

YOLO-ADual: A Lightweight Traffic Sign Detection Model for a Mobile Driving System

Abstract
:1. Introduction
- The key contributions of our research are summarized below:
- The YOLO5s-ADual model is introduced in this study. By utilizing DualConv and C3, we propose a more efficient C3Dual architecture to replace the CBL module in the backbone of the YOLOv5 object detection model. Additionally, this architecture incorporates ADown from YOLOv9 in place of the Conv module in both the head and backbone of YOLOv5s. As a result, the model becomes lightweight, enabling faster reasoning and reducing the need for hardware resources, thereby making it more suitable for mobile device deployment;
- In the actual scenario of TSD, since there are more small objects for traffic sign detection, the CBAM attention mechanism is adopted to improve the small object detection performance;
- The experimental outcomes on the TT100k dataset demonstrate that the proposed method halves the parameters of the original YOLOv5s model while enhancing the mAP by 5 points. Compared to several contemporary lightweight object detection methods, the model presented in this paper demonstrates superior accuracy and a more lightweight structure;
- The structure of the remaining sections is as follows: Section 2 provides an overview of recent research on two-stage object detection and YOLOv5s. Section 3 details the design of the C3Dual module, the structure of the ADown module, the CBAM attention mechanism, and the overall model structure. Section 4 describes the dataset, experimental setup, and the results obtained from the experiments. Finally, Section 5 offers a summary and the paper’s conclusions.
2. Related Work
2.1. Research on Two-Stage Approaches in Object Detection
2.2. Lightweight Traffic Sign Detection Network
2.3. YOLOv5s
3. Method
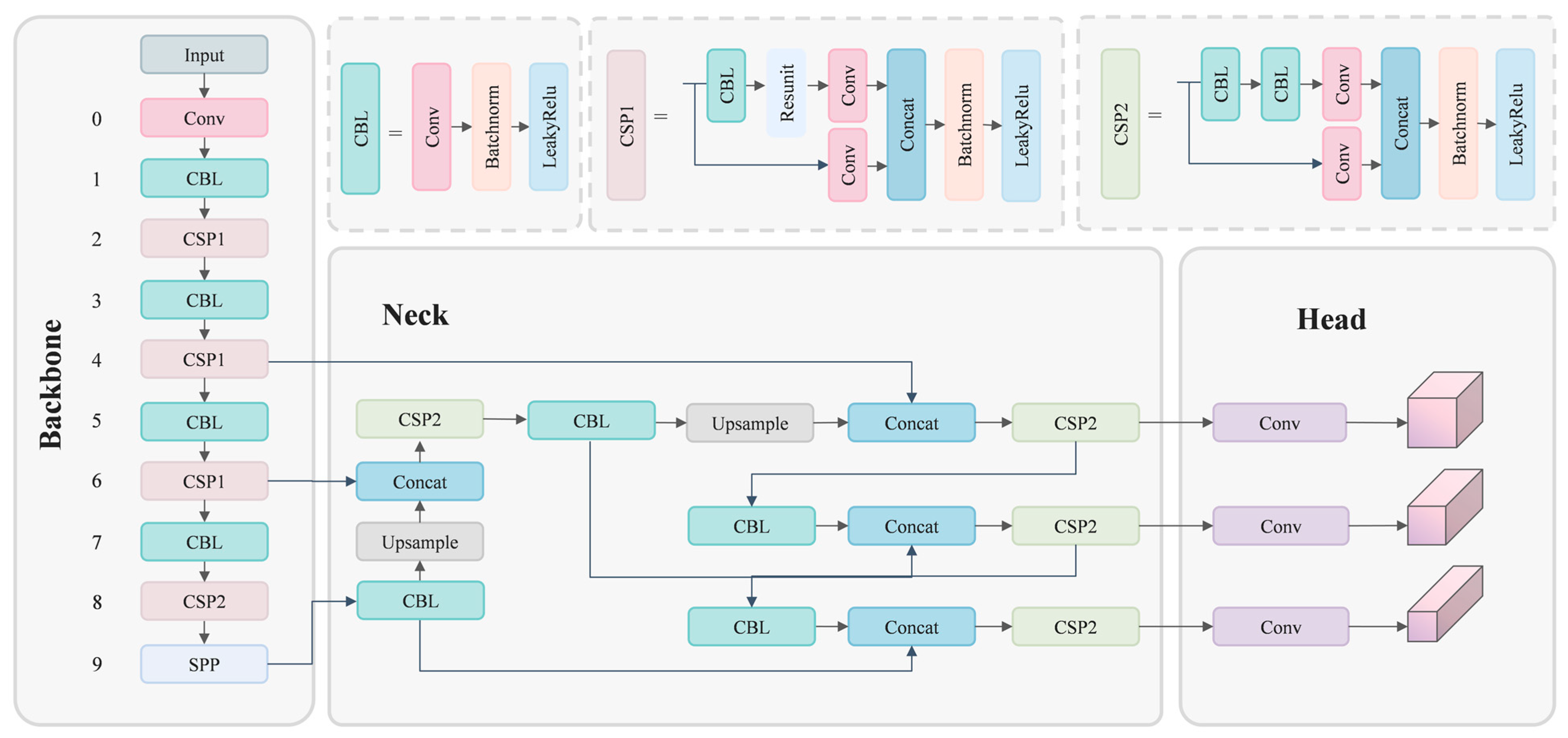
3.1. Overview of YOLO-ADual
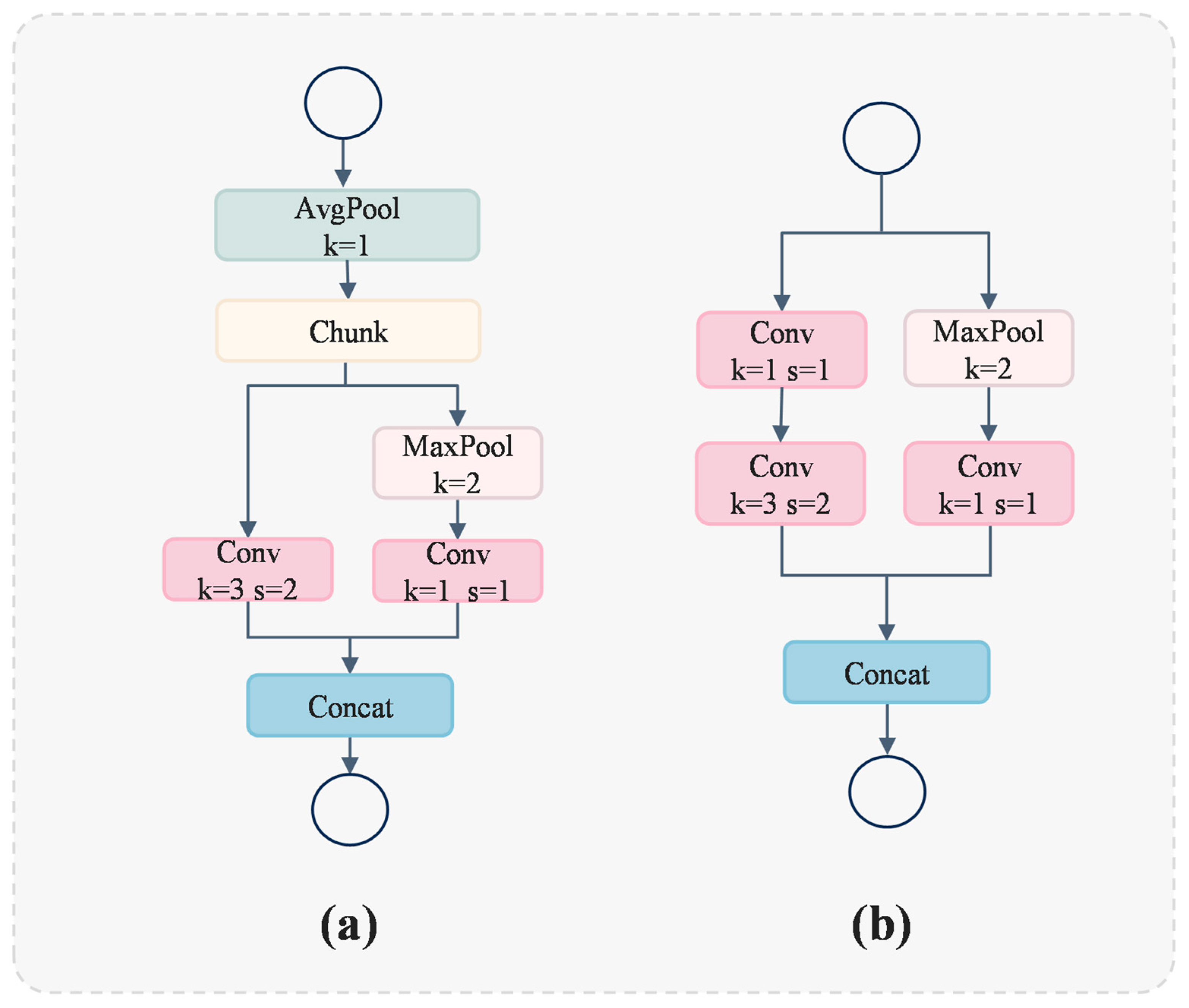
3.2. Adown
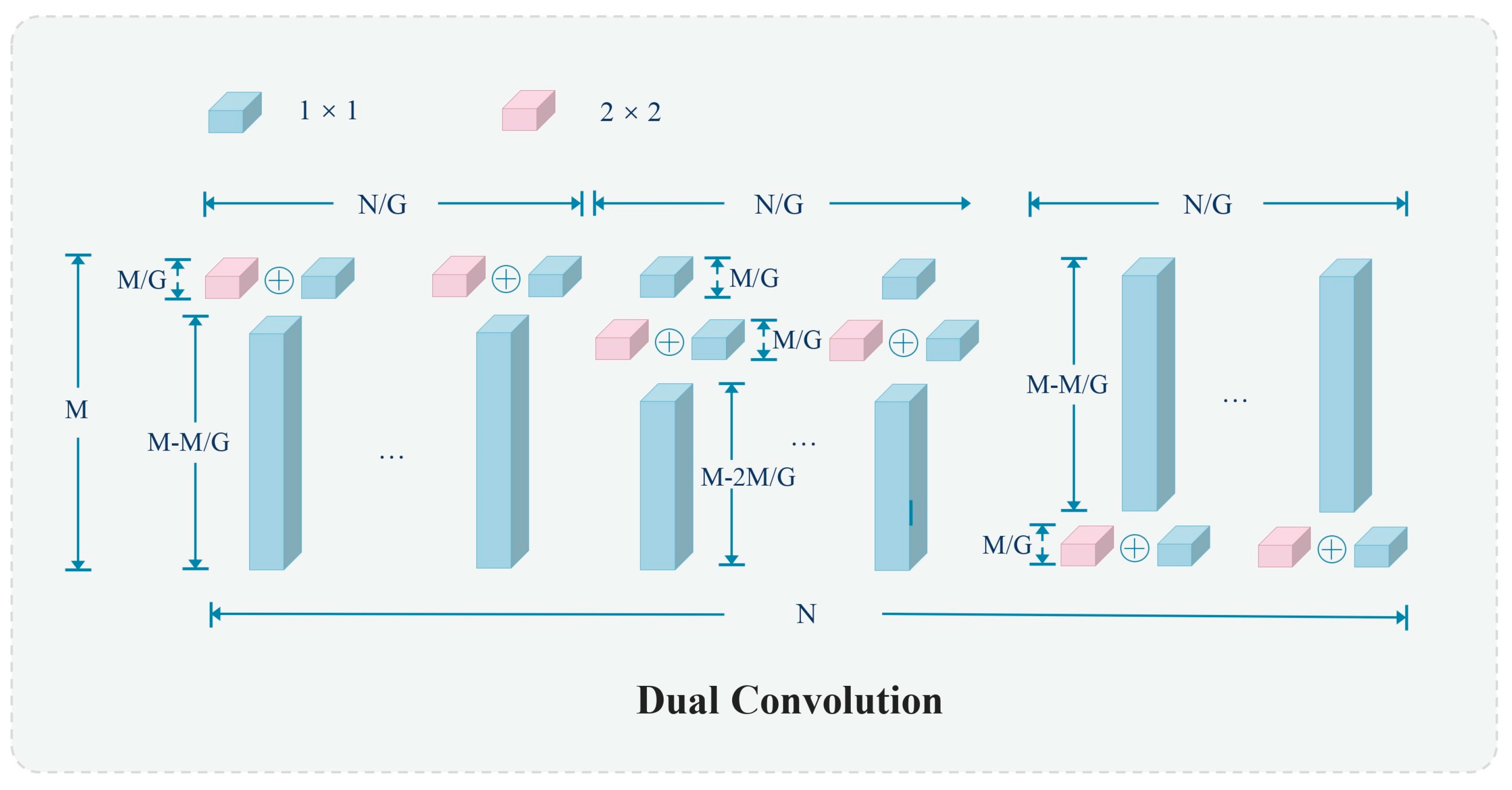
3.3. C3Dual
3.4. CBAM
3.4.1. Channel Attention Module
3.4.2. Spatial Attention Module
3.5. Algorithm Implementation
| Algorithm 1: YOLO-ADual training algorithm with transfer learning |
| Data: COCO Pretrained Weights, Specialized Datasets: TT100k Result: Fine-tuned YOLO-ADual Model Initialize YOLO-ADual neural network with COCO pre-trained weights; Initialize training parameters: batch size = 32, initial learning rate = 0.01, total epochs = 300; Initialize loss function: Loss; Initialize optimizer: Adam; Initialize evaluation metrics: Recall, Precision; for epoch ⟵ 1 to total_epochs do for batch ⟵ 1 to total_batches do // Load a batch of training data from TT100k image_batch, ground_truth_batch ⟵ LoadBatchFromDatasets(TT100k, batch_size); // Forward pass through the network predicted_boxes ⟵ YOLO-ADual(image_batch); // Calculate Loss loss ⟵ CalculateIoULoss(predicted_boxes, ground_truth_batch); // Backpropagation and weight update BackpropagateAndOptimize(loss); end // Adjust learning rate (e.g., learning rate decay) if epoch % learning_rate_decay_interval == 0 then AdjustLearningRate(optimizer, new_learning_rate); end // Evaluate the model on validation data recall, precision ⟵ EvaluateModel(YOLO-ADual, ValidationData); if recall > threshold_recall and precision > threshold_precision then // Save the model if recall and precision meet the criteria SaveModel(YOLO-ADual, ’trained_model_epoch_’ + epoch); end end |
4. Experimental Analysis
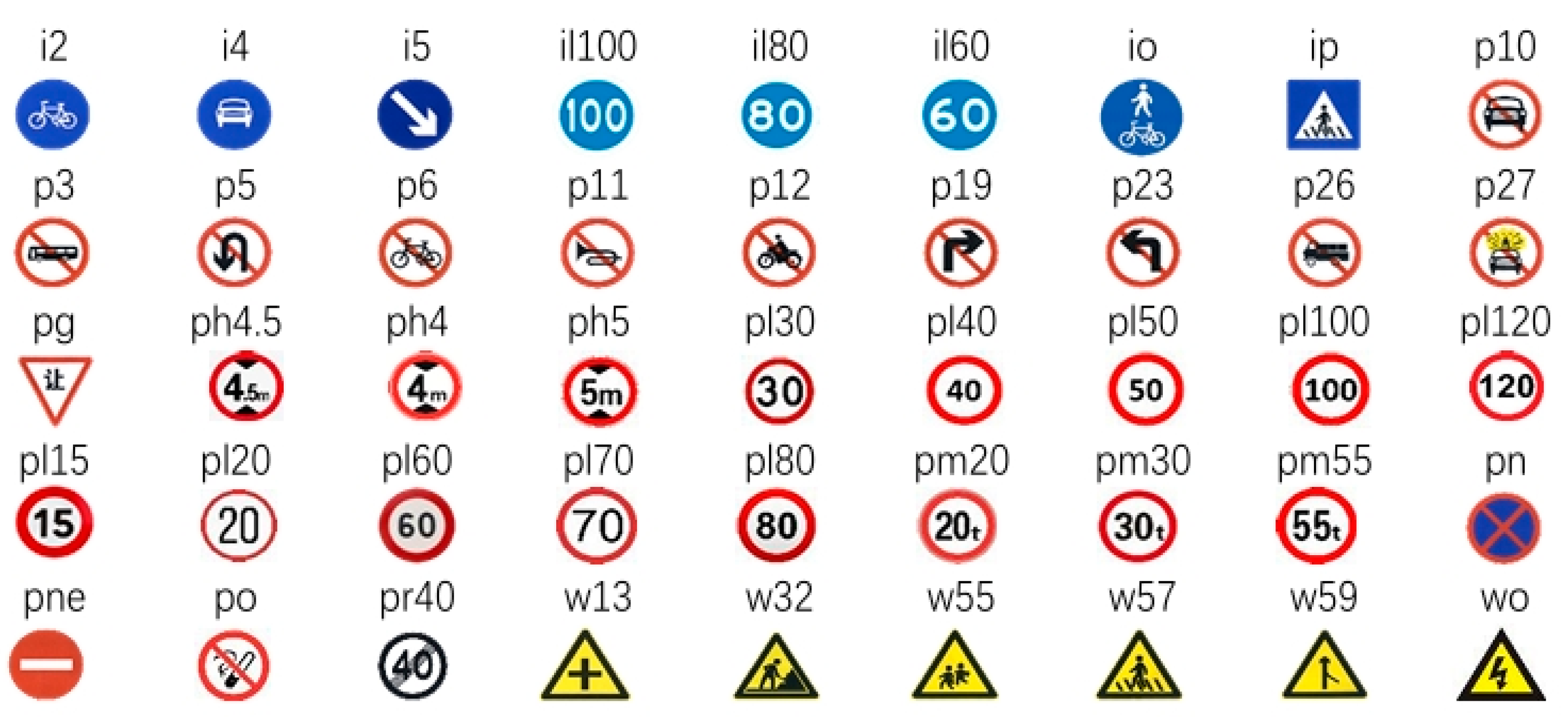
4.1. Datasets
4.2. Experimental Environment
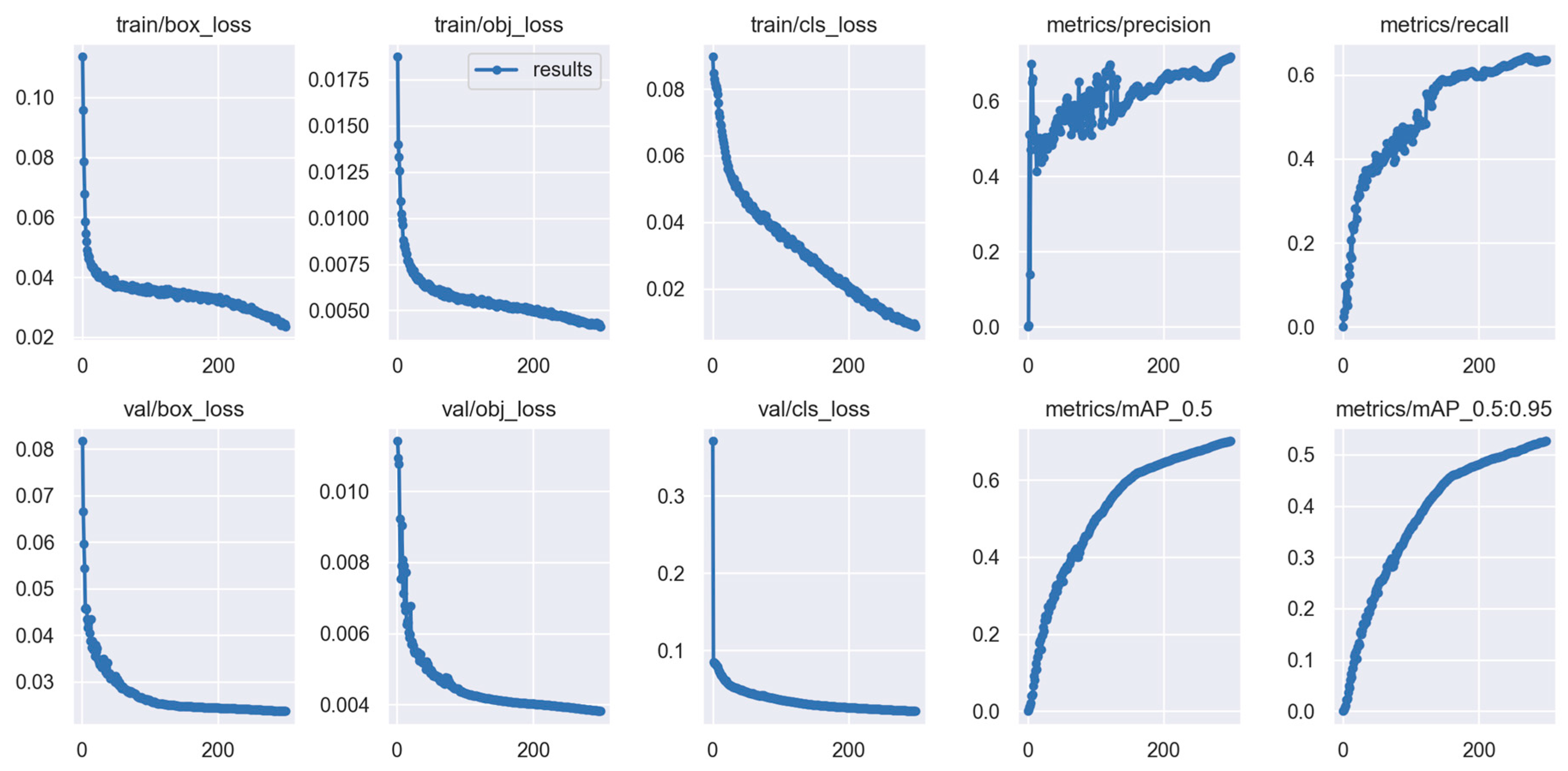
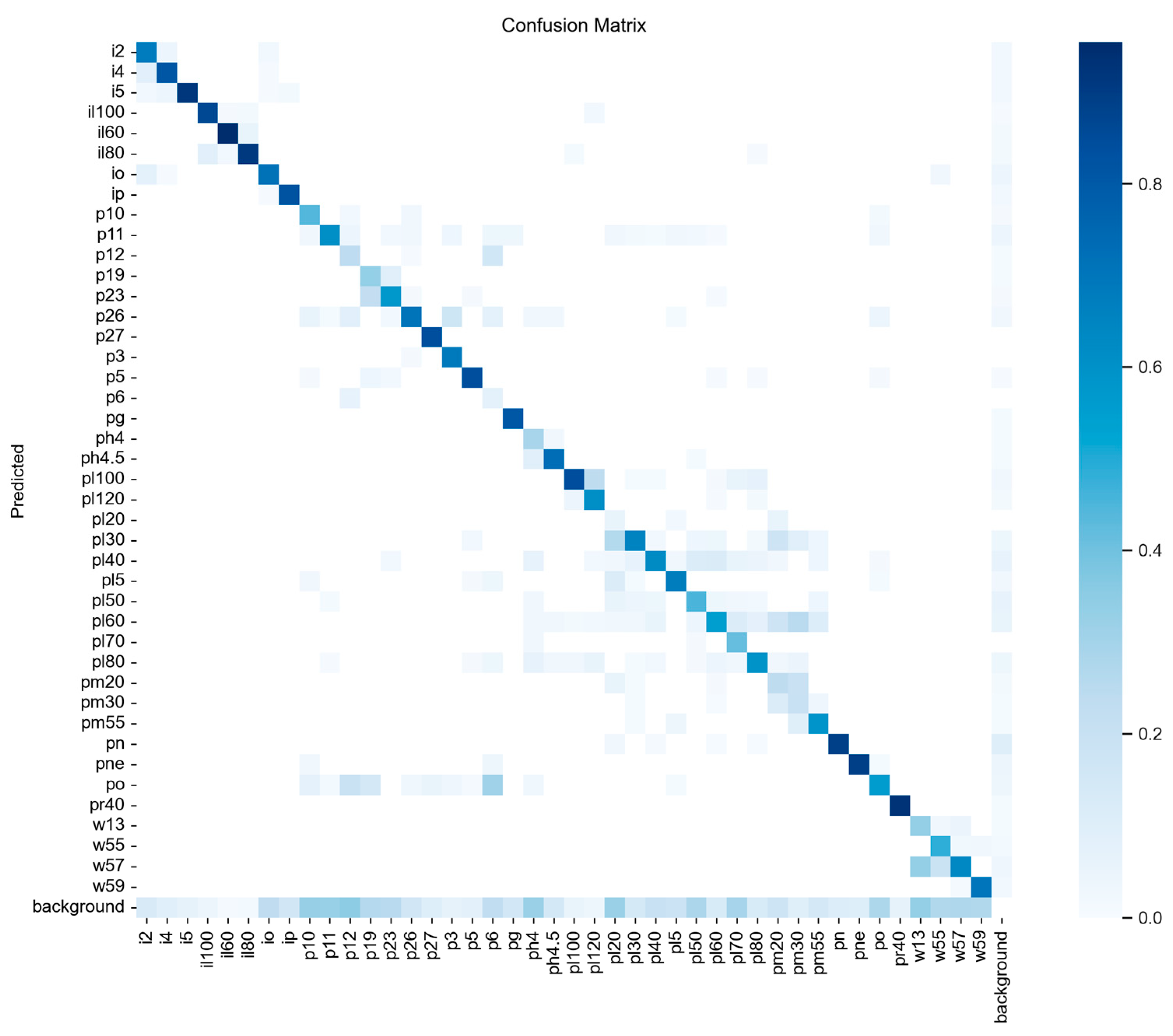
4.3. Result Analysis
4.4. Ablation Study
4.5. Visualization Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3354–3361. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:14091556. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Lopez-Montiel, M.; Orozco-Rosas, U.; Sánchez-Adame, M.; Picos, K.; Ross, O.H.M. Evaluation Method of Deep Learning-Based Embedded Systems for Traffic Sign Detection. IEEE Access 2021, 9, 101217–101238. [Google Scholar] [CrossRef]
- Zhou, L.; Deng, Z. LIDAR and Vision-Based Real-Time Traffic Sign Detection and Recognition Algorithm for Intelligent Vehicle. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 578–583. [Google Scholar]
- Rajbhandari, S.; Ruwase, O.; Rasley, J.; Smith, S.; He, Y. Zero-Infinity: Breaking the Gpu Memory Wall for Extreme Scale Deep Learning. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, St. Louis, MO, USA, 14–19 November 2021; pp. 1–14. [Google Scholar]
- Mittal, U.; Chawla, P.; Tiwari, R. EnsembleNet: A Hybrid Approach for Vehicle Detection and Estimation of Traffic Density Based on Faster R-CNN and YOLO Models. Neural Comput. Appl. 2023, 35, 4755–4774. [Google Scholar] [CrossRef]
- Ghahremannezhad, H.; Shi, H.; Liu, C. Object Detection in Traffic Videos: A Survey. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6780–6799. [Google Scholar] [CrossRef]
- Arora, N.; Kumar, Y.; Karkra, R.; Kumar, M. Automatic Vehicle Detection System in Different Environment Conditions Using Fast R-CNN. Multimed. Tools Appl. 2022, 81, 18715–18735. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:160207360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:170404861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Xia, X.; Xu, C.; Nan, B. Inception-v3 for Flower Classification. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 783–787. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NJ, USA, 2012; Volume 25. [Google Scholar]
- Koonce, B. MobileNetV3. In Convolutional Neural Networks with Swift for Tensorflow; Apress: Berkeley, CA, USA, 2021; pp. 125–144. ISBN 978-1-4842-6167-5. [Google Scholar]
- Liu, Y.; Lu, B.; Peng, J.; Zhang, Z. Research on the Use of YOLOv5 Object Detection Algorithm in Mask Wearing Recognition. World Sci. Res. J. 2020, 6, 276–284. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, R.; Meng, Z.; Hong, R.; Liu, G. On Fusing the Latent Deep CNN Feature for Image Classification. World Wide Web 2019, 22, 423–436. [Google Scholar] [CrossRef]
- Purkait, P.; Zhao, C.; Zach, C. SPP-Net: Deep Absolute Pose Regression with Synthetic Views. arXiv 2017, arXiv:171203452. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-Based Fully Convolutional Networks. In Proceedings of the Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NJ, USA, 2016; Volume 29. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Zhang, S.; Che, S.; Liu, Z.; Zhang, X. A Real-Time and Lightweight Traffic Sign Detection Method Based on Ghost-YOLO. Multimed. Tools Appl. 2023, 82, 26063–26087. [Google Scholar] [CrossRef]
- Liu, P.; Xie, Z.; Li, T. UCN-YOLOv5: Traffic Sign Object Detection Algorithm Based on Deep Learning. IEEE Access 2023, 11, 110039–110050. [Google Scholar] [CrossRef]
- Li, Z.; Chen, H.; Biggio, B.; He, Y.; Cai, H.; Roli, F.; Xie, L. Toward Effective Traffic Sign Detection via Two-Stage Fusion Neural Networks. IEEE Trans. Intell. Transp. Syst. 2024, 1–12, early access. [Google Scholar] [CrossRef]
- Ahmad, T.; Ma, Y.; Yahya, M.; Ahmad, B.; Nazir, S.; Haq, A. ul Object Detection through Modified YOLO Neural Network. Sci. Program. 2020, 2020, 8403262. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:180402767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:200410934. [Google Scholar]
- Sohan, M.; Sai Ram, T.; Reddy, R.; Venkata, C. A Review on Yolov8 and Its Advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics; Springer: Singapore, 2024; pp. 529–545. [Google Scholar]
- Li, S.; Wang, S.; Wang, P. A Small Object Detection Algorithm for Traffic Signs Based on Improved YOLOv7. Sensors 2023, 23, 7145. [Google Scholar] [CrossRef]
- Selcuk, B.; Serif, T. A Comparison of YOLOv5 and YOLOv8 in the Context of Mobile UI Detection. In Mobile Web and Intelligent Information Systems; Younas, M., Awan, I., Grønli, T.-M., Eds.; Lecture Notes in Computer Science; Springer Nature Switzerland: Cham, Switzerland, 2023; Volume 13977, pp. 161–174. ISBN 978-3-031-39763-9. [Google Scholar]
- Bian, H.; Liu, Y.; Shi, L.; Lin, Z.; Huang, M.; Zhang, J.; Weng, G.; Zhang, C.; Gao, M. Detection Method of Helmet Wearing Based on UAV Images and Yolov7. In Proceedings of the 2023 IEEE 6th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 24 February 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1633–1640. [Google Scholar]
- Yusof, N.I.M.; Sophian, A.; Zaki, H.F.M.; Bawono, A.A.; Ashraf, A. Assessing the Performance of YOLOv5, YOLOv6, and YOLOv7 in Road Defect Detection and Classification: A Comparative Study. Bull. Electr. Eng. Inform. 2024, 13, 350–360. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:240213616. [Google Scholar]
- Zheng, Y.; Cui, Y.; Gao, X. An Infrared Dim-Small Target Detection Method Based on Improved YOLOv7. In Proceedings of the 2023 Asia Conference on Computer Vision, Image Processing and Pattern Recognition, Phuket, Thailand, 28 April 2023; ACM: New York, NY, USA; pp. 1–5. [Google Scholar]
- Zhong, J.; Chen, J.; Mian, A. DualConv: Dual Convolutional Kernels for Lightweight Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9528–9535. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, Y.; Gong, Z.; Zhou, Y.; He, Y.; Huang, R. Production Evaluation of Citrus Fruits Based on the YOLOv5 Compressed by Knowledge Distillation. In Proceedings of the 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1938–1943. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Gower, R.M.; Loizou, N.; Qian, X.; Sailanbayev, A.; Shulgin, E.; Richtárik, P. SGD: General Analysis and Improved Rates. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR, 2019; Volume 97, pp. 5200–5209. [Google Scholar]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-Sign Detection and Classification in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2110–2118. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and Efficient Object Detection. Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Specific Information |
|---|---|
| Epoch | 300 |
| Image size | 640 |
| Batch size | 32 |
| Number of images | 9457 |
| Parameters | 3,817,609 |
| Layers | 246 |
| Configuration | Name | Specific Information |
|---|---|---|
| Hardware Environment | CPU | Intel(R) core(TM)i5-13490F |
| GPU | NVIDIA GeForce RTX4070Ti | |
| VRAM | 12 GB | |
| Memory | 16 GB | |
| Software Environment | Operating System | Windows 11 |
| Python Version | 3.9.12 | |
| PyTorch Version | 2.0.0 | |
| CUDA Version | 11.8 |
| Method | Precision | Recall | [email protected] | Params | GFLOPs |
|---|---|---|---|---|---|
| Faster R-CNN [43] | 47.91 | 53.79 | 53.1 | - | - |
| Zhang et al. [24] | 56.10 | 52.10 | 55.5 | 6,655,232 | 8.6 |
| SSD [44] | 51.45 | 53.76 | 53.26 | 641,473 | 3.1 |
| EfficientDet [45] | 68.80 | 46.40 | 51.30 | 5,524,683 | 9.4 |
| YOLOv7-tiny [31] | 61.70 | 57.20 | 59.9 | 6,125,934 | 13.5 |
| YOLOX [46] | 64.47 | 58.27 | 65.4 | 5,044,797 | 15.30 |
| YOLOv5n | 67.90 | 45.10 | 48.8 | 1,820,743 | 4.4 |
| YOLOv5s | 69.34 | 63.23 | 67.6 | 7,365,671 | 17.3 |
| YOLO-ADual | 71.80 | 63.50 | 70.1 | 3,817,609 | 11.2 |
| Method | Precision Improvement | Recall Improvement | [email protected] Improvement | Params Reduction | GFLOPs Reduction |
|---|---|---|---|---|---|
| Faster R-CNN [43] | 49.88% | 18.05% | 32.0% | ||
| Zhang et al. [24] | 28.08% | 21.92% | 26.12% | 42.65% | |
| SSD [44] | 39.50% | 17.87% | 31.59% | ||
| EfficientDet [45] | 4.36% | 36.68% | 36.61% | 30.91% | |
| YOLOv7-tiny [31] | 16.30% | 11.03% | 17.07% | 37.68% | 17.03% |
| YOLOX [46] | 11.37% | 9.01% | 7.25% | 24.59% | 26.80% |
| YOLOv5n | 5.73% | 40.77% | 43.65% | ||
| YOLOv5s | 3.55% | 0.43% | 3.7% | 48.17% | 35.26% |
| Method | CBAM | ADown | C3Dual | [email protected] | Params | GFLOPs |
|---|---|---|---|---|---|---|
| YOLOv5s | 67.6 | 7,365,671 | 17.3 | |||
| YOLOv5s | √ | 77.47 | 7,156,265 | 16.2 | ||
| YOLOv5s | √ | 72.2 | 5,468,903 | 12.9 | ||
| YOLOv5s | √ | 77.1 | 5,828,903 | 13.0 | ||
| YOLOv5s | √ | √ | 67.87 | 5,501,769 | 12.9 | |
| YOLOv5s | √ | √ | 69.6 | 4,163,719 | 9.5 | |
| YOLOv5s | √ | √ | √ | 70.1 | 3,817,609 | 11.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, S.; Chen, C.; Li, Z.; Zhou, M.; Wei, R. YOLO-ADual: A Lightweight Traffic Sign Detection Model for a Mobile Driving System. World Electr. Veh. J. 2024, 15, 323. https://doi.org/10.3390/wevj15070323
Fang S, Chen C, Li Z, Zhou M, Wei R. YOLO-ADual: A Lightweight Traffic Sign Detection Model for a Mobile Driving System. World Electric Vehicle Journal. 2024; 15(7):323. https://doi.org/10.3390/wevj15070323
Chicago/Turabian StyleFang, Simin, Chengming Chen, Zhijian Li, Meng Zhou, and Renjie Wei. 2024. "YOLO-ADual: A Lightweight Traffic Sign Detection Model for a Mobile Driving System" World Electric Vehicle Journal 15, no. 7: 323. https://doi.org/10.3390/wevj15070323