1. Introduction
Reinforcement learning (RL) [
1], a subset of machine learning, is predicated on the interaction between intelligent agents and their environments to facilitate decision making. This method has seen considerable advancements in areas such as systems control and gaming, and it holds significant promise for UAV trajectory planning and control [
2,
3]. However, the intricacies of UAV control and the dynamic nature of their operational environments necessitate rapid and precise decision making from these agents, challenging the capabilities of traditional RL methods.
A primary concern in this realm is sample efficiency, especially critical in UAV trajectory planning and control [
4]. The substantial costs and safety risks associated with real-world UAV flights render the extensive sample data and environmental interactions required by conventional RL frameworks impractical for actual deployment, as depicted in
Figure 1. Thus, developing methods to enhance sample efficiency is of paramount importance.
Moreover, the generalization capabilities of RL models in the context of UAV trajectory planning and control are often found wanting. Due to the variability and complexity of real-world environments, models that perform well in training scenarios may experience significant performance declines when introduced to new, unfamiliar settings. This drop in performance is often linked to the models’ strategies being too tailored to specific training environments, lacking the flexibility needed to adapt to new situations.
Additionally, traditional RL approaches are heavily reliant on the design of reward functions. Minor alterations in these functions can lead to vastly different flight strategies, making the task of crafting reward functions that accurately reflect the complex objectives of UAV missions challenging [
5,
6].
To tackle these challenges, the research community is turning towards innovative approaches such as meta-learning and imitation learning [
7,
8,
9]. Meta-learning, often described as ‘learning to learn’, empowers models with the ability to swiftly acclimate to new tasks by discerning and assimilating the underlying similarities across diverse tasks. This approach fundamentally aims to equip models with the capability to identify and abstract the core attributes of tasks, thereby leveraging accumulated knowledge to adeptly modify strategies when confronted with novel scenarios. Such a methodology enhances models’ adaptability and generalization skills, making them more versatile and effective in dynamic environments [
10,
11].
Imitation learning serves as a valuable complement to meta-learning, focusing on teaching agents to acquire strategies through the observation and replication of expert behaviors, instead of relying solely on reward signals. This learning paradigm is inspired by the human method of skill acquisition, which typically involves emulating the actions of individuals who have already achieved proficiency in a particular domain [
12,
13]. By adopting this approach, agents are able to circumvent the intricate process of reward function formulation, allowing them to directly assimilate the decision-making processes and critical maneuvers employed by experts in complex scenarios. Consequently, agents can attain or closely approximate the efficiency of experts in task execution, even in scenarios devoid of explicit reward indicators [
14,
15].
Models honed through meta-learning exhibit the remarkable ability to swiftly adjust to a variety of imitation learning tasks. Conversely, the tangible behavioral paradigms provided by imitation learning serve as invaluable practical guides for meta-learning. This synergistic blend not only mitigates the challenges associated with low sample efficiency and limited generalization but also equips models with the capacity to master intricate decision-making processes without the need for explicit reward signals.
In response to these challenges, we introduce an innovative meta-reinforcement learning algorithm that leverages the principles of Generative Adversarial Imitation Learning (GAIL) [
16]. This algorithm harmoniously integrates the strengths of both meta-learning and imitation learning, tailoring its design to meet the specific demands of UAV trajectory planning. By augmenting the UAVs’ perception of the state space with normalized methods and residual connections, we ensure consistent performance stability across diverse and challenging environments. These advanced techniques empower our algorithm to excel in UAV trajectory planning tasks, markedly enhancing both the sample efficiency and the ability to generalize across different scenarios.
In this paper,
Section 2 introduces some relevant work in the field of drones,
Section 3 provides a detailed explanation of meta-reinforcement learning and Generative Adversarial Imitation Learning, and
Section 4 presents the specific methodology of this paper.
Section 5 covers the experimental part.
2. Related Work
Researchers have actively adopted reinforcement learning methods to guide UAVs in autonomous decision making, which includes the application of basic control systems, path planning, obstacle avoidance, and advanced control techniques.
Application of Basic Control Systems: The fundamental aspects of UAV technology encompass attitude adjustment and basic flight control, with a key focus on ensuring the stability and controllability of UAVs under various flight conditions. Koch et al. [
17] utilized Deep Reinforcement Learning (DRL) to optimize UAV attitude control, especially under extreme conditions, such as strong winds and turbulence. Their research demonstrates the potential application of DRL in UAV control systems.
Path Planning and Obstacle Avoidance: Path planning is a critical component of UAV navigation, involving the efficient selection of routes and avoidance of obstacles. Zhao et al. [
18] employed the Q-learning algorithm to improve UAV path planning and obstacle avoidance capabilities, focusing on enhancing autonomous navigation technology, and confirmed the effectiveness of the algorithm in dealing with static and dynamic obstacles. Pham et al. [
19] implemented autonomous navigation of UAVs using RL and the TEXPLORE algorithm, advancing sophisticated UAV control. Their research demonstrated the efficacy of this algorithm in navigating and avoiding obstacles in unknown environments. He et al. [
20] improved the autonomous navigation capabilities of UAVs in unknown environments, particularly in path planning and obstacle avoidance, using DRL based on the Twin Delayed DDPG (TD3) algorithm. However, these methods also have drawbacks, requiring continuous trial-and-error training with low sample efficiency, and they struggle to generalize to new environments without prior examples.
Advanced Control: Advanced control in UAV technology not only includes basic flight operations but also encompasses the ability to execute complex tasks, such as formation control and advanced navigation techniques. Yang et al. [
21] significantly enhanced the formation control capabilities of UAVs using GAIL. Their method, by imitating peer actions and combining historical data, effectively improved the recognition of real-world environmental states. Additionally, Wang et al. [
22] significantly enhanced the navigation and control efficiency of racing drones by combining imitation learning with modular strategies and utilizing Convolutional Neural Networks (CNNs). Hu et al. [
23] employed meta-reinforcement learning to improve trajectory design for energy-constrained UAVs in dynamic network environments, focusing on enhancing the adaptability and response speed of UAVs as mobile base stations in unfamiliar environments.
While the applications of meta-reinforcement learning and imitation learning have achieved significant results in improving the efficiency and adaptability of UAV training, they each have their limitations. Meta-reinforcement learning (Meta-RL) often requires the manual design of reward functions to describe new tasks, which can be both cumbersome and impractical for non-experts. A more natural way to describe tasks is through demonstration, as performed in imitation learning (IL). However, IL is limited in its ability to continue improving policies and, compared to reinforcement learning methods, is constrained by the similarity between new tasks and the training dataset, leading to deficiencies in generalization capabilities [
24]. Therefore, this paper is dedicated to combining meta-reinforcement learning and imitation learning to address the aforementioned issues.
Table 1 compares our work with previous studies.
3. Preliminary
RL is typically conceptualized within the framework of a Markov Decision Process (MDP) [
25], formalized as
. Within this framework,
S delineates the set of possible states, while
A encapsulates the available actions. The function
defines the likelihood of transitioning to a subsequent state
upon the execution of an action
a in the current state
s. The reward function
quantifies the immediate benefit received upon performing action
a in state
s. Lastly, the discount factor
balances the agent’s valuation of immediate rewards against future returns, with values approaching 0 indicating a preference for immediate rewards and values nearing 1 signifying a longer-term outlook.
3.1. Meta-RL
Unlike conventional reinforcement learning approaches that are tailored for singular tasks, meta-reinforcement learning (Meta-RL) aspires to craft policies that are capable of rapid adaptation or optimization when faced with a sparse influx of data from new tasks [
26]. The prevailing methodologies in Meta-RL typically presuppose a task framework where all constituent subtasks are unified by identical state and action spaces. The distinctions among these tasks often emerge through variations in the reward functions, the probabilities of state transitions, or the distributions of initial states. For instance, in the context of robotic object-grasping experiments, diverse tasks may entail the manipulation of different objects within a consistent physical environment. Despite the variability in tasks, the robot’s action space (such as arm movements) and state space (encompassing joint angles and object locations) remain unchanged. Tasks are derived from the distribution
, with each task
characterized by
. Given the shared framework of state and action spaces across tasks, the task distribution
is delineated by the reward function and the initial state distribution
, thus formulated as
.
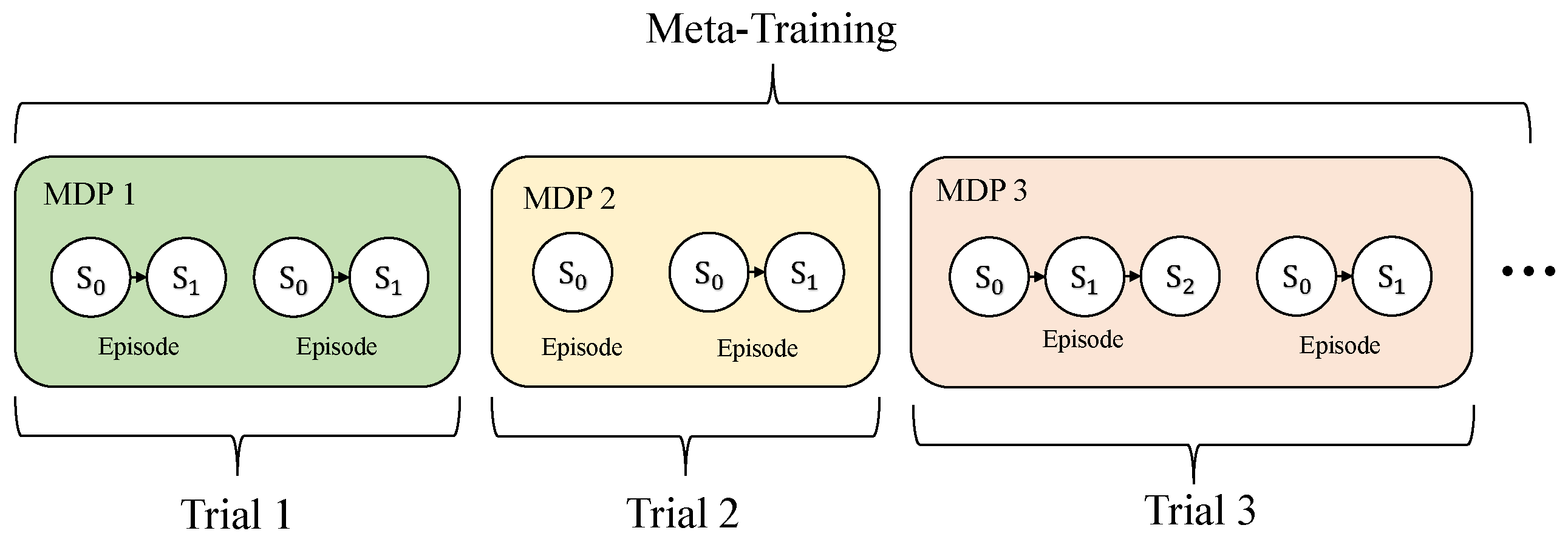
In the meta-training phase, tasks are drawn from the task distribution
to facilitate the training process. The fundamental goal during this stage is to equip the model with the ability to swiftly acclimate to novel tasks. Following this, in the meta-testing phase, the model is presented with a series of new tasks that, while related, are distinct from those encountered during training. This phase is critical for evaluating the model’s capacity for adaptability and its proficiency in assimilating new tasks. Throughout the meta-training period, the agent utilizes specific meta-learning parameters or employs update mechanisms designed to foster this rapid adaptation, which is then put to the test in the subsequent meta-testing phase. The intricacies of the meta-training process are illustrated in
Figure 2, highlighting the structured approach to achieving adaptability and flexibility in task learning.
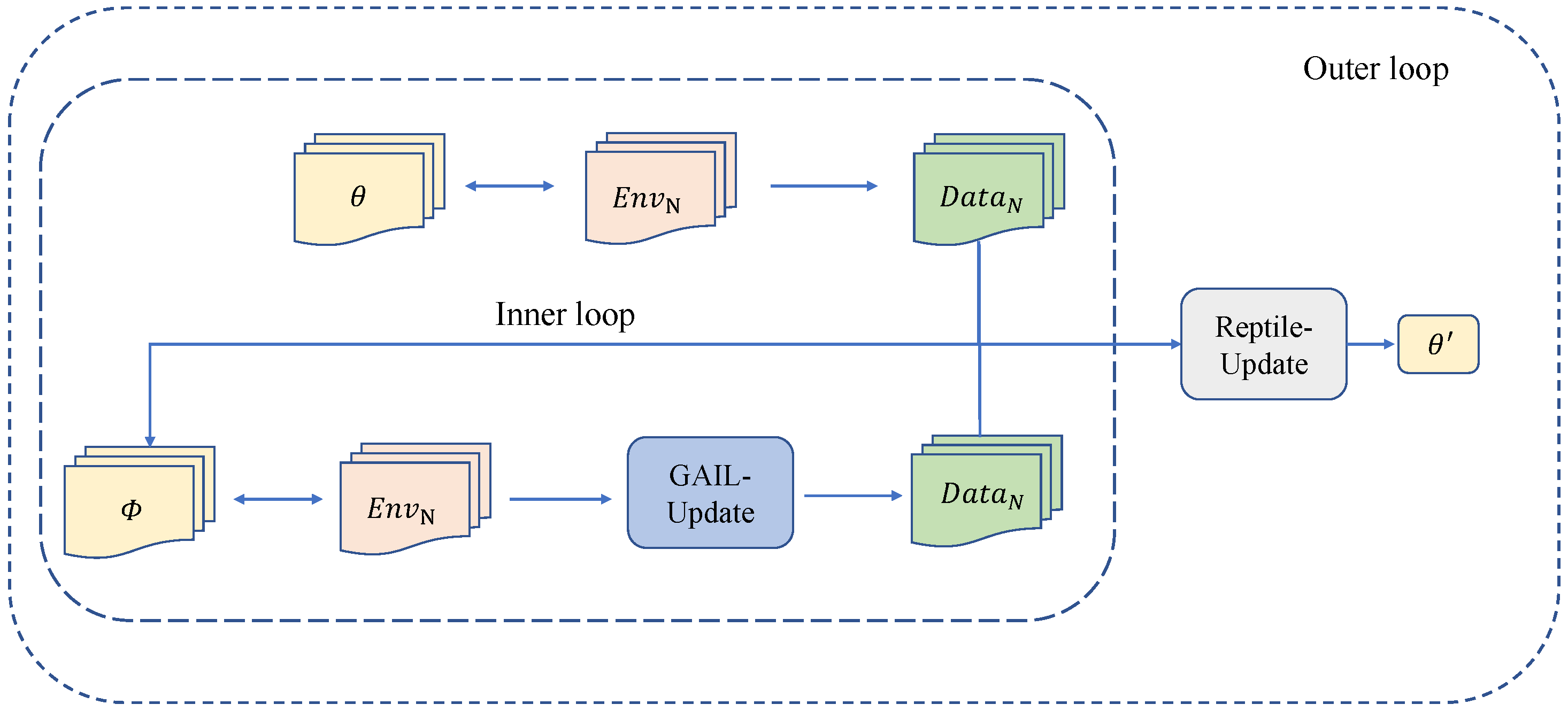
The process of meta-reinforcement learning can be subdivided into two critical cycles: the inner loop and the outer loop.
Inner Loop:
During the inner loop phase, the agent leverages meta-knowledge provided by the outer loop, which is crucial for application.
The main goal of this phase is to efficiently use meta-knowledge for quick adaptation to new tasks or environments.
The effectiveness of the meta-knowledge is gauged by the agent’s performance in this segment, serving as a vital evaluation criterion.
Outer Loop:
The outer loop’s primary role is to evolve and fine-tune the meta-knowledge itself.
This stage involves a thorough examination of similarities and differences across tasks to enhance the meta-knowledge that facilitates learning.
It also updates the meta-knowledge based on feedback from the inner loop, ensuring its efficacy across diverse tasks.
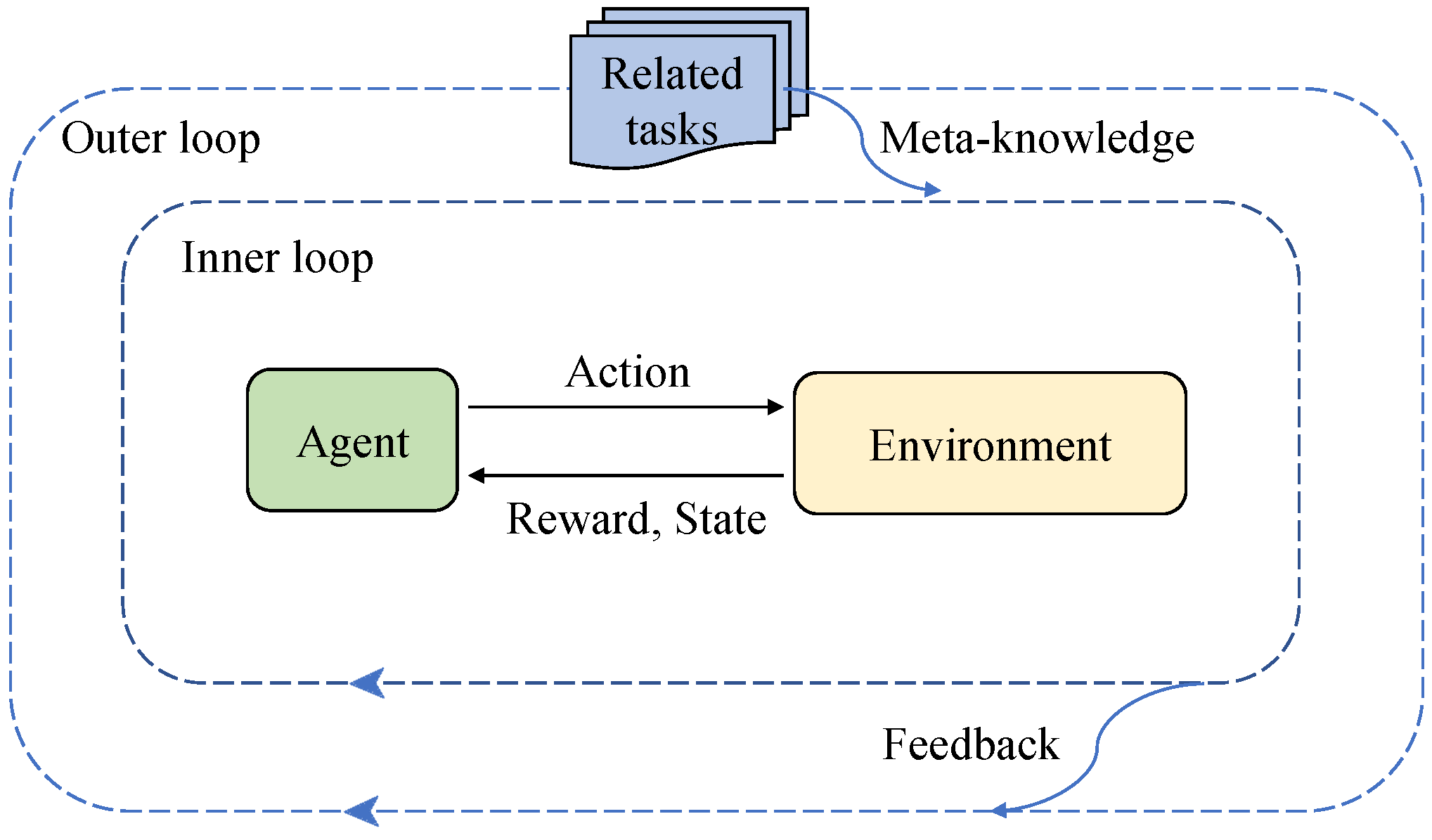
The concept of ‘meta-knowledge’ encapsulates the extensive knowledge framework an agent amasses while navigating through diverse tasks or challenges, serving as a pivotal element in its ability to swiftly adapt to novel tasks or environments [
27]. The primary aim of meta-reinforcement learning is to develop reinforcement learning algorithms endowed with the agility to adapt to new situations, with meta-knowledge at the heart of this endeavor. This knowledge domain includes, but is not limited to, learning methodologies, task-specific nuances, accumulated experiences, and environmental dynamics. The intrinsic value of meta-knowledge is rooted in its capacity for generalization—the extent to which insights gained from one task can be leveraged to enhance performance in other, ostensibly disparate tasks.
In the meta-reinforcement learning framework (shown in
Figure 3), the meta-knowledge accumulated in the outer loop significantly guides the inner loop, helping it adapt more quickly to new tasks. The essence of this learning mode lies in how effectively meta-knowledge can be extracted and utilized from multiple tasks, and how it can be adjusted according to the evolution of tasks, thus enabling the agent to rapidly adapt when facing new tasks. This approach is particularly suitable for scenarios in which the task environment frequently changes or the agent needs to handle a variety of different tasks, enhancing the model’s generalization capabilities.
3.2. GAIL
GAIL represents a sophisticated approach that synergizes the principles of Generative Adversarial Networks (GANs) with IL. This technique is particularly efficacious in complex settings where articulating a precise reward function poses significant challenges. GAIL acquires the capability to execute specific tasks by mimicking the behaviors of experts, circumventing the need for explicit reward signals in the learning process. Within this paradigm, the expert’s strategy is denoted by
, and the learner’s strategy is signified by
. The formulation for the learner’s strategy
encompasses the generation of expected trajectories, illustrating the process of learning through observation and emulation of expert actions.
Here, , , and f is an arbitrary function.
At the heart of GAIL lies the emulation of the expert policy’s state–action occupancy measure. This measure is a critical probability distribution that captures the frequency of an agent executing certain actions in given states under a specific policy. Unlike behavior cloning, which directly replicates expert trajectories without necessitating environmental interaction and consequently faces the challenge of compounding errors—where slight inaccuracies in imitation accumulate over time—GAIL necessitates active engagement with the environment. This interaction is pivotal for GAIL as it enables the learning policy to refine its actions based on the dynamic feedback from the environment, thereby mitigating the risk of error propagation inherent in behavior cloning.
The GAIL algorithm includes a discriminator D and a policy
, where policy
acts as the generator in the Generative Adversarial Network. The discriminator
D takes state–action pairs
as input and outputs a probability between 0 and 1, indicating how likely it is that the pair
originates from the agent’s policy rather than the expert’s policy. The goal of the discriminator is to make the output for expert data as close to 0 as possible and the imitator’s output close to 1, thus clearly distinguishing between the two. Based on the above, we can define the loss function for the discriminator
D as:
where
represents the parameters of the discriminator. The core idea of this algorithm is to make the trajectories generated by the policy
be misidentified by the discriminator as coming from the expert. Using this approach, we do not need to preset a specific reward function; instead, we can define the reward
as
. In this setting, if the discriminator
D judges the state–action pair
to be extremely similar to the expert’s behavior, the value of
is close to 1, and then
will be a smaller negative value, equivalent to a higher reward. Conversely, if the value of
is close to 0, implying that the discriminator considers the state–action pair unlike the expert’s behavior, then the reward
becomes a larger negative value, representing a lower reward.
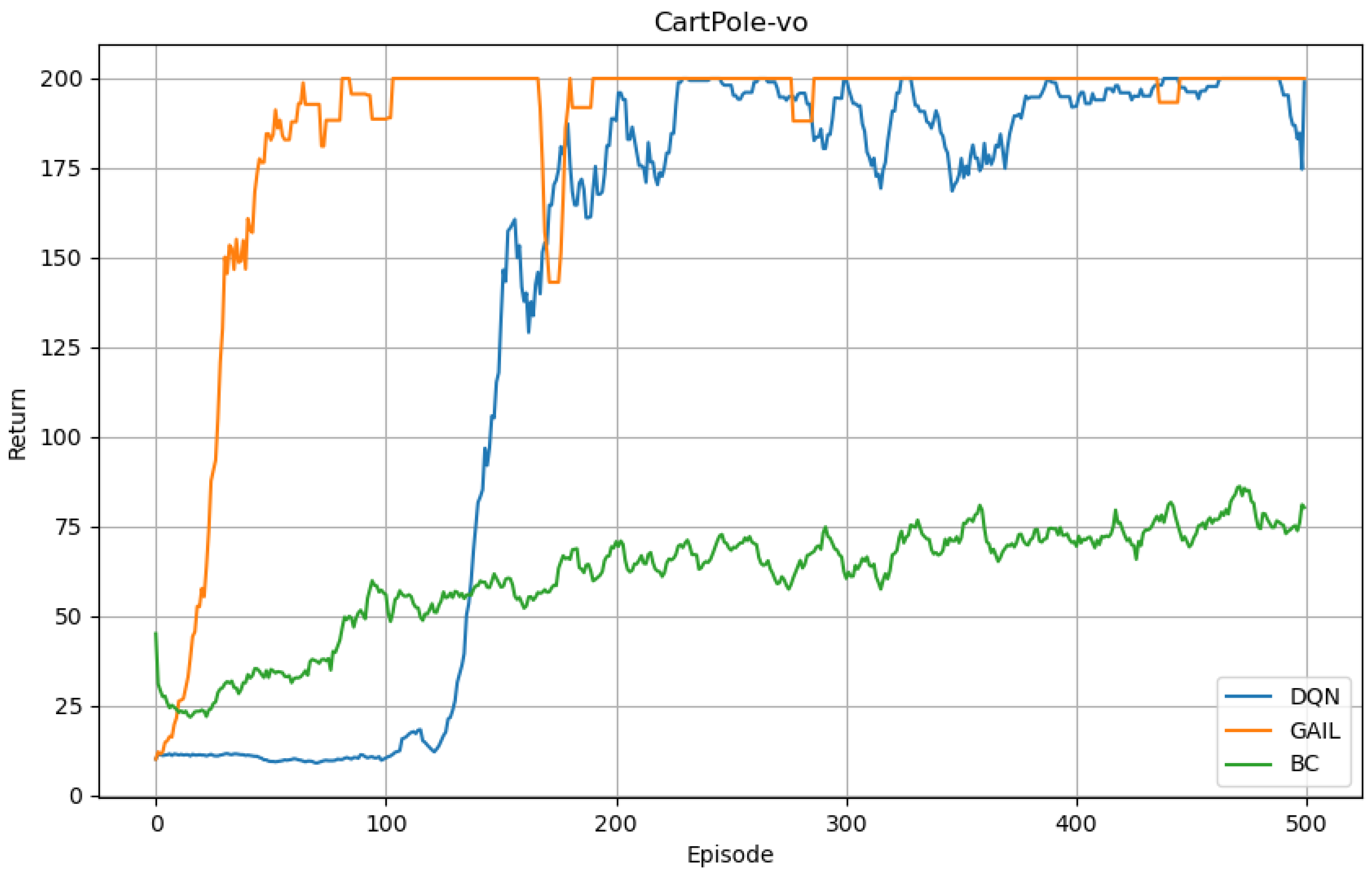
Building on the theoretical framework described, we embarked on a series of comparative analyses involving three distinct algorithms, applied to the Cartpole task. The initial step entailed the generation of expert data, for which we opted for the Proximal Policy Optimization (PPO) algorithm, given the relative simplicity of the Cartpole task. From the generated trajectory, we sampled 30 state–action pairs
. Our comparative analysis revealed that the Generative Adversarial Imitation Learning (GAIL) algorithm required merely 80 training epochs to attain the maximum reward threshold. In contrast, the traditional Deep Q-Network (DQN) algorithm necessitated a more extensive trial-and-error approach, taking approximately 200 epochs to reach a comparable performance level. Notably, the training trajectory of the model underpinned by GAIL exhibited greater stability than its DQN counterpart. The outcomes of these experimental endeavors are encapsulated in
Figure 4.
Nevertheless, given the constrained dataset of merely 30 data points, the performance of the Behavior Cloning (BC) algorithm was found to be subpar in comparison to the traditional DQN algorithm, failing to deduce the optimal strategy. This deficiency was predominantly attributed to the model’s propensity for overfitting when faced with such a scant data volume. In essence, the GAIL algorithm demonstrated its efficacy by propelling the model to attain superior performance levels more expediently, utilizing fewer data points and training epochs. Consequently, this underscores the potential merit of integrating the GAIL algorithm within the meta-reinforcement learning framework, especially for UAV tasks where articulating a precise reward function is challenging.
4. Methods
Building upon the experiments previously mentioned, we introduced the Reptile algorithm [
28] as our chosen method for meta-learning. Reptile is a gradient-based meta-learning algorithm aimed at identifying a set of initial parameters that enable rapid adaptation to new tasks with a minimal number of gradient updates. Its main strategy involves applying gradient updates across various tasks, with the goal of achieving a set of initial parameters that ensures good initial performance across a range of tasks. This approach allows the Reptile algorithm to significantly enhance the model’s adaptability and flexibility when encountering new tasks. The structure of this methodology is depicted in
Figure 5.
The Reptile algorithm offers a computational advantage over the MAML approach [
29], particularly due to its avoidance of second-order derivative computations. MAML seeks to establish a foundational model that, through minor parameter modifications across a spectrum of tasks, can adeptly adapt to new challenges. This methodology necessitates the refinement of model parameters for one task, followed by the application of these tweaked parameters to subsequent tasks, with additional adjustments required for each new task. Such a process demands intricate calculations of second-order derivatives, leading to considerable computational demands and extended processing times.
Reptile, on the other hand, adopts a strategy of executing iterative parameter updates within individual tasks, eschewing MAML’s approach of multiple parameter fine-tunings across various tasks. Reptile’s primary aim is to extract more generalizable features by repetitively adjusting parameters over a collection of tasks, thereby facilitating swifter adaptation to novel tasks. Hence, while MAML’s strength lies in crafting an initial model that can be fine-tuned for diverse tasks, Reptile streamlines the adaptation process to new tasks through a restricted series of iterative parameter modifications across tasks.
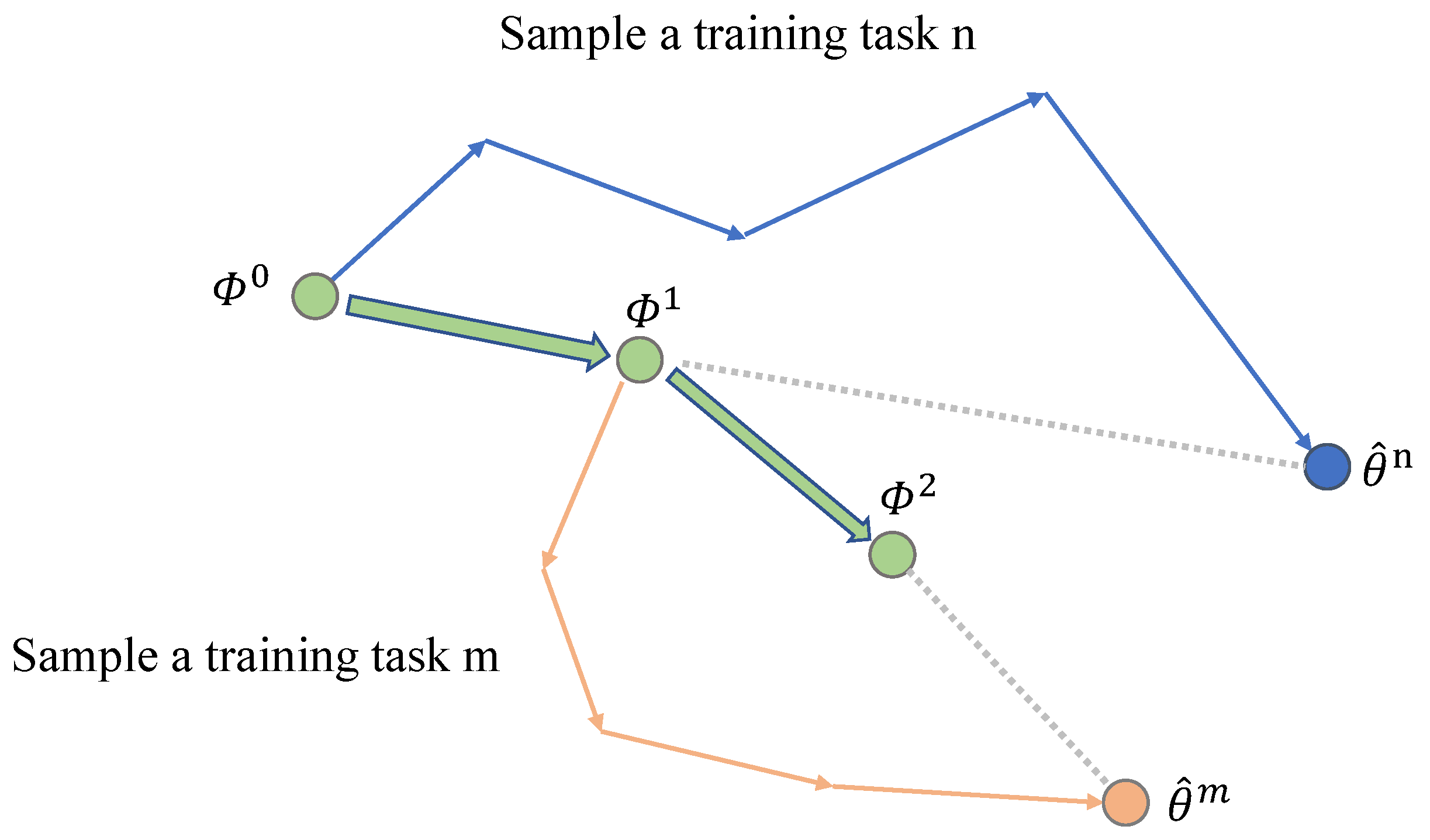
This diagram (
Figure 6) illustrates how a model updates its parameters progressively after training on multiple tasks, starting from its initial parameters, to enhance its generalization ability for new tasks. The key elements include:
Initial Model Parameters : Represent the model’s parameter settings before training begins.
Paths in Different Colors: Illustrate the optimization process of the model on various training tasks. For instance, a blue path indicates training on task n, while a light yellow path signifies training on task m.
Arrows: Indicate the direction of the model parameters’ movement in the parameter space during training.
Model Parameters : Denote the model parameters after a series of training steps.
Final Model Parameters : Represent the final state of the model parameters on their respective tasks.
The essence of the Reptile algorithm lies in iteratively updating the model parameters to swiftly adapt to new tasks. This involves executing multiple steps of gradient descent on each task and then updating the global parameters.
Assume the model parameters are , and for a randomly selected task , the model’s loss function on this task is . The parameter update rule is described as follows:
Step 1—In-task Updates: For each task
, initialize the temporary parameters
to the global parameters
. Then, perform
K iterations of gradient descent updates, expressed as:
where
is the in-task learning rate.
Step 2—Global Updates: After the
K gradient updates for task
, the global parameters
are updated based on the average gradient changes across all tasks:
where
is the global learning rate.
The specific algorithm is as Algorithm 1:
| Algorithm 1 Reptile Algorithm [28]. |
|
In the Reptile algorithm, the objective of each iteration is to minimize the loss function of task . The algorithm achieves this by performing K steps of gradient descent on task , and then uses these updates to adjust the global parameters .
In-task updates aim to quickly adapt to the current task , while the global updates seek to find a good starting point for the parameters so that for new tasks, effective learning can be achieved with only a few steps of gradient updates.
Based on the above, we combine GAIL with the meta-reinforcement learning Reptile algorithm. The core idea is to use GAIL for imitation learning when training subtasks and then use these training results to update the meta-parameters. This process can be divided into the following key steps:
Step 1: Selection and preparation of subtasks—Choose multiple subtasks from the task distribution and prepare expert demonstration data for each task.
Step 2: Training subtasks using GAIL—For each subtask, train using the GAIL framework.
Generator (i.e., policy network) training: Train the policy network by attempting to imitate expert demonstrations.
Discriminator training: The discriminator learns to distinguish between the behaviors generated by the policy network and the expert demonstrations.
Step 3: Policy network update—After completing the GAIL training for each subtask, the policy network is improved.
Step 4: Updating meta-parameters—After completing training on all selected subtasks, update the meta-parameters using the logic of the Reptile algorithm. This usually involves averaging or integrating the parameter changes obtained across multiple tasks in some form.
Step 5: Repeat the process—Repeat the above steps until the model performance reaches the expected target or until the predetermined training cycles are completed.
Additionally, during the training process, we implemented normalization of the states with the following steps:
(1) At the start of training, we first store historical training data in the experience replay buffer.
(2) Upon completion of training, we calculate the mean and variance of each dimension of the state in the replay buffer, concluding the entire training process.
(3) Before commencing the next training session, all states inputted into the network are normalized.
Through this methodology, GAIL enhances the policy network’s ability to closely replicate expert behaviors across a variety of subtasks. Following this, the Reptile algorithm amalgamates the insights gained to refine the meta-parameters, thus facilitating swift adaptation to new tasks that bear resemblance to those previously encountered. The integration of GAIL with Reptile is designed to capitalize on GAIL’s proficiency in imitation learning while harnessing Reptile’s meta-learning capabilities to boost the learning process’s overall efficiency and adaptability. This combined approach is delineated as Algorithm 2:
| Algorithm 2 Combined GAIL and Reptile meta-reinforcement learning algorithm |
| Require: Task distribution D, expert demonstrations set E, learning rate , meta-learning rate , training epochs T |
| Ensure: Optimized meta-parameters |
- 1:
Initialize meta-parameters - 2:
for to T do - 3:
Sample a set of subtasks S from D - 4:
Initialize task-specific parameters - 5:
for each subtask do - 6:
Initialize policy network with parameters - 7:
Initialize discriminator - 8:
Obtain expert demonstrations from E for task s - 9:
repeat - 10:
Train by imitating - 11:
Train using behaviors generated by and - 12:
Update to maximize the score of for the imitated behavior - 13:
until converges - 14:
Update to optimized parameters of - 15:
end for - 16:
Update meta-parameters - 17:
end for - 18:
return
|
5. Experiments
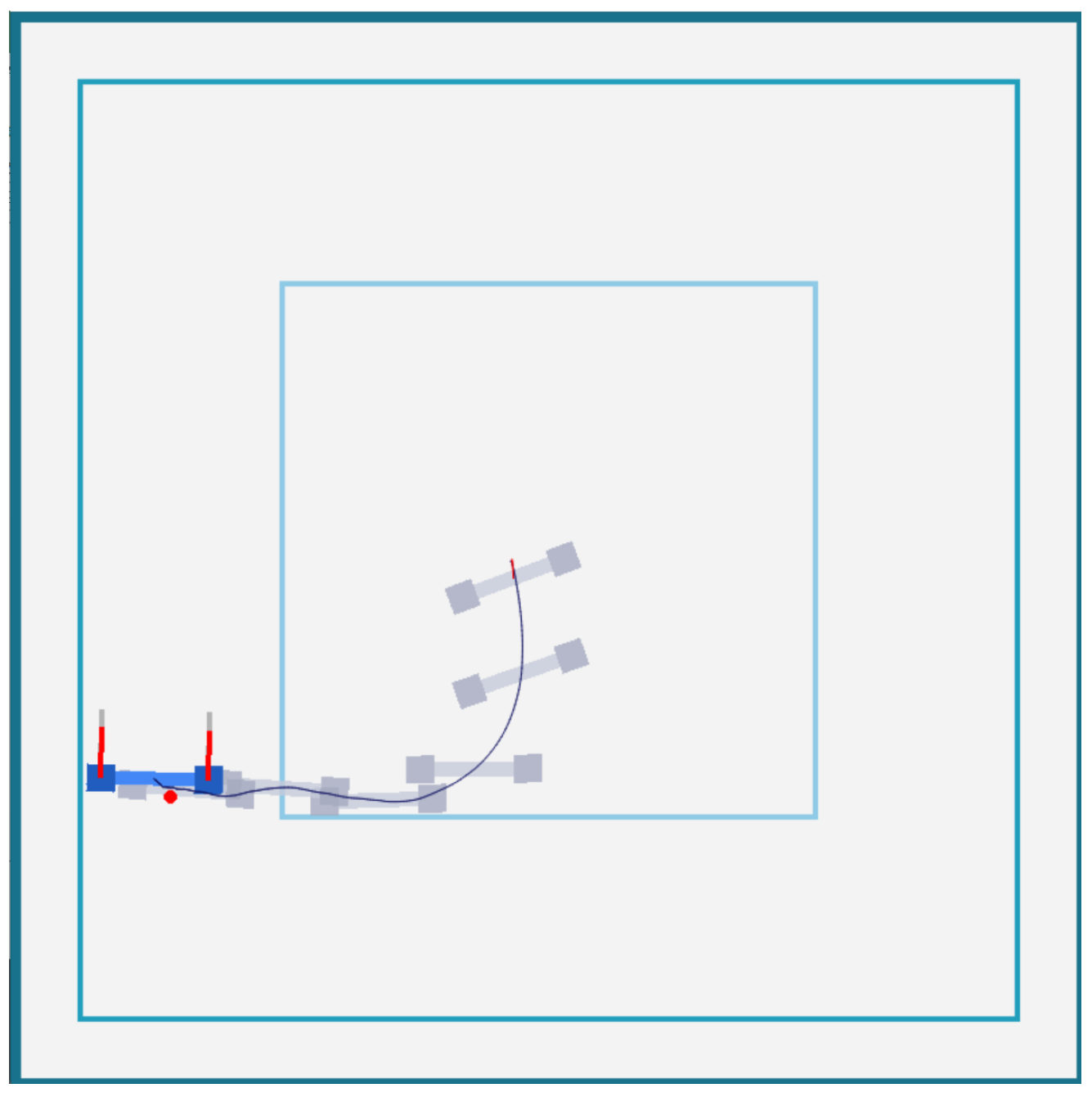
Given the complexity of drone control in three-dimensional space, we opted to conduct experimental tests on a two-dimensional plane. We utilized the experimental environment described in the literature [
30], which consists of three marked square areas. For detailed information about the specific experimental setup, please visit the following website:
https://github.com/marek-robak/Drone-2d-custom-gym-env-for-reinforcement-learning (accessed on 11 December 2023). The smallest square represents the initial space where the drone may appear, while the larger square defines the area where the target point may be located. Here, the agent needs to learn to navigate the drone to the target point. The largest square represents the boundaries of the drone’s flyable space, and if the drone flies out of this range, the current round ends.
The drone model utilized in our study is constructed from a rigid body that comprises three sections, two of which function as motors. These motors are capable of producing lift, as depicted by the elongated red lines, while the grey lines serve as a reference scale. At the initiation of each trial, the drone is propelled in an arbitrary direction, with the motors temporarily disabled for a predetermined sequence of time steps. This arrangement aims to forge a scenario in which the reinforcement learning agent is tasked with regaining control and stabilizing the drone during its descent. The portion of the trajectory delineated in red illustrates the phase of flight where the agent lacks control. Additionally, the simulation of the drone’s environment is conducted at a temporal resolution of 60 frames per second, as illustrated in
Figure 7.
In this experiment, the hardware setup used was as follows:
CPU: Manufacturer: Mechrevo, Country: China, 12th Gen Intel(R) Core(TM) i7-12650H, with a clock speed of 2300 Mhz, with 10 cores and 16 logical processors.
GPU: Manufacturer: Mechrevo, Country: China, NVIDIA GeForce RTX 4050.
For detailed configurations of the hyperparameters, refer to
Table 2.
In our study, we strategically simplified the drone’s operational context by confining its movements to the xoz plane, thereby significantly mitigating the complexities associated with navigating a fully three-dimensional space. Within this two-dimensional framework, the drone utilizes its advanced control system to navigate from an initial point to a specified target location. This experimental setup enables a concentrated examination of the drone’s control and navigational efficacy on a plane, alongside an assessment of its stability and task execution proficiency. This methodological choice not only facilitated a comprehensive analysis of the drone’s control system efficiency but also established a foundational basis for future explorations into three-dimensional spatial navigation, yielding crucial data and insights.
Figure 8 simulates the drone’s situation in three-dimensional space:
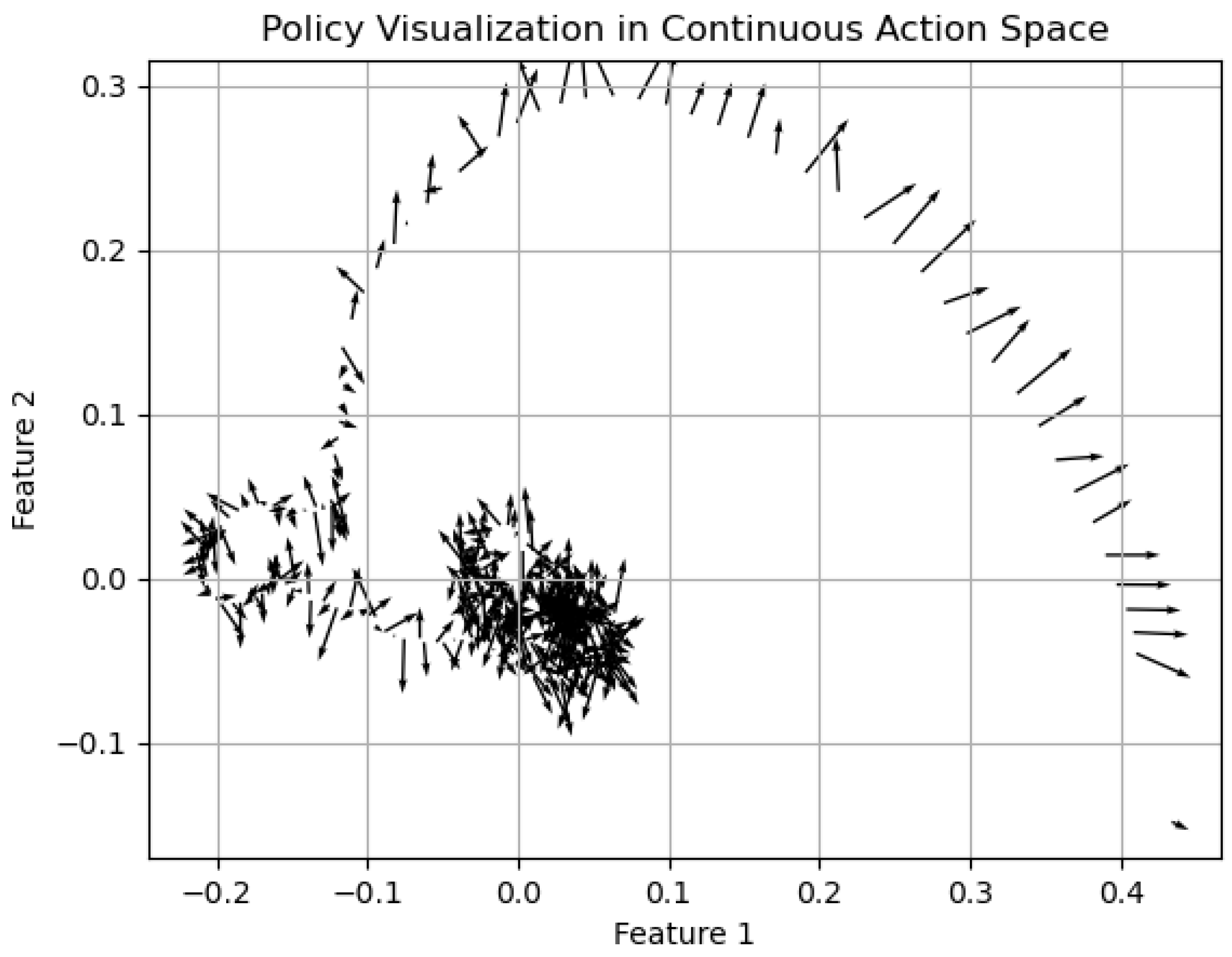
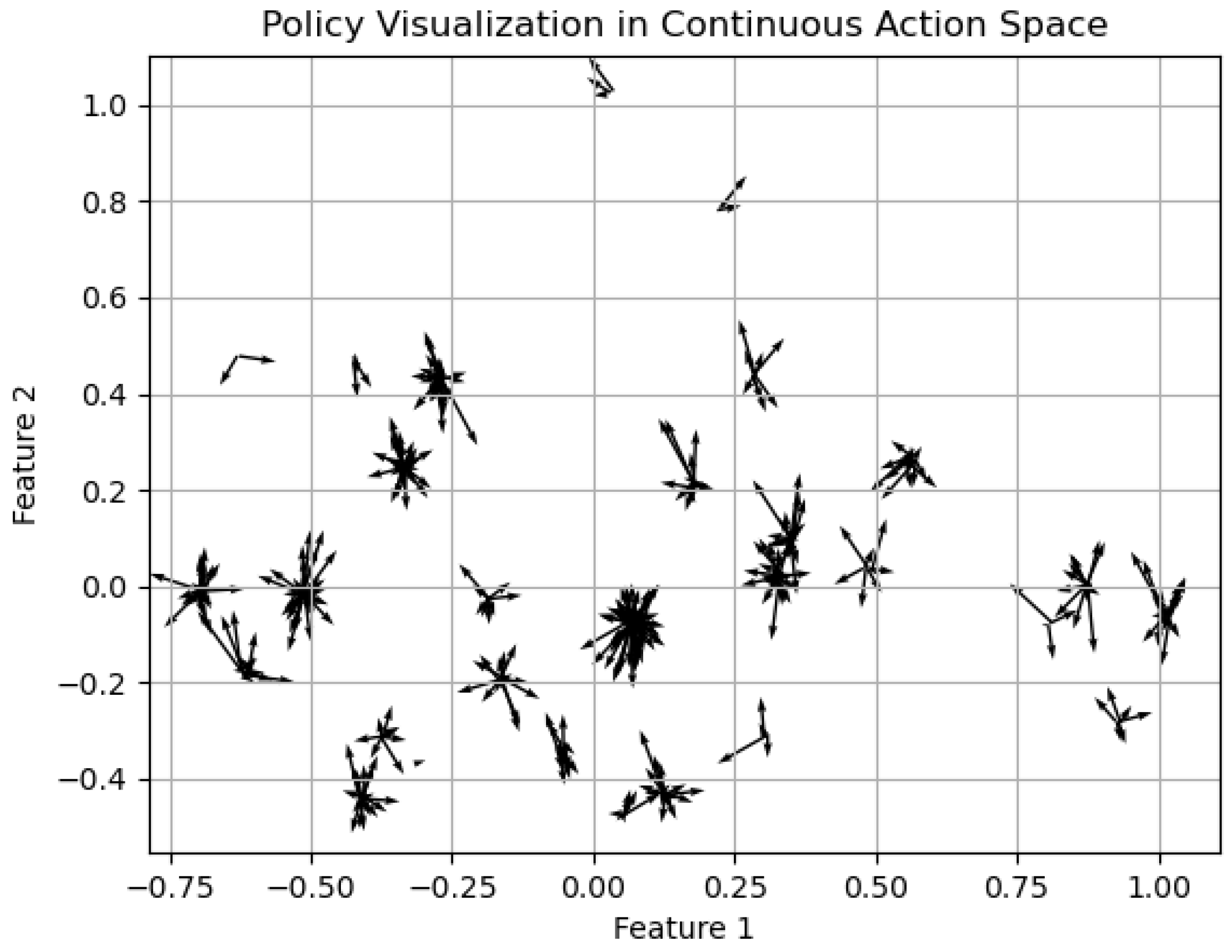
Furthermore, we have depicted our strategy through illustrations in
Figure 9 and
Figure 10. Given the original eight-dimensional state space, we employed Principal Component Analysis (PCA) to compress it into a two-dimensional space for the sake of clarity in visualization. In the derived visual representation, the orientation of the arrows signifies the actions the model is inclined to undertake in specific states. A concentration of arrows pointing in a uniform direction within certain regions implies a degree of consistency in the model’s action choices in those states. In contrast, a varied spread of arrow directions may indicate the states’ inherent uncertainty or highlight the exploratory behavior of the model during its learning phase. Moreover, the arrow lengths convey the action magnitudes, with longer arrows denoting larger actions and suggesting the model’s heightened assurance in its responses to those states. Conversely, shorter arrows could denote a more tentative or measured approach by the model in certain states.
It is particularly interesting to observe that within the core region of the feature space, both the direction and magnitude of the arrows maintain a remarkable consistency. This pattern implies that the model potentially adopts a more stable or decisive strategy when encountering states within this area. Additionally, in the top-right quadrant of the diagram, we notice a sequence of elongated arrows all pointing in the same direction, suggesting that the model exhibits a pronounced and robust inclination towards certain actions in these specific zones.
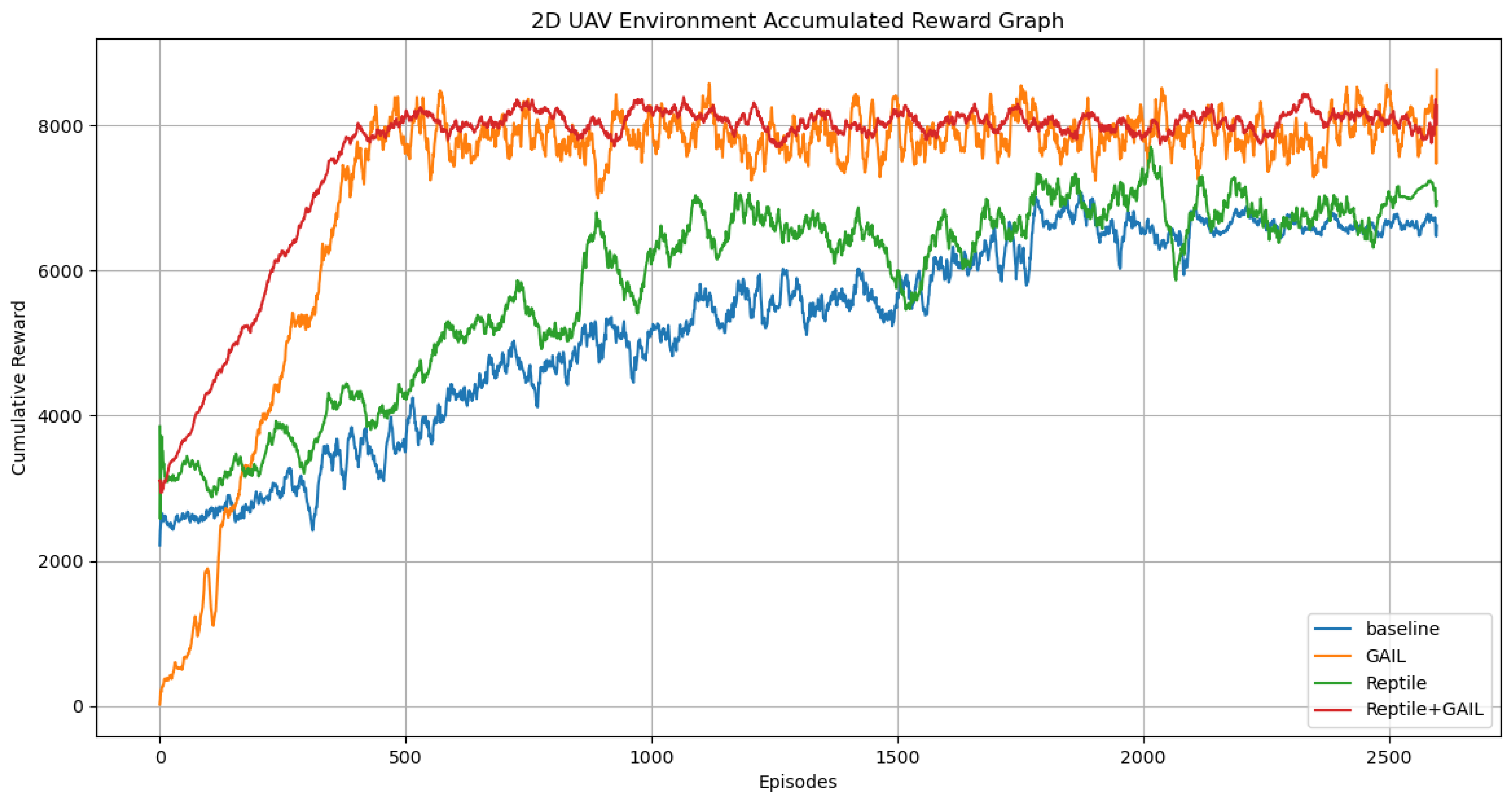
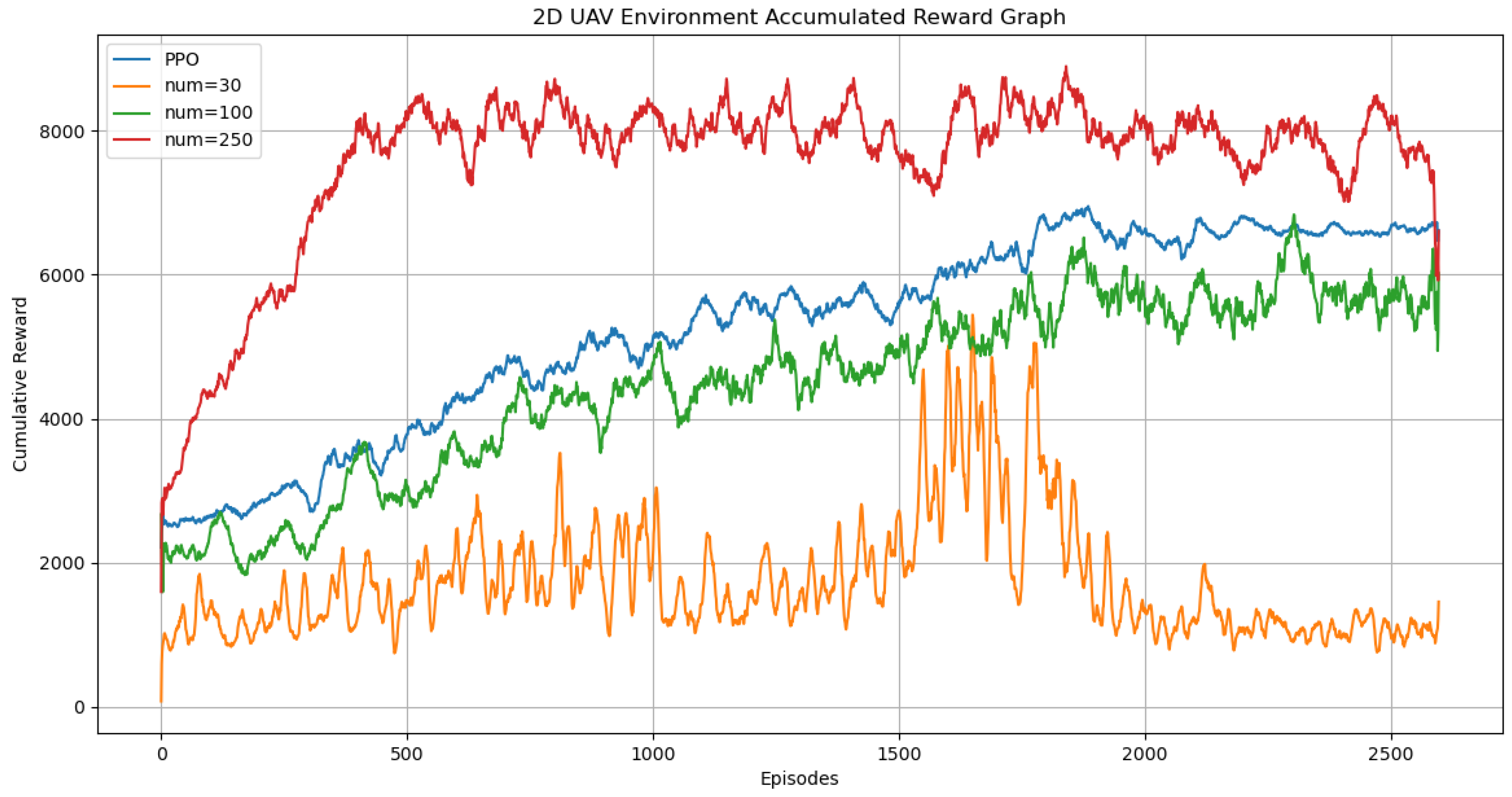
In this experimental environment, we conducted comparative tests of our algorithm using the PPO algorithm as a baseline. As shown in
Figure 11 and
Figure 12, the use of either GAIL (Generative Adversarial Imitation Learning) alone or Reptile alone positively impacted the results, with GAIL showing particularly noticeable effects. Our combined algorithm, Reptile+GAIL, demonstrated even more superior performance. Especially in the early stages of training, our algorithm was able to achieve good results quickly. During the convergence phase, compared to using GAIL alone, our algorithm exhibited better stability (
Table 3). This success is attributed to the rapid adaptability to new tasks of meta-learning and the guiding role of expert data in imitation learning.
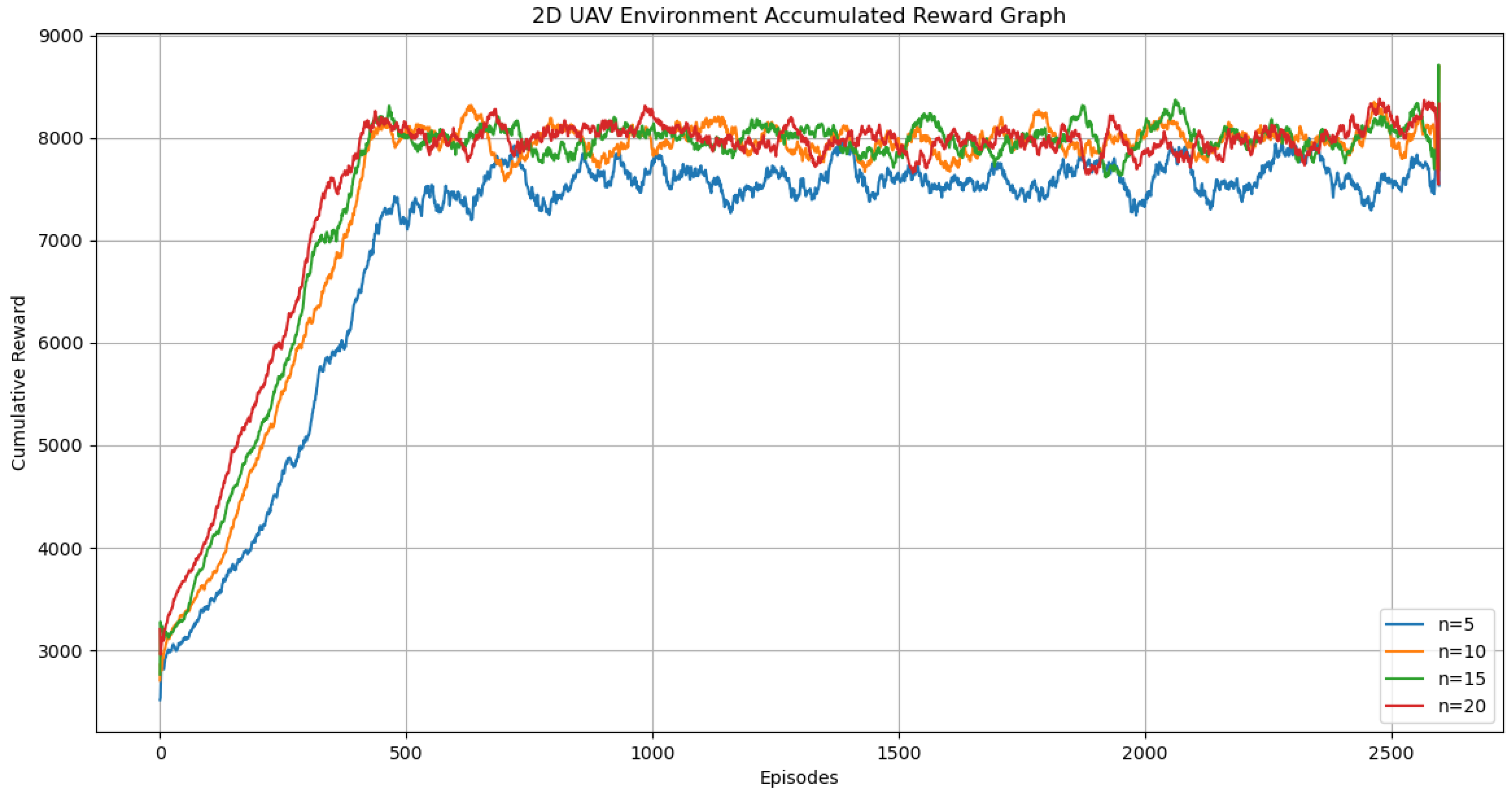
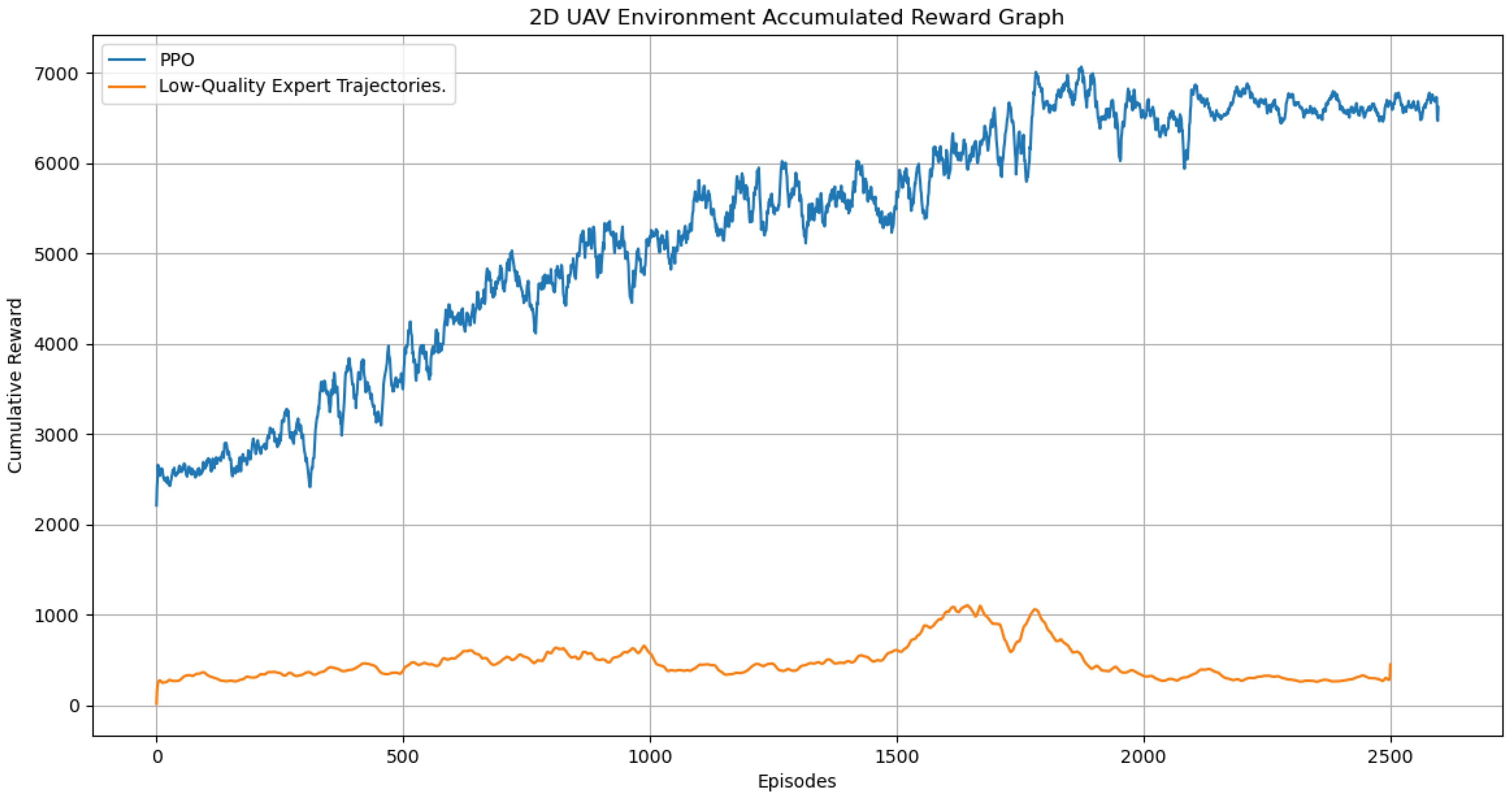
Additionally, we conducted a thorough analysis of the process for generating expert trajectories and observed some key findings. Notably, when the number of available expert trajectories is limited, or the quality of these trajectories is insufficient, we found that the experimental results were significantly below expectations (see
Figure 13). This discovery underscores the importance of high-quality and sufficient quantities of expert trajectories for the performance of our algorithm.
We further investigated the reasons behind this phenomenon. As shown in
Figure 14, with a limited number of expert trajectories, the learning algorithm faces a problem of insufficient data, which restricts the model’s learning capabilities and generalization performance. On the other hand, when the quality of trajectories is low, the algorithm may learn incorrect or suboptimal behavioral patterns, leading to poor experimental outcomes.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}