

Enhancing Autonomous Driving Navigation Using Soft Actor-Critic




Abstract
:1. Introduction
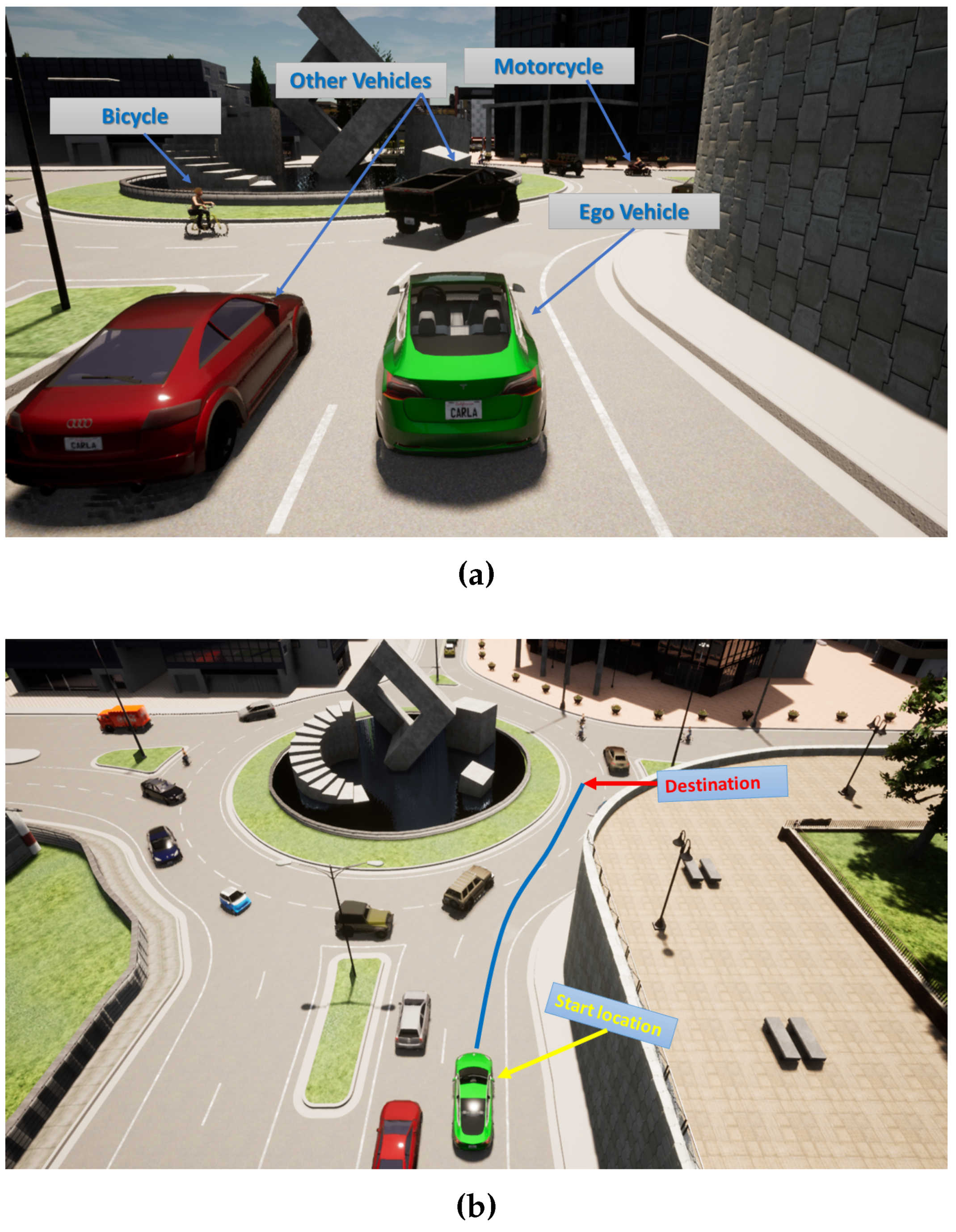
- We address the problem of entering roundabouts with dense traffic involving other vehicles, cyclists, and motorcycles.
- We propose a modified SAC algorithm in combination with CNN to extract the main features of images captured by the front camera of the AV. We combine those features with the description vector to help the AV reach its destination quickly.
- We compare our model with DQN and PPO algorithms. The results demonstrate that SAC outperforms traditional DQN and PPO models.
2. Related Work
3. Deep Reinforcement Learning: An Overview
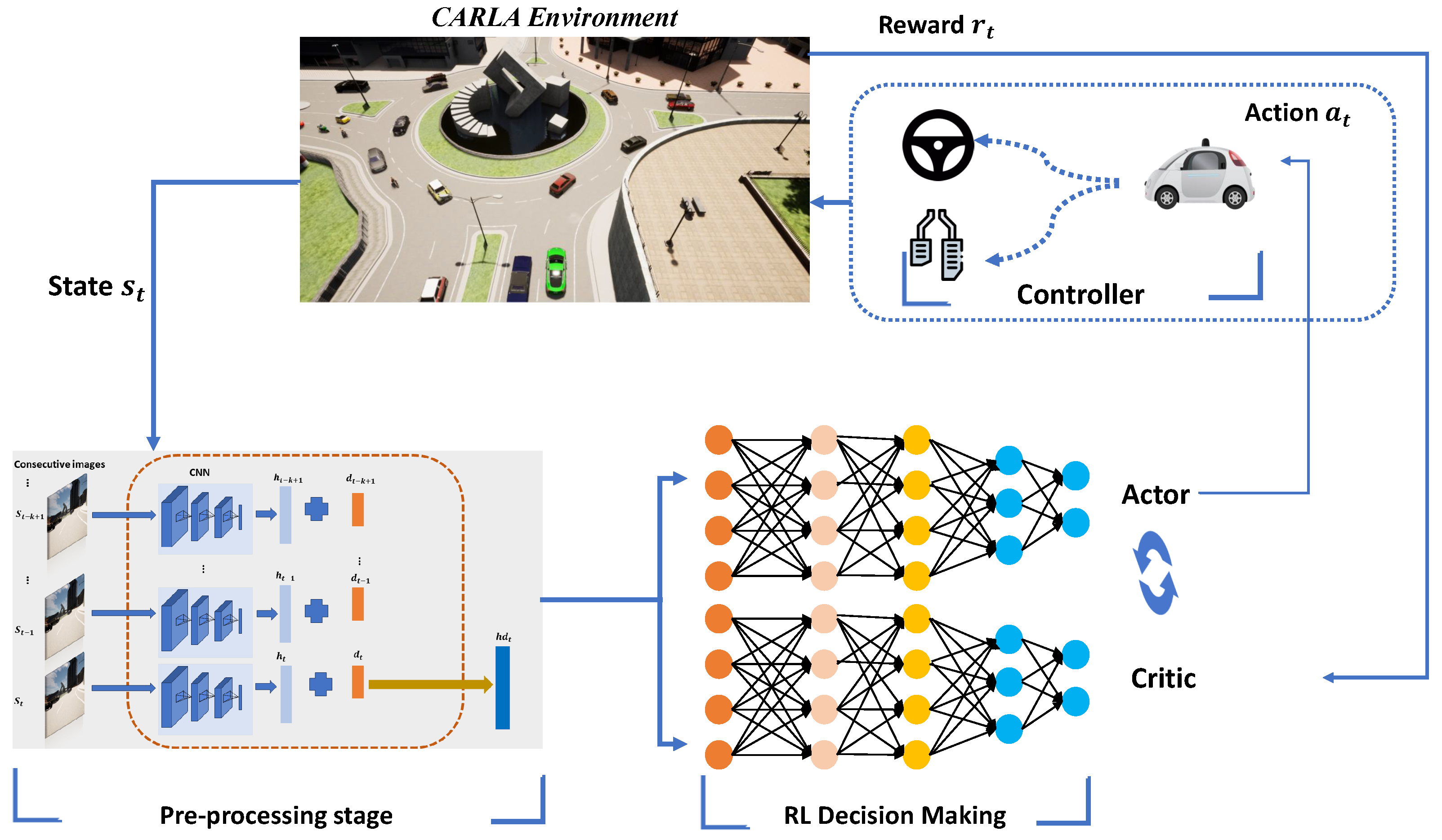
4. Methodology
4.1. Soft Actor-Critic
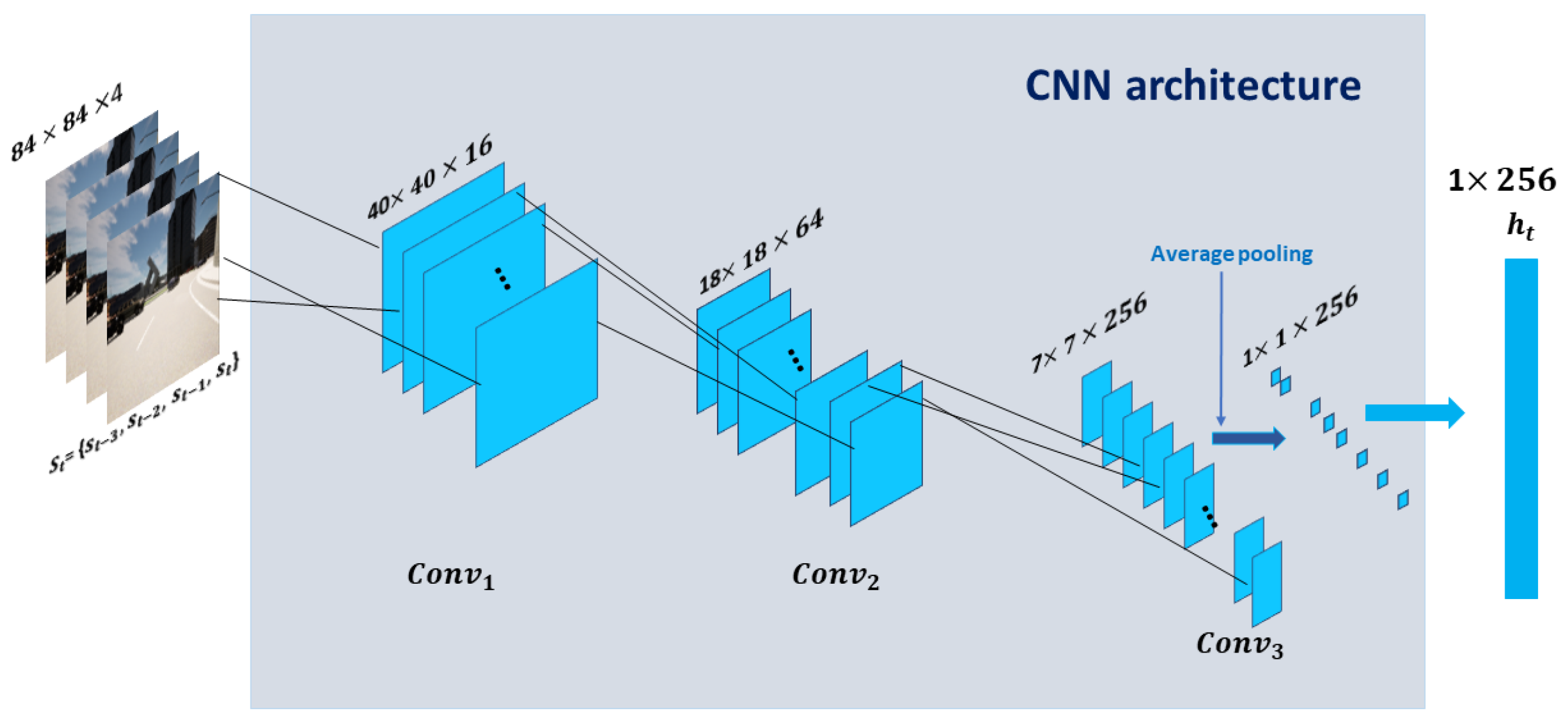
4.2. State Space
4.3. Action Space
4.4. Reward Function
4.5. Training Models
| Algorithm 1 Soft Actor-Critic with Destination Vector |
|
5. Experiments
5.1. Training Setting
5.2. Training and Testing Results
- Success rate (Succ %): During testing, we test our model for 50 episodes, and we compute the percentage of episodes in which the AV successfully reaches its destination.
- Collision rate ( Coll %): It computes the percentage of episodes when the AV collides with other vehicles. It is considered critical safety performance.
- Average time (Avg. time): It counts the time it takes for the AV to reach its destination in each episode. We computed the average time of 50 episodes.
- Average speed (Avg. Speed): It computes the average speed of the AV during episodes.
- Average Traveled Distance (Avg. Dis): is the distance traveled by the AV from its start location to its destination.
- Average Steps (Avg. Steps): the number of steps that it takes for the AV to attain its destination.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DRL | Deep Reinforcement Learning |
| SAC | Soft Actor-Critic |
| DQN | Deep Q-Network |
| DDPG | Deep Deterministic Policy Gradient |
| DL | Deep Learning |
| AI | Artificial Intelligence |
| MDP | Markov Decision Process |
| CNN | Convolutional Neural Networks |
| AVs | Autonomous Vehicles |
References
- Qureshi, K.N.; Abdullah, A.H. A survey on intelligent transportation systems. Middle-East J. Sci. Res. 2013, 15, 629–642. [Google Scholar]
- Fadhel, M.A.; Duhaim, A.M.; Saihood, A.; Sewify, A.; Al-Hamadani, M.N.; Albahri, A.; Alzubaidi, L.; Gupta, A.; Mirjalili, S.; Gu, Y. Comprehensive Systematic Review of Information Fusion Methods in Smart Cities and Urban Environments. Inf. Fusion 2024, 107, 102317. [Google Scholar] [CrossRef]
- Be. Road Traffic Injuries. 2021. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 2 April 2024).
- Gulzar, M.; Muhammad, Y.; Muhammad, N. A survey on motion prediction of pedestrians and vehicles for autonomous driving. IEEE Access 2021, 9, 137957–137969. [Google Scholar] [CrossRef]
- Elallid, B.B.; El Alaoui, H.; Benamar, N. Deep Reinforcement Learning for Autonomous Vehicle Intersection Navigation. In Proceedings of the 2023 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT), Sakheer, Bahrain, 20–21 November 2023; pp. 308–313. [Google Scholar]
- Sadaf, M.; Iqbal, Z.; Javed, A.R.; Saba, I.; Krichen, M.; Majeed, S.; Raza, A. Connected and automated vehicles: Infrastructure, applications, security, critical challenges, and future aspects. Technologies 2023, 11, 117. [Google Scholar] [CrossRef]
- Yu, G.; Li, H.; Wang, Y.; Chen, P.; Zhou, B. A review on cooperative perception and control supported infrastructure-vehicle system. Green Energy Intell. Transp. 2022, 1, 100023. [Google Scholar] [CrossRef]
- Bachute, M.R.; Subhedar, J.M. Autonomous driving architectures: Insights of machine learning and deep learning algorithms. Mach. Learn. Appl. 2021, 6, 100164. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, X.; Song, Z.; Bi, J.; Zhang, G.; Wei, H.; Tang, L.; Yang, L.; Li, J.; Jia, C.; et al. Multi-modal 3d object detection in autonomous driving: A survey and taxonomy. IEEE Trans. Intell. Veh. 2023, 8, 3781–3798. [Google Scholar] [CrossRef]
- Aradi, S. Survey of deep reinforcement learning for motion planning of autonomous vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 23, 740–759. [Google Scholar] [CrossRef]
- Garrido, F.; Resende, P. Review of decision-making and planning approaches in automated driving. IEEE Access 2022, 10, 100348–100366. [Google Scholar] [CrossRef]
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A survey of deep learning applications to autonomous vehicle control. IEEE Trans. Intell. Transp. Syst. 2020, 22, 712–733. [Google Scholar] [CrossRef]
- Elallid, B.B.; Benamar, N.; Hafid, A.S.; Rachidi, T.; Mrani, N. A Comprehensive Survey on the Application of Deep and Reinforcement Learning Approaches in Autonomous Driving. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 7366–7390. [Google Scholar] [CrossRef]
- Berge, S.H.; de Winter, J.; Cleij, D.; Hagenzieker, M. Triangulating the future: Developing scenarios of cyclist-automated vehicle interactions from literature, expert perspectives, and survey data. Transp. Res. Interdiscip. Perspect. 2024, 23, 100986. [Google Scholar] [CrossRef]
- Chao, Q.; Bi, H.; Li, W.; Mao, T.; Wang, Z.; Lin, M.C.; Deng, Z. A survey on visual traffic simulation: Models, evaluations, and applications in autonomous driving. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2020; Volume 39, pp. 287–308. [Google Scholar]
- Yadav, P.; Mishra, A.; Kim, S. A comprehensive survey on multi-agent reinforcement learning for connected and automated vehicles. Sensors 2023, 23, 4710. [Google Scholar] [CrossRef]
- Elallid, B.B.; Abouaomar, A.; Benamar, N.; Kobbane, A. Vehicles control: Collision avoidance using federated deep reinforcement learning. In Proceedings of the GLOBECOM 2023-2023 IEEE Global Communications Conference, Kuala Lumpur, Malaysia, 4–8 December 2023; pp. 4369–4374. [Google Scholar]
- Han, Y.; Wang, M.; Leclercq, L. Leveraging reinforcement learning for dynamic traffic control: A survey and challenges for field implementation. Commun. Transp. Res. 2023, 3, 100104. [Google Scholar] [CrossRef]
- Teng, S.; Hu, X.; Deng, P.; Li, B.; Li, Y.; Ai, Y.; Yang, D.; Li, L.; Xuanyuan, Z.; Zhu, F.; et al. Motion planning for autonomous driving: The state of the art and future perspectives. IEEE Trans. Intell. Veh. 2023, 8, 3692–3711. [Google Scholar] [CrossRef]
- Huang, W.; Braghin, F.; Wang, Z. Learning to drive via apprenticeship learning and deep reinforcement learning. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (Ictai), Portland, OR, USA, 4–6 November 2019; pp. 1536–1540. [Google Scholar]
- Pfeiffer, M.; Shukla, S.; Turchetta, M.; Cadena, C.; Krause, A.; Siegwart, R.; Nieto, J. Reinforced imitation: Sample efficient deep reinforcement learning for mapless navigation by leveraging prior demonstrations. IEEE Robot. Autom. Lett. 2018, 3, 4423–4430. [Google Scholar] [CrossRef]
- Cimurs, R.; Suh, I.H.; Lee, J.H. Goal-driven autonomous exploration through deep reinforcement learning. IEEE Robot. Autom. Lett. 2021, 7, 730–737. [Google Scholar] [CrossRef]
- Reda, M.; Onsy, A.; Haikal, A.Y.; Ghanbari, A. Path planning algorithms in the autonomous driving system: A comprehensive review. Robot. Auton. Syst. 2024, 174, 104630. [Google Scholar] [CrossRef]
- Moon, S.; Koo, S.; Lim, Y.; Joo, H. Routing Control Optimization for Autonomous Vehicles in Mixed Traffic Flow Based on Deep Reinforcement Learning. Appl. Sci. 2024, 14, 2214. [Google Scholar] [CrossRef]
- Elallid, B.B.; Bagaa, M.; Benamar, N.; Mrani, N. A reinforcement learning based approach for controlling autonomous vehicles in complex scenarios. In Proceedings of the 2023 International Wireless Communications and Mobile Computing (IWCMC), Marrakesh, Morocco, 19–23 June 2023; pp. 1358–1364. [Google Scholar]
- Wang, L.; Liu, J.; Shao, H.; Wang, W.; Chen, R.; Liu, Y.; Waslander, S.L. Efficient Reinforcement Learning for Autonomous Driving with Parameterized Skills and Priors. arXiv 2023, arXiv:2305.04412. [Google Scholar]
- Chen, D.; Hajidavalloo, M.R.; Li, Z.; Chen, K.; Wang, Y.; Jiang, L.; Wang, Y. Deep multi-agent reinforcement learning for highway on-ramp merging in mixed traffic. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11623–11638. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, H.; Tang, J.; Hu, L. A deep reinforcement learning-based approach for autonomous lane-changing velocity control in mixed flow of vehicle group level. Expert Syst. Appl. 2024, 238, 122158. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, X.; Wu, Z. Design of Unsignalized Roundabouts Driving Policy of Autonomous Vehicles Using Deep Reinforcement Learning. World Electr. Veh. J. 2023, 14, 52. [Google Scholar] [CrossRef]
- Ferrarotti, L.; Luca, M.; Santin, G.; Previati, G.; Mastinu, G.; Gobbi, M.; Campi, E.; Uccello, L.; Albanese, A.; Zalaya, P.; et al. Autonomous and Human-Driven Vehicles Interacting in a Roundabout: A Quantitative and Qualitative Evaluation. IEEE Access 2024, 12, 32693–32705. [Google Scholar] [CrossRef]
- Gan, J.; Zhang, J.; Liu, Y. Research on behavioral decision at an unsignalized roundabout for automatic driving based on proximal policy optimization algorithm. Appl. Sci. 2024, 14, 2889. [Google Scholar] [CrossRef]
- Li, Y.; Ge, C.; Xing, L.; Yuan, C.; Liu, F.; Jin, J. A hybrid deep learning framework for conflict prediction of diverse merge scenarios at roundabouts. Eng. Appl. Artif. Intell. 2024, 130, 107705. [Google Scholar] [CrossRef]
- Qi, J.; Zhou, Q.; Lei, L.; Zheng, K. Federated reinforcement learning: Techniques, applications, and open challenges. arXiv 2021, arXiv:2108.11887. [Google Scholar] [CrossRef]
- Haarnoja, T.; Tang, H.; Abbeel, P.; Levine, S. Reinforcement learning with deep energy-based policies. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1352–1361. [Google Scholar]
- Palanisamy, P. Hands-On Intelligent Agents with OpenAI Gym: Your Guide to Developing AI Agents Using Deep Reinforcement Learning; Packt Publishing: Birmingham, UK, 2018. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | Control Commands | ||
|---|---|---|---|
| Steering | Throttle | Brake | |
| 0.0 | 0.6 | 0.0 | |
| −0.5 | 0.5 | 0.0 | |
| 0.5 | 0.5 | 0.0 | |
| 0.0 | 0.3 | 0.0 | |
| −0.5 | 0.3 | 0.5 | |
| 0.5 | 0.3 | 0.0 | |
| 0.0 | 0.0 | 0.5 | |
| Parameter | DQN | SAC | PPO |
|---|---|---|---|
| Learning rate | 0.001 | - | - |
| Learning rate (actor) | - | ||
| Learning rate (critic) | - | ||
| Number of Episodes | 2000 | 2000 | 2000 |
| Batch size | 128 | 64 | - |
| Clipping | - | - | 0.1 |
| Num. epochs | - | - | 4 |
| Replay Buffer | - |
| Model | Dens. | Avg. Re | Avg. Time | Avg. Speed | Avg. Dis | Avg. Steps | Succ. | Coll. |
|---|---|---|---|---|---|---|---|---|
| (s) | (m/s) | (m) | (%) | (%) | ||||
| SAC | 93.01 | 6.70 | 3.77 | 31.58 | 31.64 | 98 | 2 | |
| 92.99 | 7.48 | 3.78 | 31.70 | 32.91 | 98 | 2 | ||
| 91.79 | 8.50 | 3.64 | 31.72 | 35.06 | 96 | 2 | ||
| 85.07 | 10.36 | 3.75 | 31.63 | 30.80 | 94 | 6 | ||
| PPO | 62.1 | 7.01 | 3.60 | 32.51 | 36.01 | 88 | 12 | |
| 60.8 | 8.02 | 3.68 | 32.63 | 37.20 | 86 | 14 | ||
| 57.2 | 8.70 | 3.55 | 32.72 | 38.10 | 83 | 17 | ||
| 50.1 | 10.5 | 3.70 | 32.51 | 36.20 | 80 | 20 | ||
| DQN | 35.74 | 7.89 | 3.58 | 33.48 | 47.13 | 70 | 30 | |
| 24.98 | 9.28 | 3.52 | 33.35 | 47.81 | 64 | 36 | ||
| 29.40 | 8.63 | 3.45 | 33.57 | 49.0 | 66 | 34 | ||
| 1.86 | 10.88 | 3.63 | 33.54 | 47.69 | 52 | 48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elallid, B.B.; Benamar, N.; Bagaa, M.; Hadjadj-Aoul, Y. Enhancing Autonomous Driving Navigation Using Soft Actor-Critic. Future Internet 2024, 16, 238. https://doi.org/10.3390/fi16070238
Elallid BB, Benamar N, Bagaa M, Hadjadj-Aoul Y. Enhancing Autonomous Driving Navigation Using Soft Actor-Critic. Future Internet. 2024; 16(7):238. https://doi.org/10.3390/fi16070238
Chicago/Turabian StyleElallid, Badr Ben, Nabil Benamar, Miloud Bagaa, and Yassine Hadjadj-Aoul. 2024. "Enhancing Autonomous Driving Navigation Using Soft Actor-Critic" Future Internet 16, no. 7: 238. https://doi.org/10.3390/fi16070238
APA StyleElallid, B. B., Benamar, N., Bagaa, M., & Hadjadj-Aoul, Y. (2024). Enhancing Autonomous Driving Navigation Using Soft Actor-Critic. Future Internet, 16(7), 238. https://doi.org/10.3390/fi16070238