5.1. Architecture of KubeHound
The main goal of
KubeHound is to enable automation of the detection of the microservices’ security smells of Ponce et al. [
1] by running analysis techniques such as those outlined in
Section 4.
KubeHound therefore takes as input the Kubernetes configuration files and Dockerfiles specifying the target application deployment and a configuration file specifying where to retrieve the microservices’ source code and their API specifications in the OpenAPI standard, when available. The Kubernetes cluster to which it connects to run dynamic smell-detection techniques is instead automatically retrieved from the
KUBECONFIG variable specified in the environment where
KubeHound is running.
KubeHound then processes the above-listed inputs by running the featured smell-detection techniques. In this perspective, with the examples of possibly analysis techniques outlined in
Section 4, a main requirement of
KubeHound is
extensibility, to enable a more comprehensive coverage of the possible instances of already-known security smells [
1], as well as to enable the incorporation of newly discovered security smells, if any. Newly implemented analysis techniques must be easily pluggable into
KubeHound, and it must be possible to implement them by reusing or integrating with existing security-analysis tools (as illustrated for some of the analysis techniques in
Section 4).
To realise the required extensibility, we designed
KubeHound with the
Plugin Architecture [
34] in
Figure 2.
KubeHound is composed of three core components, viz.,
Hound,
Frontend, and
Scheduler, and a set of analysis plugins, viz.,
. Each analysis plugin is responsible for implementing one or more techniques for detecting instances of microservices’ security smells. In general, analyses should be specific to a given instance of a security smell, as the overall detection capabilities of
KubeHound are derived from combining the results of all featured analyses.
The core components are instead responsible for acquiring the configuration files specifying an application deployment, parsing them, scheduling the analysis plugins implementing the featured smell-detection techniques, and collecting their results. More precisely, Hound takes the input files and orchestrates the smell detection on the microservice application specified therein. It first passes the input files to the Frontend, which is responsible for application data acquisition and parsing. Frontend then returns to Hound a collection of application objects, each representing a resource in the application’s sources, together with some metadata about them. The application objects and metadata are then passed to the Scheduler, which is responsible for invoking the plugins to run the analyses they implement, as well as for collecting and suitably merging their results. The merged results are then returned to Hound, which displays them to the end-user.
Each analysis plugin complies with a given interface, which includes the properties it should expose, e.g., the name, the description, and the required application objects. The Scheduler exploits such properties to prepare the input to each analysis and call them accordingly using the plugin interface. KubeHound’s Scheduler follows a “best effort” approach, meaning that it invokes a plugin only if the required inputs were provided by the end-user. If this is not the case, the plugin’s execution is skipped, as the analysis technique it implements cannot be performed. As a result, KubeHound always performs the largest possible subset of smell-detection techniques it can, given the inputs provided by the end-user. This has two advantages. On the one hand, it enables the development of plugins without making assumptions about the structure and/or technologies of the microservice application they will analyse. On the other hand, it enables end-users to provide only what they wish to be analysed, e.g., enabling KubeHound to work if the source code of some microservices is not available or if the users do not wish KubeHound to interact with the Kubernetes cluster where an application is running.
5.2. Implementation of KubeHound
Input Configuration File. KubeHound takes as input a YAML configuration file structured in four main YAML objects, viz., repositories, deployment, services, and properties, as shown in Listing 4.
The object repositories provides a list of named repositories storing the deployment configuration files and source code of the target microservice application. The listed repositories can be local folders or remote git repositories, which will be cloned locally by KubeHound when starting to analyse the target application. The need to organise the application source in multiple logical repositories comes from the fact that many microservice applications are developed in a “one repository per microservice” fashion, so tracking the different sources for different microservices’ files requires an additional layer of abstraction.
The object deployment indicates the repository where the configuration files specifying the target application deployment is found by also supporting regular expressions to match all deployment configuration files. Currently, only kubernetes configuration files are supported, but the syntax is intended to allow for extending the support to other deployment frameworks.
The object services lists all the microservices forming the target application by associating them with the paths to their related configuration files, source code, and the specification of their APIs in OpenAPI, if available.
The object properties provides a list of claimed properties for the services, which can be used by KubeHound to ignore some detected smells to reduce the amount of false positive reports. Currently, two properties are supported, viz., external, to indicate that a service is intentionally exposed to external clients, and performsAuthentication, to indicate that a service is known to perform authentication.
KubeHound will ignore any missing field in the configuration file, and it will apply a “best effort” approach to provide meaningful results out of the provided resources.
| Listing 4. Example of input configuration file for KUBEHOUND, with some repositories/services omitted for readability reasons. |
 |
Application Acquisition and Parsing. The repositories described in the configuration files are first acquired and parsed by KubeHound. For local folders, the acquisition phase is not present, while remote git repositories are cloned locally in the current working directory. If a folder with the same name already exists, KubeHound will try to detect if it is a git repository and will perform a pull command to fetch the latest version of the repository. This provides a mechanism to avoid always downloading the full application on each run of the tool, which can be costly for large code bases.
Once all the files are gathered, KubeHound will perform the parsing of the application, which means taking the application files and turning them into a collection of application objects. An application object is an object that represents any resource in the application. They have three main fields: type, path, and data. type specifies the type of object (viz., kubernetes_config, dockerfile, or openapi), path specifies the path of the corresponding application file, while data specifies optional metadata of the object.
For Dockerfiles and OpenAPI specifications, application objects map one-to-one to a particular file. For Kubernetes configuration files, instead, multiple application objects can be generated from the same file, one for each YAML document. KubeHound will also put in the data object the claimed properties specified in the configuration file. KubeHound will also follow a “best effort” approach for application parsing, so if there are missing resources or no metadata available for a given object, it will simply be ignored.
Analysis Scheduling and Results. The Scheduler component prepares the inputs for all the available analyses, runs them, and collects their results. For this to happen, analysis techniques must be implemented as Python classes extending the existing StaticAnalysis or DynamicAnalysis classes, as exemplified in Listing 5. The analyses expose some parameters through class variables, such as their name or their description, and implement their functionality through the run_analysis method. They also expose the input_types variable, which specifies the types of input this analysis requires. Any particular analysis is called only if there is at least one available object of the required types, passing them as a list of application objects to the run_analysis method. Custom analyses can be added to the scheduler using the register_analysis method (as shown in Listing 5.
Each analysis is expected to complete in a finite time, and this is particularly important for dynamic analyses needing to run for longer periods, e.g., to first monitor and then analyse the traffic exchanged among deployed microservices (as described in
Section 4.7). Upon completion, the analysis returns a list of results, represented as Python objects. The results returned by all the run analysis plugins are collected together by the
Scheduler, and they are suitably merged to compute the union of all detected smell instances.
KubeHound then returns the merged results as the output of the overall analysis by streamlining them to a JSON representation.
| Listing 5. Example of Python script running KUBEHOUND with an additional custom analysis (lines 14–27). The custom analysis is a static analysis called HelloWorldAnalysis (line 1), and it inputs the Kubernetes configuration files and Dockerfiles of the target application (line 6). When invoked, it prints the string “Hello, World!” and returns an empty list of detected smells (lines 8–12). |
  |
5.3. Implementation of Selected Analyses
We hereby illustrate the implementation of six of the analysis techniques described in
Section 4, which come as built-in plugins in
KubeHound. The selection of which analysis plugins to present was mainly aimed at showcasing the different types of techniques, while also demonstrating the possibility of implementing them by integrating them with existing analysis tools. For static analysis techniques, we present the plugins implementing the detection of
Insufficient Access Control in API Specifications and
Multiple Authentication Endpoints in Services’ API Specifications, both analyzing the OpenAPI specifications. We also present the detection of
Unnecessary Privileges to Kubernetes Pods, which we realised by integrating the tool Kubesec.io [
14]. For dynamic analysis techniques, instead, we present the detection of
Hardcoded Secrets in Containers’ Environment and the detection of
Exposed Kubernetes Services using External-IP Field, both of which are custom dynamic techniques applied to an unmodified cluster. We also present the plugin implementing the detection of
Unencrypted Pod-to-Pod Traffic, which exploits network probes, hence being a dynamic technique applied to a modified cluster.
Insufficient Access Control in API Specifications. We implemented the
Insufficient Access Control in API Specifications Analysis (
Section 4.1) as a plugin to
KubeHound to enable it to detect insufficient access control using the services’ OpenAPI specifications (
https://github.com/di-unipi-socc/kube-hound/blob/master/kube_hound/builtin_analyses/insufficient_access_control_openapi.py, accessed on 26 June 2023). The plugin works with the 3.1.0 version of the OpenAPI specification [
23], which allows it to describe security properties for endpoints, as shown in Listing 6. The plugin receives as input OpenAPI documents and starts by parsing them and searching the
securitySchemes field, which describes all the security schemes used by the API. Then, the plugin tries to find a global
security field, if any, and for each API endpoint, the associated
security field. Based on the service’s claimed properties, the plugin reports the security smells based on the following rules:
If no SecuritySchemes is specified or, for some endpoint, no security field is specified, a corresponding instance of the Insufficient Access Control smell is reported.
If this is the case, and if the input configuration file is not indicating that the service is external nor that it performsAuthentication, then an instance of the Centralised Authorisation smell is also reported.
| Listing 6. Example of OpenAPI specification that describes a security scheme using HTTP bearer (i.e., externalAPIKey), which secures the POST method of the /foo path. |
 |
Multiple Authentication Endpoints in Services’ API Specifications.
KubeHound features a plugin implementing the method described in
Section 4.9, which we implemented to enable the detection of multiple user authentication endpoints based on the services’ OpenAPI specifications. The implemented plugin inputs the OpenAPI specification of the APIs of the target application’s microservices, and it starts by parsing them and retrieving their security properties. If multiple endpoints are recognised as using HTTP basic authentication (i.e., username- and password-based), the plugin reports an instance of the
Multiple User Authentication smell. Services that have a corresponding
performsAuthentication property set in the input configuration file are ignored by this plugin, since they are supposed by design to perform user authentication.
Unnecessary Privileges to Kubernetes Pods with Kubesec.io. We implemented the method described in
Section 4.3 as a plugin of
KubeHound to enable the detection of unnecessary privileges to Kubernetes pods (
https://github.com/di-unipi-socc/kube-hound/blob/master/kube_hound/builtin_analyses/unnecessary_privileges_pods.py, accessed on 26 June 2023). To accomplish this, the implemented plugin integrates with the tool Kubesec.io [
14] to perform such an analysis. Kubesec.io indeed employs a suite of test cases to check for minimum privileges in Kubernetes pod configuration files, and it comes as a Docker image on DockerHub, which we can directly pull and execute. Docker will take care of fetching (if not already present on the local machine) the Kubesec.io image, hence favouring the distribution and packaging of
KubeHound. To interact with the Docker daemon, the plugin uses the Docker Python library, which exposes an API to interact with Docker containers [
36]. This plugin thus starts Kubesec.io in a Docker container, which starts a web server that exposes a REST API. The plugin submits the application’s Kubernetes configuration files using the
/scan endpoint, and the Kubesec.io server then returns a JSON response containing a list of passed and failed checks. Such results are parsed and each failing test case reported by Kubesec.io is considered as an instance of the
Unnecessary Privileges to Microservices smell.
Hardcoded Secrets in Containers’ Environment. We implemented the detection of
Hardcoded Secrets in Containers’ Environment described in
Section 4.6 by developing a plugin for
KubeHound that exploits the Kubernetes Python client library to interact with the Kubernetes API of a cluster (
https://github.com/di-unipi-socc/kube-hound/blob/master/kube_hound/builtin_analyses/hardcoded_secrets_environment.py, accessed on 26 June 2023). The plugin retrieves all the running pods of the clusters, and for each pod it retrieves all the running containers. It then executes the
env command on each container and stores the resulting output, which is then processed to detect secrets.
For detecting secrets, the plugin uses the open-source Python module
detect-secrets [
37], which provides a built-in set of secret-detection techniques. If any environment variable is detected as storing a secret, the plugin reports the
Hardcoded Secrets smell, together with a description of the variable that stores the secret. In the output of
KubeHound the actual values are obfuscated to prevent accidental secret exposure.
Exposed Kubernetes Services using External-IP Field. We implemented the detection of
Exposed Kubernetes Services using External-IP Field as a plugin for
KubeHound that dynamically looks for exposed services by retrieving the
External-IP field as described in
Section 4.2 (
https://github.com/di-unipi-socc/kube-hound/blob/master/kube_hound/builtin_analyses/exposed_services_external_ip.py, accessed on 26 June 2023). Using the Kubernetes API, the plugin retrieves the information about all the Kubernetes services running on a cluster, including its
External-IP (if any). The service names are then matched against the user-provided properties. We report an instance of the
Publicly Accessible Microservices smell for each service that has a non-empty external IP. This plugin makes use of the services’ properties claimed in the input configuration file: if some service is declared
external, it will assume that it was intentionally exposed to the public by the development team and it will not report any corresponding smell instance.
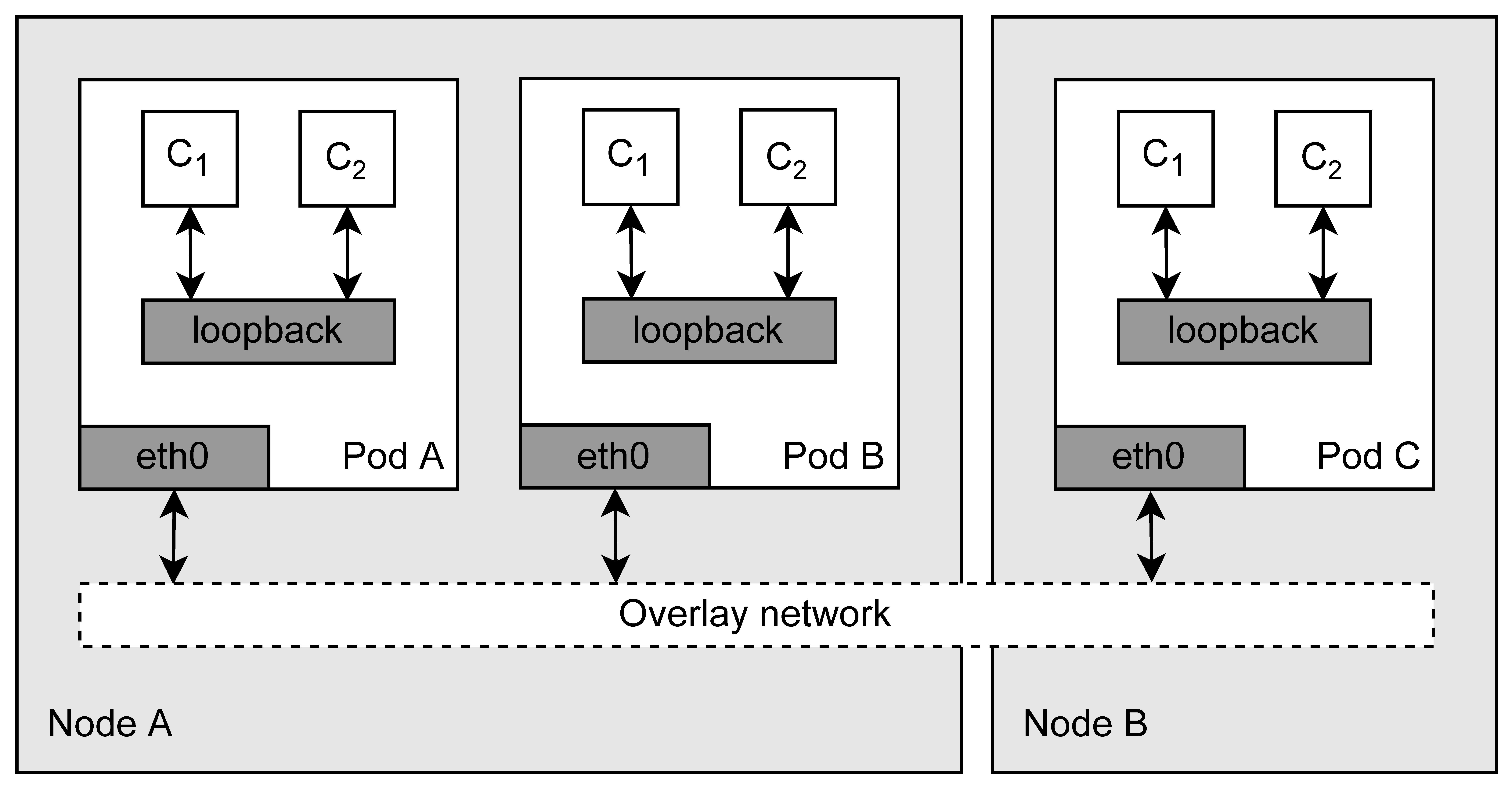
Figure 3 sketches the internals of Kubernetes networking. Each pod is assigned an IP address in the overlay network, while containers in the same pod can communicate with each other using
localhost [
38]. This implies that every container in the pod has (at least) two network interfaces: a
loopback interface and a pod-to-pod interface, typically called
eth0 [
39]. The
eth0 interface is also used for communications with external entities, e.g., health checks for the liveness of the pods [
40].
The implementation of this plugin makes use of the tool Ksniff [
41], which allows it to intercept and record traffic on clusters networked as in
Figure 3. In particular, given a pod, a container, and a network interface, Ksniff will record the network traffic and it will save it on the local disk as a
pcap file. Ksniff is run with the
-p flag set, so as to deploy a privileged pod that has access to the node’s network interfaces. This pod will run the
tcpdump program to record network packets on the target interface.
Following the network model presented above, this plugin will capture network traffic from the
eth0 interface to intercept only pod-to-pod traffic. In the presence of a service mesh that enables mTLS via a sidecar container (e.g., the Istio service mesh), it is also possible to intercept clear-text service-to-service communications by capturing packets on the
loopback interface [
42]. This, other than providing a concrete basis to implement more sophisticated types of analysis that also take into account the content of network packets, is also an example of why services should be deployed with the fewest privileges. The takeover of a privileged pod by an attacker could result in eavesdropping of clear-text communications, even in the presence of a service mesh providing mTLS.
The plugin executes the following steps: (1) Using the Kubernetes API, the external IP addresses of worker nodes are retrieved and stored in a list. (2) For each pod related to a service in the cluster, a Ksniff privileged pod is deployed on the cluster, recording on the
eth0 interface. (3) The network traffic is recorded for a configurable amount of time (the default is 30 s) and the resulting network captures are stored in a temporary directory. (4) The Ksniff pods are destroyed to clean up the cluster. (5) Using the
pyshark library (a Python wrapper to
tshark), the resulting capture file is loaded and packets are filtered by excluding those whose source or destination IP is present in the nodes IP list. This is carried out to exclude them from the analysis health check requests performed by the cluster’s nodes, since they are often made using plain HTTP [
40]. (6) Every packet in the capture file is analysed and each packet for which
tshark decoded the HTTP protocol layer is saved in a list. (7) If no HTTP packets are found, then the capture file is analysed again, trying to identify HTTP2 packets. The motivation for detecting HTTP2 is that high-level protocols such as gRPC are implemented on top of HTTP2 [
43]. The detection of the HTTP2 protocol layer is not performed by
tshark by default, and an additional decoding flag has to be specified during the capture loading. (8) Finally, if any HTTP or HTTP2 packets are detected, corresponding instances of the
Non-Secured Service-to-Service Communications smell are reported, together with a sample of the packets that triggered this report.
Sometimes tshark will incorrectly detect the HTTP protocol layer on packets that are part of a TLS stream. In our experience, this situation occurs quite commonly, even when dealing with relatively small capture files. This could lead to false positives, as unencrypted traffic could be falsely detected. To mitigate this issue, the plugin implements a heuristic that exploits the fact that HTTP packets start with a printable line. On detection of HTTP packets, the tool will try to decode the first line as ASCII. If this decoding fails then the packet is simply ignored. In our experiments, this was sufficient to eliminate false positives without impacting the effectiveness of the smell-detection technique when unencrypted HTTP traffic was present.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}