
A Method for Identifying the Mood States of Social Network Users Based on Cyber Psychometrics


Abstract
:1. Introduction
2. Related Work
2.1. Sentiment Analysis and Emotion Recognition in Social Networks
2.2. Cyber Psychometrics Method
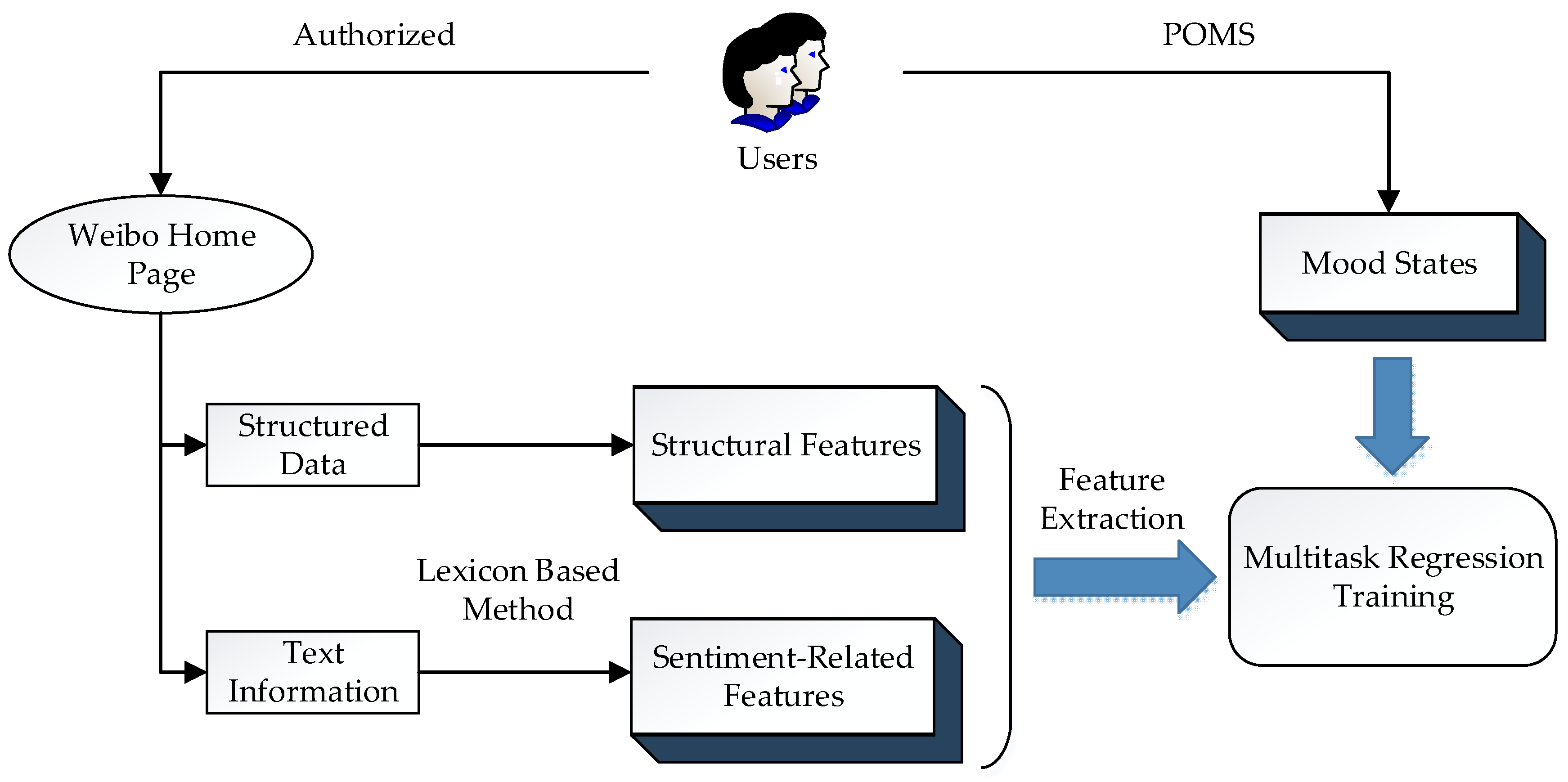
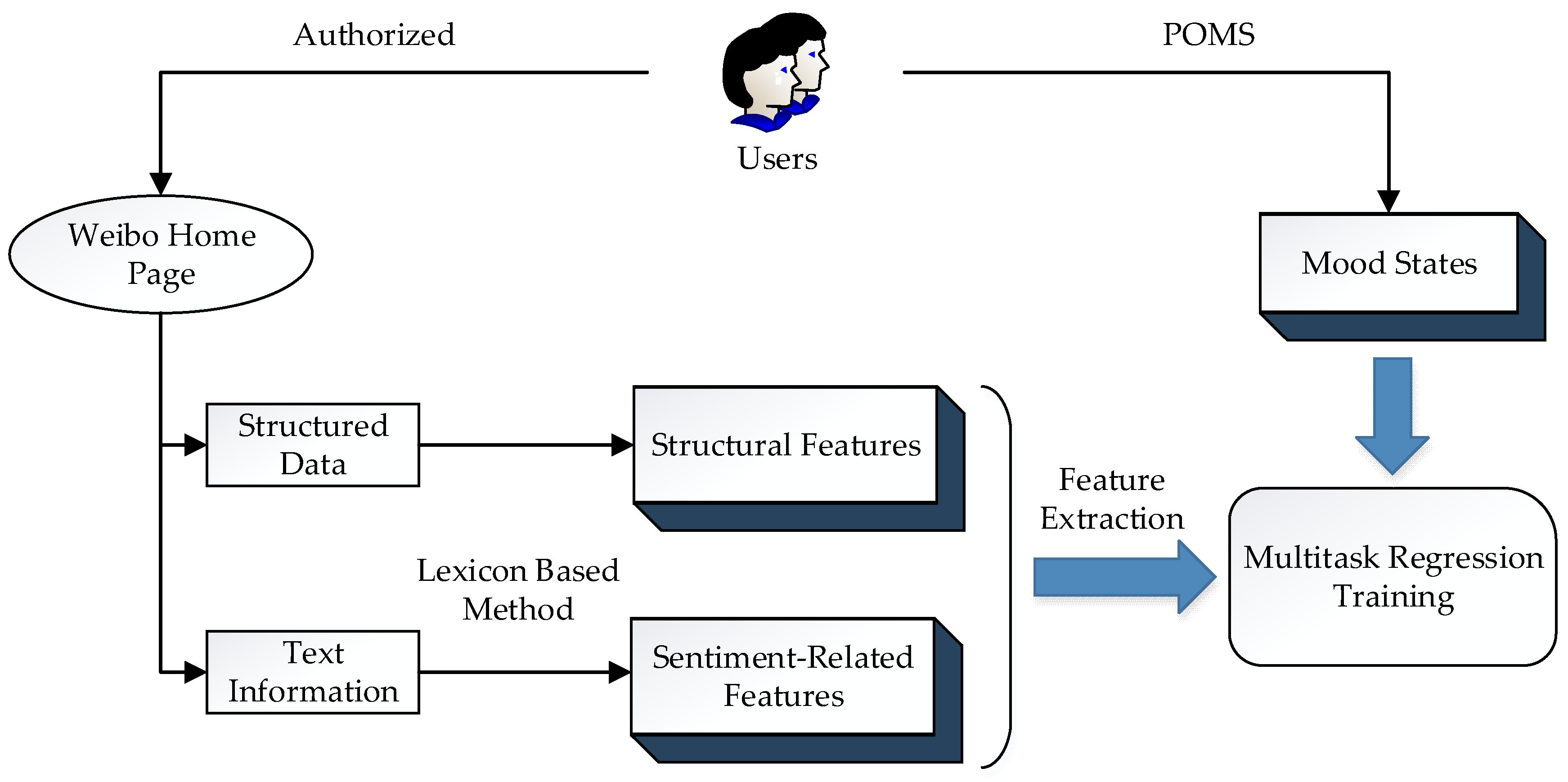
3. Materials and Methods
3.1. Data
3.2. Detecting Emotional Features of Weibo Text
3.3. The Construction and Evaluation of the Feature Set
3.4. Prediction of Mood States of Weibo Users Using Multitask Regression
4. Results and Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Loewenstein, G.; Lerner, J.S. The role of affect in decision making. Handb. Affect. Sci. 2003, 619, 3. [Google Scholar]
- Lerner, J.S.; Li, Y.; Valdesolo, P.; Kassam, K.S. Emotion and decision making. Psychology 2015, 66, 799–823. [Google Scholar] [CrossRef] [PubMed]
- Gardner, M.P. Mood states and consumer behavior: A critical review. J. Consum. Res. 1985, 12, 281–300. [Google Scholar] [CrossRef]
- Rowe, G.; Hirsh, J.B.; Anderson, A.K. Positive affect increases the breadth of attentional selection. Proc. Natl. Acad. Sci. USA 2007, 104, 383–388. [Google Scholar] [CrossRef] [PubMed]
- Ranco, G.; Aleksovski, D.; Caldarelli, G.; Grčar, M.; Mozetič, I. The effects of twitter sentiment on stock price returns. PLoS ONE 2015, 10, e0138441. [Google Scholar] [CrossRef] [PubMed]
- Martin, B.A.S. The influence of gender on mood effects in advertising. Psychol. Mark. 2003, 20, 249–273. [Google Scholar] [CrossRef]
- Maynard, D.; Gossen, G.; Funk, A.; Fisichella, M. Should i care about your opinion? Detection of opinion interestingness and dynamics in social media. Future Internet 2014, 6, 457–481. [Google Scholar] [CrossRef]
- Piryani, R.; Madhavi, D.; Singh, V. Analytical mapping of opinion mining and sentiment analysis research during 2000–2015. Inf. Process. Manag. 2017, 53, 122–150. [Google Scholar] [CrossRef]
- Mäntylä, M.V.; Graziotin, D.; Kuutila, M. The evolution of sentiment analysis—A review of research topics, venues, and top cited papers. arXiv 2016. arXiv:1612.01556. [Google Scholar]
- Nguyen, M.; Bin, Y.S.; Campbell, A. Comparing online and offline self-disclosure: A systematic review. Cyberpsychol. Behav. Soc. Netw. 2012, 15, 103–111. [Google Scholar] [CrossRef] [PubMed]
- Parkinson, B.; Briner, R.; Reynolds, S.K.; Totterdell, P. Changing Moods: The Psychology of Mood and Mood Regulation; Addison Wesley Longman: Harlow, UK, 1996. [Google Scholar]
- Grove, J.R.; Prapavessis, H. Preliminary evidence for the reliability and validity of an abbreviated profile of mood states. Int. J. Sport Psychol. 1992, 23, 93–109. [Google Scholar]
- Annunziata, M.A.; Muzzatti, B.; Flaiban, C.; Giovannini, L.; Carlucci, M. Mood states in long-term cancer survivors: An italian descriptive survey. Support. Care Cancer 2016, 24, 3157–3164. [Google Scholar] [CrossRef] [PubMed]
- Hamburger, Y.A.; Ben-Artzi, E. The relationship between extraversion and neuroticism and the different uses of the internet. Comput. Hum. Behav. 2000, 16, 441–449. [Google Scholar] [CrossRef]
- Kim, J.; Lee, S.; Yoo, W. Implementation and analysis of mood-based music recommendation system. In Proceedings of the 15th International Conference on Advanced Communication Technology (ICACT), Pyeongchang, Korea, 27–30 January 2013; pp. 740–743. [Google Scholar]
- Buelow, M.T.; Suhr, J.A. Personality characteristics and state mood influence individual deck selections on the iowa gambling task. Personal. Individ. Differ. 2013, 54, 593–597. [Google Scholar] [CrossRef]
- Morrongiello, B.A.; Stewart, J.; Pope, K.; Pogrebtsova, E.; Boulay, K.-J. Exploring relations between positive mood state and school-age children’s risk taking. J. Pediatr. Psychol. 2015, 40, 406–418. [Google Scholar] [CrossRef] [PubMed]
- Ceron, A.; Curini, L.; Iacus, S.M.; Porro, G. Every tweet counts? How sentiment analysis of social media can improve our knowledge of citizens’ political preferences with an application to italy and france. New Media Soc. 2014, 16, 340–358. [Google Scholar] [CrossRef]
- Ceron, A.; Curini, L.; Iacus, S.M. Using sentiment analysis to monitor electoral campaigns: Method matters—Evidence from the united states and italy. Soc. Sci. Comput. Rev. 2015, 33, 3–20. [Google Scholar] [CrossRef]
- Wald, R.; Khoshgoftaar, T.M.; Napolitano, A.; Sumner, C. Using twitter content to predict psychopathy. In Proceedings of the 11th International Conference on Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 12–15 December 2012; pp. 394–401. [Google Scholar]
- Yu, Y.; Duan, W.; Cao, Q. The impact of social and conventional media on firm equity value: A sentiment analysis approach. Decis. Support Syst. 2013, 55, 919–926. [Google Scholar] [CrossRef]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]
- Tan, C.; Lee, L.; Tang, J.; Jiang, L.; Zhou, M.; Li, P. User-level sentiment analysis incorporating social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1397–1405. [Google Scholar]
- Siegert, I.; Böck, R.; Wendemuth, A. Modeling users’ mood state to improve human-machine-interaction. In Cognitive Behavioural Systems; Springer: Berlin, German, 2012; pp. 273–279. [Google Scholar]
- Munezero, M.D.; Montero, C.S.; Sutinen, E.; Pajunen, J. Are they different? Affect, feeling, emotion, sentiment, and opinion detection in text. IEEE Trans. Affect. Comput. 2014, 5, 101–111. [Google Scholar] [CrossRef]
- Katsimerou, C.; Redi, J.A.; Heynderickx, I. A computational model for mood recognition. In Proceedings of the International Conference on User Modeling, Adaptation, and Personalization, Aalborg, Denmark, 7–11 July 2014; pp. 122–133. [Google Scholar]
- Barrick, M.R.; Mount, M.K. The big five personality dimensions and job performance: A meta-analysis. Pers. Psychol. 1991, 44, 1–26. [Google Scholar] [CrossRef]
- Bai, S.; Zhu, T.; Cheng, L. Big-five personality prediction based on user behaviors at social network sites. Comput. Sci. 2012, 8, e2682. [Google Scholar]
- Zhang, L.; Huang, X.; Liu, T.; Li, A.; Chen, Z.; Zhu, T. Using linguistic features to estimate suicide probability of chinese microblog users. Lect. Notes Comput. Sci. 2014, 8944, 549–559. [Google Scholar]
- Golbeck, J.; Robles, C.; Edmondson, M.; Turner, K. Predicting personality from twitter. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust (PASSAT) and Social Computing (SocialCom), Boston, MA, USA, 9–11 October 2011; pp. 149–156. [Google Scholar]
- Schwartz, H.A.; Johannes, C.E.; Margaret, L.K.; Lukasz, D.; Stephanie, M.R.; Megha, A.; Achal, S.; Michal, K.; David, S.; Martin, E.P.S.; et al. Personality, gender, and age in the language of social media: The open-vocabulary approach. PLoS ONE 2013, 8, e73791. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Zhang, Z. Improving multiview face detection with multi-task deep convolutional neural networks. In Proceedings of the 2014 IEEE Winter Conference on Applications of Computer Vision (WACV), Steamboat Springs, CO, USA, 24–26 March 2014; pp. 1036–1041. [Google Scholar]
- Castellucci, G.; Croce, D.; Basili, R. Bootstrapping large scale polarity lexicons through advanced distributional methods. In Proceedings of the Congress of the Italian Association for Artificial Intelligence, Ferrara, Italy, 23–25 September 2015; pp. 329–342. [Google Scholar]
- Passaro, L.C.; Pollacci, L.; Lenci, A. Item: A vector space model to bootstrap an italian emotive lexicon. In Proceedings of the Second Italian Conference on Computational Linguistics CLiC-it, Trento, Italy, 3–4 December 2015; pp. 215–220. [Google Scholar]
- Mäntylä, M.V.; Novielli, N.; Lanubile, F.; Claes, M.; Kuutila, M. Bootstrapping a lexicon for emotional arousal in software engineering. In Proceedings of the 14th International Conference on Mining Software Repositories, Buenos Aires, Argentina, 20–28 May 2017. [Google Scholar]
- Research Center for Social Computing and Information Retrieval. Available online: http://ir.hit.edu.cn (accessed on 1 June 2016).
- Tian, J.L.; Wei, Z. Words similarity algorithm based on tongyici cilin in semantic web adaptive learning system. J. Jilin Univ. 2010, 28, 602–608. [Google Scholar]
- Natural Language Processing & Information Retrieval Sharing Platform. Available online: http://www.nlpir.org/?action-viewnews-itemid-299 (accessed on 20 May 2016).
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Drakopoulos, G.; Megalooikonomou, V. Regularizing large biosignals with finite differences. In Proceedings of the 2016 7th International Conference on Information, Intelligence, Systems & Applications (IISA), Chalkidiki, Greece, 13–15 July 2016; pp. 1–6. [Google Scholar]
- Koh, K.; Kim, S.-J.; Boyd, S. An interior-point method for large-scale l1-regularized logistic regression. J. Mach. Learn. Res. 2007, 8, 1519–1555. [Google Scholar]
- Diener, E.; Lucas, R.E. Personality and Subjective Well-Being; Springer: Berlin, German, 2009; pp. 75–102. [Google Scholar]
- Lucas, R.E.; Fujita, F. Factors influencing the relation between extraversion and pleasant affect. J. Personal. Soc. Psychol. 2000, 79, 1039–1056. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, Q.; Li, B. Predicting multiple attributes via relative multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1027–1034. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Emotion Expression | Mood State | Sentiment |
|---|---|---|
| Duration | Relatively long | Relatively short |
| Time mode | Gradual, continuous | Rapid, episodic |
| Strength | Relatively weak | Relatively strong |
| Cause | Caused by specific events | Caused by specific events |
| Function | Shows current state information of users | Shows current state information of context |
| Orientation | No orientation | Points to specific event |
| POMS Subscales | Items | Seed Words |
|---|---|---|
| Tension | Restless, Nervous, On-edge, Tense, Uneasy, Anxious | Agitated, Anxious, Disturbed, Nervous, Edgy, Antsy, Uneasy, Concerned, Tense, Apprehensive, Strained, Impatient, Insecure, Afraid, Distressed |
| Anger | Peeved, Bitter, Resentful, Grouchy, Angry, Furious, Annoyed | Annoyed, Enraged, Heated, Resentful, Indignant, Outraged, Sullen, Bitter, Furious, Irate, Irritable, Offended, Mad |
| Fatigue | Worn out, Weary, Bushed, Fatigued, Exhausted | Bored, Bushed, Disgusted, Exhausted, Fatigued, Overworked, Jaded, Drained, Weakened, Disabled, Sleepy, Overtired |
| Depression | Hopeless, Helpless, Sad, Worthless, Miserable, Discouraged | Desperate, Forlorn, Helpless, Sad, Tragic, Dejected, Discouraging, Gloomy, Pathetic, Wretched, Useless, Despairing, Depressed, Dismayed, Pessimistic |
| Vigor | Cheerful, Vigorous, Full of pep, Active, Energetic, Lively | Animated, Bright, Optimistic, Lively, Rosy, Chirpy, Cheery, Perky, Merry, Buoyant, Active, Zealous, Potent, Dynamic, Brisk, Spirited, Vital, Peppy, Frisky |
| Confusion | Bewildered, Forgetful, Confused, Concentration, Uncertain | Addled, Puzzled, Perturbed, Distracted, Dazed, Bewildered, Befuddled, Confused, Disorganized, Forgetful, Inattentive |
| Esteem | Embarrassed, Ashamed, Proud, Competent, Satisfied | Ashamed, Abashed, Apologetic, Embarrassed, Humbled, Honored, Noble, Satisfied, Appreciative, Content, Competent, Qualified, Decent |
| Symbol | Explanation | Features Contained |
|---|---|---|
| Di | Basic information of users | Length of Weibo ID, gender, registration date, number of labels and length of personal profile |
| Sj | Social characteristics of users | Number of followers, number of follows and number of total tweets |
| Tm | Prosperities of users’ tweets | Average length of tweets, average times for the use of the @ signal, monthly average number of tweets and other related features |
| Mn | Sequential sentiment-related features of blog text | Sentimental vector of tweets in five specific periods including 1 week, 1 month, 3 months, 6 months and 1 year |
| Features | Tension | Anger | Fatigue | Depression | Vigor | Confusion | Esteem | Total Score |
|---|---|---|---|---|---|---|---|---|
| Registration date | −0.145 | −0.084 | −0.22 ** | −0.089 | 0.07 | −0.074 | −0.068 | −0.144 |
| Number of follows | 0.124 | 0.135 | 0.118 | 0.041 | −0.01 | 0.119 | 0.04 | 0.169 * |
| Average comments | −0.016 | −0.166 * | 0.131 | −0.018 | −0.197 ** | 0.025 | −0.14 | −0.081 |
| Average reposts of reposted tweets | 0.349 *** | 0.191 * | 0.085 | 0.175 * | −0.055 | 0.223 ** | −0.006 | 0.234 ** |
| Average comments of reposted tweets | −0.079 | −0.087 | −0.187 * | −0.046 | 0.026 | −0.044 | −0.027 | −0.104 |
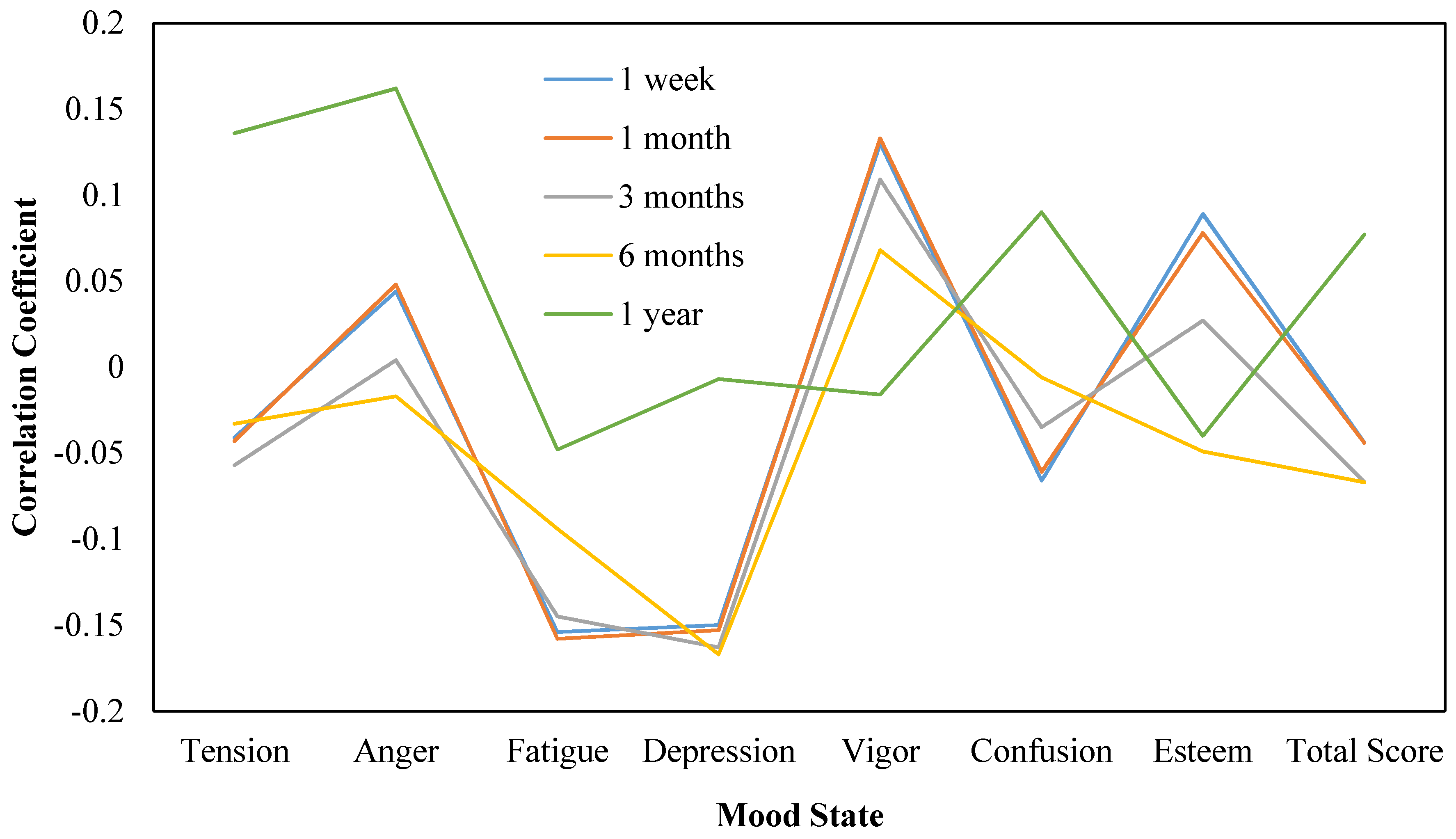
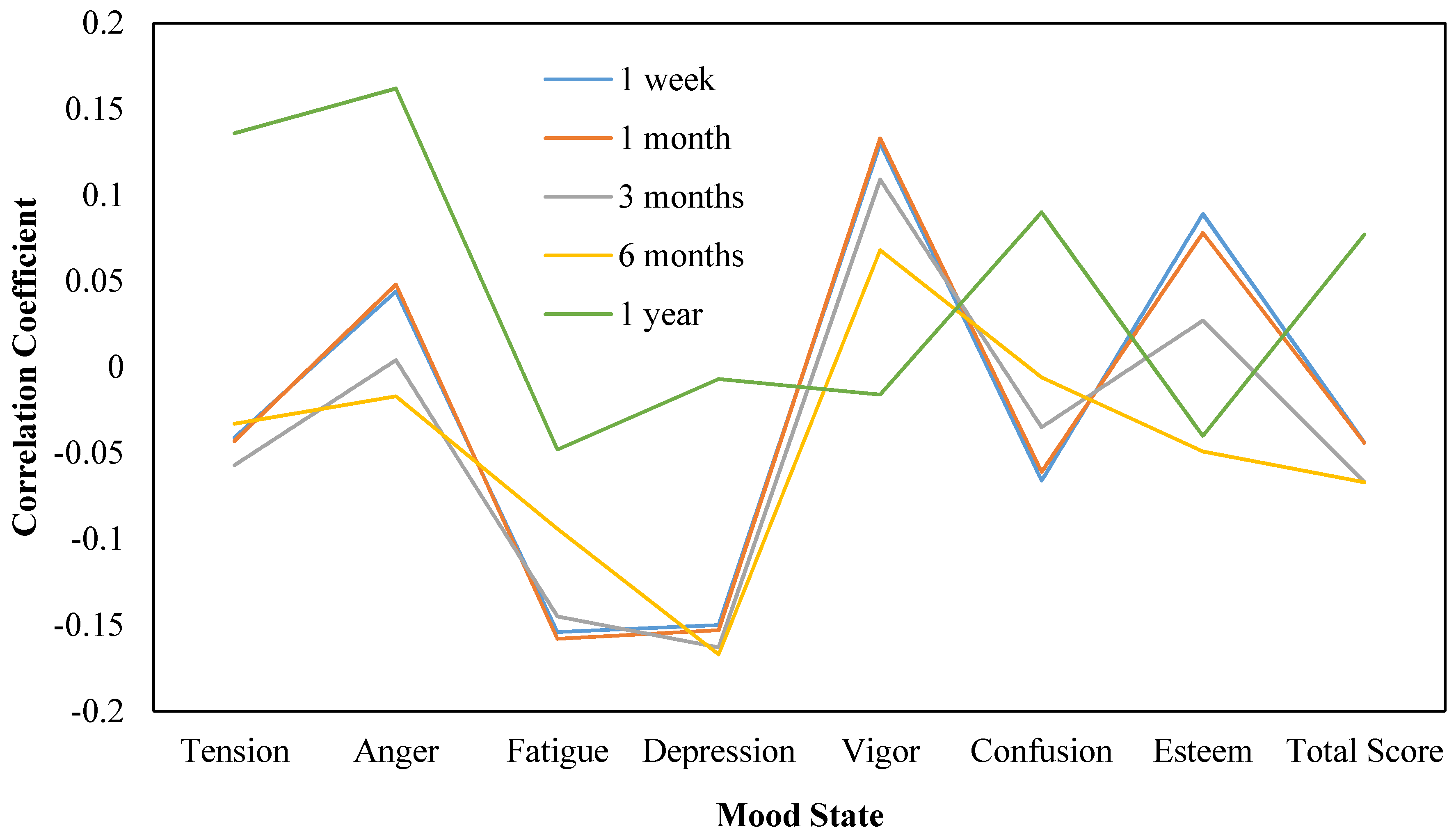
| 1 week | −0.041 | 0.044 | −0.154 * | −0.15 * | 0.130 * | −0.066 | 0.089 * | −0.044 |
| 1 month | −0.043 | 0.048 | −0.158 * | −0.153 * | 0.133 | −0.061 | 0.078 | −0.044 |
| 3 months | −0.057 | 0.004 | −0.145 * | −0.163 * | 0.109 | −0.035 | 0.027 | −0.067 |
| 6 months | −0.033 | −0.017 | −0.094 | −0.167 * | 0.068 | −0.006 | −0.049 | −0.067 |
| 1 year | 0.136 | 0.162 * | −0.048 | −0.007 | −0.016 | 0.09 | −0.04 | 0.077 |
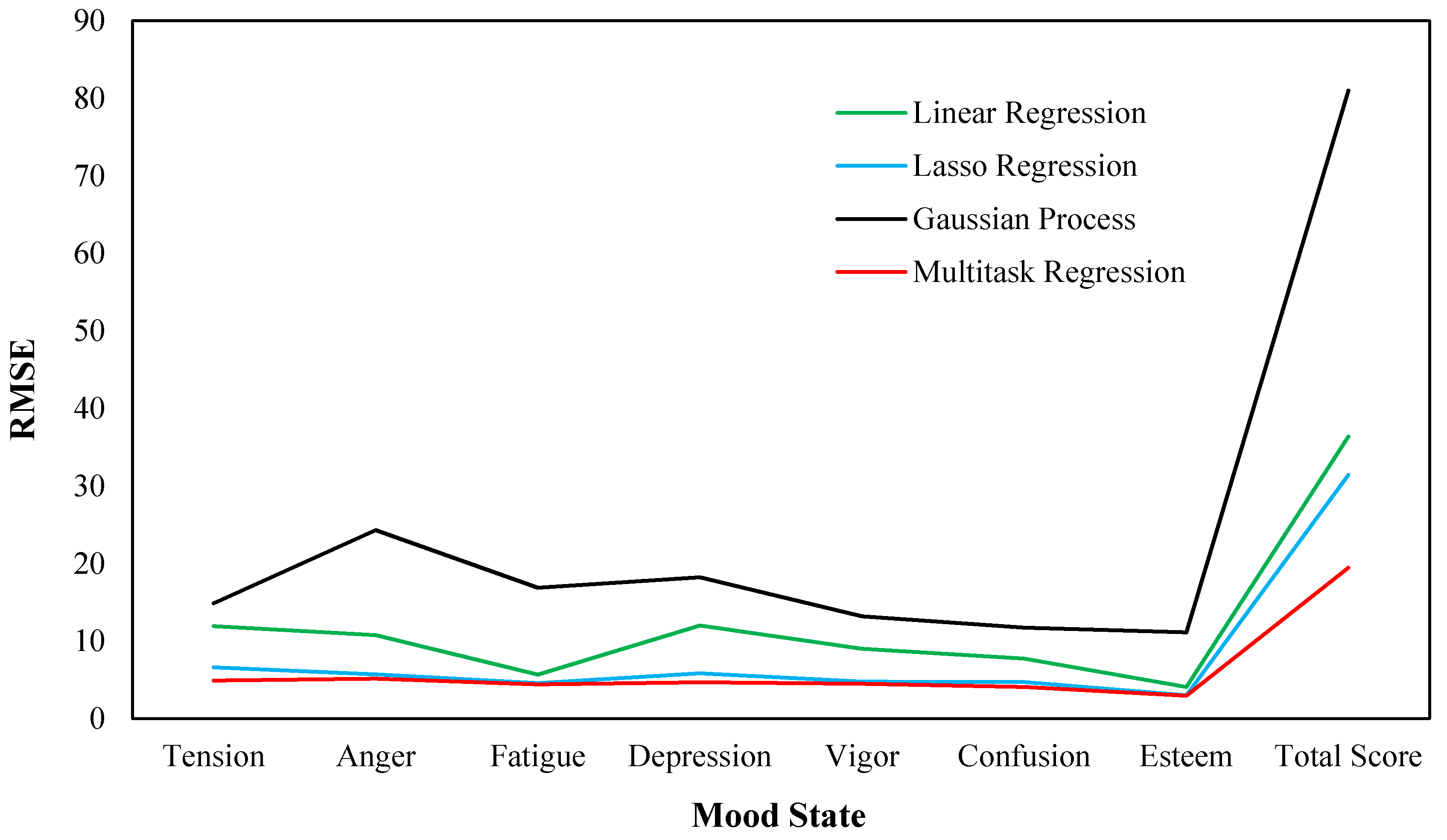
| Mood State | Linear Regression | Lasso Regression | Gaussian Regression | Multitask Regression |
|---|---|---|---|---|
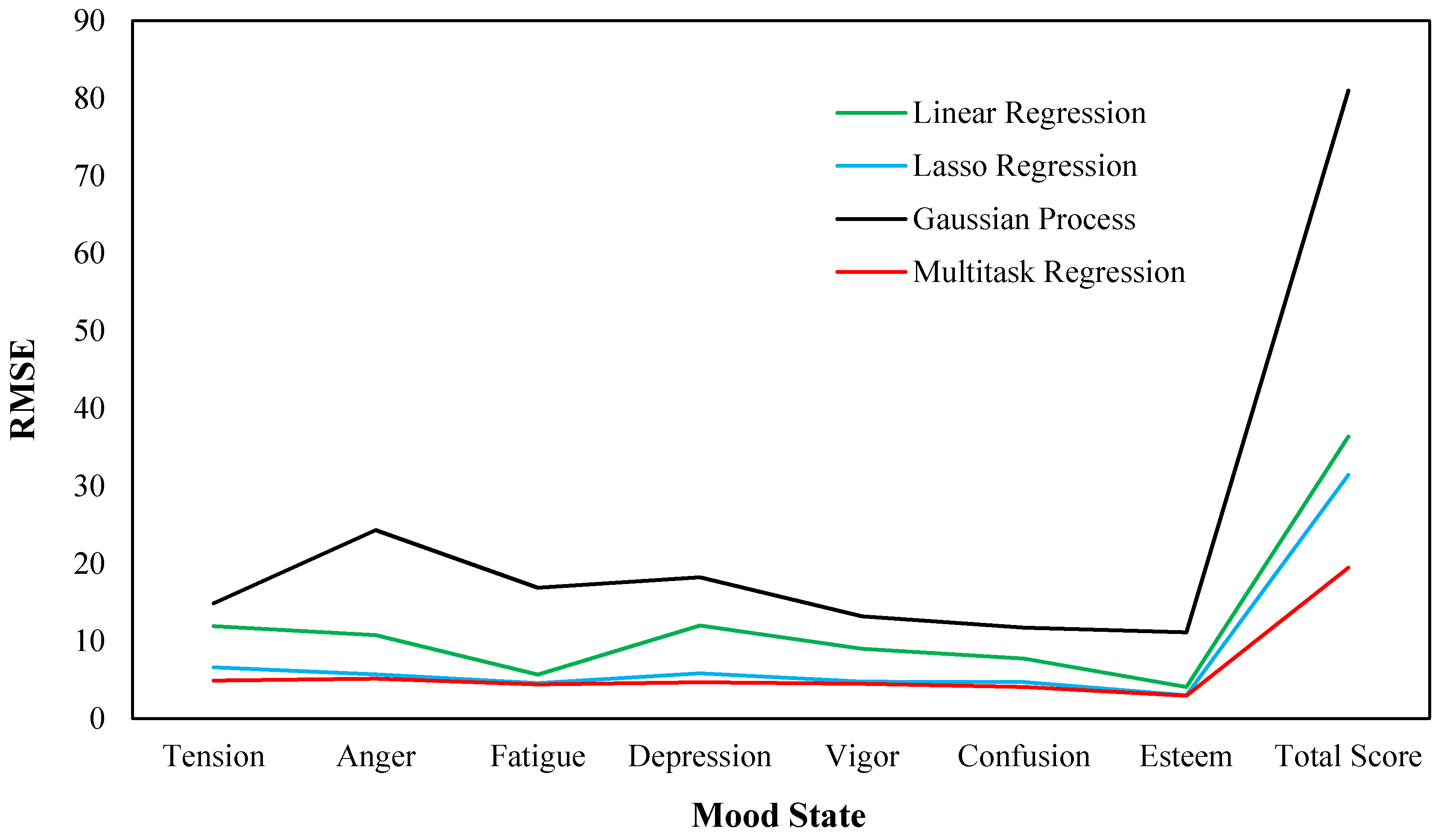
| Tension | 0.784 | 0.434 | 0.978 | 0.324 |
| Anger | 0.736 | 0.391 | 1.661 | 0.353 |
| Fatigue | 0.411 | 0.331 | 1.219 | 0.319 |
| Depression | 0.909 | 0.442 | 1.380 | 0.355 |
| Vigor | 0.487 | 0.258 | 0.713 | 0.243 |
| Confusion | 0.600 | 0.365 | 0.908 | 0.315 |
| Esteem | 0.289 | 0.214 | 0.790 | 0.210 |
| Total score | 0.583 | 0.503 | 1.297 | 0.312 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Li, Y.; Huang, Y.; Liu, H.; Zhang, T. A Method for Identifying the Mood States of Social Network Users Based on Cyber Psychometrics. Future Internet 2017, 9, 22. https://doi.org/10.3390/fi9020022
Wang W, Li Y, Huang Y, Liu H, Zhang T. A Method for Identifying the Mood States of Social Network Users Based on Cyber Psychometrics. Future Internet. 2017; 9(2):22. https://doi.org/10.3390/fi9020022
Chicago/Turabian StyleWang, Weijun, Ying Li, Yinghui Huang, Hui Liu, and Tingting Zhang. 2017. "A Method for Identifying the Mood States of Social Network Users Based on Cyber Psychometrics" Future Internet 9, no. 2: 22. https://doi.org/10.3390/fi9020022
APA StyleWang, W., Li, Y., Huang, Y., Liu, H., & Zhang, T. (2017). A Method for Identifying the Mood States of Social Network Users Based on Cyber Psychometrics. Future Internet, 9(2), 22. https://doi.org/10.3390/fi9020022