
Automated Identification of Sensitive Financial Data Based on the Topic Analysis



Abstract
:1. Introduction
- A practical and applicable method has been proposed to address the challenge of classifying text with weak semantic information at a sensitive level. This advancement significantly enhances the feasibility of implementing sensitive data classification and grading, laying a solid foundation for ensuring data security protection.
- The limitations on the extensibility of the model across different fields have been eliminated. By introducing experts’ selection of keywords, the model can now be applied to various fields, with data from different industries and domains being linked only to relevant keywords.
- Optimization strategies have been introduced for the model in real-world business scenarios to continuously improve its performance in practical applications and dynamically monitor changes in sensitive data.
2. Methodology
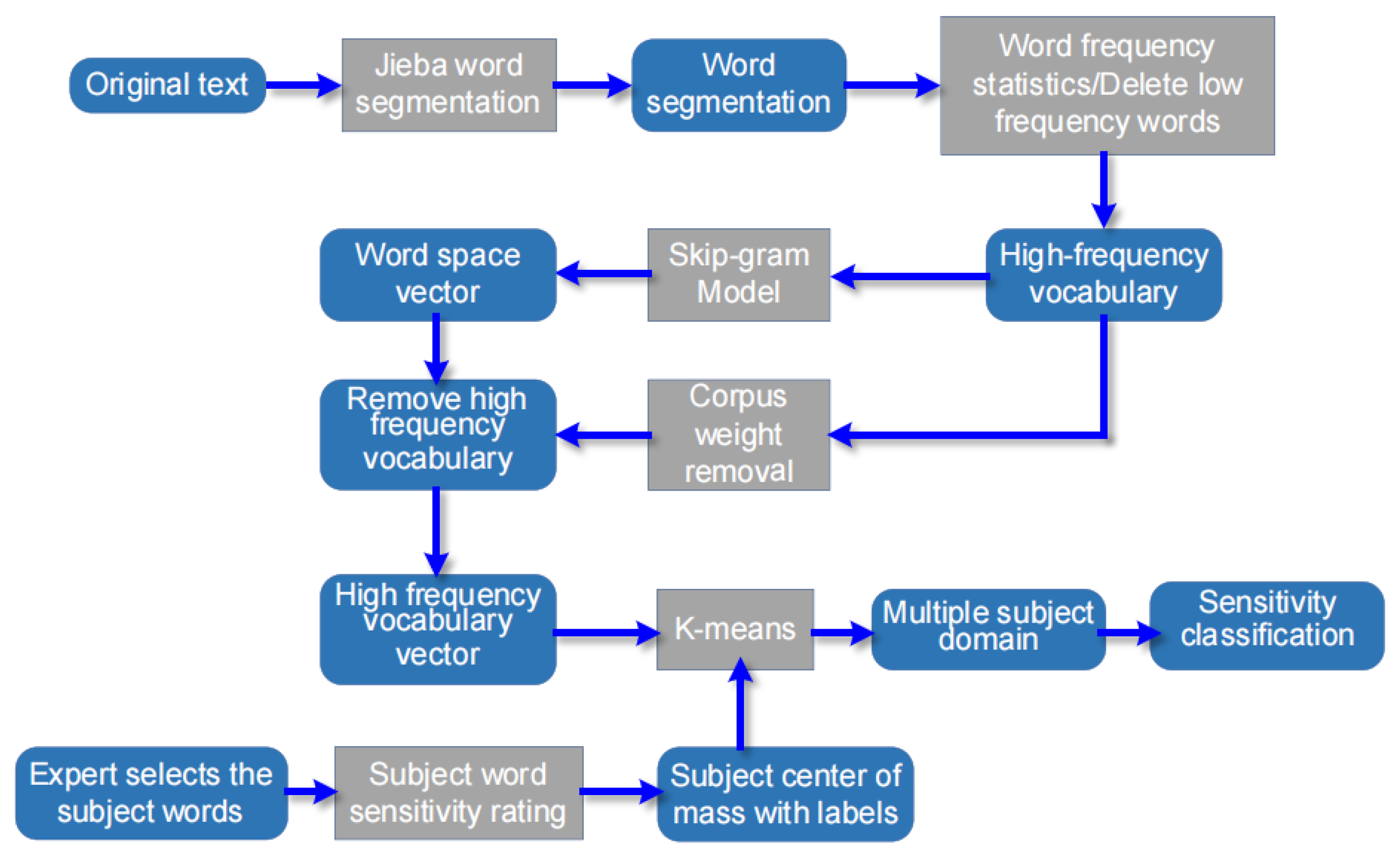
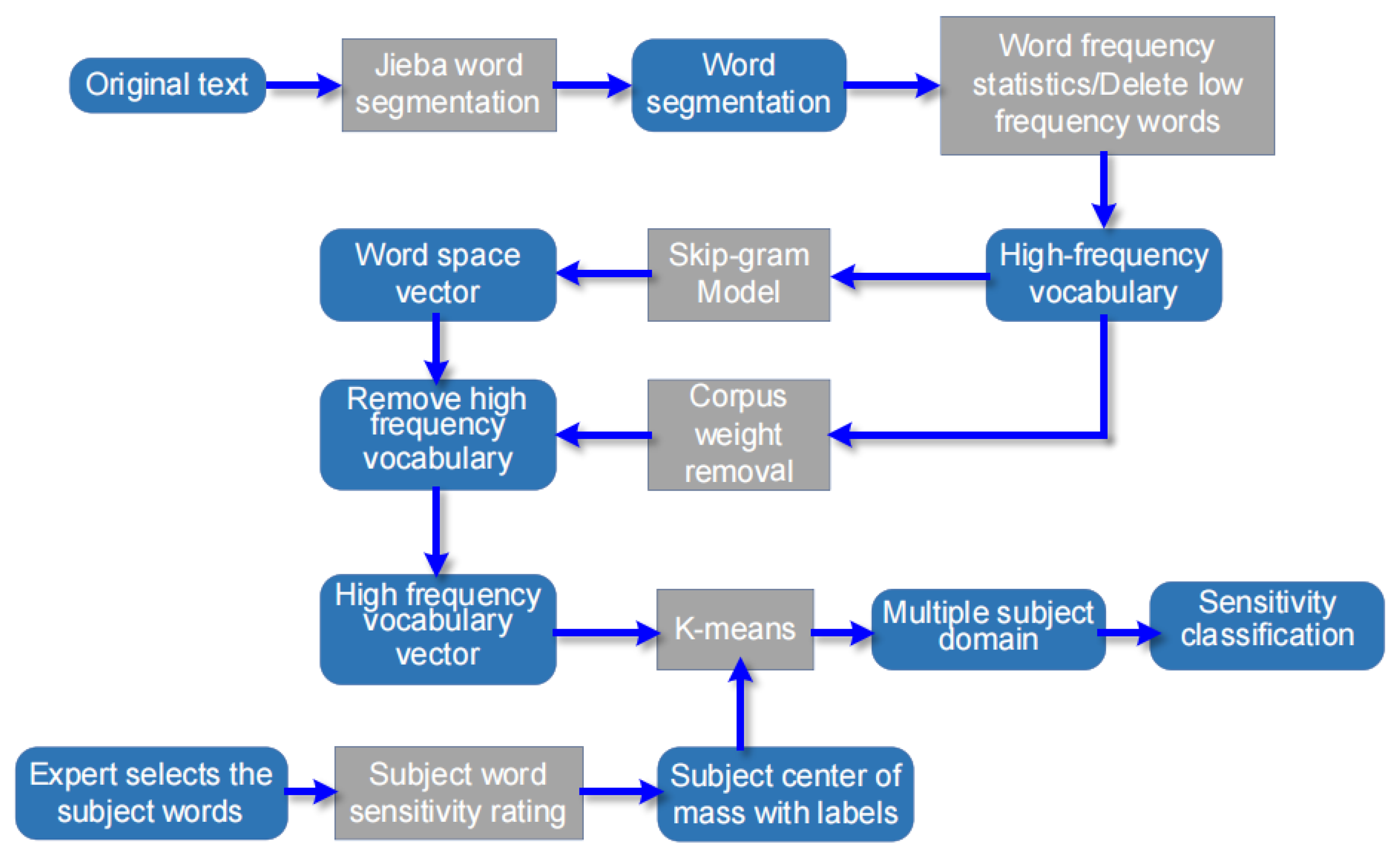
2.1. Hierarchical Model of Sensitive Data Based on Topic Domain Division
2.1.1. Parameter Definition
2.1.2. Data Preprocessing and Word Vector Acquisition
2.1.3. Selection and Annotation of Subject Words
2.2. K-Means Clustering
2.2.1. Choice of Distance Measurement Method
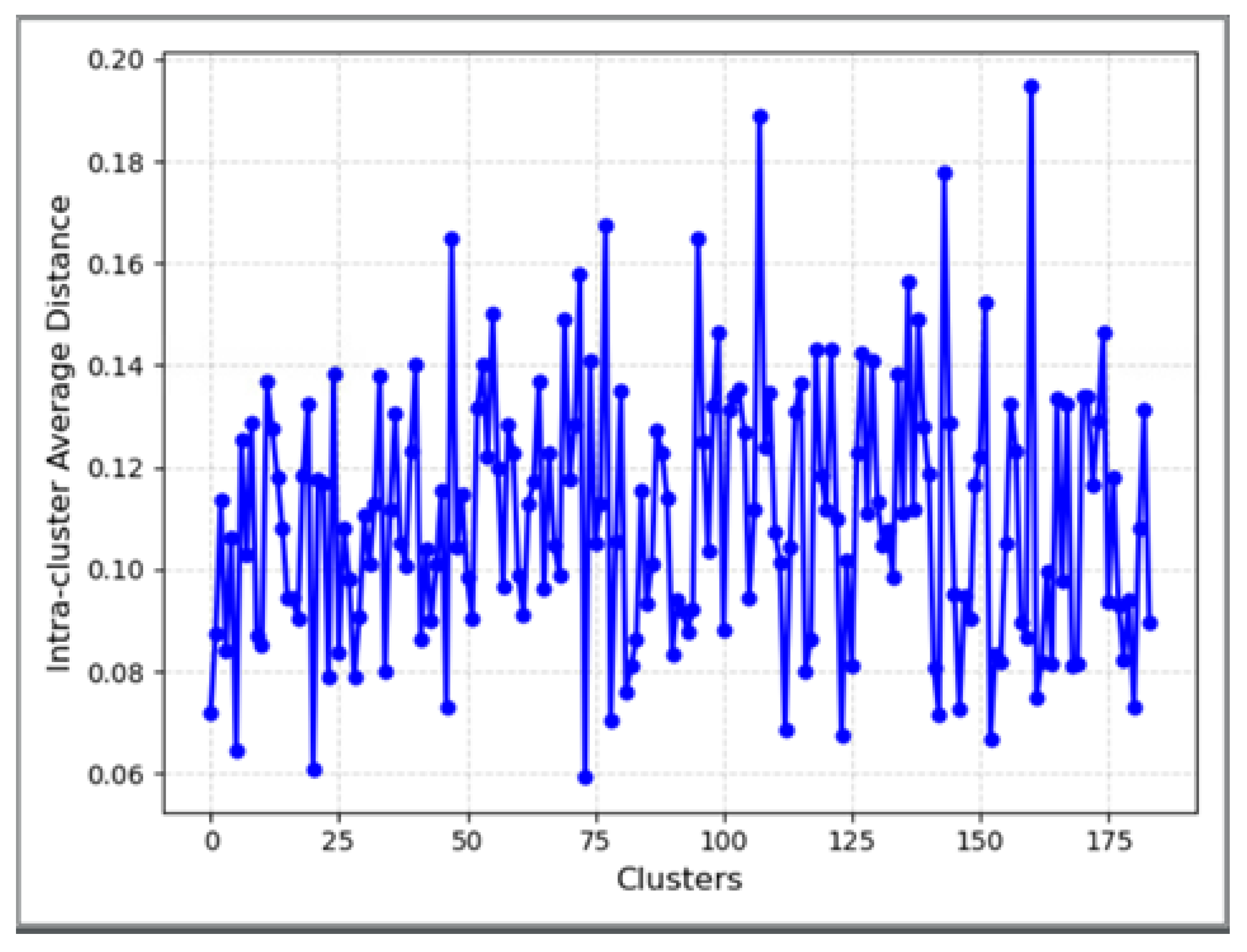
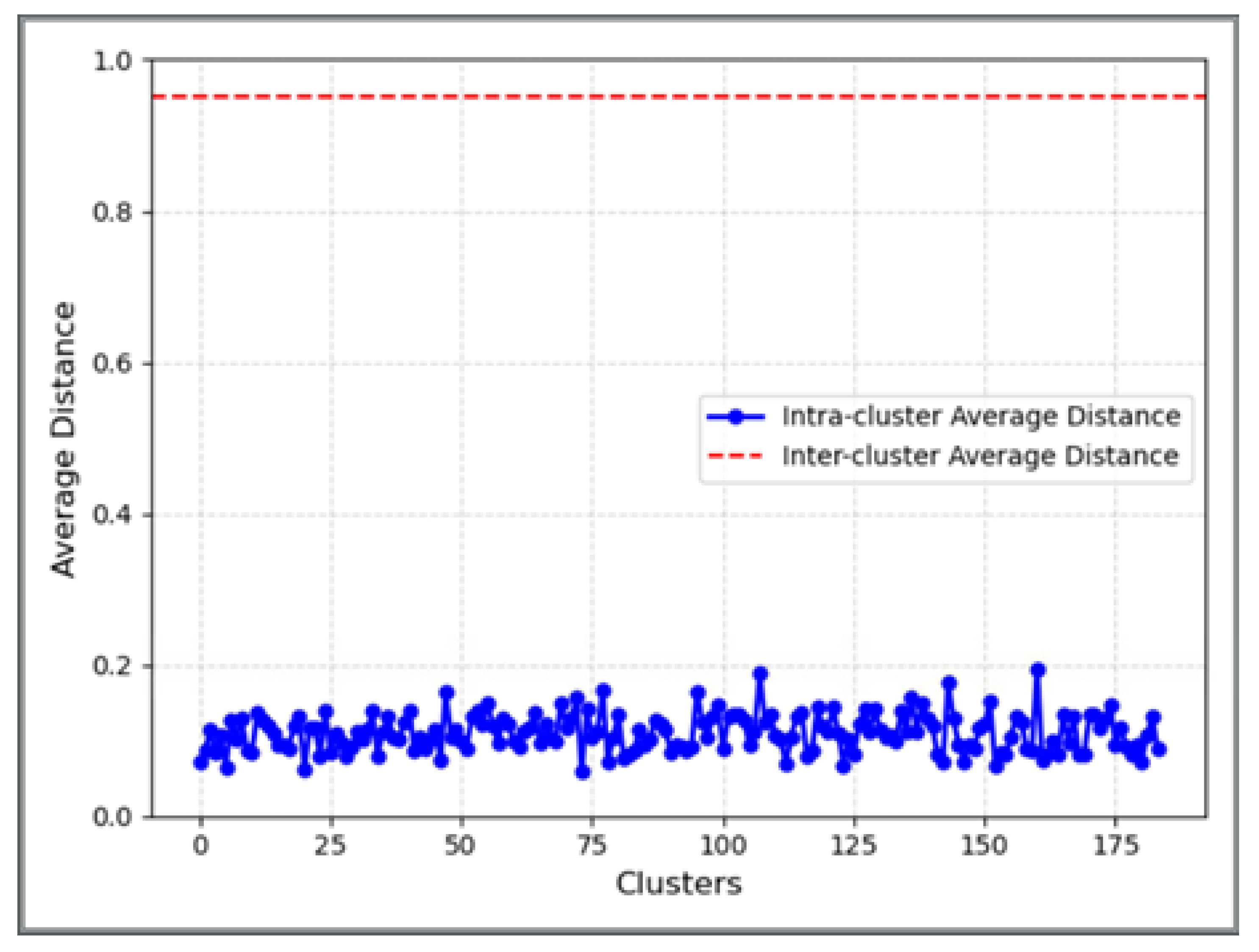
2.2.2. Optimization Process of Clustering
2.2.3. Sensitivity Level Mapping of the Topic Domain
2.3. Sensitive Data Classification Algorithm
| Algorithm 1: Sensitive data classification algorithm based on subject domain division. |
 |
3. Results and Discussion
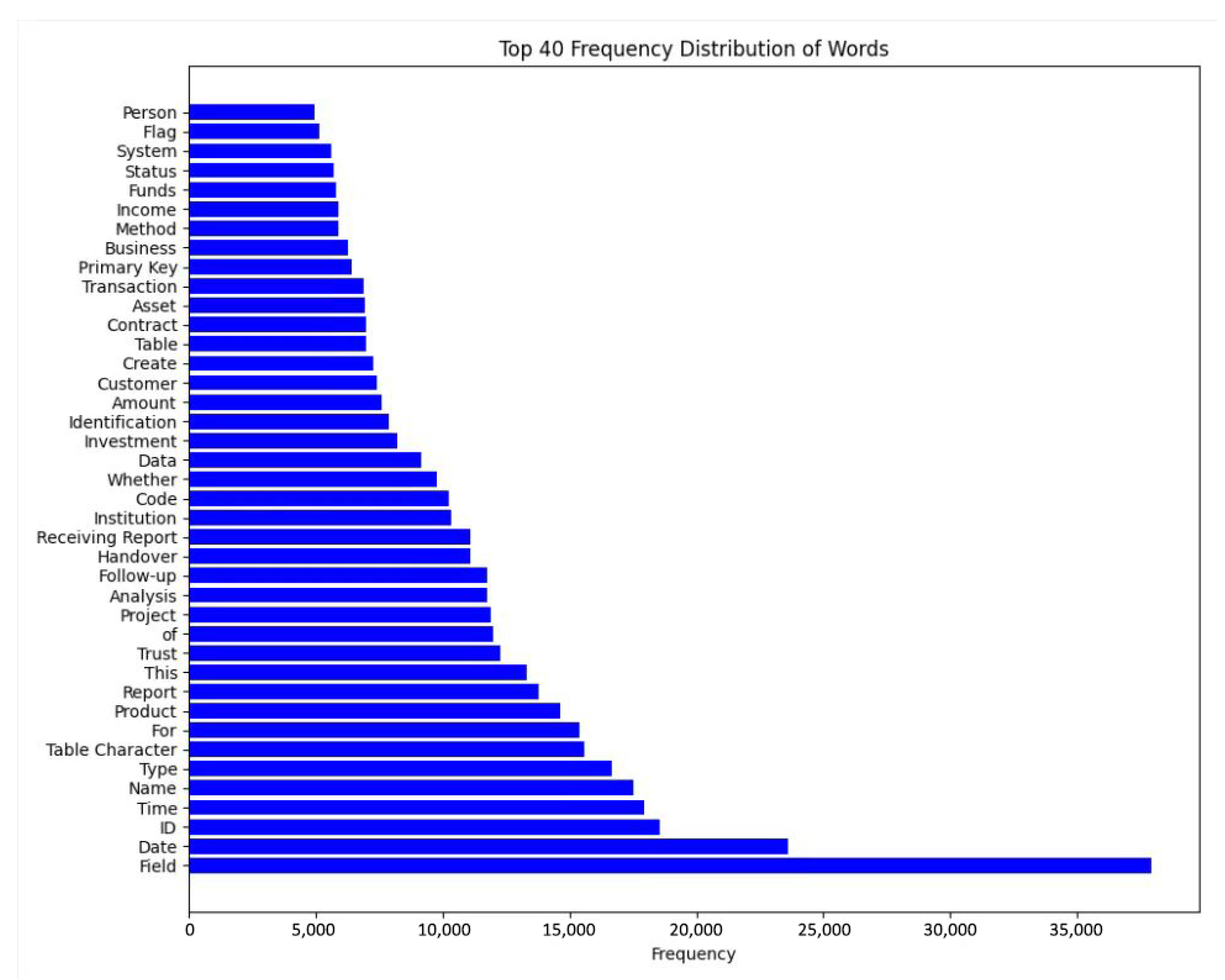
3.1. Data Set Introduction and Preprocessing
- i
- Use regular expressions to remove non-Chinese characters such as letters, symbols, and numbers from the original text.
- ii
- Perform Jieba segmentation on 334,065 texts to obtain 334,065 word segmentation materials.
- iii
- Perform word frequency statistics on the word segmentation corpus. Delete the text containing words with a word frequency of less than 100 to obtain 263,796 high-frequency word materials.
- iv
- Use the skip-gram model to train 263,796 high-frequency word materials to obtain a 10-dimensional word vector of 1414 words.
- v
- Carry out weight removal of 263,796 high-frequency word materials to obtain 21,346 high-frequency word materials.
- vi
- Select 184 subject words according to the experience of experts, and mark the corresponding sensitivity level.
3.2. Experimental Results and Index Evaluation
3.2.1. Experimental Evaluation Index Definition
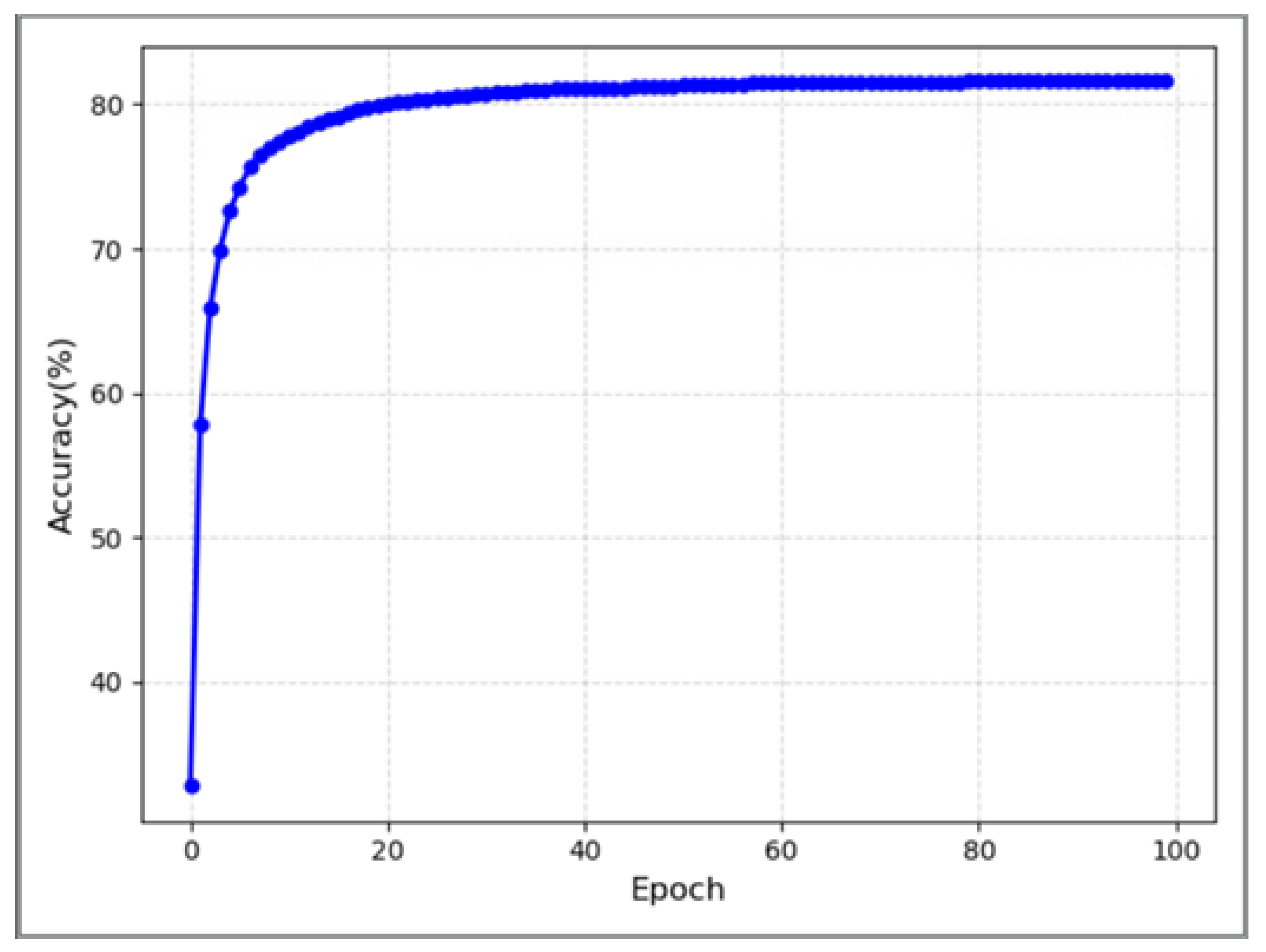
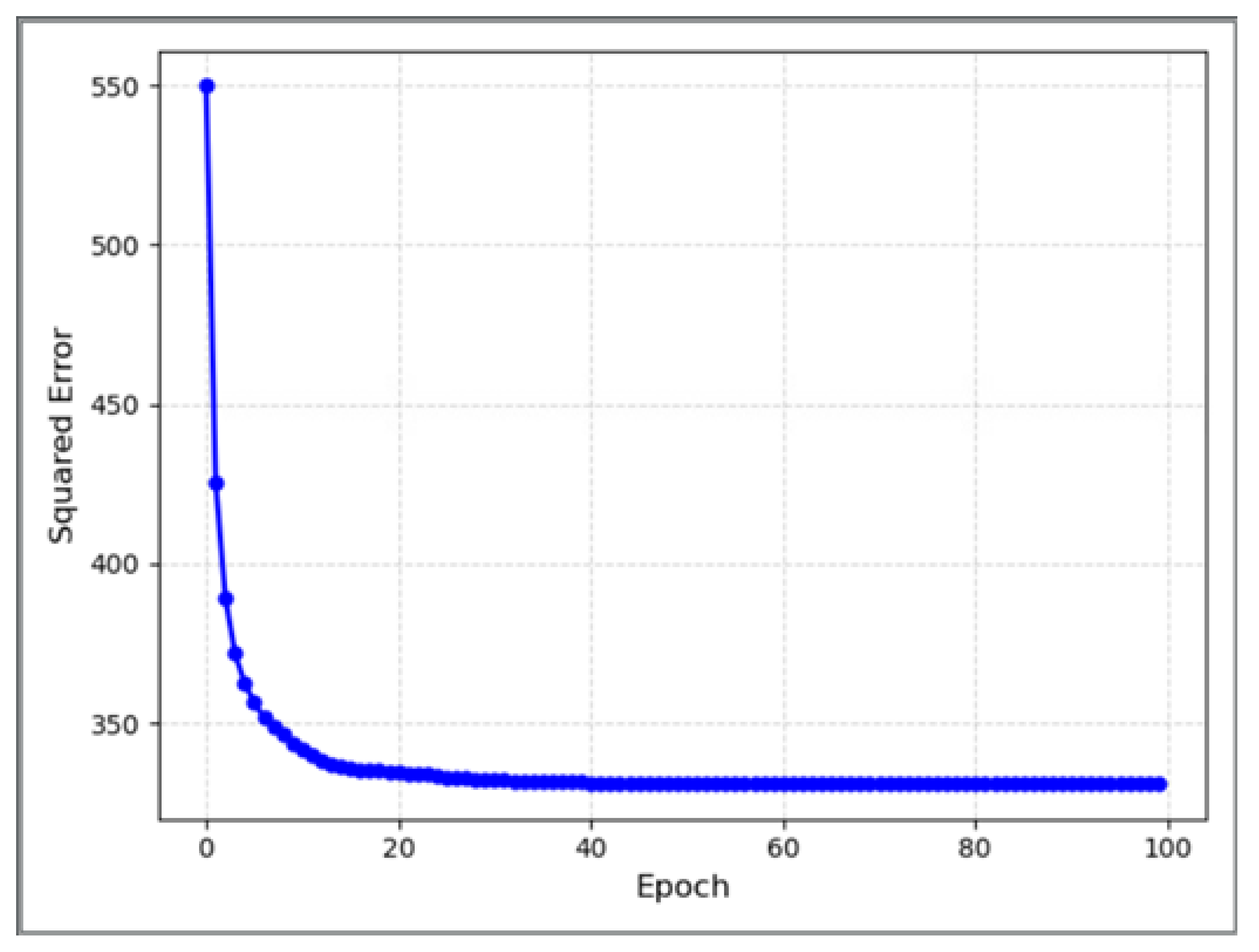
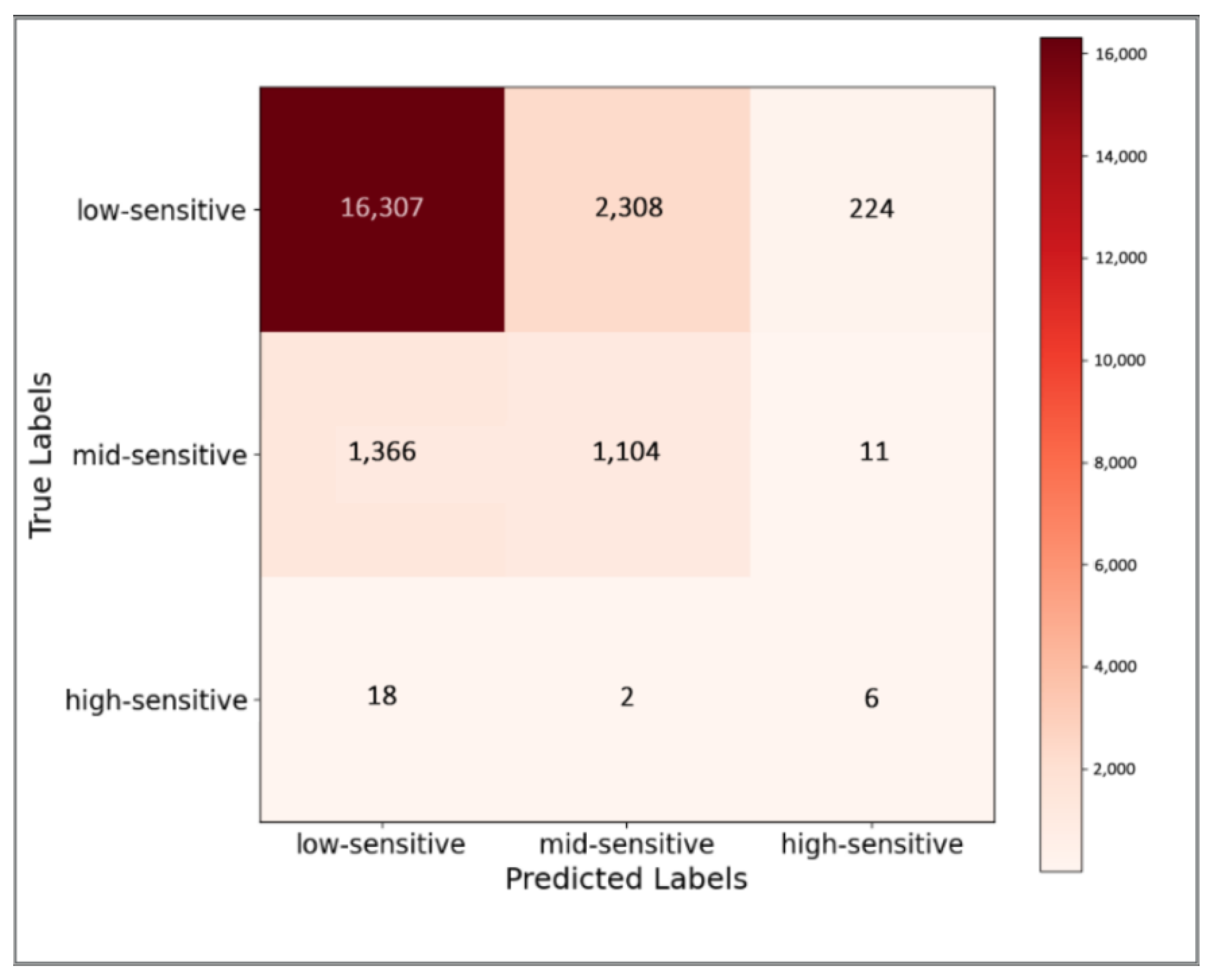
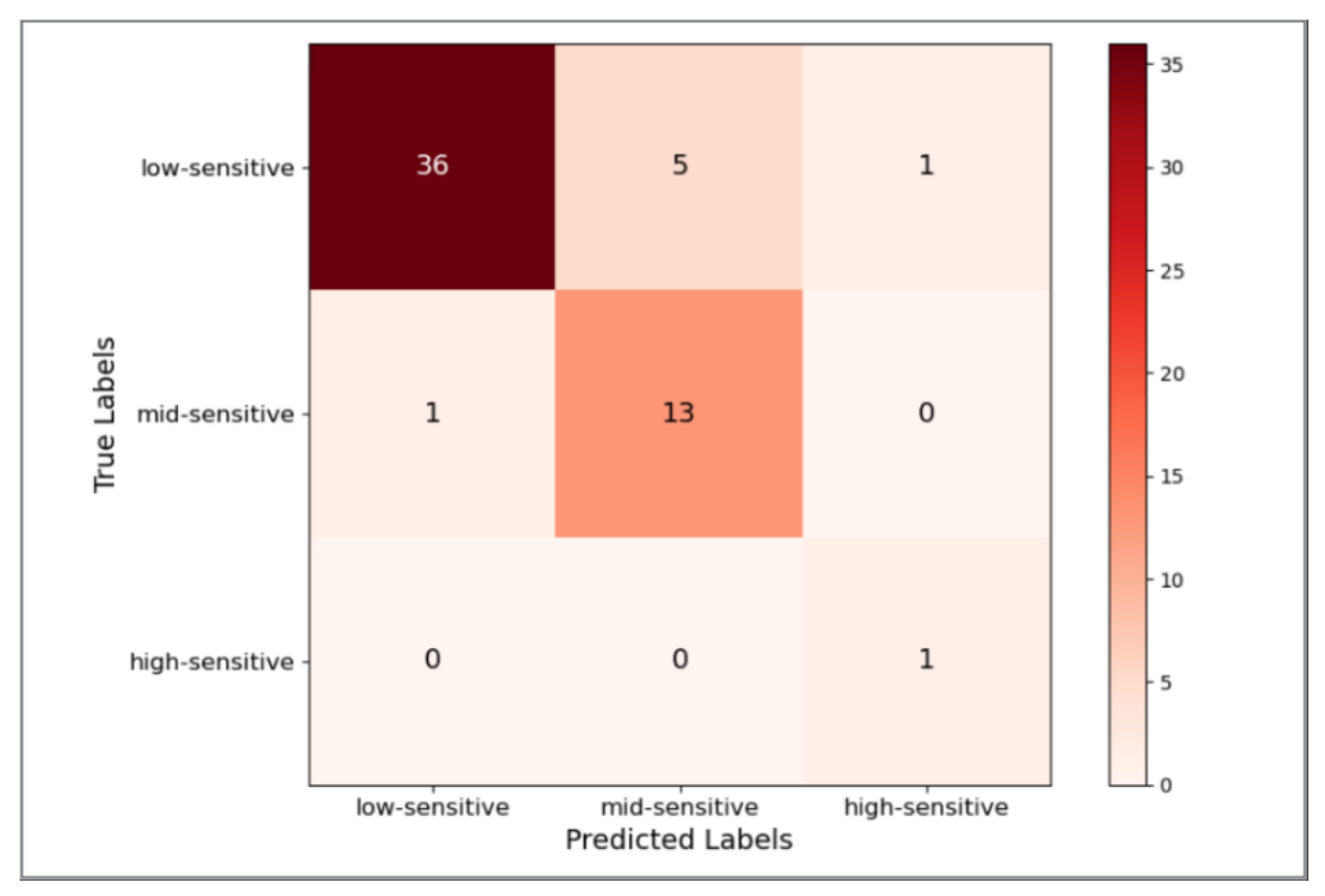
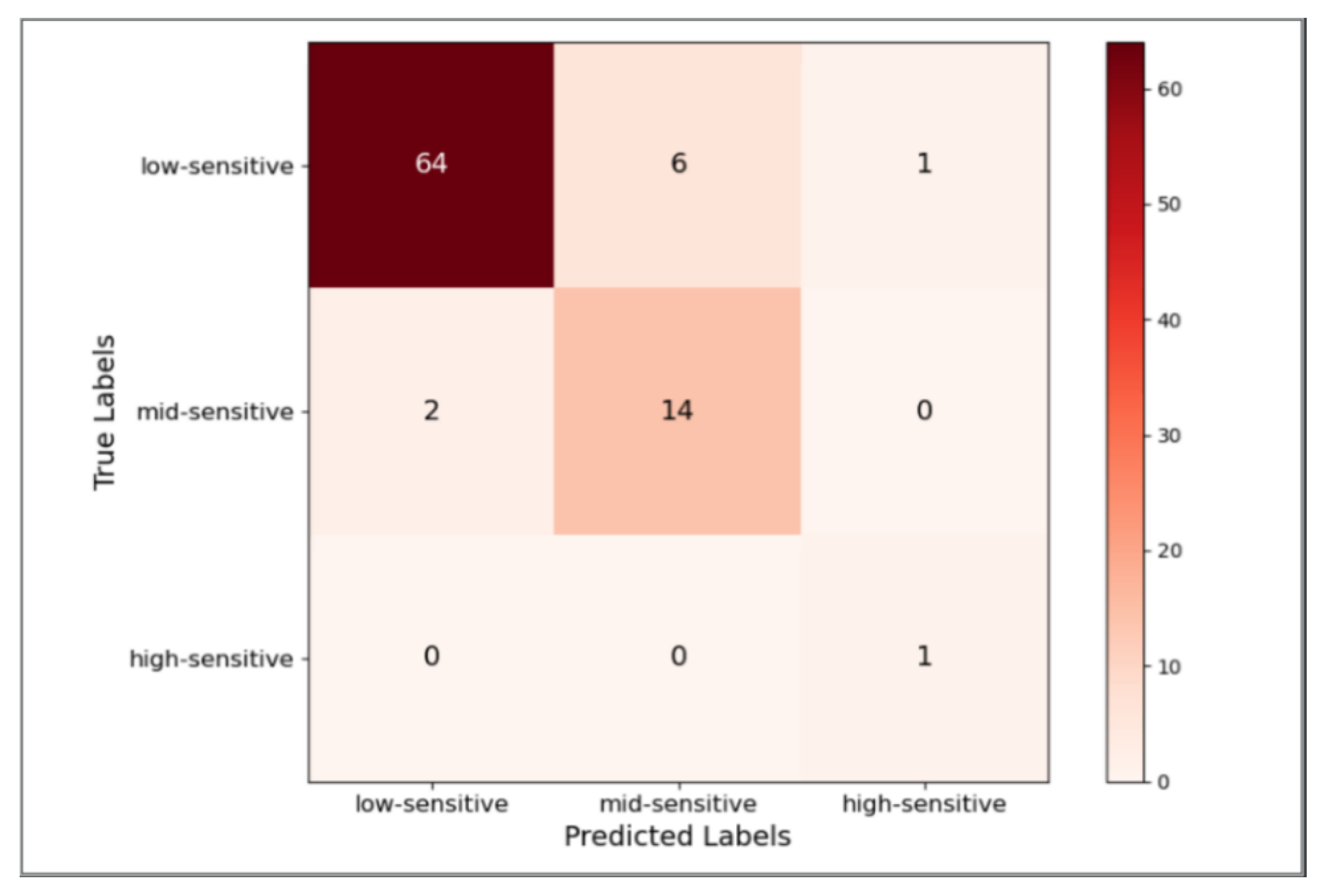
3.2.2. Validity Verification Experiment of Sensitivity Classification
3.2.3. Usability Verification Experiments for Real Business Scenarios
4. Conclusions
- a
- The issue of classifying text with weak semantic information at a sensitive level has been addressed, with the practicality and applicability of the proposed method significantly enhanced. This advancement has facilitated the implementation of sensitive data classification and grading efforts, which established a solid foundation for ensuring data security protection.
- b
- The limitations of data on the extensibility of the model were eliminated from different fields. The data of different industries and fields were only related to keywords by introducing the experts’ selection of keywords; therefore, the model could be applied to various fields.
- c
- Optimization strategies were proposed for the model in real-world business scenarios to continuously enhance its performance in practical applications and dynamically monitor changes in sensitive data.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abraham, R.; Schneider, J.; Vom Brocke, J. Data governance: A conceptual framework, structured review, and research agenda. Int. J. Inf. Manag. 2019, 49, 424–438. [Google Scholar] [CrossRef]
- Karkošková, S. Data governance model to enhance data quality in financial institutions. Inf. Syst. Manag. 2023, 40, 90–110. [Google Scholar] [CrossRef]
- Huang, J.; Li, Z.; Xiao, X.; Wu, Z.; Lu, K.; Zhang, X.; Jiang, G. SUPOR: Precise and scalable sensitive user input detection for android apps. In Proceedings of the 24th USENIX Security Symposium (USENIX Security 15), Washington, DC, USA, 12–14 August 2015; pp. 977–992. [Google Scholar]
- Nan, Y.; Yang, M.; Yang, Z.; Zhou, S.; Gu, G.; Wang, X. Uipicker: User-input privacy identification in mobile applications. In Proceedings of the 24th USENIX Security Symposium (USENIX Security 15), Washington, DC, USA, 12–14 August 2015; pp. 993–1008. [Google Scholar]
- Yang, Z.; Liang, Z. Automated Identification of Sensitive Data via Flexible User Requirements. In Security and Privacy in Communication Networks, Proceedings of the 14th International Conference, SecureComm 2018, Singapore, 8–10 August 2018; Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2018; pp. 151–171. [Google Scholar]
- Gitanjali, K.L. A novel approach of sensitive data classification using convolution neural network and logistic regression. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 2883–2886. [Google Scholar]
- Zhang, X.; Wu, P.; Cai, J.; Wang, K. A contrastive study of Chinese text segmentation tools in marketing notification texts. J. Phys. Conf. Ser. 2019, 2, 022010. [Google Scholar] [CrossRef]
- Baron, A.; Rayson, P.; Archer, D. Word frequency and key word statistics in corpus linguistics. Anglistik 2009, 20, 41–67. [Google Scholar]
- Guthrie, D.; Allison, B.; Liu, W.; Guthrie, L.; Wilks, Y. A closer look at skip-gram modelling. In Proceedings of the LREC, Genoa, Italy, 22–28 May 2006; Volume 6, pp. 1222–1225. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The global k-means clustering algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef]
- Mahmud, M.S.; Rahman, M.M.; Akhtar, M.N. Improvement of K-means clustering algorithm with better initial centroids based on weighted average. In Proceedings of the 2012 7th International Conference on Electrical and Computer Engineering, Dhaka, Bangladesh, 20–22 December 2012; pp. 647–650. [Google Scholar]
- Nadeem, M.I.; Ahmed, K.; Li, D.; Zheng, Z.; Naheed, H.; Muaad, A.Y.; Alqarafi, A.; Abdel Hameed, H. SHO-CNN: A Metaheuristic Optimization of a Convolutional Neural Network for Multi-Label News Classification. Electronics 2022, 12, 113. [Google Scholar] [CrossRef]
- Li, F.; Wang, X. Improving word embeddings for low frequency words by pseudo contexts. In Proceedings of the Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data: 16th China National Conference, CCL 2017, and 5th International Symposium, NLP-NABD 2017, Nanjing, China, 13–15 October 2017; Proceedings 16. Springer International Publishing: Cham, Switzerland, 2017; pp. 37–47. [Google Scholar]
- Danielsson, P.E. Euclidean distance mapping. Comput. Graph. Image Process. 1980, 14, 227–248. [Google Scholar] [CrossRef]
- Sinwar, D.; Kaushik, R. Study of Euclidean and Manhattan distance metrics using simple k-means clustering. Int. J. Res. Appl. Sci. Eng. Technol. 2014, 2, 270–274. [Google Scholar]
- Chiu, W.Y.; Yen, G.G.; Juan, T.K. Minimum manhattan distance approach to multiple criteria decision making in multiobjective optimization problems. IEEE Trans. Evol. Comput. 2016, 20, 972–985. [Google Scholar] [CrossRef]
- Rahutomo, F.; Kitasuka, T.; Aritsugi, M. Semantic cosine similarity. In Proceedings of the 7th International Student Conference on Advanced Science and Technology ICAST, Seoul, Republic of Korea, 29–30 October 2012; Volume 4, p. 1. [Google Scholar]
- Muflikhah, L.; Baharudin, B. Document clustering using concept space and cosine similarity measurement. In Proceedings of the 2009 International Conference on Computer Technology and Development, Kota Kinabalu, Malaysia, 13–15 November 2009; Volume 1, pp. 58–62. [Google Scholar]
- Singh, A.; Yadav, A.; Rana, A. K-means with Three different Distance Metrics. Int. J. Comput. Appl. 2013, 67, 14–17. [Google Scholar] [CrossRef]
- Kapil, S.; Chawla, M. Performance evaluation of K-means clustering algorithm with various distance metrics. In Proceedings of the 2016 IEEE 1st International Conference on Power Electronics, Intelligent Control and Energy Systems (ICPEICES), Delhi, India, 4–6 July 2016; pp. 1–4. [Google Scholar]
- Yi, J.; Nasukawa, T.; Bunescu, R.; Niblack, W. Sentiment analyzer: Extracting sentiments about a given topic using natural language processing techniques. In Proceedings of the Third IEEE International Conference on Data Mining, Melbourne, FL, USA, 22–22 November 2003; pp. 427–434. [Google Scholar]
- Caelen, O. A Bayesian interpretation of the confusion matrix. Ann. Math. Artif. Intell. 2017, 81, 429–450. [Google Scholar] [CrossRef]
- Thinsungnoena, T.; Kaoungkub, N.; Durongdumronchaib, P.; Kerdprasopb, K.; Kerdprasopb, N. The clustering validity with silhouette and sum of squared errors. Learning 2015, 3, 44–51. [Google Scholar]
- Chiang, M.M.T.; Mirkin, B. Intelligent choice of the number of clusters in k-means clustering: An experimental study with different cluster spreads. J. Classif. 2010, 27, 3–40. [Google Scholar] [CrossRef]
- Shi, C.; Wei, B.; Wei, S.; Wang, W.; Liu, H.; Liu, J. A quantitative discriminant method of elbow point for the optimal number of clusters in clustering algorithm. EURASIP J. Wirel. Commun. Netw. 2021, 2021, 31. [Google Scholar] [CrossRef]
- Dinh, D.T.; Fujinami, T.; Huynh, V.N. Estimating the optimal number of clusters in categorical data clustering by silhouette coefficient. In Knowledge and Systems Sciences, Proceedings of the 20th International Symposium, KSS 2019, Da Nang, Vietnam, 29 November–1 December 2019; Proceedings 20; Springer: Singapore, 2019; pp. 1–17. [Google Scholar]
- Wei, D.; Liu, Z.; Xu, D.; Ma, K.; Tao, L.; Xie, Z.; Pan, S. Word segmentation of Chinese texts in the geoscience domain using the BERT model. ESS Open Arch. 2022. [Google Scholar] [CrossRef]
- You, C.; Xiang, J.; Su, K.; Zhang, X.; Dong, S.; Onofrey, J.; Staib, L.; Duncan, J.S. Incremental learning meets transfer learning: Application to multi-site prostate mri segmentation. In Distributed, Collaborative, and Federated Learning, and Affordable AI and Healthcare for Resource Diverse Global Health, Proceedings of the Third MICCAI Workshop, DeCaF 2022, and Second MICCAI Workshop, FAIR 2022, Held in Conjunction with MICCAI 2022, Singapore, 18 and 22 September 2022; Proceedings; Springer Nature: Cham, Switzerland, 2022; pp. 3–16. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Name | Data Total | Number of Low-Sensitivity Fields | Number of Mid-Sensitivity Fields | Number of High-Sensitivity Fields |
|---|---|---|---|---|
| Training set | 21,346 | 18,839 | 2481 | 26 |
| Test set 1 | 56 | 42 | 14 | 1 |
| Test set 2 | 87 | 71 | 16 | 1 |
| Subject term | 184 | 150 | 33 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Liu, J.; Yang, Y. Automated Identification of Sensitive Financial Data Based on the Topic Analysis. Future Internet 2024, 16, 55. https://doi.org/10.3390/fi16020055
Li M, Liu J, Yang Y. Automated Identification of Sensitive Financial Data Based on the Topic Analysis. Future Internet. 2024; 16(2):55. https://doi.org/10.3390/fi16020055
Chicago/Turabian StyleLi, Meng, Jiqiang Liu, and Yeping Yang. 2024. "Automated Identification of Sensitive Financial Data Based on the Topic Analysis" Future Internet 16, no. 2: 55. https://doi.org/10.3390/fi16020055
APA StyleLi, M., Liu, J., & Yang, Y. (2024). Automated Identification of Sensitive Financial Data Based on the Topic Analysis. Future Internet, 16(2), 55. https://doi.org/10.3390/fi16020055