
Speech Inpainting Based on Multi-Layer Long Short-Term Memory Networks




Abstract
1. Introduction
2. Related Works
2.1. Conventional Audio Inpainting Based on Mathematics
2.2. Deep Learning-Based Audio Inpainting Methods
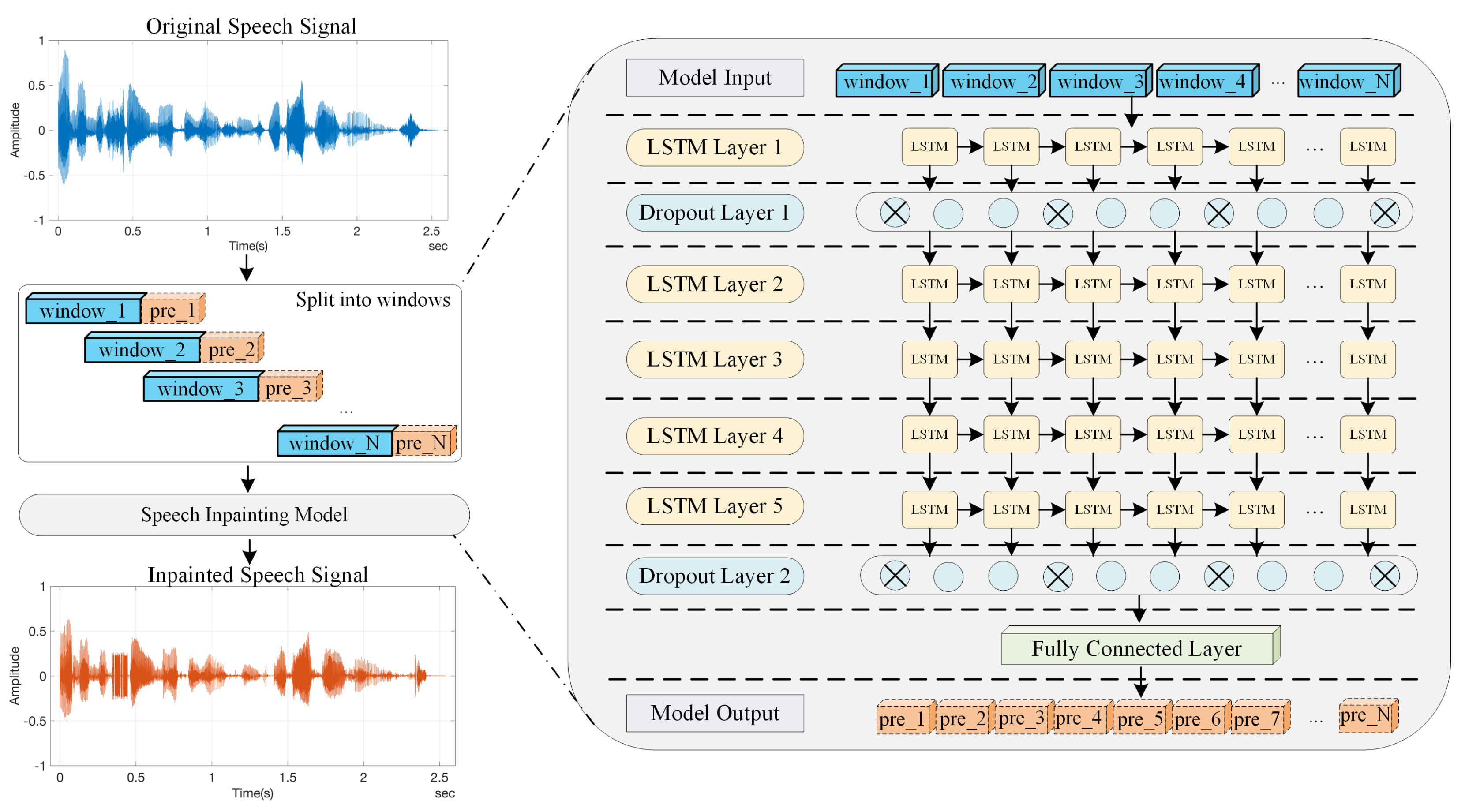
3. Proposed Speech Inpainting Methods and Model Architecture
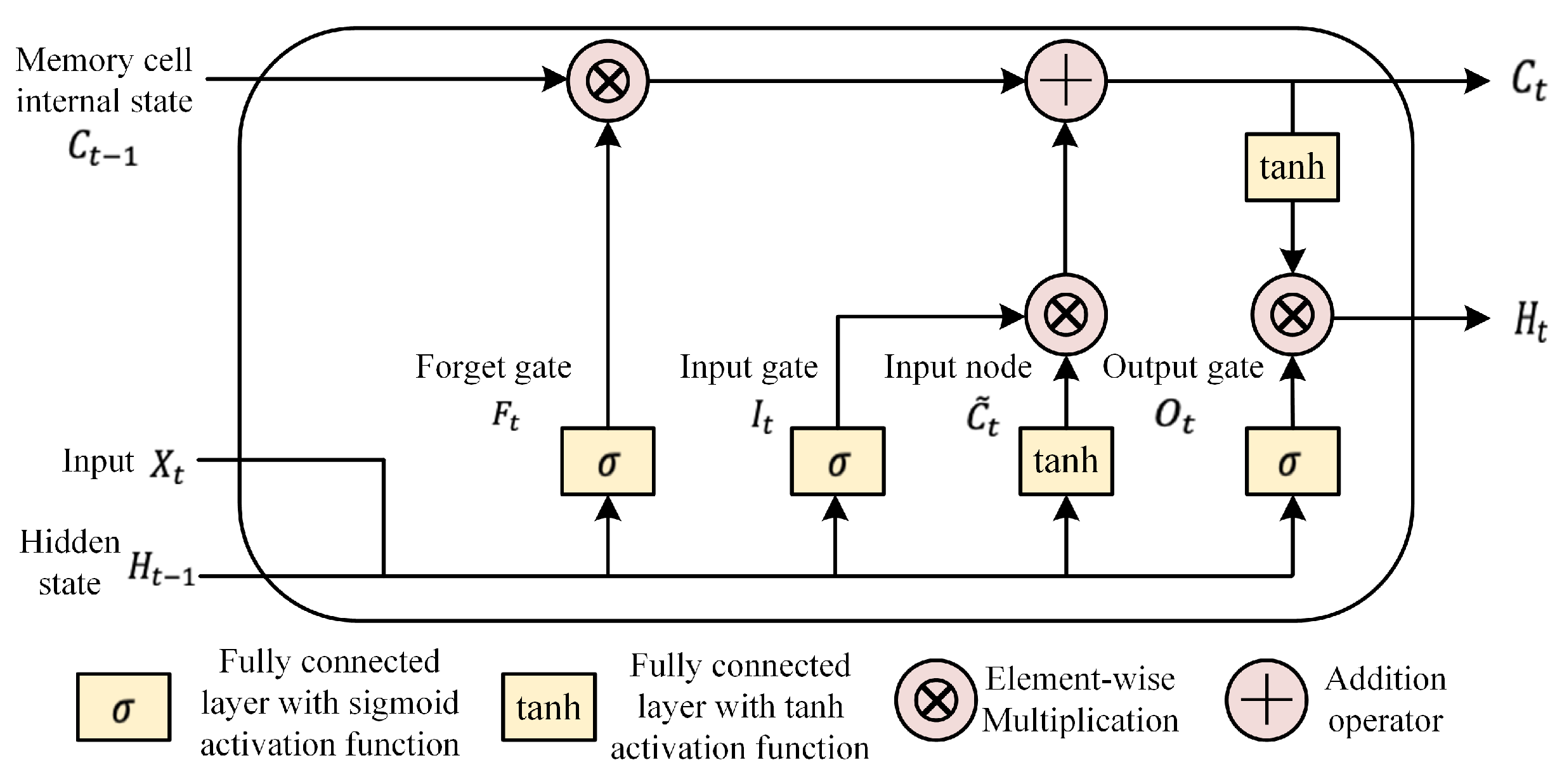
3.1. Long Short-Term Memory Networks
3.2. Series Prediction LSTM Model in Speech Inpainting
3.3. Datasets
- Single-speaker dataset:The first two datasets were built directly from the original LJSpeech and RyanSpeech datasets. The last two datasets were built from the LibriSpeech dataset, specifically from the “train-clean-100” folder, which contains speech data from multiple male and female speakers. The third dataset uses “folder 26” and the fourth uses “folder 32”. In this paper, these four datasets are referred to as LJSpeech, RyanSpeech, Libri_26, and Libri_32. Each dataset collates 400-second-long female or male speech samples at a 16 kHz sampling rate and contains one speaker.
- Multi-speaker dataset:The first dataset was built from the original Hi-Fi dataset, and the others were built from the LibriSpeech dataset. Each dataset contains 10 distinct speakers from both genders, collating 400-second-long speech samples at a 16 kHz sampling rate. These four datasets are referred to as HIFI, LibriM1, LibriM2, and LibriM3 in this paper.
3.4. Performance Evaluation
3.5. Hyperparameter Optimisation
3.5.1. Batch Size
3.5.2. Dropout Rate
3.5.3. Location of the Dropout Layers
- Location 1: dropout layers are placed after the first and last LSTM layers.
- Location 2: dropout layers are placed after the second and last LSTM layers.
- Location 3: dropout layers are placed after the third and last LSTM layers.
- Location 4: dropout layers are placed after the fourth and last LSTM layers.
- Location 5: dropout layers are placed after every LSTM layer.
4. Experiments
4.1. Experiment Setup
4.2. Model and Training Setup
4.3. Loss Function
4.4. Model Complexity
5. Results and Discussion
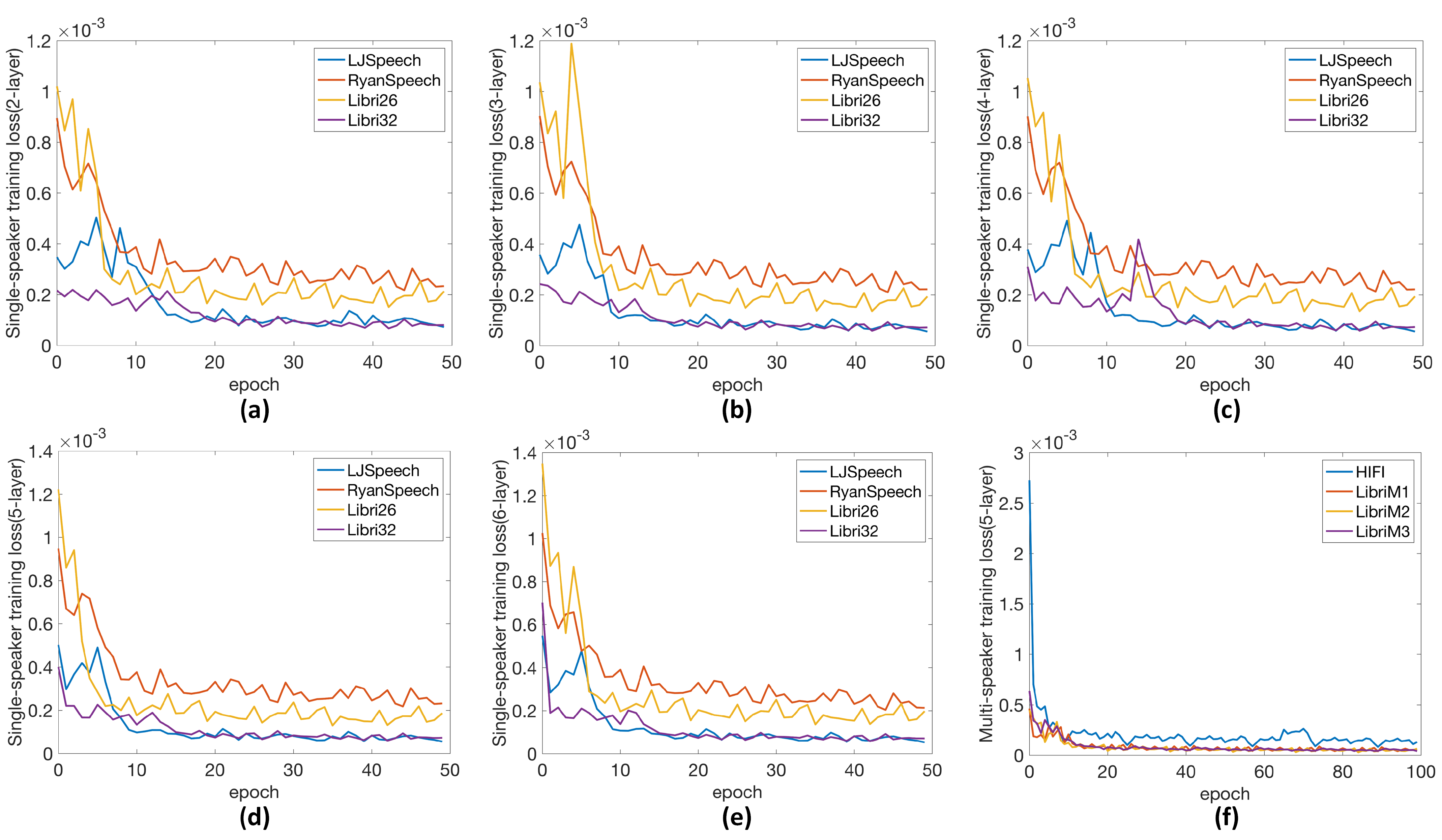
5.1. Training Performance
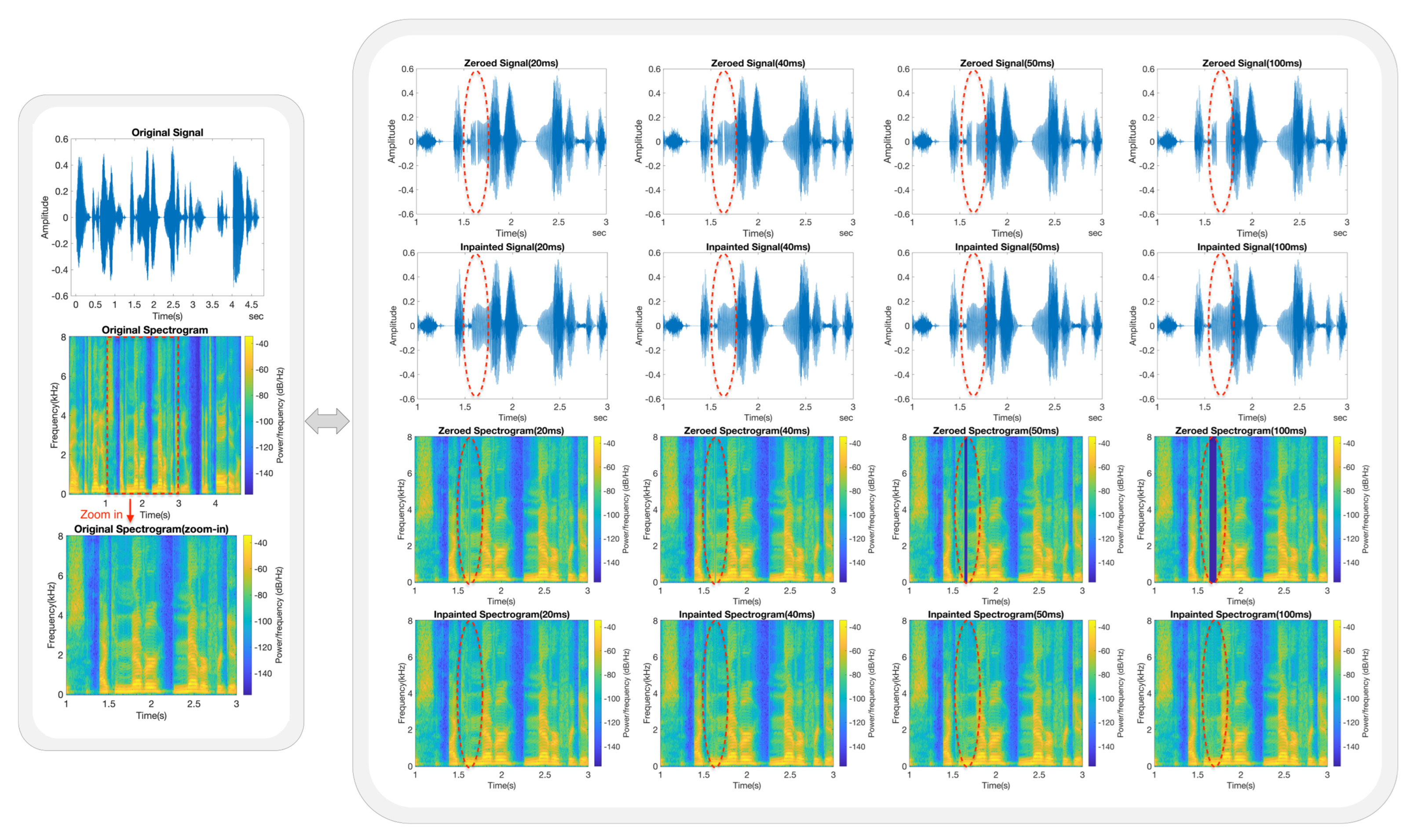
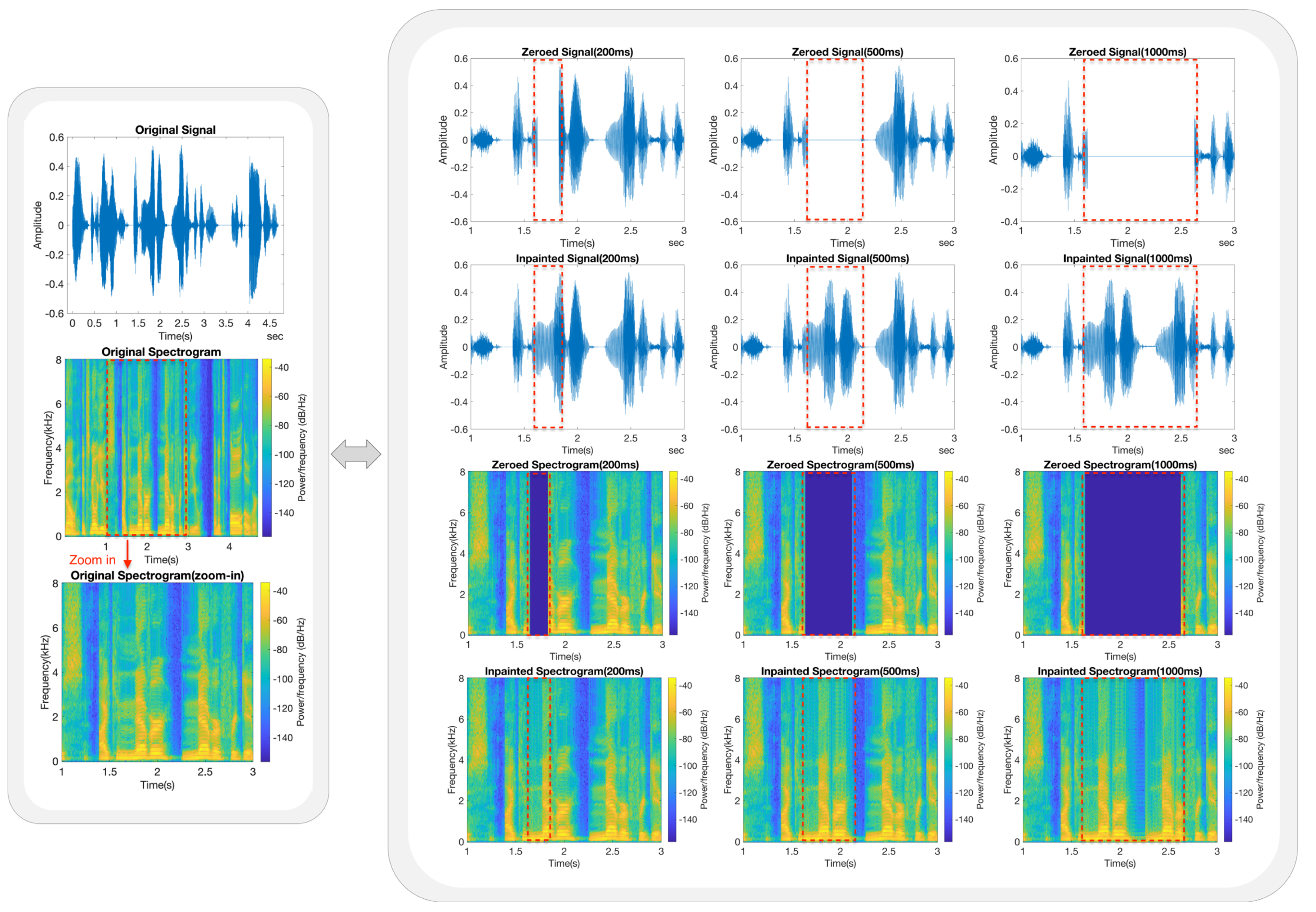
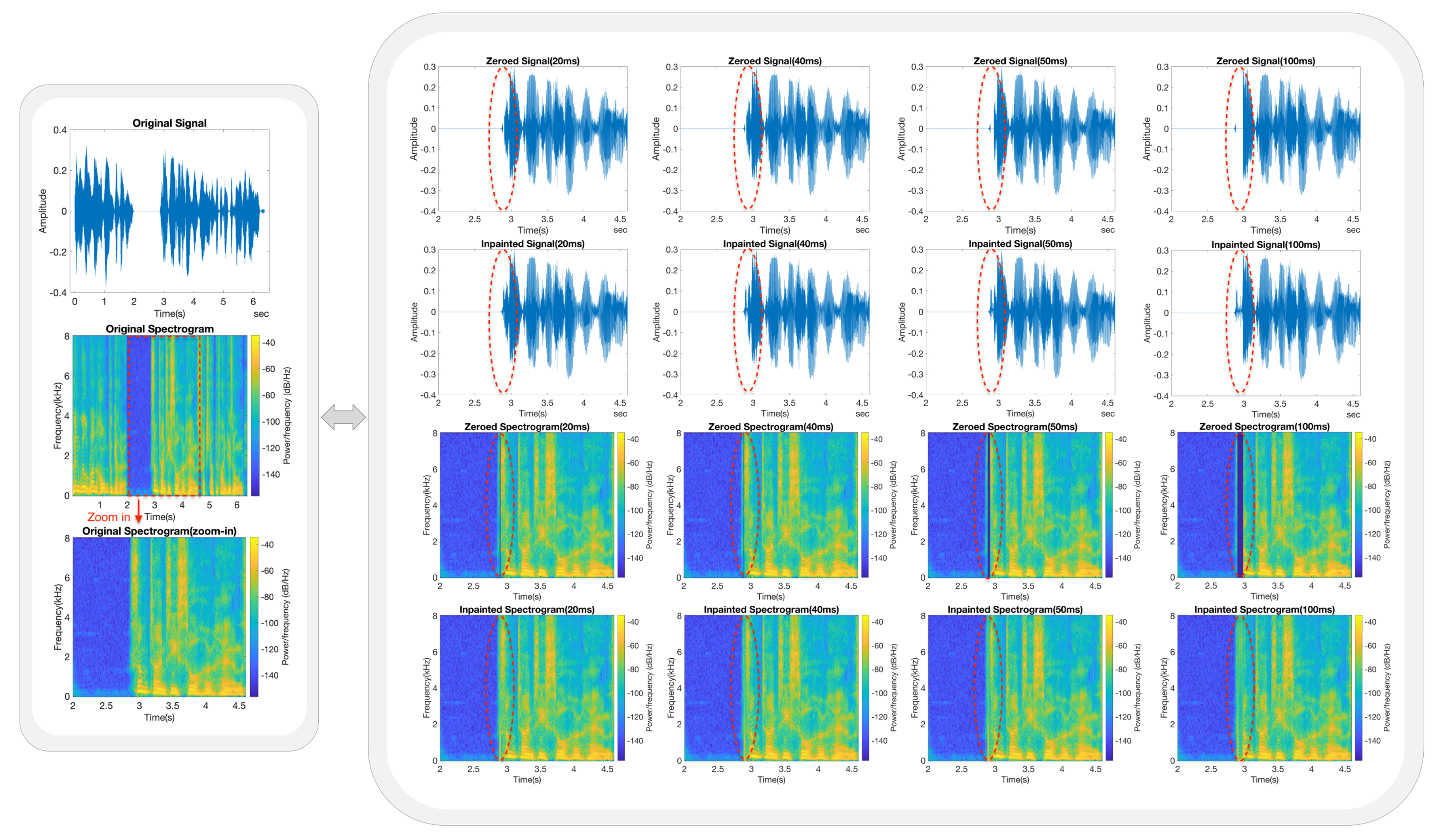
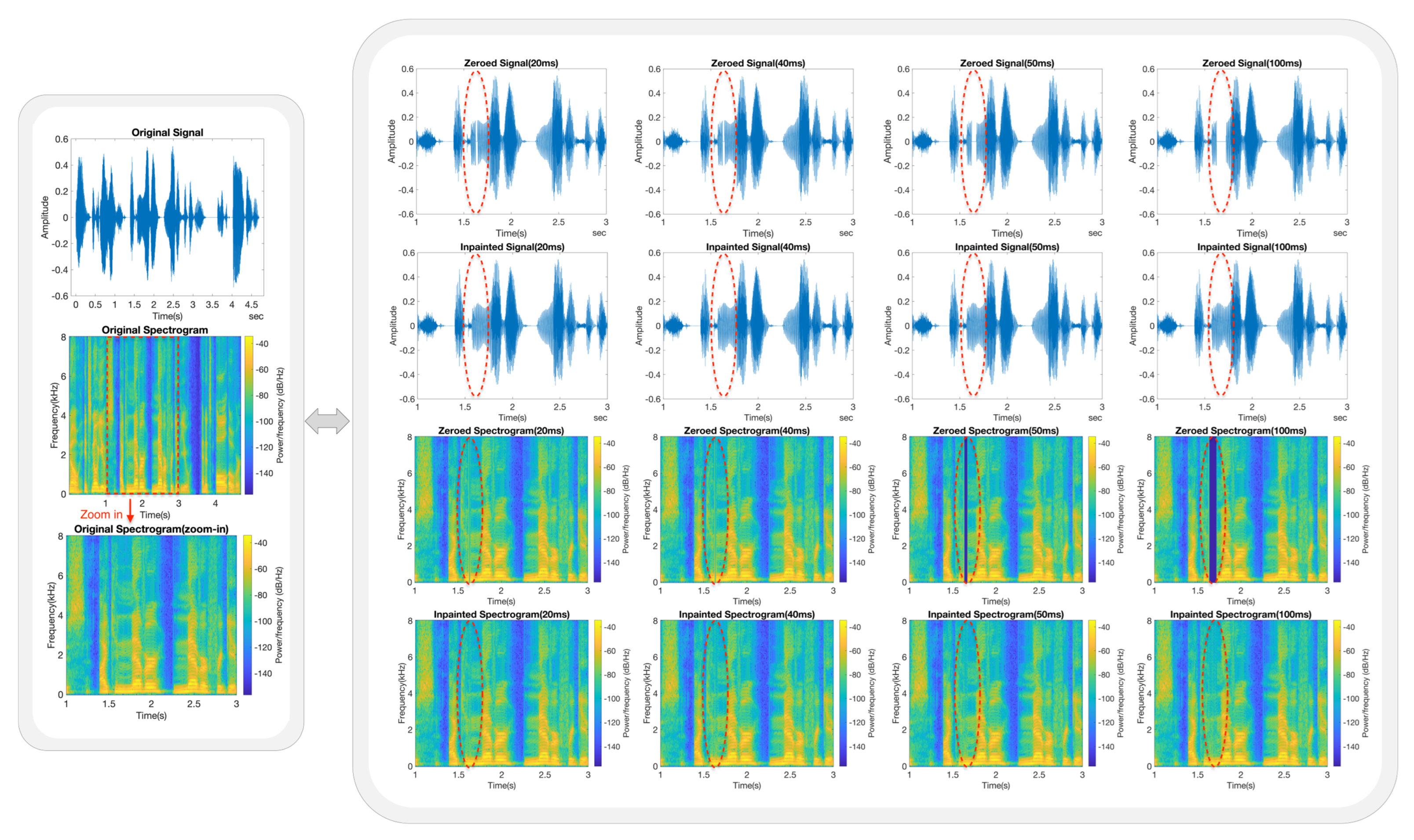
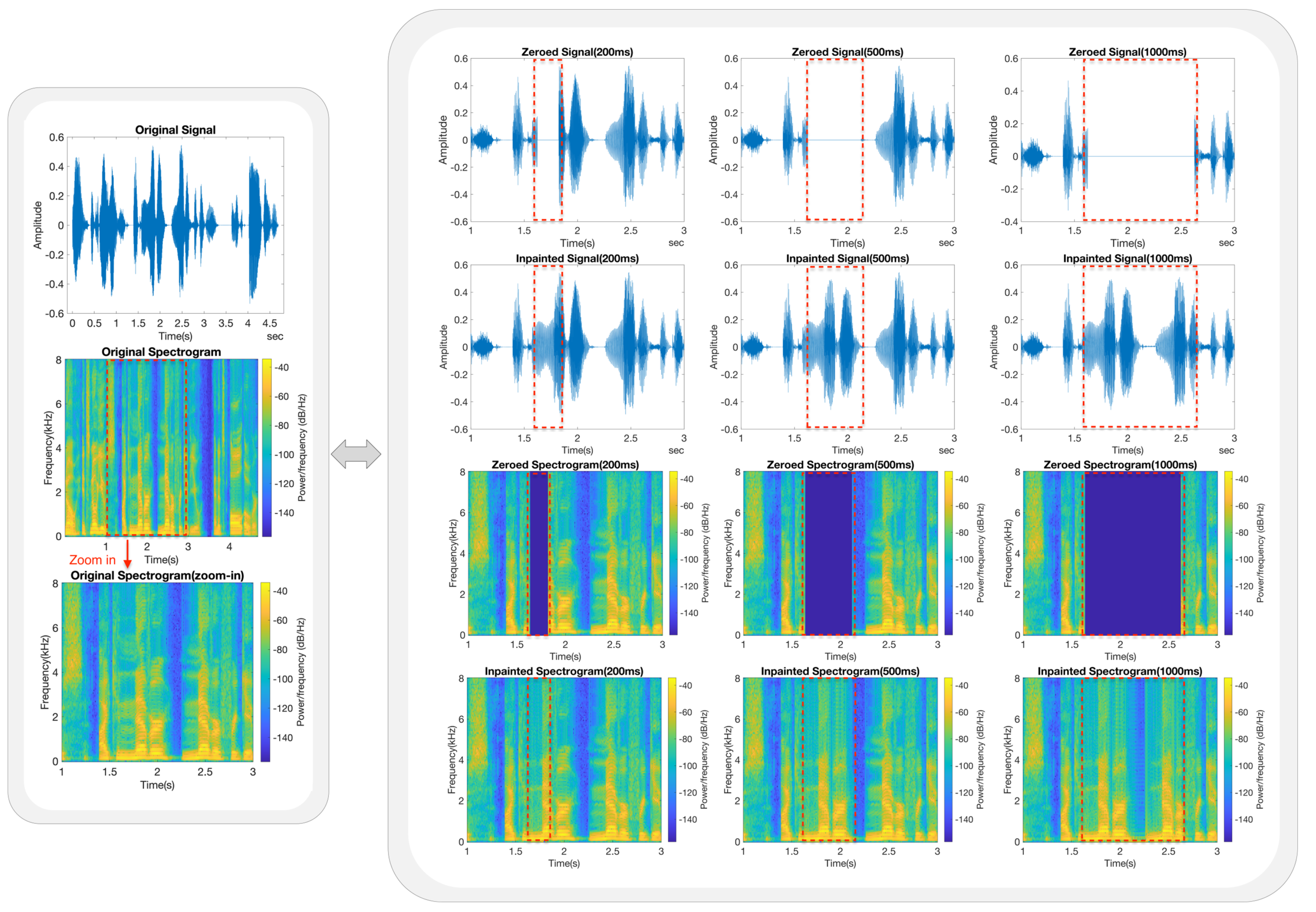
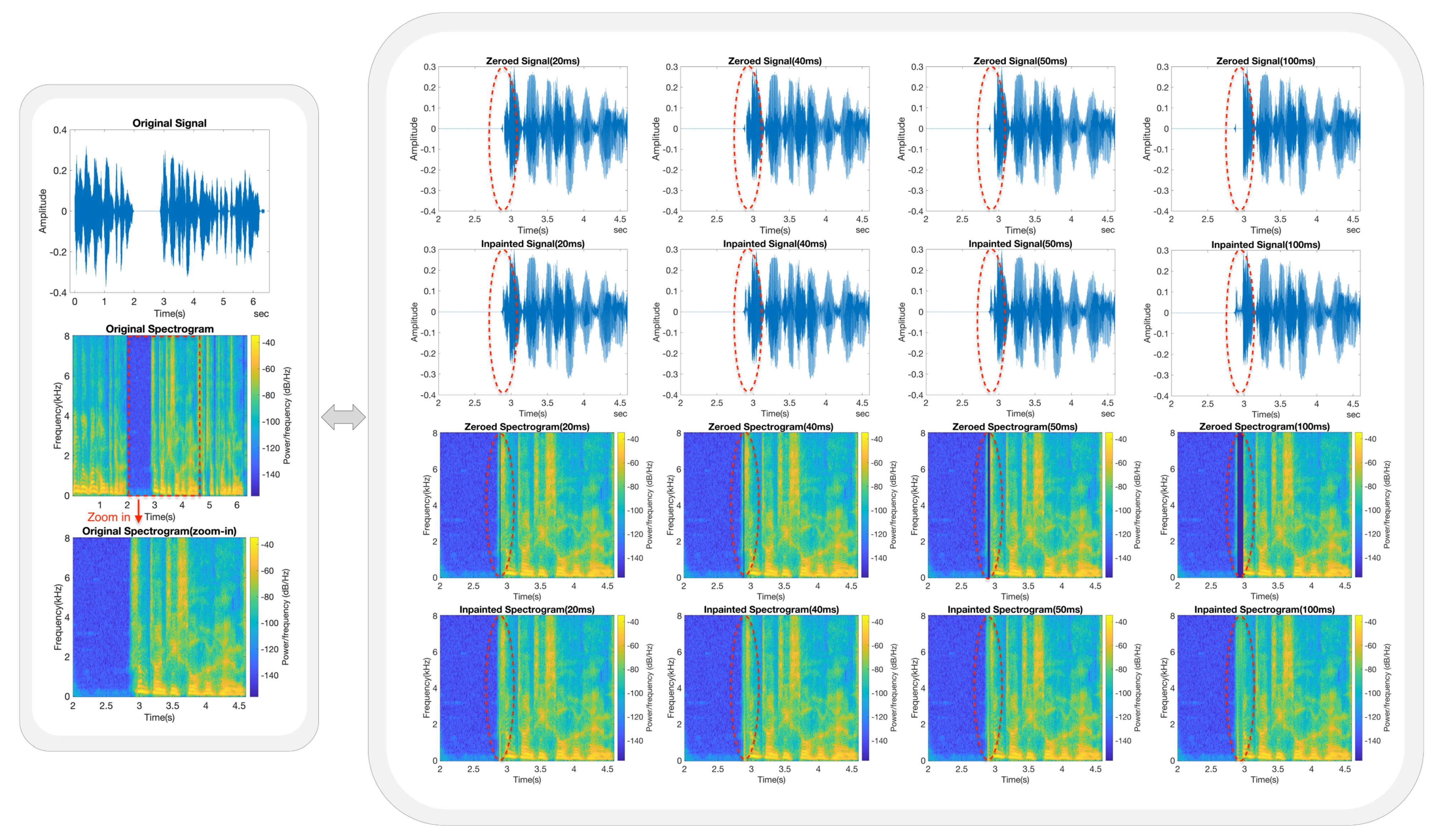
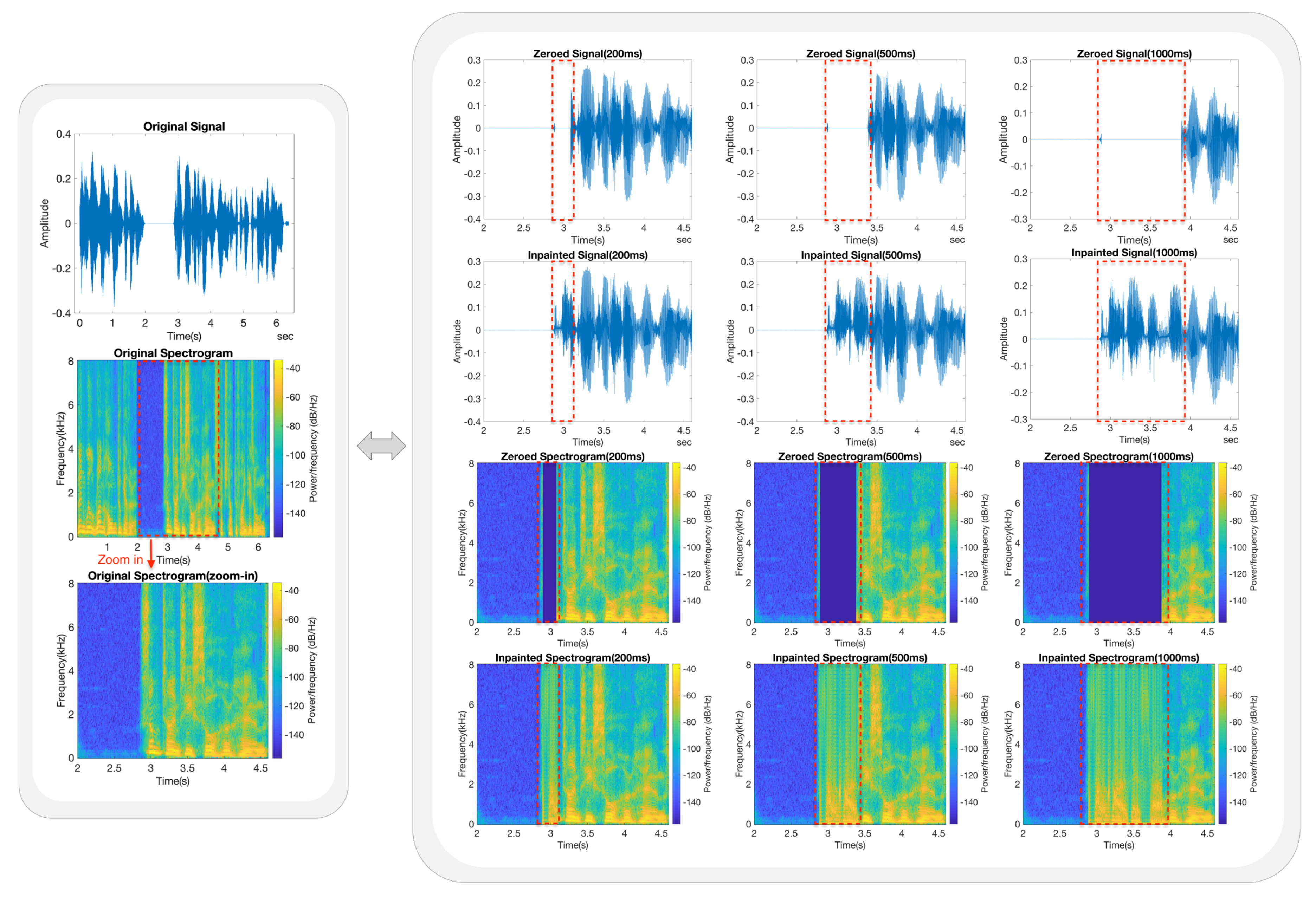
- Each trained model was subjected to a series of speech inpainting tests on ten speech signals that were entirely independent of its own dataset. The restored speech signals consistently exhibited good MOSs and listening quality across various gap lengths.
- In order to further validate the generalisation capability, we conducted additional tests to examine the models by training them on a specific dataset and applying them to completely different datasets. In this experiment, a model was first trained on a dataset consisting of only female/male voices, and the model was then applied to restore male/female speech signals from completely different datasets. The inpainting results also demonstrated high MOSs and listening quality across various gap lengths.
5.2. Inpainting Performance with Different Numbers of LSTM Layers
5.3. Inpainting Performance Based on Frequency Analysis
5.4. Inpainting Performance on Multi-Speaker Datasets
5.5. Comparison with Other Algorithms
5.6. Limitations
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Adler, A.; Emiya, V.; Jafari, M.G.; Elad, M.; Gribonval, R.; Plumbley, M.D. Audio inpainting. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 922–932. [Google Scholar] [CrossRef]
- Janssen, A.; Veldhuis, R.; Vries, L. Adaptive interpolation of discrete-time signals that can be modeled as autoregressive processes. IEEE Trans. Acoust. Speech Signal Process. 1986, 34, 317–330. [Google Scholar] [CrossRef]
- Oudre, L. Interpolation of Missing Samples in Sound Signals Based on Autoregressive Modeling. Image Process. Line 2018, 8, 329–344. [Google Scholar] [CrossRef]
- Etter, W. Restoration of a discrete-time signal segment by interpolation based on the left-sided and right-sided autoregressive parameters. IEEE Trans. Signal Process. 1996, 44, 1124–1135. [Google Scholar] [CrossRef]
- Lagrange, M.; Marchand, S.; Rault, J.B. Long interpolation of audio signals using linear prediction in sinusoidal modeling. J. Audio Eng. Soc. 2005, 53, 891–905. [Google Scholar]
- Lukin, A.; Todd, J. Parametric interpolation of gaps in audio signals. In Audio Engineering Society Convention 125; Audio Engineering Society: New York, NY, USA, 2008. [Google Scholar]
- Kauppinen, I.; Kauppinen, J.; Saarinen, P. A method for long extrapolation of audio signals. J. Audio Eng. Soc. 2001, 49, 1167–1180. [Google Scholar]
- Kauppinen, I.; Roth, K. Audio signal extrapolation–theory and applications. In Proceedings of the Proc. DAFx, Hamburg, Germany, 26–28 September 2002; pp. 105–110. [Google Scholar]
- Goodman, D.; Lockhart, G.; Wasem, O.; Wong, W.C. Waveform substitution techniques for recovering missing speech segments in packet voice communications. IEEE Trans. Acoust. Speech Signal Process. 1986, 34, 1440–1448. [Google Scholar] [CrossRef]
- Smaragdis, P.; Raj, B.; Shashanka, M. Missing data imputation for spectral audio signals. In Proceedings of the 2009 IEEE International Workshop on Machine Learning for Signal Processing, Grenoble, France, 1–4 September 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Smaragdis, P.; Raj, B.; Shashanka, M. Missing data imputation for time-frequency representations of audio signals. J. Signal Process. Syst. 2011, 65, 361–370. [Google Scholar] [CrossRef]
- Bertalmio, M.; Sapiro, G.; Caselles, V.; Ballester, C. Image inpainting. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000; pp. 417–424. [Google Scholar]
- Godsill, S.; Rayner, P.; Cappé, O. Digital Audio Restoration; Applications of digital signal processing to audio and acoustics; Springer: Berlin/Heidelberg, Germany, 2002; pp. 133–194. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sanneck, H.; Stenger, A.; Younes, K.B.; Girod, B. A new technique for audio packet loss concealment. In Proceedings of the GLOBECOM’96, 1996 IEEE Global Telecommunications Conference, London, UK, 18–28 November 1996; pp. 48–52. [Google Scholar]
- Bahat, Y.; Schechner, Y.Y.; Elad, M. Self-content-based audio inpainting. Signal Process. 2015, 111, 61–72. [Google Scholar] [CrossRef]
- Lieb, F.; Stark, H.G. Audio inpainting: Evaluation of time-frequency representations and structured sparsity approaches. Signal Process. 2018, 153, 291–299. [Google Scholar] [CrossRef]
- Adler, A.; Emiya, V.; Jafari, M.G.; Elad, M.; Gribonval, R.; Plumbley, M.D. A constrained matching pursuit approach to audio declipping. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 329–332. [Google Scholar]
- Tauböck, G.; Rajbamshi, S.; Balazs, P. Dictionary learning for sparse audio inpainting. IEEE J. Sel. Top. Signal Process. 2020, 15, 104–119. [Google Scholar] [CrossRef]
- Mokrý, O.; Rajmic, P. Audio Inpainting: Revisited and Reweighted. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2906–2918. [Google Scholar] [CrossRef]
- Chantas, G.; Nikolopoulos, S.; Kompatsiaris, I. Sparse audio inpainting with variational Bayesian inference. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Marafioti, A.; Perraudin, N.; Holighaus, N.; Majdak, P. A context encoder for audio inpainting. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 2362–2372. [Google Scholar] [CrossRef]
- Kegler, M.; Beckmann, P.; Cernak, M. Deep speech inpainting of time-frequency masks. arXiv 2019, arXiv:1910.09058. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Ebner, P.P.; Eltelt, A. Audio inpainting with generative adversarial network. arXiv 2020, arXiv:2003.07704. [Google Scholar]
- Marafioti, A.; Majdak, P.; Holighaus, N.; Perraudin, N. GACELA: A generative adversarial context encoder for long audio inpainting of music. IEEE J. Sel. Top. Signal Process. 2020, 15, 120–131. [Google Scholar] [CrossRef]
- Borsos, Z.; Sharifi, M.; Tagliasacchi, M. Speechpainter: Text-conditioned speech inpainting. arXiv 2022, arXiv:2202.07273. [Google Scholar]
- Jaegle, A.; Borgeaud, S.; Alayrac, J.B.; Doersch, C.; Ionescu, C.; Ding, D.; Koppula, S.; Zoran, D.; Brock, A.; Shelhamer, E.; et al. Perceiver io: A general architecture for structured inputs & outputs. arXiv 2021, arXiv:2107.14795. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Montesinos, J.F.; Michelsanti, D.; Haro, G.; Tan, Z.H.; Jensen, J. Speech inpainting: Context-based speech synthesis guided by video. arXiv 2023, arXiv:2306.00489. [Google Scholar]
- Morrone, G.; Michelsanti, D.; Tan, Z.H.; Jensen, J. Audio-visual speech inpainting with deep learning. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6653–6657. [Google Scholar]
- ITU; ITUTP. A Method for Subjective Performance Assessment of the Quality of Speech Voice Output Devices; International Telecommunication Union Std: Geneva, Switzerland, 1994. [Google Scholar]
- Bose, T.; Meyer, F. Digital Signal and Image Processing; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2003. [Google Scholar]
- Berouti, M.; Schwartz, R.; Makhoul, J. Enhancement of speech corrupted by acoustic noise. In Proceedings of the ICASSP’79, IEEE International Conference on Acoustics, Speech, and Signal Processing, Washington, DC, USA, 2–4 April 1979; Volume 4, pp. 208–211. [Google Scholar]
- Atal, B. Predictive coding of speech at low bit rates. IEEE Trans. Commun. 1982, 30, 600–614. [Google Scholar] [CrossRef]
- Moliner, E.; Välimäki, V. Diffusion-Based Audio Inpainting. arXiv 2023, arXiv:2305.15266. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Ito, K.; Johnson, L. The LJ Speech Dataset. 2017. Available online: https://keithito.com/LJ-Speech-Dataset/ (accessed on 9 February 2024).
- Bakhturina, E.; Lavrukhin, V.; Ginsburg, B.; Zhang, Y. Hi-Fi Multi-Speaker English TTS Dataset. arXiv 2021, arXiv:2104.01497. [Google Scholar]
- Zandie, R.; Mahoor, M.H.; Madsen, J.; Emamian, E.S. Ryanspeech: A corpus for conversational text-to-speech synthesis. arXiv 2021, arXiv:2106.08468. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QUE, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Bengio, Y. Practical recommendations for gradient-based training of deep architectures. In Neural Networks: Tricks of the Trade: Second Edition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- Enhanced Voice Services Codec for LTE, 3GPP TR 26.952. 2014. Available online: https://www.3gpp.org/news-events/3gpp-news/evs-news (accessed on 9 February 2024).
- Codec for Enhanced Voice Services (EVS); General Overview. Technical Specification (TS) 26.441 3rd Generation Partnership Project (3GPP). 2018. Available online: https://www.etsi.org/deliver/etsi_ts/126400_126499/126441/15.00.00_60/ts_126441v150000p.pdf (accessed on 9 February 2024).
- Extended Reality (XR) in 5G. Technical Specification (TS) 26.928 3rd Generation Partnership Project (3GPP). 2020. Available online: https://www.etsi.org/deliver/etsi_tr/126900_126999/126928/16.00.00_60/tr_126928v160000p.pdf (accessed on 9 February 2024).
- P.862: Revised Annex A—Reference Implementations and Conformance Testing for ITU-T Recs P.862, P.862.1 and P.862.2. 2005. Available online: https://www.itu.int/rec/T-REC-P.862-200511-I!Amd2/en (accessed on 9 February 2024).
- Patro, S.; Sahu, K.K. Normalization: A preprocessing stage. arXiv 2015, arXiv:1503.06462. [Google Scholar] [CrossRef]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- P.862.1: Mapping Function for Transforming P.862 Raw Result Scores to MOS-LQO. 2003. Available online: https://www.itu.int/rec/T-REC-P.862.1/en (accessed on 9 February 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Dataset | Component (M: Male; F: Female) | Length (s) |
|---|---|---|---|
| Single-speaker | LJSpeech [38] | 1 speaker (F) | 400 |
| RyanSpeech [40] | 1 speaker (M) | 400 | |
| LibriSpeech [41] | 1 speaker (M) | 400 | |
| LibriSpeech [41] | 1 speaker (F) | 400 | |
| Multi-speaker | Hi-Fi [39] | 10 speakers (4 F, 6 M) | 400 for each speaker |
| LibriSpeech [41] | 10 speakers (5 F, 5 M) | 400 for each speaker | |
| LibriSpeech [41] | 10 speakers (5 F, 5 M) | 400 for each speaker | |
| LibriSpeech [41] | 10 speakers (5 F, 5 M) | 400 for each speaker |
| Batch Size | Bandwidth | Gap Length (ms) | ||||||
|---|---|---|---|---|---|---|---|---|
| 20 | 40 | 50 | 100 | 200 | 500 | 1000 | ||
| 256 | NB | 3.95 | 3.80 | 3.78 | 3.67 | 3.37 | 2.93 | 2.34 |
| WB | 3.84 | 3.70 | 3.62 | 3.51 | 3.06 | 2.22 | 1.69 | |
| 512 | NB | 4.03 | 3.92 | 3.91 | 3.79 | 3.59 | 3.25 | 2.74 |
| WB | 4.03 | 3.93 | 3.87 | 3.72 | 3.44 | 2.88 | 2.27 | |
| 640 | NB | 4.08 | 3.95 | 3.92 | 3.82 | 3.62 | 3.23 | 2.72 |
| WB | 4.01 | 3.87 | 3.80 | 3.68 | 3.37 | 2.72 | 2.06 | |
| 1024 | NB | 4.08 | 3.90 | 3.89 | 3.77 | 3.52 | 3.15 | 2.62 |
| WB | 4.07 | 3.93 | 3.90 | 3.80 | 3.45 | 2.83 | 2.19 | |
| Dropout Rate | Bandwidth | Gap Length (ms) | ||||||
|---|---|---|---|---|---|---|---|---|
| 20 | 40 | 50 | 100 | 200 | 500 | 1000 | ||
| 0.1 | NB | 4.10 | 3.94 | 3.91 | 3.82 | 3.58 | 3.18 | 2.63 |
| WB | 4.11 | 3.96 | 3.90 | 3.78 | 3.48 | 2.92 | 2.25 | |
| 0.2 | NB | 4.08 | 3.90 | 3.89 | 3.77 | 3.52 | 3.15 | 2.62 |
| WB | 4.07 | 3.93 | 3.90 | 3.80 | 3.45 | 2.83 | 2.19 | |
| 0.3 | NB | 4.07 | 3.93 | 3.88 | 3.77 | 3.57 | 3.15 | 2.61 |
| WB | 4.04 | 3.92 | 3.86 | 3.75 | 3.47 | 2.90 | 2.23 | |
| 0.4 | NB | 4.13 | 3.99 | 3.94 | 3.82 | 3.61 | 3.25 | 2.77 |
| WB | 4.12 | 3.97 | 3.92 | 3.79 | 3.50 | 2.97 | 2.33 | |
| 0.5 | NB | 4.12 | 3.96 | 3.90 | 3.80 | 3.55 | 3.16 | 2.61 |
| WB | 4.14 | 3.97 | 3.91 | 3.81 | 3.51 | 2.93 | 2.25 | |
| Location | Bandwidth | Gap Length (ms) | ||||||
|---|---|---|---|---|---|---|---|---|
| 20 | 40 | 50 | 100 | 200 | 500 | 1000 | ||
| 1 | NB | 4.13 | 3.99 | 3.94 | 3.82 | 3.61 | 3.25 | 2.77 |
| WB | 4.12 | 3.97 | 3.92 | 3.79 | 3.50 | 2.97 | 2.33 | |
| 2 | NB | 4.04 | 3.92 | 3.87 | 3.76 | 3.58 | 3.20 | 2.67 |
| WB | 4.05 | 3.93 | 3.88 | 3.78 | 3.51 | 2.97 | 2.33 | |
| 3 | NB | 4.11 | 3.97 | 3.92 | 3.80 | 3.60 | 3.23 | 2.71 |
| WB | 4.12 | 3.96 | 3.91 | 3.79 | 3.51 | 2.97 | 2.33 | |
| 4 | NB | 4.02 | 3.89 | 3.84 | 3.72 | 3.54 | 3.19 | 2.69 |
| WB | 4.03 | 3.90 | 3.84 | 3.71 | 3.43 | 2.82 | 2.19 | |
| 5 | NB | 4.10 | 3.93 | 3.89 | 3.77 | 3.57 | 3.20 | 2.65 |
| WB | 4.05 | 3.92 | 3.85 | 3.72 | 3.41 | 2.79 | 2.12 | |
| Hyperparameter | Value |
|---|---|
| Batch size | 1024 |
| Dropout rate | 0.4 |
| Input sequence length | 640 |
| Output sequence length | 80 |
| Adam optimiser | = 0.9, = 0.999 |
| Epochs (single-speaker datasets) | 50 |
| Epochs (multi-speaker datasets) | 100 |
| Input dimension (single-speaker datasets) | 1 |
| Input dimension (multi-speaker datasets) | 10 |
| Nodes in each LSTM input layer | 100 |
| Nodes in each LSTM output layer | 100 |
| Nodes in the dense layer | 1 |
| Category | LSTM Layers | Total Parameters | Avg. Training Time (Hours) | Avg. Prediction Speed (Samples/s) |
|---|---|---|---|---|
| Single-speaker | 2 | 121,301 | 7.50 | 33.70 |
| 3 | 201,701 | 11.11 | 28.73 | |
| 4 | 282,101 | 14.58 | 24.98 | |
| 5 | 362,501 | 18.13 | 22.52 | |
| 6 | 442,901 | 21.67 | 20.19 | |
| Multi-speaker | 5 | 366,101 | 37.50 | 22.80 |
| Dataset | Bandwidth | LSTM Layers | Gap Length (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 20 | 40 | 50 | 100 | 200 | 500 | 1000 | |||
| LJSpeech | NB | 2 | 4.17 | 3.96 | 3.92 | 3.84 | 3.71 | 3.27 | 2.69 |
| 3 | 4.15 | 3.91 | 3.88 | 3.80 | 3.66 | 3.17 | 2.56 | ||
| 4 | 4.14 | 3.95 | 3.92 | 3.79 | 3.67 | 3.21 | 2.59 | ||
| 5 | 4.16 | 3.96 | 3.92 | 3.83 | 3.67 | 3.19 | 2.57 | ||
| 6 | 4.10 | 3.91 | 3.86 | 3.77 | 3.62 | 3.13 | 2.49 | ||
| RyanSpeech | NB | 2 | 4.08 | 3.94 | 3.89 | 3.74 | 3.48 | 3.02 | 2.52 |
| 3 | 4.15 | 4.00 | 3.94 | 3.74 | 3.53 | 3.07 | 2.56 | ||
| 4 | 4.11 | 3.96 | 3.91 | 3.73 | 3.52 | 3.03 | 2.54 | ||
| 5 | 4.07 | 3.91 | 3.85 | 3.68 | 3.43 | 2.92 | 2.44 | ||
| 6 | 4.13 | 3.97 | 3.90 | 3.73 | 3.48 | 3.01 | 2.48 | ||
| Libri_26 | NB | 2 | 4.29 | 4.15 | 4.10 | 3.90 | 3.72 | 3.25 | 2.68 |
| 3 | 4.25 | 4.13 | 4.10 | 3.93 | 3.75 | 3.29 | 2.76 | ||
| 4 | 4.25 | 4.14 | 4.11 | 3.92 | 3.77 | 3.30 | 2.78 | ||
| 5 | 4.29 | 4.17 | 4.14 | 3.98 | 3.80 | 3.37 | 2.86 | ||
| 6 | 4.24 | 4.12 | 4.09 | 3.89 | 3.71 | 3.22 | 2.67 | ||
| Libri_32 | NB | 2 | 4.26 | 4.09 | 4.03 | 3.92 | 3.66 | 3.21 | 2.75 |
| 3 | 4.29 | 4.07 | 4.02 | 3.88 | 3.64 | 3.17 | 2.69 | ||
| 4 | 4.24 | 4.06 | 4.01 | 3.84 | 3.63 | 3.19 | 2.70 | ||
| 5 | 4.24 | 4.06 | 4.00 | 3.85 | 3.61 | 3.14 | 2.66 | ||
| 6 | 4.25 | 4.10 | 4.04 | 3.91 | 3.68 | 3.21 | 2.74 | ||
| Dataset | Bandwidth | LSTM Layers | Gap Length (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 20 | 40 | 50 | 100 | 200 | 500 | 1000 | |||
| LJSpeech | WB | 2 | 4.08 | 3.89 | 3.88 | 3.77 | 3.55 | 3.00 | 2.29 |
| 3 | 4.02 | 3.86 | 3.82 | 3.70 | 3.47 | 2.89 | 2.21 | ||
| 4 | 4.03 | 3.85 | 3.81 | 3.69 | 3.44 | 2.89 | 2.21 | ||
| 5 | 4.13 | 3.94 | 3.89 | 3.74 | 3.52 | 2.94 | 2.27 | ||
| 6 | 4.03 | 3.88 | 3.83 | 3.71 | 3.46 | 2.85 | 2.13 | ||
| RyanSpeech | WB | 2 | 4.10 | 3.99 | 3.93 | 3.78 | 3.49 | 2.90 | 2.29 |
| 3 | 4.17 | 4.01 | 3.94 | 3.81 | 3.50 | 2.92 | 2.32 | ||
| 4 | 4.12 | 3.97 | 3.92 | 3.78 | 3.50 | 2.89 | 2.27 | ||
| 5 | 4.09 | 3.96 | 3.90 | 3.78 | 3.47 | 2.87 | 2.26 | ||
| 6 | 4.15 | 4.01 | 3.94 | 3.81 | 3.50 | 2.89 | 2.25 | ||
| Libri_26 | WB | 2 | 4.26 | 4.08 | 4.03 | 3.82 | 3.60 | 3.04 | 2.36 |
| 3 | 4.18 | 4.04 | 4.00 | 3.80 | 3.60 | 3.06 | 2.42 | ||
| 4 | 4.22 | 4.08 | 4.03 | 3.83 | 3.62 | 3.07 | 2.43 | ||
| 5 | 4.25 | 4.09 | 4.02 | 3.87 | 3.62 | 3.09 | 2.44 | ||
| 6 | 4.20 | 4.07 | 4.01 | 3.82 | 3.60 | 3.04 | 2.39 | ||
| Libri_32 | WB | 2 | 4.33 | 4.11 | 4.05 | 3.94 | 3.72 | 3.17 | 2.53 |
| 3 | 4.33 | 4.12 | 4.07 | 3.94 | 3.72 | 3.17 | 2.57 | ||
| 4 | 4.28 | 4.11 | 4.06 | 3.92 | 3.70 | 3.13 | 2.49 | ||
| 5 | 4.28 | 4.10 | 4.05 | 3.92 | 3.72 | 3.15 | 2.55 | ||
| 6 | 4.30 | 4.11 | 4.07 | 3.95 | 3.73 | 3.15 | 2.54 | ||
| Dataset | Bandwidth | LSTM Layers | Gap Length (ms) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 20 | 40 | 50 | 100 | 200 | 500 | 1000 | |||
| HIFI | NB | 5 | 4.13 | 4.04 | 4.00 | 3.86 | 3.58 | 3.09 | 2.39 |
| WB | 4.04 | 3.94 | 3.84 | 3.74 | 3.42 | 2.77 | 2.07 | ||
| LibriM1 | NB | 5 | 4.19 | 4.03 | 3.98 | 3.86 | 3.76 | 3.34 | 2.87 |
| WB | 4.18 | 4.07 | 4.02 | 3.85 | 3.71 | 3.19 | 2.57 | ||
| LibriM2 | NB | 5 | 4.12 | 4.00 | 3.96 | 3.80 | 3.59 | 3.13 | 2.60 |
| WB | 4.09 | 4.00 | 3.99 | 3.82 | 3.52 | 2.94 | 2.28 | ||
| LibriM3 | NB | 5 | 4.09 | 3.86 | 3.81 | 3.72 | 3.44 | 3.03 | 2.46 |
| WB | 3.70 | 3.60 | 3.57 | 3.45 | 3.21 | 2.74 | 2.13 | ||
| Method | Gap Length (ms) | MOS (NB) | MOS (WB) |
|---|---|---|---|
| Context-Encoder [22] | 64/128 | 4.02/3.57 | 3.95/3.48 |
| SpeechPainter [27] | 750–1000 | \ | 3.48 ± 0.06 |
| Audio-Visual (A+V+MTL) [31] | 100/200/400/800/1600 | \ | 4.10/3.82/3.43/2.49/1.56 |
| TF-Masks-informed (Avg. of 3 intrusions) [23] | 100/200/300/400 | \ | 3.20/2.57/2.09/1.78 |
| TF-Masks-blind (Avg. of 3 intrusions) [23] | 100/200/300/400 | \ | 3.17/2.75/2.46/2.21 |
| Proposed method (single-speaker) | 20/40/50/100 /200/500/1000 | 4.19/4.03/3.98/3.84 /3.64/3.17/2.64 | 4.18/4.02/3.97/3.82 /3.58/3.01/2.36 |
| Proposed method (multi-speaker) | 20/40/50/100 /200/500/1000 | 4.14/3.98/3.94/3.81 /3.60/3.15/2.58 | 4.01/3.91/3.86/3.72 /3.47/2.91/2.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, H.; Shi, X.; Dogan, S. Speech Inpainting Based on Multi-Layer Long Short-Term Memory Networks. Future Internet 2024, 16, 63. https://doi.org/10.3390/fi16020063
Shi H, Shi X, Dogan S. Speech Inpainting Based on Multi-Layer Long Short-Term Memory Networks. Future Internet. 2024; 16(2):63. https://doi.org/10.3390/fi16020063
Chicago/Turabian StyleShi, Haohan, Xiyu Shi, and Safak Dogan. 2024. "Speech Inpainting Based on Multi-Layer Long Short-Term Memory Networks" Future Internet 16, no. 2: 63. https://doi.org/10.3390/fi16020063
APA StyleShi, H., Shi, X., & Dogan, S. (2024). Speech Inpainting Based on Multi-Layer Long Short-Term Memory Networks. Future Internet, 16(2), 63. https://doi.org/10.3390/fi16020063