Improving Anomaly Detection for Text-Based Protocols by Exploiting Message Structures

Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
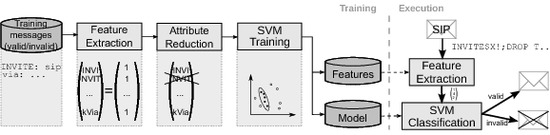
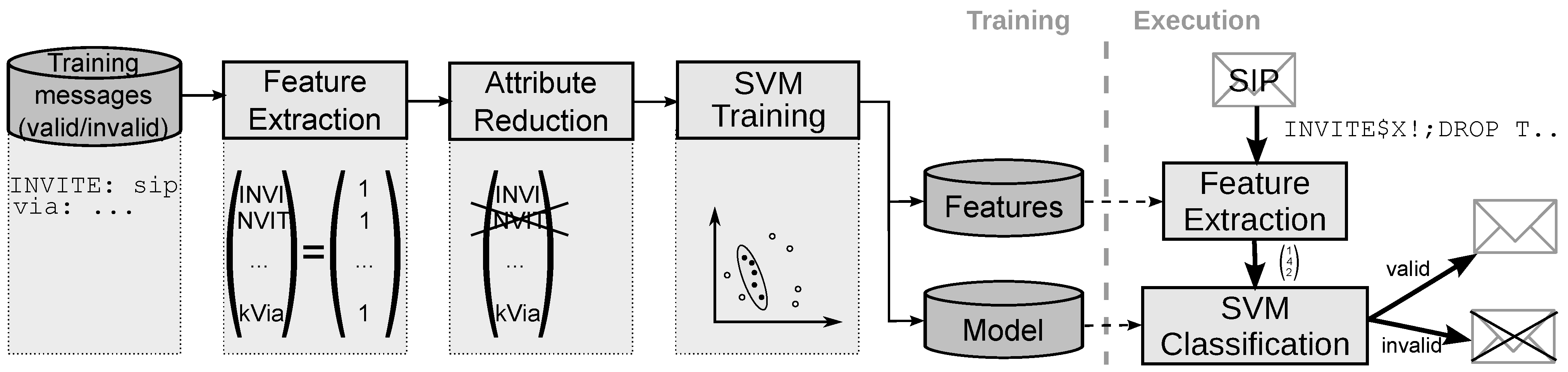
2. Approach and Improvements
2.1. Overview
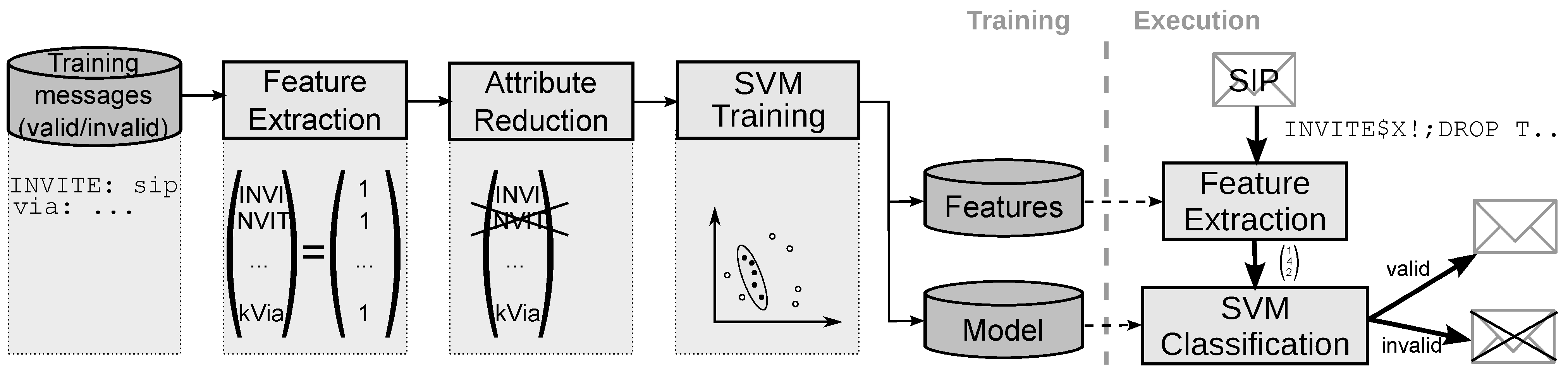
2.2. Mapping Text Messages into Feature Space
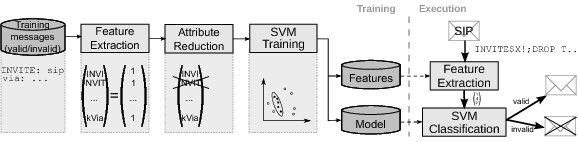
- Keyword action Counting. The detection of some protocol-specific tokens contributes more valuable information than the corresponding n-gram combination. For example, a non-standard number of occurrences can be seen as a direct indication of message anomaly. Therefore, we include additional features consisting of protocol-specific keywords and the corresponding number of occurrence in the SIP message. An example is given in Figure 2, where Via is chosen as a keyword with keyword action Counting. In this example, the value associated with feature kVia is two, given that it occurs twice in the message.
- Keyword action Value extraction. In some cases, not the number of occurrence of a keyword, but the message contents associated with a keyword are relevant for classification. Therefore, keyword action Value extraction includes additional features consisting of the protocol-specific keyword and a value, which is either a keyword-dependent value that directly occurs in the message, or the result of a regular expression over the message contents following this keyword. An example is given in Figure 2 for the Content-Length keyword. The feature vector contains the feature kContent-Length with value 0, which is the content length value found in the original message.
- Keyword action Message modification. Inside the SIP message are parts, which can be interpreted only within the context of the conversation. Given that we do not keep state information about ongoing conversations, we cannot interpret these parts and considering them leads more or less to distracting noise. To avoid producing useless features from these parts of a message, the value can be ignored, replaced with default values, or even be removed completely before n-grams are generated. Before performing such actions, however, local checks of the keyword value are performed to cover anomalies in this part of the message. If this local check fails the message can be directly marked as invalid.Figure 2 shows on the right hand side how this keyword action is used with the branch keyword. From the SIP standard [1] we take the knowledge that the branch value must be globally unique per user agent, has the defined prefix z9hG4bK, must only contain characters from a predefined set, and has no length restriction. Thus, when using 4-grams only, we observed that the value of this field adds a high number of n-grams, which are basically useless noise, and can hardly be reduced in the attribute reduction step.Therefore, we remove the value which belongs to branch after we performed a syntactic check based on the characters allowed. Figure 2 illustrates this keyword action: the branch value of the first Via line is removed, while the branch value of the second Via line does not pass the syntax check. The message containing the latter line will be marked invalid, which is illustrated by replacing the branch value by a corresponding marker in Figure 2.

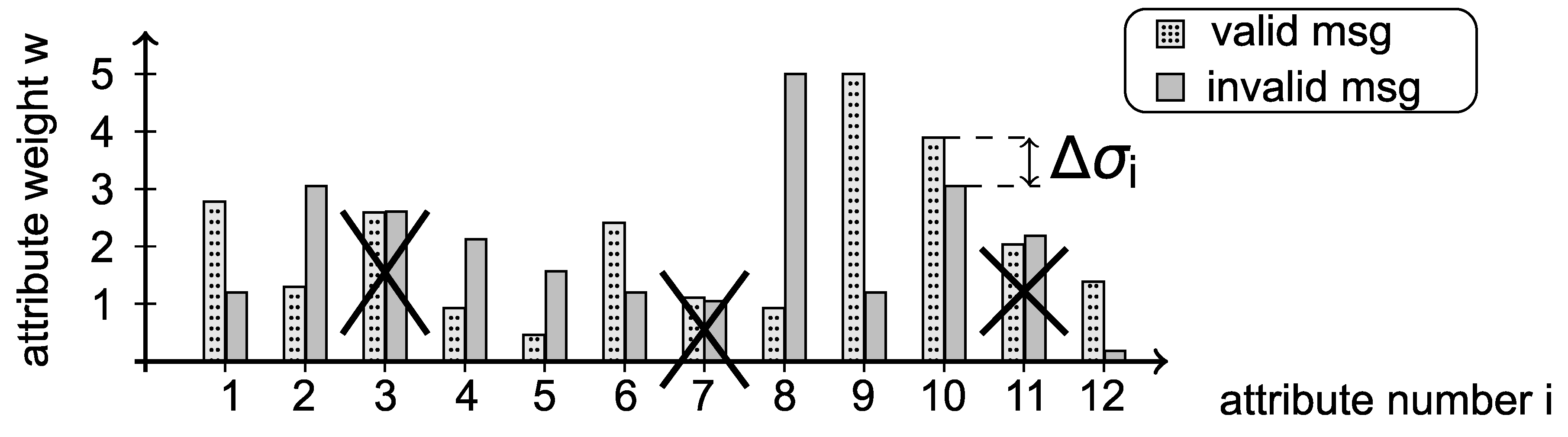
2.3. Attribute Reduction

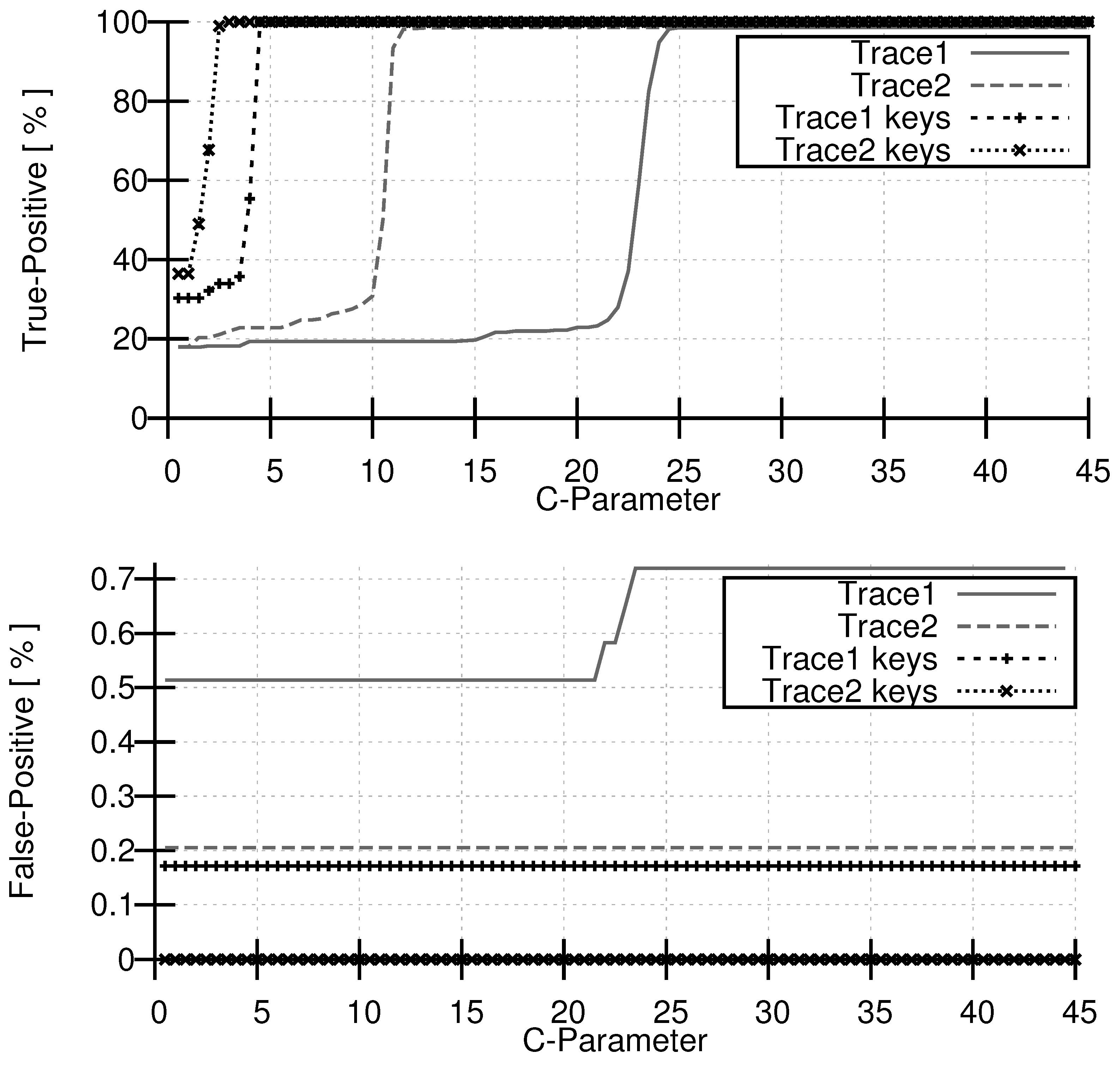
3. Evaluation
- From: Bob $<$sip:Bob@ex.com:5060;user=phone>;tag=4711
- From: Bob $<$sip:Bob@ex.com:5060>;tag=4711
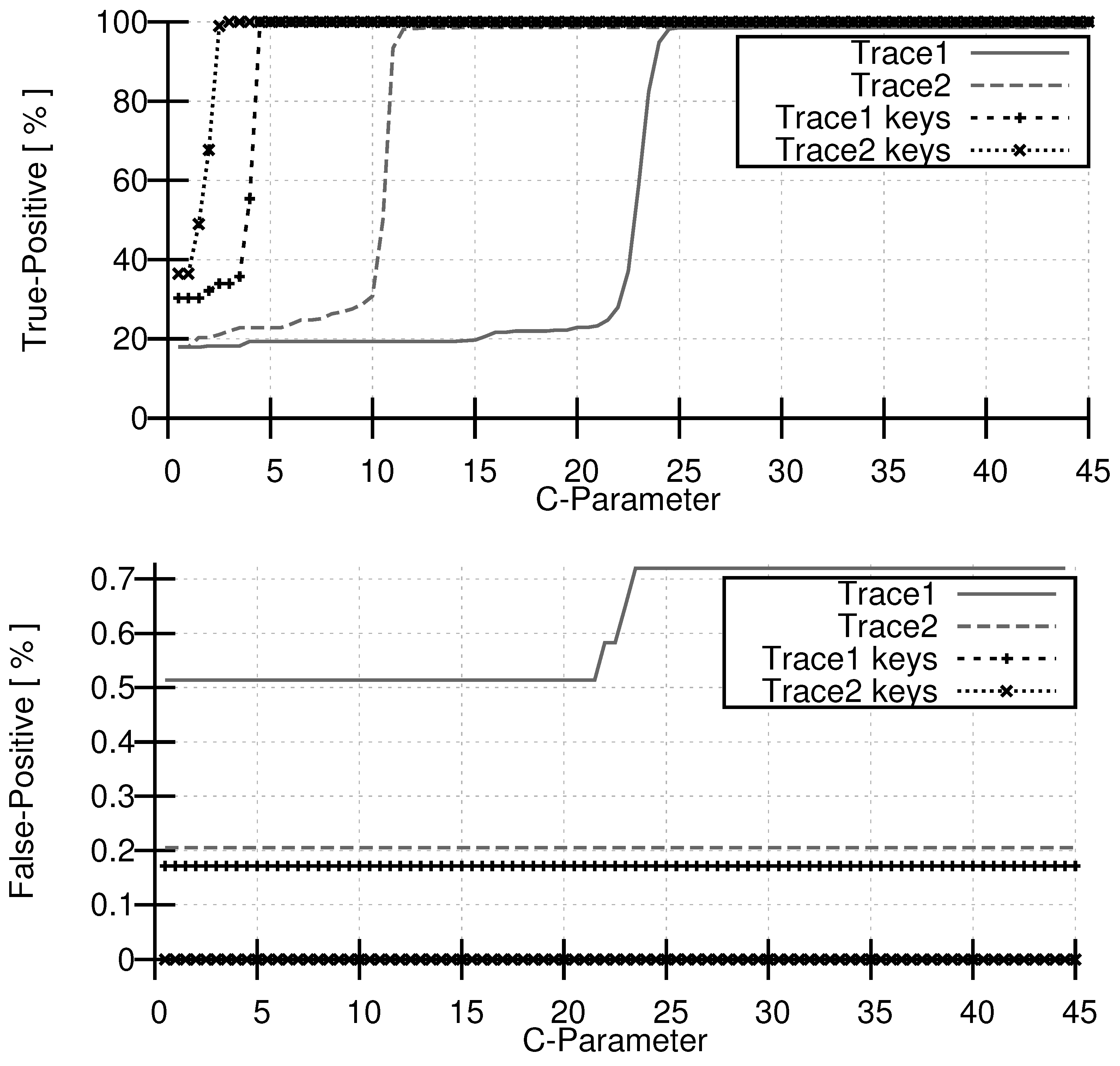
4. Conclusions
References
- Rosenberg, J.; Schulzrinne, H.; Camarillo, G.; Johnston, A.; Peterson, J.; Sparks, R.; Handley, M.; Schooler, E. SIP: Session Initiation Protocol, RFC 3261. IETF, June 2002. [Google Scholar]
- Nassar, M.; State, R.; Festor, O. Monitoring SIP Traffic Using Support Vector Machines. In Proceedings of 11th International Symposium on Recent Advances in Intrusion Detection (RAID), Cambridge, MA, USA, 15–17 September 2008.
- Tax, D.M.J.; Duin, R.P.W. Support vector domain description. Pattern Recogn. Lett. 1999, 20, 1191–1199. [Google Scholar] [CrossRef]
- Rieck, K.; Wahl, S.; Laskov, P.; Domschitz, P.; Mueller, K.-R. A Self-Learning System for Detection of Anomalous SIP Messages. Principles, Systems and Applications of IP Telecommunications. Services and Security for Next Generation Networks. In Proceedings of Second International Conference, Heidelberg, Germany, 1–2 July 2008; pp. 90–106.
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. SIGKDD Explorations 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm/ (accessed on 16 December 2010).
© 2010 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Güthle, M.; Kögel, J.; Wahl, S.; Kaschub, M.; Mueller, C.M. Improving Anomaly Detection for Text-Based Protocols by Exploiting Message Structures. Future Internet 2010, 2, 662-669. https://doi.org/10.3390/fi2040662
Güthle M, Kögel J, Wahl S, Kaschub M, Mueller CM. Improving Anomaly Detection for Text-Based Protocols by Exploiting Message Structures. Future Internet. 2010; 2(4):662-669. https://doi.org/10.3390/fi2040662
Chicago/Turabian StyleGüthle, Martin, Jochen Kögel, Stefan Wahl, Matthias Kaschub, and Christian M. Mueller. 2010. "Improving Anomaly Detection for Text-Based Protocols by Exploiting Message Structures" Future Internet 2, no. 4: 662-669. https://doi.org/10.3390/fi2040662
APA StyleGüthle, M., Kögel, J., Wahl, S., Kaschub, M., & Mueller, C. M. (2010). Improving Anomaly Detection for Text-Based Protocols by Exploiting Message Structures. Future Internet, 2(4), 662-669. https://doi.org/10.3390/fi2040662