
IoT-Portrait: Automatically Identifying IoT Devices via Transformer with Incremental Learning


Abstract
:1. Introduction
- Existing works based on machine learning [3,4,5,6,7,8,9,10,11], such as gradient boosting [5] and random forest classification algorithms [3,6], require manual feature extraction and feature filtering. Some works use deep learning [12,13,14,15] to extract features automatically, but they still need to label samples manually. Due to the amount and diversity of IoT devices, these manual works will take a lot of time and effort;
- The classification model can only identify the devices in the training set. When a new device joins the network, the old classifier cannot recognize it. One solution is to save all past samples and retrain the model with past samples and new device samples when needed. However, this will take a lot of memory space to save past samples, and it will take a long time to retrain the model. Meanwhile, in real task scenarios, the past samples cannot be fully preserved due to privacy, data storage, and computing power limitations. Therefore, the new model’s performance in the old classes will drop catastrophically after learning the new task, which is called catastrophic forgetting.
- We propose IoT-Portrait, an automatic IoT device identification framework, using a transformer network to mine the significant characteristics of the IoT device in the traffic and improve the effectiveness of IoT device identification;
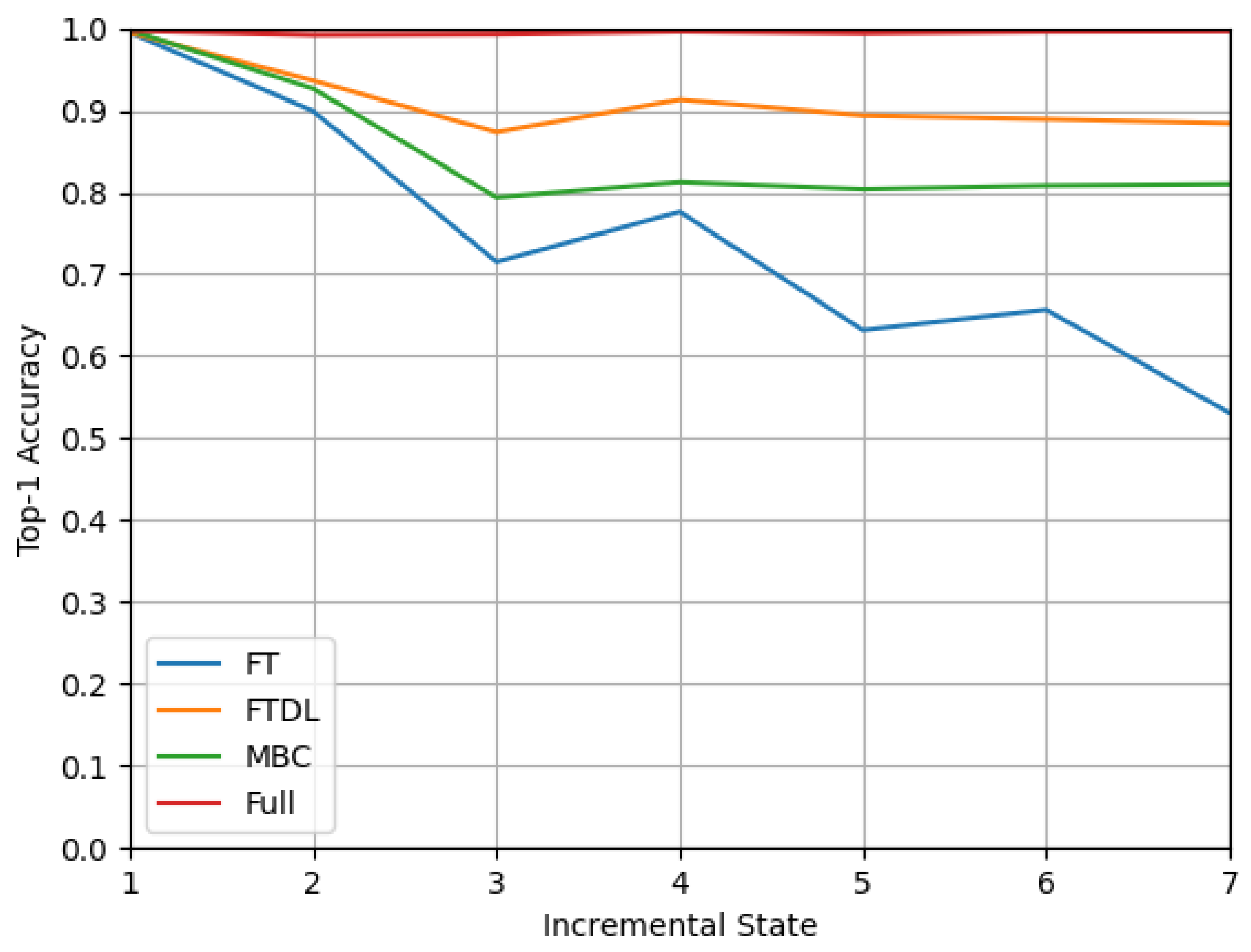
- We consider scenarios where the categories of devices increase after model training, and we do not save all old class samples. We compare several methods of resisting catastrophic forgetting and find that IoT-Portrait can achieve a small drop of accuracy using only a little storage space for old exemplars;
- We implement the IoT-Portrait prototype and evaluate it on our lab environment and open-source database. The results show that IoT-Portrait achieves a high device identification rate of up to 99% and is well resistant to catastrophic forgetting with a negligible added cost both in memory and time.
2. Novelty and Related Work
2.1. Device Identification
2.2. Compare with Previous Works
3. Analysis of IoT Traffic
3.1. IP and MAC Addresses of Device’s Communication Endpoints
3.2. Specific Ports
3.3. Specific Use of Protocols
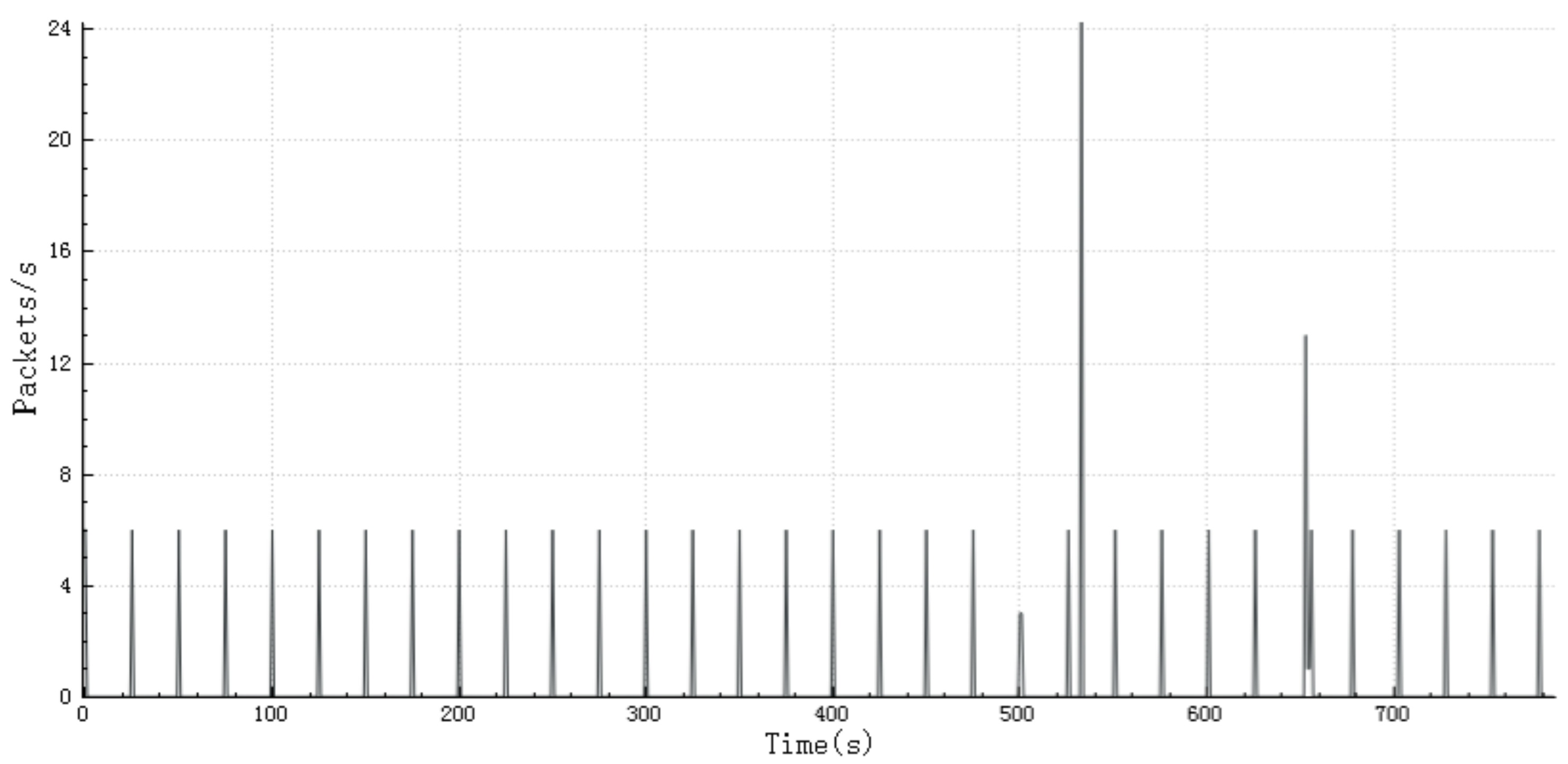
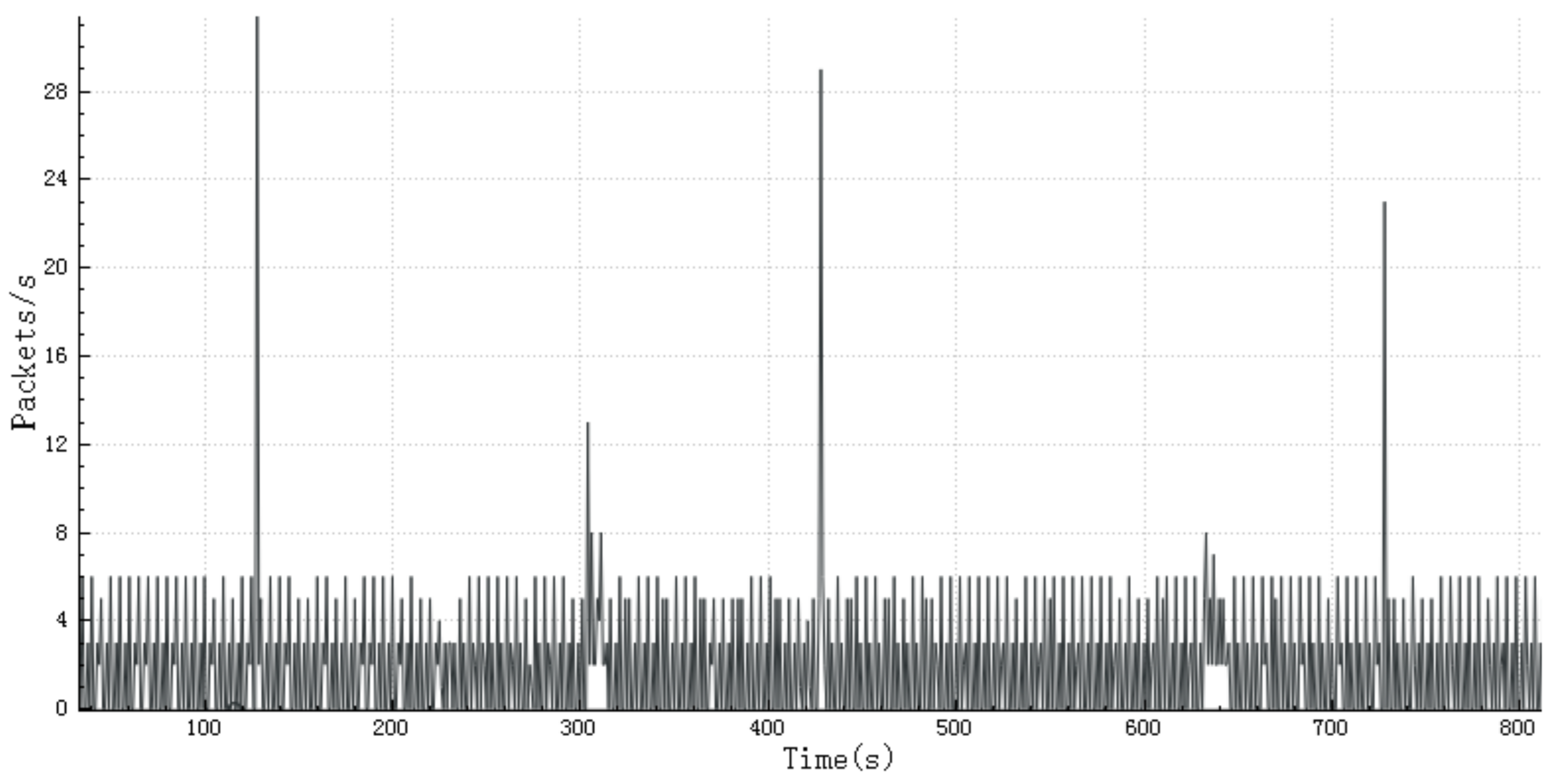
3.4. Regular Packet Rate
4. System Design
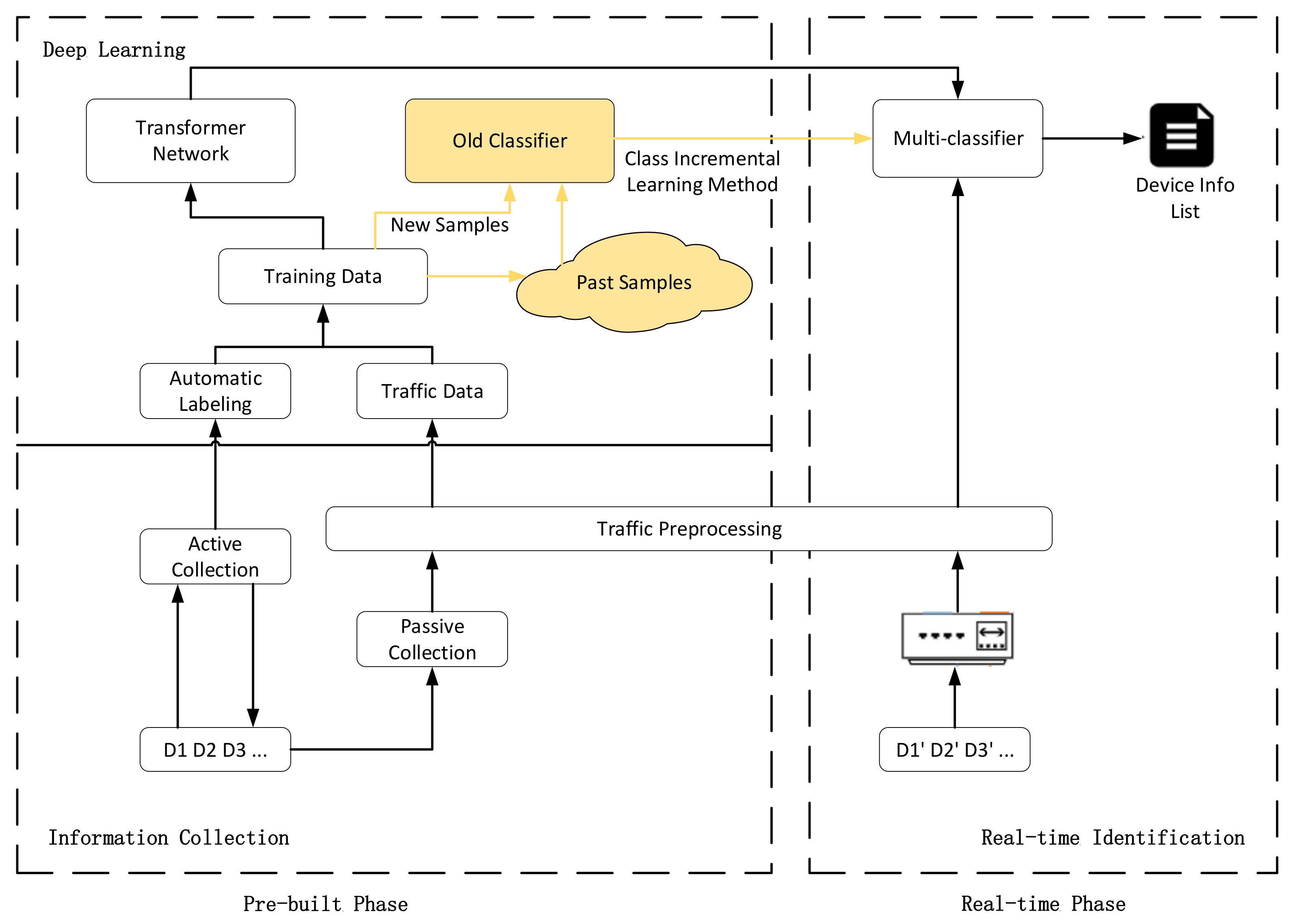
4.1. System Overview
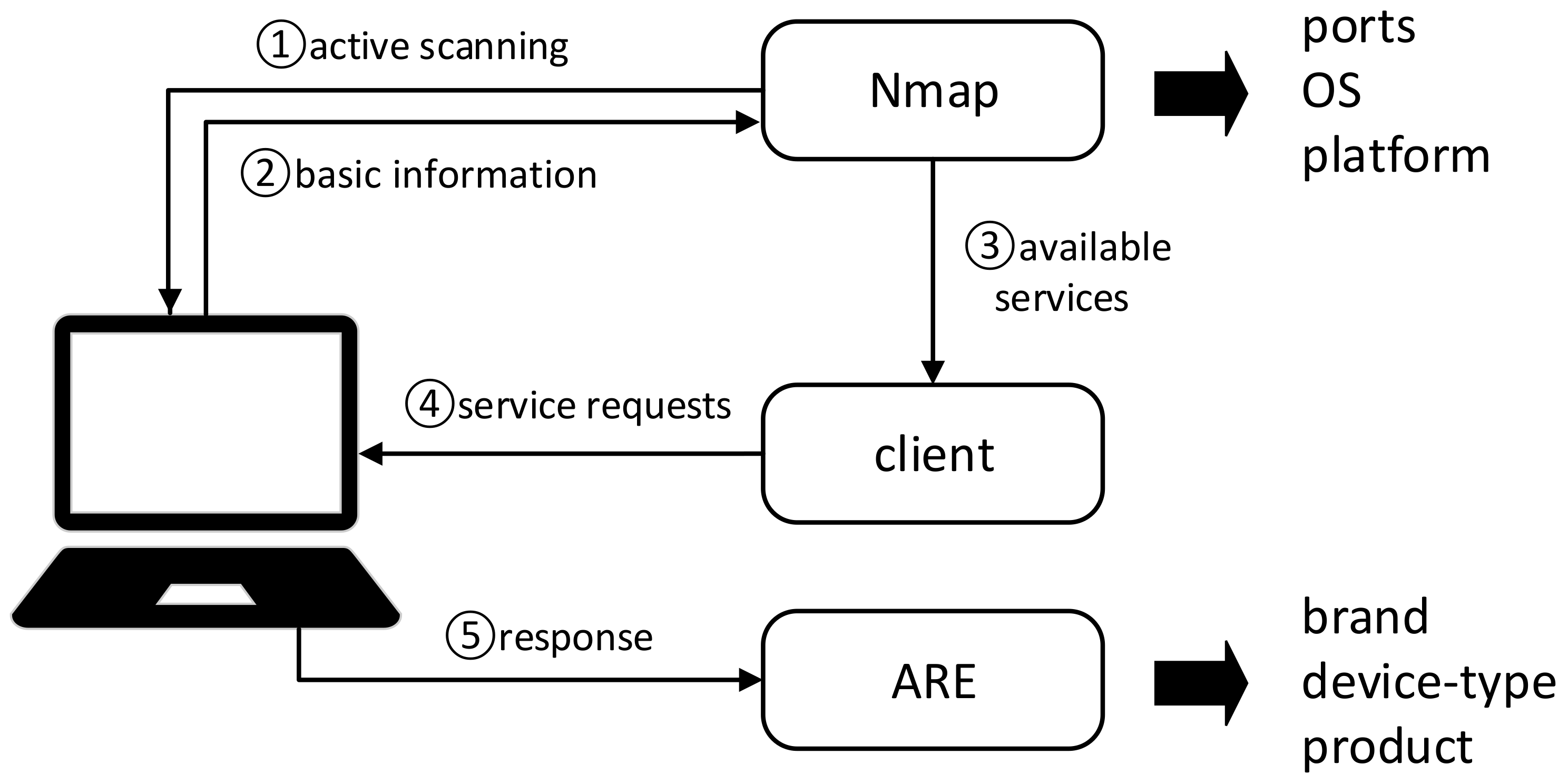
4.2. Active and Passive Information Collection
4.3. Multi-Classifier Training
4.3.1. Data Preprocessing
4.3.2. Data Sampling
4.3.3. Training Data Generation
- Some obviously important features obtained from the data packet. As analyzed in Section 3, there are distinguishable patterns between the traffic information of IoT devices and non-IoT devices, IoT devices and IoT devices (the IP and MAC addresses of the device’s communication endpoints, communication ports, and the use of protocols). In addition, the data packet length is also an important feature that data packets of different IoT devices may have different lengths.
- Other features obtained from the data packet. The data packet information (the version of IP, etc.) designed and used by each device may be different, and it is not easy for us to find the rules of this information. Therefore, we convert the information in the data packet within length into numbers and store them in the matrix.
- Calculated statistical characteristics of multiple packets. As analyzed in Section 3, IoT devices have regular communication patterns, so the traffic rate characteristic is also important. We count the number of packets within 100ms to represent the traffic rate of the device.
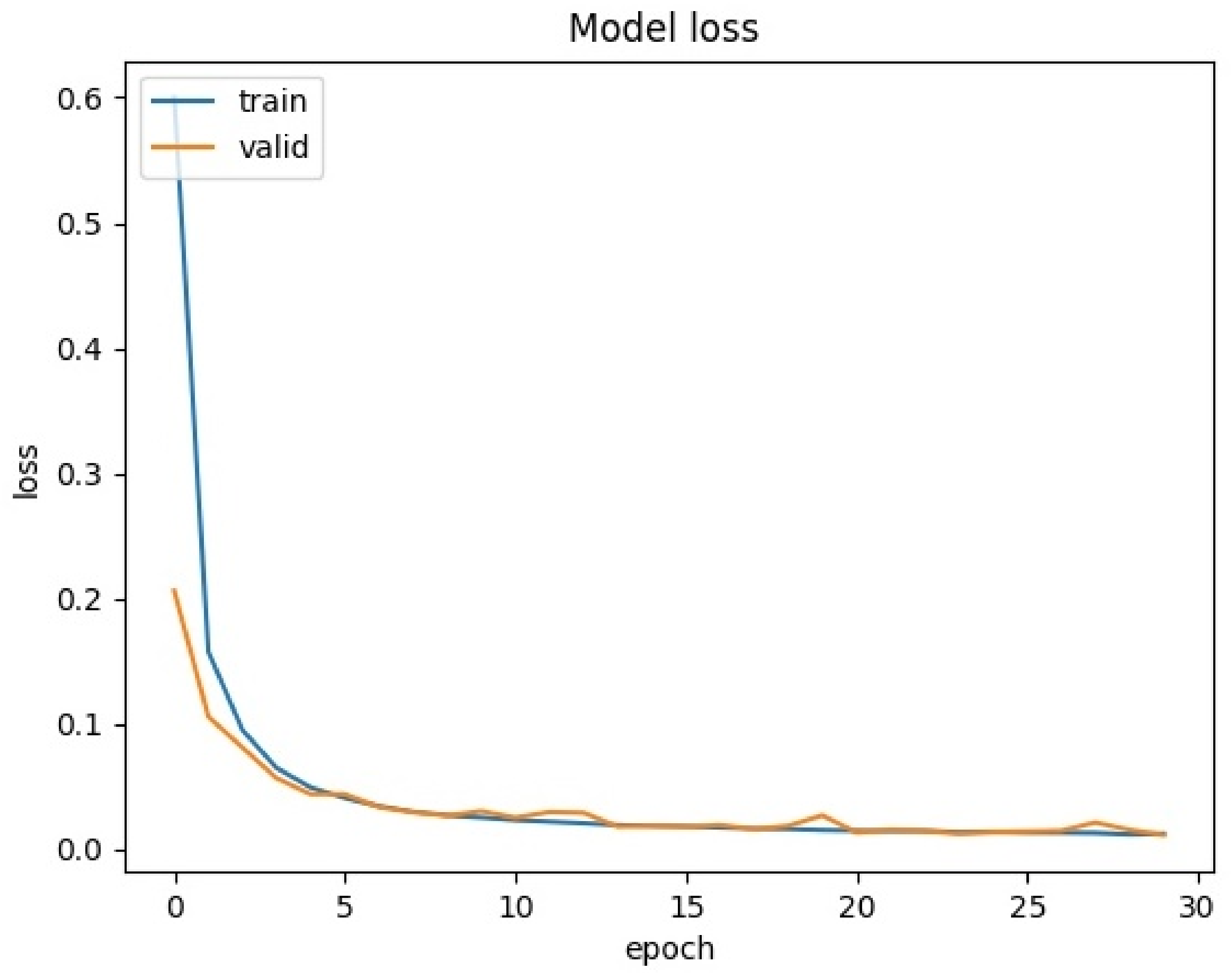
4.3.4. Model Training
4.4. Runtime Device Identification
4.5. Class Incremental Learning Method
5. Experimental Results and Analysis
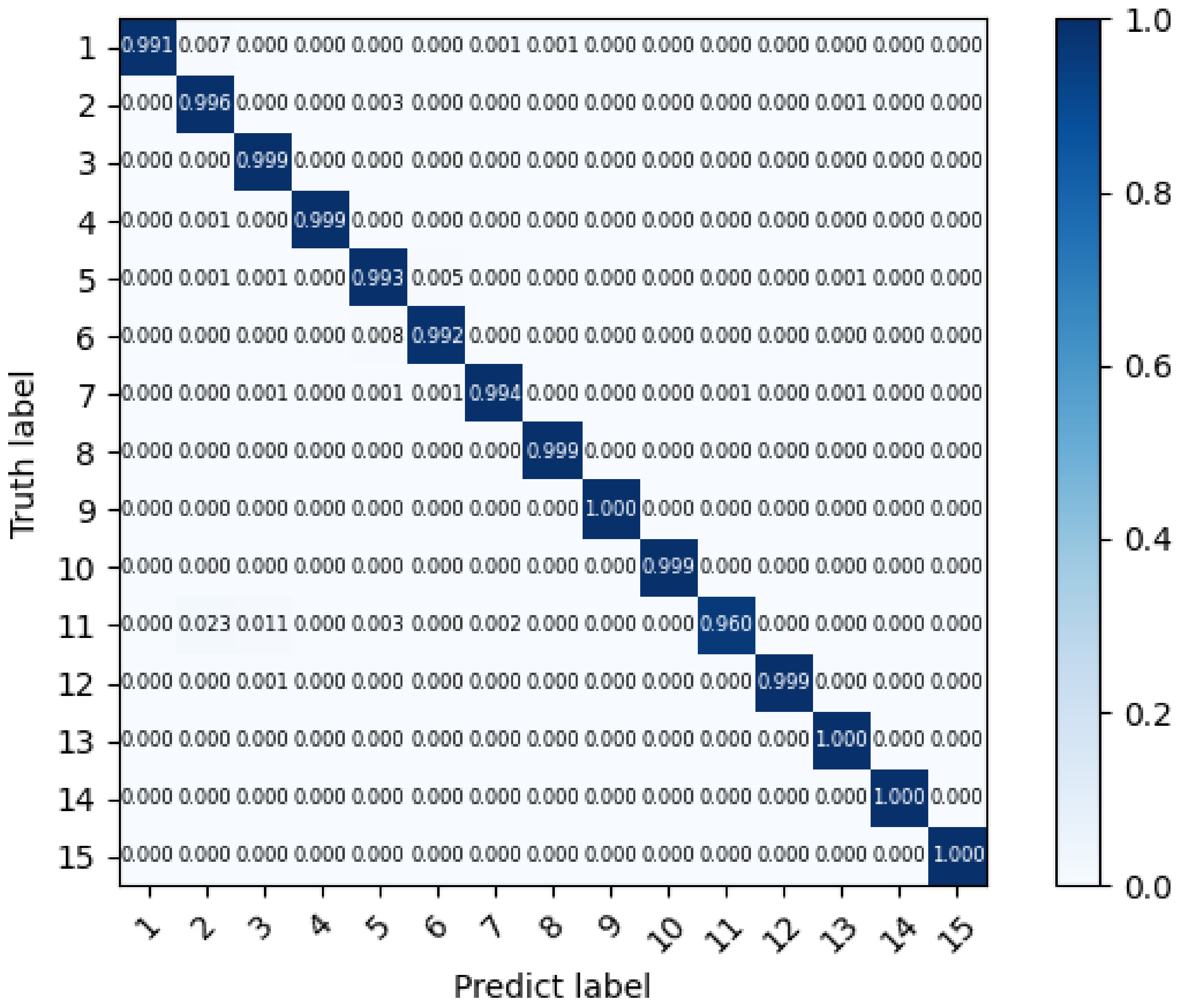
5.1. Device Identification of Lab Environment
5.2. Device Identification of Large Scale
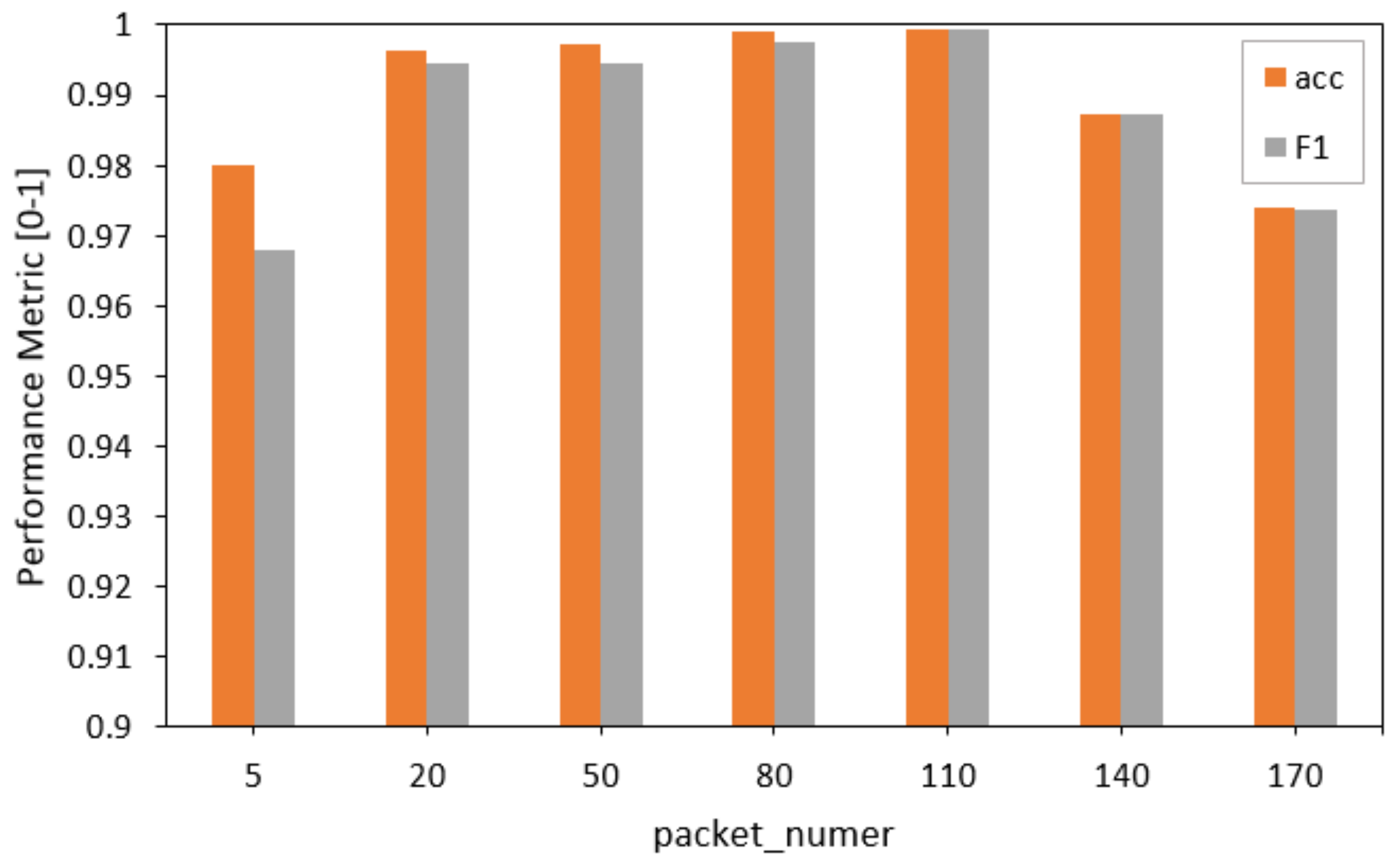
5.3. Impact of the Number of Packets
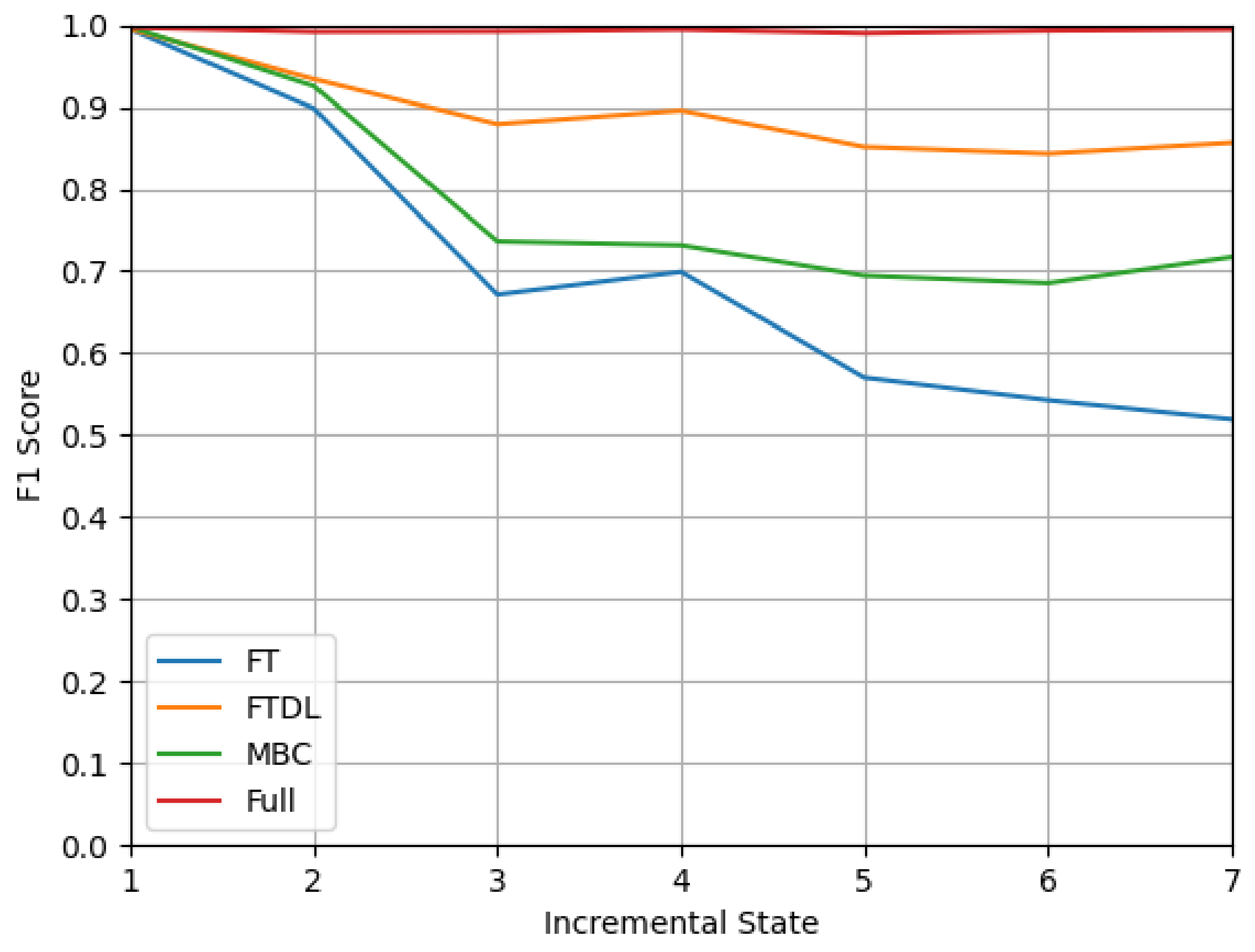
5.4. Impact of Class Incremental Learning Methods
5.5. Compare to Other Works
6. Limitations and Future Works
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| OS | Operating System |
| HTTP | Hypertext Transfer Protocol |
| SSH | Secure Shell Protocol |
| FTP | File Transfer Protocol |
| HTML | HyperText Markup Language |
| LSTM | Long short-term memory |
| TCP | Transmission Control Protocol |
| SDN | Software-Defined Networking |
| IP | Internet Protocol |
| MAC | Media Access Control |
| PC | Personal Computer |
| HTTPS | Hypertext Transfer Protocol Secure |
| UDP | User Datagram Protocol |
| DNS | Domain Name System |
| NTP | Network Time Protocol |
| MDNS | Multicast DNS |
| LAN | Local Area Network |
| ICMP | Internet Control Message Protocol |
| RNN | Recurrent Neural Network |
| UNSW | University of New South Wales |
| FT | Fine Tune |
| FTDL | Fine Tune with Distillation Loss |
| MBC | Multiple Binary Classifiers |
References
- Statista Research Department. Number of IoT Devices 2015–2025. 2016. Available online: https://www.statista.com/statistics/471264/iot-number-of-connected-devices-worldwide/things-security-report-q3-2015/ (accessed on 1 February 2023).
- Apthorpe, N.; Reisman, D.; Feamster, N. A smart home is no castle: Privacy vulnerabilities of encrypted iot traffic. arXiv 2017, arXiv:1705.06805. [Google Scholar]
- Meidan, Y.; Bohadana, M.; Shabtai, A.; Guarnizo, J.D.; Ochoa, M.; Tippenhauer, N.O.; Elovici, Y. ProfilIoT: A machine learning approach for IoT device identification based on network traffic analysis. In Proceedings of the Symposium on Applied Computing, Marrakech, Morocco, 3–7 April 2017; pp. 506–509. [Google Scholar]
- Chen, Y.; Hu, W.; Alam, M.; Wu, T. Fiden: Intelligent fingerprint learning for attacker identification in the industrial Internet of Things. IEEE Trans. Ind. Inform. 2019, 17, 882–890. [Google Scholar] [CrossRef]
- Bezawada, B.; Bachani, M.; Peterson, J.; Shirazi, H.; Ray, I.; Ray, I. Iotsense: Behavioral fingerprinting of iot devices. arXiv 2018, arXiv:1804.03852. [Google Scholar]
- Miettinen, M.; Marchal, S.; Hafeez, I.; Asokan, N.; Sadeghi, A.R.; Tarkoma, S. Iot sentinel: Automated device-type identification for security enforcement in iot. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 2177–2184. [Google Scholar]
- Radhakrishnan, S.V.; Uluagac, A.S.; Beyah, R. GTID: A technique for physical device and device type fingerprinting. IEEE Trans. Dependable Secur. Comput. 2014, 12, 519–532. [Google Scholar] [CrossRef]
- Acar, A.; Fereidooni, H.; Abera, T.; Sikder, A.K.; Miettinen, M.; Aksu, H.; Conti, M.; Sadeghi, A.R.; Uluagac, S.; Uluagac, S. Peek-a-boo: I see your smart home activities, even encrypted! In Proceedings of the 13th ACM Conference on Security and Privacy in Wireless and Mobile Networks, Linz, Austria, 8–10 July 2020; pp. 207–218. [Google Scholar]
- Duan, C.; Gao, H.; Song, G.; Yang, J.; Wang, Z. ByteIoT: A practical IoT device identification system based on packet length distribution. IEEE Trans. Netw. Serv. Manag. 2021, 19, 1717–1728. [Google Scholar] [CrossRef]
- Aksoy, A.; Gunes, M.H. Automated iot device identification using network traffic. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications, Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar]
- Salman, O.; Elhajj, I.H.; Chehab, A.; Kayssi, A. A machine learning based framework for IoT device identification and abnormal traffic detection. Trans. Emerg. Telecommun. Technol. 2022, 33, e3743. [Google Scholar] [CrossRef]
- Bai, L.; Yao, L.; Kanhere, S.S.; Wang, X.; Yang, Z. Automatic device classification from network traffic streams of internet of things. In Proceedings of the 2018 IEEE 43rd Conference on Local Computer Networks, Chicago, IL, USA, 1–4 October 2018; pp. 1–9. [Google Scholar]
- Kotak, J.; Elovici, Y. Iot device identification using deep learning. In Proceedings of the 13th International Conference on Computational Intelligence in Security for Information Systems, Burgos, Spain, 16–18 September 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; Volume 12, pp. 76–86. [Google Scholar]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Network traffic classifier with convolutional and recurrent neural networks for Internet of Things. IEEE Access 2017, 5, 18042–18050. [Google Scholar] [CrossRef]
- Dong, S.; Li, Z.; Tang, D.; Chen, J.; Sun, M.; Zhang, K. Your smart home cannot keep a secret: Towards automated fingerprinting of iot traffic. In Proceedings of the 15th ACM Asia Conference on Computer and Communications Security, Taipei, Taiwan, 5–9 October 2020; pp. 47–59. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- De Lange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385. [Google Scholar]
- Lyon, G.F. Nmap Network Scanning: The Official Nmap Project Guide to Network Discovery and Security Scanning; Insecure.com LLC: Seattle, WA, USA, 2008; 468p. [Google Scholar]
- Bodenheim, R.C. Impact of the Shodan Computer Search Engine on Internet-Facing Industrial Control System Devices. Master’s Thesis, Air Force Institute of Technology Wright-Patterson AFB OH Graduate School of Engineering and Management, Dayton, OH, USA, 2014. [Google Scholar]
- Ribeiro, T.; Vala, M.; Paiva, A. Censys: A model for distributed embodied cognition. In Proceedings of the International Workshop on Intelligent Virtual Agents, Edinburgh, UK, 29–31 August 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 58–67. [Google Scholar]
- Feng, X.; Li, Q.; Wang, H.; Sun, L. Acquisitional rule-based engine for discovering Internet-of-Things devices. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 327–341. [Google Scholar]
- Sivanathan, A.; Gharakheili, H.H.; Loi, F.; Radford, A.; Wijenayake, C.; Vishwanath, A.; Sivaraman, V. Classifying IoT devices in smart environments using network traffic characteristics. IEEE Trans. Mob. Comput. 2018, 18, 1745–1759. [Google Scholar] [CrossRef]
- Sivanathan, A.; Sherratt, D.; Gharakheili, H.H.; Radford, A.; Wijenayake, C.; Vishwanath, A.; Sivaraman, V. Characterizing and classifying IoT traffic in smart cities and campuses. In Proceedings of the 2017 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Atlanta, GA, USA, 1–4 May 2017; pp. 559–564. [Google Scholar]
- Dumpcap-The Wireshark Network Analyzer 3.0.0. Available online: https://www.wireshark.org/docs/man-pages/dumpcap.html (accessed on 1 February 2023).
- Curl. Available online: https://curl.se/ (accessed on 1 March 2023).
- Editcap-The Wireshark Network Analyzer 3.0.0. Available online: https://www.wireshark.org/docs/man-pages/editcap.html (accessed on 1 March 2023).
- Tshark-The Wireshark Network Analyzer 3.0.0. Available online: https://www.wireshark.org/docs/man-pages/tshark.html (accessed on 1 March 2023).
- Li, Z.; Hoiem, D. Learning without forgetting. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2935–2947. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010. [Google Scholar]
- Belouadah, E.; Popescu, A. DeeSIL: Deep-shallow incremental learning. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Device Name | # of IPs | Server Ports |
|---|---|---|---|
| 1 | SmartThings Hub | 12 | TCP 433 |
| 2 | NetGear Station | 21 | UDP 10001, TCP 80 |
| 3 | WoShida Cam | 4 | TCP 44730 |
| 4 | Xiaobai Cam | 6 | UDP 32100, UDP 13978 |
| 5 | Philips Hue | 4 | TCP 80, TCP 443 |
| IoT Device | MAC Address |
|---|---|
| Amazon Echo | 44:65:0d:56:cc:d3 |
| Belkin Wemo Motion Sensor | ec:1a:59:83:28:11 |
| Belkin Wemo Switch | ec:1a:59:79:f4:89 |
| Dropcam | 30:8c:fb:2f:e4:b2 |
| HP Printer | 70:5a:0f:e4:9b:c0 |
| Netatmo Weather Station | 70:ee:50:03:b8:ac |
| Netatmo Welcome | 70:ee:50:18:34:43 |
| PIX-STAR Photo-frame | e0:76:d0:33:bb:85 |
| Samsung SmartCam | 00:16:6c:ab:6b:88 |
| Smart Things | d0:52:a8:00:67:5e |
| TP-Link Day Night Cloud Camera | f4:f2:6d:93:51:f1 |
| TP-Link Smart Plug | 50:c7:bf:00:56:39 |
| Triby Speaker | 18:b7:9e:02:20:44 |
| Withings Smart Baby Monitor | 00:24:e4:11:18:a8 |
| Withings Smart Scale | 00:24:e4:1b:6f:96 |
| Method | Number of Samples | Storage Memory (MB) | Prediction Time (s) |
|---|---|---|---|
| Full | 395,037 | 96.1 | 15 |
| FT | 10,000 | 1.8 | 16 |
| FTDL | 10,000 | 1.8 | 15 |
| MBC | 10,000 | 1.8 | 251 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhong, J.; Li, J. IoT-Portrait: Automatically Identifying IoT Devices via Transformer with Incremental Learning. Future Internet 2023, 15, 102. https://doi.org/10.3390/fi15030102
Wang J, Zhong J, Li J. IoT-Portrait: Automatically Identifying IoT Devices via Transformer with Incremental Learning. Future Internet. 2023; 15(3):102. https://doi.org/10.3390/fi15030102
Chicago/Turabian StyleWang, Juan, Jing Zhong, and Jiangqi Li. 2023. "IoT-Portrait: Automatically Identifying IoT Devices via Transformer with Incremental Learning" Future Internet 15, no. 3: 102. https://doi.org/10.3390/fi15030102
APA StyleWang, J., Zhong, J., & Li, J. (2023). IoT-Portrait: Automatically Identifying IoT Devices via Transformer with Incremental Learning. Future Internet, 15(3), 102. https://doi.org/10.3390/fi15030102