In the first part of our analysis we show the results of the application of the LC model in the basic version and including covariates as well. Then we compare the results for different LC-IRT types of models (imposing different constraints on item parameters). We present the results with more details for latent variable models with covariates achieving the optimum measure of fit.
4.1. Results for LC Models
In applying the basic LC model to the subjective income perception dataset, we choose
latent classes, which corresponds to the lowest BIC (see
Table 3). The model with three latent classes will be denoted as LC; its maximum log-likelihood equal to
with 98 free parameters. The corresponding values of BIC and AIC are 6604.325 and 6236.712 respectively. Note that AIC leads to choosing a model with four number of classes; however, as usual, we prefer to rely on BIC for this choice because it leads to the most parsimonious choice. We fitted also the models with covariates presented in
Section 3.1 (family type, socio-economic status and place of living) for
. Finally, based on information criteria we choose also three as the most suitable number of latent classes for the model denoted by LC-cov. Due to limit of space in the further part of our work we present the analysis of the extended model, i.e., including covariates (LC-cov) as this model presents even better measure of fit and allows for a more detailed analysis.
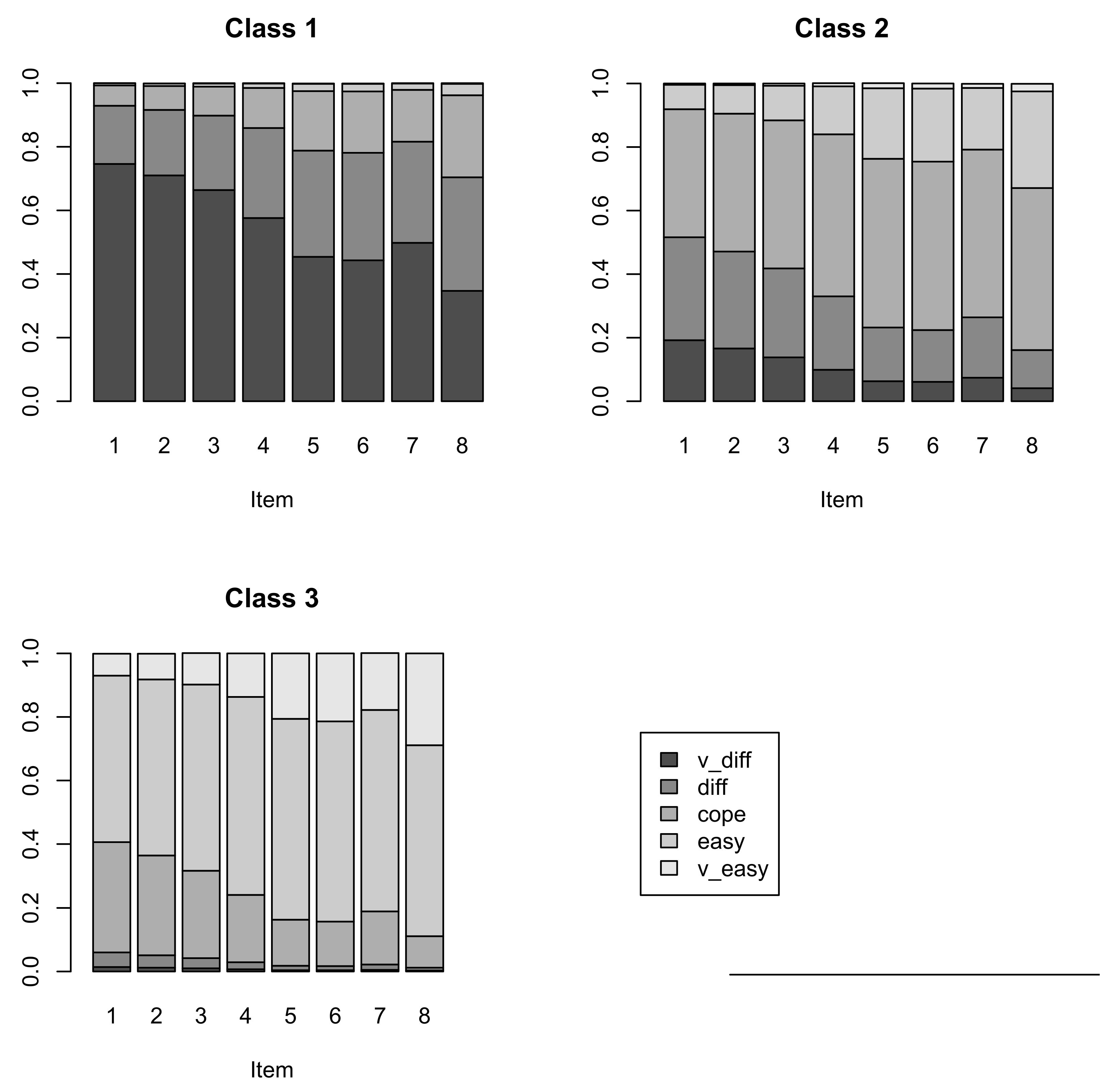
The estimates of the conditional response probabilities for the selected model (LC-cov) are reported in
Table 4, whereas the estimated class weights are given in
Table 5.
We observe that the latent classes correspond to increasing tendency to respond with the higher income satisfaction and have considerably different sizes. In particular, the third class, which is the smallest with about of subjects, corresponds to the highest income satisfaction. The second group, includes close to of subjects being generally satisfied with their income position and the first class is referred to about of Poles characterized by the lowest income perception. In fact, when s goes from 1 to 3, the conditional probability of the first category () tends to decrease for every time occasion, whereas that of the last category () tend to increase for each item (corresponding to the following years).
Note that, the highest values of conditional probabilities for the first category in the first class, corresponding to the highest dissatisfaction is observed for the sixth and seventh wave of the survey following the year of the economic crisis. However, the smallest values for the first and second categories ( and ) in this class can be observed in the last year of the study showing the improving financial situation in the recent years. As far as the latent class with the highest income satisfaction is concerned, the lowest share and its increasing tendency reaching the breaking point in the 2009 year of those coping easily with their finances can be observed. Moreover, we note also the high value of conditional probabilities for in the last wave for this group.
For a more precise check, we computed class/item-specific scores
that are obtained by the weighted average of a set of scores assigned to each response category (1 for the first, 2 for the second, and so on) and weights equal to the conditional response categories. The class/item-specific scores are presented in
Table 4 and confirm that we are essentially dealing with ordered latent classes.
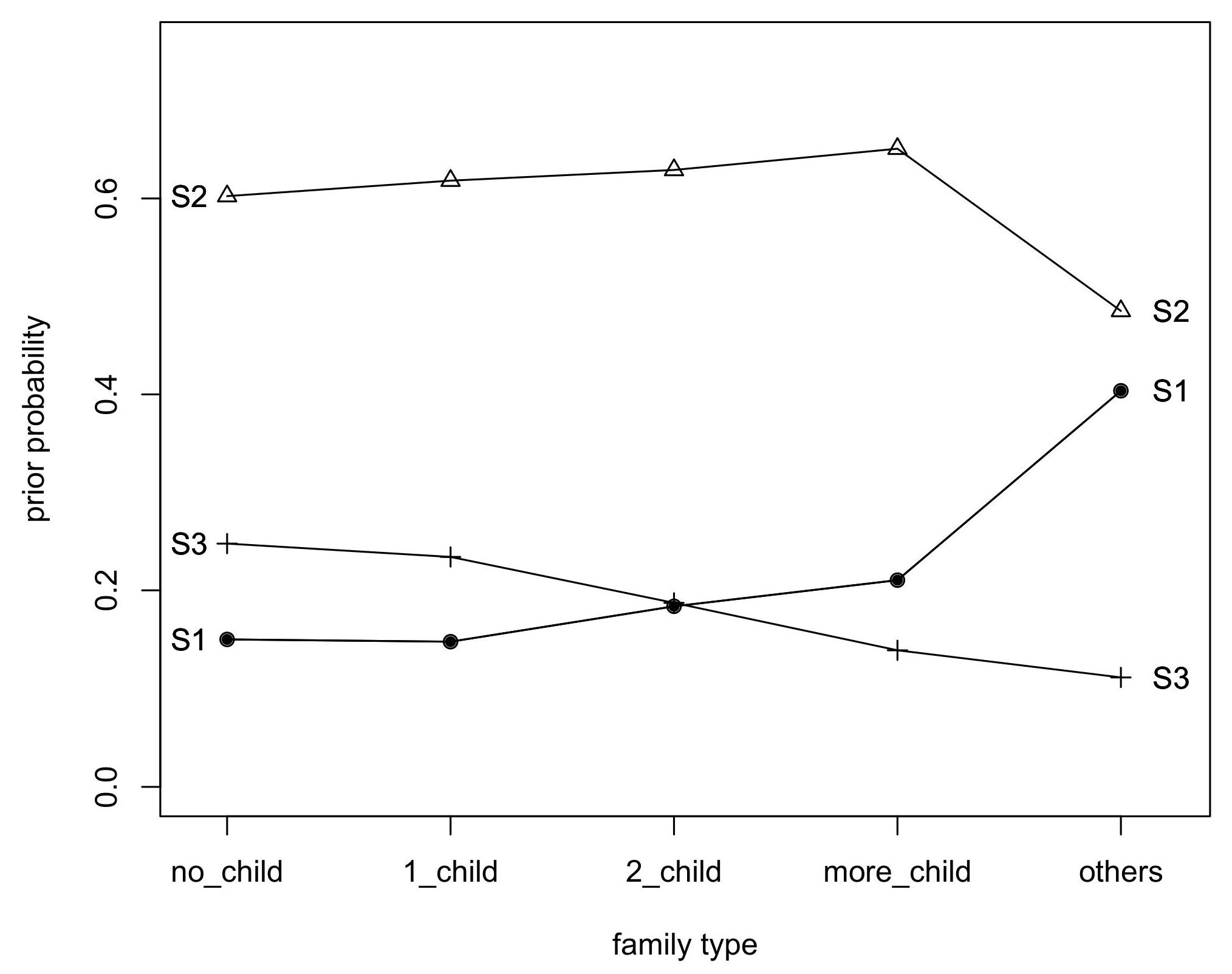
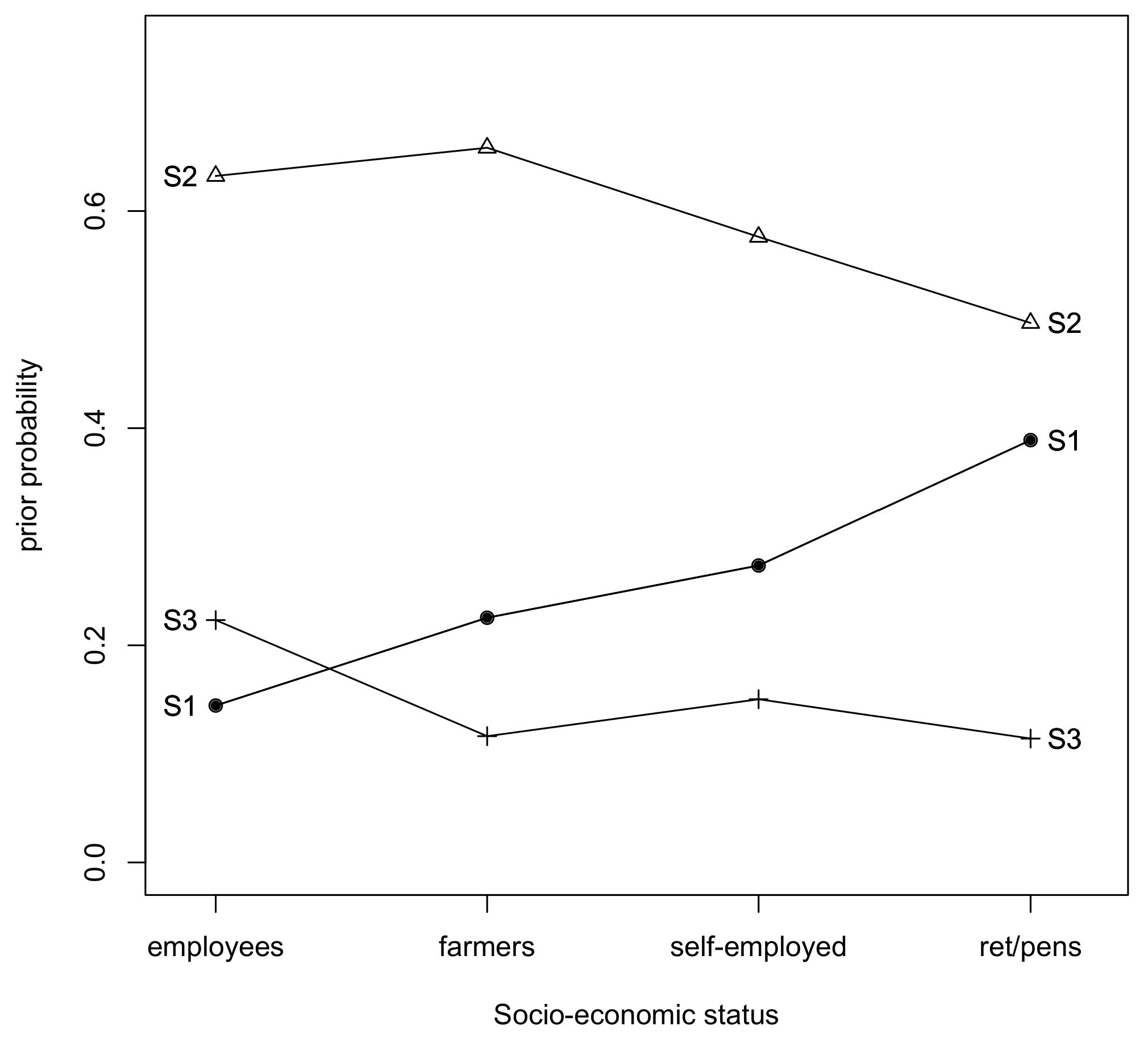
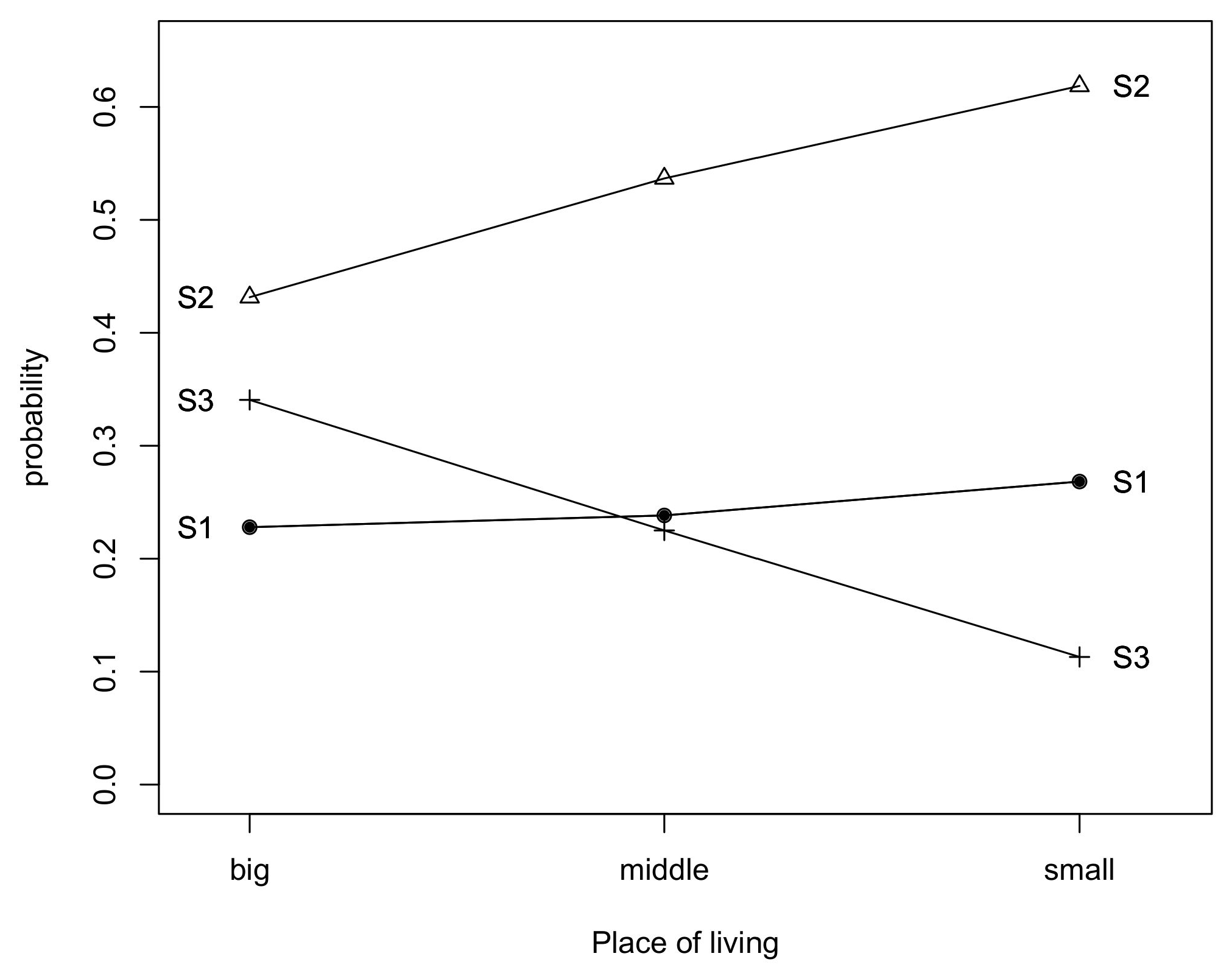
The important part of our study aimed at understanding how the covariates affect the latent trait of the model. Therefore, in the next stage of our analysis, we calculated and plotted the prior probabilities of class membership, at varying levels of covariates. The estimated prior probabilities of class membership are given separately for each family type, socio-economic status and place of living covariate and presented in
Figure 2,
Figure 3 and
Figure 4.
We observe the highest prior probability to belong to the generally satisfied group of Poles for more children family types. The other family types are most prone to belong to the completely unsatisfied group of respondents. As expected, those living in no children or one children family types have the highest chance to be fully satisfied with their financial position (see
Figure 2).
The results given in
Figure 3 present that employees have over a 20% prior of belonging to the best situated group of Poles, while pensioners, retired and other professionally inactive people have almost 40% prior of belonging to the worst situated class. However, farmers followed by employees have the highest chance to belong to the second class.
The probability of belonging to the third class is significantly higher for those living in big cities, while residents of countrysides have just slightly higher prior of belonging to the first group then to those living in middle sized or big cities of Poland. However it is interesting to observe (
Figure 4) the highest chance to belong to the group of living quite comfortably on present income (belonging to the second class) for people living in the smallest towns or villages.
4.2. Results for LC-IRT Models
In order to better understand the analyzed phenomena, we apply a constrained LC model. Accordingly, in this part of our analysis, we adopt the latent class of Item Response Theory (IRT) models. In particular, we rely on the models for polythomous ordinal items. Through these models we find latent classes of Poles with similar levels of financial satisfaction, we study the effect of different socio-economic covariates on the probability of belonging to these classes, and we assess the item characteristics.
The first stage of our LC-IRT analysis is focused on the choice of the best logit link function. A comparison between a model with global logit link and a model with local logit link is carried out on the basis of the BIC index and by assuming
latent classes, free item discriminating and diffculties parameters. Because the global logit link has to be preferred to a local logit link function (the smaller BIC and AIC values, see
Table 6) in the following we fitted different types of the LC graded response type models with free and constraint discriminating index as well as free and constrained threshold difficulty parameters, for each item.
Besides, because the compared models are nested, the parameterization is selected on the basis of an LR test and BIC, AIC criteria as well. For the sake of completeness, log-likelihood and information criteria values for local logit link function are also included in the
Table 7 (see LC-GPCM, LC-RS-GPCM, LC-PCM, LC-RSM). The results given in this table show that LC-1P-RS-GRM model has to be preferred among all of the LC-IRT models considered, that is the LC graded response model with constrained discriminant and difficulty parameters as well.
Also, it can be observed that a graded response type model has a better fit than the standard LC model, as the BIC value observed for the former is smaller () than that detected for the latter (). Therefore, the results for LC-1P-RS-GRM model including also the socio-economic features are presented in further part of this work.
The estimated conditional probabilities under the selected LC-1P-RS-GRM-cov model presented in
Figure 5 generally lead us to the same conclusions as for LC-cov model. The analysis of the conditional probabilities confirm again that the first latent class consist of those with the most difficult financial situation, the second group comprises those coping with the present income and the third class is made mainly by those satisfied with their financial position.
Note that, additionally the support points (
,
), estimated under the selected model, and the corresponding prior probabilities (
,
) reported in
Table 8 facilitate interpretation of the results. Moreover, the depicted latent trait levels in
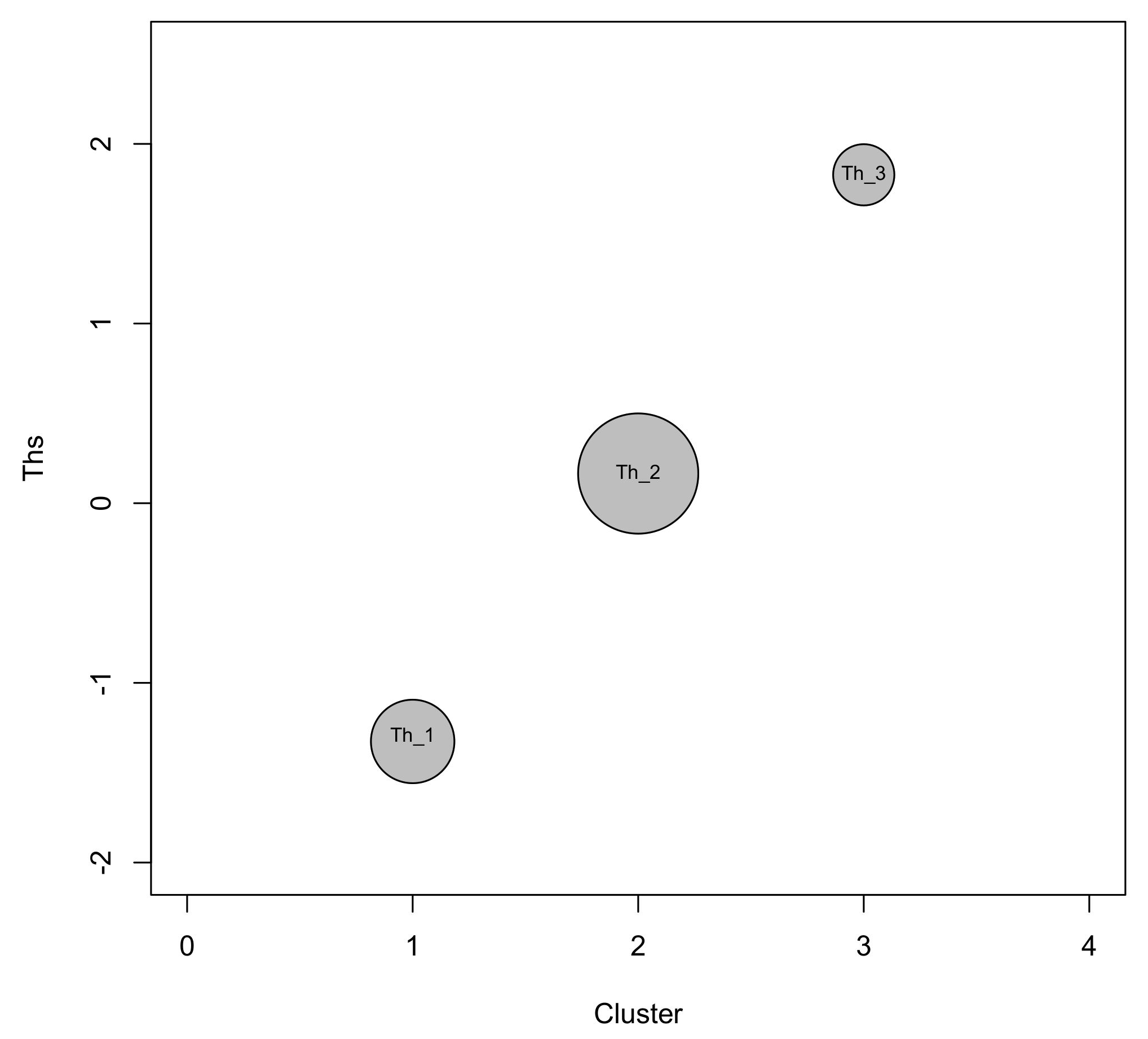
Figure 6 allow for cluster labeling in an efficient way.
We remark that, the support points are standardised so as to have null mean and unitary variance and the item parameters are transformed accordingly; (see [
38] Section 4.6) for details.
As with the previous model LC-cov we observe that most subjects (57.4%) belong again to class 2 (shown with the biggest circle in the
Figure 6), which is characterised by an intermediate level of income perception (
). This class is also characterised by the highest conditional probabilities for the third category (“coping with the present income”) among all classes (especially for
,
,
,
). Over 27% of subjects are in class 1 (represented by the smallest circle in
Figure 6) and close to 15% of subjects are in class 3, corresponding to the lowest and highest levels of subjective well-being, respectively. Note that, compared to the LC-cov the prior probability for the third class of the model LC-1P-RS-GRM-cov (see
Table 8) is slightly smaller in favour of the first class.
The estimates of the standardised item parameters (difficulty parameters) for the selected model are given in
Table 9. Note that, the selected model (LC-1P-RS-GRM-cov) is characterized by the constrained both difficulties and discrimination indices (all items discriminate in the same way). Therefore,
Table 9 presents only single discrimination parameter (the threshold parameters are the same for all response categories) for each item. We observe the highest estimate for the first item
. This means that the
(regarding the question in the first year of the analysis) is considered to have the highest difficulty level of the item. In turn, the eight item (regarding the last year of the study) is considered to have the lowest difficulty level (meaning that this is the aspect of the highest satisfaction of the interviewees).
In further analysis we ran the test for significance of the covariates coefficients. The estimates of the significant covariates coefficients for LC-1P-RS-GRM-cov model based on the multinomial logit parametrization are given in
Table 10. We observed that the significant covariates are typical family, socio-economic group, big city. The effects of the family type covariate on the logarithm of the probability of being in class 2 with respect to class 1 equals to
. Since, the latent classes of respondents are ordered from that with the lowest to that with the highest level of income perception and two estimates (for
and
) of the parameters for this covariate are negative (−0.352, −0.537 ), as the number of children increases the level of income satisfaction decreases.
Similarly, all the estimates of the parameters for the socio-economic status covariate are also negative. Respondents with other socio-economic status then employees have a lower financial perception (are characterized by the lower level of the latent trait).
Furthermore, the analysis of the estimates for the place of living covariate leads to the similar conclusions. As the size of the place of living decreases, the the level of perceived income perception also decreases (big city is assumed as the first, reference category).
Similar findings for the socio-demographic features were obtained in the results for LC-cov. Note that the interpretation parameters is not always easy. Therefore, the prior probabilities at varying levels of covariates are ofently depicted on Figures similar to those given in
Figure 2,
Figure 3 and
Figure 4 (see i.e., [
98]) or the estimates of individual weights for different pattern of covariates are compared.
Finally, we have considered also LC-1P-RS-GRM model with covariates based on the global logit parameterization (see Equation (
8)). The global logit parameterization is more parsimonious compared to multinomial logit parameterization and the interpretation of the effect of covariates is easier (there is a single regression parameter of each covariate). The estimates of the significant covariates coefficients for LC-1P-RS-GRM model based on the global logit parametrization are given in
Table 11. Similarly, the covariates have a significant, negative effect on the financial satisfaction level. Households with the higher-level category assigned (as referred to the first) report worse financial satisfaction.
For a better interpretation of results, on the basis of the estimated model the probabilities of belonging to the latent classes (
) for different patterns of covariates (see
Table 12) may be assessed. Estimated
allow for several types of prediction. For instance, respondent living in other family type, being retired and resident of countryside has the smallest chance to achieve the highest level of income perception (to be assigned to the class 3). The same probability rises slightly to 7.1% for famers (living also in other family type and in rural area of Poland). The probability to achieve the highest satisfaction level is the highest for employee, having no children and living in big city. The probability to achieve the highest satisfaction level ranges from 3.8% to 49.1%. As far as the second group is concerned, the highest chance of belonging is observed for employees with one children, living in the smallest towns or villages.
We observed that the predicted values are slightly different for global logit parameterization but generally lead to the same conclusion.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}