
Spot Market Cloud Orchestration Using Task-Based Redundancy and Dynamic Costing


Abstract
:1. Introduction
2. Related Work
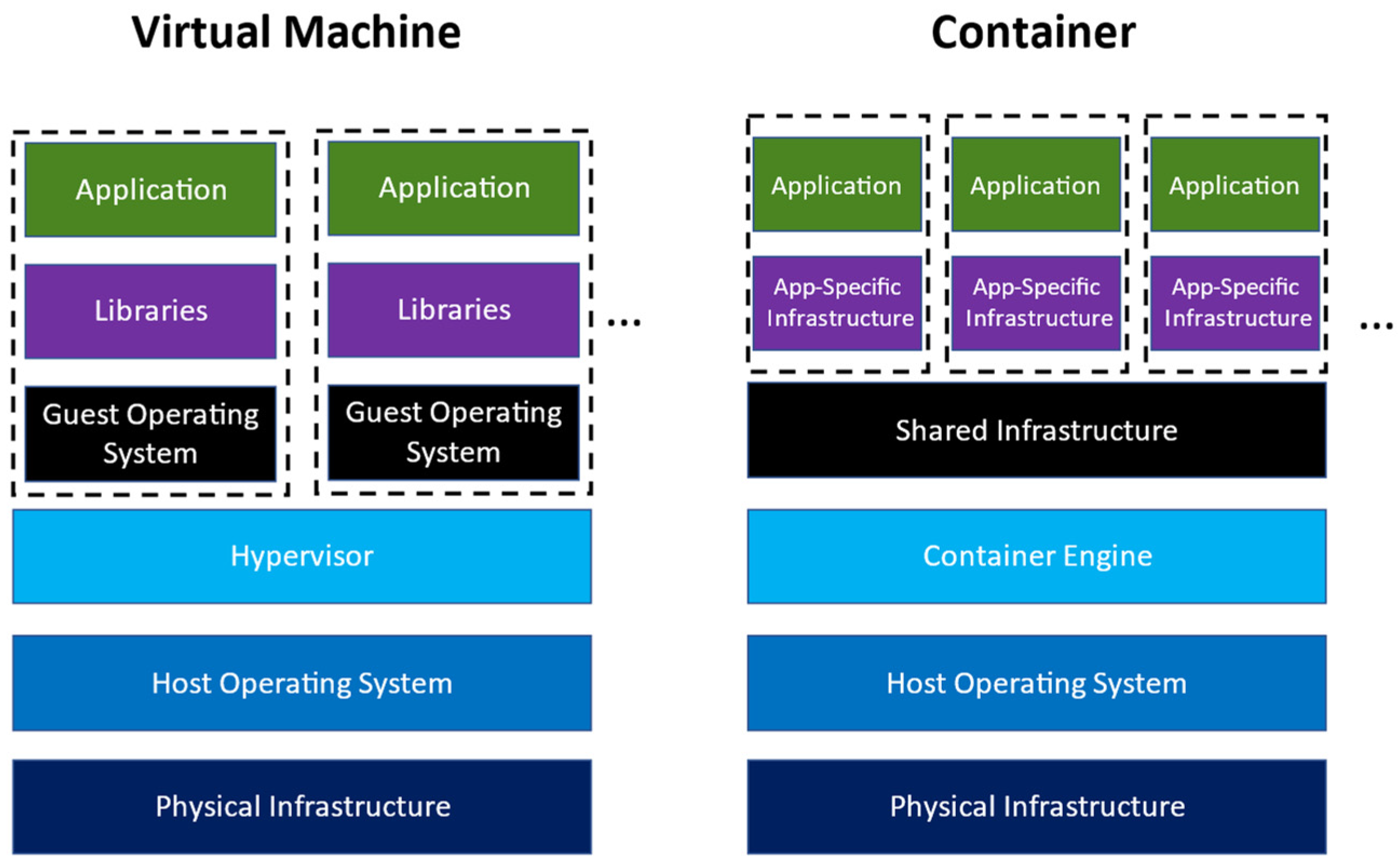
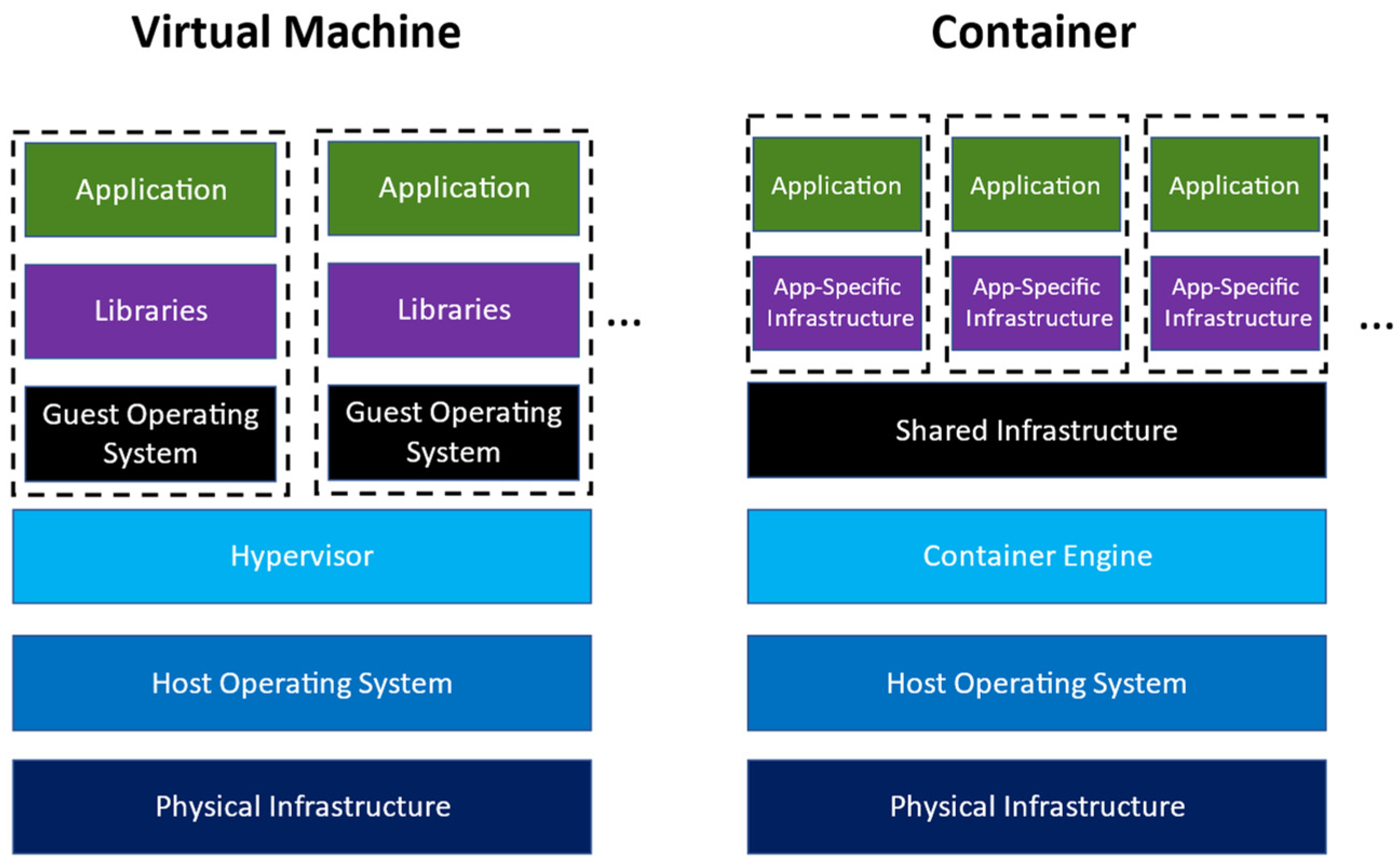
2.1. Virtualization and Containerization
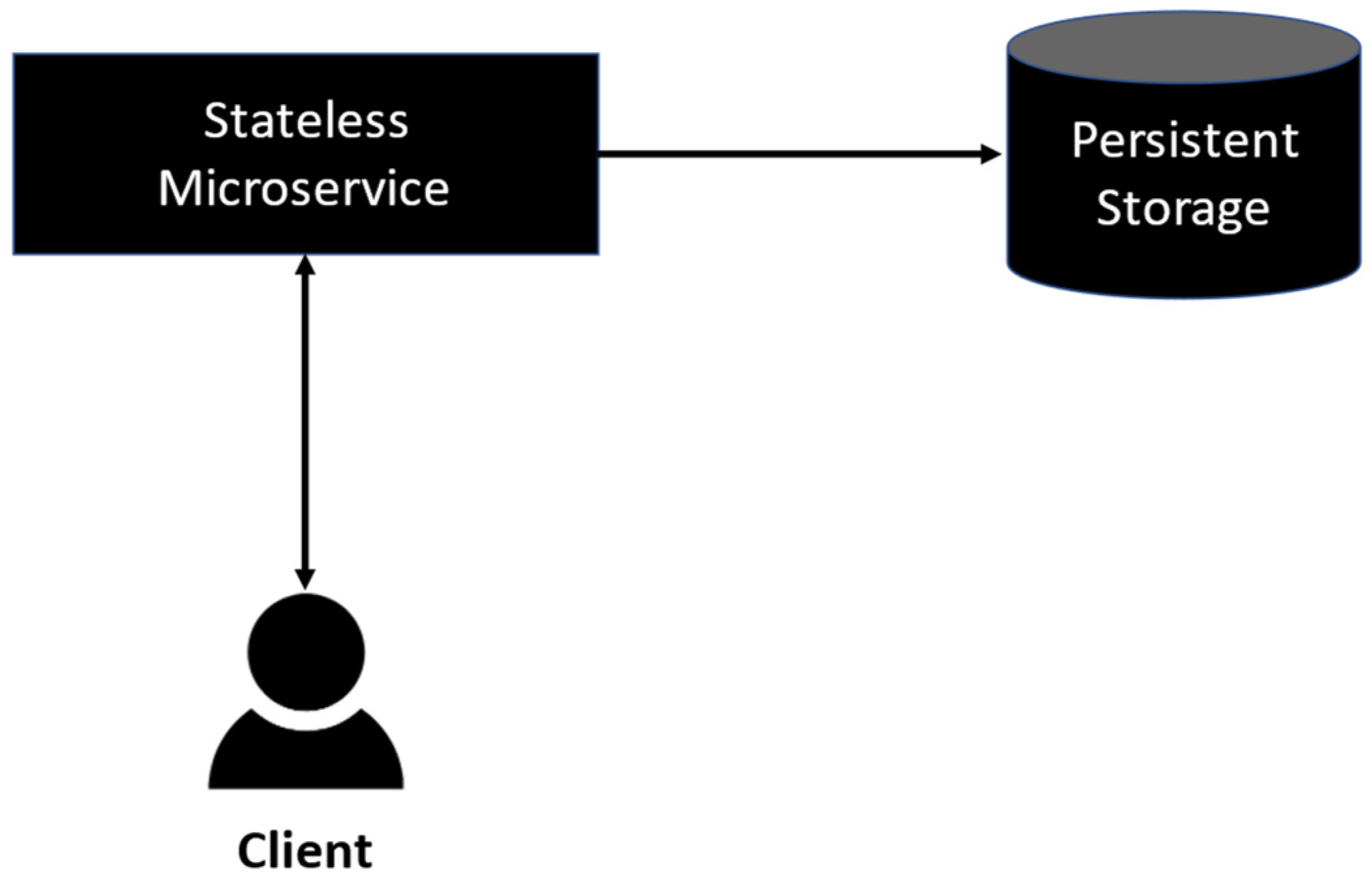
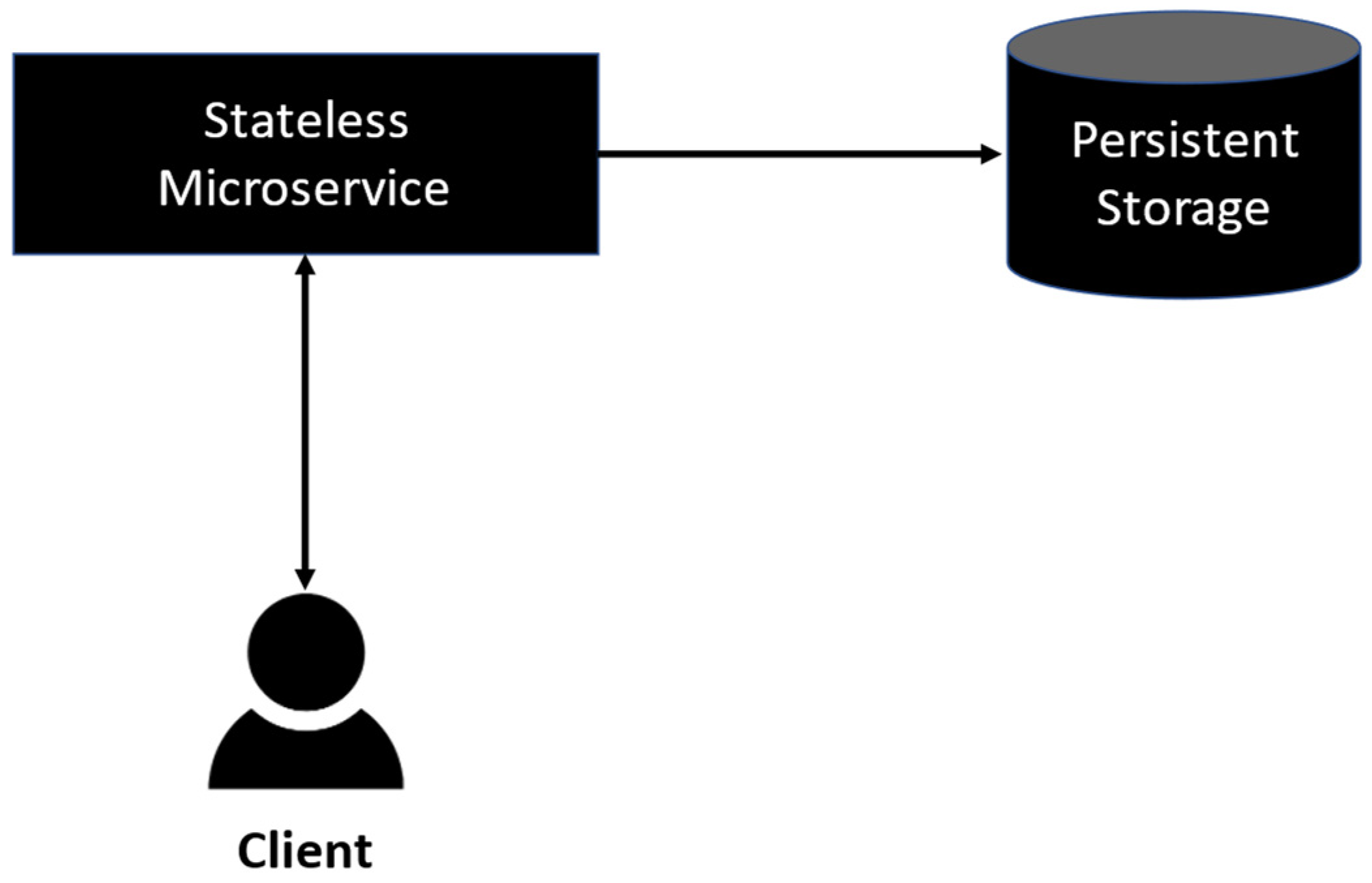
2.2. Microservices Architecture
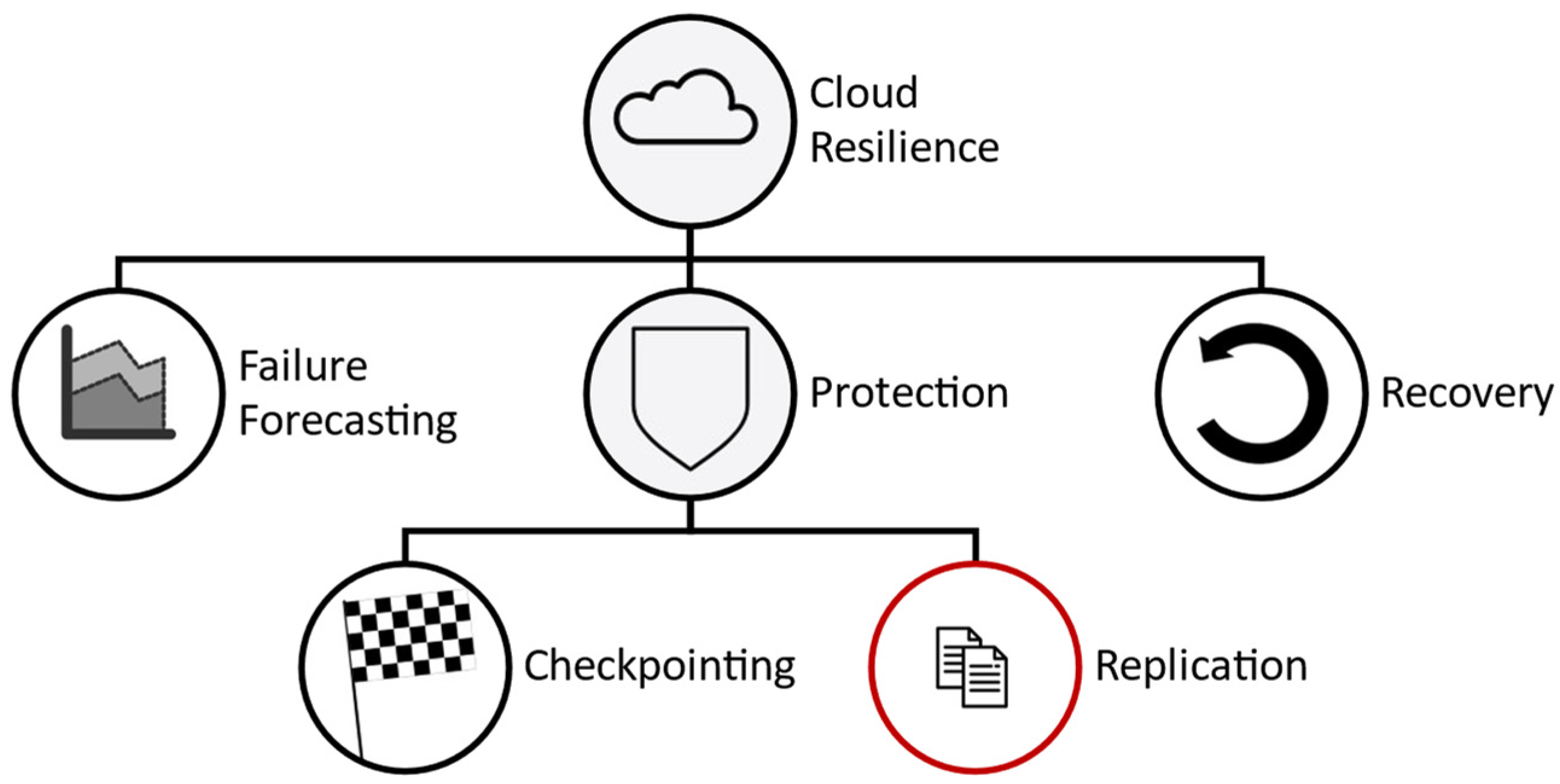
2.3. Resilience of Cloud Systems
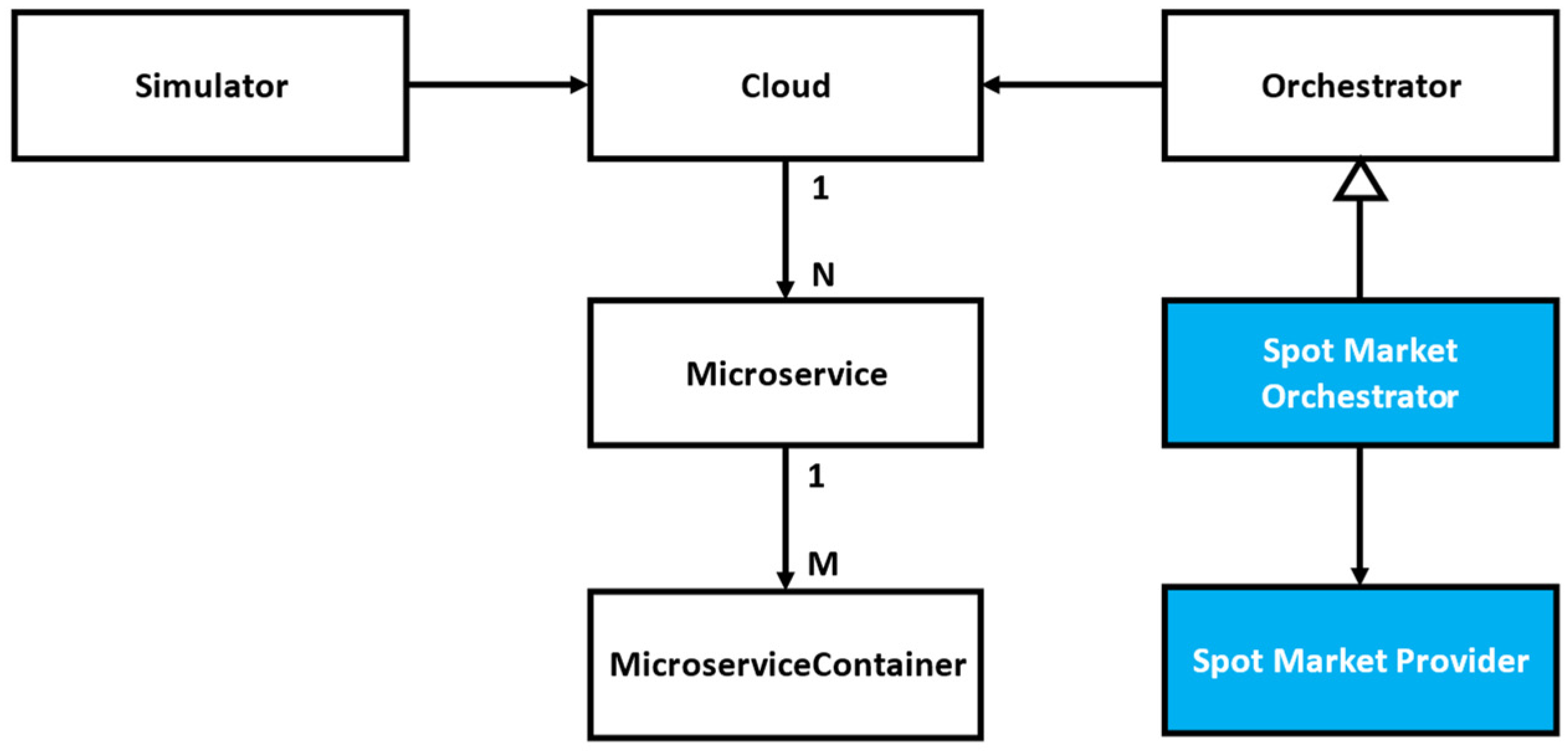
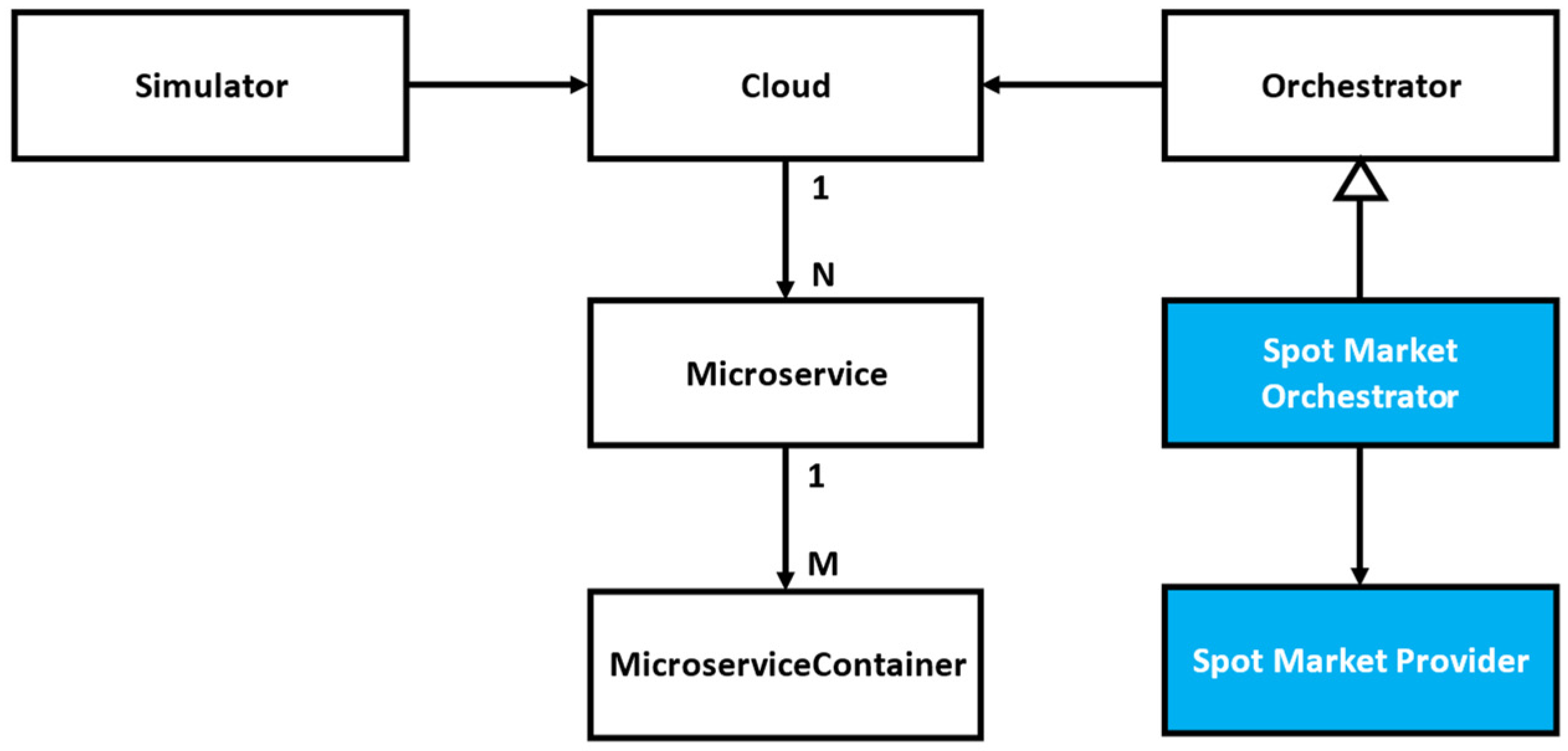
2.4. Existing Spot Market Cloud Implementations
3. Task-Based Redundancy in Cloud Systems
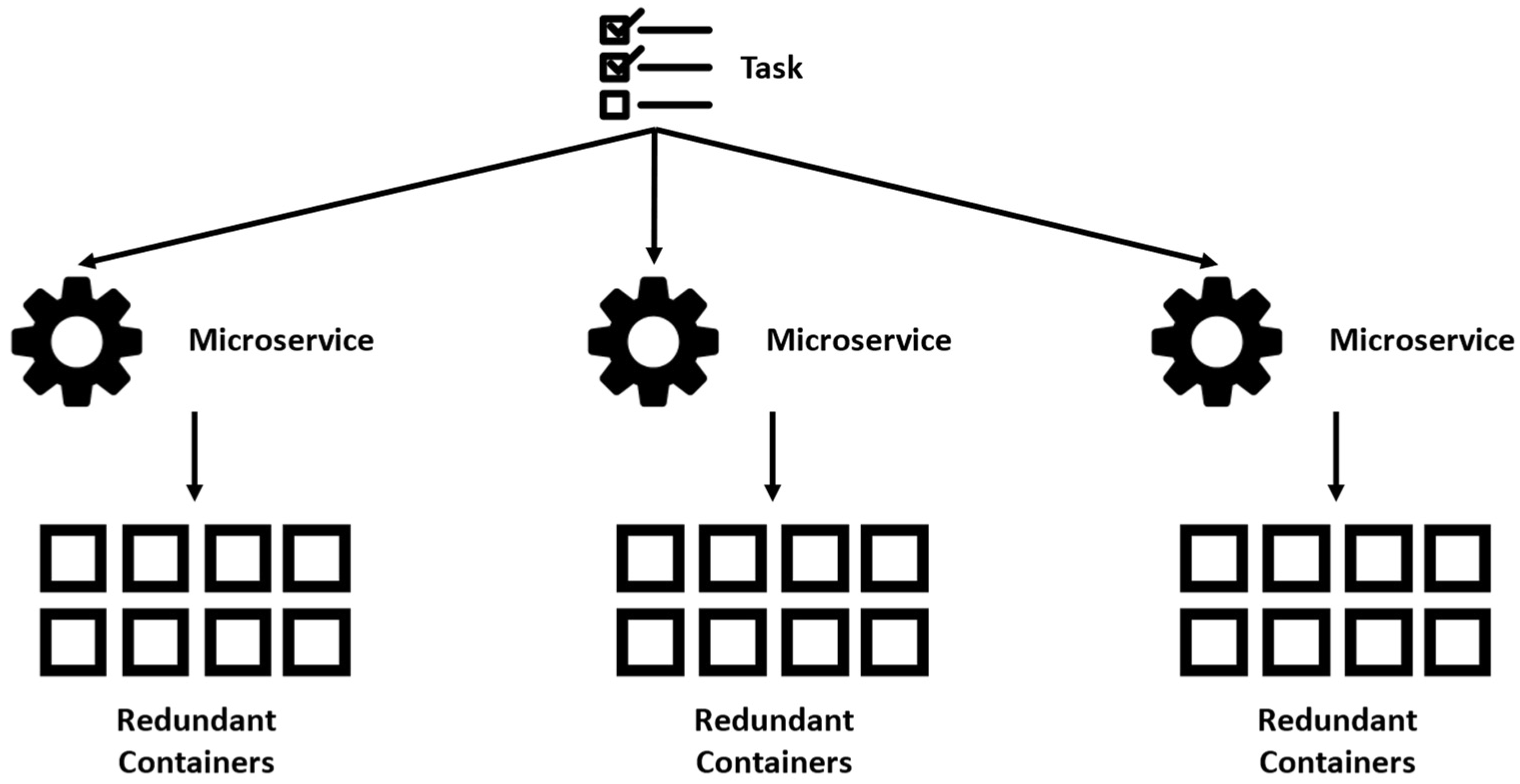
3.1. Background to Task-Based Redundancy
3.2. Applying Task-Based Redundancy to Cloud Microservices
4. Our Proposed Approach
4.1. Dynamic Costing of Cloud Resources
4.2. Quantifying the Cost of Failure
4.3. Proposed Spot Market Orchestration Algorithm
| Algorithm 1: Our proposed algorithm for Spot Market Orchestration for task T | |
| 1: | procedure OrchestrateCloud (Microservices, t) |
| 2: | Delete failed microservice containers. |
| 3: | Ensure each microservice has at least one non-failed container |
| 4: | |
| 5: | while do |
| 6: | |
| 7: | |
| 8: | for each do |
| 9: | if and then |
| 10: | |
| 11: | |
| 12: | end if |
| 13: | end for |
| 14: | if then |
| 15: | Replicate SelectedMicroservice |
| 16: | end if |
| 17: | end while |
| 18: | while do |
| 19: | |
| 20: | |
| 21: | for each do |
| 22: | for each do |
| 23: | if and then |
| 24: | |
| 25: | |
| 26: | end if |
| 27: | end for |
| 28: | end for |
| 29: | if then |
| 30: | Safely shut down SelectedContainer |
| 31: | end if |
| 32: | end while |
| 33: | end procedure |
5. Empirical Testing
5.1. Simulation Environment
5.2. Experimental Design
| Algorithm 2: The orchestration algorithm we used as a control for task T | |
| 1: | procedure OrchestrateCloud (Microservices, t) |
| 2: | Delete failed microservice containers. |
| 3: | Ensure each microservice has at least one non-failed container |
| 4: | for each do |
| 5: | while do |
| 6: | Replicate |
| 7: | end while |
| 8: | while do |
| 9: | Safely shut down a container from |
| 10: | end while |
| 11: | end for |
| 12: | end procedure |
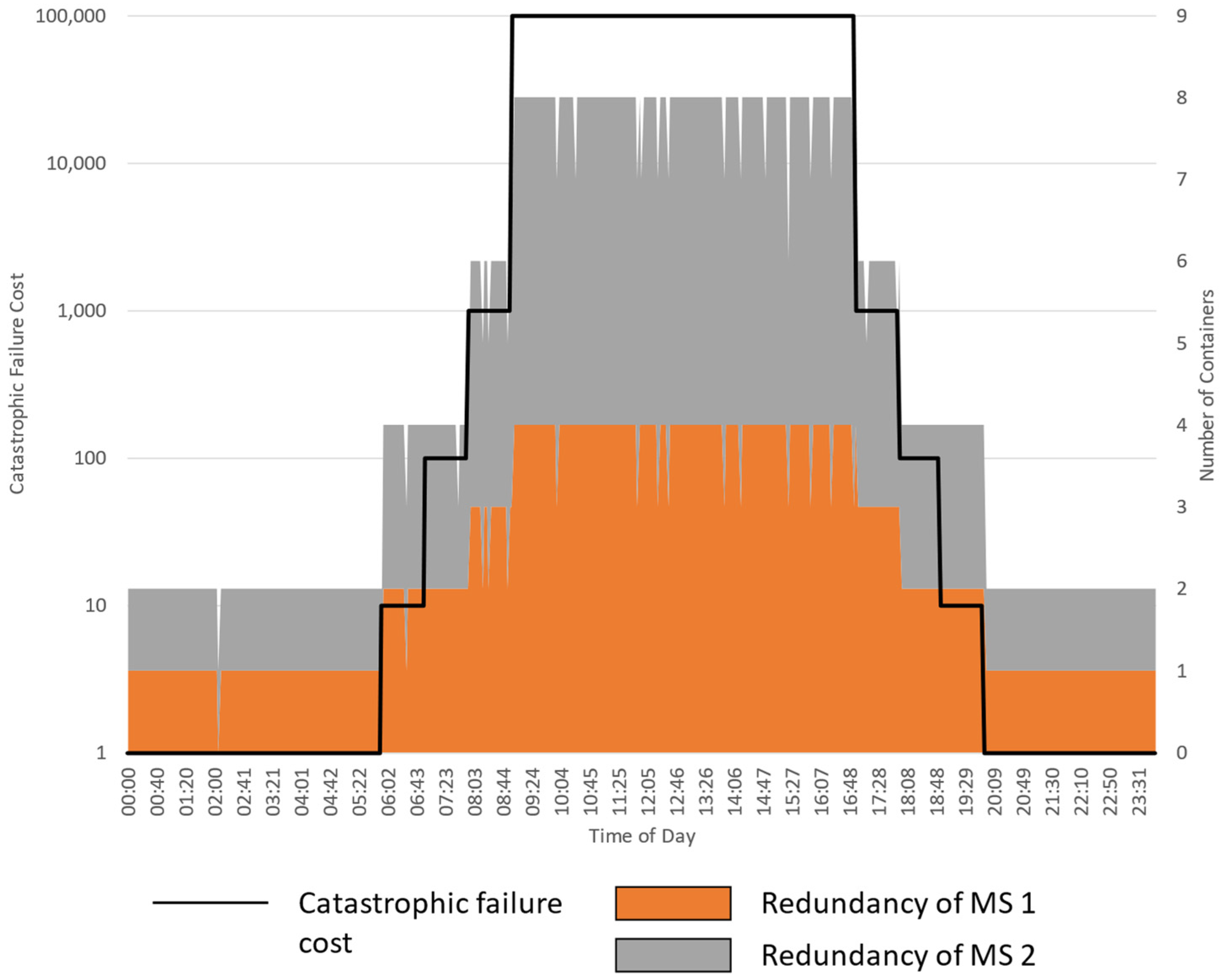
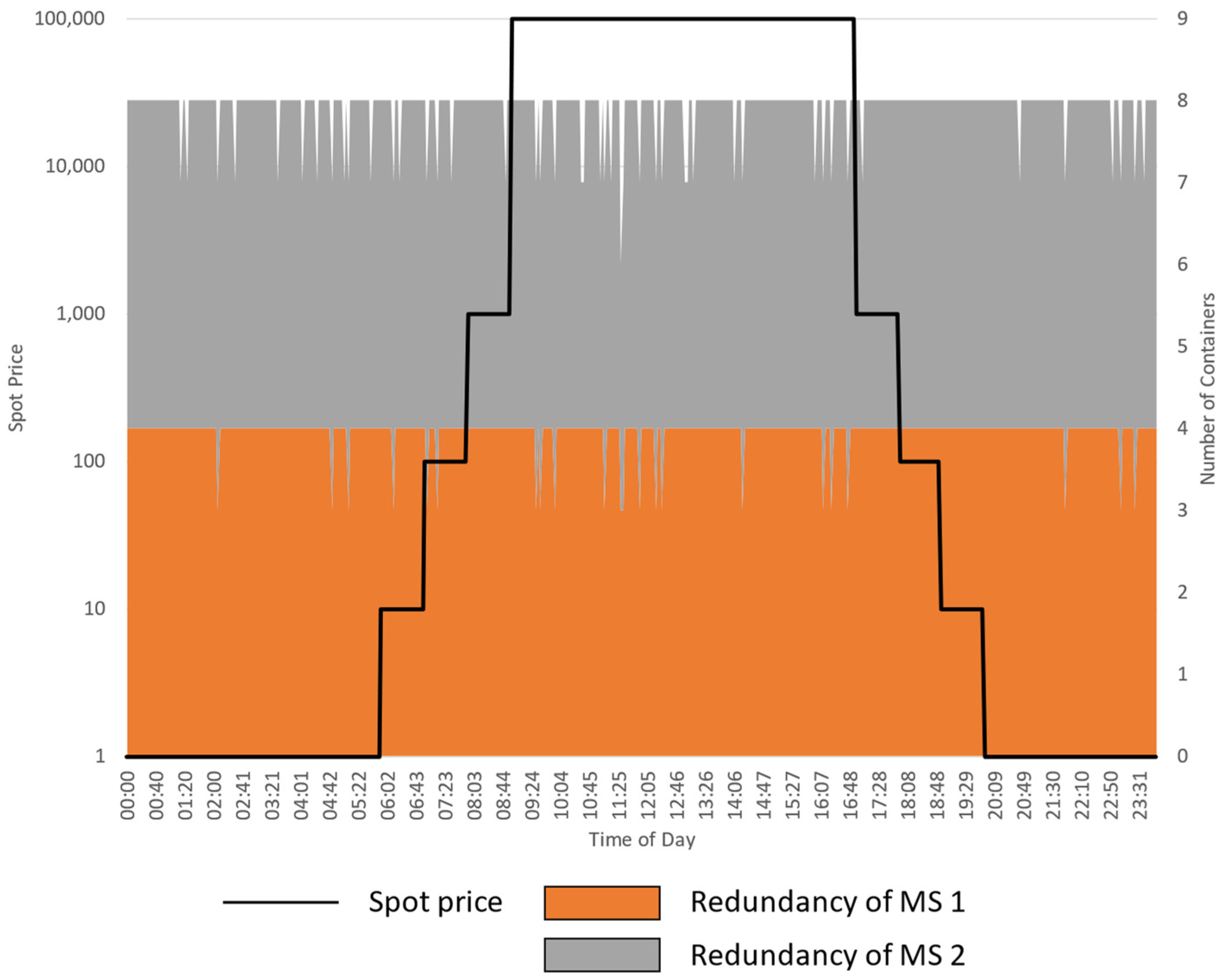
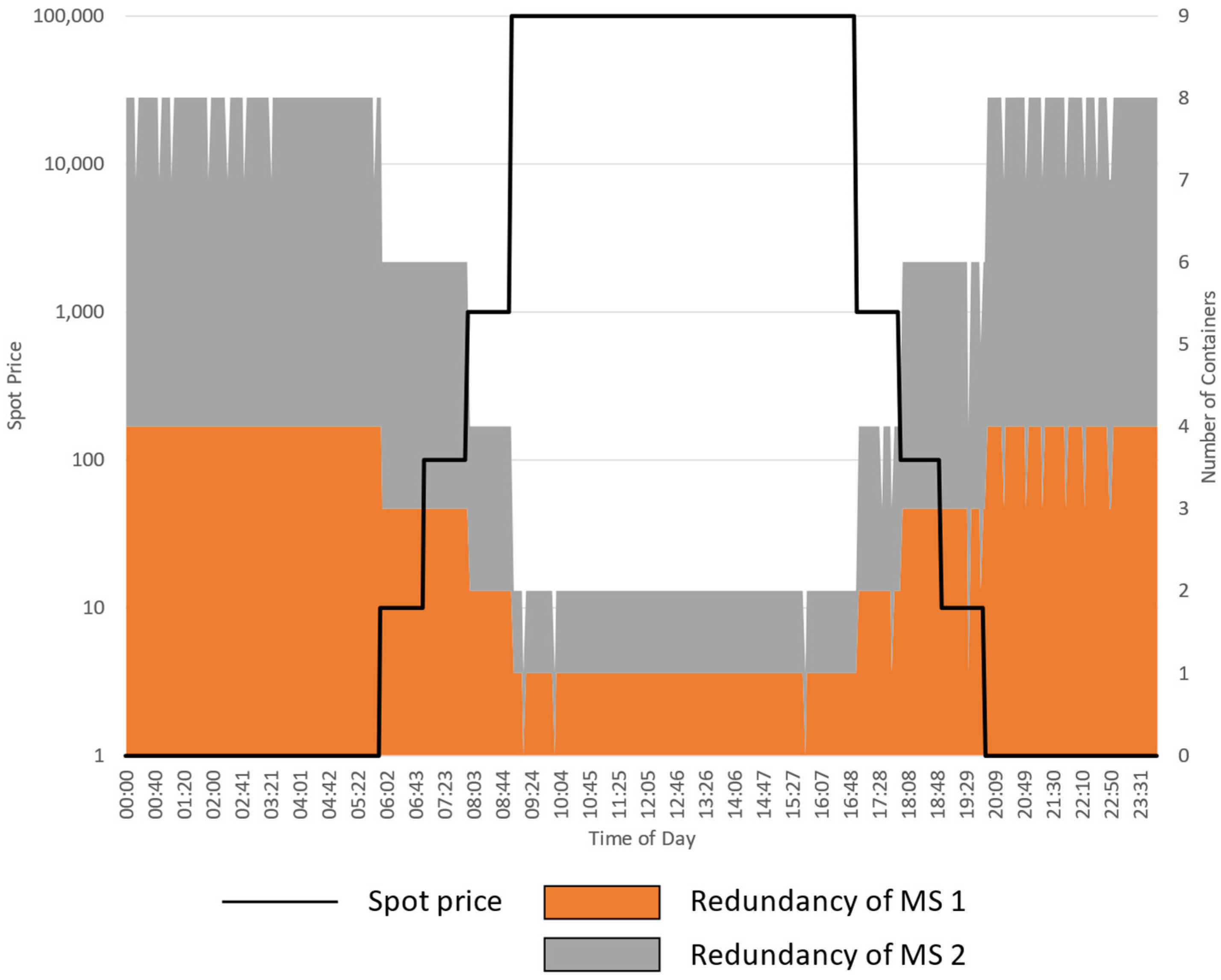
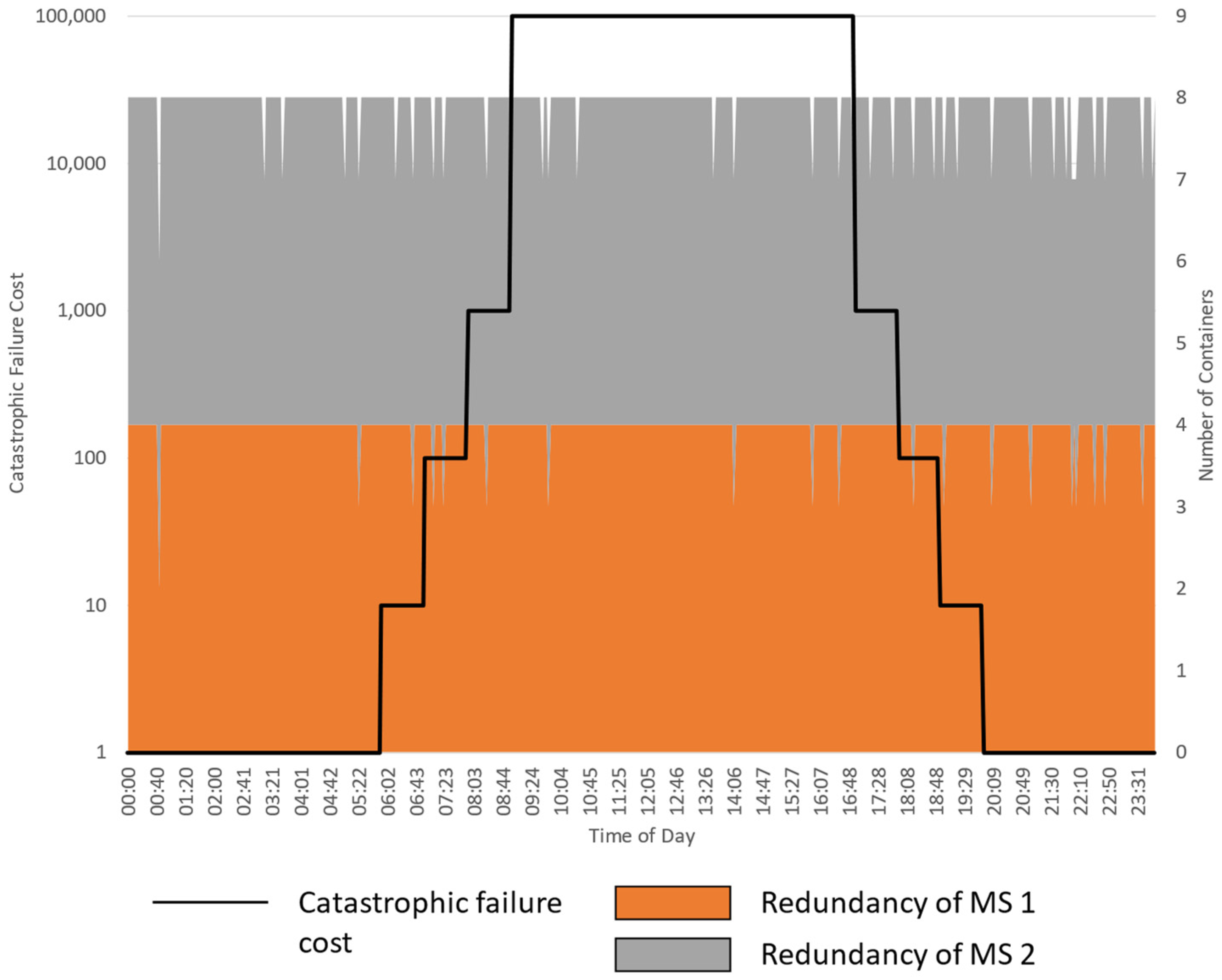
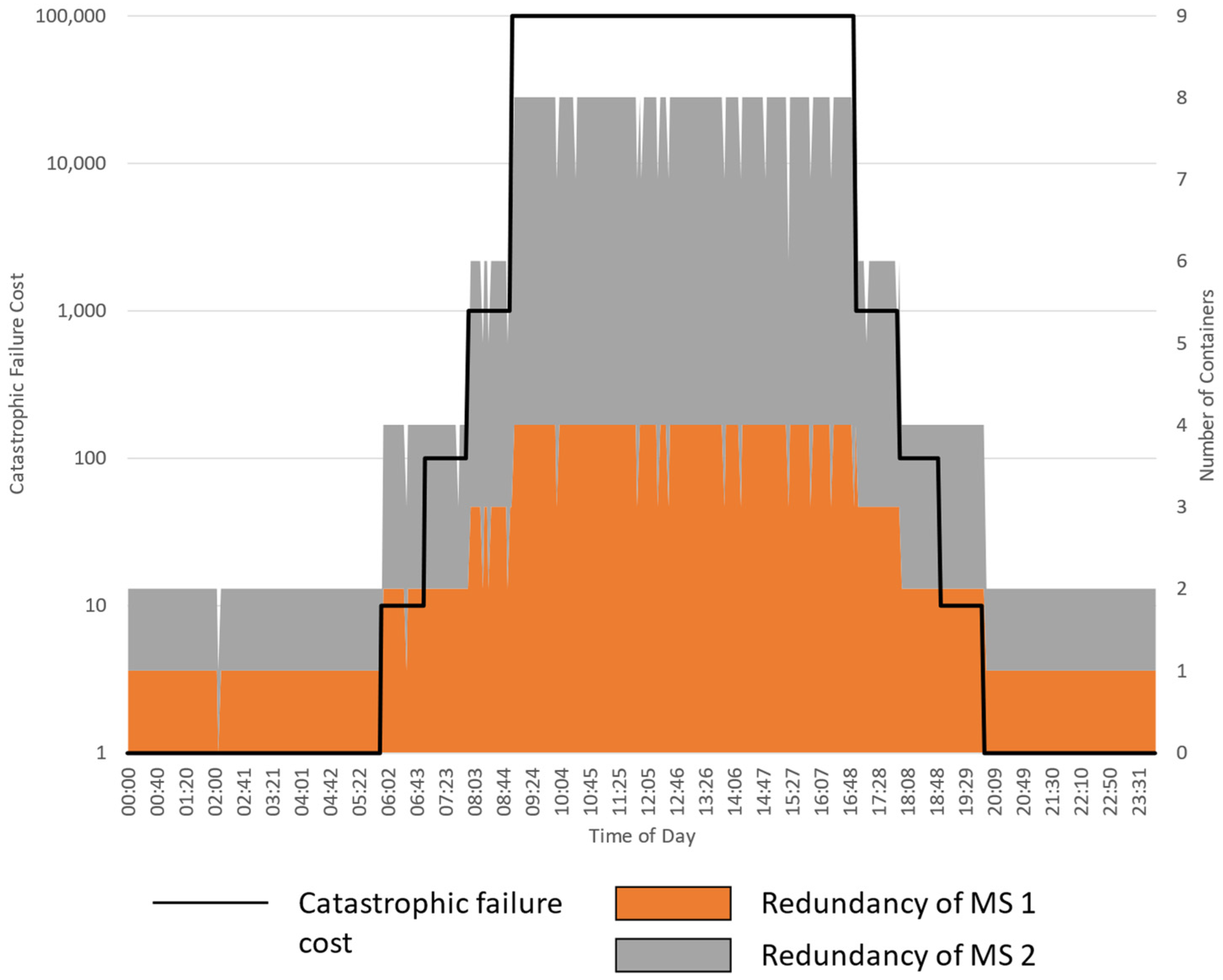
5.2.1. Experiment 1: Varying the Cost of Failure
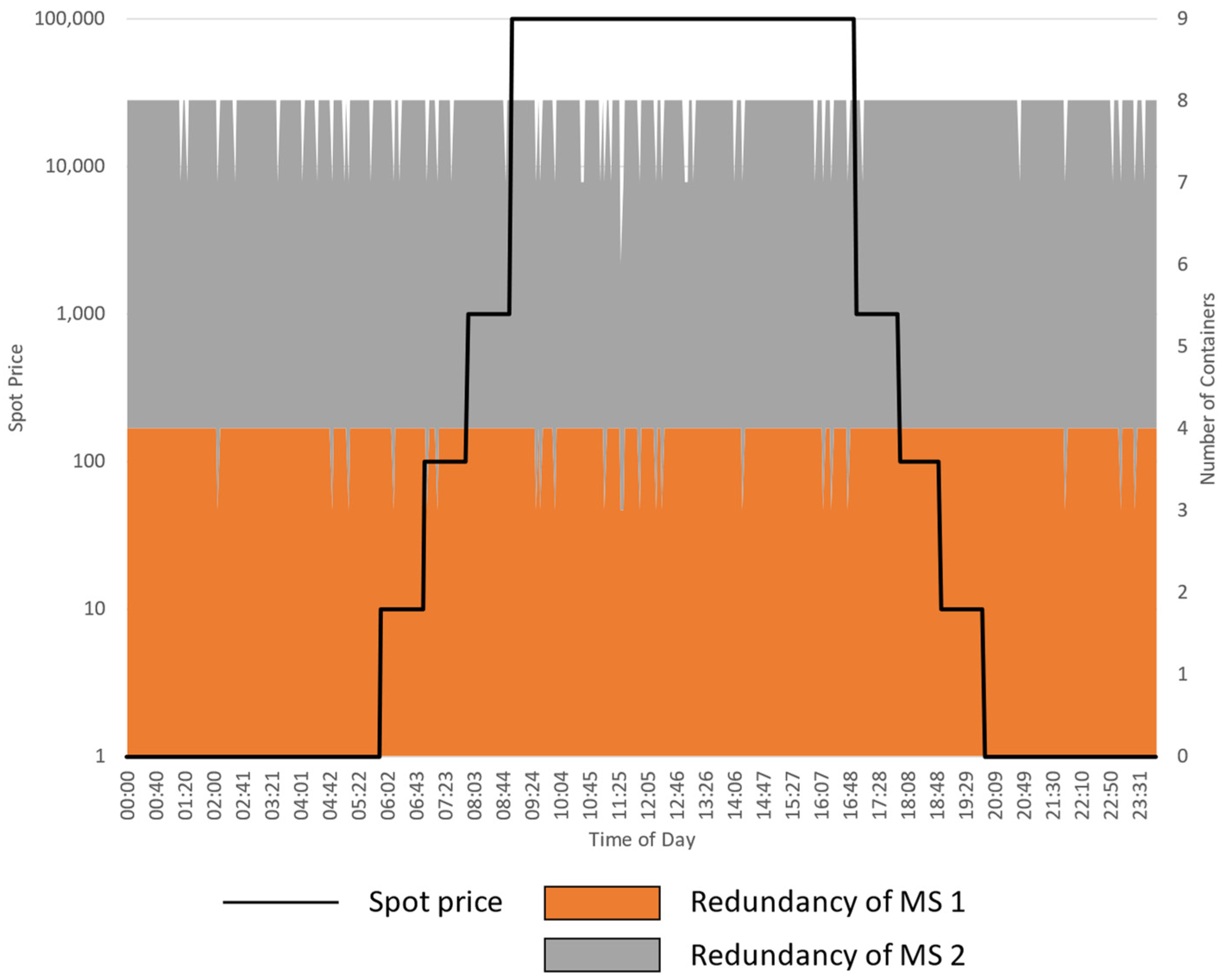
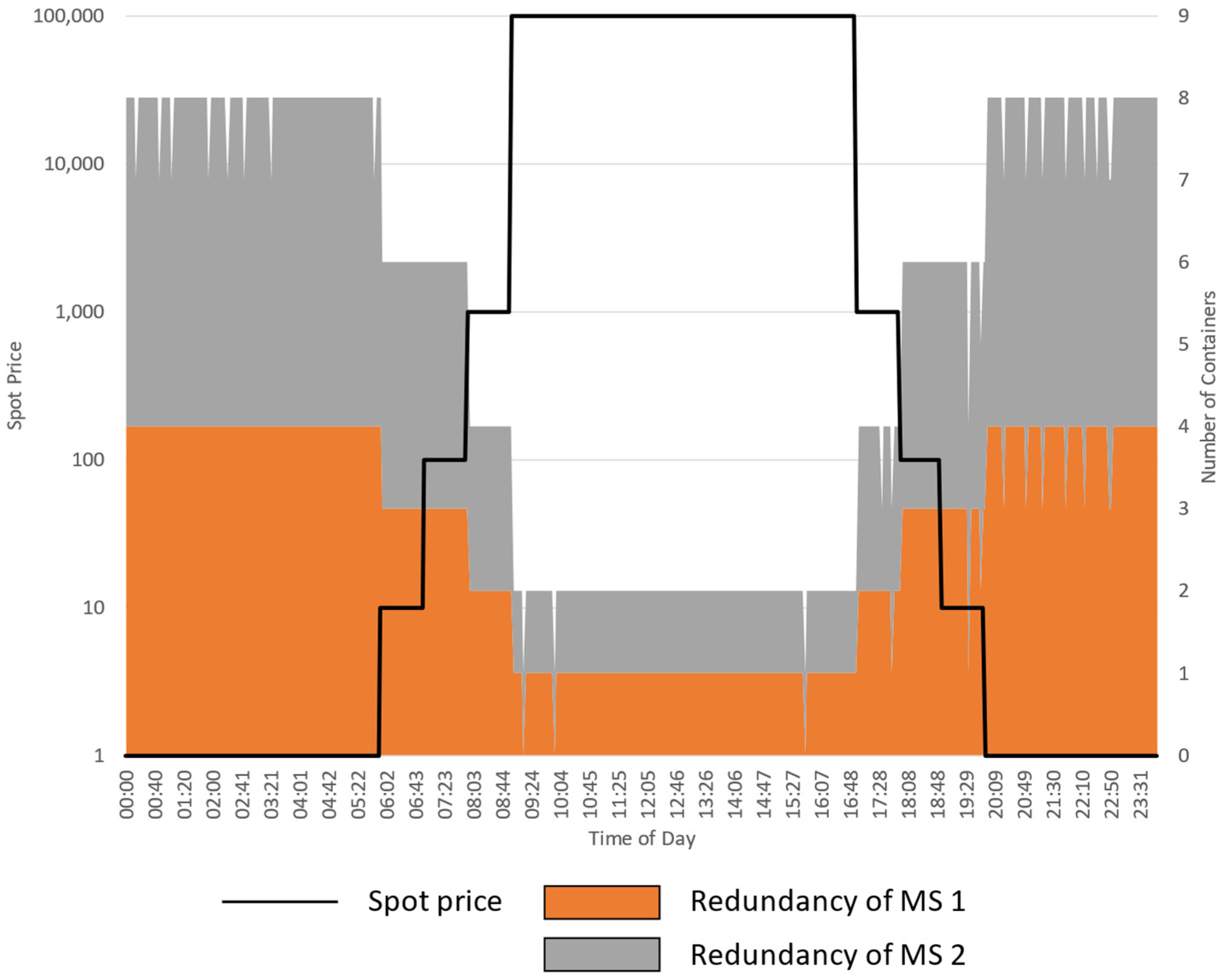
5.2.2. Experiment 2: Varying the Spot Price
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ardagna, D.; Casale, G.; Ciavotta, M.; Perez, J.; Wang, W. Quality-of-Service in Cloud Computing: Modelling Techniques and Their Applications. J. Internet Serv. Appl. 2014, 5, 11. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Rama Krishna, C. Virtualization in Cloud Computing: Moving from Hypervisor to Containerization—A Survey. Arab. J. Sci. Eng. 2021, 46, 8585–8601. [Google Scholar] [CrossRef]
- Gan, Y.; Delimitrou, C. The Architectural Implications of Cloud Microservices. IEEE Comput. Archit. Lett. 2018, 17, 155–158. [Google Scholar] [CrossRef]
- Yang, H.; Kim, Y. Design and Implementation of High-Availability Architecture for IoT-Cloud Services. Sensors 2019, 19, 3276. [Google Scholar] [CrossRef] [PubMed]
- Pahl, C.; Brogi, A.; Soldani, J.; Jamshidi, P. Cloud Container Technologies: A State-of-the-Art-Review. IEEE Trans. Cloud Comput. 2019, 7, 677–692. [Google Scholar] [CrossRef]
- O’Neill, V.; Soh, B. Orchestrating the Resilience of Cloud Microservices Using Task-Based Reliability and Dynamic Costing. In Proceedings of the IEEE Conference on Computer Science and Data Engineering, Gold Coast, Australia, 18–20 December 2022. [Google Scholar] [CrossRef]
- Dimitri, N. Pricing Cloud IaaS Computing Services. J. Cloud Comput. 2020, 9, 14. [Google Scholar] [CrossRef]
- Tao, Z.; Xia, Q.; Hao, Z.; Li, C.; Ma, L.; Yi, S.; Li, Q. A Survey of Virtual Machine Management in Edge Computing. Proc. IEEE 2019, 107, 1482–1499. [Google Scholar] [CrossRef]
- da Silva, V.; Kirikova, M.; Alksnis, G. Containers for Virtualization: An Overview. Appl. Comput. Syst. 2018, 23, 21–27. [Google Scholar] [CrossRef]
- Marquez, J.; Castillo, M. Performance Comparison: Virtual Machines and Containers Running Artificial Intelligence Applications. In Information Technology and Systems; Rocha, A., Ferras, C., Lopez-Lopez, P., Eds.; Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, L.; Pu, C.; Dou, Q.; Wu, L.; Zhou, W. A Comparative Study of Containers and Virtual Machines in Big Data Environment. In Proceedings of the IEEE 11th International Conference on Cloud Computing, San Francisco, CA, USA, 2–7 July 2018. [Google Scholar] [CrossRef]
- Gillani, K.; Lee, J. Comparison of Linux Virtual Machines and Containers for a Service Migration in 5G Multi-Access Edge Computing. ICT Express 2020, 6, 1–2. [Google Scholar] [CrossRef]
- Shirinbab, S.; Lunberg, L.; Casalicchio, E. Performance Comparison Between Scaling of Virtual Machines and Containers Using Cassandra NoSQL Database. In Proceedings of the 10th International Conference on Cloud Computing, GRIDs, and Virtualization, Venice, Italy, 5–9 May 2019. [Google Scholar]
- Balalaie, A.; Heydarnoori, A.; Jamshidi, P. Microservices Architecture Enables DevOps: Migration to Cloud-Native Architecture. IEEE Softw. 2016, 33, 42–52. [Google Scholar] [CrossRef]
- Megargel, A.; Shankararaman, V.; Walker, D. Migrating from Monoliths to Cloud-Based Microservices: A Banking Industry Example. In Software Engineering in the Era of Cloud Computing; Ramachandran, M., Mahmood, Z., Eds.; Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Singleton, A. The Economics of Microservices. IEEE Cloud Comput. 2016, 3, 16–20. [Google Scholar] [CrossRef]
- Mohamed, M.; Engel, R.; Warke, A.; Berman, S.; Ludwig, H. Extensible Persistence as a Service for Containers. Future Gener. Comput. Syst. 2019, 87, 10–20. [Google Scholar] [CrossRef]
- Colman-Meixner, C.; Develder, C.; Tornatore, M.; Mukherjee, B. A Survey on Resiliency Techniques in Cloud Computing Infrastructure and Applications. IEEE Commun. Surv. Tutor. 2016, 18, 2244–2281. [Google Scholar] [CrossRef]
- Johnson, B. Design and Analysis of Fault-Tolerant Digital Systems; Addison-Wesley: Reading, MA, USA, 1989. [Google Scholar]
- Louati, T.; Abbes, H.; Cerin, C. LXCloudFT: Towards High Availability, Fault-Tolerant Cloud System Based Linux Containers. J. Parallel Distrib. Comput. 2018, 122, 51–69. [Google Scholar] [CrossRef]
- Florin, R.; Ghazizadeh, A.; Ghazizadeh, P.; Olariu, S.; Marinescu, D. Enhancing Reliability and Availability Through Redundancy in Vehicular Clouds. IEEE Trans. Comput. 2019, 9, 1061–1074. [Google Scholar] [CrossRef]
- Ahmed, F.; Abdul Majid, M. Towards Agent-Based Petri Net Decision Making Modelling for Cloud Service Composition: A Literature Survey. J. Netw. Comput. Appl. 2019, 130, 14–28. [Google Scholar] [CrossRef]
- Liu, Z.; Fan, G.; Yu, H.; Chen, L. An Approach to Modelling and Analyzing Reliability for Microservice-Oriented Cloud Applications. Wirel. Commun. Mob. Comput. 2021, 2021, 5750646. [Google Scholar] [CrossRef]
- Ha, W. Reliability Prediction for Web Service Composition. In Proceedings of the 13th International Conference on Computational Intelligence and Security, Hong Kong, China, 15–18 December 2017. [Google Scholar] [CrossRef]
- Li, C.; Song, M.; Zhang, M.; Luo, Y. Effective Replica Management for Improving Reliability and Availability in Edge-Cloud Computing Environment. J. Parallel Distrib. Comput. 2020, 143, 107–128. [Google Scholar] [CrossRef]
- Pham, T.-P.; Ristov, S.; Fahringer, T. Performance and Behavior Characterization of Amazon EC2 Spot Instances. In Proceedings of the 11th IEEE International Conference on Cloud Computing, San Francisco, CA, USA, 2–7 July 2018. [Google Scholar] [CrossRef]
- Baughman, M.; Hass, C.; Wolski, R.; Foster, I.; Chard, K. Predicting Amazon Spot Prices with LSTM Networks. In Proceedings of the 9th Workshop on Scientific Cloud Computing, Tempe, AZ, USA, 11 June 2018. [Google Scholar] [CrossRef]
- Spot VMs. Available online: https://cloud.google.com/spot-vms (accessed on 22 August 2023).
- Azure Spot Virtual Machines. Available online: https://azure.microsoft.com/en-us/products/virtual-machines/spot (accessed on 22 August 2023).
- Kumar, D.; Baranwal, G.; Raza, Z.; Vidyarthi, D.P. A Survey on Spot Pricing in Cloud Computing. J. Netw. Syst. Manag. 2017, 26, 809–856. [Google Scholar] [CrossRef]
- O’Neill, V.; Soh, B. Improving Fault Tolerance and Reliability of Heterogeneous Multi-Agent Systems Using Intelligence Transfer. Electronics 2022, 11, 2724. [Google Scholar] [CrossRef]
- Li, Q.; Li, B.; Mercati, P.; Illikkal, R.; Tai, C.; Kishinevsky, M.; Kozyrakis, C. RAMBO: Resource Allocation for Microservices Using Bayesian Optimization. IEEE Comput. Archit. Lett. 2021, 10, 46–49. [Google Scholar] [CrossRef]
- Li, S.; Zhang, H.; Jia, Z.; Li, Z.; Zhang, C.; Li, J.; Gao, Q.; Ge, J.; Shan, Z. A Dataflow-Driven Approach to Identifying Microservices From Monolithic Applications. J. Syst. Softw. 2019, 157, 110380. [Google Scholar] [CrossRef]
- Cloud Reliability Simulator Source Code. Available online: https://github.com/vyas-oneill/cloud_reliability_sim (accessed on 30 July 2023).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Orchestrator | Mean Running Cost | Mean Actual Cost of Failures | Mean Total Cost | |
|---|---|---|---|---|
| Exp. 1 | Experimental | 0.94 | 0.06 | 1.00 |
| Control | 1.60 | 0.00 | 1.60 | |
| Exp 2. | Experimental | 13,438 | 3288 | 16,726 |
| Control | 53,590 | 0.00 | 53,590 |
| Orchestrator | Mean Running Cost | Mean Actual Cost of Failures | Mean Total Cost | |
|---|---|---|---|---|
| Exp. 1 | Experimental | 1.62 | 0.02 | 1.64 |
| Control | 3.05 | 0.00 | 3.05 | |
| Exp 2. | Experimental | 27,098 | 1424 | 28,522 |
| Control | 102,067 | 0.00 | 102,067 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
O’Neill, V.; Soh, B. Spot Market Cloud Orchestration Using Task-Based Redundancy and Dynamic Costing. Future Internet 2023, 15, 288. https://doi.org/10.3390/fi15090288
O’Neill V, Soh B. Spot Market Cloud Orchestration Using Task-Based Redundancy and Dynamic Costing. Future Internet. 2023; 15(9):288. https://doi.org/10.3390/fi15090288
Chicago/Turabian StyleO’Neill, Vyas, and Ben Soh. 2023. "Spot Market Cloud Orchestration Using Task-Based Redundancy and Dynamic Costing" Future Internet 15, no. 9: 288. https://doi.org/10.3390/fi15090288
APA StyleO’Neill, V., & Soh, B. (2023). Spot Market Cloud Orchestration Using Task-Based Redundancy and Dynamic Costing. Future Internet, 15(9), 288. https://doi.org/10.3390/fi15090288