1. Introduction
Automatic speech recognition (ASR) is a process of converting audio to text. Applications of ASR include dictation, accessibility, hearables, voice assistants, AR/VR applications, among other things. Speech recognition has improved greatly in recent times because of the adoption of deep learning based techniques for training and inferencing [
1]. However, most of the state-of-the-art speech recognition models are deployed based on cloud computing architectures where input from user devices is sent to the server for processing and results are returned back to the device. This model can not guarantee the privacy and security of user-sensitive audio data. This architecture is also prone to reliability, latency, and availability issues because of the reliance on the network.
Machine learning practitioners typically optimize for the accuracy of the model to achieve state of the art results. Recent studies focusing on GreenAI [
2,
3] reveal that after a certain point, achieving linear incremental improvements to accuracy (in this case the WER) leads to exponential increase in the energy cost for training and inference. The carbon footprint of these applications will worsen the global energy crisis as deep learning based AI applications obtain widely adopted [
4,
5]. Specifically for ASR applications, one solution is to adopt a balanced approach by using an ASR model based on its energy, accuracy, and performance trade-offs. For example, in the case of on-device dictation applications, minor and infrequent ASR errors can be tolerated as long as the app running on the device can provide a way to correct some of these errors via keyboard or scribble. Having lower WER will definitely improve the user experience. However, if the lower WER burns battery at higher rate, a sensible product decision would be to settle for an acceptable WER within the energy budget and provide other UI affordances to satisfy product or application requirements. With experimental evaluations in this paper we attempt to inform the research community about the energy and accuracy trade-offs of ASR inference on the edge.
On-device ASR inherently provides privacy and security to sensitive user data and is more reliable and performant by precluding the need for network connectivity. Apart from these obvious reasons, on-device ASR inference is also a more sustainable solution in terms of energy efficiency. For cloud based processing, the audio needs to be streamed to the server. There is also the energy cost of Wi-Fi/LTE for connection establishment and data transfer [
6], routing across the internet and computation in data centers. Moreover, the computations on data centers are more expensive than on a typical hand held device given the multicore CPUs and associated cooling mechanisms. All these energy costs will be saved by on-edge processing.
Related to our work, Ref. [
7] evaluated the on-device speech recognition performance with DeepSpeech [
8], Kaldi [
9], and Wav2Letter [
10] models. Effects of thermal throttling on CNN vision models was researched in [
11]. In [
12], authors evaluate the performance, power consumption, and thermal impact of CNN based vision inference on edge devices. Authors in [
3] predict the energy cost of NLP inference using software approach. In this paper, our objective is to measure the trade-off between accuracy, energy, and performance of ASR with a typical transformer based model on the edge. To the best of our knowledge there are no prior articles or research work which assess ASR inference on edge in terms of performance and efficiency. Many of the on-edge evaluation papers focus on CNN based models for computer vision.
We used Raspberry Pi for evaluations for a few reasons. It is an easily programmable and configurable Linux based device. We can control the environment, such as co-running apps to ensure that there are no side effects during evaluations. We could easily use off-the-shelf power meters to measure steady state and inference time energy consumption. Research completed in this paper [
4] shows that hardware based energy evaluations are at-least 20 pcs more accurate than software based energy management solutions. Further, the hardware specs of Raspberry Pi 4 are comparable to smart speaker, smart displays, AR/VR products, etc. This makes Pi a good proxy device to assess ASR performance and efficiency of typical edge devices.
Major contributions of this paper are as follows:
We present a process for measuring energy consumption of ASR inference on Raspberry Pi using an off-the-shelf energy meter;
We measure and analyze the accuracy and energy efficiency of the ASR inference with a transformer based model on an edge device and show how energy and accuracy vary across different sized models;
We examine the performance and computational efficiency of ASR process in terms of CPU load, memory footprint, load times, and thermal impact of various sized models;
We also compare on-edge WER with that of server’s for the same dataset.
The rest of the paper is organized as follows: In the background section we discuss ASR and transformers. In the experimental setup, we go through the steps for preparing the model and setting up, for inferencing and energy measurements. We go over the accuracy, performance and efficiency metrics in the results section. Finally, we conclude with a summary and outlook.
4. Results
We evaluate different sized Speech2Text models with beam width of 5 and 1 configurations for accuracy, performance and efficiency. The word-error-rate (WER) metric is used for measuring accuracy. WER is defined in Equation (
1). The real-time-factor (RTF) is used to measure performance. RTF is defined in Equation (
2). We measure energy, model load time, memory footprint, and CPU percentage of the execution script to evaluate the efficiency of the model inference.
Librispeech test and dev datasets together contain ∼21 h of audio. It would have taken us many days to execute the inference on all combinations of models with all the audio in these datasets. To save time, for this experiment, we randomly sampled 30% of the audio files in each of the four datasets for inference and evaluation. The same sampled datasets were used in all the on-device and on-server inference test runs thus ensuring that the results are comparable.
4.1. WER
Table 3 shows the WER of various models.
WER is slightly higher for the quantized models compared to the unquantized float versions. This is the cost-benefit trade-off of accuracy vs. RTF and efficient inference. Test-other and dev-other datasets have a higher WER compared to test-clean and dev-clean datasets. This is also expected because other datasets are noisier compared to clean ones. WER improves as the model obtains bigger with more number of encoder/decoder layers and parameters. For medium and large models, WER is generally lower for beam size of 5 configuration compared to beam size of 1. Since beam size of 1 means greedy search, it might exclude some of the early hypothesis which might yield better overall match at the later stages of decoder search.
The server side inference evaluation was carried out on a Google Colab instance. Essentially the same pre-trained model is imported on Colab instance except without the PyTorch dynamic quantization and mobile optimization steps. For medium and large models, the Colab WER is same as observed on the edge. However, on smaller model, the on-device WER is higher than the server based one. We are still trying to understand this specific behavior.
4.2. RTF
In our experiments, RTF is dominated by model inference time >99% compared to other two factors in Equation (
2).
Table 4 shows the RTF for all models in both beam size 1 and beam size 5 configurations. RTF does not vary between different datasets for the same models. Hence, we show RTF (avg, mean, and p75) per model instead of one per dataset.
RTF improved by 10% for small quantized model compared to unquantized floating point model. Similarly, for medium and large models the improvement is by 20% and 50%, respectively. RTF is ∼30% lower for medium and large models with beam width 1 compared to 5, whereas for small model there is no difference between two configurations. Improvements in RTF going from unqunatized to quantized, larger to smaller and beam 5 to beam 1 are expected because there will be lesser number of computations and search involved. We do not observe the improvement in RTF on small model by reducing the beam size possibly because the small model is quite refined by PyTorch mobile optimizations.
Overall, the small and medium models have RTF less than 1.0 in normal mode, making them potentially suitable for real-time inference.
4.3. Temperature
We measure the impact of long running ASR process on CPU temperature. Temperature increase is particularly significant for wearable and mobile devices where the devices are closer to the human body and, therefore, tolerance for increase is very limited, unlike for the machines in datacenter or other stand-alone home devices. As shown in
Table 5, the temperature increases close to max level 80 °C in normal mode a 28 °C increase from steady state (52 °C). In power save mode, the increase is only by 14 °C. Note that these increases do not happen for single inference session but after few minutes of continuous inference. The increase also depends on ambient temperature.
Out of curiosity, we ran ASR inference on small quantized model for long time (>1 h) to check the effects of thermal throttling on CPU frequency and ASR RTF.
Figure 4 shows the weighted-average variation in temperate, RTF, and CPU frequency. The Linux dynamic-voltage-frequency-scaling (DVFS) reduces the average CPU frequency when the temperature approaches 82 °C (thermal limit) which, in turn, increases the RTF (40%). The throttling limit can reach very quickly if the ambient temperature is higher.
4.4. Energy
Figure 5 and
Figure 6 show the watts consumption over time for small quantized model in normal and powersave modes. The steady state wattage in normal mode is 3.6 W (5.2 V × 0.7 A) on Raspberry Pi. This increases by 1.6 W when the ASR inference script is active. Similarly, in powersave mode, the increase is 0.65 W during ASR inference from steady state.
Table 6 shows the ASR energy consumption of both beam size 1 and 5 configurations for all models for a 10 s long utterance. Small model consumes 5× to 8× less power compared to larger models.
For comparison, if we run small quantized ASR model on Apple watch with a 303.8 mAh (1.17 Wh) battery capacity, ASR for a 10 s utterance would roughly consume ∼0.08% of battery capacity. This is only for the computation part. In real scenarios, such as dictation, voice commands, etc., we also need to account for power used by microphone for input capture and UI display for any associated output during the usage.
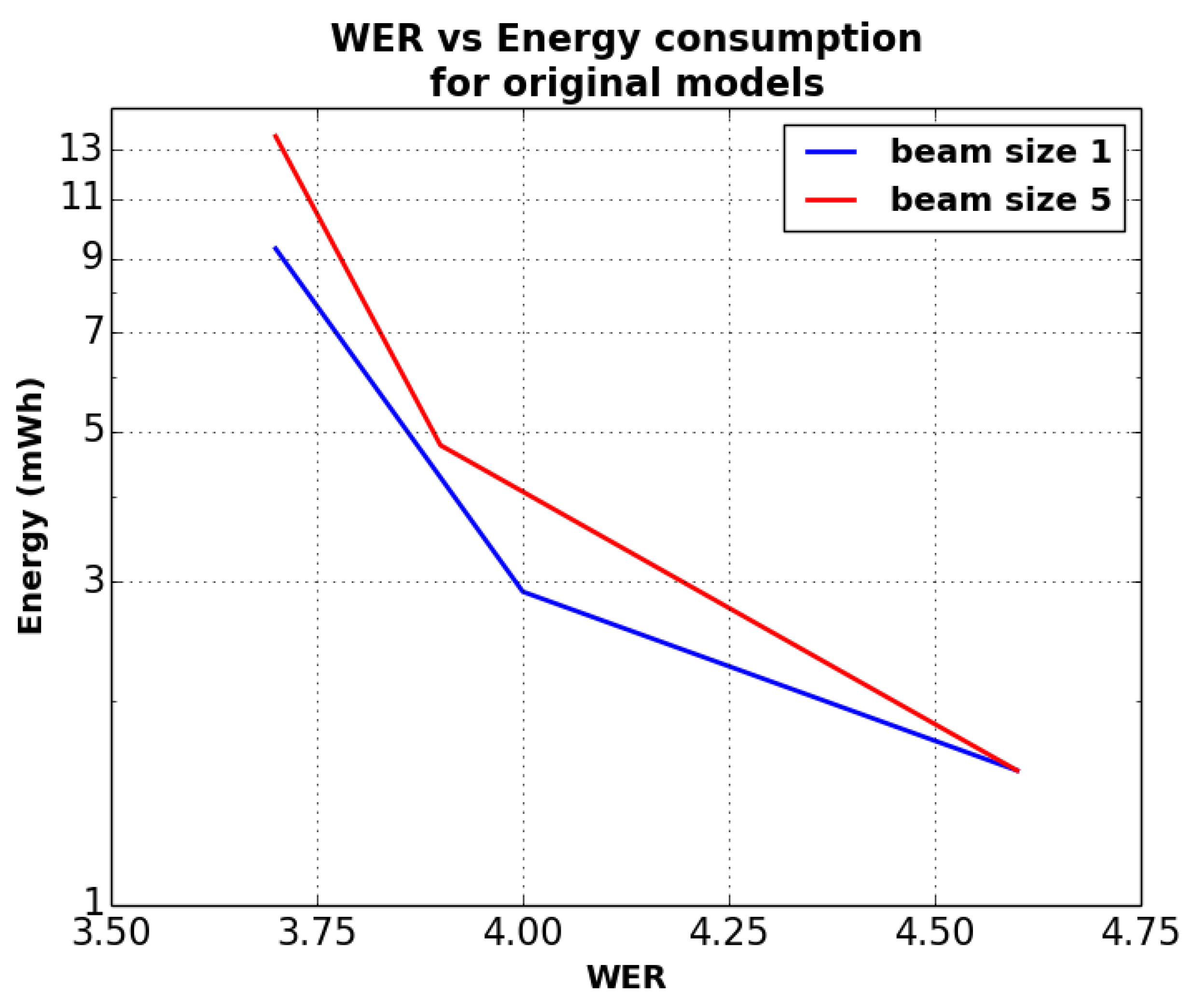
Figure 7 and
Figure 8 show the variation of energy consumption vs. WER. We have chosen test-clean dataset as a baseline for graphs since the energy consumption does not vary much across the different datasets. The energy on Y axis is plotted in log scale. The liner/geometric line of growth on the log scale, for both beam 1 and 5 configurations, clearly points toward exponential growth in energy as WER rate decreases incrementally. Improving WER on quantized model by 1.2% resulted in ∼4× to 5× increase in energy consumption. In case of unquantized model, 0.9% WER improvements resulted in ∼6× to 9× increase in energy consumption. Although the energy measurements on this model clearly show exponential growth, we also want to validate the same with larger set of models as part of future work.
4.5. Memory and CPU
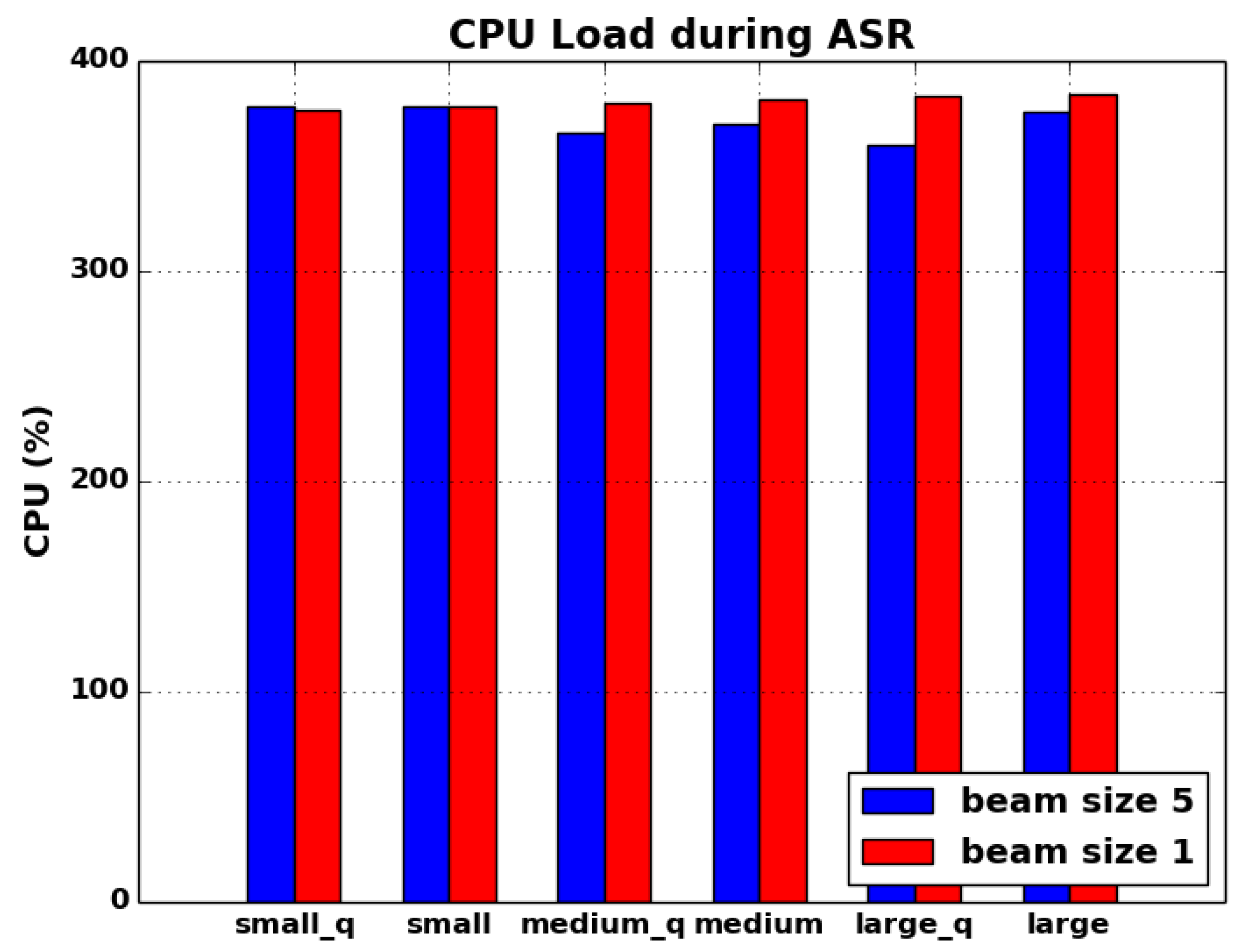
Figure 9 and
Figure 10 shows the memory and CPU consumption of all the models used in this experiment. small quantized model memory footprint is 295 MB. By quantization, memory footprint reduced by 35% for small model. For larger models, quantization reduces the memory by higher margins; 50% for medium model and 68% for larger model. The models with decoder beam size of 1 generally have slightly lower memory footprint compared to models with beam size 5. This is not surprising given that the decoder scanning space is smaller with beam 1. The overall memory accounting is a complicated process. We deduce that all processes have common memory pages because of shared libraries, code and other process infra related pages. Therefore, quantized small model does not show large gains in memory as compared to bigger models. The footprint largely co-relates to model size and the number of parameters in the models.
The memory values presented here are avg RES (resident set size) values from Linux top (
https://man7.org/linux/man-pages/man1/top.1.html, accessed on 5 November 2021) command. RES includes clean, dirty, and the shared memory pages of the process. One thing to notice is that almost all the model data pages are clean (read-only). These clean pages can be swapped (on systems with swap space) out by OS on memory pressure without terminating the process because of out-of-memory (OOM) condition.
CPU utilization is ∼95% in all cases. ASR is a CPU intensive process. All the models fully utilize all four available cores during inferencing.
Model Load Time
Table 7 shows the model load times of all the models used in this experiment. The load times are measured from clean state, i.e., after the reboot, the first-time loads are considered. Typically, the operating system caches the file pages in the memory. So, the load times can be smaller on subsequent uses. The small quantized model load time avg is 2.2 s. This is small enough to be loaded on-demand in an application for real-time dictation, voice commands, etc. The other load times roughly co-relate to the model sizes and parameters as shown in
Table 1.
5. Conclusions
We presented a methodology for measuring energy consumption on Raspberry Pi using off-the-shelf USB power meter. We evaluated the ASR accuracy, performance and efficiency of a transformer based speech2text models on Raspberry Pi. With WER ∼10%, <300 MB memory footprint and RTF well below 1.0, quantized small architecture models can be efficiently deployed on mobile and wearables devices. The small quantized model is also quite efficient in terms of power consumption. It consumes ∼0.1% of battery for 10 s audio inference on a smaller device, such as an Apple Watch 3. Larger models can be used to achieve higher accuracy at the expense of higher RTF, memory, and power. For medium and large models using lower beam size, RTF and energy consumption significantly reduce, albeit with a small degradation in WER. We believe accuracy, latency, and energy trade-offs in on-edge AI is a rich area to explore considering different types of architectures, number of hyper parameters, decoders with language model, etc. With this initial study we could deduce that inference energy consumption increases exponentially in relation to linear improvements in WER. Machine learning developers continue to research ways to improve the model accuracy. It is a well established knowledge in the research community that the training of ASR models with lower WER will also require factor of magnitude higher energy. With our study we could reason that inference is no different in that regard. Hence, we conclude that a careful consideration and balance of application’s WER requirements and energy budget is crucial before deploying an ASR model for edge inferencing. We also conclude that, temperature throttling is not an issue for short duration ASR inference but something to keep in mind during continuous long duration inference as it can affect the RTF because of throttling.
In the future, we are planning to explore streaming ASR energy consumption with latest model architectures. We are also planning to build a generic system using off-the-shelf hardware and software packages to be able to measure energy vs. accuracy trade-offs on any models agnostic to ML platforms.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}