

TQU-SLAM Benchmark Dataset for Comparative Study to Build Visual Odometry Based on Extracted Features from Feature Descriptors and Deep Learning


Abstract
1. Introduction
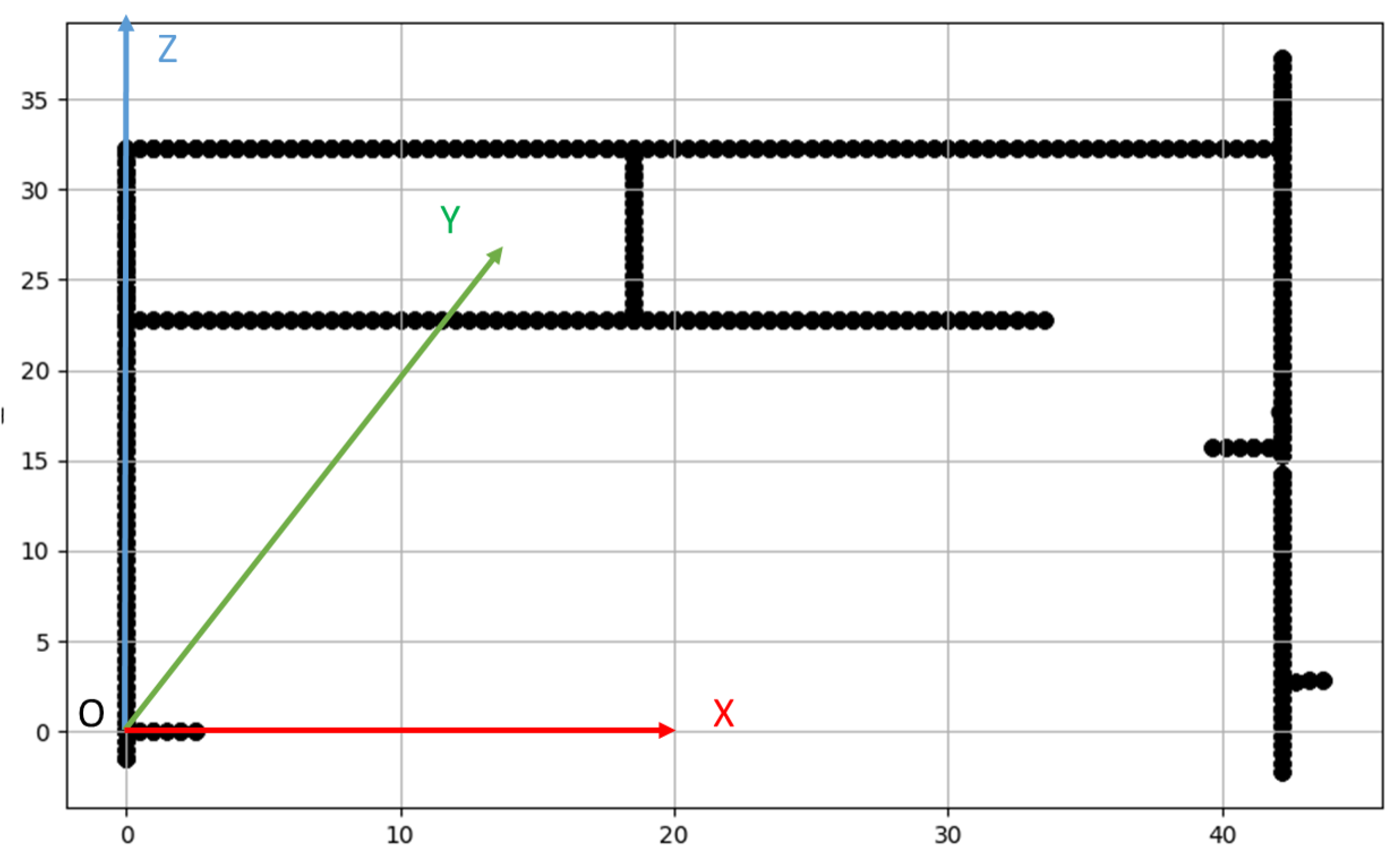
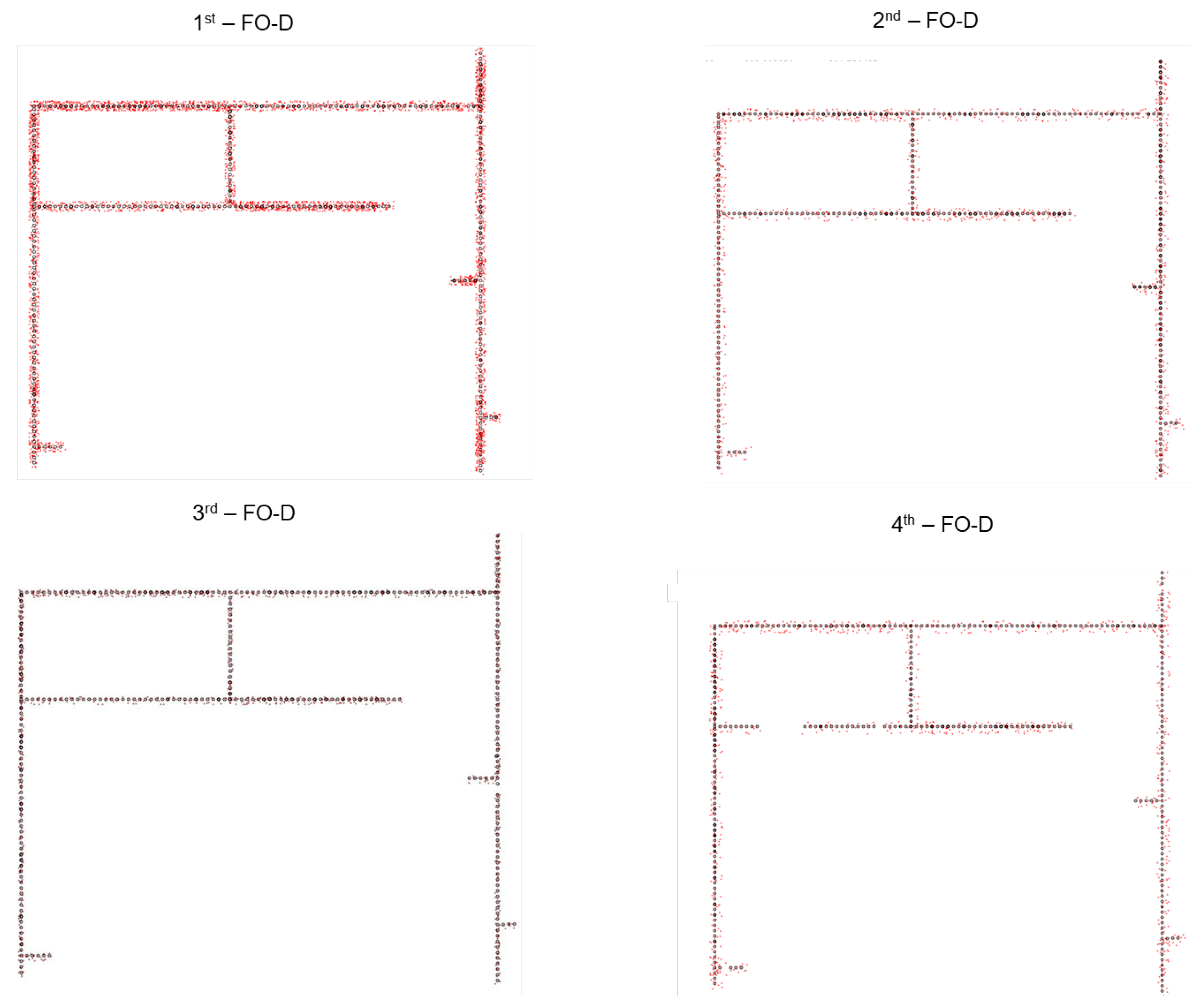
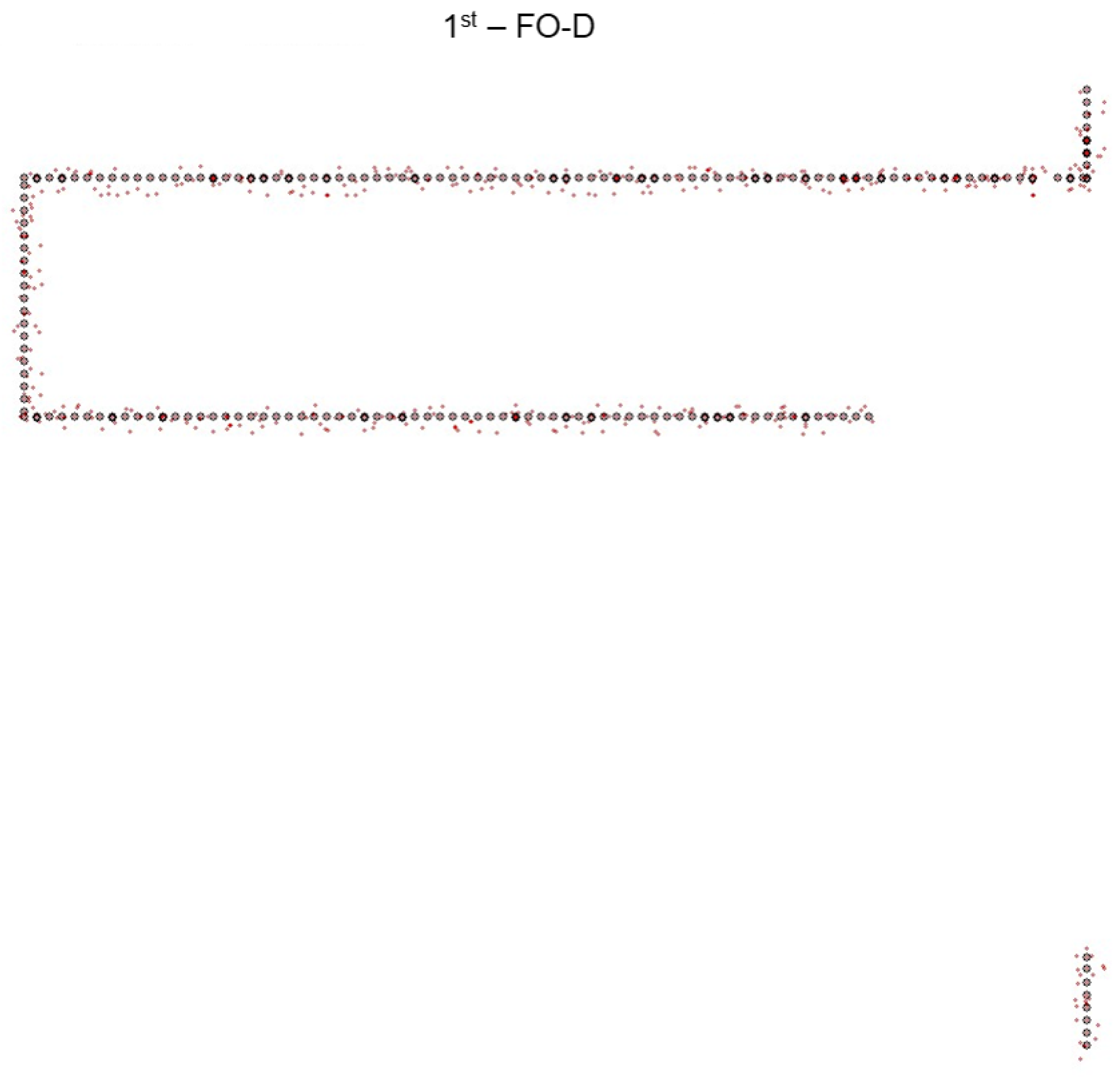
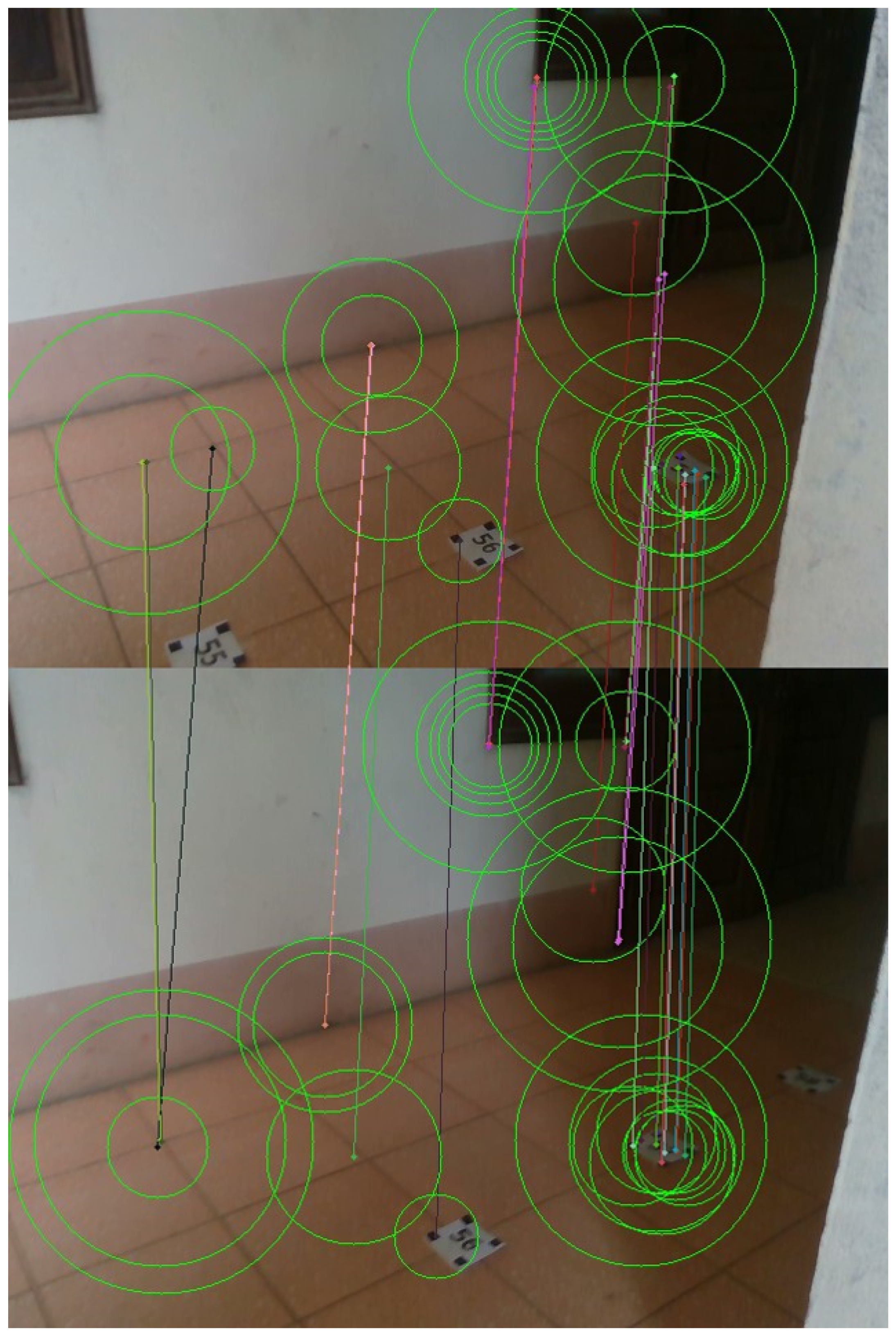
- We introduce the TQU-SLAM benchmark dataset for evaluating VO models, algorithms, and methods. The ground truth of the TQU-SLAM benchmark dataset is constructed by hand, including the camera coordinates in the real-world coordinate system, 3D point cloud data, intrinsic parameters, and the transformation matrix between the camera coordinate system and the real world.
- The results are analyzed and compared with the TQU-SLAM benchmark dataset with many types of traditional features and features extracted from DL models.
2. Related Works
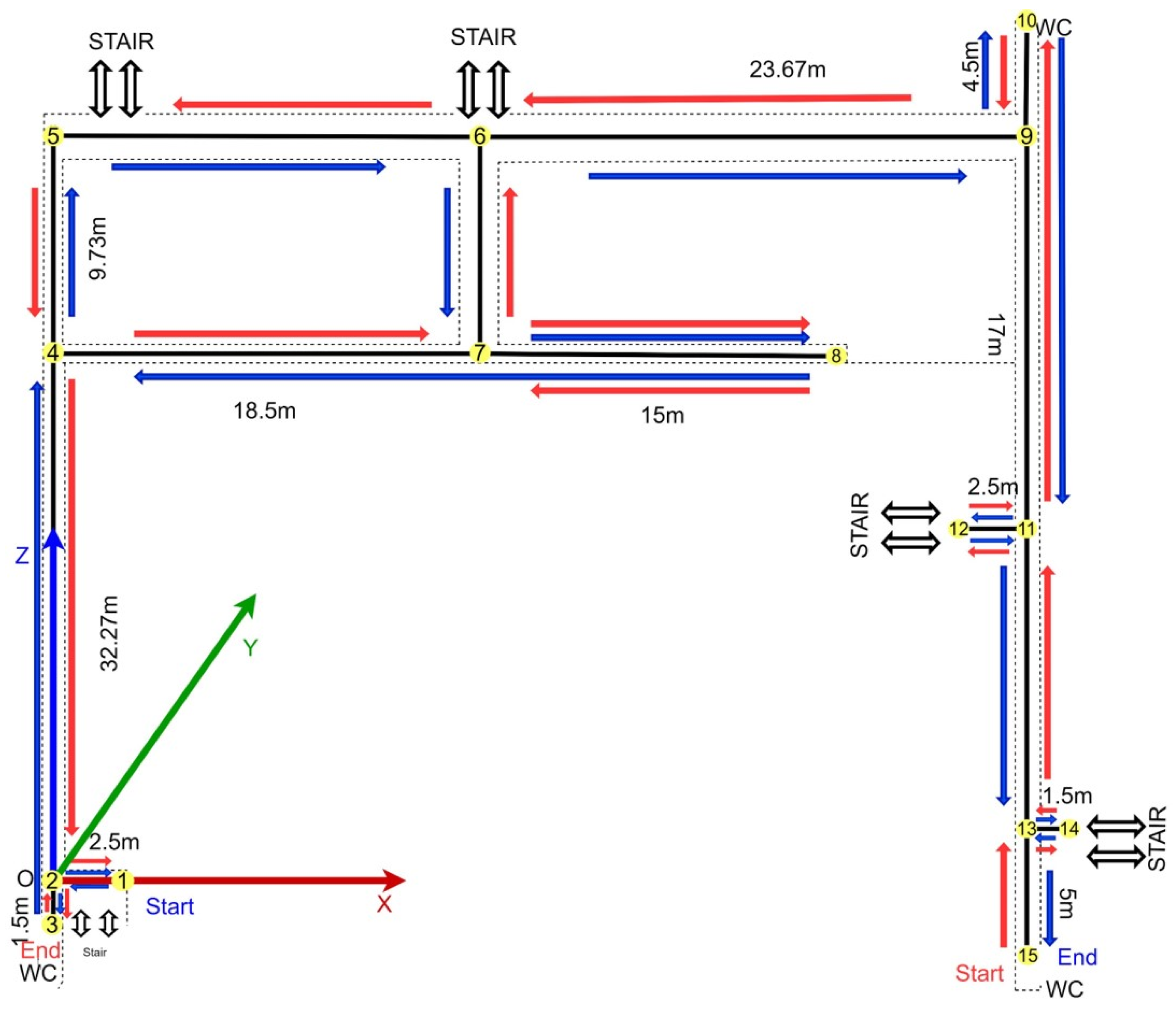
3. TQU-SLAM Benchmark Dataset
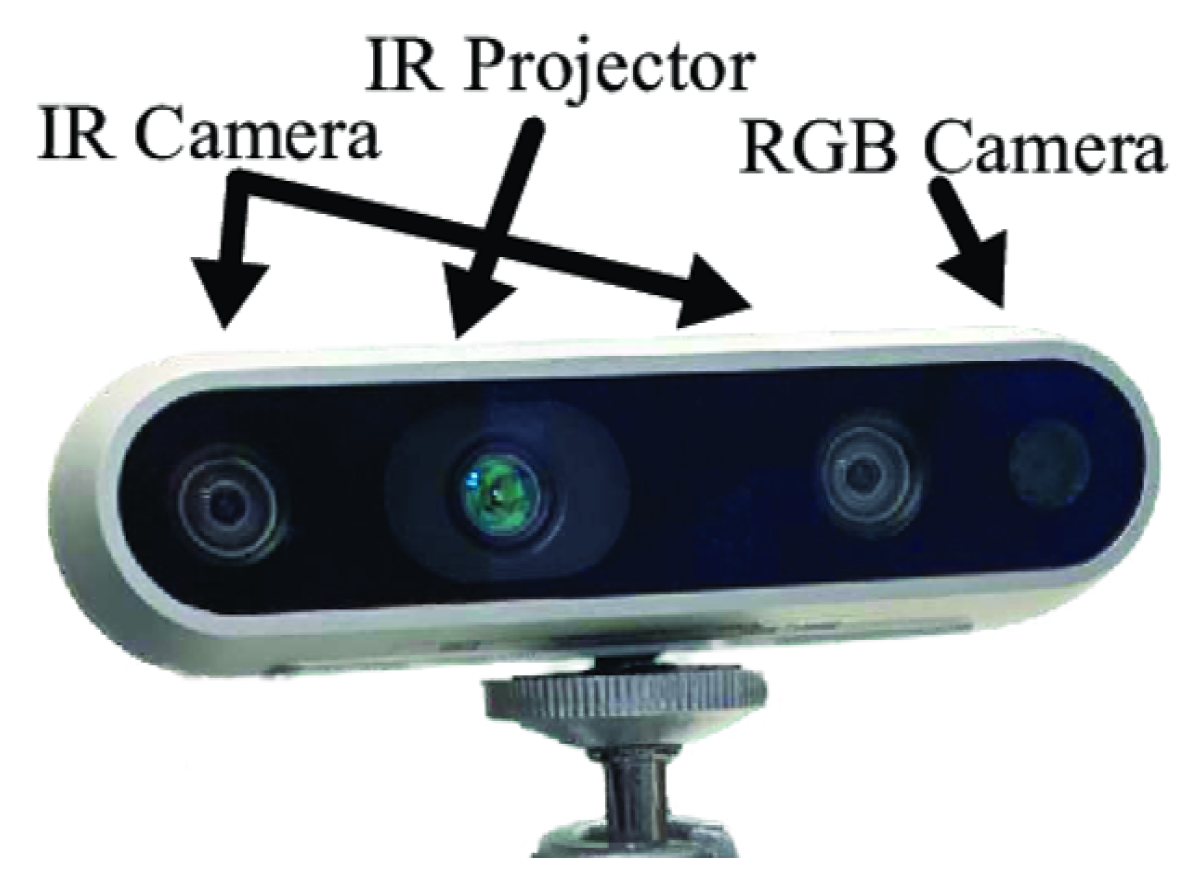
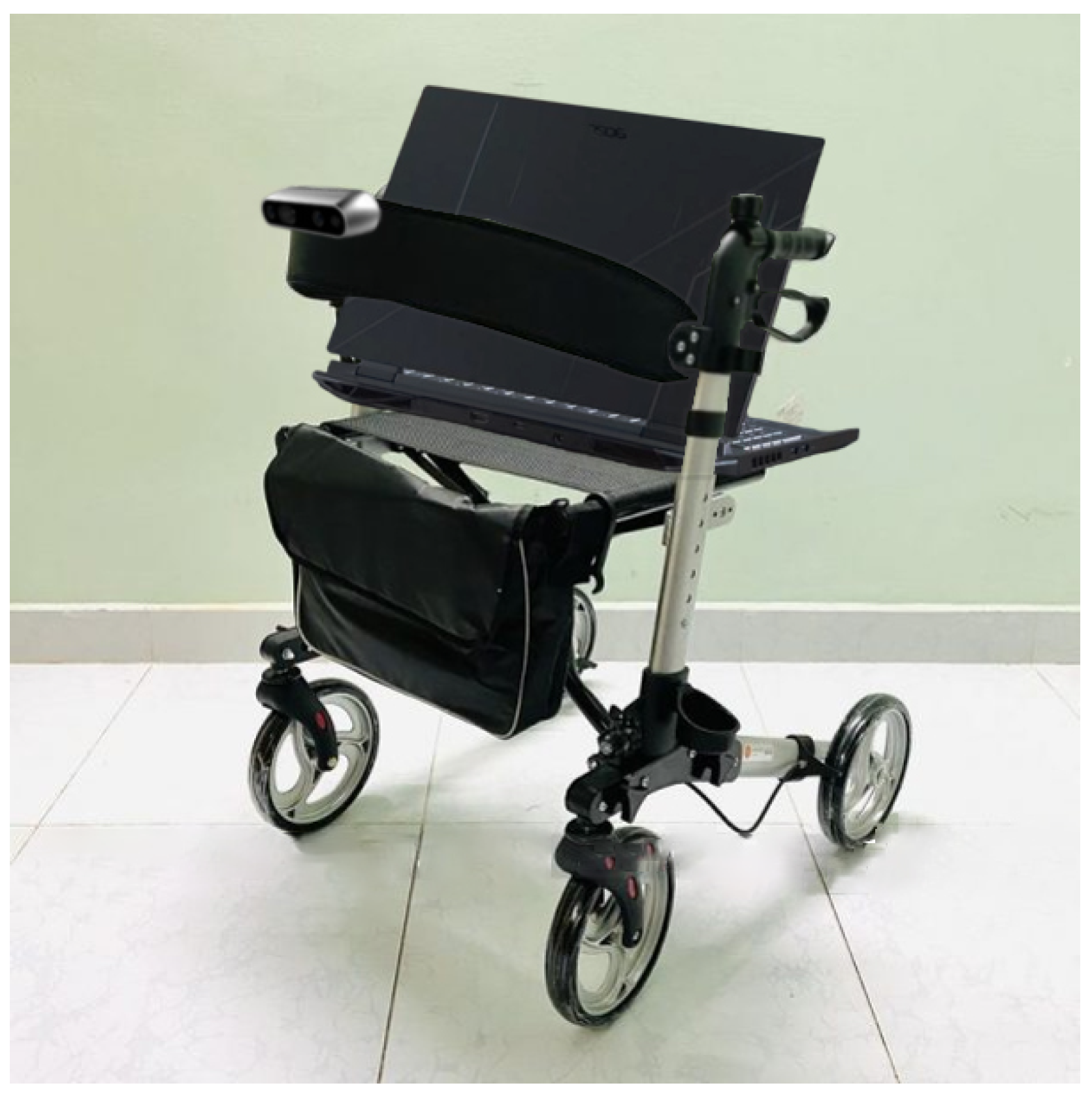
3.1. Data Collection
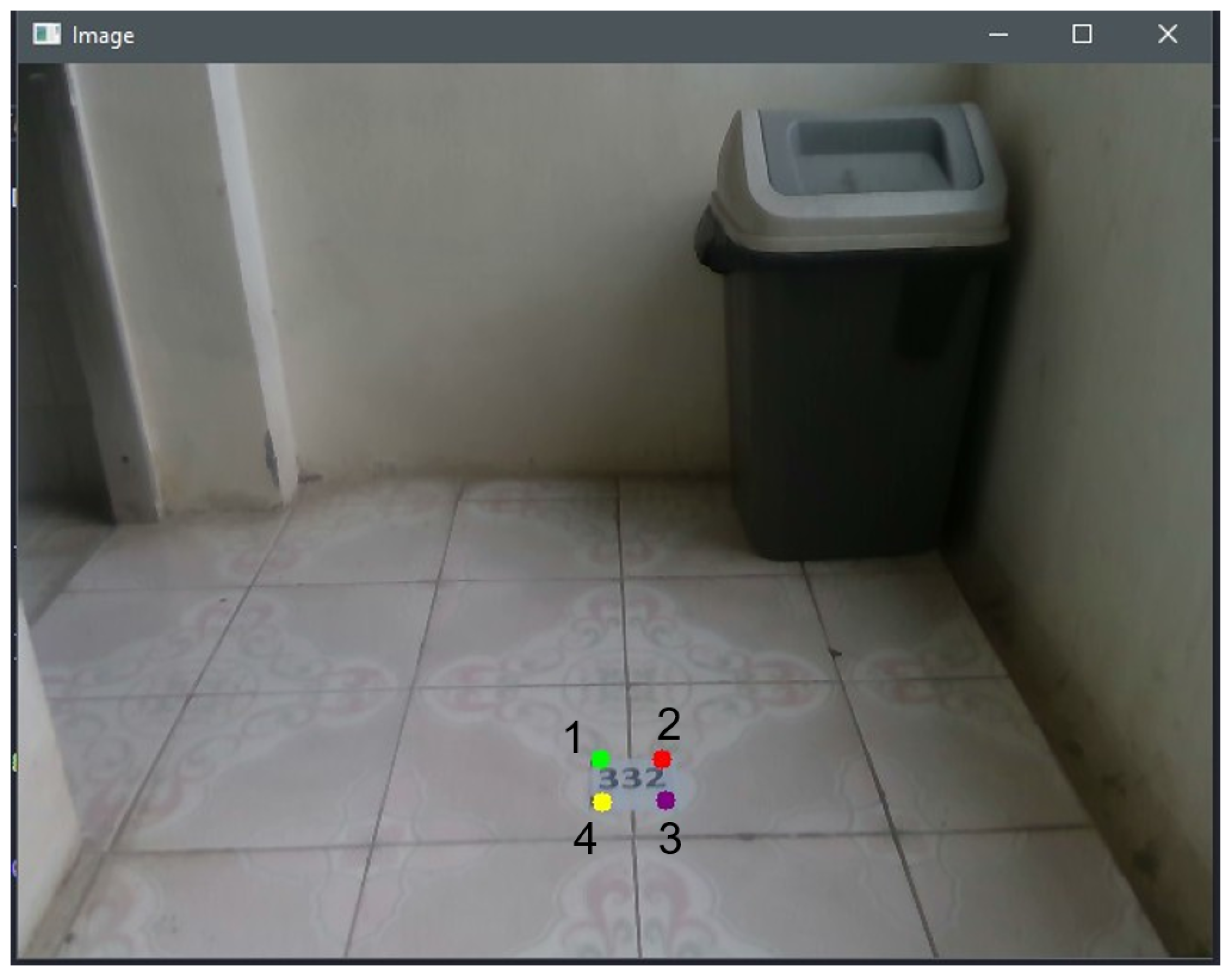
3.2. Preparing Ground-Truth Trajectory for VO
4. Comparative Study of Building VO Based on Feature-Based Methods
4.1. PySLAM
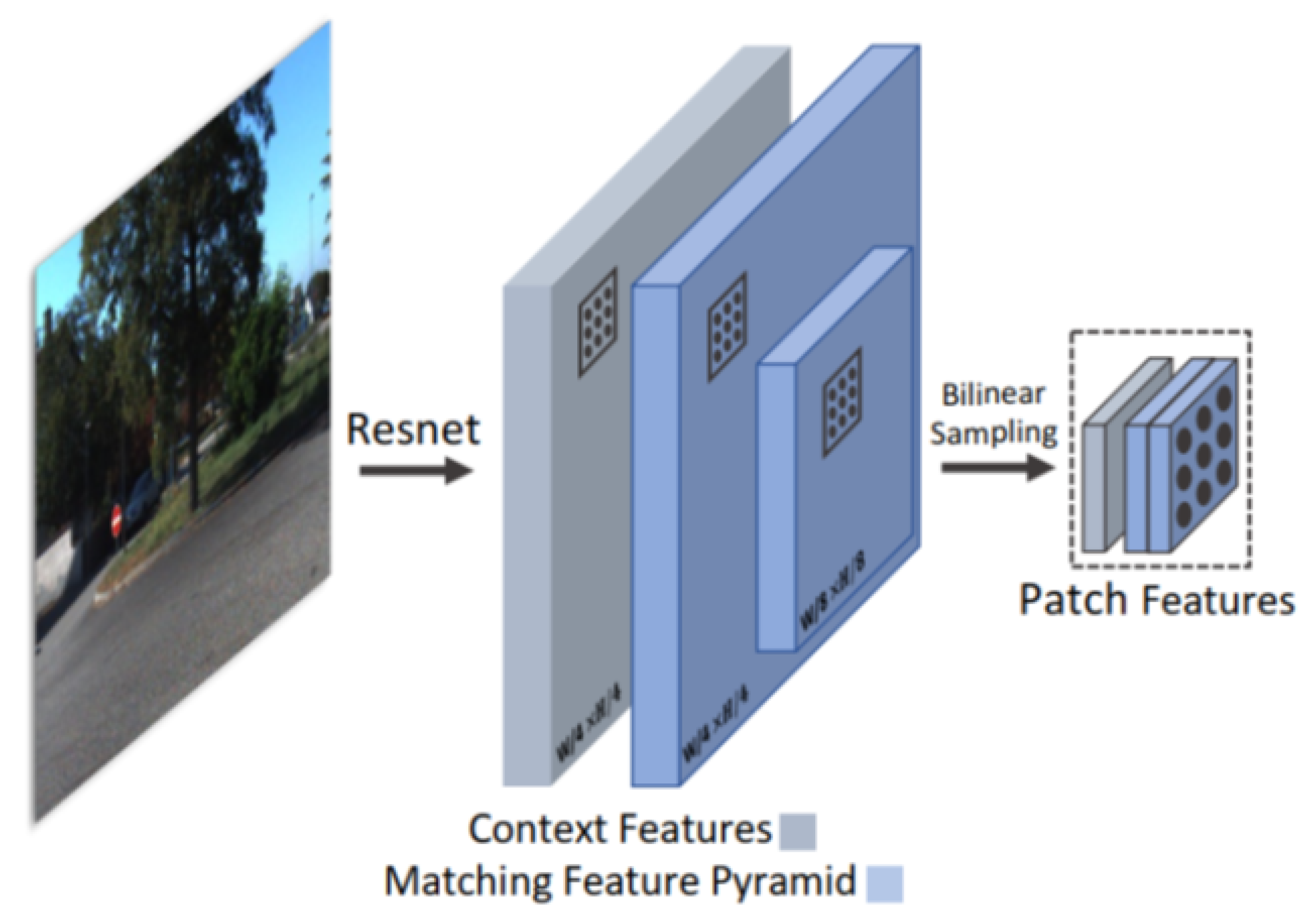
4.2. DPVO (Deep Patch Visual Odometry)
4.3. TartanVO
5. Experimental Results
5.1. Evaluation Measures
- The absolute trajectory error () [12] is the distance error between the ground-truth and the estimated motion trajectory, aligned with an optimal pose . is calculated according to Equation (14):where is the average translations drift (%) on a length of 100–800 m. is the average rotational RMSE drift (°/100 m) on a length of 100–800 m.
- We calculate trajectory error (), being the distance error between the ground-truth and the estimated motion trajectory. is calculated according to Equation (15):where N is the frame number of the frame sequence used to estimate the camera’s motion trajectory.
- In addition, we also calculate the ratio of the number of frames with detected keypoints ((%)).
5.2. Evaluation Parameters
5.3. Results and Discussions
5.4. Challenges
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, K.; Ma, S.; Chen, J.; Ren, F.; Lu, J. Approaches, Challenges, and Applications for Deep Visual Odometry: Toward Complicated and Emerging Areas. IEEE Trans. Cogn. Dev. Syst. 2022, 14, 35–49. [Google Scholar] [CrossRef]
- Neyestani, A.; Picariello, F.; Basiri, A.; Daponte, P.; Vito, L.D. Survey and research challenges in monocular visual odometry. In Proceedings of the 2023 IEEE International Workshop on Metrology for Living Environment, MetroLivEnv 2023, Milano, Italy, 29–31 May 2023; pp. 107–112. [Google Scholar] [CrossRef]
- Agostinho, L.R.; Ricardo, N.M.; Pereira, M.I.; Hiolle, A.; Pinto, A.M. A Practical Survey on Visual Odometry for Autonomous Driving in Challenging Scenarios and Conditions. IEEE Access 2022, 10, 72182–72205. [Google Scholar] [CrossRef]
- Low, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded up robust features. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Redondo Beach, CA, USA, 8–11 July 2006; Volume 3951 LNCS, pp. 404–417. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2011; pp. 2548–2555. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the IJCAI’81: Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; pp. 674–679. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2012. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; Volume 32, pp. 315–326. [Google Scholar] [CrossRef]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. Comput. Vis. ECCV2012 2012, 7578, 1–14. [Google Scholar]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar] [CrossRef]
- Hodne, L.M.; Leikvoll, E.; Yip, M.; Teigen, A.L.; Stahl, A.; Mester, R. Detecting and Suppressing Marine Snow for Underwater Visual SLAM. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. Work. 2022, 2022, 5097–5105. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardos, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE features. Lect. Notes Comput. Sci. Including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics 2012, 7577, 214–227. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Teed, Z.; Lipson, L.; Deng, J. Deep Patch Visual Odometry. Available online: https://proceedings.neurips.cc/paper_files/paper/2023/hash/7ac484b0f1a1719ad5be9aa8c8455fbb-Abstract-Conference.html (accessed on 6 May 2024).
- Wang, W.; Hu, Y.; Scherer, S. TartanVO: A generalizable learning-based VO. In Proceedings of the Conference on Robot Learning, Online, 16–18 November 2020. [Google Scholar]
- Freda, L. pySLAM Contains a Monocular Visual Odometry (VO) Pipeline in Python. 2024. Available online: https://github.com/luigifreda/pyslam (accessed on 5 April 2024).
- He, M.; Zhu, C.; Huang, Q.; Ren, B.; Liu, J. A review of monocular visual odometry. Vis. Comput. 2020, 36, 1053–1065. [Google Scholar] [CrossRef]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-Time Single Camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 104, 1292–1296. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, ISMAR, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar] [CrossRef]
- Ganai, M.; Lee, D.; Gupta, A. DTAM: Dense tracking and mapping in real-time. In Proceedings of the The International Conference on Computer Vision (ICCV), Online, 6–13 November 2012; pp. 1–11. [Google Scholar] [CrossRef]
- Izadi, S.; Kim, D.; Hilliges, O.; Molyneaux, D.; Newcombe, R.; Kohli, P.; Shotton, J.; Hodges, S.; Freeman, D.; Davison, A.; et al. KinectFusion: Real-time 3D reconstruction and interaction using a moving depth camera. In Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; Volume 11. [Google Scholar]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; Volume 41, pp. 306–308. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, China, 31 May–7 June 2014. [Google Scholar]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar]
- Bloesch, M.; Burri, M.; Omari, S.; Hutter, M.; Siegwart, R. IEKF-based Visual-Inertial Odometry using Direct Photometric Feedback. Int. J. Robot. Res. 2017, 36, 106705. [Google Scholar] [CrossRef]
- Whelan, T.; Leutenegger, S.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J. ElasticFusion: Dense SLAM without a pose graph. Robot. Sci. Syst. 2015, 11, 3. [Google Scholar] [CrossRef]
- Whelan, T.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J.; Leutenegger, S. ElasticFusion: Real-time dense SLAM and light source estimation. Int. J. Robot. Res. 2016, 35, 1697–1716. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Schneider, T.; Dymczyk, M.; Fehr, M.; Egger, K.; Lynen, S.; Gilitschenski, I.; Siegwart, R. Maplab: An Open Framework for Research in Visual-Inertial Mapping and Localization. IEEE Robot. Autom. Lett. 2018, 3, 1418–1425. [Google Scholar] [CrossRef]
- Huang, W.; Wan, W.; Liu, H. Optimization-based online initialization and calibration of monocular visual-inertial odometry considering spatial-temporal constraints. Sensors 2021, 21, 2673. [Google Scholar] [CrossRef]
- Zhou, L.; Wang, S.; Kaess, M. DPLVO: Direct Point-Line Monocular Visual Odometry. IEEE Robot. Autom. Lett. 2021, 6, 1–8. [Google Scholar] [CrossRef]
- Ban, X.; Wang, H.; Chen, T.; Wang, Y.; Xiao, Y. Monocular Visual Odometry Based on Depth and Optical Flow Using Deep Learning. IEEE Trans. Instrum. Meas. 2021, 70, 1–19. [Google Scholar] [CrossRef]
- Lin, L.; Wang, W.; Luo, W.; Song, L.; Zhou, W. Unsupervised monocular visual odometry with decoupled camera pose estimation. Digit. Signal Process. Rev. J. 2021, 114, 103052. [Google Scholar] [CrossRef]
- Gadipudi, N.; Elamvazuthi, I.; Lu, C.K.; Paramasivam, S.; Su, S. WPO-net: Windowed pose optimization network for monocular visual odometry estimation. Sensors 2021, 21, 8155. [Google Scholar] [CrossRef] [PubMed]
- Kim, U.H.; Kim, S.H.; Kim, J.H. SimVODIS: Simultaneous Visual Odometry, Object Detection, and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 428–441. [Google Scholar] [CrossRef] [PubMed]
- Turan, Y.A.M.; Sarı, A.E.; Saputra, M.R.U.; de Gusmo, P.P.B.; Markham, A.; Trigoni, N. SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation. Neurocomputing 2021, 421, 119–136. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3D: Learning 3D scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 824–840. [Google Scholar] [CrossRef] [PubMed]
- Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Roth, S. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Linear. Linear Regression. Available online: https://machinelearningcoban.com/2016/12/28/linearregression/ (accessed on 5 April 2024).
- Dusmanu, M.; Rocco, I.; Pajdla, T.; Pollefeys, M.; Sivic, J.; Torii, A.; Sattler, T. D2-Net: A trainable CNN for joint detection and description of local features. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Fraundorfer, F.; Scaramuzza, D. Visual odometry: Part II: Matching, robustness, optimization, and applications. IEEE Robot. Autom. Mag. 2012, 19, 78–90. [Google Scholar] [CrossRef]
- Le, V.H.; Vu, H.; Nguyen, T.T.; Le, T.L.; Tran, T.H. Acquiring qualified samples for RANSAC using geometrical constraints. Pattern Recognit. Lett. 2018, 102, 58–66. [Google Scholar] [CrossRef]
- Teed, Z.; Deng, J. DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras. Adv. Neural Inf. Process. Syst. 2021, 20, 16558–16569. [Google Scholar]
- Wang, W.; Zhu, D.; Wang, X.; Hu, Y.; Qiu, Y.; Wang, C.; Hu, Y.; Kapoor, A.; Scherer, S. TartanAir: A dataset to push the limits of visual SLAM. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021. [Google Scholar]
- Burri, M.; Nikolic, J.; Gohl, P.; Schneider, T.; Rehder, J.; Omari, S.; Achtelik, M.W.; Siegwart, R. The EuRoC micro aerial vehicle datasets. Int. J. Robot. Res. 2016, 35, 1157–1163. Available online: http://ijr.sagepub.com/content/early/2016/01/21/0278364915620033.full.pdf+html (accessed on 6 May 2024). [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Acquisition Times | Direction | Number of RGB-D Frames |
|---|---|---|
| 1st | FO-D | 21,333 |
| OP-D | 22,948 | |
| 2nd | FO-D | 19,992 |
| OP-D | 21,116 | |
| 3rd | FO-D | 17,995 |
| OP-D | 20,814 | |
| 4th | FO-D | 17,885 |
| OP-D | 18,548 |
| Dataset/Methods | Features | Distance Error ( (mm)) of the TQU-SLAM Benchmark Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | ||||||
| FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | ||
| PySLAM | SHI_TOMASI | 6.019 | 2.903 | 5.938 | 6.836 | 14.42 | 10.978 | 8.224 | 3.050 |
| SIFT | 38.93 | 13.02 | 37.63 | 13.58 | 23.55 | 1.63 | 32.02 | 2.11 | |
| SURF | 39.26 | 13.59 | 38.07 | 13.57 | 27.73 | 38.81 | 38.98 | 14.29 | |
| ORB | 1.42 | 14.67 | 32.48 | 12.19 | 25.93 | 13.29 | 0.75 | 2.07 | |
| ORB2 | 8.42 | 10.14 | 7.54 | 9.16 | 8.54 | 2.94 | 8.47 | 3.10 | |
| AKAZE | 40.34 | 6.72 | 37.75 | 12.67 | 30.60 | 6.78 | 37.15 | 2.11 | |
| KAZE | 38.32 | 15.55 | 31.30 | 12.45 | 15.89 | 30.87 | 41.66 | 17.22 | |
| BRISK | 1.62 | 14.38 | 28.87 | 13.56 | 12.43 | 1.67 | 9.54 | 2.16 | |
| VGG | 11.67 | 11.66 | 11.66 | 11.67 | 0.65 | 11.66 | 0.75 | 2.11 | |
| Dataset/Methods | Features | Aspect Ratio Fails to Detect Keypoints of the TQU-SLAM Benchmark Dataset ((%)) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | ||||||
| FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | ||
| PySLAM | SHI_TOMASI | 99.17 | 99.02 | 99.72 | 99.85 | 98.97 | 98.97 | 97.96 | 98.09 |
| SIFT | 99.69 | 79.57 | 97.18 | 76.65 | 44.50 | 42.58 | 86.63 | 51.80 | |
| SURF | 99.67 | 97.84 | 95.51 | 94.66 | 95.76 | 98.95 | 96.76 | 97.66 | |
| ORB | 2.84 | 34.84 | 45.39 | 49.78 | 7.02 | 38.48 | 1.53 | 3.04 | |
| ORB2 | 98.97 | 99.23 | 98.48 | 99.28 | 95.64 | 97.95 | 94.87 | 97.02 | |
| AKAZE | 88.66 | 9.71 | 76.42 | 34.20 | 67.65 | 8.94 | 54.61 | 3.08 | |
| KAZE | 90.36 | 25.51 | 75.83 | 46.15 | 89.29 | 9.04 | 76.36 | 19.20 | |
| BRISK | 1.82 | 16.26 | 6.25 | 9.32 | 39.81 | 28.98 | 12.18 | 3.10 | |
| VGG | 6.88 | 45.02 | 36.90 | 40.26 | 45.92 | 39.39 | 1.35 | 17.86 | |
| Dataset/ Measure/ Methods/ | Experimental | Distance Error ( (m)) of the TQU-SLAM Benchmark Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | ||||||
| FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | ||
| DPVO | L1 | 10.87 | 12.85 | 14.58 | 12.72 | 13.49 | 14.61 | 13.49 | 12.73 |
| L2 | 16.31 | 14.94 | 12.89 | 12.88 | 15.96 | 15.06 | 14.13 | 12.21 | |
| L3 | 14.24 | 13.72 | 12.63 | 13.71 | 15.11 | 14.25 | 13.51 | 12.01 | |
| Average | 13.81 | 13.84 | 13.37 | 13.10 | 14.85 | 14.64 | 13.71 | 12.32 | |
| TartanVO | L1 | 15.82 | 14.16 | 15.21 | 13.26 | 13.82 | 13.12 | 16.57 | 17.70 |
| L2 | 15.82 | 14.16 | 15.21 | 13.26 | 13.82 | 13.12 | 16.57 | 17.7 | |
| L3 | 15.82 | 16.16 | 15.21 | 13.26 | 13.82 | 13.13 | 16.57 | 17.7 | |
| Average | 15.82 | 14.16 | 15.21 | 13.26 | 13.82 | 13.12 | 16.57 | 17.70 | |
| Dataset/ Measure/ Methods/ | Experimental | Distance Error ( (m)) of the TQU-SLAM Benchmark Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | ||||||
| FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | ||
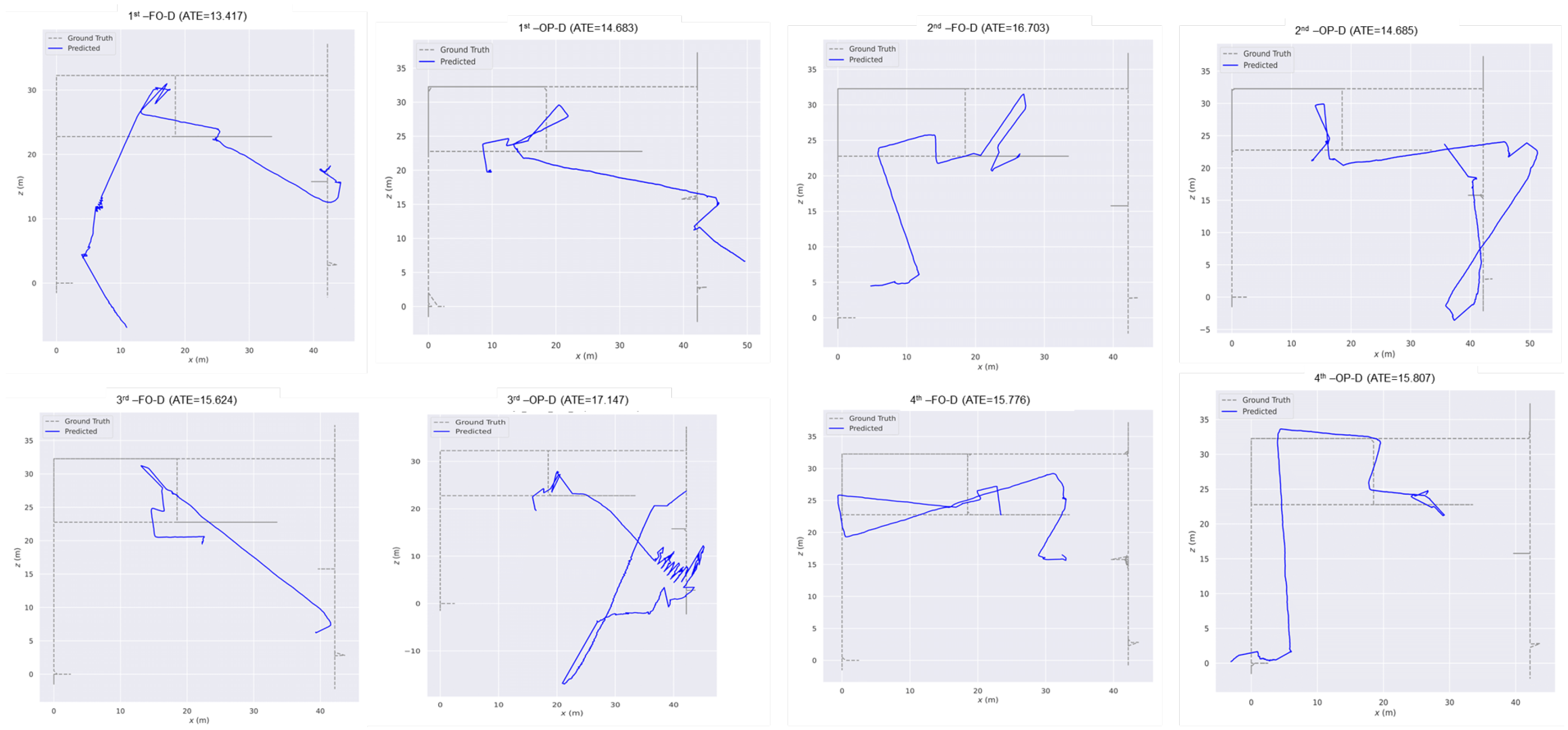
| DPVO | L1 | 13.42 | 14.68 | 16.70 | 14.69 | 15.62 | 16.46 | 15.78 | 15.81 |
| L2 | 18.14 | 17.20 | 15.83 | 15.25 | 18.08 | 17.15 | 15.52 | 14.51 | |
| L3 | 16.72 | 15.35 | 15.44 | 15.65 | 17.41 | 16.48 | 15.87 | 15.25 | |
| Average | 16.09 | 15.74 | 15.99 | 15.20 | 17.04 | 16.70 | 15.72 | 15.19 | |
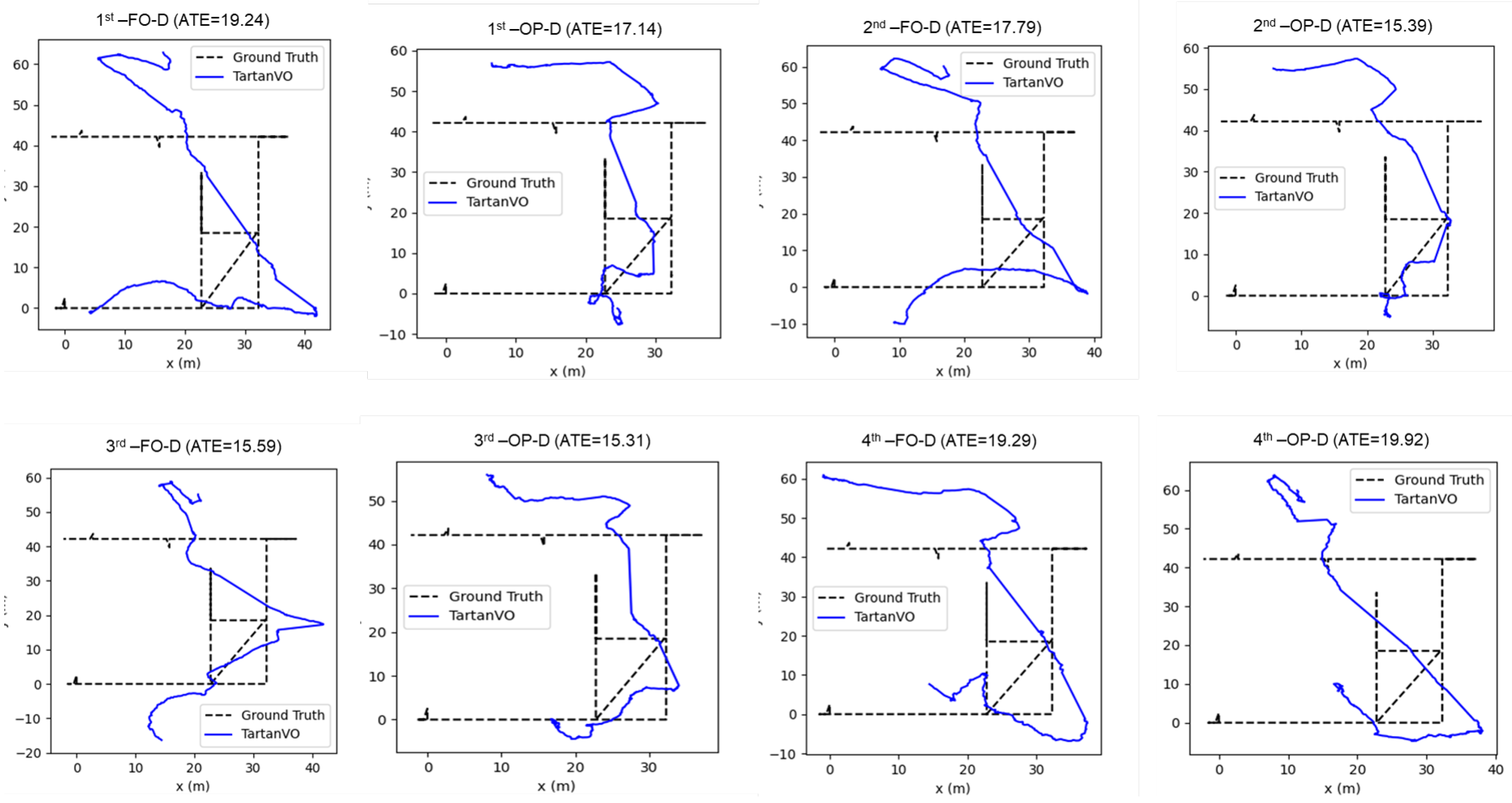
| TartanVO | L1 | 19.24 | 17.14 | 17.79 | 15.39 | 15.60 | 15.31 | 19.30 | 19.92 |
| L2 | 19.24 | 17.14 | 17.79 | 15.39 | 15.60 | 15.31 | 19.30 | 19.92 | |
| L3 | 19.24 | 17.14 | 17.79 | 15.39 | 15.60 | 15.32 | 19.29 | 19.92 | |
| Average | 19.24 | 17.14 | 17.79 | 15.39 | 15.60 | 15.31 | 19.30 | 19.92 | |
| Dataset/ Measure/ Methods/ | Experimental | Aspect Ratio Fails to Detect Keypoints of the TQU-SLAM Benchmark Dataset ((%)) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | ||||||
| FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | FO-D | OP-D | ||
| DPVO | Average | 49.85 | 49.44 | 50.00 | 50.00 | 50.00 | 50.00 | 50.90 | 47.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.-H.; Le, V.-H.; Do, H.-S.; Te, T.-H.; Phan, V.-N. TQU-SLAM Benchmark Dataset for Comparative Study to Build Visual Odometry Based on Extracted Features from Feature Descriptors and Deep Learning. Future Internet 2024, 16, 174. https://doi.org/10.3390/fi16050174
Nguyen T-H, Le V-H, Do H-S, Te T-H, Phan V-N. TQU-SLAM Benchmark Dataset for Comparative Study to Build Visual Odometry Based on Extracted Features from Feature Descriptors and Deep Learning. Future Internet. 2024; 16(5):174. https://doi.org/10.3390/fi16050174
Chicago/Turabian StyleNguyen, Thi-Hao, Van-Hung Le, Huu-Son Do, Trung-Hieu Te, and Van-Nam Phan. 2024. "TQU-SLAM Benchmark Dataset for Comparative Study to Build Visual Odometry Based on Extracted Features from Feature Descriptors and Deep Learning" Future Internet 16, no. 5: 174. https://doi.org/10.3390/fi16050174
APA StyleNguyen, T.-H., Le, V.-H., Do, H.-S., Te, T.-H., & Phan, V.-N. (2024). TQU-SLAM Benchmark Dataset for Comparative Study to Build Visual Odometry Based on Extracted Features from Feature Descriptors and Deep Learning. Future Internet, 16(5), 174. https://doi.org/10.3390/fi16050174