

MIMA: Multi-Feature Interaction Meta-Path Aggregation Heterogeneous Graph Neural Network for Recommendations


Abstract
1. Introduction
- A multi-head attention mechanism is employed to acquire the preference representation of users and items for multi-attribute feature combinations, and the meta-path representations of users and items with their attribute information are modeled for exploring recommendation relations.
- A multi-feature interactive meta-path aggregation heterogeneous graph neural network algorithm is proposed, which can more accurately uncover the underlying implicit correlations between users and items with multiple features and can aggregate meta-path semantic information to make the model more interpretable.
- Compared with other baselines on three commonly used datasets, our proposed model demonstrates significant advancements in NDCG, recall, and accuracy.
2. Related Work
2.1. Graph Neural Network
2.2. Heterogeneous Graph Neural Networks
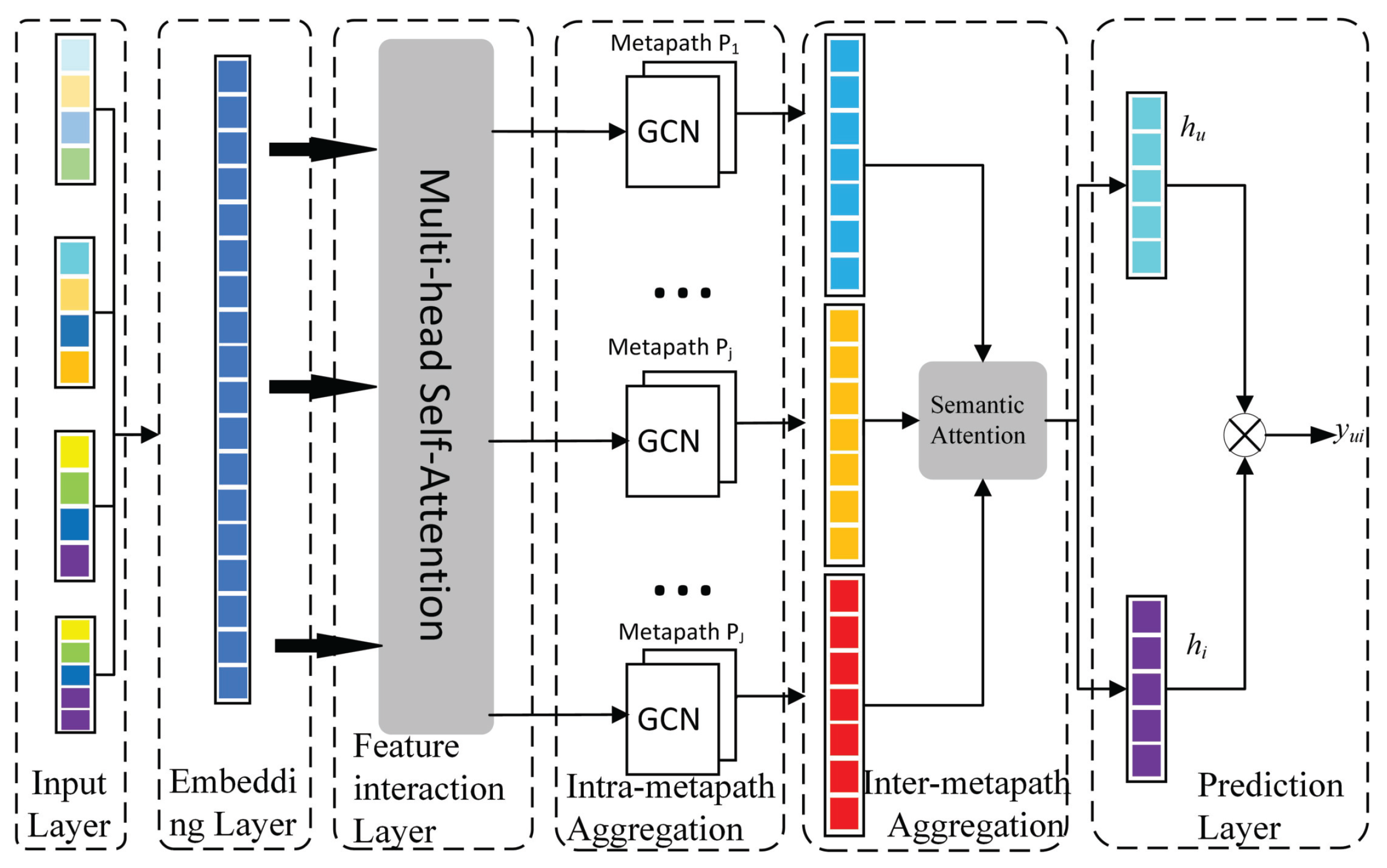
3. Method
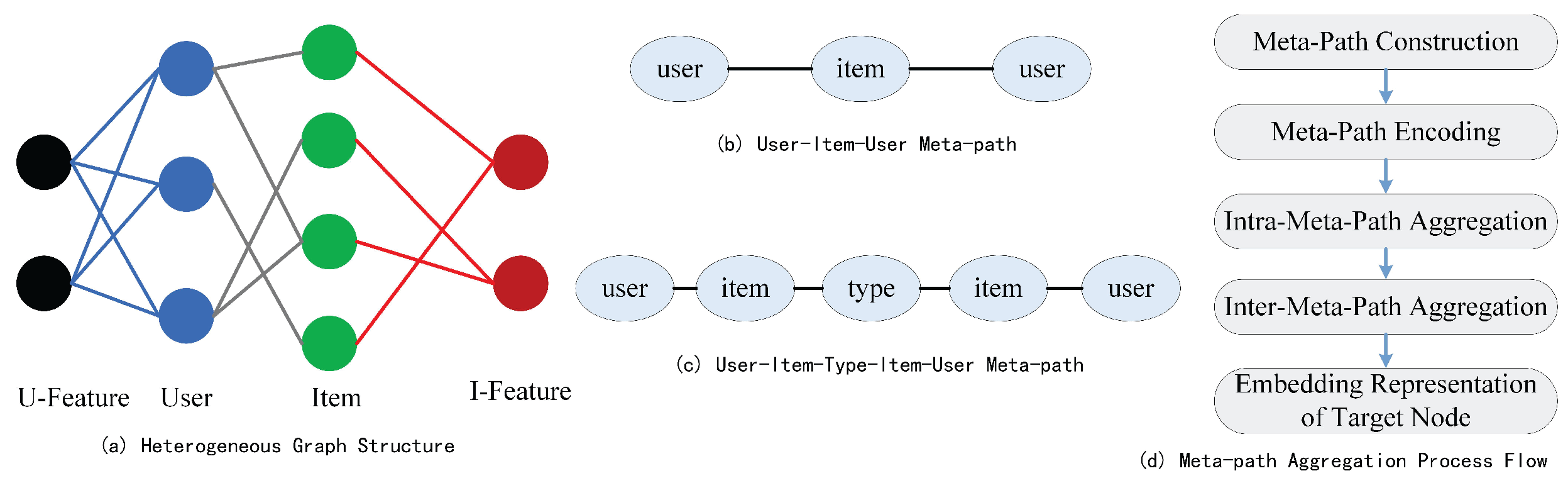
3.1. Heterogeneous Entity Path Definition
3.2. Input Layer
3.3. Embedding layer
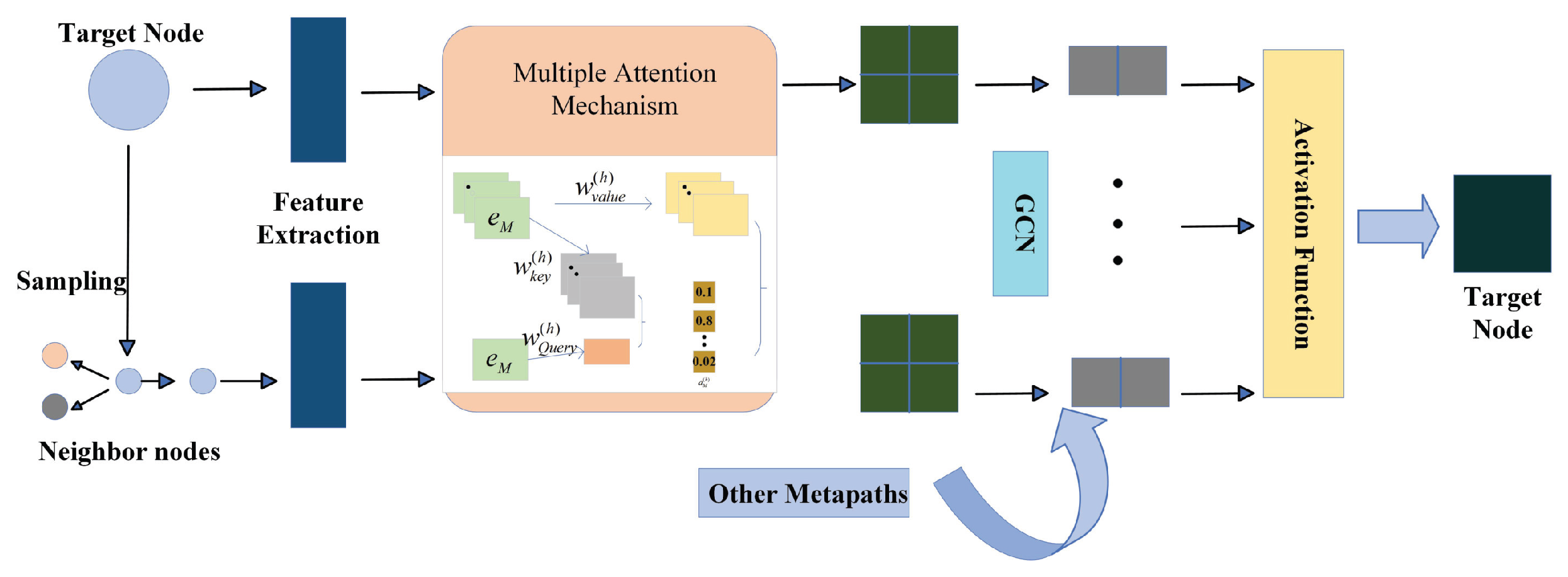
3.4. Feature Interaction Layer
3.5. Meta-Path Aggregation Layer
3.6. Prediction Layer
3.7. Model Training
| Algorithm 1 Multi-feature interaction meta-path aggregation heterogeneous graph neural network (MIMA). |
|
4. Experiment
4.1. Experimental Design
4.2. Performance Evaluation
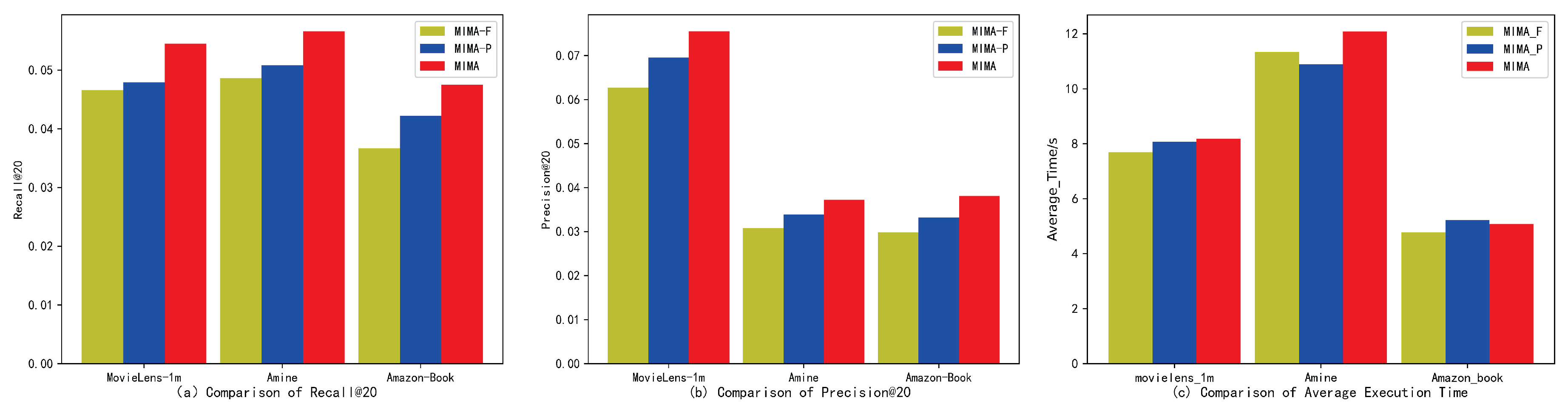
4.3. Model Analysis
4.4. The Influence of the Regularization Coefficient
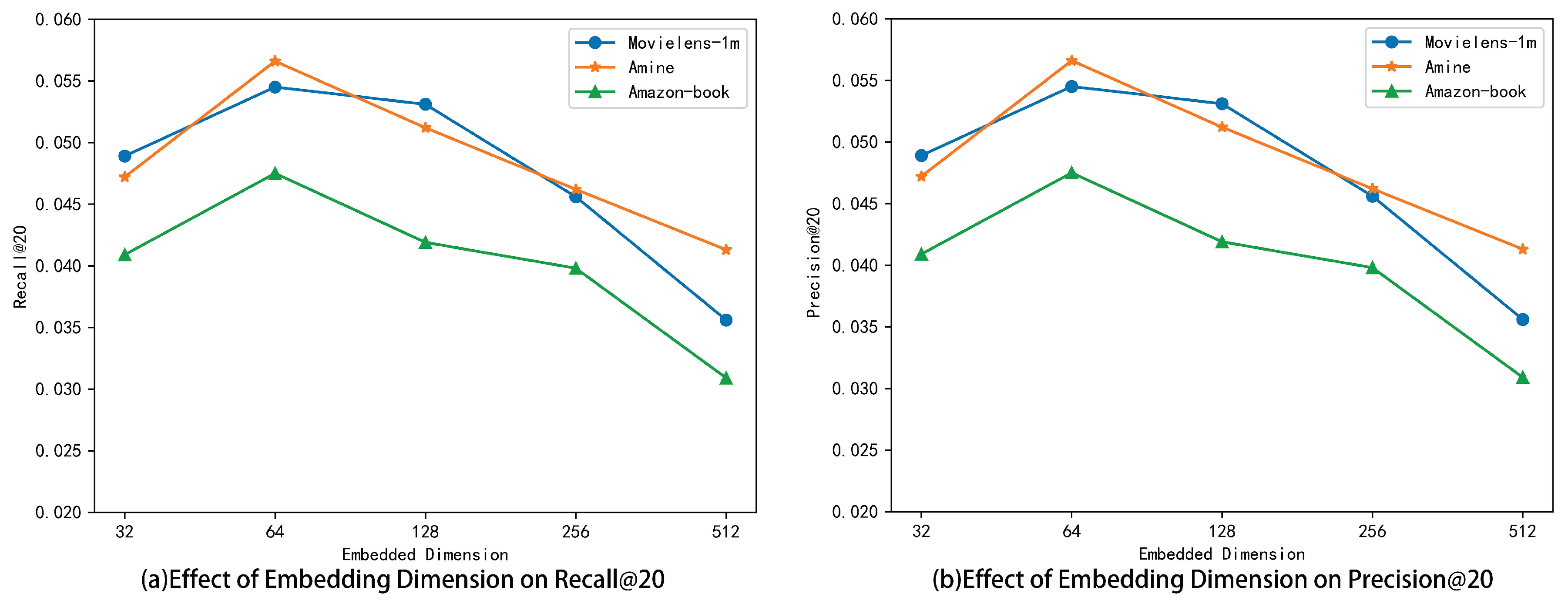
4.5. The Influence of the Feature Embedding Dimensions
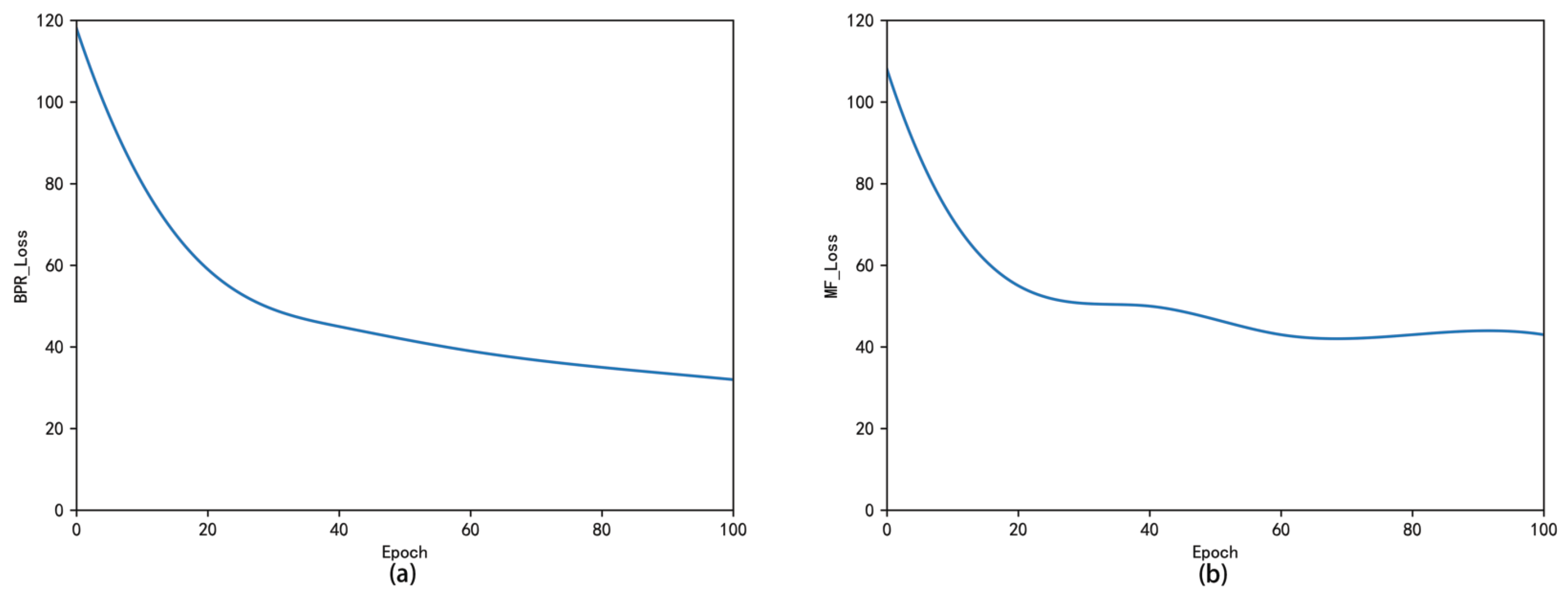
4.6. The Convergence of the MIMA Algorithm
4.7. The Influence of the Meta-Path Length
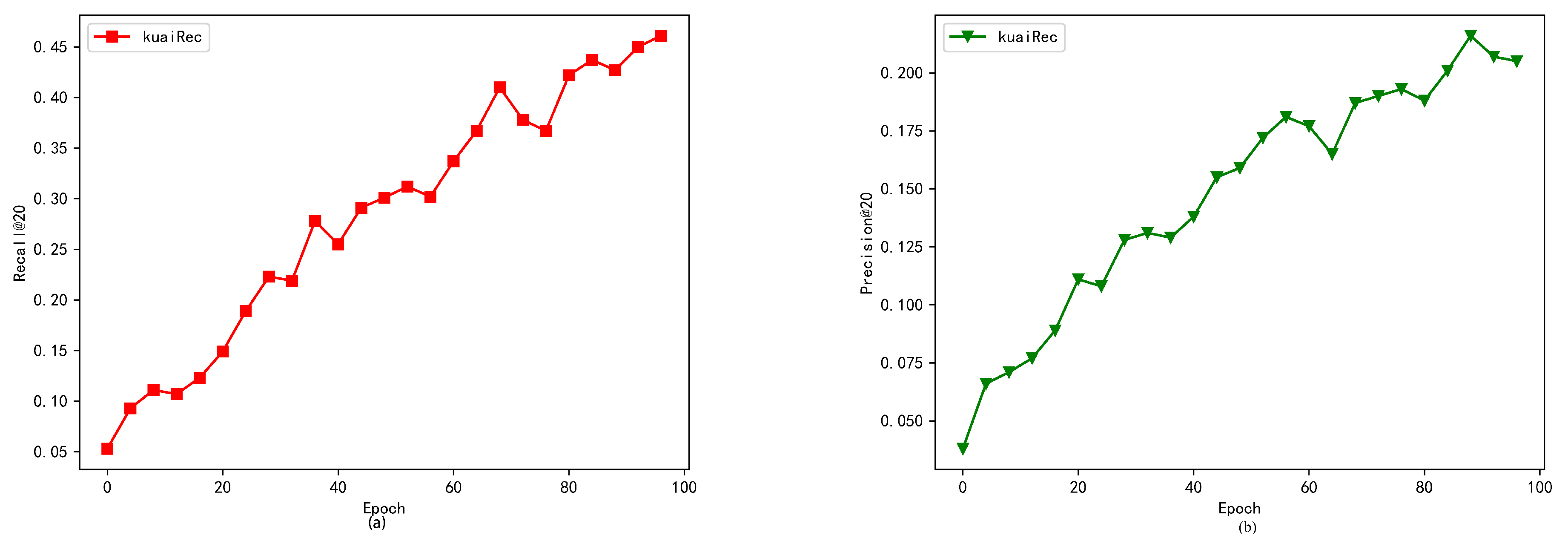
4.8. Suitability Verification
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, P.; Chartrand, G. Introduction to Graph Theory; Tata McGraw-Hill: New Delhi, India, 2006. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Battaglia, P.; Pascanu, R.; Lai, M.; Jimenez Rezende, D. Interaction networks for learning about objects, relations and physics. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar] [CrossRef]
- Fout, A.; Byrd, J.; Shariat, B.; Ben-Hur, A. Protein interface prediction using graph convolutional networks. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion convolutional recurrent neural network: Data-driven traffic forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Zhang, J.; Shi, X.; Xie, J.; Ma, H.; King, I.; Yeung, D.Y. GaAN: Gated Attention Networks for Learning on Large and Spatiotemporal Graphs. In Proceedings of the 34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018, Monterey, CA, USA, 6–10 August 2018. [Google Scholar]
- Jiang, W.; Luo, J. Graph neural network for traffic forecasting: A survey. Expert Syst. Appl. 2022, 207, 117921. [Google Scholar] [CrossRef]
- Ge, J.; Xu, G.; Zhang, Y.; Lu, J.; Chen, H.; Meng, X. Joint Optimization of Computation, Communication and Caching in D2D-Assisted Caching-Enhanced MEC System. Electronics 2023, 12, 3249. [Google Scholar] [CrossRef]
- Atwood, J.; Towsley, D. Diffusion-convolutional neural networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Cai, L.; Ji, S. A Multi-Scale Approach for Graph Link Prediction. Proc. AAAI Conf. Artif. Intell. 2020, 34, 3308–3315. [Google Scholar] [CrossRef]
- Wang, X.; Ji, H.; Shi, C.; Wang, B.; Ye, Y.; Cui, P.; Yu, P.S. Heterogeneous Graph Attention Network. In Proceedings of the World Wide Web Conference, WWW ’19, San Francisco, CA, USA, 13–17 May 2019; pp. 2022–2032. [Google Scholar]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous Graph Neural Network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’19, Anchorage, AK, USA, 4–8 August 2019; pp. 793–803. [Google Scholar]
- Berg, R.v.d.; Kipf, T.N.; Welling, M. Graph convolutional matrix completion. arXiv 2017, arXiv:1706.02263. [Google Scholar]
- Zhang, J.; Shi, X.; Zhao, S.; King, I. STAR-GCN: Stacked and Reconstructed Graph Convolutional Networks for Recommender Systems. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; p. 4264. [Google Scholar]
- Bing, R.; Yuan, G.; Zhu, M.; Meng, F.; Ma, H.; Qiao, S. Heterogeneous graph neural networks analysis: A survey of techniques, evaluations and applications. Artif. Intell. Rev. 2023, 56, 8003–8042. [Google Scholar] [CrossRef]
- Wu, S.; Sun, F.; Zhang, W.; Xie, X.; Cui, B. Graph Neural Networks in Recommender Systems: A Survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Abu-El-Haija, S.; Perozzi, B.; Kapoor, A.; Alipourfard, N.; Lerman, K.; Harutyunyan, H.; Steeg, G.V.; Galstyan, A. MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing. In Proceedings of the 36th International Conference on Machine Learning, PMLR ’39, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 21–29. [Google Scholar]
- Zhang, Y.; Wang, X.; Shi, C.; Jiang, X.; Ye, Y. Hyperbolic Graph Attention Network. IEEE Trans. Big Data 2022, 8, 1690–1701. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, L.; Shen, Q.; Pang, Y.; Wei, Z.; Xu, F.; Chang, E.; Long, B. Graph Learning Augmented Heterogeneous Graph Neural Network for Social Recommendation. ACM Trans. Recomm. Syst. 2023, 1, 1–22. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, X.; Shi, C.; Hu, B.; Song, G.; Ye, Y. Heterogeneous Graph Structure Learning for Graph Neural Networks. Proc. AAAI Conf. Artif. Intell. 2021, 35, 4697–4705. [Google Scholar] [CrossRef]
- Zhang, C.; Swami, A.; Chawla, N.V. SHNE: Representation Learning for Semantic-Associated Heterogeneous Networks. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, WSDM ’19, Melbourne, VIC, Australia, 11–15 February 2019; pp. 690–698. [Google Scholar]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Zhang, Z.; Cui, P.; Zhu, W. Deep Learning on Graphs: A Survey. IEEE Trans. Knowl. Data Eng. 2022, 34, 249–270. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, San Francisco, CA, USA, 24–27 August 2016; pp. 855–864. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Chen, H.; Yeh, C.C.M.; Fan, Y.; Zheng, Y.; Wang, J.; Lai, V.; Das, M.; Yang, H. Sharpness-Aware Graph Collaborative Filtering. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, Taipei, Taiwan, 23–27 July 2023; pp. 2369–2373. [Google Scholar]
- Sun, W.; Chang, K.; Zhang, L.; Meng, K. INGCF: An Improved Recommendation Algorithm Based on NGCF. In Algorithms and Architectures for Parallel Processing; Lai, Y., Wang, T., Jiang, M., Xu, G., Liang, W., Castiglione, A., Eds.; Springer: Cham, Switzerland, 2022; pp. 116–129. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, Xi’an, China, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural Graph Collaborative Filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR’19, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful are Graph Neural Networks? In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wei, Y.; Liu, W.; Liu, F.; Wang, X.; Nie, L.; Chua, T.S. LightGT: A Light Graph Transformer for Multimedia Recommendation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, Taipei, Taiwan, 23–27 July 2023; pp. 1508–1517. [Google Scholar]
- Yang, Z.; Dong, S. HAGERec: Hierarchical Attention Graph Convolutional Network Incorporating Knowledge Graph for Explainable Recommendation. Knowl. Based Syst. 2020, 204, 106194. [Google Scholar] [CrossRef]
- Zhao, J.; Liu, Z.; Sun, Q.; Li, Q.; Jia, X.; Zhang, R. Attention-based dynamic spatial-temporal graph convolutional networks for traffic speed forecasting. Expert Syst. Appl. 2022, 204, 117511. [Google Scholar] [CrossRef]
- Su, Y.; Zhao, Y.; Erfani, S.; Gan, J.; Zhang, R. Detecting Arbitrary Order Beneficial Feature Interactions for Recommender Systems. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’22, Washington, DC, USA, 14–18 August 2022; pp. 1676–1686. [Google Scholar]
- Kim, M.; Choi, H.-S.; Kim, J. Explicit Feature Interaction-Aware Graph Neural Network. IEEE Access 2024, 12, 15438–15446. [Google Scholar] [CrossRef]
- Liu, F.; Cheng, Z.; Zhu, L.; Liu, C.; Nie, L. An Attribute-Aware Attentive GCN Model for Attribute Missing in Recommendation. IEEE Trans. Knowl. Data Eng. 2022, 34, 4077–4088. [Google Scholar] [CrossRef]
- Yu, J.; Yin, H.; Li, J.; Gao, M.; Huang, Z.; Cui, L. Enhancing Social Recommendation with Adversarial Graph Convolutional Networks. IEEE Trans. Knowl. Data Eng. 2022, 34, 3727–3739. [Google Scholar] [CrossRef]
- Li, M.; Zhang, L.; Cui, L.; Bai, L.; Li, Z.; Wu, X. BLoG: Bootstrapped graph representation learning with local and global regularization for recommendation. Pattern Recogn. 2023, 144, 109874. [Google Scholar] [CrossRef]
- Fan, S.; Zhu, J.; Han, X.; Shi, C.; Hu, L.; Ma, B.; Li, Y. Metapath-guided heterogeneous graph neural network for intent recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2478–2486. [Google Scholar]
- Fu, X.; Zhang, J.; Meng, Z.; King, I. MAGNN: Metapath Aggregated Graph Neural Network for Heterogeneous Graph Embedding. In Proceedings of the Web Conference 2020, WWW ’20, Taipei, Taiwan, 20–24 April 2020; pp. 2331–2341. [Google Scholar]
- Ji, Z.; Wu, M.; Yang, H.; Íñigo, J.E.A. Temporal sensitive heterogeneous graph neural network for news recommendation. Future Gener. Comput. Syst. 2021, 125, 324–333. [Google Scholar] [CrossRef]
- Cai, D.; Qian, S.; Fang, Q.; Hu, J.; Xu, C. User cold-start recommendation via inductive heterogeneous graph neural network. ACM Trans. Inf. Syst. 2023, 41, 1–27. [Google Scholar] [CrossRef]
- Yang, X.; Yan, M.; Pan, S.; Ye, X.; Fan, D. Simple and Efficient Heterogeneous Graph Neural Network. Proc. AAAI Conf. Artif. Intell. 2023, 37, 10816–10824. [Google Scholar] [CrossRef]
- Jin, B.; Zhang, Y.; Zhu, Q.; Han, J. Heterformer: Transformer-based Deep Node Representation Learning on Heterogeneous Text-Rich Networks. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’23, Long Beach, CA, USA, 6–10 August 2023; pp. 1020–1031. [Google Scholar]
- Gao, X.; Zhang, W.; Chen, T.; Yu, J.; Nguyen, H.Q.V.; Yin, H. Semantic-aware Node Synthesis for Imbalanced Heterogeneous Information Networks. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, CIKM ’23, Birmingham, UK, 21–25 October 2023; pp. 545–555. [Google Scholar]
- Zheng, S.; Guan, D.; Yuan, W. Semantic-aware heterogeneous information network embedding with incompatible meta-paths. World Wide Web 2022, 25, 1–21. [Google Scholar] [CrossRef]
- Chen, M.; Huang, C.; Xia, L.; Wei, W.; Xu, Y.; Luo, R. Heterogeneous Graph Contrastive Learning for Recommendation. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, WSDM ’23, Singapore, 27 February–3 March 2023; pp. 544–552. [Google Scholar]
- Park, J.; Song, J.; Yang, E. Graphens: Neighbor-aware ego network synthesis for class-imbalanced node classification. In Proceedings of the Tenth International Conference on Learning Representations, ICLR, Virtual, 25–29 April 2022. [Google Scholar]
- Ragesh, R.; Sellamanickam, S.; Iyer, A.; Bairi, R.; Lingam, V. HeteGCN: Heterogeneous Graph Convolutional Networks for Text Classification. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, WSDM ’21, Virtual, 8–12 March 2021; pp. 860–868. [Google Scholar]
- Zhao, J.; Wang, X.; Shi, C.; Liu, Z.; Ye, Y. Network schema preserving heterogeneous information network embedding. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI’20, Yokohama, Japan, 7–15 January 2021. [Google Scholar]
- Hong, H.; Guo, H.; Lin, Y.; Yang, X.; Li, Z.; Ye, J. An Attention-Based Graph Neural Network for Heterogeneous Structural Learning. Proc. AAAI Conf. Artif. Intell. 2020, 34, 4132–4139. [Google Scholar] [CrossRef]
- Yang, Y.; Guan, Z.; Li, J.; Zhao, W.; Cui, J.; Wang, Q. Interpretable and Efficient Heterogeneous Graph Convolutional Network. IEEE Trans. Knowl. Data Eng. 2023, 35, 1637–1650. [Google Scholar] [CrossRef]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD international Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Shang, J.; Qu, M.; Liu, J.; Kaplan, L.M.; Han, J.; Peng, J. Meta-path guided embedding for similarity search in large-scale heterogeneous information networks. arXiv 2016, arXiv:1610.09769. [Google Scholar]
- Fu, T.Y.; Lee, W.C.; Lei, Z. Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1797–1806. [Google Scholar]
- Shi, C.; Hu, B.; Zhao, W.X.; Philip, S.Y. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 31, 357–370. [Google Scholar] [CrossRef]
- Song, W.; Shi, C.; Xiao, Z.; Duan, Z.; Xu, Y.; Zhang, M.; Tang, J. AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, CIKM ’19, Beijing, China, 3–7 November 2019; pp. 1161–1170. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst. 2015, 5, 1–19. [Google Scholar] [CrossRef]
- He, R.; McAuley, J. Ups and Downs: Modeling the Visual Evolution of Fashion Trends with One-Class Collaborative Filtering. In Proceedings of the 25th International Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, WWW ’01, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Rendle, S.; Krichene, W.; Zhang, L.; Anderson, J. Neural Collaborative Filtering vs. Matrix Factorization Revisited. In Proceedings of the 14th ACM Conference on Recommender Systems, RecSys ’20, Virtual, 22–26 September 2020; pp. 240–248. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, WWW ’17, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Zheng, Y.; Gao, C.; He, X.; Li, Y.; Jin, D. Price-aware Recommendation with Graph Convolutional Networks. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 133–144. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’18, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Ma, L.; Chen, Z.; Fu, Y.; Li, Y. Heterogeneous Graph Neural Network for Multi-behavior Feature-Interaction Recommendation. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2022, Bristol, UK, 6–9 September 2022; Pimenidis, E., Angelov, P., Jayne, C., Papaleonidas, A., Aydin, M., Eds.; Springer: Cham, Switzerland, 2022; pp. 101–112. [Google Scholar]
- Li, Y.; Zhao, F.; Chen, Z.; Fu, Y.; Ma, L. Multi-Behavior Enhanced Heterogeneous Graph Convolutional Networks Recommendation Algorithm based on Feature-Interaction. Appl. Artif. Intell. 2023, 37, 2201144. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Users | #Items | #Interactions | Density |
|---|---|---|---|---|
| Amine | 15,506 | 34,325 | 2,601,998 | 0.00489 |
| MovieLens-1m | 6040 | 5953 | 1,000,209 | 0.04189 |
| Amazon-Book | 51,639 | 84,355 | 2,648,963 | 0.00056 |
| Algorithm | Recall20 | Recall30 | Recall50 | Precision10 | Precision20 | Ndcg20 |
|---|---|---|---|---|---|---|
| ItemCF | 0.0286 | 0.0304 | 0.0412 | 0.0260 | 0.0201 | 0.0115 |
| MF | 0.0354 | 0.0446 | 0.0644 | 0.0311 | 0.0231 | 0.0214 |
| NCF | 0.0402 | 0.0542 | 0.0685 | 0.0342 | 0.0256 | 0.0256 |
| NGCF | 0.0434 | 0.0580 | 0.0772 | 0.0358 | 0.0294 | 0.0294 |
| PUP | 0.0482 | 0.0574 | 0.0784 | 0.0336 | 0.0296 | 0.0304 |
| PinSage | 0.0429 | 0.0553 | 0.0756 | 0.0329 | 0.0272 | 0.0295 |
| ATGCF | 0.0535 | 0.0616 | 0.0806 | 0.0372 | 0.0308 | 0.0320 |
| ATGCN | 0.0539 | 0.0621 | 0.0815 | 0.0377 | 0.0313 | 0.0322 |
| HetGNN | 0.0552 | 0.0607 | 0.0833 | 0.0476 | 0.0359 | 0.0341 |
| HAN | 0.0547 | 0.0598 | 0.0841 | 0.0452 | 0.0343 | 0.0335 |
| MIMA | 0.0566 | 0.0653 | 0.0910 | 0.0489 | 0.0372 | 0.0357 |
| Improvement | 2.5% | 5.2% | 8.2% | 2.7% | 3.6% | 4.7% |
| Algorithm | Recall20 | Recall30 | Recall50 | Precision10 | Precision20 | Ndcg20 |
|---|---|---|---|---|---|---|
| ItemCF | 0.0214 | 0.0238 | 0.0512 | 0.0332 | 0.0327 | 0.0396 |
| MF | 0.0384 | 0.0425 | 0.0748 | 0.0559 | 0.0445 | 0.0425 |
| NCF | 0.0401 | 0.0554 | 0.0864 | 0.0532 | 0.0496 | 0.0489 |
| NGCF | 0.0443 | 0.0647 | 0.1026 | 0.0604 | 0.0584 | 0.0504 |
| PUP | 0.0455 | 0.0665 | 0.1048 | 0.0588 | 0.0596 | 0.0548 |
| PinSAGE | 0.0431 | 0.0607 | 0.1015 | 0.0496 | 0.0478 | 0.0537 |
| ATGCF | 0.0482 | 0.0689 | 0.1070 | 0.0645 | 0.0627 | 0.0581 |
| ATGCN | 0.0491 | 0.0695 | 0.1093 | 0.0656 | 0.0635 | 0.0593 |
| HetGNN | 0.0533 | 0.0702 | 0.1033 | 0.0771 | 0.0747 | 0.0572 |
| HAN | 0.0529 | 0.0677 | 0.0995 | 0.0767 | 0.0729 | 0.0559 |
| AFHGCN | 0.0545 | 0.0712 | 0.1170 | 0.0820 | 0.0755 | 0.0621 |
| Improvement | 2.3% | 1.4% | 7.0% | 6.4% | 1.1% | 4.7% |
| Algorithm | Recall20 | Recall30 | Recall50 | Precision10 | Precision20 | Ndcg20 |
|---|---|---|---|---|---|---|
| ItemCF | 0.0184 | 0.0196 | 0.0452 | 0.0186 | 0.0195 | 0.0356 |
| MF | 0.0250 | 0.0267 | 0.0624 | 0.0254 | 0.0201 | 0.0518 |
| NCF | 0.0265 | 0.0288 | 0.0665 | 0.0262 | 0.0225 | 0.0542 |
| NGCF | 0.0348 | 0.0387 | 0.0731 | 0.0328 | 0.0257 | 0.0630 |
| PUP | 0.0382 | 0.0415 | 0.0754 | 0.0316 | 0.0285 | 0.0624 |
| PinSAGE | 0.0283 | 0.0357 | 0.0710 | 0.0317 | 0.0229 | 0.0545 |
| ATGCF | 0.0408 | 0.0426 | 0.0775 | 0.0358 | 0.0298 | 0.0651 |
| ATGCN | 0.0416 | 0.0433 | 0.0783 | 0.0367 | 0.0309 | 0.0658 |
| HetGNN | 0.0412 | 0.0429 | 0.0780 | 0.0381 | 0.0371 | 0.0662 |
| HAN | 0.0432 | 0.0455 | 0.0729 | 0.0377 | 0.0359 | 0.0649 |
| MIMA | 0.0475 | 0.0503 | 0.0834 | 0.0410 | 0.0381 | 0.0719 |
| Improvement | 9.9% | 10.5% | 6.5% | 7.6% | 2.7% | 8.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Yan, S.; Zhao, F.; Jiang, Y.; Chen, S.; Wang, L.; Ma, L. MIMA: Multi-Feature Interaction Meta-Path Aggregation Heterogeneous Graph Neural Network for Recommendations. Future Internet 2024, 16, 270. https://doi.org/10.3390/fi16080270
Li Y, Yan S, Zhao F, Jiang Y, Chen S, Wang L, Ma L. MIMA: Multi-Feature Interaction Meta-Path Aggregation Heterogeneous Graph Neural Network for Recommendations. Future Internet. 2024; 16(8):270. https://doi.org/10.3390/fi16080270
Chicago/Turabian StyleLi, Yang, Shichao Yan, Fangtao Zhao, Yi Jiang, Shuai Chen, Lei Wang, and Li Ma. 2024. "MIMA: Multi-Feature Interaction Meta-Path Aggregation Heterogeneous Graph Neural Network for Recommendations" Future Internet 16, no. 8: 270. https://doi.org/10.3390/fi16080270
APA StyleLi, Y., Yan, S., Zhao, F., Jiang, Y., Chen, S., Wang, L., & Ma, L. (2024). MIMA: Multi-Feature Interaction Meta-Path Aggregation Heterogeneous Graph Neural Network for Recommendations. Future Internet, 16(8), 270. https://doi.org/10.3390/fi16080270