
Fuzzy Artificial Intelligence—Based Model Proposal to Forecast Student Performance and Retention Risk in Engineering Education: An Alternative for Handling with Small Data

 ,
,  , , , ,
, , , ,
Abstract
:1. Introduction
- i.
- a comparative analysis of different methods of AI, widely recognized for their performance in forecast tasks;
- ii.
- a search in the main databases did not return studies focused on AI methods using fuzzy inference systems (FIS) to forecast retention risk in engineering education;
- iii.
- a large sample is often needed for the machine learning process, as a small dataset may be insufficient to build an accurate predictive model [20].
2. Related Works
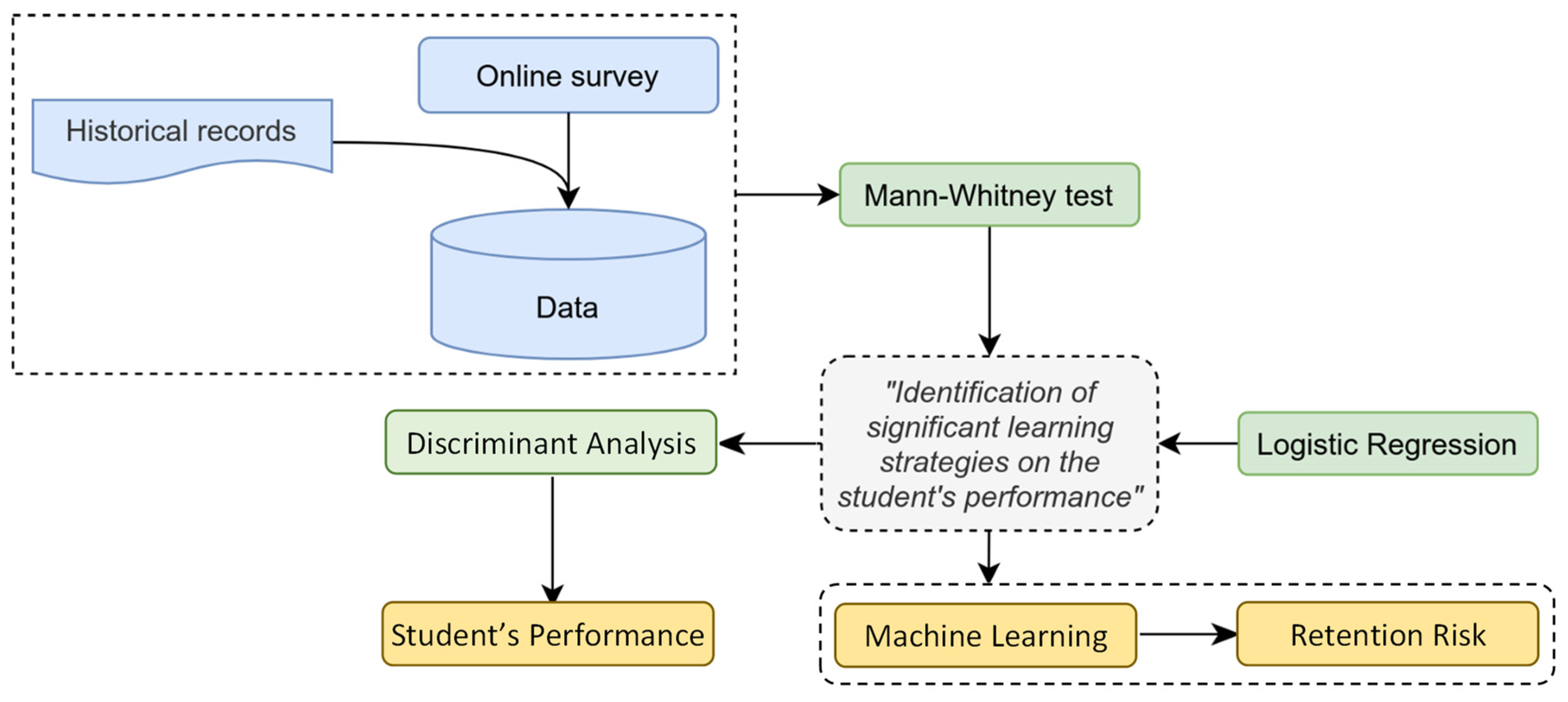
3. Material and Method
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Johri, A.; Rangwala, H. Running out of STEM: A Comparative Study across STEM Majors of College Students At-Risk of Dropping Out Early. In Proceedings of the International Conference on Learning Analytics and Knowledge, Sydney, NSW, Australia, 7–9 March 2018; pp. 270–279. [Google Scholar]
- Buttcher, C.; Davies, C.; Highton, M. Designing Learning; Routledge: London, UK, 2020. [Google Scholar]
- Nandeshawar, A.; Menzies, T.; Nelson, A. Learning patterns of university student retention. Expert Syst. Appl. 2011, 38, 14984–14996. [Google Scholar] [CrossRef]
- Bartoszewski, B.L.; Gurung, R.A.R. Comparing the relationship of learning techniques and exam score. Scholarsh. Teach. Learn. Psychol. 2015, 1, 219–228. [Google Scholar] [CrossRef]
- Souza, L.F.N.I. Learning strategies and related motivational factors. Educar 2010, 36, 95–107. [Google Scholar]
- Dembo, M.H.; Seli, H. Motivation and Learning Strategies for College Success: A Focus on Self-Regulated Learning; Routledge: New York, NY, USA, 2012. [Google Scholar]
- Séllei, B.; Stumphauser, N.; Molontay, R. Traits versus Grades-The incremental Predictive Power of Positive Psychological Factors over Pre-Enrollment Achievement Measures on Academic Performance. Appl. Sci. 2021, 11, 1744. [Google Scholar] [CrossRef]
- Warr, P.; Downing, J. Learning strategies, learning anxiety and knowledge acquisition. Br. J. Psychol. 2000, 91, 311–333. [Google Scholar] [CrossRef]
- Lu, K.; Yang, H.H.; Shi, Y.; Wang, X. Examining the key infuencing factors on college students’ higher-order thinking skills in the smart classroom environment. Int. J. Educ. Technol. High. Educ. 2021, 18, 1. [Google Scholar] [CrossRef]
- Martins, L.B.; Zerbini, T. Scale of learning strategies: Validity evidences in hybrid higher education. Psico 2014, 19, 317–328. [Google Scholar]
- Bressane, A.; Bardini, V.S.S.; Spalding, M. Active learning effects on students’ performance: A methodological proposal combining cooperative approaches towards improving hard and soft skills. Int. J. Innov. Learn. 2021, 29, 154–165. [Google Scholar] [CrossRef]
- Rastrollo-Guerrero, J.L.; Gómez-Pulido, J.A.; Durán-Domínguez, A. Analyzing and Predicting Students’ Performance by Means of Machine Learning: A Review. Appl. Sci. 2020, 10, 1042. [Google Scholar] [CrossRef] [Green Version]
- Hellas, A.; Ihantola, P.; Petersen, A.; Ajanovski, V.V.; Gutica, M.; Hynnien, T.; Knutas, A.; Leinonen, J.; Messom, C.; Liao, C. Predicting Academic Performance: A Systematic Literature Review. In Proceedings of the Companion of the 23rd Annual ACM Conference on Innovation and Technology in Computer Science Education, Lanarca, Cyprus, 2–4 July 2018. [Google Scholar]
- Csalódi, R.; Abonyi, J. Integrated Survival Analysis and Frequent Pattern Mining for Course Failure-Based Prediction of Student Dropout. Mathematics 2021, 9, 463. [Google Scholar] [CrossRef]
- Kiss, B.; Nagy, M.; Molontay, R.; Csabay, B. Predicting Dropout Using High School and First-semester Academic Achievement Measures. In Proceedings of the 17th International Conference on Emerging eLearning Technologies and Applications, Starý Smokovec, Slovakia, 21–22 November 2019. [Google Scholar]
- Tight, M. Tracking the scholarship of teaching and learning. Policy Rev. High. Educ. 2018, 2, 61–78. [Google Scholar] [CrossRef]
- Bird, K.A.; Castleman, B.L.; Mabel, Z.; Song, Y. Bringing transparency to predictive analytics: A systematic comparison of predictive modeling methods in higher education. AERA Open 2021, 7, 1–19. [Google Scholar] [CrossRef]
- Bertolini, R.; Finch, S.J.; Nehm, R.H. Quantifying variability in predictions of student performance: Examining the impact of bootstrap resampling in data pipelines. Comput. Educ. Artif. Intell. 2022, 3, e100067. [Google Scholar] [CrossRef]
- Chen, L.; Chen, P.; Lin, Z. Artificial Intelligence in Education: A Review. IEEE Open Access J. 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Lateh, M.A.; Muda, A.K.; Yusof, Z.I.M.; Muda, N.A.; Azmi, M.S. Handling a Small Dataset Problem in Prediction Model by employ Artificial Data Generation Approach: A Review. J. Phys. Conf. Ser. 2017, 892, e012016. [Google Scholar]
- Zadeh, L.A. Computing with Words; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Barros, L.C.; Bassanezi, R.C.; Lodwick, W.A. A First Course in Fuzzy Logic, Fuzzy Dynamical Systems, and Biomathematics; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Jayagowri, P.; Karpagavalli, K. A LFCM approach to student performance prediction based on learning fuzzy cognitive map. Adv. Appl. Math. Sci. 2021, 21, 3953–3965. [Google Scholar]
- Petra, T.Z.H.T.; Aziz, M.J.A. Analysing student performance in Higher Education using fuzzy logic evaluation. Int. J. Sci. Technol. Res. 2021, 10, 322–327. [Google Scholar]
- Mansouri, T.; ZareRavazan, A.; Ashrafi, A. A Learning Fuzzy Cognitive Map (LFCM) approach to predict student performance. J. Inf. Technol. Educ. Res. 2021, 20, 221–243. [Google Scholar] [CrossRef]
- Nosseir, A.; Fathy, Y.M. A mobile application for early prediction of student performance using Fuzzy Logic and Artificial Neural Networks. Int. J. Interact. Mob. Technol. 2020, 14, 4–18. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.J.; Malyscheff, A.; Imbrie, P.K. Artificial Intelligence Methods to Forecast Engineering Students’ Retention Based on Cognitive and Non Cognitive Factors. 2008. Available online: https://peer.asee.org/4315 (accessed on 7 April 2021).
- Yadav, S.; Bharadwaj, B.; Pal, S. Mining Education Data to Predict Student’s Retention: A comparative Study. Int. J. Comput. Sci. Inf. Secur. 2012, 10, 113–117. [Google Scholar]
- Kolo, D.K.; Adepoju, S.A.; Alhassan, V.K. A Decision Tree Approach for Predicting Students Academic Performance. Int. J. Educ. Manag. Eng. 2015, 5, 12–19. [Google Scholar]
- Mesarić, J.; Šebalj, D. Decision trees for predicting the academic success of students. Croat. Oper. Res. Rev. 2016, 7, 367–388. [Google Scholar] [CrossRef] [Green Version]
- Dhanalakshmi, V.; Bino, D.; Saravanan, A. Opinion mining from student feedback data using supervised learning algorithms. In Proceedings of the 2016 3rd MEC International Conference on Big Data and Smart City (ICBDSC), Muscat, Oman, 15–16 March 2016; pp. 1–5. [Google Scholar]
- Raut, A.B.; Nichat, A.A. Students Performance Prediction Using Decision Tree Technique. Int. J. Comput. Intell. Res. 2017, 13, 1735–1741. [Google Scholar]
- Rao, P.V.V.S.; Sankar, S.K. Survey on Educational Data Mining Techniques. Int. J. Eng. Comput. Sci. 2017, 4, e12482. [Google Scholar]
- Kavitha, G.; Raj, L. Educational Data Mining and Learning Analytics-Educational Assistance for Teaching and Learning. Int. J. Comput. Organ. Trends 2017, 41, 21–25. [Google Scholar] [CrossRef] [Green Version]
- Lu, O.H.; Huang, A.Y.; Huang, J.C.; Lin, A.J.; Ogata, H.; Yang, S.J. Applying learning analytics for the early prediction of students’ academic performance in blended learning. Educ. Technol. Soc. 2018, 21, 220–232. [Google Scholar]
- Buenaño-Fernández, D.; Gil, D.; Luján-Mora, S. Application of Machine Learning in Predicting Performance for Computer Engineering Students: A Case Study. Sustainability 2019, 11, 2833. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, M.; Muldoon, T.J.; Elsaadany, M. Employing Faculty, Peer Mentoring, and Coaching to Increase the Self-Confidence and Belongingness of First-Generation College Students in Biomedical Engineering. J. Biomech. Eng. 2021, 143, 121001. [Google Scholar] [CrossRef]
- Huerta-Manzanilla, E.L.; Ohland, M.W.; Peniche-Vera, R.D.R. Co-enrollment density predicts engineering students’ persistence and graduation: College networks and logistic regression analysis. Stud. Educ. Eval. 2021, 70, 101025. [Google Scholar] [CrossRef]
- Bello, F.A.; Kohler, J.; Hinrechsen, K.; Araya, V.; Hidalgo, L.; Jara, J.L. Using machine learning methods to identify significant variables for the prediction of first-year Informatics Engineering students dropout. In Proceedings of the 39th International Conference of the Chilean Computer Science Society (SCCC), Coquimbo, Chile, 16–20 November 2020. [Google Scholar]
- Ortiz-Lozano, J.M.; Rua-Vieites, A.; Bilbao-Calabuig, P.; Casadesús-Fa, M. University student retention: Best time and data to identify undergraduate students at risk of dropout. Innov. Educ. Teach. Int. 2020, 57, 74–85. [Google Scholar] [CrossRef]
- Alvarez, N.L.; Callejas, Z.; Griol, D. Predicting Computer Engineering Students’ Dropout In Cuban Higher Education With Pre-Enrollment and Early Performance Data. J. Technol. Sci. Educ. 2020, 10, 241–258. [Google Scholar] [CrossRef]
- Alvarez, N.L.; Callejas, Z.; Griol, D. Factors that affect student desertion in careers in Computer Engineering profile. Rev. Fuentes 2020, 22, 105–126. [Google Scholar]
- Hassan, H.; Anuar, S.; Ahmad, N.B.; Selamat, A. Improve student performance prediction using ensemble model for higher education. Front. Artif. Intell. Appl. 2019, 1529, 52041. [Google Scholar]
- Acero, A.; Achury, J.C.; Morales, J.C. University dropout: A prediction model for an engineering program in bogotá, Colombia. In Proceedings of the 8th Research in Engineering Education Symposium, REES 2019-Making Connections, Cape Town, South Africa, 10–12 July 2019. [Google Scholar]
- Ravikumar, R.; Aljanahi, F.; Rajan, A.; Akre, V. Early Alert System for Detection of At-Risk Students. In Proceedings of the ITT 2018-Information Technology Trends: Emerging Technologies for Artificial Intelligence, Dubai, United Arab Emirates, 28–29 November 2019. [Google Scholar]
- Fontes, L.S.; Gontijo, C.H. Active learning methodologies and their contribution to differential and integral calculus teaching. In Proceedings of the 12th Summer Workshop in Mathematics, Brasilia, Brazil, 10–14 February 2020. [Google Scholar]
- Bressoud, D.; Rasmussen, C. Seven characteristics of successful calculus programs. Not. AMS 2015, 62, 144–146. [Google Scholar] [CrossRef]
- Zimmerman, D.W. A note on consistency of non-parametric rank tests and related rank transformations. Br. J. Math. Stat. Psychol. 2012, 65, 122–144. [Google Scholar] [CrossRef] [PubMed]
- Szumilas, M. Explaining Odds Ratios. J. Can. Acad. Child Adolesc. Psychiatry 2010, 19, 227–229. [Google Scholar] [PubMed]
- McLachlan, G.J. Discriminant Analysis and Statistical Pattern Recognition; Wiley-Interscience: Hoboken, NJ, USA, 2005. [Google Scholar]
- Bressane, A.; Silva, P.M.; Fiore, F.A.; Carra, T.A.; Ewbank, H.; de-Carli, B.P.; Mota, M.T. Fuzzy-based computational intelligence to support screening decision in environmental impact assessment: A complementary tool for a case-by-case project appraisal. Env. Impact Assess. Rev. 2020, 85, 106446. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Guillaume, S.; Charnomordic, B.; Lablée, J.; Jones, H.; Desperben, L. FisPro: Fuzzy Inference System Design and Optimization; R Package Version 1.1.1; R Core Team: Auckland, New Zealand, 2022; Available online: https://CRAN.R-project.org/package=FisPro (accessed on 24 October 2022).
- R Core Team. R: A Language and Environment for Statistical Computing, Version 4.0; R Packages Retrieved from Mran Snapshot 2021-04-01; R Core Team: Auckland, New Zealand, 2021; Available online: https://cran.r-project.org (accessed on 1 January 2020).
- Sampaio, B.; Guimarães, J. Diferenças de eficiência entre ensino público e privado no Brasil. Econ. Appl. 2009, 13, 45–68. [Google Scholar] [CrossRef]
- Tinto, V. Research and practice of student retention: What next? J. Coll. Stud. Retent. Res. Theory Pract. 2006, 8, 1–19. [Google Scholar] [CrossRef]
- Jakubowski, T.G.; Dembo, M.H. Social Cognitive Factors Associated with the Academic Self-Regulation of Undergraduate College Students in a Learning and Study Strategies Course. In Proceedings of the Annual Meeting of the American Educational Research Association, New Orleans, LA, USA, 1–5 April 2002. [Google Scholar]
- Tseng, H.; Xiang, Y.; Yeh, H.T. Learning-related soft skills among online business students in higher education: Grade level and managerial role differences in self-regulation, motivation, and social skill. Comput. Hum. Behav. 2019, 95, 179–186. [Google Scholar] [CrossRef]
- Anthony, S.; Garner, B. Teaching soft skills to business students: An analysis of multiples pedagogical methods. Bus. Prof. Commun. Q. 2016, 79, 360–370. [Google Scholar] [CrossRef]
- Broadbent, J. Comparing online and blended learner’s self-regulated learning strategies and academic performance. Internet High. Educ. 2017, 33, 24–32. [Google Scholar] [CrossRef]
- Ghodousian, A.; Naeeimi, M.; Babalhavaeji, A. Nonlinear optimization problem subjected to fuzzy relational equations defined by Dubois-Prade family of t-norms. Comput. Ind. Eng. 2018, 119, 167–180. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Profiling Factors | Final Grade | ||||||
|---|---|---|---|---|---|---|---|
| obs. | min. | max. | mean | sd. | p | ||
| gender | female | 66 | 1.10 | 9.80 | 5.23 | 2.06 | 0.921 |
| male | 45 | 0.40 | 10.00 | 5.13 | 2.47 | ||
| high school | private | 30 | 0.40 | 9.80 | 5.26 | 2.22 | 0.426 |
| public | 41 | 1.10 | 10.00 | 5.06 | 2.27 | ||
| age group | young (<19) | 37 | 0.90 | 10.00 | 4.84 | 2.30 | 0.239 |
| young adult (≥19) | 74 | 0.40 | 9.80 | 5.36 | 2.18 | ||
| Cognitive | Self-Regulatory | Behavioral | ||||||
|---|---|---|---|---|---|---|---|---|
| ES | LR | BR | CM | EC | HS | CA | ||
| retention risk | ρ | 0.05 | 0.34 *** | 0.24 * | 0.08 | 0.26 ** | 0.25 ** | 0.29 ** |
| p | 0.614 | <0.001 | 0.010 | 0.390 | 0.005 | 0.008 | 0.002 | |
| Learning Strategies | p-Value | OR | Likelihood of Retention | ||
|---|---|---|---|---|---|
| (χ2) | (β) | From * | To ** | ||
| exercise solving | 0.665 | 0.666 | |||
| bibliography reading | 0.003 | 0.005 | 0.553 | 26.9% | 79.7% |
| lessons review | 0.001 | 0.001 | 0.504 | 24.7% | 83.6% |
| contextualized motivation | 0.319 | 0.322 | |||
| emotion control | 0.007 | 0.010 | 0.639 | 21.9% | 62.7% |
| class attendance | 0.003 | 0.006 | <0.001 | 0.06% | 31.2% |
| help seeking | 0.005 | 0.006 | 1.424 | 59.6% | 26.4% |
| Machine Learning Algorithm | Parameterization Setting | Accuracy (%) | |
|---|---|---|---|
| Train | Test | ||
| Cascade-correlation network (CCN) | kernel: sigmoid, gaussian; neurons: [0, 103]; candidates: 102; epoch: 103; overfitting control: cross validation | 89.91 | 63.3 |
| Decision Tree Forest (Tree Boost) | number of trees: 300, min. size node to split: 10; depth: 8; prune to min. error; min. trees in series: 10 | 86.24 | 70.64 |
| Fuzzy Inference System (FIS) | type of model: WM; type of function: triangular; terms: 5, t-norm: prod; disjunction operator: maximum | 94.02 | 91.92 |
| Gene expression programming (GEP) | population: 50; max. tries: 104; genes: 4; gene head length: 8; maximum: 2000; gen. without improvement: 10³ | 74.31 | 65.14 |
| Multilayer perceptron network (MLP) | number of layers: 03; type of function: logistic; train: scaled conjugate gradient; overfitting control: min. error over test | 67.89 | 66.97 |
| Polynomial neural network (GMDH) | maximum network layers: 20; max. polynomial order: 16; number of neuros per layer: 20 | 76.15 | 62.39 |
| Probabilistic neural network (PNN) | type of kernel function: gaussian; steps: 20; sigma: each var. [10−4, 10]; prior probability: frequency distribution | 86.24 | 69.72 |
| Radial basis function network (RBFN) | max. neurons: 103; radius: [10−2, 103]; population size: 200; maximum generations: 20; max. gen. flat: 5 | 73.39 | 58.72 |
| Support vector machine (SVM) | type: C-CSV; stopping criteria: 10−3; kernel function: RBF; optimize: minimize total error | 70.64 | 66.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bressane, A.; Spalding, M.; Zwirn, D.; Loureiro, A.I.S.; Bankole, A.O.; Negri, R.G.; de Brito Junior, I.; Formiga, J.K.S.; Medeiros, L.C.d.C.; Pampuch Bortolozo, L.A.; et al. Fuzzy Artificial Intelligence—Based Model Proposal to Forecast Student Performance and Retention Risk in Engineering Education: An Alternative for Handling with Small Data. Sustainability 2022, 14, 14071. https://doi.org/10.3390/su142114071
Bressane A, Spalding M, Zwirn D, Loureiro AIS, Bankole AO, Negri RG, de Brito Junior I, Formiga JKS, Medeiros LCdC, Pampuch Bortolozo LA, et al. Fuzzy Artificial Intelligence—Based Model Proposal to Forecast Student Performance and Retention Risk in Engineering Education: An Alternative for Handling with Small Data. Sustainability. 2022; 14(21):14071. https://doi.org/10.3390/su142114071
Chicago/Turabian StyleBressane, Adriano, Marianne Spalding, Daniel Zwirn, Anna Isabel Silva Loureiro, Abayomi Oluwatobiloba Bankole, Rogério Galante Negri, Irineu de Brito Junior, Jorge Kennety Silva Formiga, Liliam César de Castro Medeiros, Luana Albertani Pampuch Bortolozo, and et al. 2022. "Fuzzy Artificial Intelligence—Based Model Proposal to Forecast Student Performance and Retention Risk in Engineering Education: An Alternative for Handling with Small Data" Sustainability 14, no. 21: 14071. https://doi.org/10.3390/su142114071