3.1. Problem Formulation
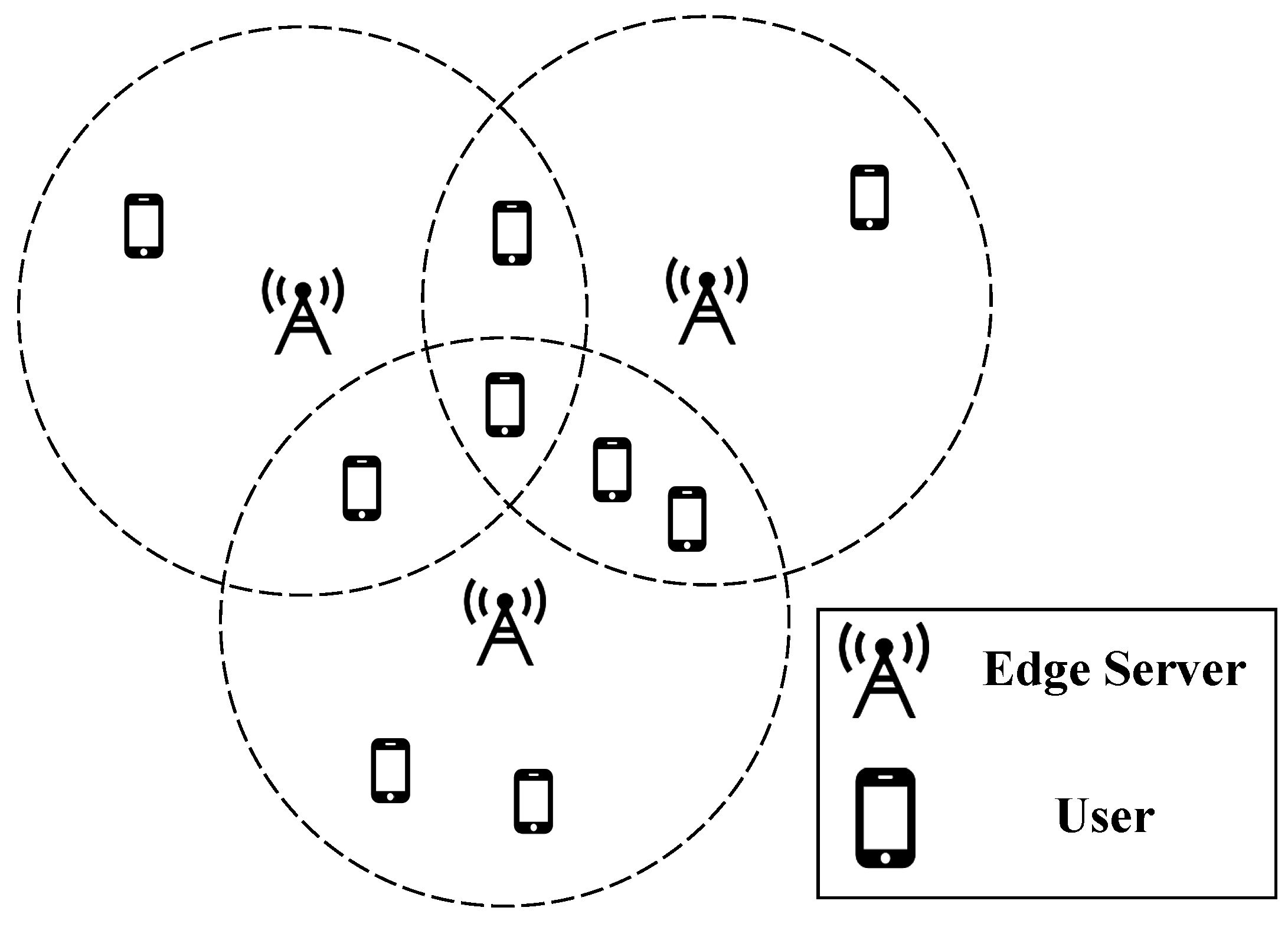
As shown in
Figure 1, there are distributed edge servers and mobile users in the edge network video streaming system. Each end user has different trajectories under specific modes of transportation, so the network connection status with adjacent edge nodes is constantly changing. As mentioned earlier, every edge server with limited resources needs to adapt to various requests online in real time, which is called the EUA problem. At the same time, each mobile user also needs to choose an appropriate bitrate based on their local network connection quality to ensure smooth playback, which is known as the bitrate selection problem. Although these two problems aim to achieve different strategies, such as server allocation or bitrate selection, their goals are similar, namely, to maximize users’ QoE with limited infrastructure resources or minimizing system costs.
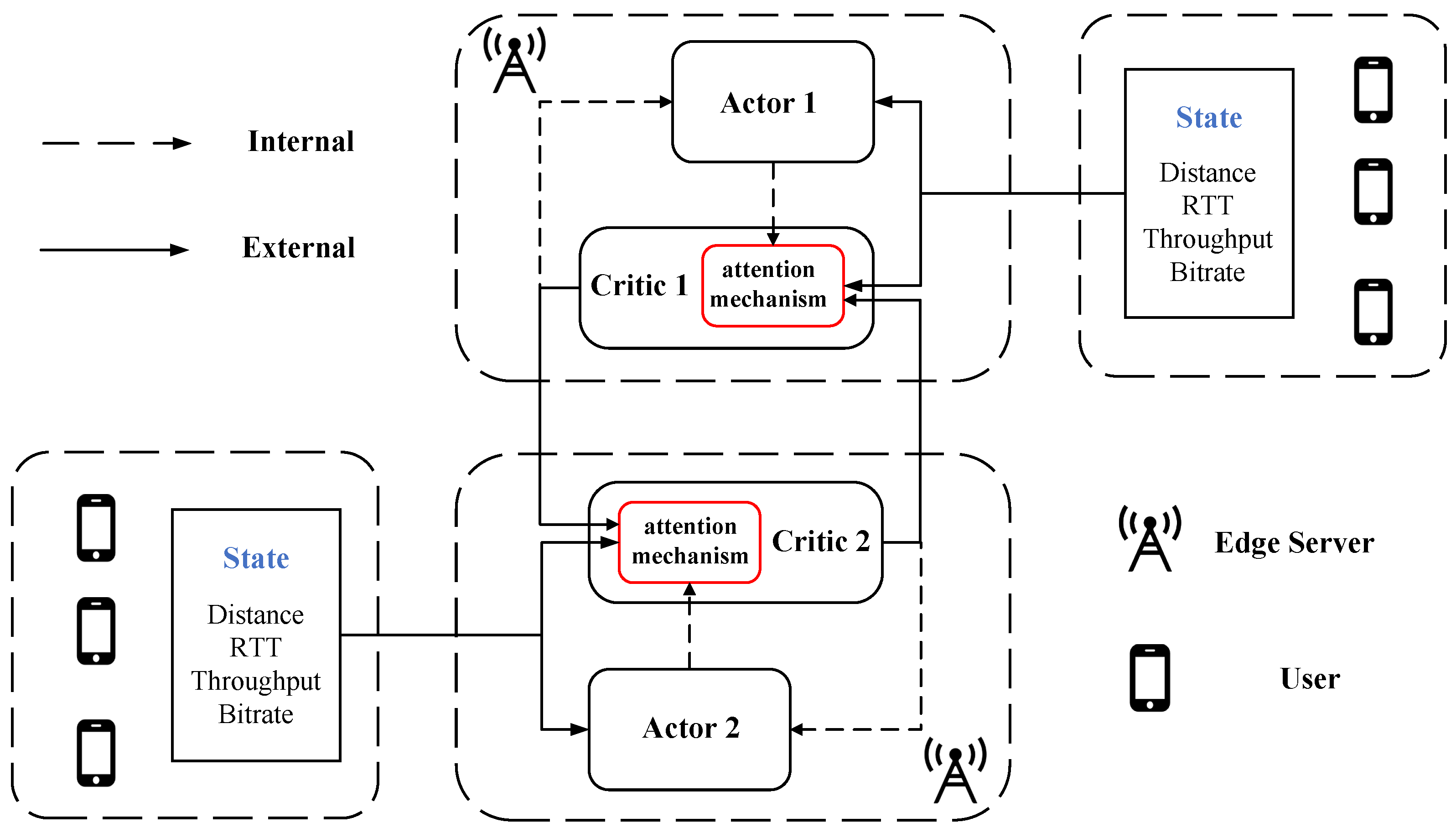
Given a video streaming system with distributed edge servers and mobile users, their interaction process is shown in
Figure 2 under the AMARL framework. Let us denote the set of edge servers as
, the users set under the coverage of
as
, the users set served by
as
, and the maximum number of connections to
as
. Denote geographic distance, round-trip time (RTT), and throughput rate between
and
as
,
, and
, respectively.
and
represent the current and last video bitrate assigned to
. Then the users’
can be defined as
Note that the absolute value of
is used to reflect the smoothness of the video bitrate change. Intuitively, if this value is too large, the user will feel that the video playback is discontinuous. In addition, it is necessary to ensure that the throughput
between
and
can support the selected bitrate
, so the throughput penalty function
is defined as
Therefore,
,
,
, and
are used as the weights of bitrate, smoothness, throughput, and RTT, respectively, in (
1).
3.2. Model Design
A fully cooperative multiagent task can be described as a Dec-POMDP, which can be denote as a tuple . denotes the true state of the environment. At each step, each agent chooses an action , and all actions form joint action . P is the state transition function depending on the environment. When all agents complete the decision, the environment will transit from the state s to the next state according to the state transition function , and return the reward at the same time. All agents share the same reward function . is the discount factor. For a Dec-POMDP, the environment is partially observable for agents. Each agent obtains its individual observation according to observation function . Each agent has an action-observation history , on which it conditions a stochastic policy . The joint policy has a joint action-value function , where is the discounted return. The goal of agents is to find a joint policy to maximize the expected discounted reward. In MARL, agents learn to make decisions by exploring the unknown environment and using the feedback received from the environment. In this setting, the objective of each agent is to maximize the shared reward.
Then the essential elements of a Dec-POMDP can be defined as follows:
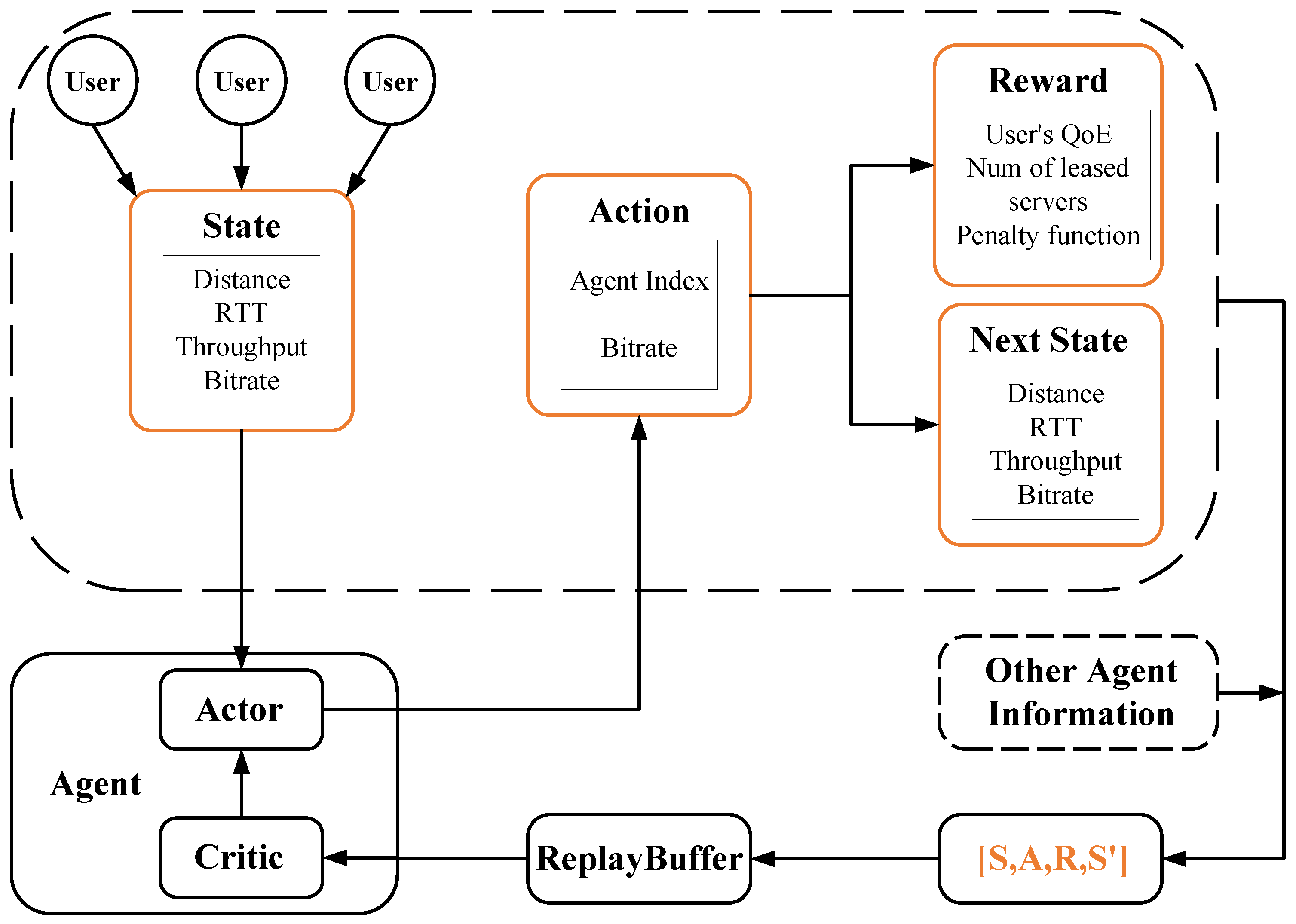
State. In this scenario, due to the difference in factors, such as latency between each user and each edge server, we define the state of a user
under the coverage of a single edge server
as
, and each
is a 4-tuple as shown in (
3).
Then the input state of the edge server
is
In (
4), we input not only the states of all users under the coverage of the edge server
into the neural network but also the number of remaining connections to
. In AMARL, the input to the actor network is the respective state
of each agent, while in the critic network, since the training is to be centralized, the input is the set of states
of each edge server
, defined as shown in (
5):
Because of the presence of other agents, the prediction of a single actor is not a global joint action. In order to reduce the impact of other agents on the current critic’s evaluation of the actor’s prediction, a masked array is used to eliminate useless information in the evaluation. The algorithm for state matrix construction is shown in Algorithm 1.
| Algorithm 1: State matrix construction algorithm. |
| | Input: Edge server set E |
| | Output: Current state |
| 1 | for E do in parallel |
| 2 | | | Collect the all information of the user that is covered by the edge |
| | | | server ; |
| 3 | | | for do in parallel |
| 4 | | | | | Return the geographical distance from the server , communication |
| | | | | | delay , throughput , current video resolution ; |
| 5 | | | end |
| 6 | | | Construct the state of the current edge server and each user according |
| | | | to (3); |
| 7 | | | Calculate the number of users served by the edge server , ; |
| 8 | | | Construct the current state vector according to (4); |
| 9 | end |
| 10 | Obtain the current state of all servers according to (5); |
Action. For each agent, the action is initially set to a list of binary groups, where each element of the list is a binary group made up of the user index and the assigned video bitrate. Denote the action of
for
as
. Further,
is a binary as shown in (
6).
Thus, the action vector
predicted by the edge server
is
However, it is a challenge to determine the actions because each agent will have access to a list of all user behaviors, requiring several decisions to be made about each user by various agents, which will certainly result in some conflict.
Section 3.3 describes the detailed solution.
Reward. In the EUA problem, the goal is to maximize the number of assigned users and minimize the number of leased servers. However, if only the user’s QoE and the number of leased servers are considered as the reward function, the capacity of each agent will be ignored. Therefore, a penalty function is introduced to prevent the number of server connections from exceeding their own capacity. Denote
as the reward of edge server
and
as the number of leased servers; then
Furthermore, in order to serve as many users as feasible within the coverage area, the penalty function
is defined in accordance with the number of connections and the number of users inside the coverage area as follows:
Actor. For each UAV agent, there is an actor and a critic. The actor is the network parameterized policy function
;
is the parameter of the network. The action of the agent can be obtained by the deterministic policy
. After all agents complete the action selection, the joint action
can be obtained. The gradient can be calculated as
where
i is the agent index,
S is the batch size,
is the actor policy, and
Q is the critic evaluation.
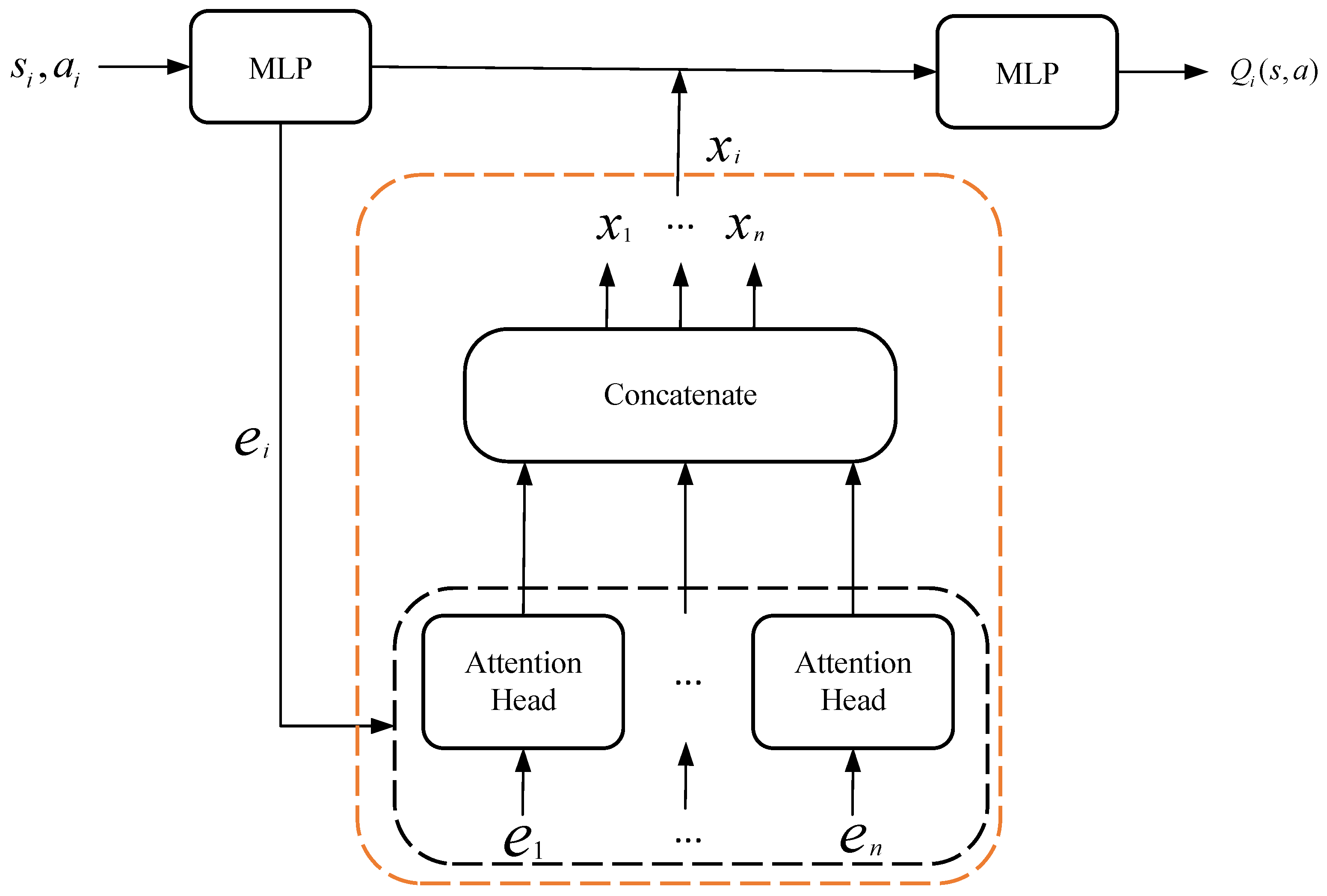
Critic. In order to more accurately evaluate the action, each agent queries other agents for information about its observations and actions and integrates it into the estimate of its value function. To compute the Q-value function
for
, the critic receives the states
and actions
.
is a function of states and actions of
and the contributions of other agents:
where
is a two-layer MLP, while
is a one-layer MLP embedding function. Denote the contribution from other agents as
, which is a weighted sum of each agent’s value:
where the value,
is the embedding of
. The attention weight
considers the correlation of
and
; that is, it is calculated according to the distance between the two agents and the overlap rate of users in the service area. The details are shown in
Figure 3.
As shown in
Figure 2, the critics of each agent can obtain the state and action information of other agents extracted by the attention mechanism during training for an objective action evaluation. After evaluation, each agent independently predicts the next action based on the evaluation value.
3.4. Computational Complexity Analysis
In this part, we analyzed the computation complexity of our proposed algorithm. During the training phase, the computational complexity of the single agent algorithm is mainly related to the number of layers of the deep neural network (DNN) used by each agent and the number of neurons used in each layer [
27]. In addition, our algorithm is a multiagent algorithm; it is also necessary to consider the impact of the number of agents.
In the training phase, the computational complexity for a single DNN to both forward propagation and update in a single step is
, where
S is the minibatch size,
L represents the number of layers, and
denotes the number of neurons in the
i-th layer. Let
,
represent the computational complexity of the actor and critic of a single agent, respectively.
,
can be calculated as
where
T represents the number of steps in each episode,
M represents the total number of episodes, and
and
represent the number of layers of actor and critic, respectively. Let
N represent the number of agents. Then the computational complexity of our algorithm in the training phase can be expressed as
During the distributed execution phase, each agent only needs to use a trained actor network to select action, so the computational complexity of our algorithm is



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











