Abstract
In driverless formula car racing, cone detection faces two significant challenges: one is recognizing cones at long distances accurately, and the other is being prone to leakage under bright light conditions. These challenges directly affect the detection accuracy and response speed. In order to cope with these problems, the thesis is based on YOLOv8s to improve the cone bucket detection algorithm. Firstly, a P2 detection layer for detecting tiny objects is added on top of YOLOv8s to detect small targets with 160 × 160 pixels, which improves the detection of small conical buckets in the distant view. At the same time, to reduce the network’s complexity to achieve lightweightness, the original 20 × 20 pixel detection header is deleted. Second, the head of the original YOLOv8 is replaced with a multi-scale fusion Dynamic Head, designed to improve the head’s ability in scale, space, and task perception to enhance the detection performance of the model in complex scenes. Again, a novel loss function, MPDIoU, is introduced, which has advantages in simplifying the bounding box similarity comparison, and it can adapt to the overlapping or non-overlapping situation of the bounding box more effectively. It reduces the phenomenon of missed detection caused by overlapping conical buckets. Finally, the LAMP pruning method is used to trim the model to make the model lightweight. By adding and modifying the above modules, the improved algorithm improves the detection accuracy from 92.2% to 95.2%, the recall rate from 84.2% to 91.8%, and the average accuracy from 91.3% to 96%, while the number of parameters is reduced from 28.7 M to 26.6 M. The detection speed still meets the real-time requirement in real-vehicle testing compared to the original algorithm. In the real car test, compared with the original algorithm, the improved algorithm shows apparent advantages in reducing the missed detection of cones and barrels, which meets the demand for high accuracy of cones and barrel detection in the complex race environment and also meets the conditions for deployment on small devices with limited resources.
1. Introduction
Driverless car intelligence is divided into three significant aspects: environment perception, path planning, and tracking control. Environmental perception is the key to realizing intelligence and is vital in subsequent research. The camera plays a crucial role in environmental sensing, and its primary function is to provide rich color information for the location of cones and buckets detected by the radar to enhance the visualization and recognition of the data. The images captured by the camera effectively combine the specific location of the cone bucket in the real world with the color characteristics to provide more comprehensive and accurate information for subsequent processing and analysis. Adopting an effective detection method is crucial for accurately recognizing conical buckets. Deep learning-based target detection algorithms are mainly categorized into two-stage detection algorithms and one-stage detection algorithms [1]. Two-stage detection first generates candidate regions and performs target detection on the candidate regions. The mainstream two-stage detection algorithm is Faster R-CNN. Although the two-stage detection algorithms have high accuracy, they require much time to complete the detection process. They are challenging to deploy in small devices due to the complexity of the model.
On the other hand, one-stage detection algorithms directly detect the objects in the image, which shortens the detection process. Two-stage detection first generates candidate regions and performs target detection on the candidate regions. The mainstream two-stage detection algorithms are Faster R-CNN [2], and so on. Although the two-stage detection algorithms have high accuracy, they require much time to complete the detection process. Due to the complexity of the model, it is challenging to deploy it in small devices.
On the other hand, one-stage detection algorithms directly detect the objects in the image, which shortens the detection process [3]. The YOLO family of algorithms is widely used in target detection due to its fast detection speed and efficient processing capability. The standard one-stage detection algorithms are YOLO [4], SSD [5], EfficientDet [6], and RT-DERT [7]. Although as a one-stage detection algorithm, YOLO may be slightly inferior to two-stage detection algorithms in terms of accuracy, its superior speed and efficiency make it stand out among many target detection algorithms [8]. With the introduction of the YOLOv8 algorithm [9], the YOLO series has taken another leap forward in detection accuracy and speed. However, in the specific application scenario of driverless formula car racing, the performance of the YOLOv8 algorithm still has room for improvement in the face of conical-barrel targets with small sizes and a low pixel occupancy ratio. In addition, the lighting conditions of the racing environment also put higher requirements on the target detection algorithm, which needs to have higher detection accuracy, a more compact model structure, and more minor parameter counts so that it can be deployed on resource-constrained small devices to realize real-time and accurate target detection.
Mengzi Hu et al. [10] improved the detection of small objects in aerial images, added a P2 detection layer to improve the detection of small targets, and reduced the redundant P5 detection layer to lighten the weight. In order to improve the small-object detection network for traffic signs in complex environments, Huaqing Lai et al. [11] adopted a small-object detection layer approach to acquire and transmit richer and more discriminative small-object features. Zixuan Zhang et al. [12] conducted an in-depth study on vehicle detection challenges at night and under bad weather conditions. They proposed an innovative approach to improving the detection head in YOLOv7 to adapt to the detection needs in complex environments. This improvement shows that the detector head has more robust adaptability and accuracy when facing low light and bad weather conditions. Tianyong Wu et al. [13] systematically researched environmental complexity and tiny object detection challenges in remote sensing. By integrating a high-performance detector head specially designed for small object detection and innovatively replacing the original architecture, they significantly improved the detection ability of small objects in remote sensing images. For the problems of weak detection ability of conical barrels and inconspicuous color differentiation, Jiyue Zhuo et al. [14] adopted the HSV color space transformation module to improve the color differentiation ability, introduced the CA attention to improving the detection ability of conical barrels, and introduced the CA attention to improving the detection ability of conical barrels. In Yulin Liu et al. [15], for problems of complex deployment and poor real-time performance on low-performance computing units, a lightweight backbone network was adopted, and Focal EIoU was used to solve the problem of accuracy degradation. Yue Guo et al. [16] explored the lightweightness of the model structure by adopting a deep separable convolutional model for the feature extraction network. Separable Convolution was used to redesign the feature extraction network. This improvement allows the new model to maintain a smaller size while significantly improving detection accuracy, effectively recognizing targets of different sizes in complex environments. Rui Shi et al. [17] proposed a pruning method for the detection network to reduce the model’s computational costs. The pruned model significantly reduces computational effort while the detection accuracy is improved, enormously meeting the demand for real-time operation on mobile devices with low-power processors. There are many programs for improving the YOLO algorithm, but choosing the right one is the key.
This study proposes a YOLOv8s algorithm improvement scheme for unmanned racing scenarios, aiming to improve the accuracy of cone bucket detection. By introducing improvement methods, such as MPDIoU and Dynamic Head, the algorithm is improved in detection accuracy. In addition, adding the P2 detection layer enhances the algorithm’s ability to recognize small targets. In order to adapt to the limited computational resources of the racing equipment, this study also adopts model compression and pruning techniques, which effectively reduce the number of parameters and computation of the model. Finally, to verify the improved algorithm’s practicality, it is deployed on a real car for testing, proving its effectiveness and reliability in practical applications.
2. Network Architecture of YOLOv8s
YOLOv8 contains five network models: YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x, whose channels increase in depth and width in sequence with the choice of the network model, and the detection accuracy increases. In this study, the choice is YOLOv8s [18]; the network structure for the YOLOv8s model is shown in Figure 1 below. The network structure consists of four main parts: input, backbone network, neck network, and head network.
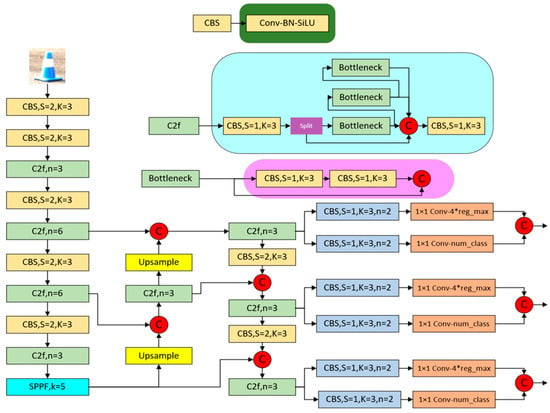
Figure 1.
Network structure of YOLOv8.
Input side: Compared with the earlier YOLO algorithm, YOLOv8 adopts the Mosaic data enhancement method on the input side, which enhances the model’s ability to adapt to variable real-world environments by performing random selection, cropping, and splicing operations on the input images. This approach endows the algorithm with stronger robustness and generalization capabilities and significantly improves the model’s detection performance in complex scenes.
Backbone Network: The YOLOv8s architecture delicately integrates the Conv module, C2f module, and SPPF module to form an efficient target detection network.
The Conv module is one of the core components of building an efficient neural network; its primary responsibilities are as follows:
- Feature extraction: The Conv module extracts useful feature information by applying a convolutional kernel to the input data. These features are helpful for subsequent classification, detection, or segmentation tasks.
- Adjustment of resolution and number of channels: Using different sizes and numbers of convolution kernels, the Conv module can change the resolution (i.e., the dimension size) of the feature maps (feature maps) and generate different numbers of feature maps.
- Combined use of nonlinear activation functions: The Conv module is usually followed by a nonlinear activation function to add nonlinearity to the network so that it can capture complex relationships and patterns. The nonlinear activation function helps the network learn better and effectively prevents overfitting because linear models are susceptible to sample noise and overfitting to the training data.
The role of the C2f module:
- Multi-scale fusion of feature maps: The C2f module combines the advantages of both SPP (Spatial Pyramid Pooling) and PAN (Path Aggregation Network) structures, enhancing the model’s ability to detect targets of different sizes through the fusion of information between feature maps at different levels.
- Reducing computation and improving efficiency: Utilizing the CSP (Cross Stage Partial Network) design idea, the C2f module divides the input data into two parts for processing. One part is passed directly, the other is processed by the convolutional layer, and then the two are merged for output. This structure effectively reduces model parameters and computation while improving the efficiency and accuracy of the model.
- Enhanced feature extraction: The C2f module adopts the DarknetBottleneck structure and improves the model performance by setting the group convolution and channel expansion parameters. These designs optimize the feature extraction capability and reduce the model complexity.
- Flexible connectivity: The C2f module can optionally use shortcut connectivity, which helps speed up the model training and inference process while providing an optimized distributed computing strategy.
- Improvement of detection performance: The C2f module is usually placed on the last few layers of the backbone network, fusing high-resolution shallow feature maps with semantically informative deep feature maps. Thus, a feature representation that is both high resolution and semantically informative is obtained, improving the performance of target detection.
Specific roles of the SPPF module:
- Improve processing speed and accuracy: SPPF is an improved version of SPP (Spatial Pyramid Pooling) that performs region pooling operations faster. It allows the network to process input images of various sizes and produce output images of the same size while maintaining a high processing speed.
- Fusion of multi-scale features: The prominent role of the SPPF module is to fuse feature information from larger scales to improve the performance of target detection. By optimizing the algorithm and reducing the amount of computation, it achieves faster speeds and lower FLOPs (floating point operations counts).
Neck network: It is mainly used to fuse feature maps from different levels or scales to improve the model’s ability to process multi-scale scenes. This fusion expands the model’s field of view, making it more adept at handling input images of various sizes.
Head network: From YOLOv3 to YOLOv5, the detection heads of the YOLO series have always adopted a “coupled” design, i.e., a single convolutional layer realizes both classification and localization functions. Until the emergence of YOLOX, this tradition was broken, and it introduced the “decoupled head” structure, which separates the extraction of category features and location features. YOLOv8 inherits and develops this concept, adopts two parallel branches to extract the category and location features independently, and then completes the classification and localization tasks through 1 × 1 convolutional layers, respectively. The classification and localization tasks are performed separately by 1 × 1 convolutional layers. This design significantly improves the model’s accuracy in localization and its adaptability to various types of scenes, as well as enhances the model’s generalization [19].
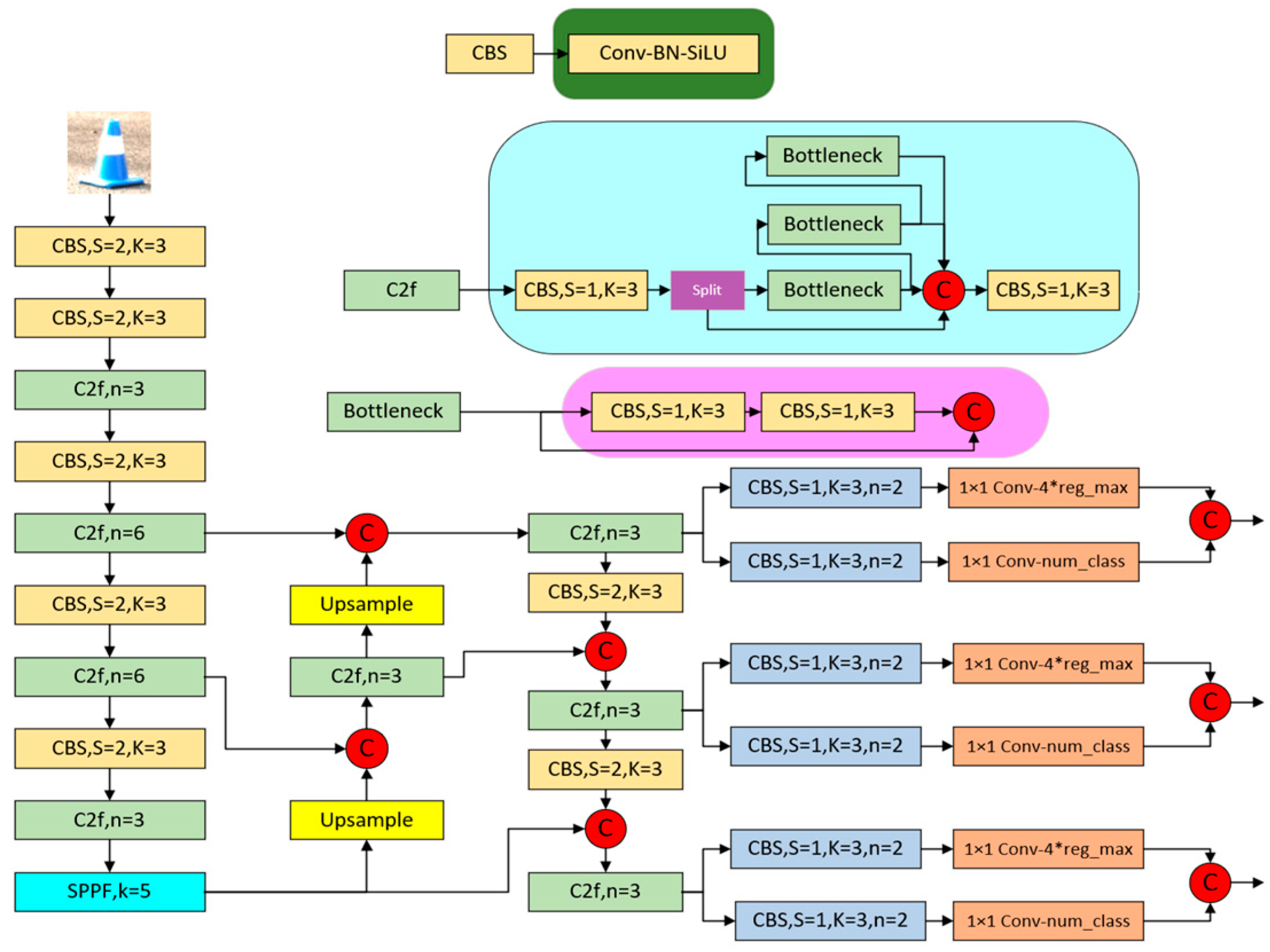
3. Adding a Tiny Detection Layer P2
It is crucial to improve the feature extraction necking network of YOLOv8 for the model to accurately recognize conical buckets at long distances. The necking network of YOLOv8 extracts feature information at 80 × 80, 40 × 40, and 20 × 20 pixel dimensions through a down-sampling process and achieves the fusion of multi-scale information through an up-sampling strategy. However, this approach ignores tiny conical buckets with dimensions smaller than 80 × 80 pixels, leading to difficulties in recognizing these small targets at long distances.
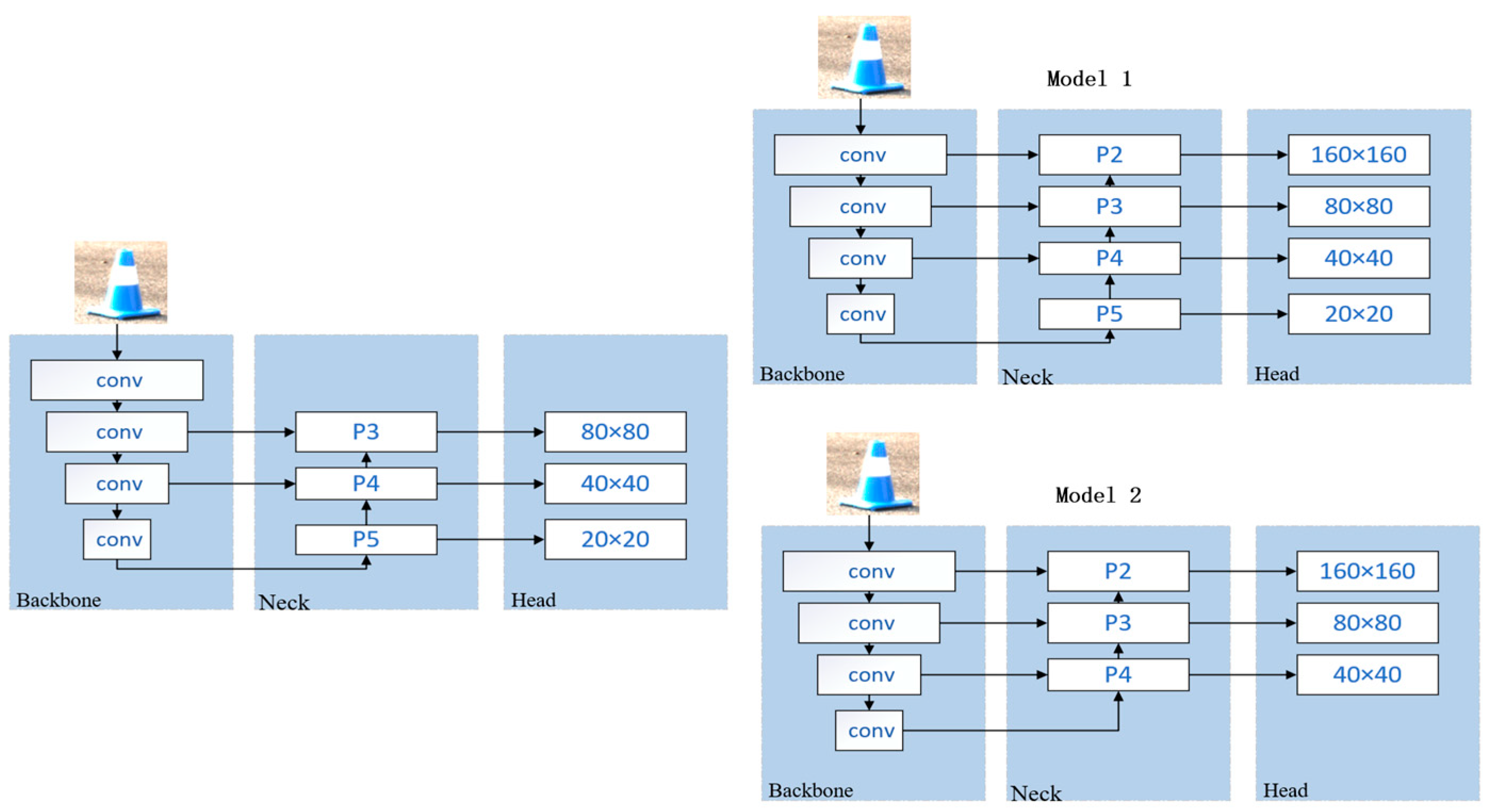
To solve this problem, we introduced an additional up-sampling layer by creating a P2 detection layer of 160 × 160 pixels, resulting in feature maps with sizes of 160 × 160, 80 × 80, 40 × 40, and 20 × 20 pixels. The exact process of this improvement is shown in Figure 2. In order to maximize the detection of tiny conical buckets smaller than 80 × 80 pixels, we propose two strategies to optimize the detection performance of small objects.
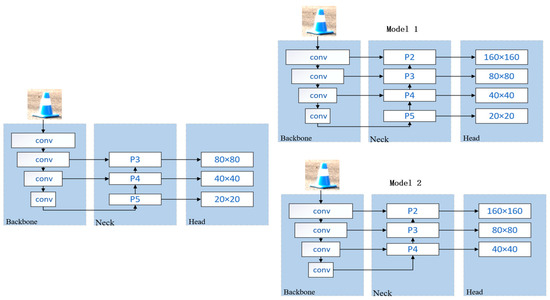
Figure 2.
Adding different detection layers.
Model 1 adds a 160 × 160 pixel detection layer to the existing architecture to enhance the detection of small objects. Model 2, on the other hand, further removes the original 20 × 20 pixel large target detection layer from Model 1 and focuses on small target recognition. These improvements aim to increase the model’s sensitivity and accuracy to small objects, thus enabling more accurate cone-and-bucket detection at long distances.
This paper conducted experimental tests under the same parameter configuration and dataset conditions to fully evaluate the performance of Model 1 and 2. The experimental results, shown in the Table 1 above, clearly demonstrate the two models’ performance on the conical bucket detection task.

Table 1.
Results of Model 1 and Model 2.
Through comparative analysis, we found that the detection performance using the Model 2 scheme is superior to that of Model 1. Model 2 performs well in terms of detection accuracy, recall, and overall detection efficiency, which is significantly better than that of Model 1. This suggests that Model 2 can provide more accurate and reliable detection results when focusing on small target recognition.
The experimental results also reveal Model 2’s advantages when dealing with the task of long-distance cone-bucket detection. By removing the original 20 × 20 pixel large target detection layer, Model 2 focuses more on small target recognition, thus achieving higher detection accuracy in the long range.
4. Replacing the Dynamic Head Inspection Head
In order to solve the problem of leakage detection under strong light conditions, it is necessary to analyze the detector head. The detector head of YOLOv8 originally summarizes the feature information by superimposing two superficial convolutional layers, but this method is prone to ignoring detailed features due to the massive model. To solve this problem, this study introduces the Dynamic Head detection head proposed by Xiyang Dai and other researchers [20]. The core advantage of the Dynamic Head detection head lies in its dynamism, which can dynamically adjust the network structure or weight assignment according to the diversity and complexity of the input data. This design gives the network greater flexibility to adapt to various complex scenarios, significantly improving the accuracy and processing efficiency of target detection.
The incorporation of the attention mechanism is a crucial point in the realization of Dynamic Head. By applying the attention mechanism at different levels, Dynamic Head can integrate and process the target’s feature information more accurately:
Attention between feature levels: Dynamic Head realizes the effective exchange of information between different feature levels through this mechanism, which enhances the perception of targets at different scales.
Attention to features between spatial locations: This allows the head to focus on vital spatial locations in the image, further enhancing the accuracy of capturing spatial information about the target.
Feature attention within the output channel: By applying the attention mechanism within the output channel, the Dynamic Head is able to perform task awareness and optimize the feature representations to better adapt to specific detection tasks.
In addition, the DyHead model, as an implementation of Dynamic Head, adopts the Anchor-Free target detection idea, which abandons the predefined anchor frame approach in traditional target detection. The DyHead model achieves target detection by adding an adaptive detection head to the output layer of the network, which automatically learns to generate the position and size information of the target. This approach not only reduces the workload of manually labeling the Anchor but also improves the accuracy and efficiency of target detection by better adapting to the size and shape changes of the target due to its adaptive nature.
Through these innovative improvements, the detection performance of the Dynamic Head detection head under complex conditions such as bright light is significantly improved, which provides strong support for improving the robustness and accuracy of the target detection model.
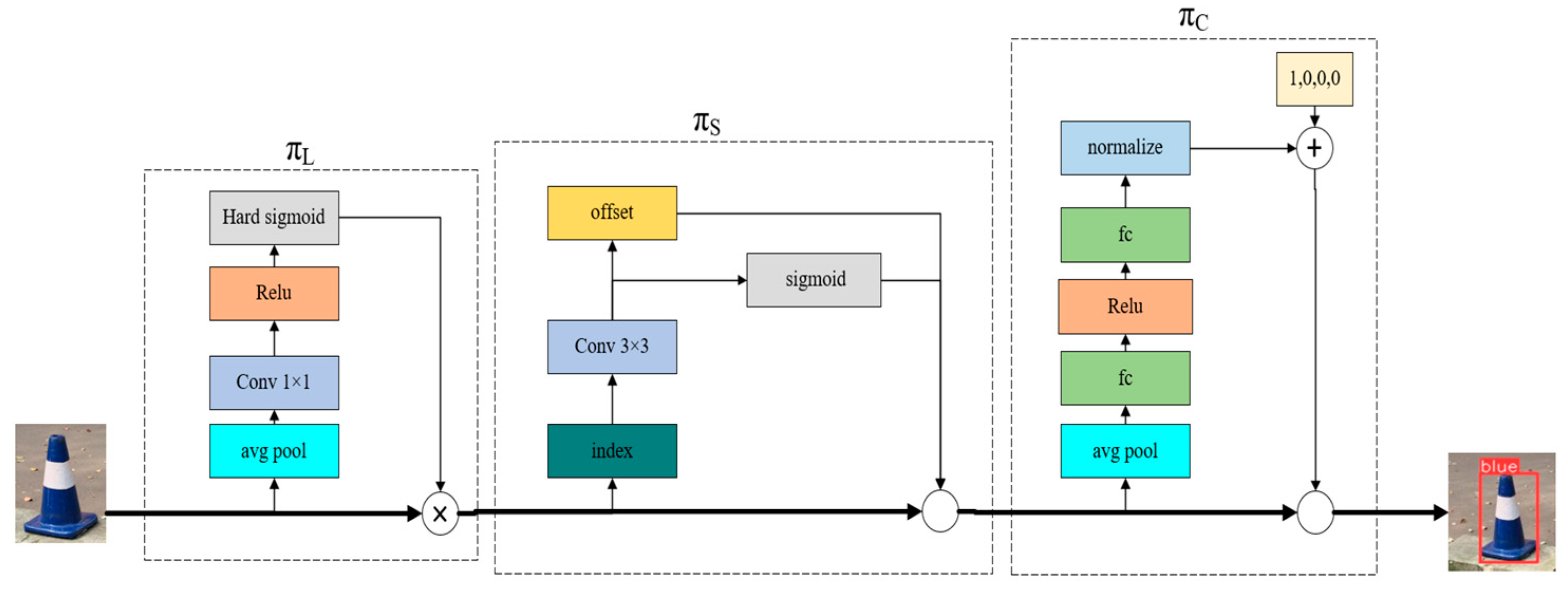
The overall structure of the Dynamic Head detection head is shown in Figure 3. The detailed implementation of each attention module is described. Scale-aware attention (πL), spatial-aware attention (πS), and task-aware attention (πC) correspond to different modules, each targeting a different dimension of feature tensor F (layer L, space S, channel C).
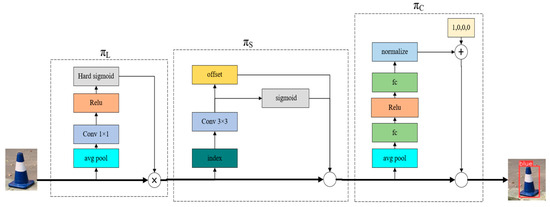
Figure 3.
Dynamic Head structure.
The scale-aware attention module uses average pooling, 1 × 1 convolution, ReLU activation, and complex Sigmoid functions.
The spatial-aware attention module includes offset learning and 3 × 3 convolution.
On the other hand, the task-aware attention module is handled by fully connected layers, ReLU activation functions, and normalization operations.
5. Optimization of the Loss Function
The traditional IOU calculation formula is shown in Equation (1); the original IoU only calculates the concatenated area of two bounding boxes and cannot distinguish cases in which two bounding boxes do not overlap. Protocols should be described in detail, while well-established methods can be briefly described and appropriately cited.
where denotes the true bounding box, and denotes the predicted bounding box.
YOLOv8 adopts the loss function of CIoU, as shown in Equations (2)–(4); CIoU introduces the Euclidean distance between the centroid of the predicted bounding box and the centroid of the actual bounding box, which can effectively reflect whether the two boxes of the actual box and the predicted box are close to each other or far away from each other. In addition, CIoU also integrates the distance of the centroid point and the aspect ratio factor, and this design is mainly aimed at the case that when the center of the predicted box is overlapped with the center of the genuine box, the conventional Euclidean distance may be invalid.
where denotes the true bounding box, denotes the predicted bounding box, denotes the Euclidean distance between the centers of the true box and the predicted box, and denotes the length of the diagonal of the smallest outer rectangle that can contain the true box of the predicted box at the same time. is a trade-off parameter used to measure the consistency of the aspect ratio.
Although CIoU is designed with the aspect ratio of the bounding box in mind, it does not adequately account for the differences in width and height between the predicted bounding box and the real one. When both have the same aspect ratio but different dimensions, the effectiveness of CIoU is affected, which may slow down the convergence of the model and limit its detection accuracy. This problem is particularly acute for small targets since their aspect ratios do not usually deviate significantly.
MPDIoU [21] addresses this problem by introducing the concept of multi-scale. MPDIoU aims to more accurately measure the model’s detection performance on targets at different scales. It evaluates the IoU at a single scale and integrates the model’s ability to detect targets at multiple scales. MPDIoU allows more attention to be paid to the model’s performance in detecting small targets by weighted averaging of the IoU at different scales. This weighting is usually based on the area of the target or other scale-dependent metrics.
, indicate the width and height of the input image.
The MPDIoU formulation is shown in Equations (5)–(8). MPDIoU simplifies the similarity comparison between two bounding boxes and can be adapted to overlapping or non-overlapping bounding box regressions. MPDIoU can provide a more comprehensive picture of the model’s performance in multi-scale target detection tasks, especially regarding accuracy and robustness when dealing with small targets.
6. Lightweighting of Models
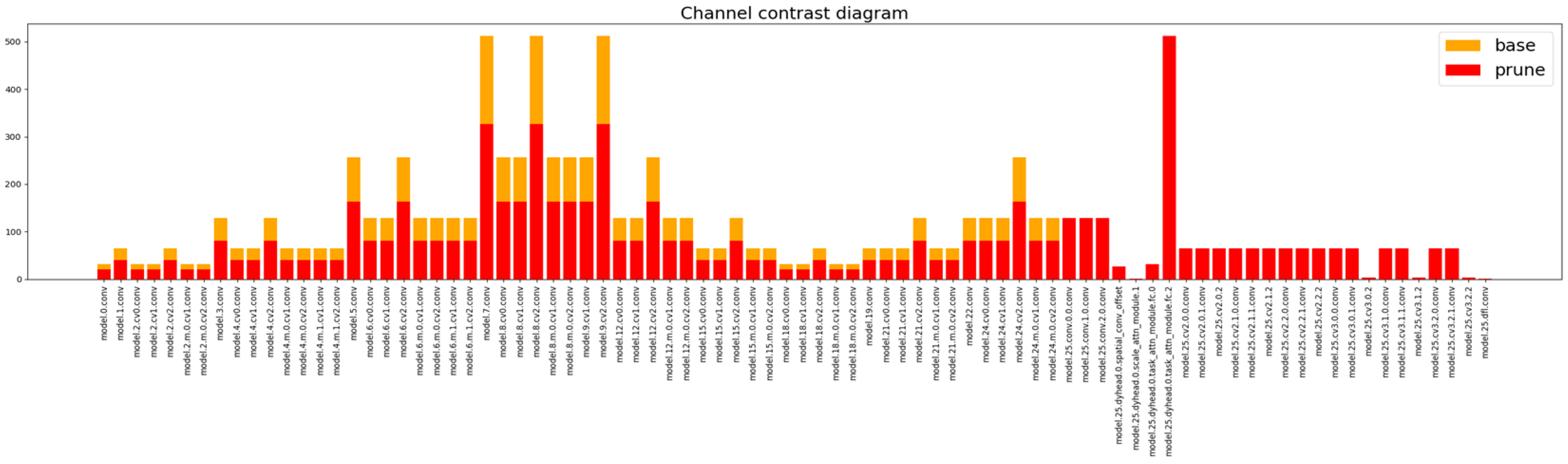
In order to make the improved YOLOv8s algorithm applicable to driverless racing devices with limited computing resources and realize real-time detection, it is necessary to process the YOLOv8s network. After experimental comparison, there are many network parameters and weights in the YOLOv8s network, which dramatically affects the computational speed of the network. In order to solve the problem, this study adopts LAMP pruning to cut off the “unimportant” weights of the model so that the model can reduce the number of parameters and computations while trying to ensure that the model’s accuracy is not affected. In order to solve this problem, this study adopts the LAMP pruning method to trim out the “unimportant” weights of the model so that the model can reduce the number of parameters and the amount of computation and, at the same time, try to ensure that the accuracy of the model is not affected. The pruned results were shown in Figure 4
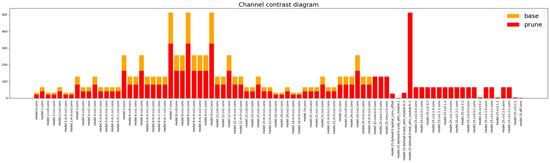
Figure 4.
Comparison of access after trimming and before trimming.
LAMP (Layer-wise Adaptive Magnification Pruning) [22] is a global network optimization technique that identifies and cuts out less influential connections by scoring the weights of each layer. It evaluates the importance of the weights in the network through a well-designed scoring mechanism and then identifies and cuts out those connections that have less impact on model performance. This process not only streamlines the network structure and reduces the complexity of the model but also reduces the demand for computational resources, which is of great significance for improving computational efficiency and the ease of model deployment.
The specific implementation steps of the LAMP pruning method are as follows:
Step 1: Pre-training. This is the foundation of the pruning process, which lays a solid foundation for the subsequent pruning algorithm by comprehensively training the network model. The purpose of pre-training is to ensure that the model has a good performance before pruning and to provide a guarantee for the accuracy of the pruning algorithm.
Step 2: Pruning. In this stage, the LAMP method filters out those weights with less impact for pruning by calculating the score of each weight (as shown in Equation (9)) and ranking them according to the size of the absolute value of the weights. Before pruning, it is necessary to determine the level of pruning and set a trimming threshold or ratio to control the degree of pruning and ensure the reasonableness of the pruning operation. After pruning, the model is evaluated to ensure that its performance meets the established requirements.
Step 3: Fine-tuning. Fine-tuning is an indispensable step after pruning, and it is crucial to recover the performance loss that may be caused by pruning. Since structural pruning changes the structure of the model, it may have an impact on the expressive ability of the model. Therefore, through fine-tuning, not only can the residual weights be optimized, but the performance of the model can also be further improved to ensure that the pruned model can still maintain close to the original model detection accuracy while remaining lightweight.
Through this series of steps, the LAMP pruning method not only realizes model streamlining but also ensures the model performance through retraining and fine-tuning. This approach is suitable for deployment on devices with limited computing resources.
where denotes the weight, and denote the items mapped by the index, and and denote the index mapping corresponding to the weights sorted in ascending order, respectively.
7. Experimental Design and Validation
7.1. Selection of Dataset and Experimental Environment
The data used in this study are all from the publicly available dataset FSACOCO dataset [23], which covers images of cones and buckets collected in daily life and at competitive events at numerous universities nationwide. The color settings of the cones in these images are consistent with the race scenarios and include red, blue, and yellow. The yellow cones represent the starting point, while the red and blue cones represent the inside and outside of the course, respectively. The course design consists of different sections for straight-line acceleration, figure-of-eight wraparound, and high-speed trajectory. All universities captured images using equipped cameras and summarized these data into a unified dataset. In order to accurately assess the ability to detect cones and buckets in variable environments, the paper specifically selects scenes under different lighting conditions, including solid light, low light, and general lighting situations. At the same time, to explore the impact of scene changes on the detection effect, the paper also selects various cone bucket photos with different backgrounds for model training. The purpose is to ensure that the research results of the thesis can effectively reflect the performance and adaptability of cone bucket detection in practical applications. A total of 7432 photos are selected for this experiment, which is divided into a training set, validation set, and test set according to 7:2:1. This experiment uses GeForceRTX4060 with CUDA version 11.7 and Pytorch version 1.13.1 for training.
7.2. Experimental Methods
The experimental methodology is designed to comprehensively evaluate the algorithm’s performance and ensure its effectiveness in practical applications. First, this thesis compares the improved algorithm with the current widely used target detection algorithms through comparative experiments. This step not only highlights the innovation of the proposed algorithm but also visualizes its performance advantages.
Subsequently, the thesis uses ablation experiments to examine the contributions of each module one by one. By gradually adding and adjusting the algorithm’s components, each module’s specific improvement effect on the overall performance can be clearly observed, thus verifying the necessity and optimization value of each module.
Finally, to demonstrate the algorithm’s practical application potential, its algorithm is deployed on a natural vehicle for testing. Real-vehicle validation is critical in testing whether the algorithm can work in the real world. By applying the algorithms to actual vehicles, the stability and reliability of the algorithms can be assessed, and valuable field data can be collected to provide a basis for further optimization and improvement of the algorithms.
7.3. Experimental Evaluation Indicators
Algorithms are mainly applicable to devices with limited computing resources, and in order to ensure the safety and competitiveness of racing, algorithms must have high accuracy and real-time performance. Therefore, when evaluating and selecting algorithms, emphasis should be placed on evaluation metrics that are directly related to accuracy and real-time performance. These parameters include precision (P), recall (R), mean accuracy (mAP), number of parameters of the model (Pa), and frames processed per second (FPS) [24].
In the process of calculating FPS, in order to ensure accuracy and that the graphics card can fully utilize its computational power, the card is first warmed up 200 times, which allows the card to reach its optimal state. Finally, 1000 tests are performed to select the average value.
where denotes the number of actual correct predictions that were also correct; denotes the number of actual incorrect predictions that were correct; and denotes the number of actual corrections that were predicted to be incorrect. is the category number.
7.4. Contrast and Ablation Experiments
In order to evaluate the effectiveness of the method proposed in this study. The improved algorithm is compared with YOLOv5, YOLOv6, YOLOv7, EfficientDet, SSD, and Faster R-CNN, and the results are shown in Table 2.
Table 2.
Comparison experiment.
It is clear from the result table that the model proposed in this study outperforms other detection algorithms in three key performance metrics: accuracy, recall, and mean average precision (mAP). Although slightly lower than the YOLOv7 algorithm in detection accuracy, our model outperforms both recall and average precision. The high recall rate means that our model can minimize missed detections and thus detect more targets. In addition, the high value of average precision indicates that our model not only ensures high precision while maintaining a low miss detection rate but also shows good adaptability to different targets, backgrounds, and environmental conditions.
The method proposed in this study outperforms other methods in terms of detection speed and efficiency. Our model’s comprehensive advantages in terms of key performance indicators, especially its performance in terms of high recall and high average precision, prove its efficiency and reliability in practical applications.
To ensure an accurate assessment of the contribution of each module, ablation experiments are carefully designed and implemented in this study. The results are shown in Table 3. The methodology allows us to observe the specific impact of each module on overall performance by gradually introducing or removing individual modules from the model. The results of the ablation experiments show that after replacing the loss function with MPDIoU, the detection accuracy of the model increases. However, improvements could be made, such as solving the leakage problem due to overlapping detection frames. In addition, after adding the tiny detection layer P2, an improvement in detection accuracy and efficiency can be observed. After further replacing it with a Dynamic Head detection head, the detection accuracy and average accuracy are improved, and the model’s ability to detect complex scenes is enhanced. Finally, by employing pruning, the model can be compressed well, thus being lightweight.
Table 3.
Ablation experiment.
7.5. On-the-Road Verification
In order to comprehensively verify the practicality and effectiveness of the algorithm, the algorithm was deployed on an actual vehicle for verification, and before the camera on the vehicle was formally enabled for data acquisition, the camera was first calibrated with accurate internal parameters, a step that is crucial because it ensures the accuracy and reliability of the image data captured by the camera, and avoids the negative impact on the target detection results due to the distortion of 4 the camera lens. The camera used for the experiment is the Mercury II industrial camera MER2-231-41U3C as the camera sensor, and the real-time image data is sent to the algorithm for verification through the ROS 20.04 operating system. Some of the camera parameters are shown in Table 4.
Table 4.
Camera Related Parameters.
The camera used in this experiment is a monocular camera, and the calibration of a monocular camera is a crucial step that ensures an accurate correspondence between the image captured by the camera and the actual scene. The Zhang Zhengyou camera calibration method, as a widely adopted camera calibration method, realizes the accurate calibration of the camera by using a calibration board with an international standard chess black and white grid.
The following are the detailed steps for monocular camera calibration using the Zhang Zhengyou calibration method:
- Fabrication of calibration board: First, a calibration board with a square grid is fabricated, and the length of each square side is set to 25 cm to ensure sufficient measurement accuracy. The corner points on the calibration board are in 7 × 6 dot matrix mode, i.e., each corner point consists of 7 rows and 6 columns of black and white squares, so as to facilitate the algorithm to accurately identify.
- Printing and fixing of calibration board: The designed calibration board is printed on white paper to ensure the clarity of the black and white squares. Subsequently, the printed calibration board was fixed on a small wooden board to ensure its stability in the calibration process.
- Placement of the calibration plate: When gluing the calibration plate to the small wooden board, make sure the paper is flat and avoid any wrinkles or bends, which may affect the accuracy of the calibration.
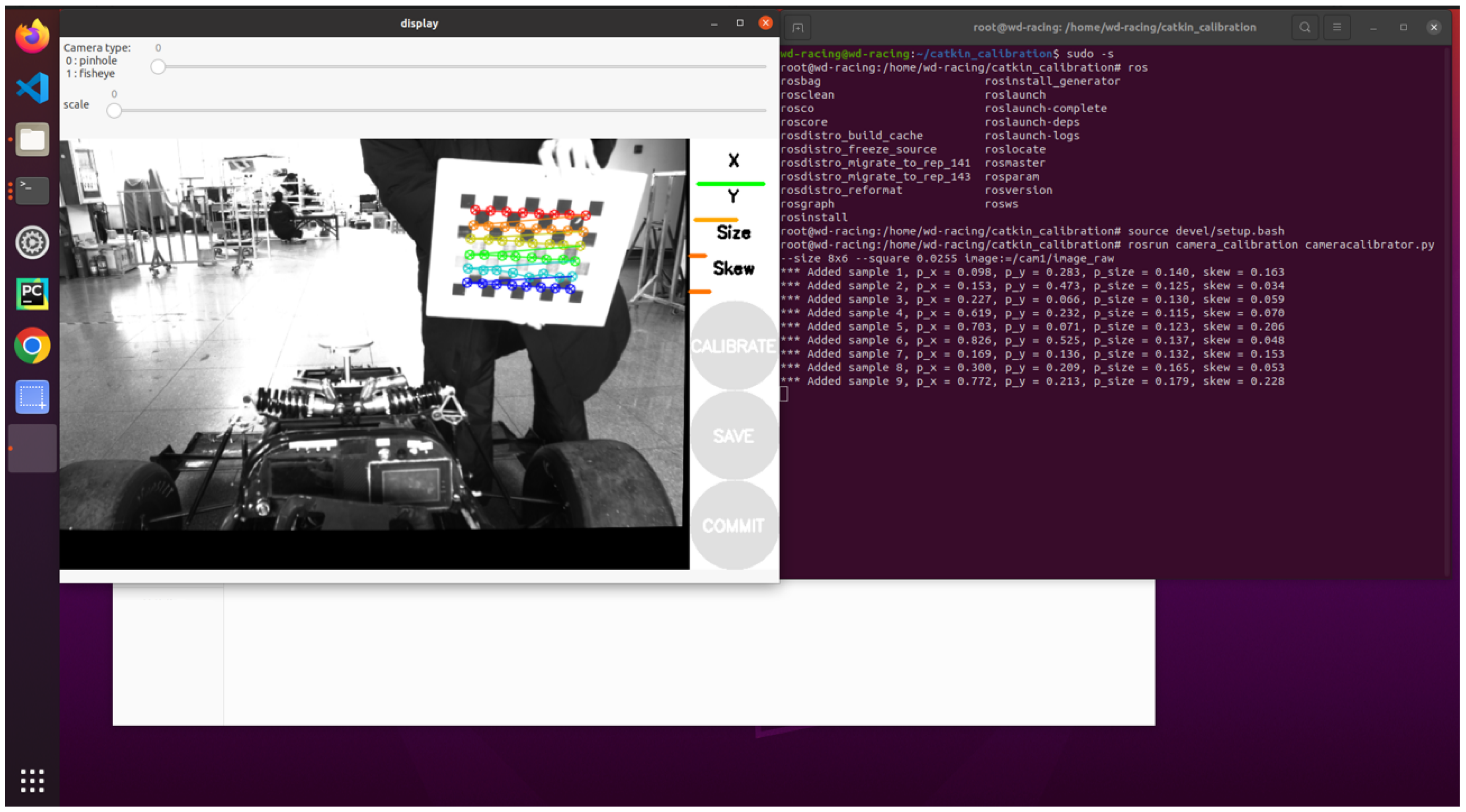
- Calibration process under ROS: In the ROS (Robot Operating System) environment, the camera calibration function package is utilized to perform the calibration of the monocular camera. After starting the function package, enter the calibration interface, as shown in Figure 5.
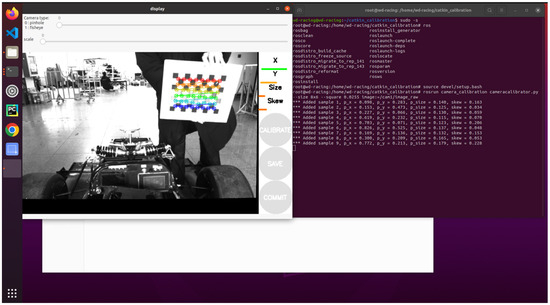 Figure 5. Camera calibration interface.
Figure 5. Camera calibration interface. - Move the calibration plate: Move the calibration plate slowly in front of the camera to ensure that each part of the calibration plate can be captured by the camera. During the moving process, the calibration board should cover the camera’s field of view from front to back, from left to right, and from top to bottom.
- Calibration progress monitoring: In the calibration interface, observe the progress bars of X, Y, Size, Skew, and other parameters on the right side of the program interface. When all these progress bars turn green, it means the calibration process has been completed.
- Save the calibration results: After the calibration is completed, click the SAVE button to save the calibration results, which are crucial for subsequent image processing and analysis.
- Configure the camera driver: Add the saved calibration results to the camera driver’s configuration file to ensure that the camera is able to apply the calibration parameters when capturing images.
- Start the camera driver: After the configuration is complete, start the camera driver to begin receiving real-time captured image information from the camera.
Through the above steps, the accurate calibration of the monocular camera can be completed under the ROS operating system, laying a solid foundation for subsequent image recognition processing tasks.
7.6. Analysis of Experimental Results
In order to ensure the rigor of the experiment and the credibility of the results, an open area was chosen as the site for the actual car test. Sufficient sunlight during the experiment provides ideal natural lighting conditions, which help simulate and reproduce various complex scenarios that might be encountered in the race. Regarding site arrangement, cones were placed strictly with the race requirements to ensure consistency between the test environment and the race scenario. This arrangement aims to maximize the simulation of the actual competition environment, thus making the experimental results closer to the actual application situation. The first test is the feasibility of adding each module, followed by the test under each scenario.
7.6.1. Replacement of the Loss Function Is Reasonable
Comparing the results presented in Figure 6 reveals that the use of MPDIoU has significantly reduced the leakage of detection when dealing with overlapping detection frames. This change indicates that the MPDIoU loss function is advantageous in simplifying the comparison of bounding box similarity and can more effectively adapt to the overlapping or non-overlapping situation of bounding boxes. Introducing MPDIoU can improve the model’s accuracy when detecting small objects like conical buckets.

Figure 6.
(a) and (c) are the detection results when using CIoU as the loss function, while (b) and (d) are the detection results after using MPDIoU as the loss function.
7.6.2. Rationalization of Dynamic Detection Head Addition
As shown in Figure 7, the left side shows the detection result without replacing the dynamic detector head, and the right side shows the result of replacing the dynamic detector head. Thus, it can be seen that the model using the dynamic detector head can effectively improve its detection in complex environments (e.g., bright light or dark places).

Figure 7.
(a) and (c) are the detection results using the detection head of the original YOLOv8 network, while (b) and (d) are the detection results using the dynamic detection head Dynamic Head.
7.6.3. Rationalization of the Addition of Tiny Detection Layer P2
As shown in Figure 8, the left side shows the detection result without replacing the tiny detection layer P2, and the right side shows the result of replacing the tiny detection layer P2. From this, it is easy to see that the detection model using the tiny detection layer is able to effectively recognize tiny cones and barrels at long distances, which makes subsequent path planning convenient.

Figure 8.
(a) and (c) are the results of detection using the original neck network, while (b) and (d) are the results of adding tiny detection layer P2 to the original neck network.
The above verifies the necessity of each module addition; the purpose of replacing the loss function is mainly to solve the problem of insufficient recognition accuracy of small targets, such as cones and buckets, when the target detection frames overlap. The purpose of adding the tiny detection layer P2 is to solve the problem of inefficient recognition of distant cones and buckets. The purpose of replacing the dynamic detection head is to cope with the problem of failing to recognize cones and buckets in complex environments (intense light or shaded areas), to enable it. The purpose of replacing the dynamic detection head is to cope with the problem of failing to recognize cones in complex environments (intense light or darkness) so that it can be better adapted to the task of recognizing cones under different lighting conditions. In order to cope with the complex competition environment, each improvement is based on considering the problems existing in the actual application scenarios, so each improvement measure is indispensable. The next is the result obtained by integrating all the improvement measures. The first is the result of detection under normal light. Figure 9 is the result of the original YOLOv8 algorithm detection, and Figure 10 is the result of the YOLOv8 algorithm detection improved by the innovative measures used in this study.

Figure 9.
Original YOLOv8 algorithm detection.

Figure 10.
Improved YOLOv8 algorithm detection.
Finally, for detection under high light, Figure 11 shows the results of the original YOLOv8 algorithm detection, and Figure 12 shows the results of the improved YOLOv8 algorithm detection using the innovative measures in this study.

Figure 11.
Original YOLOv8 algorithm detection.

Figure 12.
Improved YOLOv8 algorithm detection.
The experimental results show that the improved algorithm can reduce the leakage detection phenomenon in both normal light and more muscular light lines, which now fully demonstrates the algorithm’s feasibility. It not only meets the demand for high accuracy of cone-bucket detection in complex race course environments on a technical level but also fulfills the conditions for deployment on small devices with limited resources.
8. Conclusions
Based on the YOLOv8 algorithm, this paper investigates a new algorithm that is both lightweight and has high detection accuracy, and its conclusions include the following aspects:
- The P2 layer, which is specially designed for tiny target detection, is introduced to improve the ability to capture detailed information effectively, thus enhancing the overall detection accuracy. In terms of a lightweight design, the original P5 detection layer was streamlined to reduce the complexity and computational burden of the model.
- A multi-scale fusion Dynamic Head (Dynamic Head) is adopted, which enhances the model’s ability to perceive different scales, spaces, and tasks, and further improves the detection performance in complex scenes.
- A new loss function, MPDIoU, is introduced, which is optimized for the conical bucket overlapping problem and significantly reduces the occurrence of missed detection.
- Considering the number of model parameters, the LAMP pruning technique is applied to effectively streamline the model, removing the parts that contribute less to the model in order to achieve higher operational efficiency.
- After a series of experimental validations, the improved algorithm improves the precision, recall, and average precision (mAP) by 3%, 6.6%, and 4.7%, respectively, compared with the original YOLOv8 algorithm. In comparison, the amount of model parameters is reduced by 10%, and the FPS (Frames Per Second) index also meets real-time processing requirements. Compared with the original algorithm, the improved algorithm shows apparent advantages in reducing cone bucket leakage detection in the real-vehicle test. It meets the demand for high accuracy of cone-bucket detection in complex race track environments and also meets the conditions for deployment on small devices with limited resources.
Although the algorithm dramatically improves the detection accuracy, its FPS is still lower than that of the original YOLOv8 algorithm. Thus, it is hoped that being more lightweight means that it will be used in the future to improve the detection accuracy without reducing the FPS.
Author Contributions
Conceptualization, X.L. and G.L.; methodology, X.L. and Z.Z.; software, X.L. and G.L.; validation, X.L., G.L. and Z.Z.; formal analysis, X.L.; investigation, X.L.; resources, G.L. and X.L.; data curation, X.L. and Z.Z.; writing—original draft preparation, X.L.; writing—review and editing, X.L. and G.L.; visualization, X.L. and G.L.; supervision, G.L.; project administration, G.L.; funding acquisition, G.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China under the Joint Foundation Program (U22A2043), the Liaoning Provincial Natural Foundation Grant Program (2022-MS-376), and the scientific research project of Liaoning Provincial Department of Education (JYTZD2023081).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhai, S.; Shang, D.; Wang, S.; Dong, S. DF-SSD: An improved SSD object detection algorithm based on DenseNet and feature fusion. IEEE Access 2020, 8, 24344–24357. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Carranza-García, M.; Torres-Mateo, J.; Lara-Benítez, P.; García-Gutiérrez, J. On the performance of one-stage and two-stage object detectors in autonomous vehicles using camera data. Remote Sens. 2020, 13, 89. [Google Scholar] [CrossRef]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-size object detection algorithm based on camera sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Hu, M.; Li, Z.; Yu, J.; Wan, X.; Tan, H.; Lin, Z. Efficient-lightweight YOLO: Improving small object detection in YOLO for aerial images. Sensors 2023, 23, 6423. [Google Scholar] [CrossRef]
- Lai, H.; Chen, L.; Liu, W.; Yan, Z.; Ye, S. STC-YOLO: Small object detection network for traffic signs in complex environments. Sensors 2023, 23, 5307. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Huang, J.; Hei, G.; Wang, W. YOLO-IR-Free: An Improved Algorithm for Real-Time Detection of Vehicles in Infrared Images. Sensors 2023, 23, 8723. [Google Scholar] [CrossRef] [PubMed]
- Wu, T.; Dong, Y. YOLO-SE: Improved YOLOv8 for remote sensing object detection and recognition. Appl. Sci. 2023, 13, 12977. [Google Scholar] [CrossRef]
- Zhuo, J.; Li, G.; He, Y. Research on Cone Bucket Detection Algorithm Based on Improved YOLOv5s. World Electr. Veh. J. 2023, 14, 269. [Google Scholar] [CrossRef]
- Liu, Y.; Li, G.; Hao, L.; Yang, Q.; Zhang, D. Research on a Lightweight Panoramic Perception Algorithm for Electric Autonomous Mini-Buses. World Electr. Veh. J. 2023, 14, 179. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, S.; Zhan, R.; Wang, W.; Zhang, J. LMSD-YOLO: A lightweight YOLO algorithm for multi-scale SAR ship detection. Remote Sens. 2022, 14, 4801. [Google Scholar] [CrossRef]
- Shi, R.; Li, T.; Yamaguchi, Y. An attribution-based pruning method for real-time mango detection with YOLO network. Comput. Electron. Agric. 2020, 169, 105214. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Han, T.; Cao, T.; Zheng, Y.; Chen, L.; Wang, Y.; Fu, B. Improving the Detection and Positioning of Camouflaged Objects in YOLOv8. Electronics 2023, 12, 4213. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Siliang, M.; Yong, X. Mpdiou: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Lee, J.; Park, S.; Mo, S.; Ahn, S.; Shin, J. Layer-adaptive sparsity for the magnitude-based pruning. arXiv 2020, arXiv:2010.07611. [Google Scholar]
- Gong, H.; Feng, Y.; Chen, T.; Li, Z.; Li, Y. Fast and Accurate: The Perception System of a Formula Student Driverless Car. In Proceedings of the 2022 6th International Conference on Robotics, Control and Automation (ICRCA), Xiamen, China, 26–28 February 2022; pp. 45–49. [Google Scholar]
- Li, P.; Zheng, J.; Li, P.; Long, H.; Li, M.; Gao, L. Tomato maturity detection and counting model based on MHSA-YOLOv8. Sensors 2023, 23, 6701. [Google Scholar] [CrossRef] [PubMed]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).