

Towards Safer Cities: AI-Powered Infrastructure Fault Detection Based on YOLOv11

 ,
,  , , , ,
, , , ,  and
and 
Abstract
1. Introduction
- This study focuses on detecting faults in infrastructure to improve safety and maintenance by accurately identifying defects. First, we created a custom dataset containing 9116 images covering various fault types and environmental conditions. This extends the generalization capability of the proposed model compared with other works.
- Second, we pre-processed the custom dataset using annotation techniques to enhance the model’s performance and resilience in a variety of settings. We resized and labeled each image to ensure high-quality input for the training process. With pre-processed images, the proposed deep learning-based object detection YOLOv11 [12] model is trained to precisely detect and categorize different types of faults in real time, significantly improving the detection speed.
- Finally, a detailed analysis of the effectiveness of YOLOv11 was conducted, and indeed it is superior to other baseline models, including YOLOv8, YOLOv9, and YOLOv10. Evaluation results prove that, in all instances, the proposed YOLOv11 outperforms others.
- This research gives a significant lead in infrastructure fault detection by using a proposed YOLOv11 model and a diverse, high-quality dataset. The results have shown potential for real-world applications, especially in maintaining the safety and longevity of critical infrastructure.
2. Literature Review
3. Materials and Methods
3.1. Image Acquisition
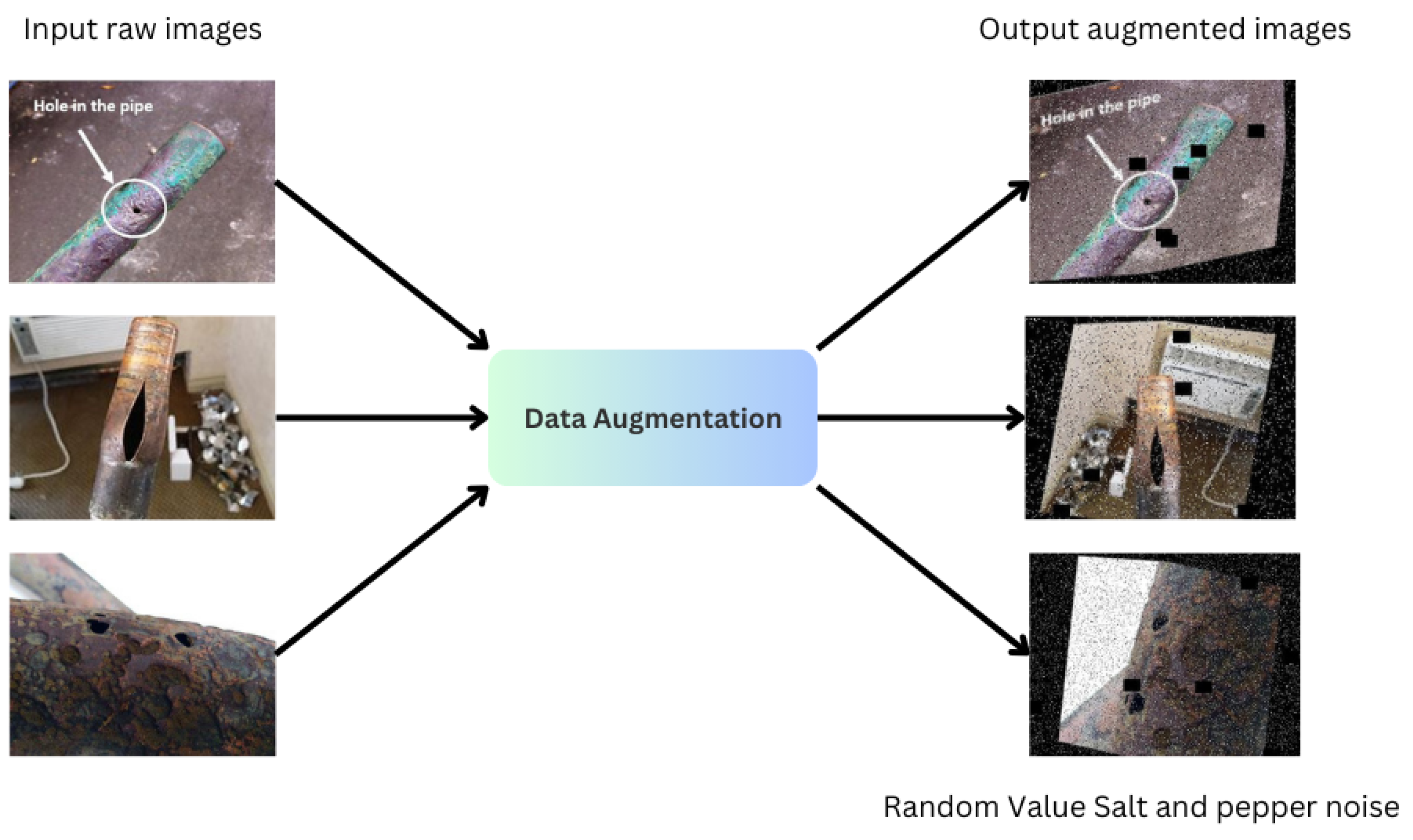
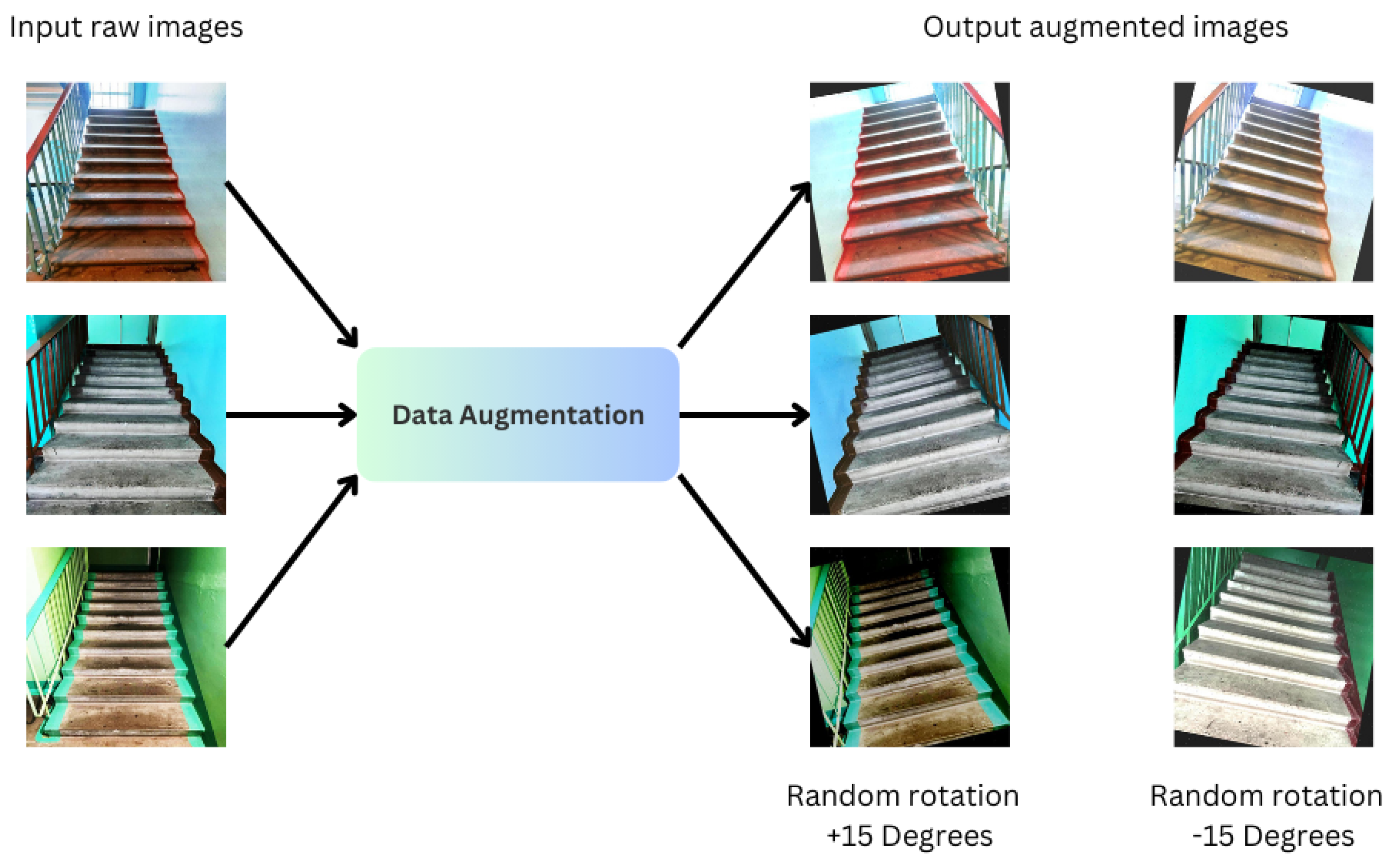
3.2. Image Pre-Processing
3.3. Image Resizing and Labeling
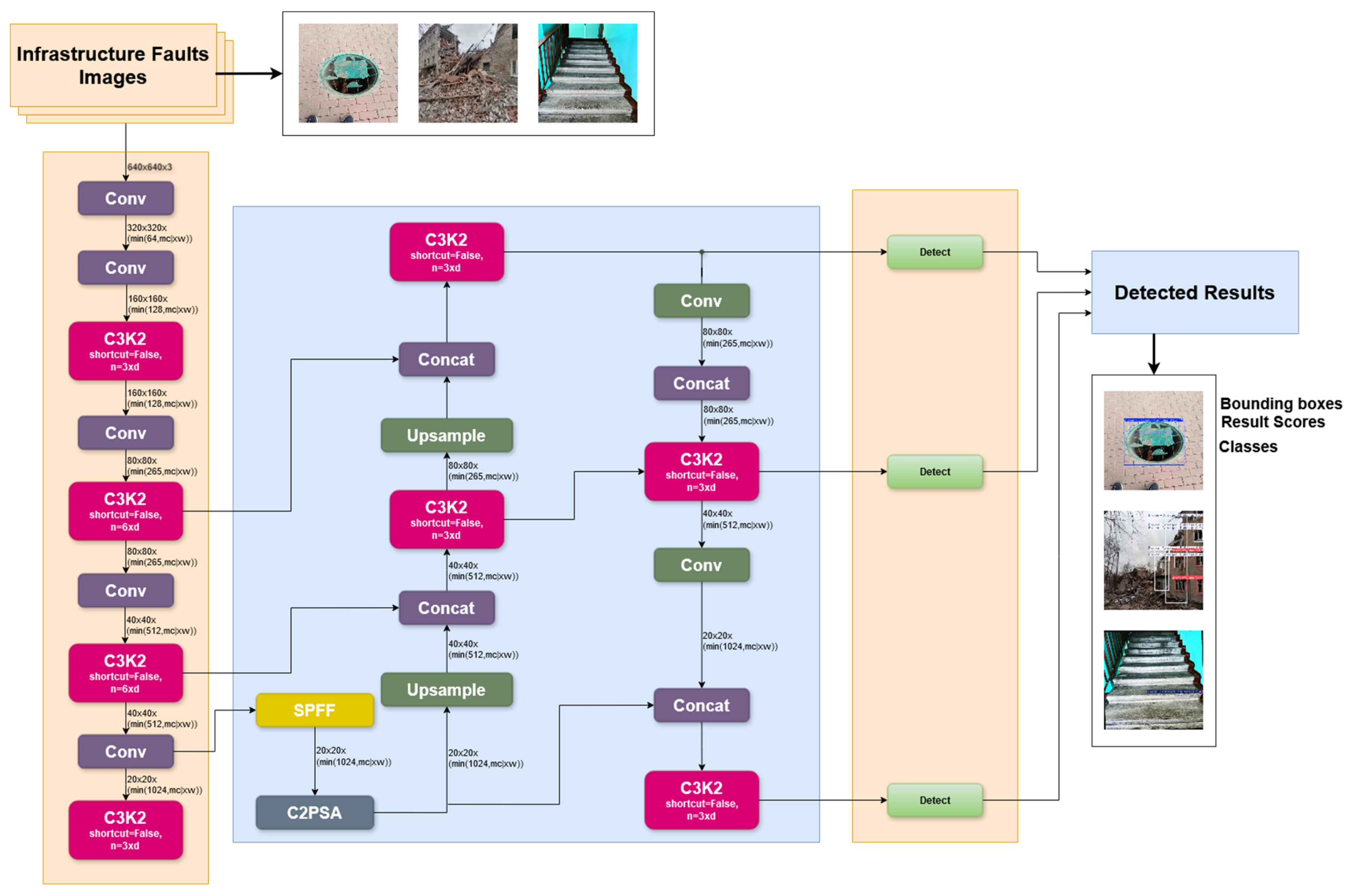
3.4. Model Architecture
4. Results
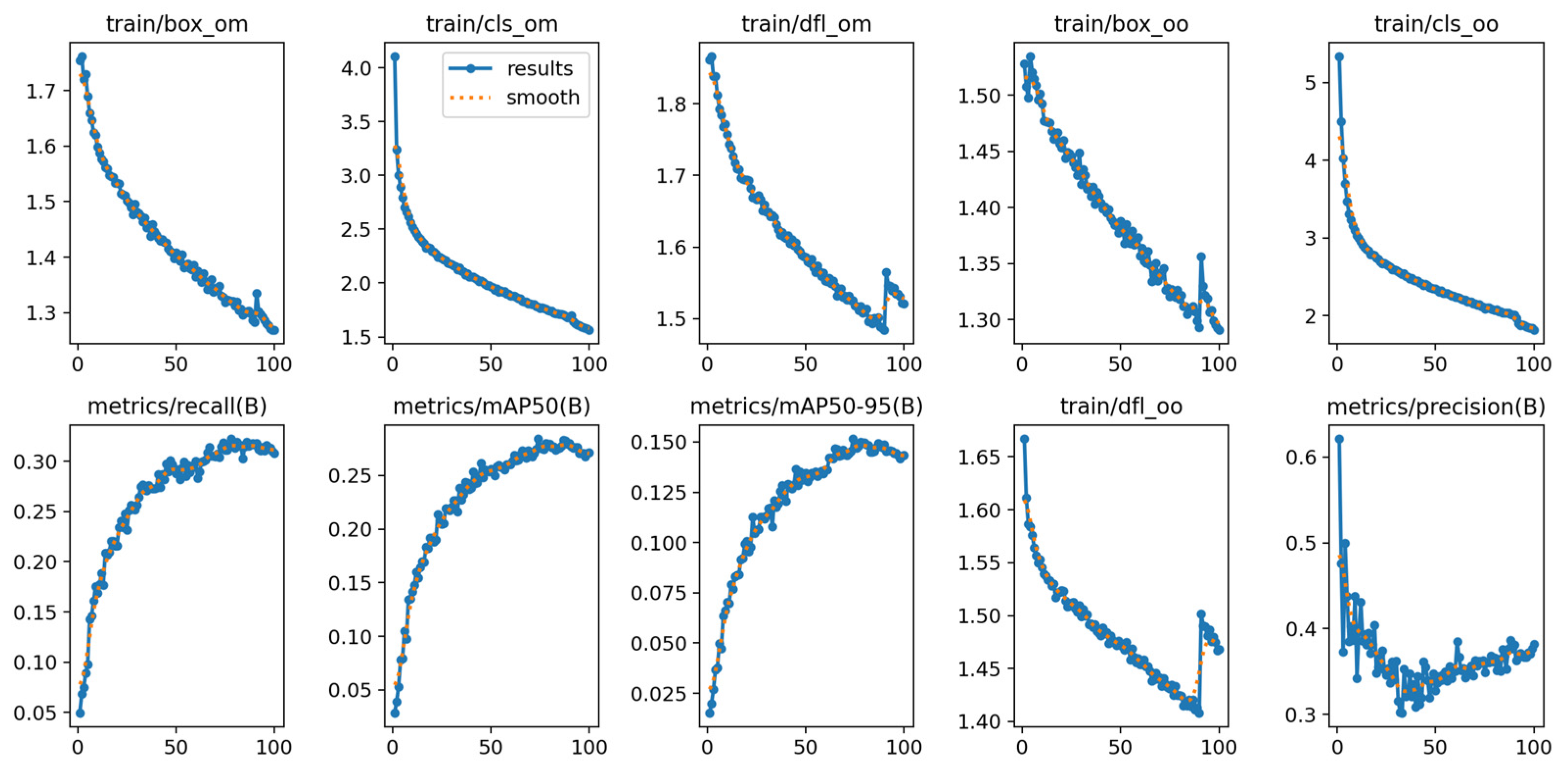
4.1. Hyperparameters
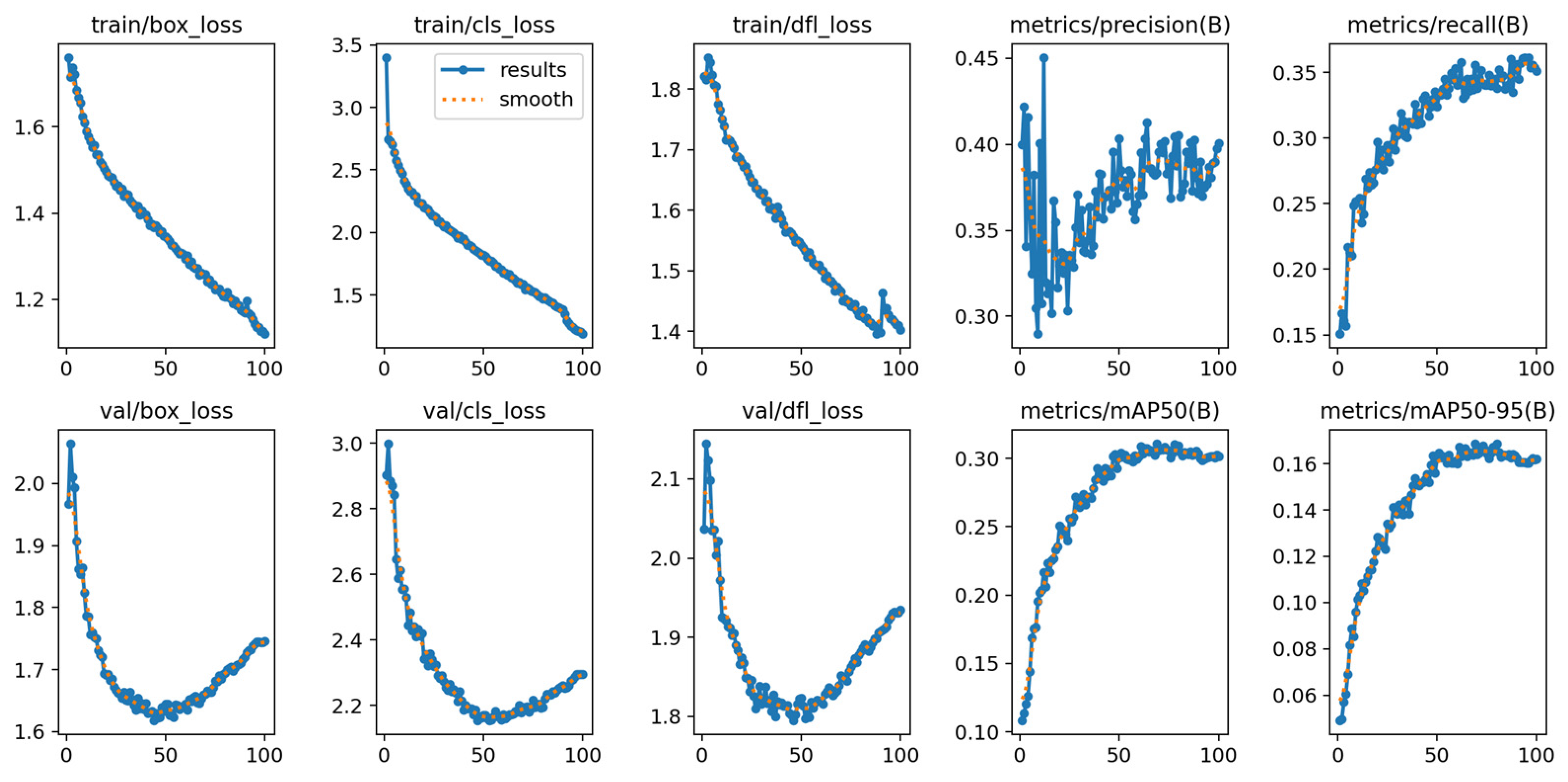
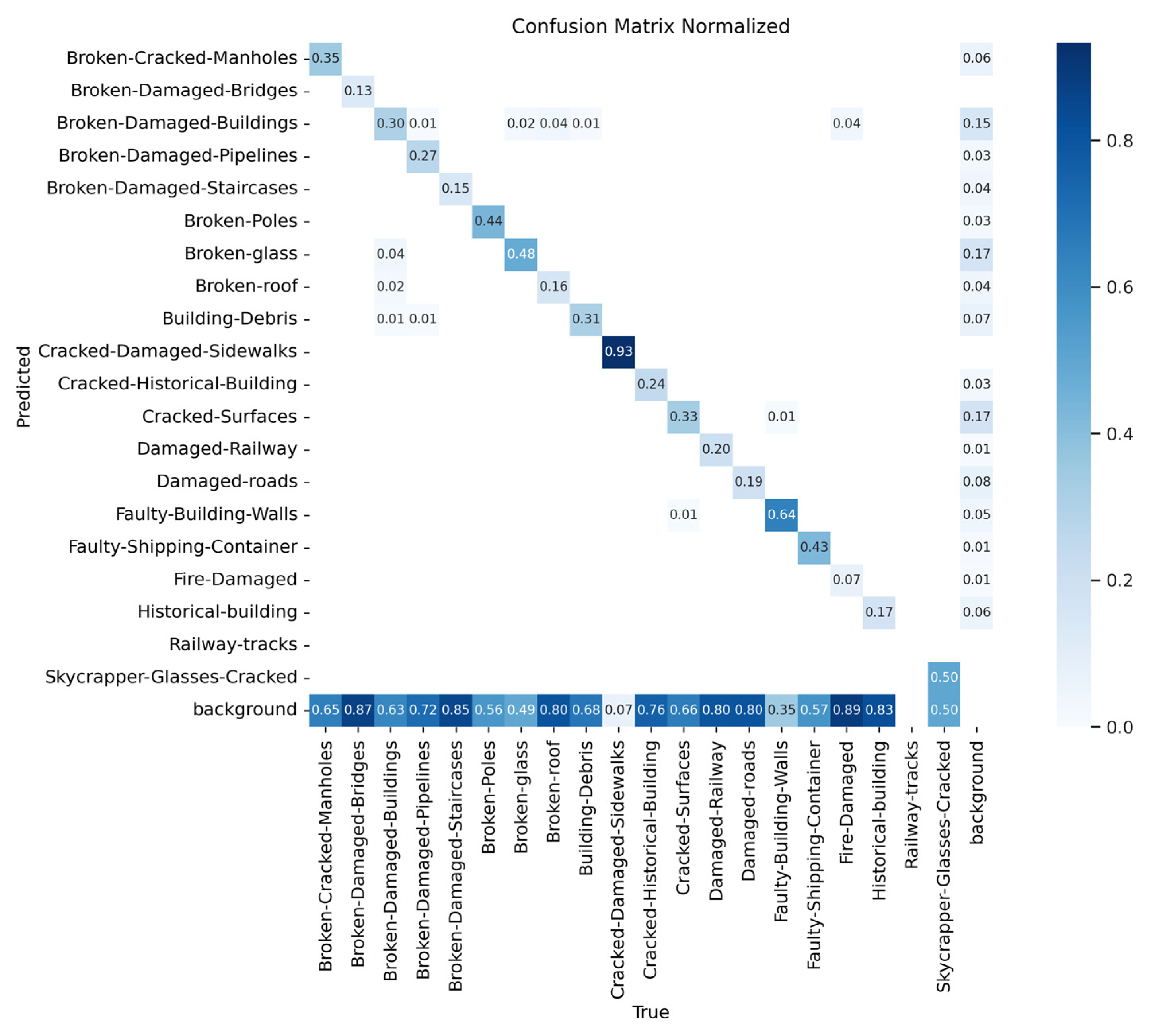
4.2. Model Evaluation
4.3. Analysis of Results
4.4. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wolniak, R.; Stecuła, K. Artificial Intelligence in Smart Cities—Applications, Barriers, and Future Directions: A Review. Smart Cities 2024, 7, 1346–1389. [Google Scholar] [CrossRef]
- Vogiatzaki, M.; Zerefos, S.; Hoque Tania, M. Enhancing city sustainability through smart technologies: A framework for automatic pre-emptive action to promote safety and security using lighting and ICT-based surveillance. Sustainability 2020, 12, 6142. [Google Scholar] [CrossRef]
- Alahi, M.E.E.; Sukkuea, A.; Tina, F.W.; Nag, A.; Kurdthongmee, W.; Suwannarat, K.; Mukhopadhyay, S.C. Integration of IoT-enabled technologies and artificial intelligence (AI) for smart city scenario: Recent advancements and future trends. Sensors 2023, 23, 5206. [Google Scholar] [CrossRef]
- Teng, S.; Liu, Z.; Li, X. Improved YOLOV3-Based Bridge Surface Defect Detection by Combining High- and Low-Resolution Feature Images. Buildings 2022, 12, 1225. [Google Scholar] [CrossRef]
- Guruvu, A.; Sree, K.B.; Sai, V.O.; Sri, T.K.; Sri, M.B. Railway Track Crack Detection with YOLOv5 and Geospatial Localization. Int. J. Creat. Res. Thoughts 2024, 12, 1928–1933. [Google Scholar]
- Akyürek, H.A.; Kozan, H.İ.; Taşdemir, Ş. Surface Crack Detection in Historical Buildings with Deep Learning-Based YOLO Algorithms: A Comparative Study. Comput. Res. Prog. Appl. Sci. Eng. 2024, 10, 1–14. [Google Scholar] [CrossRef]
- Wei, G.; Wan, F.; Zhou, W.; Xu, C.; Ye, Z.; Liu, W.; Lei, G.; Xu, L. BFD-YOLO: A YOLOv7-Based Detection Method for Building Façade Defects. Electronics 2023, 12, 3612. [Google Scholar] [CrossRef]
- Michael, G.; Shahra, E.Q.; Basurra, S.; Wu, W.; Jabbar, W.A. Real-Time Pipeline Fault Detection in Water Distribution Networks Using You Only Look Once v8. Sensors 2024, 24, 6982. [Google Scholar] [CrossRef]
- Wu, Y.; Han, Q.; Jin, Q.; Li, J.; Zhang, Y. LCA-YOLOv8-Seg: An Improved Lightweight YOLOv8-Seg for Real-Time Pixel-Level Crack Detection of Dams and Bridges. Appl. Sci. 2023, 13, 10583. [Google Scholar] [CrossRef]
- Li, T.; Li, G. Road Defect Identification and Location Method Based on an Improved ML-YOLO Algorithm. Sensors 2024, 24, 6783. [Google Scholar] [CrossRef]
- Rahman, S.; Jamee, S.M.H.; Rafi, J.K.; Juthi, J.S.; Sajib, A.A.; Uddin, J. Real-Time Smoke and Fire Detection Using You Only Look Once v8-Based Advanced Computer Vision and Deep Learning. Int. J. Adv. Appl. Sci. 2024, 13, 987–999. [Google Scholar] [CrossRef]
- Ultralytics. YOLOv11: You Only Look Once. Available online: https://github.com/ultralytics/ultralytics (accessed on 10 December 2024).
- Abdelkader, E.M.; Zayed, T.; Faris, N. Synthesized Evaluation of Reinforced Concrete Bridge Defects, Their Non-Destructive Inspection, and Analysis Methods: A Systematic Review and Bibliometric Analysis of the Past Three Decades. Buildings 2023, 13, 800. [Google Scholar] [CrossRef]
- Li, Y.; Wang, H.; Dang, L.M.; Song, H.-K.; Moon, H. Vision-Based Defect Inspection and Condition Assessment for Sewer Pipes: A Comprehensive Survey. Sensors 2022, 22, 2722. [Google Scholar] [CrossRef]
- Kim, J.W.; Choi, H.W.; Kim, S.K.; Na, W.S. Review of Image-Processing-Based Technology for Structural Health Monitoring of Civil Infrastructures. J. Imaging 2024, 10, 93. [Google Scholar] [CrossRef]
- Khan, M.A.M.; Kee, S.H.; Pathan, A.S.K.; Nahid, A.A. Image Processing Techniques for Concrete Crack Detection: A Scientometrics Literature Review. Remote Sens. 2023, 15, 2400. [Google Scholar] [CrossRef]
- Ranyal, E.; Sadhu, A.; Jain, K. Road Condition Monitoring Using Smart Sensing and Artificial Intelligence: A Review. Sensors 2022, 22, 3044. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Tang, C. Effective Small Crack Detection Based on Tunnel Crack Characteristics and an Anchor-Free Convolutional Neural Network. Sci. Rep. 2024, 14, 8361. [Google Scholar] [CrossRef]
- Hoang, N.D.; Huynh, T.C.; Tran, X.L.; Tran, V.D. A Novel Approach for Detection of Pavement Crack and Sealed Crack Using Image Processing and Salp Swarm Algorithm Optimized Machine Learning. Adv. Civ. Eng. 2022, 2022, 9193511. [Google Scholar] [CrossRef]
- Chun, P.; Izumi, S.; Yamane, T. Automatic Detection Method of Cracks from Concrete Surface Imagery Using Two-Step Light Gradient Boosting Machine. Comput. Aided Civ. Infrastruct. Eng. 2020, 36, 61–72. [Google Scholar] [CrossRef]
- Munawar, H.; Ullah, F.; Shahzad, D.; Heravi, A.; Qayyum, S.; Akram, J. Civil Infrastructure Damage and Corrosion Detection: An Application of Machine Learning. Buildings 2022, 12, 156. [Google Scholar] [CrossRef]
- Luo, C.; Yu, L.; Yan, J.; Li, Z.; Ren, P.; Bai, X.; Yang, E.; Liu, Y. Autonomous Detection of Damage to Multiple Steel Surfaces from 360° Panoramas Using Deep Neural Networks. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 1585–1599. [Google Scholar] [CrossRef]
- Bai, T.; Gao, J.; Yang, J.; Yao, D. A Study on Railway Surface Defects Detection Based on Machine Vision. Entropy 2021, 23, 1437. [Google Scholar] [CrossRef]
- Roy, Y.; Cajas, A.; Yenmy, Z.; Afredo, D. Identify Faults in Road Structure Zones with Deep Learning. J. Syst. Manag. Sci. 2022, 12, 163–191. [Google Scholar] [CrossRef]
- Mohanty, N.S. Empowering Structural Integrity: YOLO-Based Crack Detection and ML-Driven Concrete Strength Prediction of Critical Infrastructure Caused Due to Mining Operation. J. Electr. Syst. 2024, 20, 2705–2721. [Google Scholar] [CrossRef]
- Li, Y.; Bao, T. A Real-Time Multi-Defect Automatic Identification Framework for Concrete Dams via Improved YOLOv5 and Knowledge Distillation. J. Civ. Struct. Health Monit. 2023, 13, 1333–1349. [Google Scholar] [CrossRef]
- Fan, J.; Wang, M.; Li, B.; Liu, M.; Shen, D. ACD-YOLO: Improved YOLOv5-Based Method for Steel Surface Defects Detection. IET Image Process 2023, 18, 761–771. [Google Scholar] [CrossRef]
- Wei, X.; Wei, D.; Suo, D.; Jia, L.; Li, Y. Multi-Target Defect Identification for Railway Track Line Based on Image Processing and Improved YOLOV3 Model. IEEE Access 2020, 8, 61973–61988. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, Z. Road Damage Detection Algorithm for Improved YOLOv5. Sci. Rep. 2022, 12, 15523. [Google Scholar] [CrossRef]
- Xu, W.; Li, X.; Ji, Y.; Li, S.; Cui, C. BD-YOLOv8s: Enhancing Bridge Defect Detection with Multidimensional Attention and Precision Reconstruction. Sci. Rep. 2024, 14, 69722. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y.; Zhai, Y.; Wang, W.; Huang, R. A Sewer Pipeline Defect Detection Method Based on Improved YOLOv5. Processes 2023, 11, 2508. [Google Scholar] [CrossRef]
- Rahman, S.; Rony, J.H.; Uddin, J.; Samad, M.A. Real-Time Obstacle Detection with YOLOv8 in a WSN Using UAV Aerial Photography. J. Imaging 2023, 9, 216. [Google Scholar] [CrossRef]
- Salehin, S.; Rahman, S.; Nur, M.; Asif, A.; Harun, M.B.; Uddin, J. A Deep Learning Model for YOLOv9-Based Human Abnormal Activity Detection: Violence and Non-Violence Classification. Iran. J. Electr. Electron. Eng. 2024, 20, 3433–3438. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Infrastructure | Quantity | Total Data |
|---|---|---|
| Bridge | 94 | 9116 |
| Building Walls | 900 | |
| Cracked Surface | 900 | |
| Pothole/Damaged Road | 400 | |
| Damaged Building (Broken Glass, Broken Roof, Building Debris, Fire Damaged) | 3935 | |
| Historical Building Crack | 350 | |
| Historical Building | 300 | |
| Manhole | 300 | |
| Pipeline | 197 | |
| Pole | 690 | |
| Railway Track | 150 | |
| Shipping Container | 200 | |
| Sidewalk | 300 | |
| Skyscraper | 100 | |
| Staircase | 300 |
| Parameters | Value |
|---|---|
| Batch size | 16 |
| Number of epochs | 100 |
| Optimizer | auto |
| Pre-trained | COCO Model |
| Pre-trained | 0.01 |
| Weight decay | 0.0005 |
| Patience | 100 |
| Parameters | Value |
|---|---|
| Batch size | 319 |
| Model parameters | 9,435,532 |
| Gradients | 9,435,532 |
| GFLOPs | 10.79 |
| Model | Epoch | Class | Trainable Parameters | F1score | mAP@0.5 |
|---|---|---|---|---|---|
| Proposed YOLOv11 | 100 | All | 9.46 M | 0.37 | 0.30 |
| Proposed YOLOv11 | 50 | All | 9.46 M | 0.35 | 0.29 |
| YOLOv8 [32] | 100 | All | 11.17 M | 0.35 | 0.28 |
| YOLOv8 [32] | 50 | All | 11.17 M | 0.35 | 0.28 |
| YOLOv9 [33] | 100 | All | 1.98 M | 0.32 | 0.27 |
| YOLOv9 [33] | 50 | All | 1.98 M | 0.33 | 0.29 |
| YOLOv10 [33] | 100 | All | 2.73 M | 0.31 | 0.26 |
| YOLOv10 [33] | 50 | All | 2.73 M | 0.34 | 0.27 |
| YOLOv12 | 100 | All | 2.58 M | 0.30 | 0.21 |
| YOLOv12 | 50 | All | 2.58 M | 0.25 | 0.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rakin, R.Z.; Rahman, M.; Borsa, K.F.; Farid, F.A.; Rahman, S.; Uddin, J.; Karim, H.A. Towards Safer Cities: AI-Powered Infrastructure Fault Detection Based on YOLOv11. Future Internet 2025, 17, 187. https://doi.org/10.3390/fi17050187
Rakin RZ, Rahman M, Borsa KF, Farid FA, Rahman S, Uddin J, Karim HA. Towards Safer Cities: AI-Powered Infrastructure Fault Detection Based on YOLOv11. Future Internet. 2025; 17(5):187. https://doi.org/10.3390/fi17050187
Chicago/Turabian StyleRakin, Raiyen Z., Mahmudur Rahman, Kanij F. Borsa, Fahmid Al Farid, Shakila Rahman, Jia Uddin, and Hezerul Abdul Karim. 2025. "Towards Safer Cities: AI-Powered Infrastructure Fault Detection Based on YOLOv11" Future Internet 17, no. 5: 187. https://doi.org/10.3390/fi17050187
APA StyleRakin, R. Z., Rahman, M., Borsa, K. F., Farid, F. A., Rahman, S., Uddin, J., & Karim, H. A. (2025). Towards Safer Cities: AI-Powered Infrastructure Fault Detection Based on YOLOv11. Future Internet, 17(5), 187. https://doi.org/10.3390/fi17050187