Abstract
Network traffic classification is crucial for effective security management. However, the increasing prevalence of encrypted traffic and the confidentiality of protocol details have made this task more challenging. To address this issue, we propose a progressive, adaptive traffic classification method called SwiftSession, designed to achieve real-time and accurate classification. SwiftSession extracts statistical and sequential features from the first K packets of traffic. Statistical features capture overall characteristics, while sequential features reflect communication patterns. An initial classification is conducted based on the first K packets during the classification process. If the prediction meets the predefined probability threshold, processing stops; otherwise, additional packets are received. This progressive approach dynamically adjusts the required packets, enhancing classification efficiency. Experimental results show that traffic can be effectively classified by using only the initial K packets. Moreover, on most datasets, the classification time is reduced by more than 70%. Unlike existing methods, SwiftSession enhances the classification speed while ensuring classification accuracy.
1. Introduction
Network traffic classification is essential for ensuring effective network management and security. In the current network environment, the increasing use of encryption and the dynamic nature of applications have made traffic classification a more complex task. Traditional port-based classification methods, which rely on static port numbers, are no longer sufficient due to the prevalence of modern applications that use dynamic ports [1]. Deep Packet Inspection (DPI) [2,3], while effective in some scenarios before encryption became widespread, now struggles with encrypted and private protocol traffic.
Methods based on statistical features [4,5] have emerged as an alternative, as they rely on the macroscopic patterns of traffic behaviors and are not affected by the encryption of the data content. However, selecting the optimal set of features is challenging [6]. Deep learning methods also show promise [2], especially in handling encrypted traffic, but their performance varies with datasets and encryption algorithms, limiting their universality and adaptability. Methods relying on sequential features [7] conduct classification by analyzing traffic lengths and event sequences. However, these methods require waiting for the completion of traffic transmission [8], making them unsuitable for real-time applications where the timeliness of rapid classification is crucial.
Existing traffic classification methods require the entire session or multiple packets to begin recognition, limiting their ability to achieve real-time classification. To address this, we propose SwiftSession, an incremental traffic classification method. SwiftSession extracts statistical and sequential features from the initial K packets. These features are selected and processed to capture the essential characteristics of the traffic. The classification process is incremental, continuing until the classification probability surpasses a set threshold or until the packet count reaches a predefined limit. This unique approach allows for a dynamic adjustment of the classification process based on the characteristics of the traffic data, ensuring that the method can adapt to different traffic patterns and scenarios.
The main contributions of this paper are presented as follows:
- We propose a traffic classification method that uses both statistical features and sequential features. This method can classify network traffic from multiple granularities, such as behavior and protocol.
- We put forward a progressive and adaptive traffic classification architecture that strikes an optimal balance between classification accuracy and efficiency. In this architecture, the classifier initially employs the first K packets for the classification task. When the classification probability of the most probable category surpasses a pre-determined threshold, the processing halts. However, if this condition is not met, additional packets are incrementally processed until a confident classification is achieved. Such an adaptive mechanism not only guarantees accurate classification but also curtails the processing time by minimizing the number of packets needed.
- We conducted experimental comparisons of traffic behavior classification on datasets of multiple different task types, including IoT intrusion detection, encrypted traffic behavior classification, and ICS network protocol classification, to verify that our scheme can achieve good classification performance at multiple classification levels.
The remainder of this paper is organized as follows: Section 2 reviews related work on traffic classification. Section 3 provides a detailed description of SwiftSession. Section 4 outlines the experimental design and analyzes the results. Finally, we summarize the contributions and discuss directions for future research.
2. Related Works
Traffic classification techniques can be categorized based on their feature sources as follows:
2.1. Packet Feature-Based Methods
The port-based classification method identifies traffic by protocol ports, like TCP port 80 for HTTP. However, in modern networks, the increasing number of non-standard and dynamic ports makes it hard to classify accurately by port numbers [9]. Deep Packet Inspection (DPI) technology deeply analyzes packet payloads to identify complex protocols and applications [10]. However, it performs poorly when handling encrypted traffic and private protocol traffic [11]. Packet feature-based methods either overlook the sequential characteristics within a traffic flow or extract them through intricate procedures [12]. Moreover, packet-based features are more unstable than flow-based features [13].
2.2. Flow-Statistical-Feature-Based Methods
This method classifies traffic by analyzing statistical features like packet size distribution, or inter-arriving time [14]. This method allows large-scale data analysis. Monitoring large enterprise networks can effectively identify abnormal traffic and optimize resource allocation. AppScanner [15] used a support vector classifier (SVC) and random forest (RF) to classify traffic based on 54 features of mobile traffic [3]. Similarly, this method also performs well in network environments like the Internet of Things (IoT) with known malicious traffic characteristics. Shafiq et al. designed a feature-selection metric framework, selected the statistical features of IoT traffic, and used multiple machine learning algorithms to detect malicious traffic [16]. Jurkiewicz et al. centered around the problem of classifying network traffic elephants flows based on the first packet 5-tuple header field using a tree-based classifier [17] along with other classifiers [18] to improve traffic engineering and QoS applications. However, statistical feature analysis requires a large amount of calculation, making it unsuitable for real-time scenarios. Moreover, it needs complex feature engineering. This makes it difficult for small enterprises or organizations with limited resources to implement, as it requires strong hardware and professional expertise.
Sequence feature-based methods view network traffic as time-series data and achieve traffic classification by analyzing the time patterns and behavioral trends [19]. Early research on sequential features focused on Markov chains. Pan et al. classified SSL/TLS encrypted applications by combining the message type and packet length in the HTTPS handshake stage to build a second-order Markov chain model [20]. Liu et al. transformed the original packet length sequence into the length block sequence and trained the Markov model by combining the message type sequences [9]. Recent research has focused on the representation of sequential features and used machine learning methods for classification. Liu et al. proposed FS-Net, extracts feature from the original flow sequence using a multi-layer encoder–decoder structure and introducing a reconstruction mechanism [21]. Xu et al. proposed an ETC-PS method [7], introducing the traffic path and analyzing sequence features that can effectively classify encrypted traffic without decryption. Koumar et al. proposed NetTiSA [22], which uses time-series analysis inside the IP flow exporter to generate 13 known and novel features in the extended IP flow. These methods rely on a substantial number of packets arriving at the station prior to classification, which hinders their application in real-time scenarios. The method proposed in this paper is based only on a small number of the first few packets (less than 10). We also explored the feasibility of using local features for classification in Appendix A.
2.3. Deep Learning Methods
The development of deep learning has also brought new perspectives to traffic classification [23]. Lin et al. developed the ET-BERT model, using the pre-trained BERT architecture to learn traffic representation from many unlabeled data and then fine-tuning a small amount of labeled data for a specific task to achieve accurate traffic classification [24]. Aceto et al. proposed DISTILLER to achieve multimodal and multitask classification of encrypted traffic by capitalizing on the heterogeneity of traffic data [25]. Zhang et al. applied graph neural networks to traffic classification [26]. Huoh et al. further considered the flow features at the GNN [27], which improved the classification accuracy. However, these works require the use of many data packets and are difficult to apply to tasks that are sensitive to classification time, such as intrusion detection.
Some recent work also focuses on real-time classification [12,28,29,30]. Chen et al. used a 0.1 s sliding window to segment the flow, calculated 8-dimensional features, compressed the data length, and then input it into a deep learning model to achieve the online recognition of LTE traffic [31]. However, these works are all based on the fixed first N data packets, and different parameter values are set for different datasets to achieve better results. This characteristic is not conducive to the extended application of the method. The method proposed in this paper extracts local flow features from an incremental perspective, which has greater flexibility.
3. Method
In this section, we will elaborate on the design and training process of the proposed model. The input of this method consists of online or offline traffic packets captured on routers or probes. After preprocessing, the first K (variable depends on the number of data packets in the buffer) packets in the flow were sequentially placed into the flow feature buffer pool (Section 3.1). Subsequently, the local features of some flows in the current buffer pool were extracted (Section 3.2). Then, a cluster of classifiers was used to output the probability of various traffic classifications (Section 3.3). To ensure the classification speed and accuracy, we also introduced path signatures for incrementally calculating sequence features. The architecture of the proposed model with preprocessing is shown in Figure 1.
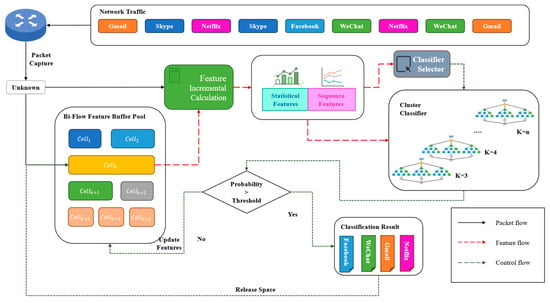
Figure 1.
The architecture of SwiftSession.
3.1. Packet Capture—Session Feature Buffer Pool
To deploy SwiftSession in a real-world environment and achieve the incremental classification of flows, we designed a structure named Session Feature Buffer Pool to temporarily store the features of the arrived data packets of a flow.
As shown in Figure 1, the flow buffer pool contains several cells. corresponds to the flow in the current network environment where data packets have been captured but not yet identified. It stores the features extracted from the captured data packets of the current flow, including the sequential feature and the statistical feature . Whenever a new data packet of this flow was captured, we calculated the new feature incrementally, which is the combination of the previously captured data packets and the current one. The descriptions in the following sections illustrate that such calculation is feasible and consumes a relatively low number of computational resources. Then, we adaptively select the corresponding ML model in the classifier cluster to identify the new flow feature and report a classification accuracy . We set a parameter, the probability threshold , to control the strictness of the method during deployment. The larger the value of τ, the more inclined the method is to obtain more data packets to ensure a higher recognition accuracy. Conversely, the smaller the value of the τ, the more inclined the method is to adopt a more aggressive reporting strategy for a faster classification speed. In practical applications, the threshold can be adjusted to respond to different scenarios flexibly.
When the classification accuracy reported by the classifier cluster is less than τ, the method temporarily stores the new feature in the flow feature buffer pool and waits for the capture of the next data packet belonging to this flow. When the reported accuracy is greater than or equal to τ, the method releases the memory occupied by this cell and reports the classification of the flow (which can be protocol, application, behavior, etc. Experiments in Section 5 proved that our method can classify traffic at multiple granularities).
Regarding memory release, we set a maximum duration and a maximum number of data packets to clear the memory occupied by invalid flows. In the examples in Section 5, the maximum duration is 300 s, and the maximum number of data packets is 10.
3.2. Features Extraction
3.2.1. Statistical Feature
The standard statistical features of network traffic cover multiple dimensions, such as the inter-arrival time of data packets, flow direction (forward or reverse), TCP flag bits (e.g., the PSH flag), etc. Moore et al. proposed over 240 statistical features in their work [32]. However, many of these features are highly correlated and redundant, and the constructed flow data are relatively large, making it difficult to deploy. The method in this paper manually reduces the feature set by screening out redundant features from the 68-dimensional feature set constructed by CICFlowMeter. Then, the Gini coefficient is used to evaluate the classification contribution of each statistical feature. To further broaden the application scope of the feature set, we calculated the Gini gains of the statistical features for the four different datasets mentioned in Section 4.1.2 under different k values (3–10 and all packets) and retained the features whose Gini gains were all greater than 0.2 in the four datasets. Subsequently, we mixed these datasets and independently calculated the Gini gains of the remaining features. Finally, through manual selection, we picked out the 8-dimensional features that exhibited relatively high Gini gains in all datasets and had low computational difficulty and were relatively independent. The selected features and the finally calculated Gini coefficients are shown in Table 1.

Table 1.
Description of feature names.
The Gini calculation process is as follows:
First, for a dataset with categories, the Gini impurity is defined as , where is the proportion of category in the dataset.
Next, for a feature , the dataset is split into subsets according to its value. The Gini gain is defined as , where is the subset divided based on feature .
Incremental Calculation
All the selected features can be calculated incrementally without storing past data packets. Although the examples provided in this paper do not select them, for features that require the calculation of standard deviation, such as pkt_len_std, the Welford algorithm [33] can be used for incremental calculation without additional space consumption for storing data packets.
Mean Calculation
Suppose we have a sequence of data points . The traditional way to calculate the mean is as follows:
Given that the mean of the first data points is , when the -h data point is added, the new mean can be calculated by the formula:
Variance Calculation
For the calculation of the variance , an incremental idea is also adopted. Given that the variance of the first data points is and the mean is , when the -th data point is added, the formula for the variance is as follows:
3.2.2. Sequence Feature
Considering the property that path signatures can be incrementally calculated, the method in this paper introduces path signatures to extract the sequential features of network flows. In practical applications, multiple sequential feature calculation methods, such as Markov chains, can also be applied according to requirements. The sequence feature extraction in this paper process is as follows: After capturing packet , we added the length of this packet to the previous length sequence , generating the updated sequence . In this sequence, indicates that the packet was sent from the client to the server; instead, indicates that the packet was sent from the server to the client.
Inspired by the work of Xu et al. [7], we extend the original sequence to seven dimensions, specifically as follows:
- Packet length sequence : Consists of the absolute values of each packet length in sequence .
- Cumulative byte sequence: The prefix sum of the packet length sequence , that is, .
- Length sequence from the client to the server: Contains all the positive subsequences in sequence .
- Cumulative length sequence from the client to the server: It is the prefix sum of the length sequence , that is, .
- Length sequence from the server to the client: Contains all the negative subsequences in sequence .
- Cumulative length sequence from the server to the client: It is the prefix sum of the length sequence , that is, .
Furthermore, to enhance the distinguishability of the calculated traffic path features, we introduced the time interval sequence IT between packets and the FLAGS field of the TCP protocol within the packet header field to calculate the sequence features. Eventually, after eliminating the redundant SL, we utilized a seven-dimensional sequence to calculate the traffic path features: IT, FLAGS, CS, U, CU, P, and CP. Table 2 presents an example of the extended sequence of the first ten packets of a VPN chat flow. This dimensional feature path was used to calculate the path signature.
Table 2.
Examples of sequential features.
The following is a brief introduction to the path signature method and its incremental calculation method. For the specific details of the path signature, please refer to the paper of [34]:
Path signatures are a feature extraction method that encodes linear and nonlinear interactions [35]. The feature vectors generated by this method have a fixed length independent of the number of data input points or sampling interval. As a mathematical tool, path signatures have significant applications in various fields, including stochastic analysis, machine learning, and differential geometry [2,4,36,37,38]. For a continuous path , the path signature is an infinitely long sequence of the path, with each order’s signature terms composed of the following:
Let be a d-dimensional path, and represents the value of the path at time .
The -th level part , is defined as follows:
where represents the tensor product.
Since the path signature is an infinitely long sequence, the signature terms of the N-th order and prior to it in the sequence are usually taken as representatives. This new sequence is known as the N-th order truncated path signature. In addition, we adopted the method in Paper [35] to achieve the incremental calculation of path signatures.
3.2.3. Feature Fusion
As shown in the structure diagram, to accelerate the calculation speed of the method in this paper, we use the splicing method to fuse the sequence feature and the statistical features to obtain the final feature. The fusion process is expressed by the following formula:
Here, “” is used to denote the concatenation of the preceding vector and the succeeding vector.
As described in the previous two subsections, since both the sequence features and statistical features used to form the fusion features can be incrementally calculated, the fusion features also support incremental calculation. This means that all the features used in the method of this paper can be calculated in real time based on the captured data packets without the need to store the data packets. In addition, in this paper, all features are column normalization. Z-Score Normalization is used to standardize the features to reduce the impact of outliers and adapt to the online traffic identification mode.
3.3. Traffic Classification—Cluster of Classifiers
To flexibly classify features under different numbers of packets, we set up a classifier cluster in SwiftSession to ensure more accurate classification when different numbers of data packets were captured. As shown in the structure Figure 1, the cluster classifier consists of models trained with the data of different numbers of packets, where the value of depends on the maximum number of packets.
During the training phase, SwiftSession obtained different feature sets with from the same training set and trained them, respectively, to obtain classification models. Each model classifies the features of the first data packets of flow, which means our models can achieve better performance during the classification phase.
During the classification phase, we set up a model selector in the classifier cluster. This simple structure can match the features obtained from the flow feature buffer pool to the corresponding model, selecting the appropriate model for classification, without consuming additional computational performance. For each classifier, the method utilizes an incremental computation method, extracting features from the first packets upon receiving the -th packet. The system dynamically determines whether to continue packet collection or output classification results based on classifier confidence, optimizing accuracy, and computational resource utilization.
SwiftSession employs a confidence-based decision mechanism for classification. Each classifier outputs a probability distribution vector , where represents the probability of the -th traffic category, with . When the maximum probability exceeds a predefined threshold, the system terminates packet collection and outputs the classification result; otherwise, it continues collecting packets for further analysis. In a binary-classification environment with two classes, A and B, the probability threshold is set at 0.8. When an unclassified flow has its initial 3rd data packet captured, the classifier outputs a probability distribution of [0.6 (A), 0.4 (B)]. Given that the maximum probability of 0.6 is less than 0.8, the system proceeds to capture the 4th data packet. After processing this packet, the classifier generates a new distribution of [0.9 (A), 0.1 (B)]. Since the classification probability of 0.9 is greater than 0.8, once the maximum probability exceeds the predefined threshold, the system halts the collection of data packets and outputs the classification result as Class A.
4. Experiment
To verify the effectiveness of the proposed SwiftSession method, we designed a series of experiments that included verifying the incremental classification strategy and comparing it with existing methods. All experiments were carried out on a computer with an AMD Ryzen 7 3.20 GHz processor, 32 GB RAM, 64-bit Windows 11, and a 12 GB GeForce GTX 4060. We utilized the Scikit-learn library (version 1.4.1) [39] and the XGBoost library (version 2.1.1). Note that, for each dataset, we used a ratio of 0.6:0.2:0.2 for the training set, validation set, and test set splits and retrained all methods individually on each dataset. After the division, we extracted the features with different values of k, respectively, and conducted training.
4.1. Experimental Set Up
4.1.1. Feature Fusion
This experiment evaluated the proposed method from two aspects: classification accuracy and speed. For traffic classification accuracy, we use accuracy (), precision (), recall (), and F1-score () as metrics. Accuracy assesses the overall correctness of classification results, while precision and recall measure the model’s ability to identify and cover the target category correctly. The F1-score, which combines precision and recall, provides a balanced evaluation of the model’s classification performance. The formulas are as follows:
where represent true positives, true negatives, false positives, and false negatives, respectively.
For multi-class classification tasks, all metrics are calculated using the weighted average method. Let be the number of classes, be the weight of the -th class, , and be the number of true positives, false positives, and false negatives of the -th class, respectively.
In SwiftSession, traffic classification speed is measured by method classification time, which depends on the number of packets received before the result. Assuming packets are received, the classification time is as follows:
where , , represent time from the first packet’s arrival to the -th packet’s arrival, feature extraction time after the -th packet, inference time for the -th packet, and decision time for the -th classification, respectively (assuming is greater than ).
Since the number of packets varies in different SwiftSession sessions, we introduce the “average arrival time” metric to represent the average time of packet arrival when the final classification is made.
For other methods, the classification time is as follows:
where represents session duration between the first and the last packet when classification is possible, feature extraction time, and inference time based on features, respectively (In this study, session duration, which is much longer than , is used as the traffic classification time for the comparison methods. Different methods use varying numbers of packets: ETC-PS uses 40, while FineWP and FS-Net use 32 session packets. The session duration for comparison is determined accordingly).
4.1.2. Benchmark Test Dataset
To verify the effectiveness of the method proposed in Section 3 and its ability to perform multi-granularity classification well, we selected the following datasets for experiments, which included multi-classification tasks: protocol classification (ICSC Dataset), user behavior classification (ISCX dataset), and intrusion detection (MQTT-IDS). It should be noted that only MQTT-IDS pertains to binary classification. In contrast, the remaining datasets are involved in multi-class classification tasks:
- Self-established industrial control dataset (ICSC Dataset)
The industrial control Internet has high requirements for the time of network protocol classification. In this paper, the dataset established by Zhai et al. in 2020 [40] is used. In addition, following their method, we supplement some traffic data of ICS protocols based on the original dataset. The supplementary data include the benign part of the following sites from 2020 to 2025: Netresec [41], TriStation [42], AWS Cloud [43], NREL [44], ITHACA [45], the Electra power system control traffic dataset [46], IEC datasets [47], and the Modbus dataset from CEST16 [48]. These sources provided updated industrial control network traffic data from 2020 to 2025. The dataset includes both annotated and unannotated traffic data. Tshark was utilized to label the unlabeled traffic data with protocol information. Table 3 provides statistical details of the ICSC dataset.
Table 3.
Protocol statistics in ICSC dataset.
- MQTT-IoT-IDS-2020 [49]
Intrusion detection is also one of the tasks with high requirements for classification time. MQTT is one of the most used protocols on the Internet of Things. In this paper, a binary classification task is carried out on this dataset. We labeled each flow according to the author’s instructions in the document.
- ISCX Datasets
In addition, to verify that our method can also be applied to encrypted traffic classification, we selected two well-known datasets. Although these two datasets were established in 2016, there has still been a lot of research work conducted on them recently, such as the studies of [7,12,22,24,25,26,27].
ISCX VPN-nonVPN 2016 (Referred to as VPN Dataset) [50]: This dataset, well recognized in the traffic classification research community, comprises 150 PCAP files totaling 28.0 GB. We based text to classify it into 11 categories: Chat, Email, File Transfer, Streaming, VoIP, VPN Chat, VPN Email, VPN File Transfer, VPN Streaming, VPN VoIP, and VPN Torrent.
ISCX Tor-nonTor 2016 (Referred to as Tor Dataset) [51]: This dataset includes 85 PCAP files, totaling 22.8 GB. We based text to classify it into 12 categories: Browsing, Chat, Email, File Transfer, Streaming, Tor Browsing, Tor Chat, Tor Email, Tor File Transfer, Tor Streaming, Tor VoIP, and VoIP.
4.1.3. Data Preprocessing
For all datasets, in our experiments, we removed data packet flows with less than three packets. We considered such sessions too short to play a role in the transmission process, so they were not worthy of consideration. At the same time, we excluded the data packets from the first two handshakes in the TCP three-way handshake. For all datasets, we used the SplitCap tool [52] to split them into the form of files for each session.
4.2. Parameter Optimization
4.2.1. Threshold Search
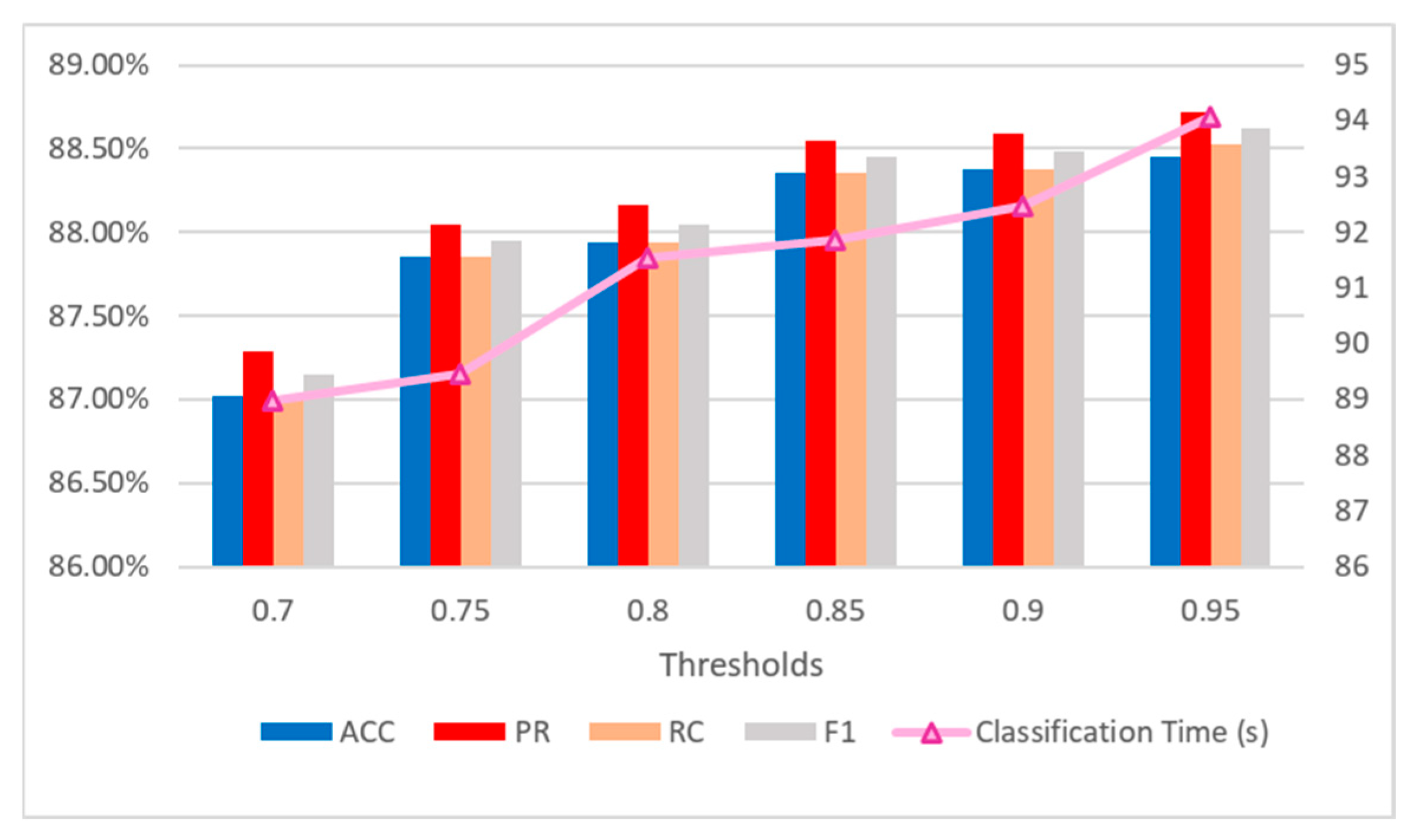
This section compares the traffic classification accuracy and speed when the incremental strategy is adopted, and the threshold varies from 70% to 95%. The aim is to evaluate the impact of these thresholds on the algorithm’s performance. XGBoost is used as the benchmark classifier, taking the VPN-nonVPN dataset as an example. The analyzed indicators include classification accuracy, precision, recall, F1-score, and classification time. The detailed results are shown in Figure 2.
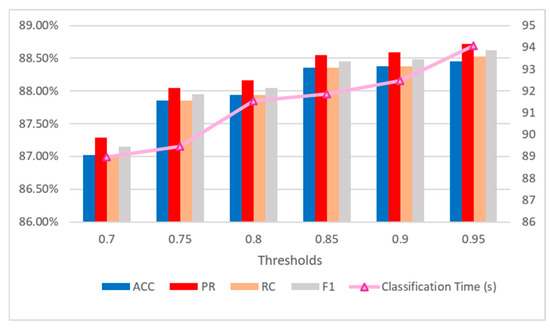
Figure 2.
Classification performance with different confidence thresholds in the incremental strategy.
Overall, it is evident from the experimental results presented in the tables that adjusting the confidence threshold has a significant impact on traffic classification, accuracy, and speed. Both classification accuracy and classification time are positively correlated with the threshold, which is consistent with the inference we provided in Section 3. Taking all factors into comprehensive consideration, it is more appropriate to select a confidence threshold in the range of 0.8 to 0.9. Although a threshold lower than 0.8 may result in a faster speed, it may reduce the accuracy. In contrast, a threshold higher than 0.9 can improve accuracy in some cases, but it is likely to cause excessive data packet processing and an extension of waiting time. Considering both the classification time and classification accuracy, the threshold used in the following examples in this paper is 85%.
In addition, we also list in Table 4 the changes in the average number of data packets when different thresholds are used to obtain the classification results of the method in the VPN dataset. As the threshold increases, an increasing number of flows are classified by classifiers with larger K-values. As can be seen from the experiments in Section 4.4, classifiers with larger K-values have a higher classification accuracy compared to those with lower K-values. Therefore, as the threshold increases, the classification accuracy is correspondingly enhanced.
Table 4.
The average number of packets awaited when classification results are given.
4.2.2. ML Classifier Selection
SwiftSession assesses various machine learning models to identify the optimal classifier, including Random Forest (RF), Extremely Randomized Trees (ET), C4.5, and XGBoost which are commonly used classifiers in traffic classification.
These models exhibit strong performance in real-time classification tasks. The final selection is based on a thorough operational efficiency evaluation, classification accuracy, and resource consumption. The comprehensive benchmarking of accuracy, speed, and resource utilization informs the choice of the optimal classifier.
Details of the classifier’s hyperparameters and the average size after training on four datasets are shown in Table 5. Hyperparameters not mentioned in the table adopt default values. After comprehensive evaluation, we found that XGBoost achieved relatively good results and performance. We also list the classification results and classification times of each classifier on the VPN dataset in Table 5 for reference. Therefore, the XGBoost model was selected for subsequent comparative experiments.
Table 5.
Hyperparameters and size of ML classifiers.
4.3. Comparison with Existing Methods
This section provides a comprehensive comparison of the classification accuracy and time of SwiftSession against four representative methods across three datasets, assessing the advantages and disadvantages of SwiftSession relative to current mainstream approaches. The selected comparison algorithms are all notable for their classification performance, computational efficiency, and applicability to diverse datasets.
FSNet: An efficient encrypted traffic classifier based on GRU [21], FSNet embeds the raw packet sequences of flows and utilizes a double-layer bidirectional GRU to extract deep features.
ETC-PS: This method classifies encrypted traffic based on path signature features [7]. ETC-PS constructs traffic paths to represent bidirectional client–server interactions, utilizing only packet length information within sessions.
FineWP: A fine-grained webpage fingerprinting method that utilizes only packet-length information from encrypted traffic [53]. This classifier extracts critical features from the uplink-dominant stage, including block and sequence features.
ITCT Transformer: Based on the Tab Transformer architecture [54], it classifies IoT traffic through unique feature processing and attention mechanisms.
The specific experimental results are shown in Table 6. In the experiment on the VPN-nonVPN dataset, SwiftSession (XGBoost) demonstrated outstanding performance. It far exceeded other methods in terms of accuracy and recall and had a relatively short classification time, thus showing significant advantages in both efficiency and accuracy. In contrast, FineWP had a relatively low precision rate, indicating a potential for many misjudgments. The performance of FSNet and ETC-PS was at a medium level, and all three of them had relatively long classification times.
Table 6.
Comparison experiment results.
For the Tor-nonTor dataset, SwiftSession (XGBoost) still maintained a high standard, with almost perfect indicators in all aspects, and its classification time was significantly shorter. ETC-PS also showed good performance and could effectively identify categories. However, FineWP had a relatively low recall rate, which might lead to missing many true categories, and the overall performance of FSNet was relatively weak.
In the ICSC-Dataset, both ETC-PS and SwiftSession (XGBoost) exhibited extremely high classification accuracy. SwiftSession (XGBoost) had a significant advantage in classification time, as it was much faster than other methods.
In the experiment on the MQTT-IDS-2020 dataset, SwiftSession (XGBoost) was significantly higher than the ITCT Transformer in both accuracy and recall. Although their classification times were similar, SwiftSession (XGBoost) was superior in terms of accuracy.
Based on the experimental results of various datasets, SwiftSession (XGBoost) has the advantages of high accuracy and fast classification on multiple datasets and thus has greater potential in practical applications. ETC-PS has high accuracy in some datasets, but its classification time needs to be optimized. The performance of FSNet and FineWP is relatively unstable, and their classification times are generally long. Although the ITCT Transformer has a short classification time, its accuracy is relatively low. Future research could focus on improving the time efficiency and accuracy of other methods to meet the requirements of more application scenarios.
4.4. Verification of Incremental Classification Strategy
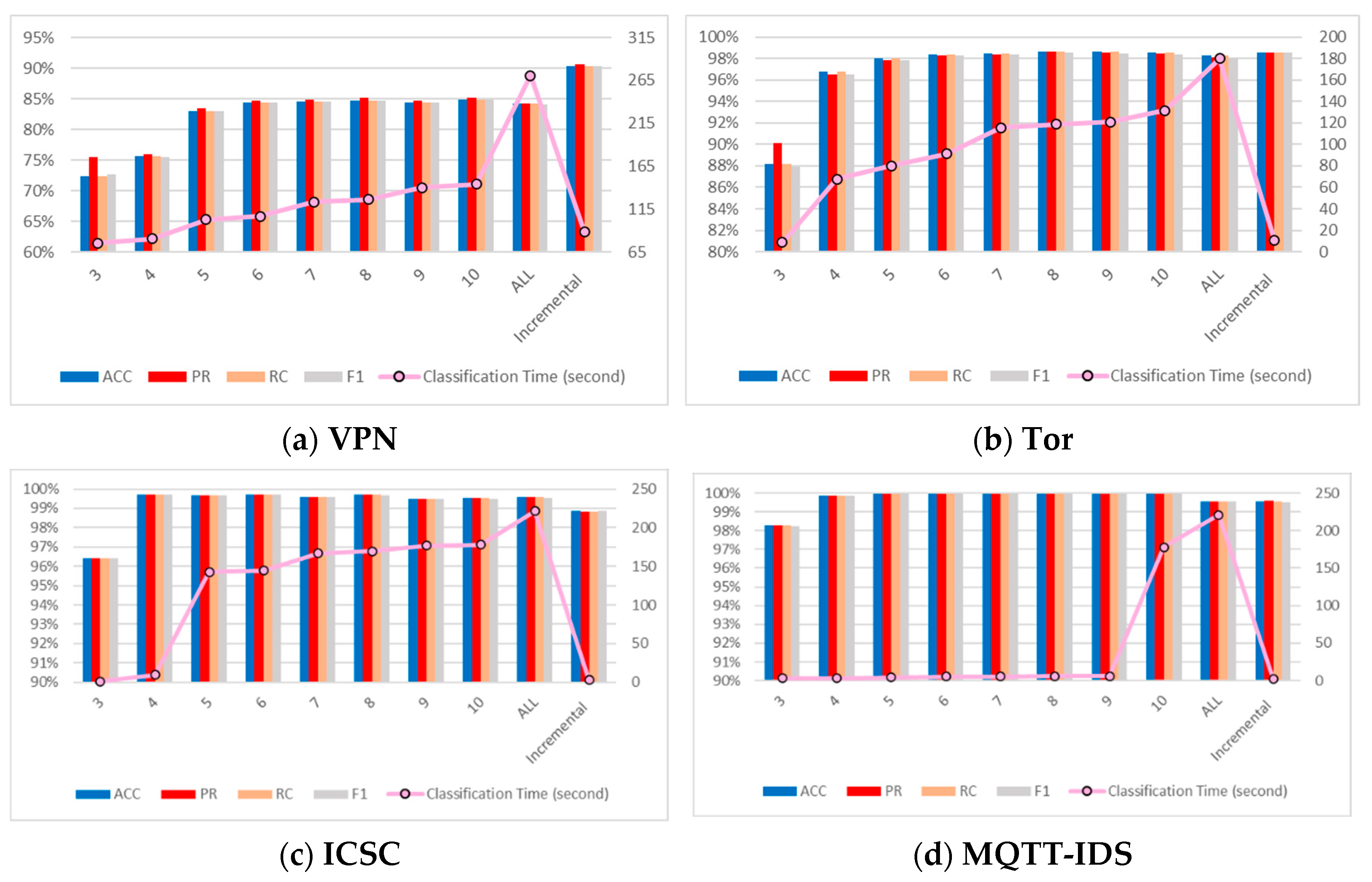
In this experiment, for the four datasets of ICSC, VPN, TOR, and MQTT, by varying the value of K (the number of data packets) and applying the incremental calculation method, we evaluated the performance indicators of the classification strategy, including ACC, PR, RC, F1, as well as the classification time, to verify the relevant theoretical conclusions. The experimental results are shown in Figure 3.
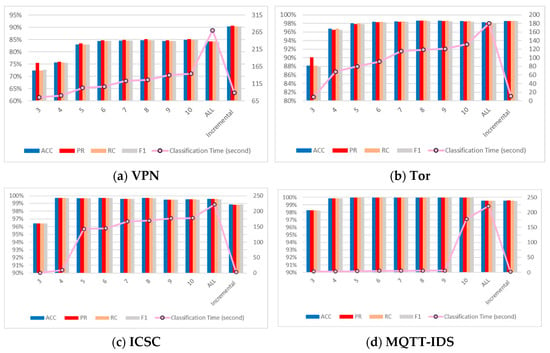
Figure 3.
Experimental results of different K values and incremental method.
In each dataset, as the value of K increases from 3 to 10, the classification accuracy indicators generally show an upward trend or remain stable at a high level, indicating that an increase in the number of data packets helps to ensure or improve the classification accuracy. When all data packets are used, the accuracy indicators show a slight decline in some datasets, possibly due to the introduction of complex factors resulting from the excessive data volume but remain at a relatively high level overall.
In datasets such as ICSC and MQTT, the incremental method demonstrates slightly reduced performance for high-K-value scenarios compared to fixed-K classifiers. This phenomenon primarily stems from its inherent tendency to make classification decisions at lower K values, as evidenced by Table 4 showing an average consumption of 4–5 data packets per classification—indicating that most determinations occur by the third packet. When the third-packet classifier produces suboptimal results despite showing high confidence probabilities, the incremental approach underperforms relative to classifiers employing larger K values (e.g., 7, 8, 9), though the performance disparity remains marginal at less than 1%. Crucially, this minor limitation does not diminish the incremental method’s significant advantages over fixed-K-value approaches, as it successfully maintains an optimal balance between rapid classification speed (achieving decisions in 3–5 packets) and sustained high accuracy across various operational scenarios.
In addition, on the four datasets, the accuracy indicators obtained by the incremental method are comparable to those at a high K value and are even better in some datasets. The classification time, compared with that at a high K value, is significantly shortened, with the maximum time being no more than 90% of the classification time at a high K value, greatly improving the classification efficiency. The experiments conducted on these four datasets have comprehensively validated the theory concerning the influence of the incremental method on classification performance and time. As the K value increases, more packet information is utilized for classification, resulting in an increase in classification time. The classification accuracy stabilizes when the K value reaches a certain point. In contrast, the incremental method not only ensures a high accuracy rate but also features an extremely rapid classification speed, demonstrating remarkable advantages across different datasets. This provides a solid foundation for the selection of classification strategies and offers an efficient solution for large-scale data classification.
5. Discussion
The experiments assessed the performance of various feature selection methods and classification strategies across the VPN, Tor, and ICSC traffic datasets. Based on the previous results and analyses, the following key conclusions can be drawn:
(1) Balanced Confidence Levels for Practical Applications
Increasing the confidence threshold enhances classification accuracy for VPN traffic, whereas classification accuracy for Tor and ICSC traffic remains stable across confidence levels. Notably, classification time for Tor and ICSC traffic at a 100% confidence level significantly increases, indicating that excessively high thresholds can reduce processing efficiency. It is crucial to balance classification accuracy and processing efficiency in practical applications, adapting the confidence threshold according to specific requirements. For scenarios demanding high classification accuracy, the threshold can be increased, but considerations regarding efficiency must be made. Conversely, in cases where processing efficiency is paramount, high confidence thresholds should be avoided to maintain system responsiveness.
(2) Advantages of the Incremental Strategy
The incremental strategy balances classification accuracy and speed more effectively than the fixed K-value method. This approach optimizes classification performance in response to real-time traffic variations by dynamically adjusting the K value. This method achieves a favorable combination of high classification accuracy and reduced classification time across datasets, particularly in VPN and ICSC datasets, where classification accuracy is nearly at the maximum level of the fixed K-value approach but with significantly less time required. The flexibility of the incremental strategy allows it to adapt to changing traffic conditions, overcoming limitations inherent in fixed K-value methods. Additionally, it reduces redundant computations and enhances processing efficiency, making it particularly beneficial for large-scale traffic data processing.
(3) Performance of SwiftSession in Real-Time Scenarios
SwiftSession demonstrates superior classification accuracy and speed performance compared to existing methods. Future research should investigate the potential of SwiftSession to enhance classification accuracy across different traffic types while preserving its time efficiency, exploring combinations with advanced algorithms for improved performance.
(4) Limitations of the SwiftSession Method
SwiftSession’s performance may be challenging in complex network environments with diverse applications and protocols. While it performs well in the tested datasets, it may need help with traffic that exhibits convoluted patterns or diverges significantly from the training data. For example, networks with numerous custom-built applications may present challenges for the statistical and sequential features utilized by SwiftSession, leading to potential misclassifications. Additionally, as network traffic volume continues to grow exponentially, the scalability of SwiftSession must be further evaluated. Despite the incremental strategy easing computational burdens, the real-time handling of massive traffic data may still need to be improved, particularly during peak influxes. This could impact the method’s real-time performance, which is a crucial advantage. The method and its advantages discussed in this paper are applicable to environments with long flows (More than four packets). It is not capable of classifying small flows effectively.
Future Work
In future research work, the following aspects can be explored:
- Consider performing feature extraction at intervals of every data packet, and explore the effectiveness and performance of feature extraction under this approach.
- In the machine-learning model part, select a model with a wider recognition ability to reduce the model’s space consumption and improve its operational efficiency.
- Conduct in-depth research and introduce more advanced feature extraction techniques. Meanwhile, explore the technology for automatically selecting statistical features in different environments to enhance the system’s adaptability in complex environments.
6. Conclusions
This paper introduces SwiftSession, a flow recognition method that concurrently extracts sequential and statistical features from original flow sequences to classify traffic flows. SwiftSession incrementally models flow based on the initial K packets, utilizing path signatures to compute sequential features and integrating statistical features from these packets for classification. The combination of statistical and sequential features enables SwiftSession to effectively capture representative information, thereby enhancing classification performance. Additionally, leveraging the initial packets contributes to the method’s efficiency in practical applications. Our validation on real-world network datasets shows that SwiftSession achieves exceptional classification capabilities.
Author Contributions
Formal analysis, Q.Z.; investigation, Q.Z. and X.Q.; methodology, Q.Z.; software, T.X., H.Y. and Z.S.; validation, G.X.; writing—original draft, T.X.; writing—review and editing, Q.Z., T.W., H.Y., C.C. and Z.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported in part by the Key Research Project of Zhejiang Province, China (No. 6692023C01025).
Data Availability Statement
The self-built ICSC dataset in our study can be viewed on the website https://github.com/XiTieqi/SwiftSession (accessed on 27 February 2025).
Conflicts of Interest
The funders had no role in the design of this study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| DPI | Deep Packet Inspection |
| SVC | Support vector classifier |
| RF | Random forest |
| ML | Machine learning |
Appendix A. Local Feature
Network traffic classification methods usually depend on many data packets’ statistical and sequential features. Although this approach guarantees high classification accuracy, it is often time consuming as it requires processing the many traffic data. In practical applications like network security and traffic management, rapid traffic identification is essential, and the reducing of classification time is a critical issue.
Recent studies have proposed classifying network traffic based on early packets to address this challenge, extracting features from only the initial few packets of a session (excluding the three-way handshake) [55]. However, these methods face two main limitations. First, they must explain why early packets are sufficient for traffic classification. Second, they need more insight into the performance differences between early-packet and full-packet classification regarding statistical and sequential features, constraining the further development of early-packet-based techniques.
Our work aims to bridge these gaps by thoroughly analyzing the feature variations at different session stages across multiple datasets. It focuses on the statistical and sequential feature differences between early packets and total traffic, demonstrating how features from early packets can effectively distinguish among application types in a session’s initial phase. Additionally, it examines the impact of these differences on classification performance. Our analysis sampled a specific traffic type from the ISCX VPN-nonVPN dataset, calculating statistical features for both early packets and the entire packet sequence, as shown in Table A1 and Table A2.
- Flow Duration: In the early stage of flow, VPN chat apps have a wide flow duration range (0.14–30 s), while other apps like chat, email, and FTP are steadier. For all packets, overall differences narrow, but VPN chat has more internal changes due to encryption.
- Data Transmission Rate: In the early stage of streaming, streaming apps transmit data at a speed of approximately 22 MB/s, which is much higher than that of email (40 KB/s) and FTP (19 KB/s). In the middle stage of streaming, the rate differences between FTP and torrent apps narrow, while chat apps maintain a relatively high rate.
Table A1.
Partial statistical features of network traffic based on the first 5 packets.
Table A1.
Partial statistical features of network traffic based on the first 5 packets.
| flow_duration | flow_byts_s | pkt_size_mean | flow_iat_mean | Label |
|---|---|---|---|---|
| 0.10 | 2426.92 | 80.67 | 0.0499 | VoIP |
| 0.22 | 1099.92 | 80.67 | 0.1100 | VoIP |
| 2.40 | 174.18 | 139.33 | 1.1999 | VPN Chat |
| 30.00 | 6.00 | 60.00 | 15.0000 | VPN Chat |
| 0.05 | 7261.71 | 116.67 | 0.0241 | |
| 0.05 | 13,023.78 | 228.33 | 0.0263 | |
| 0.0007 | 19.72 | 80.00 | 0.0004 | File transfer |
| 0.0013 | 18.48 | 240.33 | 0.0007 | File transfer |
| 0.07 | 6128.84 | 138.67 | 0.0339 | Streaming |
| 0.04 | 23,487.33 | 284.67 | 0.0182 | Streaming |
Table A2.
Statistical features of network traffic based on the full session.
Table A2.
Statistical features of network traffic based on the full session.
| flow_duration | flow_byts_s | pkt_size_mean | flow_iat_mean | Label |
|---|---|---|---|---|
| 329.49 | 3.34 | 100.18 | 32.9489 | VoIP |
| 329.49 | 3.34 | 100.18 | 32.9489 | VoIP |
| 436.69 | 61.46 | 135.55 | 2.2167 | VPN Chat |
| 600.17 | 4.54 | 64.83 | 14.6382 | VPN Chat |
| 1.98 | 4252.05 | 240.71 | 0.0583 | |
| 1.18 | 4156.22 | 153.47 | 0.0381 | |
| 701.55 | 11.55 | 117.42 | 10.3169 | File transfer |
| 0.01 | 13,622.71 | 1000.95 | 0.0001 | File transfer |
| 0.17 | 35,446.63 | 373.31 | 0.0112 | Streaming |
| 61.65 | 194.83 | 800.80 | 4.404 | Streaming |
- Packet Size: In the early stage of streaming, the average packet length of streaming apps is about 200 bytes, and the packet size range of file-transfer apps is quite wide. As time goes by, the differences in packet size among different apps increase, as is the case with email apps.
- Inter-Arrival Time: In the early stage of streaming, file-transfer apps have the shortest packet inter-arrival time (about 0.0005 s), and the inter-arrival time of VPN chat apps fluctuates. During the entire session, for apps like VOIP, the inter-arrival time within the app also varies.
In summary, early packet features help quickly identify app types as they reflect initial traits. On the other hand, all-packet features capture apps’ dynamic behaviors over time to understand their patterns.
The features of early packets accurately reflect the initial transmission characteristics, making them ideal for quickly identifying applications. In contrast, the features derived from all packets capture the dynamic behaviors of applications over time, making them more suitable for recognizing application behaviors.
References
- Moore, A.W.; Papagiannaki, K. Toward the Accurate Identification of Network Applications. In Proceedings of the Passive and Active Network Measurement, Boston, MA, USA, 31 March–1 April 2005; Dovrolis, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 41–54. [Google Scholar]
- Cheng, J.; Shi, D.; Li, C.; Li, Y.; Ni, H.; Jin, L.; Zhang, X. Skeleton-Based Gesture Recognition with Learnable Paths and Signature Features. IEEE Trans. Multimed. 2024, 26, 3951–3961. [Google Scholar] [CrossRef]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. Robust Smartphone App Identification via Encrypted Network Traffic Analysis. IEEE Trans. Inf. Forensics Secur. 2018, 13, 63–78. [Google Scholar] [CrossRef]
- Barcelos, L.; Lai, T.; Oliveira, R.; Borges, P.; Ramos, F. Path signatures for diversity in probabilistic trajectory optimisation. Int. J. Robot. Res. 2024, 43, 1693–1710. [Google Scholar] [CrossRef]
- Chen, K.-T. Integration of Paths—A Faithful Representation of Paths by Noncommutative Formal Power Series. Trans. Am. Math. Soc. 1958, 89, 395–407. [Google Scholar] [CrossRef]
- Wu, H.; Wu, Q.; Cheng, G.; Guo, S.; Hu, X.; Yan, S. SFIM: Identify User Behavior Based on Stable Features. Peer-to-Peer Netw. Appl. 2021, 14, 3674–3687. [Google Scholar] [CrossRef]
- Xu, S.-J.; Geng, G.-G.; Jin, X.-B.; Liu, D.-J.; Weng, J. Seeing Traffic Paths: Encrypted Traffic Classification with Path Signature Features. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2166–2181. [Google Scholar] [CrossRef]
- Li, B.; Springer, J.; Bebis, G.; Hadi Gunes, M. A Survey of Network Flow Applications. J. Netw. Comput. Appl. 2013, 36, 567–581. [Google Scholar] [CrossRef]
- Karagiannis, T.; Broido, A.; Faloutsos, M.; Claffy, K. Transport Layer Identification of P2P Traffic. In Proceedings of the 4th ACM SIGCOMM Conference on Internet Measurement, Taormina Sicily, Italy, 25–27 October 2004; Association for Computing Machinery: New York, NY, USA; pp. 121–134. [Google Scholar]
- De La Torre Parra, G.; Rad, P.; Choo, K.-K.R. Implementation of Deep Packet Inspection in Smart Grids and Industrial Internet of Things: Challenges and Opportunities. J. Netw. Comput. Appl. 2019, 135, 32–46. [Google Scholar] [CrossRef]
- Cheng, J.; He, R.; Yuepeng, E.; Wu, Y.; You, J.; Li, T. Real-Time Encrypted Traffic Classification via Lightweight Neural Networks. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Velan, P.; Medková, J.; Jirsík, T.; Čeleda, P. Network Traffic Characterisation Using Flow-Based Statistics. In Proceedings of the NOMS 2016—2016 IEEE/IFIP Network Operations and Management Symposium, Istanbul, Turkey, 25–29 April 2016; pp. 907–912. [Google Scholar]
- Azab, A.; Khasawneh, M.; Alrabaee, S.; Choo, K.-K.R.; Sarsour, M. Network Traffic Classification: Techniques, Datasets, and Challenges. Digit. Commun. Netw. 2024, 10, 676–692. [Google Scholar] [CrossRef]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. AppScanner: Automatic Fingerprinting of Smartphone Apps from Encrypted Network Traffic. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016; pp. 439–454. [Google Scholar]
- Shafiq, M.; Tian, Z.; Bashir, A.K.; Du, X.; Guizani, M. CorrAUC: A Malicious Bot-IoT Traffic Detection Method in IoT Network Using Machine-Learning Techniques. IEEE Internet Things J. 2021, 8, 3242–3254. [Google Scholar] [CrossRef]
- Jurkiewicz, P.; Kadziołka, B.; Kantor, M.; Wójcik, R.; Domżał, J. Elephant Flow Detection with Random Forest Models under Programmable Network Dataplane Constraints. IEEE Access 2024, 12, 158561–158578. [Google Scholar] [CrossRef]
- Jurkiewicz, P.; Kadziołka, B.; Kantor, M.; Domżał, J.; Wójcik, R. Machine Learning-Based Elephant Flow Classification on the First Packet. IEEE Access 2024, 12, 105744–105760. [Google Scholar] [CrossRef]
- Panchenko, A.; Lanze, F.; Pennekamp, J.; Engel, T.; Zinnen, A.; Henze, M.; Wehrle, K. Website Fingerprinting at Internet Scale. In Proceedings of the NDSS’16, San Diego, CA, USA, 21–24 February 2016. [Google Scholar]
- Pan, W.; Cheng, G.; Tang, Y. WENC: HTTPS Encrypted Traffic Classification Using Weighted Ensemble Learning and Markov Chain. In Proceedings of the 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, Australia, 1–4 August 2017; pp. 50–57. [Google Scholar]
- Liu, C.; Cao, Z.; Xiong, G.; Gou, G.; Yiu, S.-M.; He, L. MaMPF: Encrypted Traffic Classification Based on Multi-Attribute Markov Probability Fingerprints. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–10. [Google Scholar]
- Liu, C.; He, L.; Xiong, G.; Cao, Z.; Li, Z. FS-Net: A Flow Sequence Network For Encrypted Traffic Classification. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1171–1179. [Google Scholar]
- Koumar, J.; Hynek, K.; Pešek, J.; Čejka, T. NetTiSA: Extended IP Flow with Time-Series Features for Universal Bandwidth-Constrained High-Speed Network Traffic Classification. Comput. Netw. 2024, 240, 110147. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. Mobile Encrypted Traffic Classification Using Deep Learning: Experimental Evaluation, Lessons Learned, and Challenges. IEEE Trans. Netw. Serv. Manag. 2019, 16, 445–458. [Google Scholar] [CrossRef]
- Lin, X.; Xiong, G.; Gou, G.; Li, Z.; Shi, J.; Yu, J. ET-BERT: A Contextualized Datagram Representation with Pre-Training Transformers for Encrypted Traffic Classification. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 633–642. [Google Scholar]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. DISTILLER: Encrypted Traffic Classification via Multimodal Multitask Deep Learning. J. Netw. Comput. Appl. 2021, 183–184, 102985. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, L.; Xiao, X.; Li, Q.; Mercaldo, F.; Luo, X.; Liu, Q. TFE-GNN: A Temporal Fusion Encoder Using Graph Neural Networks for Fine-Grained Encrypted Traffic Classification. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; Association for Computing Machinery: New York, NY, USA; pp. 2066–2075. [Google Scholar]
- Huoh, T.-L.; Luo, Y.; Li, P.; Zhang, T. Flow-Based Encrypted Network Traffic Classification with Graph Neural Networks. IEEE Trans. Netw. Serv. Manag. 2023, 20, 1224–1237. [Google Scholar] [CrossRef]
- Pashamokhtari, A.; Batista, G.; Gharakheili, H.H. Efficient IoT Traffic Inference: From Multi-View Classification to Progressive Monitoring. ACM Trans. Internet Things 2023, 5, 1–30. [Google Scholar] [CrossRef]
- Pinto, D.; Vitorino, J.; Maia, E.; Amorim, I.; Praça, I. Flow Exporter Impact on Intelligent Intrusion Detection Systems 2024. arXiv 2024, arXiv:2412.14021. [Google Scholar]
- Trinh, H.D.; Fernández Gambín, Á.; Giupponi, L.; Rossi, M.; Dini, P. Mobile Traffic Classification through Physical Control Channel Fingerprinting: A Deep Learning Approach. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1946–1961. [Google Scholar] [CrossRef]
- Chen, Y.; Tong, Y.; Hwee, G.B.; Cao, Q.; Razul, S.G.; Lin, Z. Real-Time Traffic Classification in Encrypted Wireless Communication Network. In Proceedings of the 2023 IEEE International Symposium on Circuits and Systems (ISCAS), Monterey, CA, USA, 21–25 May 2023; pp. 1–5. [Google Scholar]
- Moore, A.W.; Zuev, D. Internet Traffic Classification Using Bayesian Analysis Techniques. SIGMETRICS Perform. Eval. Rev. 2005, 33, 50–60. [Google Scholar] [CrossRef]
- Efanov, A.A.; Ivliev, S.A.; Shagraev, A.G. Welford’s Algorithm for Weighted Statistics. In Proceedings of the 2021 3rd International Youth Conference on Radio Electronics, Electrical and Power Engineering (REEPE), Moscow, Russia, 11–13 March 2021; pp. 1–5. [Google Scholar]
- Chevyrev, I.; Kormilitzin, A. A Primer on the Signature Method in Machine Learning 2016. arXiv 2016, arXiv:1603.03788. [Google Scholar]
- Zhou, S. Signatures, Rough Paths and Applications in Machine Learning. Bachelor’s Thesis, Utrecht University, Utrecht, The Netherlands, 2019. [Google Scholar]
- Gyurkó, L.G.; Lyons, T.; Kontkowski, M.; Field, J. Extracting Information from the Signature of a Financial Data Stream. arXiv 2014, arXiv:1307.7244. [Google Scholar]
- Xu, X.; Lee, D.; Drougard, N.; Roy, R.N. Signature Methods for Brain-Computer Interfaces. Sci. Rep. 2023, 13, 21367. [Google Scholar] [CrossRef] [PubMed]
- Yin, Z.; Ding, X.; Zhang, X.; Wu, Z.; Wang, L.; Xu, X.; Li, G. Early Autism Diagnosis Based on Path Signature and Siamese Unsupervised Feature Compressor. Cereb. Cortex 2024, 34, 72–83. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zhai, L.; Zheng, Q.; Zhang, X.; Hu, H.; Yin, W.; Zeng, Y.; Wu, T. Identification of Private ICS Protocols Based on Raw Traffic. Symmetry 2021, 13, 1743. [Google Scholar] [CrossRef]
- SCADA/ICS PCAP Files from 4SICS. Available online: https://www.netresec.com/?page=PCAP4SICS (accessed on 26 June 2023).
- DynamiteLab—A Free Online PCAP File Viewer and Analyzer. Available online: https://lab.dynamite.ai/ (accessed on 20 October 2024).
- A Realistic Cyber Defense Dataset (CSE-CIC-IDS2018)—Registry of Open Data on AWS. Available online: https://registry.opendata.aws/cse-cic-ids2018/ (accessed on 20 October 2024).
- Balamurugan, S.P.; Granda, S.; Haile, S.; Petersen, A. A Dataset of Cyber-Induced Mechanical Faults on Buildings with Network and Buildings Data 2023. 12 Files. Available online: https://data.nrel.gov/submissions/210 (accessed on 3 July 2024).
- Radoglou-Grammatikis, P.; Kelli, V.; Lagkas, T.; Argyriou, V.; Panagiotis, S. DNP3 Intrusion Detection Dataset 2022. Available online: https://ieee-dataport.org/documents/dnp3-intrusion-detection-dataset (accessed on 3 August 2024).
- Electra Dataset: Anomaly Detection ICS Dataset. Available online: http://perception.inf.um.es/ICS-datasets/ (accessed on 20 October 2024).
- Radoglou-Grammatikis, P.; Rompolos, K.; Lagkas, T.; Argyriou, V.; Sarigiannidis, P. IEC 60870-5-104 Intrusion Detection Dataset. IEEE Dataport 2022, 104. [Google Scholar] [CrossRef]
- CSET ’16. Available online: https://www.usenix.org/conference/cset16 (accessed on 20 October 2024).
- Hindy, H. MQTT-IoT-IDS2020: MQTT Internet of Things Intrusion Detection Dataset 2020. Available online: https://ieee-dataport.org/open-access/mqtt-iot-ids2020-mqtt-internet-things-intrusion-detection-dataset (accessed on 20 October 2024).
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of Encrypted and VPN Traffic Using Time-Related Features. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy, Rome, Italy, 19–21 February 2016; SCITEPRESS—Science and and Technology Publications: Rome, Italy, 2016; pp. 407–414. [Google Scholar]
- Habibi Lashkari, A.; Draper Gil, G.; Mamun, M.; Ghorbani, A. Characterization of Tor Traffic Using Time Based Features. In Proceedings of the 3rd International Conference on Information Systems Security and Privacy (ICISSP 2017), Porto, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar]
- SplitCap—A Fast PCAP File Splitter. Available online: https://www.netresec.com/?page=SplitCap (accessed on 13 January 2025).
- Fang, C.; Liu, J.; Lei, Z. Fine-Grained HTTP Web Traffic Analysis Based on Large-Scale Mobile Datasets. IEEE Access 2016, 4, 4364–4373. [Google Scholar] [CrossRef]
- Bazaluk, B.; Hamdan, M.; Ghaleb, M.; Gismalla, M.S.M.; Correa da Silva, F.S.; Batista, D.M. Towards a Transformer-Based Pre-Trained Model for IoT Traffic Classification. In Proceedings of the NOMS 2024-2024 IEEE Network Operations and Management Symposium, Seoul, Republic of Korea, 6–10 May 2024; pp. 1–7. [Google Scholar]
- Liu, Y.; Chen, J.; Chang, P.; Yun, X. A Novel Algorithm for Encrypted Traffic Classification Based on Sliding Window of Flow’s First N Packets. In Proceedings of the 2017 2nd IEEE International Conference on Computational Intelligence and Applications (ICCIA), Beijing, China, 8–11 September 2017; pp. 463–470. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).