Abstract
Agriculture is an irrefutable part of food policy. This paper aims to introduce an integrated method using MICMAC and AHP techniques to deal with understanding the key strategic variables of agricultural system. MICMAC was used to determine the classifications of variables and AHP was applied to weigh these classifications. MICMAC is a structural analysis tool used to structure ideas and AHP is an effective tool to deal with complex decision making and helps decision-makers making the best decision. The results show that strategic variables had different types of influence and direct, indirect, and potential dependencies did not have the same importance. AHP-MICMAC not only considers these differences, but also puts a total priority weight for each variable. These characteristics have an important role in forming strategies and scenarios for agricultural development. Therefore, the case of Iran was used to illustrate the application of MICMAC aiming to supply instructions for the development of agriculture system.
1. Introduction
Agriculture is a complex system [1], but due to the risky and diverse nature of agriculture in developing countries, the systemic complexity is greater [2]. In a complex system, there are a variety of autonomous actors, just as a variety of actors and processes of adaptation can be found within the agricultural system [3]: humans (farmers, laborers, consumers, policy makers, experts, agents, etc.) [4,5], economy (market, cost, income, etc.) [6], nature (weather and climate, topology, etc.) [7,8,9], policy (plans, policies, strategies, etc.) [10], regulations (heritage, property rights, trade, etc.) [11], infrastructures (transportation, processing, saving, marketing, insurance, etc.) [12,13,14], inputs (land, water, seed, fertilizer, technology, etc.) [5,15,16,17].
Determining what kind of factors or variables need to be considered by decision and policy-makers is challenging [18]. Policy-makers tend to use different criteria and methodologies in order to determine strategic variables and factors influencing agricultural development [19]. Yet, because of the complexity of agricultural systems, the ability of researchers and policy-makers to prioritize variables is often limited. As a result, the majority of previous studies have dealt with this subject from a limited point of view (such as insurance or risk management) and on a micro level (such as a single farmer or farm). For instance, Pascucci and de-Magistris [20] implemented a multivariate probit model to evaluate the effects of different types of agricultural extension and innovation systems on farmers’ strategies in Italy. Allen [21] used the bet-hedging model and Neo-Darwinian theory (risk management strategies) to offer a way of evaluating the historical development of dryland agriculture as well as the long-term outcomes of variant agronomic strategies in Kona, Hawaii. Qingshui and Xuewei [22] and Zhou et al. [23] used empirical research to develop and improve strategies for the agricultural insurance system in rural of China by considering income sources, mean of production, labor opportunities, government supports, and communication channels. In Anambra, Nigeria, Amadi [14] evaluated the impact of rural road construction and its adjacent infrastructures (electricity, pipe-borne water and irrigation technology) that were used as a strategy for rural and agricultural development. Ames [4] emphasized investment in human capital as a strategy for implementing changes in agricultural policy, research, and extension activities.
Most of these studies only considered a few limiting factors or variables and their intensities, but none of them attended to characteristics such as dependent or independent variables, direct or indirect impacts, or the weight of each variable or factor. These characteristics have an important role in forming strategies and scenarios for agricultural development. As a result, there is a methodological gap that the present study aims to fill by providing a new integrated method. This new integrated method applies Impact Matrix Cross-reference Multiplication to a classification (MICMAC) [24,25] and analytic hierarchy process (AHP) [26]. The case of the agricultural system in Iran is used to show the application of this new methodology. Agriculture is one of the most important sectors of the Iranian economy, accounting for about 11% of GDP, 23% of the employed population, and 15% of the foreign exchange revenue (form non-oil exports). In addition to the fact that products from the agriculture and animal husbandry have been major export commodities, including pistachios, raisins, and even carpets. About 20% of Iran is arable, with some northern and western areas that support rain-fed agriculture, while other areas require irrigation.
Each of these methods alone has advantages and limitations for example MICMAC can investigate multiple variables at the same time, but it does not give an overall priority score for each variable. On other side, AHP considers only direct impact of variables, but it gives and overall priority score for each variable. This study has tried to overcome these constraints and to consider their advantages by combining them and proposing an integrated method. It is our hope that this new integrated method will supply instructions for the development of agriculture, and find wider applications in complex systems.
2. Materials and Methods
2.1. MICMAC Method
The Impact Matrix Cross-Reference Multiplication Applied to a Classification (MICMAC) is a structural analysis tool used to structure ideas and as a forecasting method created by Michel Godet. MICMAC can be considered a qualitative system dynamics approach [27] and provides the possibility to describe a system with the help of a matrix connecting all its components. By studying these relations, the method also makes it possible to reveal the variables essential to the evolution of the system. It is possible to use MICMAC as an aid for reflection and/or for decision making, or as a part of a more complex forecasting activity [28]. MICMAC tries to pinpoint the independent and dependent variables by building a typology in both direct and indirect classifications [28]. In MICMAC we depart from the definition of the system’s variables and their interrelations, both of which were provided by experts. This method has at least three main phases [25,28,29]:
Phase (1) Considering all the variables: This phase begins by considering all of the variables or factors that characterize the studied system. Brainstorming and intuitive methods or a panel of experts are useful methods for this phase. A detailed explanation of the variables is also essential because it will allow the relations between these variables to be perceived better in the analysis. The final output of this phase is a homogeneous list of internal and external variables (Table 1) and should not exceed more than 70 to 80 variables.

Table 1.
A sample list of internal and external variables.
Phase (2) Constructing the structural analysis matrix (description of the relations between the variables): In a systemic vision, a variable is a part of the relational web. A structural analysis matrix is a squared matrix that allows the variables to connect directly. The cells store the degree of influence between each pair of variables, i and j (0 no influence, 1 weak influence, 2 medium, 3 strong and P potential) (Table 2) (A group of experts filled this matrix). This filling-in phase helps place N × (N − 1) questions for N variables. Additionally, the questioning procedure not only enables us to avoid errors, but also helps us organize and classify ideas by creating a common group language. It also allows for the variables to be redefined and therefore makes analysis of the system more accurate. Figure 1 indicates the structural diagram of Table 2.
Table 2.
A sample structural analysis matrix (M) with four variables.
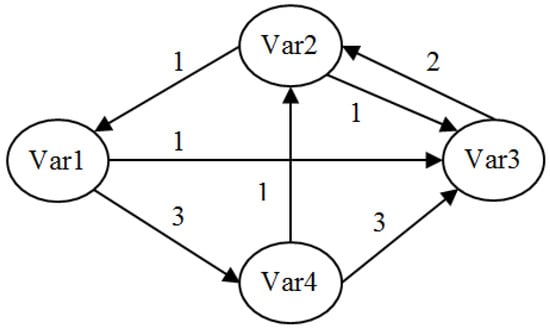
Figure 1.
A structural diagram (based on the data of Table 2).
Phase (3) Identification of the key variables: This phase consists of identifying variables essential to the system’s development. At first, this was accomplished by using direct classification, then through indirect classification and, finally, by potential classification. Comparing the hierarchy of variables in the various types of classifications (direct, indirect, and potential) is a rich source of information. It enables us not only to confirm the importance of certain variables, but also to uncover variables which play an important role yet were not identifiable through direct classification in the initial process. The direct influence and dependence of a variable are the aggregate of its row and column. The sum of each row indicates the importance of the influence of a variable on the whole system (other variables) (Equation (1)) and the sum of a column indicates the degree of dependence of a variable on the other variables (Equation (2)):
Indirect classification is obtained after increasing the power of the matrix M (matrix multiplication M2 = M × M, M3 = M × M × M, and so on). For example, in Figure 1 Var1 has a direct (DI13 = V1→V3 = 1) and indirect (II13 = V1→V4→V3) influence on Var3. To calculate indirect influence or dependence of a path, we should increase the power of the matrix by considering the number of paths and loops of length (1, 2, …, N) that result from or arrive at each variable (for example, for II13 = V1→V4→V3, the power of the matrix should be Equation (2)). The MICMAC then allows us to study the diffusion of the impacts through the paths and loops of feedback. Generally, the classification becomes stable after a degree of multiplication of 3, 4 or 5 [29].
| M = | 0 | 0 | 1 | 3 | → M2 = | 0 | 5 | 9 | 0 |
| 1 | 0 | 1 | 0 | 0 | 2 | 1 | 3 | ||
| 0 | 2 | 0 | 0 | 2 | 0 | 2 | 0 | ||
| 0 | 1 | 3 | 0 | 1 | 6 | 1 | 0 |
A potential direct or indirect classification is a direct or indirect relation (influence or dependence) that considers potential relations. To calculate potential relations, we ought to first replace P in matrix M with an ordinal number (1, 2, or 3, depending on the intensity of influence) and then increase the power of the new matrix to a point where the row and column priorities become stable. If there is no potential influence or dependence, the degree of potential relations will be equal to existing relations. In simple terms, feedback loops may take a number of iterations to come to a settled state. The number of times that the matrix can be multiplied depends upon how long it takes to stabilize.
MICMAC compared to the results (direct, indirect, and potential classification) provides the possibility to confirm the importance of variables. The main result of this phase is a matrix m × n (Table 3), which we named matrix R; where m is the number of various types of relations (various types of classifications). Here it includes eight types: Direct Influence (DI), Indirect Influence (II), Direct Dependence (DD), Indirect Dependence (ID), Potential Direct Influences (PDI), Potential Indirect Influence (PII), Potential Direct Dependence (PDD), and Potential Indirect Dependence (PID). N represents the number of variables. A comparison of the hierarchy within the variables provides a rich source of information.
Table 3.
Identification of the key variables according to various types of classifications (Matrix R).
2.2. AHP Method
The analytic hierarchy process (AHP) is a structured technique developed by Thomas L. Saaty in the 1970s. It is an effective tool when dealing with complex decision making and helps decision-makers to set priorities and make the best decision. AHP uses a series of paired comparisons to reduce complex decisions. Then, by synthesizing the results, it helps capture both the subjective and objective aspects of a decision. Additionally, AHP is used to reduce bias in a decision making process and incorporates a useful technique that checks the consistency of the decision-maker’s judgments [26,30,31].
The AHP can be implemented through the following steps:
- Define the problem and determine the objectives, criteria, sub-criteria, and alternatives.
- Structure the decision hierarchy from the top (the goal of the decision), down (the alternatives).
- Construct a set of paired comparison matrices. Each element on an upper level is used to compare the elements at the level immediately below it.
- Compute the vector of criteria weights.
- Compute the matrix of option scores. For each element in the level below, add its weighed values and obtain its overall or global priority.
- Rank the options (alternatives).
Each step will be described in detail. We assume that the m evaluation criteria are considered as evaluated n options or alternatives (in our study, 45 variables).
(1) Define the problem: Our problem or goal was determining the strategic variables of agricultural development based on various types of classifications.
(2) Structure the decision hierarchy: The structure of our decision hierarchy is shown in Figure 2. This hierarchical process includes three levels: (a) Goal (in our study it was to determine the strategic variables of an agricultural system), (b) criteria (in our study they were eight types of classifications: DI, II, DD, ID, PDI, PII, PDD, and PID), and (c) alternative variables.
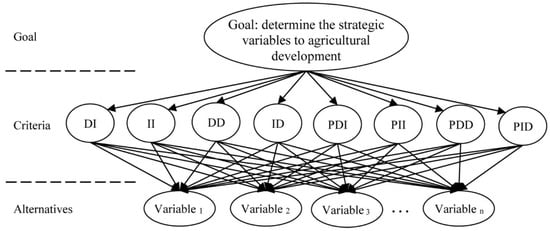
Figure 2.
The structure of the decision hierarchy.
(3) Create a paired comparison matrix (A): Matrix A is a m × m matrix. Each entry, aij, presents the importance of the ith criterion relative to the jth criterion. If aij = k and k > 1, it means that the ith criterion is k times more important than the jth criterion, while if aij = k and k < 1, it means that the ith criterion is k times less important than the jth criterion. If k = 1, then the two criteria have the same importance. The entries aij and aji satisfy this constraint, aij × aji = 1 (aij = 1/aji). The relative importance between two criteria is measured according to a numerical scale, from 1 to 9 (1 for equal importance of i and j, …, 9 absolutely i is more important than j). The consistency index (CI) [31] was used to check the reliability of the paired comparisons.
| a1 | a2 | .. | aj | ||
| A = | a1 | a11 | a12 | .. | a1j |
| a2 | a21 | a22 | .. | a2j | |
| ai | ai1 | ai2 | .. | aij |
(4) Compute the vector of criteria weight: Once matrix A is built, it should be normalized. To this purpose, the sum of the entries on each column should be made equal to 1. In the resulting matrix (Anorm), each entry āij is computed as (Equation (3)):
Finally, the criteria weight vector w is built by averaging the entries in each row of matrix Anorm (Equation (4)).
(5) Compute the matrix of option scores: This matrix is a m × n real matrix (S). Each entry sij of S represents the score of the ith option with respect to the jth criterion. In our study this matrix was the output of the MICMAC method and was a 8 × 45 matrix (8 types or relations and 45 strategic variables).
(6) Rank the options or alternatives (variables): in this phase a vector v of global scores is obtained by multiplying matrix S and vector w, i.e., vj = S × wi.
2.3. AHP-MICMAC Integrated Method
Although the MICMAC method is useful when identifying key variables and it gives us the priority of each variable according to different types of relations (from direct influence to potential indirect dependence), it couldn’t calculate a proper weight for the types of relations or an overall priority ranking with respect to these weights of each variable. Thus, we introduced an integrated method (AHP-MICMAC) to deal with this problem. As Figure 3 indicates, AHP-MICMAC can be implemented in eight simple consecutive steps:
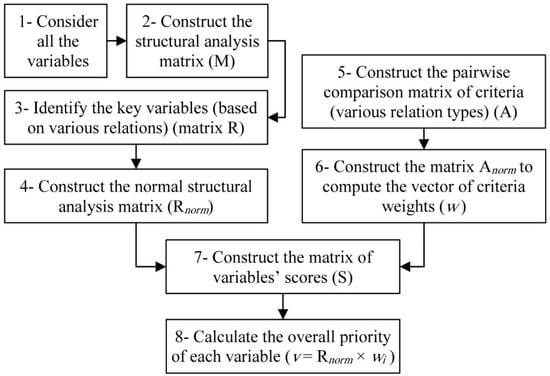
Figure 3.
The process of the AHP-MICMAC method.
(1) Consider all the variables: At first, we prepared a list of important variables extracted from literature review. Then, we organized a panel of 10 experts (including five faculty members of Agricultural Economics and Development at University of Tehran and five experienced experts of Agricultural Ministry) in order to prepare a final list of all variables that are fundamental for the development of agriculture in Iran. Brainstorming among the group, the panel finally extracted 45 variables as the key variables of agricultural development (Table 4).
Table 4.
The key variables for agricultural development.
(2) Construct the structural analysis matrix (M): We constructed a 45 × 45 matrix of key variables and asked a panel of experts to score the degree of influence between each pair of variables on a scale from 0 to 3 (0 no influence; 1, weak influence; 2, medium influence; and 3, strong influence) (Table 5).
Table 5.
A part of the constructed structural analysis matrix (M).
(3) Identify the key variables (based of various relations) (matrix R): Using MICMAC software (Version 6.1.2 [32]), we identified the key variables based on 8 different types of relations: Direct Influence (DI), Indirect Influence (II), Direct Dependence (DD), Indirect Dependence (ID), Potential Direct Influences (PDI), Potential Indirect Influence (PII), Potential Direct Dependence (PDD), and Potential Indirect Dependence (PID) (Table 3 and Table 6).
Table 6.
The key variables based on various relations (matrix R and matrix Rnorm).
(4) Construct the normal structural analysis matrix (Rnorm): During this phase, Equation (3) was applied to matrix R to convert to matrix Rnorm (Table 6).
(5) Construct the paired comparison matrix of criteria (A): Since the MICMAC method includes eight different types of classifications (DI, II, DD, ID, PDI, PII, PDD and PID), there are eight criteria. Therefore, the paired comparison matrix A is an 8 × 8 matrix. The following matrix is the constructed matrix A for this study:
| DI | II | DD | ID | PDI | PII | PDD | PID | ||
| A= | DI | 1.00 | 2.00 | 2.00 | 4.00 | 2.00 | 4.00 | 4.00 | 8.00 |
| II | 0.50 | 1.00 | 1.00 | 2.00 | 1.00 | 2.00 | 2.00 | 4.00 | |
| DD | 0.50 | 1.00 | 1.00 | 2.00 | 1.00 | 2.00 | 2.00 | 4.00 | |
| ID | 0.25 | 0.50 | 0.50 | 1.00 | 0.50 | 1.00 | 1.00 | 2.00 | |
| PDI | 0.50 | 1.00 | 1.00 | 2.00 | 1.00 | 2.00 | 2.00 | 4.00 | |
| PII | 0.25 | 0.50 | 0.50 | 1.00 | 0.50 | 1.00 | 1.00 | 2.00 | |
| PDD | 0.25 | 0.50 | 0.50 | 1.00 | 0.50 | 1.00 | 1.00 | 2.00 | |
| PID | 0.13 | 0.25 | 0.25 | 0.50 | 0.25 | 0.50 | 0.50 | 1.00 |
(6) Construct the matrix Anorm to compute the vector of criteria weights (w): The matrix Anorm and the vector of criteria weights (w) were calculated, respectively, using Equations (3) and (4). The matrix and vector for our study are indicated below:
| DI | II | DD | ID | PDI | PII | PDD | PID | wi | ||
| Anorm = | DI | 0.296 | 0.296 | 0.296 | 0.296 | 0.296 | 0.296 | 0.296 | 0.296 | 0.296 |
| II | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | |
| DD | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | |
| ID | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | |
| PDI | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | 0.148 | |
| PII | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | |
| PDD | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | 0.074 | |
| PID | 0.037 | 0.037 | 0.037 | 0.037 | 0.037 | 0.037 | 0.037 | 0.037 | 0.037 | |
| 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | ||
| Inconsistency Index = 0.000 | ||||||||||
(7) Compute the matrix of the variables’ scores (construct the matrix S): Matrix S is a matrix that includes the matrix Rnorm and the vector of criteria weights (w). Table 7 represents a part of this matrix. The first row is include the criteria weights and the rest rows are include the normalized scores of the variables. Constructing this table will help researchers to calculate the overall priority of each variable.
Table 7.
A part of matrix S.
(8) Calculate the overall priority of each variable: In order to calculate the overall priority for each variable, we mulitplied matrix Rnorm on vector wi (v = Rnorm × wi). Table 8 includes the total priority (TP = OPI + OPD), overall priority of influences (OPI = DI + II + PDI + PII), and the overall priority of dependences (OPD = DD + ID + PDD + PID) for all variables. To determine the model’s validity (the differences between model results and the realities), we asked the experts to judge the results of the proposed integrated method (AHP-MICMAC).
Table 8.
The total (TP), overall influences (OPI) and overall dependences (OPD) priorities.
3. Results and Discussion
3.1. The Weights of Various Types of Classifications
In the AHP-MICMAC method, unlike the MICMAC method, various classes of variables do not have the same weights. As matrix Anorm shows, the direct influences (DI) and potential indirect dependence (PID), respectively, have had the highest (0.296) and the lowest (0.037) weights among the various types of classifications. Additionally, the weights of II, DD, and PDI classes (0.148) were the same as each other, but their weights were two times more than the ID, PII, and PDD classes (0.074), which have the same weight. Based on Table 8, the sum of the overall priorities of influences (0.667) is two times more than the sum of the overall priorities of dependences (0.333). This means that the experts believe the characteristics of the influences of variables are more important than the characteristics of the dependencies of variables of agricultural development. It is also true for the sum of potential weights (PDI + PII + PDD + PID = 0.667) compared to actual weights (DI + II + DD + ID = 0.333). As is shown in the following section, the application of these weights may change the priority of variables.
3.2. The Most Influence and Dependence Variables
Table 6 demonstrates that for an agricultural development system, the most and the least direct and indirect influence variables (both actual and potential) were, respectively, V19 (government policies and programs) and V5 (consumers’ access to agricultural products). The influences of government policies and programs on agricultural development have been discussed by other authors [33,34], but the emphasis of this paper is on the type, the weight, and the rank of these influences. After V19 came V30, V06, and V43, in order of increasing influence. The degree of influence of the other variables is represented in Table 6.
Furthermore, the most and the least direct and indirect dependence variables have, in order, been the amount of agricultural production (V17) and topology (V35). The dependence of agricultural production on other factors and variables has been investigated by numerous scholars and organizations [16,35,36,37]. Table 6 shows that V12 and V19 are the next most important dependent variables that should be considered by planners and policy-makers. The degree of dependency of other variables is mentioned in Table 6.
3.3. The Key Variables
Table 9 is sorted in the MICMAC TP column, indicating the key variables of agricultural development based on both methods (MICMAK and AHP-MIKMAC). In the MICMAK method there are eight types of priorities (see Table 6) with the same weights for each variable; if we needed an overall priority, there is no difference between the various types of variable classes. Yet, as previously noted, the priorities of the variables in AHP-MIKMAC are also dependent on the weights of the variable classes. As it can be seen in Table 9, some of the ranks of the OPI, OPD, and TP have changed (for example: V22, V30, V11, and V43). Aside from this, in the MICMAC part of Table 9, there are a number of similar ranks, such as rank 20 and 37 within the TP column. This means that V16 (trade incentives and restrictions) and V32 (agricultural land area) or V33 (agricultural land laws and regulations) and V41 (the international prices of agricultural products) can have similar roles in agricultural development, but in Iran, this is not the case.
Table 9.
The TP, OPI, and OPD scores and ranks of variables based on MICMAK and AHP-MICMA.
In addition, a few variables, such as V44 (disasters: droughts, floods, earthquakes, etc.), V45 (crop insurance) and V15 (storage facilities), changed drastically in their ranking. In recent years, disasters have played an important role in the agricultural sector of developing countries [38,39]. On the other hand, despite the fact that insurance is an appropriate risk management tool in agriculture [40,41], some variables, including “agricultural extension and education” (V31), “water efficiency” (V28), and “farmers’ knowledge, awareness, and skills” (V24) are more important. For this reason, crop insurance (V45) is more dependent than these variables. Storage facilities (V15) is also an important variable in developing countries for agricultural development [42,43], but other variables, such as V24, V26, V28, and V31, are more important.
3.4. The Influence-Dependence Chart
If we draw the same chart as Figure 4a, in which the horizontal and vertical axis scales, respectively, are OPD and OPI, then we will have a chart that contains five separate sectors (A, B, C, D and E). Each variable is associated with their influential and dependent indicator (OPI and OPD) across the whole System. All of the variables can then be positioned on an influence-dependence chart (Figure 4b). Each identified area in this chart represents a type of the following variables [29]:
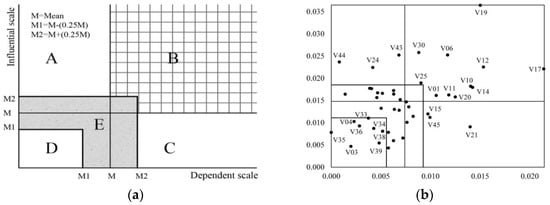
Figure 4.
The influence-dependence chart. (a) The influence-dependence chart area of variables; and (b) the position of study variables on the influence-dependence chart.
(A) Input variables: These variables are highly influential and less dependent. They tend to describe the dynamics of the system and the conditions of the other variables. Because of this, they are the first choice when developing different scenarios and strategies. According to Figure 4b, agricultural development in Iran has three input variables: V44, V24, and V43. This means that in order to develop dynamic and sustainable agricultural development in Iran, we must manage disasters, organize farmers, and improve farmers’ knowledge, awareness, and skills. Pavelic et al. [44] and Das [39] showed that flood and drought management is very important for agricultural development in Thailand and India. Also, there are many studies that emphasize the importance of human resources and capital (including schooling, training, organizing, and skills) for agricultural development [4,16,45]. Undoubtedly, building the human capital of smallholder farmers can play a critical role in agricultural growth and development.
(B) Relay or intermediate variables: These variables are highly influential and highly dependent. Any change will have high flow throughout the rest variables of the system. Figure 4b demonstrates 11 relay variables for agricultural development in Iran. Among these variables V19 (government policies and programs), V17 (the amount of agricultural production), V12 (agricultural products price), and V06 (marketing) are the most important. Our findings were in line with various studies [11,42,46] in other areas.
(C) Resultant variables: These variables have a low degree of influence and are highly dependent. Result variables are influenced by both the input variables or determinants (A) and the relay variables (B). Based on Figure 4b, there are three resultant variables in Iran’s agriculture system. These are V15 (storage facilities), V21 (farmers’ interest and motivation), and V45 (crop insurance). Some studies, such as John and Samuel Noi [33] and Qingshui and Xuewei [22], have also noted the importance of these variables for agricultural development in other areas of the world.
(D) Excluded or independent variables: This group is relatively unconnected to the system. They only have a few relationships within it and are neither influential nor dependent variables. Due to their relatively autonomous character and lack of connection to the system, they are not determinants of the future of the system. Therefore, they can be excluded from the next steps of the analysis. As seen in Figure 4b, there are eight excluded variables (V03, V04, V34, V35, V36, V38, and V39) in our study.
(E) Average variables: These variables cannot be clearly allocated to the remaining sectors because they are not sufficiently influential or dependent. Though they should be recognized and studied more closely in the future. The remainder of the variables in this study belong to this group.
3.5. The Stability and Instability of Agricultural Development System
The pattern of distribution in Figure 4 can not only inform us about the various types of variables, but also presents the stability or instability of a system. The stability of an agricultural system is very important, because agriculture can play an important role in global stability [22,47]. This, then is very helpful to know and informs us about the stability of agriculture system. As Figure 5 shows, if the points are distributed around the main diagonal (see Figure 5a), then the system is unstable. But if the cloud of points is spread along the axis (as L shape: see Figure 5b), it means that the system is stable. The advantage of a stable system is that it introduces a dichotomy between the influential variables, on which one can or cannot act, and the resultant variables which depend on them [27,29]. Based on these explanations and as Figure 5c indicates, the agricultural development system in Iran is unstable. Each variable is both influential and dependent, and any action on one variable has repercussions on all the others and on the original variable. The instability of the Iranian agricultural system has also been highlighted by other studies [48] and in other areas [49,50,51,52].
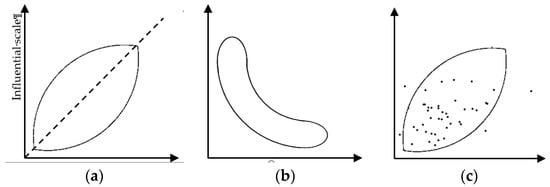
Figure 5.
System stability according to the influence-dependence chart (a) Unstable system; (b) Stable system; and (c) Iran agricultural development system.
4. Conclusions
Agricultural systems, especially in developing countries, are typically complex, and when forming strategies and scenarios, available methods have failed to reveal the essence of such complex systems. Therefore, the main objective of this study was to address this problem by using an integrated method. We integrated the MICMAC and AHP methods, using the MICMAC to determine the various classifications of variables and the AHP method to apply weights to these different variables. The case of the agricultural system of Iran was used to indicate an application of this new integrated method. The results revealed that the various types of variables in agricultural systems, from “actual direct influence” to “potential indirect dependence”, did not present similar influences or dependencies on each other. As a result, the ranks of key variables may change by applying the weight of different classification types of variables. Additionally, the AHP-MICMAC method allows us to have a total priority for each variable that helps policy and decision makers to recognize the most important variable according to its dependency and influence on other variables.
For example, in the Iran case, based on the total priority scores of the strategic variables, “farmers’ organizing and institutionalizing”, “farmers’ knowledge, awareness, and skills”, and “disasters”, respectively, are three main variables that describe the conditions and the dynamics of the other variables of agricultural systems. Therefore, they have a critical role in agricultural growth and development. “Government policies and programs” is the most important intermediate variable for agricultural development. It means the instability of the policies and programs will have high flow throughout the rest variables of the system. “Farmers’ interest and motivation”, “storage facilities”, and “crop insurance” are three main highly dependent variables that are influenced by both input and intermediate variables. There also are some variables, such as “agricultural support system”, “water efficiency”, “agricultural research”, “pricing system”, “rural welfare and comforting”, “agricultural land area”, “transportation and communications”, and “trade incentives and restrictions”, that they should be recognized and studied more closely in the future.
According to expert opinion, the use of the AHP-MICMAC method has led to a more realistic ranking of the variables and this combination has been able to improve results. It then facilitates the ranking of the variables according to their different types of influences and dependency weights. Without a doubt, any improvement in our understanding of the key variables of a system will lead to forming better scenarios and strategies for development of that system. Although the AHP-MICMAC method is more capable of illustrating the complexities among the variables than many other current methods, it still needs to be developed further so that it can better reflect the interdependency of variables, including economic, social, environmental, religious, etc., which can lead to risky, diverse, and complex agriculture in developing countries, such as Iran. In this regard, performing a study in order to compare the effectiveness of various methods, such as system dynamic modeling, AHP-MICMAC, or cross-impact analysis to display these complexities, is very crucial.
Author Contributions
Conceptualization, A.A.B. and H.A., methodology, A.A.B. and M.D.P.; software, A.A.B. and M.Q.; validation, P.L. and H.A.; formal analysis, A.A.B.; investigation, A.A.B. and M.D.P.; resources, A.A.B. and M.D.P.; data curation, A.A.B. and M.Q.; writing—original draft preparation, A.A.B.; writing—review and editing, H.A. and P.L.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhao, S.; Li, P.; Xiong, Y.; Zhang, X.; Chai, L. Complex agricultural system evolution basing on fourth thermodynamic law. In Proceedings of the 2012 Eighth International Conference on Natural Computation (ICNC), Chongqing, China, 29–31 May 2012; pp. 20–24. [Google Scholar]
- Mudgal, R. Poverty Alleviation and Rural Development; Sarup & Sons.: New Delhi, India, 2006. [Google Scholar]
- Nesheim, M.C.; Oria, M.; Yih, P.T. A Framework for Assessing Effects of the Food System; National Academies Press: Washington, DC, USA, 2015. [Google Scholar]
- Ames, G.C.W. Human capital, agricultural development and the African food crisis. Agric. Adm. Ext. 1988, 28, 1–17. [Google Scholar] [CrossRef]
- Schreinemachers, P.; Berger, T. An agent-based simulation model of human–environment interactions in agricultural systems. Environ. Model. Softw. 2011, 26, 845–859. [Google Scholar] [CrossRef]
- Viaggi, D.; Raggi, M.; Gomez y Paloma, S. Modelling and interpreting the impact of policy and price scenarios on farm-household sustainability: Farming systems vs. result-driven clustering. Environ. Model. Softw. 2013, 43, 96–108. [Google Scholar] [CrossRef]
- Kusunose, Y.; Mahmood, R. Imperfect forecasts and decision making in agriculture. Agric. Syst. 2016, 146, 103–110. [Google Scholar] [CrossRef]
- Wang, J.; Chen, J.; Ju, W.; Li, M. IA-SDSS: A GIS-based land use decision support system with consideration of carbon sequestration. Environ. Model. Softw. 2010, 25, 539–553. [Google Scholar] [CrossRef]
- Balbi, S.; Prado, A.d.; Gallejones, P.; Geevan, C.P.; Pardo, G.; Pérez-Miñana, E.; Manrique, R.; Hernandez-Santiago, C.; Villa, F. Modeling trade-offs among ecosystem services in agricultural production systems. Environ. Model. Softw. 2015, 72, 314–326. [Google Scholar] [CrossRef]
- Archer, D.W.; Dawson, J.; Kreuter, U.P.; Hendrickson, M.; Halloran, J.M. Social and political influences on agricultural systems. Renew. Agric. Food Syst. 2008, 23, 272–284. [Google Scholar] [CrossRef]
- Schirmer, S. Market Regulation and Agricultural Development; Econometric Research Southern Africa, University of the Witwatersrand: Johannesburg, South Africa, 2001. [Google Scholar]
- Yanli, Z. An Introduction to the Development and Regulation of Agricultural Insurance in China. Geneva Pap. Risk Insur. Issues Pract. 2009, 34, 78–84. [Google Scholar]
- Pinstrup-Andersen, P.; Shimokawa, S. Rural Infrastructure and Agricultural Development; World Bank: Washington, DC, USA, 2006; Available online: http://siteresources.worldbank.org/INTDECABCTOK2006/Resources/Per_Pinstrup_Andersen_Rural_Infrastructure.pdf (accessed on 17 July 2019).
- Amadi, B.C. The impact of rural road construction on agricultural development: An empirical study of Anambra state in nigeria. Agric. Syst. 1988, 27, 1–9. [Google Scholar] [CrossRef]
- FAO. Improving Agricultural Extension: A Reference Manual; Swanson, B.E., Bentz, R.P., Sofranko, A.J., Eds.; FAO: Rome, Italy, 1997. [Google Scholar]
- Alexandratos, N.; Bruinsma, J. World Agriculture towards 2030/2050: The 2012 Revision; ESA Working paper; ESA: Rome, Italy, 2012. [Google Scholar]
- Rótolo, G.C.; Montico, S.; Francis, C.A.; Ulgiati, S. How land allocation and technology innovation affect the sustainability of agriculture in Argentina Pampas: An expanded life cycle analysis. Agric. Syst. 2015, 141, 79–93. [Google Scholar] [CrossRef]
- de Olde, E.M.; Moller, H.; Marchand, F.; McDowell, R.W.; MacLeod, C.J.; Sautier, M.; Halloy, S.; Barber, A.; Benge, J.; Bockstaller, C.; et al. When experts disagree: The need to rethink indicator selection for assessing sustainability of agriculture. Environ. Dev. Sustain. 2017, 19, 1327–1342. [Google Scholar] [CrossRef]
- Musakwa, W.J.E. Identifying land suitable for agricultural land reform using GIS-MCDA in South Africa. Dev. Sustain. 2018, 20, 2281–2299. [Google Scholar] [CrossRef]
- Pascucci, S.; de-Magistris, T. The effects of changing regional Agricultural Knowledge and Innovation System on Italian farmers’ strategies. Agric. Syst. 2011, 104, 746–754. [Google Scholar] [CrossRef]
- Allen, M.S. Bet-hedging strategies, agricultural change, and unpredictable environments: historical development of dryland agriculture in Kona, Hawaii. J. Anthropol. Archaeol. 2004, 23, 196–224. [Google Scholar] [CrossRef]
- Qingshui, F.; Xuewei, Z. Development Strategies on Agricultural Insurance under the Building of New Countryside. J. Agric. Sci. Tech. 2010, 1, 13–23. [Google Scholar] [CrossRef][Green Version]
- Zhou, Y.; Wang, X.; Cai, Y. Reasons and Improving Strategies of Slow Development of Agricultural Insurance System in China. J. Northeast Agric. Univ. (Engl. Ed.) 2011, 18, 92–96. [Google Scholar] [CrossRef]
- Villacorta, P.J.; Masegosa, A.D.; Castellanos, D.; Lamata, M.T. A linguistic approach to structural analysis in prospective studies. In Proceedings of the International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Catania, Italy, 9–13 July 2012; pp. 150–159. [Google Scholar]
- Godet, M. The art of scenarios and strategic planning: tools and pitfalls. Technol. Forecast. Soc. Chang. 2000, 65, 3–22. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision making with the analytic hierarchy process. Int. J. Serv. Sci. 2008, 1, 83–98. [Google Scholar] [CrossRef]
- Mirakyan, A.; De Guio, R. Three Domain Modelling and Uncertainty Analysis: Applications in Long Range Infrastructure Planning; Springer: Germany, Switzerland, 2015. [Google Scholar]
- Godet, M. Manuel of Strategic forecasting. Volume 2 (Manuel de Prospective Stratégique. Tome 2); Dunod: Berlin, France, 1997. [Google Scholar]
- Godet, M. From Anticipation to Action: A Handbook of Strategic Prospective; UNESCO Publishing: Dunod, Paris, 1994. [Google Scholar]
- Saaty, T.L. The analytic hierarchy and analytic network measurement processes: Applications to decisions under risk. Eur. J. Pure Appl. Math. 2007, 1, 122–196. [Google Scholar]
- Saaty, T.L. The Analytic Hierarchy Process; McGraw-Hill International: New York, NY, USA, 1980. [Google Scholar]
- Godet, M.; Durance, P. Strategic Foresight for Corporate and Regional Development; Unesco: Paris, France, 2011. [Google Scholar]
- John, B.-B.; Samuel Noi, A. The Effect of Government Policies on Agricultural Prices and Output in a Developing Country. J. Dev. Areas 1995, 30, 91–112. [Google Scholar]
- Norton, J.P.; Reckhow, K.H. Modelling and Monitoring Environmental Outcomes in Adaptive Management. In Developments in Integrated Environmental Assessment; Jakeman, A.J., Chen, S.H., Eds.; Elsevier: Amsterdam, The Netherlands, 2008; Volume 3, pp. 181–204. [Google Scholar]
- Bowman, M.S.; Zilberman, D. Economic Factors Affecting Diversified Farming Systems. Ecol. Soc. 2013, 18. [Google Scholar] [CrossRef]
- Van Velthuizen, H. Mapping Biophysical Factors that Influence Agricultural Production and Rural Vulnerability; Food and Agriculture Organization of the United Nations: Rome, Italy, 2007. [Google Scholar]
- World Bank. World Development Report 2008: Agriculture for Development; World Bank: Washington, DC, USA, 2007. [Google Scholar] [CrossRef]
- Mousavi, S.-F. Agricultural drought management in Iran. In Water Conservation, Reuse, and Recycling: Proceedings of an Iranian-American Workshop; National Academies Press: Washington, DC, USA; pp. 106–113.
- Das, H.P. Agricultural Drought Mitigation and Management of Sustained Agricultural Development in India. In Natural Disasters and Extreme Events in Agriculture: Impacts and Mitigation; Sivakumar, M.V.K., Motha, R.P., Das, H.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 277–303. [Google Scholar] [CrossRef]
- Hazell, P.B.; Pomareda, C.; Valdes, A. Crop Insurance for Agricultural Development: Issues and Experience; IICA Biblioteca Venezuela: Caracas, Venezuela, 1986. [Google Scholar]
- Skees, J.; Hazell, P.B.; Miranda, M. New Approaches to Crop Yield Insurance in Developing Countries; International Food Policy Research Institute (IFPRI): Washington, DC, USA, 1999. [Google Scholar]
- Adigal, V.; Singh, S. Agricultural marketing vis-a-vis warehousing facility (Case study of Central Warehousing Corporation). Bus. Manag. Rev. 2015, 5, 43. [Google Scholar]
- Jouanjean, M.-A. Targeting Infrastructure Development to Foster Agricultural Trade and Market Integration in Developing Countries: An Analytical Review; Overseas Development Institute: London, UK, 2013. [Google Scholar]
- Pavelic, P.; Srisuk, K.; Saraphirom, P.; Nadee, S.; Pholkern, K.; Chusanathas, S.; Munyou, S.; Tangsutthinon, T.; Intarasut, T.; Smakhtin, V. Balancing-out floods and droughts: Opportunities to utilize floodwater harvesting and groundwater storage for agricultural development in Thailand. J. Hydrol. 2012, 470–471, 55–64. [Google Scholar] [CrossRef]
- Parman, J. Good schools make good neighbors: Human capital spillovers in early 20th century agriculture. Explor. Econ. Hist. 2012, 49, 316–334. [Google Scholar] [CrossRef]
- Akinbamowo, R. A review of government policy on agricultural mechanization in Nigeria. J. Agric. Ext. Rural Dev. 2013, 5, 146–153. [Google Scholar]
- Tilman, D.; Cassman, K.G.; Matson, P.A.; Naylor, R.; Polasky, S. Agricultural sustainability and intensive production practices. Nature 2002, 418, 671–677. [Google Scholar] [CrossRef]
- Karshenas, M. Oil, State and Industrialization in Iran; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Hathaway, D.E. Agriculture in an Unstable Economy Revisited. J. Farm Econ. 1959, 41, 487–499. [Google Scholar] [CrossRef]
- ICARDA; FAO; AARINENA; CIHEAM. The National Agricultural Research Systems in the West Asia and North Africa Region; ICARDA: Aleppo, Syria, 1999; Volume vii. [Google Scholar]
- Sharma, M.; Dhiman, R. Agribusiness Strategies to Promote Exports: An Analysis of Growth and Instability. Int. J. Manag. Soc. Sci. 2015, 3, 622–637. [Google Scholar]
- Squires, V.R. The Role of Food, Agriculture, Forestry and Fisheries in Human Nutrition—Volume IV; EOLSS Publications: Paris, France, 2011. [Google Scholar]





© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).