1. Introduction
The tourist hotel is an important part of the tourism industry. The tourist destination hotels flow is the indicator of hotel revenue; accurate passenger flow forecasting is the key link in the hotel revenue management [
1], which helps related companies and organizations allocate limited tourism resources scientifically and reasonably to maintain market competitiveness [
2]. However, the tourism demands such as the overnight passenger flow of hotels has characteristics of complex nonlinear fluctuations. The uncertainty of the passenger flow during the tourist season makes the decision-making of relevant departments into a dilemma, either overestimating or underestimating of the passenger flow will result in unnecessary waste of resources in tourism-related industries; additionally, the actual overnight passenger flow released by the statistical department has serious hysteresis. On the other hand, existing non-linear prediction methods are difficult to adapt to the increasing experimental data, and unable to extract feature information automatically, affecting the forecasting accuracy. With the all-round development of the Internet, a large amount of online query index generated by the consumer information search provides a new direction for an overnight traffic forecasting of tourist hotels [
3]. This study addresses the aforementioned problems and expands the previous research by introducing appropriate nonlinear forecasting methods and constructing deep learning (DL) forecasting frameworks.
Existing prediction methods of tourism demands include linear and nonlinear technologies. Linear forecasting technologies mainly include the time series forecasting models represented by the autoregressive integrated moving average (ARIMA) and econometric models. Nevertheless, these methods need to meet the stability of the economic environment and the stability assumptions of the time series. In practice, it is often unable to fully simulate complex nonlinear characteristics of the destination demands [
4]. The nonlinear technologies represented by the regression version of the support vector machine (SVR) method have certain nonlinear forecasting abilities when dealing with small sample data sets [
4,
5,
6], but these methods are shallow learning technologies. Hence, in the aspect of practical applications, it’s hard for these methods to meet the growing data samples. Additionally, these methods cannot automatically extract features information, but also easily fall into the local optimum as well as over-fitting problems.
With the comprehensive development of the Internet, the information query has become a crucial basis for decision-making [
7,
8]. A large number of records generated by information query possess real-time and accessible features. These data mainly from the Baidu or Google search engine are objective reflections of consumers’ latent demands for travel and have become increasingly important for tourism demand forecasting [
3].
Existing literatures mainly use the consumer search data to forecast the tourist flow in scenic areas. Predictive results based on the linear model suggested that the Internet search index can improve the forecasting performance [
9,
10,
11,
12,
13]. For instance, Yang et al. [
11] applied the web index from Google and Baidu as input sets of the ARIMA model for a comparative study on the Chinese tourist volume. Huang et al. [
12] used the query data from Baidu as a predictive variable of the ARIMA model to forecast the tourist arrivals of the Imperial Palace in Beijing. Taking Xi’an as an example, Wei and Cui [
13] used the seasonal adjustment method to explore the correlation between the search data from Baidu and the tourist flow. However, the linear model needs to satisfy the stationary assumption of the time series and the stable economic environment, and it is difficult to effectively simulate the nonlinear relationship of tourism demands.
In order to cope with the nonlinear, existing literature used the Internet query index as input sets of nonlinear tools such as the artificial neural network (ANN) and the regression version of the support vector machine, to predict the tourist flow [
5,
6,
14]. For example, Sun et al. [
6] applied the web query data to construct a single-layer feed-forward neural network (FFNN) to simulate the tourist flows in Beijing. The empirical analysis shows that the search query data can effectively fit the dynamic characteristics of the tourist arrivals and improve the predictive accuracy of the constructed method. Li et al. [
14] developed a composite forecasting tool using the back propagation algorithm (BPNN) and used the Baidu index to predict the tourist volume. Despite this, models such as the SVR and ANN are essentially shallow learning methods that are difficult to meet the growing samples of the tourism data, and challenge the predictive accuracy.
Previous studies forecasted the demands of tourist hotels mainly based on linear models [
15,
16,
17,
18,
19]. For example, Choi [
18] identified key economic indicators of the hotel industry in the US and built synthetic indicators to forecast the US hotel demands successfully. Aliyev et al. [
19] used fuzzy time series models to forecast the hotel occupancy. There was very rare research specializing in the hotel demand forecasting using the Internet search data. For example, Pan et al. [
20] utilize the Google trend index as model inputs to forecast the hotel occupancy. The results indicated that the addition of network queries can obviously reduce the prediction error. However, these studies mainly use the Google trend data as predictive variables of linear models. In China, consumers mainly use the Baidu search engine for information search. There is no relevant literature using the Baidu search data to forecast the demands for the tourist hotel accommodation. Whether the Baidu search data has a predictive effect on the demands of tourist hotels remains to be investigated. In addition, with the increase in the data samples, linear-based forecasting techniques are difficult to fully simulate the nonlinearity of the hotel accommodation demands.
In recent years, with the popularity of artificial intelligence, neural network models with more hidden layers can learn the characteristic information and the relevance behind the complex dataset. The DL technology has attached increasing importance in both academia and the industry [
21]. According to the consensus of most current researches, for traditional machine learning algorithms, as the data sample increases, the forecast performance increases according to the power law, but tends to be stable after a while. But for the DL method, its performance increases logarithmically with the increased sample capacity [
22]. Compared to other DL models, the long short-term memory (LSTM) exhibits unique advantages in terms of forecasting with sequence as inputs [
23,
24,
25]. In the field of tourism, for example, Chang and Tsai [
26] used the deep neural network (DNN) model based on official statistics to forecast Taiwan’s tourist flow. There is no research on the hotel accommodation demand forecasting based upon such DL methods.
The application of the DL models in the complex time series forecasting of tourism demands is explored in this paper. Taking Hainan as an example, the internet search data generated by the consumers’ information search and LSTM models with excellent forecasting ability for the complex time series are used to forecast the overnight passenger flows of tourist hotels. For the purpose of comparing the forecasting power of the developed models, the deep belief network (DBN), BPNN, and C-LSTM (only using past observations of the overnight passenger flow as predictive variables) were constructed as benchmark counterparts. With the empirical results suggesting that the developed LSTM network can effectively forecast hotel demands compared to its competitors.
The contribution of this study to the existing research is twofold. Firstly, we construct a theoretical analysis framework based on the tourism motivation theory and information search behaviour theory for the first time, which provides a theoretical basis for the tourism demand forecasting research based on the web search data. Secondly, unlike previous studies, forecasting tools such as the ANN and SVR cannot adapt to the ever-increasing tourism data. This paper introduces the LSTM with an excellent prediction ability for the complex time series data and constructs an empirical analysis framework to forecast hotel accommodation demands. This method provides a feasible solution for other complex time series predictions under relatively large sample conditions.
The rest of the study proceeds as follows:
Section 2 is the theoretical analysis. In
Section 3, the design of the forecasting method is shown.
Section 4 gives the empirical results of the overnight passenger flow forecasting.
Section 5 presents the conclusions.
2. Theoretical Analysis
It is observed from the tourism motivation theory [
27,
28] and tourist information search behavior theory [
7,
29] that tourism is a dynamic process in the temporal and spatial dimension, which can be divided into three stages namely, the pre-tour plan, in-tour experience and post-tour evaluation. The logic framework of the tourist information search is shown in
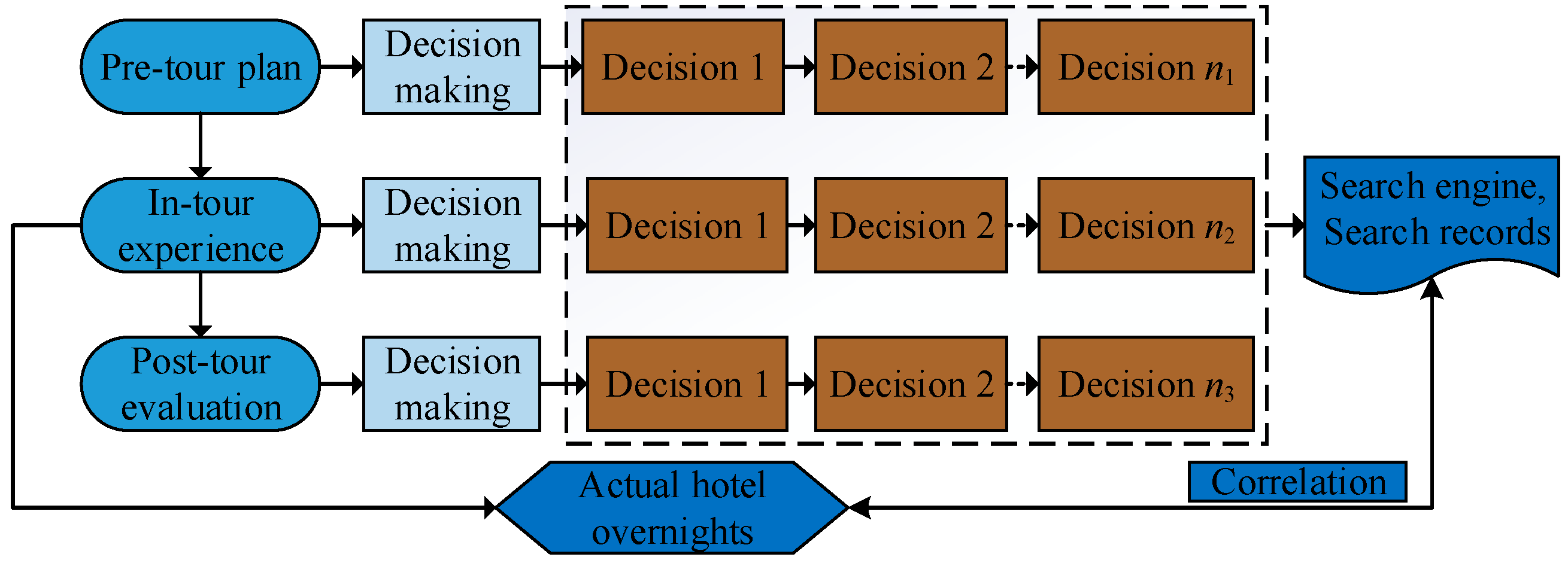
Figure 1.
The decision-making of tourism at each stage in the Internet environment relies heavily on the Internet information search. Once a tourism decision is made, tourists will try to fulfill their specific tourism demands. The pre-tour plan refers to a series of plans made by the consumers inspired by the tourism demands. They make tourism decisions by using the Internet to search information thereby, developing an optimal travel plan. The in-tour experience refers to the entire tourism implementation process from the source to the tour destination. It is the process of the tourists’ actual experience on tourism products and services. At this stage, tourists mainly use mobile communication devices such as mobile phones and tablet phones to inquire the tourism-related information they care about, thereby making travel decisions. Post-tour evaluation is an objective evaluation of witnessed tourism products or services after the end of the tour, visitors often use various social media tools to comment on tourism products and services and share their travel experiences.
Jeng and Fesenmaier [
30] noted that in the whole process of the pre-tour plan and in-tour experience, tourists would make different tourism decisions for six elements of tourism such as eating, accommodation, transportation, travelling, shopping and entertainment. During this process, the tourists’ potential tourism demands are expressed by the Internet information search on the search engine, which makes a true record of the search information. The consumer information search objectively reflects the tourists’ potential travel motivation. The characteristic information that has the potential influence on the tourism demands can be determined from the Internet information search. The information is the pre-reflection of the passenger flow of tourists destination hotels hence, it becomes an important data source in tourism demand forecasting [
3].
3. Design of Forecasting Method
3.1. LSTM Network
The advantage of the traditional recurrent neural network (RNN) model is that it can learn complex temporal dynamic characteristics through the following recurrent equations when dealing with forecasting tasks of sequence input objects:
where,
represents the inputs of the model,
denotes a hidden layer with the N hidden units,
denotes the output at the moment t, and
represent the weight and offsets parameters that need to be learned. For the input sequence with the length T, the update of the data is handled in a cycle way.
Although RNN has been successfully applied in areas such as speech recognition as well as text generation [
31,
32], this method has some difficulties in learning and storing long-term memory information, which can be attributed to disappearing and the explosion of gradients when RNN is optimized in some time steps. The consequence is that the model cannot retain the past memory information over a long time.
LSTM is a variant of RNN, proposed by Hochreiter and Schmidhuber [
23] whose core contribution is the introduction of the ingenious concept of self-looping. LSTM provides a solution for a fusion memory cell unit that allows the network to learn the previously forgotten hidden unit and update the hidden unit based on the new information. In addition to the hidden unit
, the LSTM network also includes the input gate, forgotten and input adjustment ones, and memory cell. The memory cell unit fuses the state of the previous memory cells, these memory cell units are adjusted by the forgotten gate and the input adjustment gate as well as the previous hidden state, which is adjusted by the input gate. These additional memory cell units enable the LSTM architecture to learn extremely complex long-term time dynamics, ensuring the long-term memory function of the LSTM. The architecture of an LSTM model can be expressed as follows:
where, tanh represents the activation function.
The biggest contribution from RNN is the increased hidden state
in LSTM, which determines how much information to add or remove from the previous memory state by using the sigmoid activation function
and the point multiplication defined layer. The first gate is the forgotten gate
, which controls how much data is discarded from the previous memory state. This is followed by the input gate, which remembers some of the current information and determines which values will be updated. Then, new cell state merges the past and present memory information and selects the information of vector
through the forgotten gate, which provides a mechanism for deleting past irrelevant information and adding relevant information from the current time step. Finally, the output layer
controls how much memory data will be utilized in the update of the next phase [
33].
3.2. Training Method and Model Selection
The back propagation through time (BPTT) commonly used in the RNN network was adopted to train the LSTM network, which is the standard algorithm for training RNN-like network models. The RMSProp, an improved stochastic gradient descent algorithm, was selected for parameter iterative updating. In the LSTM network, in addition to the default activation functions of the model, the other layers use the tanh function as the activation function, which has a more stable gradient and is commonly used in the regression problem.
Over-fitting is an unavoidable phenomenon in the field of DL. The Dropout algorithm developed by Hinton et al. [
34] was utilized for solving this defect. This method is a model selection algorithm and a powerful tool to solve the over-fitting in the current DL field.
3.3. Forecasting Framework Construction
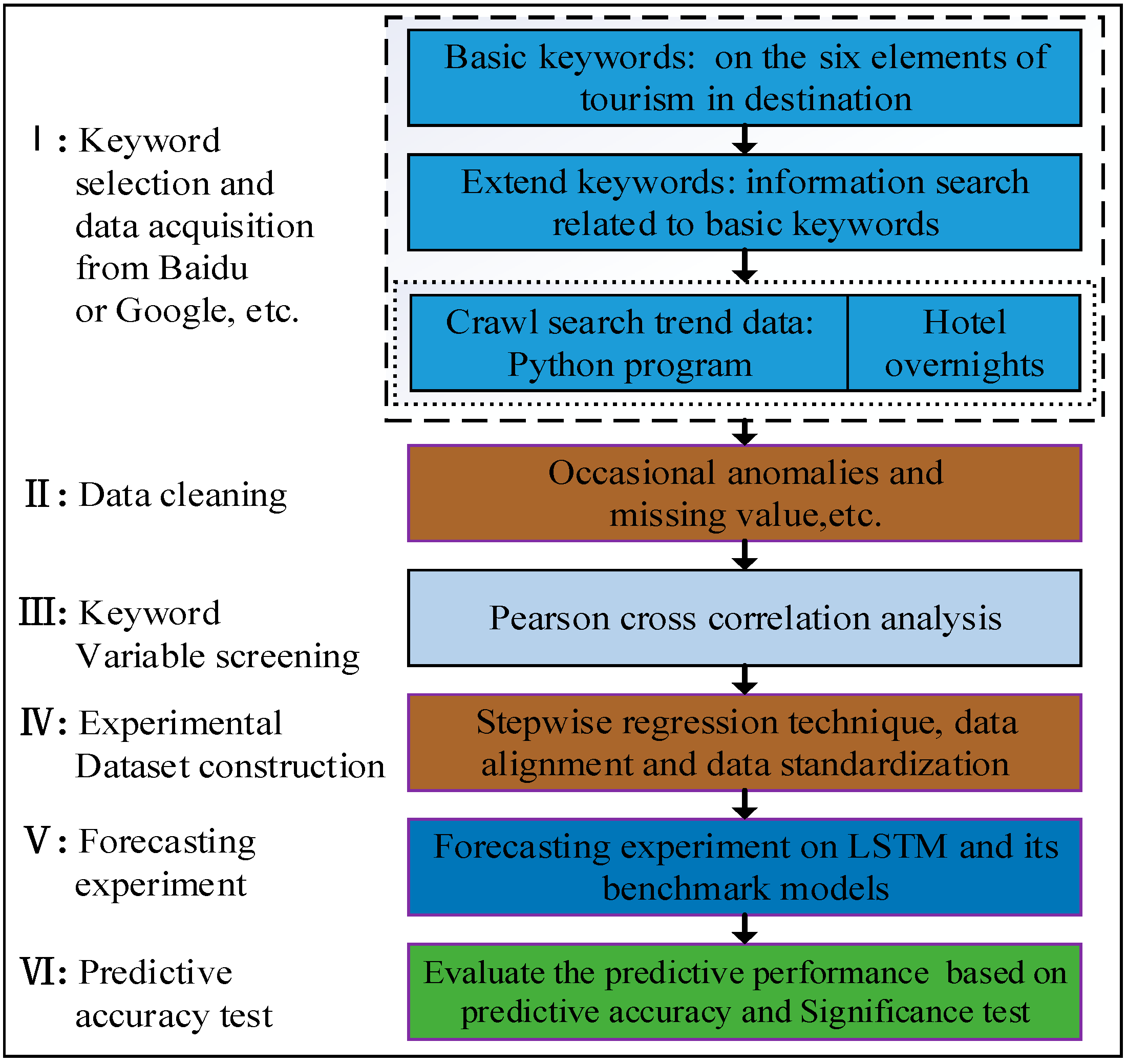
After the introduction of the LSTM model, a prediction framework based upon consumer queries was constructed (as shown in
Figure 2). This framework illustrates the entire empirical analysis, including keyword selection, variable observations acquisition and cleaning, keyword variable screening, predictive variable selection, experimental dataset construction, forecasting experiment and predictive accuracy test. The detailed steps are as follows:
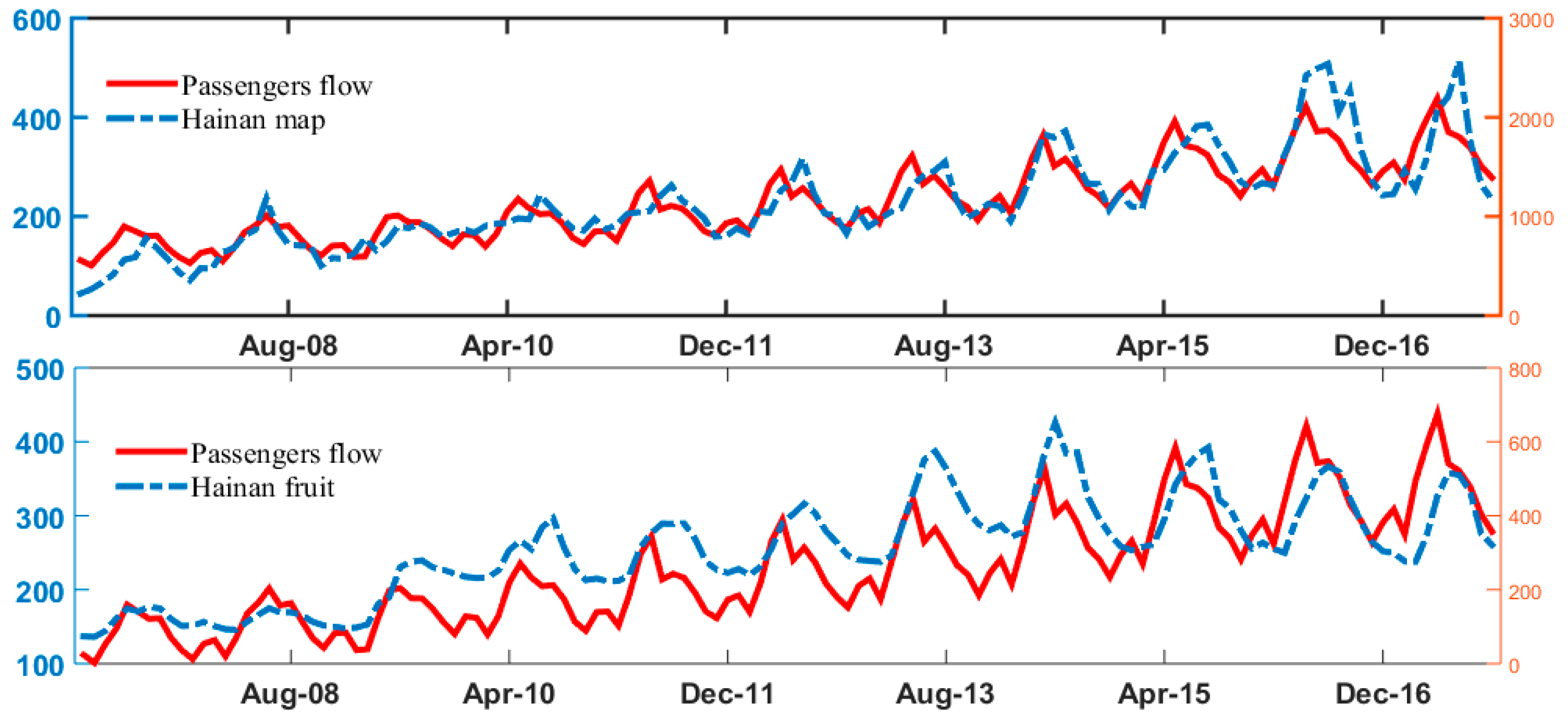
Step 1: Experimental dataset acquisition. After determining the search engine, for the purpose of handling the information omission, we selected six elements related to the destination as the benchmark queries, and then inquired extended keywords related to the benchmark keywords circularly. Eventually, we used Python to crawl the structured query volume data of each keyword, and obtained an alternate experimental dataset composed of data of the overnight passenger flow of tourist hotels.
Step 2: Data cleaning. The passenger flow is very sensitive to promotion schemes, emergencies, etc., thereby data may have abnormal values in different periods. In addition, some keyword variables or predicted variables have the problem of missing data, which will affect the prediction of the model. Thus, the individual outliers were replaced by the moving average method, which eliminated the influence of the noise while retaining the basic data characteristics.
Step 3: Predictive variable screening. In order to further find predictive variables that are significantly correlated with the predicted variables, the cross-correlation analysis was used to analyze the connection between the keyword variables and lag variables of the predicted variables. The Pearson cross-correlation analysis is a statistical analysis method, which acquired the Pearson correlation coefficient between the 1–12 order lag variables of the predictive variable and the predicted variable, respectively. The lag variable corresponding to the maximum correlation coefficient was taken as an alternate predictive variable. The threshold was defined, and the keyword variable with the correlation coefficient exceeding was retained as the keyword predictive variable. The same method was used to find the lag variable of the predicted variable as the predictive variable.
Step 4: Experimental dataset construction. For the purpose of reducing the complexity of model training, the stepwise regression analysis was further performed on the potential predictive variables to obtain the final predictive variable with excellent predictive ability. To reduce the training complexity, help the network converge faster, and reduce the prediction error rate, a standardized method was used to standardize the experimental dataset, where represents the value of the time series in the experimental dataset at point represent the minimum and maximum values of respectively. Eventually, all the standardized variables were then aligned based on the optimal lag structure of each variable and composed experimental dataset.
Step 5: Forecasting experiment. The experimental sample was split into the training section and the test section. The former was utilized for training and the latter was utilized for the predictive test. Predictive experiments were conducted under the Keras framework [
35].
Step 6: Predictive accuracy test. The predictive accuracy was determined by metric indices including the root mean squared error (RMSE), mean absolute percent error (MAPE), relative mean bias (PBIAS) and goodness-of-fit index R. The calculations of these statistical indicators are shown in Equations (9) ‒ (12). A significant test of the difference in the predictive accuracy between LSTM and its benchmark models was performed using the Paired t test [
36].
where,
represent the actual tourist flows and simulated records, respectively,
represents the forecasting period, and
are the average of
, respectively.
The absolute indicator RMSE and the relative indicator MAPE were designed to determine the forecasting accuracy between the actual and the fitted records. The smaller the score, the higher was the predictive accuracy [
5]. The relative metric indicator PBIAS measured the average result of the deviations between the fitted and actual observed values [
37]. The expected score of the PBIAS was zero. The positive and negative scores implied underestimating or overestimating the actual passenger flow in the sense of average, respectively. The purpose of R was to describe the goodness of fit between the predictive and the predicted variables. The closer its score to one, the better was the simulating effect.
5. Conclusions
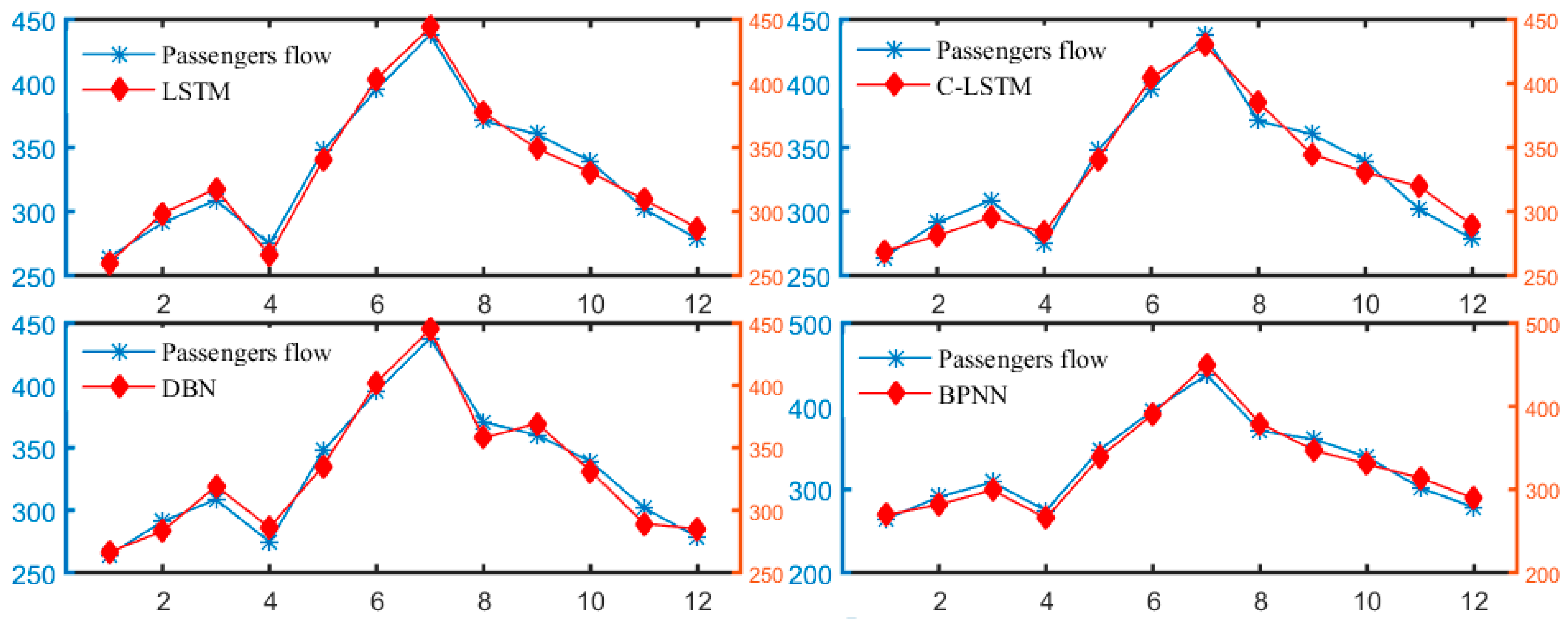
Hotel accommodation demands exhibit a cyclical fluctuation and complex nonlinear characteristics. Considering that the traditional prediction techniques cannot meet the ever-increasing data samples, and unable to automatically extract feature information, a forecasting framework based on DL was constructed in this paper. Taking Hainan in China as an empirical example, the LSTM model with a good predictive power for the complex time series was developed, and the Internet query index was used as the model inputs to forecast the overnight passengers flow of tourist hotels. The experimental outcomes implied that as compared to the benchmark models, LSTM improved the model predictive ability to different degrees, displayed satisfactory prediction ability and powerful generalization, and can simulate the dynamic characteristics of the passenger flow as well.
The preferable forecast performance can be attributed to the following three aspects. Firstly, additional memory units and special network structures enable the LSTM to learn the complex dynamic information of the passengers flow time series with a relatively large sample. Therefore, as compared to the DBN model, the LSTM model can learn the characteristic information of the passenger flows, which obviously improves the predictive ability of the model. Secondly, with the advent of the Internet environment, the consumer’s information query objectively reflects the potential demands for travel, and can forecast the trend of the overnight passenger flows of tourist hotels in advance. Therefore, the incorporation of the network query index makes the LSTM model better fit the dynamics of the overnight passenger flow in tourist hotels, and significantly improves the predictive performance of the developed LSTM network, which agree with the theoretical analysis. Finally, different optimization algorithms and a special network structure design make the learning ability and predictive ability of the LSTM significantly different from that of BPNN.
The research in this paper has a prominent theoretical significance. Firstly, an empirical framework based on web queries was constructed for the ever-growing sample of tourism data. Secondly, the LSTM deep learning model was introduced for the first time to forecast the hotel accommodation demands, extending the application of DL methods in hotel demand forecasting. Finally, it is confirmed that LSTM can simulate the relationship between the Internet queries and the tourism demands of hotels. This breaks through the limitations of the traditional forecasting technology and provides a typical application case for the deep integration of tourism data with a relatively large dataset, artificial intelligence and real economy.
As far as applications are concerned, the constructed forecasting framework provides a new solution for the hotel accommodation demand forecasting done by managers of tourism-related departments under the Internet environment, which helps tourism-related departments to dynamically monitor the hotel overnights; it provides decision support for realizing the information of the destination management. In addition, the constructed empirical framework can be used to forecast other destination demands such as hotel revenues, etc. It can further be extended to other similar prediction fields.
Nevertheless, in the context of the voluminous data, there may be other characteristic information that may reflect the tourists’ potential tourism demands. In future research, it is necessary to further expand other sources of information reflecting the dynamic characteristics of the hotel accommodation demands. In addition, the volume of the available sample data collection limits the research results. As the data sample further increases, the validity of the empirical framework can be tested by the actual cases.







{kind=link}
{kind=link}
{kind=link}
{kind=link}