
Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations

 , , and
, , and
Abstract
:1. Introduction
2. Related Works
2.1. Target Identification and Classification
2.2. Robot Picking
3. Proposed Approach
3.1. Acquisition and Processing of Picture Data
3.2. Grasping Solutions of Goods
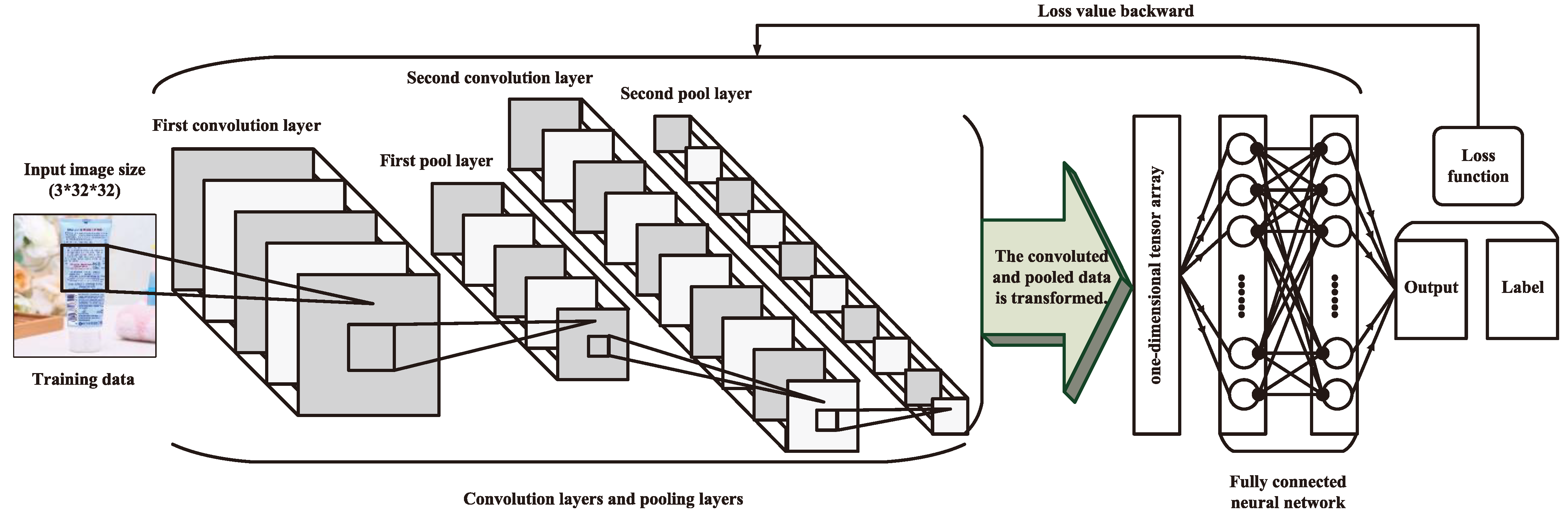
3.3. Recognition Model Construction
3.3.1. Feature Extraction
3.3.2. Mapping Output
3.3.3. Batch Processing
4. Results and Analysis
4.1. Model Training and Parameter Setting under Three Channels
4.2. Visualization of the Goods Grabbing Model under Three Channels
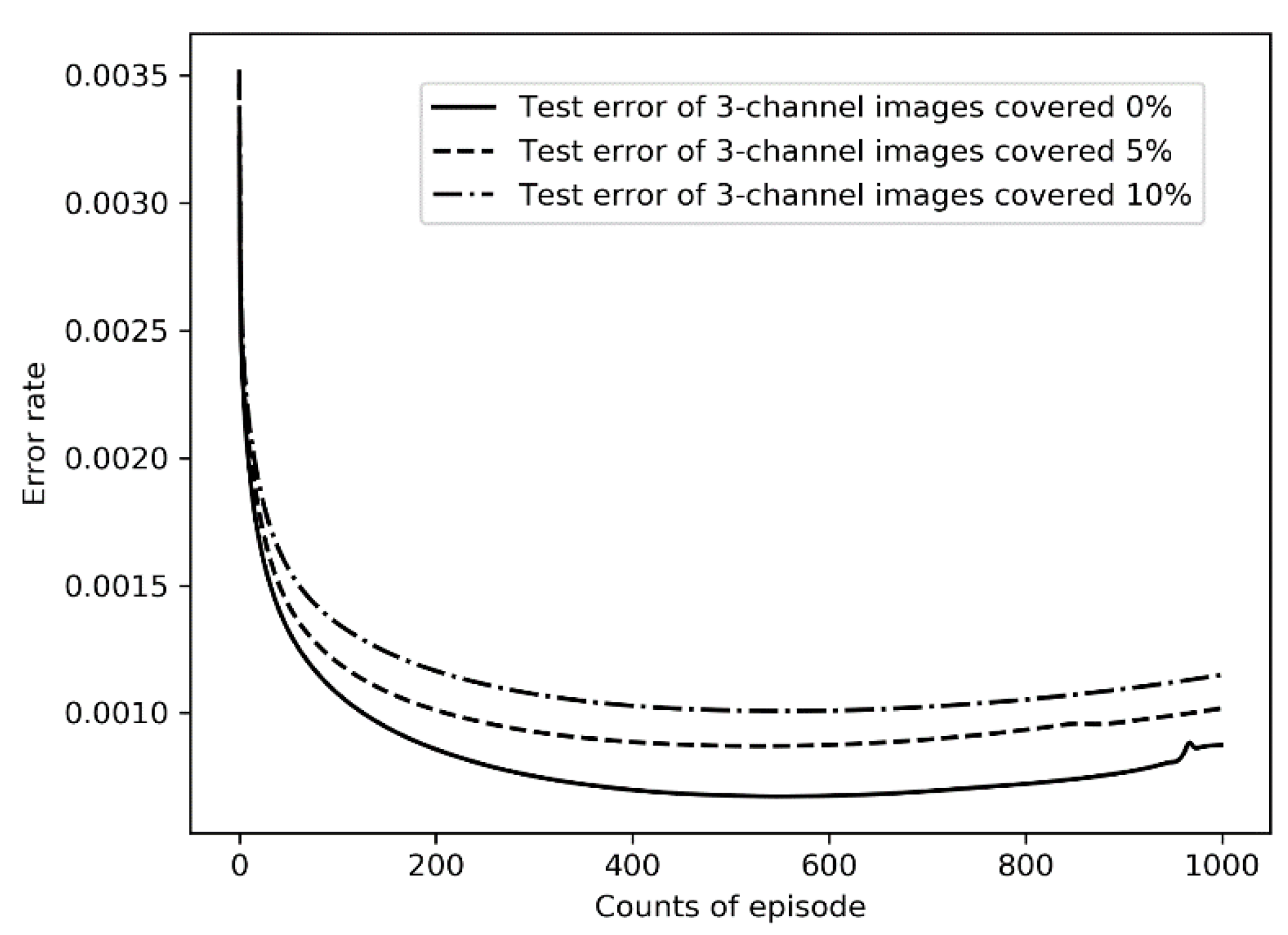
4.2.1. Analysis of Training Error and Test Error
4.2.2. Analysis of Training Accuracy and Test Accuracy
4.3. Unusual Conditions
- Three-channel pictures can provide more information from more dimensions, and the training results are significantly better than that of single-channel images. Although it takes a little more time to read the three-channel image data than to read the single-channel image data, CNN used in this study makes the training and recognition speed of the three-channel image basically equal to that of the single-channel images through the operation of the convolution layer.
- In the case of different channel numbers and covered rates, the training error is slightly lower than the test error, and the training accuracy is slightly higher than the test accuracy, indicating that there is a certain overfitting phenomenon. However, with the increase in training rounds, the test error is kept at a low level, the test accuracy rate is maintained at a high level, and there is a trend of continuous improvement, and the phenomenon of overfitting is also within the acceptable range.
- With the increase in the covered rate, although the training accuracy and test accuracy decreased slightly, the decreased range of the training accuracy and test accuracy was far lower than the increased range of the covered rate. Especially in the three-channel image data set, when the covered rate reaches 10%, the recognition accuracy still exceeds 83%. This shows that the CNN model selected in this study can adapt to the complex and changeable data environment and meet the requirements of practical application.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Fang, J.Y.; The State Council of China. The Internal Panorama of JD Shanghai “Asia One” Was Exposed for the First Time. Available online: http://www.360doc.com/content/15/1102/15/19476362_510206943.shtml (accessed on 21 June 2022).
- Khalid, B.; Naumova, E. Digital transformation SCM in View of Covid-19 from Thailand SMEs Perspective. Available online: https://pesquisa.bvsalud.org/global-literature-on-novel-coronavirus-2019-ncov/resource/pt/covidwho-1472929 (accessed on 21 June 2022).
- Barykin, S.Y.; Kapustina, I.V.; Sergeev, S.M.; Kalinina, O.V.; Vilken, V.V.; de la Poza, E.; Putikhin, Y.Y.; Volkova, L.V. Developing the physical distribution digital twin model within the trade network. Acad. Strateg. Manag. J. 2021, 20, 1–18. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid R-CNN. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cui, J.; Zhang, J.; Sun, G.; Zheng, B. Extraction and Research of Crop Feature Points Based on Computer Vision. Sensors 2019, 19, 2553. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Liu, M.; Zheng, P.; Yang, H.; Zou, J. A smart surface inspection system using faster R-CNN in cloud-edge computing environment. Adv. Eng. Inform. 2020, 43, 101037. [Google Scholar] [CrossRef]
- Chen, R.; Wang, M.; Lai, Y. Analysis of the role and robustness of artificial intelligence in commodity image recognition under deep learning neural network. PLoS ONE 2020, 15, e0235783. [Google Scholar] [CrossRef] [PubMed]
- Hong, Q.; Zhang, H.; Wu, G.; Nie, P.; Zhang, C. The Recognition Method of Express Logistics Restricted Goods Based on Deep Convolution Neural Network. In Proceedings of the 2020 5th IEEE International Conference on Big Data Analytics (ICBDA), Xiamen, China, 8–11 May 2020. [Google Scholar]
- Dai, Y.; Liu, W.; Li, H.; Liu, L. Efficient Foreign Object Detection between PSDs and Metro Doors via Deep Neural Networks. IEEE Access 2020, 8, 46723–46734. [Google Scholar] [CrossRef]
- Eigenstetter, A.; Takami, M.; Ommer, B. Randomized Max-Margin Compositions for Visual Recognition. In Proceedings of the 2014 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2Det: A Single-Shot Object Detector Based on Multi-Level Feature Pyramid Network. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Hilton Hawaiian Village, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Xie, L.; Liu, Y.; Jin, L.; Xie, Z. DeRPN: Taking a further step toward more general object detection. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Improved Inception-Residual Convolutional Neural Network for Object Recognition. Neural Comput. Appl. 2020, 32, 279–293. [Google Scholar] [CrossRef] [Green Version]
- Yue, J.; Zhao, W.; Mao, S.; Liu, H. Spectral–spatial classification of hyperspectral images using deep convolutional neural networks. Remote Sens. Lett. 2015, 6, 468–477. [Google Scholar] [CrossRef]
- Zhou, W.; Shao, Z.; Diao, C.; Cheng, Q. High-resolution remote-sensing imagery retrieval using sparse features by auto-encoder. Remote Sens. Lett. 2015, 6, 775–783. [Google Scholar] [CrossRef]
- Villalba-Diez, J.; Schmidt, D.; Gevers, R.; Ordieres-Meré, J.; Buchwitz, M.; Wellbrock, W. Deep Learning for Industrial Computer Vision Quality Control in the Printing Industry 4.0. Sensors 2019, 19, 3987. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Luo, J.; Huang, H. Toward automatic quantification of knee osteoarthritis severity using improved Faster R-CNN. Int. J. Comput. Ass. Rad. 2020, 15, 457–466. [Google Scholar] [CrossRef]
- Li, G.; Tang, H.; Sun, Y.; Kong, J.; Jiang, G.; Du, J.; Tao, B.; Xu, S.; Liu, H. Hand gesture recognition based on convolution neural network. Clust. Comput. 2019, 22, 2719–2729. [Google Scholar] [CrossRef]
- Hu, B.; Wang, J. Deep Learning Based Hand Gesture Recognition and UAV Flight Controls. Int. J. Autom. Comput. 2020, 17, 17–29. [Google Scholar] [CrossRef]
- Pigou, L.; Aäron, V.D.O.; Dieleman, S.; Herreweghe, M.V.; Dambre, J. Beyond Temporal Pooling: Recurrence and Temporal Convolutions for Gesture Recognition in Video. Int. J. Comput. Vis. 2018, 126, 430–439. [Google Scholar] [CrossRef] [Green Version]
- Wan, S.; Goudos, S. Faster R-CNN for Multi-class Fruit Detection using a Robotic Vision System. Comput. Netw. 2020, 168, 107036. [Google Scholar] [CrossRef]
- Pourdarbani, R.; Sabzi, S.; Kalantari, D.; Hernández-Hernández, J.L.; Arribas, J.I. A Computer Vision System Based on Majority-Voting Ensemble Neural Network for the Automatic Classification of Three Chickpea Varieties. Foods 2020, 9, 113. [Google Scholar] [CrossRef] [Green Version]
- Aukkapinyo, K.; Sawangwong, S.; Pooyoi, P.; Kusakunniran, W. Localization and Classification of Rice-grain Images Using Region Proposals-based Convolutional Neural Network. Int. J. Autom. Comput. 2020, 17, 233–246. [Google Scholar] [CrossRef]
- Afrakhteh, S.; Mosavi, M.R.; Khishe, M.; Ayatollahi, A. Accurate Classification of EEG Signals Using Neural Networks Trained by Hybrid Population-physic-based Algorithm. Int. J. Autom. Comput. 2020, 17, 108–122. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Ku, Y.; Yang, J.; Fang, H.; Xiao, W.; Zhuang, J. Optimization of Grasping Efficiency of a Robot Used for Sorting Construction and Demolition Waste. Int. J. Autom. Comput. 2020, 17, 691–700. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, W. Vision-based robot sorting system. In Proceedings of the International Conference on Manufacturing Technology, Materials and Chemical Engineering, Wuhan, China, 14–16 June 2019. [Google Scholar]
- Morrison, D.; Corke, P.; Leitner, J. Learning robust, real-time, reactive robotic grasping. Int. J. Robot. Res. 2020, 39, 183–201. [Google Scholar] [CrossRef]
- Arapi, V.; Zhang, Y.; Averta, G.; Catalano, M.G.; Rus, D.; Santina, C.D.; Bianchi, M. To grasp or not to grasp: An end-to-end deep-learning approach for predicting grasping failures in soft hands. In Proceedings of the 2020 3rd IEEE International Conference on Soft Robotics (RoboSoft), New Haven, CT, USA, 15 May–15 July 2020. [Google Scholar]
- Fang, K.; Zhu, Y.; Garg, A.; Kurenkov, A.; Mehta, V.; Li, F.; Savarese, S. Learning task-oriented grasping for tool manipulation from simulated self-supervision. Int. J. Robot. Res. 2020, 39, 202–216. [Google Scholar] [CrossRef] [Green Version]
- Jiang, P.; Ishihara, Y.; Sugiyama, N.; Oaki, J.; Tokura, S.; Sugahara, A.; Ogawa, A. Depth Image–Based Deep Learning of Grasp Planning for Textureless Planar-Faced Objects in Vision-Guided Robotic Bin-Picking. Sensors 2020, 20, 706. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Coninck, E.D.; Verbelen, T.; Molle, P.V.; Simoens, P.; Dhoedt, B. Learning robots to grasp by demonstration. Robot. Auton. Syst. 2020, 127, 103474. [Google Scholar] [CrossRef]
- Wang, Z.; Xu, Y.; He, Q.; Fang, Z.; Fu, J. Grasping pose estimation for SCARA robot based on deep learning of point cloud. Int. J. Adv. Manuf. Technol. 2020, 108, 1217–1231. [Google Scholar] [CrossRef]
- Yang, F.; Gao, X.; Liu, D. Research on Positioning of Robot based on Stereo Vision. In Proceedings of the 2020 4th International Conference on Robotics and Automation Sciences (ICRAS), Wuhan, China, 12–14 June 2020. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Driving Methods | Structural Features | Freedom of Installation and Control | Output Grip | Positioning Accuracy | Speed of Response | Reliability | Cost |
|---|---|---|---|---|---|---|---|
| Hydraulic | Complex | High | Strong | General | Fast | High | High |
| Pneumatic | Simple | High | Weak | General | Slow | Low | Low |
| Electric | Complex | Medium | Weak | Very high | Fast | Medium | Low |
| Mechanical | Medium | Low | Weak | Very high | Fast | Low | Low |
| Crawl Method | Working Principle | Structural Features | Application |
|---|---|---|---|
| Hook bracket | The robot uses the actions of holding, hooking and holding to hold the goods. | The structure is simple, the driving requirements are low, and the horizontal or vertical conveying operation can be completed. | Suitable for large machinery and equipment. |
| Spring-loaded | The grasping action mainly depends on the force of the spring to clamp the goods. | No special drive is required. | Mostly used to grab small and light goods. |
| Grab-type | Grabs the goods with mechanical fingers. | According to the target product, different shapes and numbers of mechanical fingers are designed. | It is most common in industrial robots. |
| Air suction | The suction cup compresses the gas and generates adsorption force through the pressure difference. | Simple structure, easy to buy, easy to operate, and low requirements for goods positioning. | Wide range of applications, and especially when only one side of the product can be contacted, the air suction type is the best. |
| Classification Name | Content | Number of Images | Example | |
|---|---|---|---|---|
| 1 | Facial toiletries | Cleansing cream, sun cream, eye cream, lotion, etc. | 2537 | Figure 1a |
| 2 | Freezing and refrigerated | Noodles, vegetarian food, dumplings, sausages, pot vegetables, fast food, etc. | 5626 | Figure 1b |
| 3 | Stationery | Crayons, pencils, crayons, pastels, etc. | 5635 | Figure 1c |
| 4 | Drinks and beverages | Tea drinks, functional drinks, fruit juices, carbonated drinks, spirits, wines, fruit wines, beer, drinking water, etc. | 1784 | Figure 1d |
| 5 | Laundry supplies | Laundry liquid, laundry disinfectant, etc. | 2407 | Figure 1e |
| 6 | Puffed food | Biscuits, pastries, rice crackers, roasted nuts, snacks, etc. | 6906 | Figure 1f |
| 7 | Paper products | Paper, wipes, sanitary napkins and pads, etc. | 5425 | Figure 1g |
| 8 | Miscellaneous department store items | Hangers, shoe brushes, toothbrushes, hooks, keychains, table lamps, etc. | 3216 | Figure 1h |
| Cargo Variety | Specification | Features | Drive Methods | Fetching Solution |
|---|---|---|---|---|
| Facial toiletries | 100~150 g | Packaging of plastic cylinder. | Pneumatic | Gripping of variable diameter and one-hand pneumatically driven. |
| Freezing and refrigerated | 200~1000 g | Some quotients are soft. | Electric | Flexible hands holding. |
| Stationery | 40~100 g | Packaging of plastic strip. | Pneumatic | Pneumatic grip with both hands. |
| Drinks and beverages | 235~2000 mL | Glass and plastic bottles. | Pneumatic | Three-jaw chuck with suction cup. |
| Laundry supplies | 110~4260 g | Plastics pot. | Hydraulic | Hydraulically driven with both hands. |
| Puffed food | 16~70 g | Lightweight vacuum bag. | Pneumatic | Bionic software robot with suction cup for grasping. |
| Paper products | 300~400 g | Bag is the smallest unit and resistant to crushing. | Electric | Electric-powered and two-handed telescopic splint for gripping. |
| Miscellaneous department store items | — | No obvious regularity in shape. | Electric | Grab by electric-powered bionic robot. |
| Number of Channels | Covered Rate | Training Error | Test Error | Training Accuracy | Test Accuracy |
|---|---|---|---|---|---|
| Single channel | 0% | 0.000500 | 0.000962 | 93.42% | 85.49% |
| 5% | 0.000645 | 0.001236 | 90.95% | 79.47% | |
| 10% | 0.001025 | 0.001356 | 84.58% | 76.49% | |
| Three channels | 0% | 0.000102 | 0.000672 | 99.24% | 90.35% |
| 5% | 0.000179 | 0.000869 | 98.46% | 86.49% | |
| 10% | 0.000256 | 0.001007 | 97.31% | 83.72% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Zhou, L.; Zhao, J.; Wang, F.; Yang, J.; Liang, K.; Li, Z. Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations. Sustainability 2022, 14, 7781. https://doi.org/10.3390/su14137781
Liu H, Zhou L, Zhao J, Wang F, Yang J, Liang K, Li Z. Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations. Sustainability. 2022; 14(13):7781. https://doi.org/10.3390/su14137781
Chicago/Turabian StyleLiu, Huwei, Li Zhou, Junhui Zhao, Fan Wang, Jianglong Yang, Kaibo Liang, and Zhaochan Li. 2022. "Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations" Sustainability 14, no. 13: 7781. https://doi.org/10.3390/su14137781
APA StyleLiu, H., Zhou, L., Zhao, J., Wang, F., Yang, J., Liang, K., & Li, Z. (2022). Deep-Learning-Based Accurate Identification of Warehouse Goods for Robot Picking Operations. Sustainability, 14(13), 7781. https://doi.org/10.3390/su14137781