
Edge-Enhanced TempoFuseNet: A Two-Stream Framework for Intelligent Multiclass Video Anomaly Recognition in 5G and IoT Environments



Abstract
1. Introduction
- This study meticulously identifies and articulates two critical issues inherent in surveillance videos: high intra-class variability and low inter-class variability. These challenges, which are inextricably linked to the temporal properties of video streams, both short- and long-term, are exacerbated by the prevalence of low-quality videos.
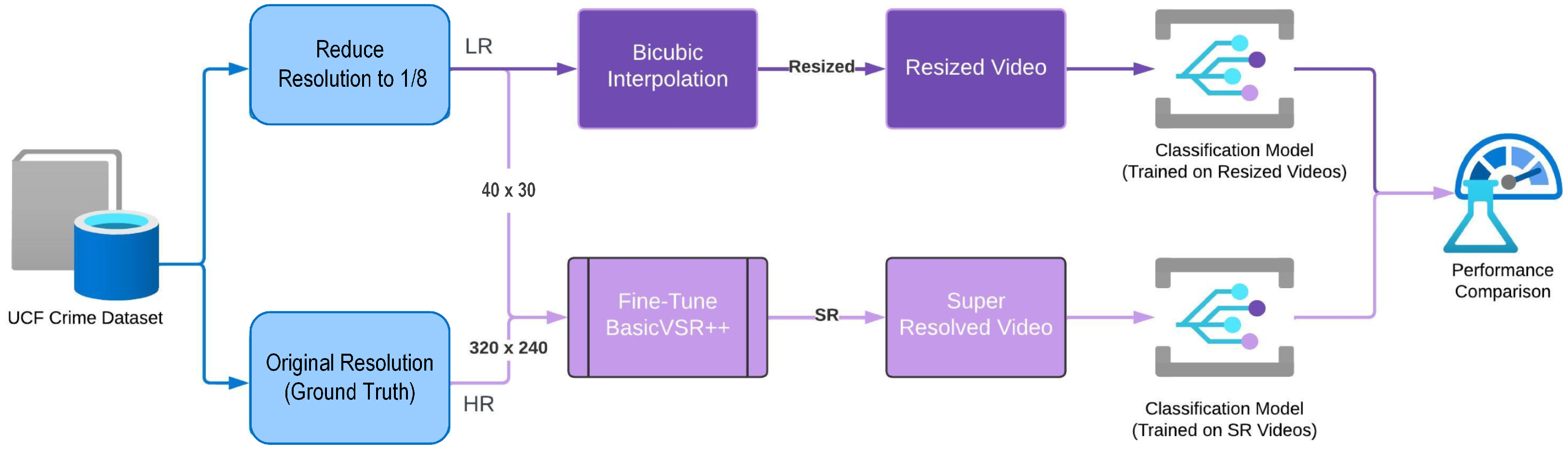
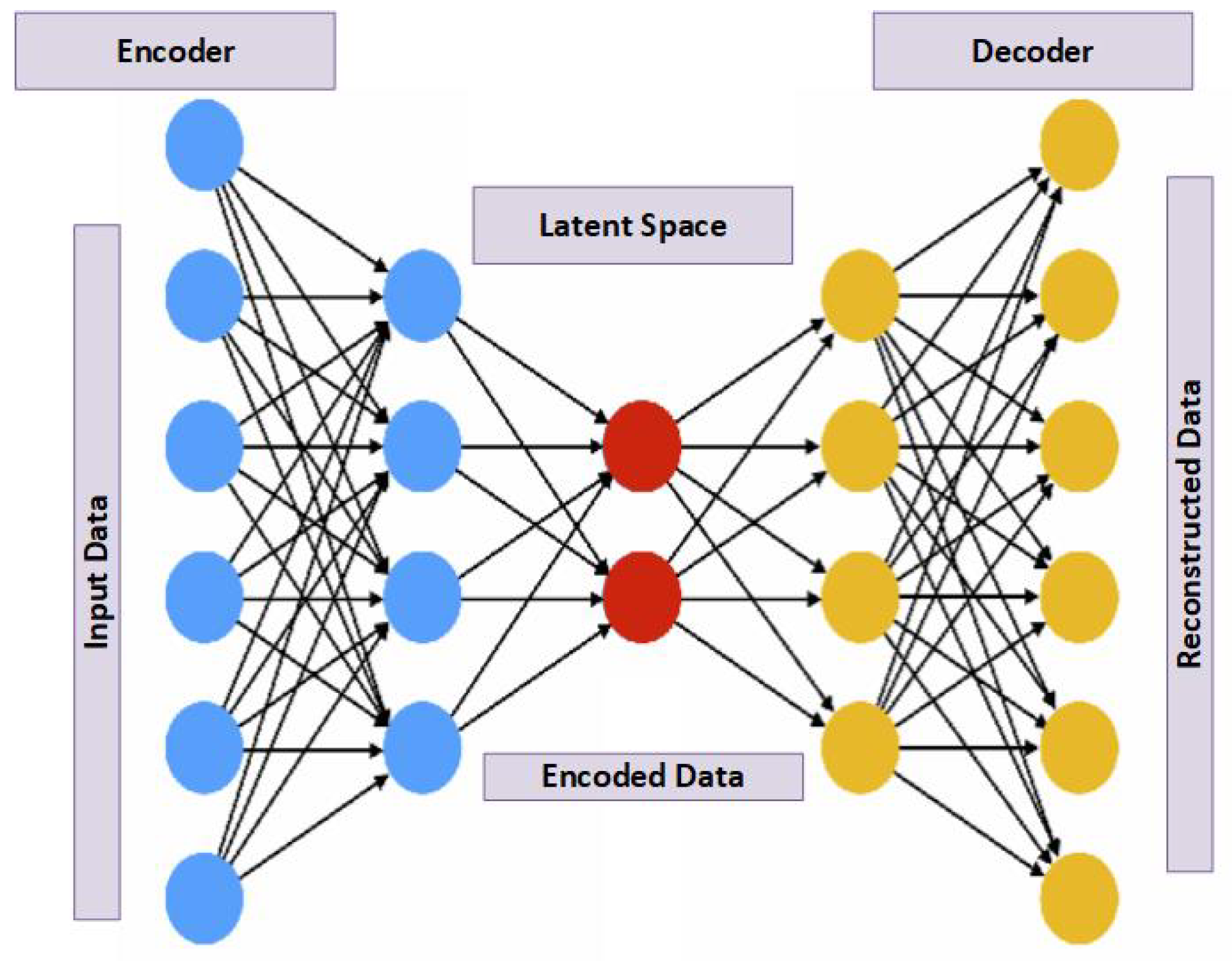
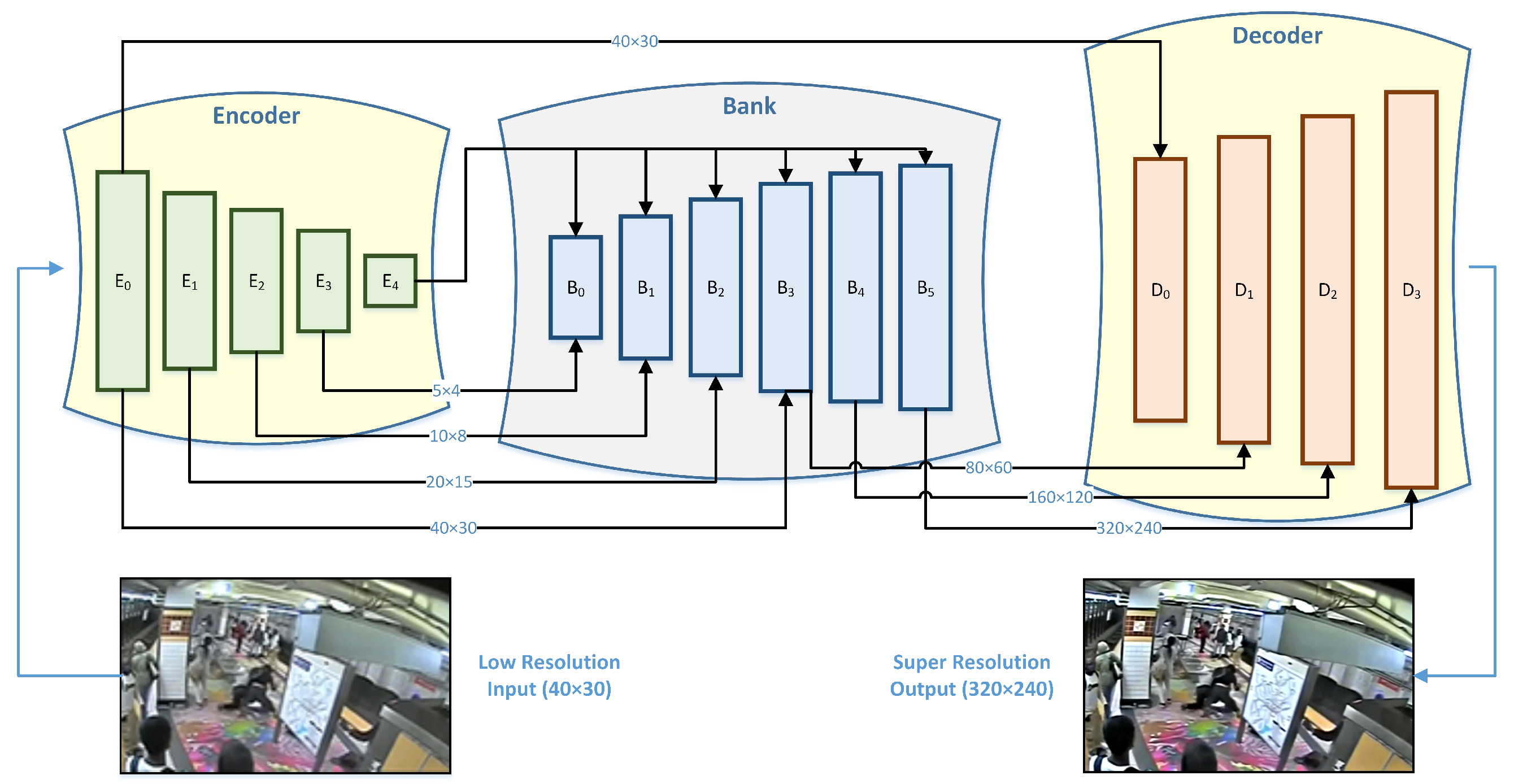
- This study makes an outstanding contribution by introducing an innovative super-resolution approach designed to mitigate the impact of low-quality videos caused by downscaling. This approach outperforms traditional bicubic interpolation by using an encoder–bank–decoder configuration to upscale videos. The primary goal is to improve the spatial resolution of videos in order to increase the accuracy of anomaly detection. The addition of a pre-trained StyleGAN as a latent feature bank is a critical step forward that enriches the super-resolution process and, as a result, improves anomaly classification accuracy.
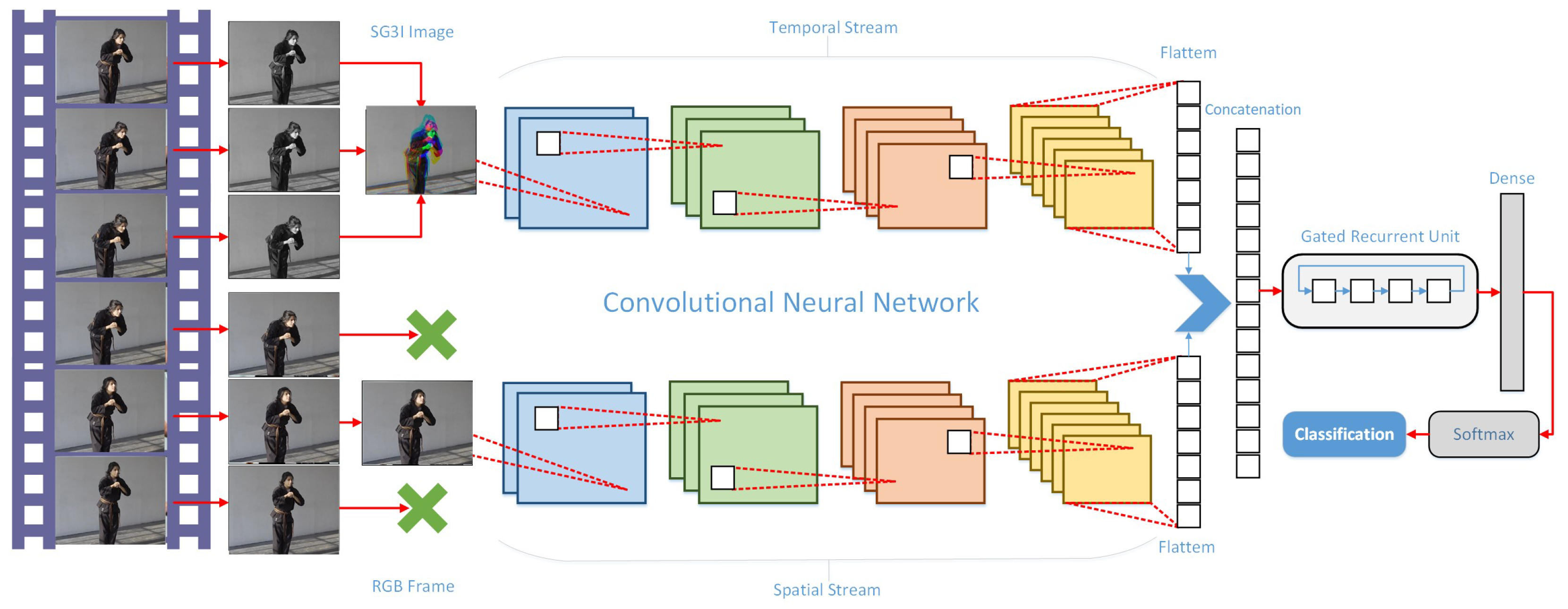
- The study implies a two-stream architecture for anomaly classification. The spatial stream uses a pre-trained CNN model for feature extraction, whereas the temporal stream employs an innovative approach known as Stacked Grayscale Image (SG3I). SG3I effectively lowers the computational costs associated with optical flow computation while accurately capturing short-term temporal characteristics. The extracted features from both streams are concatenated and fed into a Gated Recurrent Unit (GRU) layer, which allows the model to learn and exploit long-term dependencies.
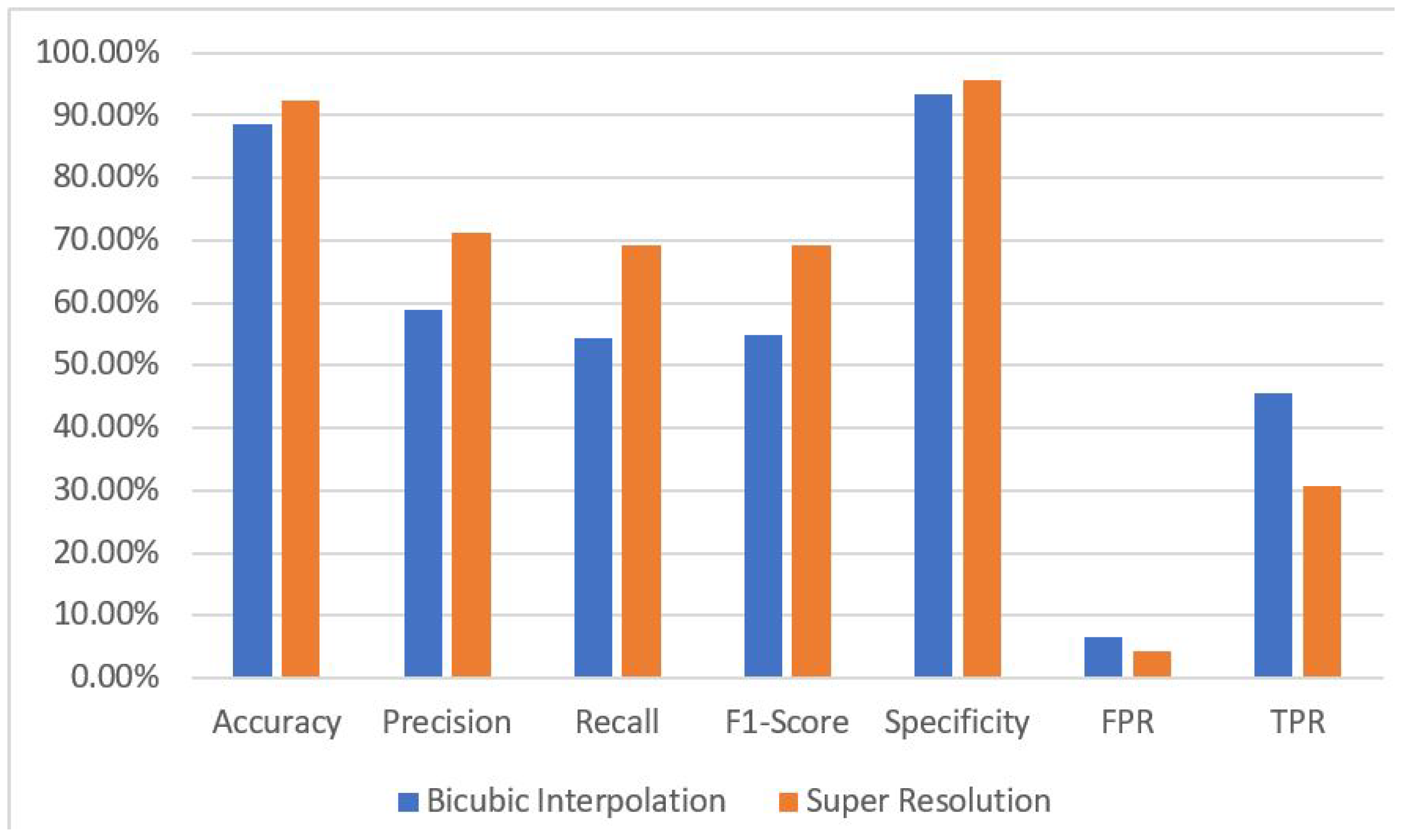
- Experiments show that the super-resolution model improves classification accuracy by 3.7% when compared to traditional bicubic interpolation methods. When combined with the encoder–bank–decoder super-resolution model, the classification model achieves an impressive accuracy of 92.28%, an F1-score of 69.29%, and a low false positive rate of 4.41%.
2. Related Work
3. Materials and Methods
3.1. Dataset
Data Preparation
3.2. Video Upscaling
3.3. Video Super Resolution
3.4. Upscaling Performance
| Algorithm 1: Video Super Resolution with GLEAN |
 |
| Algorithm 2: Anomaly Classification with Two-Stream Architecture |
 |
3.5. Anomaly Classification
3.5.1. Spatial Stream
3.5.2. Temporal Stream
3.5.3. Late Temporal Modeling
4. Experiments
4.1. Experimental Setup
4.2. Evaluation Method and Metrics
5. Results
5.1. Classification Performance
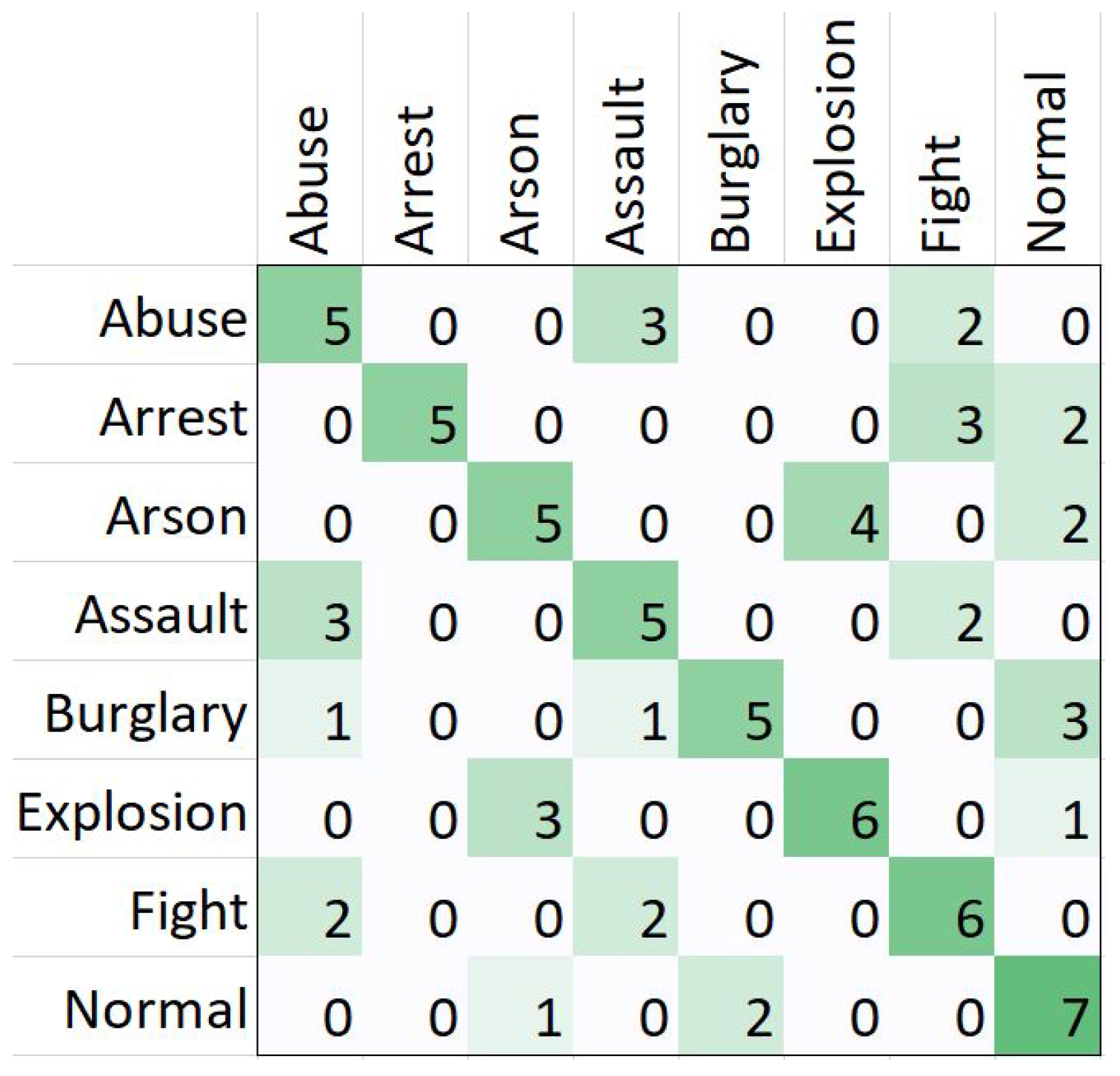
5.1.1. Bicubic Interpolation of Videos
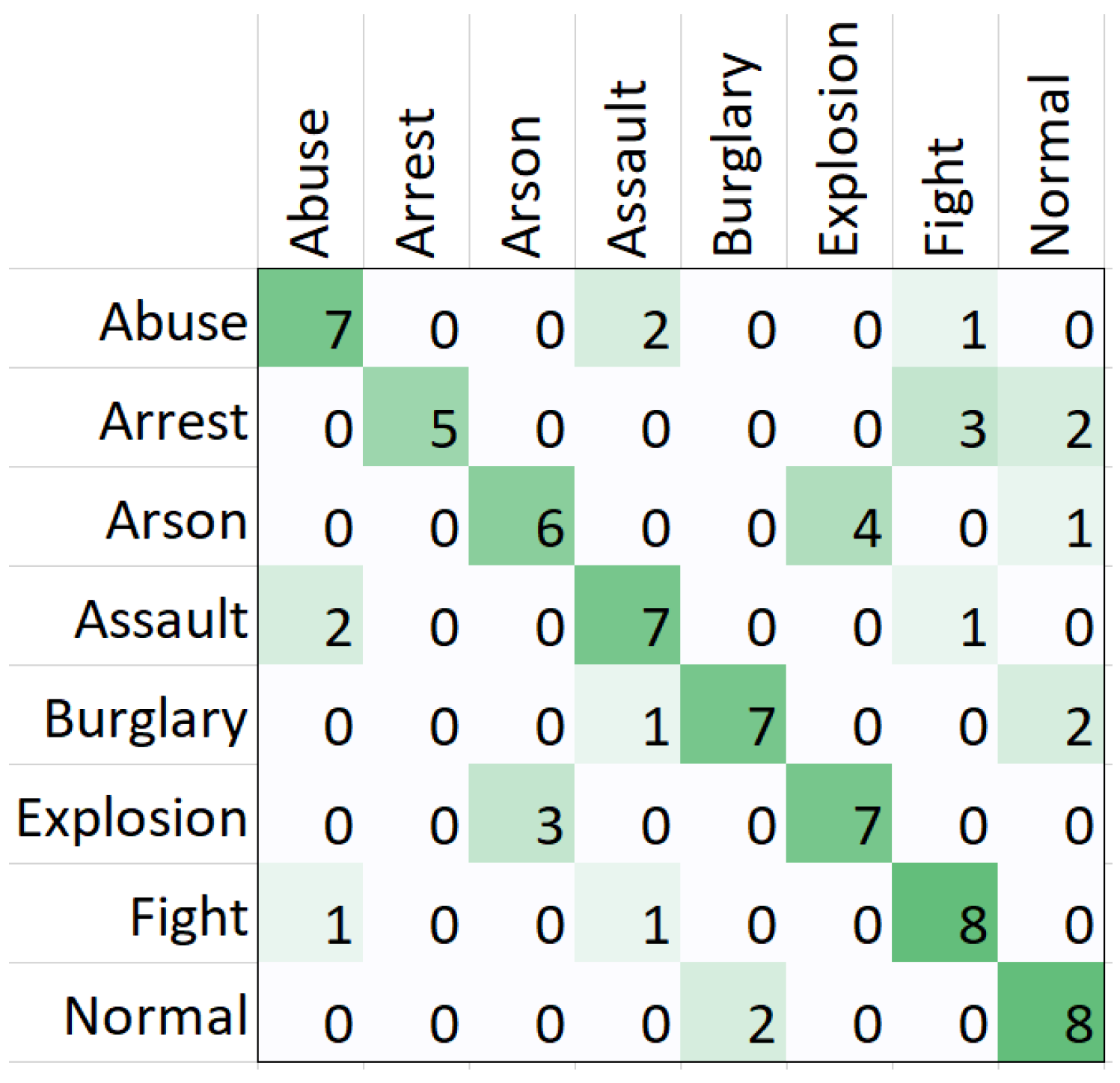
5.1.2. Super-Resolution Videos
5.2. Comparison with Existing Approaches
5.3. Comparison of Bicubic Interpolation and Super-Resolution Approaches
6. Conclusions
Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 733–742. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Zhong, J.X.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1237–1246. [Google Scholar]
- Akhtar, M. Automated analysis of visual leaf shape features for plant classification. Comput. Electron. Agric. 2019, 157, 270–280. [Google Scholar]
- Ahmad, N.; Asif, H.M.S.; Saleem, G.; Younus, M.U.; Anwar, S.; Anjum, M.R. Leaf image-based plant disease identification using color and texture features. Wirel. Pers. Commun. 2021, 121, 1139–1168. [Google Scholar] [CrossRef]
- Aslam, M.A.; Wei, X.; Ahmed, N.; Saleem, G.; Amin, T.; Caixue, H. Vrl-iqa: Visual representation learning for image quality assessment. IEEE Access 2024, 12, 2458–2473. [Google Scholar] [CrossRef]
- Ahmed, N.; Asif, H.M.S. Perceptual quality assessment of digital images using deep features. Comput. Inform. 2020, 39, 385–409. [Google Scholar] [CrossRef]
- Ahmed, N.; Asif, H.M.S. Ensembling convolutional neural networks for perceptual image quality assessment. In Proceedings of the 2019 13th International Conference on Mathematics, Actuarial Science, Computer Science and Statistics (MACS), Karachi, Pakistan, 14–15 December 2019; pp. 1–5. [Google Scholar]
- Saleem, G.; Bajwa, U.I.; Raza, R.H.; Alqahtani, F.H.; Tolba, A.; Xia, F. Efficient anomaly recognition using surveillance videos. PeerJ Comput. Sci. 2022, 8, e1117. [Google Scholar] [CrossRef]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S. A review of video surveillance systems. J. Vis. Commun. Image Represent. 2021, 77, 103116. [Google Scholar] [CrossRef]
- Duong, H.T.; Le, V.T.; Hoang, V.T. Deep Learning-Based Anomaly Detection in Video Surveillance: A Survey. Sensors 2023, 23, 5024. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, N.; Asif, H.M.S.; Khalid, H. Image quality assessment using a combination of hand-crafted and deep features. In Proceedings of the Intelligent Technologies and Applications: Second International Conference, INTAP 2019, Bahawalpur, Pakistan, 6–8 November 2019; Revised Selected Papers 2; Springer: Singapore, 2020; pp. 593–605. [Google Scholar]
- Khalid, H.; Ali, M.; Ahmed, N. Gaussian process-based feature-enriched blind image quality assessment. J. Vis. Commun. Image Represent. 2021, 77, 103092. [Google Scholar] [CrossRef]
- Ahmed, N.; Asif, S. BIQ2021: A large-scale blind image quality assessment database. J. Electron. Imaging 2022, 31, 053010. [Google Scholar] [CrossRef]
- Ahmed, N.; Asif, H.M.S.; Saleem, G.; Younus, M.U. Image quality assessment for foliar disease identification (agropath). J. Agric. Res. 2021, 59, 177–186. [Google Scholar]
- Ahmed, N.; Shahzad Asif, H.; Bhatti, A.R.; Khan, A. Deep ensembling for perceptual image quality assessment. Soft Comput. 2022, 26, 7601–7622. [Google Scholar] [CrossRef]
- Ahmed, N.; Asif, H.M.S.; Khalid, H. PIQI: Perceptual image quality index based on ensemble of Gaussian process regression. Multimed. Tools Appl. 2021, 80, 15677–15700. [Google Scholar] [CrossRef]
- Ullah, W.; Ullah, A.; Hussain, T.; Khan, Z.A.; Baik, S.W. An efficient anomaly recognition framework using an attention residual LSTM in surveillance videos. Sensors 2021, 21, 2811. [Google Scholar] [CrossRef]
- Zhou, Y.; Du, X.; Wang, M.; Huo, S.; Zhang, Y.; Kung, S.Y. Cross-scale residual network: A general framework for image super-resolution, denoising, and deblocking. IEEE Trans. Cybern. 2021, 52, 5855–5867. [Google Scholar] [CrossRef]
- Kwan, C.; Zhou, J.; Wang, Z.; Li, B. Efficient anomaly detection algorithms for summarizing low quality videos. In Proceedings of the Pattern Recognition and Tracking XXIX, Orlando, FL, USA, 15–19 April 2018; SPIE: Bellingham, WA, USA; Volume 10649, pp. 45–55. [Google Scholar]
- Zhou, J.; Kwan, C. Anomaly detection in low quality traffic monitoring videos using optical flow. In Proceedings of the Pattern Recognition and Tracking XXIX, Orlando, FL, USA, 15–19 April 2018; SPIE: Bellingham, WA, USA, 2018; Volume 10649, pp. 122–132. [Google Scholar]
- Lv, Z.; Wu, J.; Xie, S.; Gander, A.J. Video enhancement and super-resolution. In Digital Image Enhancement and Reconstruction; Elsevier: Amsterdam, The Netherlands, 2023; pp. 1–28. [Google Scholar]
- Wu, J. Introduction to convolutional neural networks. Natl. Key Lab Nov. Softw. Technol. Nanjing Univ. China 2017, 5, 495. [Google Scholar]
- Nguyen, T.N.; Meunier, J. Hybrid deep network for anomaly detection. arXiv 2019, arXiv:1908.06347. [Google Scholar]
- Ryoo, M.; Kim, K.; Yang, H. Extreme low resolution activity recognition with multi-siamese embedding learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; PKP Publishing Services Network. Volume 32. [Google Scholar]
- Saleem, G.; Bajwa, U.I.; Raza, R.H. Toward human activity recognition: A survey. Neural Comput. Appl. 2023, 35, 4145–4182. [Google Scholar] [CrossRef]
- Nayak, R.; Pati, U.C.; Das, S.K. A comprehensive review on deep learning-based methods for video anomaly detection. Image Vis. Comput. 2021, 106, 104078. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal segment networks for action recognition in videos. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2740–2755. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Maqsood, R.; Bajwa, U.I.; Saleem, G.; Raza, R.H.; Anwar, M.W. Anomaly recognition from surveillance videos using 3D convolution neural network. Multimed. Tools Appl. 2021, 80, 18693–18716. [Google Scholar] [CrossRef]
- Luo, W.; Liu, W.; Gao, S. Remembering history with convolutional lstm for anomaly detection. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 439–444. [Google Scholar]
- Ullah, M.; Mudassar Yamin, M.; Mohammed, A.; Daud Khan, S.; Ullah, H.; Alaya Cheikh, F. Attention-based LSTM network for action recognition in sports. Electron. Imaging 2021, 2021, 302–311. [Google Scholar] [CrossRef]
- Riaz, H.; Uzair, M.; Ullah, H.; Ullah, M. Anomalous human action detection using a cascade of deep learning models. In Proceedings of the 2021 9th European Workshop on Visual Information Processing (EUVIP), Paris, France, 23–25 June 2021; pp. 1–5. [Google Scholar]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection—A new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6536–6545. [Google Scholar]
- Landi, F.; Snoek, C.G.; Cucchiara, R. Anomaly locality in video surveillance. arXiv 2019, arXiv:1901.10364. [Google Scholar]
- Sabokrou, M.; Khalooei, M.; Fathy, M.; Adeli, E. Adversarially learned one-class classifier for novelty detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3379–3388. [Google Scholar]
- Zhou, Y.; Qu, Y.; Xu, X.; Shen, F.; Song, J.; Shen, H. BatchNorm-based Weakly Supervised Video Anomaly Detection. arXiv 2023, arXiv:2311.15367. [Google Scholar]
- Pu, Y.; Wu, X.; Wang, S. Learning Prompt-Enhanced Context Features for Weakly-Supervised Video Anomaly Detection. arXiv 2023, arXiv:2306.14451. [Google Scholar]
- Gan, K.Y.; Cheng, Y.T.; Tan, H.K.; Ng, H.F.; Leung, M.K.; Chuah, J.H. Contrastive-regularized U-Net for Video Anomaly Detection. IEEE Access 2023, 11, 36658–36671. [Google Scholar] [CrossRef]
- Ryoo, M.; Rothrock, B.; Fleming, C.; Yang, H.J. Privacy-preserving human activity recognition from extreme low resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Chen, J.; Wu, J.; Konrad, J.; Ishwar, P. Semi-coupled two-stream fusion convnets for action recognition at extremely low resolutions. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 139–147. [Google Scholar]
- Xu, M.; Sharghi, A.; Chen, X.; Crandall, D.J. Fully-coupled two-stream spatiotemporal networks for extremely low resolution action recognition. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1607–1615. [Google Scholar]
- Demir, U.; Rawat, Y.S.; Shah, M. Tinyvirat: Low-resolution video action recognition. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 7387–7394. [Google Scholar]
- Hou, W.; Wang, X.; Chouinard, J.Y.; Refaey, A. Physical layer authentication for mobile systems with time-varying carrier frequency offsets. IEEE Trans. Commun. 2014, 62, 1658–1667. [Google Scholar] [CrossRef]
- Ataer-Cansizoglu, E.; Jones, M.; Zhang, Z.; Sullivan, A. Verification of very low-resolution faces using an identity-preserving deep face super-resolution network. arXiv 2019, arXiv:1903.10974. [Google Scholar]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. Sod-mtgan: Small object detection via multi-task generative adversarial network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 206–221. [Google Scholar]
- Wang, Z.; Ye, M.; Yang, F.; Bai, X.; Satoh, S. Cascaded SR-GAN for scale-adaptive low resolution person re-identification. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; Volume 1, p. 4. [Google Scholar]
- Lu, C.; Shi, J.; Jia, J. Abnormal event detection at 150 fps in matlab. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2720–2727. [Google Scholar]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Beijing, China, 24–28 October 2010; pp. 1975–1981. [Google Scholar]
- Han, D. Comparison of commonly used image interpolation methods. In Proceedings of the Conference of the 2nd International Conference on Computer Science and Electronics Engineering (ICCSEE 2013), Los Angeles, CA, USA, 1–2 July 2013; Atlantis Press: Amsterdam, The Netherlands, 2013; pp. 1556–1559. [Google Scholar]
- Chan, K.C.; Xu, X.; Wang, X.; Gu, J.; Loy, C.C. GLEAN: Generative latent bank for image super-resolution and beyond. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3154–3168. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8110–8119. [Google Scholar]
- Barkhordar, E.; Shirali-Shahreza, M.H.; Sadeghi, H.R. Clustering of Bank Customers using LSTM-based encoder-decoder and Dynamic Time Warping. arXiv 2021, arXiv:2110.11769. [Google Scholar]
- Kim, J.H.; Won, C.S. Action recognition in videos using pre-trained 2D convolutional neural networks. IEEE Access 2020, 8, 60179–60188. [Google Scholar] [CrossRef]
- Tiwari, A.; Chaudhury, S.; Singh, S.; Saurav, S. Video Classification using SlowFast Network via Fuzzy rule. In Proceedings of the 2021 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Luxembourg, 11–14 June 2021; pp. 1–6. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Type | Specifications |
|---|---|---|
| 1 | System | Dell Precision T5600 |
| 2 | CPU | 2× Intel® Xeon® Processor E5-2687W |
| 3 | RAM | 32GB DDR3 |
| 4 | GPU | GeForce RTX 2070 |
| 5 | GPU Memory | 8GB GDDR6 |
| 6 | CUDA Cores | 2304 |
| 7 | Storage | 512GB SSD |
| # | Training Parameter | Value |
|---|---|---|
| 1 | Optimizer | Adam |
| 2 | Initial Learning Rate | 0.003 |
| 3 | Learning Rate Schedule | Piecewise |
| 4 | Learning Rate Drop Factor | 0.5 |
| 5 | Gradient Decay Factor | 0.9 |
| 6 | L2 Regularization | 0.0001 |
| 7 | Max Epochs | 100 |
| 8 | Mini Batch Size | 32 |
| 9 | Loss Function | Categorical cross-entropy |
| 10 | Validation Check | Every epoch |
| Class | Accuracy | Precision | Recall | F1-Score | Specificity | FPR | FNR |
|---|---|---|---|---|---|---|---|
| Abuse | 86.42% | 45.45% | 50.00% | 47.62% | 91.55% | 8.45% | 50.00% |
| Arrest | 93.83% | 100.00% | 50.00% | 66.67% | 100.00% | 0.00% | 50.00% |
| Arson | 87.65% | 55.56% | 45.45% | 50.00% | 94.29% | 5.71% | 54.55% |
| Assault | 86.42% | 45.45% | 50.00% | 47.62% | 91.55% | 8.45% | 50.00% |
| Burglary | 91.36% | 71.43% | 50.00% | 58.82% | 97.18% | 2.82% | 50.00% |
| Explosion | 90.12% | 60.00% | 60.00% | 60.00% | 94.37% | 5.63% | 40.00% |
| Fight | 86.42% | 46.15% | 60.00% | 52.17% | 90.14% | 9.86% | 40.00% |
| Normal | 86.42% | 46.67% | 70.00% | 56.00% | 88.73% | 11.27% | 30.00% |
| Macro-Average | 88.58% | 58.84% | 54.43% | 54.86% | 93.48% | 6.52% | 45.57% |
| Class | Accuracy | Precision | Recall | F1-Score | Specificity | FPR | FNR |
|---|---|---|---|---|---|---|---|
| Abuse | 92.59% | 70.00% | 70.00% | 70.00% | 95.77% | 4.23% | 30.00% |
| Arrest | 95.06% | 100.00% | 60.00% | 75.00% | 100.00% | 0.00% | 40.00% |
| Arson | 90.12% | 66.67% | 54.55% | 60.00% | 95.71% | 4.29% | 45.45% |
| Assault | 91.36% | 63.64% | 70.00% | 66.67% | 94.37% | 5.63% | 30.00% |
| Burglary | 93.83% | 77.78% | 70.00% | 73.68% | 97.18% | 2.82% | 30.00% |
| Explosion | 91.36% | 63.64% | 70.00% | 66.67% | 94.37% | 5.63% | 30.00% |
| Fight | 92.59% | 66.67% | 80.00% | 72.73% | 94.37% | 5.63% | 20.00% |
| Normal | 91.36% | 61.54% | 80.00% | 69.57% | 92.96% | 7.04% | 20.00% |
| Macro-Average | 92.28% | 71.24% | 69.32% | 69.29% | 95.59% | 4.41% | 30.68% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saleem, G.; Bajwa, U.I.; Raza, R.H.; Zhang, F. Edge-Enhanced TempoFuseNet: A Two-Stream Framework for Intelligent Multiclass Video Anomaly Recognition in 5G and IoT Environments. Future Internet 2024, 16, 83. https://doi.org/10.3390/fi16030083
Saleem G, Bajwa UI, Raza RH, Zhang F. Edge-Enhanced TempoFuseNet: A Two-Stream Framework for Intelligent Multiclass Video Anomaly Recognition in 5G and IoT Environments. Future Internet. 2024; 16(3):83. https://doi.org/10.3390/fi16030083
Chicago/Turabian StyleSaleem, Gulshan, Usama Ijaz Bajwa, Rana Hammad Raza, and Fan Zhang. 2024. "Edge-Enhanced TempoFuseNet: A Two-Stream Framework for Intelligent Multiclass Video Anomaly Recognition in 5G and IoT Environments" Future Internet 16, no. 3: 83. https://doi.org/10.3390/fi16030083
APA StyleSaleem, G., Bajwa, U. I., Raza, R. H., & Zhang, F. (2024). Edge-Enhanced TempoFuseNet: A Two-Stream Framework for Intelligent Multiclass Video Anomaly Recognition in 5G and IoT Environments. Future Internet, 16(3), 83. https://doi.org/10.3390/fi16030083