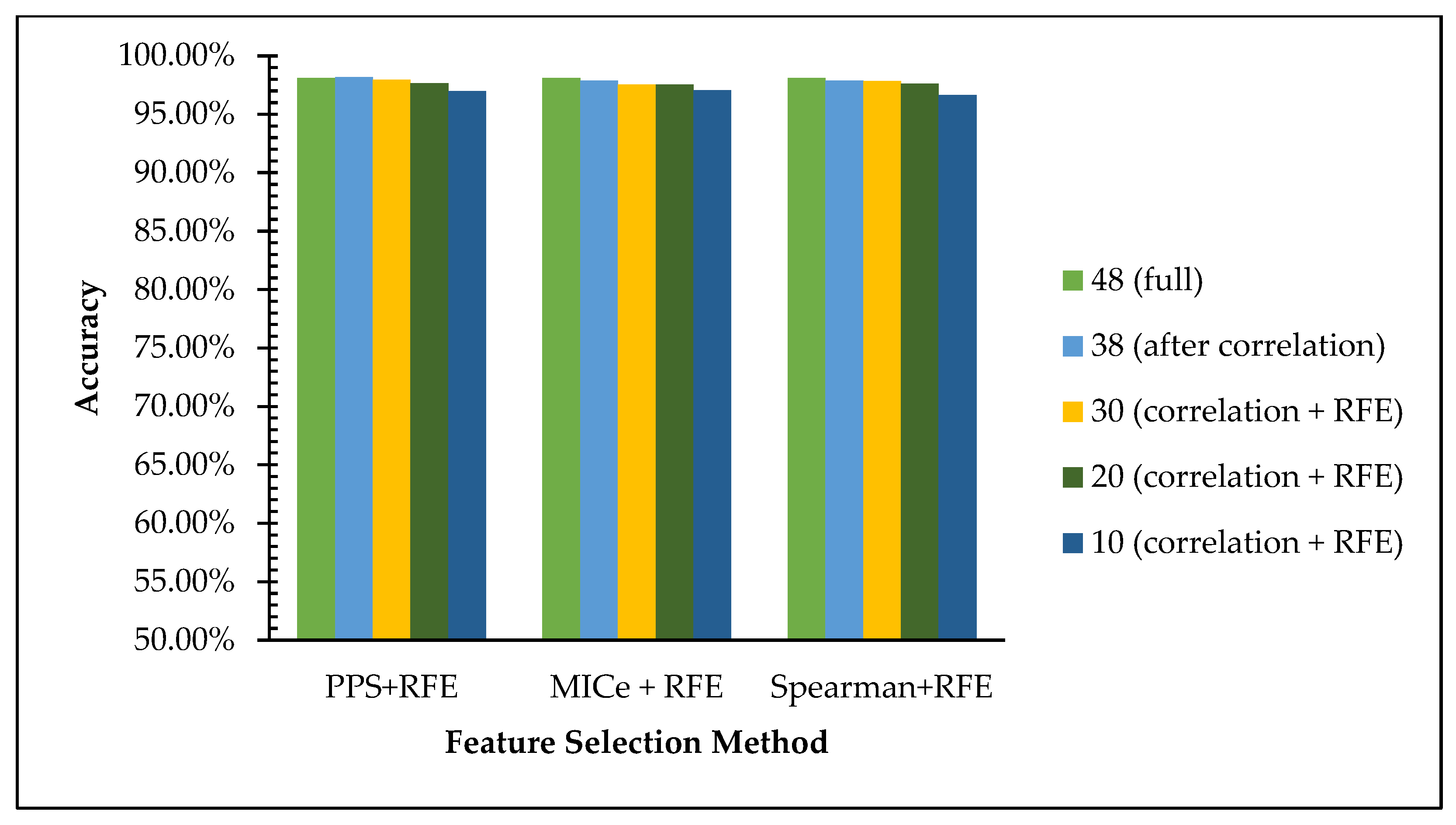
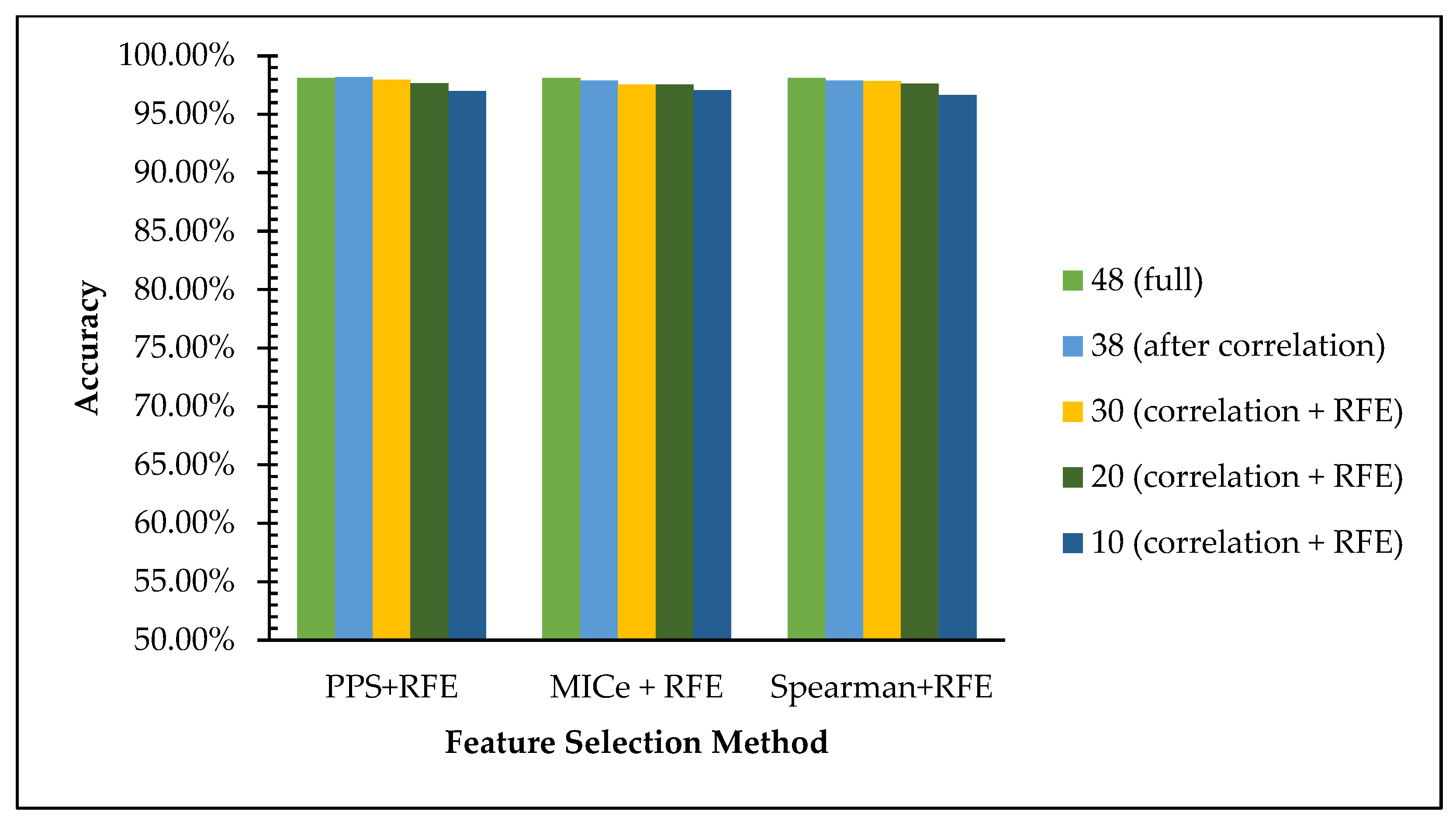
Table 15 shows the accuracy and execution time comparison of the selected features of each scenario for dataset 1. In light of the analysis of the accuracy value comparison in the graph in
Figure 5, we can see that the accuracy using the Random Forest algorithm the accuracy value is maintained even with the reduction of features using three existing methods. The accuracies on the full features are achieved at 98.1%, and it declines insignificantly from 97% to 96% on 38, 30, and 20 features to 10 features. This data is in line with the hypothesis that reducing low-impact features leads to simpler computation with an insignificant decline in the web phishing dataset recognition rate.
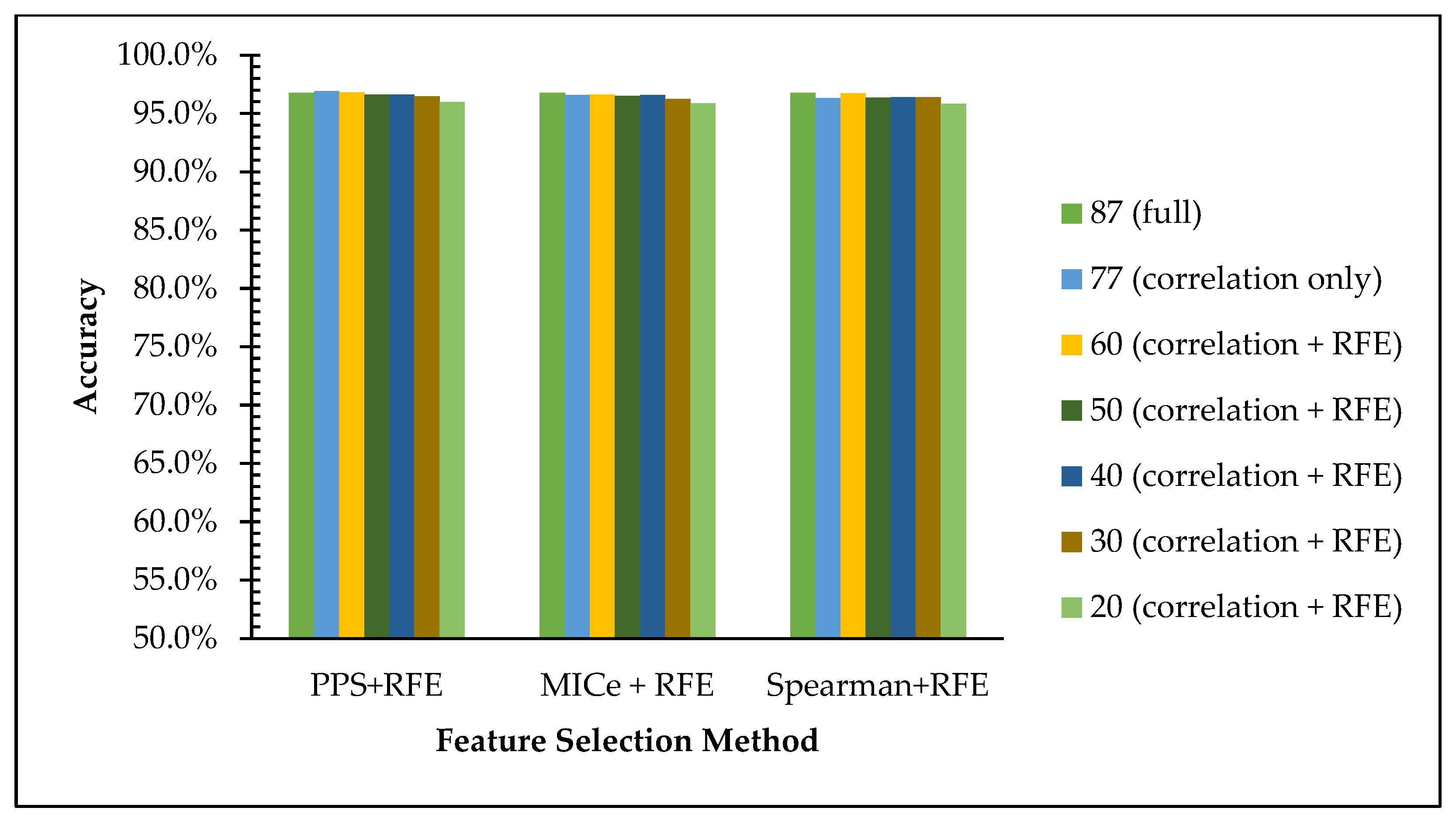
Table 16 shows the accuracy and execution time comparison of the selected features of each scenario for dataset 2. In light of the analysis of the accuracy value comparison in the graph in
Figure 6, we can see that the accuracy using the Random Forest algorithm the accuracy value is maintained even with the reduction of features using three existing methods. The accuracies on the full features are achieved at 96.76%, and it declines insignificantly from 96% to 95% on 77, 60, 50, 40, 30, and 20 features to 10 features. This data is in line with the hypothesis that reducing low-impact features leads to simpler computation with an insignificant decline in the web phishing dataset recognition rate.
As we can see in
Table 15 and
Table 16, the accuracy is decrease as the number of features reduced, however the gap is small. For the first scenario—PPS + RFE, for example—the gap between full feature and the 10 features is less than 1% for reducing 78 features as shown on
Table 16 on the second column. All experiments scenarios with two datasets shown no more than 2% gap of accuracy between full and 10 features set. The experimental result shows that reducing the features for binary classification (normal/phihing) class do not affect too much for the recognition ability of the model.
Figure 5 and
Figure 6 also show that reducing the number of feature do not suffer to much on recognition rate.
To decide the class, machine learning algorithms do not need to calculate all the impact of each feature in input space. Not all features share the similar impact to the class label, low correlation between input variable and the class label indicate that the data less powerful to decide the class of the input. Removing low correlation input will help to speed up the classification process. This effect clearly presented in the execution time in
Table 15 and
Table 16 where smaller number of features need smaller amount of time.
According to
Table 15 and
Table 16, removing the 10 weakest features leads to a better recognition rate because involving features with low or negative correlation cause the model to learn from disrupting information. The proof that in both datasets, accuracy improved from 96.76 to 96.93 and 98.1 to 98.16 at the first removal of the 10 weakest features in dataset1 and dataset2, respectively. In the first removal of 10 features, correlation between a pair of features is evaluated. A pair of features with correlation indicates redundant information in input side. Removing one of a pair of corelated features will not suffer the recognition rate. Some of removed features with negative correlation to the target labels as shown in
Table 13 and
Table 14 indicate that the features do not support the output class and therefore removing those features gives positive effect to the accuracy.
Three studies on this topic utilize the same dataset, namely the Tan dataset [
15]. The results of comparing the accuracy values with the number of features extracted for each study’s methodology are presented in
Table 17. According to the
Table 17, our method outperformed the accuracy value from another method that uses the same dataset.
Table 17 shows the achievement of our proposed approaches compared to the existing work. Refs. [
8,
17] utilize the Tan’s dataset [
15] with similar proportion of training and testing at 70% and 30%.
There is only one study on this topic utilize the second dataset, namely the Hannousse and Yahiouche [
16] dataset. The results of comparing the accuracy values with the number of features extracted for each study’s methodology are presented in
Table 18. According to the
Table 18, our method outperformed the accuracy value from another method that uses the same dataset.
Table 18 shows the achievement of our proposed approaches compared to the existing work. Hannousse and Yahiouche [
16] utilize dataset 2 with similar proportion of training and testing at 70% and 30%. The accuracy of RF classification of 10 selected features slightly better than the result reported in [
16] with more features considered in their approach.
After feature selection, we learn about what is important: redundant features on both datasets. Although both datasets have different set of data, they share some high rank features such as length of the host name, path level and the number of hyperlink. Those high ranking features remain in the 10 most important features in the final feature selection. The first 10 removed features are redundant and it was proven removing them lead to improvement of the classification performance. For example, both “nb_dots” (number of dots) and “nb_subdomains” (number of sub domain) are highly correlated since number dots (.) are the separators between domain and subdomains and therefore removing one of them will not suffer the quality of the model, since they represent the same thing.
5. Conclusions
Removal of inter-correlated features and low and negative correlation features to the output label leads to a better recognition rate of phishing dataset. The subset of phishing datasets selected with PPS+RFE scenario slightly over-performs compared to MICe TICe+RFE and Spearman+RFE. According to the experimental result, Random Forest (RF) achieves better accuracy in recognizing the phishing website in Tan’s [
15] and Hannousse and Yahiouche ’s [
16] dataset. Our approach to feature selection and classification using random forest achieves slightly better accuracy on Tan’s [
15] dataset at 96,96% of accuracy, compared to the result reported in [
7] and [
18] at 94,6% and 93.7%, respectively. On Hannousse and Yahiouche’s [
16] dataset, our method of feature selection and classification using random forest also produces marginally better accuracy at 97.96%. This assumes that unimportant features can be removed without the recognition rate suffering too much. Therefore, we implement feature selection. We are aware that reducing the feature will definitely reduce the amount of information and our experiment result shows that consequent although the gap between full features and minimum subset (10 features) is less than 2% of accuracy. However, as far as accuracy is concerned, the option of using dimensionality reduction such as principal component analysis (PCA) or autoencoder would be an interesting exploration. Another remaining problem of phishing is the evolving technique of phishing itself; therefore, exercising the new evidence by providing the latest dataset is always a challenge in the future.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}