
Enhancing Sensor Data Imputation: OWA-Based Model Aggregation for Missing Values



Abstract
1. Introduction
2. OWA Methodology
2.1. Ordered Weighted Averaging
2.2. Learning Algorithm
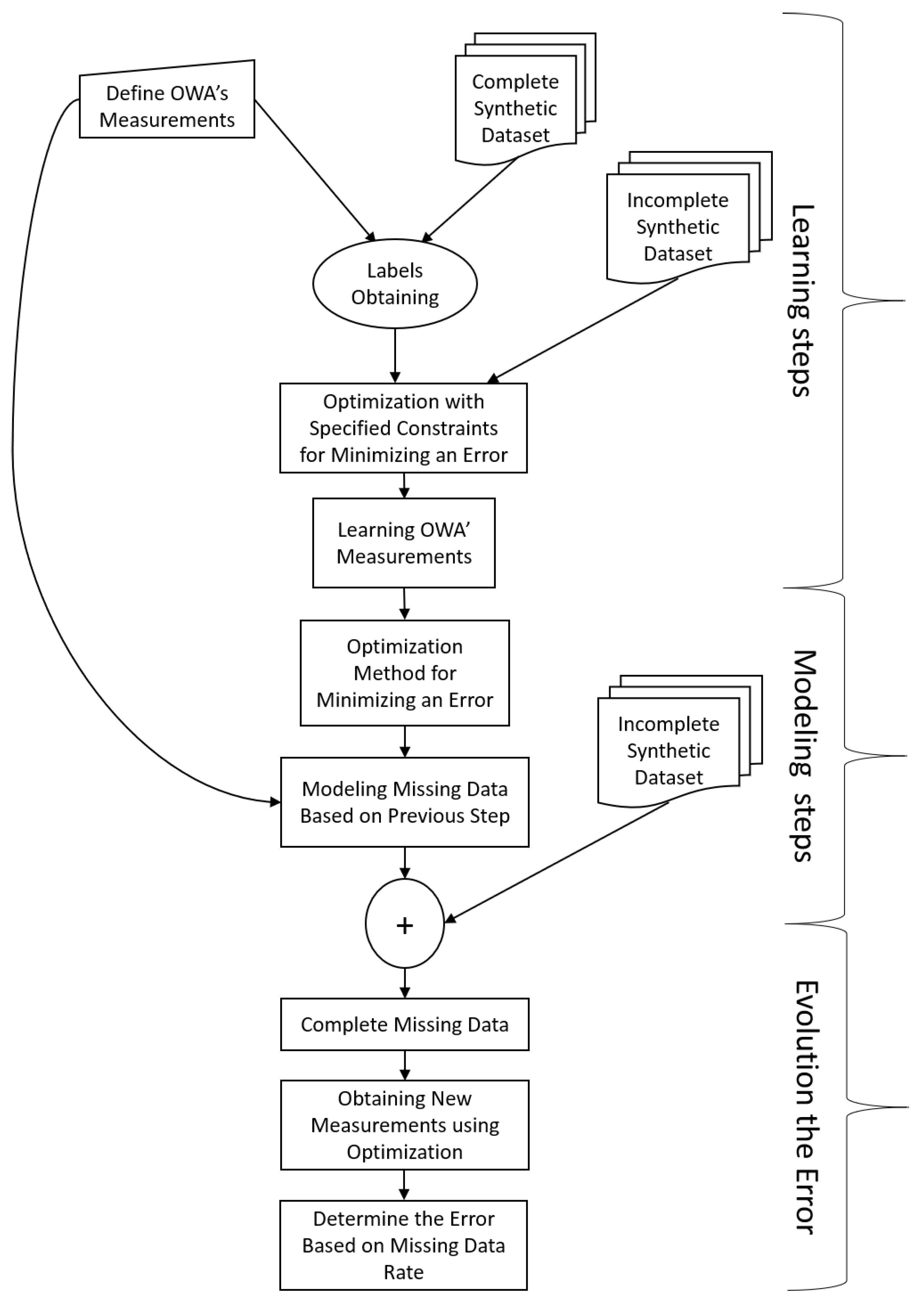
3. The Proposed Formulation
3.1. Modeling Missing Inputs
3.1.1. Synthetic Dataset
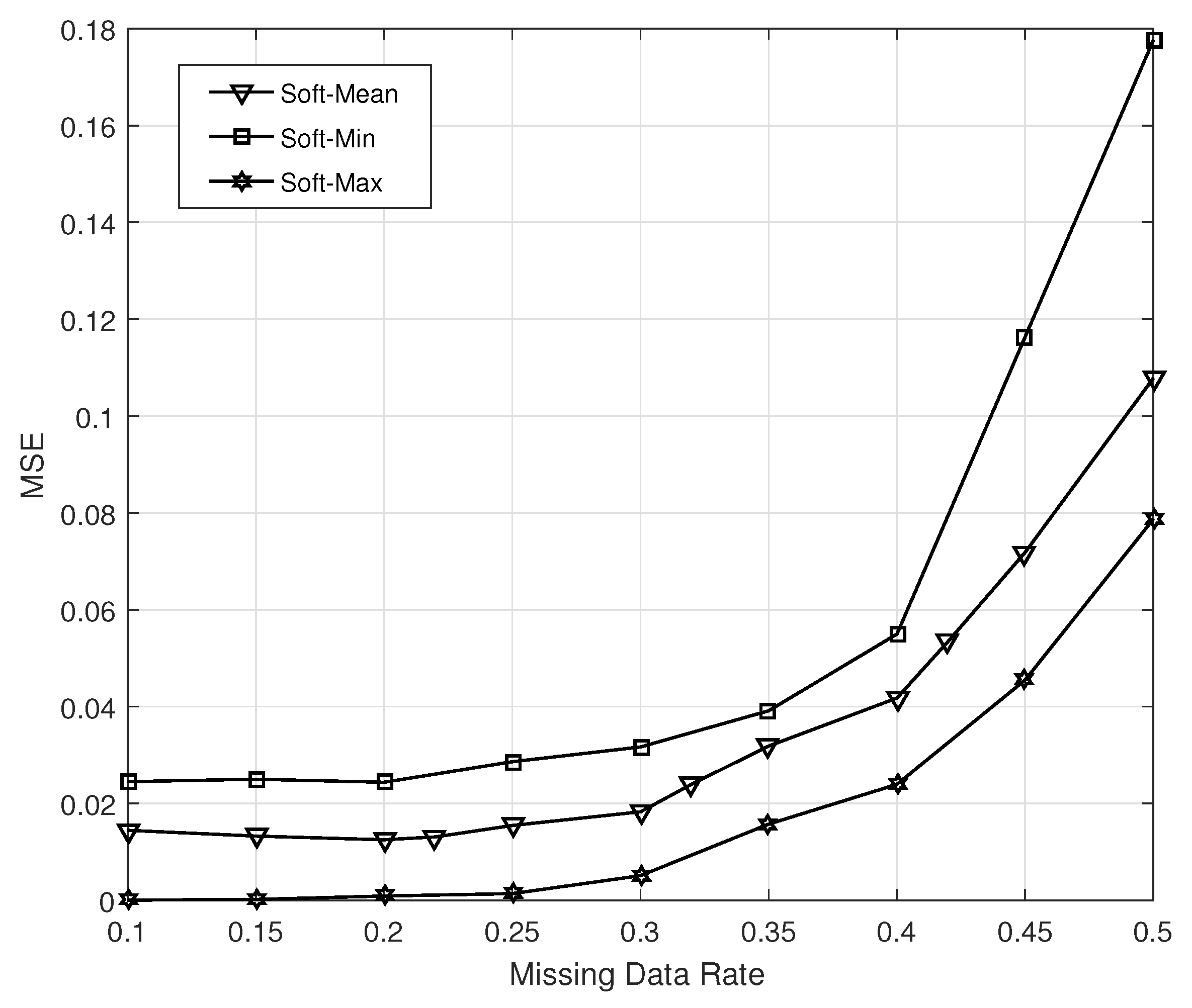
3.2. Experimental Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| OWA | = | Ordered weighted averaging |
| Min | = | Minimum value |
| Max | = | Maximum value |
| FM | = | Fuzzy measurements |
| QP | = | Quadratic programming |
| MSE | = | Mean square error |
| SSE | = | Sum square error |
| i.i.d. | = | Independent and identically distributed |
| Lightface letters | = | Define a scalar value |
| Boldface-lower-case letters | = | Define a vector |
| Boldface-upper-case | = | Define a matrix |
| Variables | ||
| = | Permutation of the arguments | |
| = | Transpose of the vector | |
| = | Estimated or predicated value | |
| Ô | = | Mean of the variables |
| = | The ceiling of the variable | |
| = | Most significant digit | |
| = | Least significant digit | |
References
- Ma, L.; Wang, M.; Peng, K. A missing manufacturing process data imputation framework for nonlinear dynamic soft sensor modeling and its application. Expert Syst. Appl. 2024, 237, 121428. [Google Scholar] [CrossRef]
- Zhang, Y.; Thorburn, P.J. Handling missing data in near real-time environmental monitoring: A system and a review of selected methods. Future Gener. Comput. Syst. 2022, 128, 63–72. [Google Scholar] [CrossRef]
- Peng, D.; Zou, M.; Liu, C.; Lu, J. RESI: A region-splitting imputation method for different types of missing data. Expert Syst. Appl. 2021, 168, 114425. [Google Scholar] [CrossRef]
- Sareen, K.; Panigrahi, B.K.; Shikhola, T.; Sharma, R. An imputation and decomposition algorithms based integrated approach with bidirectional LSTM neural network for wind speed prediction. Energy 2023, 278, 127799. [Google Scholar] [CrossRef]
- Li, D.; Zhang, H.; Li, T.; Bouras, A.; Yu, X.; Wang, T. Hybrid missing value imputation algorithms using fuzzy c-means and vaguely quantified rough set. IEEE Trans. Fuzzy Syst. 2021, 30, 1396–1408. [Google Scholar] [CrossRef]
- Huang, Z.; Ng, M.K. A fuzzy k-modes algorithm for clustering categorical data. IEEE Trans. Fuzzy Syst. 1999, 7, 446–452. [Google Scholar] [CrossRef]
- Wang, A.; Ye, Y.; Song, X.; Zhang, S.; James, J. Traffic prediction with missing data: A multi-task learning approach. IEEE Trans. Intell. Transp. Syst. 2023, 24, 4189–4202. [Google Scholar] [CrossRef]
- Hammon, A. Multiple imputation of ordinal missing not at random data. AStA Adv. Stat. Anal. 2023, 107, 671–692. [Google Scholar] [CrossRef]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2019; Volume 793. [Google Scholar]
- Islam, M.A.; Anderson, D.T.; Petry, F.; Smith, D.; Elmore, P. The fuzzy integral for missing data. In Proceedings of the 2017 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Naples, Italy, 9–12 July 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Zhang, C.; Qin, Y.; Zhu, X.; Zhang, J.; Zhang, S. Clustering-based missing value imputation for data preprocessing. In Proceedings of the 2006 4th IEEE International Conference on Industrial Informatics, Singapore, 16–18 August 2006; pp. 1081–1086. [Google Scholar]
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for imputation of missing values in air quality data sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Tseng, S.M.; Wang, K.H.; Lee, C.I. A pre-processing method to deal with missing values by integrating clustering and regression techniques. Appl. Artif. Intell. 2003, 17, 535–544. [Google Scholar] [CrossRef]
- Schneider, T. Analysis of incomplete climate data: Estimation of mean values and covariance matrices and imputation of missing values. J. Clim. 2001, 14, 853–871. [Google Scholar] [CrossRef]
- Engemann, K.J.; Filev, D.P.; Yager, R.R. Modelling decision making using immediate probabilities. Int. J. Gen. Syst. 1996, 24, 281–294. [Google Scholar] [CrossRef]
- Bai, C.; Zhang, R.; Song, C.; Wu, Y. A new ordered weighted averaging operator to obtain the associated weights based on the principle of least mean square errors. Int. J. Intell. Syst. 2017, 32, 213–226. [Google Scholar] [CrossRef]
- Merigo, J.M.; Casanovas, M. Fuzzy Generalized Hybrid Aggregation Operators and its Application in Fuzzy Decision Making. Int. J. Fuzzy Syst. 2010, 12, 15–23. [Google Scholar]
- Liu, D.; Li, T.; Liang, D. An integrated approach towards modeling ranked weights. Comput. Ind. Eng. 2020, 147, 106629. [Google Scholar] [CrossRef]
- Lee, K.J.; Carlin, J.B.; Simpson, J.A.; Moreno-Betancur, M. Assumptions and analysis planning in studies with missing data in multiple variables: Moving beyond the MCAR/MAR/MNAR classification. Int. J. Epidemiol. 2023, 52, 1268–1275. [Google Scholar] [CrossRef] [PubMed]
- Woods, A.D.; Gerasimova, D.; Van Dusen, B.; Nissen, J.; Bainter, S.; Uzdavines, A.; Davis-Kean, P.E.; Halvorson, M.; King, K.M.; Logan, J.A.; et al. Best practices for addressing missing data through multiple imputation. Infant Child Dev. 2024, 33, e2407. [Google Scholar] [CrossRef]
- Al-Amidie, M.; Al-Asadi, A.; Micheas, A.C.; Islam, N.E. Spectrum sensing based on Bayesian generalised likelihood ratio for cognitive radio systems with multiple antennas. IET Commun. 2019, 13, 305–311. [Google Scholar] [CrossRef]
- Park, J.; Müller, J.; Arora, B.; Faybishenko, B.; Pastorello, G.; Varadharajan, C.; Sahu, R.; Agarwal, D. Long-term missing value imputation for time series data using deep neural networks. Neural Comput. Appl. 2023, 35, 9071–9091. [Google Scholar] [CrossRef]
- Sun, Y.; Li, J.; Xu, Y.; Zhang, T.; Wang, X. Deep learning versus conventional methods for missing data imputation: A review and comparative study. Expert Syst. Appl. 2023, 227, 120201. [Google Scholar] [CrossRef]
- Honghai, F.; Guoshun, C.; Cheng, Y.; Bingru, Y.; Yumei, C. A SVM regression based approach to filling in missing values. In Proceedings of the International Conference on Knowledge-Based and Intelligent Information and Engineering Systems, Melbourne, Australia, 14–16 September 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 581–587. [Google Scholar]
- Zhang, Y.; Wei, X.; Li, C. Manifold clustering optimized by adaptive aggregation strategy. Knowl. Inf. Syst. 2023, 65, 379–408. [Google Scholar] [CrossRef]
- Yager, R.R. On ordered weighted averaging aggregation operators in multicriteria decisionmaking. IEEE Trans. Syst. Man Cybern. 1988, 18, 183–190. [Google Scholar] [CrossRef]
- Dujmovic, J.J. Continuous preference logic for system evaluation. IEEE Trans. Fuzzy Syst. 2007, 15, 1082–1099. [Google Scholar] [CrossRef]
- Calvo, T.; Mesiar, R.; Yager, R.R. Quantitative weights and aggregation. IEEE Trans. Fuzzy Syst. 2004, 12, 62–69. [Google Scholar] [CrossRef]
- Merigó, J.M.; Gil-Lafuente, A.M. The induced generalized OWA operator. Inf. Sci. 2009, 179, 729–741. [Google Scholar] [CrossRef]
- Grabisch, M.; Sugeno, M. Multi-attribute classification using fuzzy integral. In Proceedings of the [1992 Proceedings] IEEE International Conference on Fuzzy Systems, San Diego, CA, USA, 8–12 March 1992; pp. 47–54. [Google Scholar]
- Anderson, D.T.; Price, S.R.; Havens, T.C. Regularization-based learning of the choquet integral. In Proceedings of the 2014 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Beijing, China, 6–11 July 2014; pp. 2519–2526. [Google Scholar]
- Cho, S.B.; Kim, J.H. Combining multiple neural networks by fuzzy integral for robust classification. IEEE Trans. Syst. Man Cybern. 1995, 25, 380–384. [Google Scholar]
- Waugh, S.; Adams, A. Pruning within cascade-correlation. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 3, pp. 1206–1210. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Measurement | w1 | w2 | w3 | w4 |
|---|---|---|---|---|
| Soft-Min | 0.1 | 0.2 | 0.3 | 0.4 |
| Soft-Max | 0.4 | 0.3 | 0.2 | 0.1 |
| Mean | 0.25 | 0.25 | 0.25 | 0.25 |
| Attribute Information | |||
|---|---|---|---|
| Name | Data Type | Measurement Unit | Description |
| Sex Attribute | Nominal value | M, F, and I (infant) | |
| Length Attribute | Continuous value | mm | Longest shell measurement |
| Diameter Attribute | Continuous value | mm | Perpendicular to length |
| Height Attribute | Continuous value | mm | With meat in shell |
| Whole Weight Attribute | Continuous value | grams | Whole abalone |
| Shucked Weight Attribute | Continuous value | grams | Weight of meat |
| Viscera Weight Attribute | Continuous value | grams | Gut weight, after bleeding |
| Rings Attribute | Integer | +1.5 gives the age in years | |
| Length | Diameter | Height | Whole Weight | Rings |
|---|---|---|---|---|
| 0.455 | 0.365 | 0.095 | - | 15 |
| 0.35 | - | 0.09 | - | 7 |
| 0.53 | 0.42 | 0.135 | 0.677 | 9 |
| 0.44 | - | 0.125 | 0.516 | 10 |
| 0.33 | 0.255 | 0.08 | 0.205 | 7 |
| 0.425 | 0.3 | 0.095 | - | 8 |
| 0.53 | - | 0.15 | - | 20 |
| 0.545 | 0.425 | 0.125 | 0.768 | 16 |
| 0.475 | - | 0.125 | 0.5095 | 9 |
| 0.55 | 0.44 | 0.15 | 0.8945 | 19 |
| 0.525 | 0.38 | - | 0.6065 | 14 |
| 0.43 | 0.35 | 0.11 | 0.406 | 10 |
| 0.49 | - | 0.135 | 0.5415 | 11 |
| - | 0.405 | - | 0.6845 | 10 |
| 0.47 | 0.355 | 0.1 | 0.4755 | 10 |
| 0.5 | 0.4 | 0.13 | 0.6645 | 12 |
| 0.355 | 0.28 | 0.085 | 0.2905 | 7 |
| 0.44 | 0.34 | 0.1 | - | 10 |
| 0.365 | 0.295 | 0.08 | 0.2555 | 7 |
| 0.45 | - | 0.1 | 0.381 | 9 |
| 0.355 | 0.28 | 0.095 | 0.2455 | 11 |
| 0.38 | 0.275 | 0.1 | 0.2255 | 10 |
| 0.565 | - | 0.155 | - | 12 |
| 0.55 | 0.415 | - | 0.7635 | 9 |
| 0.615 | 0.48 | 0.165 | 1.1615 | 10 |
| 0.56 | 0.44 | - | 0.9285 | 11 |
| - | 0.45 | 0.185 | - | 11 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Amidie, M.; Alzubaidi, L.; Islam, M.A.; Anderson, D.T. Enhancing Sensor Data Imputation: OWA-Based Model Aggregation for Missing Values. Future Internet 2024, 16, 193. https://doi.org/10.3390/fi16060193
Al-Amidie M, Alzubaidi L, Islam MA, Anderson DT. Enhancing Sensor Data Imputation: OWA-Based Model Aggregation for Missing Values. Future Internet. 2024; 16(6):193. https://doi.org/10.3390/fi16060193
Chicago/Turabian StyleAl-Amidie, Muthana, Laith Alzubaidi, Muhammad Aminul Islam, and Derek T. Anderson. 2024. "Enhancing Sensor Data Imputation: OWA-Based Model Aggregation for Missing Values" Future Internet 16, no. 6: 193. https://doi.org/10.3390/fi16060193
APA StyleAl-Amidie, M., Alzubaidi, L., Islam, M. A., & Anderson, D. T. (2024). Enhancing Sensor Data Imputation: OWA-Based Model Aggregation for Missing Values. Future Internet, 16(6), 193. https://doi.org/10.3390/fi16060193