Abstract
This paper introduces an innovative framework for visualisation design ideation, which includes a collection of terms for creative visualisation design, the five-step process, and an implementation called VisAlchemy. Throughout the visualisation ideation process, individuals engage in exploring various concepts, brainstorming, sketching ideas, prototyping, and experimenting with different methods to visually represent data or information. Sometimes, designers feel incapable of sketching, and the ideation process can be quite lengthy. In such cases, generative AI can provide assistance. However, even with AI, it can be difficult to know which vocabulary to use and how to strategically approach the design process. Our strategy prompts imaginative and structured narratives for generative AI use, facilitating the generation and refinement of visualisation design ideas. We aim to inspire fresh and innovative ideas, encouraging creativity and exploring unconventional concepts. VisAlchemy is a five-step framework: a methodical approach to defining, exploring, and refining prompts to enhance the generative AI process. The framework blends design elements and aesthetics with context and application. In addition, we present a vocabulary set of 300 words, underpinned from a corpus of visualisation design and art papers, along with a demonstration tool called VisAlchemy. The interactive interface of the VisAlchemy tool allows users to adhere to the framework and generate innovative visualisation design concepts. It is built using the SDXL Turbo language model. Finally, we demonstrate its use through case studies and examples and show the transformative power of the framework to create inspired and exciting design ideas through refinement, re-ordering, weighting of words and word rephrasing.
1. Introduction
Visualisation ideation is the process of brainstorming, conceptualising, and generating novel data visualisation ideas. It involves synthesising knowledge and skills from visualisation, design, analytics, and art to discover effective ways to communicate ideas. In this work, we focus on creative visualisation design. When creating brochures, visualisation posters, infographics, explanatory visuals, interactive visualisation tools, and similar materials, designers often move beyond traditional bar charts, line graphs, scatter plots, and other familiar visualisations, opting instead to develop innovative and unique design concepts. These visualisations blend art and data in novel ways to tell stories and provide insights that traditional charts might not communicate as effectively.
For example, the poppyfield (http://poppyfield.org, accessed on 3 October 2024) visualisation is a powerful and emotive interactive visualisation that honours the soldiers who died during different wars through symbolic digital poppies. Each poppy represents a war, with the size of the poppy head indicating the quantity of deaths, while the angle of the stem represents the length of the war. The Visual Capitalist’s (https://www.visualcapitalist.com/visualized-the-worlds-population-at-8-billion/, accessed on 3 October 2024 infographic provides a detailed and visually engaging representation of global population growth, depicted through a large circle comprising colourful segments. Each segment reflects different regions or countries, illustrating the distribution of the world’s population in an accessible and captivating manner. Federica Fragapane’s (https://www.behance.net/gallery/110024405/Stolen-paintings, accessed on 3 October 2024)) stolen painting visualisations represent each artwork by a line, with a curved line indicating when they were stolen and/or recovered. The “Wind Map” (http://hint.fm/wind, accessed on 3 October 2024) by Fernanda Viégas and Martin Wattenberg is an interactive real-time visualisation of wind patterns across the U.S., with the “Dear Data” (http://dear-data.com, accessed on 3 October 2024) project by Giorgia Lupi and Stefanie Posavec featuring creative hand-drawn personal data visualisations. The “Carbon Map” (http://carbonmap.org, accessed on 3 October 2024) by Duncan Clark and Robin Houston is an interactive visualisation of carbon emissions across different countries; the data distort the map proportionally based on various data variables. “The Refugee Project” (http://therefugeeproject.org, accessed on 3 October 2024) by Hyperakt is an interactive historical timeline that maps refugee migration trends, with the length and direction of the lines conveying the scale and complexity of global displacement, highlighting the stories behind the numbers. Lastly, in recent work by the authors, inspired by Chernoff faces [1], we present world happiness data through faces—happiness is mapped to the mouth shape, social support by smile width, generosity by eyebrow length, GDP by face size, and life expectancy by ear length [2].
Individuals often explore many tens of alternative design ideas through a rapid discovery process; they sketch, prototype, and experiment with different visual elements. These initial low-fidelity design concepts are deliberate and critiqued either individually or collaboratively within teams to determine the optimal approach for data visualisation. Subsequently, the chosen designs are implemented to produce the final output. Sketching is often used to outline initial ideas. However, while the sketched design strategy yields faster results than individually implementing and evaluating each solution, it still necessitates time to sketch or prototype these ideas. For example, the Five Design Sheets [3] is often employed to help organise the sketched design process. It prompts designers to sketch numerous ideas (sheet 1), narrow down to three alternatives (sheets 2, 3, and 4), and then finalise the design (on sheet 5). The complete sketching process using the Five Design Sheets method can take hours to finish. Although quick sketches can be conducted in seconds, the outcomes are inherently rough. By leveraging AI, designers can explore a wide range of alternative design possibilities in seconds. However, crafting effective prompts can be difficult. Our solution is to provide a method that guides designers through brainstorming prompts, using a visualisation-focused interface that offers control over parameters, alongside a set of indicative terms to inspire and encourage the exploration of diverse possibilities.
Imagine wishing to explore creative ways to display political data for a political magazine (see Figure 1). We may wish to explore different design ideas and critique each before implementing the final visualisation. Even with this brief scenario, we know we will have different political parties, an understanding of how their popularity has shifted over time, and we may assume that each party is associated with typical colours. We can use this knowledge to help describe narratives, to help us drive the creation of generative pictures. When embarking on the ideation journey, beginning with a “bar chart of political data” may be overly restrictive in scope. Generalising the prompt to “a creative visualisation to show political data” gives a more imaginative picture but is biased towards a human face (Figure 1A). Adding a purpose could enhance clarity, such as “a creative visualisation of political data, arranged sequentially to guide users through a narrative or series of events” (Figure 1B, and rerun to produce C). Prioritising the word “narrative” helps refine the image (D and E). In this example, we are refining our prompts by leveraging our visualisation and design knowledge.

Figure 1.
Generated examples (using GenCraft) to demonstrate potential ideas for ‘a creative visualisation to show political data’. (A) from “a creative visualisation to show political data”, (B) with the addition “to guide users through a narrative or series of events”. (C) a repeat of (B), with (D,E) prioritising the word “narrative”.
This example highlights the potential, but it depends heavily on a deep knowledge of the domain and expertise in visualisation design. While it illustrates how narratives can be constructed to inspire creative designs, it lacks general guidance for designers. Moreover, it raises several research questions. How can we help individuals create effective sentences? How can we structure the sentences to derive new visualisation designs? What key vocabulary can guide users in forming appropriate sentences? How can we support individuals in structuring creative sentences effectively? Is it possible to automate the generation of varied sentence phrasings? What is required is a structure to help designers create intuitive designs, a set of indicative words that designers can use in their own design work, and a tool to help people structure and engineer appropriate sentences.
The objectives of this paper are to explore the potential use of artificial intelligence in this design process. VisAlchemy started with the vision of being able to take a thought or an image in our imagination and rapidly translate that into a detailed concept. Hence, there is a need for a practical interface to guide the user through the stages to extract context relevant to the generation of these conceptual images. The vocabulary of words was a product of this early exploration, which was powerful enough to drive the generative AI in a specific direction more than glue words.
We make four contributions: (1) the five-part framework and design language for prompt engineering in Section 4; (2) a suite of over 300 terms, developed from several underpinning corpuses in Section 5; (3) VisAlchemy implementation that prompts users within the five-part framework, helping to engineer appropriate prompts, in Section 6; and (4) five usage scenarios that demonstrate how the tool can be applied in different contexts, along with a final discussion of the work, in Section 7. Our framework, consisting of five stages, helps individuals focus their prompts on appropriate visualisation vocabulary. Additionally, it serves as inspiration for vocabulary selection. Our suite of visualisation ideation terms acts as an aide memoir for developers but can also be used to ‘roll the dice’ in the implementation, further helping creative output. Our implementation tool (VisAlchemy) uses the SDXL model and runs on a local machine. Individuals can input appropriate descriptions through our interface and change the narrative order and weighting. Our design methodology is particularly well suited for exploring alternative and imaginative visual representations, as well as generating potential design concepts applicable to data art and creative visualisations. The resultant images serve as design inspiration. Selected ideas can be subsequently refined and applied to real data, ultimately culminating in finalised visualisation solutions. In the context of visualisation, we borrow the term alchemy to emphasise the idea of transformation, synthesis, and creative experimentation. We suggest that designers have the ability to take raw materials, ideas, and influences, and through a process of creative synthesis and refinement, use them to generate something new and valuable.
This paper offers a valuable set of vocabulary that can be applied across various generative tools, helping developers create inspiring AI-generated visualisations. It also provides researchers with a comprehensive set of terms that can be adapted and applied to other generative projects. Lastly, end users can leverage the five-part strategy and underlying principles to meet their specific needs and generate custom visualisation designs.
The structure we chose for this paper really guides the user through the process and demonstrates its usefulness. In Section 2, we explore the foundation. Section 3 is broken into three parts: “Creativity and Inspiration”, “Keyword Selection”, and “Generative AI in Visualisation”, each building on the foundational knowledge required for this work. Then, Section 4 demonstrates how the process was developed. Getting Section 5 right was important, and this section dives into how these words were chosen. Section 6 is the user interface that was developed that enhances the process. Section 7 show a practical example of how the process works and gives example outputs that demonstrate the usefulness of artificial intelligence in conceptual work. Finally, Section 8 discusses and concludes the whole paper and invokes some potential pathways for future work.
2. Background
We have been exploring methods for design inspiration, specifically techniques that promote creativity in the visualisation design process (cf. [3,4]). Our focus is on encouraging individuals to think outside the box and explore alternative, perhaps even unconventional, design concepts. Ideating new design ideas is not easy. It requires the designer to consider the task, have foresight how the visualisation will be used, and put their mind in that of the end user. They need to have knowledge of what is possible, doable in the timescale, as well as an idea of the current state of the art and current trends. Based on our extensive experience with VisDice [5] and the Five Design Sheets [3] methods spanning decades, we acknowledge that this challenge is particularly pronounced for learners. Learners frequently find themselves constrained by a limited set of design solutions, often gravitating towards familiar options such as bar charts, line graphs, pie charts, and dashboards. Encouraging them to explore alternative approaches can be incredibly challenging.
We presented VisDice at IEEE VIS 2023 [5], a process that encourages people to consider new ideas and is inspired from symbols on bespoke dice. The randomness from rolling the dice with symbols helps the developer explore new ideas. By using dice, individuals craft oral narratives, which in turn aid them in exploring novel ideas. VisDice was itself inspired by story cubes. Players roll the cubes, typically with different images or symbols on each face, and then use the images that appear facing up to inspire or guide the creation of a story. The randomness of the dice roll encourages improvisation and creativity, as storytellers must incorporate the images into their narratives in imaginative ways. Story cubes are often used in educational settings, creative writing exercises, and group storytelling activities to stimulate creativity, enhance communication skills, and inspire storytelling. VisDice itself can be used to inspire the creation of new visualisation ideas. At our IEEE VIS 2023 poster presentation, in addition to receiving positive feedback, researchers questioned how VisDice could be automated, especially how ideation can be automated. Along with previous research, we started to consider what strategies can be used to create suitable narratives for generative-AI-driven design and how it could be used to create inspiring images that can be used in a visualisation process. But the move to AI is a shift of effort, moving from considering how to sketch designs towards engineering appropriate prompts and narratives. Subsequently, individuals must grasp appropriate design vocabulary to effectively engage in the process.
This paper focuses on developing narratives as prompts for generative AI, along with providing tools (including both key terms and a practical implementation) to enable users to create them. We define the five-part framework in Section 4. Not only do we look at the overall structure of the prompts but also the vocabulary used. We draw on our previous knowledge and analysis of the visualisation corpus (cf. [6]) and the related literature to develop a suite of terms (see Section 5). Crafting a well-honed prompt is essential to unlocking the full potential of text-to-image generation. The framework we propose mirrors the stages of transformation: (i) defining the task, (ii) exploring keywords, (iii) refining the narrative into a prompt, and (iv) creating the output image. In pursuit of creating a prompt that is underpinned by the literature, we started to delve into the nuances of each stage, especially to define the task. To underpin our design, we created three corpuses and used a fourth, the British National Corpus (BNC); see the development of the vocabulary list in Section 5.
3. Related Work
Through visual thinking, individuals use sketches, diagrams, or storyboards to explore ideas and concepts visually, which can lead to fresh insights and perspectives. These ideas are shaped by personal preferences, experiences, and the specific problem being addressed. Our focus is on fostering creativity and inspiration, selecting keywords, and telling stories through visualisation.
3.1. Creativity and Inspiration
The first stage to any solution must be to comprehend the challenge. de Bono [7] articulated that “creative work starts with problem formulation and ends with evaluation plus refinement”, a principle supported by various models such as Wallas’ [8] model: preparation, incubation, illumination, and verification. Jonassen’s instructional design model [9] expresses a similar set of stages. First, articulate the goal, relate it to the challenge, and clarify alternative perspectives before generating problem solutions and rejecting/accepting them before implementing and adapting the solution. Shneiderman [10], in his Genex framework, expresses similar processes: collect, relate, create (think, explore, compose, and review), and donate. Seldmair et al. [11] described a similar iterative process tailored specifically for visualisation design, which involves the stages of learn and winnow, cast and discover, design, implement, and deploy. In this approach, the emphasis is on iterative refinement and exploration to create effective visualisations that address specific user needs and objectives. Ideas help spark the ideation process. Ideation, as discussed by Bachmann and Graham [12], illuminates the lifecycle of ideas, emphasizing the birth and evolution necessary for creative discovery. Whatever design process used (whether sketching or engineering an AI prompt), individuals must learn the process, understand and interpret the results for their application, and must iterate through various design ideas.
Regardless of the method, there is a focus on generating numerous potential solutions. When queried about his inspiration, Nobel Prize-winning chemist Linus Pauling remarked, “The best way to have a good idea is to have lots of ideas” [13]. Inspiration serves as the driving force behind every step of this creative process [14]. But where do these ideas come from? Johnson [15], in his book “where good ideas come from”, explains that there is no ‘eureka moment’, and instead talks of a ‘slow hunch’. Ideas come from a long, hard effort of mixing ideas, talking with people, research, and reflection. Indeed, Shneiderman explains that ideas are “1% inspiration and 99% perspiration” [10]. Similarly, Oleynick and Thrash [16] underscored the importance of ‘effort’ and significant hard work and dedication in the creative process. Even when utilising AI to craft designs, individuals must familiarise themselves with visualisation principles and employ appropriate vocabulary. Merely experimenting with words without understanding their significance is not conducive to effective design.
Ideas and novel concepts can emerge through the fusion of unusual and unconventional terms. Through the process of lateral thinking [7], individuals are encouraged to explore unexpected connections and break free from established norms. In ‘The Act of Creation’, [17] introduces us to bi-association, where the juxtaposition of ideas leads to creative insights. Koestler’s exploration of humour and creativity highlights the unexpected connections that drive innovation. This is at the heart of our work. By merging different ideas together, we can create new design ideas. In VisDice [5], different symbols are used to inspire. The ideas are sparked by observing symbols from a dice roll. In the Five Design Sheets framework [3], alternative ideas emerge through the combination of different design solutions, which are then refined iteratively. With VisAlchemy, people are encouraged to include diverse terms and to create novel pictures. In design activities, the utilisation of analogies serves as a powerful method to stimulate creative thought [18]. While Shneiderman’s work on creativity in user interfaces offers a glimpse into how technology can become a conduit for innovation [10], inspiration needs to be ignited by something. Thrash and Elliot [14] describe the idea as being “evoked by” or “inspired to” do something, emphasising the notion that inspiration prompts action or motivation to engage in a particular activity or pursuit. Hence, what is necessary is a stimulus object [16], which may arise from experiences, conversations, or discoveries in one field and be applied to another. Indeed, analogy can be a powerful stimulus. Boden emphasises analogy and metaphor in creative thinking [19]. For example, biology has inspired computing algorithm development, from particle swarm and genetic algorithms to ant colony optimisations (bioinspiration). Or, inspiration can come from ancient materials (paleo-inspiration). Different symbols, inspirational objects, and analogies help the designer create alternative viewpoints and different narratives. Ward’s exploration of creative cognition and conceptual combination [20] resonates with the essence of crafting visual imagery from textual prompts. Indeed, through the lens of creative writing by Stephen R. Donaldson, Ward delves into how diverse ideas are merged to create intricate narratives [20]. With VisAlchemy, we help individuals contemplate alternative narratives (prompts), which are used to create different pictures. By substituting different words and phrases within the narrative, we can generate alternative prompts that showcase varied perspectives, facilitating the development of imaginative designs.
3.2. Keyword Selection
Keywords are crucial in guiding the generative AI system to produce visual representations that align with the intended theme or concept. English literature is renowned for its extensive utilisation of symbolism and imagery to convey complex ideas and emotions [21,22]. Keywords drawn from literary works often carry layers of meaning and evoke powerful visualisations. For instance, phrases such as “serene sunset”, “whispering winds”, or “enchanted forest” are rich with vivid imagery, capable of inspiring the creation of evocative visual scenes [23,24]. By leveraging these literary keywords, generative AI systems can be directed to craft visual representations that resonate with the depth and richness found in classic and contemporary literature [25,26]. Specific keywords in English literature are selected for their capacity to evoke distinct emotions or moods [27,28]. Terms such as “melancholy”, “ecstasy”, “nostalgia”, or “yearning” not only describe emotions but also elicit them in readers [29,30]. When used as prompts for text-to-image synthesis, these emotionally charged keywords can guide the AI system to create images that capture the desired sentiment. Whether it is the melancholic hues of a rainy day or the euphoric colours of a vibrant celebration, these keywords bridge the written word and visual representation, imbuing the generated images with a profound emotional resonance [31,32]. Themes and archetypes prevalent in English literature provide a rich source of keywords that resonate with universal human experiences and narratives [33,34]. Keywords such as “hero’s journey”, “star-crossed lovers”, or “forbidden fruit” evoke entire story arcs and mythic structures [35,36]. By incorporating these keywords into prompts, generative AI can weave visual narratives that resonate with cultural motifs [37,38].
These keywords serve as concise representations of expansive narratives, directing the AI to generate images that are not only visually captivating but also infused with the depth and familiarity of literary archetypes [39,40]. In essence, selecting keywords from English literature is a deliberate process aimed at harnessing the rich tapestry of symbolism, emotion, and narrative in literary works. By choosing carefully curated keywords, practitioners of generative AI can tap into centuries of literary tradition to inspire the creation of visually captivating and thematically resonant images.
Prompt engineering is a technique for enhancing the collaborative narrative between humans and AI. It is a promising direction for future narrative creation and interactive storytelling [41]. The exploration of interactive systems like PromptMagician, which aids in refining prompts for text-to-image generation, illustrates the potential of user-centric design in prompt engineering [42]. Further, developing automatic prompt engineering methods like PE2 showcases advanced techniques for improving LLMs’ efficiency in custom tasks [43]. The introduction of frameworks, such as CLEAR, highlights the importance of structured approaches in interacting with AI models [44]. The CLEAR framework principles are Concise, Logical, Explicit, Adaptive, and Reflective, and help to develop better AI-generated content. Studies on GitHub Copilot’s use in solving programming problems emphasise the role of natural language prompts in code generation and the emerging skill of prompt engineering [45]. Research on visual prompt engineering for Artificial General Intelligence (AGI) underscores the significance of visual cues in enhancing model understanding and performance [46]. Lastly, using generative language models in entrepreneurship to create compelling narratives demonstrates the broader applications of prompt engineering in various fields [47].
3.3. Generative AI in Visualisation Storytelling
The intersection of generative AI and visualisation storytelling is a burgeoning field highlighted by diverse research efforts and the pivotal role and integration of traditional art colours through AI, enriching modern graphic and interactive design with culturally resonant visual experiences [48]. The adaptation of traditional crafts in the digital era suggests using generative AI to bridge traditional aesthetics with modern design needs [49]. Complementing these perspectives, scholars have assessed how generative AI can inform HCI technology’s future, facilitating the creation of culturally infused, interactive designs [50]. Adding a tangible dimension to storytelling through AI-driven tactile experiences enhances narrative immersion [51]. The fusion of AI with storytelling and cultural motifs offers a vision for future-oriented narratives in design [52]. The evolving landscape of design, underscored by the integration of generative AI and phenomenological perspectives, presents a multifaceted approach to visualisation storytelling. Critiquing the prevailing digital-centric design paradigms, advocating for a phenomenological method that emphasises direct engagement with natural forms is crucial [53]—delineating the spectrum of future-oriented design strategies, where generative AI plays a critical role in navigating between optimising the present (affirmative design) and imagining radical alternatives [54]. The practical aspects of implementing generative AI tools in design collaboration, especially in online product ideation, need clarity. It highlights that there is a necessity for tools that better support creativity and teamwork in digital environments, pointing towards a future where AI aids in overcoming the limitations of current online collaboration tools [55]. Exemplifying the power of storytelling in visualisation, aided by AI, to expand the horizons of design thinking and future scenario planning is an asset [56]. PlotThread demonstrates the potential of reinforcement learning to enhance visual stories’ narrative coherence and aesthetic appeal and the practical application of AI in improving the design and communication of complex narratives [57].
Recent research sheds light on the potential and pitfalls of current methodologies and theoretical frameworks in the domain of generative AI and its application to storytelling and narrative design, particularly within interactive digital narratives (IDNs) and education. There are inherent biases in AI-generated storytelling, emphasising the necessity of reparative strategies to foster inclusivity and counteract stereotypes, especially within higher education and creative sectors [58]. There is a real-time solution to narrative generation, which is critical for developing more immersive and user-responsive storytelling environments and highlighting the effectiveness of state constraints for real-time narrative control and scalability [59]. There are recommendations for avoiding theoretical pitfalls in IDN research and design, which is invaluable for scholars and practitioners aiming to deepen their understanding and improve the crafting of interactive narratives [60]. There is an inherent need to prepare students for future digital communication challenges [61]. AI technologies should augment rather than diminish human narrative creativity [62]. The impact of digital storytelling in fostering learning, skill development, and community engagement among women in Science, Technology, Engineering, and Maths (STEM) fields underscores the power of narratives from female technology leaders [63]. Demonstrating Virtual Reality’s (VR) capacity to influence participants’ cultural perceptions and values emphasises VR storytelling’s potential as a transformative educational tool [64]. MEMEX is a tool that leverages AI and Augmented Reality (AR) to make digital storytelling more inclusive. By focusing on communities at risk of exclusion, MEMEX showcases the potential of cutting-edge technologies to bridge the digital divide and ensure that marginalised narratives are heard [65]. The concept of “perspective story sifting”, a methodology for enhancing narrative completeness and participant engagement, highlights the potential for generative and emergent narrative techniques to coalesce in interactive storytelling environments [66].
Clarity in how to create valuable narratives is crucial, which could be done with a tool that simplifies the process of designing branching narratives and integrating them with visual elements. The Unity plugin democratises complex narrative creation and enriches the interactive storytelling ecosystem [67]. An exciting concept that could be applied to generative AI is an interactive model that allows users to navigate a story world without definitive conclusions, expanding the possibilities for storytelling in VR environments where the narrative is perpetually unfolding [68]. People playing with AI Dungeon, an LLM-powered text adventure, highlighted the dynamic relationships between players and AI-driven narratives, revealing insights into player motivations and the impact of technology on storytelling experiences [69]. Thanks to a standardised dataset of novel objects, cognitive science can be explored deeper, enabling further exploration into how humans process visual information that does not conform to familiar patterns [70]. An educational tool that simplifies the exploration and understanding of generative adversarial networks (GANs) called GAN Lab is crucial in demystifying complex deep learning models and encouraging broader engagement with AI technologies by facilitating hands-on experimentation and real-time observations of GAN training processes [71]. Collectively, these studies showcase the innovative application of technology in narrative and cognitive research, pushing the boundaries of how stories are told, experienced, and understood. They underscore the ongoing evolution of narrative mediums, the critical role of technological advancements in shaping narrative possibilities, and the potential for new research directions in cognitive science and interactive storytelling, which is the goal of all visualisations: to tell compelling stories about data.
4. Developing and Defining the Five-Part Framework
To develop the formal framework, we explored key areas of generative AI, prompt engineering, storytelling, visualisation design, as well as creativity and inspiration. From reviewing the related work across these domains, we identified several foundational concepts and techniques to guide our approach. To structure and refine our ideas, we employed affinity diagramming. This method allowed us to group similar ideas together and categorise and organise them to help refine insights. This process helped us establish clear relationships between different elements and define the framework.
In order to produce suitable outputs in prompt engineering [72], the autoregressive language model requires individuals to input context. There needs to be clarity in the prompt and specificity providing clear instructions to define the relevant topic, style, format, and output. The phrases need to be relevant to the topic, and balance needs to be made between providing enough detail to guide the AI output while allowing for creative interest and freedom. Templates and recipes have therefore emerged; in fact, OpenAI’s documentation provides over 30 prompt-phrasing recipes, guiding people to use the system effectively. For instance, to prompt a visual art piece, the recipe suggests people define a [theme] (such as to start with “a futuristic cityscape” scene); add in key details to define the mood, such as “with glowing neon lights”; and add an [art style], such as “in watercolour” and any other [elements], perhaps “mist” or “floating cars”.
Oppenlaender [73], explaining example art prompts from freelancers and bloggers, suggested a template of [medium] [subject] [artist] [details] [image repository support]. For example, we can envision “playing cards of mermaids in the style of Greg Rutkowski with seaweed, starfish and bright colours as trending on DeviantArt”. However, context is crucial. For example, in this instance, are we referring to “a mermaid playing cards” or “a pack of mermaid playing cards”? Each option would yield distinct outputs. Prompt formulations should be organised as narratives, with a clearly defined subject. Unfortunately, prompts may not always produce the desired outcome. The phrase ‘AI whispering’ is used to describe the nuanced communication of AI systems and humans. Whispering draws a parallel akin to the contrast between active and passive voice in grammar, with each narrative creating a different image. For instance, “the visualisation created by Sarah” places focus on the creation of the visualisation, whereas the focus shifts to Sarah in “Sarah created the visualisation”. Pavlichenko and Ustalov [74] pivot keywords () around a central description, describing a process where . For instance, “landscape painting” is the main description in “breathtaking landscape painting featuring a majestic mountain range, bathed in the golden light of sunrise, in the style of renowned artist Bob Ross”. The subject is influenced or tailored by “style phrases” (sometimes referred to as “vitamin phrases” or “clarifying keywords” [73]). Phrases act as catalysts or guiding principles that steer the AI model towards producing more relevant, coherent, and contextually appropriate responses. They can include descriptive adjectives, contextual cues, specific instructions, or thematic keywords designed to shape the direction and tone of the generated text. While Oppenlaender’s framework offers a foundation for general art, and Pavlichenko and Ustalo focus on keywords, our objective differs. We aim to concentrate specifically on visualisation design and thus need to look at foundational visualisation design research.
Designers of data visualisation solutions place emphasis on comprehending the data, carefully mapping key components to visual variables, and the presentation of information within its relevant context. For instance, Jacques Bertin [75] identified seven “visual variables” that are fundamental to designing effective visual representations of data; position (xy), size, shape, value, colour hue, orientation, and texture. These variables help convey the structure of the data and are the building blocks of information graphics, such as maps, charts, and graphs. They enable designers to create alternative designs, where a numerical value can be presented by position from a common scale, or mapped to a colour, or alternatively mapped to size. Bertin advocated for rearrangement, emphasizing that modifying the arrangement of data—such as reorganizing rows and columns in tables or matrices—can uncover patterns that may not be apparent in the raw data. He also highlighted visual rearrangement, which involves changing the implantation (point, line, area, and 3D) or altering its arrangement (linear, circular, hierarchical, and grid). Bertin also identified various design types. He emphasised maps (any representation where locations correspond to real-world geographic meanings), networks (connected visualisations like graphs or trees, such as the London Underground map), diagrams (schematised sequences of steps), and symbols. Consequently, when designing visualisations, we can instruct the AI to not only render the image in a particular art style but to concentrate on elements like a network graph or geographic map. Alternatively, we can incorporate specific types of visualisations, such as bar charts, line graphs, pie charts, and others. Work from other visual designers can be also added. For instance, both John Tukey and Eduard Tufte [76] emphasise simplicity, with Tufte suggesting that chartjunk and other unnecessary decorative elements should be removed. Shneiderman, in his Genex framework (Collect, Relate, Create, Donate), emphasises experimentation to discover new solutions. Rosling [77] was well known for his interactive presentations aimed at challenging misconceptions, frequently utilising real-world examples and physical objects to convey his message.
Using an affinity diagramming technique, we gathered key terms from various visualisation designers and placed them on a shared board. This collaborative space allowed us to organise and rearrange the terms. Drawing from related work methodologies, design strategies, and our affinity diagramming process, we identified several important insights. First, the subject matter is crucial, and second, the aesthetics and presentation of the visualisation are equally vital, an aspect that we call aesthetics. This gives us two of our first major categories in our five-part process, see Figure 2.
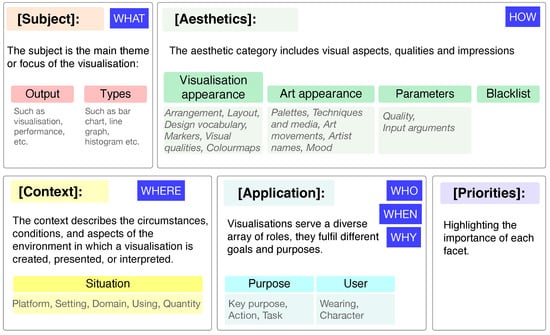
Figure 2.
The 5-part framework for crafting a visualisation design prompt includes considering the [subject] with specific [aesthetics] in a given [context] for [application] with specific [priorities]. Each category is further broken into sub-categories, such as output or types of visualisation in the subject, visualisation appearance, and artistic appearance and parameters or constraints within the aesthetics category. Context and application have additional tertiary categories that are defined to provide deeper detail.
The [subject] guides the development process by clarifying what is needed. Are we designing a dashboard; a highly manipulative interface with buttons, sliders, and pull-down menus; or an infographic, geographic map, network diagram, or something else? Each output represents a unique display or output device, each serving a specific purpose. We categorise outputs into two variants: general outputs or specific visualisation types. In the general sense, we might create a ‘visualisation’, ‘information visualisation’, ‘scientific visualisation’, or other ‘display’ style. For instance, a general output could be an exploratory visualisation tool that allows users to interactively explore data, a dashboard for analysing specific data, or an infographic that tells a story, accompanied by text. Alternatively, we can be more specific, requesting design types such as a bar chart, line graph, scatter plot, or violin plot. However, requesting specific visualisation types can be challenging in AI, as they strongly shape the output and can dominate the overall design, limiting flexibility and creativity in the visualisation. Subsequently, designers must maintain a clear focus on visualisation design while avoiding specific phrases that could overly dictate or dominate the final display. Phrases like “a visualisation design” steer the AI towards generating broad visual representations, whereas terms such as “a bar chart showing” or “line graph of ..” may narrow down the output, potentially hindering the creation of inspiring design images. Subsequently, it is crucial to formulate prompts using expansive and descriptive language, utilising design terminology that fosters a wide spectrum of interpretation, akin to the divergent expressions that facilitate a broad range of design ideations, rather than employing language that narrows down possibilities.
Second, the [aesthetics] and structure of the visualisation are crucial. We add four sub-categories: visualisation appearance, art appearance, parameters, and blacklist. Each help to define the aesthetic appeal and appearance of the work. In visualisation, designers will use techniques from, e.g., Bertin [75] to exchange the data variables with visual variables. This involves carefully mapping the data to appropriate retinal variables, such as the position, colour, size, shape, or texture to ensure the information is both clear and impactful. How these visual elements are organised greatly influences how the data are understood. We define these as visualisation appearance terms. Visualisations can adopt various layouts—such as circular, linear, hierarchical, grid-based, or more complex non-linear formats—based on the nature of the data and the intended message. As a result, we define tertiary categories like arrangement, layout, design vocabulary, and more, see Figure 2. The choice of arrangement should enhance readability and highlight relationships or patterns in the data, helping users to grasp key insights more effectively. In addition to the visualisation appearance, we can define aesthetics in terms of general art appearance. In traditional prompt engineering for image generation, users often employ a variety of artistic descriptive terms. These can influence the colour palette, art techniques, and media appearance; reference specific art movements (such as pointillism or others); evoke the style of a particular artist (e.g., Picasso); or convey the mood of the piece (which we categorise as tertiary terms). Parameters also shape the visual appearance by specifying attributes such as the quality (e.g., resolution and aspect ratio) or other factors (e.g., format and rendering style). Finally, we can specify what should be excluded by blacklisting certain aesthetic terms.
The third primary category of our framework is [context]. Context encompasses the circumstances, conditions, and environment in which a visualisation is created, presented, or interpreted, all of which affect its design. Developers may create a visualisation for various platforms, such as the web, an app, a smartwatch, a powerwall, or a magazine. Each of these contexts impacts design decisions as the medium and user experience differ according to the platform. In the Nested Model for visualisation design, Munzner [78] proposes that designers take into account the context of the task, user, and data. Her model emphasises the importance of understanding the domain and the purpose of the visualisation. Moere and Purchase [79] explore the role of context and presentation style in visualisation, highlighting how the environment in which a visualisation is presented, such as public spaces or digital interfaces, affects user interpretation and engagement. Sedlmair et al. [11] discuss the role of context and environment in the design of domain-specific visualisations, focusing on how the needs of a particular field or task influence visualisation design choices. Context is, therefore, crucial for visualisation design. We identify several tertiary terms within the context of the situation, including the platform, which indicates where the visualisation will be displayed, and the setting, which refers to the location of the visualisation—whether indoors, outdoors, on a powerwall, or in a public space (often referred to as the environment). We define the domain of the subject, which could encompass areas like medicine, physical sciences, or humanities; how the user interacts with the output, such as through a mouse, keyboard, or wheelchair; and the quantity of the users, ranging from a single individual to an audience of thousands.
The fourth category of the framework is [application]. Ultimately, visualisations are crafted for a specific end user, customised for a particular purpose, and serve multiple functions. In other words, they fulfil a distinct [application]. Shneiderman [80] emphasises the ways in which users engage with visualisations based on specific tasks. By concentrating on these tasks, designers can develop more intuitive and user-friendly visualisations that address the unique needs of their audience. Similarly, when prompt engineering visualisation designs, a developer should aim for the output to be tailored for a specific purpose or a particular user. This means considering the intended goals of the visualisation, such as whether it is meant for exploratory analysis, data presentation, or decision making. Understanding the user’s background, expertise, and preferences is crucial to ensure that the visualisation effectively communicates the necessary information. For instance, if the target audience consists of data scientists, the developer might incorporate more advanced analytical features and technical terminology. In contrast, if the audience includes non-technical stakeholders, the visualisation should prioritise clarity and simplicity, avoiding jargon and focusing on key insights. By clearly defining the purpose and user profile, developers can create visualisations that not only meet the functional requirements but also enhance user engagement and comprehension. This approach fosters a more effective interaction with the data, ultimately leading to better decision making and insights. In prompt engineering, we may also want to visualise a specific type of user, such as someone who appears casual, formal, or is wearing a hat.
The final part is to define the [priorities] of the terms. With visualisation design, we must express a story that fuses the subject with the aesthetics and appearance of the design of the visualisation, which sits in a particular context and could be applied for a specific purpose. Weights can be assigned to each term to indicate its significance in the overall design. This can be accomplished using a numerical scale (e.g., 1 to 5) or a qualitative scale (e.g., low, medium, and high). When determining the weight of each term, designers should consider factors such as the target audience for the visualisation and whether context is more critical than appearance. Different purposes may necessitate varying emphases. For instance, a report might prioritise clarity and accuracy, while a futuristic design in Virtual Reality could benefit from a more sketchy or artistic aesthetic. Balancing and weighting the terms can guide generative AI towards specific visual styles. Prioritising these terms helps create a balance that aligns with the overall objectives of the visualisation.
5. Developing a Detailed Design Vocabulary for Visualisation Design Prompt Engineering
In order to craft effective prompts, it is essential to comprehend both the language of visualisation design and the language required for guiding generative models. Selecting words with significance in meaning is crucial, and their choice is influenced by the context provided by surrounding words. Especially understanding word collocation [6] and term frequency is important for appropriate AI prompt design. Collocation refers to the natural combination of words that often occur together in a language. By leveraging natural and contextually appropriate word combinations, prompt engineers can enhance the clarity, relevance, and overall quality of the generated outputs, resulting in a more productive interaction with the model. While an expert visualisation designer may inherently understand important terms, a learner will need to discover them through exploration and learning. Subsequently, we offer a compilation of words that readers may utilise. Additionally, we can integrate these words into our system to enable a “dice throw” function, facilitating the generation of random prompts, using these terms. Furthermore, we present a summary of our words in Tables (e.g., Table 2), which readers can employ in their own applications or use to guide other text-to-image generative AI systems.
We use a corpus-based approach to analyse language data. By analysing the corpora, we are able to empirically analyse the language based on real-world use rather than prescriptive grammar, and we can identify the patterns, frequencies, and occurrences of words. This helps to contribute to a better understanding of the language in context. We base our analysis on Kilgarriff et al. [81] as used by Roberts et al. [6]. We proceeded as follows:
Our initial objective is to determine the corpus we want to create, followed by selecting the journal papers to include in it. We wanted a breadth of corpuses for different purposes. We needed a general yet comprehensive visualisation corpus (V7) to analyse the visualisation words and look at visualisation types. We also needed a way to investigate specific visualisation design words and specific art phrases. Subsequently, we developed a specialist corpus composed of terms from visualisation design papers (VC) and the other sourced from art papers (AC). Finally, we needed a way to explore general terms in the English language. We chose the British National Corpus, BNC, because it is well used and convenient to utilise.
- To develop the visualisation corpus, we use the corpus that we had used in our multiple views terminology study. This is a 6-million-word corpus of all IEEE visualisation publications from 2012 to 2017 [6] (V7), created through SketchEngine [81]. Our goal for this corpus was to generally investigate visualisation words and specifically create a list of visualisation chart types.
- We created a subject-specific corpus of ‘visualisation design’ publications, referred to as the VC corpus. This corpus was developed to analyse the terminology used within the visualisation design domain. To curate the set of papers, we utilised the database of titles and abstracts from the updated vispubdata.org data, which cover visualisation publications from 1990 to 2022 [82]. This includes a comprehensive collection of papers from the IEEE VIS conference, the Transactions on Visualisation and Computer Graphics journal, and other prominent visualisation venues. We filtered for papers with ‘design’ and ‘visualisation’ in the title or abstract, yielding a list of 43 research papers. The corpus was compiled using AntConc, resulting in a dataset of 616,323 words.
- Additionally, we developed a second subject-specific corpus focused on art design, art theory, and visual communication, named the AP corpus, including a list of 45 papers. We found the papers using jstor, resulting in a set of 360,353 words.
- Finally, we used the British National Corpus (BNC), which is a large, structured collection of texts that serves as a resource for studying the English language. It consists of approximately 100 million words of written English, from books, newspapers, magazines, and academic journals.
Similar to the V7 corpus and the development of visualisation types, we employed both top-down and bottom-up approaches. We began by extracting words from the literature and concepts from related work and scenarios to generate a list of potential terms. These terms were then explored within each corpus. Additionally, we examined collocated words (n-tuples) in the corpus to further expand and refine our list of terms. We organised the terms into four main categories: [subject], [aesthetics], [context], and [application], as outlined in Section 4, and added a fifth with [priorities]. Each category contains either a visualisation-specific phrase or a general term that would be suitable for generating an image in any generative AI narrative system. We conducted a frequency analysis, reporting the frequency where applicable , and explored word collocations using the five-part framework (Figure 2), including secondary and tertiary categories.
5.1. Subject: Output
The terms representing the [subject] are essential as they establish the core focus or theme of the visual. These terms define the primary object or topic being depicted. In our categorisation, we differentiate between general terms, referred to as the output (see Figure 2) and those specifically related to visualisation designs, which we classify as types. A commonly used general term is “view” [83]. The terms “view” and “visualisation” are often used interchangeably [6]. To perform an analysis of indicative words, we used the V7 corpus in SketchEngine [81]. Using this database, we created a synonym set on the word “visualisation”. This gives us an idea of some general terms that we could use to start the narrative. For instance, if we ask it to give us a picture of a system or a representation, the top 60 results (ordered by their LogDice score of similarity [81]) are as follows:
analysis, datum, view, technique, system, model, method, representation, design, task, approach, interaction, information, result, feature, graph, set, structure, tool, dataset, space, type, algorithm, map, process, study, pattern, user, exploration, value, layout, application, field, image, point, cluster, function, interface, example, time, comparison, group, plot, selection, region, chart, case, node, data, work, network, distribution, change, number, rendering, display, size, tree, colour, object.
While useful as a broad set of words, we believe a specific set will be more useful. Furthermore, some of these words are general words (outputs) while others are specific (types). To refine the list, we look to the VC corpus. We can imagine that someone may request to “create a representation of person-to-person network data” or ask the generative AI tool to “give me a data visualisation of..”. Any of these phrases can be used to start the generative AI narrative. Each choice dictates the style and elucidates the primary design concept, and is likewise common within our specialist (VC) corpus. For example, we can imagine requiring “a visual presentation of ..”. , including the following: to design a ‘visualisation of’ , or to create a specific ‘data visualisation’ , perform a ‘visual analytics’ or develop a ‘method for’ or ‘representation of’ , create a ‘visualisation system’ , or explain a ‘method to’ . Bertin [75] also listed a set of output types, diagrams (and infographics), networks (and graphs), maps, charts (and plots), symbols, images, and pictures, which we add into the word list. Subsequently, we finalise a set of 32 indicative terms, see Table 1. We can imagine that instead of asking for “a visualisation to display data”, we can swap in any of these ideas, such as “I want a system that will display data” or “give me a holographic display” and so on.

Table 1.
Visualisation outputs collated from the V7 broad list of words, refined by words in VC, and compared against their use in AC and the BNC. When used in a visualisation context, these terms tend to appear more frequently in the visualisation (VC) corpus and less often in the art (AC) or general corpus (BNC). The reverse is also true.
5.2. Subject: Types
We acknowledge that there are many resources that include types, such as the data visualisation catalogue, which can be referenced. Because many of these lists are hand curated, we decided to take a corpus approach. To compile our reference list of visualisation types, we applied both top-down and bottom-up strategies. We began by reviewing a selection of foundational papers on visualisation tools, including ManyEyes [84] (e.g., Viegas et al. [84] provided insights on the usage frequency of specific visualisation types in ManyEyes), Infovis Toolkit [85], D3.js [86], Obvious [87], Jigsaw [88], and Keshif [89]. These papers were chosen to span various years and represent a broad spectrum of visualisation tools, from JavaScript libraries to comprehensive toolkits, and gave us a set of indicative visualisation types. We decided to concentrate on traditional chart types while deliberately excluding interaction techniques. For instance, although Fekete et al. [85] explore operations like fisheye and lens-based interactions, these were omitted from our list. The next approach we used was to look at the thesaurus of words from the V7 corpus. This gives us a list of 35 words, which we again order by the strength logDice score [81] as follows:
bar, boxplot, chart, cluster, contour, drawing, glyph, graph, grid, heatmap, histogram, isosurface, line, list, map, matrix, MDS, metric, network, PCA, PCP, plot, reeb, scatter, scatterplot, splom, statistic, subgraph, table, text, timeline, tree, treemap, trellis, violin.
We can then analyse these words in the V7 corpus to observe their frequency, which lists a specialised set of 40 visualisation types, as shown in Table 2. We emphasise a note of caution, as the inclusion of a specific visualisation type in the narrative tends to dominate the output. For instance, requesting a “pie chart of ..” will steer the output towards pie charts. Our cautionary note underscores the need to craft prompts with broader, more open-ended language to encourage diverse and creative outputs from generative AI systems.
Table 2.
Visualisation types ordered by frequency (f.) from V7 corpus (6-million-word corpus of all IEEE visualisation publications from 2012 to 2017). Map, scatterplot, diagram histogram, parallel coordinate plot (PCP) timeline, and bar chart are all extremely popular.
Aesthetics helps to determine how the design will look. Many of the terms can be generally applied to any art creation. We define four main categories: visualisation appearance, art appearance, parameters, and blacklist. Each category helps to control a specific part of the aesthetic appearance of the output.
5.3. Aesthetics: Visualisation Appearance
With visualisation appearance, we look at how visualisations can be arranged. Bertin [75] describes this process as implantation, which refers to the placement or positioning of graphical elements within a visual display. It involves making deliberate decisions about the arrangement: the location, size, orientation, and alignment of graphical elements within the visualisation. For example, we can delineate circular, linear, and hierarchical arrangements, as well as other patterns, such as the F-pattern, zigzag, and so forth. Design visualisations also can consider wider layout designs, such as trees, dashboards, or multiple views and define the design vocabulary such as the shape, pattern, messiness, and markers such as a point, line, and shape (from Bertin [75]), as well as visual quantities such as those used in side-by-side and multiple view layouts or the colourmaps used (e.g., rainbow, sequential, and diverging). We collate words from V7 and VC to create a suite of suitable words, see Table 3.
Table 3.
Terms from the V7 corpus under the aesthetic: visualisation appearance category focus on the aesthetic aspects of visualisation. The frequency of these terms is analysed across the VC and AC specialised corpora, as well as the BNC general corpus. The analysis reveals that terms with a strong visualisation focus tend to appear less frequently in the general corpus and vice versa.
We include results where zeros appear, as shown in Table 3, because we consider these terms to be important and influential in generative AI visualisation design. Descriptive phrases like “gritty texture”, “fisheye”, or “inset view” hold significant value within this context and contribute positively to the design process. Terms around colourmaps are more visualisation-specific (cf. work by Brewer et al. [90]) and are included in this category, such as the following: sequential, diverging, qualitative, sequential single-hue, sequential multi-hue, diverging two-hue, diverging three-hue, qualitative arbitrary, and qualitative miscellaneous colourmaps.
5.4. Aesthetics: Art Appearance
We include terms that could be generally applied to any image-based generative AI purpose in the aesthetics:art appearance category. Terms that are about aesthetics yet specific to visualisation are included in the previous category. For example, “a visualisation to be used in a magazine in a grid layout” provides aesthetic details about its form, whereas “A visualisation to be used in a magazine in the style of Picasso with a watercolour appearance” focuses on the artistic appearance of the output. Requesting a “professional” aesthetic or suggesting a “Pollock” style would infuse an abstract vibe, possibly evoking the pour-painting appearance synonymous with Pollock’s renowned style. These terms can be broadly applied to any creation within the realm of data art, including descriptors such as messy, realistic, and textured. We split art appearance into six further tertiary categories: palettes, techniques and media, art movements, artist names, and mood, see Table 4. Palettes include terms such as tones, bold, vibrant, and earthy, and techniques and media include the art media, including photography, oil painting, and pastels. Art movements include Cubism, Expressionism, Graffiti, and so forth. The mood of an expression refers to the emotional atmosphere that the visualisation represents. The phrasing helps to define the overall tone of the picture, which can range from serene and peaceful to vibrant and energetic or from sombre and melancholic to joyful and exuberant. Artists serve as excellent references to define the context and output. In the context of visualisation, the mood is influenced by the colour, composition, and positioning of various items in the display.
Table 4.
Terms for aesthetic: visualisation art are shown. These terms help to define the artistic appearance of the output and are generally applicable for many generative AI projects. Terms are listed in order by their frequency in the VC corpus, and then alphabetical.
Blacklist phrases or words help to direct the output away from unacceptable or undesirable outcomes. Finally, parameters can be added to tailor the output to specific requirements, such as to control the resolution or aspect ratio. Words can be repeated to emphasise significance or enclosed within brackets to denote importance. In our implementation, terms can be weighted, which translates into brackets within the phrase.
5.5. Aesthetics: Parameters and Blacklist
When constructing terms for AI-generated visualisations, two further aesthetic factors come into play: the quality of the AI generation and specific input arguments to control its appearance. The first quality refers to the output’s visual fidelity, clarity, and overall effectiveness in conveying information. It encompasses elements like the resolution, colour accuracy, and the visual coherence of the design. We could ask for an SD, HD, 4 k, or 8 k image, or change the aspect from four by two to ultra-wide, or change it from being realistic or even ultra-realistic. Input arguments help to also adapt the appearance; we could add a seed, or name the image “xyz” to be able to reference it in further conversations, or adapt the aspect on the parameters, or add some chaos 0..100 depending on the system used. We may also want to remove or tweak some aspects by blacklisting particular words or phrases. For instance, if a particular style, colour scheme, or design feature is not desired, we can blacklist those terms to ensure the AI does not incorporate them into the final visualisation.
5.6. Context: Situation
The concept of context in visualisation design refers to the circumstances, conditions, and environment in which a visualisation is created, presented, or interpreted. It plays a crucial role in shaping how the data are displayed, understood, and interacted with by the user. Not only does it affect how the user will interact with the visualisation but also how they control their task [80]. There are many factors; for instance, we can consider where the visualisation will be viewed (e.g., a web browser, mobile app, or smartwatch), the physical or virtual setting (e.g., indoors, outdoors, in a public space, or on a personal device), and the user’s specific environment (e.g., viewing a dashboard in an office or reading an infographic in a magazine). It also encompasses the subject domain (e.g., healthcare, education, or business), the tools available to the user (e.g., mouse or touch interface), and the size and nature of the audience (e.g., a single individual vs. a large audience). We can consider an example scenario of a need to create “a visualisation intended for magazine use”. The phrase qualifies the context: the visualisation is intended to be used in print form or on a computer screen. The magazine style also implies that the visualisation will appear alongside a textual description, perhaps where text flows around the image, and maybe in a column format.
The context and environment in which a visualisation occurs significantly impacts decisions over the design, presentation, and tools used. For terms related to the context of visualisations, we draw from both practical experience and research papers. For example, when contemplating various platforms, we can utilise proxemics to prompt us to consider different devices, ranging from nearby mobile phones and tablets to tabletop screens and projected walls within arm’s reach, as well as room displays and powerwalls. To look at settings, we consider the range of publication and usage scenarios, including ebooks, magazines, for personal use on a screen, public display, in a conference hall, etc. When considering tasks and uses, we can look to research (cf. [80,91]) and consider different human–computer interface devices to use, e.g., a mouse, touchscreen, keyboard, trackpad, joystick, game controller, stylus, graphic tablet, voice recognition, gesture recognition devices, motion controllers, trackball, eye tracking, foot pedal, scanner, microphone, or haptic devices. Finally, designers need to determine the audience, whether it is for individuals, group use, or remote access. We separate the list of indicative words into platform, setting, domain, using, and quantity.
5.7. Application: Purpose and Application: User
The final set of phrases focuses on the application and utilisation of the visualisation Table 5, see Shneiderman’s ‘task by task’ [80] and Shultz et al.’s [92] ‘design space of tasks’. We define the main purpose, task, and how it effectively meets the intended goals. For example, the visualisation could be utilised to compare different groups of people in the data or to demonstrate how the data have evolved over time. Keywords encompass the purpose of the visualisation, such as to explore, confirm, or present, achieved through navigation, reorganisation, establishing relationships, looking at outliers, gaining an overview, or comparing distributions. Visualisations could focus on actions such as the following: zoom, filter, brush and link, hover-over tooltips, sort, details on demand, focus+context, animate, and highlight. Key purposes include presentation, monitoring and reporting, prediction and forecasting, storytelling, and education/training, decision support.
Table 5.
Context in visualisation design refers to the circumstances, conditions, and environment in which a visualisation is created, presented, or interpreted. We classify the context by a situation and define five tertiary categories that allow people to consider the exact situation. We include the platform, setting, using, and quantity.
Ultimately, images may feature individuals, users, or people. However, generative systems may lack the contextual understanding and nuanced interpretation skills possessed by human artists, which means that they do not accurately capture the form or essence of a human subject. Consequently, the inclusion of people in generative art may produce images that feel unnatural or out of place. We also acknowledge potential bias in generative AI, especially in generating pictures with humans. It is a concern as it has the potential to perpetuate stereotypes, reinforce societal biases, and produce inaccurate or unfair representations of individuals. Subsequently, depictions of people may not be ideal in a visualisation design.
6. User Interface Design and Implementation
The user interface of VisAlchemy (see Figure 3) is designed to guide users through the visualisation generation. With a focus on simplicity and clarity, the UI provides a straightforward method that prompts individuals to add the next statement before generating the visualisations. The breadcrumb interface at the top of the form displays the current step and allows users to navigate between sections and move between steps. Completed steps are indicated by a checkmark, providing clear visibility of the user’s progress. Users can move between sections using the back and next buttons. Additionally, they can click on the stepper numbers at the top to jump to specific steps, offering flexibility in navigation. To accommodate varying user preferences and avoid imposing restrictions, we do not adapt the strings or restrict the wording in any way. Prompts can be left blank. The power of the approach is to lead people through the narrative structure; individual prompts can be easily weighted differently, the weights can be easily altered (and the prompt run again), and any stage can be exchanged for new text to run a subset of the intended prompt.
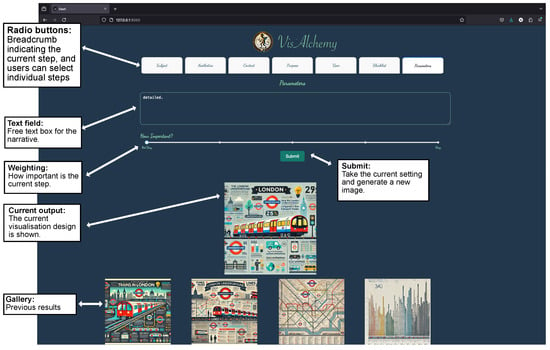
Figure 3.
Screenshot of VisAlchemy interface. Users are prompted to enter the narrative for each variable: subject, aesthetics, situation, purpose, user, blacklist, and parameters.
Upon completing the form, a loading state is activated to inform users that their visualisation is being generated. The generated picture is shown below the input fields, and the history of previously generated images is shown in a gallery below. Remember that the whole point of this process is to trigger inspiration. This is why the gallery plays a pivotal role by seeing the differences between the ideas, as this in itself triggers a moment of inspiration.
The architecture of VisAlchemy leverages Django for its back-end operations and JavaScript for its front-end interactions. Leveraging JavaScript’s extensive library and framework ecosystem streamlined the development process and quickly integrated complex features with less coding effort. JavaScript is used to construct a JSON object that encapsulates seven distinct stages: subject, aesthetics, situation, purpose, user, blacklist, and parameters. We concatenate the user-defined phrases along with articles (such as “the”, “a”, and “an”), prepositions (such as “in”, “on”, and “at”), conjunctions (such as “and”, “but”, and “or”), and pronouns (for the user). These words help to structure sentences, convey relationships between elements, and ensure grammatical correctness, but they do not carry significant semantic content on their own. These stages and their associated weightings form the foundation of the system’s functionality. The weightings are designated as follows:
- A zero indicates no influence (no parentheses).
- A 0.25 signifies minimal influence (one set of parentheses).
- A 0.5 denotes moderate influence (two sets of parentheses).
- A 0.75 represents significant influence (three sets of parentheses).
- A one implies total influence (four sets of parentheses).
These weightings are integrated into a prompt, and subsequently, the prompt is forwarded to the SDXL-Turbo Large Language Model created by Stability AI, which was free and readily available for this project through the diffusers library, utilizing the AutoPipelineForText2Image. Users can choose the number of steps that should be executed for each image generation, with the default setting being 20 steps. Given the computational intensity of these algorithms, utilizing a CUDA-enabled device is highly recommended to expedite the process. However, understanding the limitations posed by hardware requirements, pre-generated samples are available for demonstration purposes. Moreover, the live demo is optimised to utilise fewer steps, allowing for an expedited demonstration while maintaining the essence of the process. This approach ensures that users can experience the capabilities of VisAlchemy without the need for extensive computational resources. Finally, it is worth noting how important context is in these prompts, see Table 6 for hints on vocabulary to use to get the most from context.
Table 6.
The application of visualisation refers to how a visualisation is designed and used to fulfil a specific purpose, perform a particular action, or address a defined task. Each visualisation is created with an intent, and understanding this intent helps shape the design to ensure it meets the needs of the end user. Words are taken from literature and V7 and applied to the VC, AC, and BNC. Although some terms were not found in either the specialised corpora (VC and AC) or the general BNC, we retained them in this list for reference and potential use with generative AI visualisation design systems.
7. Case Studies
In this section, we explore a series of case studies summarised below. At the end of the section, we summarise the case studies in a similar format.
- Case 1: the goal is to visualise the terms most searched for on Amazon.
- Case 2: how to visualise the data from a students union survey.
- Case 3: visualise the annual migration pattern of birds.
- Case 4: the visualisation of data art for public consumption.
- Case 5: the visualisation of population data in the form of an infographic.
This process began with approaching five individuals in our department to create a prompt for us that they might enter into a generative AI platform to generate any visualisations. The selected individuals were perfect as they used these tools but needed more exposure to the underlying technology of Large Language Models or text-to-image software. This allows us to get basic prompts that the average user might type into one such platform and, from there, transmute their original prompt through meticulous deconstruction and restructuring without deviating too far from their original prompt to reveal more inspiring visualisations. We start with the given prompt and restructure it to fit with the seven sections subject, aesthetics, situation, purpose, user, blacklist, and parameters Figure 4. As we progress through each stage, we dynamically adjust each section’s vocabulary, weightings, or both, as described below. We fine-tune the prompt to unearth visuals that fulfil the initial prompt and ignite inspiration. In the first case study, shown in Figure 5, we only change the weightings. The second case study, shown in Figure 6, focuses on only changing the vocabulary. In the third case study, shown in Figure 7, we pick just two of the seven sections, aesthetics and situation, and manipulate the vocabulary. In the fourth case study, shown in Figure 8, we pick three of the seven sections, subject, purpose, and user and manipulate the vocabulary and weightings. Finally, as shown in Figure 9, we change the vocabulary in all sections as well as all the weightings.

Figure 4.
Using our five-part framework (see Figure 2), phrases can be built using the keywords, see Section 5. We suggest concatenating key terms together with appropriate transition words and linking phrases. For instance, generate a “visualisation (subject) with a grid-like shape (aesthetics)for a research report (context) to explain the data (task/application) and for a desktop user (user)”, shown with keywords in bold and linking phrases in italics. These steps directly map to the Radio buttons in VisAlchemy and are individually controlled by adapting their weighting, see Figure 3.

Figure 5.
(I) The first image was generated with equal weighting on all stages. (II) More emphasis on the aesthetics. (III) We removed any priority to the aesthetics and style and focused on the data itself. (IV) Once we were happy with the data, we began to focus specifically on overlaying the data as a meaningful visualisation while trying to avoid standard chart types. (V) is the final output.

Figure 6.
(I) The first image was generated with the vocabulary provided by the original prompt. (II) Subject was adapted to include the word “Info-graphic”. (III) We included some more visualisation types bar, line and also blacklisted clutter. (IV) Pie chart represented question data the best so we removed the other types of visualisations. (V) is the final output.

Figure 7.
(I) The first image was generated using the vocabulary provided by the original prompt. (II) was generated by changing the vocabulary situation. (III) was created by modifying the aesthetics. (IV) was a final alteration to both. (V) is the final output with these settings.

Figure 8.
(I) The first image was generated with equal weighting on all stages. (II) Here, we boosted the weighting of the three sections we wanted to manipulate. (III) We included data art in the purpose. (IV) For something more inspirational, we changed the glue word between the two art forms, resulting in a collaboration between the two styles.

Figure 9.
(I) The first image was generated with equal weighting on all stages. (II) Having already been inspired by the previous image, the goal was to focus on the map. (III) This was a really interesting output but was missing emphasis on the data. (IV) Having found the right balance for the map, we again focused on the data. (V) is the final output.
Our first case study visually depicted Amazon’s most frequently searched product terms, as shown in Figure 5. Our approach involved breaking down the original prompt into four main steps, comprising seven sections. Starting from the initial request, our process unfolded as follows: we defined the subject: visual representation. Aesthetics: most used search terms graph. Situation: similar to the Amazon platform. Purpose: understanding search trends. User: Amazon users and analysts. Blacklist: irrelevant information. Parameters: data accuracy and visual clarity. This breakdown led to the creation of image I in Figure 5. Initially, without prioritising any aspects, all elements were treated equally, requiring users to adjust the weightings to achieve their desired outcome. Image II shows the result of placing more weight on the graph’s aesthetics, leading to a more stylised look. Image III then shifts focus, reducing the weight on aesthetics while increasing it on situation and purpose, demonstrating a balance between these elements. Finally, image IV illustrates the successful balance among aesthetics, situation, and purpose, resulting in an inspiring visualisation. The VisAlchemy tool proved its worth in this case study by enabling us to refine our visual output to meet specific goals. This method allowed us to create an informative, innovative, and inspiring visual. The success of this approach in our first case study highlights its flexibility and effectiveness in tackling various data visualisation challenges.
The second case study began with the following: “Data that the students union collated from a student survey. Make tables for charting the data and an attractive pie chart for describing the data below in a fun way”, see Figure 6. Image I was produced using the prompt created by methodically deconstructing the original prompt into our seven-stage framework: Subject: fun and attractive. Aesthetics: tables and pie chart. Situation: students union survey. Purpose: data description. User: students and decision makers. Blacklist: presentation. Parameters: accuracy and aesthetic appeal. Image II was created by adding the term infographic to the prompt. Subject: fun and attractive infographic, which resulted in a cluttered infographic. Image III was created by adding some vocabulary to the prompt: aesthetics: tables, pie, bar, line; blacklist: cluttered, which resulted in a less cluttered infographic with more chart types. IV. at this stage, we had a less cluttered infographic, but the other chart types distracted us from the purpose of visualising the responses to the questions. Therefore, aesthetics: tables and pie chart was restored. It resulted in an infographic that could inspire the creation of a visualisation to display student data in a fun and attractive way. VisAlchemy once again proved its prowess in transforming complex data into engaging visual outputs tailored to inspiration. Its success in addressing the unique requirements of the students union survey underscores its adaptability and effectiveness in turning data visualisation challenges into opportunities for innovative, inspirational, and purposeful design.
We began with a straightforward request: “Visualise the annual migration patterns of birds across the UK, highlighting their flight paths and nesting grounds”, with the outcomes illustrated in Figure 7. The initial image [I] was produced after restructuring the original prompt into the VisAlchemy structure. Subsequent visuals were derived by methodically adapting the vocabulary and weightings for appearance and situation. The original prompt after being adapted for AlechemyVis was as follows: Subject: realistic with an artistic touch. Aesthetics: a comprehensive map of the UK showcasing avian migration routes. Situation: a resource aimed at avian research and preservation efforts. Purpose: to facilitate a more profound comprehension of avian migratory behaviours. User: targeted towards ornithologists and environmental conservationists. Blacklist: exclusion of overly simplistic, cartoon-like depictions. Parameters: emphasis on the delivery of high-fidelity, precise visual data. II. It was clear that the individual who made this prompt wanted to display the data on a map, and specifying the UK from the beginning would be too restrictive; therefore, that was removed from the aesthetics, resulting in a comprehensive map showcasing avian migration routes. Image III presented a fascinating concept and sparked inspiration; however, it does not meet the requirements of being a map, so the weight on aesthetics and situation was increased. This resulted in image IV. Concluding the third case study, VisAlchemy again illustrated its capacity to elevate inspiration for data visualisation. VisAlchemy created a comprehensive map tailored specifically for ornithologists and environmental conservationists. The success of this case study underlines VisAlchemy’s flexibility and precision, proving its utility in crafting visuals that are informative, inspirational, and, above all, meaningful to its intended audience.
Our journey began with the following: “Craft a Jeff Koons or Damien Hirst-inspired sculpture representing data. Display in public for interaction. Avoid typical charts; focus on unique form, lighting, materials”. See Figure 8 for results. The first image was generated using the vocabulary provided by the original prompt. Subsequent visuals were created by methodically changing the vocabulary in the subject: purpose and user sections. Subject: Jeff Koons- or Damien Hirst-inspired. Aesthetics: abstract, three-dimensional sculpture representing data. Situation: displayed in a public space for interaction. Purpose: avoid typical chart formats; focus on a unique form, lighting, and materials. User: general public and art enthusiasts. Blacklist: traditional chart formats. Parameters: emphasise intriguing forms, dynamic lighting, and unconventional materials. II. The first step was to set the weighting higher for the three areas that this case study was testing. III. Curious how the sculpture would look outside, we modified the aesthetics to include this option and removed “Avoid typical chart formats” from the purpose as it was covered in the blacklist already. IV. The only change made here was the wording of the subject: to have both artists, not one or the other. In this case study, VisAlchemy successfully blurred the lines between data visualisation and contemporary art by creating a sculpture inspired by the iconic styles of Jeff Koons and Damien Hirst. It paves the way for future explorations into inspiring data art, demonstrating the potential to engage data art enthusiasts in the inspiration process.
In the final case study, our challenge began with the following: “Create an infographic detailing the population demographics of People in a city, from men and women to children”, with the outcomes illustrated in Figure 9. The first image was generated using the vocabulary provided by the original prompt. Subsequent visuals were created by methodically manipulating the original prompt vocabulary and weightings in the VisAlchemy framework: Subject: modern, infographic design. Aesthetics: demographic breakdown of the city population. Situation: city planning and social research. Purpose: understand population composition. User: urban planners and researchers. Blacklist: avoid overly complex visuals. Parameters: clear data presentation and a concise design. II. Seeing the city layout in the first infographic sparked the idea to have a map, so the aesthetics was changed: aesthetics: demographic breakdown of the city population on a map. The weighting was also increased in this section. III. This produced the desired effect but could be improved if a three-dimensional view were to be implemented: subject: modern, infographic design. This was the highest weighting. IV. Again, the previous image was fascinating but did not ignite as many ideas as hoped. So, the weighting on 3D was decreased. We needed to focus more on the data. The users and parameters weighting were both increased and everything else was decreased apart from aesthetics remaining the same. In this case study, VisAlchemy transformed complex urban demographic data into a streamlined and modern infographic, showing the population composition of a city in an accessible and visually appealing manner. The successful visualisation of this case study highlights VisAlchemy’s ability to distil a simple prompt into an intricate visualisation, reinforcing its role as a resource in data visualisation by facilitating inspiration to a diverse audience.
Through the meticulous application of the VisAlchemy seven-step process, each case study demonstrates the transformative power of thoughtful prompt engineering. The results in Figure 5, Figure 6, Figure 7, Figure 8 and Figure 9 demonstrate enhanced visualisations that adhere closely to the original requests and elevate them to inspire more profound inspiration. This journey reaffirms the importance of a structured approach in navigating the complex landscape of prompt engineering in visualisation, especially when tailored to varied users’ unique perspectives and needs.
- Case 1: weighting the importance of words is key in prompt engineering, and there is clear progression on the concepts being utilised to inspire the creation of visualisations, most noticeably the inspiration to include demographic data.
- Case 2: Such a generic prompt highlights why context is so important to these Large Language Models. Changing the weighting and some vocabulary did yield better results by driving it towards an infographic.
- Case 3: such a strong example of how weighting influences these Large Language Models; the map gets clearer and outputs an image that could inspire the creation of this visualisation.
- Case 4: data art is an area that gets forgotten, so it seemed right to include a case study on it, and this demonstrates how AI can help model real-world visualisations.
- Case 5: population data are always fascinating, and the fact that we gravitate toward infographics demonstrates how even with constraints, the Large Language Model is capable of pushing the boundaries of what we may initially consider, allowing us to gain inspiration.
8. Discussion
This paper introduces the five-part framework and VisAlchemy tool, which provides a novel approach to visualisation ideation that integrates artificial intelligence (AI) to enhance the creativity and effectiveness of images generated through AI for design and visualisation ideation. Through our exploration, we identified key areas that significantly impact the creation of visualisations, from subject and aesthetics to blacklist and parameters, and organised a set of terms to help developers create imaginative visualisation designs.
It was critical to address the challenge of creating an intuitive yet powerful interface for the VisAlchemy framework. Our interface aimed to balance the complexity of prompt engineering with user-friendliness to maximise designer engagement without overwhelming them with technicalities. Additionally, automating the generation of diverse phrasings posed a unique challenge, leveraging Large Language Models (LLMs) to construct context-based prompts for inspirational imagery.
The VisAlchemy tool focuses on prompt engineering for visualisation design. By providing a structured method for crafting effective prompts, we enable designers to better communicate their ideas to AI systems, leveraging their capability to generate innovative visual concepts. Indeed, this paper provides an array of phrases and vocabulary to assist individuals in steering generative designs for visualisations. This approach streamlines the ideation process and opens new possibilities for creativity and exploration. The demonstration of the framework showcases the practical application of our approach. We offer a structure previously unseen in prompt engineering by allowing users to adjust their narrative and weighting, contributing to a more nuanced and tailored design process where the individual’s expertise and creativity are paramount. Our case study illustrates the effectiveness of the framework and VisAlchemy tool in generating imaginative and relevant visualisation concepts. This practical application demonstrates the framework’s potential to transform raw ideas into refined and impactful visual narratives that can inspire visualisation designers.
8.1. How to Use This Work
This paper provides a comprehensive framework and set of methodologies designed to support the effective use of AI in visualisation design. Below, we outline key ways in which different readers, including researchers, designers, and developers, can benefit from and apply the content presented here.
- Researchers in the field of AI and data visualisation can leverage the five-part framework presented in this paper to extend existing models or explore new avenues in prompt engineering, design generation, and visualisation aesthetics. The discussions around design vocabularies, corpus analysis, and the application of visualisation principles offer a foundation for further study and experimentation. The analysis of corpora and frequency-based term investigation may serve as a springboard for a more in-depth analysis of visualisation trends across different domains. The five-part framework (subject, aesthetics, context, application, and priorities) offers a structured approach to prompt engineering for visualisation, helping users fine-tune AI models to generate tailored visuals.
- Designers working with AI-generated visualisations will find practical guidelines and useful design references to guide their process. By following the main five-part framework, along with the secondary and tertiary categories, they will gain a comprehensive understanding of the various aspects of visualisation design. The provided vocabulary can be directly applied to inspire and develop new generative ideas.
- AI developers and engineers can use this paper to improve their models’ generative capabilities by focusing on the core concepts of weighting terms, understanding contextual influences, and balancing between artistic and functional requirements in visual outputs. The insights into prompt engineering, alongside the use of specialised corpora, provide developers with the tools to enhance both back-end processes (e.g., data manipulation) and front-end visual outputs (e.g., clarity and aesthetic balance).
- We also provide tables summarising the frequency analysis and collocated terms to provide quick reference points for readers to identify commonly used terms and their associated contexts, whether designing for exploratory visualisation, dashboards, or other applications. These sections offer practical tools that can be applied in real time when using generative AI systems to create visual outputs.
- This paper includes practical examples and case studies demonstrating how the proposed methods can be applied in different scenarios. Readers can use these examples as templates for similar use cases or adapt them for more specific needs.
Future research will refine the VisAlchemy tool and expand its use across various contexts, including a usage study on participants using the tool. We plan to build upon the Large Language Model, making it more of a visualisation-specific AI model, which may perform better on complex design briefs. However, using the current, generally trained models, we enable more diverse image suggestions and consider that a specifically trained one may be too focused or convergent to current design ideas. Our plans also include investigating different interface layouts and integrating them with a design process, such as the Five Design Sheets method. We aim to enhance the framework’s ability to produce inspirational visuals and explore its educational benefits by incorporating it into design education, thereby equipping future designers with AI-driven creative skills. The VisAlchemy tool and five-part framework are promising developments in visualisation design, aiming to foster creativity and AI collaboration. Continued exploration and refinement will yield significant insights and innovations. Our research opens new avenues for exploring how AI can contribute to creative processes beyond visualisation design. The framework’s principles may apply to other design domains, suggesting a broader impact on creative industries.
8.2. Conclusions
In conclusion, the five-part framework, vocabulary set of terms, and VisAlchemy tool are designed to help visualisation designers find inspiration through generative AI. The VisAlchemy tool demonstrates the potential of integrating artificial intelligence (AI) with the art and science of visualisation design. This fusion paves the way for forms of creativity and innovation and fosters synergy between human intuition and machine intelligence. As we delve deeper into refining and expanding the capabilities of the five-part framework, the horizon of possibilities continues to broaden, possibly redefining the landscape of design in ways we are only beginning to imagine.
The journey of integrating AI into visualisation design is symbolic of a more significant movement towards harmonising human creativity with computational power. This endeavour has its challenges, including the need for interfaces that cater to both novice and expert users, algorithms that can generate diverse and contextually relevant ideas, and systems that support iterative and collaborative design processes. However, these challenges also serve as catalysts for innovation, driving us to develop solutions that enhance designers’ creativity and productivity. The impact of the framework extends beyond the confines of design studios and academic labs; it can potentially influence a wide array of fields where visualisation plays a crucial role. From scientific research and data journalism to education, creating compelling, informative, and aesthetically pleasing visualisations is increasingly essential. By making advanced visualisation techniques more accessible and collaborative, we can help these fields convey complex information.
Integrating AI into the creative process with tools like VisAlchemy encourages us to re-evaluate our relationship with technology. AI becomes not just a tool for automation or a job competitor but a creative partner, a source of inspiration, and a way to discover new realms of expression and innovation. This viewpoint is critical to unlocking AI’s potential in design and other fields. As we progress, developing VisAlchemy and similar technologies will be critical in creating the next wave of design tools and methods, blending AI and design to improve our visualisation capabilities and enrich our comprehension. This evolving field, driven by a commitment to exploration, innovation, and collaboration, aims for a future where design is more inclusive, expressive, and impactful. The development and analysis of the framework highlight the revolutionary impact of combining AI with visualisation design, underscoring our dedication to unlocking the synergy between technology and creativity for advanced visualisation design.
Author Contributions
As the lead author, A.E.O. made significant contributions to the development of VisAlchemy, including the AI, interface, and generation of all examples. He played a significant role in writing the paper and the design and development of the case studies. J.C.R. was responsible for providing the underlying research on the platform’s choice of recommended words and vocabulary, creating Figure 2, and paper editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data created during this study were the prompts that were used in the case studies which are present in the paper.
Acknowledgments
We acknowledge the users, especially Nida Ambreen, who were crucial in giving feedback on the tool, and Dan Boyce for his early prototype of the UI. We thank the participants who provided prompts for our case studies.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial intelligence. |
| SD | Standard Definition |
| HD | High Definition |
| LLM | Large Language Model |
| GAN | generative adversarial networks |
| MDS | Multidimensional scaling |
| PCA | Principal component analysis |
| PCP | Parallel Coordinate Plot |
| BNC | British National Corpus |
| VR | Virtual Reality’s |
| AR | Augmented Reality |
| IDNs | interactive digital narratives |
| IEEE | Institute of Electrical and Electronics Engineers Professional organisation company |
| IEEE VIS | Annual IEEE Visualization and Visual Analytics conference |
| SDXL | Stable Diffusion XL model |
References
- Chernoff, H. The use of faces to represent points in k-dimensional space graphically. J. Am. Stat. Assoc. 1973, 68, 361–368. [Google Scholar] [CrossRef]
- Roberts, J.C. Creating Data Art: Authentic Learning and Visualisation Exhibition. In Proceedings of the Computer Graphics and Visual Computing (CGVC); Hunter, D., Slingsby, A., Eds.; The Eurographics Association: Eindhoven, The Netherlands, 2024. [Google Scholar] [CrossRef]
- Roberts, J.C.; Headleand, C.; Ritsos, P.D. Sketching Designs Using the Five Design-Sheet Methodology. IEEE Trans. Vis. Comput. Graph. 2016, 22, 419–428. [Google Scholar] [CrossRef] [PubMed]
- Roberts, J.C.; Ritsos, P.D.; Jackson, J.R.; Headleand, C. The Explanatory Visualization Framework: An Active Learning Framework for Teaching Creative Computing Using Explanatory Visualizations. IEEE Trans. Vis. Comput. Graph. 2018, 24, 791–801. [Google Scholar] [CrossRef] [PubMed]
- Owen, A.E.; Roberts, J.C. Inspire and Create: Unveiling the Potential of VisDice in Visualization Design. In Proceedings of the Poster IEEE Conference on Visualization (IEEE VIS), Melbourne, Australia, 21–27 October 2023. [Google Scholar]
- Roberts, J.C.; Al-maneea, H.; Butcher, P.W.S.; Lew, R.; Rees, G.; Sharma, N.; Frankenberg-Garcia, A. Multiple Views: Different meanings and collocated words. Comput. Graph. Forum 2019, 38, 79–93. [Google Scholar] [CrossRef]
- De Bono, E. Lateral Thinking: Creativity Step by Step; Penguin: London, UK, 2009. [Google Scholar]
- Wallas, G. The Art of Thought; J. Cape: London, UK, 1926. [Google Scholar]
- Jonassen, D.H. Instructional design models for well-structured and Ill-structured problem-solving learning outcomes. Educ. Technol. Res. Dev. 1997, 45, 65–94. [Google Scholar] [CrossRef]
- Shneiderman, B. Creating Creativity: User Interfaces for Supporting Innovation. ACM Trans. Comput.-Hum. Interact. 2000, 7, 114–138. [Google Scholar] [CrossRef]
- Sedlmair, M.; Meyer, M.D.; Munzner, T. Design Study Methodology: Reflections from the Trenches and the Stacks. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2431–2440. [Google Scholar] [CrossRef]
- Bachmann, T.T.; Graham, D. Ideation The Birth and Death of Ideas; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Crick, F. The Impact of Linus Pauling on Molecular Biology. In Proceedings of the The Pauling Symposium: Special Collections; The Valley Library, Oregon State University: Corvallis, OR, USA, 1996. [Google Scholar]
- Thrash, T.M.; Elliot, A.J. Inspiration: Core characteristics, component processes, antecedents, and function. J. Personal. Soc. Psychol. 2004, 87, 957. [Google Scholar] [CrossRef]
- Johnson, S. Where Good Ideas Come From: The Seven Patterns of Innovation; Penguin: London, UK, 2011. [Google Scholar]
- Oleynick, V.C.; Thrash, T.M.; LeFew, M.C.; Moldovan, E.G.; Kieffaber, P.D. The scientific study of inspiration in the creative process: Challenges and opportunities. Front. Hum. Neurosci. 2014, 8, 846. [Google Scholar] [CrossRef]
- Koestler, A. The Act of Creation; Hutchinson: London, UK, 1964. [Google Scholar]
- Bonnardel, N. Creativity in design activities: The role of analogies in a constrained cognitive environment. In Proceedings of the 3rd Conference on Creativity & Cognition, Loughborough, UK, 11–13 October 1999; pp. 158–165. [Google Scholar]
- Boden, M.A. The Creative Mind: Myths & Mechanisms; Basic Books: New York, NY, USA, 1991. [Google Scholar]
- Ward, T.B. Creative cognition, conceptual combination, and the creative writing of Stephen R. Donaldson. Am. Psychol. 2001, 56, 350–354. [Google Scholar] [CrossRef]
- Abrams, M.H. The Mirror and the Lamp: Romantic Theory and the Critical Tradition; Oxford University Press: New York, NY, USA, 1971; Volume 360. [Google Scholar]
- Miller, J.H. The Ethics of Reading: Kant, de Man, Eliot, Trollope, James, and Benjamin; Columbia University Press: New York, NY, USA, 1987. [Google Scholar]
- Hill, J.S. A Coleridge Companion: An Introduction to the Major Poems and the Biographia Literaria; Springer: Berlin/Heidelberg, Germany, 1984. [Google Scholar]
- Coleridge, S.T.; Wordsworth, W. Lyrical Ballads: 1798 and 1800; Broadview Press: Peterborough, ON, USA, 2008. [Google Scholar]
- Shakespeare, W. A midsummer night’s dream. In One-Hour Shakespeare; Routledge: London, UK, 2019; pp. 19–74. [Google Scholar]
- Eliot, T.S. The Waste Land 1922; Grolier Club: New York, NY, USA, 1964. [Google Scholar]
- Keats, J. Ode to a Nightingale; Good Press: Glasgow, UK, 2023. [Google Scholar]
- Poe, E.A. The Tell-Tale Heart. 1843. In The Tales of Edgar Allan Poe; Longmeadow Press: Stamford, CT, USA, 1983. [Google Scholar]
- Austen, J. Pride and Prejudice (1813); Cadell & Davies: London, UK, 1993. [Google Scholar]
- Gross, A.S.; Scott Fitzgerald, F. The Great Gatsby (1925). In Handbook of the American Novel of the Twentieth and Twenty-First Centuries; De Gruyter: Berlin, Germany, 2017. [Google Scholar]
- Childs, P. Emily Brontë Wuthering Heights (1847). In Reading Fiction: Opening the Text; Palgrave: London, UK, 2001. [Google Scholar]
- Carroll, L. Alice’s Adventures in Wonderland; Maecenas Press: Solon, IA, USA, 1969. [Google Scholar]
- Campbell, J. The Hero with a Thousand Faces; New World Library: Novato, CA, USA, 2008; Volume 17. [Google Scholar]
- Jung, C.G. The Archetypes and the Collective Unconscious; Routledge: London, UK, 2014. [Google Scholar]
- Melville, H. Moby Dick (1851). In Moby-Dick, Billy Budd, and Other Writings; Library of America: New York, NY, USA, 1967. [Google Scholar]
- Milton, J. Paradise Lost, 1667; Scolar Press: London, UK, 1968. [Google Scholar]
- Schrero, E.M. Exposure in “The Turn of the Screw”. Mod. Philol. 1981, 78, 261–274. [Google Scholar] [CrossRef]
- Pihl, A.L. Voices and Perspectives: Translating the Ambiguity in Virginia Woolf’s To the Lighthouse. In Proceedings of the VAKKI Symposium XXXIII. Vaasa 7–8.2. 2013; Vakki Publications: Vaasa, Finland, 2013; pp. 281–291. [Google Scholar]
- James, J. Ulysses; Ripol Classic: Moscow, Russia, 2017. [Google Scholar]
- Tatlock, J.S. The Canterbury Tales in 1400. PMLA 1935, 50, 100–139. [Google Scholar] [CrossRef]
- Harmon, S.; Rutman, S. Prompt Engineering for Narrative Choice Generation. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 208–225. [Google Scholar]
- Feng, Y.; Wang, X.; Wong, K.K.; Wang, S.; Lu, Y.; Zhu, M.; Wang, B.; Chen, W. PromptMagician: Interactive Prompt Engineering for Text-to-Image Creation. IEEE Trans. Vis. Comput. Graph. 2024, 30, 295–305. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Z.; Zhao, L.; Wu, Z.; Ma, C.; Yu, S.; Dai, H.; Yang, Q.; Liu, Y.; Zhang, S.; et al. Review of large vision models and visual prompt engineering. Meta-Radiology 2023, 1, 100047. [Google Scholar] [CrossRef]
- Lo, L.S. The CLEAR path: A framework for enhancing information literacy through prompt engineering. J. Acad. Librariansh. 2023, 49, 102720. [Google Scholar] [CrossRef]
- Denny, P.; Kumar, V.; Giacaman, N. Conversing with Copilot: Exploring Prompt Engineering for Solving CS1 Problems Using Natural Language. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1, New York, NY, USA, 15–18 March 2023; SIGCSE 2023. pp. 1136–1142. [Google Scholar] [CrossRef]
- Strobelt, H.; Webson, A.; Sanh, V.; Hoover, B.; Beyer, J.; Pfister, H.; Rush, A.M. Interactive and Visual Prompt Engineering for Ad-hoc Task Adaptation with Large Language Models. IEEE Trans. Vis. Comput. Graph. 2023, 29, 1146–1156. [Google Scholar] [CrossRef] [PubMed]
- Short, C.E.; Short, J.C. The artificially intelligent entrepreneur: ChatGPT, prompt engineering, and entrepreneurial rhetoric creation. J. Bus. Ventur. Insights 2023, 19, e00388. [Google Scholar] [CrossRef]
- Li, M.; Choe, Y.H. Analysis of the Influence of Visual Design Elements of Regional Traditional Culture in Human-Computer Interaction. In Proceedings of the Cross-Cultural Design; Rau, P.L.P., Ed.; Springer: Cham, Switzerland, 2023; pp. 84–97. [Google Scholar]
- Zhang, J.; Xu, R.; Yang, Z. An Analysis on Design Strategy of Traditional Process in Global Digitization. In Proceedings of the Cross-Cultural Design; Rau, P.L.P., Ed.; Springer: Cham, Switzerland, 2023; pp. 142–154. [Google Scholar]
- Chan, T.; Fu, Z. The HCI Technology’s Future Signals: The Readiness Evaluation of HCI Technology for Product and Roadmap Design. In Proceedings of the Cross-Cultural Design; Rau, P.L.P., Ed.; Springer: Cham, Switzerland, 2023; pp. 169–179. [Google Scholar]
- Chiang, I.Y.; Lin, P.H.; Lin, R. Haptic Cognition Model with Material Experience: Case Study of the Design Innovation. In Proceedings of the Cross-Cultural Design; Rau, P.L.P., Ed.; Springer: Cham, Switzerland, 2023; pp. 180–193. [Google Scholar]
- Fu, Z.; Li, J. Design Futurescaping: Interweaving Storytelling and AI Generation Art in World-Building. In Proceedings of the Cross-Cultural Design; Rau, P.L.P., Ed.; Springer: Cham, Switzerland, 2023; pp. 194–207. [Google Scholar]
- Lin, Y.; Liu, H. Research on Natural Objects and Creative Design from the Perspective of Phenomenology. In Proceedings of the Cross-Cultural Design; Rau, P.L.P., Ed.; Springer: Cham, Switzerland, 2023; pp. 221–236. [Google Scholar]
- Xia, Q.; Fu, Z. Two Categories of Future-Oriented Design: The Affirmative Design and the Alternative Design. In Proceedings of the Cross-Cultural Design; Rau, P.L.P., Ed.; Springer: Cham, Switzerland, 2023; pp. 285–296. [Google Scholar]
- Ye, Y.; Tian, H.; Pei, T.; Luo, Y.; Chen, Y. Online Collaborative Sketching and Communication to Support Product Ideation by Design Teams. In Proceedings of the Cross-Cultural Design; Rau, P.L.P., Ed.; Springer: Cham, Switzerland, 2023; pp. 315–330. [Google Scholar]
- Zhu, L.; Fu, Z. New Space Narrative: Responding to Multiple Futures with Design Perspective. In Proceedings of the Cross-Cultural Design; Rau, P.L.P., Ed.; Springer: Cham, Switzerland, 2023; pp. 331–345. [Google Scholar]
- Tang, T.; Li, R.; Wu, X.; Liu, S.; Knittel, J.; Koch, S.; Ertl, T.; Yu, L.; Ren, P.; Wu, Y. PlotThread: Creating Expressive Storyline Visualizations using Reinforcement Learning. IEEE Trans. Vis. Comput. Graph. 2021, 27, 294–303. [Google Scholar] [CrossRef]
- Jackson, D.; Courneya, M. Unreliable Narrator: Reparative Approaches to Harmful Biases in AI Storytelling for the HE Classroom And Future Creative Industries. Braz. Creat. Ind. J. 2023, 3, 50–66. [Google Scholar] [CrossRef]
- Julie, P.; Marc, C.; Fred, C. Applying planning to interactive storytelling: Narrative control using state constraints. ACM Trans. Intell. Syst. Technol. 2010, 1, 1–21. [Google Scholar] [CrossRef]
- Koenitz, H.; Eladhari, M.P. When Has Theory Ever Failed Us? - Identifying Issues with the Application of Theory in Interactive Digital Narrative Analysis and Design. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 21–37. [Google Scholar]
- Barbara, J.; Koenitz, H.; Pitt, B.; Daiute, C.; Sylla, C.; Bouchardon, S.; Soltani, S. IDNs in Education: Skills for Future Generations. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 57–72. [Google Scholar]
- Fisher, J.A. Centering the Human: Digital Humanism and the Practice of Using Generative AI in the Authoring of Interactive Digital Narratives. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 73–88. [Google Scholar]
- Frade, R.L.; Vairinhos, M. Digital Storytelling by Women in Tech Communities. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 89–102. [Google Scholar]
- Gong, Z.; Gonçalves, M.; Nanjappan, V.; Georgiev, G.V. VR Storytelling to Prime Uncertainty Avoidance. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 103–116. [Google Scholar]
- Nisi, V.; James, S.; Bala, P.; Del Bue, A.; Nunes, N.J. Inclusive Digital Storytelling: Artificial Intelligence and Augmented Reality to Re-centre Stories from the Margins. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 117–137. [Google Scholar]
- Clothier, B.; Millard, D.E. Awash: Prospective Story Sifting Intervention for Emergent Narrative. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 187–207. [Google Scholar]
- Kousta, D.; Katifori, A.; Lougiakis, C.; Roussou, M. The Narralive Unity Plug-In: Towards Bridging the Gap Between Intuitive Branching Narrative Design and Advanced Visual Novel Development. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 226–235. [Google Scholar]
- Mazarei, M. Story-Without-End: A Narrative Structure for Open-World Cinematic VR. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 329–343. [Google Scholar]
- Yong, Q.R.; Mitchell, A. From Playing the Story to Gaming the System: Repeat Experiences of a Large Language Model-Based Interactive Story. In Proceedings of the Interactive Storytelling; Holloway-Attaway, L., Murray, J.T., Eds.; Springer: Cham, Switzerland, 2023; pp. 395–409. [Google Scholar]
- Cooper, P.S.; Colton, E.; Bode, S.; Chong, T.T.J. Standardised images of novel objects created with generative adversarial networks. Sci. Data 2023, 10, 575. [Google Scholar] [CrossRef] [PubMed]
- Kahng, M.; Thorat, N.; Chau, D.H.; Viégas, F.B.; Wattenberg, M. GAN Lab: Understanding Complex Deep Generative Models using Interactive Visual Experimentation. IEEE Trans. Vis. Comput. Graph. 2019, 25, 310–320. [Google Scholar] [CrossRef] [PubMed]
- Liu, V.; Chilton, L.B. Design Guidelines for Prompt Engineering Text-to-Image Generative Models. In Proceedings of the Proc CHI22, New Orleans, LA, USA, 29 April–5 May 2022; ACM: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Oppenlaender, J. A taxonomy of prompt modifiers for text-to-image generation. Behav. Inf. Technol. 2023, 1–14. [Google Scholar] [CrossRef]
- Pavlichenko, N.; Ustalov, D. Best Prompts for Text-to-Image Models and How to Find Them. In Proceedings of the Proc ACM SIGIR, Taipei, Taiwan, 23–27 July 2023; ACM: New York, NY, USA, 2023; pp. 2067–2071. [Google Scholar] [CrossRef]
- Bertin, J. Semiology of Graphics; University of Wisconsin Press: Madison, WI, USA, 1983. [Google Scholar]
- Tufte, E.R. Envisioning Information; Graphics Press: Cheshire, CT, USA, 1990. [Google Scholar]
- Rosling, H.; Rosling, O.; Rönnlund, A.R. Factfulness: Ten Reasons We’Re Wrong About The World—And Why Things Are Better Than You Think; Sceptre: London, UK, 2018. [Google Scholar]
- Munzner, T. A Nested Process Model for Visualization Design and Validation. IEEE Trans. Vis. Comput. Graph. 2009, 15, 921–928. [Google Scholar] [CrossRef] [PubMed]
- Vande Moere, A.; Purchase, H. On the Role of Design in Information Visualization. Inf. Vis. 2011, 10, 356–371. [Google Scholar] [CrossRef]
- Shneiderman, B. The eyes have it: A task by data type taxonomy for information visualizations. In Proceedings of the 1996 IEEE Symposium on Visual Languages, Boulder, CO, USA, 3–6 September 1996; pp. 336–343. [Google Scholar]
- Kilgarriff, A.; Baisa, V.; Bušta, J.; Jakubíček, M.; Kovář, V.; Michelfeit, J.; Rychlý, P.; Suchomel, V. The Sketch Engine: Ten years on. Lexicography 2014, 1, 7–36. [Google Scholar] [CrossRef]
- Isenberg, P.; Heimerl, F.; Koch, S.; Isenberg, T.; Xu, P.; Stolper, C.; Sedlmair, M.; Chen, J.; Möller, T.; Stasko, J. vispubdata.org: A Metadata Collection about IEEE Visualization (VIS) Publications. IEEE Trans. Vis. Comput. Graph. 2017, 23, 2199–2206. [Google Scholar] [CrossRef]
- Roberts, J.C. Visualization display models-ways to classify visual representations. Int. J. Comput. Integr. Des. Constr. 2000, 2, 241–250. [Google Scholar]
- Viegas, F.B.; Wattenberg, M.; van Ham, F.; Kriss, J.; McKeon, M. ManyEyes: A Site for Visualization at Internet Scale. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1121–1128. [Google Scholar] [CrossRef]
- Fekete, J.D. The InfoVis Toolkit. In Proceedings of the IEEE Symposium on Information Visualization, Washington, DC, USA, 10–12 October 2004; INFOVIS ’04. pp. 167–174. [Google Scholar] [CrossRef]
- Bostock, M.; Ogievetsky, V.; Heer, J. D3 Data-Driven Documents. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2301–2309. [Google Scholar] [CrossRef]
- Fekete, J.; Hémery, P.; Baudel, T.; Wood, J. Obvious: A meta-toolkit to encapsulate information visualization toolkits—One toolkit to bind them all. In Proceedings of the 2011 IEEE Conference on Visual Analytics Science and Technology (VAST), Providence, RI, USA, 23–28 October 2011; pp. 91–100. [Google Scholar] [CrossRef]
- Stasko, J.; Görg, C.; Liu, Z. Jigsaw: Supporting investigative analysis through interactive visualization. Inf. Vis. 2008, 7, 118–132. [Google Scholar] [CrossRef]
- Yalçın, M.A.; Elmqvist, N.; Bederson, B.B. Keshif: Rapid and Expressive Tabular Data Exploration for Novices. IEEE Trans. Vis. Comput. Graph. 2018, 24, 2339–2352. [Google Scholar] [CrossRef] [PubMed]
- Harrower, M.; Brewer, C.A. ColorBrewer. org: An online tool for selecting colour schemes for maps. Cartogr. J. 2013, 40, 27–37. [Google Scholar] [CrossRef]
- Munzner, T. Visualization Analysis and Design; A.K. Peters Visualization Series; A K Peters: Natick, MA, USA, 2014. [Google Scholar]
- Schulz, H.J.; Nocke, T.; Heitzler, M.; Schumann, H. A design space of visualization tasks. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2366–2375. [Google Scholar] [CrossRef]
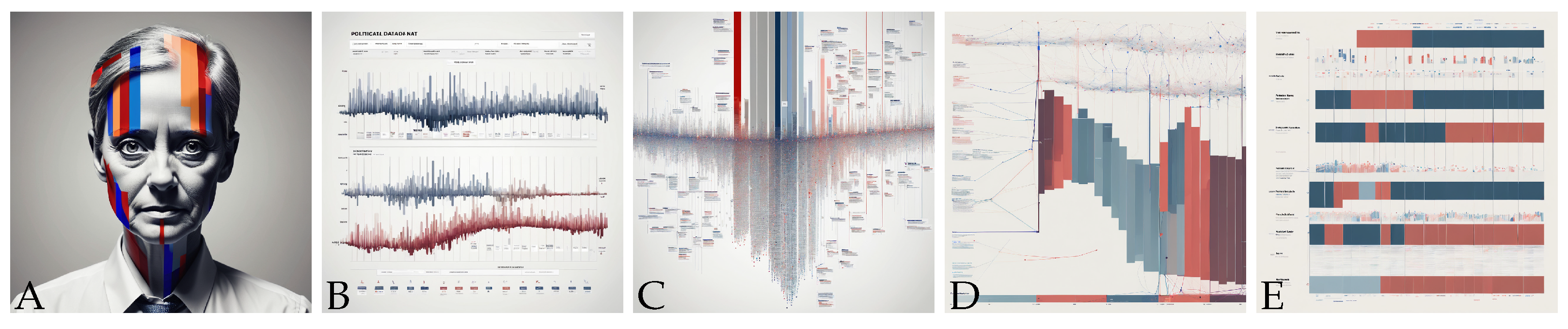

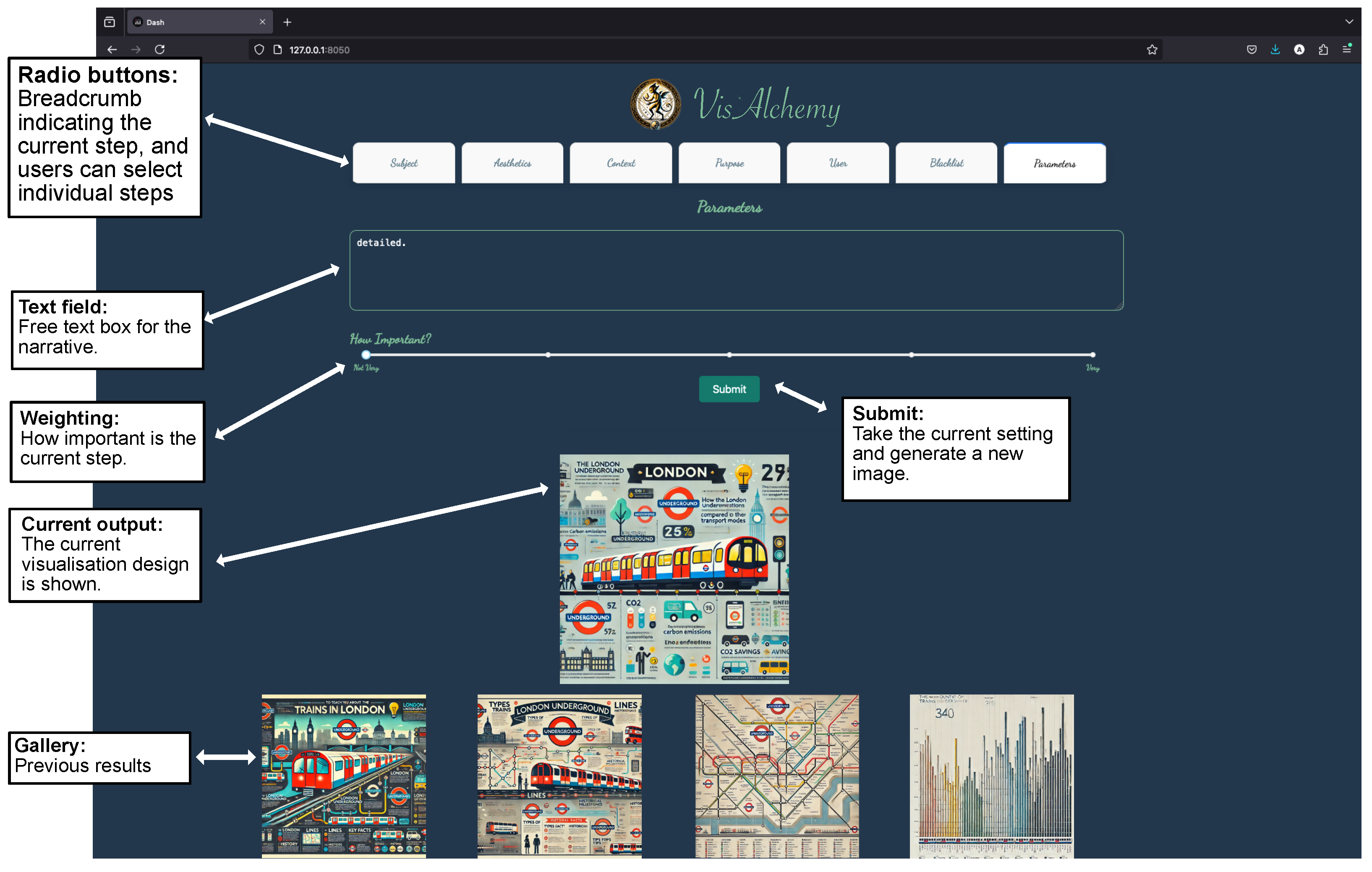






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).