1.1. Background and Purpose
Social media provide a venue for individuals to engage in online activities and interact with others [
1,
2]. On this wise, the advent and extension of social media have been producing big data, and they are undoubtedly leading the era of big data [
2,
3]. Moreover, with the COVID-19 outbreak, social media has become the platform of more choices for public opinions, perceptions, and attitudes toward various events, including public health policies [
4].
Now the developed capacity to collect and analyze such social media big data provides unprecedented opportunities for social science research areas, whose primary interest has been human dynamics [
3,
5]. Specifically, gender has been continuously receiving attention in prior research works to understand human dynamics through social media for sustainable societies [
6,
7]. In addition, since gender information is required to perform all gender research, it is essential to obtain gender information, e.g., gender labels, to study gender and related issues through social media big data for sustainable societies.
However, while it is inevitably difficult to obtain individual gender data [
8], the anonymity and privacy policy of social media have made it difficult or impossible to acquire gender information from social media [
9]. As a result, most prior gender research with social media has been made by using small-size or large-size data, where gender information could be collected [
10,
11]. If unavailable, gender information had to be manually annotated by researchers [
12], or simple estimation approaches were adopted based on relevant cues such as names [
13,
14].
Nevertheless, manual labeling cannot be applied to the size of social media big data. In addition, if the social media data are anonymous in accordance with a privacy policy, even a simple estimation approach using names as relevant cues cannot be adopted. Hence, prior gender researchers have not even tried to collect anonymous social media big data whose gender information is incomplete, i.e., partially open to the public, due to anonymity, and it led to a situation of little gender research using various sources of anonymous social media big data.
In the same context, anonymous news comment data of news portals in South Korea, possibly useful for gender research as social media big data, have rarely been considered for gender research and remain unexplored. However, fortunately, one of the Korean news portals, naver.com, provides the gender information of anonymous news commenters for a news article, i.e., male and female rates as gender distribution. Therefore, Lee and Ryu [
15] could use naver.com to study gender differences among news categories and sub-topics. However, for each news category, they used only the top 30 most-viewed news articles, whose gender distributions were available, i.e., labeled news articles.
Like this, naver.com has the policy to make the gender distribution for a news article open to the public only if the number of its direct news comments exceeds a specific number, i.e., 100. News comments on a news article in naver.com can be classified into two: (i) news comments that reply directly to the news article and (ii) replies to news comments. In this paper, news comments were used to represent both, while the term ‘direct news comment’ was adopted to be distinguished from the replies to news comments.
Because of such a restrictive policy, the gender distribution for almost all news articles, which have less than 100 direct news comments, remains unrevealed on naver.com, and therefore, those news articles can be considered unlabeled, i.e., unlabeled news articles. This study also found that in around 90% of news articles published on naver.com for two months, from 6/1 to 7/31 in 2018, the gender distribution of news commenters of a news article is not disclosed. Therefore, to use all the anonymous news comment data in naver.com as social media big data for gender research, it is necessary and valuable to think of a method to predict the gender distribution of anonymous new commenters for a news article.
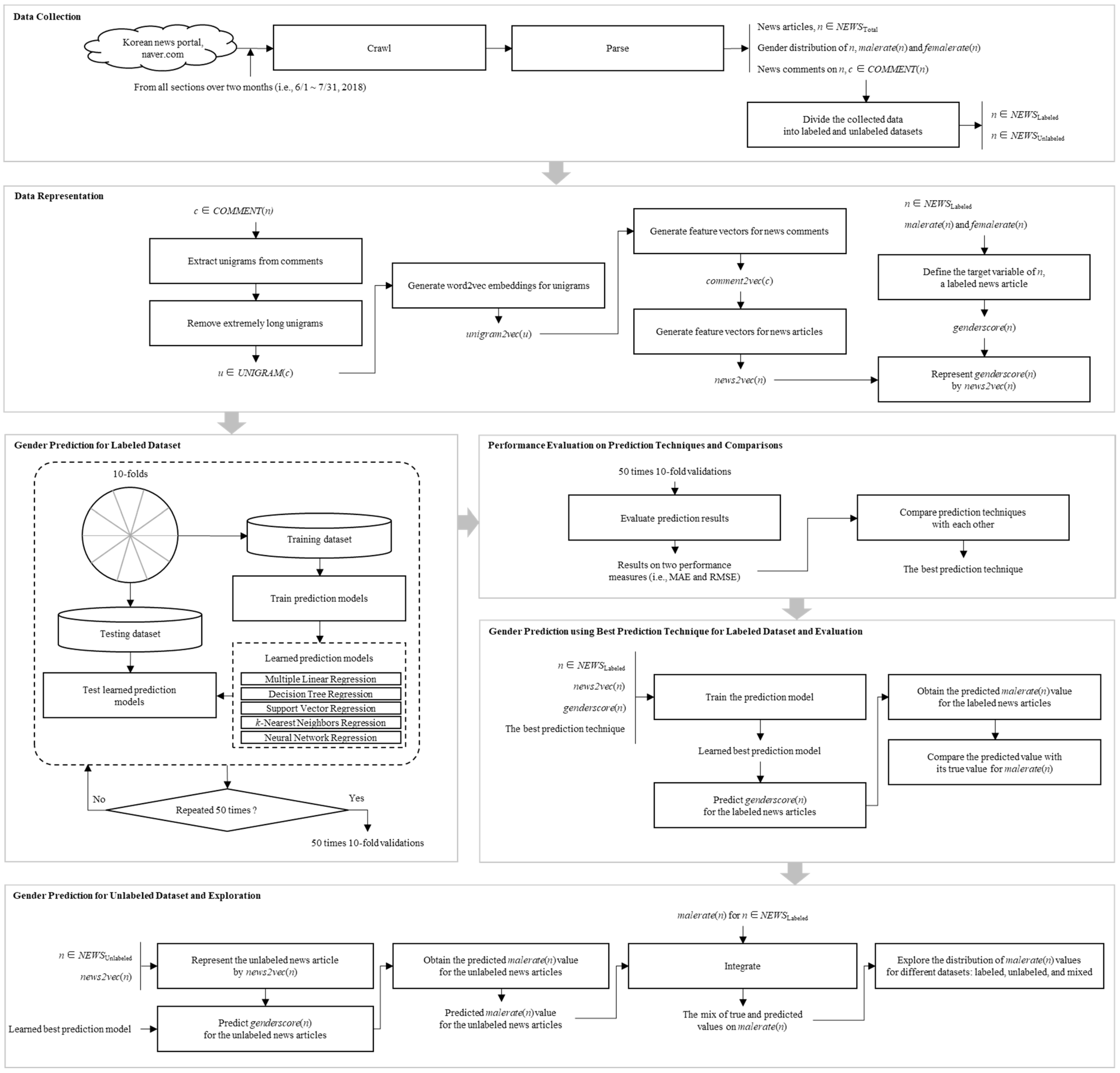
In these circumstances, focusing on the Korean news portal, naver.com, this paper aimed to enable its anonymous news comments to be used as social media big data for gender research. To do so, this paper proposed a machine-learning-based method for predicting the gender distribution of anonymous news commenters for a news article, represented by the characteristics based on the news comments of the news article. Using the labeled news articles, the proposed method was evaluated with different prediction techniques, and the best prediction technique was explored and selected. In addition, for the unlabeled news articles, their unknown gender distributions were predicted using the chosen best prediction technique and the labeled news articles. The predicted gender distributions for the unlabeled news articles were explored and compared with the known gender distributions for the labeled news articles.
1.2. Reviews on Related Works
Table 1 describes the recent works on gender research that used social media, and they can be summarized from various aspects such as purpose, data, and the used gender information. The findings in
Table 1 can be summarized as follows:
First, the purposes of recent works on gender research that used social media can be divided into two: (i) gender prediction and (ii) gender analysis with the collected or predicted gender information, but most of the prior works have aimed at gender prediction.
Second, in terms of data, various data sources have been used for gender prediction, but news articles and their comments have rarely been considered so far. In addition, the social media data of prior research have come from many kinds of languages, but Korean social media data have rarely been studied for gender prediction. The data size used by the previous works in
Table 1 varied from ten units to million units but did not exceed millions of units.
Third, regarding the used gender information, most previous works have targeted user gender, binary as male or female. Still, no prior work has been conducted on gender distribution in user collectives. In cases with gender labels available, small and large data, where gender information could be verified and collected, were used; users without gender information were to be excluded from the initially collected data [
10,
13,
16].
Fourth, on the other hand, if gender labels were not available, gender labels were manually annotated by researchers, or simple estimation approaches were adopted based on related cues, e.g., name, even though they could be unreliable because they discarded users whose gender could not be ascertained (e.g., neutral names). However, such manual annotation is inappropriate for big data, and simple estimation approaches have an increased risk of inaccurate estimates. Though the name-based estimation for gender prediction has been adopted frequently, it cannot be applied to anonymous social media data such as in this study.
Thus, to overcome the problem of incomplete gender information, gender prediction using machine learning has gained much attention from recent gender research on social media. Regarding the machine-learning-based labeling for gender, prior studies shown in
Table 1 can be classified by their data representations and prediction techniques, and it is as shown in
Table 2.
In detail, according to their data sources, prior gender research from social media, shown in
Table 1, has used various features for machine-learning-based gender prediction from social media. Recently, unstructured data such as images, voices, and textual data have been the features of their interest.
Particularly to represent gender by using textual data, most prior works have adopted the vector space model based on linguistic features such as a bag of words (BOW). Previous approaches to extracting linguistic features can be divided into closed and open vocabularies. While the prior works using the open vocabulary disregarded less informative linguistic features [
23], gender could be differentiated by the open vocabulary in social media [
24]. Moreover, recently, a few works have started adopting word embeddings. Specifically, the word2vec approach for word embeddings could include and use all linguistic features without disregarding linguistic features, and therefore, word embeddings were used to generate sentence embeddings [
25].
Most of the prior studies in
Table 1, which used machine-learning labeling approaches to identify gender from social media, have used various prediction techniques. They are summarized as shown in
Table 2. Because most of the prior works considered gender as binary, the prediction techniques used for gender prediction in social media were mostly classifiers such as logistic regression (LR), decision tree (DT), and support vector machine (SVM).
In terms of the taxonomies mentioned above, theoretically, this paper can be classified as shown in
Table 1 and
Table 2. In detail,
Table 1 shows that this paper focused on gender prediction as a research purpose. This study eventually extends and contributes to the literature by enabling gender research even with incomplete gender information from anonymous social media big data. Moreover, this paper introduced and used anonymous news comments as a new data source for gender research in social media. Compared to prior works in
Table 1, this study introduced news comments written mainly in Korean, and it extends the literature in terms of language diversity.
Unlike prior works in
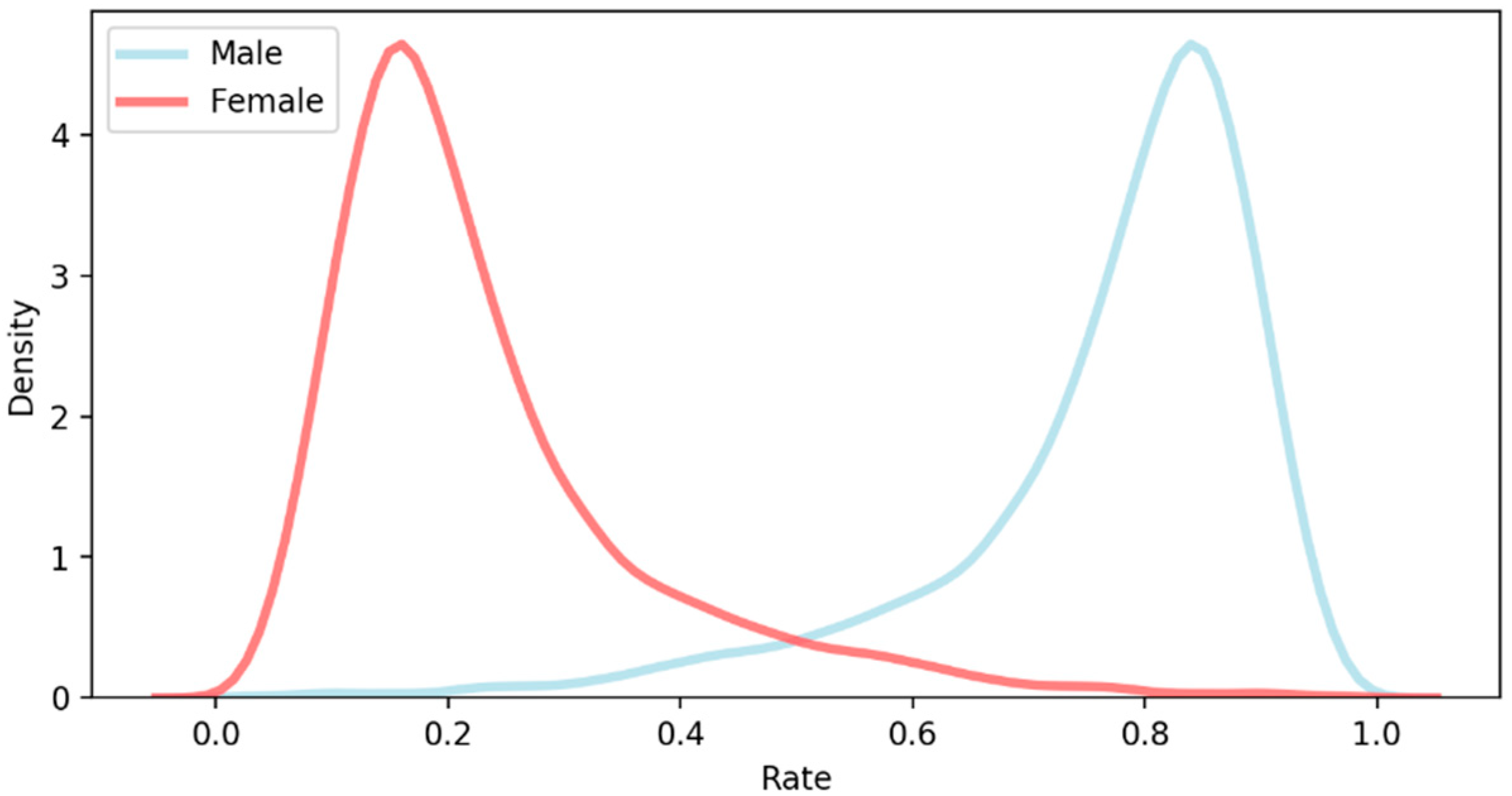
Table 1, when considering the characteristic of gender information of the Korean news portal, naver.com, according to its privacy protection, the gender distribution of news commenters for a news article was chosen as gender information, not binary but continuous between 0 and 1. By doing so, this study provided a new perspective on dealing with gender, i.e., a collective gender. It helps to extend the scope of gender from the individual to the collective level.
Related to data representation in
Table 2, this study used news comments as text data to represent the gender distribution of collective users. However, it is hard to find explicit cues for gender prediction in news comments due to the following reasons: (i) most of the news comments are very short, while they vary in length; (ii) they are not grammatically correct in most cases; and (iii) they contain different kinds of unstructured features such as emojis and characters of facial expressions.
Hence, unlike most previous works that used linguistic features for text data representation, this study adopted word embeddings, word2vec, to construct text data representation. In detail, to generate text representation for a news article, this study aggregated the word embeddings of words in the news comments of the news article.
Moreover, in terms of prediction techniques in
Table 2, because this study considered the gender distribution of news commenters for a news article as a continuous value between 0 and 1, not binary, prediction techniques commonly used for the continuous target variable in machine-learning applications were used. In addition, their performances were evaluated and compared with each other.
1.3. Research Gaps and Questions
The research gaps, identified from the literature reviews, could be summarized as follows:
First, the previous gender research has rarely paid attention to using news articles and their anonymous news comments as social media big data for both predicting gender information and gender research using the predicted gender information.
Second, it is currently unclear how information technologies can be used to predict the gender distribution of anonymous news commenters for labeled news articles.
Third, it has not been explored how different the predicted gender distributions for unlabeled news articles, which are far more than labeled news articles, will be when compared to the true gender distributions for labeled news articles.
Eventually, considering the findings from the related works and the above-mentioned research gaps, the research questions of this study could be formulated as below:
First, regarding the task of predicting the gender distribution of anonymous news commenters for a labeled news article,
RQ1. Which prediction technique will be best suited in a statistically significant way? In detail, if 10-fold cross-validation as an experiment is repeated 50 times for each prediction technique, which prediction technique will be best? Will this result be the same as the comparison results by pairwise t tests?
Second, if the best prediction technique is used,
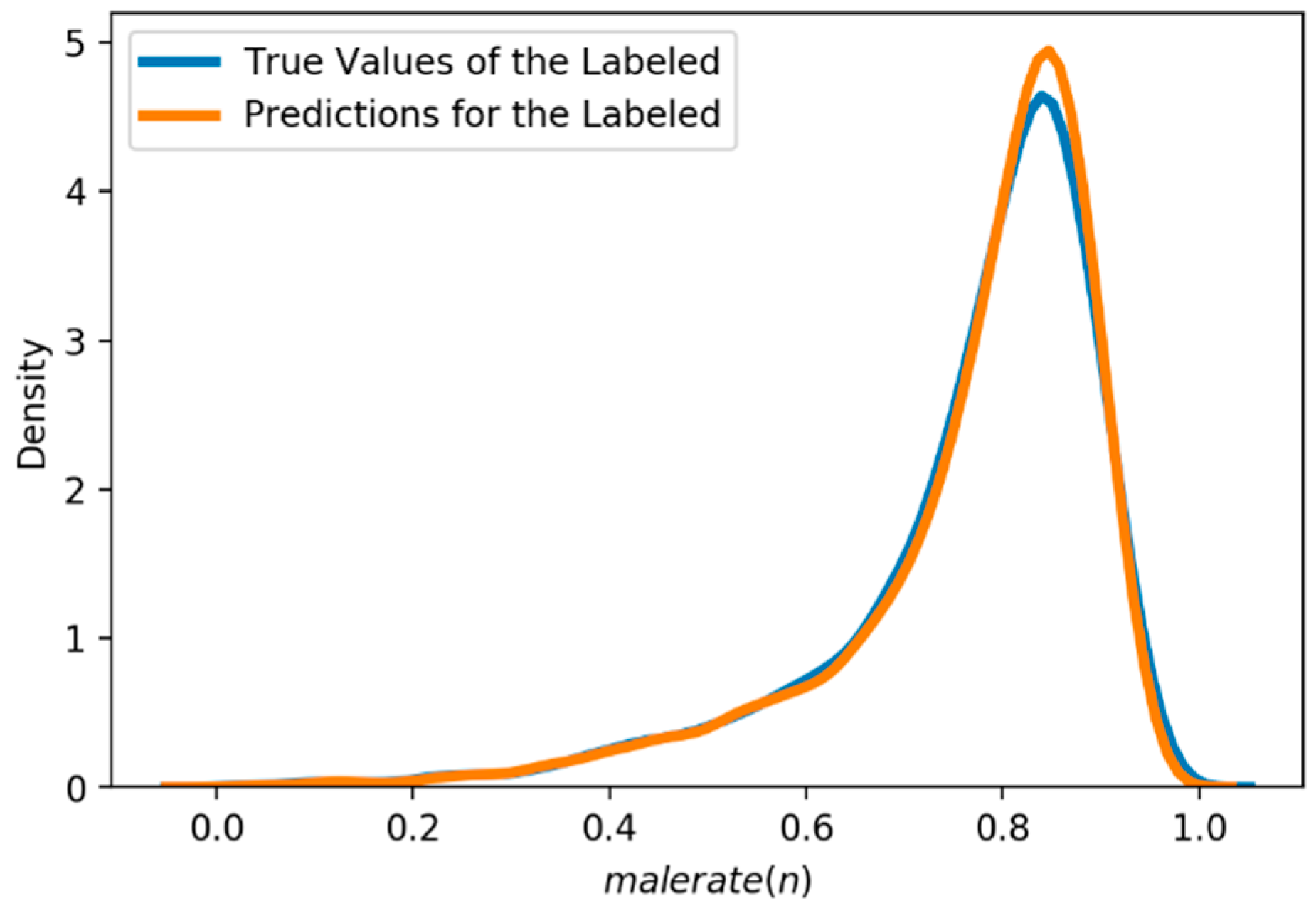
RQ2. How well can it be trained to predict the gender distribution of anonymous news commenters for a labeled news article?
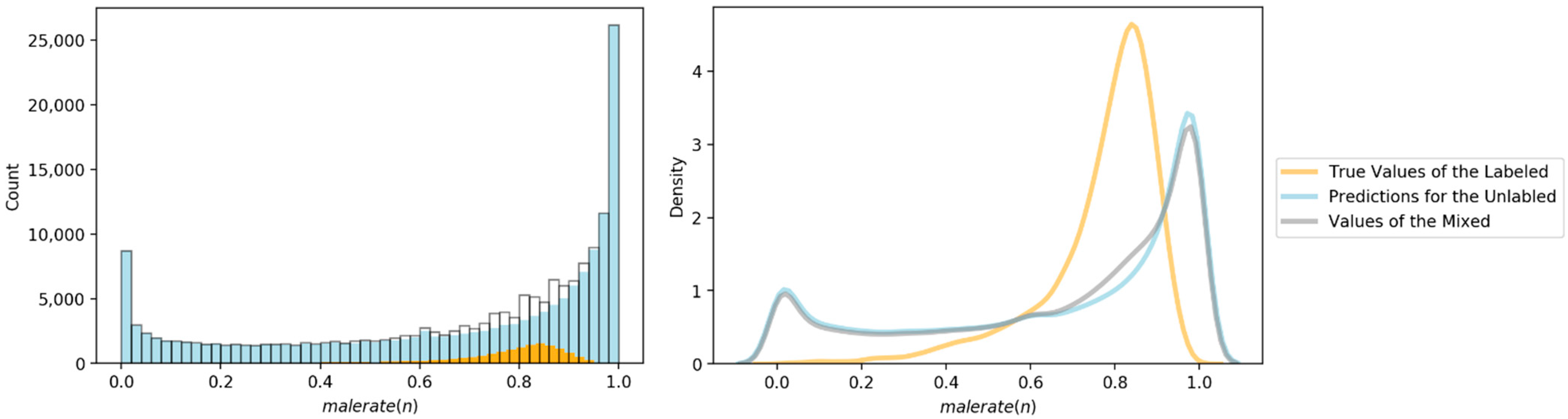
RQ3. How different will the predicted gender distributions for unlabeled news articles be when compared to the true gender distributions for labeled news articles? Particularly, in terms of their histograms and descriptive statistics.








{kind=link}
{kind=link}
{kind=link}
{kind=link}