A Methodology for Retrieving Information from Malware Encrypted Output Files: Brazilian Case Studies

Abstract
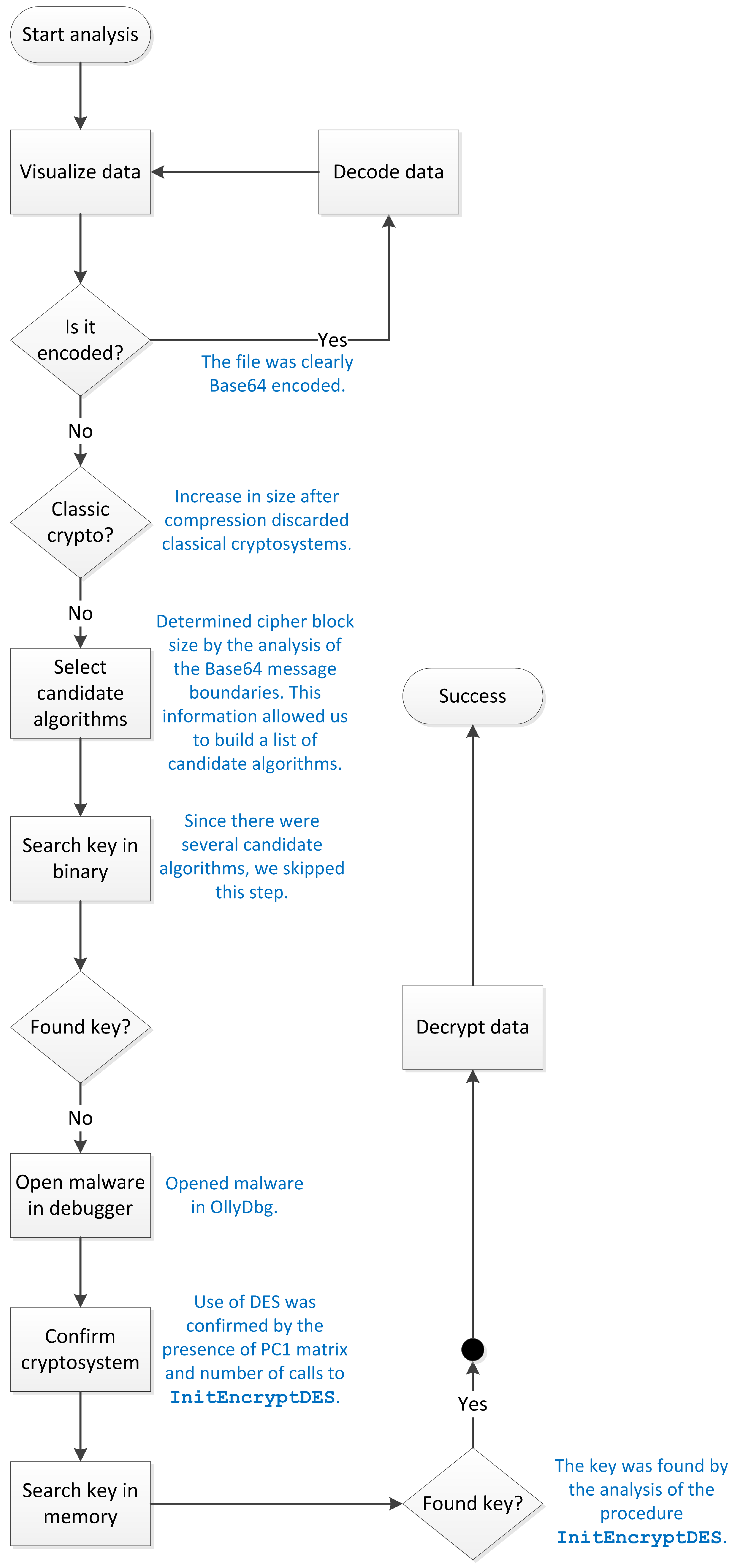
:1. Introduction
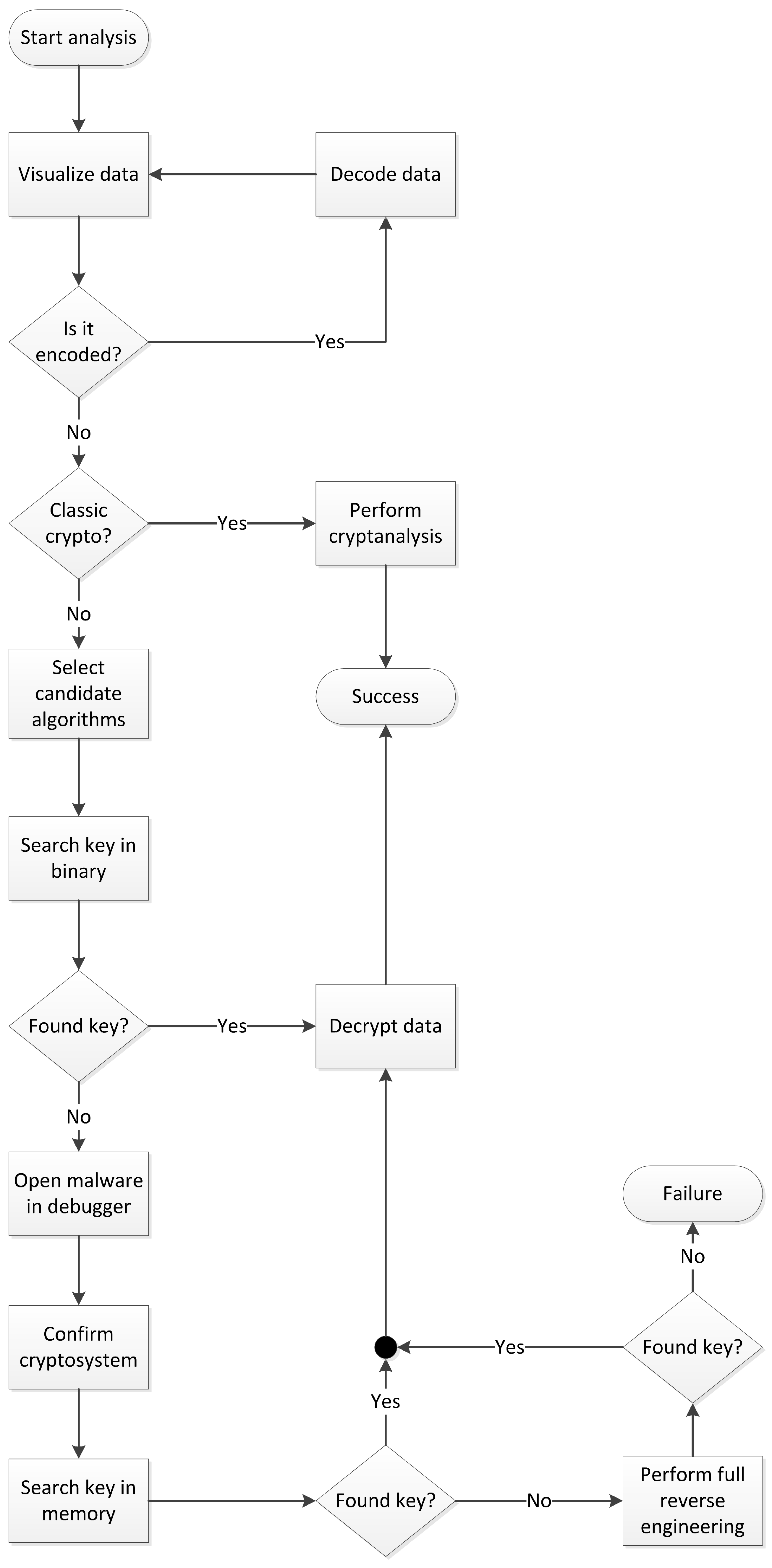
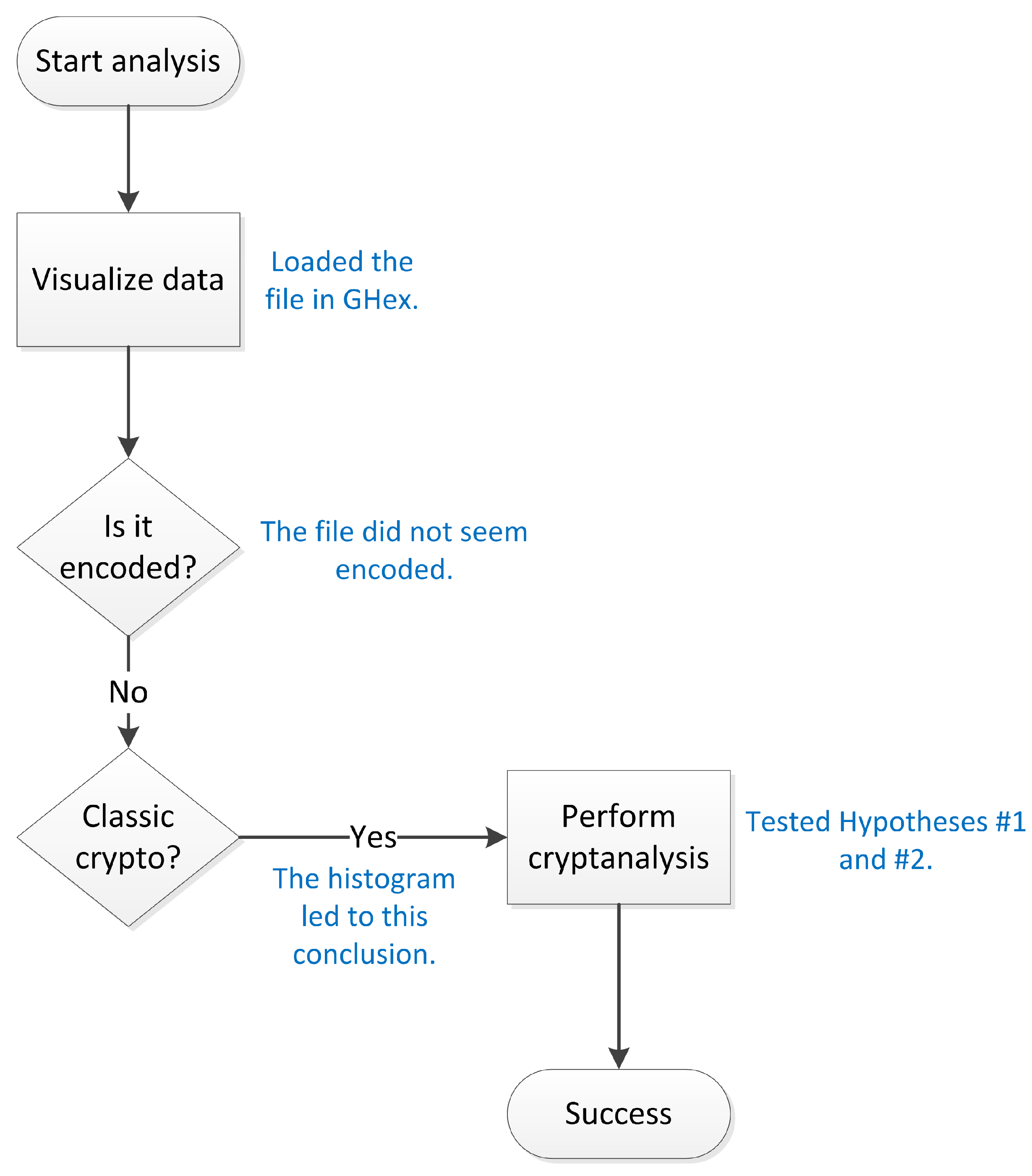
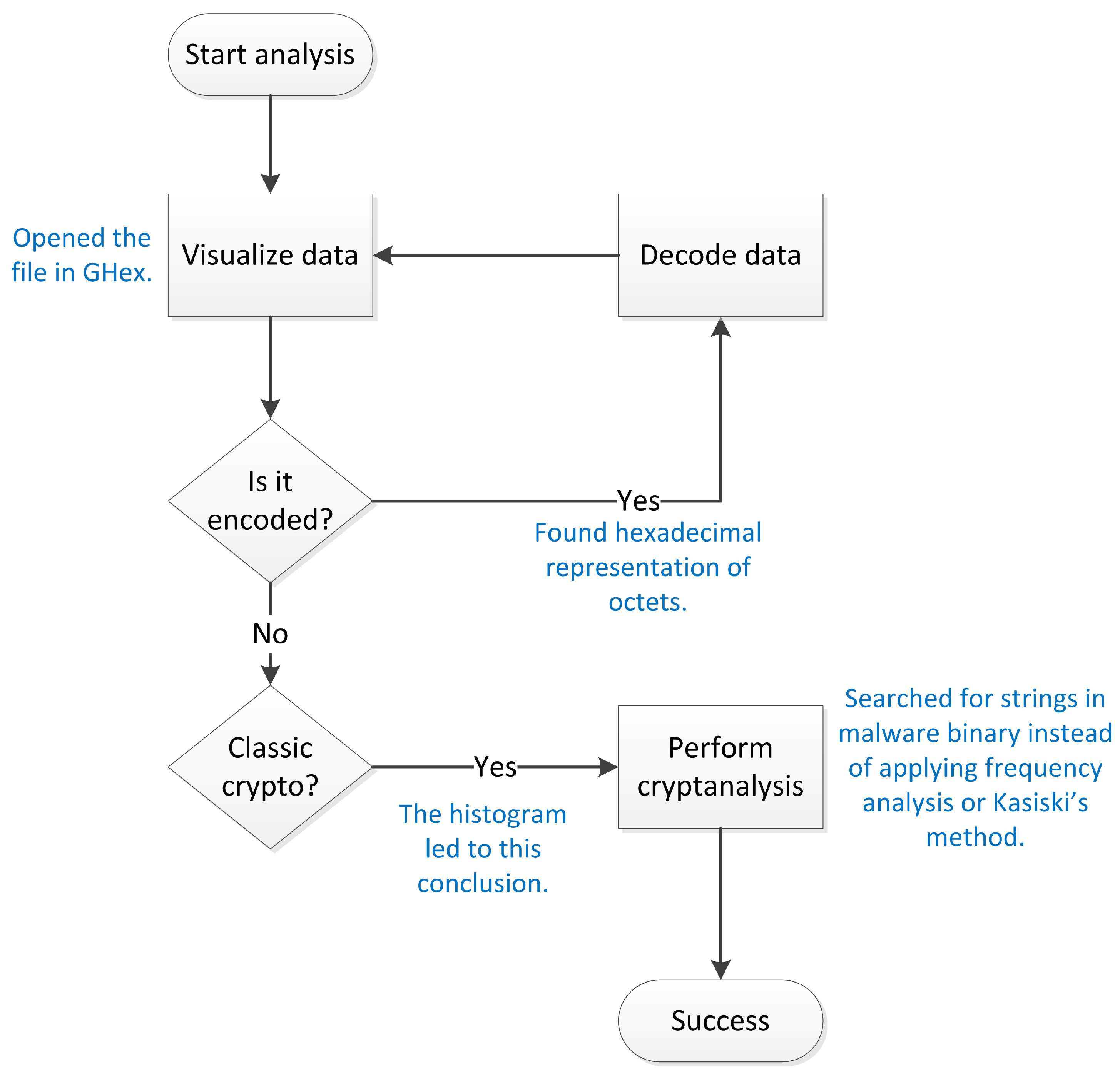
2. The Proposed Methodology

3. Case Studies
3.1. First Malware
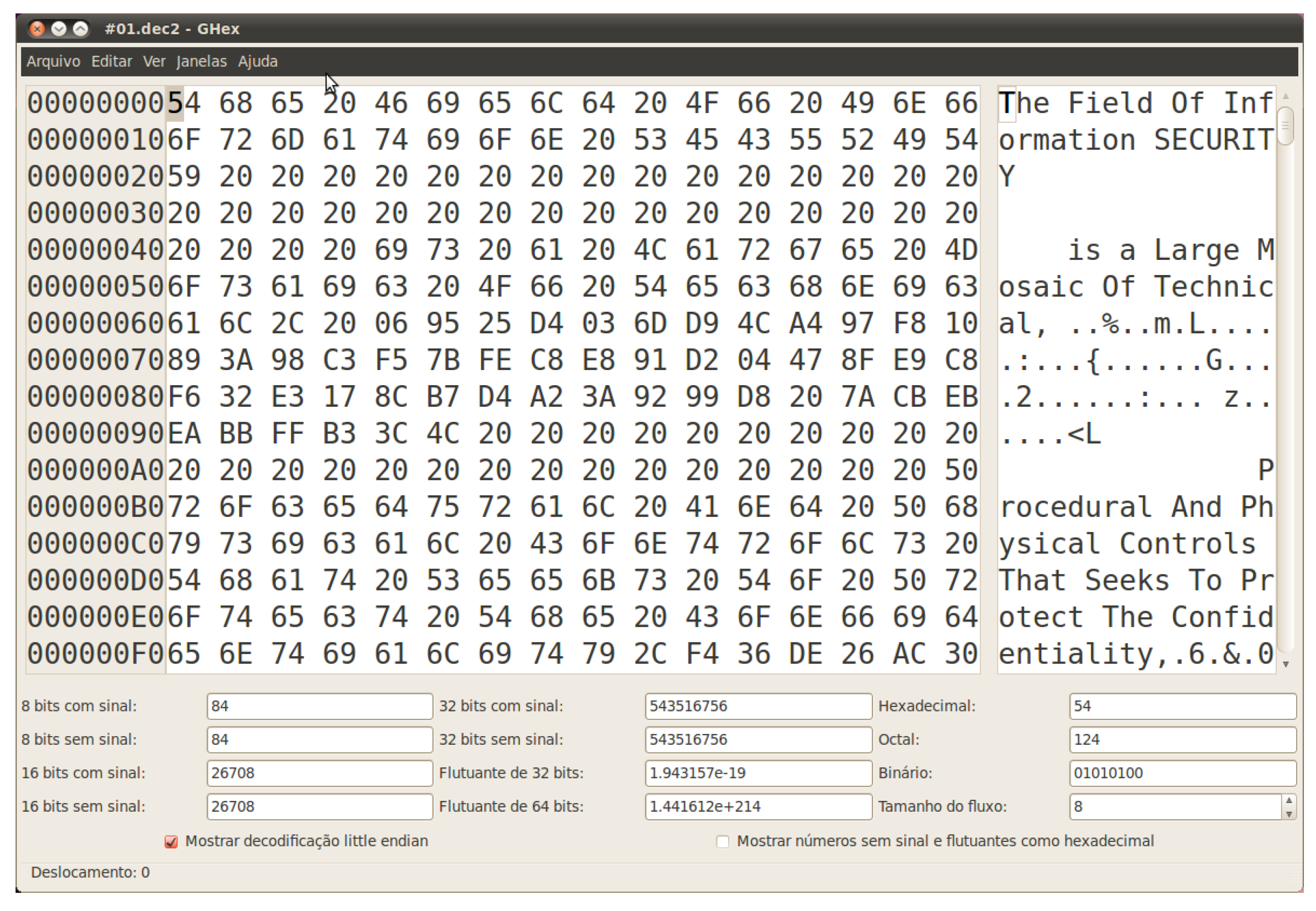
3.1.1. Description of the Malware and the Encrypted File

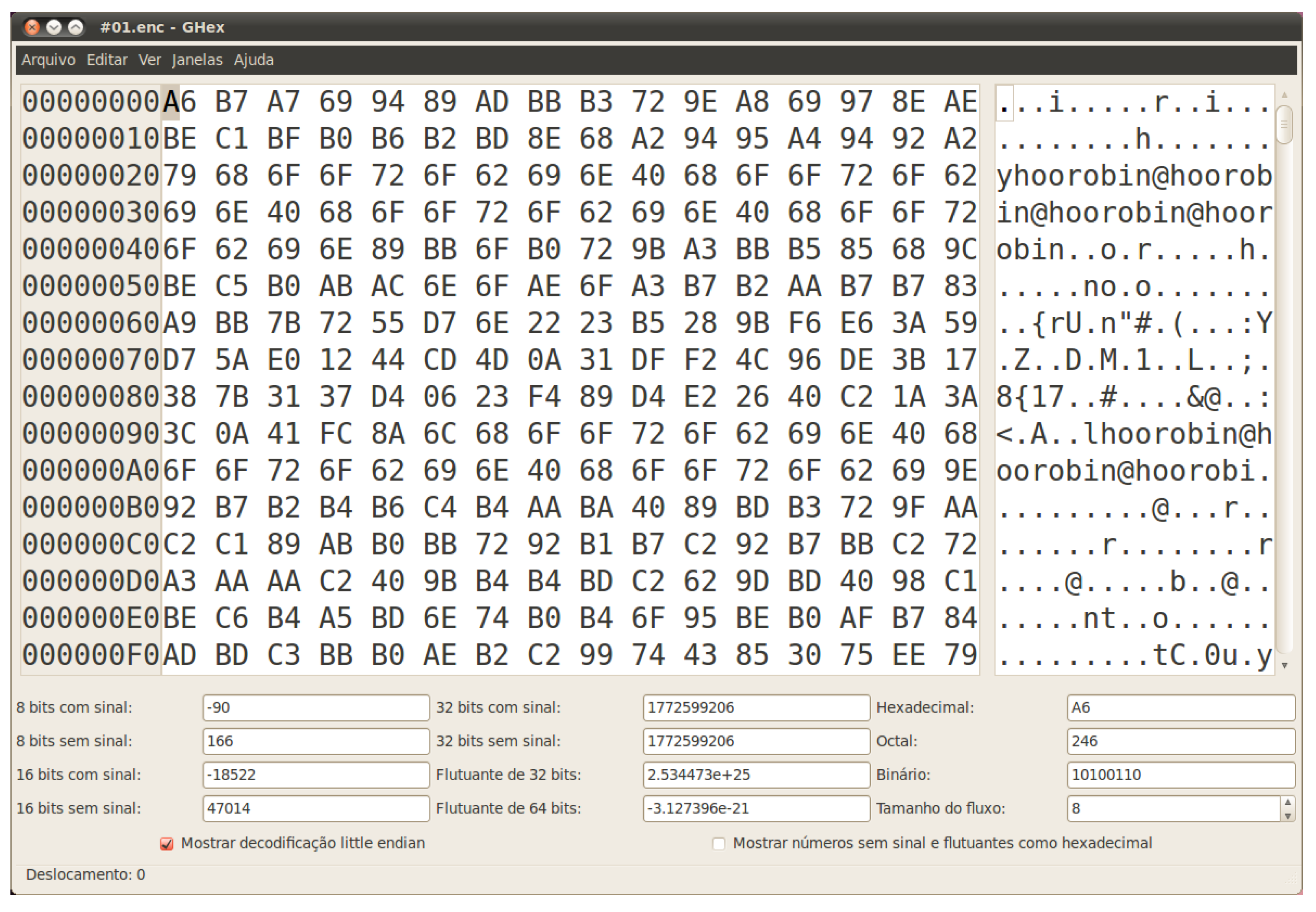
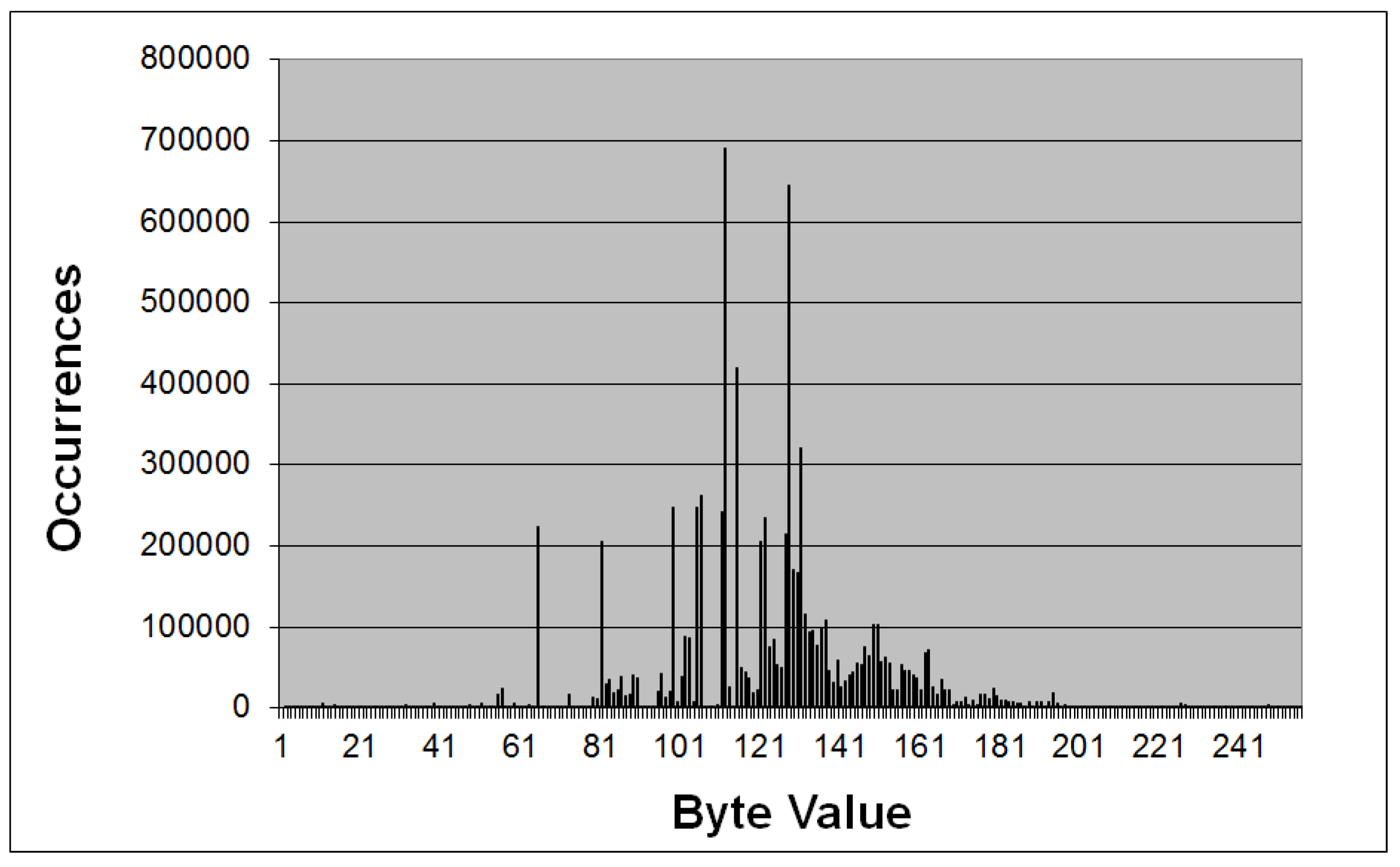
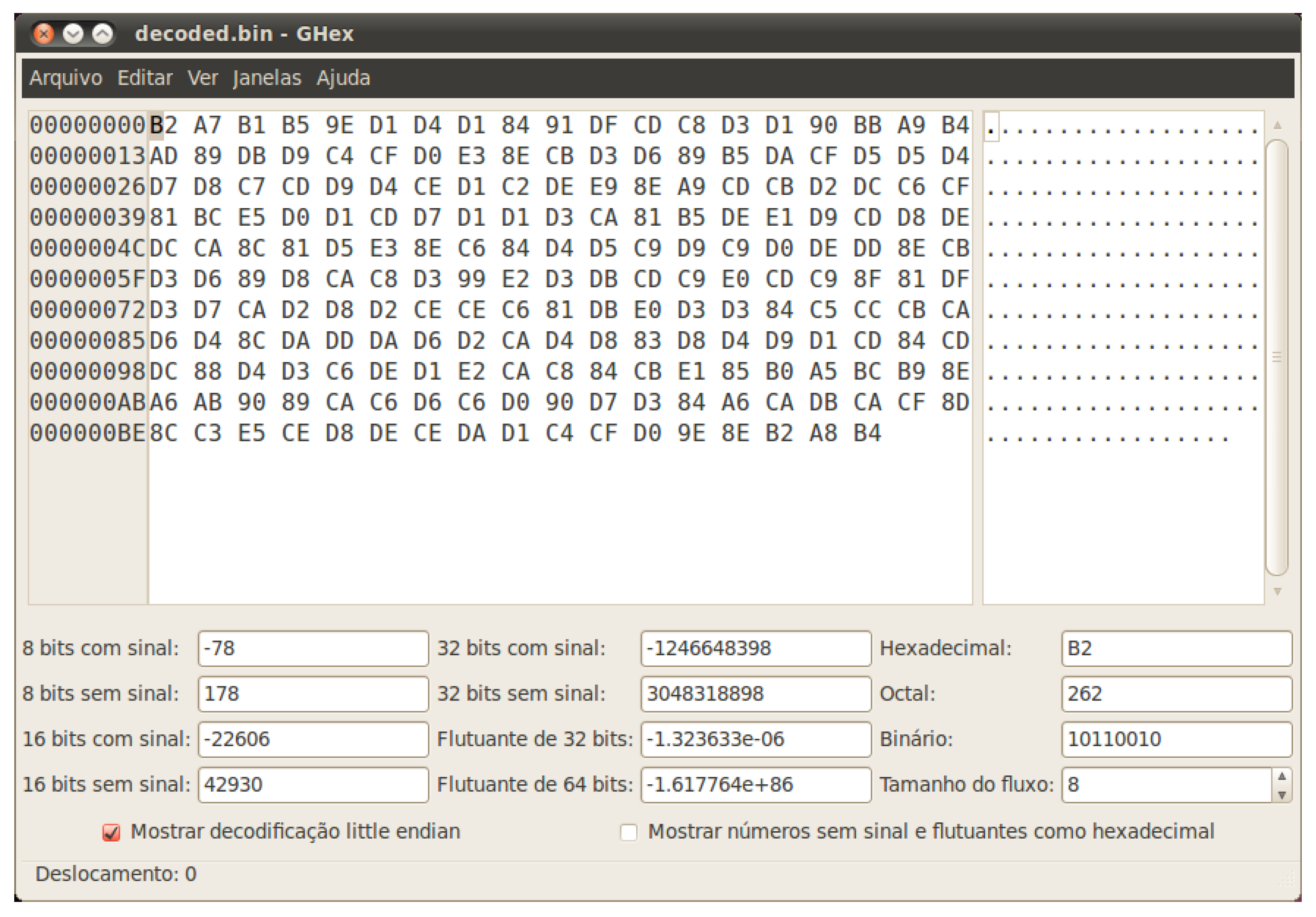
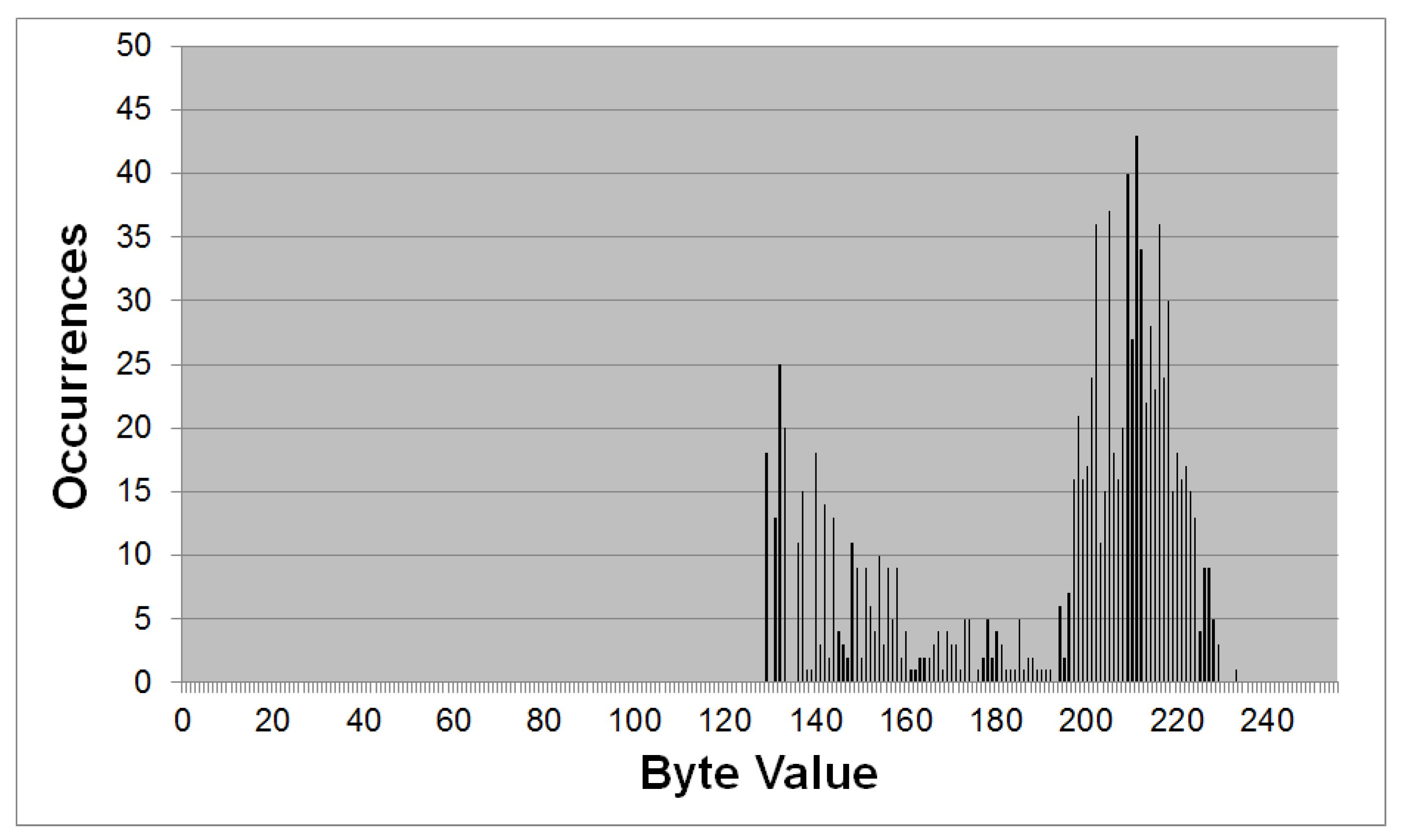
3.1.2. Analysis of the Encrypted File

- Hypothesis #1: a constant number is added to each byte modulo 256 and a given string is repeated several times in the plaintext, resulting in the occurrences of the string “robin@hoo”. Although this is not likely, it should be tested, by simply trying every one of the 256 possible keys, and checking if a meaningful message pops out from the process. As expected this test fails and does not solve the problem.
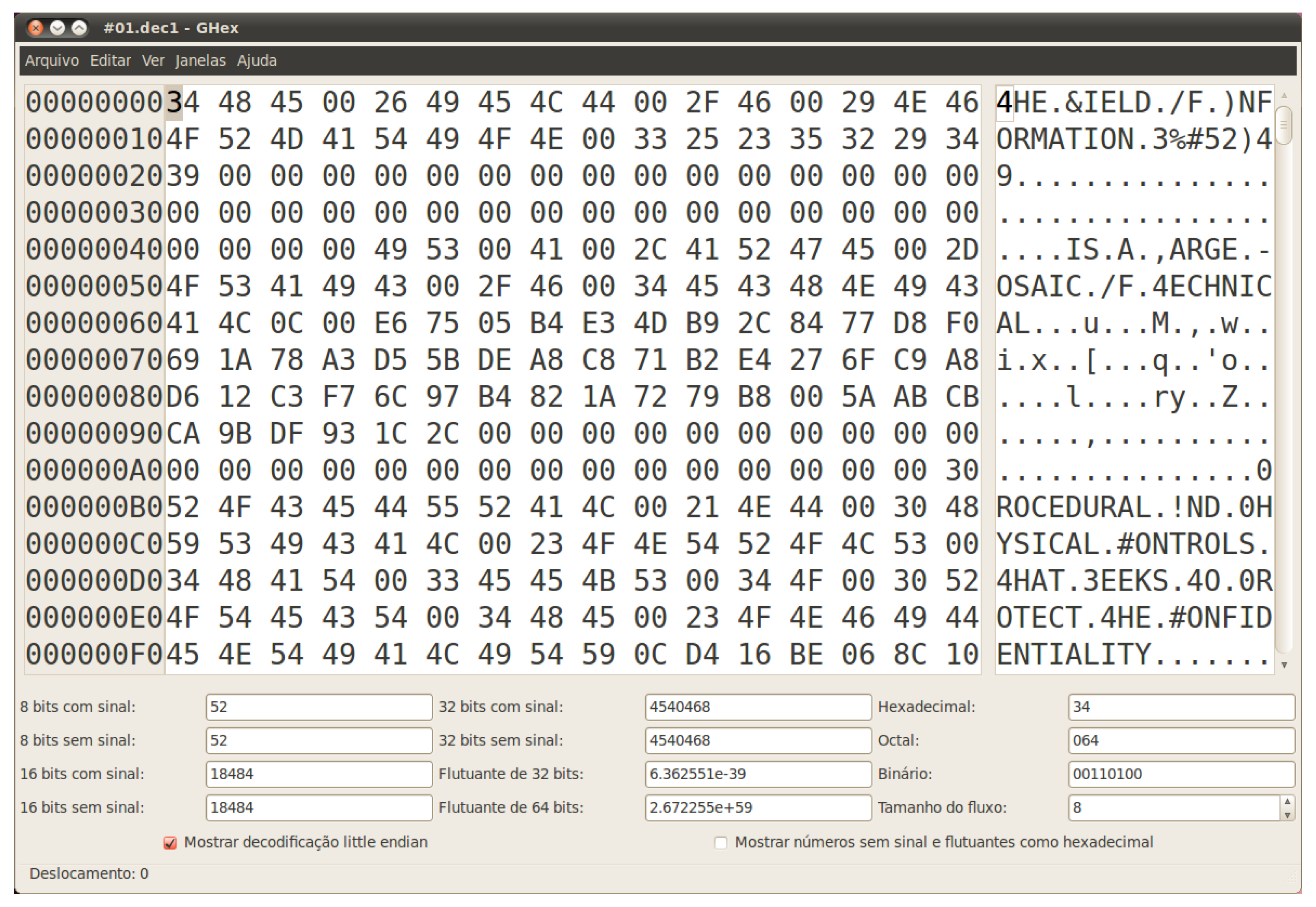
- Hypothesis #2: a Vigenère cipher [5] over an alphabet of 256 elements and a period that equals 9 is used by the malware. Of course, in this scenario, the candidate key is the aforementioned string, which is probably being added to a sequence of null bytes present in the original message. Testing this theory results in the text shown in Figure 4, in which the beginning of words seems to be incorrectly decrypted. Taking a closer look to the wrong letters, under the light of the ASCII code, one can see that the distance to the expected values is always thirty-two, implying this amount should be subtracted from every single byte of the candidate key. The final and successful result can be seen in Figure 5.


3.1.3. Summary of the Analysis

3.1.4. Description of the Cipher and the Key
- Alphabet of definition:
- Plaintext:
- Ciphertext:
- Key: (ROBIN HOO)
- Encryption function:
- Decryption function:
3.2. Second Malware
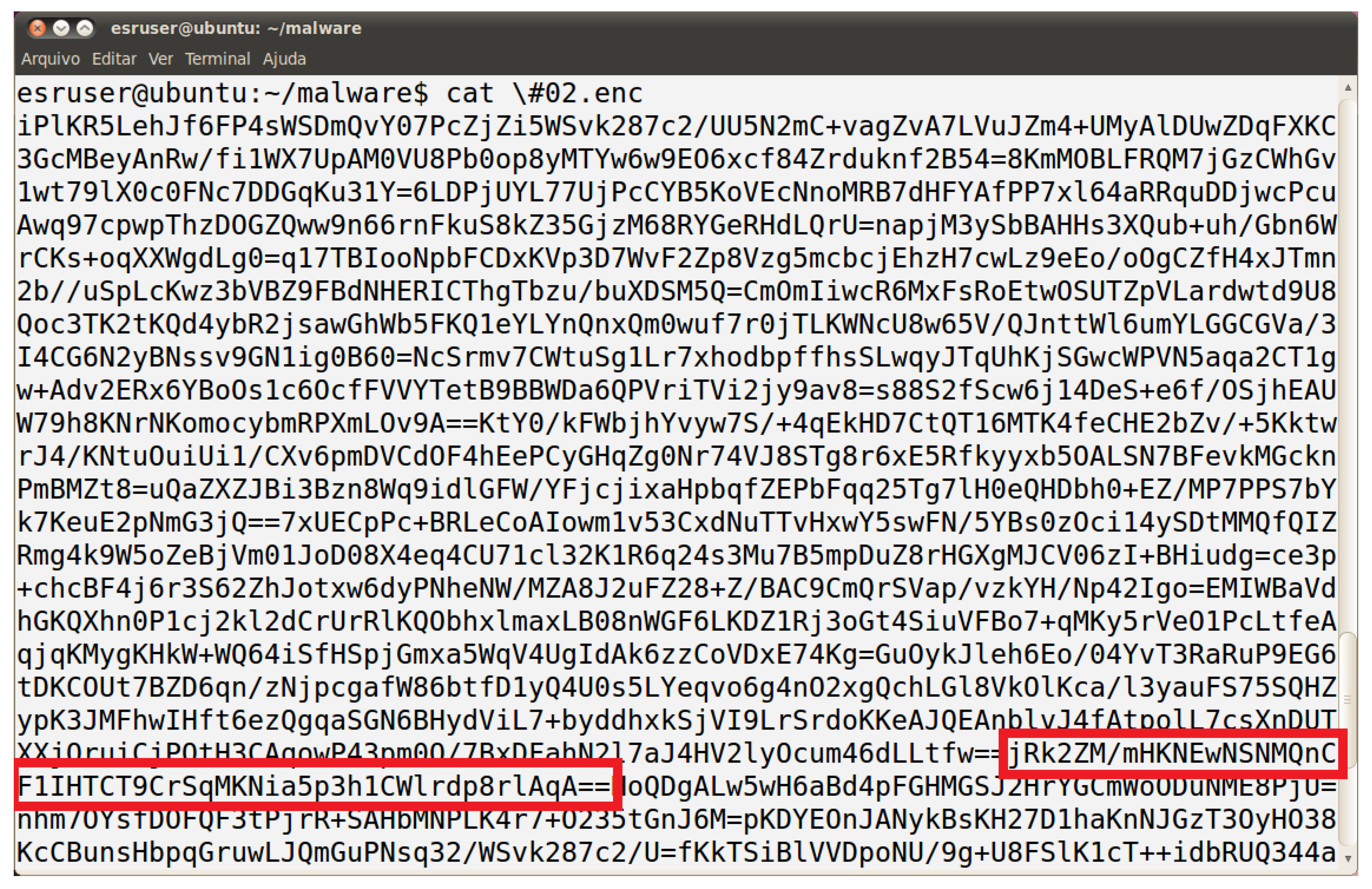
3.2.1. Description of the Malware and the Encrypted File

3.2.2. Analysis of the Encrypted File


- strings cftmon.exe
- strings -e l cftmon.exe
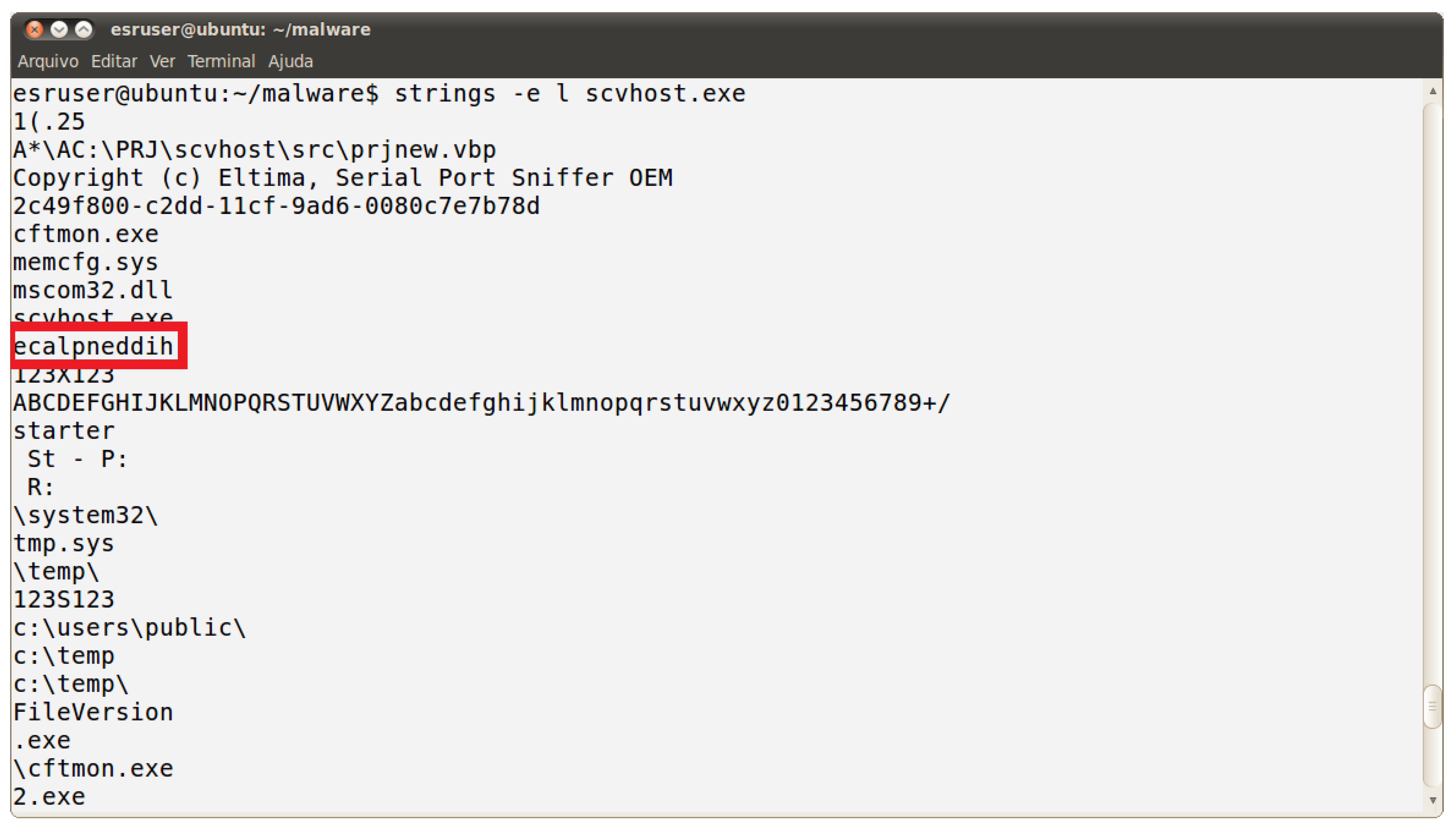
- strings scvhost.exe
- strings -e l scvhost.exe

3.2.3. Summary of the Analysis
3.2.4. Description of the Cipher and the Key
- Alphabet of definition:
- Plaintext:
- Ciphertext:
- Key: (ecalpneddih)
- Encryption function:
- Decryption function:

3.3. Third Malware
3.3.1. Description of the Malware and the Encrypted File

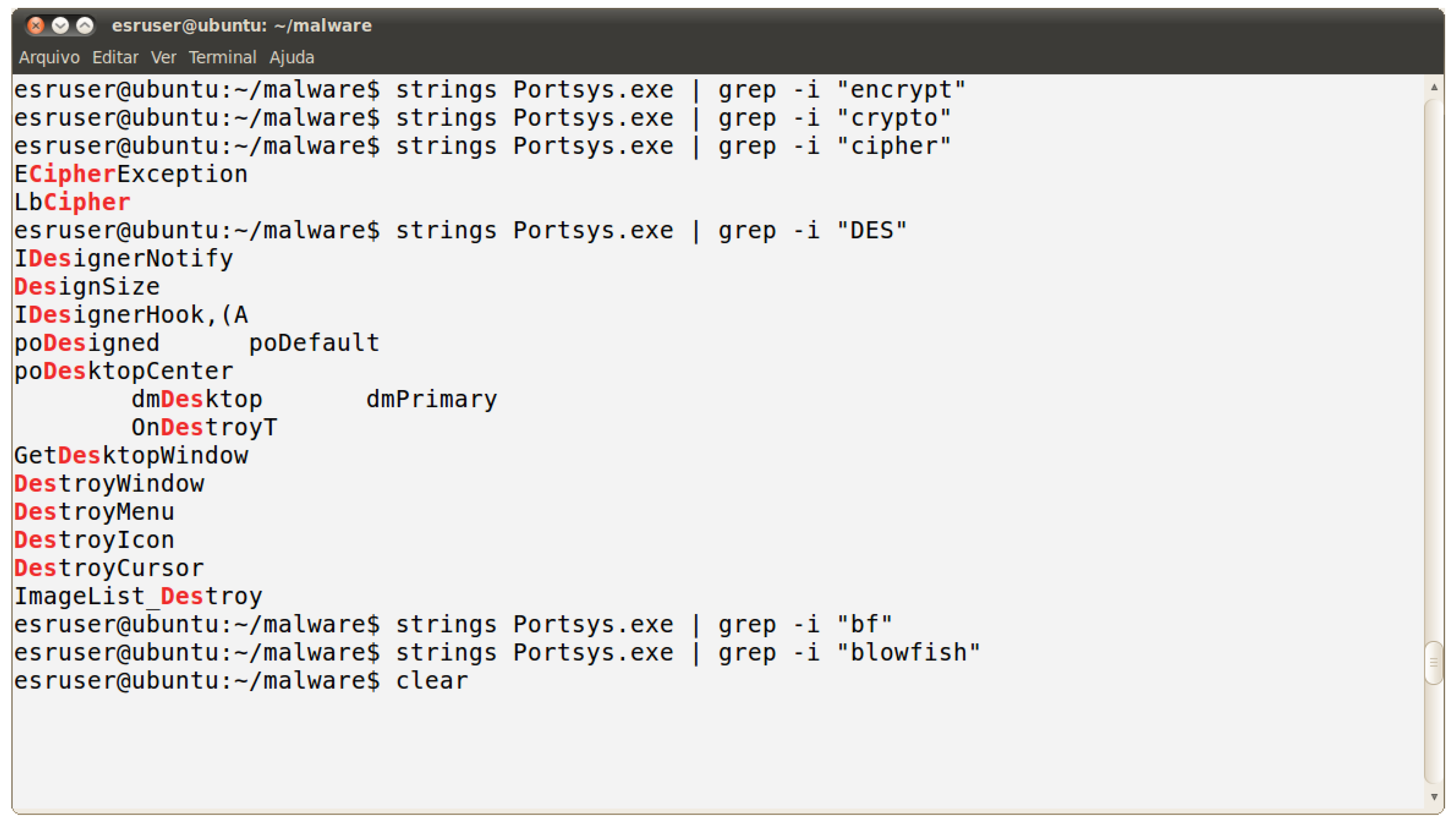
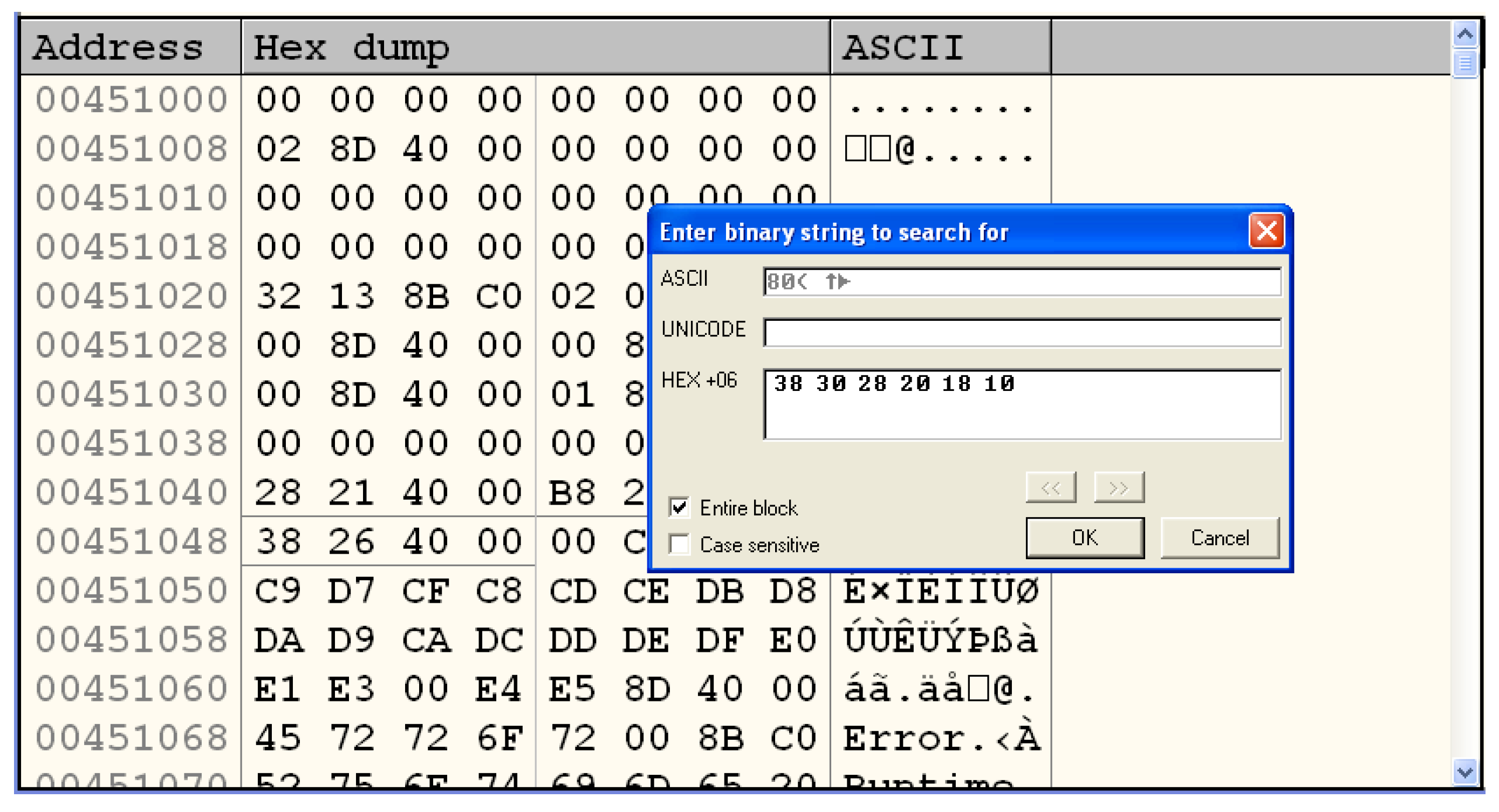
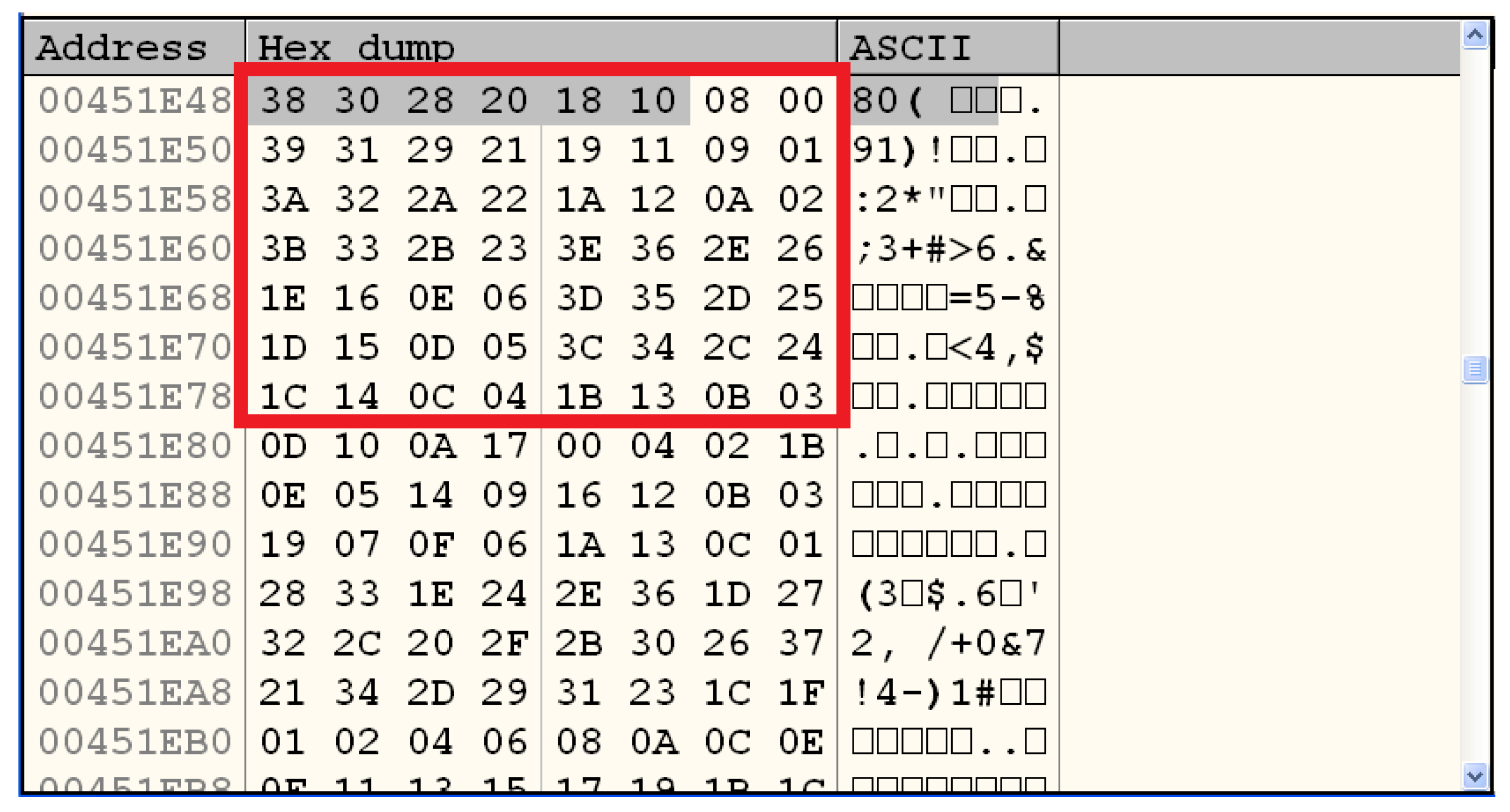
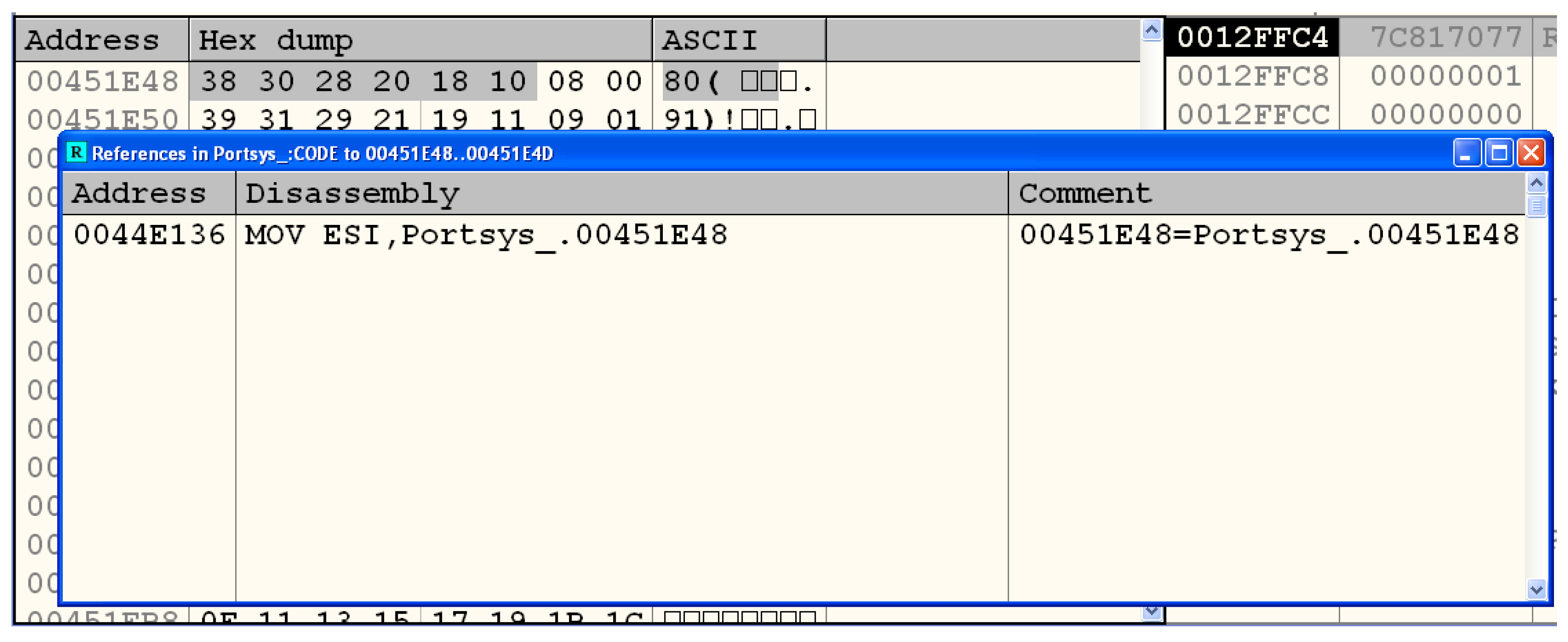
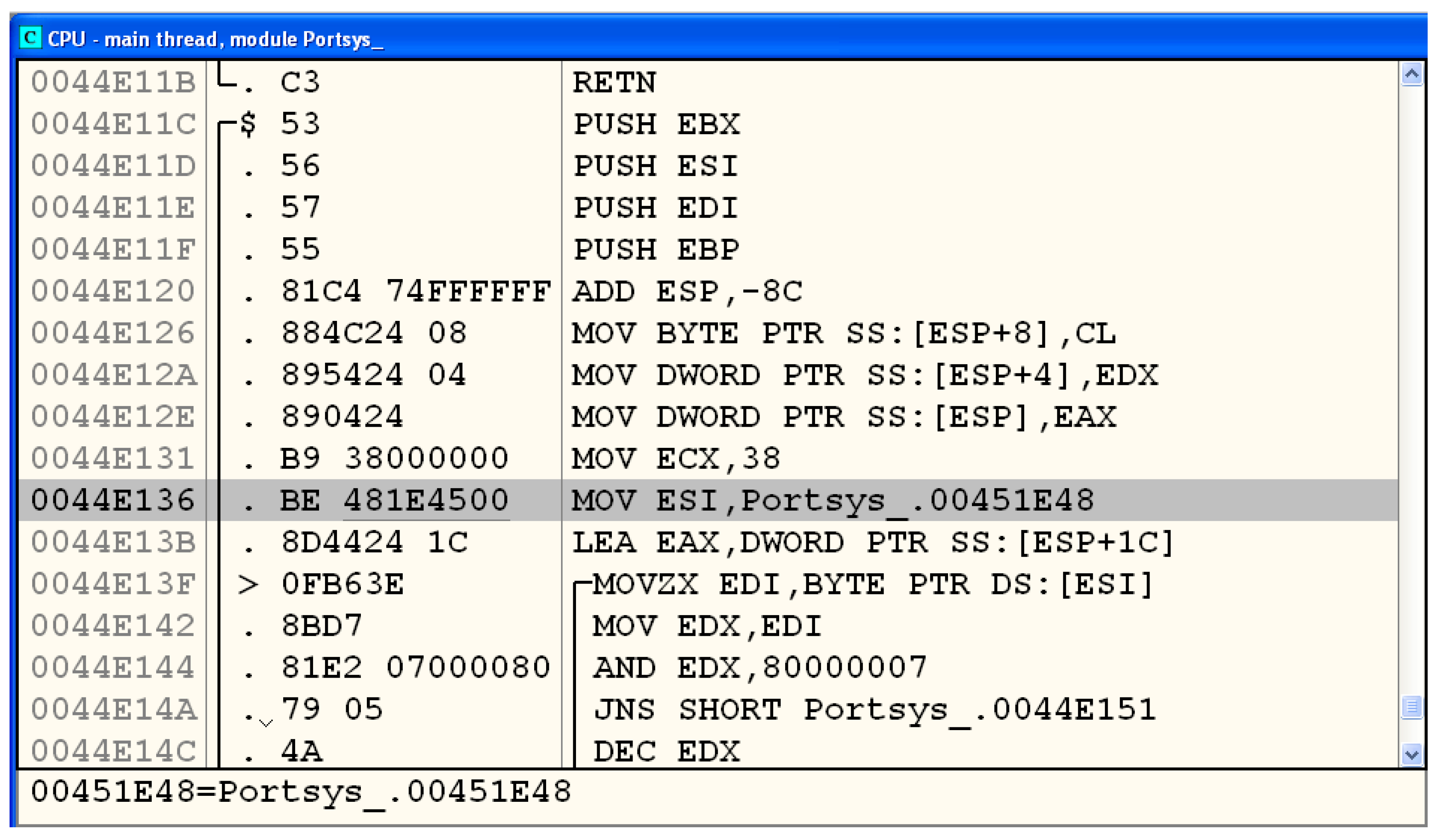
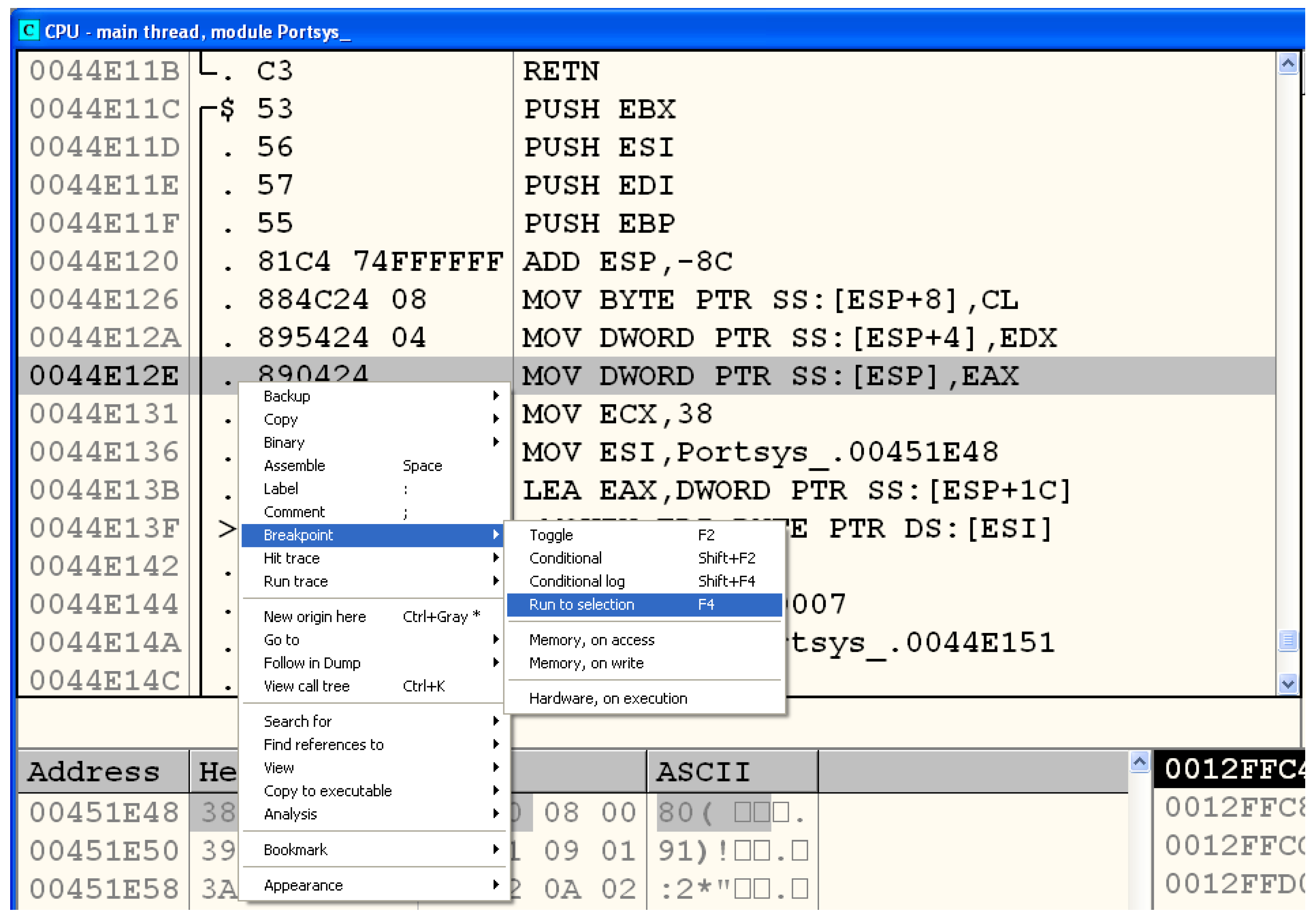
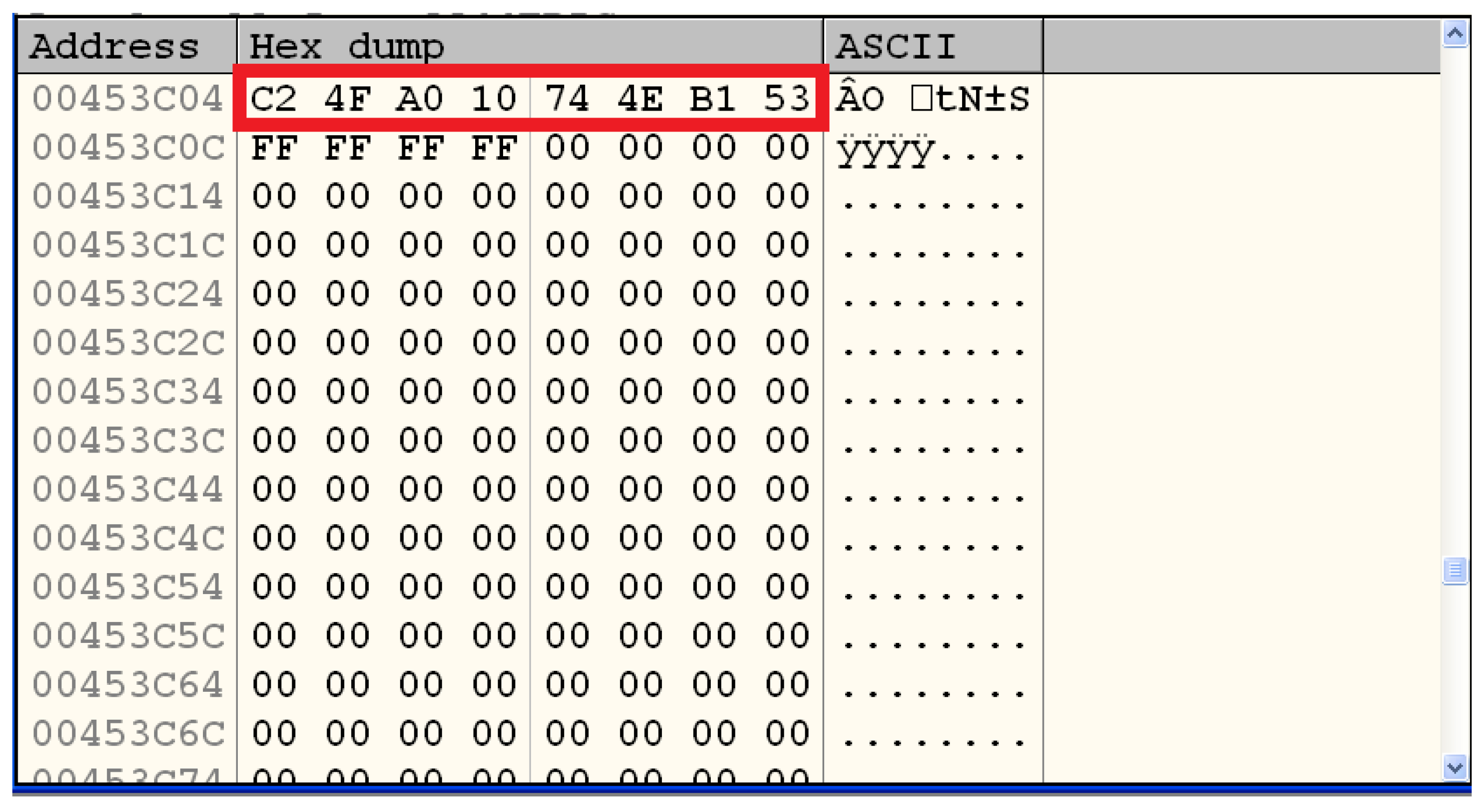
3.3.2. Analysis of the Encrypted File



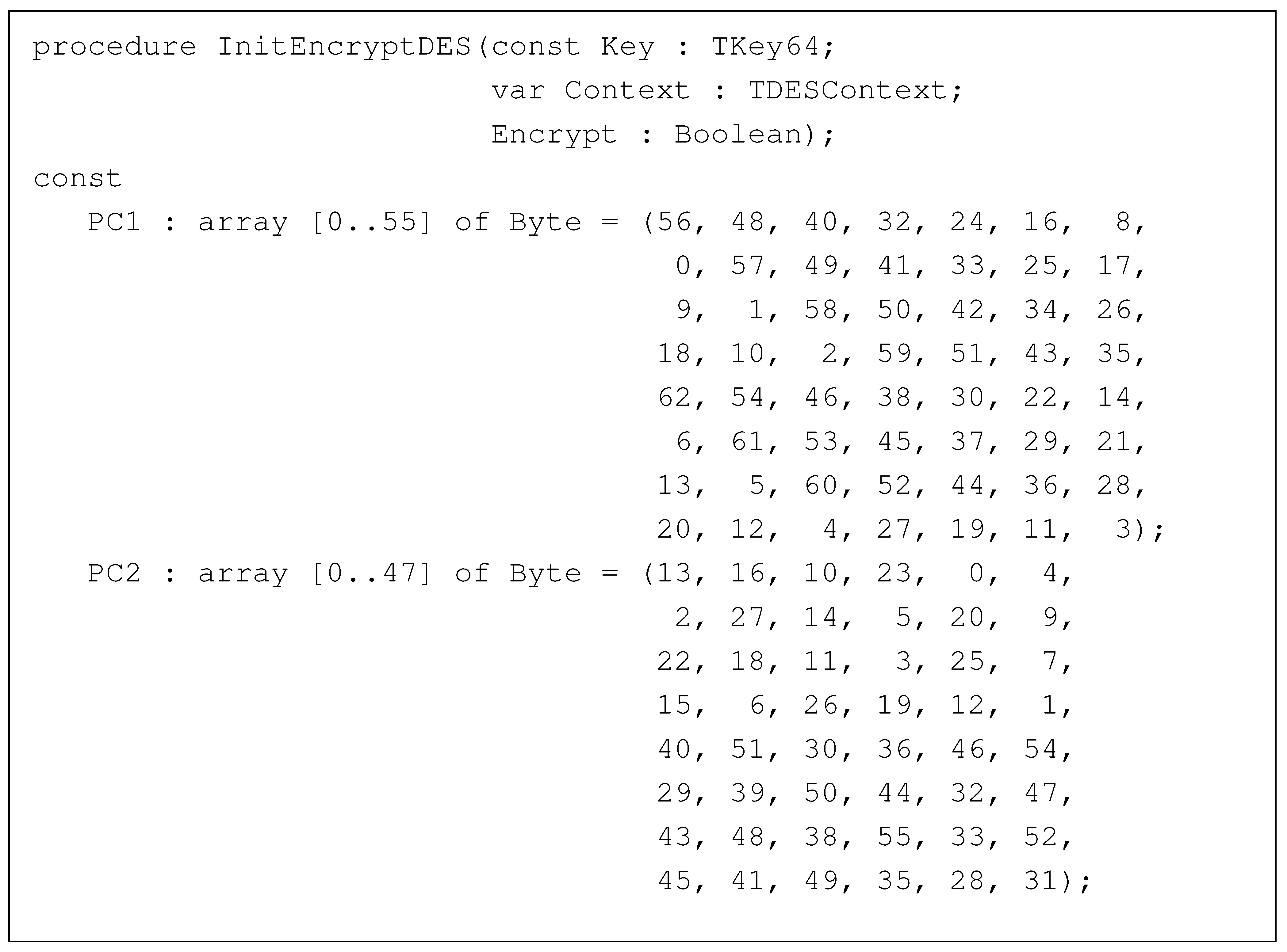
- DES—acronym for Data Encryption Standard, the first commercial-grade encryption algorithm with open specification;
- Triple DES with 2 keys—consists in successively applying DES three times with the first key being equal to the third and different from the second one [17];
- Triple DES with 3 keys—consists in successively applying DES three times with the keys being pairwise different [17];
- FEAL—the acronym for Fast Data Encipherment Algorithm, a block cipher proposed by Shimizu and Miyaguchi [18] that uses a 64-bit key to generate a 256-bit key;
- IDEA—block cipher created by Lai and Massey [19] that uses a 128-bit key;
- SAFER K-64— the acronym for Secure And Fast Encryption Routine with a Key of length 64 bits, a byte-oriented block cipher proposed by Massey [20];
- RC5—created by Rivest [21] and designed to be fast, both in hardware and software, having a variable number of rounds and variable-length cryptographic key, and to be adaptable to architectures with different word sizes;
- Loki—cipher created by Pieprzyk et al. [22] that employs a 64-bit key;
- Blowfish—this cipher was created by Schneier [23] and can use key lengths up to 448 bits; and
- KATAN64—one of the members of a family of hardware oriented block ciphers, all using 80-bit keys, created by Cannière et al. [24].




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Procedure name | Number of calls |
|---|---|
| Plain DES | 1 |
| InitEncryptTripleDES | 4 |
| InitEncryptTripleDES3Key | 6 |
| ShrinkDESKey | 2 |



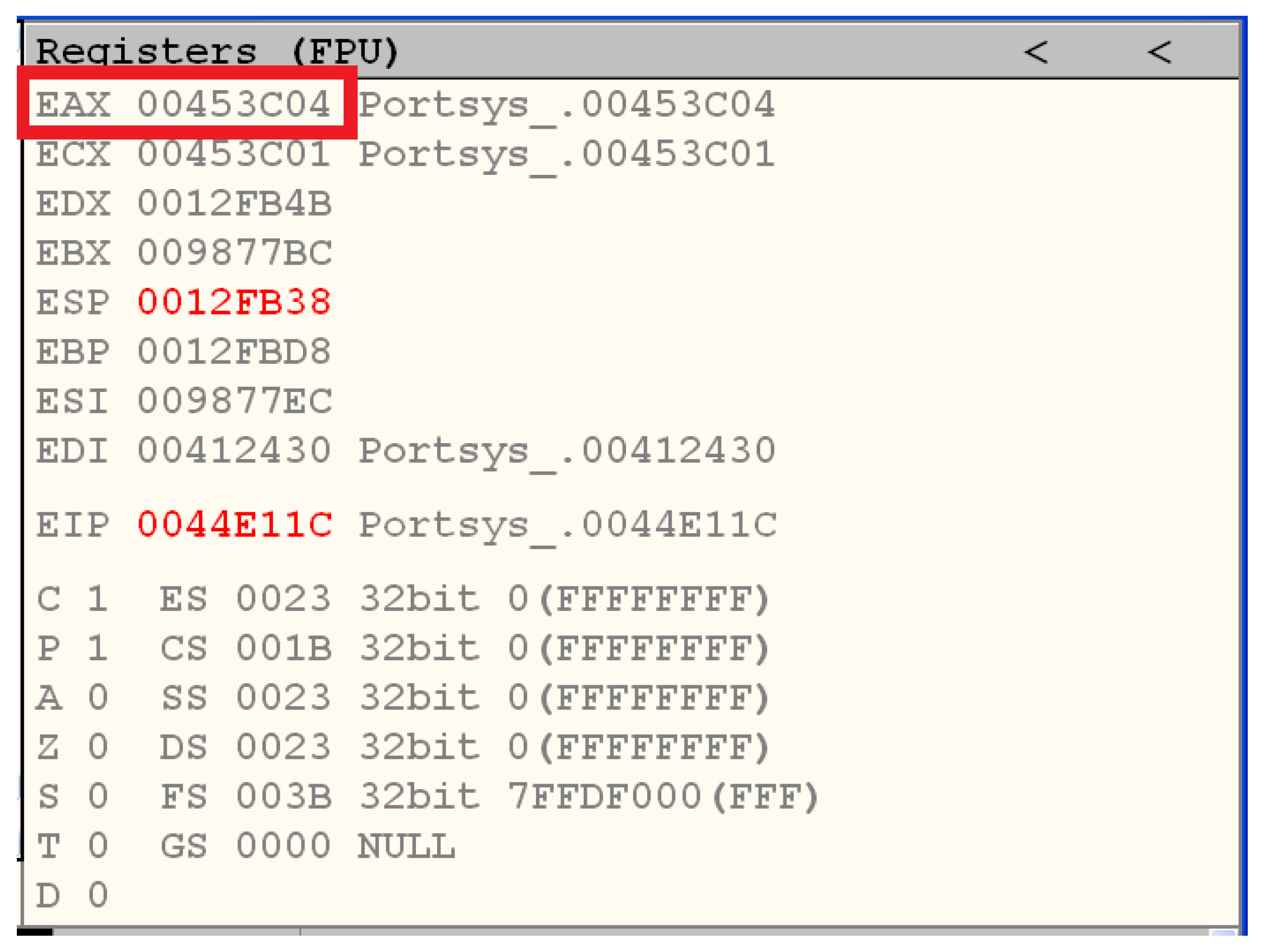
- 1st parameter—EAX register;
- 2nd parameter—EDX register;
- 3rd parameter—ECX register;
- Remaining parameters—stack;




3.3.3. Summary of the Analysis
3.3.4. Description of the Cipher and the Key
- Encryption algorithm: DES
- Mode of operation: ECB
- Key:

4. Related Work
- Draft Crypto Analyzer (DRACA) [34]—it is an old command line tool, written by Ilya Levin and Fyodor Yarochkin, that can identify some block ciphers and hash functions;
- Krypto Analyzer (KANAL) [35]—it is a plugin for PEiD that is able to identify cryptographic algorithms and related constants, functions, and libraries;
- Signsrch [36]—it is a signature based tool, created by Luigi Auriemma, that can be used to identify compression, cryptographic, and multimedia algorithms. The signature database is frequently updated and contains thousands of items;
- SnD Crypto Scanner [37]—this tool, created by Loki, works as a plugin for OllyDbg and searches for cryptographic signatures.
5. Automation
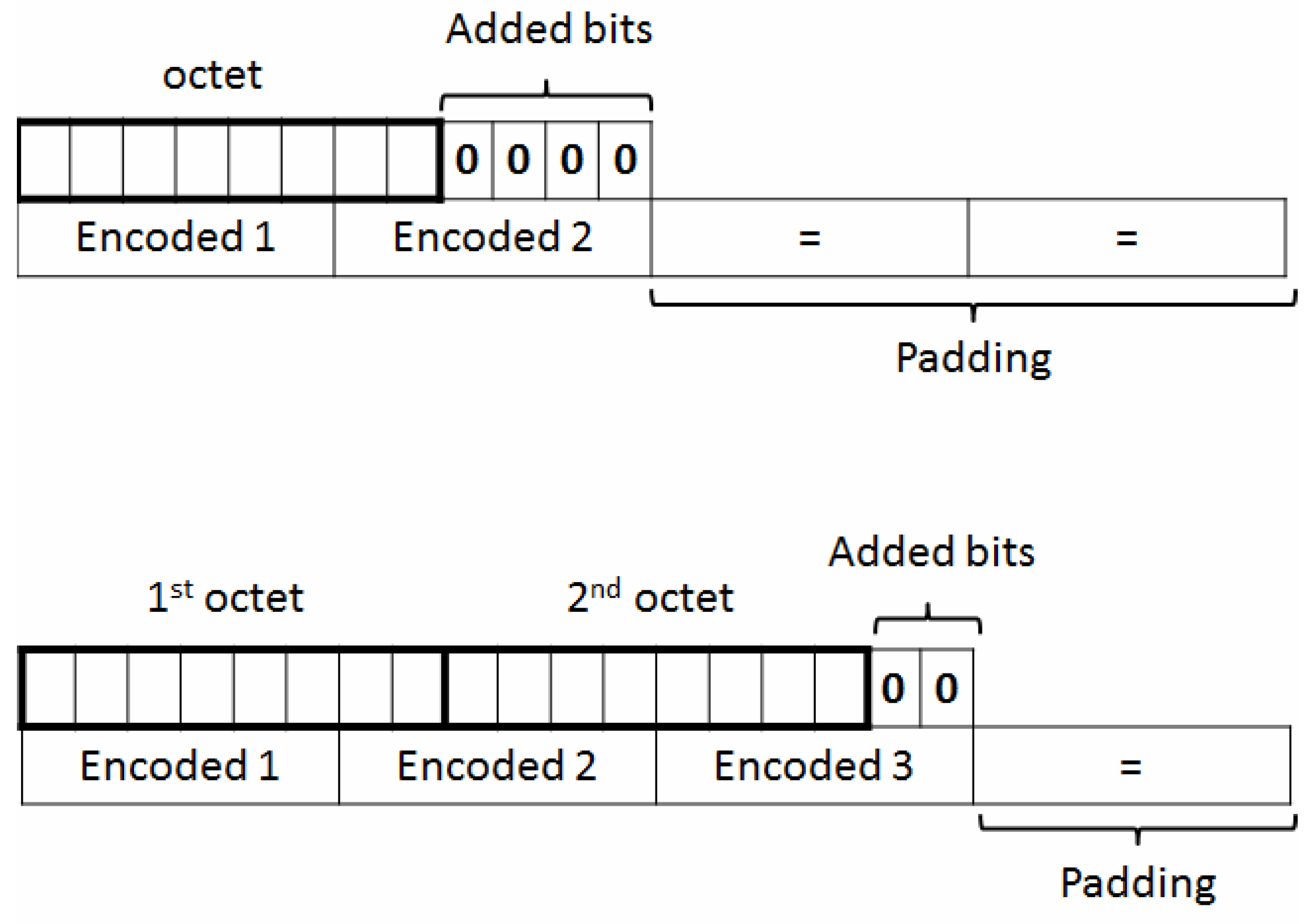
- Decoding—detecting several encoding schemes and decoding the input are simple tasks that can be grouped in a single utility. One should consider, at least, the following schemes: ASCII, Unicode, UTF, EBCDIC, and hexadecimal representation;
- Cryptanalysis of classical algorithms—one can implement automatic frequency analysis, Kasiski’s method, and index of coincidence, giving the user the possibility to define the alphabet to be used in the process. In order to check the success or failure of the operation, one should compare the statistics of the output against the one expected for the original information. Normally, this can be accomplished with high success and low false positive rates;
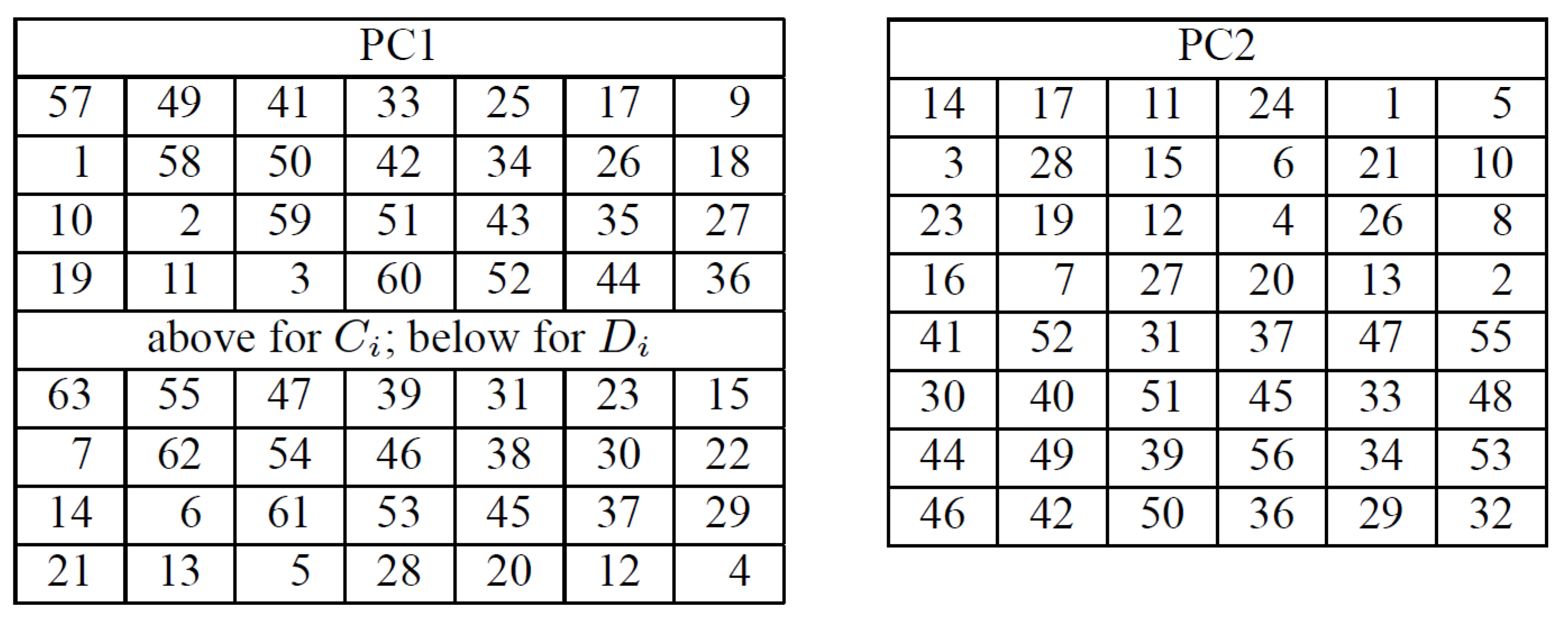
- Identification of cryptosystems—cryptosystems can be identified by searching the malware binary or process memory for data structures that might be used by specific algorithms. For instance, for Data Encryption Standard, one should search for PC1 and PC2 matrices; for Advanced Encryption Standard, forward or inverse S-Boxes matrices; for Camellia [40], the key generation constants; and so on. Several times, this process leads to the cryptographic key as well, as a nice collateral effect. This type of functionality is best implemented as a plugin for debugger software, such as OllyDbg and IDA Pro [41], and examples can be found in Section 4;
- Key search—it is not uncommon for malware authors (actually, software developers in general) to use weak cryptographic keys, even when strong algorithms are employed. In order to find keys in such a situation, one should have a dictionary of common keys, words, and patterns, and use it to search the malware binary and process memory. Sometimes, this can save a lot of time, as we showed in the analysis of the second malware. For strongly generated keys, the recommendation is to use Shamir’s algorithm [9], using a window size according to the encryption mechanism identified in the previous step. The key search method should be implemented as a plugin for debugger software, together with the cryptosystem identification functionality.
6. Conclusions
Acknowledgements
References
- Falliere, N.; Murchu, L.O.; Chien, E. W32.Stuxnet Dossier-Version 1.4; Symantec Security Response Technical Report; Symantec: Mountain View, CA, USA, 2011. [Google Scholar]
- sKyWIper (a.k.a. Flame a.k.a. Flamer): A Complex Malware for Targeted Attacks; Technical Report for Laboratory of Cryptography and System Security (CrySyS Lab): Budapest, Hungary, 2012.
- Rivest, R.L. RFC 1321–The MD5 Message-Digest Algorithm; MIT Laboratory for Computer Science and RSA Data Security, Inc.: Bedford, MA, USA, 1992. [Google Scholar]
- Stevens, M.; Lenstra, A.; Wegger, B. Chosen-prefix collisions for MD5 and colliding X.509 certificates for different identities. Lect. Notes Comput. Sci. 2007, 4515, 1–22. [Google Scholar]
- Menezes, A.; van Oorschot, P.; Vanstone, S. Handbook of Applied Cryptography, 5th ed.; CRC Press: Boca Raton, FL, USA, 2001. [Google Scholar]
- Friedman, W.F. The Index of Coincidence and Its Applications in Cryptology; Department of Ciphers Publ 22, Riverbank Laboratories: Geneva, IL, USA, 1922. [Google Scholar]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Sikorski, M.; Honig, A. Practical Malware Analysis: The Hands-On Guide to Dissecting Malicious Software, 1st ed.; No Starch Press: San Francisco, CA, USA, 2012. [Google Scholar]
- Shamir, A.; van Someren, N. Playing “hide and seek” with stored keys. Lect. Notes Comput. Sci. 1999, 1648, 118–124. [Google Scholar]
- Data Encryption Standard (DES); FIPS Pub 46-3; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1999.
- Advanced Encryption Standard (AES); FIPS Pub 197; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2001.
- Eilam, E. Reversing: Secrets of Reverse Engineering; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- VirusTotal. Available online: https://www.virustotal.com/en/ (accessed on 16 April 2013).
- PE iDentifier. Available online: http://www.peid.info (accessed on 16 April 2013).
- Zimmerman, M.W. Microsoft Visual Basic 6.0: Programmer’s Guide; Microsoft Press: Redmond, WA, USA, 1998. [Google Scholar]
- Pacheco, X. Borland Delphi 6 Developer’s Guide; Sams: Indianapolis, IN, USA, 2001. [Google Scholar]
- Barker, W.C.; Barker, E. Recommendation for the Triple Data Encryption Algorithm (TDEA) Block Cipher; NIST SP 800-67, Revision 1; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2012. [Google Scholar]
- Shimizu, A.; Miyaguchi, S. Fast data encipherment algorithm FEAL. Lect. Notes Comput. Sci. 1988, 304, 267–278. [Google Scholar]
- Lai, X.; Massey, J.L. A proposal for a new block encryption standard. Lect. Notes Comput. Sci. 2006, 473, 389–404. [Google Scholar]
- Massey, J.L. SAFER K-64: A byte-oriented block-ciphering algorithm. Lect. Notes Comput. Sci. 1994, 809, 1–17. [Google Scholar]
- Rivest, R.L. The RC5 encryption algorithm. Lect. Notes Comput. Sci. 1995, 1008, 86–96. [Google Scholar]
- Brown, L.; Pieprzyk, J.; Seberry, J. LOKI–A cryptographic primitive for authentication and secrecy applications. Lect. Notes Comput. Sci. 1990, 453, 229–236. [Google Scholar]
- Schneier, B. Description of a new variable-length key, 64-bit block cipher (Blowfish). Lect. Notes Comput. Sci. 1994, 809, 191–204. [Google Scholar]
- Cannière, C.; Dunkelman, O.; Knezevic, M. KATAN and KTANTAN—A family of small and efficient hardware-oriented block ciphers. Lect. Notes Comput. Sci. 2009, 5747, 272–288. [Google Scholar]
- OllyDbg. Available online: http://www.ollydbg.de/ (accessed on 16 April 2013).
- Wang, Z.; Jiang, X.; Cui, W.; Wang, X.; Grace, M. ReFormat: Automatic reverse engineering of encrypted messages. Lect. Notes Comput. Sci. 2009, 5789, 200–215. [Google Scholar]
- Caballero, J.; Poosankam, P.; Kreibich, C. Dispatcher: Enabling Active Botnet Infiltration Using Automatic Protocol Reverse-Engineering. In Proceedings of the 2009 ACM Conference on Computer and Communications Security, Sydney, Australia, 10–12 March 2009.
- Cho, C.Y.; Caballero, J.; Grier, C.; Paxson, V.; Song, D. Insights from the Inside: A View of Botnet Management from Infiltration. In Proceedings of the 3rd USENIX Workshop on Large-Scale Exploits and Emergent Threats, San Jose, CA, USA, 27 April 2010.
- Gröbert, F.; Willems, C.; Holz, T. Automated identification of cryptographic primitives in binary programs. Lect. Notes Comput. Sci. 2011, 6961, 41–60. [Google Scholar]
- Luk, C.; Cohn, R.S.; Muth, R.; Patil, H.; Klauser, A.; Lowney, P.G.; Wallace, S.; Reddi, V.J.; Hazelwood, K.M. Pin: Building Customized Program Analysis Tools with Dynamic Instrumentation. In Proceedings of the ACM SIGPLAN 2005 Conference on Programming Language Design and Implementation, Chicago, IL, USA, 12–15 June 2005.
- Calvet, J.; Fernandez, J.M.; Marion, J. Aligot: Cryptographic Function Identification in Obfuscated Binary Programs. In Proceedings of the ACM Conference on Computer and Communications Security, CCS ’12, Seoul, Korea, 2–4 May 2012.
- ASProtect. Available online: http://www.aspack.com/asprotect.html (accessed on 16 April 2013).
- Holz, T.; Steiner, M.; Dahl, F.; Biersack, E.; Freiling, F.C. Measurements and Mitigation of Peer-to-Peer-Based Botnets: A Case Study on Storm Worm. In Proceedings of the First USENIX Workshop on Large-Scale Exploits and Emergent Threats, San Francisco, CA, USA, 15 April 2008.
- Levin, I.; Yarochkin, F. Draft Crypto Analyzer (DRACA). Available online: http://www.literatecode.com/draca (accessed on 16 April 2013).
- Krypto Analyzer (KANAL). Available online: http://www.peid.info (accessed on 16 April 2013).
- Auriemma, L. Signsrch. Available online: http://aluigi.altervista.org/mytoolz.htm (accessed on 16 April 2013).
- Loki. SnD Crypto Scanner. Available online: http://www.woodmann.com/collaborative/tools/index.php/SnD_Crypto_Scanner_(Olly/Immunity_Plugin) (accessed on 16 April 2013).
- Zheng, Y.; Pieprzyk, J.; Seberry, J. HAVAL—A One-way hashing algorithm with variable length of output. Lect. Notes Comput. Sci. 1993, 718, 81–104. [Google Scholar]
- Kilian, J.; Rogaway, P. How to protect DES against exhaustive key search (an analysis of DESX). J. Cryptol. 2001, 14, 17–35. [Google Scholar] [CrossRef]
- Aoki, K.; Ichikawa, T.; Kanda, M.; Matsui, M.; Moriai, S.; Nakajima, J.; Tokita, T. Specification of Camellia–a 128-bit Block Cipher; Technical Report for Nippon Telegraph and Telephone Corporation: Osaka, Japan, 2000. [Google Scholar]
- IDA. Available online: https://www.hex-rays.com/products/ida/index.shtml (accessed on 16 April 2013).
© 2013 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Uto, N. A Methodology for Retrieving Information from Malware Encrypted Output Files: Brazilian Case Studies. Future Internet 2013, 5, 140-167. https://doi.org/10.3390/fi5020140
Uto N. A Methodology for Retrieving Information from Malware Encrypted Output Files: Brazilian Case Studies. Future Internet. 2013; 5(2):140-167. https://doi.org/10.3390/fi5020140
Chicago/Turabian StyleUto, Nelson. 2013. "A Methodology for Retrieving Information from Malware Encrypted Output Files: Brazilian Case Studies" Future Internet 5, no. 2: 140-167. https://doi.org/10.3390/fi5020140