1. Introduction
Web search constitutes an application of information retrieval [
1]. Even from before the dawn of the new millennium, search engines became an essential part of the ever-expanding World Wide Web. Search transitioned from a marginally utilized service for the majority of Internet users to the default interface for computing in this information age [
2]. Search engines along with social media platforms were in the front of algorithmic culture, fundamentally altering the nature of the Internet and, by extension, our interactions with each other [
3]. With multiple search engine alternatives appearing in the early 90s, it became apparent that in order to better serve the needs of the users and, thus, increase revenue, search engines had to rank their results in a manner that satisfied user needs [
4]. This ability to prioritize the results a user wants to see is what led to Google’s prevalence in the field and it was, according to O’Brien [
5], a “success at modeling human behavior”. The PageRank algorithm, as it was described by Brin and Page in their introduction of Google [
6], constituted essentially a method of modeling search engine user behavior. The effort of using behavioral information to improve web search ranking continued in the subsequent decades, with Agichtein arguing that incorporating implicit feedback could heavily increase ranking accuracy [
7]. User behavior during a search may change based on the intended result of the search. Mishne and de Rijke identified different topics of engagement for blog searchers as opposed to general web searchers [
8], while Kelly and Cool suggested that topic familiarity might alter informational search behavior [
9]. At the same time, users seem to prefer seeking information at a search engine for reasons of convenience. The familiarity with a resource, the perception of its ease of use, and its proximity are all factors that contribute to its convenience [
10].
In this research, the behavior of search engine users was studied, with emphasis put specifically on the fields of art and cultural heritage. Cultural heritage comprises of objects created or endowed with significance by human action [
11]. In this way, it consists or combines objects of any conceivable format, material, size, or genre. Objects can consist of a single item or a collection of items whose significance is derived from their collective presentation. Cultural heritage artifacts are man-made, adapted, added to, or otherwise altered natural world objects, or natural world objects that acquired the status of cultural heritage object because a cultural community ascribed them meaning [
12]. As part of ongoing research, the Art Boulevard platform was developed: Art Boulevard is a search engine that allows users to search for content related to art and cultural heritage using the principles of federated search and aggregating results from a series of art and culture related online repositories. The Art Boulevard platform was made available to the general public through the World Wide Web in the form of a website at the URL
https://artboulevard.org (accessed on 16 February 2023) and through smartphone storefronts in the form of a mobile application.
Art and culture always played an important role in the development of human existence [
13]. The interest in digital cultural heritage and the preservation of historical materials for future generations increased in the recent years [
14]. Although there are several intriguing ICT applications that were developed in the context of art-related websites over the past few decades [
13], in the vast landscape of the World Wide Web, where commerce and technology often steal the spotlight, fields such as art and cultural heritage are often overlooked. The effort to better understand the needs of users searching for material in fields related to humanities throughout the years included researching the behavior of scholars with access to informational databases such as the Getty Art History Information Program [
15], documenting the feedback of undergraduate students on the usage of full-text databases [
16], and more. Searching for content relating to art and cultural heritage may lead to differentiations in user behavior based on topic familiarity [
9], on specific characteristics of the interested parties such as educational level or age, and on the nature of the topic itself. Mehrotra et al.’s findings on the affinity of various topics to be better suited for multitask or single-task searches indicated the existence of inherent characteristics of the various topics themselves and how they may influence user behavior [
17]. In Mehrotra’s research, the arts appeared to be a topic more prone to appear in multi-task searches [
17].
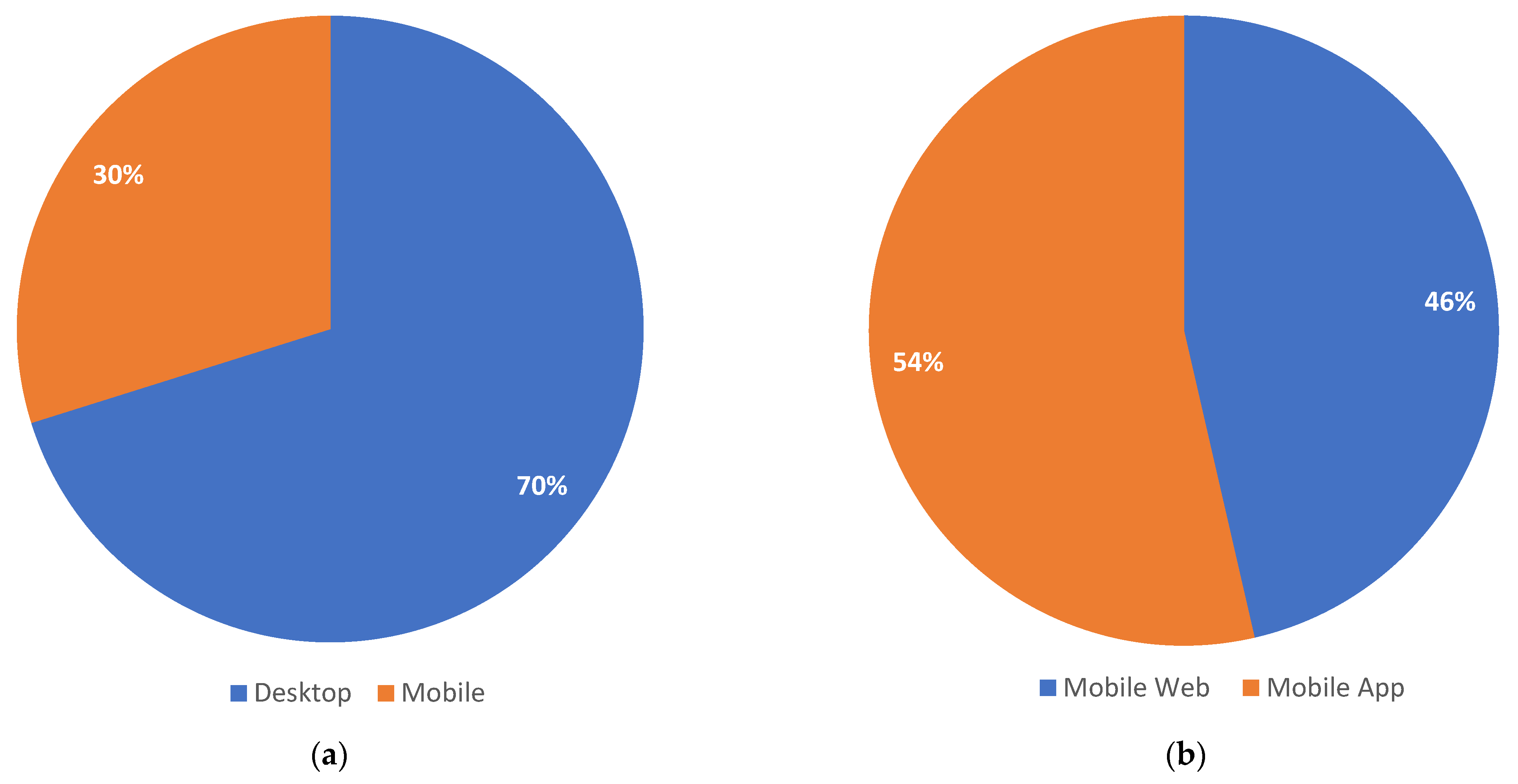
Another factor that influences user behavior is the device or platform which is used to access the content. Song et al. presented findings based on a three month log-based study that indicated significant differences in search patterns based on what platform was being used (mobile, tablet, or desktop) [
18]. Query length in mobile and tablet was longer, query category distribution was different, and usage time also fluctuated [
18]. Kim et al. [
19] argued in their lab study that screen size difference corresponds to different eye-tracking patterns, which leads to differences in behavior. In smaller screens, there is less eye movement, which makes extracting information more strenuous [
19]. Furthermore, the interaction with the mobile device’s interface is different compared to a desktop or a laptop, since it is carried out via different touch actions such as touching, swiping, zooming on results, and writing via screen touching [
20]. Harvey and Pointon [
21] also pointed out the effect of fragmented attention when it came to searching the web from mobile. In their study, they found out that when users were distracted in some way, they tended to rush on their web searches and perceived search as more difficult. Such behavioral differences also became a subject of this article.
The use of mobile devices also helped with the introduction of voice recognition technology into search engines. According to Song et al., more and more platforms take advantage of voice search features [
18]. Beyond speech recognition, speech synthesis also started appearing in search engine platforms as a tool to help with multilingual content or accessibility. Adell Mercado et al. studied the introduction speech acquisition, recognition, and synthesis in the field of information retrieval in their development of the Buceador multi-lingual search engine [
22].
Another technology that evolved alongside traditional query-based searching is content-based search: the ability to search for information using an image or other media instead of keywords. Lew et al. [
23] argued that such systems may be especially useful when textual annotations that describe the search object are not available or can even increase search accuracy alongside traditional keywords. The Art Boulevard platform implements features that use both voice and visual search technologies in order to study user behavior regarding these fields.
Moving beyond technologies and towards the social aspect of online searching, the Art Boulevard platform also implemented a simple user system. Such a system can increase user engagement [
24] and provide a social environment that is very important in the fields of arts and culture. Moreover, this system allows personalization of the platform’s user interface, which can ensure an environment that adapts to the users preferences and demands [
25]. According to Jackson et al., who studied anonymous contributors in online communities [
26], anonymity or the lack of anonymity has implications on user behavior. This was also supported by Cho et al.’s study of the real name policy used in the Web in South Korea, but which is also encountered internationally in specific websites [
27]. Deciding to login or not is in itself a user-behavior-related decision, but further than that, the interactions between a logged in user and an anonymous user might provide insight into how anonymity might effect user behavior.
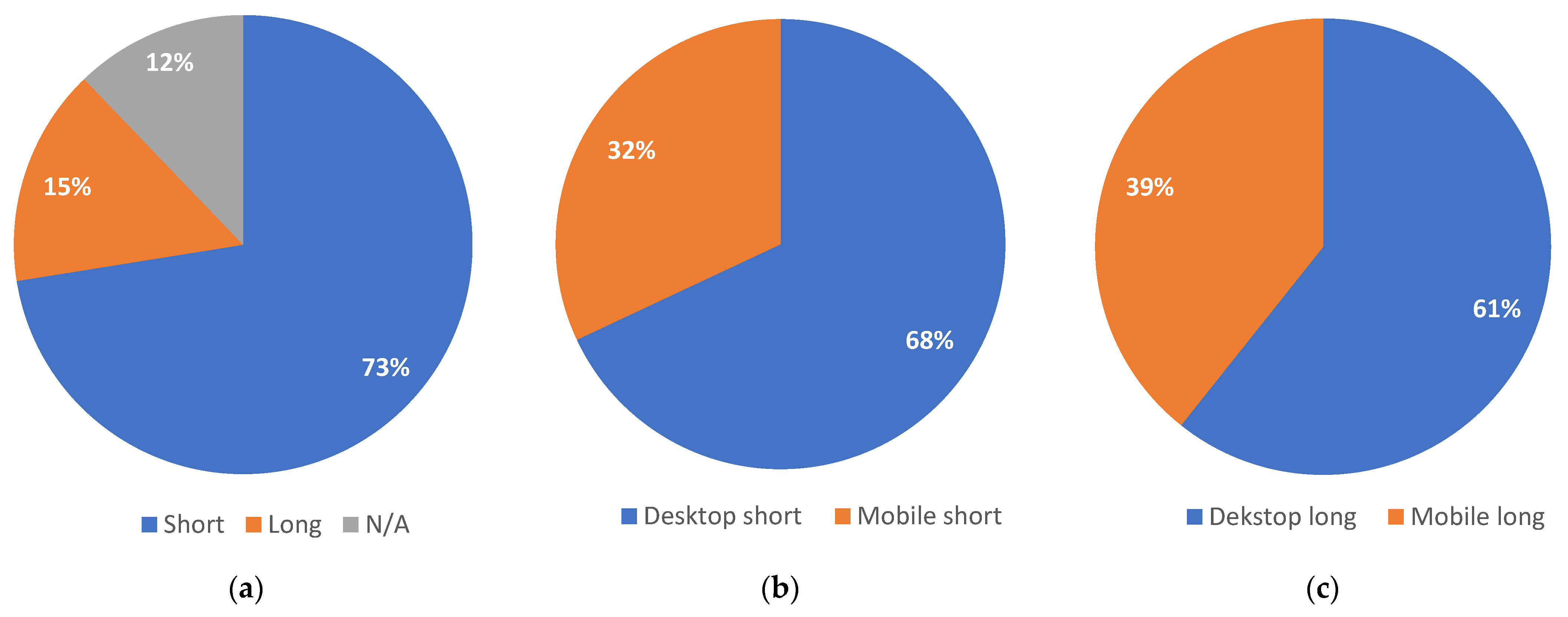
The duration of different search sessions may vary greatly. According to Jansen et al. [
28], the intent of a web search session might be classified as informational, transactional, or navigational based on the intent of the searcher. Mendoza and Baeza-Yates’ findings indicated that the intent of a search session, and whether it is informational or not, may affect the search’s duration [
29]. However, a long duration, as Hassan et al. mentioned [
30], might be a sign of either exploring to discover interesting alternatives or struggling to find something useful. Studying how other implicit measurements change based on a search session’s total duration might provide better insight on both intent and on how user behavior changes through the course of a session.
Another factor that should be taken into account when it comes to engaging with a search engine is the user themselves. For instance, Alen et al. [
31] argued that children (between 6 and 12 years old) desired more dynamic means of navigating search results and icon-based interaction options. According to White, people favored positive results over negative ones and sought confirmation of their beliefs, when searching online [
32], implying a bias or an echo chamber effect. Web searches biases occur when searchers seek or are presented with information that deviates significantly from actual probabilities [
32]. A well-known and extensively researched bias is the position or trust bias, which causes users to select more frequently higher-ranked results. Users believe that higher-ranked results are more pertinent because they have confidence in the search engine and retrieval function [
33]. Another well known bias is the bias that is related to the reputation of a site or a domain. More popular or well-known websites are also more trusted and are, thus, more likely to be clicked if they appear on the results’ page of a search engine [
34]. Mao et al. [
20] also argued about another type of bias, the click necessity bias. In this bias, some results will have low clicks because they are self-explanatory, meaning that they provide the answer the users are searching for without requiring to be clicked to present it.
In the effort to identify and describe user behavior, various types of studies may be employed. According to Dumais et al., lab studies include participants in a controlled environment and may incorporate detailed instrumentation as well as great amounts of explicit feedback [
35]. Field studies take place in the wild, but still include two-way communication and feedback [
35]. Finally, log studies involve members of the general public in the most natural environment and despite not providing any explicit feedback may provide a large number of implicit signals [
35]. Log studies are based on the analysis of data collected by a specific application in full production status and because they involve unmonitored or uncensored behavior, they provide valuable insights in behavior that the user would misremember or purposefully avoid during a lab or field study [
35]. Implicit behavioral measures, as demonstrated by Fox et al. [
36], may be used to analyze search user behavior and even provide good predictions of explicit judgments on user satisfaction. In a previous stage of this research, an extended lab study was carried out with a prototype version of the Art Boulevard platform [
37]. That study combined limited quantitative metrics during a beta testing period with explicit qualitative feedback from semi-structured group interviews provided by the platform’s testers. In the present article, an analytics study based on the production instance of the Art Boulevard platform is presented. Actual usage analytics were collected by the platform itself over a six-month period, during which the general public had full access to it. Using this collected information, the present study attempts to answer the following research questions:
RQ1: What are the key values that describe the behavior of users searching online for art and culture and how do they compare to findings regarding general purpose search engines or other area-specific search engines?
RQ2: How are these key values that describe the behavior of users searching online for art and culture affected by the device used to perform the search session, the users’ choice to login and the session’s total duration?
This research’s innovation in terms of data collection comes from the fact that the study combines traditional query and result-related data, which were collected with server-side algorithms and are commonplace in search engine log analyses, with user interaction metrics such as scrolling, cursor distance, and clicks on interface elements, which were mined in real-time with client-side algorithms from the searchers’ browsers. This process created a very diverse and robust dataset of information, which, in combination with the fact that it came from members of the general public using the platform candidly in the wild, reinforced the objectiveness of the findings.
The innovative scientific contribution of this article is a result of the research’s focus on the thematic fields of art and culture and is presented thoroughly in the discussion section, through a multidimensional comparison between the behavior of art searchers and that of general purpose searchers, as well as the analysis of the factors that influence the process of art search. This study identified some interesting and significant differences between the process of searching for art and culture and general purpose searching, thus highlighting the different needs and habits that emerge during specialized search, which need to be met by institutions and individuals that act as content providers in these fields. The produced knowledge that outlined user behavior when searching for art- or cultural-heritage-related content online may help providers and repository developers design and implement better and more efficient platforms and ultimately enhance the findability and diffusion of said content and the satisfaction of their target audience.
2. Methodology
2.1. Research Design
The research that is the subject of this article was carried out in three distinct stages:
The development of the platform;
The collection of real usage data;
The analysis of this information in order to provide valuable metrics.
The first stage, which involved the development of the Art Boulevard platform along with its data collection mechanism, was deemed necessary in order to collect multifaceted behavioral information specifically from the fields of art and cultural heritage. Winkler et al. [
38] maintained that software prototyping is essential in investigating promising research directions. Going beyond prototyping and releasing a full production application allows for high external validity by taking the research “in the large” [
39].
During the second stage of research, the Art Boulevard platform collected user behavioral information over a period of six months. According to Henze et al., mobile apps that record their users’ behavior may be used to investigate research questions while ensuring both numerous degrees of freedom and a diverse user base [
39]. The data collected during the platform’s usage from the general public consisted not only of query and result related information, as would be typical in a log analysis [
35,
40], but also of implicit user behavioral measurements, which Fox et al. [
36] claimed can provide good predictions of user satisfaction and other behavioral aspects. The study of query-related information to investigate user intent is a commonplace practice [
41,
42]. It is often combined by mining context from the results that users show preference for [
42]. Caruccio et al. [
43], in their study on user intent, demonstrated the added importance of interaction mining, in order to achieve a more detailed understanding of searcher intent. In this study, the collection of query- and result-related information, alongside data derived from interaction mining, achieved a robust dataset that was used to analyze art searcher behavior.
Finally, after the information was collected in the platform’s database, a rigorous data analysis process was carried out. Descriptive statistics were used as a tool to analyze search engine transaction logs in multiple occasions [
35,
40]. Jansen [
40] discussed in detail how data that were collected needed to be prepared by converting the textual information of the log into clean structured data. Art Boulevard, since it was designed from the start with the intention to collect behavioral data, begins the preparation of data from the moment the user interacts with it. Moreover, useful interaction metrics such as screen scrolling, cursor movement distance, clicking of interface elements, etc., are also seamlessly stored in the platform’s database, providing valuable behavioral information [
36,
43]. Using these data as its basis, this study explores various staple search behavior related metrics such as query length, query repeatability, result ranking, session duration, device usage, and more.
2.2. Presenting the Art Boulevard Platform
The Art Boulevard platform is essentially a federated search engine. Its main functionality is accomplished by taking the user input in the form of a textual search query consisting of one or multiple keywords and providing it to seven different online repositories through their respective application programming interfaces (APIs). It then proceeds to collect the results from said repositories, integrate them, and present them in a unified manner to the end user.
The online repositories used as content sources for Art Boulevard are:
An online aggregation of European Cultural Heritage objects from multiple content providers and include millions of digital representations of works.
- 2.
Harvard Art Museums
The online presence of Harvard-supported museums, providing a variety of digital content derived from their physical collections.
- 3.
The Metropolitan Museum of Art
One of the most popular art museums on the planet, providing datasets of information on more than 470,000 artworks from the museum’s collection.
- 4.
The National Gallery of Denmark (SMK)
The biggest art museum of Denmark featuring more than 260,000 pieces of art, focusing mainly on traditional visual arts.
- 5.
Artsy
An online art marketplace with over 4000 partners and millions of works of art from both established and emerging artists.
- 6.
Crossref
A digital object identifier registration agency and scientific paper aggregator.
- 7.
The Open Library
An open library catalogue containing a large number of published books and aiming to catalog every book in existence.
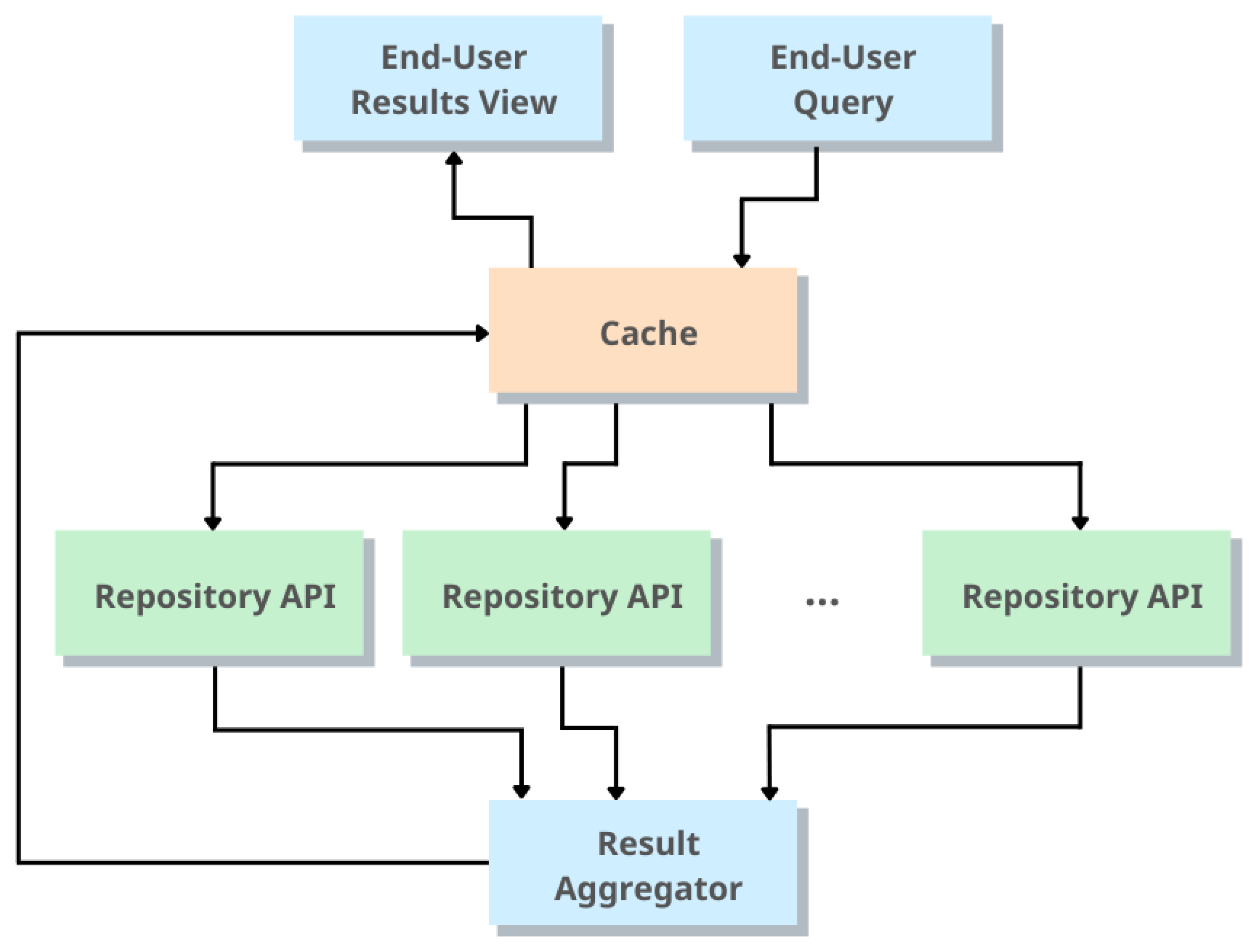
Figure 1 presents a visualization of the result aggregation process performed by the platform [
37]. Art Boulevard uses an advanced caching algorithm to avoid putting unnecessary burden on the various repositories, while at the same time improving search performance.
In addition to the basic search functionality, Art Boulevard implements the following additional technologies:
Speech Synthesis—Using the Speech Synthesis Web API, the platform offers all result titles and descriptions as audio. This greatly increases the accessibility of the platform while at the same time providing better usability for all its users.
Speech Recognition—Using the Microsoft Azure’s Speech to Text service, the platform can interpret user speech input into a textual query and then use it to perform its basic search process.
Content-Based Search—Using the Microsoft Azure Visual Search API, the platform can search the Web for visually similar images to any result and, thus, broaden the users’ search scope based on their initial search interest.
User Profile System—A simple user system that allows users to bookmark results they are interested in, create a public profile, and follow other users. The system supports social sign up through Google, Facebook, and Apple, as well as an independent sign up process.
Moreover, the platform offers advanced search functionality, provides various previous search queries and results on its front page and also offers the users a list of related results for every result they decide to view.
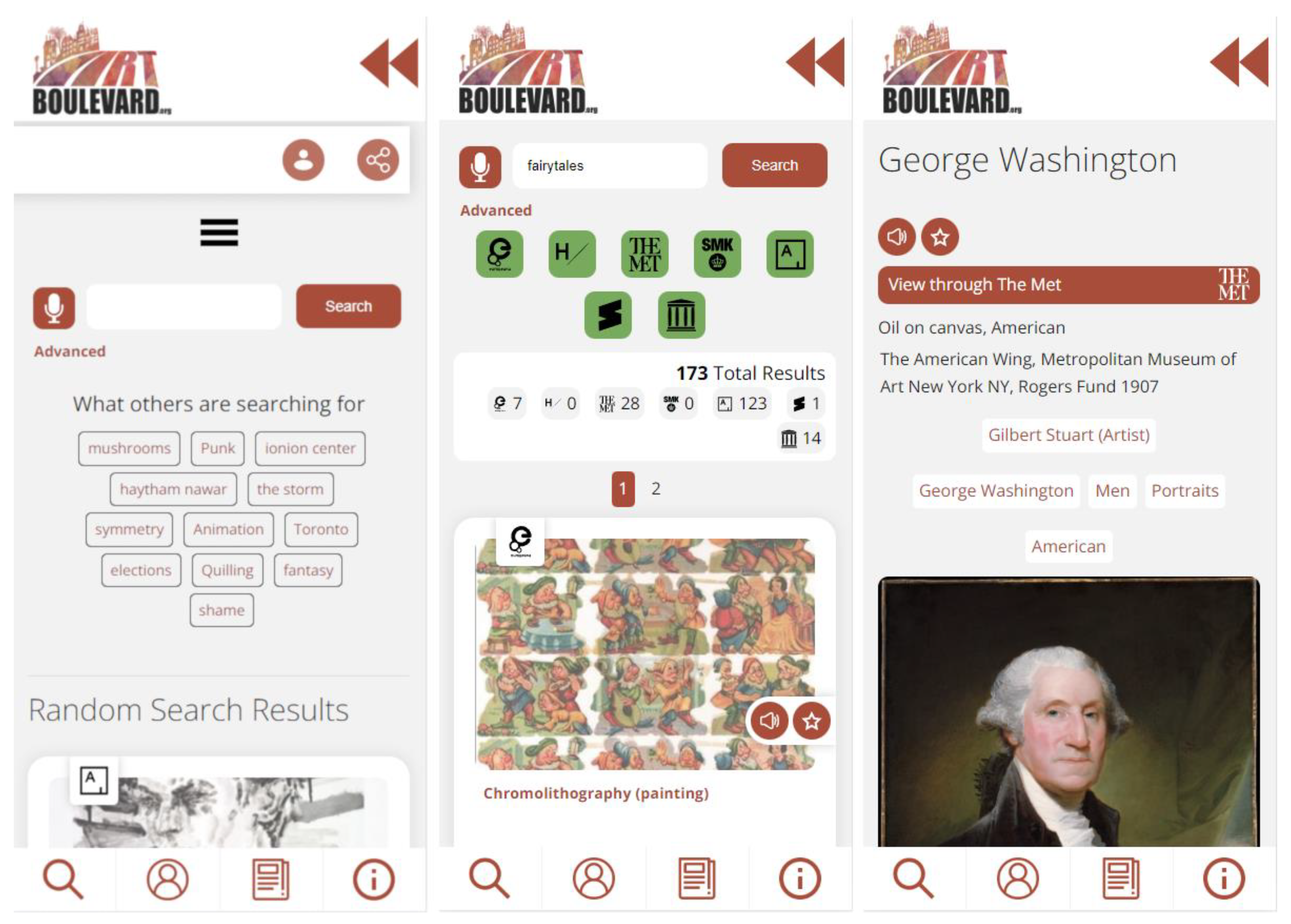
Figure 2 presents a screenshot of the front page of the platform.
The web version of the platform officially launched in 15 July 2022. Soon after, the Art Boulevard mobile app launched for Android on the Google Play storefront and for iOS on the Apple Store storefront. The choice to use PWA technologies to bring Art Boulevard to the mobile app space was made in order to ensure a uniform user experience in both the web and the mobile app, while at the same time taking advantage of the advantages that the technology offers. According to Magomadov, PWAs offer cost-effectiveness, better search engine optimization and independence from application storefronts [
44]. Taking a step for further integration in the mobile ecosystem, using the tools provided by Microsoft’s PWABuilder community, the platform was translated to an application format applicable for mobile storefronts.
Figure 3 presents a series of screenshots from the mobile app version of the Art Boulevard platform.
For the purpose of brevity, this article avoided a very detailed description of the platform’s operation. Such an analysis of its functionality, specifics about the additional technologies implemented, an overview of its data model used during the aggregation of the results, and a look at its UI/UX design are provided in the authors’ previously published research concerning the beta testing of the platform [
37].
2.3. Behavioral Data Collection
The period of data collection lasted from 15 July 2022 to 15 January 2023. In order to achieve maximum diffusion of the Art Boulevard platform, a social media presence was established early on and a marketing campaign followed. Moreover, best practices were followed in terms of search engine optimization in order to increase organic visits through other search engines. In terms of structured data, the Open Graph and Twitter Cards metadata protocols were implemented, as well as the schema.org JSON-LD data model. This type of integration of semantic web elements not only helps with the platform’s SEO and ranking performance but can also play an important role, specifically in audiovisual and media content diffusion, as Dimoulas et al. established [
45].
During its operation, the platform recorded in its relational database system information regarding the users’ queries and the results collected from the various APIs, as well as user interaction information. In order to achieve this, the platform used a combination of server-side and client-side data collection algorithms. The basic query data that would be equivalent to a search engine’s transaction log data were collected during the search process itself. Since Art Boulevard was designed from the start as both a federated search engine and a tool for collecting searcher behavior information, this was accomplished with minimum overhead to the performance of the platform. Moreover, the platform recorded information concerning the results that were presented to the users and especially those that users interacted with. This information consisted not only of the URL of the external source providing the result, as is commonplace in log studies [
42], but also from rich metadata regarding the result, collected directly from each repository.
User interaction mining was achieved through the collaboration of the platform with the users’ browsers. Using JS alongside AJAX techniques, in a manner similar to Caruccio [
43], the searchers’ browser collected session information including duration, page scrolling, cursor distance, and user clicks, and delivered it to the platform. For the purposes of this study, a session was defined as the series of interactions between the user and the platform regardless of duration, as long as there was no extended period of inactivity or there was no change in the users’ device or software agent (e.g., changing browsers). The inactivity timer was set at 24 min, which is the default duration of the global session variables in the PHP language.
Query-related data collected included:
The terms of each query;
The existence of any advanced query information;
How many pages of results were requested;
The total results the query returned;
The results returned per repository;
Cursor tokens for pagination purposes for the repository APIs that supported cursor based pagination;
The dates that the query was first and last performed on.
Result-related data collected included the following details for each item:
Repository of origin;
Type (artwork/article/book);
Ranking in the results as they were delivered by their repository;
Title;
Link to source repository;
Description;
Image;
Metadata elements such as artist name, creation date, location, methods, techniques, subject, provenance, and more;
The first and last date the result was discovered.
Session information included:
Country of origin of the user;
IP;
HTTP User Agent header;
Device which the user was using;
Total duration of the session in seconds;
Total distance the user mouse (or tap) moved in pixels;
Total scrolling in pixels;
Date/times on which the session started and ended;
Login ID (if the user logged in the platform).
In order to retain information regarding the many-to-many relationships between queries, results, sessions, and user interactions, the necessary relational database structure was established. These relationships included which user performed each query, which results were produced by each query, which results were liked by each user, and so on.
As mentioned above, during a user’s interaction with the platform, a series of interaction events were recorded in the platform’s database. In order to achieve this, the platform made use of a specialized table using the entity–attribute–value (EAV) data model. This table was called the session timeline table (STT). For each event, the database stored information regarding its one-to-many relationship with a session (treated as the entity of the EAV model), the date and time the event was triggered, the URL that the event originated from, as well as the URL that it occurred in or produced if it was a click-through event, the type of event (treated as the attribute of the EAV model), and a value further clarifying the interaction (treated as the value of the EAV model). The events recorded with their type variable names are presented below in
Table 1.
An important metric of user engagement in search engines are click-through events. These are events that trigger when the user clicks on a link that will provide them with further information and, according to Xue et al., they provide a valuable indication of the user’s intention and its relationship with the clicked link [
46]. The events from the list above that were considered click-through events are those that implied that the user had found something that furthered their interest; for example, viewing a result page or clicking an external link.
2.4. Behavioral Data Processing
After the data collection period was concluded, various metrics were derived from the information stored in the database regarding queries, results, sessions, and session events. A series of algorithms were created that aggregated some measurements from the platform’s operational database tables, while at the same time mining some other measurements from the session timeline table. This information was stored in different tables in the platform’s database. Using different tables allowed the researchers to proceed with data analysis tasks without interfering with the platform’s normal operation, which went on and is still ongoing.
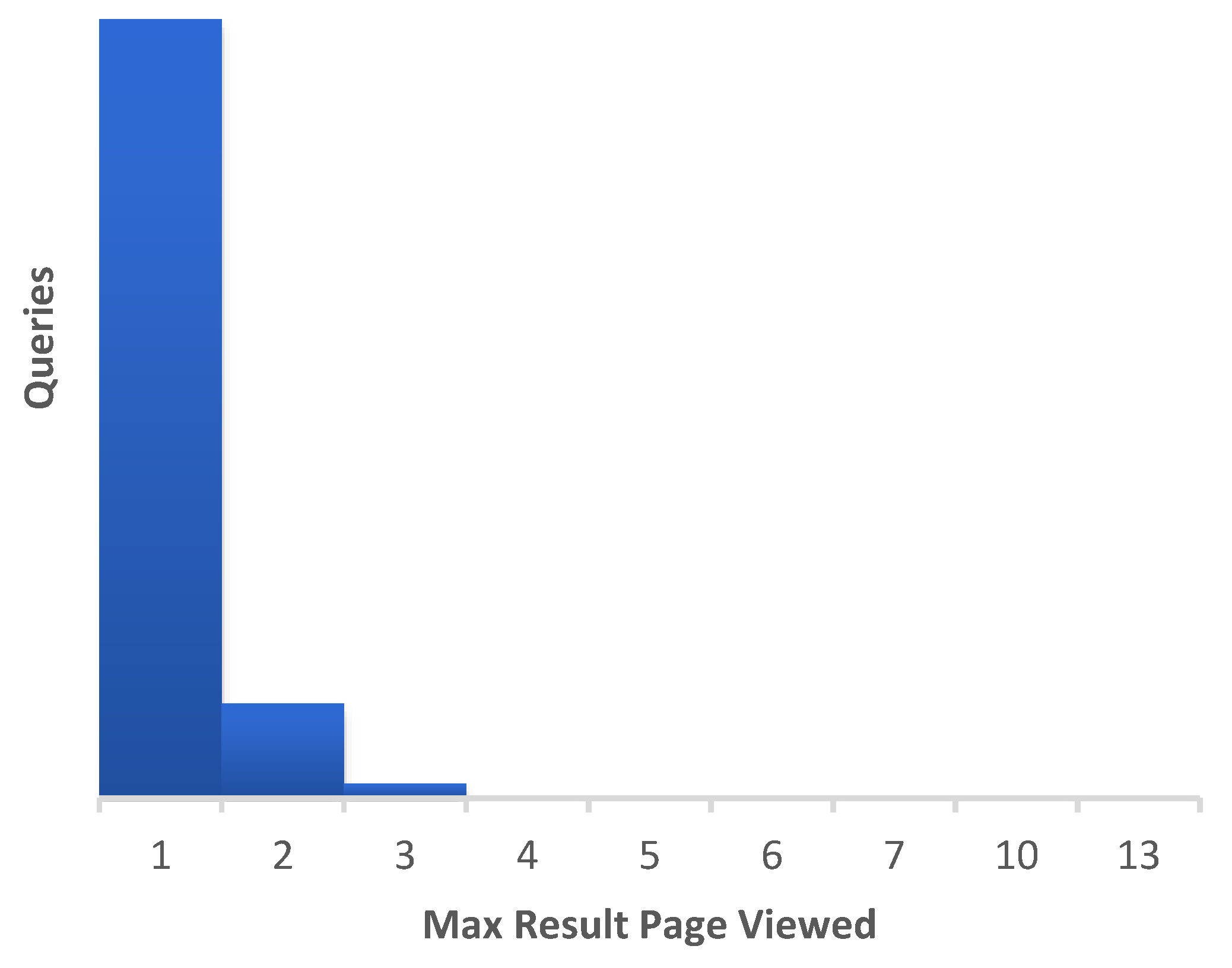
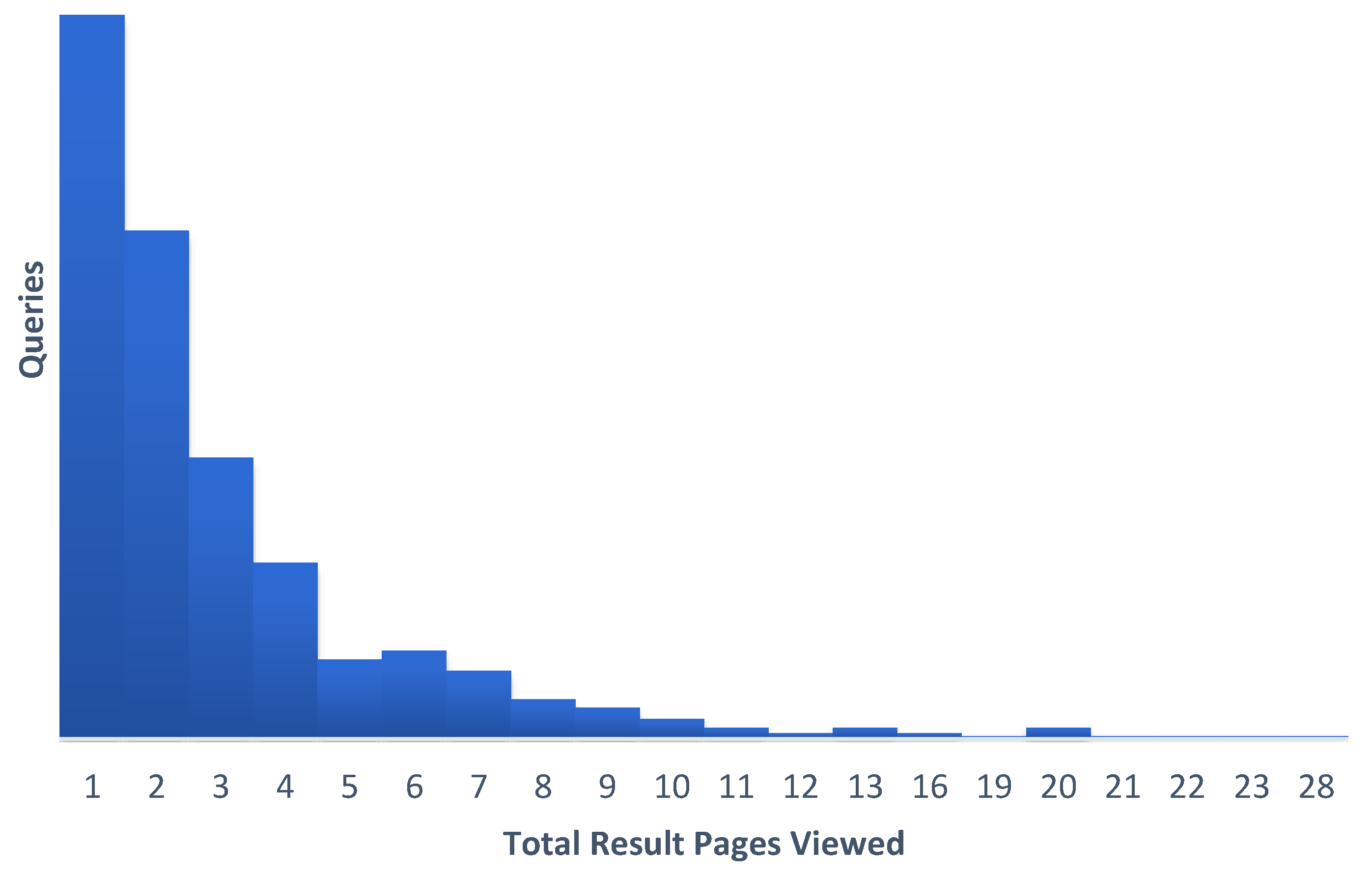
With regard to search queries, the algorithm collected the number of keywords each query string consisted of, how many times a unique query string was used, whether the query included any advanced search terms, how many queries initiated from a voice recognition process, how many queries initiated from a click to a result’s related term, how many total pages of results were presented to users by the platform, what was the maximum page number which a user navigated to, how many were the total items the query discovered in the various repositories, and how many results were provided by each repository.
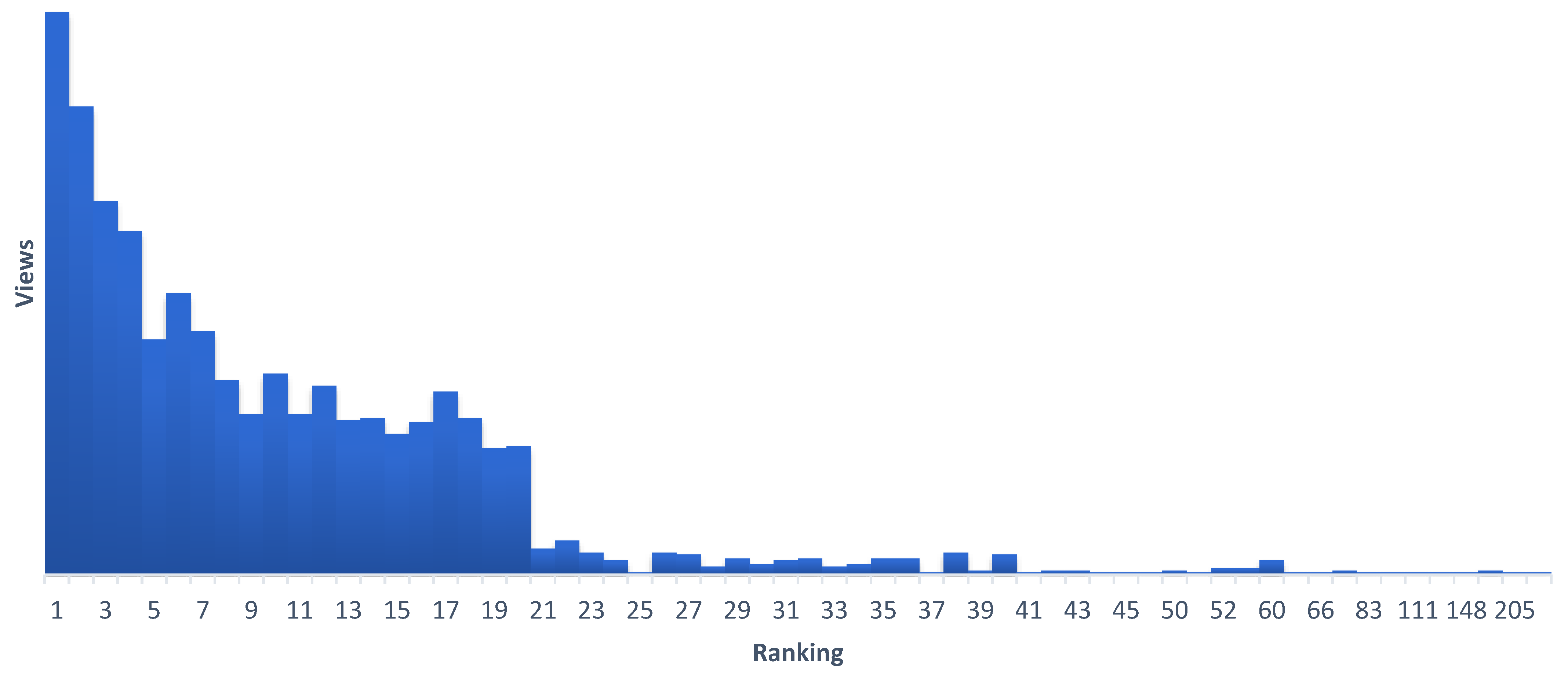
With regard to results, the algorithm collected for each unique result listed by the platform the repository that provided it, the type of the result (artwork, article, or book), its ranking based on relevance as provided by the source repository, whether the result had a title, description, and image, the total length in characters of the textual metadata available for each result, the number of times a user navigated to the view page of each result, and the number of times a user opened the external source link of each result. A secondary process was developed to specifically collect this information for every time a user navigated to the view page for such a result. The data on unique results listed provided insight into the nature of the results the platform collected, while the data on each result viewed provided insight into which results piqued a user’s interest.
Finally, with regard to sessions, the algorithm collected whether the session was performed by a normal searcher or a bot, calculated the session’s total duration, the total mouse or tap distance covered during a session, the total page scroll, the number of total session events, the number of total click-through events for each session, whether a user was logged into the platform’s user system during each session, and how many events of each type of session event were documented for each session. An algorithm based on regular expressions was developed that identified bots based on the HTTP User-Agent, so their requests would not skew the behavioral findings. In addition to the above, the algorithm used the URLs recorded in the STT to identify how many results were navigated to by clicking a related result from a previous result’s view page, how many results were navigated to by clicking a random result from the homepage, and how many results were navigated to directly through use of their URL, which would mean that users arrived to the result view page via means outside the platform (social media share, organic search result from Google, etc.).
In addition to session event variables, three meta variables that included the sum of different types of events were calculated. The variable _visual_search included all visual search related events (type “Visual Search” in
Table 1), the variable _voice included all events related to speech recognition or speech synthesis technologies (type “Voice” in
Table 1), and the variable _user_system included all events related to the platform’s user system (type “User system” in
Table 1).
Table 2 presents the series of additional metrics that were derived during the initial stage of the data analysis phase based on the collected data. The later stages of data analysis which involve calculation of statistic measurements and formulation of graphs and diagrams will be presented in detail in the results section.
5. Conclusions
In this article, a quantitative analysis of various metrics concerning the behavior of users searching for art- and cultural-heritage-related content was presented. The various measurements were collected during a six-month period of real world usage of the Art Boulevard platform, which implements federated search engine functionality using several repositories of artworks, research articles, and books. The metrics were recorded by an analytics system fully integrated with the platform, and the results presented were a product of data analysis on this information and corresponded to the actions of general public users.
The findings presented in detail in the discussion section converge to create a draft profile of an average art searcher who prefers searching for concepts and people while avoiding long queries, is keen on revisiting old searches and reviewing results, is not satisfied with just the first few results but delves a bit further, is attracted to visually and textually rich content and wants to avoid the attention issues that often accompany mobile search. The same findings also create an impression of duality in the search process itself, which, on the one hand, may be very involved, making use of social features and advanced functions and displaying an informational user intent and, on the other hand, may be short and purposeful, avoiding distractions and displaying a more transactional user intent.
The study produced some interesting findings but was limited in two factors:
Although the newly launched platform did display a satisfactory amount of traffic, its collected data still dwarfed in comparison to the millions of queries analyzed in major general purpose search engines;
The nature of the platform itself might have had an effect in some of these measurements, that skewed the influence of the thematic nature of the searches for art- and culture-related content, which was the focus of this study.
Work in this field may continue through the collection of a greater data sample and through the analysis of other metrics concerning the behavior of users, such as query reformulation and edit distance, session abandonment, query content analysis, and more. Additionally, the use of machine learning can be used to perform clustering based on the datasets collected by the platform, which would allow conclusions to be drawn regarding the varying nature of search sessions. Since the session timeline is very thoroughly recorded in the platform’s database, a method of visualizing such a session could lead to interesting results and would allow human expert observers to notice behavioral patterns in these sessions which would be hard to notice on a spreadsheet of numbers. Finally, using the research design and methodology of this study, alongside similar tools, this type of analysis could be applied to other fields of content, such as news, sports, entertainment, etc., in order to identify variations of user behavior based on the search’s topic.
Behavioral analysis was a very important aspect of research surrounding search engines. Unfortunately, more often than not, most studies focused solely on general purpose search engines or on e-commerce and marketing-related specialized platforms. This created a discrepancy between the quality of the experience offered by the commercial part of the Web and the non-commercial part. Through this research and its findings, it became apparent that art searchers, in particular, display differences in behavior, as opposed to general purpose searchers in a variety of ways. By highlighting and documenting these differences, a better understanding of their needs can be achieved. Content providers can then use this understanding to provide better services both in terms of the search process itself and in terms of how results are presented. This can lead to a better overall search experience, specifically suited to the characteristics of the fields of art and culture, which would be beneficial for both providers and searchers. The Art Boulevard platform and the ongoing research deriving from its usage are aiming to provide such useful insight on the behavior and needs of searchers, specifically in the fields of art and cultural heritage and, thus, allow for a more optimal art search experience moving forward.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
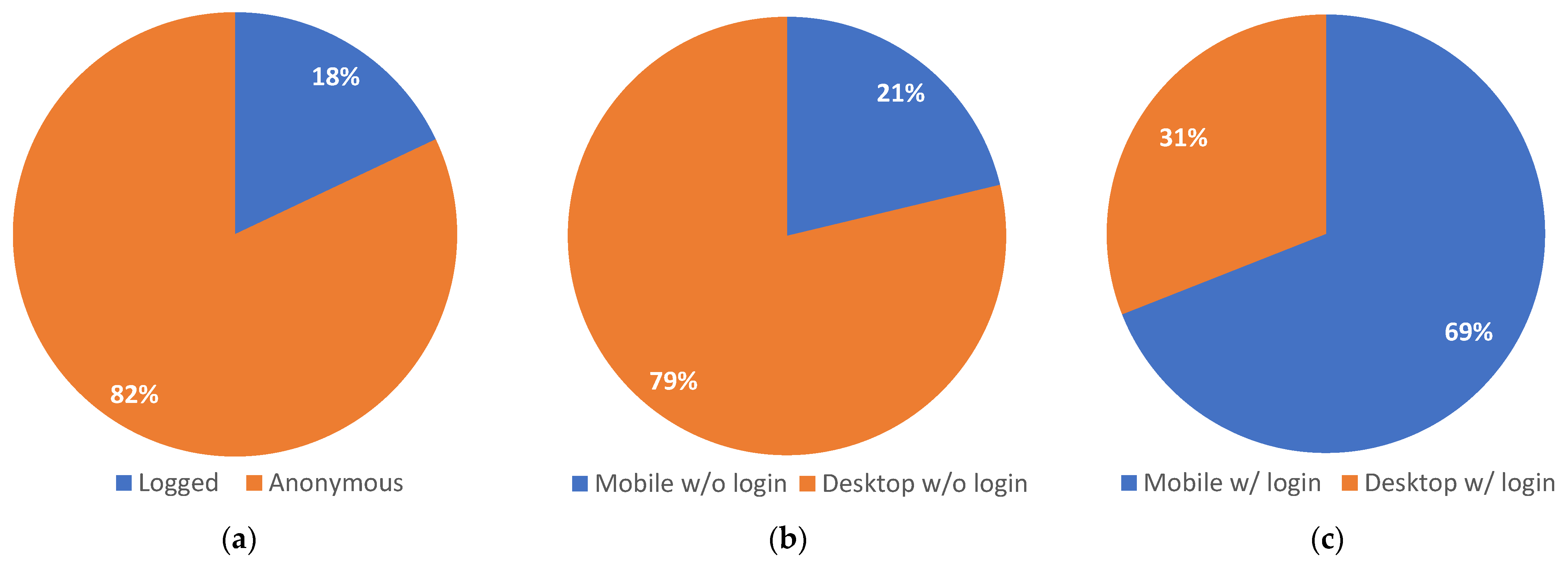{kind=link}
{kind=link}