We propose the combined model of two artificial intelligence techniques, SVMs and GA for achieving effective corporate financial distress prediction. Thus, we first review prior studies on corporate financial distress prediction and examine their limitations. Next, we examine the basic concepts of SVMs and GA, which are the core algorithms of this study. Finally, we review previous studies that attempted to optimize SVM and GA.
2.1. Prior Studies on Financial Distress Prediction
Since predicting corporate financial distress is critical for risk management in companies and financial institutions, there has been substantial research in this area by academics. Most prior studies have tried to predict corporate financial distress using the signals of financial data or ratios. To do this, they adopted various data-driven techniques including DA, LOGIT, DT, CBR and ANN.
For example, Altman [
3] tried to predict corporate financial distress using DA. A more recent study by Ohlson [
4] used LOGIT and PROBIT to predict the financial distress. Falbo [
25] proposed a modified DA model for credit scoring in order to improve discriminatory power by reflecting trend and stability of multiple year financial/operating ratios.
In contrast to early studies that had applied statistical techniques in corporate financial distress prediction, modern studies started to apply artificial intelligence (AI) techniques to predict financial distress. For example, Odom and Sharda [
5] and Tam and Kiang [
6] proposed ANN as a classifier for predicting corporate financial distress. Tam [
26] and Malhotra and Malhotra [
27] also applied ANN to predict bank financial distress and problem consumer loans, respectively. Several later studies further investigated the use of AI or data mining techniques in financial distress prediction. A large portion of these studies mainly applied ANN and tested its feasibility in predicting corporate financial distress because of its high prediction accuracy. However, ANN has many drawbacks, including the risk of overfitting problems, the need to determine the value of the control parameters and the number of processing elements in the layer. In addition, training ANN generally requires a large sized training dataset. Thus, SVMs have recently attracted increasing attention. SVMs are known to mitigate the limitations of ANN, and numerous prior studies report that SVMs outperform ANN from the perspective of prediction accuracy. As a result, several recent studies on predicting financial distress have adopted SVMs as an alternative to ANN [
9,
10,
11,
12,
14].
2.2. SVM and its Application to Financial Forecasting
The basic SVM concept, proposed by Vapnik [
28], was designed for mitigating typical binary (two-class) classification problems. It is based on two main ideas—(1) maximum margin classification, and (2) nonlinear mapping of the input vectors into a high-dimensional feature space.
Basically, SVMs are designed to use a special kind of linear model for classification, which is called ‘the maximum margin hyperplane.’ Given a training dataset, SVMs seek to find an optimal separating hyperplane with the maximum-margin separation between the decision classes. At this time, the training samples closest to the maximum margin hyperplane are called support vectors. In SVMs, only support vectors are used for defining the class boundary. Thus, when the number of training samples is not enough, SVMs are known to be more robust compared to ANN.
In order to implement nonlinear classification using a linear model, SVM adopts nonlinear mapping of the input vectors into a higher dimension. It means that SVM transforms inputs into the high-dimensional feature space and constructs a linear model in order to implement nonlinear class boundaries. The function
, termed ‘kernel function,’ is used for this transformation. There are several types of kernel functions, but among them, two types are generally adopted in applications [
21]. They are (1) the polynomial kernel
and (2) the Gaussian radial basis function (RBF)
, where d is the degree of the polynomial kernel and
is the bandwidth of the Gaussian RBF kernel. Among these two kernel types, the Gaussian RBF is known to be superior to the polynomial kernel in terms of accuracy and efficiency [
21,
29,
30].
The SVM described above works properly only for the separable case, that is, the case where the training data is linearly separable. However, in reality, the most cases are linearly inseparable. For these non-separable cases, SVM has to adopt an additional penalty function associated with misclassification. This leads to the use of an additional parameter
C, which is the upper bound of the Lagrange multipliers for finding the optimal hyperplane. The parameter
C should be set to reflect the knowledge of the noise on the data, but it is mostly set by heuristics since it is difficult to seize the distribution of noise in the data in advance [
10,
22,
28,
30]. For more details on how the SVM algorithm works, readers may refer to Gunn [
31].
SVMs have many advantages over ANN. First, the parameters of SVMs to be tuned are few. Except for the upper bound
for the non-separable cases, and some parameters (e.g.,
or
) contained in the kernel functions, there are no parameters to be determined in SVMs [
32]. Overfitting is also unlikely to occur with SVMs. Overfitting lies in excessive flexibility in the decision boundary, but the maximum hyperplane of SVMs is relatively robust and allows for little flexibility [
33].
There have been some studies on applying SVMs to financial forecasting. Mukherjee et al. [
34] and Tay and Cao [
35] examined the predictability of financial time-series data with SVMs. Especially, Tay and Cao [
35] showed that SVM is superior to ANN according to the several criteria including normalized mean square error, directional symmetry and so on. Similar to Tay and Cao [
35], Kim [
36] used SVMs to forecast the future direction (up or down) of the stock market index in Korea. In this study, the author compared the performance of SVMs with that of other techniques like ANN and CBR, and reported that SVMs showed the best prediction accuracy.
Several recent studies investigated the applicability of SVMs to corporate financial distress prediction. Fan and Palaniswami [
9] showed that SVMs outperformed other traditional techniques, such as DA, multi-layer perceptron (MLP), and learning vector quantization (LVQ), in predicting corporate financial distress. Shin et al. [
10] empirically showed that the accuracy and generalization performance of SVMs were better than those of ANN, as the training set size decreased. Min and Lee [
11] also showed that SVMs outperformed LOGIT, DA, and ANN in predicting corporate financial distress. Other than these studies, Ahn et al. [
24], Chen and Hsiao [
21], Huang et al. [
37], Wu et al. [
38], and Zhou et al. [
39] also empirically validated the superiority of SVMs or SVM-based hybrid techniques for predicting financial distress.
2.3. Genetic Algorithm (GA)
GA is known as an efficient and effective search method that attempts to simulate the biological evolution phenomenon. It is popularly employed to find near-optimal solutions for large search spaces [
40]. With the application of genetic operations, it is designed to gradually improve the search results. In particular, a mechanism like mutation prevents GA from falling into the local optima, and a mechanism like crossover can reduce search time. The general evolution process of GA proceeds as follows.
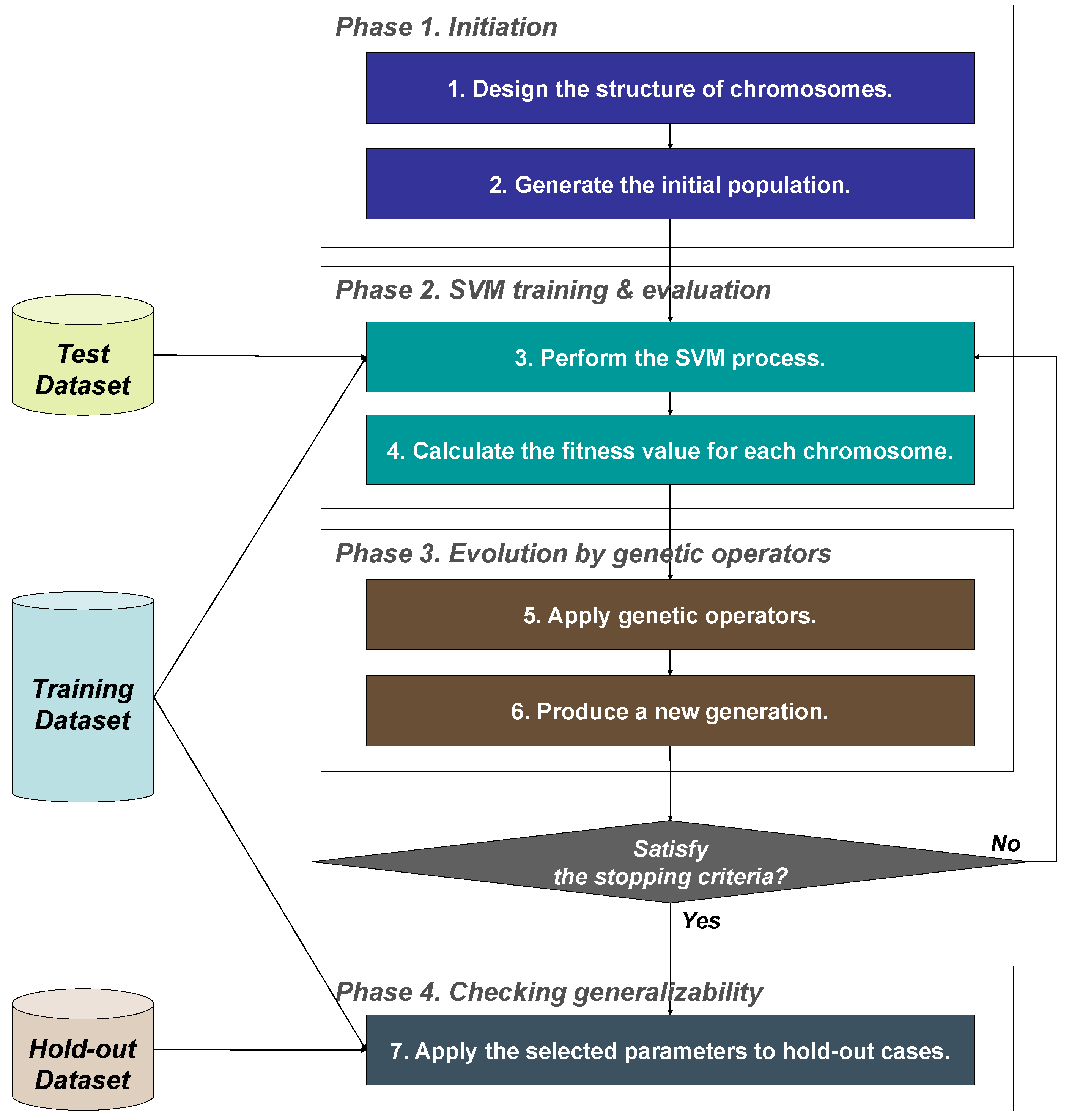
First, a set of solutions is randomly created. This set is called a population. Additionally, each solution in the population is called a chromosome. A chromosome should be designed to represent a solution, and it is designed in most cases as the form of a binary string.
After generating the initial population, genetic operators are applied to the population. There are many kinds of genetic operators, but selection, crossover, and mutation are popularly used. The selection operator selects the fittest chromosomes by evaluating the fitness value of each chromosome. Here, the fitness value of each chromosome is calculated from a user-defined function, called fitness function. In general, accuracy is used as a fitness function for the classification problems. The crossover operator exchanges the genes of two parent chromosomes to obtain new offspring to achieve better solutions. In the mutation operator, the bits that are arbitrarily selected with very low probability are inverted. By applying these genetic operators, a new population is formed, consisting of the fittest chromosomes as well as offspring of these chromosomes, based on the philosophy of survival of the fittest.
The above evolution procedure that applies genetic operators and creates a new population is repeated until the stopping conditions are satisfied [
41,
42].
2.4. Optimization of SVM Using GA
Until now, many researchers have proposed various ways for optimizing the design factors of SVMs using GA. Their approaches can be classified into four categories. The first category is to apply GA to optimize ‘the kernel function and its parameters.’ For example, Pai and Hong [
29] used GA to optimize free parameters used in the kernel function of SVMs. In particular, they used Gaussian RBF as the kernel function, proposed a novel SVM model that used optimized
, ε parameters through GA.
Wu et al. [
38] also proposed a GA based SVM model to optimize some parameters of SVM,
C and
, for obtaining the highest accuracy and generalization ability. They used a real-valued GA to optimize two parameters of SVMs for predicting financial distress. They compared the accuracy of the proposed model with that of other models including DA, LOGIT, PROBIT, ANN, and conventional SVMs. The paper showed that the proposed model outperformed the other comparative models.
Chen and Hsiao [
21] integrated GA and SVMs to create a model to diagnose the business crisis of Taiwan firms by optimizing
and
of SVMs. They compared the prediction performance of the integrated GA-SVM with all available variables and that of the GA-SVM with the selected variables from DA. The results showed that the GA-SVM with the selected variables from DA performed better than the other models including the GA-SVM with all variables and conventional DA.
Gu et al. [
43] proposed a hybrid of GA and SVM (termed ‘G-SVM’) approaches in housing price forecasting. In their study, SVMs were proven to be a robust and competent algorithm for both classification and regression in many applications. They also applied GA to simultaneously optimize the parameters of SVMs and compared the results with those of the grey model. The experimental results showed that the forecasting accuracy of the G-SVM approach was superior to that of the grey model.
Howley and Madden [
44] tried to extend the targets of optimization. Specifically, they proposed a new GA-SVM model that the optimized kernel parameters as well as kernel function. As a result, they could present the globally-optimized kernel function and parameters.
The second category of GA-optimization of SVM is ‘feature (subset) selection.’ Feature selection is to select only a small subset of features that are relevant to the dependent variable. The proper selection of the input features may enhance classification performance by characterizing each sample more accurately [
37,
45]. Moreover, it reduces the space of input vectors, so it makes the classification work more efficiently. For these reasons, studies on feature selection have been conducted for a long time, and many of them have adopted GA as a tool for achieving optimal feature selection regardless of their classifiers. At an early stage, feature selection using GA was mainly applied to the classifiers like CBR or ANN. However, some recent studies have tried to optimize the feature selection of SVMs using GA in order to solve various problems. For example, Lee and Byun [
46] and Sun et al. [
47] applied this technique for identification of the images and Li et al. [
23] employed it for detecting cancer. It is also applied in gear fault detection [
48], abnormal keystroke detection [
49], direct marketing [
50], and stock market prediction [
51].
The third category is the ‘simultaneous optimization of kernel parameters and feature subset selection.’ Since both kernel parameters and appropriate feature selection affect the classification performance of SVMs, it is more reasonable to optimize these factors all at once. Nonetheless, there are only a few prior studies that tried this approach.
Kim et al. [
23] applied this technique for detecting network intrusion and Jack and Nandi [
52] used this for detection of machinery faults. Zhao et al. [
53] suggested that this approach can improve protein sequence classification. Additionally, Min et al. [
12] used this approach for corporate financial distress prediction. All of them reported that the prediction performance of their proposed models are superior to other comparative models.
Huang and Wang [
20] tried several real-world datasets using GA-based simultaneous optimization model of kernel parameters and feature selection. They found that their proposed approach significantly improved the classification accuracy as well as decreased the number of the input features for SVMs compared with the grid algorithm—a traditional method of performing parameters searching.
Huang et al. [
37] tested the usability of the hybrid GA-SVM model in the context of credit scoring area. They proposed three SVM-based modes: The first mode is to optimize the model parameters using the grid search, the second is to calculate the F-score to select the input features, and the last mode is to simultaneously optimize model parameters and input features using genetic algorithms. The experimental results showed that SVMs with the GA model outperformed the other two models for two real-world credit datasets. They concluded that the hybrid GA-SVM model achieved good classification performance with a small feature subset.
The final category is to simultaneously optimize feature selection, instance selection, and kernel parameters. Similar to feature selection, instance (subset) selection is the method of selecting an appropriate subset of the training samples. It is also called ‘editing’ or ‘prototype selection’ [
8]. It may enhance the quality of prediction by avoiding the selection of noisy or distorted training samples as support vectors. Due to its advantages, it has long been applied to various classification techniques, including ANN [
54] and CBR [
55]. However, there have been few studies that introduced instance selection using GA for SVMs. Only a few premature studies like our preliminary study [
24], Tahayna et al. [
56] and Tahayna et al. [
57] tried to adopt the simultaneous optimization of the design factors in SVMs including instance selection by using GA. Especially, as far as we know, there have been no attempts to simultaneously optimize all of the design factors in SVMs using GA in order to build a better financial distress prediction model. From this perspective, we propose a global optimization model that optimizes the selection of proper features, instances, and kernel parameters of SVMs using GA for financial distress prediction.






{kind=link}