1. Introduction
The DTN (delay/disruption tolerant networking) [
1,
2] is being studied intensively as a network that provides a means of communication when base stations in a mobile network are damaged by a disaster. However, there is a concern about whether a service that is not used in normal times can really work in an emergency. If we are to ensure that a DTN works in an emergency, it is desirable to promote general use of the DTN, so that it will also be used in normal times. Most studies on the DTN for use in times of disaster assume the use of mobile terminals owned by users or rescuers as relay nodes [
3,
4,
5]. Since the DTN capability needs to be installed in these mobile terminals, any service that is designed only for use in times of disaster cannot be cost effective. If a DTN is to use devices that are not dedicated to networking, such as mobile terminals and vehicles, as relay nodes, it is important to use a routing protocol that does not impose a large processing load on relay nodes. DTN routing methods that do not require dedicated relay nodes include epidemic routing [
6], spray and wait routing [
7], location-based routing [
8] and motion vector routing (MoVe) [
8]. None of these sufficiently reduces the processing load on relay nodes. An existing routing that uses traveling nodes that are dedicated to relay nodes is the message ferry routing [
9,
10,
11]. However, it has a problem with feasibility, because the DTN is dedicated to a specific purpose, and thus, the ferry nodes must travel to all nodes or clusters in the network. Many DTN protocols have also been proposed in the field of vehicular networks (VNs) [
12,
13]. These protocols focus on use in intelligent transport systems (ITSs). As such, their application is limited to the promotion of and support for safe driving and P2P data communication between vehicles. They have been studied for unicast communication and dissemination. No studies on these protocols have been made for the application to point-to-multipoint, multicast communication.
In this paper, we consider the use of a DTN for a day-to-day service of delivering content to a specific area and propose a routing that is based on information about the routes of fixed route-traveling nodes and the concept of “destination area”. The destination of a bundle is specified not by a terminal identifier, but by an area, which is identified by its location information. This makes it possible to multicast data to multiple terminals in the destination area. Public transportation vehicles that travel fixed routes are used as relay nodes. We present an outbound-type bundle protocol, which is used by relay nodes when they have received a forwarding-bundle request from a sending terminal and try to determine whether the bundle can reach its destination area. Using simulation, we have evaluated the proposed routing in terms of the bundle arrival rate and factors that affect the network load on relay nodes, such as the number of bundle copies, the number of hops and the maximum required buffer size of relay nodes. The evaluation results indicate that the proposed routing is better than existing routing methods at reducing the network load.
Section 2 summarizes existing routing methods.
Section 3 proposes a new routing method that is based on information about the routes of fixed-route traveling nodes.
Section 4 presents the outbound-type bundle protocol, which makes the proposed routing possible.
Section 5 describes the simulation system used to evaluate the proposed routing and protocol.
Section 6 presents the evaluation conditions used.
Section 7 discusses evaluation results.
Section 8 gives conclusions and future issues.
2. Existing Routing Methods for the DTN
The application area of the DTN routing has been expanding in recent years, and many application-dependent protocols have been studied. This paper proposes a new routing method and compares it to existing routing methods in terms of performance. The existing methods compared are “epidemic routing” [
6] and “spray and wait” [
7], both of which are well known as original routing methods, and “location-based routing” [
8] and “motion vector routing (MoVe)” [
8], both of which are representative routing methods that use location information as the source of routing knowledge.
In “epidemic routing”, each node tries to deliver a bundle to the destination node by unconditionally propagating bundle copies to nodes in its neighborhood. This routing can achieve the theoretically highest bundle arrival rate, but it propagates so many copies that the network can become congested. It requires an enormous amount of network resources, such as radio bandwidths and memory buffers. To remedy this problem, “spray and wait routing” restricts consumption of resources by setting an upper limit to the number of copies. The downside is that it cannot deliver bundles to as far places as the epidemic routing can.
The “location-based routing” assumes that all relay nodes know the location of the destination node. Each relay node selects a node that is closer to the destination node than itself and sends a bundle to it. While the routing algorithm is the simplest, there is no assurance that the bundle can reach the destination node quickly with a small number of hops. The “motion vector routing” tries to increase the probability at which each selected relay node approaches the destination node quickly by using moving speed vectors instead of simply using information on the location of the destination node.
One of the existing routing methods that uses dedicated relay nodes is “message ferry routing” [
9,
10,
11]. It defines the places where mobile terminal owners or chased wild animals tend to come together as “clusters” and defines a relay node that travels from one cluster to another as a “ferry node”. It always achieves the highest bundle arrival rate among the different routing methods because the ferry node ensures that the bundle reaches the destination. This routing is also the most efficient, because the number of bundle copies and the number of hops are theoretically the smallest. However, since it assumes that the network is dedicated to a specific purpose, the ferry node needs to visit every node or cluster. This requirement restricts its feasibility and extensibility.
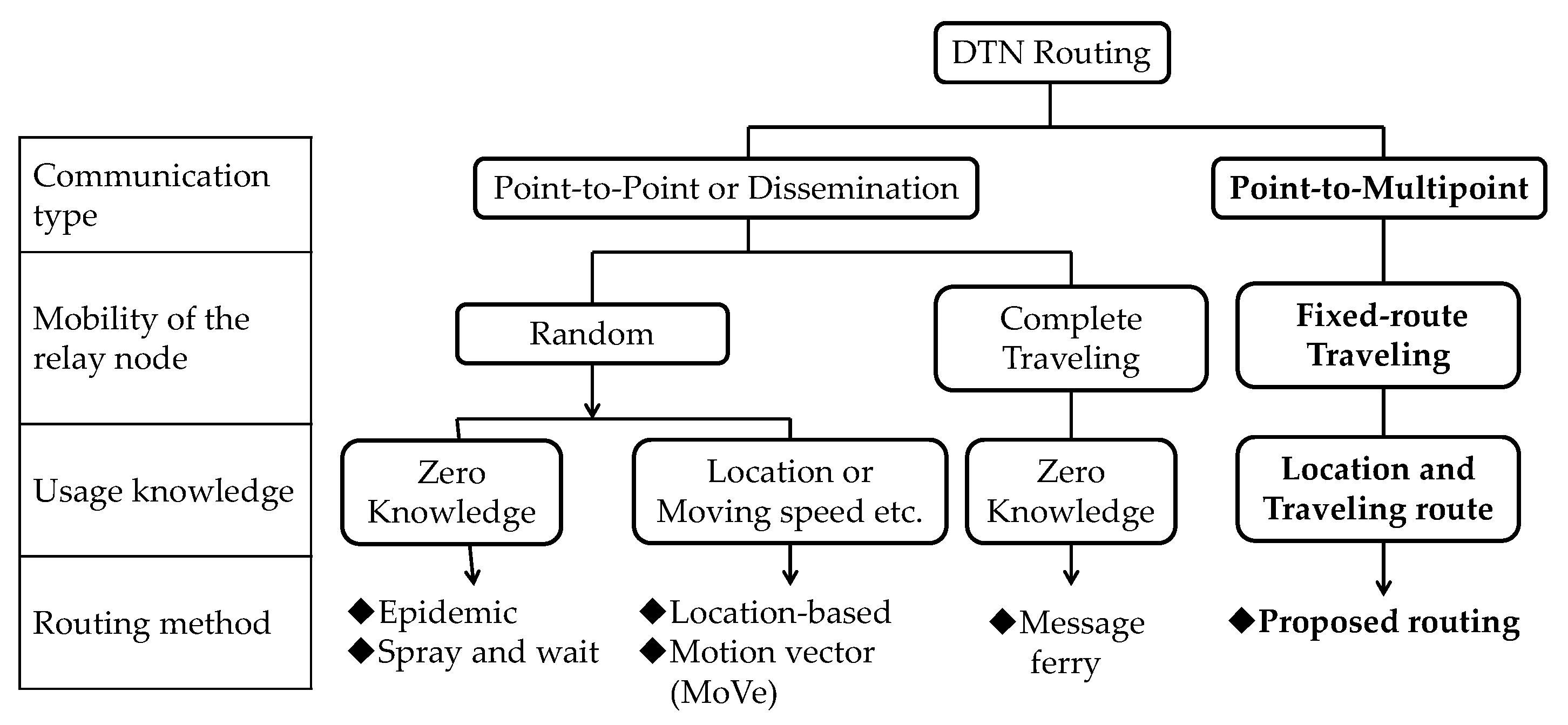
The characteristics of the different routing methods are summarized in
Table 1.
Table 2 compares these routing methods in terms of the bundle arrival rate, number of copies, number of hops and the buffer size required at each node.
In addition, the existing routing methods are intended only for point-to-point transfer or dissemination,
i.e., transfer of data to unspecified nodes. They do not consider point-to-multipoint transfer, which is needed for content delivery. The classification of the proposed and the existing routing methods is illustrated in
Figure 1.
3. Routing Based on Information about the Routes of Traveling Nodes and the Concept of the Destination Node
This paper proposes a routing that is based on information about the routes of traveling nodes and the concept of “destination area”. This routing is hereinafter referred to as “traveling route information-based routing”. As shown in
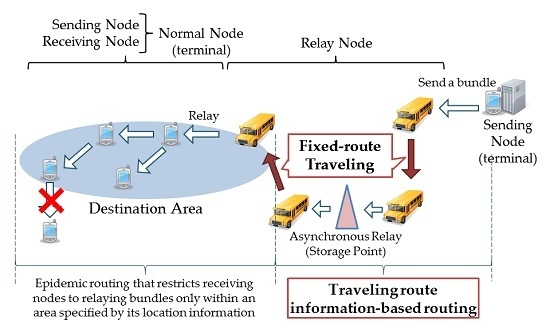
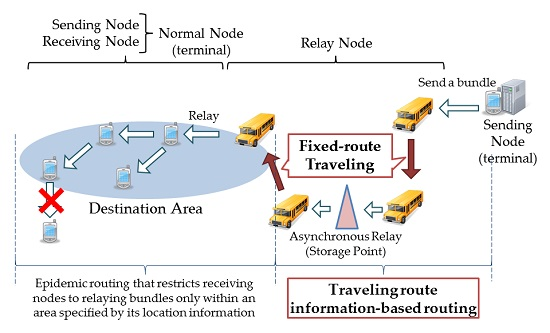
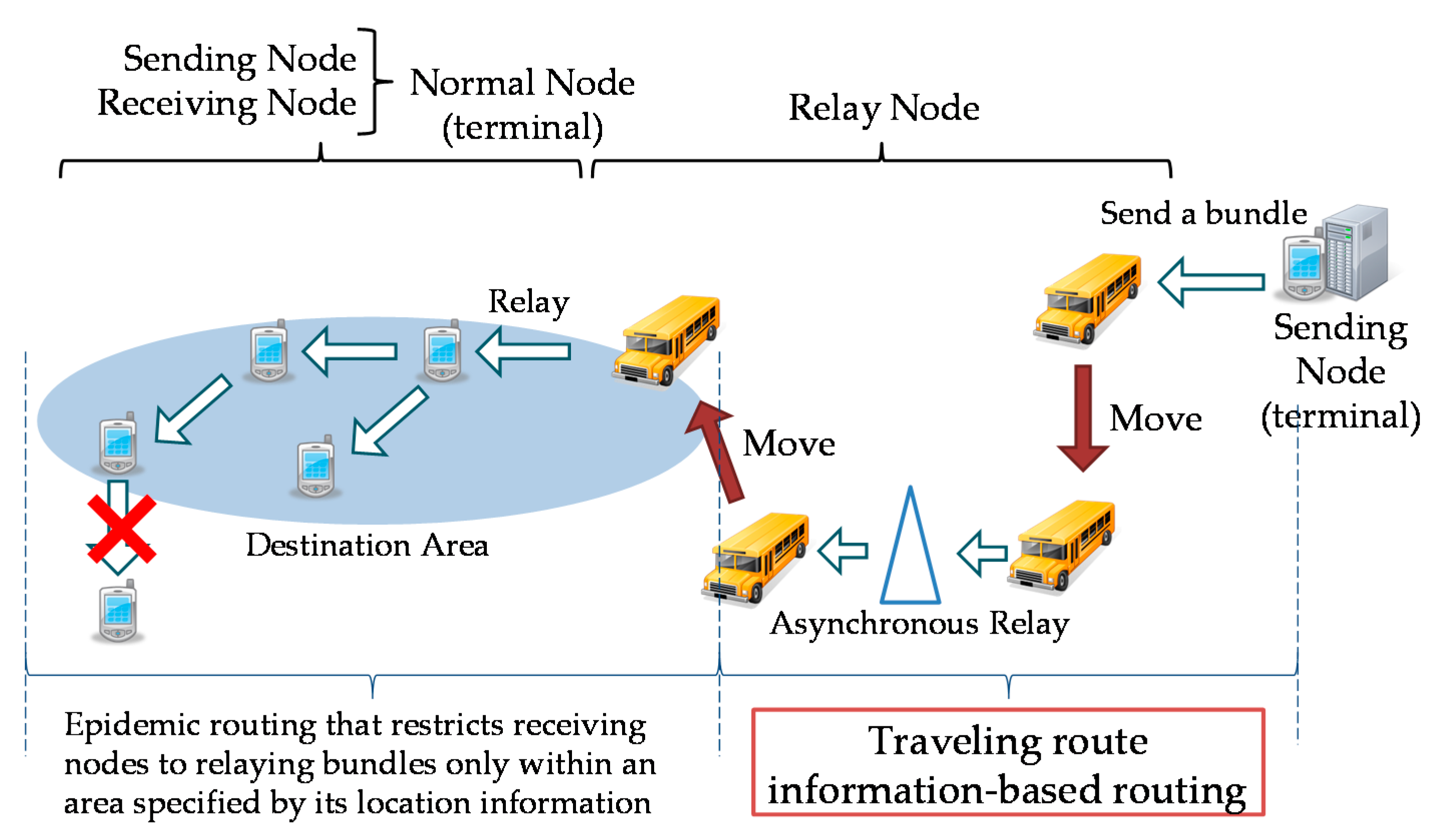
Figure 2, this routing uses three types of node: mobile terminals, traveling nodes and storage points. Mobile terminals are terminals owned by pedestrians. Traveling nodes are buses or trains that travel on fixed routes and are equipped with capabilities to store, transport and relay data. The idea is to use public transportation vehicles as dedicated relay nodes, thereby removing routing restrictions imposed by the message ferry routing, which requires dedicated relay nodes to visit all of the clusters. Storage points are fixed devices located at places where multiple traveling nodes come and stop temporarily. They relay a bundle from one relay node to another.
Traveling nodes and storage points are together referred to as “relay nodes”. Receiving nodes are mobile terminals. A destination area, which is identified by its location information, contains a cluster of receiving nodes. Within a destination area, bundles are relayed by receiving nodes using epidemic routing. An upper limit is set to the number of hops within a destination area in order to avoid traffic concentrating on any specific receiving node when a receiving node receives a bundle from a traveling node. A service of local content delivery assumed for the DTN is shown in
Figure 2. In this service, a bundle is destined to unspecified terminals within a specific destination area. The destination area is located not very far from the sending terminal. Delivery of content is considered to be useful even if there is a transmission delay in the order of several hours to several days. It is also assumed that it is not a serious problem, even if some intended receiving terminals cannot receive a bundle.
This paper focuses on two issues related to the traveling route information-based routing. The first is how to define a multipoint address based on location information when terminals within a specific destination area are receiving terminals. The second is how to enable the sending node to learn in advance whether the bundle it is going to send can reach its destinations. The aim is to reduce the network load that would be generated by futile attempts to store and relay bundles that cannot reach their destinations. For the former issue, we introduce the concept of “destination area”, which will be described in detail in
Section 3.1. For the latter, we introduce the concept of “covered area”. Whether a bundle can reach its destinations is determined based on whether a covered area overlaps with the destination area, as will be described in
Section 3.2 to
Section 3.3.
3.1. Destination Area
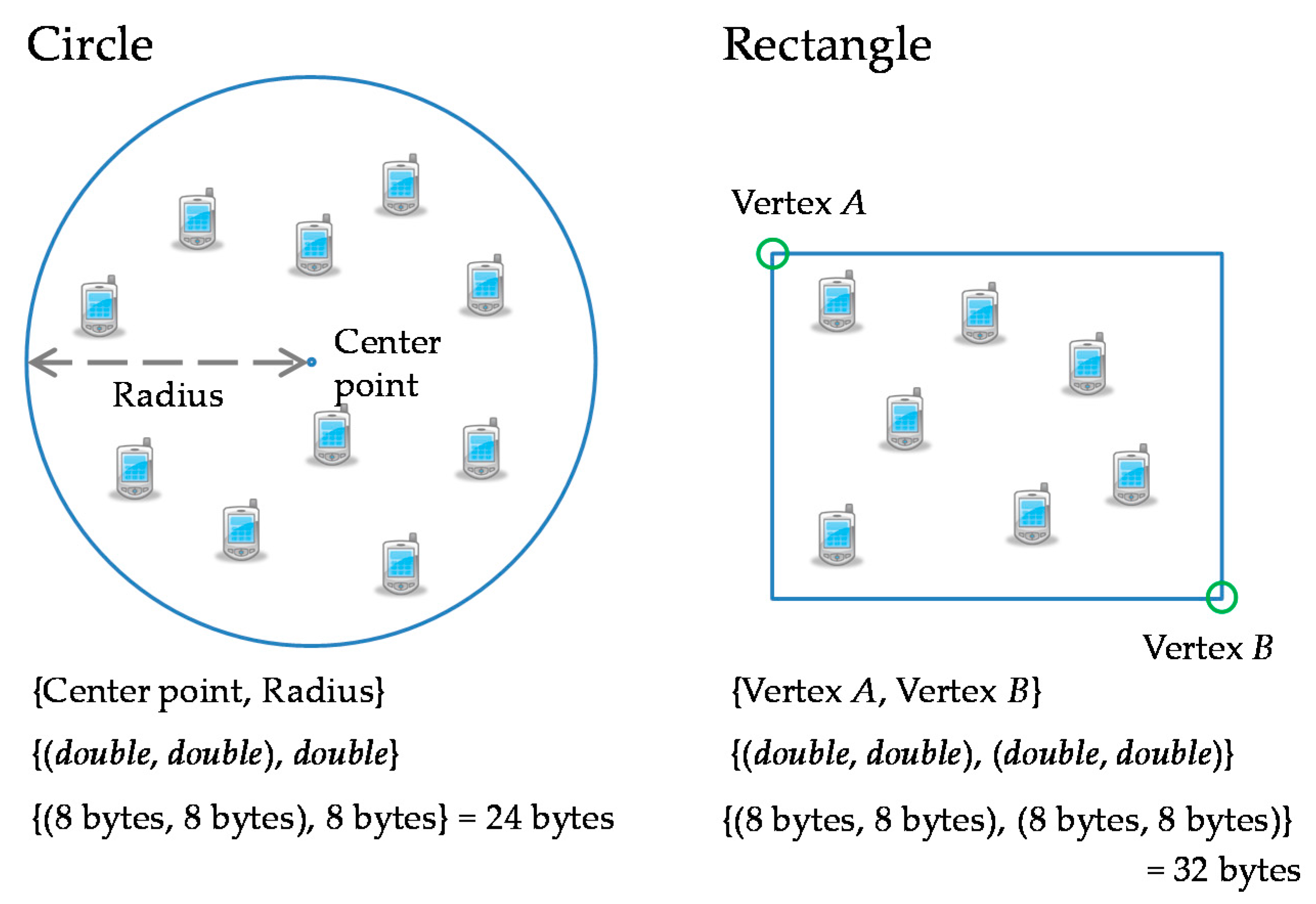
We define a destination area in order to specify a multi-point address. A destination area is a polygon, which is identified by its location. When a bundle is carried to a destination area, all nodes within the destination area become receiving nodes. Typical shapes of a destination area are a circle and a rectangle, as shown in
Figure 3. The sending node needs only to specify a destination area rather than individual receiving nodes.
3.2. Covered Area
Traveling route information-based routing uses information about the route of a traveling node to define the geographical area in which the traveling node is supposed to be able to relay bundles asynchronously. This geographical area is referred to as a “covered area”. Specifically, we consider two types of covered area: circular covered area and vectorial covered area.
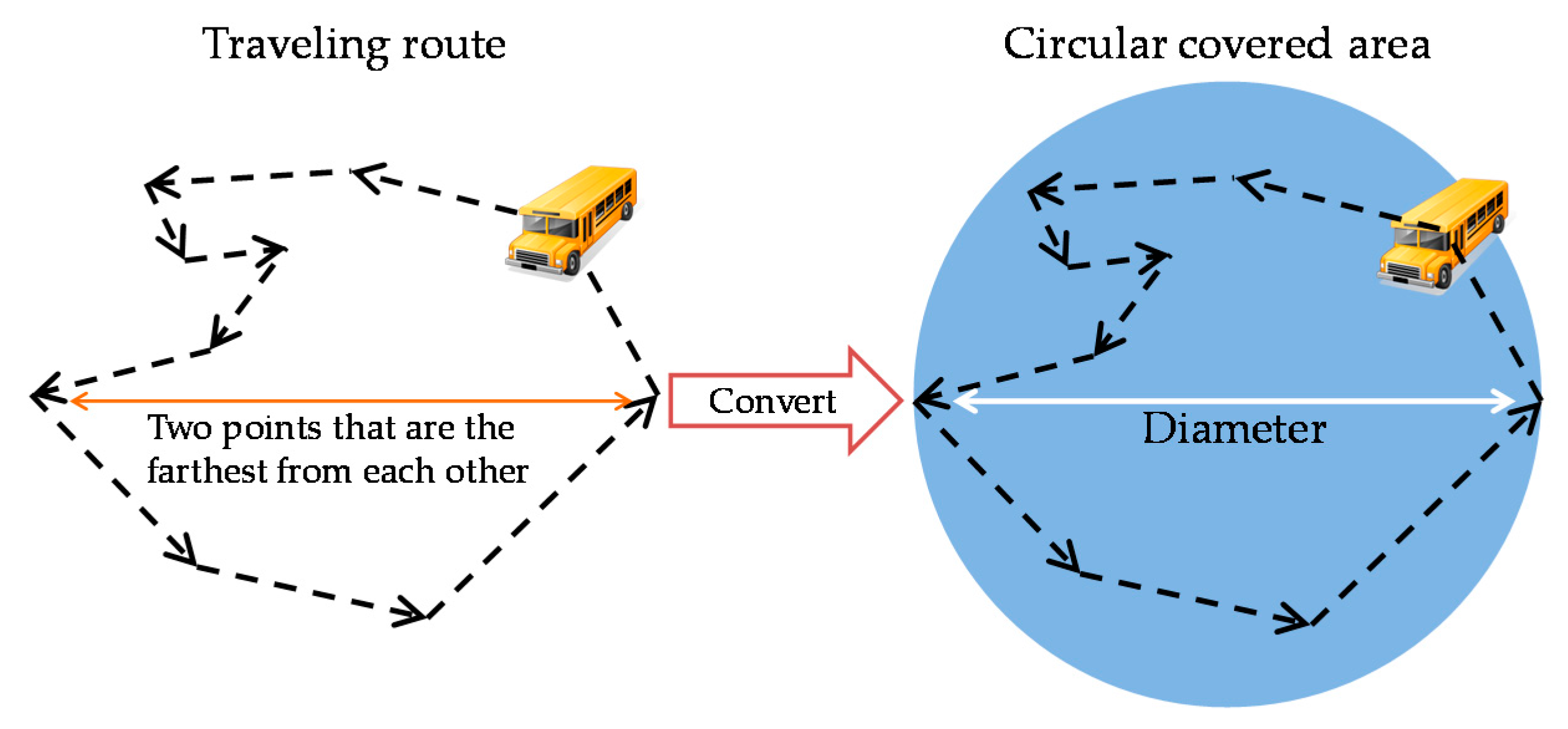
As shown in
Figure 4, a circular covered area is a circle that contains the traveling route. A covered area is associated with its location information. An advantage of using a circular covered area is that it can be identified by extremely simple location information. The data size required for this information is fixed and small. A downside is that its oversimplification of a complex shape into a circle means that a covered area can contain pockets of area to which bundles cannot actually be relayed.
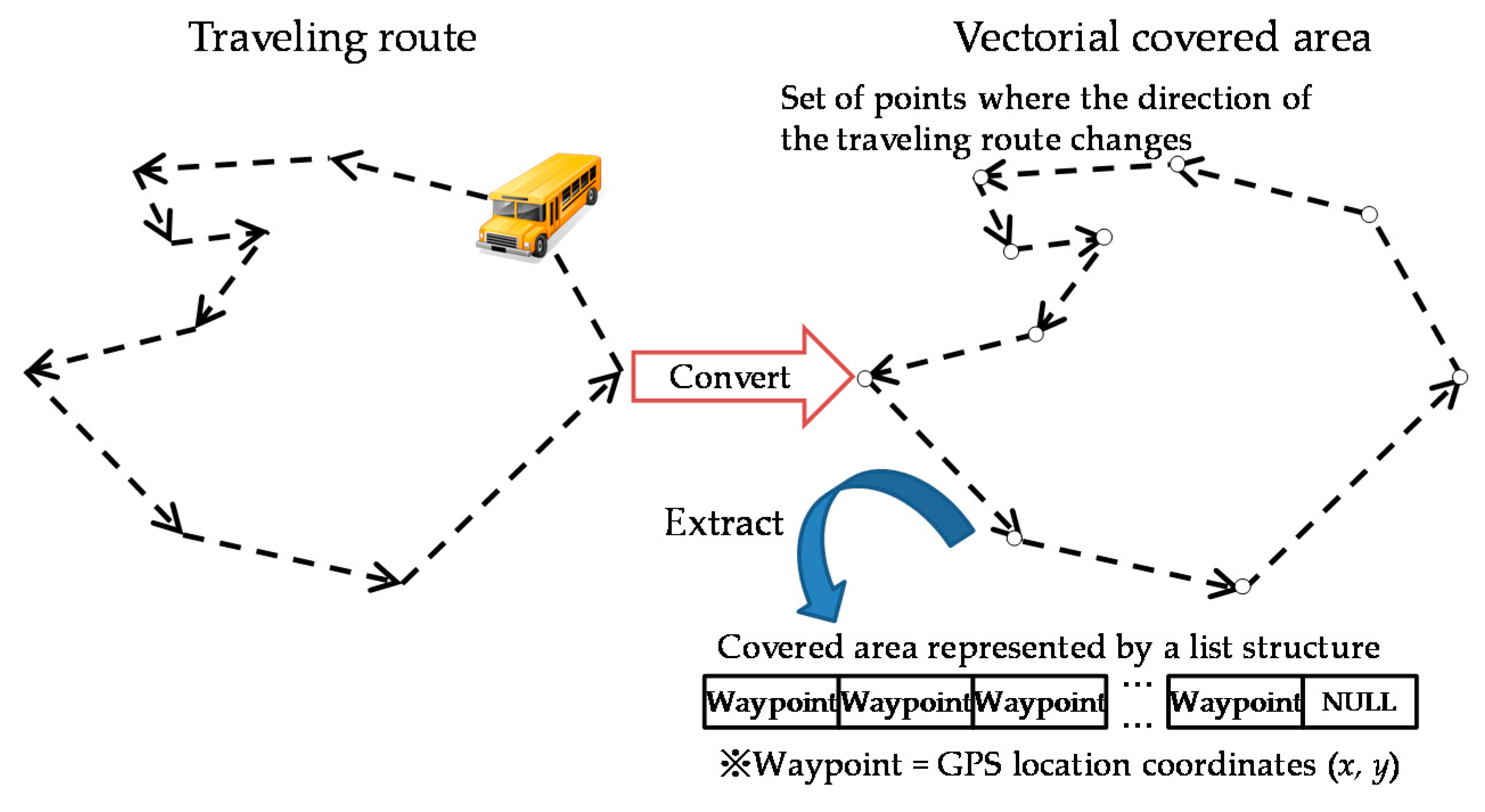
A vectorial covered area is a set of points where the direction of the traveling route changes, as shown in
Figure 5. A vectorial covered area represents the actual area more accurately than a circular covered area, but the data size of information needed to represent its shape is variable and much larger.
3.3. How to Determine Whether a Bundle Can Reach Its Destination Area and Routing
When a DTN is constructed, each relay node initializes its covered area. When two relay nodes come in contact with each other, they exchange information about covered areas, so that all relay nodes will gain knowledge about the connectivity of all covered areas in the network. The knowledge is propagated to all relay nodes in multiple hops.
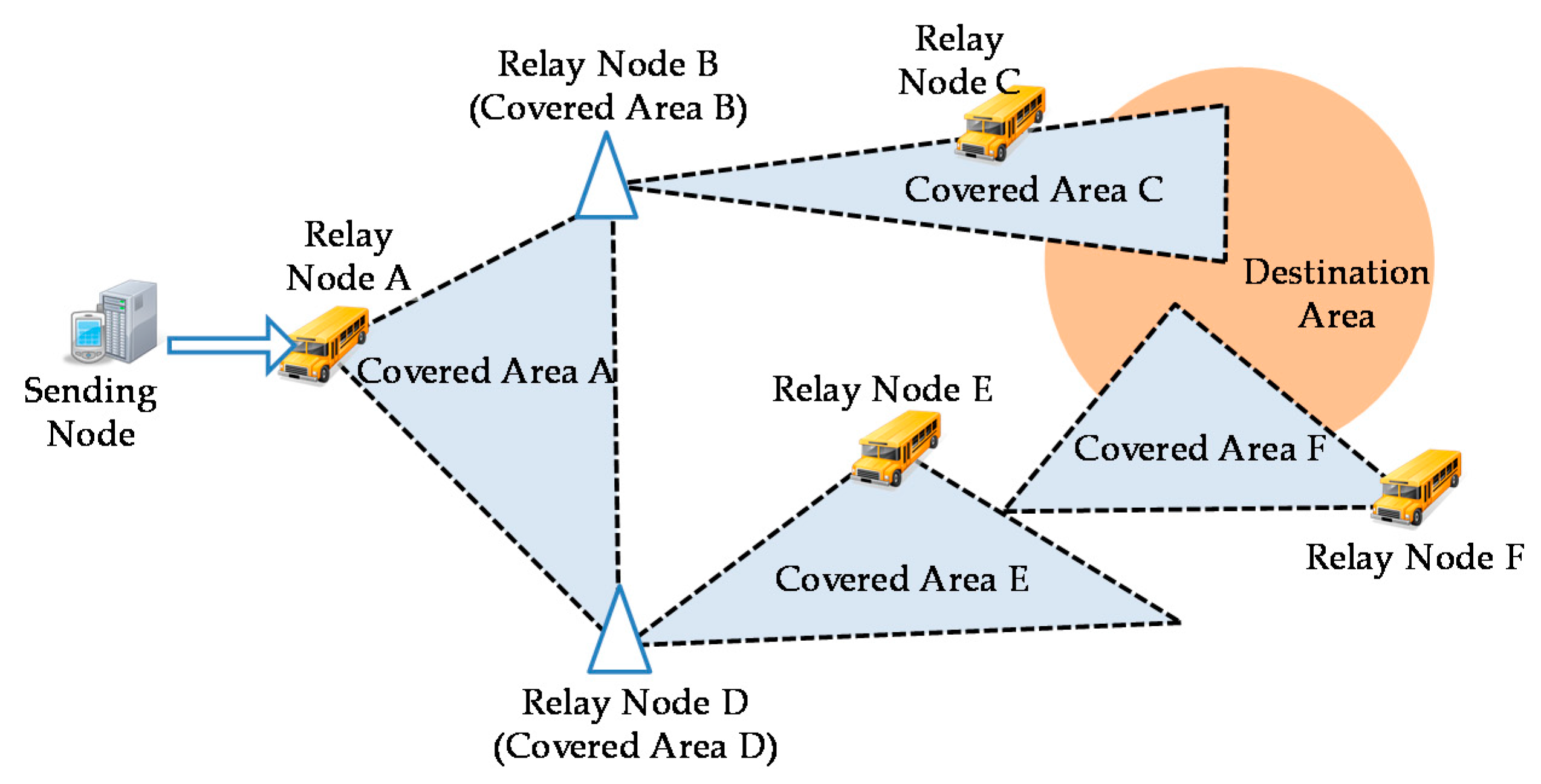
When a sending node sends a forwarding-bundle request to a relay node, the relay node checks whether the bundle can reach its destination area. Specifically, the relay node decides that the bundle can reach its destination area if the destination area overlaps with a covered area that is reachable for that relay node. Only when this has been confirmed, the relay node receives the bundle and sends it in multiple hops to the node that has the covered area that overlaps with the destination area. Suppose that the sending node sends a forwarding-bundle request to Node A in a case where covered areas and the destination area are laid out as shown in
Figure 6. Node A knows that the covered areas of Nodes C and F overlap with the destination area. Therefore, Node A receives the bundle from the sending node and forwards it to Nodes C and D. All relay nodes except Nodes C and F discard the bundle after relaying it to another relay node. In contrast, Nodes C and F retain the bundle after relaying it to a receiving node because they may be able to relay it to other receiving nodes.
When the bundle has been relayed to the relay node that has a covered area that overlaps with the destination area, and this relay node comes in contact with a receiving node in the destination area, it relays the bundle to that receiving node. The receiving node relays the bundle to other receiving nodes within the destination area. This continues in multiple hops to propagate the bundle in the destination area.
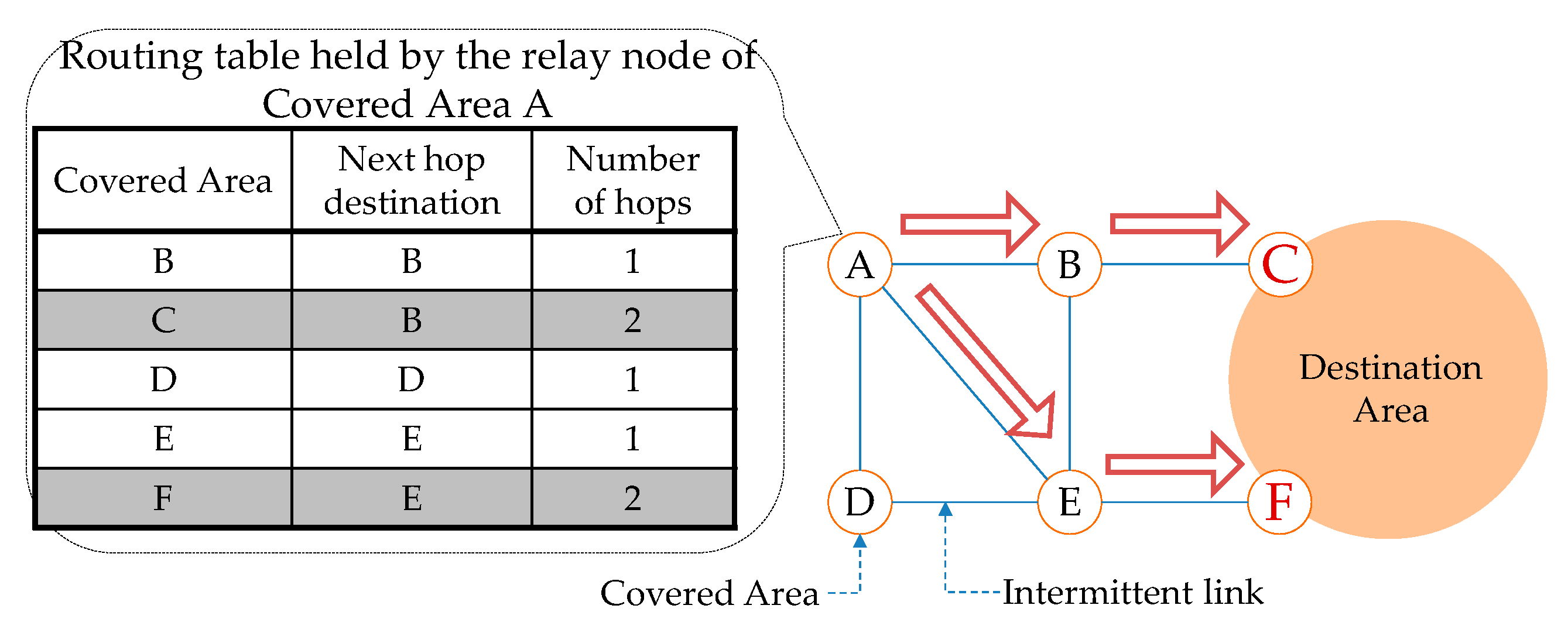
An example of the routing table held by the relay node of Covered Area A in
Figure 6 is shown in
Figure 7. The routing between relay nodes is determined based on the number of hops. The route with the smallest number of hops is selected. In the case of the routing table shown in
Figure 7, the route from Covered Area A to Covered Area C goes through the relay node of Covered Area B, while the route to Covered Area F goes through the relay node of Covered Area E.
4. Outbound-Type Bundle Protocol
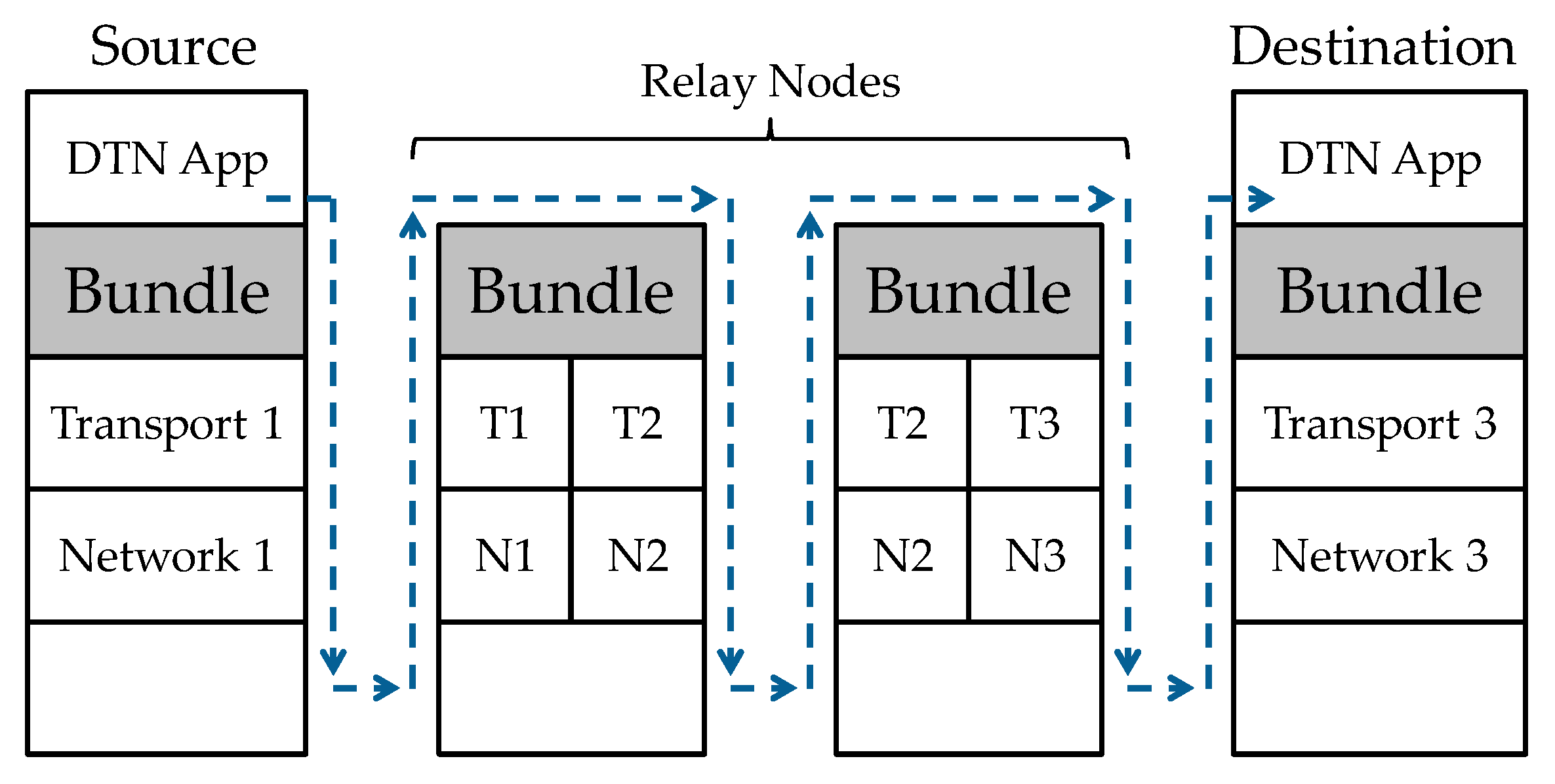
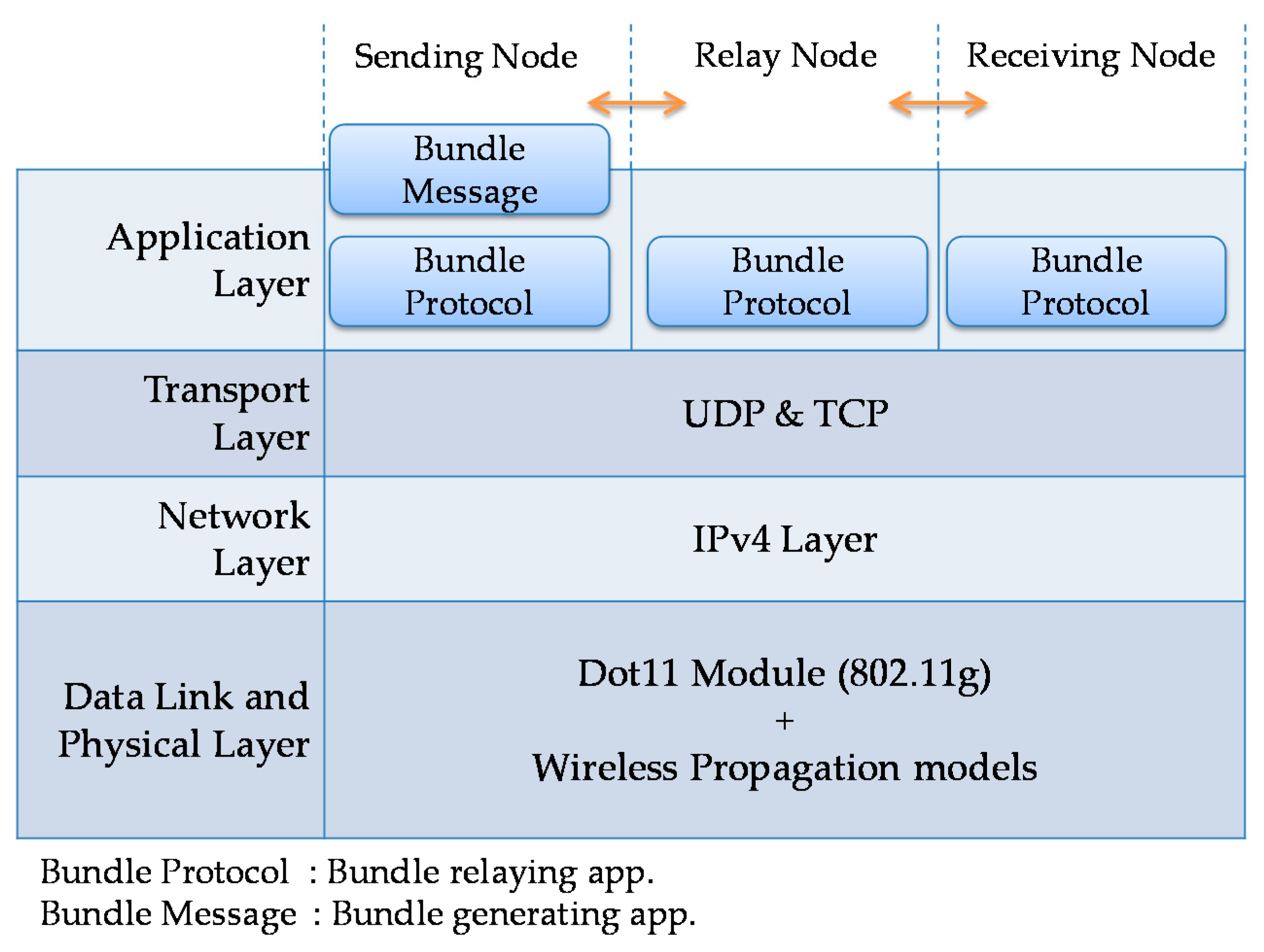
RFC (Request for Comments) 5050 [
14] proposes a bundle layer as a practical implementation model for store-carry forwarding in a DTN. As shown in
Figure 8, the bundle layer is situated between the transport layer and the application layer in the existing network layer model. The bundle layer provides the relaying function. Communication in the transport or lower layer is terminated at each relay node. The bundle layer is independent of the differences in the transport and lower layers and, thus, allows a variety of terminals to be incorporated into the network.
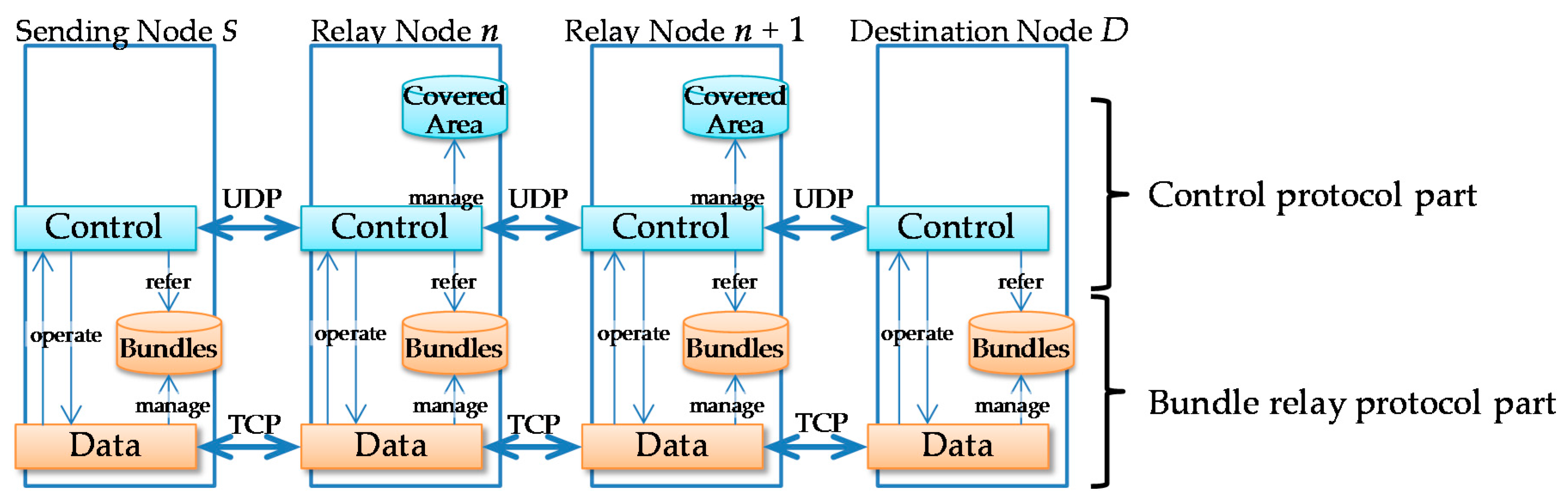
Although RFC 5050 describes the use of the bundle protocol, which is the core element in a DTN, for exchange of bundles between adjacent nodes, it declares that it does not explicitly specify the routing algorithm. The traveling route information-based routing follows this approach and adopts an outbound-type protocol. It divides the bundle layer into a control protocol part and a bundle relay protocol part, as shown in
Figure 9, in order to implement the functions stated in
Section 3.3 efficiently. The control protocol part communicates with adjacent nodes using UDP (User Datagram Protocol). It exchanges control messages with adjacent nodes and instructs the bundle relay part to relay or delete a bundle. The bundle relay protocol part communicates with adjacent nodes using TCP (Transmission Control Protocol). It establishes TCP connections with adjacent nodes, receives bundles and sends, relays or deletes bundles at the instruction of the control protocol part.
The only difference between the traveling node and the storage point is that the former has a covered area and moves, while the latter does not have a covered area and stands still. Therefore, we do not clearly distinguish between the two and treat both as relay nodes. The control protocol part of a relay node manages any additions of covered areas and exchanges information about covered areas with adjacent relay nodes. In other words, information about covered areas is shared by relay nodes through relaying of this information in multiple hops. It is managed semi-locally. A group of covered areas thus linked to each other constitutes a network area within which bundles can be successfully relayed. Specifically, before sending node S sends a bundle to relay node n, relay node n uses its control protocol part to check whether the destination area of the bundle overlaps with any of the covered areas whose information relay node n has.
One of the control messages exchanged by control protocol parts is a hello message. This message is periodically broadcast to enable the node concerned to detect the presence of adjacent nodes. If the sender is a normal node, including a receiving node, the hello message contains GPS (Global Positioning System)-based location information. When a relay node has received a hello message from a normal node, it checks whether the location in the location information in the message is included in the destination areas of the bundles it holds. If the normal node is within the destination area of one of these bundles, the relay node asks the normal node using a control message if it owns that bundle. If the normal node does not own the bundle, the relay node relays the bundle to it.
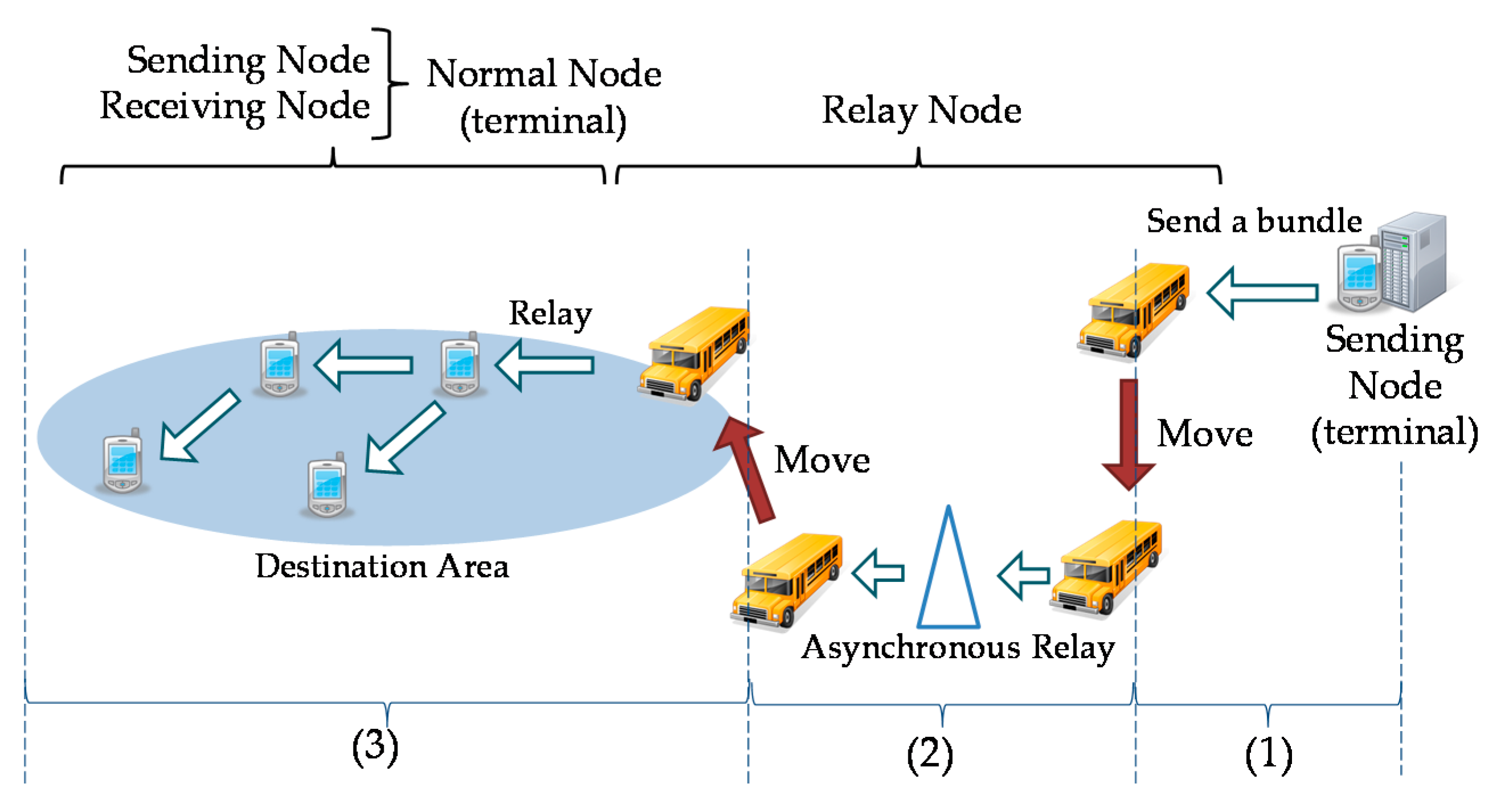
4.1. Message Sequence
The traveling route information-based routing uses covered areas of traveling nodes for routing. Protocols used in Sections (1), (2) and (3) in
Figure 10 are described below.
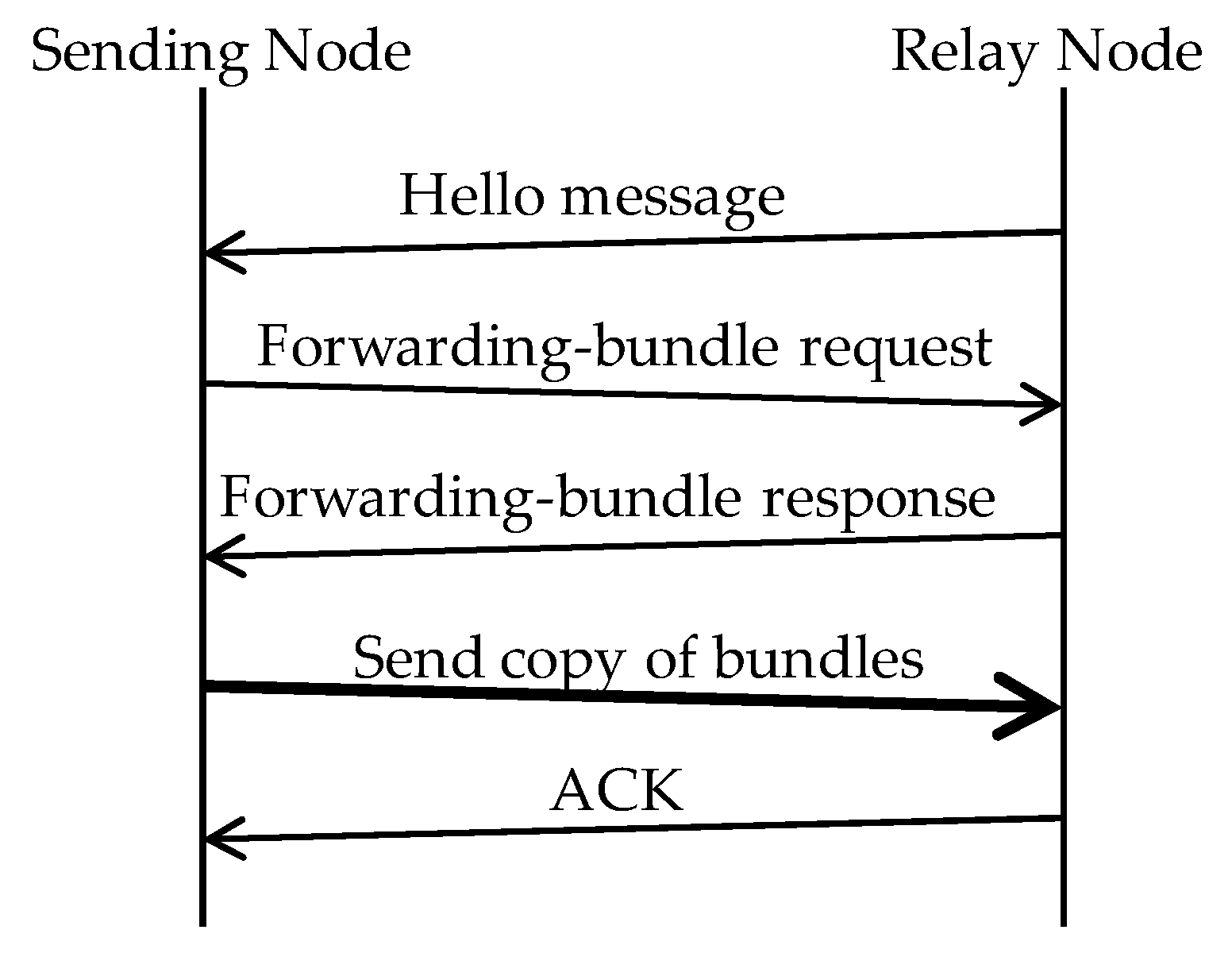
4.2. Section between the Sending Node and a Relay Node
The message sending sequence between the sending node and a relay node is shown in
Figure 11. The algorithm for determining whether a bundle can reach its destination area is described below:
- Step 1:
After the sending node receives a “hello message” from a relay node, it sends a “forwarding-bundle request”, which contains information about the destination area of the bundle, to the relay node in order to get permission to send the bundle.
- Step 2:
When the relay node receives the request, it compare the information about the destination area in the request with information it owns about the covered areas of other traveling nodes and sends a “forwarding-bundle response”, which includes information about whether the bundle can reach its destination area.
- Step 3:
The sending node that has received the response sends a copy of the bundle to the relay node if the response says that the bundle can reach its destination area.
- Step 4:
The relay node that has received the bundle sends an ACK (acknowledgement) message to the sending node to acknowledge that it has received the bundle. The sending node never again sends a bundle that has the same bundle identifier as that contained in the ACK message.
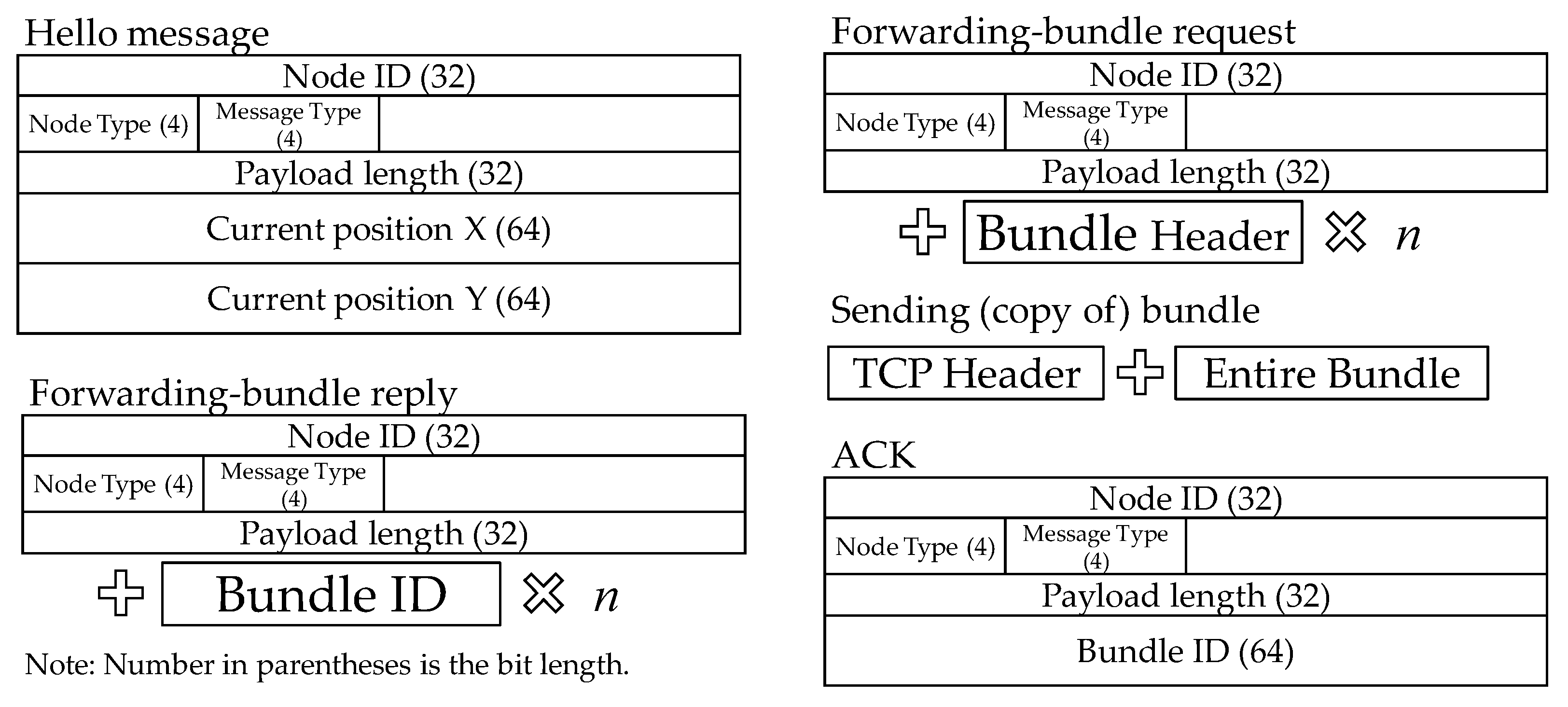
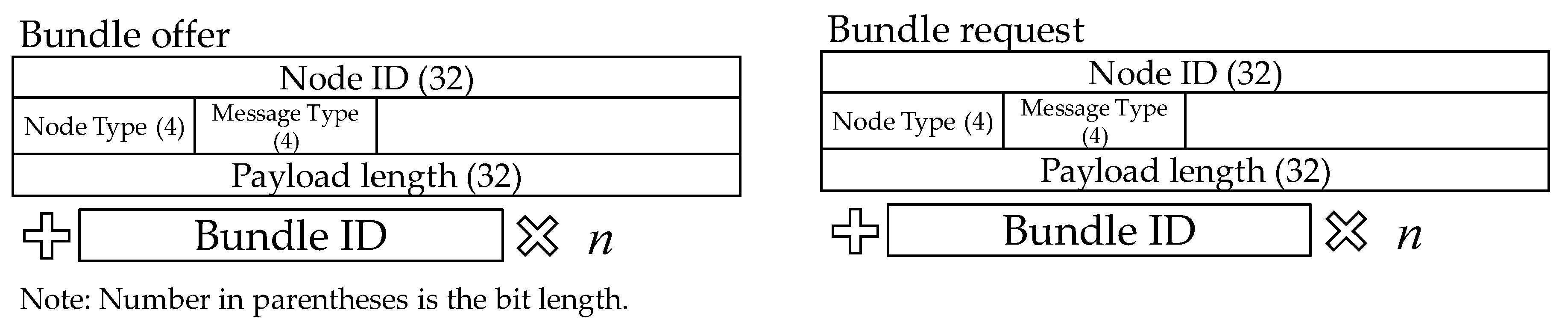
The structures of the messages exchanged above are shown in
Figure 12. Node ID is a globally unique node identifier, and since the DTN is an
ad hoc network, each node must have a unique identifier. Bundle ID is a unique bundle identifier. Since a considerable time can pass for a bundle to reach the receiver in a DTN, bundles can stay in the network for an extremely long time. To avoid confusion of bundles, we assign a unique identifier to each bundle.
4.3. Section between Relay Nodes
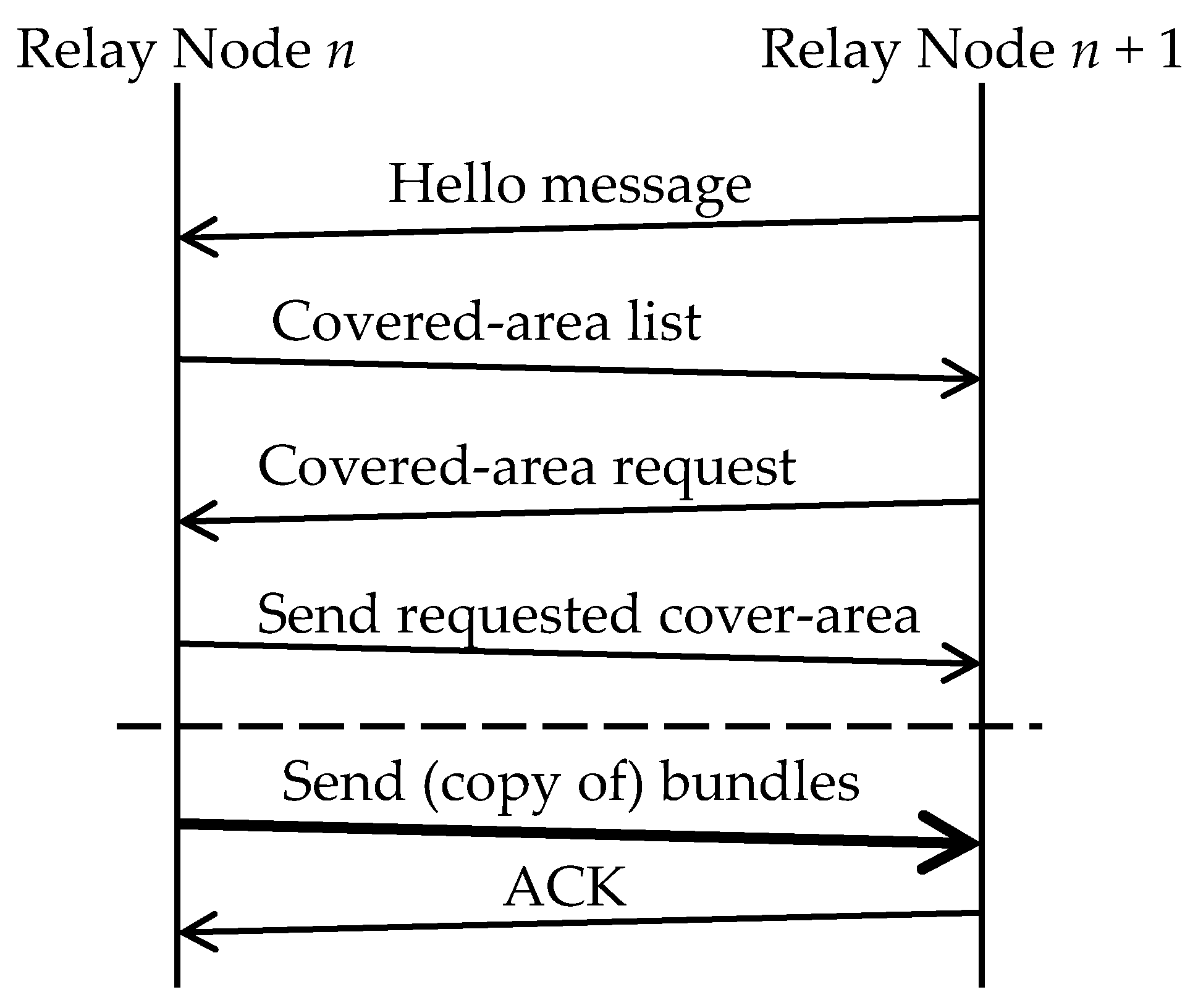
The message sending sequence between relay nodes is shown in
Figure 13. This is described in detail below.
- Step 1:
After relay node n has received a “hello message” from relay node n + 1, it sends the list of node identifiers of the covered areas it owns (covered area list).
- Step 2:
Relay node n + 1 receives it and checks for information about any nodes that it does not have in the list. If it does not have information about certain nodes, it requests relay node n for that information (covered area request).
- Step 3:
Relay node n sends the requested information (send requested covered area).
If there are still bundles that relay node
n needs to send to relay node
n + 1 after the above processing, the following procedure occurs:
- Step 1:
If relay node n + 1 is linked to the covered area of the traveling node that can carry bundles to the destination area, relay node n sends the bundle to relay node n + 1 (send bundles).
- Step 2:
Relay node n + 1 returns an ACK to notify that it has received the bundle.
- Step 3:
After relay node n has received the ACK, it retains the bundle if its own covered area overlaps with the destination area, but discards the bundle if it does not.
When relay nodes exchange bundles, they simultaneously exchange information about covered areas. Each covered area is associated with a node identifier. A covered area list includes a set of node identifiers of the covered areas whose information the relay node in question has. When a relay node receives a covered area list, it checks for the node identifiers of the covered areas whose information it does not have. If there are such node identifiers, it includes them in its covered area request and sends the request. The relay node that has received the request returns the requested information. In this way, all relay nodes concerned come to share information about covered areas.
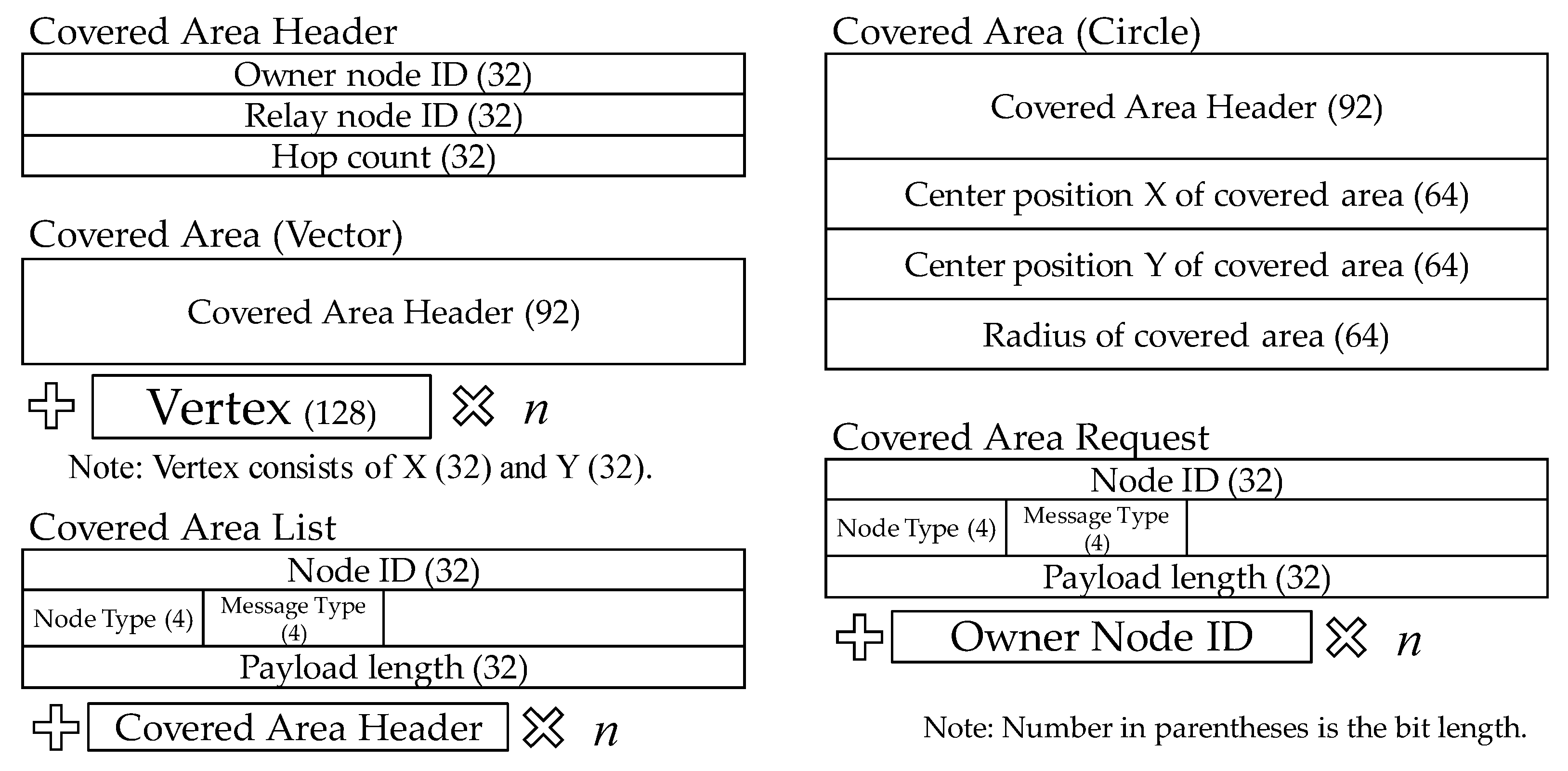
The structures of the messages exchanged above are shown in
Figure 14. Owner node ID in the covered area header is the node that has created that covered area. Relay node ID is the node that sent the information about the covered area one hop back. “Hop count” is the number of hops needed to reach the node that owns the covered area in question. The latter two parameters are updated each time a bundle is relayed.
4.4. Section between a Relay Node and the Receiving Node
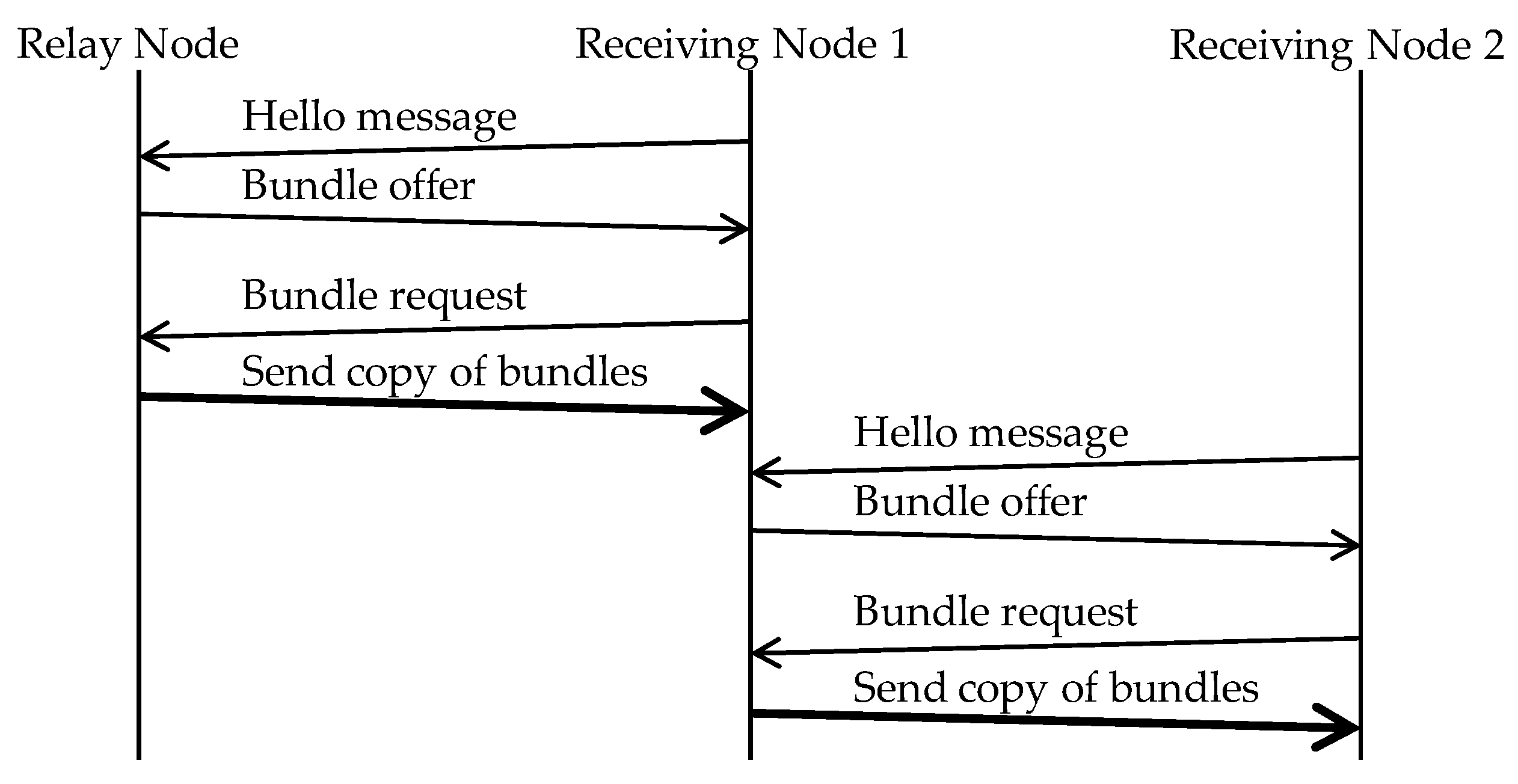
The message sending sequence between a relay node and a receiving node is shown in
Figure 15. Details are described below.
- Step 1:
Relay node receives a “Hello message” from Receiving Node 1. It returns a “bundle offer”, which contains the bundle identifiers of the bundles that are destined to the destination area in which Receiving Node 1 resides.
- Step 2:
Receiving Node 1 returns a “bundle request”, which contains the bundle identifiers of those bundles in the “bundle offer” that it does not have.
- Step 3:
Relay node sends the requested bundles to Receiving Node 1.
- Step 4:
When Receiving Node 1 comes in contact with another receiving node (Receiving Node 2) while it is still in the destination area, it sends a copy of the bundle to that receiving node.
- Step 5:
Receiving Node 2, which has received the bundle from Receiving Node 1, also sends a copy of the bundle to another receiving node that comes in contact with it, just as Receiving Node 1 did, while it still stays in the destination area.
Even after the relay node has sent bundles to receiving nodes in the destination area, it continues to relay bundles. Receiving nodes also continue to send bundles to other receiving nodes in the same destination area. Relay nodes can move only on fixed routes. Therefore, relaying of bundles between receiving nodes is necessary if the bundles concerned are to reach all receiving nodes in the destination area. The structures of the messages exchanged above are shown in
Figure 16.
5. Development of a Simulation System for Evaluation
To evaluate the proposed routing, we used a Scenargie simulator [
15], which is a discrete event network simulator from Space-Time Engineering. We additionally used two enhancement modules: a Dot11 module, which implements the IEEE 802.11 radio propagation model, and a multi-agent module, which virtually reproduces the decision-making process and operations of humans and public transportation systems on a computer. These products come with a source code written in C/C++ and related documents.
In the Scenargie simulator, a node ID, a four-byte identifier, is assigned to each node so that each node can be identified with its identifier. This is true for all applications that are installed by default. However, at the transport and lower layers, network addresses or other identifiers that are assigned to individual node interfaces are used. As shown in
Figure 17, two applications are installed by default: Bundle Protocol and Bundle Message. However, Bundle Protocol and Bundle Message are integrated into a Bundle Protocol class in the source code. Within the Bundle Protocol class, a Bundle ID, which is an eight-byte identifier, is assigned to each bundle. Bundle ID is used to identify the bundle.
Bundle Protocol was already present in the original source code. However, it covered only “epidemic routing” and “spray and wait routing”. Therefore, we extended the source code to implement the other existing routing methods, as well as our proposed routing.
6. Evaluation Conditions
Using simulation, we compared the circular covered area model and the vectorial covered area model in the proposed traveling route information-based routing. We also compared the traveling route information-based routing with existing routing methods, including “epidemic routing”, “spray and wait routing”, “location-based routing” and “motion vector routing”. This section presents the evaluation conditions that were commonly used for the proposed and existing routing methods and the implementation conditions for destination areas in the existing methods.
6.1. Evaluation Conditions Commonly Used for the Proposed and Existing Routing Methods
The simulation conditions are shown in
Table 3. The GIS (geographical information system) for simulation scenarios was built by downloading the relevant map information from Open Street Map [
16] into the Scenargie simulator. However, since this map information was old, we partially reformed and supplemented the map. The routes and timetables of traveling nodes were based on eight buses on three bus routes of Nishi Tokyo Bus Company (Hachoji, Tokyo, Japan) [
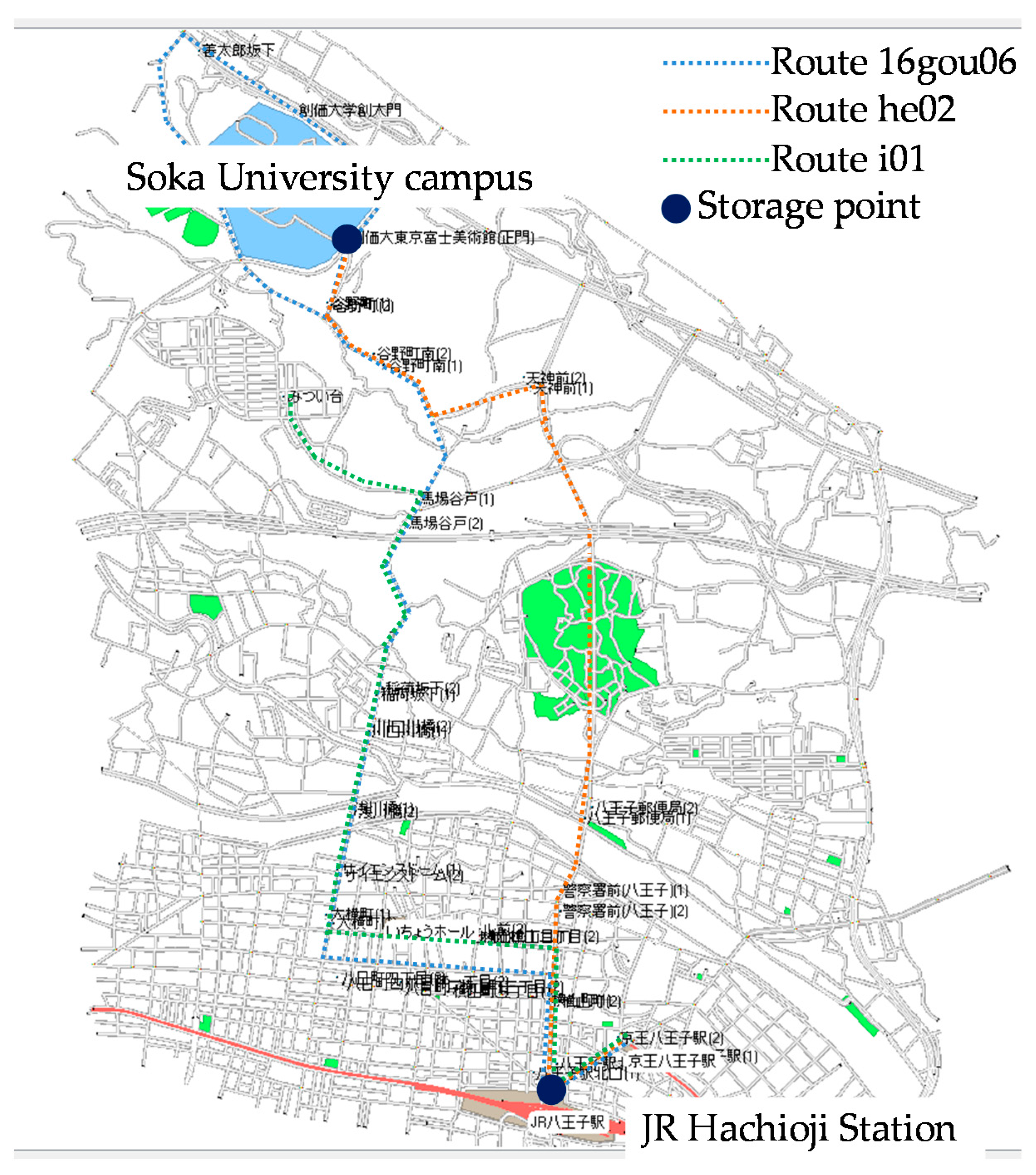
17]. The routes of the traveling nodes and locations of the storage points are shown in
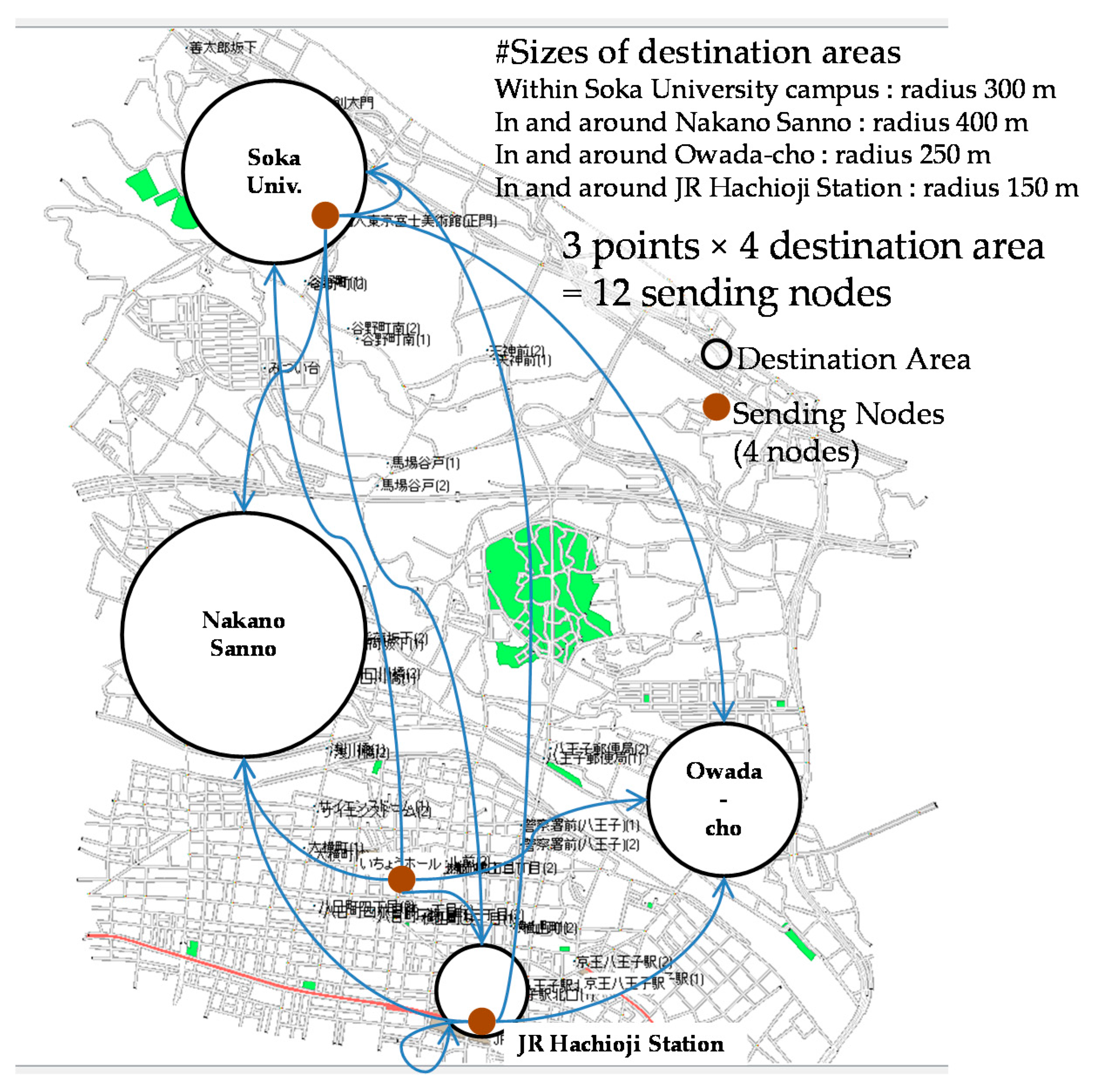
Figure 18. There were three sending points and four destination areas, as shown in
Figure 19. A total of 12 sending nodes were used, which were derived by multiplying three sending points by four destination areas. There were about 100 terminals in each destination area. For our proposed routing, we set the upper limit to the number of the copy and relay operations by a receiving node to one. The simulation time was 2 h, which was the length of time it took for a traveling node to make two rounds on its route. We selected two rounds because, if we select only one round, the simulation can end before the operation for sharing information about covered areas completed.
The number of mobile terminals was 1000. Although this may seem small when you take the population density of Hachioji City into consideration, we chose this number because the simulation load and computation time increase exponentially with the number of nodes and because sufficient evaluation results can be obtained with 1000 mobile terminals. We used GIS-based random waypoints for the movements of mobile terminals. In this model, the destinations of mobile terminals were selected at random from the entire geographical area of the simulation scenario, and mobile terminals moved along GIS objects (roads). These processes were repeated. Mobile terminals moved at a speed of 1.0 to 5.1 km/h, which assumed the walking speed of humans. However, mobile terminals that became sending nodes remained stationary at their initial positions because their movements greatly affect the evaluation results. At the beginning of the simulation, a sending node generated a bundle of a size of 100 KBytes. We thought this data size was sufficient for the purpose of our evaluation, although it may seem a bit too small for the digital content being used these days.
6.2. Implementation Conditions for Destination Areas in the Existing Routing Methods
We compared the traveling route information-based routing that uses the circular covered area model and the traveling route information-based routing that uses the vectorial covered area model with the existing routing methods mentioned in
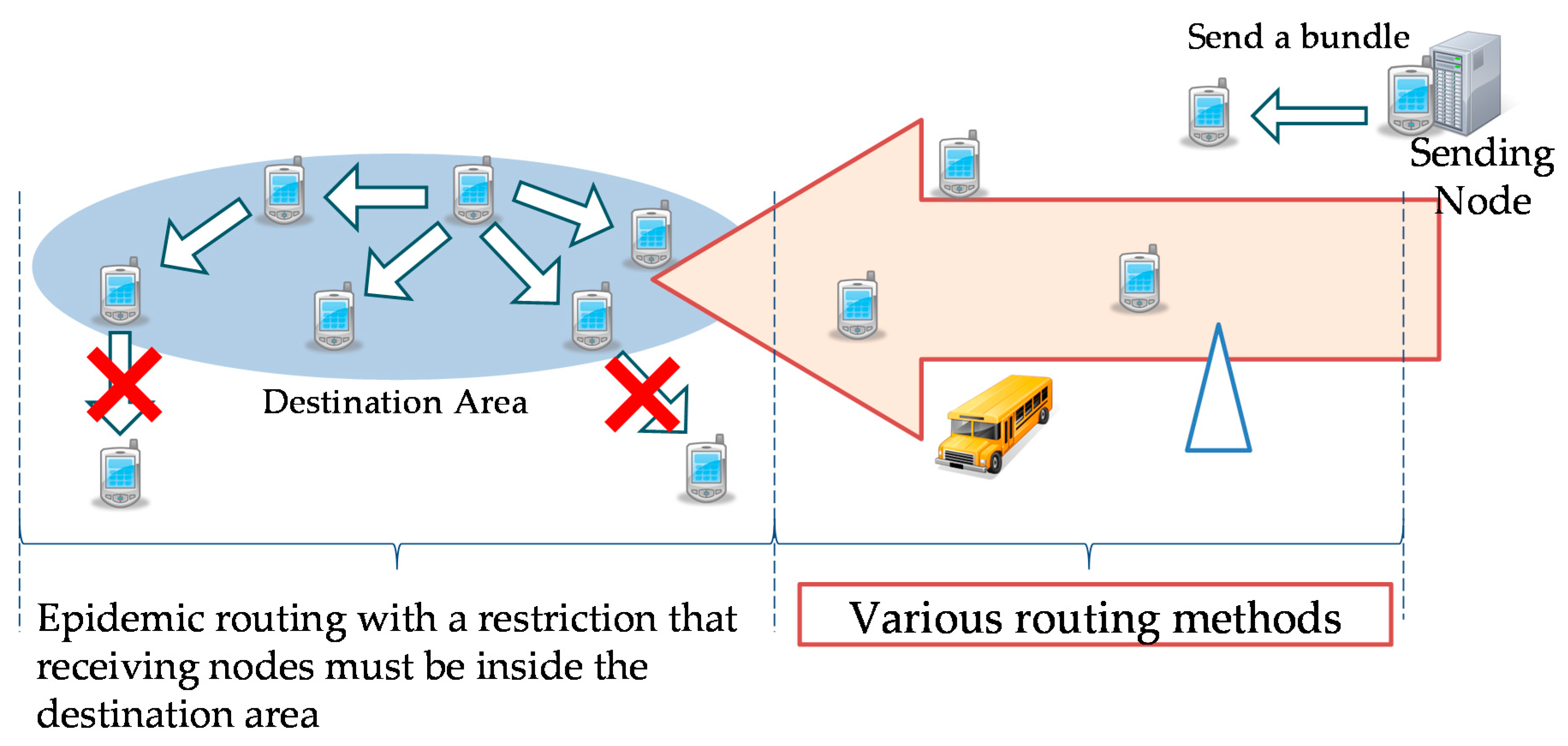
Section 3: “epidemic routing”, “spray and wait routing”, “location-based routing” and “motion vector routing”. The destination of a bundle is designated with destination areas in all of the routing methods so that they can be compared under the same conditions. Routing that takes place outside destination areas was based on each existing routing method, but within a destination area, bundles were relayed using “epidemic routing” with a restriction that all receiving nodes must be inside the destination area, as shown in
Figure 20.
Both “location-based routing” and “motion vector routing” essentially perform routing based on the location of destination nodes. In our simulation, the coordinates of the center of a destination area were used as the location of the destination nodes within its area. Once a bundle reached inside a destination area, it was propagated using “epidemic routing”.
For “spray and wait routing”, we used a binary method with the number of copies limited to up to 512. Since 512 is 29, up to nine hops were allowed outside destination areas.
7. Evaluation Results
A routing method with the highest bundle arrival rate is not necessarily the best, because it is necessary to consider how big the relaying loads on all nodes are. Therefore, we compared the proposed routing with the existing routing methods in terms of not only the bundle arrival rate, but also the number of copies, the number of hops and the maximum required buffer size.
7.1. Number of Bundles Sent
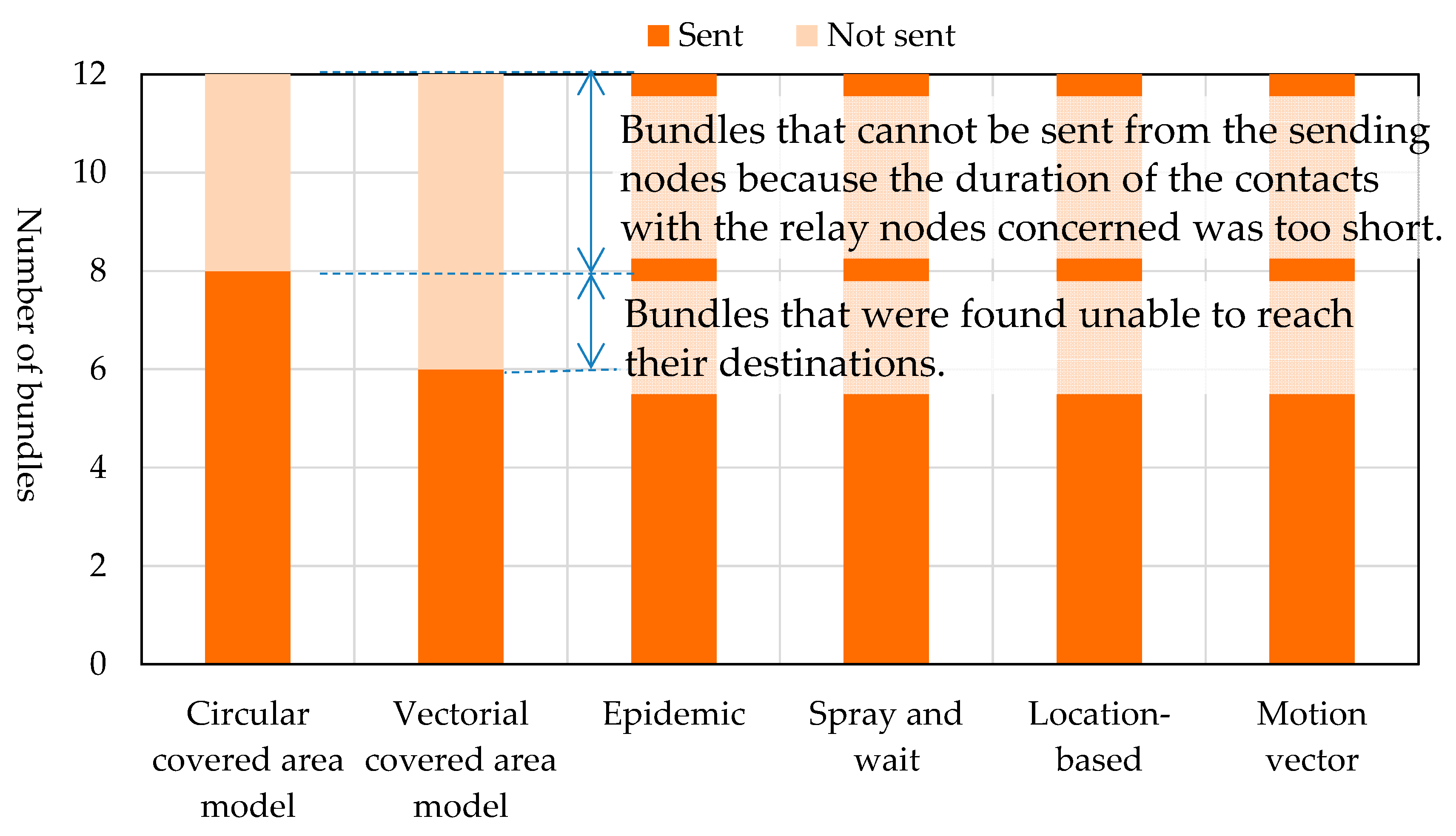
In our simulation, one sending node in each of the three points sent bundles to four destination areas. Thus, 12 bundles were sent. The number of bundles that were actually sent and the number of bundles that were not sent are shown in
Figure 21. With the proposed routing, whether the circular covered area model or the vectorial covered area model was used, four bundles were not sent because the duration of contacts between sending nodes and relay nodes was too short. In the case of the vectorial covered area model, two more bundles were not sent because the relay nodes concerned decided that these bundles could not reach their destinations. This means that the shape of the covered area affects the number of the bundles that are found unable to reach their destinations. The following evaluation considers only those bundles that were actually sent.
7.2. Bundle Arrival Rate
The bundle arrival rate for each bundle is a ratio of the number of receiving nodes that have received the bundle within the destination area to the number of receiving nodes within the destination area. It can be expressed as:
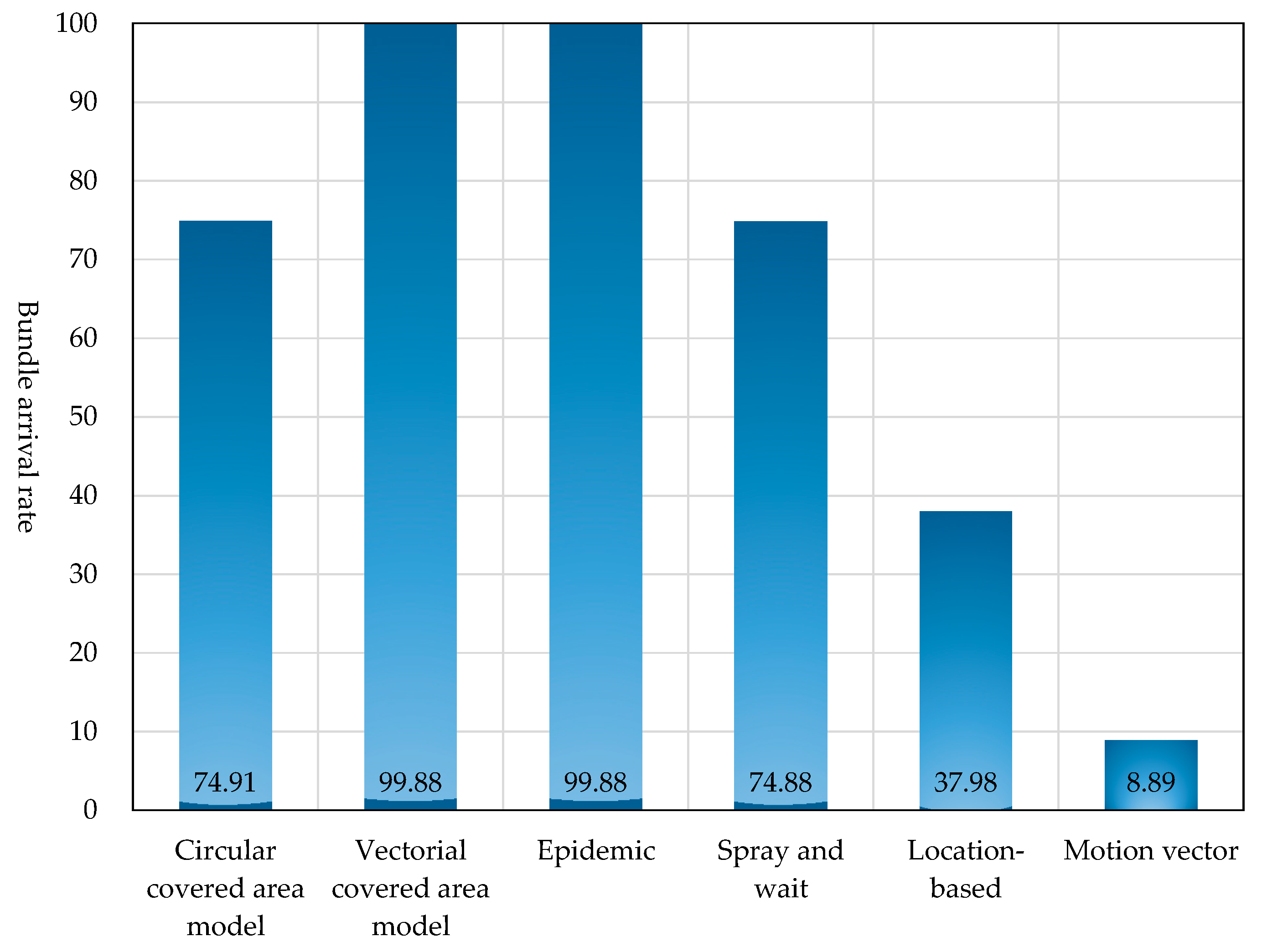
The bundle arrival rates of different routing methods are shown in
Figure 22. The vectorial covered area model and “epidemic routing” both attained a bundle arrival rate of almost 100%. They were followed by the circular covered area model and “spray and wait routing”, which both recorded a bundle arrival rate of about 75%. The bundle arrival rates of “location-based routing” and “motion vector routing” were about 40% and about 10%, respectively. Since both the circular covered area model and vectorial covered area model of the proposed routing determine in advance based on the traveling route information whether the bundle can reach its destinations and relay the bundle only when it is sure that it can reach its destinations, their arrival rates were higher than those of the existing routing methods. The circular covered area model had a somewhat lower bundle arrival rate than the vectorial covered area model because circular covered areas can contain pockets of areas that cannot be reached. “Location-based routing” and “motion vector routing” attempt to relay a bundle to a node that is closer to the destination or that is moving towards the destination. However, they often selected nodes that did not go to the destination.
7.3. Number of Copies
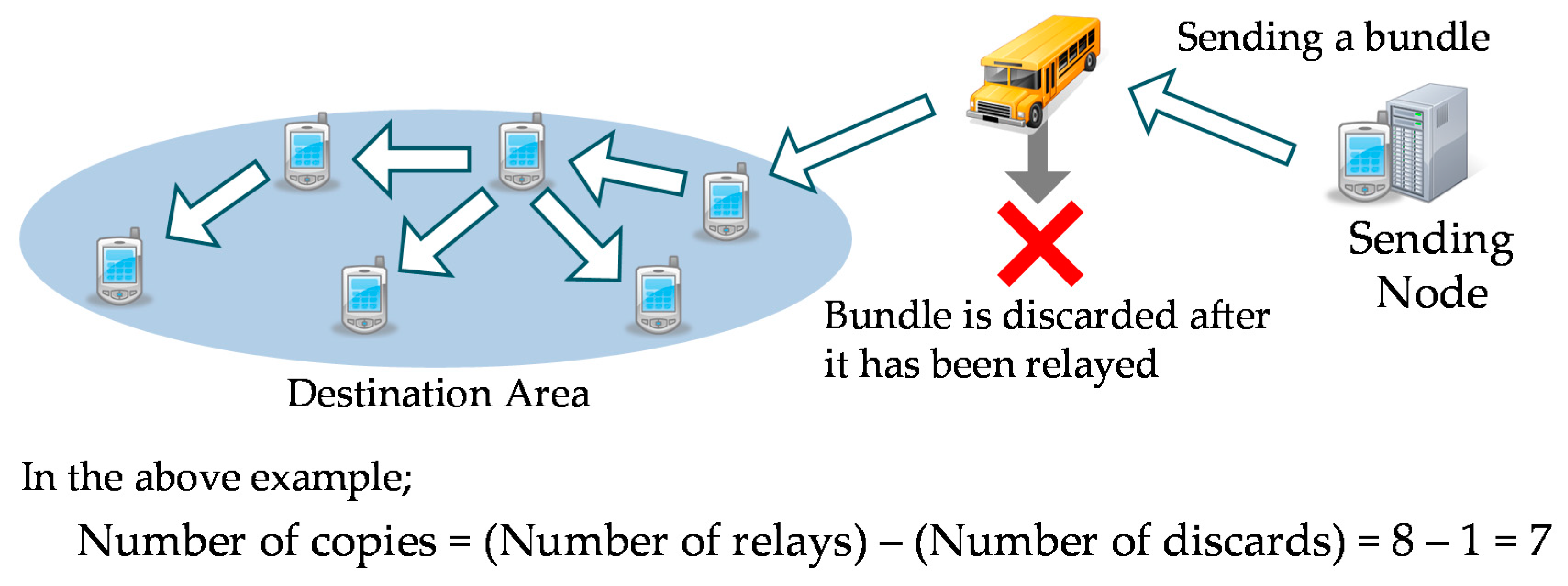
We measured the number of copies of each bundle generated for each bundle in the network. The first generated copy was excluded from this number. As shown in
Figure 23, the number of copies is equal to the number of relays between nodes minus the number of discards.
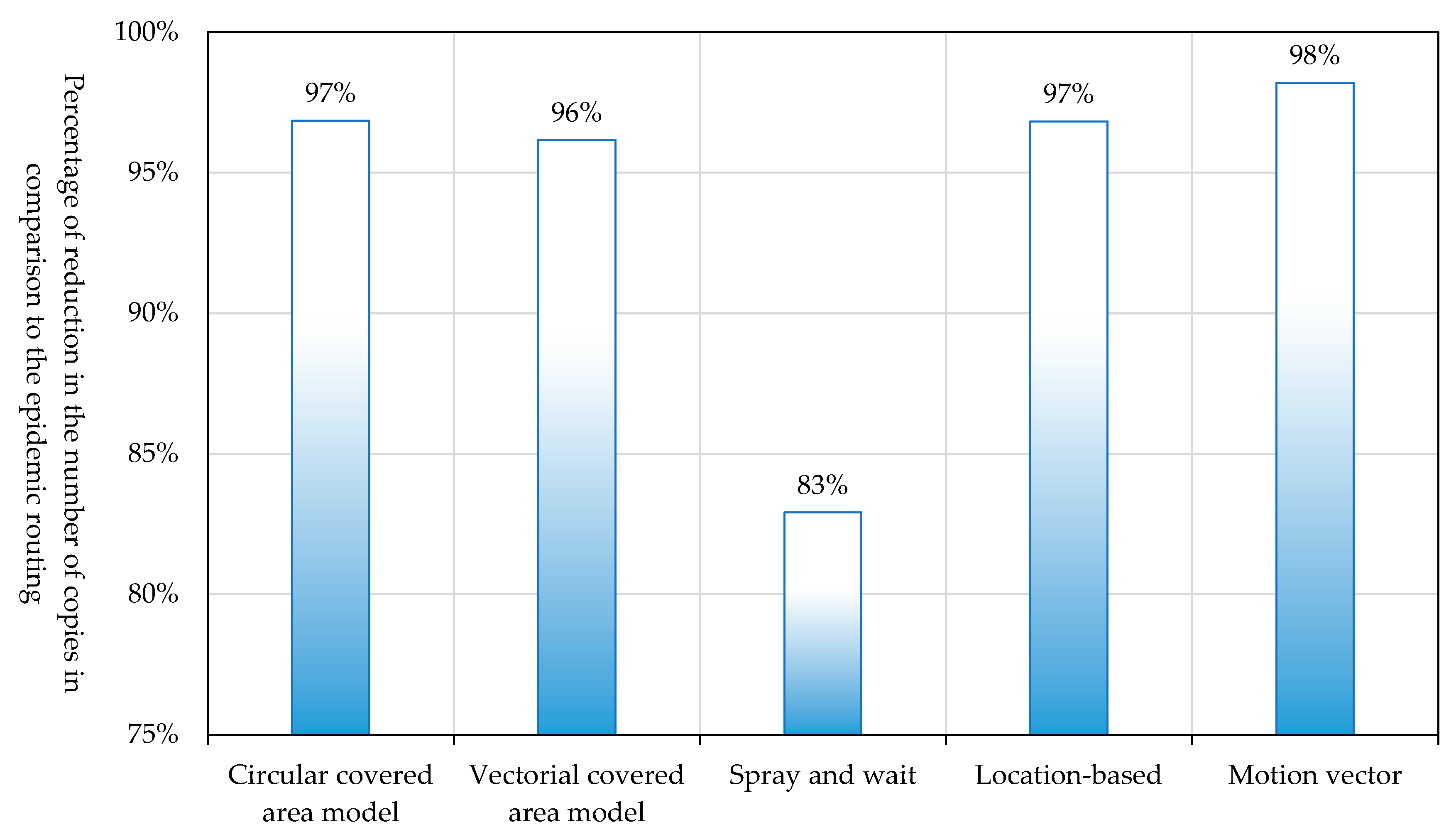
The percentages of the reduction in the numbers of copies required by different routing methods in comparison to the number of copies required by “epidemic routing” are shown in
Figure 24. The circular covered area model, the vectorial covered area model and all routing methods, except “spray and wait routing”, showed a dramatic reduction in the number of copies in comparison to the epidemic routing. “Motion vector routing” generated the smallest number of copies. This was because, with this routing, the bundle arrival rate was low with the consequence that there were few needs to propagate bundles within destination areas. If we do not count the copies generated during the propagation of bundles within destination areas, our proposed routing, “location-based routing” and “motion vector routing” generated no copies, and thus, only a single bundle existed in the network. This was the reason why differences between all routing methods, other than “spray and wait routing”, were small.
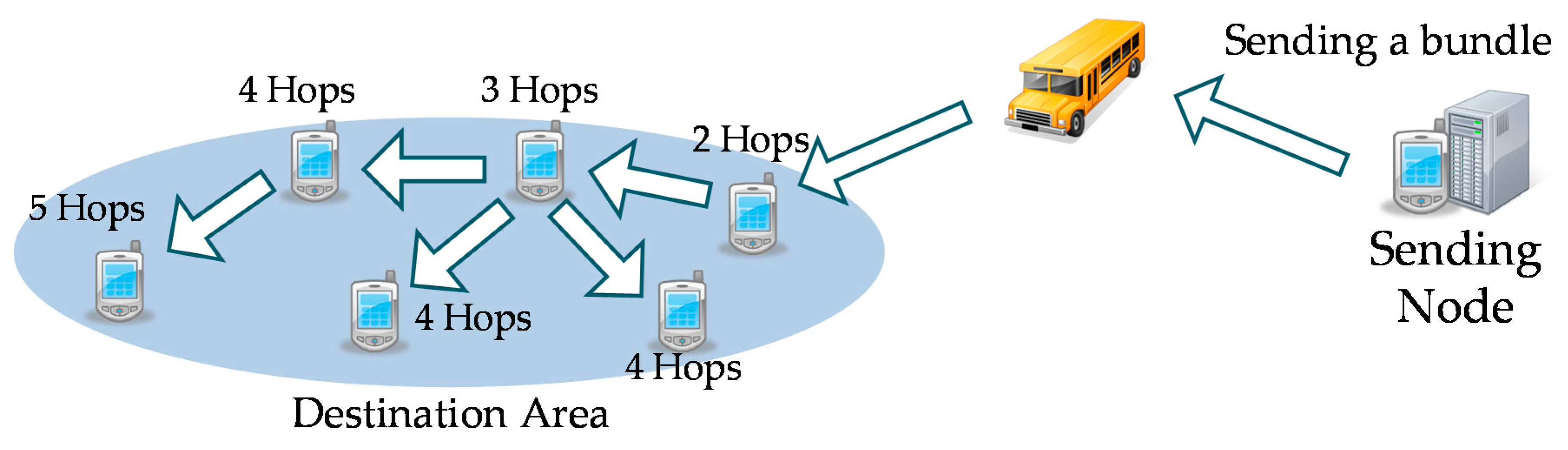
7.4. Number of Hops
We measured the number of hops made from the sending terminal to the first receiving node within the destination area, as shown in
Figure 25.
The measured numbers of hops are shown in
Table 4. “Location-based routing” recorded the largest number of hops with a maximum of 77 and an average of 32. The maximum number of hops of “motion vector routing” was 16. This is enormous considering that the bundle arrival rate is low, which means that the bundles reached only those destination areas that are close to the sending nodes. The maximum number of hops and the average number of hops of the “epidemic routing” were 35 and 12.8, respectively, and those of the “spray & wait routing” were 23 and 9.6, respectively. Those of both the circular covered area model and the vectorial covered area model were 16 and 5.5, respectively whichever covered area model was used. Those were the smallest among the different routing methods. This is because the role of relaying bundles over a long distance was assigned to traveling nodes.
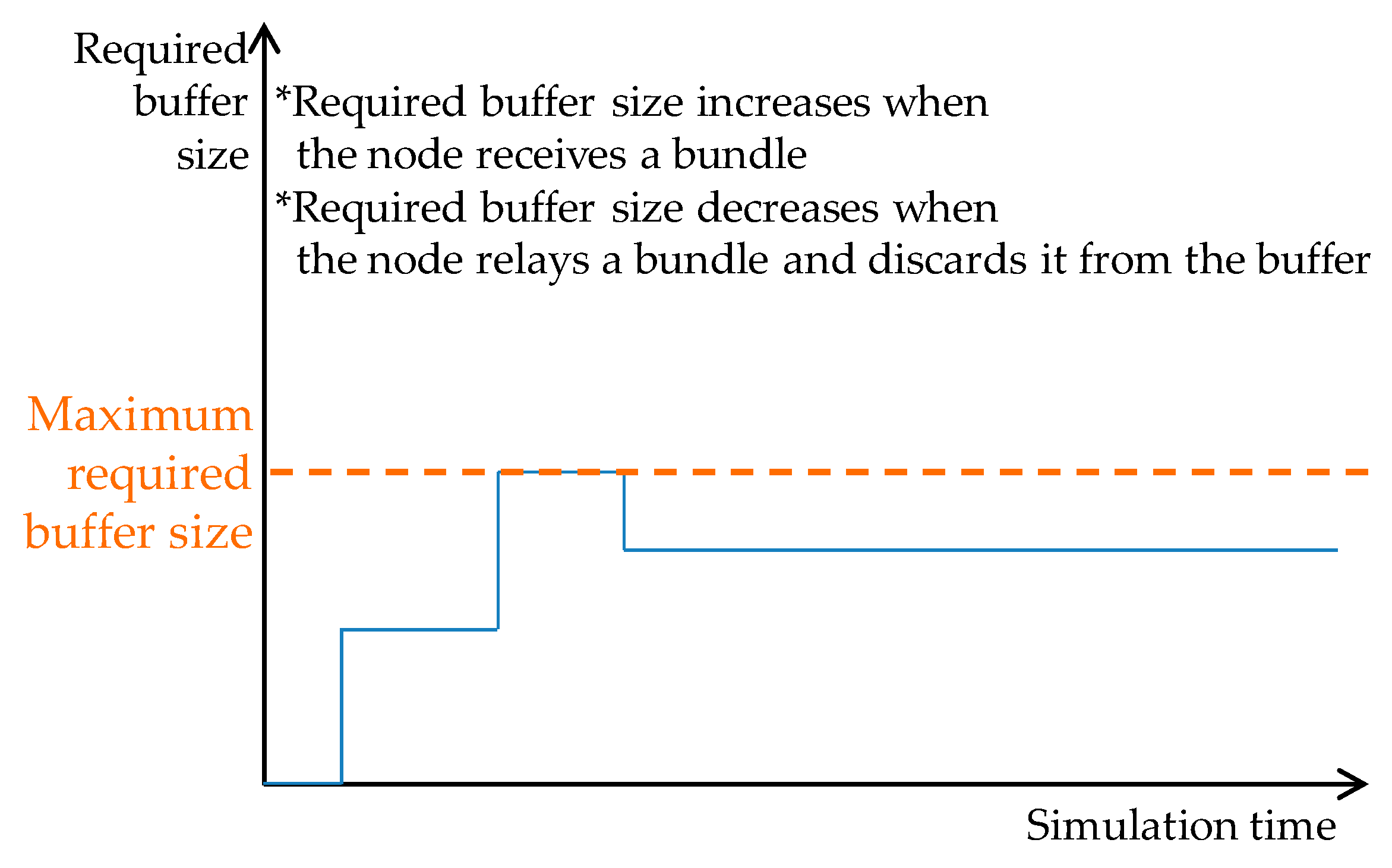
7.5. Maximum Required Buffer Size
We measured the maximum required buffer size of each node in the network. The required buffer size of a node varies over time as shown in
Figure 26.
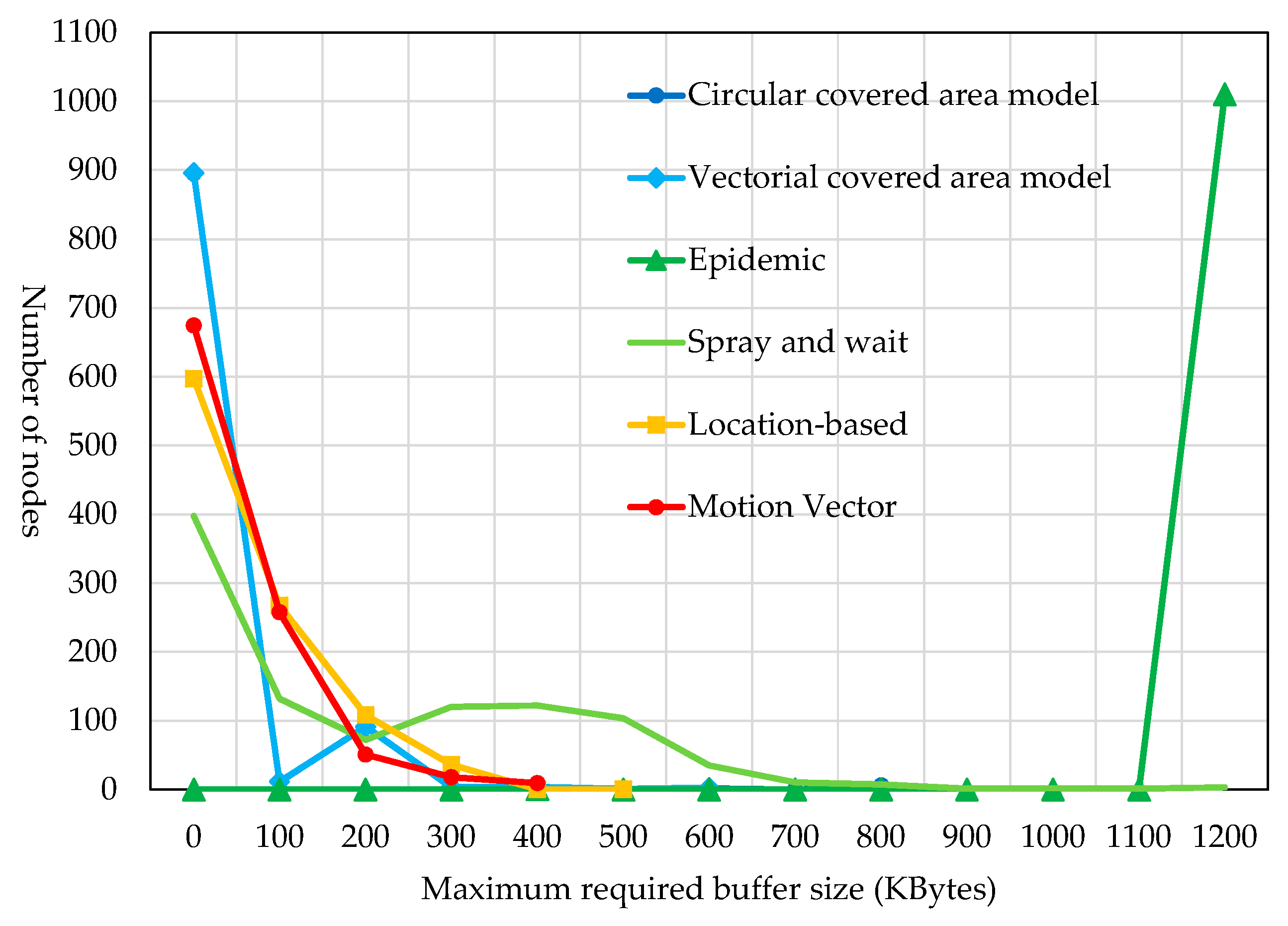
The distribution of the number of nodes for each maximum buffer size is shown for each routing method in
Figure 27. The proposed routing with the circular covered area model and that with the vectorial covered area model had more or less the same result, with 90% of nodes requiring no buffer. This was followed by “location-based routing” and “motion vector routing”, both of which resulted in 60% to 70% of nodes requiring no buffer. In contrast, with “spray and wait routing”, only 40% of nodes required no buffer. With “epidemic routing”, almost all nodes required a buffer size of 1.2 MBytes.
The reason why the proposed traveling route information-based routing had 90% of nodes requiring no buffer was that only traveling nodes, which are dedicated to relaying bundles, relayed bundles. Therefore, bundles were not relayed to 90% of mobile terminals that were outside the destination area concerned. These mobile terminals were not involved in the relaying of bundles. On the other hand, since relay nodes are solely responsible for relaying bundles, their maximum required buffer sizes were very large: 800 KBytes for the circular covered area model and 600 KBytes for the vectorial covered area model.
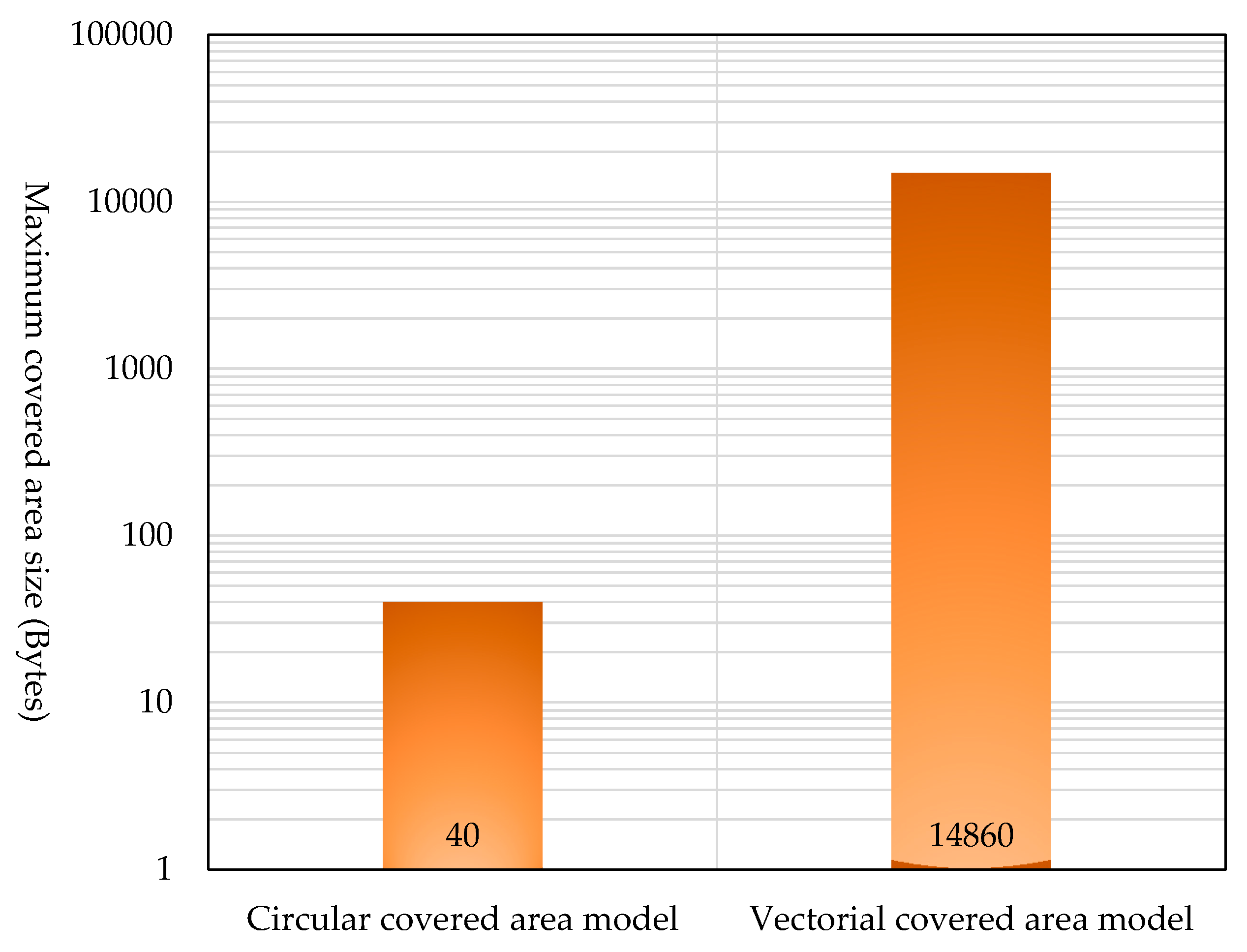
7.6. Maximum Covered Area Data Size
We measured the maximum covered area data sizes required by our proposed routing using the circular covered area model and the same routing using the vectorial covered area model. The result is shown in
Figure 28. The covered area data size of the routing using the circular covered area model was fixed at 40 KBytes. In contrast, the routing using the vectorial covered area model had a covered area that was made up of 928 vertices, requiring a covered area data size of 14.86 KBytes.
Although the routing using the vectorial covered area model requires an enormous amount of covered area data, covered areas do not change frequently, and covered area information is held only by relay nodes. Therefore, we consider that the routing using the vectorial covered area model is superior to the same routing using the circular cover area model because its bundle arrival rate is higher, as shown in
Figure 22.
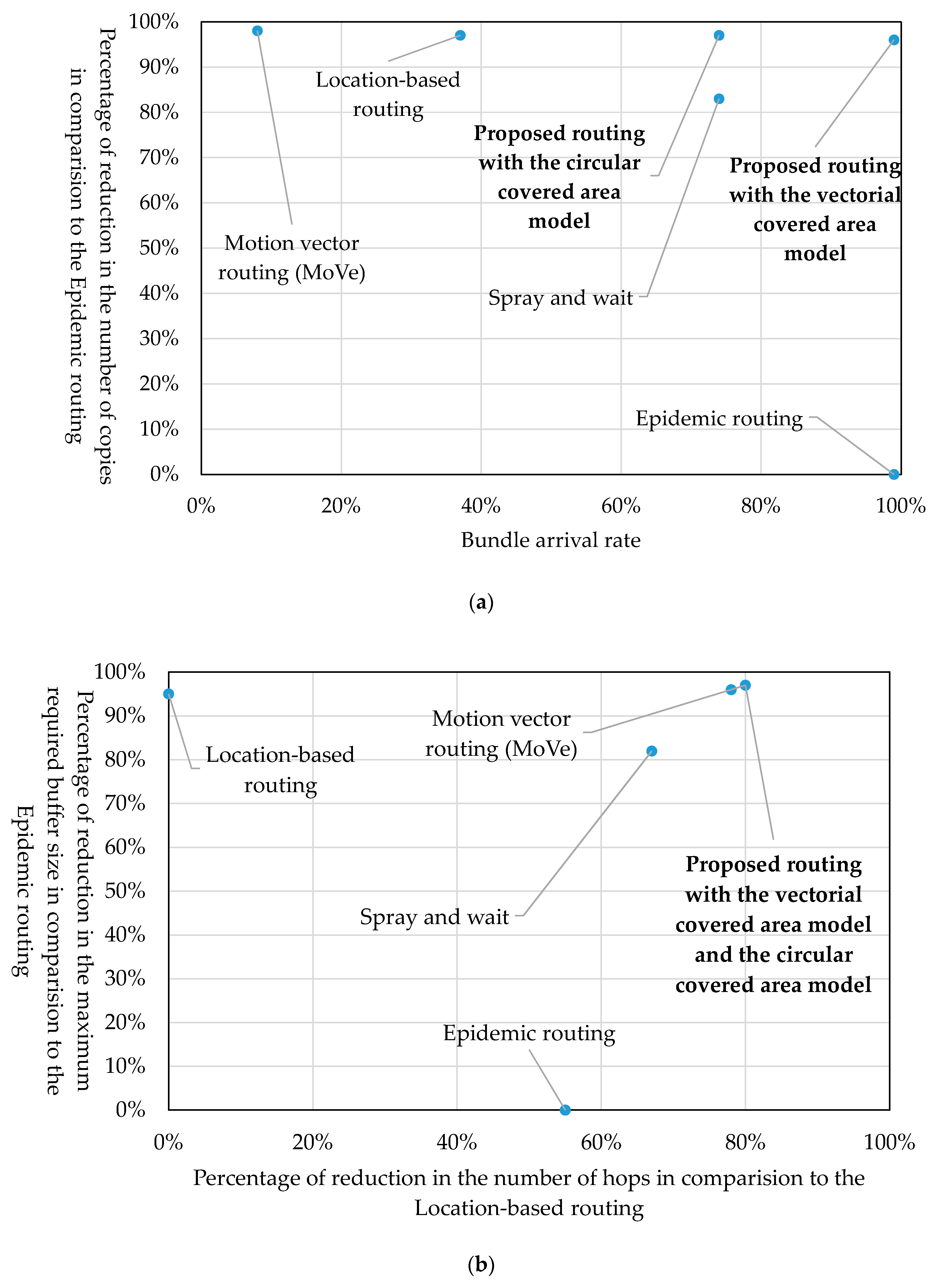
7.7. Comprehensive Evaluation
Table 5 and
Figure 29 compare different routing methods in terms of the bundle arrival rate, the reduction in the number of copies in comparison to “epidemic routing”, the reduction in the number of hops in comparison to “location-based routing” and the reduction in the required buffer size in comparison to “epidemic routing”. Our proposed routing, whether using the circular covered area model or the vectorial covered area model, maintained a high bundle arrival rate and achieved a high reduction in the number of copies, the number of hops and the required buffer size. In particular, the proposed routing using the vectorial covered area model marked a high score. The proposed method had a high bundle arrival rate, because it determines in advance based on the traveling route information whether the bundle can reach its destinations and relays the bundle only when it is sure that it can reach its destinations. The number of copies was small because the proposed method is such that relaying nodes do not make copies, and thus, only one bundle exists. The number of hops was small because the role of relaying bundles over a long distance is assigned to traveling nodes. The required buffer size was small, because only traveling nodes, which are dedicated to relaying bundles, relay bundles.
8. Conclusions and Future Issues
With a view to applying a DTN to a content delivery service in daily use, this paper has proposed a routing method that is designed to reduce network loads. This new routing is based on information about the routes of fixed-route traveling nodes, such as buses. It expresses the destination of a bundle not by the identifier of each receiving terminal, but by the location information of the destination area that contains receiving terminals. It uses fixed-route traveling nodes as relay nodes. When a relay node receives a forwarding-bundle request from a sending terminal, it checks whether the bundle can reach its destination area. The paper has presented an outbound-type bundle protocol, which makes the above check possible. Using simulation, the proposed routing was compared to the existing DTN routing methods. It was shown that the proposed routing imposes smaller network loads than the existing routing methods.
One of the future issues is to implement the proposed routing in a hardware system in order to evaluate how effective the new routing can be when it is applied to a commercial service. Other issues are to consider cases where the routes of traveling nodes need to be updated and cases where content filtering is used in coordination with the application concerned. It is also necessary to address the general issues related to the DTN, such as security, battery power consumption, the problems of low communication quality and low throughput in outdoor use, the problem of how to assign globally unique terminal addresses and standardization of bundle identifiers. In addition, it is necessary to ascertain the superiority of the proposed method by comparing it with the vehicular delay-tolerant network (VDTN) protocol, which has been studied mainly for the application to inter-vehicle communication and by evaluating it with a wider variety of simulation scenarios.

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}