1. Introduction
Recent years have seen a remarkable acceleration in the advancement of language models, pushing the boundaries of the state-of-the-art (Brown et al. [
1], Ouyang et al. [
2], OpenAI [
3]). This progress has significantly impacted dialogue applications, where the interaction between humans and these models plays a pivotal role. These models, such as BlenderBot 3 (BB3) (Shuster et al. [
4]), have made significant strides in improving the quality of interaction, exhibiting an impressive ability to understand and respond in a human-like manner. The current state-of-the-art in the field of open-domain chatbots involves using a large language model (LLM) to perform various steps before the generation of a final utterance—typical steps are to decide whether to use external knowledge, knowledge extraction, and long-term memory inclusion (Shuster et al. [
4], University of California [
5], Stevens Institute of Technology [
6]). However, like any technology, there is always room for further enhancement and innovation.
In this work, we extensively analyze the fundamental elements of the BlenderBot 3 chatbot, evaluating both their conversational capabilities, including engagement and knowledge, and their adherence to behavioral standards. Notably, we are focusing on the BlenderBot 3 version with the three-billion-parameters (3B) encoder–decoder generative model, as it is easily accessible to the public due to its low computational requirements with respect to its larger versions. However, our work also applies to other LLMs, such as Llama (Touvron et al. [
7]).
In our commitment to transparency and the advancement of collective knowledge, we have made the conscious decision to open-source our work (
https://github.com/kobzaond/Enhancements_in_BlenderBot_3, accessed on 2 October 2023). We believe that by making our improved model accessible to everyone, we can foster a collaborative environment that propels further improvements in this field.
Our paper begins with an examination of the relevant literature and research, following which we delve into our comprehensive study of the BlenderBot 3 pipeline. The ensuing two sections shed light on our methodological approach aimed at overcoming various inconsistencies detected during the study. The concluding segment furnishes the outcomes of our proposals, thereby substantiating the assertions we made earlier in the Analysis section.
2. Related Work
A number of studies have been conducted in the area of open-domain chatbots. Roller et al. [
8] introduced a process for developing these chatbots, leading to the creation of BlenderBot’s first version, the Blended Skill dataset, and a rudimentary method for the integration of external knowledge from Wikipedia dumps. Contrary to past practices focusing on enhancing performance via parameter amplification, BlenderBot 1.0 improves conversational capabilities via the utilization of blended task datasets, including those related to empathy, persona, and knowledge.
The second iteration, BlenderBot 2 (
https://parl.ai/projects/blenderbot2/, accessed on 16 July 2021), adopts the knowledge-based generation concepts suggested by Komeili et al. [
9], such as Fusion-in-Decoder (FiD) (Izacard and Grave [
10]), Retrieval-Augmented-Generation (RAG) (Lewis et al. [
11]), and Dense Passage Retrieval (DPR) (Karpukhin et al. [
12]). This version is built upon their unique dataset, Wizard of Internet (WoI), and incorporates the Multi-Session Chat dataset (MSC, Xu et al. [
13]), yielding a tool for storing user preferences in long-term memory for multi-session dialogues. The WoI dataset is inspired by the Wizard of Wikipedia dataset (Dinan et al. [
14]) but captures more topics and therefore provides better generalization. According to Shuster et al. [
15], incorporation of external knowledge (or memory) will ground the generation process and reduce hallucinations (making up the model’s own ‘facts’). Hallucination of LLMs is a well-known problem elaborated in many studies (e.g., Ji et al. [
16], Shuster et al. [
15], or Zhang et al. [
17]).
Furthermore, Lee et al. [
18] highlighted multiple challenges in BlenderBot 2, ranging from dataset issues to long-term memory problems, complications due to external knowledge integration, internet search capability, and inappropriate responses. They suggested a number of improvements, many of which were implemented in BlenderBot 3 Shuster et al. [
4].
The third version improved knowledge integration, using a method proposed by Shuster et al. [
19]. It introduced several classification tasks, notably determining when to conduct a search or utilize long-term memory and the addition of an entity extraction component. Notably, all of these proposed tasks were managed by one single generative model. BlenderBot 3 comes in pre-trained transformer models (Vaswani et al. [
20]), with varieties ranging from a 3B encoder–decoder version (same architecture as proposed by Lewis et al. [
21]) to a 175B decoder-only model. Due to computational demands, our research focuses predominantly on the 3B model. We provide a detailed description of BlenderBot 3 in
Appendix A.
Recently, novel LLMs were released, boosting the overall NLP field. Touvron et al. [
7] proposed the Llama model and Penedo et al. [
22] proposed Falcon LLM. These models can be utilized in the open-domain chatbots either as they are or integrated within a pipeline. Stanford University [
23] utilized Falcon and BlenderBot 3 in their open-chat system, using Falcon 40B for pregenerating dialogue trees and BlenderBot’s model to generate utterances in real-time (addressing the major drawback of Falcon—i.e., latency). University of California [
5] and Stevens Institute of Technology [
6] incorporated Llama-based models into their chatbots, achieving top results in the Amazon SocialBot Grand Challenge competition (
https://www.amazon.science/alexa-prize/socialbot-grand-challenge, accessed on 16 August 2021).
Following the success of instruction-based models, Taori et al. [
24] introduced the Alpaca LLM, and Chung et al. [
25] introduced several instruction-based models building upon T5 (Raffel et al. [
26]) and PaLM (Chowdhery et al. [
27]).
In the realm of conversational settings, there has been a significant amount of work dedicated to creating innovative conversational datasets. For instance, Rashkin et al. [
28] presented the Empathetic Dialogues, while Radlinski et al. [
29] introduced CCPE. Additionally, Henderson et al. [
30] established a repository of conversational datasets.
Numerous studies demonstrate the ability of comparatively smaller models to perform competitively against larger Language Learning Models (LLMs) on the General Language Understanding Evaluation (GLUE) tasks (Wang et al. [
31], Jiao et al. [
32], Clark et al. [
33]). This implies that deploying smaller models may be more suitable for certain challenges as opposed to utilizing excessively large models.
3. Analysis
Our examination focused on specific modules of the BB3 chatbot, where we aimed to tackle significant performance deficiencies along with latency and computational complexity problems. Note that the major generative model in our refined pipeline can be with Llama, Falcon, or any other LLM. However, in this work, we focus on the BB3 3B model due to its relatively low memory and computational requirements and, therefore, use the original BB3 model as a reference for our comparisons.
Twelve linguist participants, selected through interviews conducted by experts from the Alquist group (
http://alquistai.com/, accessed on 14 October 2016) and PromethistAI (
https://promethist.ai/, accessed on 3 October 2022), were assigned the task of evaluating the BB3 chatbot under a predefined setting. As illustrated in
Table 1 and
Table 2, the resulting evaluations should be interpreted in comparison to the baseline analysis of the reference 3B BB3. During the interviews, the participants analyzed several conversations between the Alquist chatbot and Alquist team members. Based on this analysis, the experts then selected the twelve most promising linguists.
The outcomes of the analyses in this section are mostly preemptive findings, which are then further elaborated in the Method and Results
Section 4 and
Section 5. We first elaborate on the flaws of the whole BlenderBot 3 system, and afterward, we dive into the analysis of particular modules of the BB3 pipeline.
3.1. General Flaws
During the testing of BB3, we identified the following problems (for each of the problems, we provide an example in
Appendix B):
Sometimes, it does not foster the conversation more deeply, resulting in shallow conversations. This resembles more superficial discussions, contrasting with the natural human tendency to delve deeper into particular issues. Rapidly changing subjects can sound unnatural and potentially irritating.
Repetitions: i.e., the chatbot sometimes replies with semantically the same utterances as it did in the conversation before. This significantly reduces the overall feel of conversations with the chatbot.
Occasionally, the chatbot produces irrelevant outputs, disrupting the conversation’s consistency.
The chatbot’s responses are frequently too terse. While a chatbot should indeed be engaging, a single-word response is more likely to hinder the conversation rather than facilitate it.
Hallucinations, i.e., making up the chatbot’s own ‘facts,’ which are not true. The standard solution is to condition the generation by a ‘knowledge’ so that the generative model uses the knowledge in its input context and, therefore, does not have to make up its own ‘facts’ [
15]. Since BlenderBot 3 specifically adopts this approach, the frequency of hallucination is relatively low; however, the flaw is not eliminated entirely.
We also found instances of contradictions and failure to comprehend user input. The prevalence of this issue often correlates with the model’s size, so we will not delve into this problem in depth here.
Lastly, we found the chatbot’s high latency an issue, as waiting several seconds for a response can be inconvenient.
3.2. Relevant Entity Recognition
BlenderBot 3 extracts a pertinent entity from the comprehensive input context in instances where neither memory nor knowledge is necessitated. This extraction of the relevant entity underpins the ultimate response, potentially assisting the generative model to pinpoint the ‘centroid’ of the conversation, thereby improving the quality and relevance of the generated responses.
Nonetheless, our initial manual testing revealed that integrating the entity into the model’s context sometimes results in semantic repetitions. In other words, the model may produce an utterance that is semantically identical to one previously present in the context history or cycle back to previously discarded topics. Another clear limitation of this method is the increase in computational complexity, which adversely affects the overall latency.
3.3. Long Term Memory
Recently, research has found that providing long-term memory functionality to generate and store memories extracted dynamically from conversations is effective in improving the conversation quality of chatbots (Xu et al. [
13]). However, the current state-of-the-art architectures for memory incorporation, as seen in chatbots like BB3, are not flawless. Atkins et al. [
34] examined the possibilities of misinformation injection through long-term memory, finding out that when a chatbot is questioned on the misinformation topic, it increases the magnitude of misinformation generation by more than two times.
Furthermore, our findings suggest that employing memory in the BB3 setup tends to increase the percentage of repetitive outputs from the generative model, as shown in
Table 2. Upon further empirical investigation, we learned that incorporating memory into the input tends to enhance output utterance quality, mainly when a user refers to previous turns. However, one negative side effect is the model’s tendency to dwell on or revert back to a specific topic despite a user’s desire to shift the conversation elsewhere.
3.4. Memory and Search Decision
The search and memory decision classifications are crucial in obtaining relevant information about the current topic and getting a past context. In these steps, the modules are tasked with deciding whether it is necessary to conduct an internet search or memory retrieval to get the main generative model relevant pieces of information concerning the current conversation.
It is important to note that while regarding memory decision, we are interested in false positives and false negatives equally, concerning the search decision module, we must be cautious about false positives (predicting that the search is required even though it is not). This is because the internet search is a rather time-consuming operation.
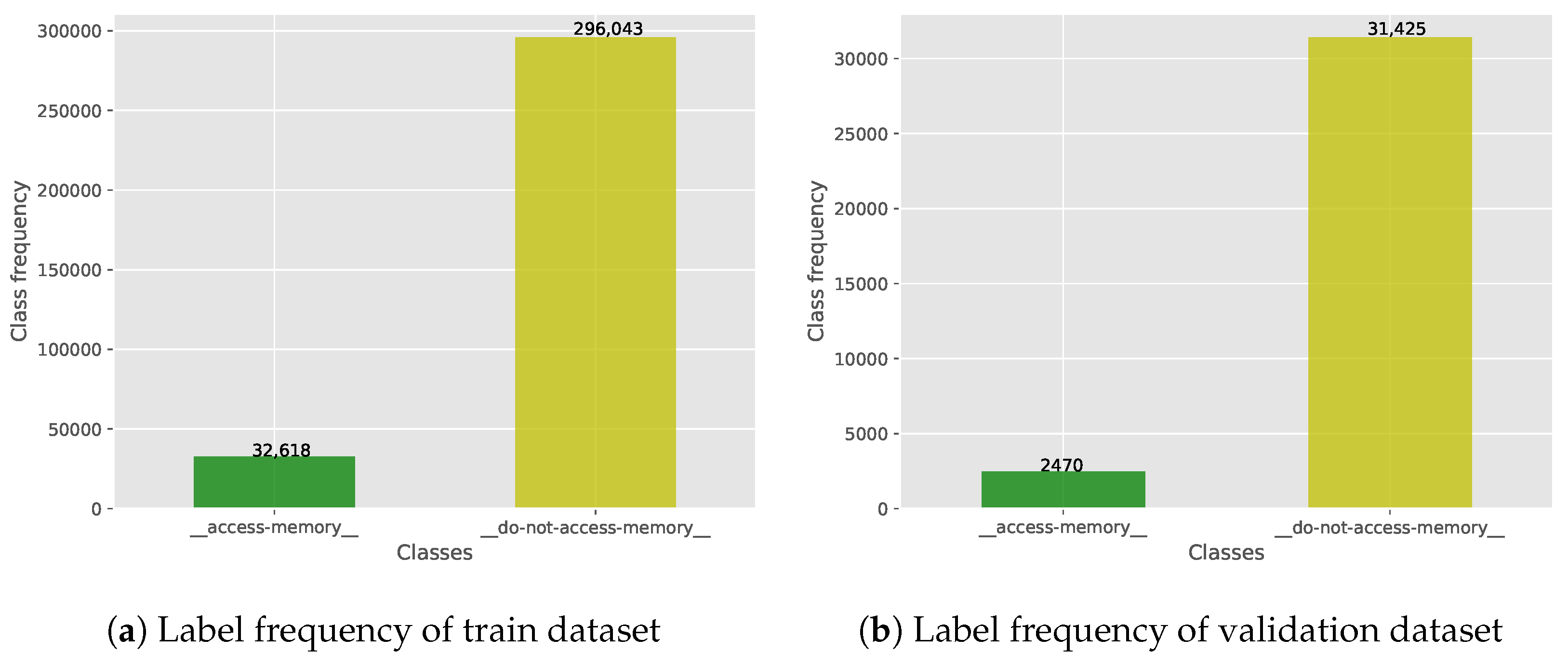
Regarding memory decision, the training (and validation) datasets utilized for BB3 on this task, as depicted in
Figure 1a,b, are significantly imbalanced. This inherent imbalance inevitably influences the model’s efficiency on this task, reducing the overall performance due to inaccurate memory decision classifications and resulting in the aforementioned flaws.
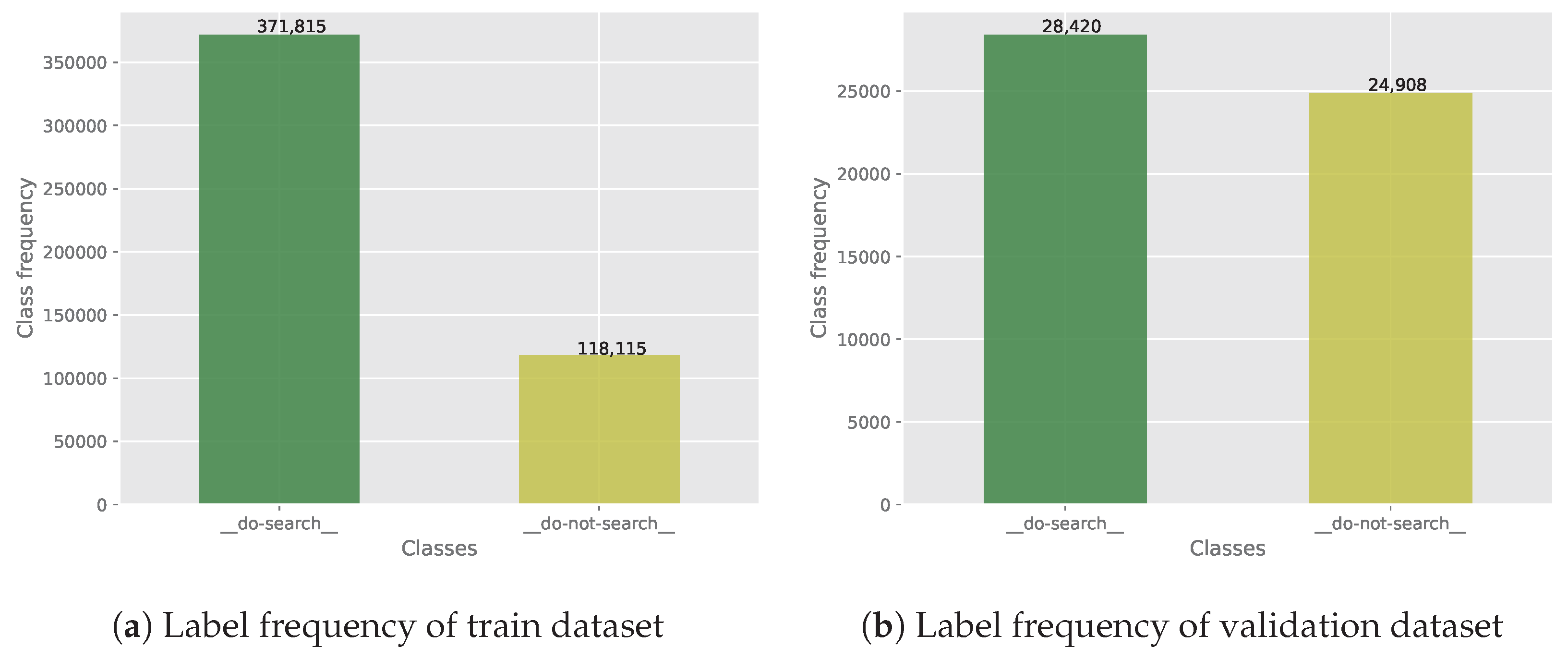
Similarly to the memory decision training dataset, the classes for the search decision training data are imbalanced, however in the validation set, they are not (as shown in
Figure 2a,b). This imbalance in the training set potentially leads to an increased risk of a substantial bias during the training phase. At the same time, the evaluation dataset should reveal such bias during the training process.
3.5. Query Generation
In the query generation task, the model is tasked with generating a query for an internet search based on the given user utterance. The relevance and specificity of the generated query are of the highest importance. Irrelevant queries may yield unrelated information from the search engine, leading the generative model to provide a non-relevant response to the user’s utterance, whereas queries not specific enough will result in retrieved knowledge that is too general and prevent the chatbot from diving more deeply into the currently discussed topic.
3.6. Knowledge Extraction
BlenderBot 3 is remarkably proficient in amalgamating external knowledge with the given context before producing the final response. Initially, it formulates a query that is submitted to a search engine such as Mojeek (
https://www.mojeek.com/, accessed on 23 November 2013). This then retrieves
k documents, which are processed by the BB3 model using FiD. Based on our empirical examinations, this method is reasonably practical. However, it does have a notable drawback: latency. The entire sequence of knowledge extraction can require over a second, significantly slowing down the response time.
3.7. Final Response Generation
The final response generation of BB3 is marked by a series of challenges. A primary issue, as evidenced in
Table 1, is the system’s tendency towards repetition. It appears that BB3 often reformulates previously generated responses, thereby recycling them in its conversation flow.
Moreover, we empirically found instances of contradictions and hallucinations within the system’s outputs, indicating a lack of consistency and accuracy. Despite attempts to rectify these errors through the integration of additional models, the issues persist. A detailed overview of these findings, complete with examples, is provided in
Appendix B.
We posit that these challenges might stem from the language model’s limited exposure to conversational data. To address the issue of repetition, we have implemented a strategy involving negative sampling. The specifics of this approach are elaborated on in
Section 4.7.
4. Method
In our proposed improvements, we address the aforementioned bulk of drawbacks. This includes offering novel datasets, fresh models, and a reimplementation of the BB3 pipeline aimed at improving the identified deficiencies.
Our guiding philosophy is the Occam’s Razor principle. We simplified the existing pipeline using smaller, more efficient models that have superior performance. This refined pipeline has been designed to simplify operations, boost performance, and curtail latency substantially.
To address the imbalances in BlenderBots’ evaluation datasets, which primarily come from the same sources as their training equivalents (and are likely derived from the same or very similar probability distribution, potentially introducing bias), we created our own test datasets. These were explicitly targeted at decision making in search, memory recall, and query generation areas. Through these new datasets, we aim to showcase the true performance potential of the respective models.
4.1. Test Datasets
The creation of each test dataset was carried out following a three-stage process. In the first step, we manually scrutinized the inputs and corresponding outputs from all modules during the BlenderBot 3 (empirical) testing phase, aided by inputs from our twelve Turkers. Through these investigations, we detected specific problematic patterns. The associated user utterances were then utilized to construct the initial seed.
The second stage consisted of manually expanding the initial seed; our goal was to encompass a wider range of instances rather than solely focusing on the several identified challenging patterns.
The final phase hinged on the advanced abilities of OpenAI’s ChatGPT (
https://chat.openai.com, accessed on 30 November 2022) to further bolster the dataset refined in Stage 2. We supplied the model with ten manually picked representative samples from the preceding stages and asked ChatGPT to produce
n additional samples. Each test set consists of a total of 300 samples.
4.2. Quality Measures
We evaluated the overall effectiveness of BB3 and the cumulative influence of our proposals through two distinct methodologies:
User Ranking: Our user group, consisting of twelve Turkers, was tasked with interacting with the bot under varying conditions and rating each bot’s response on a scale of 1 to 5. Four attributes were identified for rating. For the criteria overall feel and engagingness, a higher score is deemed better. For the criteria of repetition and hallucination, a lower score is favorable. Each attribute was rated independently, meaning just one attribute was evaluated in a single session. We collected over 2000 turns in total.
Frequency of Flaws: The Turkers were provided with the conversations that were obtained during the previous testing phase and were requested to assign labels to each utterance made by the bots. The assessment involved identifying five specific flaws in the bot’s utterances: repetitions, irrelevant and nonsensical outputs, contradictions, and hallucinations. The labeling task was binary, meaning that for each flaw mentioned (e.g., repetition), the Turkers were required to label each utterance made by the bots as either containing the flaw or not containing it.
It is worth noting that the Turkers were directed to concentrate on a single attribute or flaw per session for both methodologies. We opted for this setup to ensure the Turkers’ full attention to every single attribute and flaw.
4.3. Relevant Entity Recognition
Following the empirical scrutiny delineated in the previous section, we proposed the possibility of excluding this process entirely. We inferred that this action may not degrade the overall output quality. On the contrary, it could streamline the framework, minimize the occurrence of some defects, enhance latency, and decrease computational complexity. According to the outcomes (
Table 1 and
Table 2), there are not any statistically significant positive effects on performance, and therefore, in terms of latency improvement, we decided to omit this module in our implementation.
4.4. Memory and Search Decision
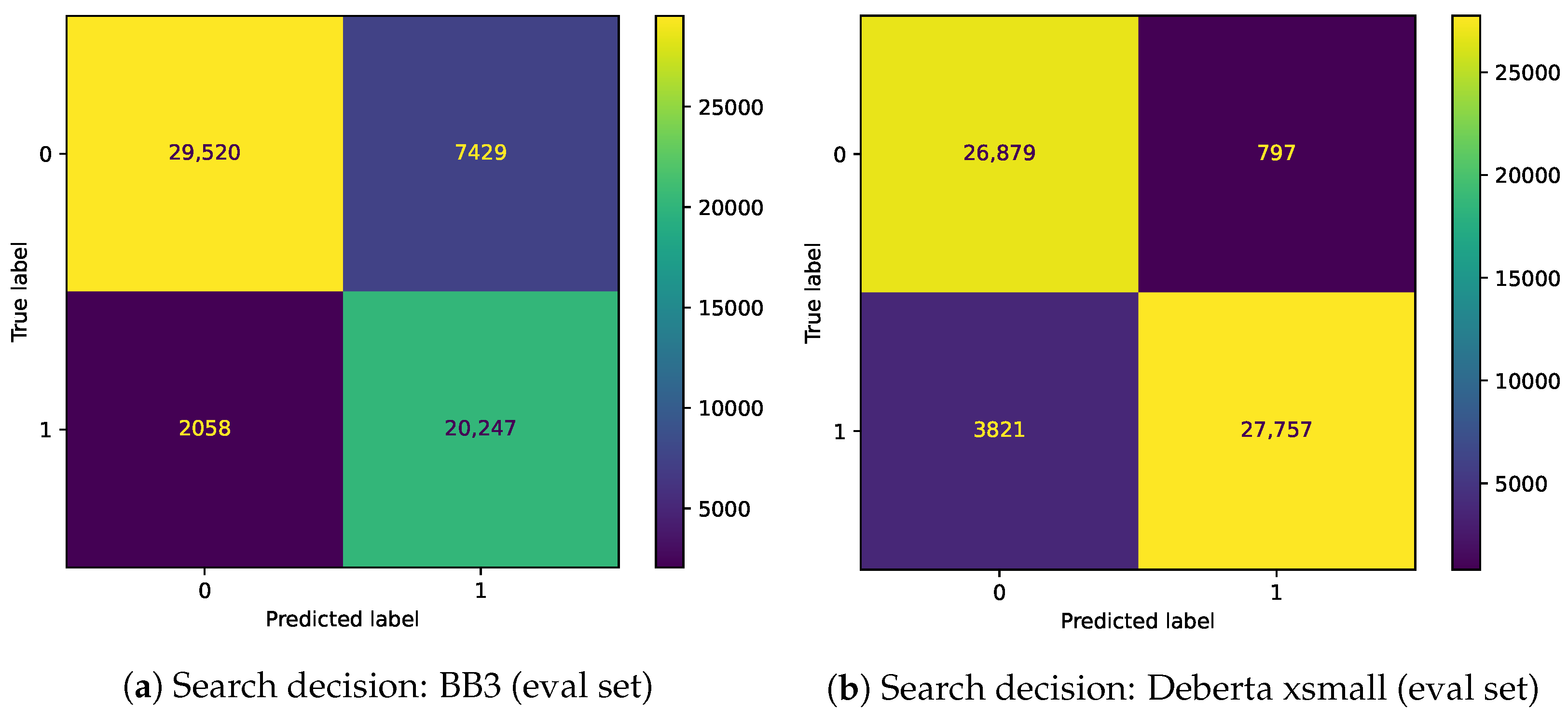
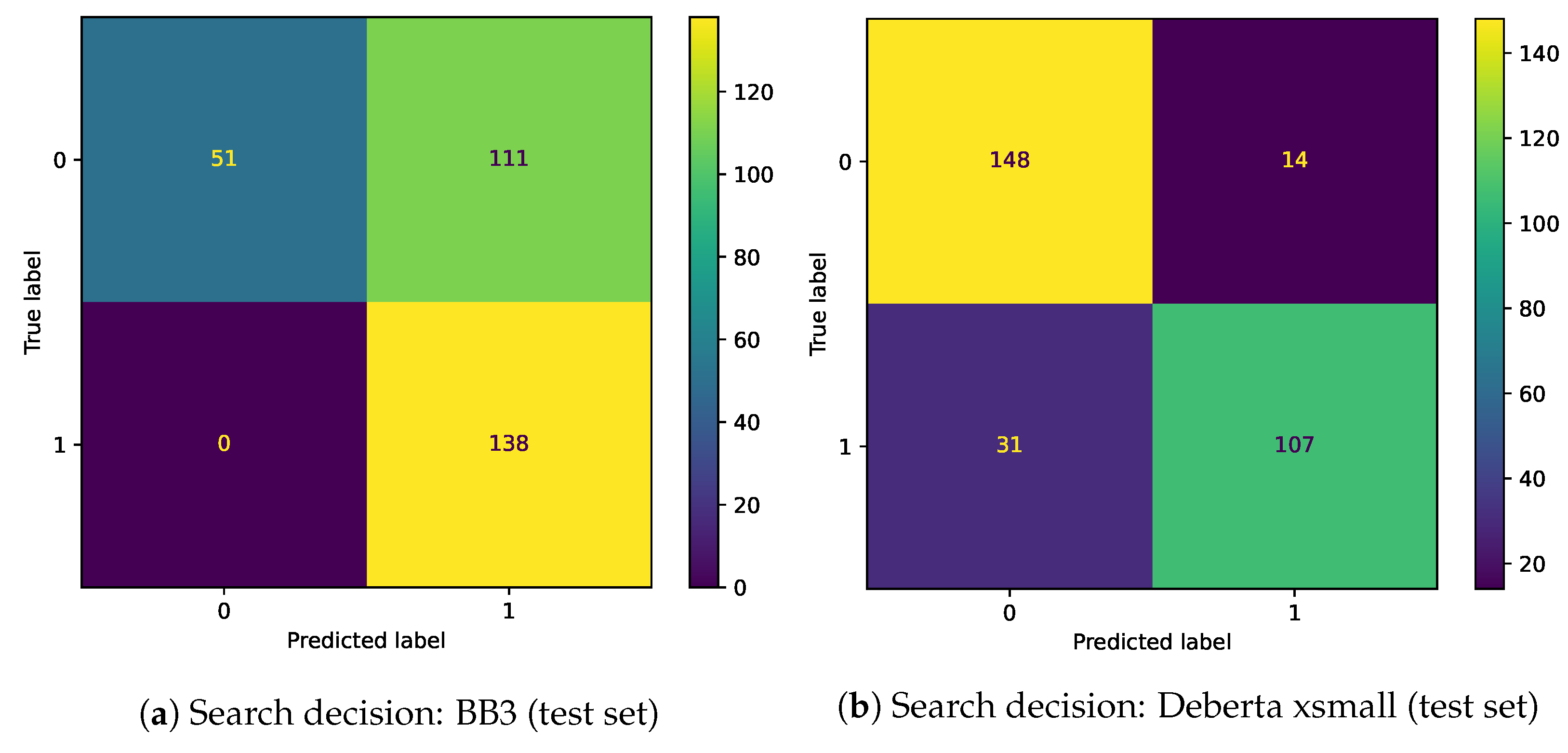
Our assumption was that the complexity of these two classification tasks could be sufficiently addressed using a comparatively smaller Transformer encoder. To this end, we sought to fine-tune smaller models such as BERT-tiny and ELECTRA-small and thus follow Occam’s Razor principle. Our efforts yielded several models where our DeBERTa-xsmall shows superior performance with respect to all other models, including BB3 3B. Based on our results, which are presented below, we conclude that using a large overparameterized model for this particular problem does not bring any benefit.
4.5. Knowledge Extraction
In contrast to utilizing a search engine such as Mojeek, as is the case with BB3, we suggest the employment of a robust QA engine like Amazon EVI (i.e., Alexa’s semantic knowledge graph, which is also used in production to answer Alexa questions). The advantage is that it retrieves key information directly, eliminating the need for a list of documents and thus obviating the requirement for a knowledge extraction module. This modification substantially improves latency. The underlying reasons are two-fold: firstly, EVI surpasses Mojeek in speed by an average of 380 ms, and secondly, the omission of the knowledge extraction module accelerates the entire system by over 500 ms. Consequently, the total system speed is enhanced by approximately 1 s.
However, acknowledging that EVI does not consistently return an answer, we also recommend integrating a semantic similarity retrieval from a Wikipedia dump, pipelined to FiD, to serve as a backup solution. We call this overall knowledge retrieval system APIHUB.
4.6. Query Generation
Based on our empirical findings, the BB3 model usually generates high-quality search queries. However, considering its relatively high latency, we sought to develop an alternative model with competitive query generation performance but a significantly reduced latency. Therefore, we designed query generators based on the FLAN-T5 base and large models, both of which have fewer parameters than the BB3 model (FLAN-T5-Base has 250M parameters, FLAN-T5-Large has 780M parameters, while BB3 has 3B parameters). Note that latency is critical in this step, as the workflow query generation -> search -> knowledge extraction cannot be parallelized, i.e., the ‘knowledge extraction’ workflow is the main bottleneck in terms of overall latency.
4.7. Improving Final Response Generations
Our comprehensive analysis of the general BB3 3B generative model itself led us to two significant findings. Firstly, the language model’s limited exposure to conversational data resulted in less engaging responses. Secondly, the system exhibited a propensity for repetitive and contradictory responses.
In response to these challenges, we devised a two-pronged strategy. Initially, we fine-tuned the original model using a more extensive conversational dataset to enhance the quality of responses. These datasets were CCPE, Empathetic Dialogues, and other conversational data from Reddit and OpenSubtitles.
To address the issue of contradictions in the language model’s outputs, we employed negative sampling. The crux of this method is the creation of a dataset comprising examples of conversations riddled with contradictions, hallucinations, and repetitions. This dataset serves as a reservoir of negative examples for the model. Subsequently, we modified the loss function to minimize inverse cross entropy (Equation (
1)), thereby encouraging the model to unlearn these problematic patterns.
4.8. Parallelization
The original BlenderBot 3 from the ParlAI library lacks an inference pipeline supporting parallelization. Our proposed enhancement enables the concurrent execution of query generation, search, and memory decision tasks. The obtained results are processed in parallel within the knowledge and (in certain settings) memory retrieval. Knowledge querying utilizes Amazon EVI or a semantic Wikipedia search combined with FiD. Memory retrieval via semantic similarity occurs alongside extraction by FiD. User input, context, knowledge, and memory are integrated into the 3B generative model, yielding the final response.
Our new, compact models ensure manageable deployment with the proposed paralleled pipeline since their small size ensures low memory and computational requirements. Conversely, implementing the 3B model for every task would make parallelization more memory and computation-intensive.
5. Results
In this section, we present the results of our experiments regarding specific modules and the overall performance of the chatbot across different settings/modules. Furthermore, we analyze the effects of various settings and the impact of our proposed solutions on the major flaws identified during the analysis of BB3.
Based on our comprehensive analysis, we have significantly improved the performance of this chatbot. Ineffective models, as identified by our analysis, have been eliminated. We have successfully increased the chatbot’s speed and efficiency through various enhancements, such as the integration of APIHUB (described in
Section 4.5) and the simplification of certain models. Our modifications were motivated by the famous Occam’s razor principle—i.e., we simplified the chatbot and obtained better performance—our modified chatbot outperforms the original BlenderBot 3 by almost 9% in terms of overall quality and is more than three times faster.
We evaluated the performance concerning search and memory decision activities through standard metrics such as accuracy and F1 score. Concerning query generation, we provide SacreBLEU scores along with two manually acquired scores: Accuracy and Weak Accuracy, as explained in
Table 3, which displays the comparison of the query generation task, where we compare our two best checkpoints with the original BlenderBot 3 model. In this case, we were unable to reach a definitive conclusion on whether our new models are generally better or worse than BB3. However, considering that latency is a significant bottleneck for the chatbot, we decided to implement the FLAN-T5-base-based model in our revised ‘BlenderBot’ system.
The performance of our classification models is shown in
Table 4. The evaluation datasets, referred to as eval datasets, are obtained by merging the evaluation datasets from all the data used for each specific task by BB3. On the other hand, the test datasets are our newly designed datasets (described in
Section 4.1).
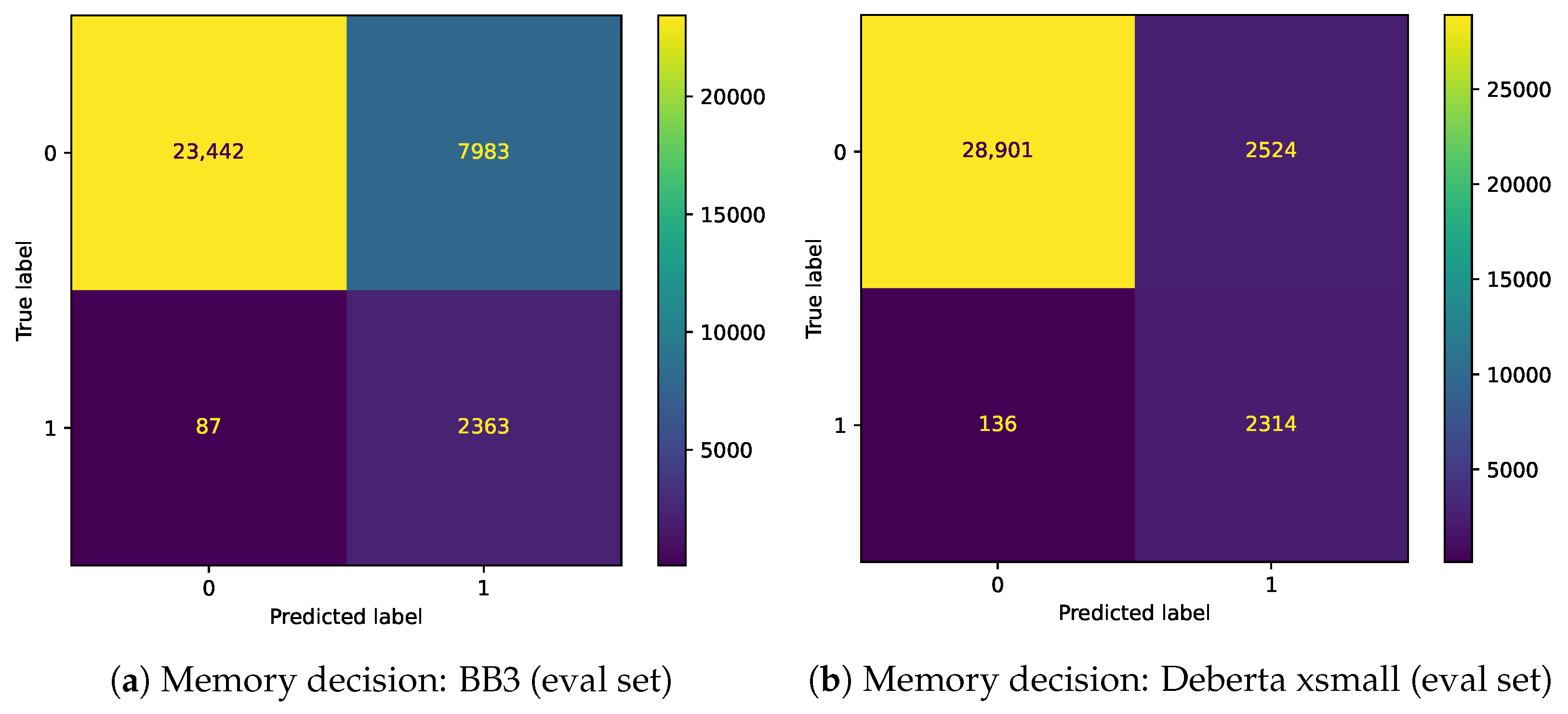
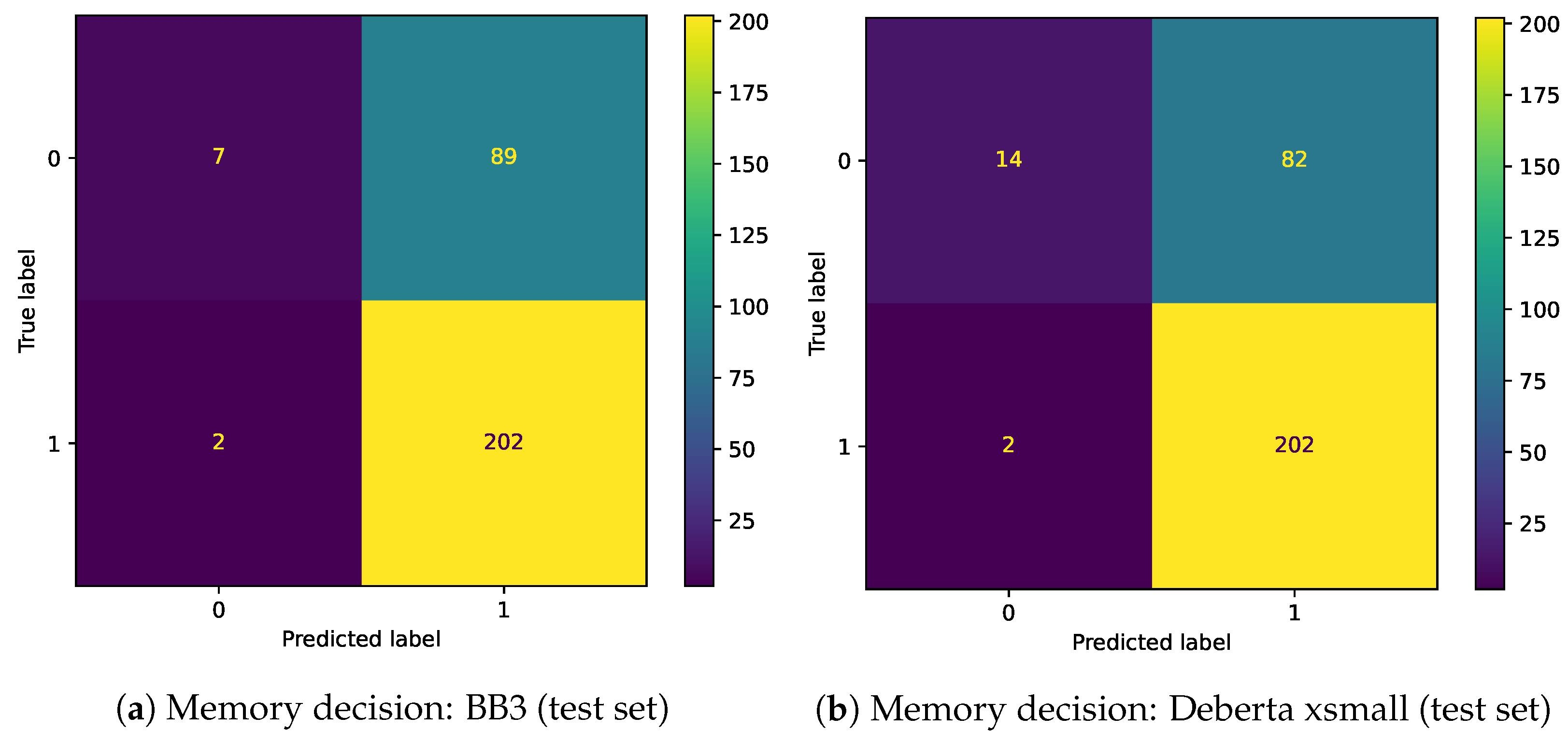
Figure 3,
Figure 4,
Figure 5 and
Figure 6 show confusion matrices of BB3 and the fine-tuned classification models for Memory decision and Search decision.
The impact of specific pipeline settings (including our enhancements) on major flaws such as repetitions and contradictions is presented in
Table 2. The results were obtained through the manual labeling of the chatbot’s output utterances. We consider several settings to test the impact of long-term memory, dominant entity, external knowledge, as well as our our new proposed setting, which has superior performance in three out of the four categories. Note that ‘Vanilla BB3’ refers to a setting where all side modules (external knowledge, memory, and entity) are discarded, and the 3B model generates a response solely based on the user’s utterance and context.
Table 1 provides an overview of the overall performance of the chatbot under various settings, as evaluated by Turkers on a scale from 1 to 5. The reported scores include Overall Feel and Engagingness (higher score is better), as well as Repetition and Hallucination (lower score is better). We hypothesize that for some categories, especially the Overall Feel, latency could make a certain impact on the resulting scores. The results presented in
Table 1 clearly show a significant improvement in our implementation in the ‘Overall Feel’ and Repetition categories while showing similar performance to the original BB3 in the ‘Hallucination’ and ‘Engagingness’ categories. It is important to note that although the Turkers were instructed to be as objective as possible, the results may slightly deviate from the hypothetical rankings made by a different group of Turkers;
Table 5 and
Table 6 provide insights into the differences of rankings among Turkers.
Table 7 shows an overview of latencies of particular chatbot’s pipelines and relative speed with respect to the original BB3 chatbot. Our enhanced chatbot has an estimated latency of 1.5 s and is more than three times faster than BB3.
For enhanced lucidity, we also include the standard deviations of ratings from the Turkers (
Table 5 and
Table 6). This not only illustrates the degree of consensus or disparity amongst the Turkers but also serves as an indicator of the impartiality or subjectivity embodied in the evaluation.
6. Conclusions
Our research thoroughly scrutinizes and enhances the BlenderBot 3 generative chat model and proposes a chatbot framework that (although it runs by default with the BB3 3B model) can run with any generative model, such as BlenderBot or Llama. We identified and addressed several issues in the original BlenderBot 3, such as long-term memory and entity recognition, resulting in an improved system with superior performance and efficiency.
Our study highlights the importance of dataset quality in task performance and demonstrates that simpler models like DeBERTa-xsmall can outperform complex ones like BlenderBot 3 when fine-tuned with carefully curated datasets. We found that eliminating ineffective processes can streamline the system, decreasing semantic repetitions and computational complexity.
We propose using robust tools (like Amazon EVI, a semantic Wikipedia search, and FiD) for knowledge extraction. We also fine-tuned the model on an expansive conversational dataset using negative sampling, leading to more engaging responses and especially reducing repetitions.
Our enhancements not only boost the chatbot’s performance but also streamline its architecture, improving computational efficiency (our modified chatbot outperforms the original BlenderBot 3 by almost 9% in terms of overall quality and is more than three times faster). These advancements lay the groundwork for future generative chat model research. Our work is open-sourced for transparency and shared knowledge.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}