1. Introduction
Crude oil is one of the most important kinds of energy at present. The fluctuation of crude oil prices has a substantial impact on world economic activities in many ways. Brent, West Texas Intermediate (WTI), and Dubai/Oman are three benchmarks of the crude oil market. Recently, Shanghai crude oil futures were officially listed on 36 March 2018 to better satisfy the demands of the Asian market [
1]. The price trend of crude oil can have a significant impact on the country’s economic development, corporate earnings, and household budgets. In turn, the price of crude oil is also affected by a number of factors. In addition to the two fundamental factors of supply and demand, a variety of factors influence the price of oil at different frequencies. In the energy market, the production and sale of natural gas, coal, and renewable energy can also indirectly lead to oil price fluctuations due to their potential substitution effects. Other factors, such as financial markets, economic growth, and the development of oil extraction technologies, also affect oil prices to varying degrees. The non-linear relationship between these factors and the price of crude oil fluctuated wildly. Forecasting oil prices is therefore a rather difficult task. Despite the difficulties in predicting oil price sequences, accurate oil price forecasts will provide important decision-making support for the manufacturing, logistics, and government sectors, since crude oil is the dominant energy source in the world today.
Many classical econometric models are used to forecast the price of crude oil, including random walk [
2], autoregressive integrated moving average (ARIMA) model [
3], generalized autoregressive conditional heteroscedasticity (GARCH) model [
4], error correction model (ECM) [
5] and so on. However, traditional econometric models are often constructed under linear assumptions. The accuracy predicted by these models is far from enough when these models are applied to predict the crude oil price in the real-world.
In order to better capture the nonlinear characteristics hidden in crude oil prices, many researchers use a variety of machine learning methods to predict crude oil prices. The most typical and commonly used machine learning methods include artificial neural network [
6] and support vector machine (SVM) [
7]. These machine learning-based methods provide powerful tools for nonlinear crude oil prices. The above traditional machine learning methods for predicting the price of crude oil can be summed up as a shallow network model (a neural network with only one hidden layer). The traditional machine learning models are relatively slow in convergence and weak in representation.
Recently, with the development of deep neural networks, deep learning has greatly improved the accuracy of tasks such as classification and feature extraction. A deep neural network has better representation ability than traditional machine learning methods. Deep learning methods have become the mainstream of machine learning technology [
8,
9] in many domains, such as computer vision, speech recognition, and time series prediction. When new data comes, it is easy to update the model parameters through stochastic gradient descent. Compared with traditional machine learning, it can automatically extract features from data and has better applicability to various forms of information. Deep learning is rich in network structures, which can be chosen accordingly for different problems. At present, popular deep learning models include Restricted Boltzmann Machine (RBM) [
10], convolution neural network (CNNs) [
11], deep belief network (DBN) [
12], recurrent neural network (RNN) [
13], long-term and short-term memory (LSTM) network [
14] and so on. Due to its ability to learn complex patterns in high-dimensional data, deep learning has become popular in finance and economics [
15].
The long-term and short-term memory (LSTM) network is a special variant of recurrent neural network (RNN) [
16]. It is well known that the original fully connected RNN has the gradient vanishing issue in long-time series modeling. To solve the gradient vanishing problem, LSTM replaces the ordinary node in a hidden layer with a memory cell with complex internal gate structure. Complex gate structure endows LSTM a powerful learning capability. Due to its the ability to extract the feature automatically, and incorporate exogenous variables very easily, LSTM is proven to be very useful in crude oil prediction [
17,
18].
When applying deep learning method to practical problems, the prediction accuracy and the amount of data are closely related. Deep learning does not predict well when training data is insufficient. Transfer learning can effectively solve the problem of insufficient data. Transfer learning improves the prediction accuracy by learning information from closed related domains when there is not enough data. Transfer learning is very popular in deep learning where pre-trained model is used as starting point. The transfer learning methods have been successfully applied to many domains, such as image classification, natural language processing, and computer vision.
In this paper, we aim to predict the price of Shanghai crude oil. Compared with West Texas Intermediate crude oil, Dubai and Brent crude oil futures, the existing trading data of Shanghai crude oil prices are very few. At present, the theoretical and empirical aspects of the application of deep learning are rarely combined with the characteristics of Shanghai crude oil futures market. Due to the short start time of Shanghai crude oil futures market, there is a lack of data. Transfer learning is an important tool to solve the problem of insufficient training data in machine learning. Although the price trends of different crude oil futures are not the same, they are very similar on the whole. In order to overcome the deficiency of Shanghai crude oil futures training data, this paper intends to adopt the method of deep transfer learning. Specifically, this paper intends to train the Long Short Term Memory Network (LSTM) model on the existing Brent crude oil data, and then use the Shanghai crude oil data for training fine-tuning.
The rest of this paper is organized as follows. In
Section 2, a transfer learning based model is proposed for Shanghai crude oil price forecasting. Numerical experiment is provided in
Section 3 to verify the proposed model. Finally, a conclusion is included in
Section 4.
2. Methodology
In this section, we first briefly review the RNN model, LSTM model, and transfer learning. Then, a transfer learning based LSTM model is proposed.
2.1. Description of LSTM Model
In the traditional feed forward neural network, each input is assumed to be independent of each other, and the output only depends on the current input, regardless of the relationship between samples. However, in many practical problems, the output of the current moment will depend on the sample data of previous moments. In addition, the dimension of input and output of the feed forward neural network needs to be fixed. Therefore, it is not convenient to deal with data of variable length.
Recurrent Neural Network (RNN) is a kind of neural network with short-term memory ability. It can deal with time-related problems with variable data length.
Figure 1 shows the structure of the RNN model. The basic model of RNN is on the left side of the diagram and the unfolded version of the RNN is on the right side of the diagram. The update formula for the hidden layer of the basic RNN is as follows
where
t represents a certain time,
represents the sample input of the network,
represents the hidden state,
is the hidden layer state at the previous time, and
represents the nonlinear activation function (the logistic function or
function is usually used here),
U represents the hidden layer state-state weight matrix,
b is offset, and
W is the input-state weight matrix. It can be seen from the above formula that the hidden state of the current moment is not only related to the current input, but also affected by the hidden state of the previous moment. Finally, the output
is computed by
where
V is the output weight matrix.
The current output of RNN depends on the output of the previous moment, and the network will memorize the previous information. However, in the process of training of RNN, the norm of the gradient may decay exponentially, resulting in the well-known gradient vanishing problem. Long Short-Term Memory (LSTM) network is a special kind of RNN, which introduces an internal state and gate mechanism to alleviate the vanishing gradient problem. The gates determine whether information needs to be saved or transmitted. We define
,
,
as the forgetting gate, the input gate, and the output gate, respectively. The three gates are calculated as follows:
where
is the logistic function. At the same time, the LSTM network introduces a new internal state
. This new internal state is especially responsible for transmitting linear cyclic information and selectively outputting information to the external state
of the hidden layer. The internal state
and external state
is computed as follows:
where the symbol ⊙ represents the multiplication operation of vector elements,
is the candidate state computed as follows:
Figure 2 is a schematic diagram of the recurrent unit structure of the LSTM network.
In the above setting, forgetting gate is used to record how much information needs to forget. The value range is [0, 1], which indicates the probability that the cell state of the previous layer will not be forgotten. Input gate is used to record how much information needs to save, so as to remove useless information, improve the effectiveness of information, and delete invalid information. Output gate determines how much information needs to be output to the external state .
2.2. Transfer Learning
In this subsection, we briefly review the method of transfer learning.
A domain
D is composed of feature space
and the probability of distribution
over the feature space
, where
,
. A task
T is to learn the prediction function
from feature space
to the label space
, where
,
. In transfer learning, the source domain
is defined to be the domain that contains knowledge. The target domain
is the domain in which the knowledge needs to be learned. The purpose of transfer learning is to help the target domain
learn through the knowledge of the source domain
.
Figure 3 shows the unrolled LSTM network.
The method of transfer learning in deep learning [
19] can be mainly classified into four categories:
- 1.
Instance-based deep transfer learning is to choose some instances from the source domain and add them to the data set in the target domain by using appropriate weight adjustment strategies;
- 2.
Mapping-based deep transfer learning maps data from the source domain and target domain into new data space. After mapping, the instances of the target domain and the source domain are similar in the new data space, which is suitable for simultaneous learning with the same neural network;
- 3.
Adversarial-based deep transfer learning is a transfer learning method guided by generated adversarial network (GAN) to find transferable representations that are applicable to both source and target domains;
- 4.
Network-based transfer learning method that is focused on the same learning tasks in the source domain and the target domain . The target domain can obtain effective information knowledge according to the weight of the neural network obtained by training the source domain data. The model trained on the data in the source domain is applied to the target domain data only by changing some of the parameters, thereby transferring the information and knowledge learned in the source domain to the target domain.
Fine-tuning is a common technology of weight-based transfer learning applied to deep learning. The fine-tuning technique includes the following steps: The first step is to pre-train the neural network model on the source domain , namely the source model . The second step is to create a new neural network model, namely the target model . This model preserves some or all of the model design and its parameters on the source model . We assume that these model parameters contain the knowledge learned from the source domain , and that this knowledge is also applicable to the target domain . The third step is to train the target model on the target data set. We can choose to keep the parameters of some layers unchanged, while the parameters of the remaining layers will be fine-tuned according to the target data set.
2.3. The Proposed Transfer Learning Based Forecasting Model
In this subsection, we propose a deep transfer learning based forecasting model for Shanghai crude oil price. Shanghai crude oil futures were officially listed on 36 March 2018. Due to the short listing time, the data of crude oil futures price is relatively few. Therefore, it is difficult to predict the price of Shanghai crude oil futures trading and get good prediction accuracy. Transfer learning is a technology that uses the similarity of data to solve the problem of lack of data. The key of transfer learning lies in the similarity of the data. Brent crude oil futures is one of the most important crude oil futures in the world. The Brent crude oil price and Shanghai crude oil price has the similar movements in practice.
Due to the similarity between the Brent crude oil and Shanghai crude oil, we adopt transfer learning and use the Brent crude oil price as the source domain data to train the model and transfer it to the data of Shanghai crude oil price, which can solve the problem of insufficient data.
In this paper, we apply the LSTM algorithm to predict the price in next day by using last
m day’s data.
Shanghai crude oil price and Brent crude oil price are denoted as and respectively. The proposed deep transfer learning based forecasting model (denoted as T-LSTM) is summarized as follows:
- 1.
The Shanghai price data , is split into training set , and test set };
- 2.
Pre-processing the data by normalization;
- 3.
Pretrain the deep neural network on Brent crude oil ;
- 4.
Fine-tuning the neural network on Shanghai crude oil using training set ;
- 5.
Predict the price of Shanghai crude oil on the test set based on the LSTM.
In step 3, we keep the weights of hidden layers of the pre-trained model unchanged and fine-tune the weights of the neural network using the price data of Shanghai crude oil futures. The initial layer is usually considered to capture generic characteristics, while the later layers are more focused on the specific task at hand. The transfer learning model proposed in this paper only fine-tunes the weight values of the last layer of the neural network model so that it varies according to the training data of the Shanghai crude oil futures price. The weights of the remaining layers are frozen and do not vary with the training on the price of Shanghai crude oil futures.
3. Experiment
3.1. Data Description
In this paper, we consider the sampling period of Shanghai crude oil from 26 March 2018 to 26 October 2021 with a total of 871 observations. The mean, standard deviation, min, and max of Shanghai crude oil price are 411.71, 87.77, 205.30, and 590.60, respectively.
The sample data of Shanghai crude oil is divided into a training set and test set. The sample data of Shanghai crude oil from 26 March 2018 to 31 December 2020 is treated as the training set with 676 observations, which accounts for 77.6% of the total samples. The remaining Shanghai crude oil price data are treated as the test set, used to evaluate the accuracy of prediction.
Figure 4 shows the crude oil price of Shanghai.
Due to the lack of Shanghai crude oil price data, we need to use other crude oil price data for pre-training. The correlation coefficients between Shanghai crude oil price and other crude oil prices from 25 March 2018 to 31 December 2020 are shown in the
Table 1. The correlation coefficients between Brent crude oil price and Shanghai crude oil price is 0.945, showing a strong correlation. It shows that the price fluctuation of Brent and Dubai crude oil are very similar to that of Shanghai crude oil. In this paper, due to the strong correlation, we choose Brent crude oil to pre-train the LSTM model in the transfer learning model.
In order to show the effectiveness of the proposed deep transfer learning based algorithm, the closing price of Brent crude oil is selected as experimental samples. The Brent crude oil price from 29 August 2000 to 31 December 2020 is used to pre-train the neural network.
Figure 5 shows the crude oil price of Brent.
Before building the prediction model for Shanghai crude oil, we need to perform the data pre-processing. Since Shanghai crude oil and Brent crude oil use Chinese yuan and USD, respectively, to mark the price, the numerical range of two crude oil prices is very different. It is necessary to normalize the data. The most common normalization process is to normalize the price to [0, 1], which is done as follows:
Moreover, normalize the price to [0, 1] will also be good for the training of LSTM.
3.2. Evaluation Criteria
In order to evaluate the experimental results, four common indicators in the prediction problem, root mean square error, mean of absolute value of errors, mean absolute percentage error, and directional accuracy ratio, are used in this paper, called RMSE, MAE, MAPE, and DAR, respectively. The RMSE is computed by the following formula:
where
is the exact value and
is the predicted value. The MAE is defined as follows
The DAR is defined by the following formula
3.3. LSTM Model Construction
The network structure of this paper consists of three layers: input layer, one hidden layer, and output layer. To decide the input layer, we need to determine the rolling window size of LSTM. In our experiment, the size of the rolling window is defined to be r. So the input layer is dimension. The size of the hidden layer is defined to be n. The output layer is 1 dimension, that is, the output closing price. Therefore, the label data of this experiment is composed of the closing price on the day after the corresponding date. In the numerical experiment, we will test different r and n to do the sensitivity analysis and choose the best parameters.
In the transfer learning, we first train the the LSTM network by using Brent data. The Adam optimization algorithm is used to learn the parameters of the LSTM network. The procedure of building the prediction model for Shanghai crude oil price is almost the same as Brent crude oil price prediction model. The only difference is that the weight parameters of the hidden layer in the corresponding LSTM network are not initialized with random numbers, but with the corresponding parameters of Brent crude oil price prediction model. In this paper, the early stopping is applied for the model training to avoid overfitting. The maximum number of epochs is set to 400. The patience of early stopping is set to be 30. If we continue to train this network, it is likely to cause over fitting results. Finally, the data of the test set is input and predicted by the learned network. By comparing the difference between the predicted value and the real value, the generalization ability of the LSTM network is verified.
3.4. Experimental Result
In this section, we compare the experimental result of the proposed transfer learning based LSTM method (T-LSTM) with auto-regressive integrated moving average (ARIMA), damped trend exponential smoothing, and LSTM without transfer learning. All experiments were run on a personal computer with CPU 2.7 GHz and 32 GB RAM. T-LSTM and LSTM were conducted in Python 3.7 via Keras 2.3.1. The neural networks were trained using Adam algorithm with default learning rate 0.001.
We first report the result when the number of neurons of hidden layers
n equals 50. We test the T-LSTM and LSTM for different rolling window size {6, 15, 30} and batch size {16, 32, 64}. Here
r represents the rolling window size. The Diebold-Mariano (DM) test is applied to determine whether the predictions of T-LSTM and LSTM are significantly different. As we can see from
Table 2, for most of the cases, the p value is less than 0.1. It means that the predictions of T-LSTM and LSTM are significantly different. It can be seen from the
Table 2 that T-LSTM has smaller predictive error than LSTM in most cases. The proposed T-LSTM obtains the best performance when the rolling window size equals 6 and batch size equals 32.
To do the sensitivity analysis, we compare the results of T-LSTM and LSTM for a number of neurons of hidden layers
and
. As we can see from
Table 2, T-LSTM has best performance when the rolling window equals 6. In the following experiment, the rolling window size will be fixed to be 6. The results are shown in
Table 3 and
Table 4 for different batch sizes. It can be seen from
Table 3 and
Table 4 that the transfer learning based method T-LSTM has better performance than LSTM without transfer learning.
In the following, we report the result of ARIMA and damped trend exponential smoothing, which are benchmarks for time series analysis. It can be seen from
Figure 4 that the mean of Shanghai crude oil is not stationary, which is also confirmed by the values of the autocorrelation in
Figure 6. We can see from
Figure 7 that the series of Shanghai crude oil is stationary after first order difference.
Figure 8 and
Figure 9 shows the autocorrelation and partial differenced Shanghai crude oil price respectively. The ARIMA model used in this paper is the ARIMA(3, 1, 2) which is determined by the auto ARIMA using pmdarima package. For the damped trend exponential smoothing method, the smoothing level is equal to 0.8 and the smoothing slope is equal to 0.2.
The result of the different algorithms are shown in
Table 5. For the T-LSTM and LSTM, the number of neurons of hidden layers
n equals 50, the rolling window size equals 6, and batch size equals 32. Note that the results of T-LSTM and LSTM are selected from
Table 2 using the same parameters. From the
Table 5, it can be seen that the proposed T-LSTM obtains the best performance, which has the smallest RMSE, MAE, and MAPE. The directional accuracy ratio (DAR) of T-LSTM is highest among the four methods.
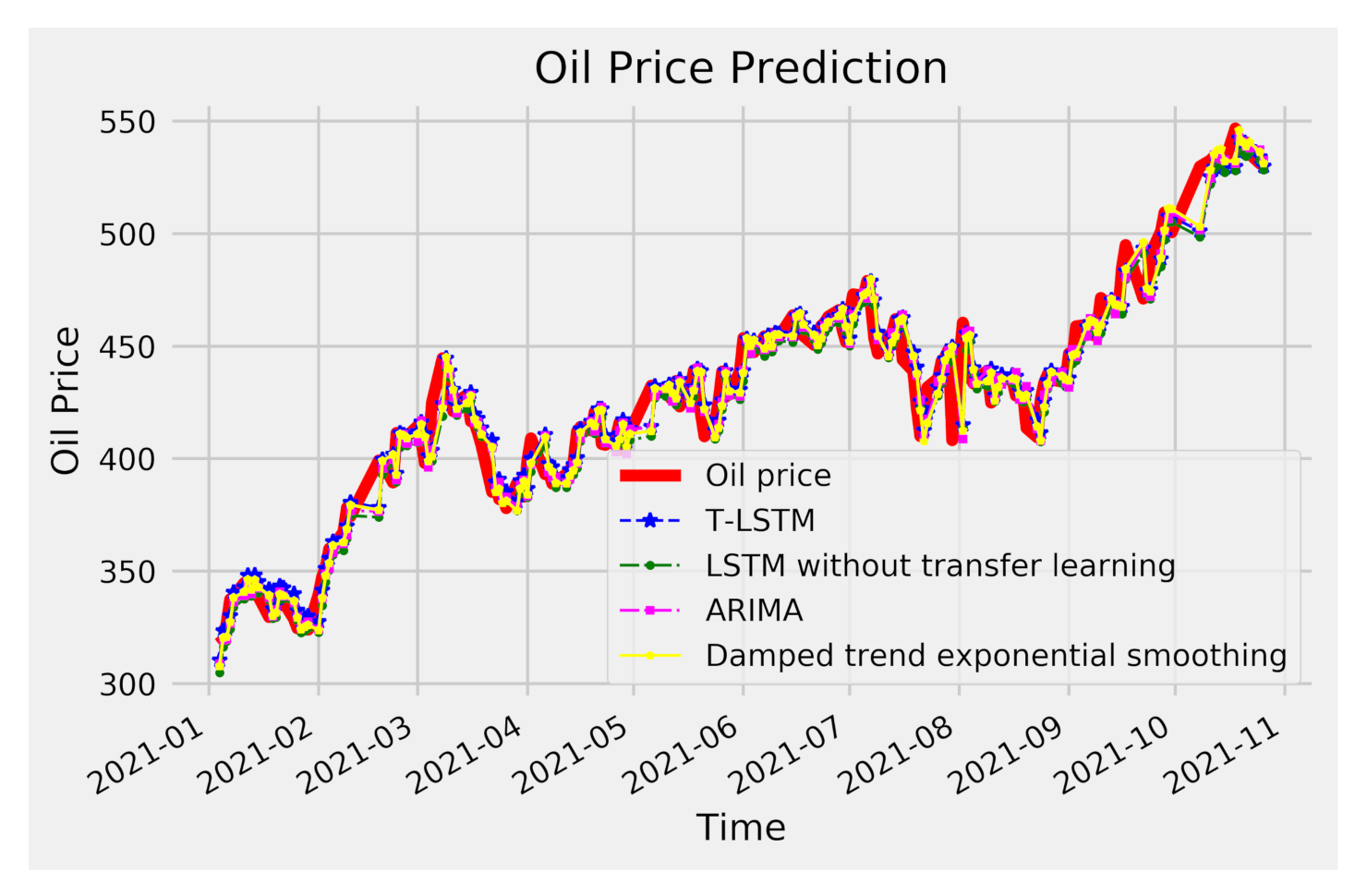
We also plot the predicted oil prices of four methods in
Figure 10. It can be seen that the prediction curve with Brent data is more suitable for the real data curve than the prediction curve with Shanghai data only, which shows that the prediction effect of the model using Brent data for transfer learning is better. With the help of Brent data, the trend of the predicted value and the real value is basically consistent, and the numerical prediction is also similar, and the two curves almost coincide.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}