Knowledge and information from experts in traditional buildings were organised into datasets to train the AI model [
8]. Depending on the purpose, an appropriate algorithm was selected for classification and object recognition [
9]. After a comparative analysis of the characteristics and limitations, an algorithm was selected considering the work environment of traditional buildings.
2.1. Features of Traditional Buildings in Korea, China, and Japan
The traditional buildings of the three countries include wooden structures with a superstructure made of columns, beams, and roof trusses. The wooden structures are built by stacking structural members in the direction of gravity. The structural members are fitted and joined assembly-style [
10]. To use AI for classifying images of East Asian traditional buildings and recognising structural members, features need to be organised so that a group of experts can recognise the style of each country. To train the AI, the theory must be developed first. Then, each image in the dataset can be classified and labelled. After the classification, an image recognition algorithm is used to find feature points and patterns.
The traditional buildings of the three countries reflect their respective cultures and have individual features that can be used to train the AI. The AI only needs basic guidelines to learn these features. Korea, China, and Japan have several shared cultural aspects, and they have closely interacted with each other throughout history. The knowledge required for AI training has already been organised in previous studies comparing Korea, China, and Japan, such as Yongun Kim’s ‘cycle of history’ [
11] and Donguk Kim’s [
4] comparative studies of Korean, Chinese, and Japanese traditional buildings. Based on previous studies, features including the roof and colour scheme were used to train the AI to recognise traditional buildings of the three countries.
As an example of the different roof shapes of the three countries, the Yu Garden Pavilion in China has rich ornamentation and a highly curved roof [
12]. In Japan, the roof of Izumotaisya has a steep slope and even curvature. In Korea, the pillars of Munmyo Daeseongjeon are not standing in a straight line, the centre is bent slightly inward, and the entire building forms a curve.
Thus, the roofs of wooden buildings in East Asia have larger features than the buildings, and they form curves.
In China, bright colours such as red, orange, gold, and blue are commonly used. Furthermore, buildings tend to be planned with a left–right symmetry, and they have many courtyards. The buildings are decorated and large in scale. To make single-storey buildings look like two- or multi-storey buildings, awnings are sometimes placed beneath the roof. In Chinese architecture, the imposing scale of construction, which reflects the country’s vast overall landmass, stands out.
In Japan, dark-coloured schemes are often used, and they mainly include white, grey, red, and green. Buildings are often designed to be asymmetrical, and they have many gardens. Chinese buildings display grandeur and size, while Japanese buildings are characterised by minimalism. Japanese buildings reflect a mechanical precision that is not seen in Korea or China, and the roofs are straight and steeply sloped to deal with rain and snow. Additionally, because of the humid climate, Japanese architecture tends to be open and well ventilated. Overall, Japanese buildings are simple and subtle. Their restrained splendour and minimalism are apparent.
Korea mainly uses colours such as black, green, red, white, and dark blue. Chinese architecture tends to restrain nature artificially, while Japanese architecture uses gardens to present a nature-friendly appearance. Meanwhile, Korean architecture blends structures with nature to achieve harmony.
For example, rocks and wood that are taken from nature are not processed separately but used as construction materials without modification. Natural and unmodified materials and topography are used to display Korea’s unique natural beauty.
Moreover, the roofs of Korean buildings are the smoothest among the three countries because of the natural and comfortable curves of their tiled eaves. The aesthetics of the architecture stands out owing to its stable and comfortable appearance.
Figure 2 shows the organisation of the major features used for classification by the AI platform [
4].
2.2. Deep Learning with R-CNN and YOLO
In this study, two deep learning algorithms were used for object recognition: R-CNN and YOLO. Hui [
13] argued that deep learning algorithms are based on various concepts, so no model is best suited to all environments, and fair comparisons are difficult to make. This means that each algorithm should be tested for specific situations, and its suitability should be understood before application.
Figure 3 compares performance indicators of major deep learning algorithms for object recognition. The performance indicators were derived with the PASCAL VOC (Visual Object Classes) 2007 test set.
Figure 3a compares the accuracy of the object recognition and detection: YOLO had an accuracy of 78.6% with a unit module of 554 pixels, and Faster R-CNN had an accuracy of 70.4%.
Figure 3b compares the processing speed: Faster R-CNN and YOLO were at five and 40 frames per second (fps), respectively, at a low detection speed and 17 and 91 fps, respectively, at a high detection speed. R-CNN demonstrated a higher speed and accuracy than YOLO for object recognition.
The biggest difference between R-CNN and YOLO is that the former can recognise and detect objects inside a building through detailed masking. This is advantageous for analysing detailed architectural elements when classifying architecture. Other advantages include utilising pre-trained datasets in a cloud environment and not having to build servers for separate training. However, the drawback of using R-CNN to classify images is that it incurs continuous costs to maintain the cloud environment. Furthermore, the detailed masking task slows down the speed and places a constant load on the computer, which restricts processing of videos in real time. Therefore, the design elements considered for the masking task should be repetitive for easy classification; if the design elements are not repetitive and are few in number, there is a risk of frequent failures of classification and identification. The advantages of YOLO include a fast processing speed that is close to real time and a high accuracy relative to the speed. This algorithm is optimised for recognising components through block-type object detection but has the disadvantage of being unable to detect overlapping objects in an image. In particular, object recognition is limited when front-face data are mainly used to train a deep learning model and test images are viewed from different angles or objects in a given image have a low degree of exposure. However, YOLO can achieve a high recognition rate relative to the amount of learning and is optimised for object recognition, despite its limitations at classifying detailed designs. Therefore, an appropriate deep learning algorithm should be identified for different purposes. Accurately determining which algorithm to use should be based on a logical organisation of the work process, which should be in conjunction with relevant expert knowledge and field information input by the user. R-CNN was used to classify traditional buildings by country, and YOLO was used to recognise structural members. To examine the rationality of using two different algorithms, the same photograph was analysed with the same weight values for each algorithm.
R-CNN combines region proposal with a CNN structure and is executed as follows.
Region proposal is performed to ascertain the locations of objects.
CNN is used to extract feature maps from areas that have undergone region proposal.
Bounding boxes are drawn around objects extracted by a linear support vector machine (SVM) for classification via the extracted feature map.
Figure 4 shows the imaging procedure. R-CNN was not executed in a cloud environment but as a local task. The processes were performed on a photograph taken at a Japanese convenience store, and a pre-trained Common Objects in Context (COCO) image dataset was used. The COCO dataset, which was released in 2015, was trained beforehand with a variety of objects. The format of the dataset was used to include data on traditional buildings from each country and structural members. The results showed that R-CNN could partially recognise the refrigerator and cans in the refrigerator. A major feature of R-CNN is its sophistication at analysing overlapping results. By changing the threshold value, it could detect a large number of cans in the refrigerator. However, the threshold value was fixed at 0.5 for comparison with YOLO.
The main features of R-CNN are its recognition rate for overlapping objects and its ability to classify small objects. Thus, it can be used to analyse the detailed aesthetic design of buildings from each country. However, it was not designed for real-time processing [
11] and has a low processing speed. In addition, R-CNN lacks certain areas related to imitating human vision owing to its complex processing procedures. Thus, YOLO was used to classify and detect the locations of structural members in traditional buildings. YOLO uses a brief computation process for object recognition; this is similar to a person discerning the details of objects in an image at a glance. However, the brief computation process means that YOLO has low accuracy compared to algorithms with complex computation methods like R-CNN. Moreover, it can only detect one object when several objects overlap. The main concept of YOLO is as follows.
Grid lines are drawn on the input image at fixed intervals (S) as in graph paper.
N bounding boxes are created based on the grid, and the reliability is predicted to verify whether objects are within the bounding boxes.
A CNN is used to determine the accuracy of the bounding boxes and confirm whether objects are in the bounding boxes.
The probability of objects within the confirmed boxes being similar to objects in the dataset is calculated. Bounding boxes with high probabilities are labelled as recognised objects.
Thus, YOLO leverages a computer’s ability to perform repetitive tasks and recognises objects by drawing boxes randomly and then comparing them to a dataset all at once. This method is much faster than other object recognition algorithms. According to Hui [
13], the difference in speed of YOLO and Faster R-CNN, which is a real-time version of R-CNN, is 91 fps to 5 fps. However, YOLO has limited ability to recognise overlapping objects because of the structure of its algorithmic process. For example, it was unable to detect the cans in the refrigerator, as shown in
Figure 5. Thus, this algorithm should be used when it suits the objective and situation. YOLO is suitable for recognising and analysing East Asian traditional buildings because the structural members are assembled by a stacking method. In this study, YOLO was used to recognise structural members. The above analysis indicates that R-CNN should be used in environments that allow a slow work speed but require high accuracy, and YOLO should be used in environments that require a high work speed with relatively low accuracy and do not require overlapping objects to be recognised.
2.3. Machine Learning in a Cloud Environment
Machine learning can be used in a cloud environment as well as local environment [
14]. In the case of image recognition, cloud environments allow for higher accuracy at a faster pace than local environments. This is mainly because cloud environments have pre-trained models. For example, Google has an image-based storage system called Google Photos that provides a large comparison group for reference. However, when this process is run on a local computer, increasing the accuracy requires a long time because of the limited data in the comparison group. When an image recognition algorithm is implemented in a local environment, the task of pre-emptively procuring a dataset to increase the accuracy during the learning process incurs a load. This is because few pre-trained datasets are available, and referring to data of other objects has limited value during the learning process. Machine learning in a cloud environment allows pre-trained datasets provided by large-scale platform services to be used, along with additional datasets from specialised fields. Recently, Forbes predicted a 42.8% increase in the combined annual growth rate of platforms incorporating cloud-based machine learning from 2018 to 2024 [
15].
Additionally, cloud computing is often used for machine learning tasks on existing platform services. This allows hardware systems with a fast replacement period to be rented and operated remotely over the Internet. In addition, the machine learning can be updated in real time. Platforms for object recognition in a cloud environment include Cloud Vision and Auto Machine Learning (AutoML).
2.3.1. Cloud Vision
Cloud Vision is an application programming interface (API) for deep learning [
16]-based image analysis. Users can automatically find features in images that have been classified by individuals [
17]. Images can be quickly analysed according to thousands of categories, and defined labels can be detected. Defined objects and faces can be recognised in images, and words that are printed in images can be read to extract text. Datasets can be used to define various functions, such as reviewing harmful content, analysing emotions, and recognising logos. Then, mass processing can be performed.
Table 1 presents the functions that can be performed. Cloud Vision can also be used for customised tasks using image recognition algorithms such as R-CNN and YOLO.
2.3.2. Cloud AutoML
Cloud AutoML is a deep learning optimisation method that allows even users with minimal machine learning [
18] knowledge to customise high-quality models to fit their business needs through the Cloud Vision API. Cloud AutoML provides a graphical user interface (GUI) environment that can be used to train, evaluate, improve, and distribute a model based on the user’s own data. Therefore, custom machine learning models can be created on a web console [
19]. Because it is completely integrated with other Google cloud services, users can use a consistent access method for all of Google’s product lines. In Cloud AutoML, if a grouped and labelled dataset is placed in AutoML, the train, deploy, and serve processes are performed internally. The serve process can be used to publish a platform created by deep learning on all platforms including webpages, mobile devices, and computers, as shown in
Figure 6. Thus, it provides a work environment with excellent and immediate scalability. Because Cloud AutoML supports Python and REST (Representational State Transfer) API for model generation, it can be used to create application programs. Once a deep learning model has been built, realising practical utilisation is simple. Therefore, it can be used intuitively in needed areas, and feedback is possible. The biggest advantage is that a model can be made smarter continuously and gradually after development by using data results with the user’s approval. The traditional buildings classification model requires specialised knowledge as reference data for deep learning. AI is used to obtain desired feature points within the image by itself, and the points are reviewed with non-training data to increase the accuracy further. Thus, a deep learning model can train itself in real time and improve its own performance [
20].
This is the difference between cloud-based and local deep learning. Cloud-based deep learning has a pipeline structure in which the algorithm gradually becomes smarter as it is used. However, the specific algorithms and learning method must be set according to the type of data and situation. When a pre-trained model is used in a cloud environment, basic functionalities such as cloud vision, natural language, and translation can be operated. However, when a model incorporating specialised theory is developed, customisation is necessary. Therefore, AutoML was used to incorporate certain requirements.
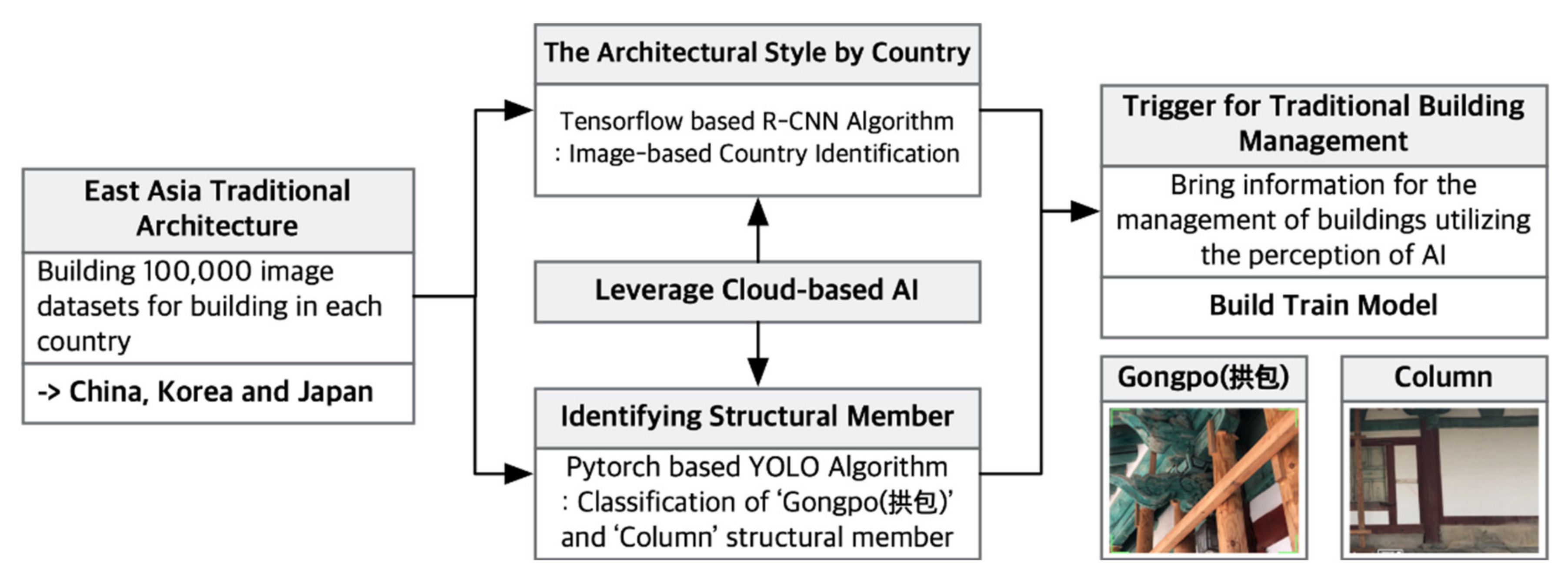
2.4. AI-Based Model for Traditional Buildings and Structural Member Classification
R-CNN was used to classify traditional buildings by country (Korea, Japan, and China) [
7], and YOLO was used to detect structural members [
7]. This section summarises the purpose-specific datasets and construction process of the deep learning model [
21].
2.4.1. Datasets for Classifying Traditional Buildings by Country and Structural Members
Non-experts may have difficulty distinguishing traditional buildings styles by country. To train a deep learning model with relevant expert knowledge and allow non-experts to distinguish architecture styles, data need to be collected to train and test object recognition.
Figure 7 shows the ways that the object recognition data were used in this study.
The first approach was type classification, which is an object recognition technique. Images were used to train the AI in classifying traditional buildings styles by country. Experts classify the architecture styles of the three East Asian countries by the exterior colour scheme and curvature of the roof. Rather than teaching these rules to the computer in detail, a playground was created so that the computer could learn on its own. A dataset for deep learning was completed by grouping together images that depict building styles and saving their labels in a cloud AutoML dataset. Because the dataset was constructed in a cloud environment, this task can easily be completed by a computer running a web browser.
Figure 8 diagrams a dataset in which images have been grouped for classification and labels have been applied. This was done with Google Teachable Machine, which is a cloud-based object-recognition platform that can easily construct datasets to popularise AI. However, the platform can only be used for specific image classification tasks without specifying the deep learning algorithm. This limits its ability to perform intermediate deep learning tasks such as image calibration and weight adjustment. For a simple classification test, 1500 images were used. The epoch value was set to 50 (i.e., the training process was repeated 50 times), and the batch size was set to 16. The batch size is the number of hidden layers and refers to the degree of resolution. In other words, the features of an image are decomposed into 16 stages and analysed. A real-time test was performed on Gyeongbokgung Palace in Korea. The analysis results showed a 75% probability that it was a traditional Korean building and 25% probability that it was Japanese.
The second approach was to combine object recognition with location. As shown in
Figure 7b, this method requires not only classifying structural members but also locating them in the image. In this study, this task was performed with a pre-trained model on Google Cloud Platform (GCP). Therefore, the model did not yield specific names of structural members in traditional Korean buildings or specialised information but rather analysed buildings, people, and clothing types. This task requires not only grouping data but also labelling members accurately. Square bounding boxes were drawn around the structural members in images (i.e., masking). To create the dataset for structural member classification, images containing gongpo and columns [
22] were labelled with Supervisely, which is a cloud-based labelling tool.
As shown in
Figure 9, the basic learning task was performed by masking the major structural members of traditional buildings. The bounding box and masking tasks were performed on the gongpo and columns in parallel. These structural members were labelled so that the computer could recognise them.
First, 16,478 traditional buildings-related data were masked (A in
Figure 9). The deep learning algorithm (B-2) was combined with the masking data (B-1). The model was then built (C), and the type classification and location recognition tasks were performed. The number of images was increased by a factor of four by stretching, resizing, and distorting each image. This transformation task is a special training that allows the model to recognise objects when viewing images with various perspectives. The image data were masked and labelled on Supervisely, but a personal Linux server had to be prepared to compute the deep learning algorithm. Because Supervisely is a free service, it is structured so that personal hardware is needed to create an actual model. The basic requirements of the deep learning algorithm were a Linux operating system and Nvidia 1080 Ti professional-grade graphics hardware.
Thus, a Linux server was built to implement the deep learning algorithm. The dataset created by this process was uploaded to the GCP’s dataset server by a backend system so that it could be used by the deep learning model. Datasets were created for object recognition of traditional Korean architecture with the two approaches. The methods for creating the deep learning model using these datasets are presented in the next section.
2.4.2. Deep Learning Model for Classifying Traditional Buildings Styles and Structural Members
Separate datasets were created for classifying the architecture types and structural members. Next, a deep learning [
23] model was created with TensorFlow and trained with the datasets and different algorithms: R-CNN for type classification and YOLO for structural member recognition. As discussed in
Section 2.2, R-CNN and YOLO use different methods for object recognition but the same structure for deep learning. They only differ in methodology for learning datasets.
Figure 10 shows the deep learning structure.
Image data were used for training. The deep learning process is similar to solving problems in a workbook; labels in a large dataset were matched to the correct country without being taught to the computer. For this experiment, the dataset was divided at a 7:3 ratio for training and testing, respectively. For the training, the epoch and batch size of the model were calibrated to ensure the appropriate percentage for accuracy.
An accuracy that is too high or too low can cause overfitting or underfitting, respectively. With overfitting, the AI can only solve problems used during training and performs poorly at solving new problems. With underfitting, the AI needs more training because it cannot solve either the training problems or new problems. The epoch was set to 50, and problems corresponding to 70% of the given dataset were solved 50 or more times. The batch size refers to how many problems are solved at once before an answer is produced during each epoch.
For example, if 70 problems must be solved and the batch size is set to 7, all 70 problems are solved in one epoch, but an answer is produced after 10 problems are solved simultaneously. Thus, the AI creates patterns for studying to increase accuracy.
Finally, the calibrated variables were used to set the number of hidden layers. As shown on the right side of
Figure 10, an image of Gyeongbokgung in Seoul [
24] was inserted in the input layer. Then, the outlined part was extracted in hidden layer 1. As the layers increased, image elements were split gradually to create samples for analysis.
The number of samples that segmented the image also increased. R-CNN analysed the image in detail; this algorithm is structured so that the weights of the hidden layers have a greater effect than in YOLO. In the experiments, R-CNN classified buildings according to country by a detailed analysis of patterns in the data that were depicted externally, such as the aesthetic elements of the building, curvature of the roof, and colour scheme. The values of the hidden layers were used as a variable that correlates with accuracy. Meanwhile, YOLO can quickly scan images and videos to classify and locate objects in real time. It can recognise structural members that are stacked to create a prefabricated structure. Thus, the accuracy was more affected by the sophistication of the labelling performed in Supervisely than the settings for the batch size and epoch.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}