



EMCS: An Energy-Efficient Makespan Cost-Aware Scheduling Algorithm Using Evolutionary Learning Approach for Cloud-Fog-Based IoT Applications
 , and
, and
Abstract
:1. Introduction
- An algorithm named EMCS task scheduling is proposed for cloud-fog-based IoT applications.
- The multi-objective optimization algorithm minimizes execution time, cost, and energy consumption simultaneously, while the parameters are adjusted using an evolutionary method to obtain better performance.
- The simulation results with various cloud and fog nodes also prove that the balance between cloud and fog nodes gives better performance.
2. Related Works
3. System Model
3.1. Network Model
3.2. Communication Model
- IoT Device Layer: In this layer, the devices communicate with the fog nodes which are within the communication range using different wireless communicate protocols.
- Fog Layer: In this layer, the fog nodes communicate with each other using device-to-device (D2D) communication. All the fog nodes follow a uniform wireless communication protocol.
- Cloud layer: This layer consists of multiple cloud servers which are kept in a centralized data center. The servers are connected through wired links for communication. The communication pattern followed between the cloud and fog layer is wireless in nature.
3.3. Process Flow Model
- Step 1: The IoT devices collect the data and send a request to the closest fog node.
- Step 2: The fog node immediately transfers the request to the .
- Step 3: To process a request, the request is decomposed into numerous dependent tasks which can be executed in the processors.
- Step 4: Then, the resource usages and the number of instructions of a task are estimated.
- Step 5: The task scheduler runs a scheduling algorithm and finds an optimal scheduling scheme.
- Step 6: As a result of the scheduling algorithm, the task are offloaded to the corresponding cloud and fog nodes.
- Step 7: The task collects the data from preceding tasks which completed their processes either in cloud node or fog node.
- Step 8: Each task is executed in the corresponding node.
- Step 9: After task execution was completed, the results are returned to the .
- Step 10: After the completion of all tasks, the results of a request are combined by the .
- Step 11: The aggregated result is bundled as a response and sent to the IoT device through the fog node.
3.4. Problem Formulation
3.5. Earliest Finish Time Model
3.6. Cost Model
3.7. Energy Model
4. Proposed EMCS Task Scheduling Algorithm
| Algorithm 1 Algorithm for fitness value computation |
Input: DAG of task, chromosome, location Output: fitness value
|
| Algorithm 2 Algorithm for best solution selection |
Input: Fitness value, chromosome, location Output: best_solution (chromosome, fitness, pop_location)
|
4.1. Chromosome Encoding
4.2. Population Initialization
4.3. Fitness Function
4.4. Genetic Operators
- Crossover: The crossover generates new individuals by crossing the genes of two individuals of the population. In this work, the traditional two-point crossover is applied to the parents for inheriting the quality genes in offspring. The process is shown in Figure 5, where two points are selected randomly and the genes between these two points of the first and second parents are exchanged with each other, while the remaining genes are unchanged to generate new offspring.The selection of parents in the crossover process can influence the algorithm. The crossover rate of every individual is . The parents are selected for crossover by applying a roulette wheel process. From this technique, the best individual with a maximum fitness value has a chance to be the parent, ensuring the offspring have good genes.
- Selection Process: The selection process selects a set of individuals on the basis of Darwin’s law of survival and forms a population for the next generation. After the crossover operation, the fitness value of the offspring is calculated. Here, 40% of parents are selected for the next generation, and the remaining population will be formed with offspring of the highest fitness value. Other individuals are discarded in this process. In this selection process, individuals with lesser fitness values are not discarded rapidly, and they are used to explore the search area, so that the population deviance is maintained in each generation.
- Mutation Operator: N chromosomes are formed with a new population after the completion of crossover and selection operations. Each individual with mutation rate has participated in a one-point mutation process. A random gene of each individual as shown in Figure 6 is selected, and the value of that gene is changed to a different value ranging from [1:m], which assigns the chosen task to be executed in another processor.The mutation overcomes the limitations of crossover by exploring the other areas in the solution space and avoiding local solutions. A set of modifications in GA was introduced in the proposed EMCS algorithm. Those are as follows:
- -
- Parent Selection: 75% of the population are selected as parents for crossover operations. This selection process adopts the roulette wheel technique of selecting parents for mating.
- -
- Selection Strategy: After crossover, 40% of parents are preserved for the next generation, and the remaining population is selected with offspring of larger fitness.
- In step 3, assign processor with (i.e. selected processor for processing task );
- In steps 4–7, check whether is the entry task or not. If is an entry task, then the set time for completion of the preceding tasks is 0; otherwise, compute using Equation (2). For each node of , compute steps 9–15.
- In step 9, set with .
- In steps 10–15, check ; if true, then compute data transferring time from node to node using Equation (2); otherwise, set as 0.
- Step 1 requires times for topological sort.
- The time required for executing step 2 to step 18 is , where is the number of incoming edges to a node T.
- The time complexity of step 19 is 1.
- Similarly, the complexity of each step 20 and step 21 is 1.
- Step 1 and step 2 has a time complexity of 1.
- Step 3 to step 7 has a time complexity of .
- Step 8 has a time complexity of 1.
5. Performance Evaluation
5.1. Experimental Setup
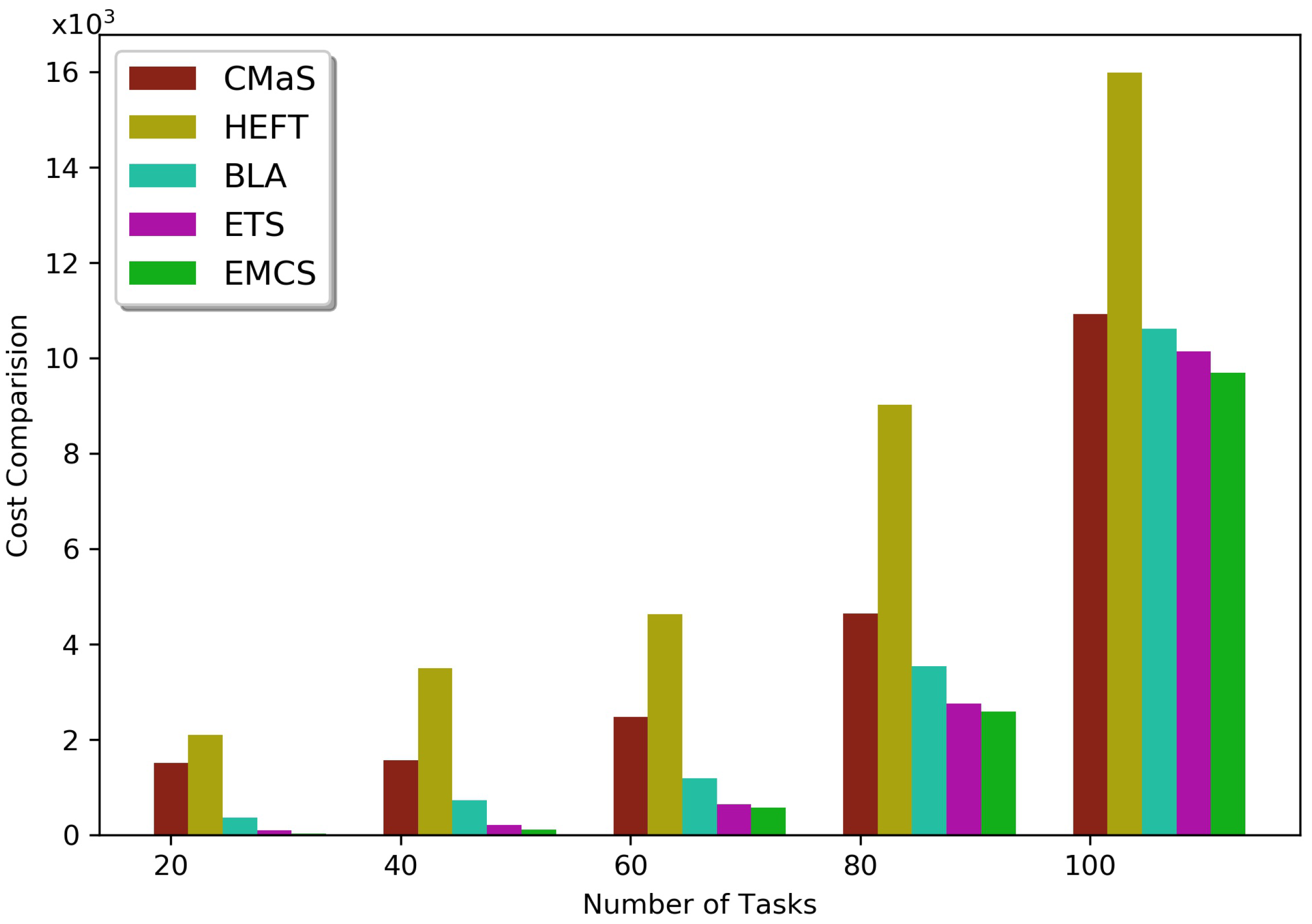
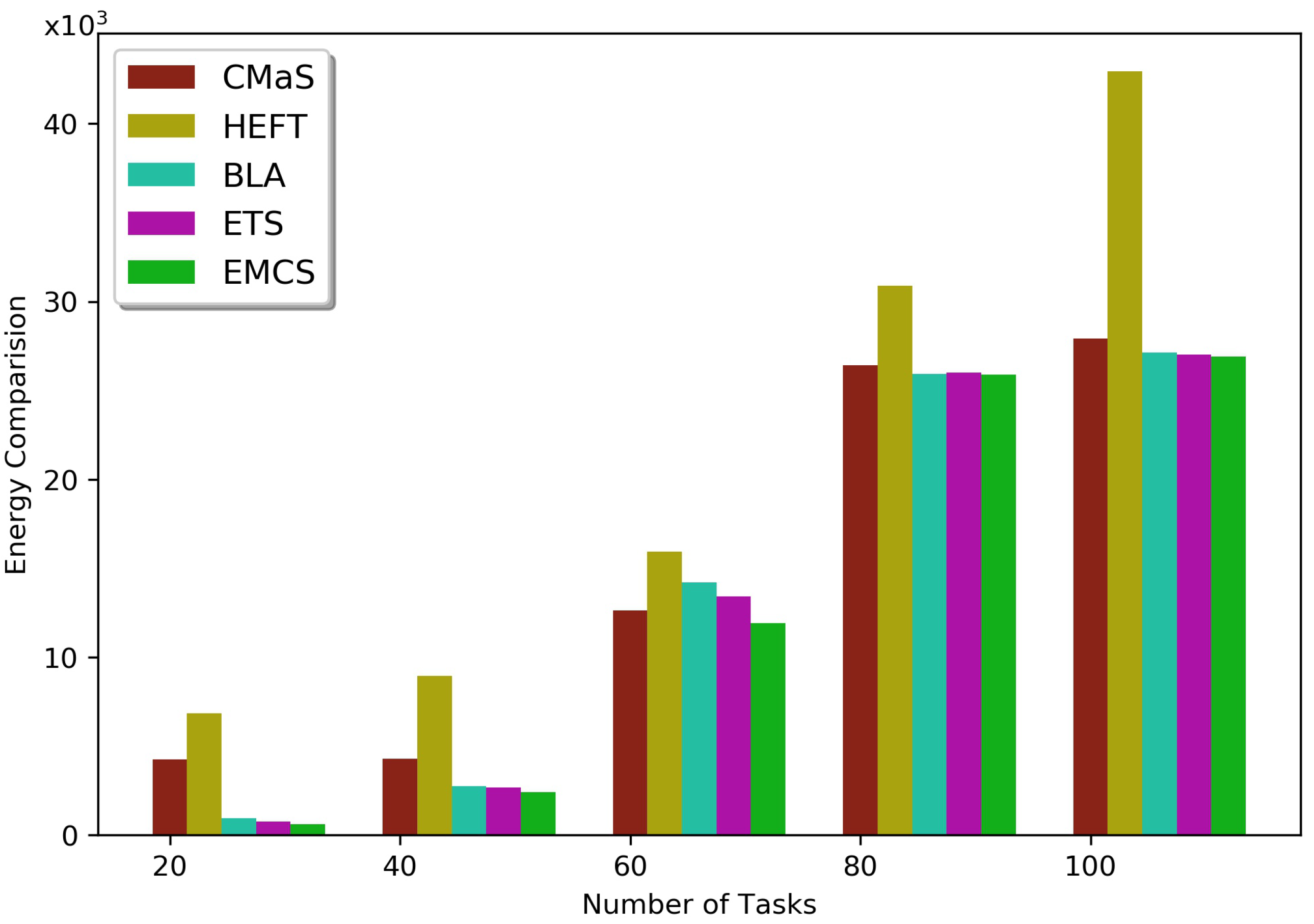
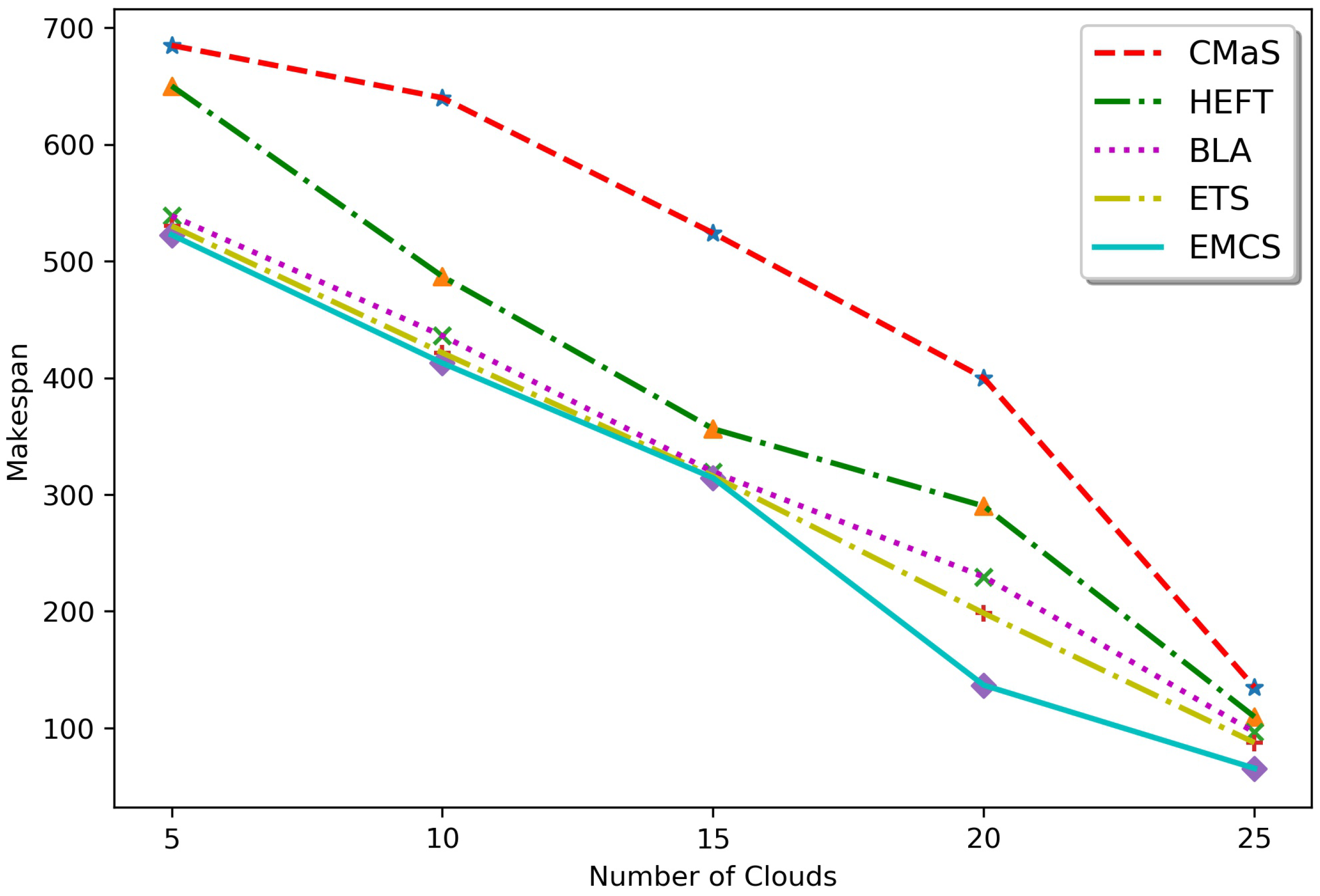
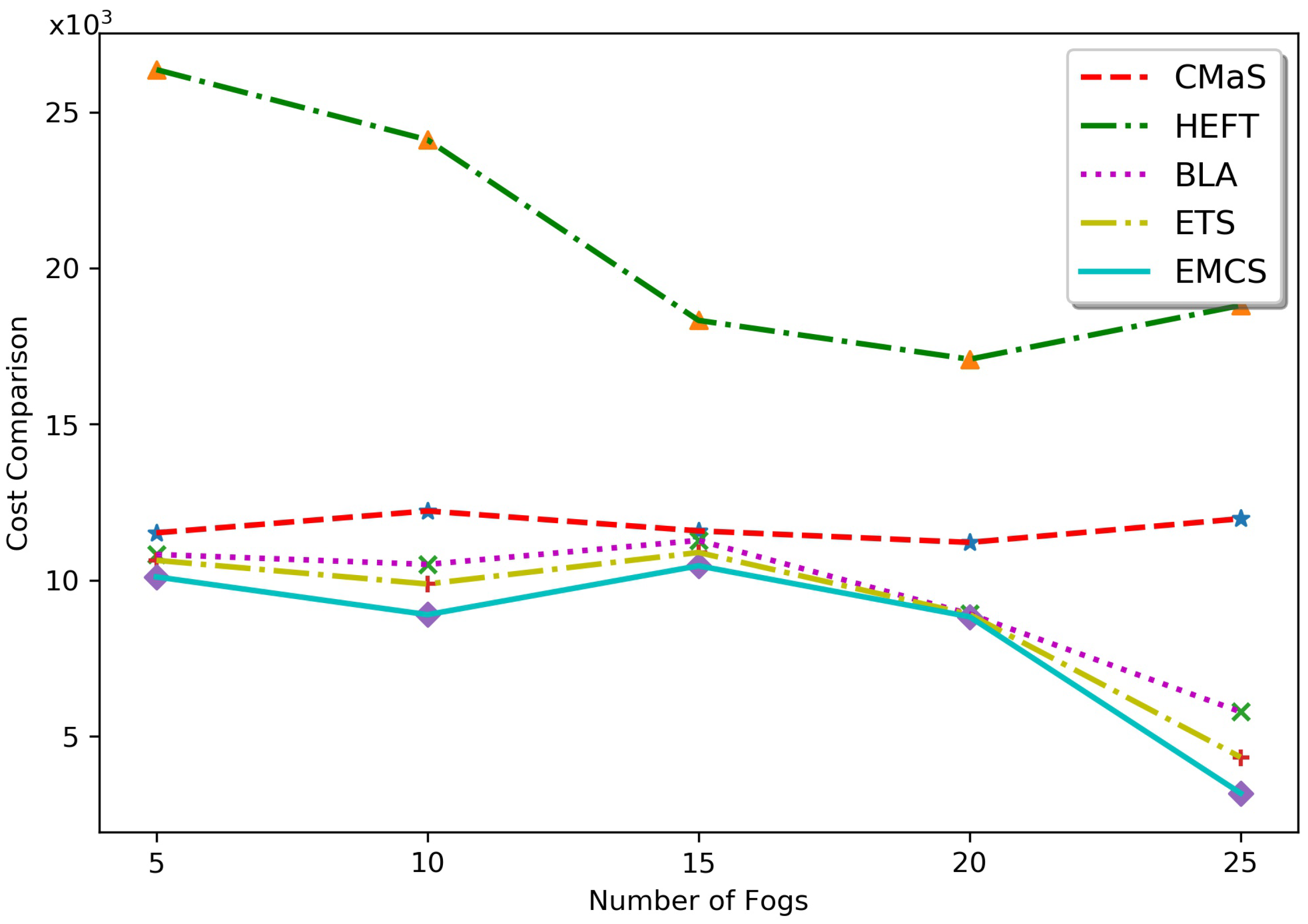
5.2. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pham, X.Q.; Man, N.D.; Tri, N.D.T.; Thai, N.Q.; Huh, E.N. A cost-and performance-effective approach for task scheduling based on collaboration between cloud and fog computing. Int. J. Distrib. Sens. Netw. 2017, 13, 1550147717742073. [Google Scholar] [CrossRef] [Green Version]
- Sahoo, K.S.; Tiwary, M.; Luhach, A.K.; Nayyar, A.; Choo, K.K.R.; Bilal, M. Demand–Supply-Based Economic Model for Resource Provisioning in Industrial IoT Traffic. IEEE Internet Things J. 2021, 9, 10529–10538. [Google Scholar] [CrossRef]
- Nguyen, B.M.; Thi Thanh Binh, H.; Do Son, B. Evolutionary algorithms to optimize task scheduling problem for the IoT based bag-of-tasks application in cloud–fog computing environment. Appl. Sci. 2019, 9, 1730. [Google Scholar] [CrossRef] [Green Version]
- Fog Computing and the Internet of Things: Extend the Cloud to Where the Things Are. Available online: https://studylib.net/doc/14477232/fog-computing-and-the-internet-of-things–extend (accessed on 2 September 2021).
- Naha, R.K.; Garg, S.; Georgakopoulos, D.; Jayaraman, P.P.; Gao, L.; Xiang, Y.; Ranjan, R. Fog computing: Survey of trends, architectures, requirements, and research directions. IEEE Access 2018, 6, 47980–48009. [Google Scholar] [CrossRef]
- Mukherjee, M.; Shu, L.; Wang, D. Survey of fog computing: Fundamental, network applications, and research challenges. IEEE Commun. Surv. Tutor. 2018, 20, 1826–1857. [Google Scholar] [CrossRef]
- Bhoi, S.K.; Panda, S.K.; Jena, K.K.; Sahoo, K.S.; Jhanjhi, N.; Masud, M.; Aljahdali, S. IoT-EMS: An Internet of Things Based Environment Monitoring System in Volunteer Computing Environment. Intell. Autom. Soft Comput. 2022, 32, 1493–1507. [Google Scholar] [CrossRef]
- Mao, L.; Li, Y.; Peng, G.; Xu, X.; Lin, W. A multi-resource task scheduling algorithm for energy-performance trade-offs in green clouds. Sustain. Comput. Inform. Syst. 2018, 19, 233–241. [Google Scholar] [CrossRef]
- Wu, C.; Li, W.; Wang, L.; Zomaya, A. Hybrid evolutionary scheduling for energy-efficient fog-enhanced internet of things. IEEE Trans. Cloud Comput. 2018, 9, 641–653. [Google Scholar] [CrossRef]
- Kabirzadeh, S.; Rahbari, D.; Nickray, M. A hyper heuristic algorithm for scheduling of fog networks. In Proceedings of the 2017 21st Conference of Open Innovations Association (FRUCT), Helsinki, Finland, 6–10 November 2017; pp. 148–155. [Google Scholar]
- Ma, X.; Gao, H.; Xu, H.; Bian, M. An IoT-based task scheduling optimization scheme considering the deadline and cost-aware scientific workflow for cloud computing. Eurasip J. Wirel. Commun. Netw. 2019, 2019, 249. [Google Scholar] [CrossRef] [Green Version]
- Hoang, D.; Dang, T.D. FBRC: Optimization of task scheduling in fog-based region and cloud. In Proceedings of the 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, Australia, 1–4 August 2017; pp. 1109–1114. [Google Scholar]
- Topcuoglu, H.; Hariri, S.; Wu, M.Y. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parallel Distrib. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef]
- Bitam, S.; Zeadally, S.; Mellouk, A. Fog computing job scheduling optimization based on bees swarm. Enterp. Inf. Syst. 2018, 12, 373–397. [Google Scholar] [CrossRef]
- Abdulredha, M.N.; Bara’a, A.A.; Jabir, A.J. An Evolutionary Algorithm for Task scheduling Problem in the Cloud-Fog environment. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1963, p. 012044. [Google Scholar]
- Liu, Q.; Wei, Y.; Leng, S.; Chen, Y. Task scheduling in fog enabled internet of things for smart cities. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology (ICCT), Chengdu, China, 15 May 2017; pp. 975–980. [Google Scholar]
- Liu, L.; Qi, D.; Zhou, N.; Wu, Y. A task scheduling algorithm based on classification mining in fog computing environment. Wirel. Commun. Mob. Comput. 2018, 2018, 2102348. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Hao, Z.; Zhang, R.; Sun, X. A method based on the combination of laxity and ant colony system for cloud-fog task scheduling. IEEE Access 2019, 7, 116218–116226. [Google Scholar] [CrossRef]
- Benblidia, M.A.; Brik, B.; Merghem-Boulahia, L.; Esseghir, M. Ranking fog nodes for tasks scheduling in fog-cloud environments: A fuzzy logic approach. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocco, 24–28 June 2019; pp. 1451–1457. [Google Scholar]
- Zhao, H.; Qi, G.; Wang, Q.; Wang, J.; Yang, P.; Qiao, L. Energy-efficient task scheduling for heterogeneous cloud computing systems. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications, IEEE 17th International Conference on Smart City, IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Zhangjiajie, China, 10–12 August 2019; pp. 952–959. [Google Scholar]
- Boveiri, H.R.; Khayami, R.; Elhoseny, M.; Gunasekaran, M. An efficient Swarm-Intelligence approach for task scheduling in cloud-based internet of things applications. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 3469–3479. [Google Scholar] [CrossRef]
- Aladwani, T. Scheduling IoT healthcare tasks in fog computing based on their importance. Procedia Comput. Sci. 2019, 163, 560–569. [Google Scholar] [CrossRef]
- Jena, R. Energy efficient task scheduling in cloud environment. Energy Procedia 2017, 141, 222–227. [Google Scholar] [CrossRef]
- Ben Alla, S.; Ben Alla, H.; Touhafi, A.; Ezzati, A. An efficient energy-aware tasks scheduling with deadline-constrained in cloud computing. Computers 2019, 8, 46. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Li, D. Task scheduling based on a hybrid heuristic algorithm for smart production line with fog computing. Sensors 2019, 19, 1023. [Google Scholar] [CrossRef] [Green Version]
- Rahbari, D.; Nickray, M. Scheduling of fog networks with optimized knapsack by symbiotic organisms search. In Proceedings of the 2017 21st Conference of Open Innovations Association (FRUCT), Helsinki, Finland, 6–10 November 2017; pp. 278–283. [Google Scholar]
- Rahbari, D.; Nickray, M. Low-latency and energy-efficient scheduling in fog-based IoT applications. Turk. J. Electr. Eng. Comput. Sci. 2019, 27, 1406–1427. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.Y.; Lee, C.R. Energy efficient scheduling for heterogeneous fog computing architectures. In Proceedings of the 2018 IEEE 42nd annual computer software and applications conference (COMPSAC), Tokyo, Japan, 23–27 July 2018; Volume 1, pp. 555–560. [Google Scholar]
- Tang, C.; Hao, M.; Wei, X.; Chen, W. Energy-aware task scheduling in mobile cloud computing. Distrib. Parallel Databases 2018, 36, 529–553. [Google Scholar] [CrossRef]
- Li, G.; Yan, J.; Chen, L.; Wu, J.; Lin, Q.; Zhang, Y. Energy consumption optimization with a delay threshold in cloud-fog cooperation computing. IEEE Access 2019, 7, 159688–159697. [Google Scholar] [CrossRef]
- Mazumdar, N.; Nag, A.; Singh, J.P. Trust-based load-offloading protocol to reduce service delays in fog-computing-empowered IoT. Comput. Electr. Eng. 2021, 93, 107223. [Google Scholar] [CrossRef]
- Singh, H.; Tyagi, S.; Kumar, P. Cloud resource mapping through crow search inspired metaheuristic load balancing technique. Comput. Electr. Eng. 2021, 93, 107221. [Google Scholar] [CrossRef]
- Lin, K.; Pankaj, S.; Wang, D. Task offloading and resource allocation for edge-of-things computing on smart healthcare systems. Comput. Electr. Eng. 2018, 72, 348–360. [Google Scholar] [CrossRef]
- Ibrahim, H.; Aburukba, R.O.; El-Fakih, K. An integer linear programming model and adaptive genetic algorithm approach to minimize energy consumption of cloud computing data centers. Comput. Electr. Eng. 2018, 67, 551–565. [Google Scholar] [CrossRef]
- Shishido, H.Y.; Estrella, J.C.; Toledo, C.F.M.; Arantes, M.S. Genetic-based algorithms applied to a workflow scheduling algorithm with security and deadline constraints in clouds. Comput. Electr. Eng. 2018, 69, 378–394. [Google Scholar] [CrossRef]
- Kumar, M.; Sharma, S.C. Deadline constrained based dynamic load balancing algorithm with elasticity in cloud environment. Comput. Electr. Eng. 2018, 69, 395–411. [Google Scholar] [CrossRef]
- Panda, S.K.; Nanda, S.S.; Bhoi, S.K. A pair-based task scheduling algorithm for cloud computing environment. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 1434–1445. [Google Scholar] [CrossRef]
- Bhoi, S.; Panda, S.; Ray, S.; Sethy, R.; Sahoo, V.; Sahu, B.; Nayak, S.; Panigrahi, S.; Moharana, R.; Khilar, P. TSP-HVC: A novel task scheduling policy for heterogeneous vehicular cloud environment. Int. J. Inf. Technol. 2019, 11, 853–858. [Google Scholar] [CrossRef]
- Panda, S.K.; Bhoi, S.K.; Khilar, P.M. A Semi-Interquartile Min-Min Max-Min (SIM 2) Approach for Grid Task Scheduling. In Proceedings of the International Conference on Advances in Computing, Kumool, India, 22–23 April 2013; pp. 415–421. [Google Scholar]
- Abd Elaziz, M.; Abualigah, L.; Attiya, I. Advanced optimization technique for scheduling IoT tasks in cloud-fog computing environments. Future Gener. Comput. Syst. 2021, 124, 142–154. [Google Scholar] [CrossRef]
- Guevara, J.C.; da Fonseca, N.L. Task scheduling in cloud-fog computing systems. Peer-Peer Netw. Appl. 2021, 14, 962–977. [Google Scholar] [CrossRef]
- Ali, H.S.; Rout, R.R.; Parimi, P.; Das, S.K. Real-Time Task Scheduling in Fog-Cloud Computing Framework for IoT Applications: A Fuzzy Logic based Approach. In Proceedings of the 2021 International Conference on COMmunication Systems & NETworkS (COMSNETS), Bangalore, India, 5–9 January 2021; pp. 556–564. [Google Scholar]
- Movahedi, Z.; Defude, B. An efficient population-based multi-objective task scheduling approach in fog computing systems. J. Cloud Comput. 2021, 10, 1–31. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, T.; Pang, S. Task scheduling algorithm based on improved firework algorithm in fog computing. IEEE Access 2020, 8, 32385–32394. [Google Scholar] [CrossRef]
- Bian, S.; Huang, X.; Shao, Z. Online task scheduling for fog computing with multi-resource fairness. In Proceedings of the 2019 IEEE 90th Vehicular Technology Conference (VTC2019-Fall), Honolulu, HI, USA, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Karagiannis, V. Compute node communication in the fog: Survey and research challenges. In Proceedings of the IoT-Fog 2019—2019 Workshop on Fog Computing and the IoT, Montreal, QC, Canada, 15–18 April 2019; pp. 36–40. [Google Scholar]
- BIN PACKING Proof of NP Completeness and Hardness. Available online: https://cs.ubishops.ca/home/cs567/more-np-complete/rangasamy-bin-packing.pdf (accessed on 2 September 2021).
- Azizi, S.; Shojafar, M.; Abawajy, J.; Buyya, R. Deadline-aware and energy-efficient IoT task scheduling in fog computing systems: A semi-greedy approach. J. Netw. Comput. Appl. 2022, 201, 103333. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sl. No. | Article | Tar System | Ideas | Improved Criteria | Limitations |
|---|---|---|---|---|---|
| 1 | Pham et al. (2017) [1] | Cloud-Fog System | Utility function considering makespan and mandatory cost to prioritized tasks | Execution time and mandatory cost | Small dataset |
| 2 | Nguyen et al. (2019) [3] | Cloud-Fog System | Genetic algorithm | Makespan and total cost | Budget, deadline, and resource limitations are not considered |
| 3 | Bitam et al. (2018) [14] | Fog Computing | Bees Life algorithm | CPU execution time and memory allocation | Small dataset |
| 4 | Topcouglu et al. (2002) [13] | Heterogeneous Computing | Priority of tasks | Execution time | Complex network |
| 5 | Liu et al. (2018b) [16] | Fog Computing | Genetic algorithm | Makespan and communication cost | Based on the smart city database |
| 6 | Liu et al. (2018a) [17] | Fog Computing | Classification of mining | Execution time and waiting time | Bandwidth between processors is not considered |
| 7 | Xu et al. (2019) [18] | Cloud-Fog System | Laxity and ant colony optimization | Energy consumption | Small dataset |
| 8 | Benblidia et al. (2019) [19] | Cloud-Fog System | Fuzzy logic | Execution delay and energy consumption | Very small dataset |
| 9 | Boveiri et al. (2019) [21] | Cloud System | Max–Min ant system | Scheduling length | Small dataset and in the cloud environment |
| 10 | Aladwani (2019) [22] | Fog Computing | Max–Min system | Total execution time, total waiting time, and total finish time | Small dataset |
| 11 | Zhao et al. (2019) [20] | Cloud Computing | Greedy-based algorithm | Power consumption | Network optimization is not considered |
| 12 | Jena (2017) [23] | Cloud Computing | Clonal selection algorithm | Energy consumption and makespan | Data centers and jobs are dynamic |
| 13 | Alla et al. (2019) [24] | Cloud Computing | Best-worst and TOPSIS method | Makespan and energy consumption | Not used in the large-scale data center |
| 14 | Wang et al. (2019) [25] | Fog Computing | Hybrid heuristic algorithm based on IPSO and IACO | Delay and energy consumption | Only used for tasks generated from the smart production line |
| 15 | Rahbari and Nichkray (2018) [26] | Fog Computing | Knapsack-based symbiotic organism search | Energy consumption, total network usage, execution cost, and sensor lifetime | Implemented on tasks based on camera sensors with actuators |
| 16 | Wu and Lee (2018) [28] | Fog Computing | Heuristic algorithm on ILP model | Energy consumption | Two types of heterogeneous fog nodes |
| 17 | Kabirzadeh et al. (2018) [10] | Fog Computing | Hyper-heuristic algorithm selecting from GA, PSO, ACO, and SA | Energy consumption, network usage, cost | Limited to camera dataset |
| 18 | Tang et al. (2018) [29] | Mobile Cloud Computing | Greedy, Group and GA | Energy consumption | Small task graph and applied in MCC |
| 19 | Li et al. (2019) [30] | Cloud-Fog System | Nonlinear programming and STML approach | Energy consumption and delay | Fog nodes are homogeneous |
| 20 | Wu et al. (2021) [9] | Cloud-Fog System | Partition of graph with EDA | Energy consumption, makespan, and lifetime of IoT | Small but real-time data |
| 21 | Abdulredha et al. (2021) [15] | Cloud-Fog System | Evolutionary algorithm | Energy and makespan | Energy consumption is not considered |
| Sl. No. | Notation | Description |
|---|---|---|
| 1 | Represents IoT devices | |
| 2 | Represents fog nodes | |
| 3 | Represents cloud nodes | |
| 4 | Cloud fog manager | |
| 5 | Set of tasks | |
| 6 | Individual task where | |
| 7 | Number of instructions of task | |
| 8 | Set of processors | |
| 9 | Individual processor where | |
| 10 | Numerous cloud nodes | |
| 11 | Numerous fog nodes | |
| 12 | Entry task that does not have predecessors | |
| 13 | Exit task that does not have sucessors | |
| 14 | Bandwidth of processor k | |
| 15 | Time for completion of preceding tasks of | |
| 16 | Total input to processor for task | |
| 17 | Task earliest start time on processor | |
| 18 | Task earliest finish time on processor | |
| 19 | Available of processor | |
| 20 | Task execution time on processor | |
| 21 | Energy required to process task on processor | |
| 22 | Energy for communication of a task on processor | |
| 23 | Processing cost per unit time for fog and cloud | |
| 24 | Communication cost per unit time for fog and cloud | |
| 25 | Energy required per unit for a execution of a task | |
| 26 | Energy used when fog is idle | |
| 27 | Energy per unit for transmission of data | |
| 28 | Energy per unit for execution of the task in the cloud | |
| 29 | ,, | Balance coefficient |
| 30 | Probability of crossover | |
| 31 | Probability of mutation |
| Sl. No. | Hardware/Software | Configuration |
|---|---|---|
| 1 | System | Intel® Core ™ i5-4590 CPU @ 3.30 GHz |
| 2 | Memory (RAM) | 4 GB |
| 3 | Operating System | Windows 8.1 Pro |
| Sl. No. | Parameter | Value |
|---|---|---|
| 1 | Tasks | |
| 2 | Cloud nodes () | |
| 3 | Fog nodes () | |
| 4 | Processing rate of cloud () | MIPS |
| 5 | Processing rate of fog () | MIPS |
| 6 | Bandwidth of cloud () | 10, 100, 512, 1024 Mbps |
| 7 | Bandwidth of fog () | 1024 Mbps |
| 8 | Amount of communication data () | MB |
| 9 | Processing cost per time unit for cloud () | 0.5 G$/s |
| 10 | Processing cost per time unit for fog () | G$/s |
| 11 | Communication cost per time unit for cloud () | $/s |
| 12 | Communication cost per time unit for fog () | G$/s |
| 13 | Number of instructions () | Instructions |
| 14 | Energy per unit time for execution of the task in fog () | w |
| 15 | Energy used when fog node is idle () | 0.05 w |
| 16 | Energy per unit for transmission of data () | w |
| 17 | Energy per unit for execution of task cloud () | w |
| 18 | Balance coefficient () | and |
| Name | GA | ETS | BLA |
|---|---|---|---|
| Length of chromosome | |||
| Number of iterations | 100 | 100 | 100 |
| Probability of crossover () | 0.9 | 0.9 | 0.9 |
| Probability of mutation () | 0.1 | 0.1 | 0.1 |
| Population size | 100 | 100 | Q = 1 D = 30 W= 69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sing, R.; Bhoi, S.K.; Panigrahi, N.; Sahoo, K.S.; Bilal, M.; Shah, S.C. EMCS: An Energy-Efficient Makespan Cost-Aware Scheduling Algorithm Using Evolutionary Learning Approach for Cloud-Fog-Based IoT Applications. Sustainability 2022, 14, 15096. https://doi.org/10.3390/su142215096
Sing R, Bhoi SK, Panigrahi N, Sahoo KS, Bilal M, Shah SC. EMCS: An Energy-Efficient Makespan Cost-Aware Scheduling Algorithm Using Evolutionary Learning Approach for Cloud-Fog-Based IoT Applications. Sustainability. 2022; 14(22):15096. https://doi.org/10.3390/su142215096
Chicago/Turabian StyleSing, Ranumayee, Sourav Kumar Bhoi, Niranjan Panigrahi, Kshira Sagar Sahoo, Muhammad Bilal, and Sayed Chhattan Shah. 2022. "EMCS: An Energy-Efficient Makespan Cost-Aware Scheduling Algorithm Using Evolutionary Learning Approach for Cloud-Fog-Based IoT Applications" Sustainability 14, no. 22: 15096. https://doi.org/10.3390/su142215096