1. Introduction
Vehicle lane change is an essential maneuver for drivers while commuting. It is also a behavioral reflex closely related to road safety and traffic efficiency [
1,
2]. Studies have shown that lane changing causes about 4% of all traffic crashes and about 0.5% of all traffic fatalities in the United States [
3]. Moreover, driver decision errors account for 75% of all lane-change-related crashes [
4]. Eberhard et al. [
5] mentioned that the main cause of lane-changing accidents is the driver’s misjudgment of the current traffic environment. Subsequently, the driver behavior model developed by Shawky [
6] shows that drivers who suddenly change lanes are 2.53 times more likely to be involved in a traffic accident than others.
In order to reduce drivers’ psychological load during lane change and subsequently reduce the rate of related accidents, most current studies focuse on vehicle warning systems that notify drivers when they change lanes [
7,
8,
9]. However, the warning rules of current warning systems do not always correlate with the cognitive perception of drivers. Many users reported that the warning from the system is triggered too early, which is a nuisance, leading them to abandon the use of the lane change warning system altogether. In addition, lane change warning systems are not yet fully available in Chinese vehicles [
10]. Therefore, drivers more often make lane change decisions based on their own subjective assessment of risk. It is valuable to investigate the driver’s real-time decision-making paradigm in such a scenario.
The driver’s lane-changing decision-making process is a balance between the driver’s willingness to change lanes and his or her assessment of the related risk [
11,
12]. The driver’s assessment of the lane changing risk is mainly derived from the estimation of the distance and speed between the subject vehicle and the target vehicle. Furthermore, the accuracy of the driver’s assessment of the distance and speed between the target vehicle and the subject vehicle directly impacts the driver’s lane-changing decision and even the associated risk. If the driver tends to overestimate the speed of the target vehicle while underestimating the distance between the subject vehicle and the target vehicle, the driver will abandon the lane change operation and, thus, miss the time to change lanes. Conversely, if the driver underestimates the speed of the target vehicle and overestimates the distance between the two vehicles, the driver may perform the lane change, which will ultimately result in a significant lane change accident risk. Shawky [
6] noted that drivers who look in the side mirror and out the window before changing lanes are, respectively, 4.61 and 3.85 times less likely to be involved in a crash than their counterparts who do not. Therefore, the key parameter for drivers to accurately assess the risk of lane change is to correctly perceive the relative motion state of the target vehicle and their own vehicle.
The relative motion state of the primary vehicle and the surrounding vehicles is the key input factor for researchers to build lane-change decision models. Qiu [
13] chose the longitudinal distance and relative speed of the subject vehicle and the surrounding vehicles as the input variables of the lane change decision model and built a lane change decision model using traditional machine learning algorithms and gradient boosting decision trees (GBDTs), respectively, with the result showing the best overall prediction performance of GBDT. Xu et al. [
14] also modeled the driver’s lane change decision based on the GBDT algorithm using the safe collision time between the subject car and the car behind the target lane and the traffic state around the subject car, and the model achieved good prediction performance. Although all of the above studies have good performance in predicting the lane change decision, the driver’s factor was not considered in these studies. In addition, the driver’s lane change process is generally divided into three stages: information perception, lane change decision, and action implementation. Most studies in the current research area focused on the study of lane change decisions and ignored the study of driver’s information perception.
Speed perception emerged in the field of traffic psychology. Volunteers undergo speed perception tests in order to evaluate their ability to accurately assess the speed of a moving object and rate their impatience and their tendency to drive precariously. Speed perception is a valid parameter for the assessment of driving safety since less experienced drivers have higher speed perception than average professional drivers [
15], while drivers with poor driving behavior (with violation records) have lower speed perception than their average counterparts [
16]. From the driver’s perspective, many parameters affect speed and distance perception. Drivers tend to underestimate the speed of a target object if it is large and in poor visibility conditions [
17,
18,
19]. Driving speed also affects the driver’s ability to estimate speed, with drivers perceiving speed more accurately at moderate speeds (40–64 km/h) than at low speeds (5–32 km/h) and high speeds (72–97 km/h). The most accurate perception of speed is in the range of 40–56 km/h, but speeds below this range tend to be overestimated and speeds above this range are more likely to be underestimated [
20,
21]. In addition, factors such as continuous driving time, age, and driving seniority can affect the driver’s speed and distance perception [
22]. The researchers also suggested that even veteran drivers tend to underestimate their driving speed while commuting [
23,
24].
The above studies all investigate the drivers’ ability to perceive their own vehicle, but other vehicles on the road are also a factor to be concerned about during vehicle operation, especially during lane-changing maneuvers. In the lane-changing study, the recognition model than can identify the drivers’ lane change intention was established by Peng et al. (2015) using the speed of the self-car and the relative motion state between the self-car and the surrounding vehicles. In the Action Point Models proposed by Michaels [
25], it is believed that the driver relies on the change in size of the preceding vehicle in the field of view to perceive the change in relative speed between the front and rear vehicles and judge whether he/she is approaching the front vehicle in the process of car following. Once the driver’s perception exceeds a certain threshold, he/she will perform deceleration until he/she can no longer perceive the change in relative speed. There is a significant difference between drivers’ spatial distance as well as speed discrimination in a dynamic traffic flow environment and in an idle state. Kang [
26] analyzed drivers’ spatial distance discrimination in a dynamic ground environment and qualitatively analyzed the effect of color characteristics on drivers’ spatial distance discrimination. Wei et al. [
27] conducted a distance perception test on drivers and analyzed the effect of obstacle color, ambient light characteristics, and vehicle speed on drivers’ distance discrimination characteristics.
The lane change behavior is similar to the car-following behavior in that the relative motion status between the vehicle and the other vehicles needs to be evaluated. However, during car-following behaviors, the driver can obtain the motion status of the vehicle in front of him/her by directly scanning it with his/her eyes. In lane-changing decisions, the driver needs to capture the motion information of the target vehicle, which means that the driver can acquire the relative motion status between the target vehicle and the driver’s own vehicle mainly through the rearview mirror instead of directly through the eyes [
9]. There is a significant difference between the driver acquiring the relative motion state between the vehicle and other vehicles directly through the eyes and through the rearview mirror.
Few of the studies so far have examined the driver’s ability to estimate speed and distance through the rearview mirror, which is an important factor affecting lane change safety. In addition, experiments in related studies are rarely conducted in actual highway environments. Considering the actual road conditions in China, drivers have more demand for lane change on highways than on city roads, and drivers have different speed estimation and distance estimation abilities on highways than on ordinary roads, it is valuable to acquire data on drivers’ speed estimation and distance estimation through the rearview mirror on highways. In order to build a ground truth for the above scenarios, this study is conducted as a road experiment on the highway, during which the participants were asked to drive in a fixed lane at different speeds and to report the speed of the vehicle behind the left lane and the distance between it and their own vehicle through the rearview mirror at all times. The gathered information is used to investigate the speed estimation error and distance estimation error of the driver through the rearview mirror.
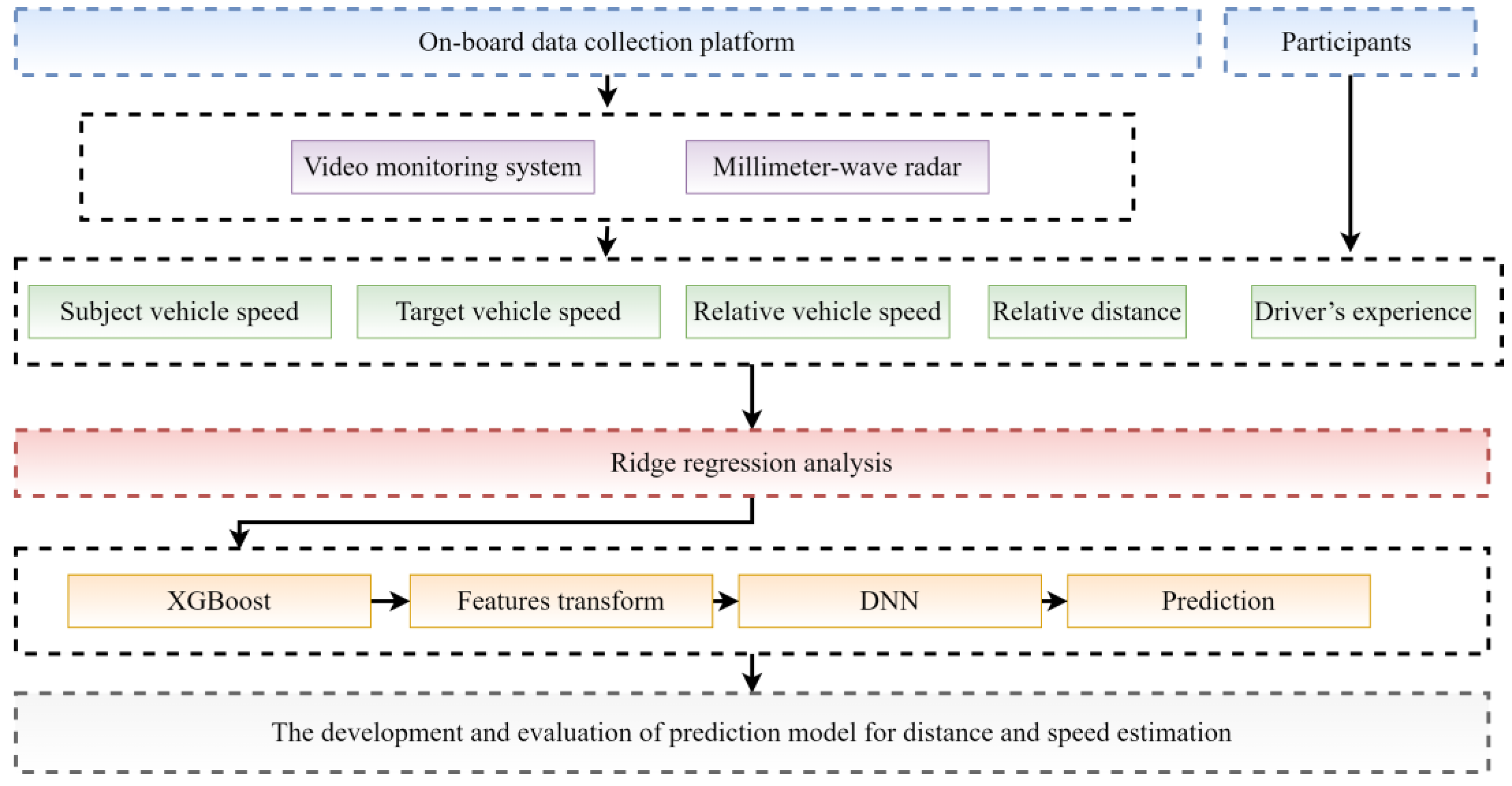
The research framework of this paper is shown in
Figure 1, and it is organized as follows.
Section 2 introduces the algorithms used to model the speed estimation and distance estimation.
Section 3 presents the experiment and elaborates on the data sources for this study. The factors that affect the accuracy of driver speed estimation and distance estimation are analyzed in
Section 4. In
Section 5, the modeling process of XGBoost-DNN is shown, and the prediction performance of extreme gradient boosting (XGBoost) combined with deep neural network (DNN) algorithms proposed in this paper is compared with that of traditional machine learning algorithms.
Section 6 discusses the results.
Section 7 concludes the study and provides insights into future work.
3. Study Implementation
3.1. Participants
A total of 14 participants (2 females and 12 males) volunteered in the experiment, with ages ranging from 27 to 48 years (mean = 34.7 years) and having 3 to 23 years (mean = 8.4 years) of driving experience. Seven experienced drivers (>5 years of driving experience) and seven non-experienced drivers (<5 years of driving experience) were included. The details of the participants’ information are described in
Table 1. All participants had a valid driving license and had not experienced a major traffic accident in the past three years. Participants were prohibited from taking drugs and functional drinks the day before the trial. All were in good health on the day of the trial, and there were no traffic risks during the trial. Each participant willingly volunteered to engage in the experiment, which was approved by the Ethics Committee of Chang’an University. Each participant was given CNY 500 after the trial as compensation for their time.
3.2. Apparatus and Experimental Route
A multifunctional test platform combining a common vehicle and multiple data acquisition devices was deployed for this experiment, and the components of the multifunctional test platform are shown in
Figure 5. The millimeter-wave radar was mounted on the center of the rear bumper of the subject vehicle to capture the relative position and relative vehicle speed data between the target vehicle and the subject vehicle. The video monitoring system was used to record the movement of the target vehicle; the GPS was used to record the geographic location of the subject vehicle; the CAN acquisition card obtained the speed information of the subject vehicle; and the wireless button recorded the moment while the participant was performing the task for subsequent data calibration. An industrial control computer was used to collect the data acquired by all components.
In this study, participants were required to look into the rearview mirror several times to estimate the speed and distance of the target vehicle, which may cause distractions while driving. To ensure the safety of the participants, the Xi’an roundabout highway was chosen as the experimental road, where the traffic volume is relatively light, with a two-way six-lane road and having a speed limit of 120 km/h. The total length of the experimental route is 135 km.
3.3. Experimental Design and Procedure
The ability of a driver to decide to change lane depends on an accurate estimation of the speed and distance of the target vehicle. To investigate such an ability, this study conducted realistic road tests at different vehicle speeds. Considering that the daily driving speed for commuters in China mainly ranges from 60 km/h to 90 km/h, we chose 60 km/h, 70 km/h, 80 km/h, and 90 km/h as test speeds. Considering that CCS (Cruise Control System) is becoming more and more common and is increasingly used on highways, in this study, it was simultaneously used to reduce the driver’s workload during driving and to control the longitudinal speed of the subject vehicle. The subject vehicle was required to drive in the middle lane during the test, while the target lane was the left lane (as shown in
Figure 6). The target vehicle at the closest distance to the self-vehicle has the greatest influence on the lane change decision during the lane change process, and the driver obtains information about this vehicle through the rearview mirror in daily driving. Therefore, during the test, we requested the driver to estimate the speed and relative distance between the target vehicle and the subject vehicle by using the left rearview mirror.
Before the experiment, the participants were asked to sign an informed consent form and to fill out the basic personal information form. All volunteers were provided a brief description of the trial’s procedure and underwent training on speed and distance estimation tasks, and the formal trial started after the participants were able to complete secondary tasks proficiently.
During the experiment, participants were asked to estimate the speed of the target vehicle and the relative distance to the subject vehicle by using the rearview mirror as many times as possible, verbally report their estimations, and simultaneously press a wireless button mounted on the left side of the steering wheel under the premise of safe driving. In this experiment, an advisor was seated in the rear seat of the subject vehicle and was responsible for monitoring the target vehicle and alerting the participant to make corresponding speed and distance estimations, as well as recording the subject’s verbal report of the results. To ensure driving safety, a veteran driver was always seated in the co-driver’s seat of the subject vehicle to monitor the driving environment and alert the participant if there was a driving risk.
3.4. Variables Definition
In this study, the effects of the speed of the subject vehicle, the speed of the target vehicle, and the relative speed and relative distance between the subject vehicle and the target vehicle on the driver’s speed and distance estimation errors were investigated. Therefore, the analytical variables are the speed of the subject vehicle, the speed of the target vehicle, the relative speed, and the distance. Moreover, the variables are calculated as shown below.
The relative velocity between the subject vehicle and the target vehicle was expressed as follows:
where
the speed of the subject vehicle
, and
is the speed of the target vehicle
.
< 0 indicates that the speed of the subject vehicle
is less than the speed of the target vehicle
.
Driver’s speed estimation errors were expressed as follows:
where
is the estimated speed of the target vehicle
from the subject vehicle
, and
is the real speed of the target vehicle
.
< 0 indicates that the driver underestimates the speed of the target vehicle
, and
> 0 indicates that the driver overestimates the speed of the target vehicle
.
Driver’s distance estimation errors were evaluated as follows:
where
is the estimated distance between the target vehicle and the subject vehicle, and
is the real distance between them.
< 0 indicates that that the driver underestimates the distance between the two vehicles;
> 0 indicates that that the driver overestimates the distance between the two vehicles.
5. Modeling of Relative Distance and Velocity Estimation
Based on the factors affecting the driver speed estimation and distance estimation errors selected in the previous section, a prediction model for driver speed estimation and distance estimation based on the integrated learning eXtreme Gradient Boosting (XGBoost) algorithm is developed in this section. Firstly, a coarser two-class prediction model is established; that is, the driver’s estimation results are classified into two categories: overestimation and underestimation. Subsequently, the driver’s estimation results were further subdivided into three categories: overestimation, normal, and underestimation. A more detailed three-classification prediction model is derived.
A total of 1542 sets of speed estimation samples and 2116 sets of distance estimation samples were obtained from the actual road tests. In this paper, the data set was divided into 80% training set and 20% testing set. The input parameters of the model are divided into two categories. One is the driver’s experience; the other is the vehicle motion parameters: subject vehicle speed, target vehicle speed, relative vehicle speed, and relative distance.
5.1. Model Construction
5.1.1. Model Label Settings
To provide a comprehensive overview of the classification performance of the speed and distance estimation model, this paper sets the classification of the speed and distance estimation errors into two cases, namely, two and classifications, according to the specific values of the speed and distance estimation three errors and the distribution of the error values. Specifically, “two classification” is used to classify the driver’s estimation into “overestimation” and “underestimation”. Without a loss of generality, “three classification” is used to classify the driver’s estimation error into “overestimation”, “normal estimation”, and “underestimation”.
In the two-classification of the estimation error, the estimation error value 0 is used as a threshold, when the estimation error is greater than 0, the error value label is set to 1 (overestimation); when the estimation error is less than 0, the error label is set to 0 (underestimation), as shown in Equation (1). In the two-classification model, there are 1020 labels of class 0 and 1096 labels of class 1 in the distance estimation dataset; while in the speed estimation dataset, there are 795 labels of class 0 and 747 labels of class 1.
For tri-classification of estimation errors, the 50% median interval of estimation errors was used as label 2 (normal), the upper 25% interval was used as label 3 (overestimation), and the lower 25% interval was as label 1 (underestimation), as shown in Equations (2) and (3). For the three classifications, there are 519 labels of category 1, 1089 labels of category 2, and 508 labels of category 3 in the distance estimation dataset. In the velocity estimation dataset, there are 374 labels of category 1, 802 labels of category 2, and 366 labels of category 3.
5.1.2. Model Parameter Settings
In the process of training the prediction model based on XGBoost-DNN algorithm, the parameters were adjusted to achieve the best prediction performance. In the XGBoost model, the key parameters include the learning rate, the number of decision trees, and the maximum depth of the decision trees in which the learning rate can control the step length of updating weights in each iteration of training. The maximum depth of the tree can affect the overfitting phenomenon: The smaller the value, the slower the model training speed is and the easier the model is underfitted, while the larger the value, the easier the model is overfitted.
The main parameters of DNN models include the number of hidden layers and the number of neurons per layer, learning rate, activation function, and optimizer. The deeper the number of layers, the stronger the theoretical performance of the model, but it is prone to overfitting, and too many neurons will also result in overfitting. The learning rate affects the model loss function and changes the convergence rate of the model; the role of the activation function is used to incorporate nonlinear factors to solve problems that cannot be solved by a general linear model; and the role of the optimizer is to update and calculate the model network parameters to approximate or reach the optimal value.
In this paper, the model prediction accuracy is the main criterion to measure the parameter selection. In this paper, we start by determining the value range of each parameter, and then we use iterative calculation and control variables to obtain the value for each parameter that maximizes the model’s prediction accuracy. The specific parameter values are shown in
Table 2.
In this paper, we use the Python-Sklearn package to train the model with an Intel i9-12900 K CPU and 64 GB of running memory. In the DNN module, the parameter tol is the condition for the model to stop training, and we set tol to 0.001, which means the model stops training when the loss value is less than or equal to 0.001. To avoid overfitting, we adjust the parameter’s subsample and colsample-bytree in the XGBoost module, which represent the ratio of the data and features used in training each tree to the total training set and features, respectively, with typical values of 0.5–1. By adjusting these two parameters, the overfitting of the model can be prevented.
5.2. Model Evaluation
5.2.1. Model Evaluation Methods
Confusion matrices with good visualization are often used to evaluate the performance of machine learning models [
39,
40,
41]. In this paper, the confusion matrix is used to evaluate the performance of the binary prediction model and the triple classification prediction model. For
k-element classification, the confusion matrix is represented as a matrix of size
k ×
k. As an example, the binary confusion matrix is described in
Table 2. True Positive (TP), False Negative (FN), True Negative (TN), and False Positive (FP) are the main indicators of the confusion matrix, and the substantial meaning of each indicator is shown in
Table 3.
The metrics accuracy rate (
), precision rate (
), recall rate (
), and
-score (
F1), which are commonly used for classification model evaluation, can be calculated using these metrics [
42]. The formula for each metric is shown below.
The Receiver Operating Characteristic (ROC) curve is also used to measure the training performance of the model. The ROC curve shows the probability of TP rate and FP rate under different threshold settings, while the Area Under Curve (AUC), which is the region under the ROC curve, reveals better classification performance when its value ranges from 0.5 to 1. The ROC curve is more suitable for evaluating the binary prediction problem; therefore, when evaluating the latter, it is used in addition to the confusion matrix.
5.2.2. Model Evaluation Results
Without loss of generality, in order to verify the applicability of the prediction model based on the XGBoost-DNN mixed algorithm for predicting the driver’s lane change speed and distance estimation, this paper compared its performance with traditional machine algorithm models such as Logistic Regression (LR) [
43], Random Forest (RF) [
44], Support Vector Machine (SVM) [
45,
46], K-Nearest Neighbor (KNN) [
47], Deep Neural Networks (DNN) [
34,
35], Gradient Boosting Decision Tree (GBDT) [
48], and XGBoost models [
49].
Table 4 reports the results of the two-classification model evaluation for speed estimation and distance estimation, and it was found that the model’s accuracy reaches 91.03% in speed estimation and 92.46% in distance estimation.
It can be observed from
Table 4 that XGBoost-DNN has the highest recognition accuracy of 91.03% in speed estimation, which is about 22% greater than the accuracy of SVM model. Compared with RF, LR, KNN, and GBDT models, XGBoost-DNN showed considerable advantages. In addition, the recognition accuracy of XGBoost-DNN is about 2.25% higher than that of the XGBoost model. Similar results are found in distance estimation, and the recognition accuracy of XGBoost-DNN is also the highest, reaching 92.46%, which is about 24% higher than that of the SVM model. Moreover, the recognition accuracy of XGBoost-DNN is about 1.91% higher than that of XGBoost model.
Figure 13 depicts the values of model evaluation metrics for speed estimation and distance estimation for the two-classification case for different models. It is apparent from
Figure 13 that the XGBoost-DNN proposed in this paper outperforms the other seven models. Moreover, the prediction performance of XGBoost is ranked second among the seven prediction models.
Figure 14 depicts that the AUC values of the XGBoost-DNN speed estimation model and distance estimation model are 0.957 and 0.963, respectively, which are higher than those obtained using traditional machine learning models. This indicates that the ROC curves also support the observation that the XGBoost-DNN model has better performance in the two-classification cases.
Table 5 reports the results of the three-classification model evaluation for speed estimation and distance estimation, and it was found that the model accuracy reaches 87.18% in speed estimation and 87.59% in distance estimation.
Figure 15 depicts the values of model evaluation metrics for speed estimation and distance estimation for the three-classification case for different models. It is apparent from
Figure 15 that the XGBoost-DNN proposed in this paper outperforms the other seven models. Moreover, the prediction performance of XGBoost is ranked second among the seven prediction models.
In summary, for the two-classification problem, high performance is achieved by all three models where the accuracy of all three models is above 72%. However, the XGBoost-DNN model has the highest prediction accuracy, with, respectively, 91.03% and 92.46% for speed and distance estimations, which is much higher than traditional machine learning models, proving excellent prediction accuracy. When compared to the two-classification prediction models, the performances of the three-classification prediction models built using the traditional machine learning algorithms and the XGBoost-DNN mixed algorithm proposed in this paper all plummeted. However, the XBoost-DNN model showed the lowest drop in performance. For speed and distance estimations, the accuracy is 87.18% and 87.59%, respectively, and the prediction accuracy is still better compared to the other traditional machine learning models.
6. Discussion
The risk assessment in driver lane changing mainly comes from the assessment of relative speed and relative distance between the target vehicle and the subject’s own vehicle, and the results of driver assessments are directly related to traffic risk and traffic efficiency. However, in the current lane-change research area, few researchers have conducted studies on the speed and distance estimation of drivers by using the rearview mirror during the lane-changing decision process. For this reason, in this study, an actual live highway test was conducted, during which the participants were asked to turn on CCS and make sequential estimates of the absolute speed of the target vehicle and the distance from the subject vehicle at four speeds controlled by CCS: 60, 70, 80, and 90 km/h. Firstly, we explored the surrounding factors that affect driver’s speed estimation and distance estimation errors. Subsequently, two- and three-classification prediction models for driver speed estimation and distance estimation results were developed based on the XGBoost-DNN mixed algorithm.
The results of the ridge regression showed that, in the speed and distance estimations, the speed of the subject vehicle, the speed of the target vehicle, the relative speed, and the relative distance between the subject vehicle and the target vehicle all had significant impact on the estimation error. The larger the relative speed and target vehicle speed, the more the driver tends to underestimate the speed and distance of the target vehicle. The smaller the relative speed and target speed, the more the driver tends to overestimate the speed and distance of the target vehicle. In addition, it can be observed in speed estimation that the higher the speed of the subject vehicle, the more the driver tends to underestimate the speed of the target vehicle; the lower the speed of the subject vehicle, the more the driver tends to overestimate the speed of the target vehicle. However, in distance estimation, the lower the speed of the subject vehicle, the more the driver tended to underestimate the relative distance; the higher the speed of the subject vehicle, the more the driver tended to overestimate the relative distance. In this study, we did not find a conclusive effect of driving experience on speed estimation error and distance estimation error. In addition, it can be observed from the coefficients of the variables in the ridge regression model that both the target vehicle speed and the relative vehicle speed have a large effect on the errors in speed estimation and distance estimation. This study on the effect of test and target vehicle speeds on driver estimation error is consistent with the findings by Wang, et al. [
50].
In this study, a driver speed estimation and distance estimation model based on XGBoost-DNN mixed algorithm was established. In the two-classification models, we classify drivers into two categories based on their estimation errors with respect to zero: underestimation and overestimation. The prediction accuracy of the XGBoost-DNN algorithm-based binary classification model for speed estimation and distance estimation reached 91.03% and 92.46%, respectively, which is about two percentage points higher than that of the XGBoost algorithm. Both the confusion matrix method and the ROC curve method proved that the prediction model based on XGBoost-DNN for the two-classification estimation outperformed other traditional machine learning models. In the three-classification model, drivers in the data sample were classified into three categories according to their estimation error distribution: underestimation, normal, and overestimation. The prediction accuracy of the three-classification model based on XGBoost-DNN algorithm reached 87.18% and 87.59% for speed estimation and distance estimation, respectively. The performance of the XGBoost-DNN algorithm-based dichotomous estimation prediction model was verified to be better than that of traditional machine learning models by the confusion matrix method.
Although the prediction accuracy of the XGBoost-DNN algorithm-based driver speed estimation and distance estimation three-classification prediction model is lower than that of the two-classification model, its classification is more specific and can predict the driver’s estimation error situation more accurately.
7. Conclusions and Future Work
In this study, we found that environmental factors affect drivers’ estimation results. The greater the relative speed and target vehicle speed, the more drivers tend to underestimate the speed and distance of the target vehicle. Therefore, drivers should be reminded to focus extra attention to lane-change safety in such cases. We suggest that driver training efforts can be carried out to train drivers to correctly estimate the target vehicle. The XGBoost-DNN model has a better prediction of driver estimation, which is helpful for providing a theoretical basis for a smarter warning rule for driver lane change warning systems.
In order to further improve the intelligence of the lane change warning system, we will continue to extend this research work in the future. Firstly, we will conduct larger scale trials on real roads to obtain more participants’ environmental estimation data. Secondly, we will recruit more types of participants (e.g., more age and driving experience coverage) in future trials, and we will try to achieve gender balance in the participants. Finally, the driver’s lane change process can be divided into three stages: information perception, lane change decision, and action execution. In this study, we explore the process of information perception, and we will gradually explore the other two stages in our future research.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}