

Smart Embedded System for Skin Cancer Classification


Abstract
1. Introduction
- 1.
- Tool for dual-model design: an automatic tool for generating a dual-model inference solution. It receives two trained models and determines the entropy threshold, constrained by the accuracy tolerance, and estimates of the accuracy and speedup;
- 2.
- Vitis-AI integration: the integration of the dual-model inference with Vitis-AI. It automatically quantizes the solutions, compiles both models, and generates the runtime application;
- 3.
- Design space exploration with ResNet: a systematic design space exploration of ResNet models by changing the repetition pattern of layers and the number of filters and resizing the input;
- 4.
- System for skin cancer classification: a low-cost implementation of a system for skin cancer classification with a high accuracy.
2. Background and Related Work
2.1. Convolutional Neural Networks
2.2. Mapping CNNs on FPGAs
2.3. Skin Cancer Detection Using Deep Learning
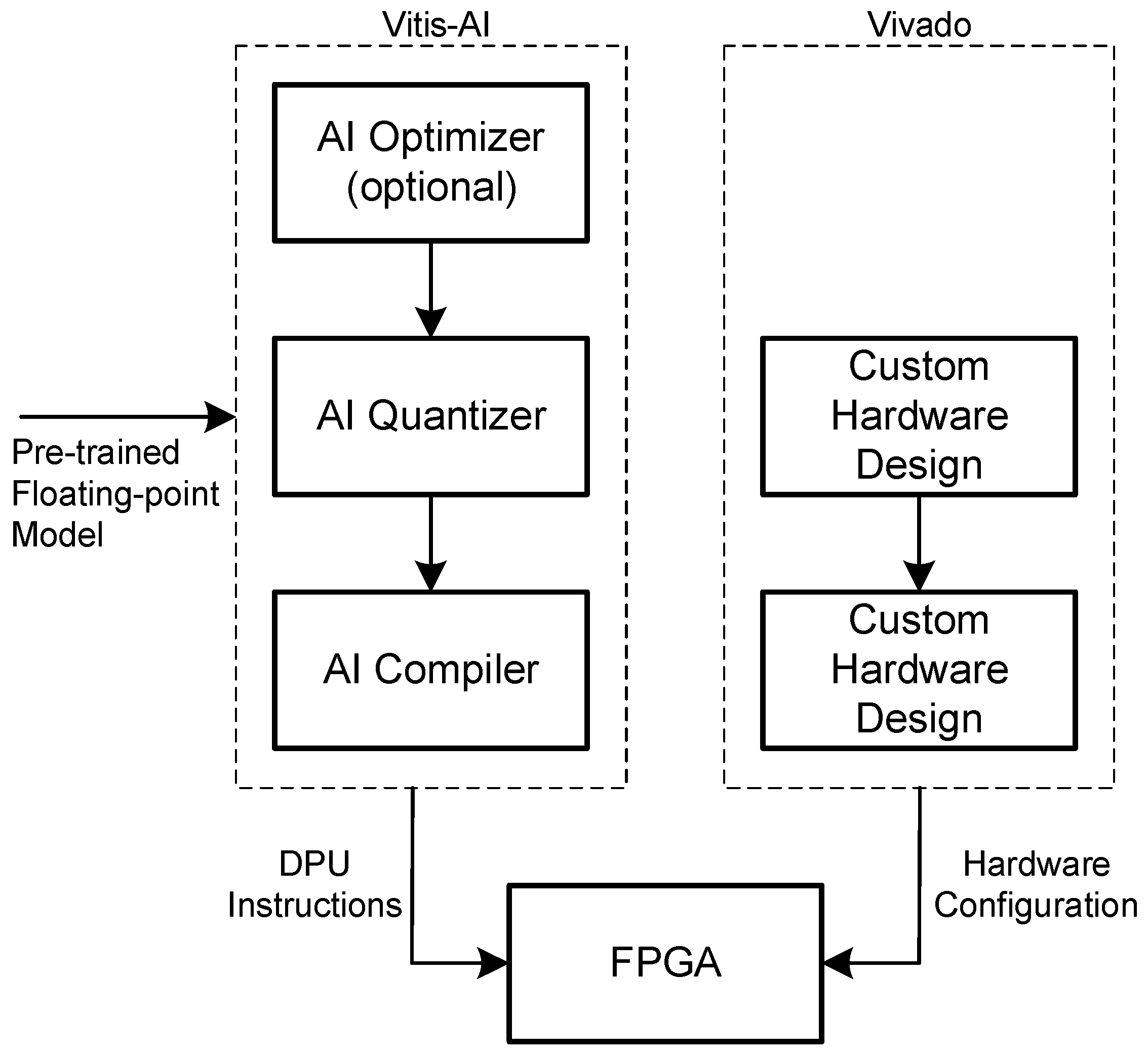
2.4. Vitis AI
- Number of cores: A DPU instance can include up to four different cores. The greater the number of cores, the greater the implementation performs, but the amount of resources used increase accordingly;
- Architecture: Different types of architectures based on the level of parallelism. A number of designs are available based on the number of operations that they can perform per clock cycle: B512, B800, B1024, B1152, B1600, B2304, B3136 and B4096. This value is directly correlated with the level of parallelism. In particular, the higher the parallelism, the higher the number of executable operations and necessary resources;
- RAM usage: To increase performance, on-chip RAM memory is used to store weights, bias, and intermediate results. When instantiating the DPU module, it is possible to choose the amount of RAM that will be reserved for the CNN. This can be done by selecting between the high RAM usage and low RAM usage option;
- Channel augmentation: An approach that exploits the fact that, in some models, the number of input channels is lower than the parallelism between the channels in the architecture. By enabling this option when this condition is met, the performance can be improved at the cost of using more resources;
- Depth-wise convolution: With standard convolution, each input channel needs to perform some operations with one specific kernel. Then, all of the results of all of the channels are combined to obtain the final result. When depth-wise convolution is enabled, the convolution operation is split into two parts: depth-wise and point-wise. The former allows for processing the input channels in parallel, whereas the latter performs convolution with a 1 × 1 kernel. This combines the results of the previous step to obtain the final value. With this approach, the parallelism of the depth-wise convolution is lower than that of pixel parallelism, allowing for more than one activation map to be evaluated per clock cycle.
2.5. Embedded Systems for Portable Health Devices
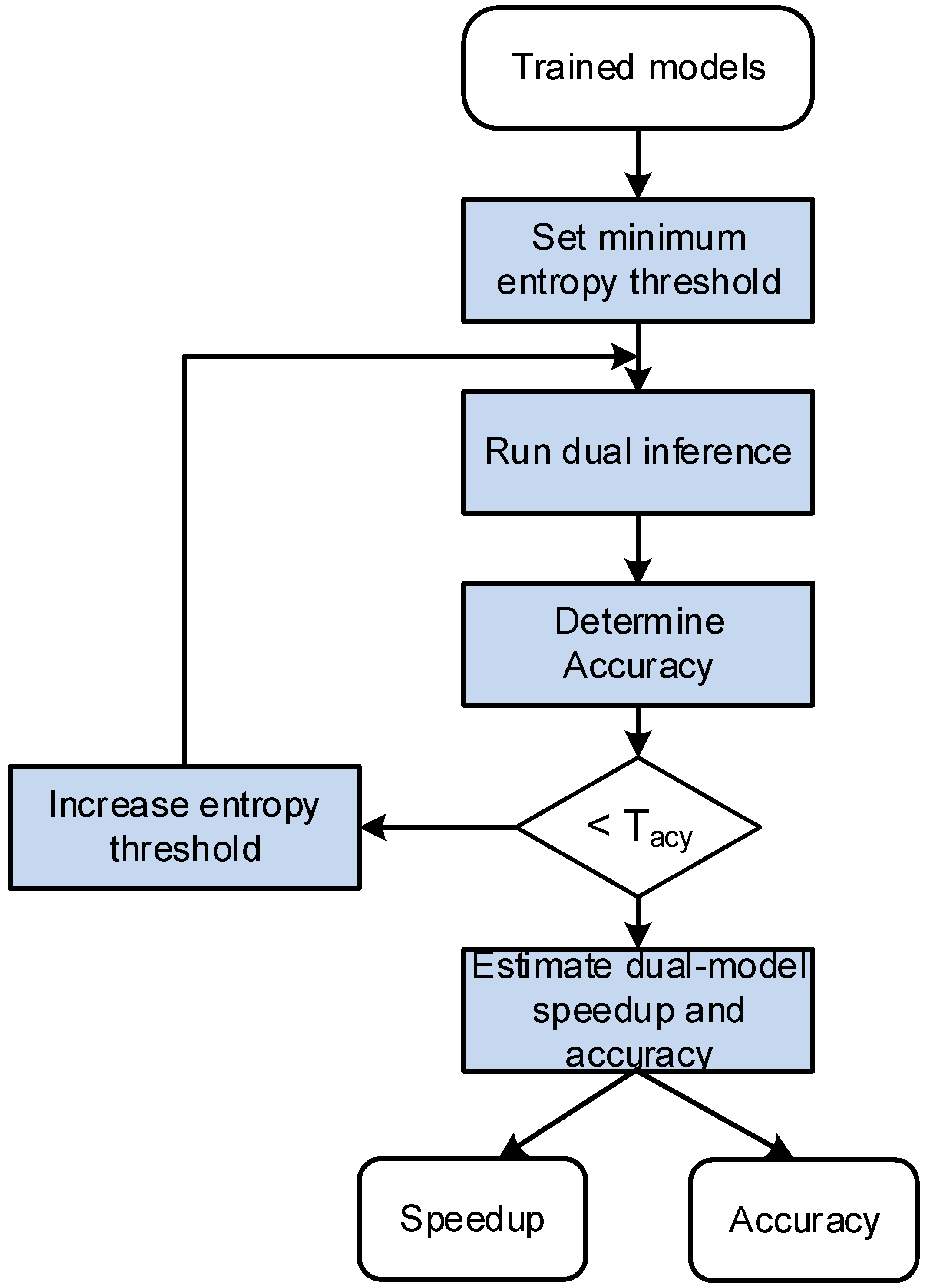
3. Dual-Model Design
- 1.
- Trained Models—The models are previously trained;
- 2.
- Set minimum entropy threshold—The minimum initial entropy threshold and the entropy increment are defined. As explained above, this threshold is used by the confidence predictor. In this work, both parameters were initialized at 0.1;
- 3.
- Run dual inference—The dual-model inference is run with the entropy threshold set previously. The task runs the inference with the smaller model and the training dataset. For each sample, it finds the entropy. If the entropy is higher than the entropy threshold, it runs the second model. This process allows us to determine the accuracy of the dual model;
- 4.
- Determine accuracy—The accuracy corresponds to the number of samples correctly classified by the first model and by the second model, whenever it runs, divided by the total number of samples. If the accuracy is within the accuracy tolerance, the entropy threshold is increased by 0.1 and the process repeats;
- 5.
- Estimate speedup and accuracy—The speedup is estimated as follows:where is the number of operations of the model, and is the percentage of inputs executed by model X. The accuracy is given by the previous step.
4. Results
4.1. HAM10000 Dataset
4.2. Single Network Model
- 1.
- True Positive (TP): Correctly predicted positive values;
- 2.
- True Negative (TN): Correctly predicted negative values. Both predicted and actual values are negative;
- 3.
- False Positive (FP): The predicted value is positive but the correct value is negative;
- 4.
- False Negative (FN): The predicted value is negative but the correct value is positive.
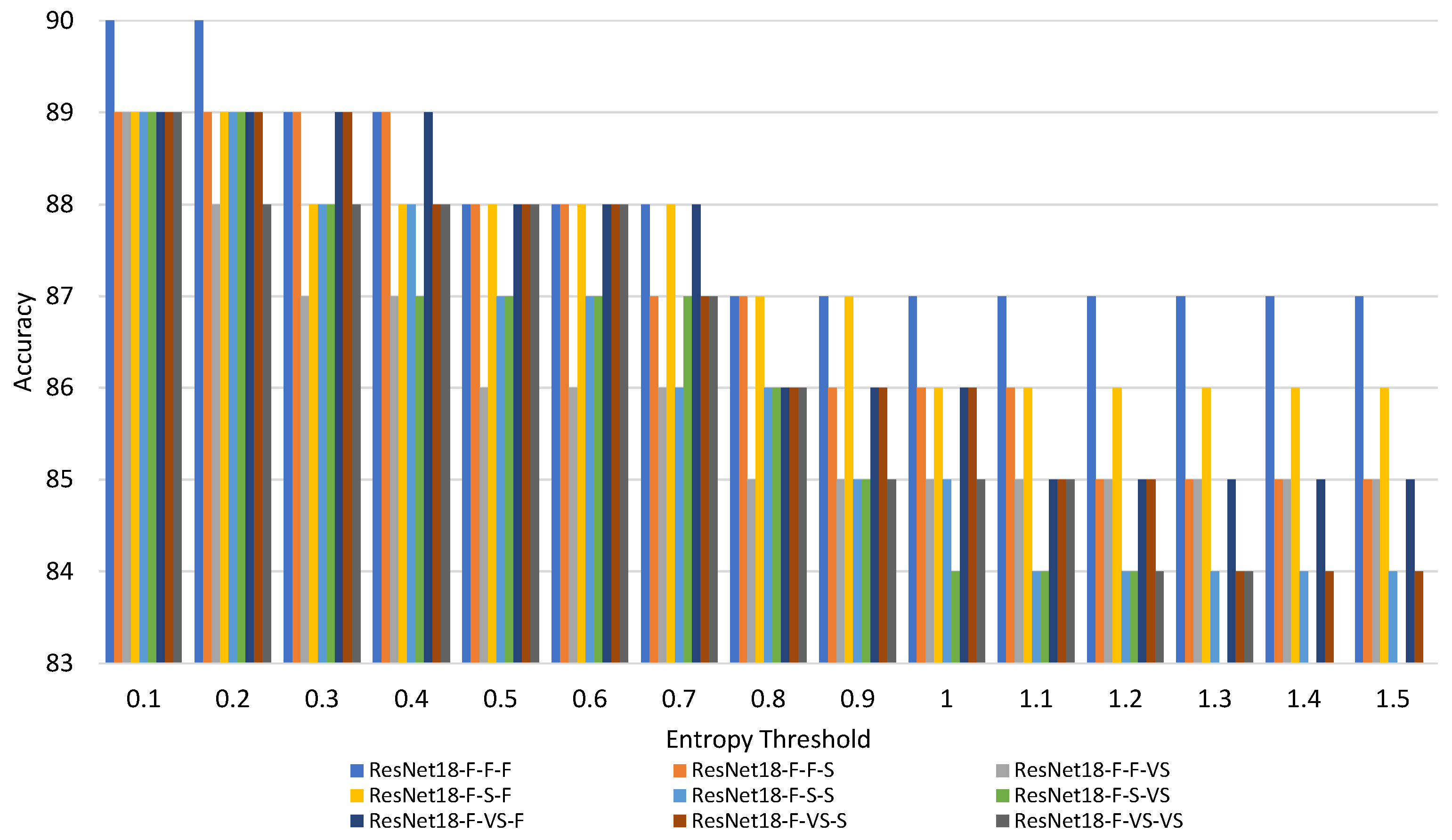
- 1.
- X: Indicates the repetition pattern of the basic block. Two repetition patterns are considered: (F) the original ResNet18 repetition pattern, [2, 2, 2, 2], and (S) a reduced repetition pattern, [1, 1, 1, 1];
- 2.
- Y: Indicates the number of filters. Three different variations are considered: the original (F), one with half of the filters in all layers (S) and another with a quarter of the filters in all layers (VS);
- 3.
- M: Indicates the size of the images. Three different resizes are considered: (F), (S) and (VS).
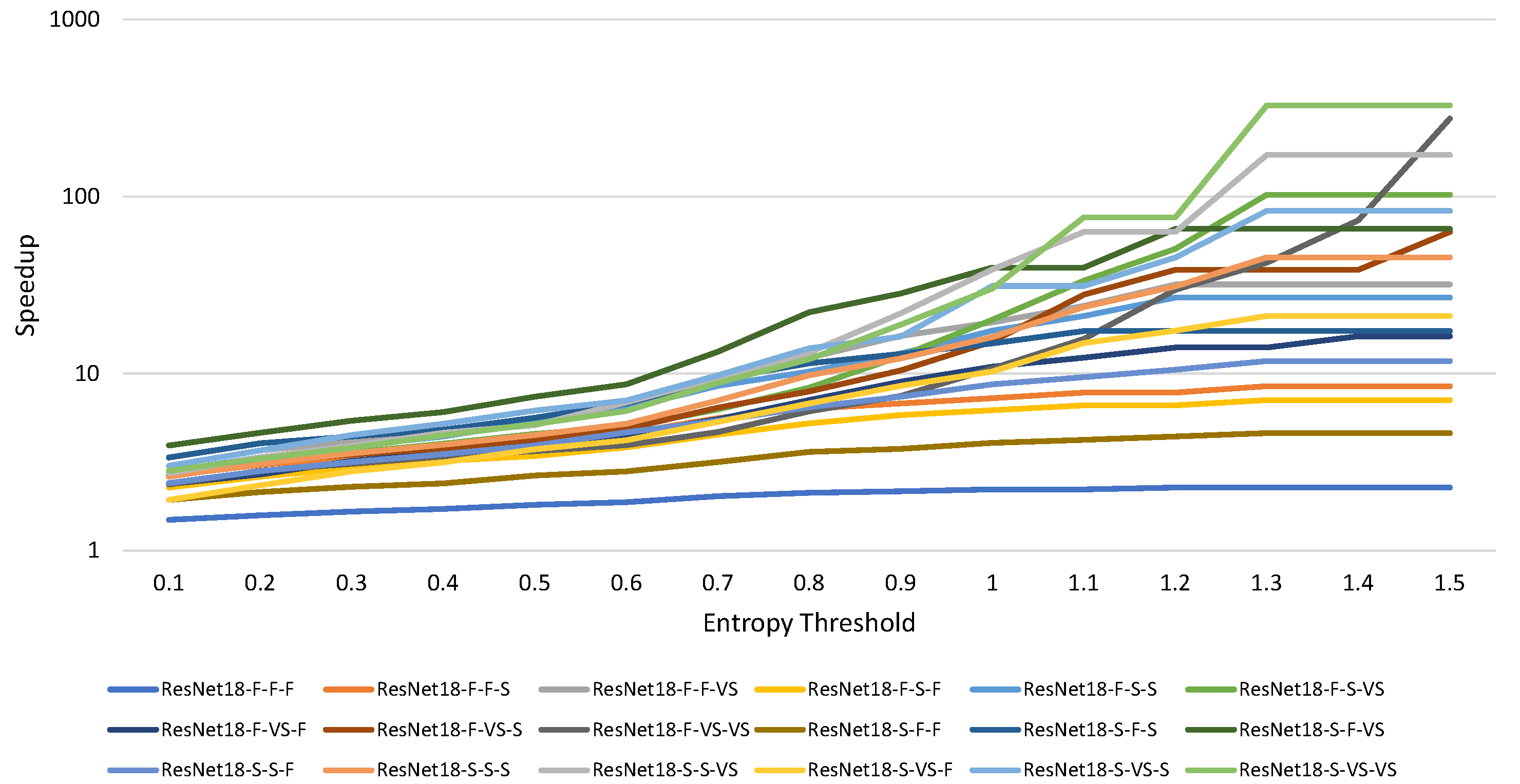
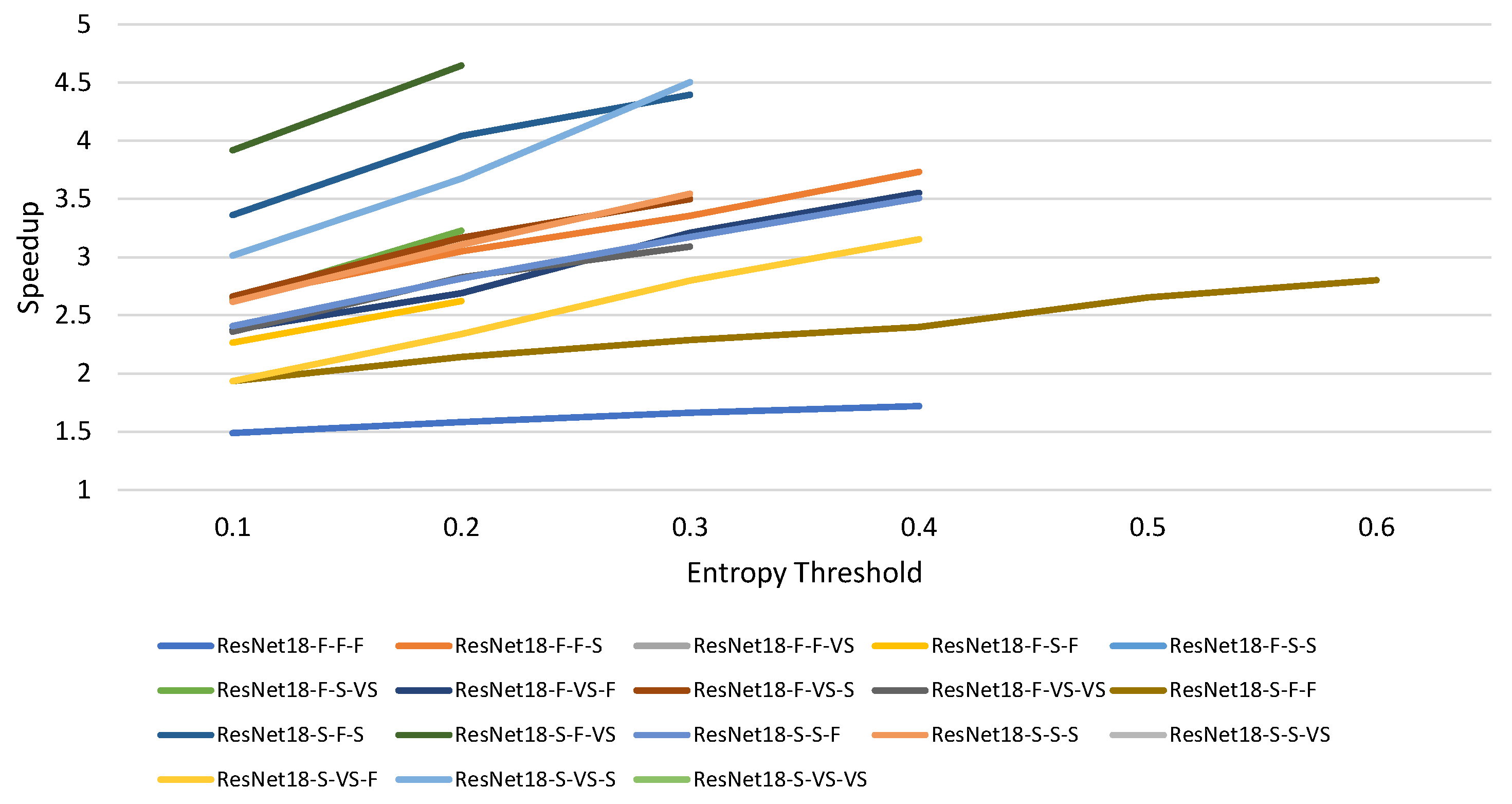
4.3. Dual Model
4.4. Performance of the Accelerator
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Egger, J.; Gsaxner, C.; Pepe, A.; Pomykala, K.L.; Jonske, F.; Kurz, M.; Li, J.; Kleesiek, J. Medical deep learning—A systematic meta-review. Comput. Methods Programs Biomed. 2022, 221, 106874. [Google Scholar] [CrossRef] [PubMed]
- Gholami, A.; Kim, S.; Dong, Z.; Yao, Z.; Mahoney, M.W.; Keutzer, K. A Survey of Quantization Methods for Efficient Neural Network Inference. arXiv 2021, arXiv:2103.13630. [Google Scholar]
- Alqahtani, A.; Xie, X.; Jones, M.W. Literature Review of Deep Network Compression. Informatics 2021, 8, 77. [Google Scholar] [CrossRef]
- Wu, C.; Wang, M.; Chu, X.; Wang, K.; He, L. Low-Precision Floating-Point Arithmetic for High-Performance FPGA-Based CNN Acceleration. ACM Trans. Reconfigurable Technol. Syst. 2021, 15, 1–21. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Kouris, A.; Venieris, S.I.; Bouganis, C. CascadeCNN: Pushing the Performance Limits of Quantisation in Convolutional Neural Networks. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 26–30 August 2018; pp. 155–1557. [Google Scholar] [CrossRef]
- De Sousa, A.L.; Véstias, M.P.; Neto, H.C. Multi-Model Inference Accelerator for Binary Convolutional Neural Networks. Electronics 2022, 11, 3966. [Google Scholar] [CrossRef]
- Guo, P.; Ma, H.; Chen, R.; Li, P.; Xie, S.; Wang, D. FBNA: A Fully Binarized Neural Network Accelerator. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 27–31 August 2018; pp. 51–513. [Google Scholar] [CrossRef]
- Véstias, M.P. A Survey of Convolutional Neural Networks on Edge with Reconfigurable Computing. Algorithms 2019, 12, 154. [Google Scholar] [CrossRef]
- Venieris, S.; Kouris, A.; Bouganis, C. Toolflows for Mapping Convolutional Neural Networks on FPGAs: A Survey and Future Directions. ACM Comput. Surv. 2018, 51, 1–39. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Véstias, M.P.; Duarte, R.P.; de Sousa, J.T.; Neto, H.C. A fast and scalable architecture to run convolutional neural networks in low density FPGAs. Microprocess. Microsyst. 2020, 77, 103136. [Google Scholar] [CrossRef]
- Sharma, H.; Park, J.; Mahajan, D.; Amaro, E.; Kim, J.K.; Shao, C.; Mishra, A.; Esmaeilzadeh, H. From high-level deep neural models to FPGAs. In Proceedings of the Microarchitecture (MICRO), 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture, Taipei, Taiwan, 15–19 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–12. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014, arXiv:1408.5093. [Google Scholar]
- Venieris, S.I.; Bouganis, C.S. fpgaConvNet: A Framework for Mapping Convolutional Neural Networks on FPGAs. In Proceedings of the 2016 IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Washington, DC, USA, 1–3 May 2016; pp. 40–47. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, J.; Han, Y.; Li, H.; Li, X. DeepBurning: Automatic generation of FPGA-based learning accelerators for the Neural Network family. In Proceedings of the 2016 53nd ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 5–9 June 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Blott, M.; Preußer, T.B.; Fraser, N.J.; Gambardella, G.; O’Brien, K.; Umuroglu, Y. FINN-R: An End-to-End Deep-Learning Framework for Fast Exploration of Quantized Neural Networks. arXiv 2018, arXiv:1809.04570. [Google Scholar] [CrossRef]
- Wilson, Z.T.; Sahinidis, N.V. The ALAMO approach to machine learning. arXiv 2017, arXiv:1705.10918. [Google Scholar] [CrossRef]
- Vloncar; Summers, S.; Duarte, J.; Tran, N.; Kreis, B.; Jngadiub; Ghielmetti, N.; Hoang, D.; Kreinar, E.J.; Lin, K.; et al. Fastmachinelearning/hls4ml: Coris (v0.6.0). arXiv 2021, arXiv:1804.06913. [Google Scholar]
- Tavakolpour, S.; Daneshpazhooh, M.; Mahmoudi, H. Skin Cancer: Genetics, Immunology, Treatments, and Psychological Care. In Cancer Genetics and Psychotherapy; Springer International Publishing: Cham, Switzerland, 2017; pp. 851–934. [Google Scholar] [CrossRef]
- Niino, M.; Matsuda, T. Age-specific skin cancer incidence rate in the world. Jpn. J. Clin. Oncol. 2021, 51, 848–849. [Google Scholar] [CrossRef]
- Wolner, Z.J.; Yélamos, O.; Liopyris, K.; Rogers, T.; Marchetti, M.A.; Marghoob, A.A. Enhancing Skin Cancer Diagnosis with Dermoscopy. Dermatol. Clin. 2017, 35, 417–437. [Google Scholar] [CrossRef]
- Popescu, D.; El-khatib, M.; Ichim, L. Skin Lesion Classification Using Collective Intelligence of Multiple Neural Networks. Sensors 2022, 22, 4399. [Google Scholar] [CrossRef]
- Srinivasu, P.N.; SivaSai, J.G.; Ijaz, M.F.; Bhoi, A.K.; Kim, W.; Kang, J.J. Classification of Skin Disease Using Deep Learning Neural Networks with MobileNet V2 and LSTM. Sensors 2021, 21, 2852. [Google Scholar] [CrossRef]
- Khan, M.A.; Zhang, Y.D.; Sharif, M.; Akram, T. Pixels to Classes: Intelligent Learning Framework for Multiclass Skin Lesion Localization and Classification. Comput. Electr. Eng. 2021, 90, 106956. [Google Scholar] [CrossRef]
- Khan, M.A.; Sharif, M.; Akram, T.; Damaševičius, R.; Maskeliūnas, R. Skin Lesion Segmentation and Multiclass Classification Using Deep Learning Features and Improved Moth Flame Optimization. Diagnostics 2021, 11, 811. [Google Scholar] [CrossRef]
- Thurnhofer-Hemsi, K.; Domínguez, E. A Convolutional Neural Network Framework for Accurate Skin Cancer Detection. Neural Process. Lett. 2021, 53, 3073–3093. [Google Scholar] [CrossRef]
- Chaturvedi, S.S.; Gupta, K.; Prasad, P.S. Skin Lesion Analyser: An Efficient Seven-Way Multi-class Skin Cancer Classification Using MobileNet. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; pp. 165–176. [Google Scholar] [CrossRef]
- Ameri, A. A Deep Learning Approach to Skin Cancer Detection in Dermoscopy Images. J. Biomed. Phys. Eng. 2020, 10, 801–806. [Google Scholar] [CrossRef] [PubMed]
- Khushi, M.; Shaukat, K.; Alam, T.M.; Hameed, I.A.; Uddin, S.; Luo, S.; Yang, X.; Reyes, M.C. A Comparative Performance Analysis of Data Resampling Methods on Imbalance Medical Data. IEEE Access 2021, 9, 109960–109975. [Google Scholar] [CrossRef]
- Mukherjee, S.; Suleman, S.; Pilloton, R.; Narang, J.; Rani, K. State of the Art in Smart Portable, Wearable, Ingestible and Implantable Devices for Health Status Monitoring and Disease Management. Sensors 2022, 22, 4228. [Google Scholar] [CrossRef] [PubMed]
- Tornetta, G.N. Entropy Methods for the Confidence Assessment of Probabilistic Classification Models. Statistica 2021, 81, 383–398. [Google Scholar] [CrossRef]
- Tschandl, P. The HAM10000 Dataset, a Large Collection of Multi-Source Dermatoscopic Images of Common Pigmented Skin Lesions, Harvard Dataverse, V3; Medical University of Vienna: Vienna, Austria, 2018. [Google Scholar] [CrossRef]
- Afifi, S.; GholamHosseini, H.; Sinha, R. A system on chip for melanoma detection using FPGA-based SVM classifier. Microprocess. Microsyst. 2019, 65, 57–68. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
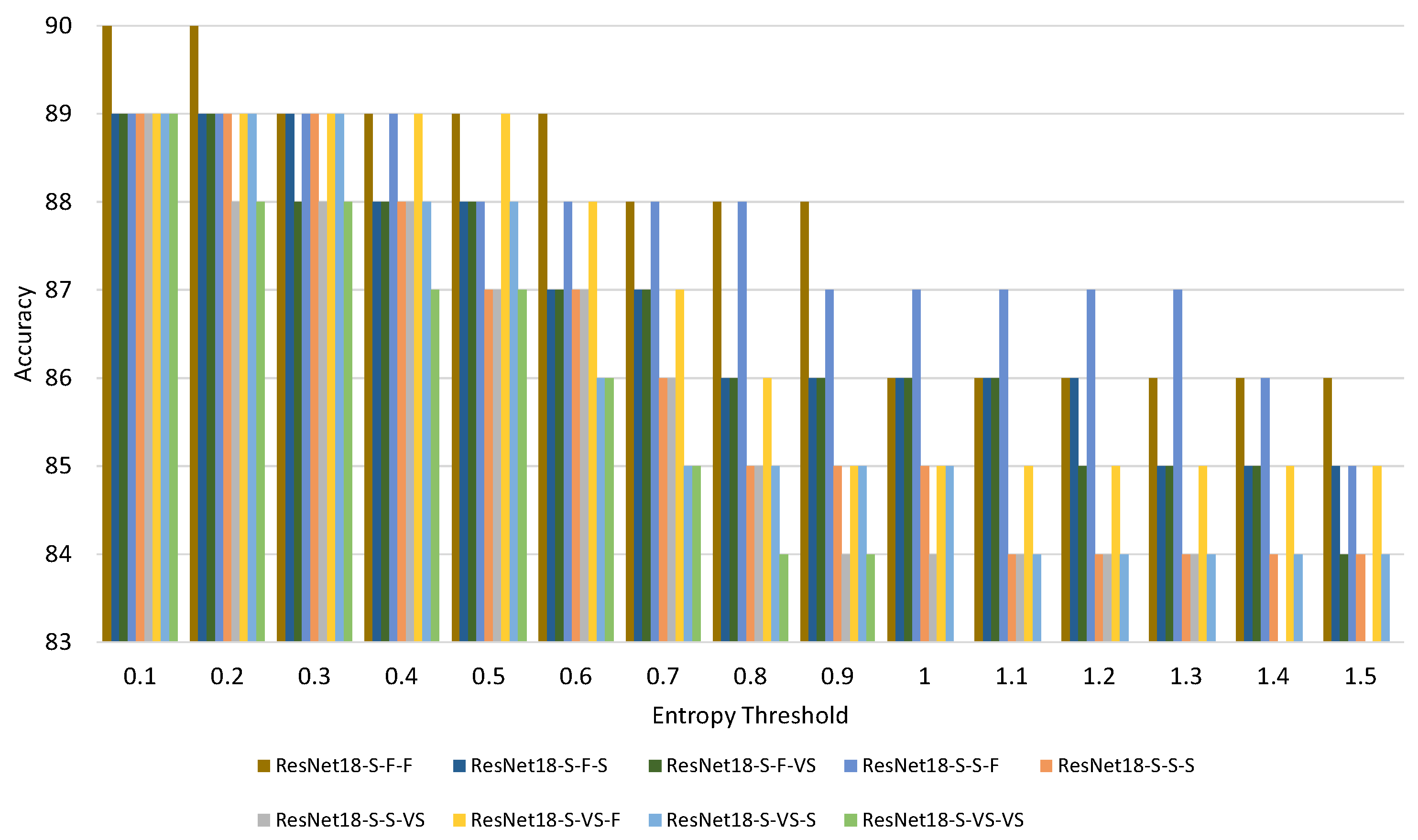{kind=link}
{kind=link}
{kind=link}
| Lesion Name | Lesion Abreviation |
|---|---|
| Actinic keratoses and intraepithelial carcinoma | akiec |
| basal cell carcinoma | bcc |
| benign keratosis-like lesions | bkl |
| dermatofibroma | df |
| melanoma | mel |
| melanocytic nevi | nv |
| vascular lesions | vasc |
| Model | Param () | FLOPS () | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| ResNet18 | 11.18 | 1.83 | 0.88 | 0.87 | 0.88 | 0.86 |
| ResNet50 | 23.5 | 4.13 | 0.89 | 0.88 | 0.88 | 0.87 |
| ResNet101 | 44.5 | 7.61 | 0.90 | 0.90 | 0.89 | 0.88 |
| Model | Param () | MOPS () | Accuracy |
|---|---|---|---|
| ResNet18-F-F-F | 11.18 | 1.83 | 0.88 |
| ResNet18-F-F-S | 11.18 | 0.49 | 0.86 |
| ResNet18-F-F-VS | 11.18 | 0.13 | 0.85 |
| ResNet18-F-S-F | 2.82 | 0.58 | 0.84 |
| ResNet18-F-S-S | 2.82 | 0.15 | 0.85 |
| ResNet18-F-S-VS | 2.82 | 0.04 | 0.84 |
| ResNet18-F-VS-F | 0.72 | 0.25 | 0.87 |
| ResNet18-F-VS-S | 0.72 | 0.07 | 0.85 |
| ResNet18-F-VS-VS | 0.72 | 0.02 | 0.84 |
| ResNet18-S-F-F | 4.90 | 0.90 | 0.88 |
| ResNet18-S-F-S | 4.90 | 0.24 | 0.86 |
| ResNet18-S-F-VS | 4.90 | 0.06 | 0.87 |
| ResNet18-S-S-F | 1.25 | 0.35 | 0.86 |
| ResNet18-S-S-S | 1.25 | 0.09 | 0.85 |
| ResNet18-S-S-VS | 1.25 | 0.02 | 0.84 |
| ResNet18-S-VS-F | 0.33 | 0.20 | 0.86 |
| ResNet18-S-VS-S | 0.33 | 0.05 | 0.86 |
| ResNet18-S-VS-VS | 0.33 | 0.01 | 0.84 |
| DPU | LUT | FF | DSP | BRAM | URAM | FPS |
|---|---|---|---|---|---|---|
| B4096 | 54533 | 99952 | 528 | 254 | 1 | 220 |
| B2304 | 46718 | 72314 | 304 | 166 | 1 | 121 |
| B1024 | 38696 | 51848 | 144 | 102 | 1 | 51 |
| B512 | 33374 | 39540 | 80 | 70 | 1 | 24 |
| Param () | Performance (FPS) | Energy/Frame (J) | ||
|---|---|---|---|---|
| Model | Acc = 88% | Acc = 87% | Acc = 87% | |
| ResNet50 | 23.5 | — | 3.1 | 1.61 |
| ResNet18-F-F-F | 34.7 | 4.6 | 5.0 | 1.00 |
| ResNet18-F-F-S | 34.7 | — | 10.8 | 0.46 |
| ResNet18-F-F-VS | 34.7 | — | 8.8 | 0.57 |
| ResNet18-F-S-F | 26.3 | — | 7.6 | 0.66 |
| ResNet18-F-S-S | 26.3 | — | 9.8 | 0.51 |
| ResNet18-F-S-VS | 26.3 | — | 9.4 | 0.53 |
| ResNet18-F-VS-F | 24.2 | — | 10.3 | 0.49 |
| ResNet18-F-VS-S | 24.2 | — | 10.1 | 0.50 |
| ResNet18-F-VS-VS | 24.2 | — | 6.8 | 0.74 |
| ResNet18-S-F-F | 28.4 | 6.2 | 8.1 | 0.62 |
| ResNet18-S-F-S | 28.4 | — | 12.7 | 0.39 |
| ResNet18-S-F-VS | 28.4 | — | 13.5 | 0.37 |
| ResNet18-S-S-F | 24.8 | — | 10.2 | 0.49 |
| ResNet18-S-S-S | 24.8 | — | 10.3 | 0.49 |
| ResNet18-S-S-VS | 24.8 | — | 7.9 | 0.63 |
| ResNet18-S-VS-F | 23.8 | — | 10.8 | 0.46 |
| ResNet18-S-VS-S | 23.8 | — | 13.1 | 0.38 |
| ResNet18-S-VS-VS | 23.8 | — | 8.2 | 0.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Durães, P.F.; Véstias, M.P. Smart Embedded System for Skin Cancer Classification. Future Internet 2023, 15, 52. https://doi.org/10.3390/fi15020052
Durães PF, Véstias MP. Smart Embedded System for Skin Cancer Classification. Future Internet. 2023; 15(2):52. https://doi.org/10.3390/fi15020052
Chicago/Turabian StyleDurães, Pedro F., and Mário P. Véstias. 2023. "Smart Embedded System for Skin Cancer Classification" Future Internet 15, no. 2: 52. https://doi.org/10.3390/fi15020052
APA StyleDurães, P. F., & Véstias, M. P. (2023). Smart Embedded System for Skin Cancer Classification. Future Internet, 15(2), 52. https://doi.org/10.3390/fi15020052