
Cross-Domain Fake News Detection Using a Prompt-Based Approach


Abstract
:1. Introduction
Contributions of This Work
- In contrast to the straightforward prompt-based learning approach, we propose a GPT-based model with contextualized prompt-based learning augmented by auxiliary information, such as domain information, for FND in English. The results of our experiments demonstrate that this model, when trained on a multi-domain dataset, outperforms a model without auxiliary information. Furthermore, we establish benchmark results for English-language FND using the TALLIP dataset.
- We conducted ablation studies on various prompt design choices to assess their impact on performance.
- We conducted experiments to compare the effectiveness of a contextualized prompt-tuning approach against a context-independent model in cross-domain FND.
- We found that the context-aware GPT model is effective in zero-shot cross-domain settings, significantly outperforming existing strong baselines. Our experimental evaluation indicates that feature representations are highly transferable across different domains.
2. Related Work
3. Methodology
Task Formulation
4. Experiments
4.1. Experimental Setting
4.2. Dataset
4.3. Evaluation Metrics
4.4. Baseline Models
- GPT2: In this model, initially, the input text and the prompt are combined and processed through a natural language template. Subsequently, the model generates a prediction by completing the blank space, and the output is categorized into the default class (fake/real) using the verbalizer (as shown in Figure 1a).
5. Results
5.1. Overall Performance
5.2. Cross-Domain Zero-Shot Transfer Learning Analysis
5.3. Prompt-Engineering Sensitivity
- Verbalizer wording: We examine the impact of alternative verbalizer labels by comparing our default choices of “fake/real” with “false/true”. Our findings demonstrate that the performance of the GPT2-D model is influenced by the specific wording used for the target concept (i.e., veracity). The observed difference in performance between the two labelling schemes (i.e., “fake/real”, Table 2, vs. “false/true”, Table 4) has a moderate to potentially major impact on the model’s accuracy. This sensitivity to the phrasing of target words highlights the importance of careful label selection when applying the GPT2-D model to an FND task.
- Template formatting: We explore two modifications to the prompt template:
- −
- Quote addition: We introduce quotation marks around the prompt text, in contrast to the approach of Schick et al. [24], where quotes around input text were omitted. Table 5 presents the model’s performance after surrounding the prompt with quotation marks. Compared to the original results (shown at the bottom of Table 2), a noticeable decline in accuracy is observed across most categories. Therefore, adding quotation marks seems to negatively impact the model’s performance, at least at this level of analysis.
- −
- Prompt wording variations: This analysis examines the influence of varying the prompt wording on the performance of the GPT2-D model for FND. As illustrated in Table 6 and Table 7, the prompt wording significantly influences the performance of the GPT2-D model. While all variations lead to a decline in accuracy compared to the original setup, the extent of the impact varies. Simpler prompts with less specific terminology seem to perform better.
5.4. The Challenge of Domain Shift
- Sports-to-Business Shift: The misclassification of the “Justice League” trailer article as “legit” when it was actually “fake” highlights the model’s difficulty in handling domain-specific cues that were not present in the sports training data. The mismatch between sports and business content likely led to confusion in classifying the legitimacy of business-related news.
- Education-to-Technology Shift: The error in classifying the Fossil Group smartwatch announcement as “fake” suggests that the model may struggle with content that deviates significantly from the educational domain. This discrepancy points to the model’s potential inadequacy in capturing the subtleties of technology-related news when trained on educational data.
- Business-to-Entertainment Shift: The misclassification of Alec Baldwin’s article as “legit” instead of “fake” reflects the challenges of transferring learned features from business to entertainment contexts. This result implies that the model’s training on business news did not effectively prepare it for the nuances of entertainment content.
6. Discussion
7. Leveraging the Proposed Solution for FND in Social Networking Services
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Conroy, N.K.; Rubin, V.L. News in an online world: The need for an “automatic crap detector”. Proc. Assoc. Inf. Sci. Technol. 2015, 52, 1–4. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Gu, Y.; Han, X.; Liu, Z.; Huang, M. Ppt: Pre-trained prompt tuning for few-shot learning. arXiv 2021, arXiv:2109.04332. [Google Scholar]
- Loem, M.; Kaneko, M.; Takase, S.; Okazaki, N. Exploring Effectiveness of GPT-3 in Grammatical Error Correction: A Study on Performance and Controllability in Prompt-Based Methods. arXiv 2023, arXiv:2305.18156. [Google Scholar]
- Hu, Y.; Chen, Q.; Du, J.; Peng, X.; Keloth, V.K.; Zuo, X.; Zhou, Y.; Li, Z.; Jiang, X.; Lu, Z.; et al. Improving large language models for clinical named entity recognition via prompt engineering. J. Am. Med. Inform. Assoc. 2024, ocad259. [Google Scholar] [CrossRef] [PubMed]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Moens, M.F., Huang, X., Specia, L., Yih, S.W.T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3045–3059. [Google Scholar] [CrossRef]
- Schick, T.; Schütze, H. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Himeur, Y.; Al-Maadeed, S.; Kheddar, H.; Al-Maadeed, N.; Abualsaud, K.; Mohamed, A.; Khattab, T. Video surveillance using deep transfer learning and deep domain adaptation: Towards better generalization. Eng. Appl. Artif. Intell. 2023, 119, 105698. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Lan, L.; Huang, T.; Li, Y.; Song, Y. A Survey of Cross-Lingual Text Classification and Its Applications on Fake News Detection. World Sci. Annu. Rev. Artif. Intell. 2023, 1, 2350003. [Google Scholar] [CrossRef]
- Schick, T.; Schütze, H. It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tur, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 2339–2352. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 6 June 2019. [Google Scholar]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3816–3830. [Google Scholar] [CrossRef]
- De, A.; Bandyopadhyay, D.; Gain, B.; Ekbal, A. A transformer-based approach to multilingual fake news detection in low-resource languages. Trans. Asian -Low-Resour. Lang. Inf. Process. 2021, 21, 1–20. [Google Scholar] [CrossRef]
- Peng, Z.; Li, M.; Wang, Y.; Ho, G.T. Combating the COVID-19 infodemic using Prompt-Based curriculum learning. Expert Syst. Appl. 2023, 229, 120501. [Google Scholar] [CrossRef] [PubMed]
- Peng, Z.; Lin, N.; Zhou, Y.; Zhou, D.; Yang, A. Prompt Learning for Low-Resource Multi-Domain Fake News Detection. In Proceedings of the 2023 International Conference on Asian Language Processing (IALP), Singapore, 18–20 November 2023; pp. 314–319. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI blog 2019, 1, 9. [Google Scholar]
- Alghamdi, J.; Lin, Y.; Luo, S. Fake news detection in low-resource languages: A novel hybrid summarization approach. Knowl.-Based Syst. 2024, 296, 111884. [Google Scholar] [CrossRef]
- Mohawesh, R.; Liu, X.; Arini, H.M.; Wu, Y.; Yin, H. Semantic graph based topic modelling framework for multilingual fake news detection. AI Open 2023, 4, 33–41. [Google Scholar] [CrossRef]
- Jiang, Z.; Xu, F.F.; Araki, J.; Neubig, G. How can we know what language models know? Trans. Assoc. Comput. Linguist. 2020, 8, 423–438. [Google Scholar] [CrossRef]
- Schick, T.; Schütze, H. Exploiting cloze questions for few shot text classification and natural language inference. arXiv 2020, arXiv:2001.07676. [Google Scholar]
- Schick, T.; Udupa, S.; Schütze, H. Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in nlp. Trans. Assoc. Comput. Linguist. 2021, 9, 1408–1424. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Silva, A.; Luo, L.; Karunasekera, S.; Leckie, C. Embracing domain differences in fake news: Cross-domain fake news detection using multi-modal data. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 557–565. [Google Scholar]
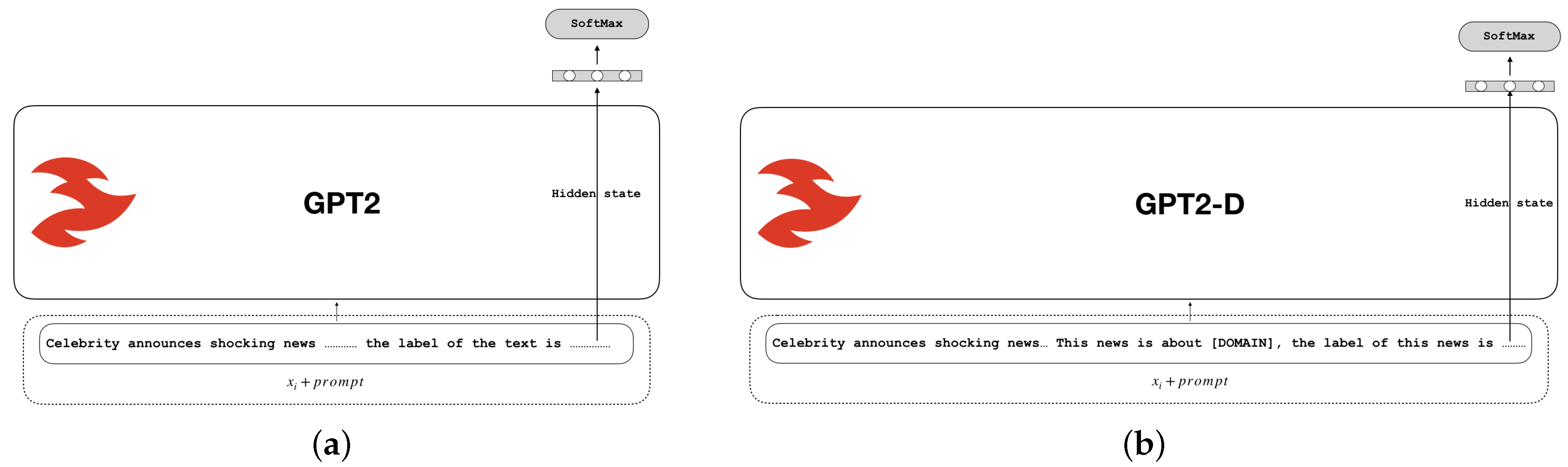

{kind=link}
{kind=link}
| Data (# Samples) | Label | |
|---|---|---|
| Train (1163) | Legit | 593 |
| Fake | 570 | |
| Test (753) | Legit | 390 |
| Fake | 363 | |
| Study | Train | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| Bus. | Edu. | Tech. | Entert | Politi. | Sports | Celeb. | ||
| [16] | Bus. | 77.42 | 73.33 | 70.00 | 63.33 | 86.67 | 70.00 | 54.00 |
| Edu. | 50.00 | 95.53 | 93.33 | 53.33 | 96.67 | 53.33 | 53.50 | |
| Tech. | 46.67 | 93.33 | 97.32 | 46.67 | 100.00 | 50.00 | 50.50 | |
| Entert. | 46.67 | 43.33 | 46.67 | 80.43 | 50.00 | 46.67 | 50.50 | |
| Politi. | 50.00 | 96.67 | 100.00 | 50.00 | 97.94 | 50.00 | 53.00 | |
| Sports | 93.33 | 70.00 | 53.33 | 83.33 | 63.33 | 77.41 | 56.00 | |
| Celeb. | 36.67 | 50.00 | 63.33 | 26.67 | 60.00 | 50.00 | 77.83 | |
| [21] | Bus. | - | 66.67 | 76.67 | 66.61 | 70.00 | 56.67 | - |
| Edu. | 56.67 | - | 56.67 | 60.00 | 53.33 | 46.67 | - | |
| Tech. | 50.00 | 86.67 | - | 63.33 | 96.67 | 76.67 | - | |
| Entert. | 53.33 | 50.00 | 50.00 | - | 50.00 | 53.33 | - | |
| Politi. | 50.00 | 96.67 | 93.33 | 56.67 | - | 53.33 | - | |
| Sports | 66.67 | 66.00 | 46.67 | 66.67 | 60.00 | - | - | |
| Celeb. | - | - | - | - | - | - | - | |
| GPT2 | Bus. | 96.23 | 49.00 | 50.00 | 57.14 | 51.67 | 95.52 | 53.56 |
| Edu. | 54.72 | 96.72 | 97.14 | 50.79 | 96.67 | 55.22 | 51.72 | |
| Tech. | 49.06 | 98.36 | 97.14 | 50.79 | 98.33 | 55.22 | 49.37 | |
| Entert. | 96.36 | 47.54 | 50.00 | 96.83 | 51.67 | 89.55 | 49.37 | |
| Politi. | 49.06 | 77.05 | 97.14 | 50.79 | 100.00 | 55.22 | 50.63 | |
| Sports | 79.25 | 49.18 | 49.30 | 96.83 | 51.67 | 97.01 | 48.55 | |
| Celeb. | 56.60 | 54.10 | 51.43 | 47.62 | 58.33 | 47.76 | 86.81 | |
| GPT2-D | Bus. | 100.00 | 50.82 | 50.00 | 93.65 | 55.00 | 97.01 | 53.92 |
| Edu. | 64.15 | 100.00 | 97.18 | 53.97 | 98.33 | 61.19 | 52.66 | |
| Tech. | 52.83 | 100.00 | 100.00 | 53.97 | 100.00 | 55.22 | 49.60 | |
| Entert. | 98.11 | 50.82 | 51.43 | 96.83 | 53.33 | 92.54 | 54.62 | |
| Politi. | 58.49 | 96.72 | 100.00 | 50.79 | 100.00 | 55.22 | 52.77 | |
| Sports | 98.11 | 50.82 | 50.00 | 100.00 | 53.33 | 100.00 | 51.45 | |
| Celeb. | 62.26 | 62.30 | 57.14 | 58.73 | 68.33 | 64.18 | 87.86 | |
| Testing (Target Domain) | Metrics (Baseline GPT2) | Metrics (GPT2-D) | ||||||
|---|---|---|---|---|---|---|---|---|
| A(%) | P (%) | R (%) | F1 (%) | A(%) | P (%) | R (%) | F1 (%) | |
| Bus. | 92.73 | 93.67 | 92.73 | 92.70 | 98.11 | 98.18 | 98.11 | 98.11 |
| Edu. | 96.72 | 96.93 | 96.72 | 96.72 | 100.00 | 100.00 | 100.00 | 100.00 |
| Tech. | 97.18 | 97.34 | 97.18 | 97.18 | 100.00 | 100.00 | 100.00 | 100.00 |
| Entert. | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Politi. | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| Sports | 88.06 | 88.06 | 88.06 | 88.06 | 91.04 | 92.29 | 91.04 | 90.88 |
| Celeb. | 86.33 | 86.38 | 86.33 | 86.33 | 87.86 | 87.86 | 87.86 | 87.86 |
| Study | Train | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| Bus. | Edu. | Tech. | Entert. | Politi. | Sports | Celeb. | ||
| GPT2-D | Bus. | 98.11 | 47.54 | 50.00 | 93.65 | 51.67 | 95.52 | 52.77 |
| Edu. | 50.94 | 100.00 | 94.29 | 53.97 | 98.33 | 56.72 | 49.87 | |
| Tech. | 45.28 | 100.00 | 100.00 | 53.97 | 98.33 | 55.22 | 49.60 | |
| Entert. | 67.92 | 47.54 | 50.00 | 96.83 | 51.67 | 92.54 | 51.98 | |
| Politi. | 45.28 | 96.72 | 94.29 | 53.97 | 100.00 | 55.22 | 50.13 | |
| Sports | 90.57 | 49.18 | 50.00 | 98.41 | 53.33 | 100.00 | 53.56 | |
| Celeb. | 66.04 | 60.66 | 60.00 | 50.79 | 75.00 | 56.72 | 91.03 | |
| Study | Train | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| Bus. | Edu. | Tech. | Entert. | Politi. | Sports | Celeb. | ||
| GPT2-D | Bus. | 98.11 | 45.90 | 50.00 | 96.83 | 51.67 | 98.51 | 52.51 |
| Edu. | 50.94 | 96.72 | 94.29 | 50.79 | 98.33 | 58.21 | 50.13 | |
| Tech. | 49.06 | 96.72 | 94.29 | 55.56 | 98.33 | 55.22 | 47.76 | |
| Entert. | 96.23 | 45.90 | 50.00 | 96.83 | 51.67 | 92.54 | 51.19 | |
| Politi. | 49.06 | 91.80 | 94.29 | 50.79 | 100.00 | 55.22 | 49.87 | |
| Sports | 96.23 | 49.18 | 50.00 | 96.83 | 53.33 | 98.51 | 51.72 | |
| Celeb. | 45.28 | 50.82 | 58.57 | 58.73 | 55.00 | 55.22 | 85.75 | |
| Model | Training Domain | Test Domains | ||||||
|---|---|---|---|---|---|---|---|---|
| Bus. | Edu. | Tech. | Entert. | Politi. | Sports | Celeb. | ||
| GPT2-D | Bus. | 92.45 | 45.90 | 50.00 | 93.65 | 51.67 | 74.63 | 58.05 |
| Edu. | 49.06 | 96.72 | 94.29 | 53.97 | 100.00 | 55.22 | 50.13 | |
| Tech. | 45.28 | 96.72 | 98.57 | 53.97 | 98.33 | 55.22 | 50.13 | |
| Entert. | 81.13 | 49.18 | 78.57 | 93.65 | 83.33 | 89.55 | 53.83 | |
| Politi. | 58.49 | 96.72 | 94.29 | 50.79 | 96.67 | 53.73 | 47.76 | |
| Sports | 100.00 | 49.18 | 48.57 | 96.83 | 51.67 | 100.00 | 53.56 | |
| Celeb. | 58.49 | 59.02 | 64.29 | 53.97 | 65.00 | 58.21 | 87.34 | |
| Study | Train | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| Bus. | Edu. | Tech. | Entert. | Politi. | Sports | Celeb. | ||
| GPT2-D | Bus. | 100.00 | 49.18 | 50.00 | 93.65 | 51.67 | 95.52 | 53.30 |
| Edu. | 49.06 | 100.00 | 97.14 | 50.79 | 98.33 | 52.24 | 49.08 | |
| Tech. | 47.17 | 96.72 | 100.00 | 47.62 | 98.33 | 55.22 | 50.13 | |
| Entert. | 98.11 | 49.18 | 48.57 | 93.65 | 53.33 | 89.55 | 52.24 | |
| Politi. | 49.06 | 96.72 | 94.29 | 47.62 | 96.67 | 53.73 | 49.34 | |
| Sports | 100.00 | 49.18 | 50.00 | 95.24 | 53.33 | 100.00 | 49.87 | |
| Celeb. | 50.94 | 55.74 | 60.00 | 50.79 | 48.33 | 46.27 | 89.71 | |
| News | Train | Test | Actual | Pred |
|---|---|---|---|---|
| When the new trailer for “Justice League” appeared on Saturday, most fans, and even casual viewers alike, noted the obvious lack of the iconic Superman. Most felt that the “Justice League” was not complete, or even valid, … | Sports | Bus. | Fake | Legit |
| Fossil Group is going all-in on connected watches. The company previously announced that it planned to release 300 new smartwatches, hybrid watches and fitness trackers across multiple brands in 2017 … | Edu. | Tech. | Legit | Fake |
| Alec Baldwin has decided to up his role playing on Saturday Night Live after a secret meeting with President Trump. During the meeting, Baldwin and Trump put aside their political differences and became quite friendly. Baldwin stated “I am truly sorry for portraying Trump in a bad light but at the time I was totally against what he stood for, … | Bus. | Entert. | Fake | Legit |
| Training | Testing | ||||||
|---|---|---|---|---|---|---|---|
| Bus. | Edu. | Tech. | Entert. | Politi. | Sports | Celeb. | |
| Bus. | 100.00 | 93.44 | 94.29 | 95.24 | 95.00 | 97.01 | 61.74 |
| Edu. | 66.04 | 100.00 | 97.18 | 63.49 | 98.33 | 85.07 | 69.92 |
| Tech. | 96.23 | 100.00 | 100.00 | 90.48 | 100.00 | 88.06 | 60.95 |
| Entert. | 98.11 | 88.52 | 94.29 | 96.83 | 96.67 | 92.45 | 63.06 |
| Politi. | 73.58 | 96.72 | 100.00 | 87.30 | 100.00 | 86.57 | 64.91 |
| Sports | 98.11 | 93.44 | 87.14 | 100.00 | 85.00 | 100.00 | 63.06 |
| Celeb. | 88.68 | 95.08 | 74.29 | 88.89 | 96.67 | 76.12 | 87.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alghamdi, J.; Lin, Y.; Luo, S. Cross-Domain Fake News Detection Using a Prompt-Based Approach. Future Internet 2024, 16, 286. https://doi.org/10.3390/fi16080286
Alghamdi J, Lin Y, Luo S. Cross-Domain Fake News Detection Using a Prompt-Based Approach. Future Internet. 2024; 16(8):286. https://doi.org/10.3390/fi16080286
Chicago/Turabian StyleAlghamdi, Jawaher, Yuqing Lin, and Suhuai Luo. 2024. "Cross-Domain Fake News Detection Using a Prompt-Based Approach" Future Internet 16, no. 8: 286. https://doi.org/10.3390/fi16080286