
Enhancement of Multi-Class Structural Defect Recognition Using Generative Adversarial Network


Abstract
:1. Introduction
2. Literature Review
2.1. Structural Defect Recognition Using Deep Convolutional Neural Networks
2.2. Data Augmentation for Improvement of Deep Convolutional Neural Network Performance
3. Methodology
3.1. Dataset Collection of Concrete Damage Images
3.2. Data Augmentation Using Geometric Transformation
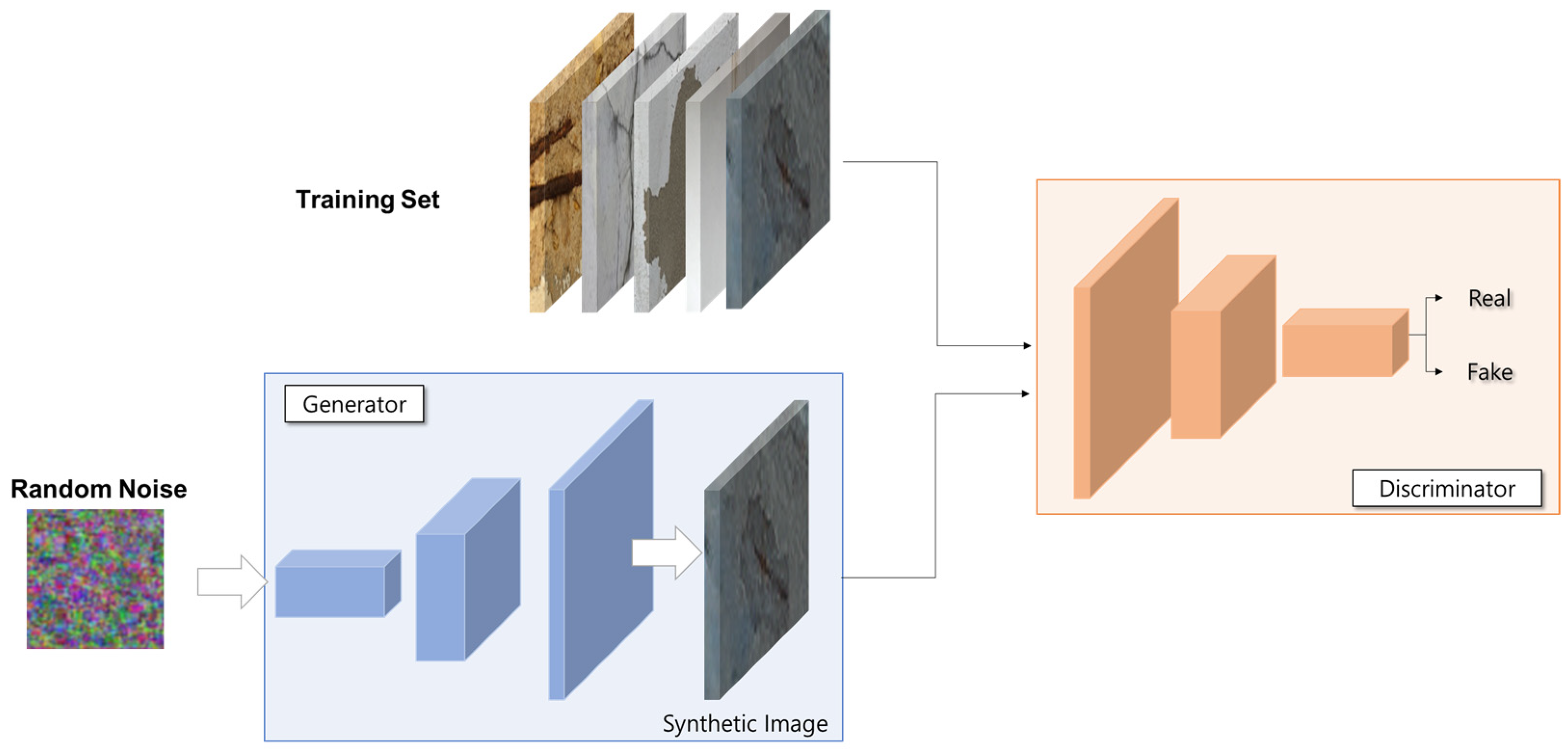
3.3. Data Augmentation Using Generative Adversarial Network
3.4. Establishment of the Concrete Damage Image Dataset
4. Experiments
4.1. Experimental Settings
4.2. Experimental Metrics
5. Results
5.1. Scenario 1: Experiments with a Small Dataset
5.2. Scenario 2: Experiments with Data Augmentation
6. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liang, X. Image-based post-disaster inspection of reinforced concrete bridge systems using deep learning with Bayesian optimization. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 415–430. [Google Scholar] [CrossRef]
- Lin, Y.Z.; Nie, Z.H.; Ma, H.W. Structural Damage Detection with Automatic Feature-Extraction through Deep Learning. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 1025–1046. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Sharma, M.; Anotaipaiboon, W.; Chaiyasarn, K. Concrete crack detection using the integration of convolutional neural network and support vector machine. Sci. Technol. Asia 2018, 23, 19–28. [Google Scholar]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Liu, Z.; Zhong, X.; Dong, T.; He, C.; Wu, B. Delamination detection in composite plates by synthesizing time-reversed Lamb waves and a modified damage imaging algorithm based on RAPID. Struct. Control Health Monit. 2017, 24, 1–17. [Google Scholar] [CrossRef]
- Dinh, K.; Gucunski, N.; Duong, T.H. An algorithm for automatic localization and detection of rebars from GPR data of concrete bridge decks. Autom. Constr. 2018, 89, 292–298. [Google Scholar] [CrossRef]
- Atha, D.J.; Jahanshahi, M.R. Evaluation of deep learning approaches based on convolutional neural networks for corrosion detection. Struct. Health Monit. 2018, 17, 1110–1128. [Google Scholar] [CrossRef]
- Dong, Y.; Wang, J.; Wang, Z.; Zhang, X.; Gao, Y.; Sui, Q.; Jiang, P. A Deep-Learning-Based Multiple Defect Detection Method for Tunnel Lining Damages. IEEE Access 2019, 7, 182643–182657. [Google Scholar] [CrossRef]
- Wang, N.; Zhao, Q.; Li, S.; Zhao, X.; Zhao, P. Damage Classification for Masonry Historic Structures Using Convolutional Neural Networks Based on Still Images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1073–1089. [Google Scholar] [CrossRef]
- Deng, J.; Lu, Y.; Lee, V.C.S. Concrete crack detection with handwriting script interferences using faster region-based convolutional neural network. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 373–388. [Google Scholar] [CrossRef]
- Antoniou, A.; Storkey, A.; Edwards, H. Data augmentation generative adversarial networks. arXiv 2017, arXiv:1711.04340. [Google Scholar]
- Nhat-Duc, H.; Nguyen, Q.L.; Tran, V.D. Automatic recognition of asphalt pavement cracks using metaheuristic optimized edge detection algorithms and convolution neural network. Autom. Constr. 2018, 94, 203–213. [Google Scholar] [CrossRef]
- Lee, J.; Ahn, Y.; Lee, S. Post-Handover Defect Risk Profile of Residential Buildings Using Loss Distribution Approach. J. Manag. Eng. 2020, 36, 04020021. [Google Scholar] [CrossRef]
- Lee, K.; Hong, G.; Sael, L.; Lee, S.; Kim, H.Y. MultiDefectNet: Multi-Class Defect Detection of Building Façade Based on Deep Convolutional Neural Network. Sustainability 2020, 12, 9785. [Google Scholar] [CrossRef]
- Antoniou, A.; Storkey, A.; Edwards, H. Augmenting image classifiers using data augmentation generative adversarial networks. In Proceedings of the 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 594–603. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Hauberg, S.; Freifeld, O.; Lindbo Larsen, A.B.; Fisher, J.W.; Hansen, L.K. Dreaming more data: Class-dependent distributions over diffeomorphisms for learned data augmentation. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, AISTATS 2016, Cadiz, Spain, 9–11 May 2016; Volume 41, pp. 342–350. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Chandran, P.; Asber, J.; Thiery, F.; Odelius, J.; Rantatalo, M. An Investigation of Railway Fastener Detection Using Image Processing and Augmented Deep Learning. Sustainability 2021, 13, 12051. [Google Scholar] [CrossRef]
- Engstrom, L.; Tran, B.; Tsipras, D.; Schmidt, L.; Madry, A. A rotation and a translation suffice: Fooling cnns with simple transformations. In Proceedings of the International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems 27; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016—Conference Track Proceedings 2016, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–16. [Google Scholar]
- Gauthier, J. Conditional generative adversarial nets for convolutional face generation. Cl. Proj. Stanf. CS231N Convolutional Neural Netw. Vis. Recognit. Winter Semester 2014, 2014, 2. [Google Scholar]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the International Symposium on Biomedical Imaging 2018, Washington, DC, USA, 4–7 April 2018; pp. 289–293. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, Australia, 6–11 August 2017; Volume 4, pp. 2941–2949. [Google Scholar]
- Gao, Y.; Kong, B.; Mosalam, K.M. Deep leaf-bootstrapping generative adversarial network for structural image data augmentation. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 755–773. [Google Scholar] [CrossRef]
- Lee, S.; Kim, J.; Lee, G.; Hong, J.; Bae, J.H.; Lim, K.J. Prediction of Aquatic Ecosystem Health Indices through Machine Learning Models Using the WGAN-Based Data Augmentation Method. Sustainability 2021, 13, 10435. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Kitchen, A.; Seah, J. Deep Generative Adversarial Neural Networks for Realistic Prostate Lesion MRI Synthesis. arXiv 2017, arXiv:1708.00129. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | C0 | C1 | C2 | C3 | C4 | Total |
|---|---|---|---|---|---|---|
| Raw Dataset | 412 | 530 | 268 | 563 | 208 | 1954 |
| Train | 297 | 382 | 194 | 406 | 151 | 1430 |
| Val | 74 | 95 | 48 | 101 | 37 | 355 |
| Test | 41 | 53 | 26 | 56 | 20 | 196 |
| Category | C0 | C1 | C2 | C3 | C4 | Total |
|---|---|---|---|---|---|---|
| Raw Dataset | 412 | 530 | 268 | 563 | 208 | 1954 |
| Train Dataset | 297 | 382 | 194 | 406 | 151 | 1430 |
| Val Dataset | 74 | 95 | 48 | 101 | 37 | 355 |
| Test Dataset | 41 | 53 | 26 | 56 | 20 | 196 |
| Train Dataset _DA | 16,000 | 16,000 | 16,000 | 16,000 | 16,000 | 80,000 |
| Val Dataset _DA | 4000 | 4000 | 4000 | 4000 | 4000 | 20,000 |
| Test Dataset _DA | 2368 | 2988 | 1436 | 3036 | 1092 | 10,920 |
| Models | Loss | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| AlexNet | 0.8778 | 0.8469 | 0.8468 | 0.8418 | 0.8443 |
| VGG16 | 1.5567 | 0.8571 | 0.8697 | 0.8506 | 0.8600 |
| ResNet50 | 1.3334 | 0.7500 | 0.7561 | 0.7449 | 0.7504 |
| InceptionV3 | 0.7465 | 0.8367 | 0.8484 | 0.8316 | 0.8398 |
| MobileNetV2 | 1.2994 | 0.6888 | 0.6961 | 0.6786 | 0.6871 |
| Average | 1.1627 | 0.7959 | 0.8009 | 0.7908 | 0.7957 |
| Models | Loss | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| AlexNet+DA | 0.4199 | 0.9235 | 0.9429 | 0.9184 | 0.9300 |
| VGG16+DA | 0.1562 | 0.9755 | 0.9704 | 0.9704 | 0.9704 |
| ResNet50+DA | 0.1924 | 0.9605 | 0.9603 | 0.9608 | 0.9608 |
| InceptionV3+DA | 0.1017 | 0.9756 | 0.9771 | 0.9750 | 0.9760 |
| MobileNetV2+DA | 0.1194 | 0.9685 | 0.9698 | 0.9680 | 0.9686 |
| Average | 0.1972 | 0.9607 | 0.9651 | 0.9595 | 0.9621 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, H.; Ahn, Y.; Tae, S.; Gil, H.; Song, M.; Lee, S. Enhancement of Multi-Class Structural Defect Recognition Using Generative Adversarial Network. Sustainability 2021, 13, 12682. https://doi.org/10.3390/su132212682
Shin H, Ahn Y, Tae S, Gil H, Song M, Lee S. Enhancement of Multi-Class Structural Defect Recognition Using Generative Adversarial Network. Sustainability. 2021; 13(22):12682. https://doi.org/10.3390/su132212682
Chicago/Turabian StyleShin, Hyunkyu, Yonghan Ahn, Sungho Tae, Heungbae Gil, Mihwa Song, and Sanghyo Lee. 2021. "Enhancement of Multi-Class Structural Defect Recognition Using Generative Adversarial Network" Sustainability 13, no. 22: 12682. https://doi.org/10.3390/su132212682
APA StyleShin, H., Ahn, Y., Tae, S., Gil, H., Song, M., & Lee, S. (2021). Enhancement of Multi-Class Structural Defect Recognition Using Generative Adversarial Network. Sustainability, 13(22), 12682. https://doi.org/10.3390/su132212682