1. Introduction
Neural networks have received careful attention with the development of artificial intelligence by virtue of their ‘black-box’ capability in model approximation via a data-driven manner [
1,
2,
3,
4]. It commonly known that the primary way for training a neural network with fixed architecture is the back-propagation (BP) algorithm, which has become one of the main driving forces in deep learning domains [
5]. However, it is generally accepted that the BP algorithm has certain drawbacks in different perspectives: (1) the effectiveness of the BP algorithm to some extent relies on the design of network architecture. However, it is generally difficult to predefine an optimal architecture for a given task. The commonly used way for designing the network architecture is the trial-and-error method, which is time-consuming and potentially impacts the effectiveness of the resulting model; (2) it suffers from several issues such as the weight initialisation, local minima, and sensitivity of the learning performance with respect to the learning rate setting. Empirically, this gradient-based learning method could not produce meaningful or interpretable internal representations from each hidden outputs [
6]; (3) it usually tends to be trained slowly when all of the neural network parameters must be iteratively tuned from scratch.
Randomized algorithms for training neural networks have been explored and developed since the 1980s [
7,
8] and well discussed in the early- to mid-1990s [
9,
10,
11,
12,
13]. It is empirically verified that neural networks with random weights (NNRWs) are computationally efficient since their input weights are randomly assigned and remain fixed during the training process. There are many different formulation/concepts related to NNRWs [
14,
15], such as Random Vector Functional-link (RVFL) network [
11,
12,
13], Random Kitchen Sinks (RKS) [
16], Random Features for Kernel Machines (RFKM) [
17], Stochastic Configuration Networks (SCN) [
18], etc. A fundamental issue for NNRWs is that of whether or in which perspective the randomized learner model has universal approximation capability (UAC), which is the most important theoretical basis for algorithm implementation. In particular, the UAC of RVFL networks has been theoretically verified in [
13] and further refined in [
19]. Both the approximation and estimation error bounds are proved for RKS in [
16]. These theoretical results, however, only ensure that there exists suitable random distribution
such that a randomized neural network with the weights and biases randomly selected from
has universal approximation capability in the sense of probability. Given a training dataset, as for the algorithm implementation in practice, it is not trivial to set a proper distribution (range) for problem solving. In other words, once the random distribution is not reasonably pre-defined, the universal approximation of the randomized neural network model cannot be ensured [
20,
21,
22]. To the best of our knowledge, SCN [
18] is the first work that constructs effective NNRWs by stochastically configuring the hidden weights and biases according to a data-dependent supervisory mechanism. Importantly, the universal approximation theory of SCN is guaranteed in a deterministic way, and, in comparison with RVFL networks, its favorable capability and good potential in dealing with both regression and classification problems has been well verified in various scenarios [
23,
24,
25,
26,
27,
28]. In this work, therefore, we focus on the extension of SCN, and the RVFL network is considered as a baseline.
In some domains, such as industry, finance, meteorology, etc., the data samples are collected in a sequential/streaming manner, that is, samples are available via the one-by-one or chunk-by-chunk way. In addition, in some applications, batch learning algorithms are not suitable, as the process of retraining, whenever new data are received, is impractical for problem-solving. Under this problem formulation, in this paper, we aims to further extent the framework of SCN, which is formulated in batch mode (i.e., considering all the available data at once), to be capable for building randomized neural networks with sequential training data. In particular, an effective Online Sequential Stochastic Configuration (OSSC) algorithm is proposed for problem-solving. The whole process of the OSSC algorithm can be formulated by two main steps: (i) initialization phase, where the stochastic configuration algorithm [
18] is applied to construct a base (initial) random learner model with generally acceptable (initial) approximation error; (ii) sequential updating phase, where the widely-used recursive least square (RLS) approach is performed for the purpose of renewing recursively the output weights of the initial model. The algorithmic convergence can be guaranteed, provided that the initialization phase is successfully processed. To highlight the effectiveness of OSSC, we also summarize some remarks to present the advantages of OSSC over the baseline OS-RVFL (i.e., a straightforward/trivial extension of RVFL network to its online sequential learning version). Extensive experimental studies, including two synthetic examples for 1D function approximation, one example for nonlinear dynamic system modeling, one example of Mackey–Glass time-series prediction, and one case study for foreign exchange rate forecasting application, are conducted to demonstrate the merits of our proposed OSSC, in comparison with OS-RVFL. We also provide a robustness analysis to study empirically the influence of chunk size on the model’s performance. All of the experimental results show clearly the fact that OSSC is effective and has a good potential for dealing with sequential data modeling tasks.
In summary, our contributions are as follows:
An effective Online Sequential Stochastic Configuration (OSSC) algorithm is proposed for training neural networks with sequential training data. As a favorable randomized learner model, OSSC further supplements the variants of SCNs [
18];
Based on the extensive experimental studies, where OSSC is compared with OS-RVFL on several online learning tasks, we uncover certain uncertainty issues and also provide some useful clues, which are empirically beneficial for interested readers to have a clear and accurate understanding about developing online version of neural networks with random weights.
The remainder of this paper is organized as follows:
Section 2 briefly reviews RVFL networks.
Section 3 recalls the stochastic configuration framework with both theoretical and algorithmic description. An effective Online Sequential Stochastic Configuration (OSSC) algorithm is proposed in
Section 4. Extensive experimental investigations are provided in
Section 5. Finally,
Section 6 concludes this work and gives further expectations for future work.
2. Basics of RVFL Networks
RVFL networks can be treated as a class of random learner models with a remarkable feature that the input weights and biases are randomly selected and remain fixed during the training phase. In this paper, we only consider RVFL networks without a direct link from the input to the output, which is equivalent to a single hidden layer feedforward neural network (SLFN) that can be mathematically described as
where
L is the number of hidden nodes,
is the input vector,
g is the activation function,
is the bias,
is the input weight,
is the output weight connecting the
j-th hidden node and the output node. Now, we briefly describe the learning process for RVFL networks. Assume that we are given a training set
with
N samples of the target function (
),
,
. Remember that
and
are randomly selected and fixed in the training phase; therefore, the learning objective is to solve the following optimization problem:
which is equivalent to a standard least square (LS) problem
where
is the hidden layer output matrix,
,
. Finally, a close form solution of the output weights can be obtained by using the pseudo-inverse method, i.e.,
.
In passing, the universal approximation theorem of RVFL networks [
13,
19] can only ensure that there exists a certain appropriate range for randomly assigning the hidden parameters rather than totally independent with the training information, indicating the fact that the random selection scope for the input weights and biases has a significant impact on the random learner’s performance. In other words, a trivial range
for randomly assigning input weights and biases may fail in leading to a universal approximator. Indeed, an inappropriate selection scope from which the hidden parameters are randomly generated will incur very bad learning and generalization performance. Li and Wang [
21] have addressed some ‘risky’ aspects caused by the randomness, revealing some practical issues and pitfalls when using this kind of random learner model. These ‘risky’ aspects may still exist and/or cause outrageous results in the process of applying a sequential learning framework for RVFL networks, in the case that training observations are sequentially provided. This motivates us to find a better online learning system by reconsidering the stochastic configuration algorithm that has sufficient effectiveness in constructing a random learner with good learning and generalization capabilities [
18], as delineated in the next section.
3. Revisit of the Stochastic Configuration Algorithm
In [
18], stochastic configuration algorithms were proposed to circumvent those awkward issues in applying RVFL networks, by incrementally constructing an universal approximator with random hidden parameters found on the basis of specified supervisory mechanism. The selection scope for the hidden parameters is determined randomly but with an objective to decrease the residual error incrementally, instead of being fixed in advance. The simulation results in [
18] have shown the merits of the SC algorithm in comparison with some existing RVFL-based randomized algorithms.
Here, we revisit the constructive process of the SC framework, followed by the restatements of both the theoretical and algorithmic results. Let denote the space of all Lebesgue-measurable vector-valued functions on a compact set , with the norm defined as . For a target function , assume a single layer feed-forward network (SLFN) with hidden nodes () have already been constructed, that is, (). If the current residual error denoted as is still unacceptable, the SC framework is concerned with how to add , ( and ) leading to until the residual error is suitable for the given task, that is, is smaller than an expected specific tolerance .
Theorem 1 ([
18])
. Given that span (Γ) is dense in and , for some . Given and a nonnegative real number sequence, with and . For , denote a factorIf is selected to satisfyandthenwhere . Given a training set with inputs
,
and outputs
,
. We denote
as the corresponding residual error vector before the
L-th new hidden node is added. The hidden layer output matrix (with
L hidden nodes) can be formulated as
, where
is the activation of the new hidden node for each input
,
. In practice, we use
as a consistent estimate version of Equation (
2). With these notations, the detailed stochastic configuration algorithm [
18] is summarized as the following Algorithm 1.
| Algorithm 1: SC |
| Given inputs , and outputs , . Set maximum number of hidden neurons , expected error tolerance , maximum times of random configuration . Choose , and a set of the scale parameters in sigmoid |
| 1. Initialize , denote two empty sets and W; |
| 2. For, Do |
| 3. For, Do |
| 4. For, Do |
| 5. Randomly select and from and |
| 6. Calculate and . Set |
| 7. If |
| 8. Save and in W, in , respectively; |
| 9. Else go back to Procedure 4 |
| 10. End For (corresponds to Procedure 4) |
| 11. IfW is not empty |
| 12. Break |
| 13. End If |
| 14. End For (corresponds to Procedure 3) |
| 15. IfW is empty |
| 16. Reset and return to Procedure 3; |
| 17. Else find , that maximize in |
| 18. Calculate , , and |
| 19. If |
| 20. Return, , and ; |
| 21. Else go back to Procedure 2 |
| 22. End For (corresponds to Procedure 2) |
It should be noted that the vanilla version of the Algorithm 1 is a batch mode that considers all the available data at once during the training process, which in other words can be viewed as a batch learning algorithm. However, when new data samples are received, one needs to retrain the whole model from scratch using the SC algorithm again, which is impractical for some real-world applications with special concerns on real-time processing. For problem-solving, it is necessary to extend the current Algorithm 1 to a more advanced one that supports sequential learning, which allows iteratively updating the model’s trainable parameters (on the basis of the parameters obtained in the last iteration session), instead of retaining the whole model, when new data samples are available via the one-by-one or chunk-by-chunk way. We detail the proposed new variant of SC algorithm in the following section.
4. Online Sequential Stochastic Configuration Algorithm
In this section, the SC algorithm is generalized into a sequential learning version, by executing the widely-used recursive least square (RLS) approach. We will first provide the mathematical deduction step by step to finalize the iteration equations for the output weights. Then, the whole procedures are summarized as the Algorithm 2 OSSC, followed by further comments about its inherent superiority over the OS-RVFL algorithm, that is, a similar sequential learning method that uses RVFL networks as a base model during the online training process.
The whole process can be formulated by two main steps including initialization phase and sequential updating phase, where the Algorithm 1 is applied in the first phase and consequently obtains a base (initial) random leaner, and the RSL approach is performed in the second phase for renewing output weights of the initial model, detailed as follows.
Initialization Phase: We use the SC algorithm on the first available training data; suppose that the constructed random learner has L hidden nodes, i.e., . Let be the current output weights. The associated hidden layer output matrix is denoted as (here, we remove its top right corner index L for simplicity, i.e., ).
Sequential Updating Phase: At time instant
,
, suppose the hidden layer output matrix corresponding to the new available data are
, then the optimization problem becomes
The RLS approach aims at calculating the weight
recursively from
without directly solving the above minimization problem (
4).
It is straightforward to observe that
where
By using the matrix inversion lemma [
29], we can obtain that
To summarize, let
, and the online update of the weight can be achieved by the following operation:
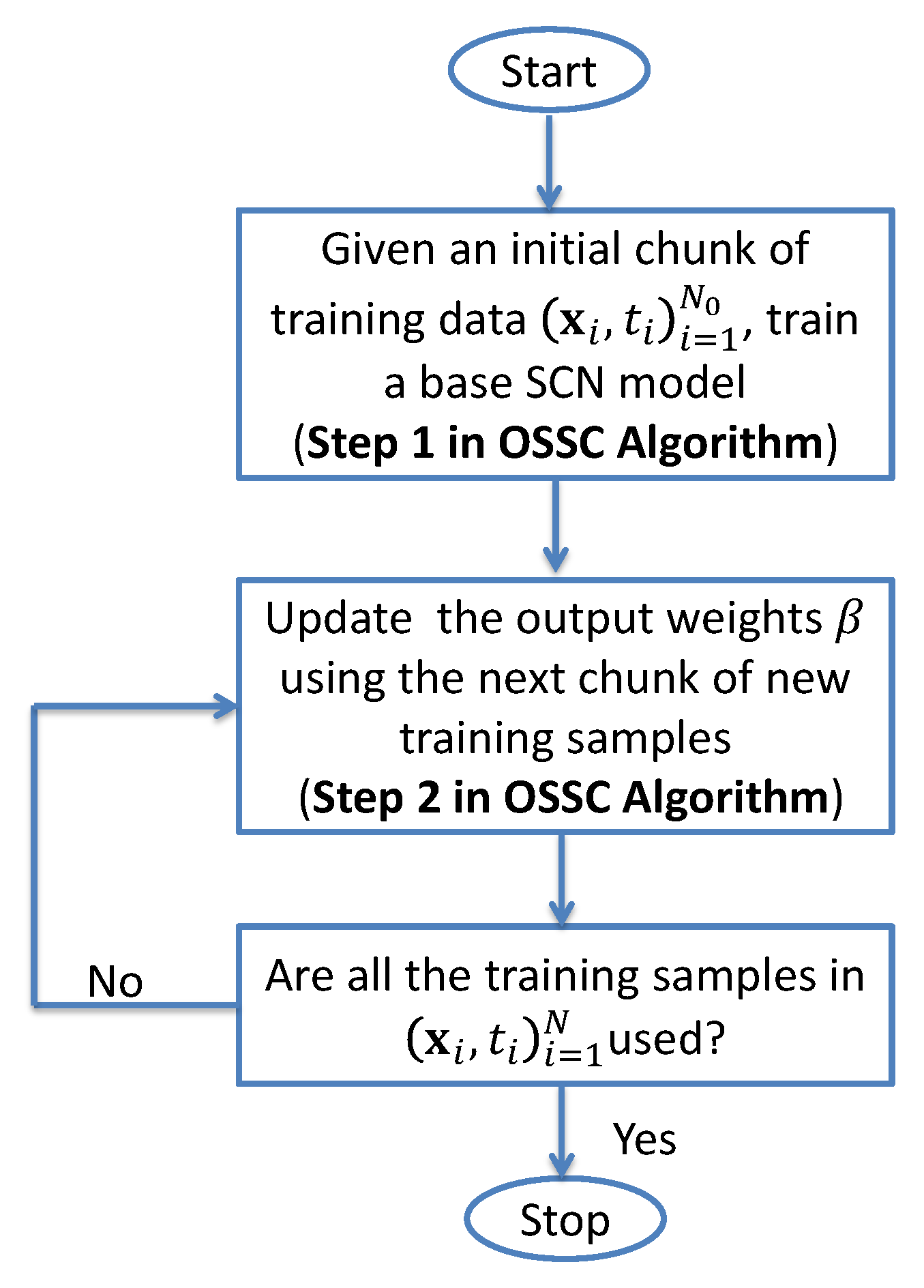
The whole schematic of OSSC algorithm (i.e., Algorithm 2) can be summarized as follows.
| Algorithm 2: OSSC |
| Input: Training dataset arriving sequentially , initial number of training samples , the number of observations in the k-th chunk, . |
| Output: Output weight . |
| Begin |
| Step 1. Use the Algorithm 1 on , obtain and set k:= 0; |
| Step 2. Provide the (k + 1)-th chunk of new observations and calculate k:= k + 1 and repeat Step 2 until all the observations in are used; |
| End |
The general process of Algorithm 2 (OSSC) is illustrated in the following
Figure 1.
Remark 1. It is easy to find that the whole algorithmic procedures can be immediately used on the original RVFL networks that lead to its online sequential learning version, termed OS-RVFL. That is to say, instead of conducting the SC algorithm in the initialization phase (Step 1 in Algorithm 2), the initial model is offered by implementing the randomized learning algorithm for RVFL networks, i.e., randomly assigning input weights and biases from certain scopes and only optimizing the output weights, as recalled in Section 2. Later for the sequential learning process, the basic iteration procedures remain the same as Step 2 in Algorithm 2. Remark 2. The existing convergence results of RLS methodology [
30,
31]
can lend some support to ensure the convergence of our Algorithm 2 (OSSC), provided the initialization phase is successfully processed. In other words, the sequential learning process might be meaningless if the initialization model has not been appropriately trained either due to insufficient training information provided, or because of unreasonable neural network structure and/or parameter setting. On the other hand, for the OS-RVFL algorithm, some undesirable impacts of randomness, for instance, an inappropriate random selection range for input weights and biases, fails in bringing a universal approximator [
21],
will still exist or be enhanced during the sequential learning phase. That is, the reason why more attention should be raised when applying OS-RVFL for modeling due to the ‘risky’ aspects caused by randomness in RVFL networks. Remark 3. Compared with OS-RVFL, our Algorithm 2 (OSSC) incrementally constructs the initial model based on Theorem 1 that can effectively build a random learner with good learning and generalization capabilities. Importantly, the the SC algorithm (i.e., Algorithm 1) performed in the initialization phase can circumvent the awkward setting of the number of hidden nodes, and also find an effective choice of random parameters resulting in a universal approximator on the basis of the first available data. The merits of SC algorithm stated in [
18]
benefit the following sequential learning processes and bring inherent advantages for OSSC in comparison with OS-RVFL, just like the SC algorithm outperforms the RVFL algorithm shown in [
18].
Remark 4. It should be mentioned that the chunk size, i.e., the number of observations arrived at each time instant, does not necessarily have to be equal. On the other hand, the problem of the minimum number of observations that are needed in the initialization phase is application and problem-dependent. As a whole, the influence of the initial number of observations and the chunk size on the system’s performance should be investigated in depth, as conducted in our experimental study in the next section.
Overall, the key technical differences between OSSC and OS-RVFL (Here, without loss of generality, OS-RVFL represents a broad class of existing models that uses neural networks with random weights assigned via a data-independent manner, which inevitably causes some uncertainly issues as mentioned in the remarks, to name a few) can be summarized as follows in
Table 1.
5. Experiments
In this section, we compare the proposed OSSC algorithm with OS-RVFL on different tasks, in order to demonstrate its merits and good potential in dealing with online sequential learning problems. First, we revisit the toy examples used in [
21] and change their formulation as a online learning task, by which the advantages of OSSC (over OS-RVFL), which can successfully find some workable random parameters (input weights and biases) and consequently lead to a universal approximator, are illustrated. Then, the effectiveness of our OSSC algorithm is assessed in the problem of nonlinear dynamic system modeling and Mackey–Glass time-series prediction, respectively. In the performance comparison, several scenarios with different parameter settings are performed. Root Mean Square Error (RMSE) that is commonly used in data analysis literature is calculated to measure the performance. Both the average value and standard deviation of RMSE are reported. The parameter setting will be specified in each task. All simulations are carried out in the MATLAB 2020b environment running on a core i7, 2.9 G HZ CPU, and 8 GB RAM.
5.1. 1D Function Approximation
First, to better demonstrate the advantages of OSSC over OS-RVFL with performance visualization, we use two examples for 1D function approximation. In particular, the first regression task is about the followed target function, which has also been used in [
21], i.e.,
The second target function is a rapidly changing continuous SinE function
, i.e.,
To fit the problem formulation of sequential learning task, we sample samples as the initial training samples (i.e., ) and then add training samples sequentially (e.g., 1 by 1, 20 by 20, 50 by 50) as the instances used in training time instants , and finally 500 samples as the test samples (which we assume are used for the performance evaluation at the time instant ).
As shown in
Table 2, it is clear that OSSC outperforms OS-RVFL in all cases. For example, for the case of
, the RMSE values of OS-RVFL are larger than
in all situations with different settings of
and chunk size. In contrast, the best test result of OSSC is
, which means that OS-RVFL’s error is approximately 25 times larger than that of OSSC. This verifies the effectiveness of OSSC as discussed in Remark 2 in
Section 4. Approximately, OSSC has obtained 25 times lower RMSE than OS-RVFL. As for
, the same finding can be obtained, that is, the best test result of OSSC is
, while the RMSE values of OS-RVFL are all larger than
. In
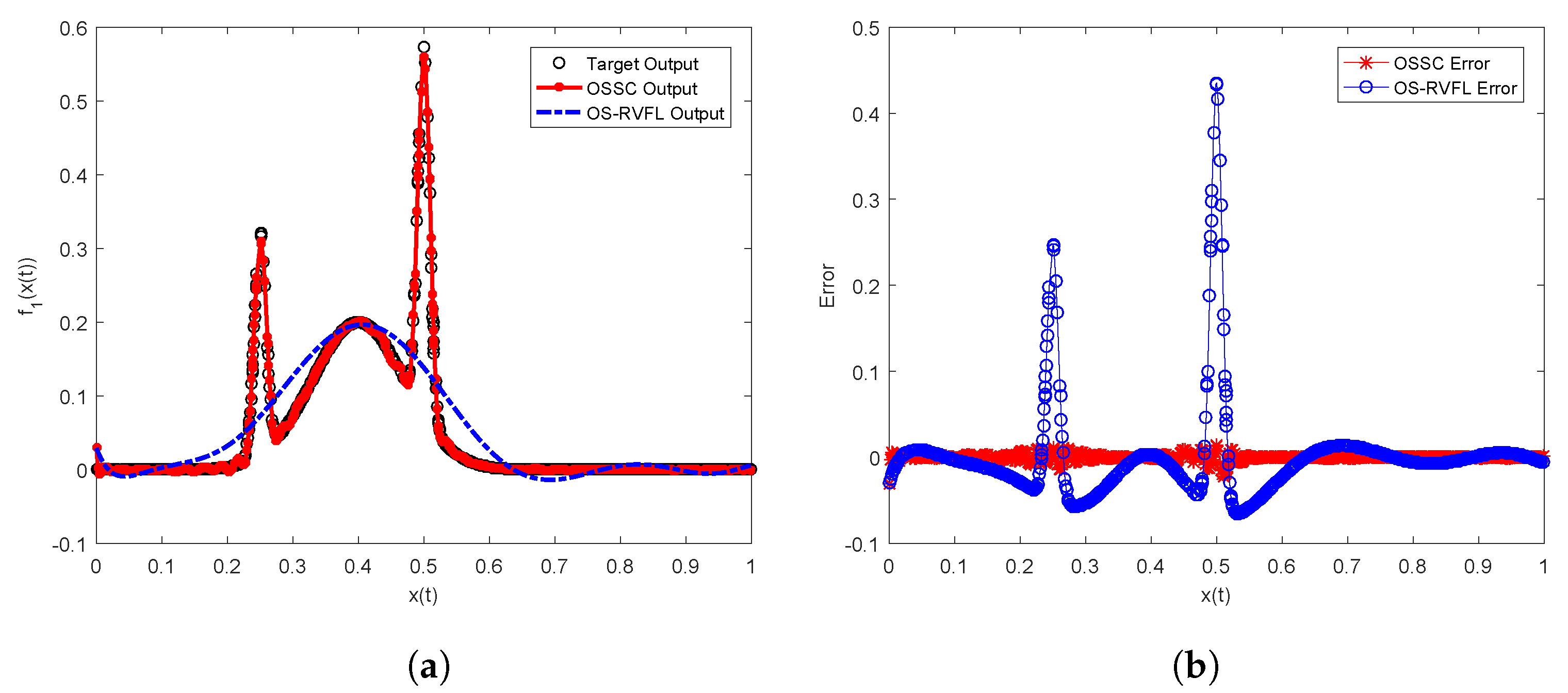
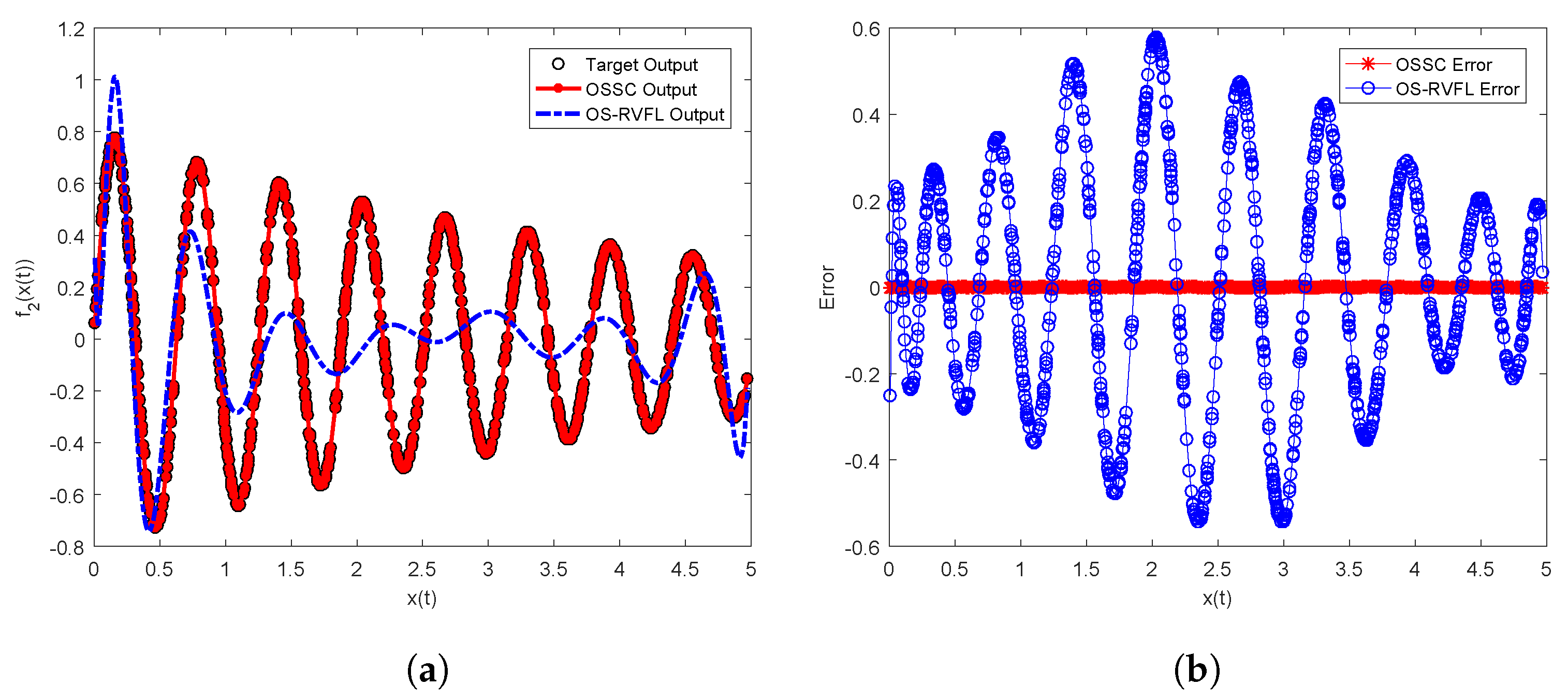
Figure 2 and
Figure 3, for the case of
and
, respectively, we plot the target test outputs, OSSC outputs, OS-RVFL outputs, as well their associated error curves. As can be seen clearly, identical to the findings shown in
Table 2, OSSC achieves much better performance than OS-RVFL in both
and
sequential learning tasks. Obviously, the error curves of OS-RVFL show that the resulting learner models are not well sequentially trained and then do not have acceptable generalization capabilities.
In summary, similar to the findings presented in [
21], the random distribution (corresponding to
) is of great importance to induce an effective randomized learner model. Furthermore, users should ensure that the initialization phase of online sequential learning can lead to a good initial model; otherwise, the following sequential updating phase is meaningless.
5.2. Nonlinear Dynamic System Modeling
The second task that we consider in our experiments is a nonlinear dynamic system modeling (nDSM) example. In particular, the following artificial example is a widely-used one to demonstrate the neural networks’ feasibility on nDSM:
where
,
,
.
We compare OSSC and OS-RVFL on this task, in which 900 points are generated using Equation (
5) and split into two parts, 300 (
), 600 (
) for training and test, respectively. For either OSSC or OS-RVFL, the inputs used for model training are given by
and the corresponding target output is
.
In
Table 3, it is clear that OSSC have obtained better test results than OS-RVFL in all the situations considered in the experiments. For example, when
, chunk size is set to 50, the resulting averaged RMSE of OS-RVFL is
while that of OSSC is
, which means that OS-RVFL’s error is nearly 1.5 times larger than that of OSSC. To further uncover the potential advantages of OSSC over OS-RVFL, we fix the chunk size as 1, consider two settings of initial training samples, i.e.,
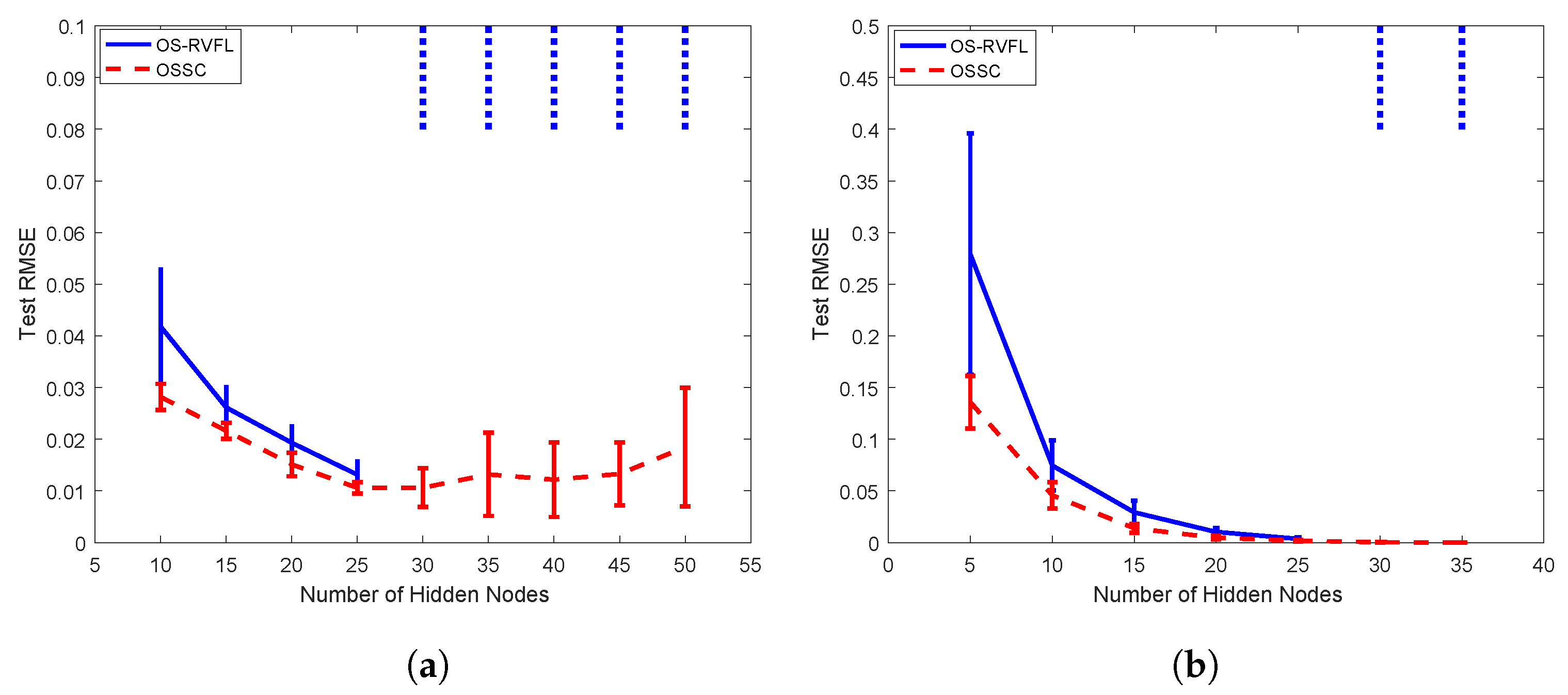
, respectively, and try different setting of the number of hidden nodes (e.g.,
L) for both OSSC and OS-RVFL. As shown in
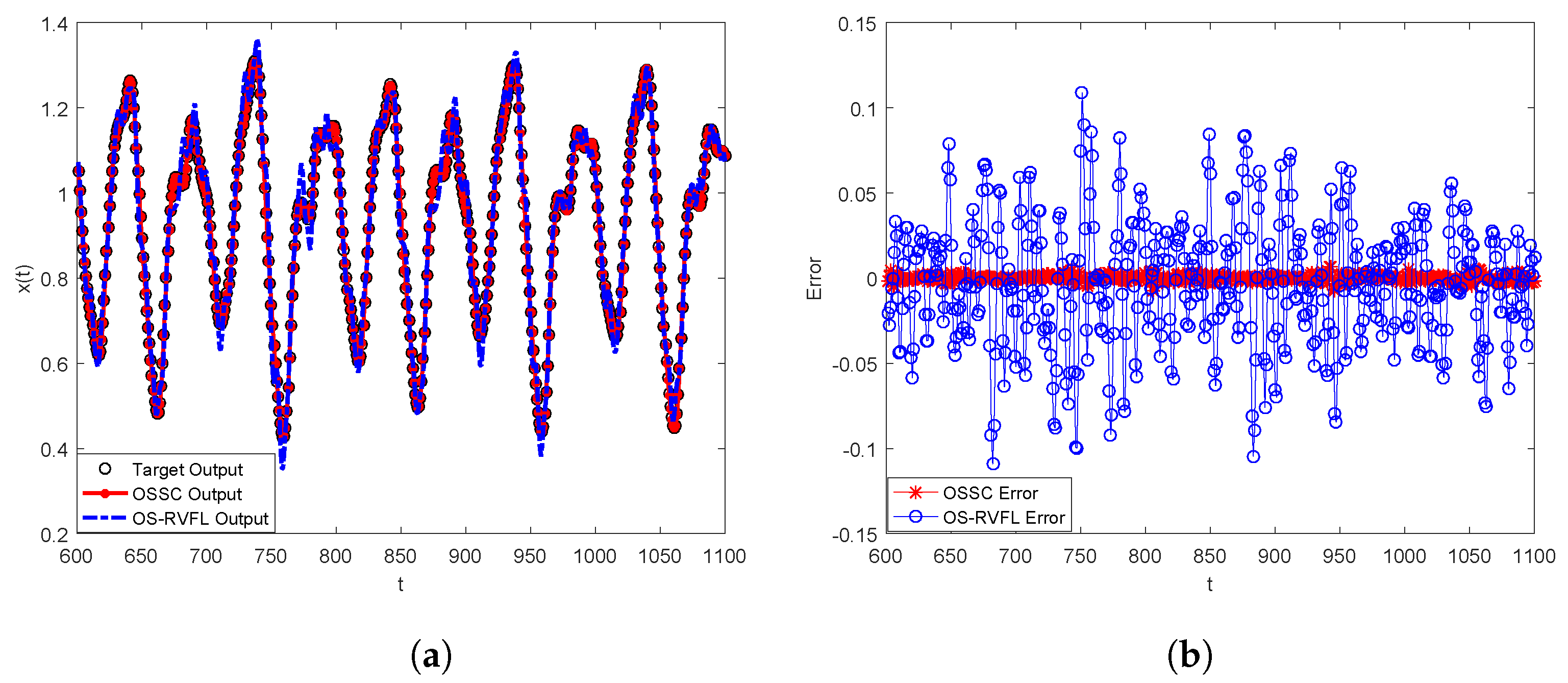
Figure 4, it is interesting that OS-RVFL fails in certain cases, as marked as the blue dotted ellipses, while OSSC is feasible and effective in all the cases. Specifically, as can be seen in
Figure 4a, when the number of hidden nodes of OS-RVFL is larger than 30, the resulted model significantly overfits the test samples, which in other words leads to a huge test error. This is why we have used the blue dotted ellipses to reflect this ‘abnormal’ phenomenon, in contrast to the stable and favorable performance of OSSC. Similar findings, for example when the number of hidden nodes exceeds 30, can also be found in
Figure 4b. In addition, we see clearly in
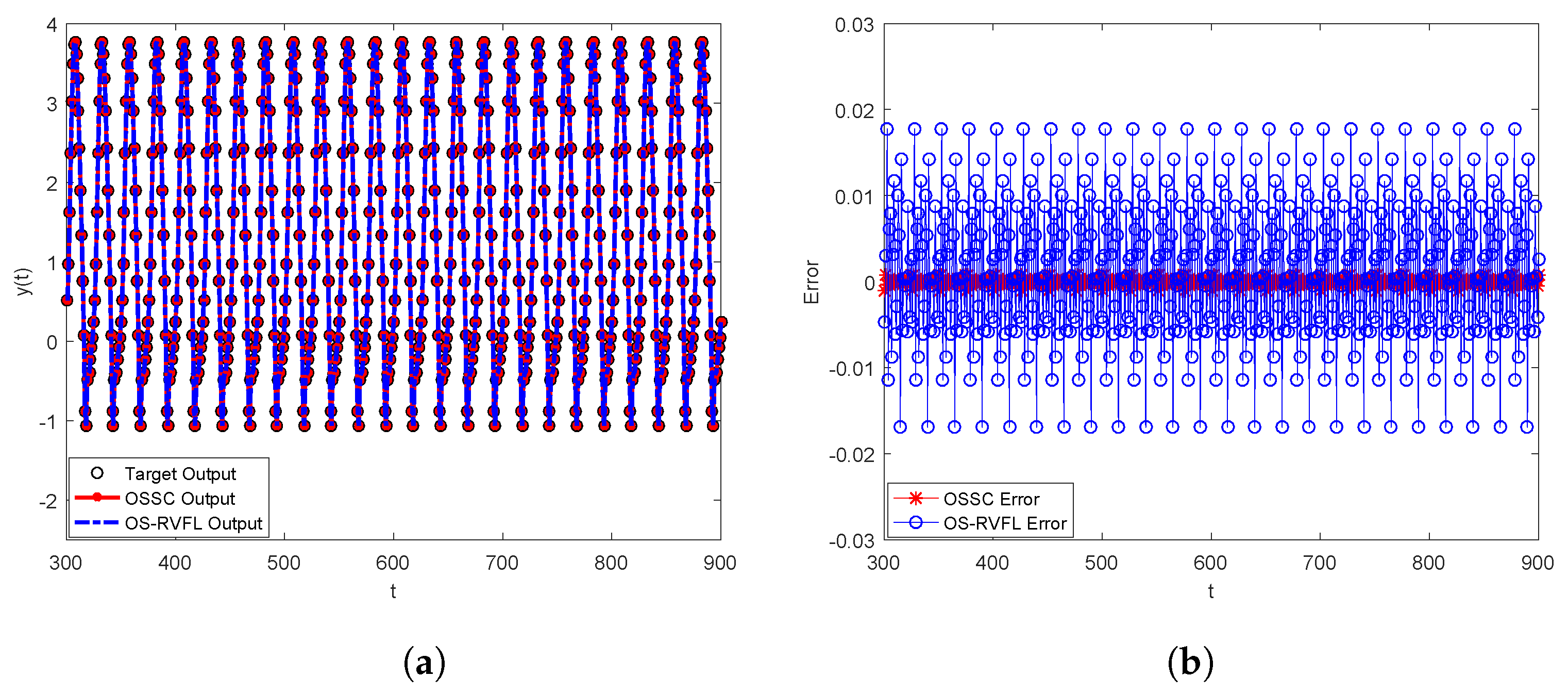
Figure 5 that the error curve of OS-RVFL is much worse than that of OSSC. Therefore, OSSC outperforms OS-RVFL in problem-solving for this kind of sequential learning task.
5.3. Mackey–Glass Time-Series Prediction
The third task we consider in our experimental study is the classic Mackey–Glass time-series prediction, which has been widely used in literature to test the performance of neural networks on nonlinear chaotic system modeling. The time series used in this part is derived from a time-delay differential system with the following form:
where
,
,
,
, and the initial condition
.
The aim of this experiment is to model the Mackey–Glass chaotic system using OSSC and OS-RVFL, respectively, and to predict the value from . Five hundred data points with are chosen as the training samples, and five hundred data points with are used as test samples to evaluate the performance of OSSC and OS-RVFL.
As shown in
Table 4, OSSC outperforms OS-RVFL in all the cases. For example, when
, chunk size is 50, the averaged test RMSE of OSSC is 3.4146 ×
while that of OS-RVFL is
. Approximately, OS-RVFL’s error is 11 times larger than that of OSSC. Furthermore, as can be seen in
Figure 6, similar to the findings found in
Figure 2,
Figure 3 and
Figure 5, the error curves of OSSC reflect its better generalization capabilities than OS-RVFL. In summary, OSSC works more favorably than OS-RVFL in dealing with the Mackey–Glass time-series prediction problem, which further verifies the good potential of OSSC algorithm for (online) sequential learning. Furthermore, OSSC shows better stability over OS-RVFL, as demonstrated in
Figure 7.
5.4. Application in Foreign Exchange Rate Forecasting
To further explore the effectiveness and advantages of OSSC for problem-solving in real-world applications, we compare OSSC and OS-RVFL with a real dataset for the foreign exchange rate forecasting task. In particular, we start with a detailed description of the data preparation process, then demonstrate the performance comparison based on extensive experimental results, followed by a robust analysis to investigate empirically the influence of the chunk size on the model’s performance. All the experimental results have verified the advantages of OSSC over OS-RVFL, delineated as follows.
5.4.1. Data Preparation
The datasets utilized in this part are all downloaded from the official website of American Federal Reserve Bank (
https://fred.stlouisfed.org/fred-addin/, accessed on 1 March 2022), in which 2542 exchange rates from 1 January 2004 to 27 September 2013 are chosen to verify the effectiveness of OSSC and OS-RVFL. In particular, four types of foreign exchange, including US Dollar/Euro, U.S. Dollar/Australia Dollar, Danish Kroner/U.S. Dollar, and Canadian Dollar/U.S. Dollar. The missing observations in the above period are removed from the chosen data. Finally, we can obtain 2453 observations for each data set. The time window size for the following 1-day-ahead forecasting is chosen as 5. Hence, there are 2448 samples for each data set. Among them, based on the partition of time-series, 1836 samples, 306 samples, and 306 samples are utilized as the training set, validation set, and test set, respectively.
5.4.2. Performance Illustration
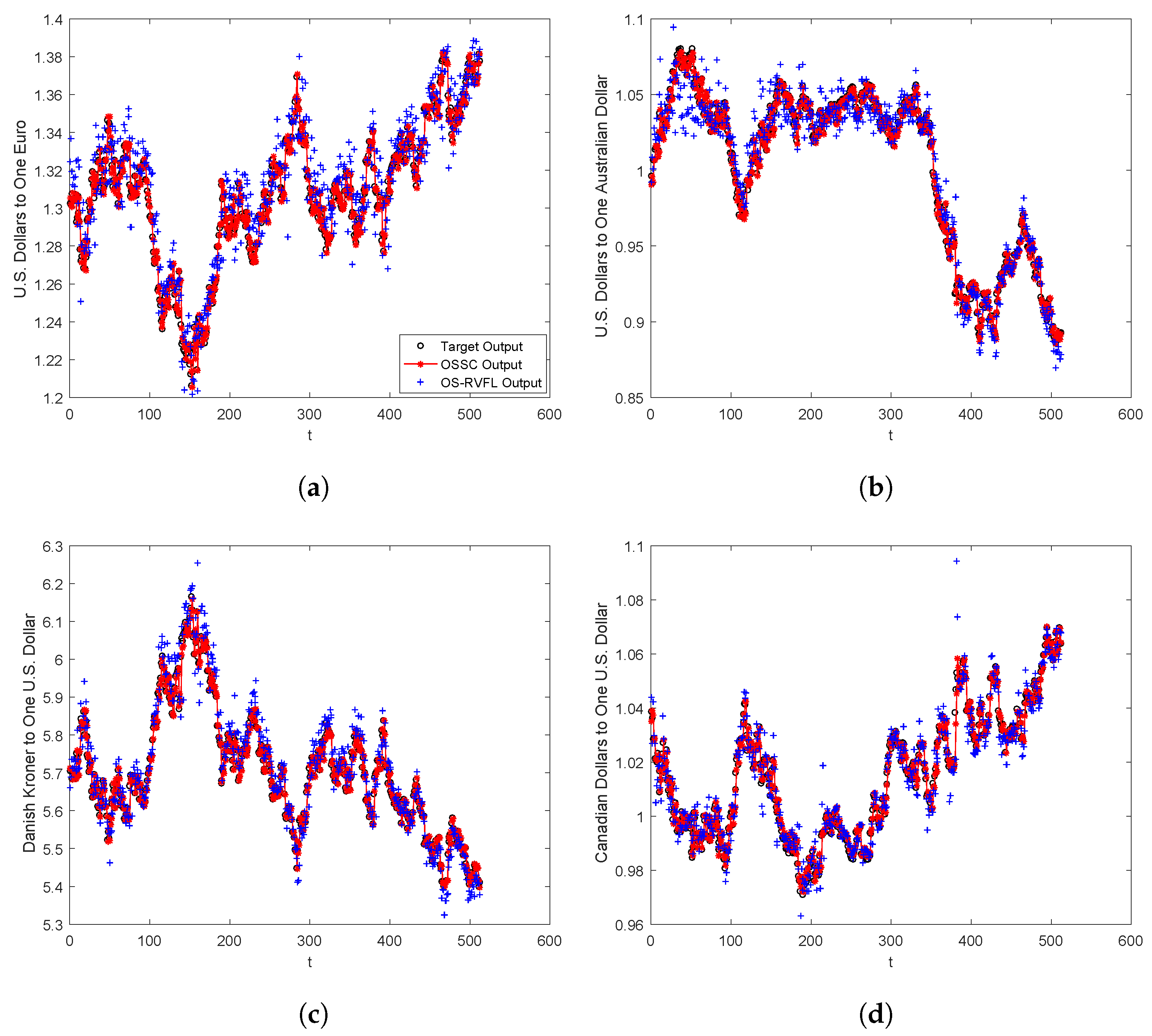
In
Table 5, it is clear that OSSC outperforms OS-RVFL on all the four datasets with different chunk size settings. For example, for the case of U.S. Dollar/Euro, the averaged RMSE values obtained by OS-RVFL are generally two times larger than that of OSSC in all the situations. As for the other cases, such as U.S. Dollar/Australia Dollar, Danish Kroner/U.S. Dollar, Canadian Dollar/U.S. Dollar, the averaged RMSE values resulted by OS-RVFL are nearly four times larger than that of OSSC in all the situations. To better indicate the performance comparison, in
Figure 8, we plot the target outputs, OSSC outputs, OS-RVFL outputs, respectively, for all the four datasets. As can be seen clearly, OSSC achieves better prediction than OS-RVFL for all the four cases, which is consistent with the test RMSE records summarized in
Table 5.
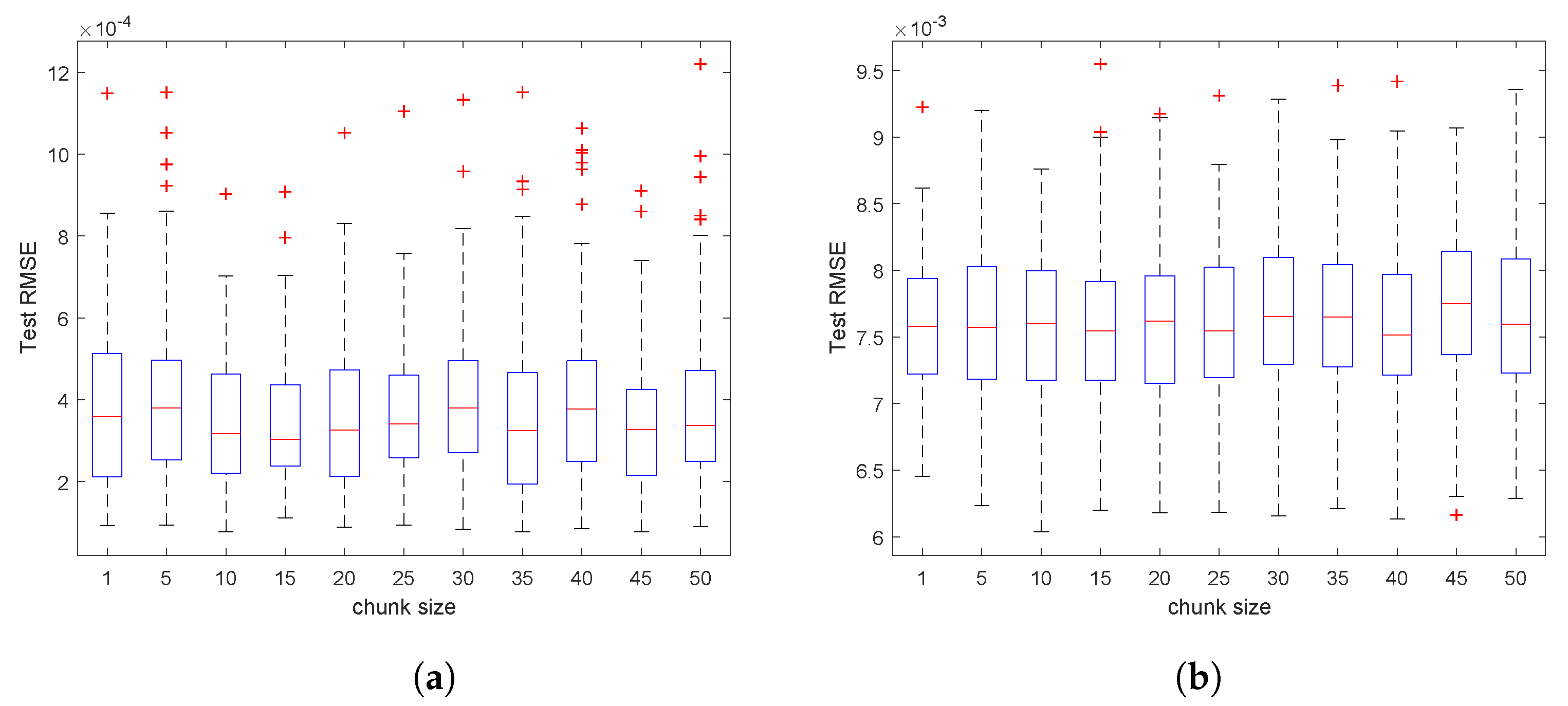
5.4.3. Robust Analysis
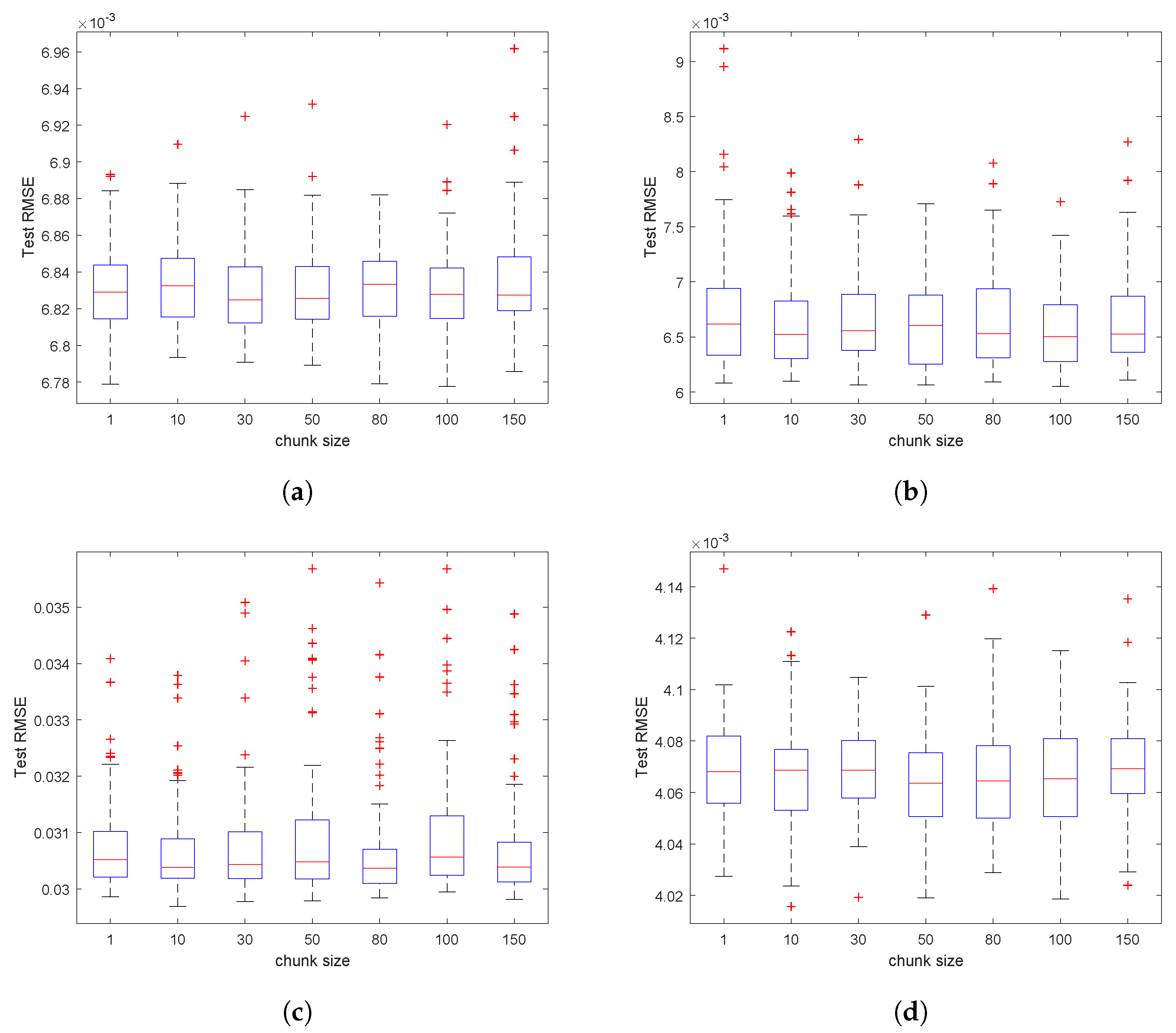
To further demonstrate the merits of OSSC for the problem-solving of foreign exchange rate forecasting, in this part, we investigate empirically the impact of the chunk size on the OSSC’s test performance. In particular, for each dataset, we run 50 trials independently for each chunk size settings (=
, respectively), then draw the boxplot for each case, of which the central mark indicates the median, and the bottom and top edges of the box indicate the 25th and 75th percentiles, respectively, and the outliers are plotted individually using the ‘
+’ marker symbol, see
Figure 9. It shows clearly that OSSC works stably for all the settings of different chunk size, which to some extent offers some guidance for users when employing OSSC in similar tasks.
Overall, based on all the presented experimental results and discussion in this section, we can draw a convincing conclusion that OSSC can be used as an effective online sequential learning algorithm for neural networks, and it has good potential to contribute to favorable learner models with sufficient capability for streaming data modeling tasks, such as nonlinear dynamic system modeling, time-series prediction, foreign exchange rate forecasting, and so on.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}