
Dynamic Tracking Method Based on Improved DeepSORT for Electric Vehicle

Abstract
:1. Introduction
2. Current Research
2.1. Traditional Target Tracking Algorithm
2.2. Target Tracking Algorithm Based on Deep Learning
2.3. Improved Target Tracking Algorithm Based on Deep Learning
2.4. Shortcomings of Existing Methods
2.5. Novelty and Contribution
3. Overview of DeepSORT Algorithm
3.1. Kalman Filtering Algorithm
3.2. Data Association and Cascade Matching
3.3. Feature Extraction Network
4. Improved DeepSORT Algorithm
4.1. Frontend Detector Optimization
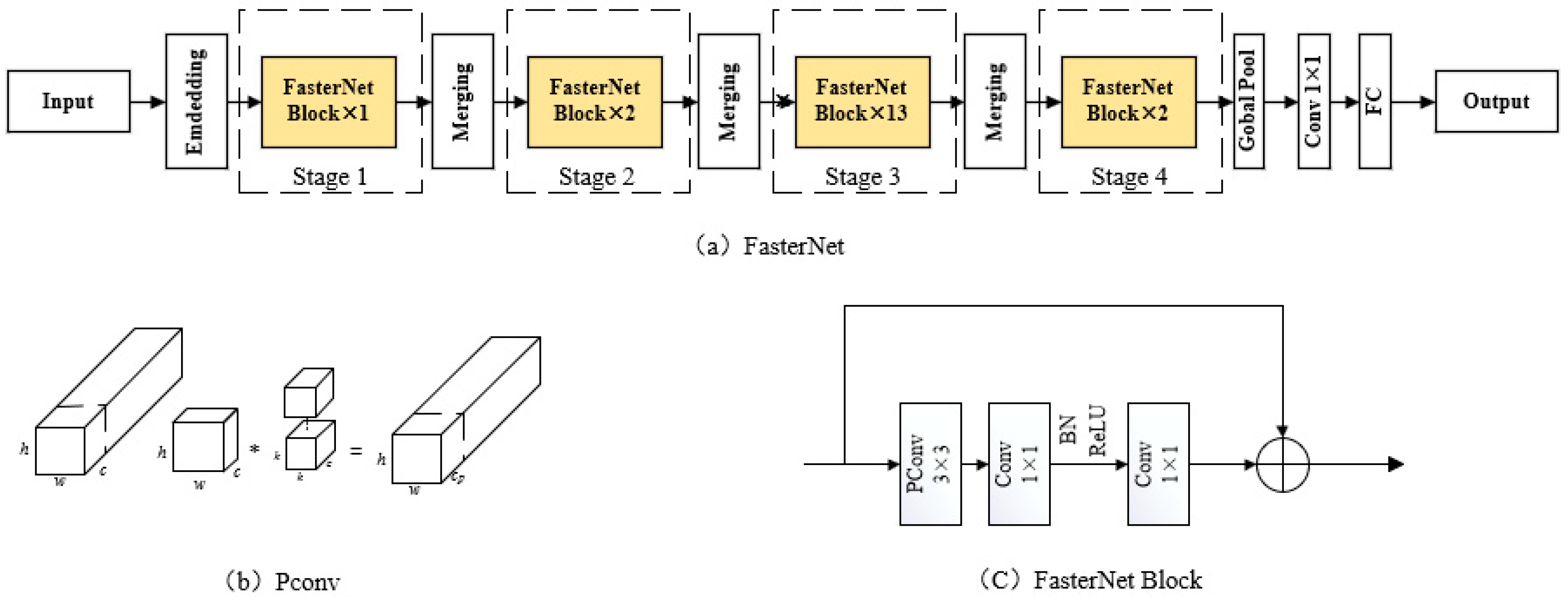
4.2. Target Feature Extraction Optimization
4.3. Kalman Filter Improvement
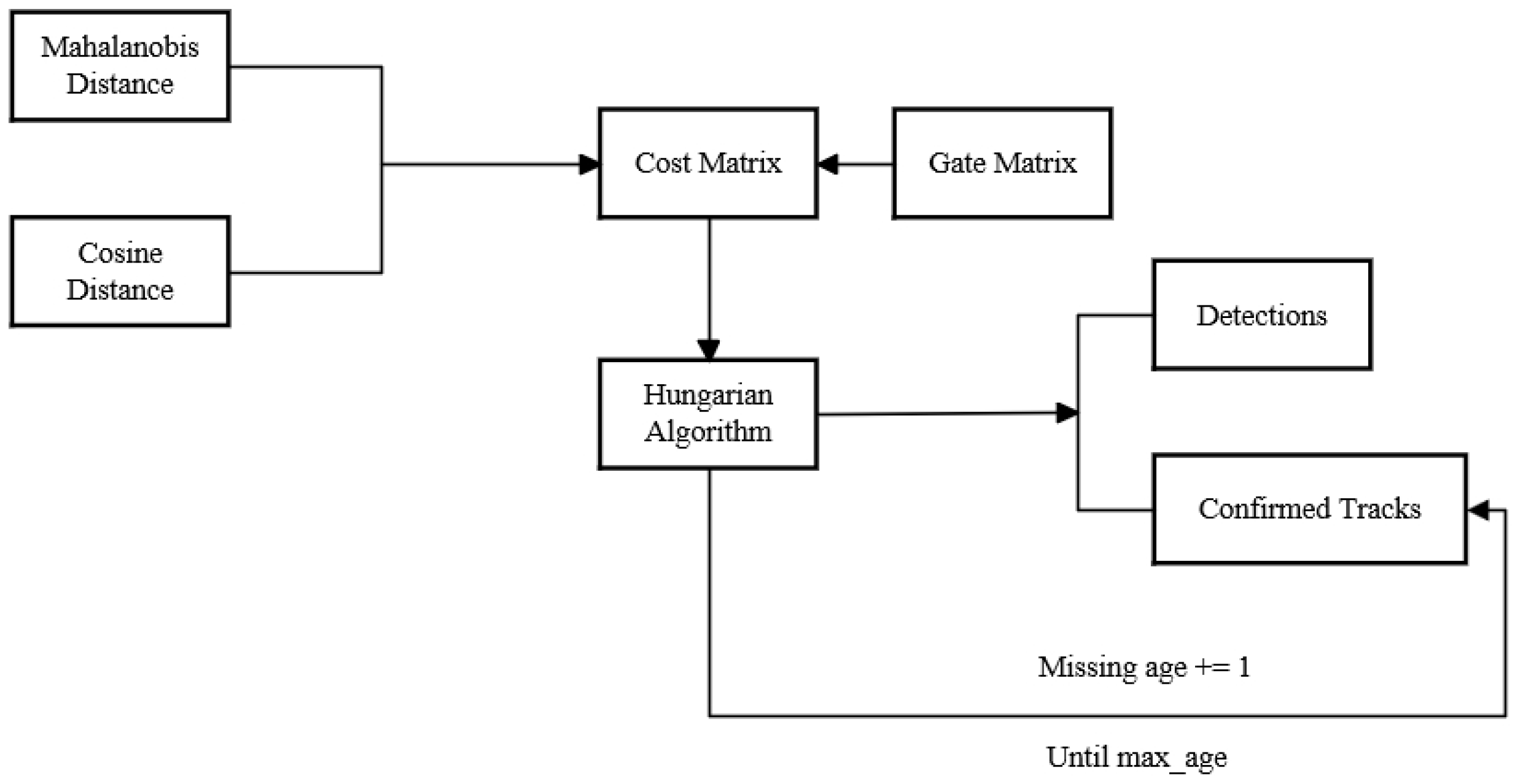
4.4. Global Linear Matching
5. Experiment Results and Analysis
5.1. Materials and Methods of Work
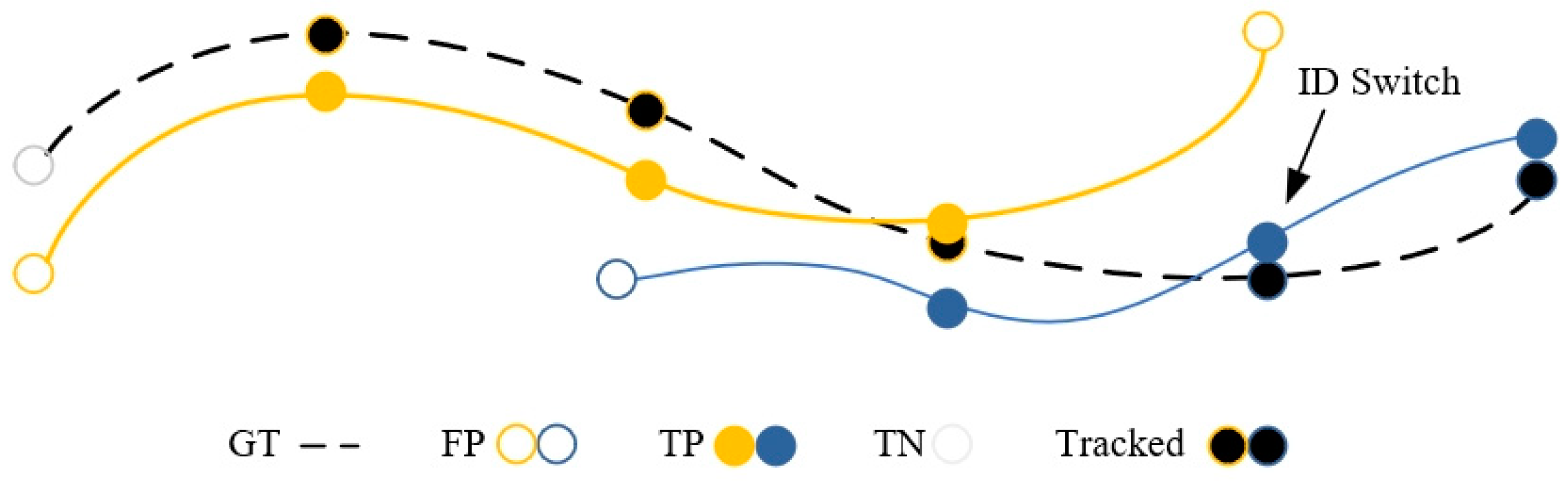
5.2. Evaluation Metrics
5.3. Training Results of Feature Extraction Network
5.4. Analysis of Evaluation Metric Results
5.5. Analysis of Visualization Results
5.6. Comparison with Existing Achievements
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Patil, L.N.; Khairnar, H.P. Investigation of Perceived Risk Encountered by Electric Vehicle Drivers in Distinct Contexts. Appl. Eng. Lett. 2021, 6, 69–79. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Nummiaro, K.; Koller-Meier, E.; Van Gool, L. An adaptive color-based particle filter. Image Vis. Comput. 2003, 21, 99–110. [Google Scholar] [CrossRef]
- Stenger, B.; Thayananthan, A.; Torr, P.H.; Cipolla, R. Model-based hand tracking using a hierarchical Bayesian filter. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1372–1384. [Google Scholar] [CrossRef] [PubMed]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef]
- Ma, C.; Huang, J.-B.; Yang, X.; Yang, M.-H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Danelljan, M.; Robinson, A.; Shahbaz Khan, F.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 472–488. [Google Scholar]
- Zolfaghari, M.; Singh, K.; Brox, T. Eco: Efficient convolutional network for online video understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 695–712. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 474–490. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. Fairmot: On the fairness of detection and re-identification in multiple object tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, P.; Jiang, Y.; Yu, D.; Weng, F.; Yuan, Z.; Luo, P.; Liu, W.; Wang, X. Bytetrack: Multi-object tracking by associating every detection box. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 1–21. [Google Scholar]
- Cho, K.; Cho, D. Autonomous driving assistance with dynamic objects using traffic surveillance cameras. Appl. Sci. 2022, 12, 6247. [Google Scholar] [CrossRef]
- Patel, A.S.; Vyas, R.; Vyas, O.P.; Ojha, M.; Tiwari, V. Motion-compensated online object tracking for activity detection and crowd behavior analysis. Vis. Comput. 2023, 39, 2127–2147. [Google Scholar] [CrossRef]
- Ge, Y.; Lin, S.; Zhang, Y.; Li, Z.; Cheng, H.; Dong, J.; Shao, S.; Zhang, J.; Qi, X.; Wu, Z. Tracking and counting of tomato at different growth periods using an improving YOLO-Deepsort network for inspection robot. Machines 2022, 10, 489. [Google Scholar] [CrossRef]
- Perera, I.; Senavirathna, S.; Jayarathne, A.; Egodawela, S.; Godaliyadda, R.; Ekanayake, P.; Wijayakulasooriya, J.; Herath, V.; Sathyaprasad, S. Vehicle tracking based on an improved DeepSORT algorithm and the YOLOv4 framework. In Proceedings of the 2021 10th International Conference on Information and Automation for Sustainability (ICIAfS), Negambo, Sri Lanka, 11–13 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 305–309. [Google Scholar]
- Pei, Y.C. Research and Application of Pedestrian Multitarget Tracking Algorithm Based on DeepSORT. Master’s Thesis, Qilu University of Technology, Jinan, China, 2022. [Google Scholar]
- Jin, L.S.; Hua, Q.; Guo, B.C.; Xie, X.Y.; Yan, F.G.; Wu, B.T. Multi-target tracking of vehicles based on optimized DeepSort. J. Zhejiang Univ. Eng. Sci. 2022, 55, 1056–1064. [Google Scholar]
- Song, Y.; Zhang, P.; Huang, W.; Zha, Y.; You, T.; Zhang, Y. Multiple object tracking based on multi-task learning with strip attention. IET Image Process. 2021, 15, 3661–3673. [Google Scholar] [CrossRef]
- Kesa, O.; Styles, O.; Sanchez, V. Multiple object tracking and forecasting: Jointly predicting current and future object locations. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 4–8 January 2022; IEEE: Snowmass, CO, USA, 2022; pp. 560–569. [Google Scholar]
- Chen, Y.; Chen, Z.; Zhang, Z.; Bian, S. AdapTrack: An adaptive FairMOT tracking method applicable to marine ship targets. AI Commun. 2023, 36, 127–145. [Google Scholar] [CrossRef]
- He, J.; Zhong, X.; Yuan, J.; Tan, M.; Zhao, S.; Zhong, L. Joint re-detection and re-identification for multi-object tracking. In Proceedings of the International Conference on Multimedia Modeling, Prague, Czech Republic, 5–8 January 2022; Springer International Publishing: Cham, Switzerland, 2022; pp. 364–376. [Google Scholar]
- Zou, Z.; Huang, J.; Luo, P. Compensation tracker: Reprocessing lost object for multi-object tracking. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 4–8 January 2022; IEEE: Snowmass, CO, USA, 2022; pp. 307–317. [Google Scholar]
- Peng, J.; Wang, T.; Lin, W.; Wang, J.; See, J.; Wen, S.; Ding, E. TPM: Multiple object tracking with tracklet-plane matching. Pattern Recognit. 2020, 107, 107480. [Google Scholar] [CrossRef]
- Liang, T.; Lan, L.; Zhang, X.; Luo, Z. A generic MOT boosting framework by combining cues from SOT, tracklet and re-identification. Knowl. Inf. Syst. 2021, 63, 2109–2127. [Google Scholar] [CrossRef]
- Chen, X.Y. Research on Behavior Recognition Algorithm Based on Deep Learning. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2020. [Google Scholar]
- Chen, Z.Q.; Zhang, Y.L. An improved Deep Sort target tracking algorithm based on YOLOv4. J. Guilin Univ. Electron. Technol. 2021, 41, 140–145. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Zhang, X.H.; Yan, J.X.; Zhang, C. Abnormal behavior recognition of coal blocks based on improved YOLOv5s + DeepSORT. Ind. Mine Autom. 2022, 48, 77–86, 117. [Google Scholar]
- Du, Y.; Zhao, Z.; Song, Y.; Zhao, Y.; Su, F.; Gong, T.; Meng, H. Strongsort: Make deepsort great again. IEEE Trans. Multimed. 2023, 25, 8725–8737. [Google Scholar] [CrossRef]
- Martyushev, N.V.; Malozyomov, B.V.; Kukartsev, V.V.; Gozbenko, V.E.; Konyukhov, V.Y.; Mikhalev, A.S.; Kukartsev, V.A.; Tynchenko, Y.A. Determination of the Reliability of Urban Electric Transport Running Autonomously through Diagnostic Parameters. World Electr. Veh. J. 2023, 14, 334. [Google Scholar] [CrossRef]
- Gu, Z.C.; Zhu, K.; You, S.T. YOLO-SSFS: A method combining SPD-Conv/STDL/IM-FPN/SIoU for outdoor small target vehicle detection. Electronics 2023, 12, 3744. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H. Run, Don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; IEEE: Vancouver, BC, Canada, 2023; pp. 12021–12031. [Google Scholar]
- He, W.K.; Peng, Y.H.; Huang, W.; Yao, Y.J.; Chen, Z.H. Research on Dynamic Vehicle Multi-object Tracking Method Based on DeepSort. Automob. Technol. 2023, 11, 27–33. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 213–226. [Google Scholar]
- Xu, Y.; Osep, A.; Ban, Y.; Horaud, R.; Leal-Taixé, L.; Alameda-Pineda, X. How to train your deep multi-object tracker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6787–6796. [Google Scholar]
- He, S.L.; Zhang, J.J.; Zhang, L.J.; Mo, D.Y. An Improved Vehicle Tracking Algorithm Based on Transformer-Enhanced YOLOv5+DeepSORT. Automot. Technol. 2024, 7, 9–16. [Google Scholar]
- Cao, J.; Weng, X.; Khirodkar, R.; Pang, J.; Kitani, K. Observation-centric sort: Rethinking sort for robust multi-object tracking. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 9686–9696. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Kernel Size/Step | Output Size |
|---|---|---|
| Conv1 | 3 × 3/1 | 32 × 128 × 64 |
| Conv2 | 3 × 3/1 | 32 × 128 × 64 |
| MaxPool | 3 × 3/2 | 32 × 64 × 32 |
| Residual 1 | 3 × 3/1 | 32 × 64 × 32 |
| Residual 2 | 3 × 3/1 | 32 × 64 × 32 |
| Residual 3 | 3 × 3/2 | 64 × 32 × 16 |
| Residual 4 | 3 × 3/1 | 64 × 32 × 16 |
| Residual 5 | 3 × 3/2 | 128 × 16 × 8 |
| Residual 6 | 3 × 3/1 | 128 × 16 × 8 |
| Dense 10 | 128 | |
| BN | 128 |
| Combination Module | Type | Convolution Kernel | Convolution Stride | Output |
|---|---|---|---|---|
| Embedding | Conv1 | 4 × 4 | 4 | 128 × 16 × 32 |
| Stage1 | PConv1 | 3 × 3 | 1 | 128 × 16 × 32 |
| Conv2 | 1 × 1 | 1 | 256 × 16 × 32 | |
| Conv3 | 1 × 1 | 1 | 128 × 16 × 32 | |
| Merging 1 | Conv4 | 2 × 2 | 2 | 256 × 8 × 16 |
| Stage 2 | PConv2 | 3 × 3 | 1 | 256 × 8 × 16 |
| Conv5 | 1 × 1 | 1 | 512 × 8 × 16 | |
| Conv6 | 1 × 1 | 1 | 256 × 8 × 16 | |
| Merging 2 | Conv7 | 2 × 2 | 2 | 512 × 8 × 16 |
| Stage 3 | PConv3 | 3 × 3 | 1 | 512 × 4 × 8 |
| Conv9 | 1 × 1 | 1 | 512 × 4 × 8 | |
| Conv10 | 1 × 1 | 1 | 512 × 4 × 8 | |
| Merging 3 | Conv11 | 2 × 2 | 2 | 1024 × 2 × 4 |
| Stage 4 | PConv4 | 3 × 3 | 1 | 1024 × 2 × 4 |
| Conv13 | 1 × 1 | 1 | 1024 × 2 × 4 | |
| Conv14 | 1 × 1 | 2 | 1024 × 2 × 4 | |
| Classifier | GAP | 4 × 2 | 1 | 1024 × 1 × 1 |
| Conv | 1 × 1 | 1 | 1024 × 1 × 1 | |
| FC | 1024 |
| Video ID | Number of Frames | Number of Tracked Vehicles | Data Annotation |
|---|---|---|---|
| 1 | 145 | 120 | 8547 |
| 2 | 265 | 52 | 3061 |
| 3 | 420 | 125 | 16,111 |
| Name | Model Specifications | |
|---|---|---|
| Hardware Information | CPU | AMD Ryzen 7 5800H with Radeon Graphics |
| GPU | NVIDIA GeForceRTX3060 laptop GPU 6 GB | |
| Software Information | OS | Windows 11 |
| CUDA | 11.3 | |
| cuDNN | 8.2.1 | |
| Pytorch | 1.11.0 | |
| OpenCV | 4.5.0 |
| Re-Identification Network Names | Accuracy/% | Time |
|---|---|---|
| 6-Layer Residual Network | 90.38 | 25.72 |
| FasterNet | 94.71 | 27.77 |
| Algorithm Improvement Process | MOTA/% | MOTP/% | ID Sw/Time |
|---|---|---|---|
| DeepSORT | 58.71 | 72.32 | 45 |
| DeepSORT + NSA Kalman | 59.07 | 72.17 | 43 |
| DeepSORT + NSA Kalman + Global Matching Association | 61.67 | 73.41 | 37 |
| Video Numbering | Combination Numbering | MOTA/% | MOTP/% | ID Sw/Time |
|---|---|---|---|---|
| One | 1 | 57.30 | 72.03 | 49 |
| 2 | 60.09 | 73.28 | 42 | |
| 3 | 61.67 | 75.41 | 37 | |
| Two | 1 | 58.11 | 72.06 | 32 |
| 2 | 61.13 | 72.21 | 25 | |
| 3 | 63.27 | 75.06 | 20 | |
| Three | 1 | 32.65 | 72.41 | 117 |
| 2 | 33.37 | 74.21 | 110 | |
| 3 | 37.41 | 75.35 | 109 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, K.; Dai, J.; Gu, Z. Dynamic Tracking Method Based on Improved DeepSORT for Electric Vehicle. World Electr. Veh. J. 2024, 15, 374. https://doi.org/10.3390/wevj15080374
Zhu K, Dai J, Gu Z. Dynamic Tracking Method Based on Improved DeepSORT for Electric Vehicle. World Electric Vehicle Journal. 2024; 15(8):374. https://doi.org/10.3390/wevj15080374
Chicago/Turabian StyleZhu, Kai, Junhao Dai, and Zhenchao Gu. 2024. "Dynamic Tracking Method Based on Improved DeepSORT for Electric Vehicle" World Electric Vehicle Journal 15, no. 8: 374. https://doi.org/10.3390/wevj15080374