
Congestion Control Mechanism Based on Backpressure Feedback in Data Center Networks


Abstract
:1. Introduction
- We summarize and reveal the shortcomings of the existing end-to-end congestion control and traffic management in a high-bandwidth DCN.
- This paper defines a new method for congestion detection and congested flow identification. This method uses the queue length in the buffer and the time that packets reside in the queue to classify congestion into three different cases. Switches can effectively detect congestion and identify the real-congested flow based on the queue occupancy.
- This paper designs a switch-driven rate congestion control. In this approach, upstream switches can respond to congestion based on the downstream congestion feedback in a one-hop RTT. This adjustment process helps accelerate the convergence of speeds.
- BFCC is implemented in the PDP, and extensive simulation experiments confirm that this congestion control mechanism maintains high throughput and low latency with a low buffer.
2. Motivation and Related Work
2.1. Congestion Control in Data Centers
2.2. Traffic Management in Data Centers
3. Congestion Detection and Identification
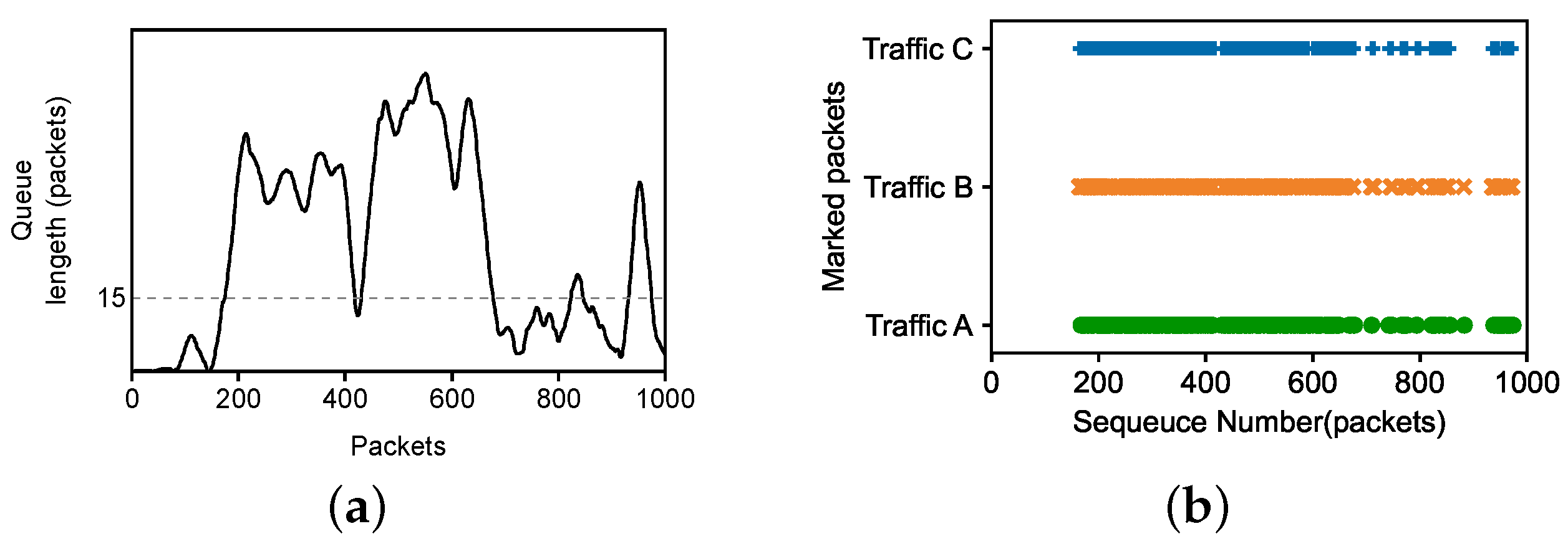
3.1. Observations and Insights
3.2. Congestion Determination
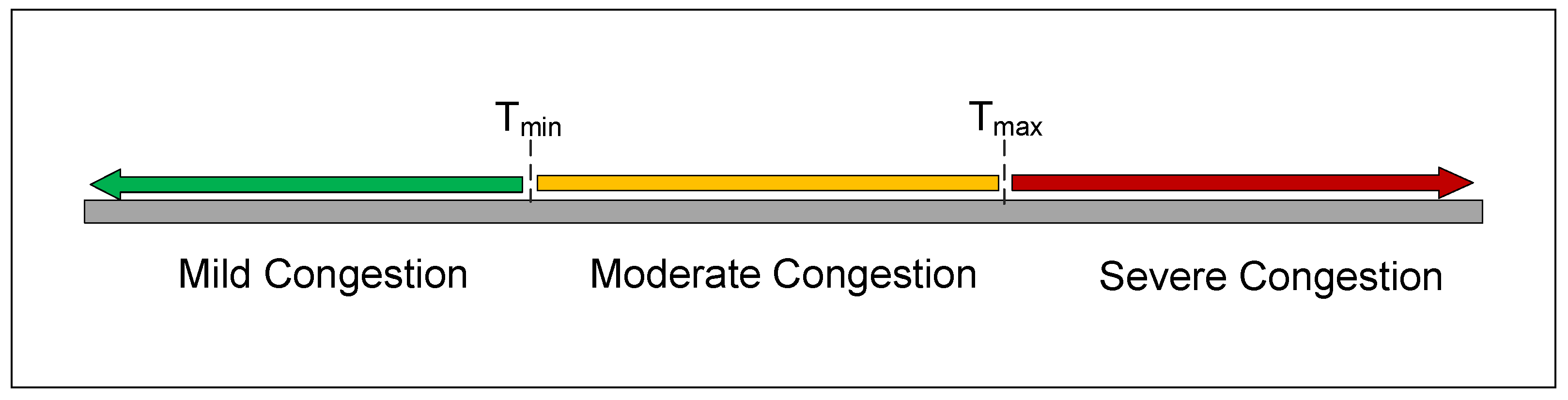
3.2.1. Division of Congestion Degree
3.2.2. Congested Flow Identification
4. BFCC
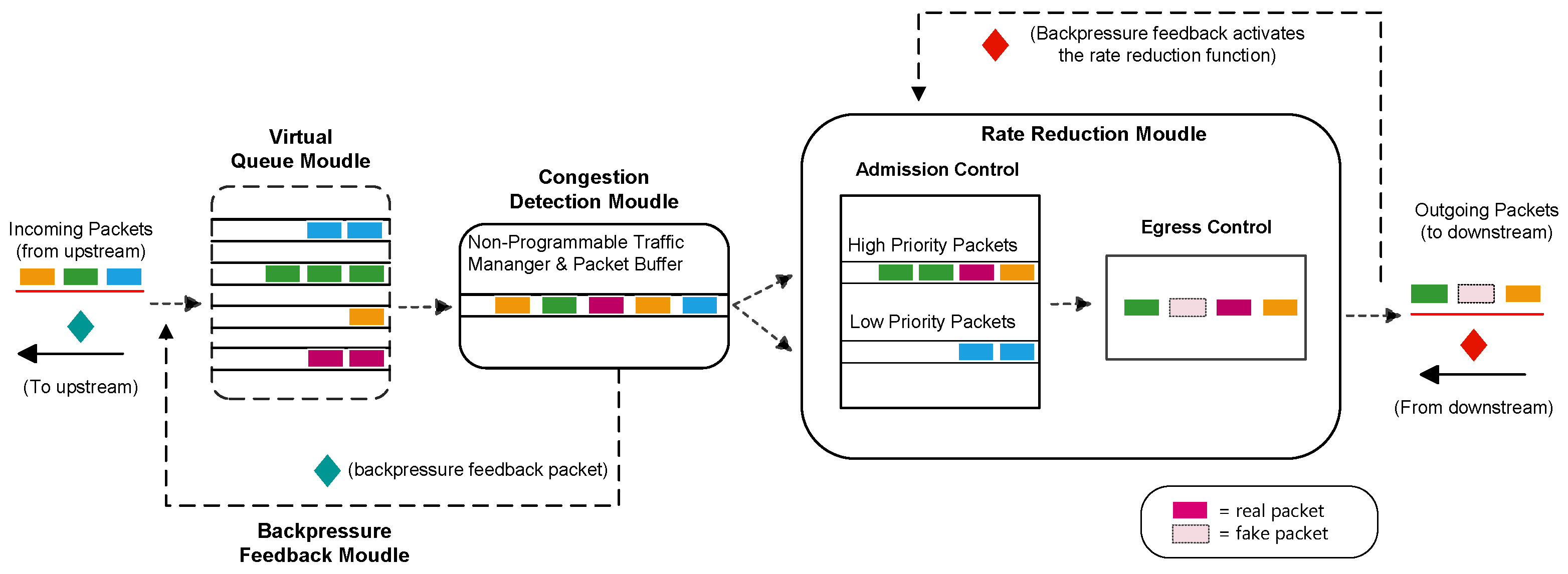
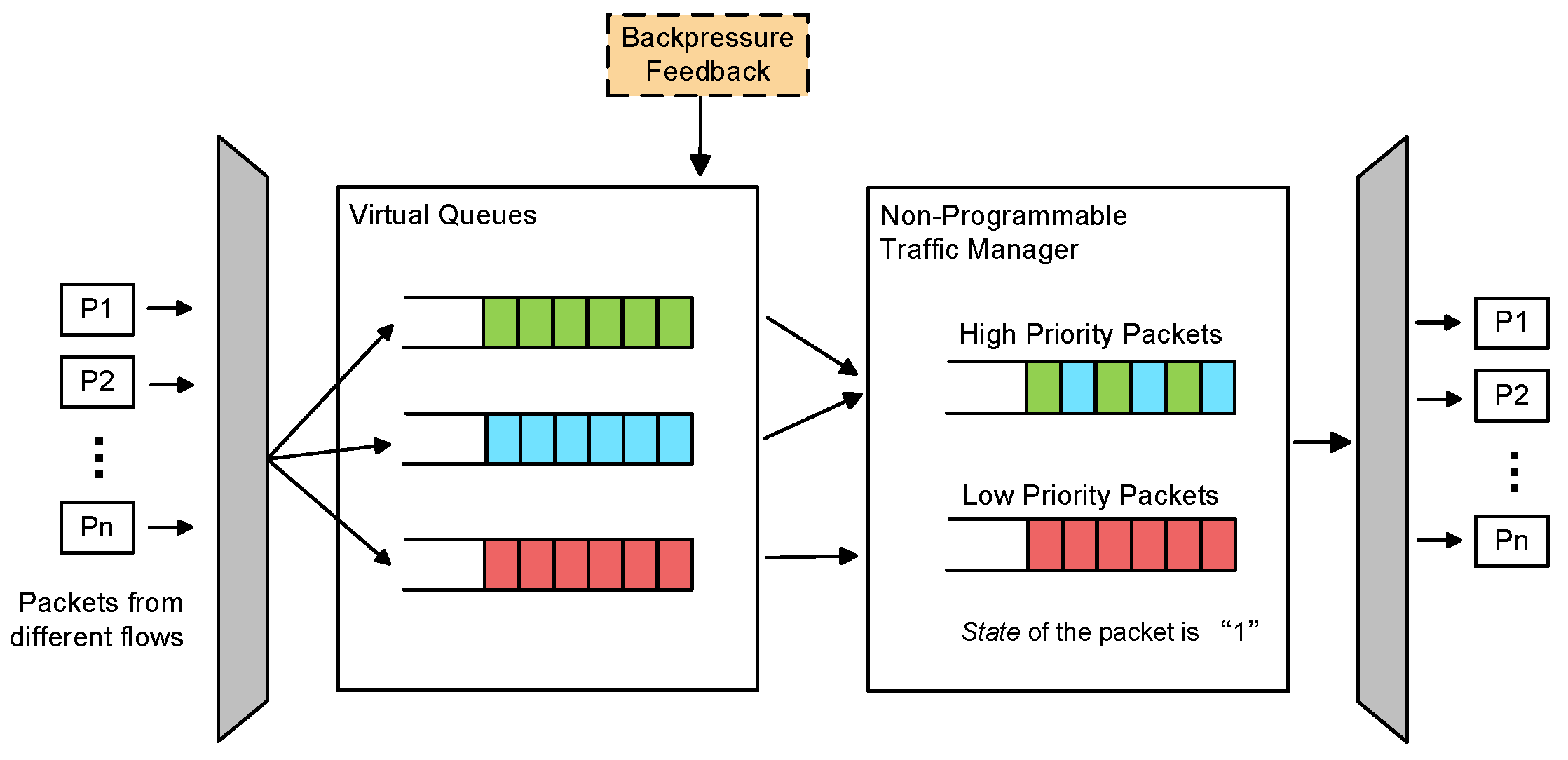
4.1. Structure Design
4.2. Rate Reduction Module
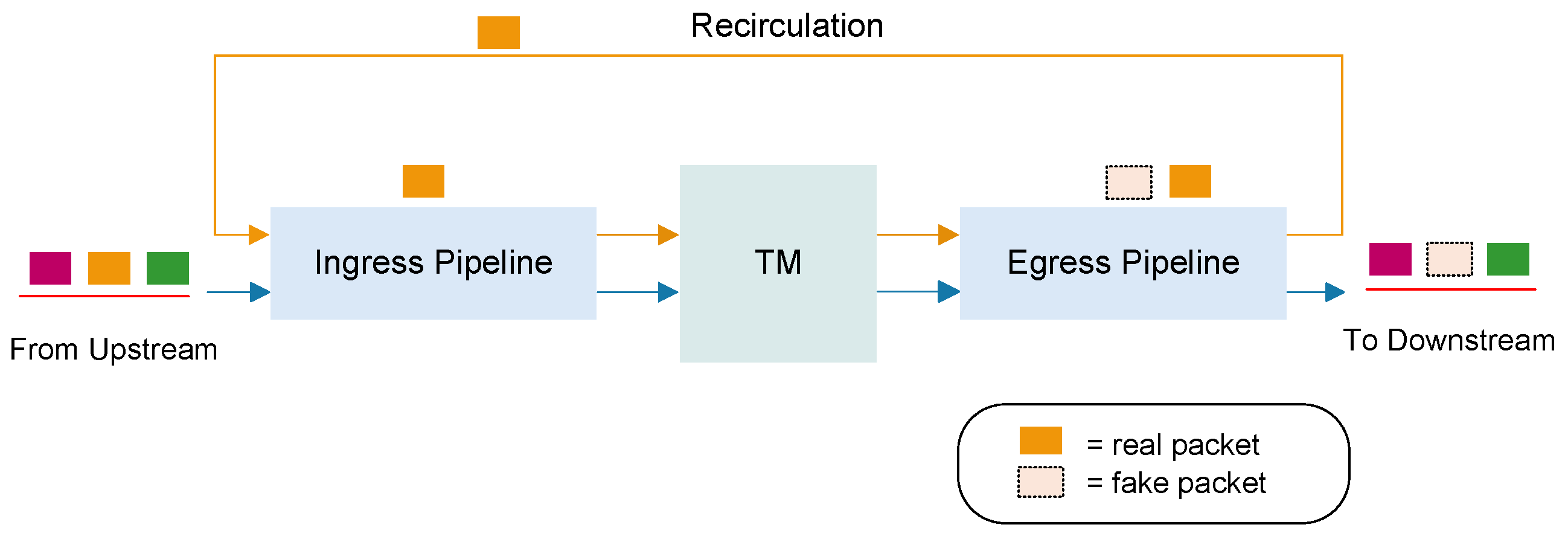
4.2.1. Admission Control
| Algorithm 1 Pseudo-code of the BFCC algorithm implemented at the ingress pipeline of the PDP |
|
4.2.2. Egress Control
| Algorithm 2 Pseudo-code of the BFCC algorithm implemented at the egress pipeline of the PDP. |
|
5. Evaluation
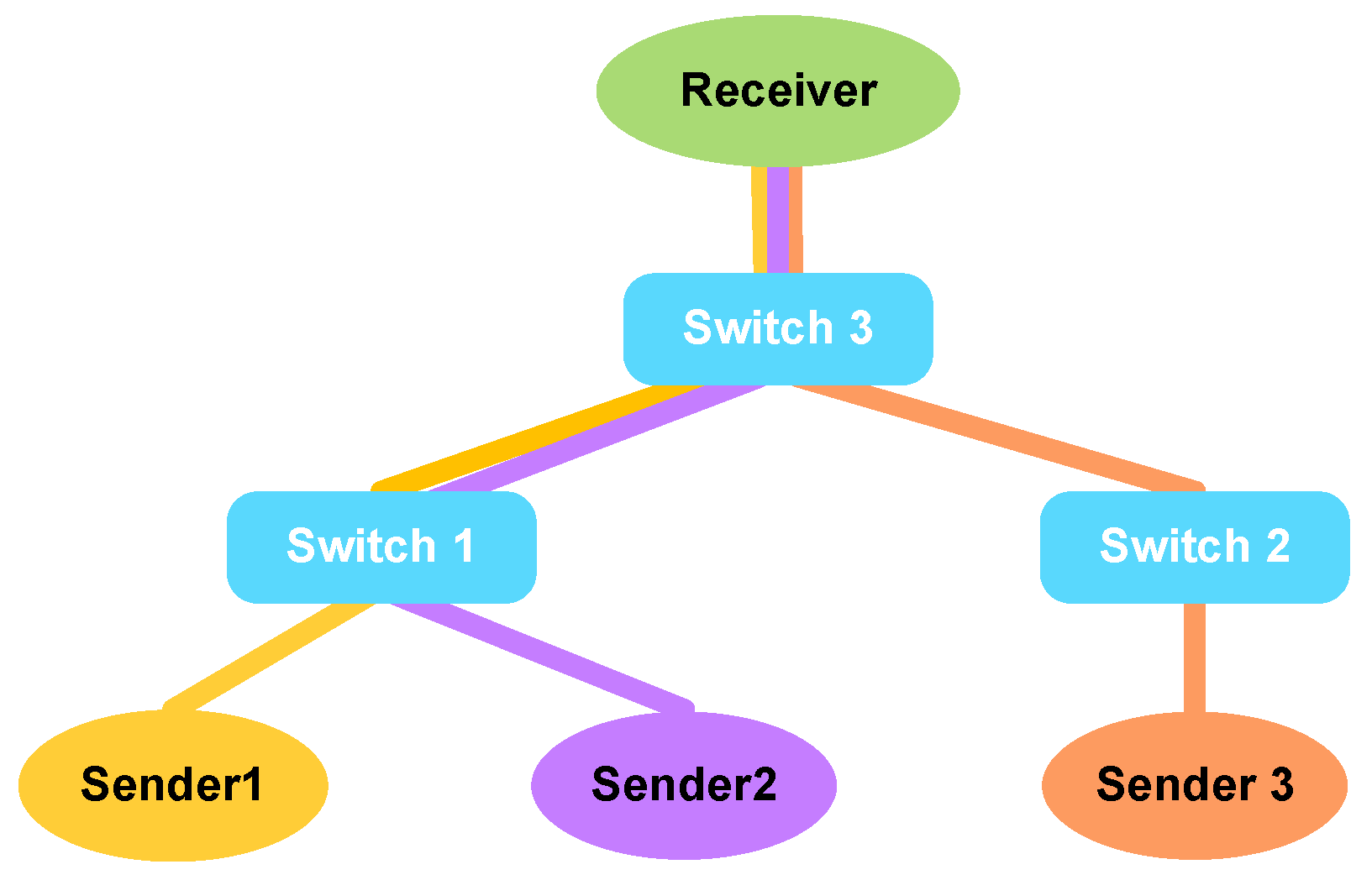
5.1. Evaluation of Single-Receiver Topology
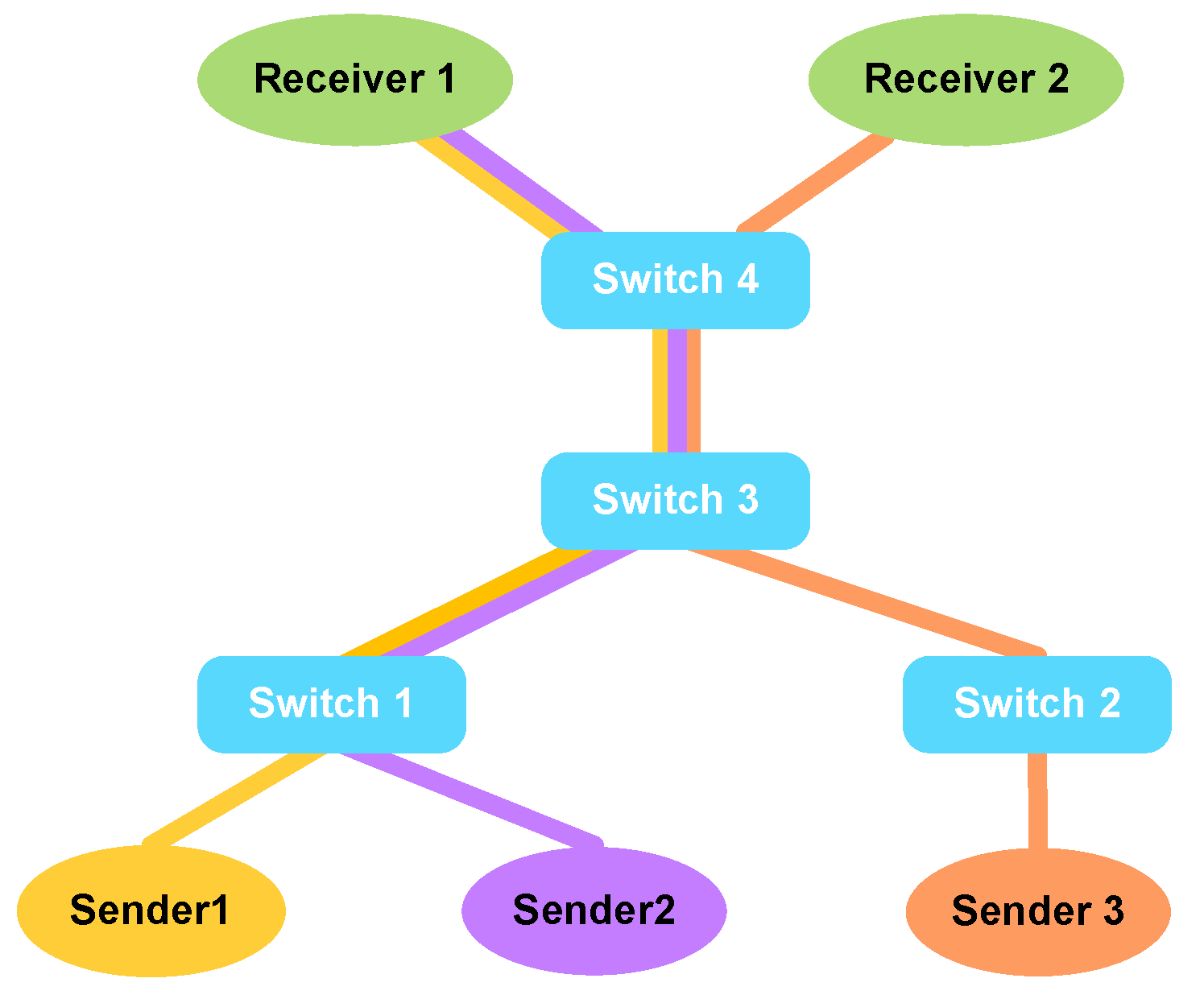
5.1.1. Experiment Settings
- Sender Group 1 → Switch 1 → Switch 3 → Receiver
- Sender Group 2 → Switch 1 → Switch 3 → Receiver
- Sender Group 3 → Switch 2 → Switch 3 → Receiver
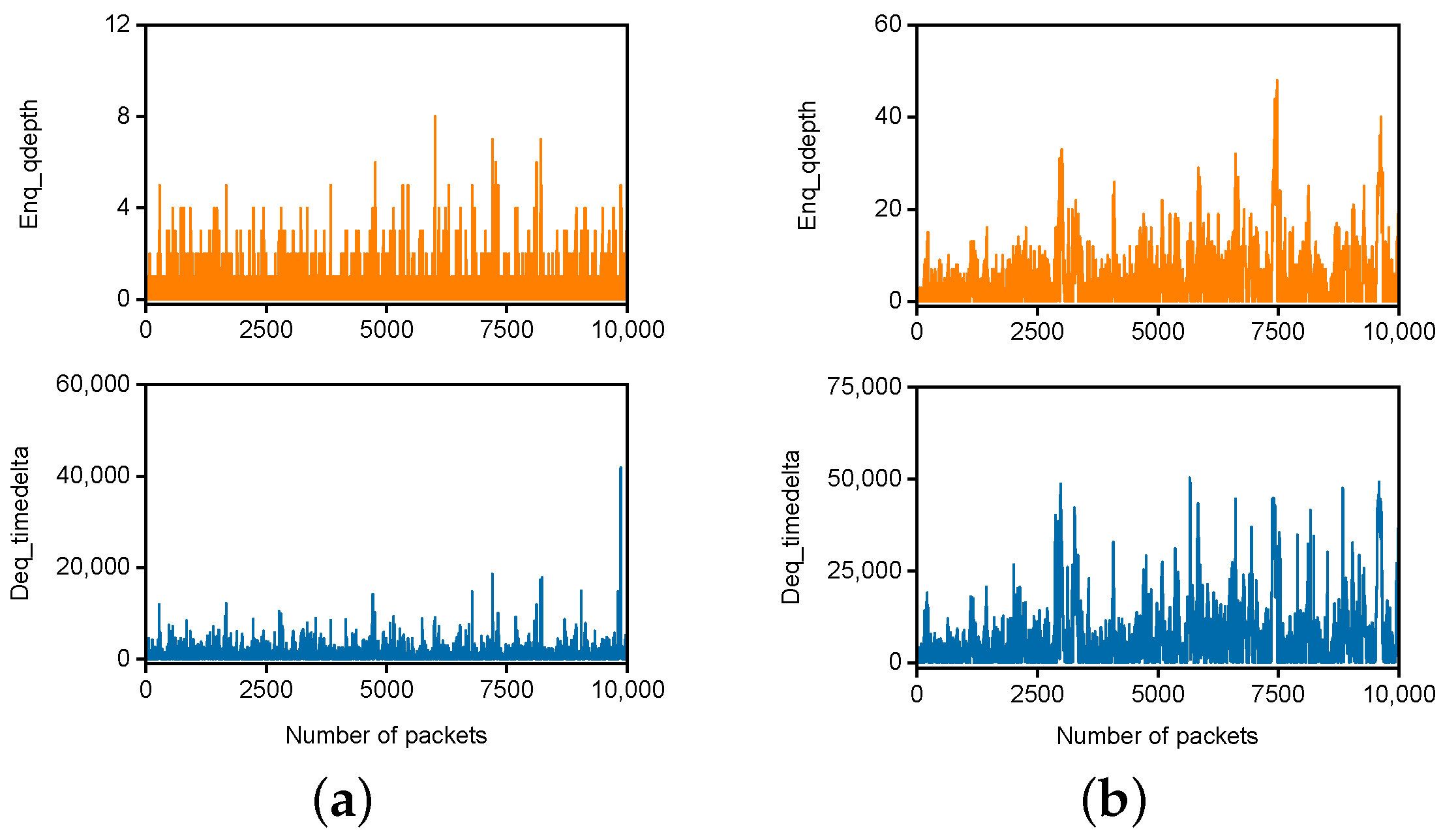
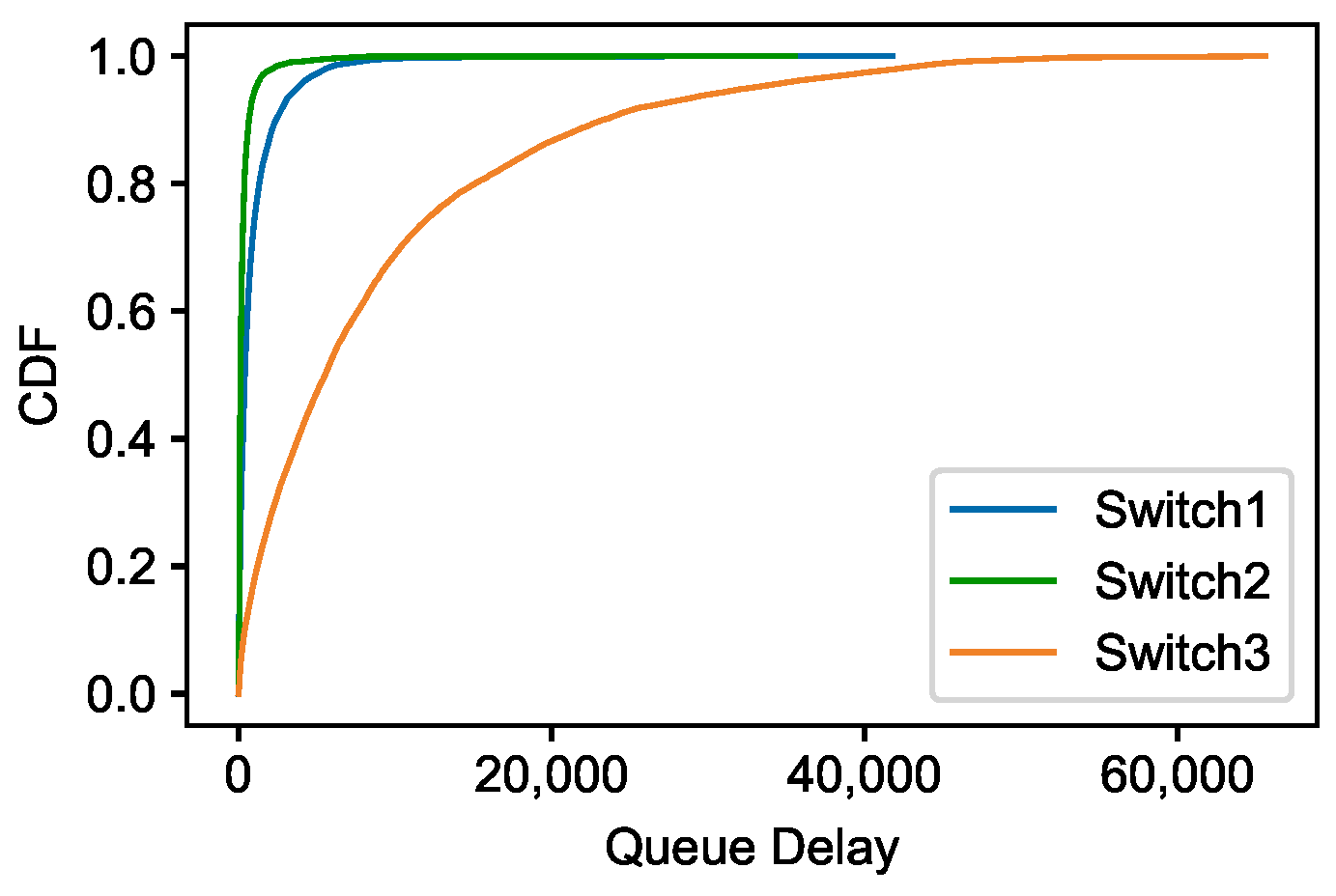
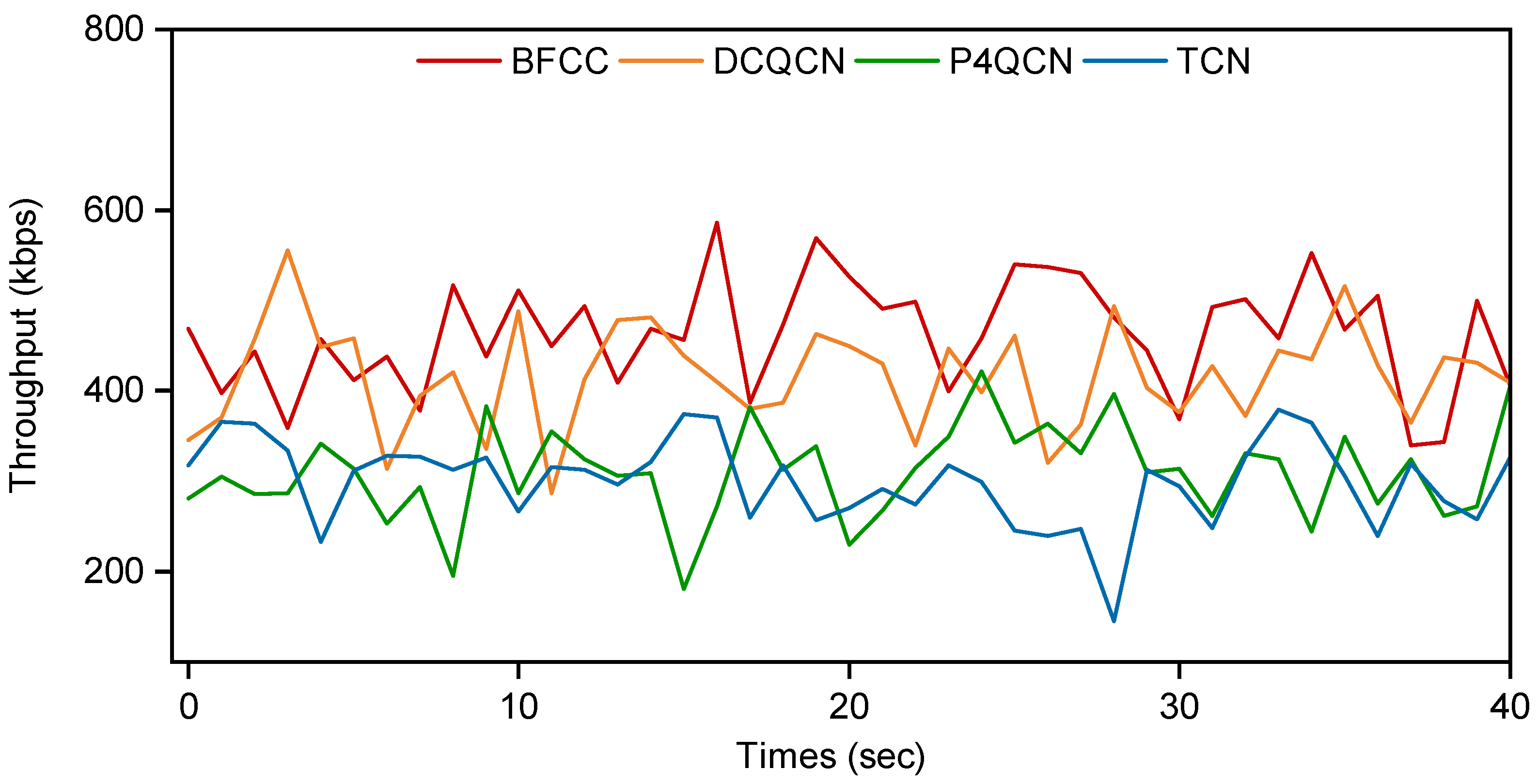
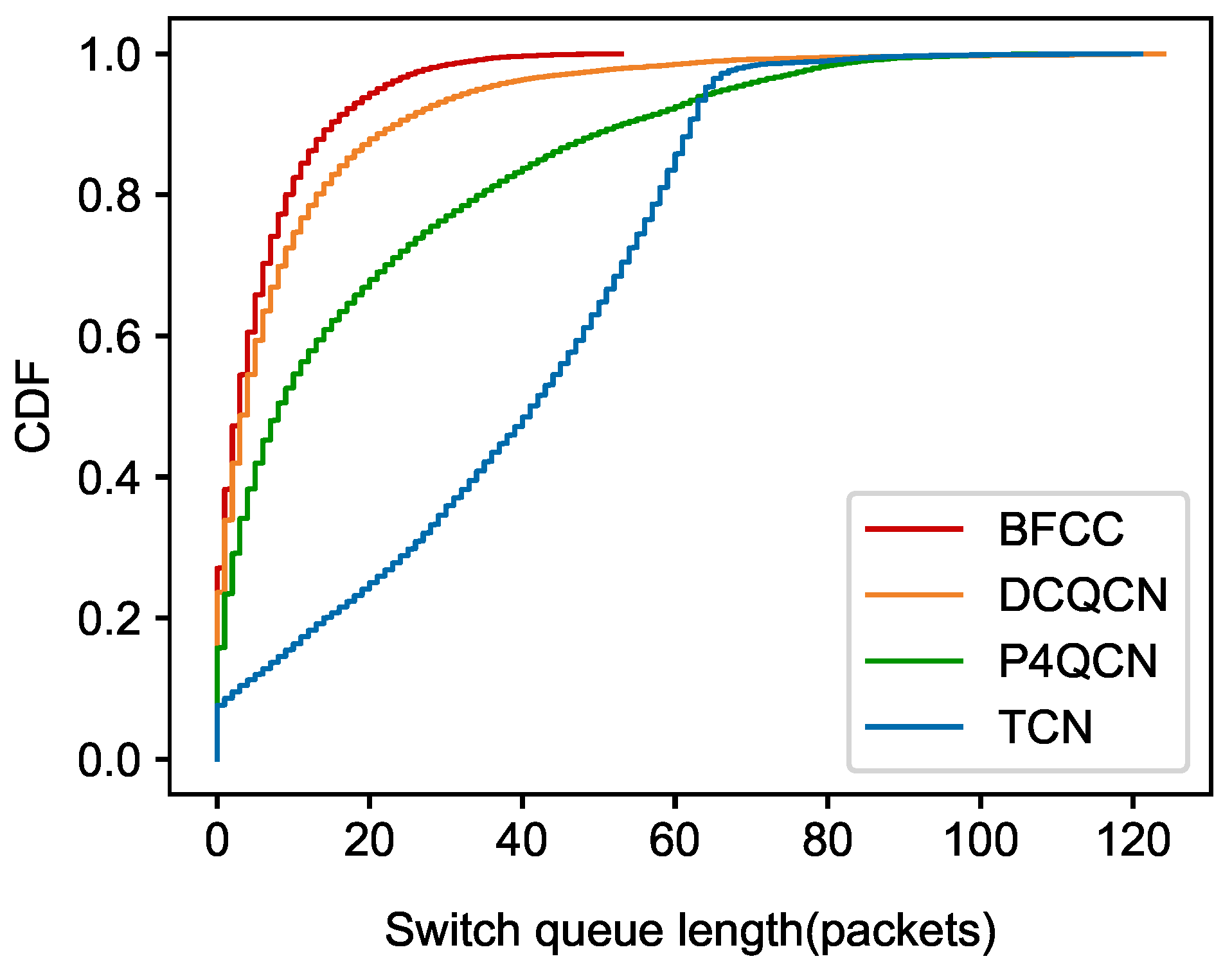
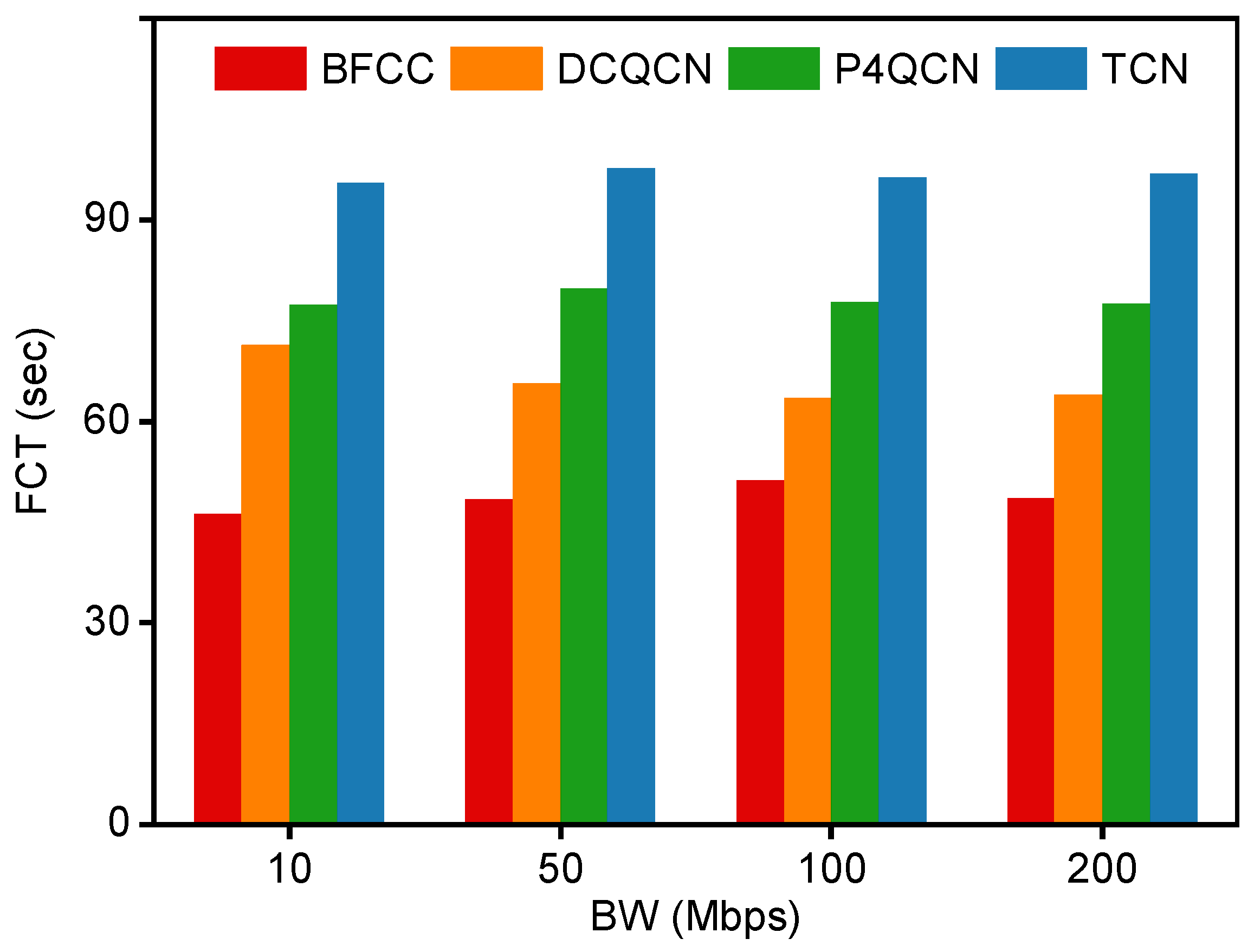
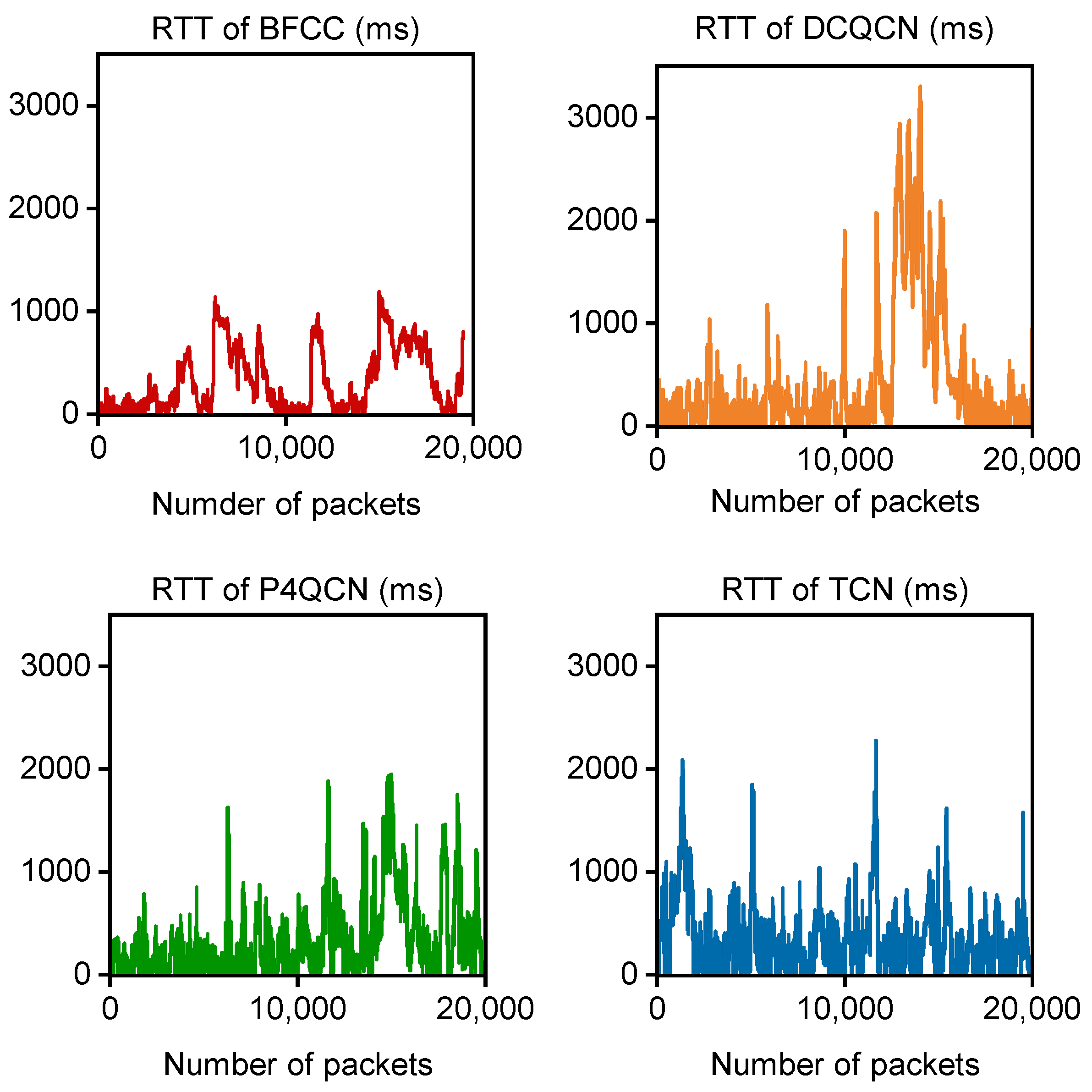
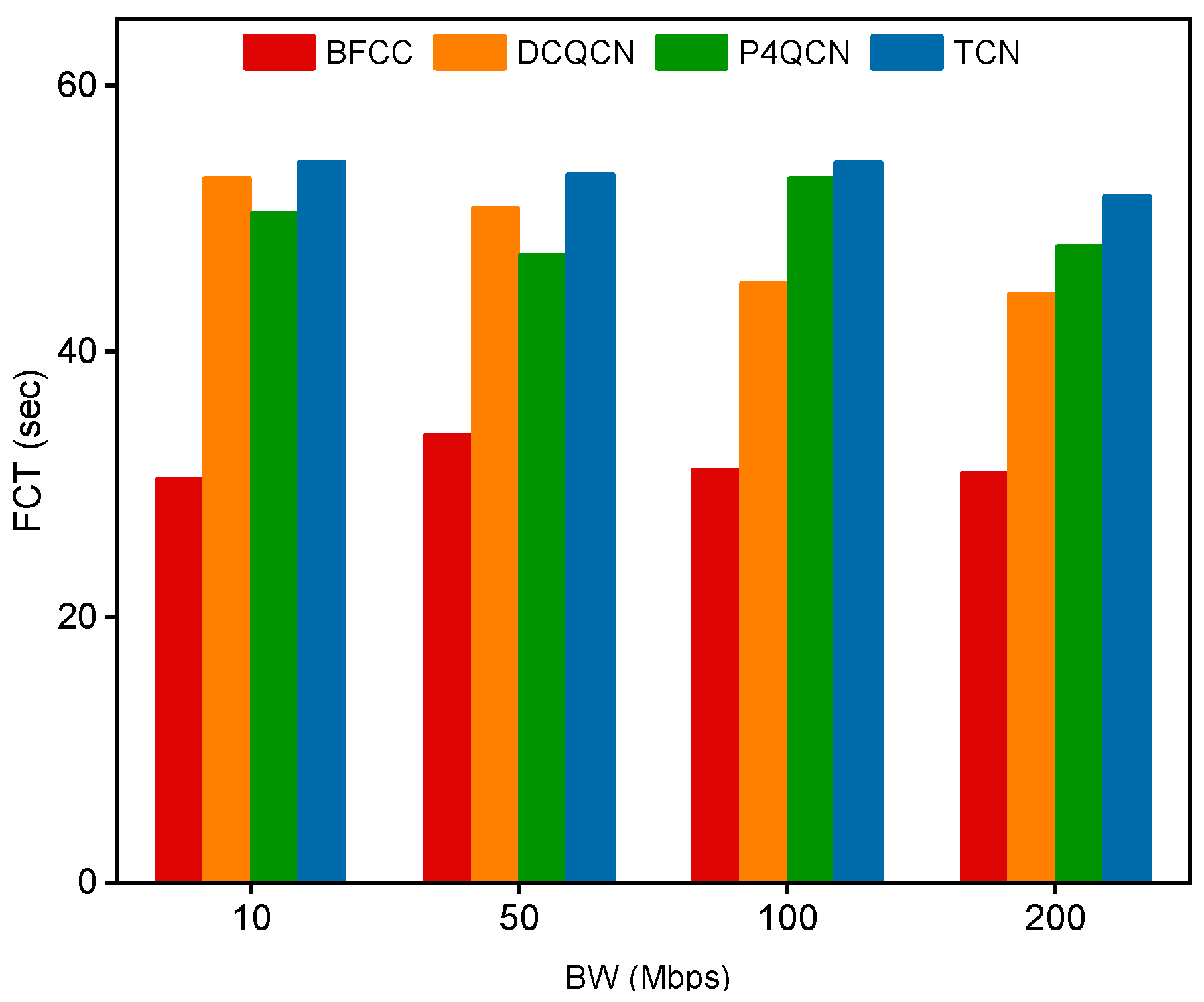
5.1.2. Experiment Results
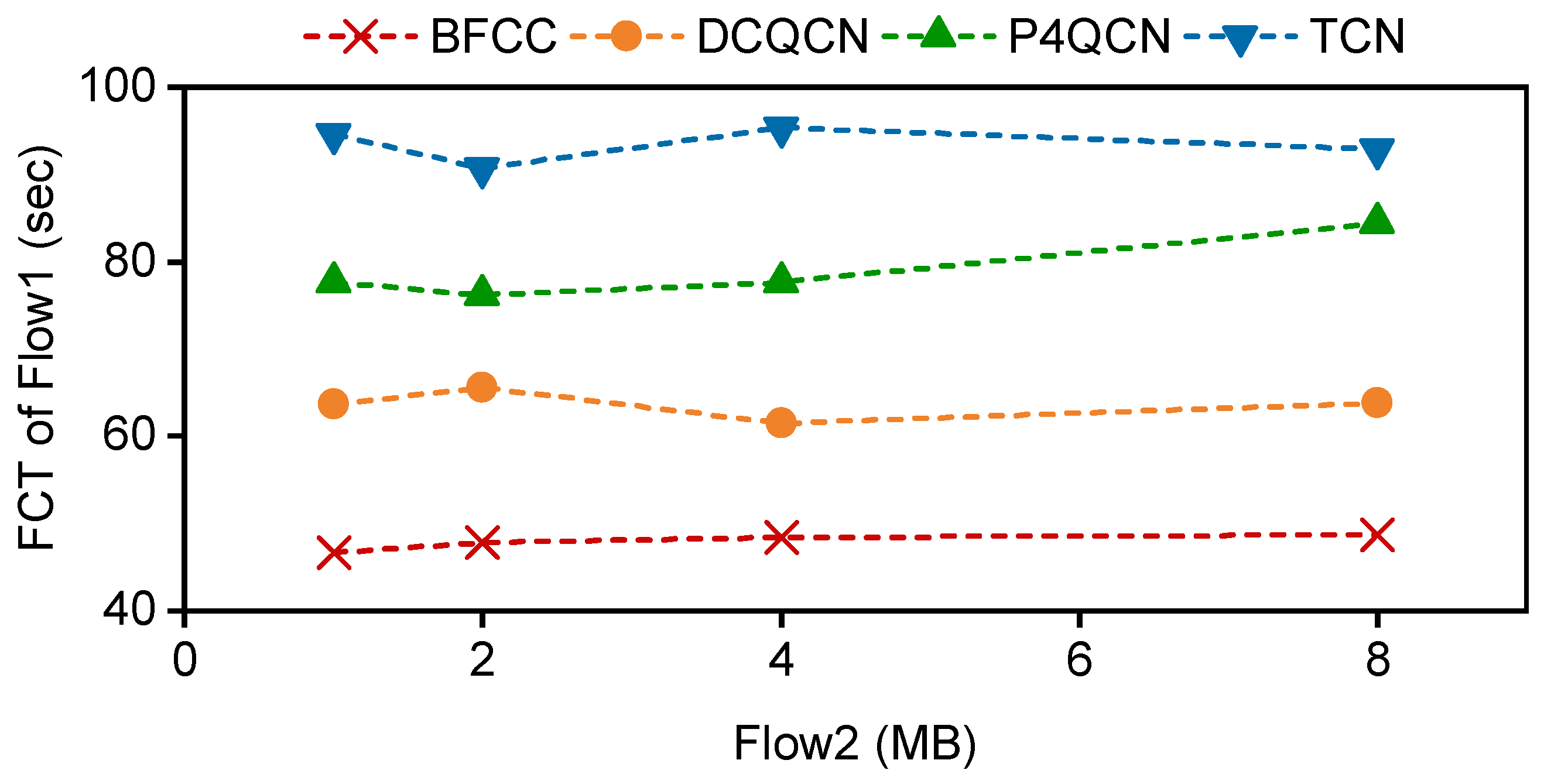
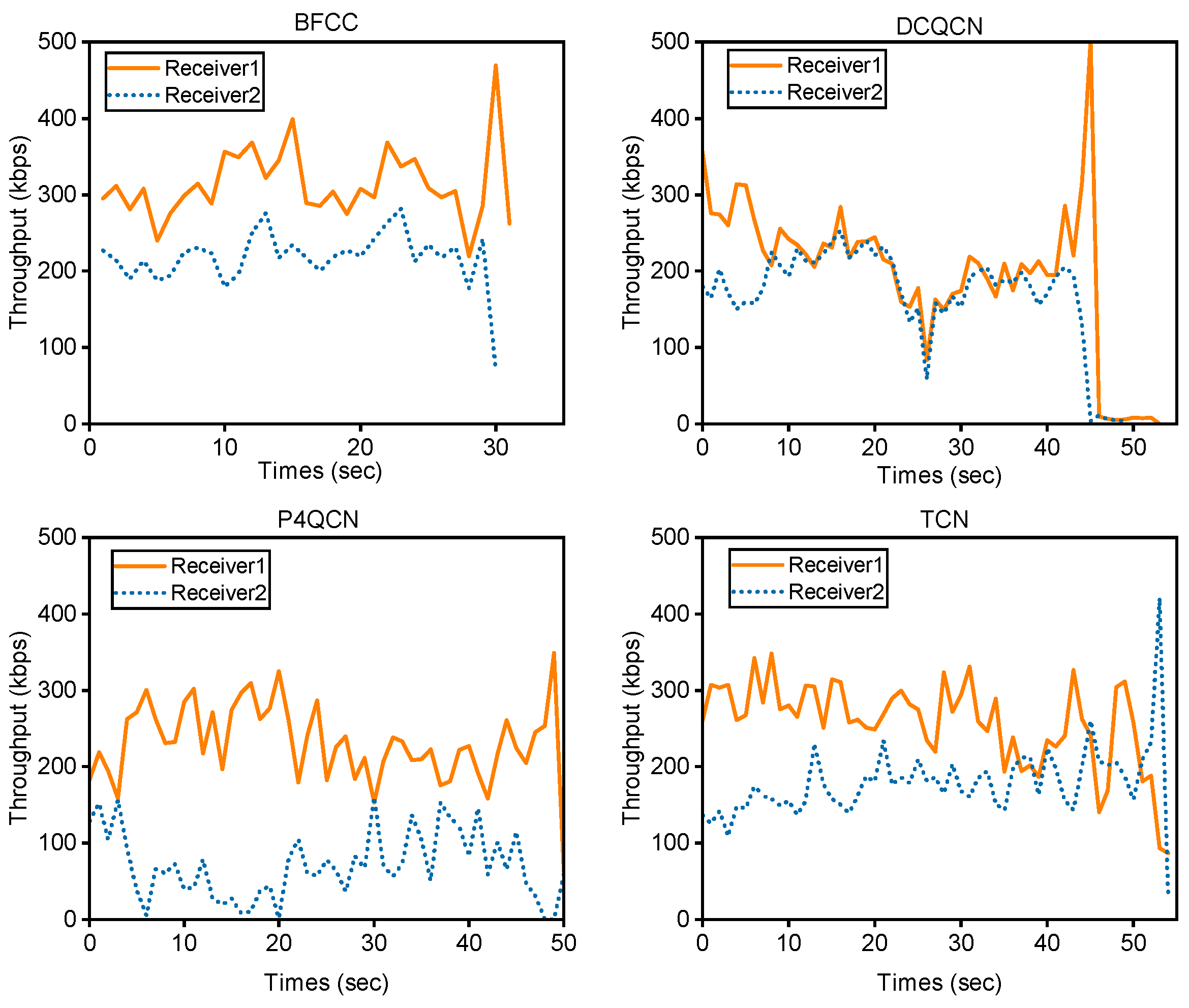
5.2. Evaluation of Two-Receiver Topology
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gibson, D.; Hariharan, H.; Lance, E.; McLaren, M.; Montazeri, B.; Singh, A.; Wang, S.; Wassel, H.M.; Wu, Z.; Yoo, S. Aquila: A unified, low-latency fabric for datacenter networks. In Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), Renton, WA, USA, 4–6 April 2022; pp. 1249–1266. [Google Scholar]
- Prateesh, G.; Preey, S.; Kevin, Z.; Georgios, N.; Mohammad, A.; Thomas, A. Backpressure flow control. In Proceedings of the Symposium on Network System Design and Implementation, NSDI, Renton, WA, USA, 4–6 April 2022; pp. 779–805. [Google Scholar]
- Joshi, R.; Song, C.H.; Khooi, X.Z.; Budhdev, N.; Mishra, A.; Chan, M.C.; Leong, B. Masking Corruption Packet Losses in Datacenter Networks with Link-local Retransmission. In Proceedings of the ACM SIGCOMM 2023 Conference, New York, NY, USA, 10–14 September 2023; pp. 288–304. [Google Scholar]
- Poutievski, L.; Mashayekhi, O.; Ong, J.; Singh, A.; Tariq, M.; Wang, R.; Zhang, J.; Beauregard, V.; Conner, P.; Gribble, S. Jupiter evolving: Transforming google’s datacenter network via optical circuit switches and software-defined networking. In Proceedings of the ACM SIGCOMM 2022 Conference, Amsterdam, The Netherlands, 22–26 August 2022; pp. 66–85. [Google Scholar]
- Li, Q. TCP FlexiS: A New Approach To Incipient Congestion Detection and Control. IEEE/ACM Trans. Netw. 2023; 1–16. [Google Scholar] [CrossRef]
- Arslan, S.; Li, Y.; Kumar, G.; Dukkipati, N. Bolt: Sub-RTT Congestion Control for Ultra-Low Latency. In Proceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), Boston, MA, USA, 17–19 April 2023; pp. 219–236. [Google Scholar]
- Liu, W.-X.; Liang, C.; Cui, Y.; Cai, J.; Luo, J.-M. Programmable data plane intelligence: Advances, opportunities, and challenges. IEEE Netw. 2022, 37, 122–128. [Google Scholar] [CrossRef]
- Bolanowski, M.; Gerka, A.; Paszkiewicz, A.; Ganzha, M.; Paprzycki, M. Application of genetic algorithm to load balancing in networks with a homogeneous traffic flow. In Proceedings of the International Conference on Computational Science, Prague, Czech Republic, 3–5 July 2023; pp. 314–321. [Google Scholar]
- Zaher, M.; Alawadi, A.H.; Molnár, S. Sieve: A flow scheduling framework in SDN based data center networks. Comput. Commun. 2021, 171, 99–111. [Google Scholar] [CrossRef]
- Scazzariello, M.; Caiazzi, T.; Ghasemirahni, H.; Barbette, T.; Kostić, D.; Chiesa, M. A High-Speed Stateful Packet Processing Approach for Tbps Programmable Switches. In Proceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), Boston, MA, USA, 17–19 April 2023; pp. 1237–1255. [Google Scholar]
- Xiao, L.Y.S.; Jun, B.I.; Yu, Z.; Cheng, Z.; Ping, W.J.; Zheng, L.Z.; Ran, Z.Y. Research and Applications of Programmable Data Plane Based on P4. Chin. J. Comput. 2019, 42, 2539–2560. [Google Scholar]
- Namkung, H.; Liu, Z.; Kim, D.; Sekar, V.; Steenkiste, P. Sketchovsky: Enabling Ensembles of Sketches on Programmable Switches. In Proceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), Boston, MA, USA, 17–19 April 2023; pp. 1273–1292. [Google Scholar]
- Agarwal, S.; Krishnamurthy, A.; Agarwal, R. Host Congestion Control. In Proceedings of the ACM SIGCOMM 2023 Conference, New York, NY, USA, 10–14 September 2023; pp. 275–287. [Google Scholar]
- Kundel, R.; Krishna, N.B.; Gärtner, C.; Meuser, T.; Rizk, A. Poster: Reverse-path congestion notification: Accelerating the congestion control feedback loop. In Proceedings of the 2021 IEEE 29th International Conference on Network Protocols (ICNP), Dallas, TX, USA, 1–5 November 2021; pp. 1–2. [Google Scholar]
- Alizadeh, M.; Greenberg, A.; Maltz, D.A.; Padhye, J.; Patel, P.; Prabhakar, B.; Sengupta, S.; Sridharan, M. Data center tcp (dctcp). In Proceedings of the ACM SIGCOMM 2010 Conference, New Delhi, India, 30 August–3 September 2010; pp. 63–74. [Google Scholar]
- Vamanan, B.; Hasan, J.; Vijaykumar, T. Deadline-aware datacenter tcp (d2tcp). ACM SIGCOMM Comput. Commun. Rev. 2012, 42, 115–126. [Google Scholar] [CrossRef]
- Wu, H.; Feng, Z.; Guo, C.; Zhang, Y. ICTCP: Incast congestion control for TCP in data center networks. IEEE/ACM Trans. Netw. 2013, 2, 235–358. [Google Scholar]
- Zhu, Y.; Eran, H.; Firestone, D.; Guo, C.; Lipshteyn, M.; Liron, Y.; Padhye, J.; Raindel, S.; Yahia, M.H.; Zhang, M. Congestion control for large-scale RDMA deployments. ACM SIGCOMM Comput. Commun. Rev. 2015, 45, 523–536. [Google Scholar] [CrossRef]
- IEEE. 802.11Qau-Congestion Notification. Available online: https://1.ieee802.org/dcb/802-1qau/ (accessed on 10 April 2024).
- Wu, H.; Ju, J.; Lu, G.; Guo, C.; Xiong, Y.; Zhang, Y. Tuning ECN for data center networks. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies, Nice, France, 10–13 December 2012; pp. 25–36. [Google Scholar]
- Munir, A.; Qazi, I.A.; Uzmi, Z.A.; Mushtaq, A.; Ismail, S.N.; Iqbal, M.S.; Khan, B. Minimizing flow completion times in data centers. In Proceedings of the 2013 Proceedings IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 2157–2165. [Google Scholar]
- Shan, D.; Ren, F. Improving ECN marking scheme with micro-burst traffic in data center networks. In Proceedings of the IEEE INFOCOM 2017-IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Chen, J.; Jing, Y.; Xie, H. Multiple Bottleneck Topology TCP/AWM Network Event-triggered Congestion Control with New Prescribed Performance. Int. J. Control Autom. Syst. 2023, 21, 2487–2503. [Google Scholar] [CrossRef]
- Mittal, R.; Lam, V.T.; Dukkipati, N.; Blem, E.; Wassel, H.; Ghobadi, M.; Vahdat, A.; Wang, Y.; Wetherall, D.; Zats, D. TIMELY: RTT-based congestion control for the datacenter. ACM SIGCOMM Comput. Commun. Rev. 2015, 45, 537–550. [Google Scholar] [CrossRef]
- Kumar, G.; Dukkipati, N.; Jang, K.; Wassel, H.M.; Wu, X.; Montazeri, B.; Wang, Y.; Springborn, K.; Alfeld, C.; Ryan, M. Swift: Delay is simple and effective for congestion control in the datacenter. In Proceedings of the Annual Conference of the ACM Special Interest Group on Data Communication on the Applications, Technologies, Architectures, and Protocols for Computer Communication, Online, 10–14 August 2020; pp. 514–528. [Google Scholar]
- Wang, W.; Moshref, M.; Li, Y.; Kumar, G.; Ng, T.E.; Cardwell, N.; Dukkipati, N. Poseidon: Efficient, Robust, and Practical Datacenter CC via Deployable INT. In Proceedings of the 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23), Boston, MA, USA, 17–19 April 2023; pp. 255–274. [Google Scholar]
- Lim, H.; Kim, J.; Cho, I.; Jang, K.; Bai, W.; Han, D. FlexPass: A Case for Flexible Credit-based Transport for Datacenter Networks. In Proceedings of the Eighteenth European Conference on Computer Systems, Rome, Italy, 8–12 May 2023; pp. 606–622. [Google Scholar]
- IEEE. 802.1Qbb—Priority-Based Flow Control. Available online: http://www.ieee802.org/1/pages/802.1bb.html (accessed on 10 April 2024).
- Alizadeh, M.; Yang, S.; Sharif, M.; Katti, S.; McKeown, N.; Prabhakar, B.; Shenker, S. pfabric: Minimal near-optimal datacenter transport. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 435–446. [Google Scholar] [CrossRef]
- Montazeri, B.; Li, Y.; Alizadeh, M.; Ousterhout, J. Homa: A receiver-driven low-latency transport protocol using network priorities. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 221–235. [Google Scholar]
- Handley, M.; Raiciu, C.; Agache, A.; Voinescu, A.; Moore, A.W.; Antichi, G.; Wójcik, M. Re-architecting datacenter networks and stacks for low latency and high performance. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 29–42. [Google Scholar]
- Cheng, W.; Qian, K.; Jiang, W.; Zhang, T.; Ren, F. Re-architecting congestion management in lossless ethernet. In Proceedings of the 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20), Santa Clara, CA, USA, 25–27 February 2020; pp. 19–36. [Google Scholar]
- Zhang, Y.; Liu, Y.; Meng, Q.; Ren, F. Congestion detection in lossless networks. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, Online, 23–27 August 2021; pp. 370–383. [Google Scholar]
- Hauser, F.; Häberle, M.; Merling, D.; Lindner, S.; Gurevich, V.; Zeiger, F.; Frank, R.; Menth, M. A survey on data plane programming with p4: Fundamentals, advances, and applied research. J. Netw. Comput. Appl. 2023, 212, 103561. [Google Scholar] [CrossRef]
- P4 16 PSA Specification. Available online: https://p4lang.github.io/p4-spec/docs/PSA-v1.1.0.html (accessed on 10 April 2024).
- P4 Behavioral Model (BMV2). Available online: https://github.com/p4lang/behavioral-model (accessed on 10 April 2024).
- Geng, J.; Yan, J.; Zhang, Y. P4QCN: Congestion control using P4-capable device in data center networks. Electronics 2019, 8, 280. [Google Scholar] [CrossRef]
- Bai, W.; Chen, K.; Chen, L.; Kim, C.; Wu, H. Enabling ECN over generic packet scheduling. In Proceedings of the 12th International on Conference on emerging Networking EXperiments and Technologies, Irvine, CA, USA, 12–15 December 2016; pp. 191–204. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2 Bit | Meaning |
|---|---|
| 00 | Non-congestion |
| 01 | Mild congestion |
| 10 | Moderate congestion |
| 11 | Severe congestion |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Ren, M.; Liu, Y.; Li, C.; Qian, H.; Zhang, Z. Congestion Control Mechanism Based on Backpressure Feedback in Data Center Networks. Future Internet 2024, 16, 131. https://doi.org/10.3390/fi16040131
Li W, Ren M, Liu Y, Li C, Qian H, Zhang Z. Congestion Control Mechanism Based on Backpressure Feedback in Data Center Networks. Future Internet. 2024; 16(4):131. https://doi.org/10.3390/fi16040131
Chicago/Turabian StyleLi, Wei, Mengzhen Ren, Yazhi Liu, Chenyu Li, Hui Qian, and Zhenyou Zhang. 2024. "Congestion Control Mechanism Based on Backpressure Feedback in Data Center Networks" Future Internet 16, no. 4: 131. https://doi.org/10.3390/fi16040131
APA StyleLi, W., Ren, M., Liu, Y., Li, C., Qian, H., & Zhang, Z. (2024). Congestion Control Mechanism Based on Backpressure Feedback in Data Center Networks. Future Internet, 16(4), 131. https://doi.org/10.3390/fi16040131